Recommended
PDF
지금 핫한 Real-time In-memory Stream Processing 이야기
PPTX
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
PDF
Apache kafka intro_20150313_springloops
PDF
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
PDF
[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼
PDF
[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화
PDF
[112]clova platform 인공지능을 엮는 기술
PDF
백억개의 로그를 모아 검색하고 분석하고 학습도 시켜보자 : 로기스
PDF
Real-time Big Data Analytics Practice with Unstructured Data
PDF
[214] data science with apache zeppelin
PDF
PDF
[233]멀티테넌트하둡클러스터 남경완
PDF
PPTX
PDF
[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)
PDF
[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현
PDF
[252] 증분 처리 플랫폼 cana 개발기
PDF
PDF
[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어
PDF
인공지능추천시스템 airs개발기_모델링과시스템
PDF
PDF
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
PPTX
Apache ZooKeeper 로
분산 서버 만들기
PDF
Understanding of Apache kafka metrics for monitoring
PDF
[211]대규모 시스템 시각화 현동석김광림
PPTX
[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술
PDF
[215]네이버콘텐츠통계서비스소개 김기영
PPTX
Streaming platform Kafka in SK planet
PDF
Twitter의 대규모 시스템 운용 기술 어느 고래의 배속에서
PDF
More Related Content
PDF
지금 핫한 Real-time In-memory Stream Processing 이야기
PPTX
[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.
PDF
Apache kafka intro_20150313_springloops
PDF
카프카(kafka) 성능 테스트 환경 구축 (JMeter, ELK)
PDF
[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼
PDF
[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화
PDF
[112]clova platform 인공지능을 엮는 기술
PDF
백억개의 로그를 모아 검색하고 분석하고 학습도 시켜보자 : 로기스
What's hot
PDF
Real-time Big Data Analytics Practice with Unstructured Data
PDF
[214] data science with apache zeppelin
PDF
PDF
[233]멀티테넌트하둡클러스터 남경완
PDF
PPTX
PDF
[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)
PDF
[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현
PDF
[252] 증분 처리 플랫폼 cana 개발기
PDF
PDF
[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어
PDF
인공지능추천시스템 airs개발기_모델링과시스템
PDF
PDF
Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안
PPTX
Apache ZooKeeper 로
분산 서버 만들기
PDF
Understanding of Apache kafka metrics for monitoring
PDF
[211]대규모 시스템 시각화 현동석김광림
PPTX
[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술
PDF
[215]네이버콘텐츠통계서비스소개 김기영
PPTX
Streaming platform Kafka in SK planet
Similar to 검색로그시스템 with Python
PDF
Twitter의 대규모 시스템 운용 기술 어느 고래의 배속에서
PDF
PDF
H3 2011 파이썬으로 클라우드 하고 싶어요
PDF
2011 H3 컨퍼런스-파이썬으로 클라우드 하고 싶어요
PDF
H3 2011 파이썬으로 클라우드 하고 싶어요_분산기술Lab_하용호
PDF
[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버
PDF
PDF
PDF
PDF
More Effective Python 3st (Multitask)
PPTX
PPTX
PPTX
Python study 1강 (오픈소스컨설팅 내부 강의)
PDF
주니어 개발자의 서버 로그 관리 개선기
PPTX
PDF
GDB와 strace로 Hang 걸린 Python Process 원격 디버깅
PDF
[2015-05월 세미나] 파이선 초심자의 Openstack
PDF
[RAG Tutorial] 02. RAG 프로젝트 파이프라인.pdf
PPTX
PPTX
20180320 python3 async_io
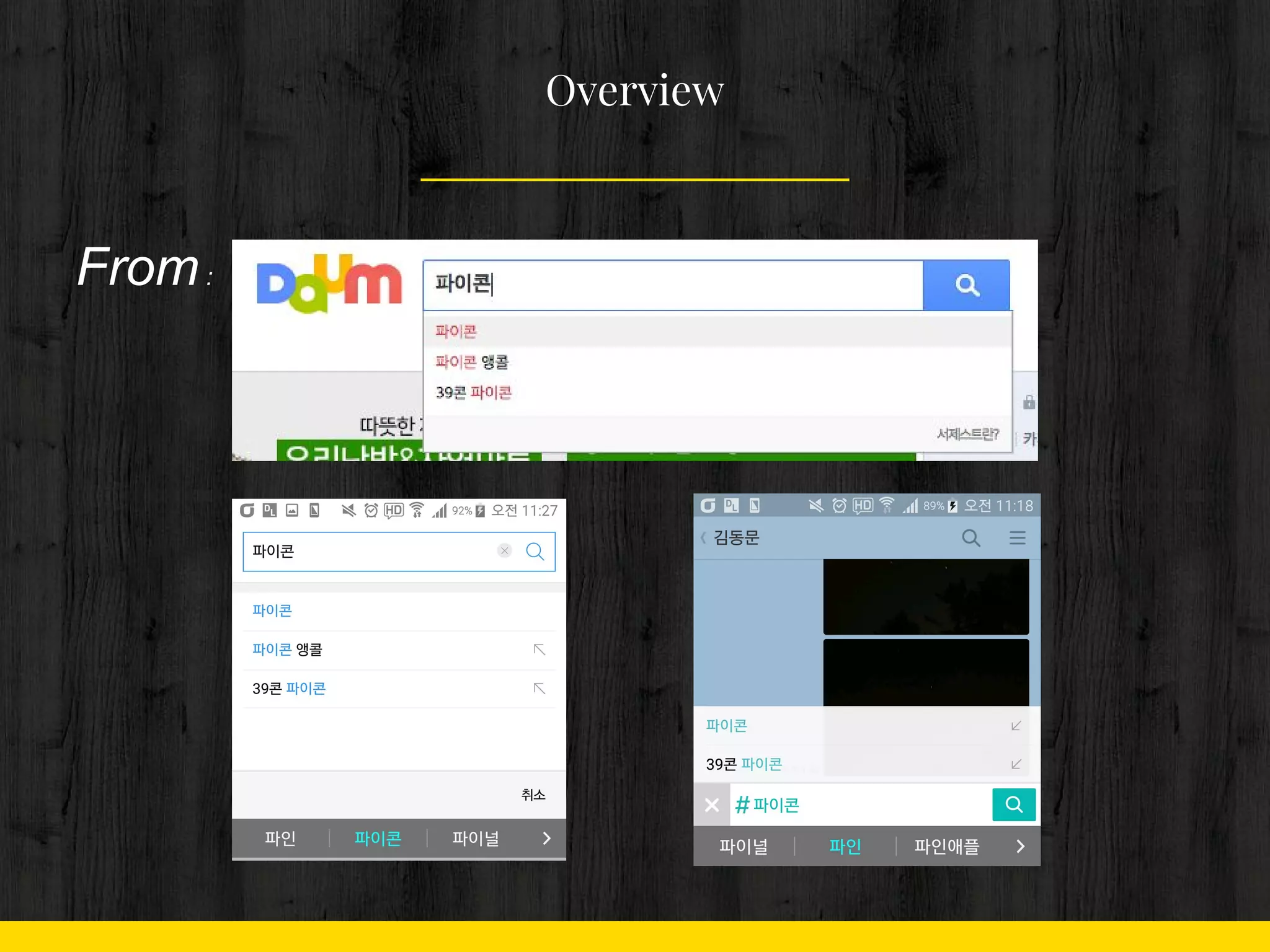
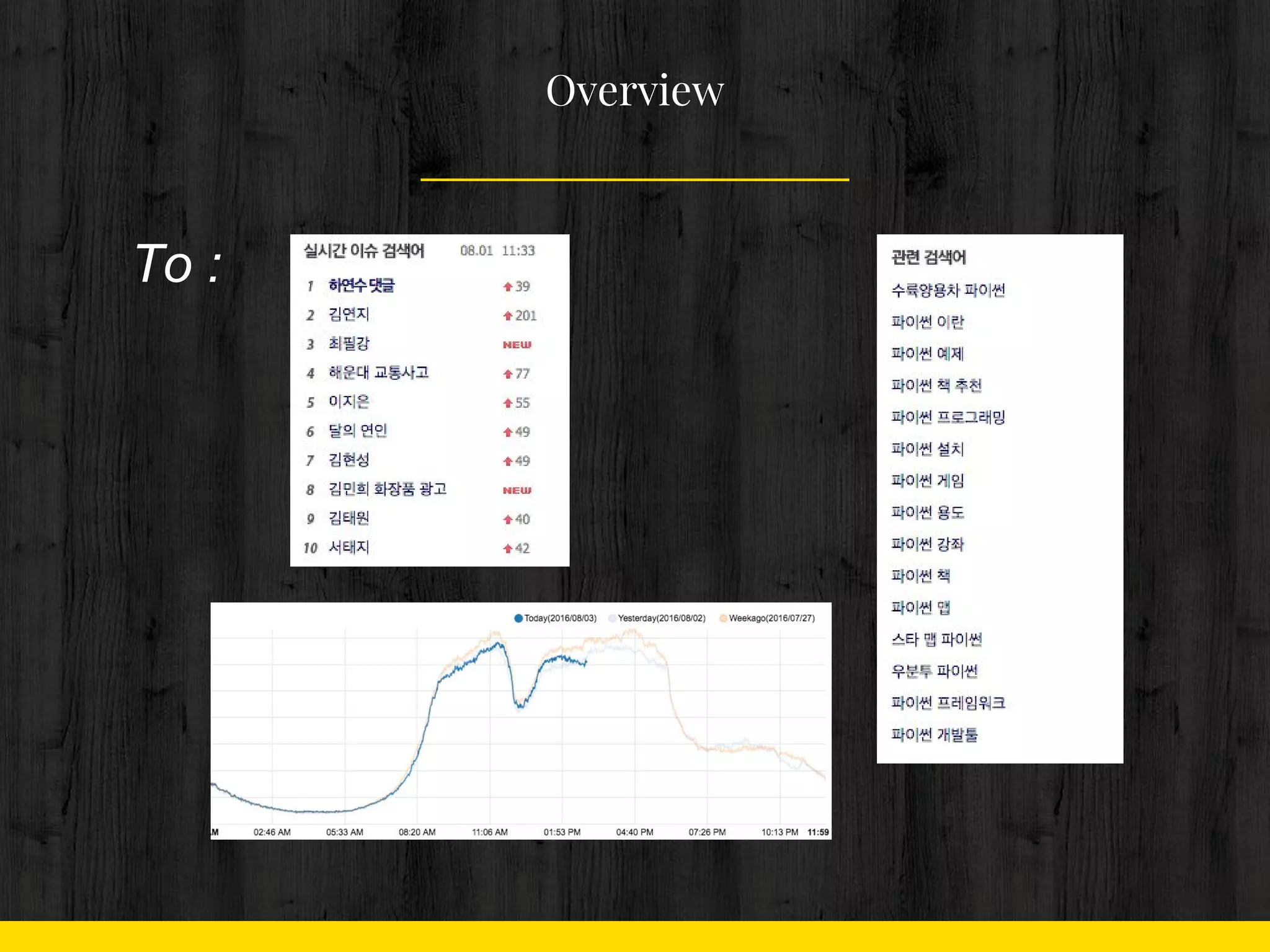
검색로그시스템 with Python 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 1. 작업은 모두 1분 내
- 밀리기 시작하면, 다음 프로세스에
영향
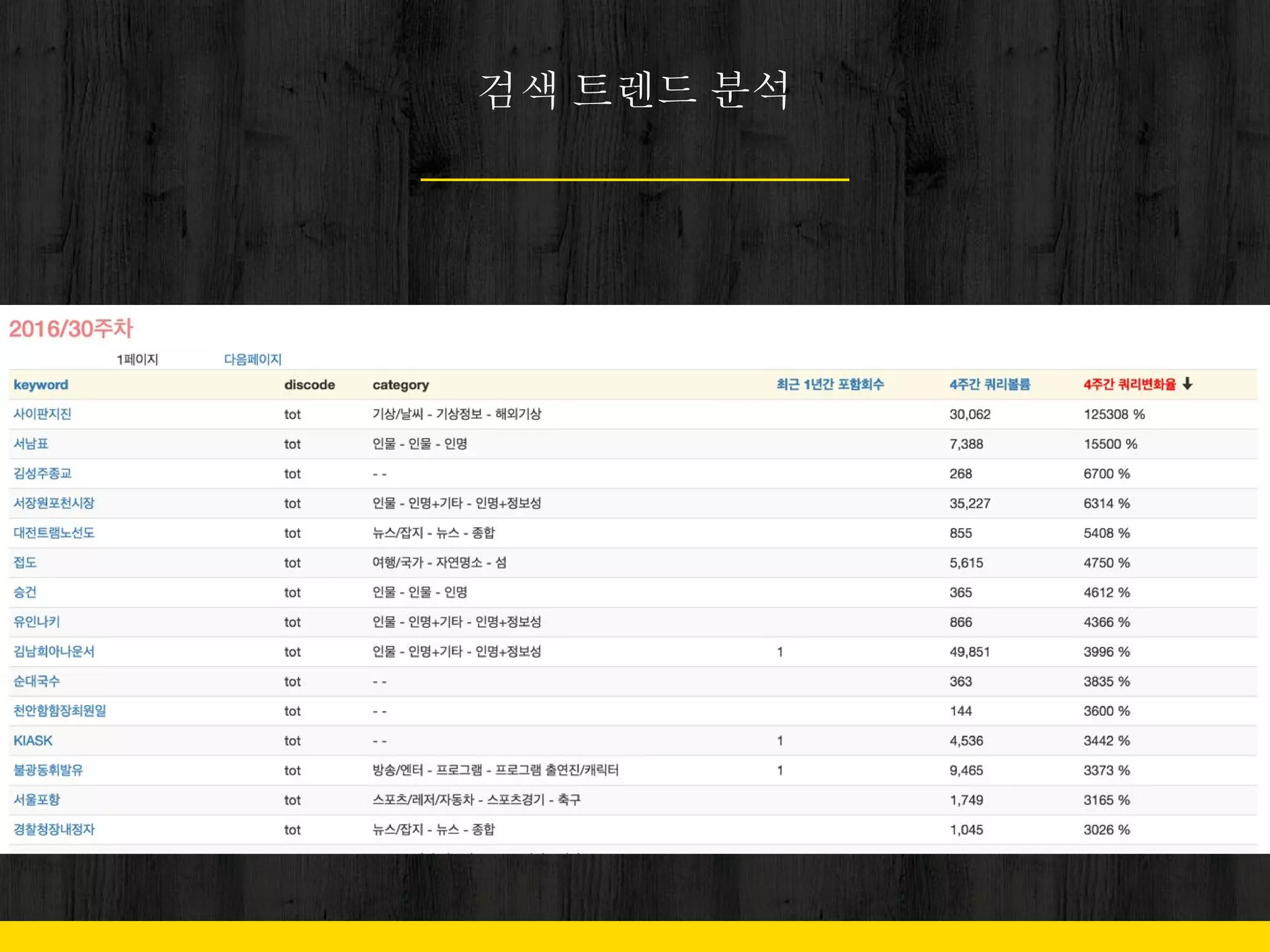
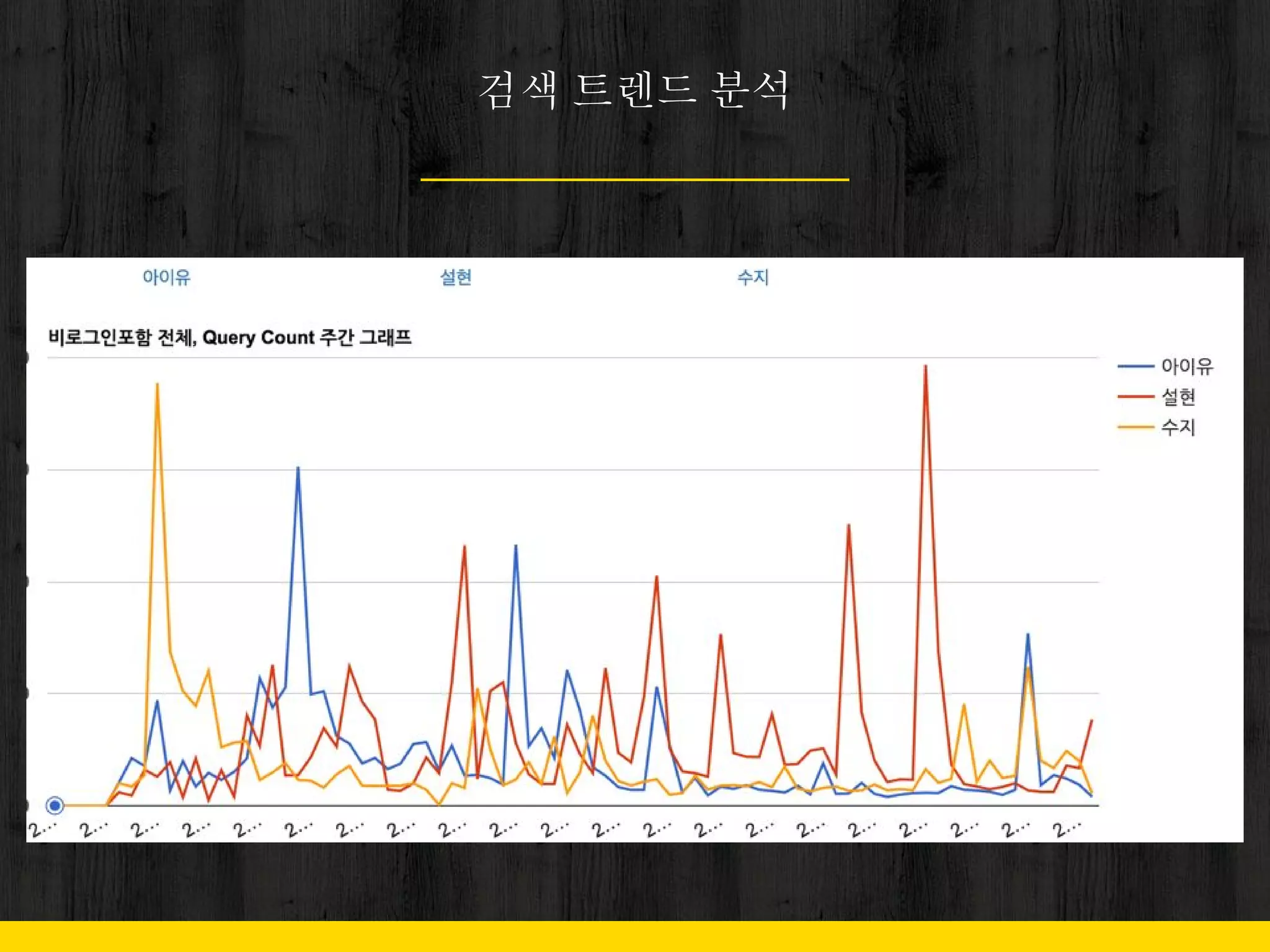
Problem
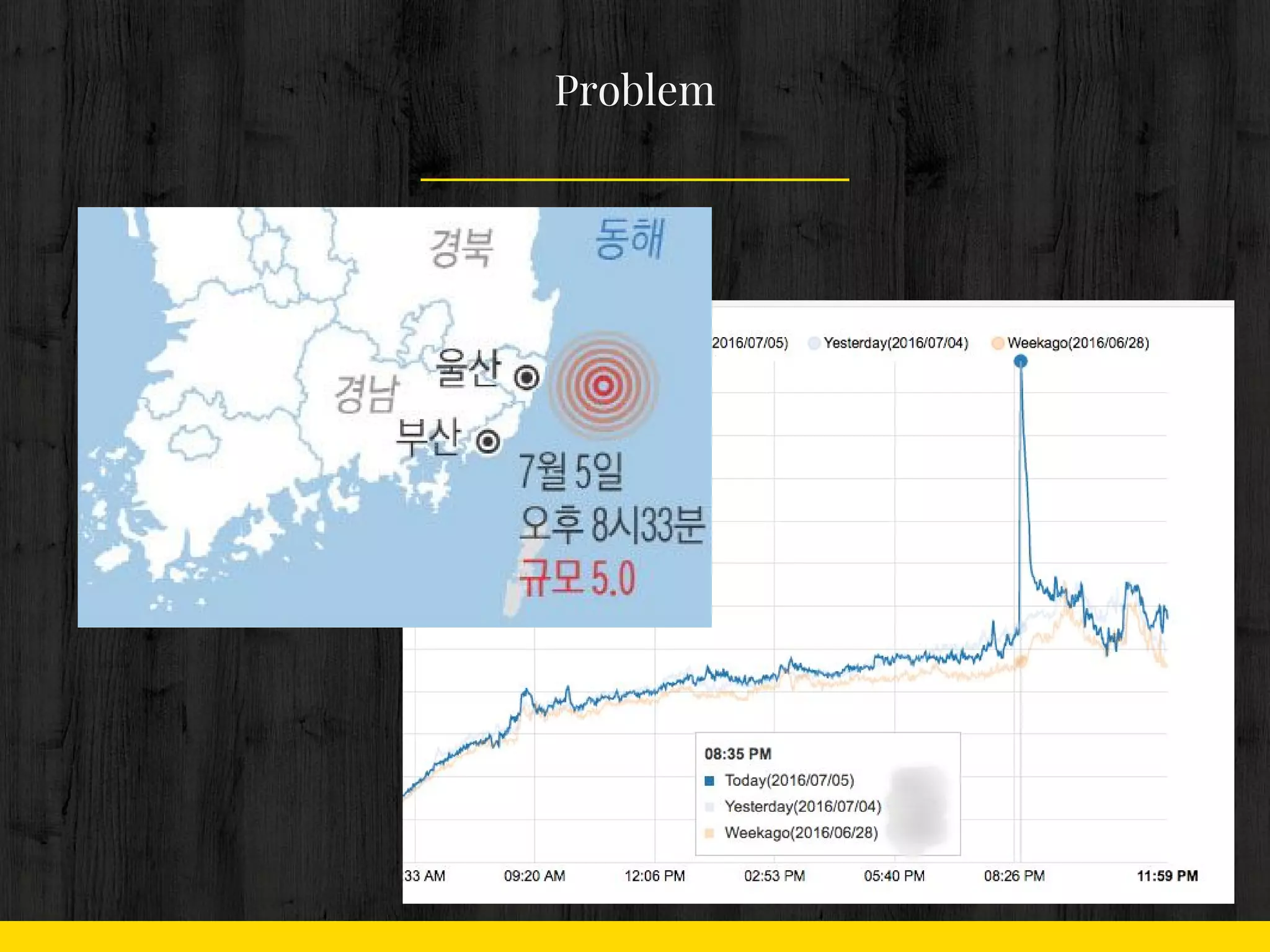
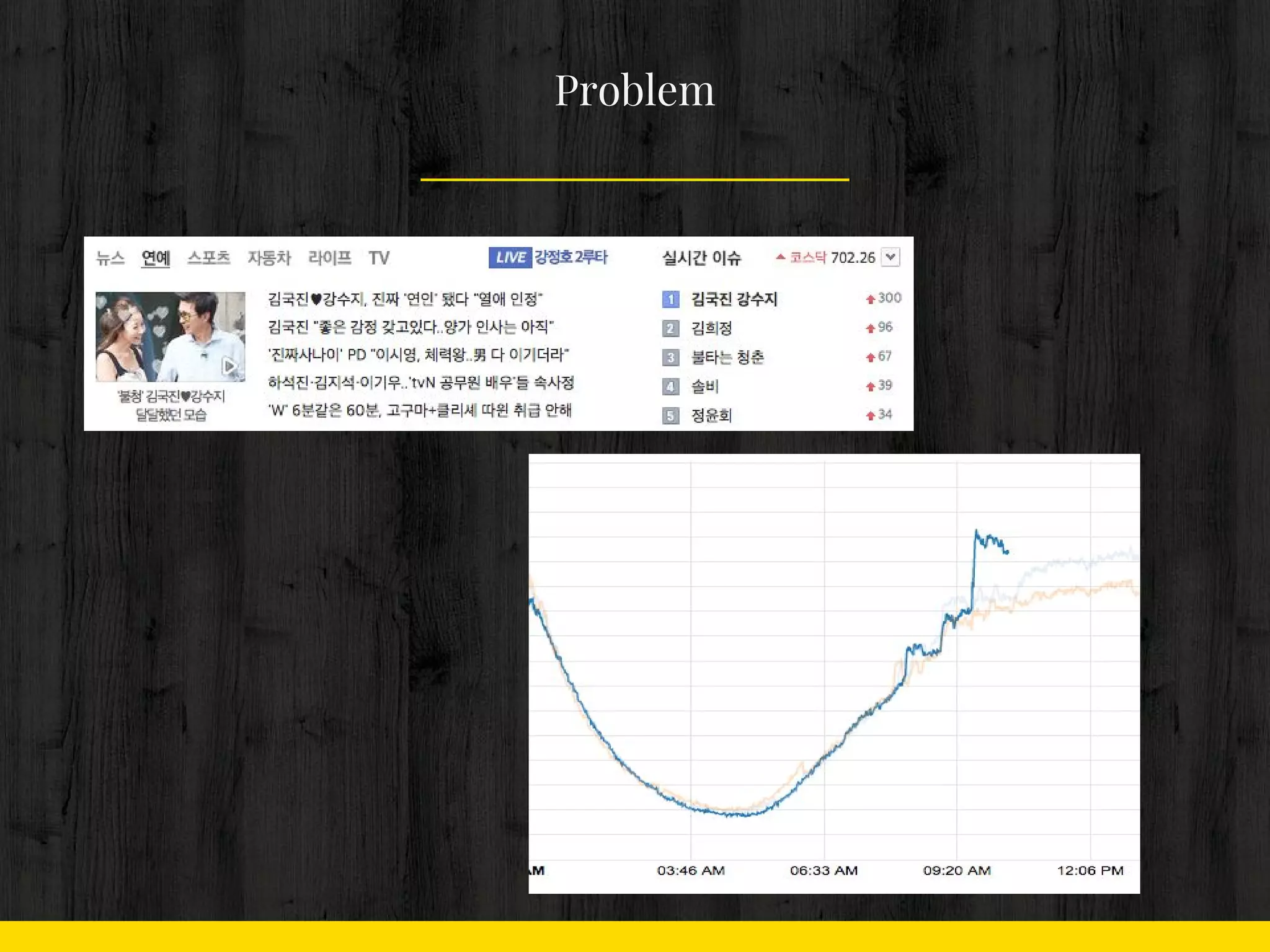
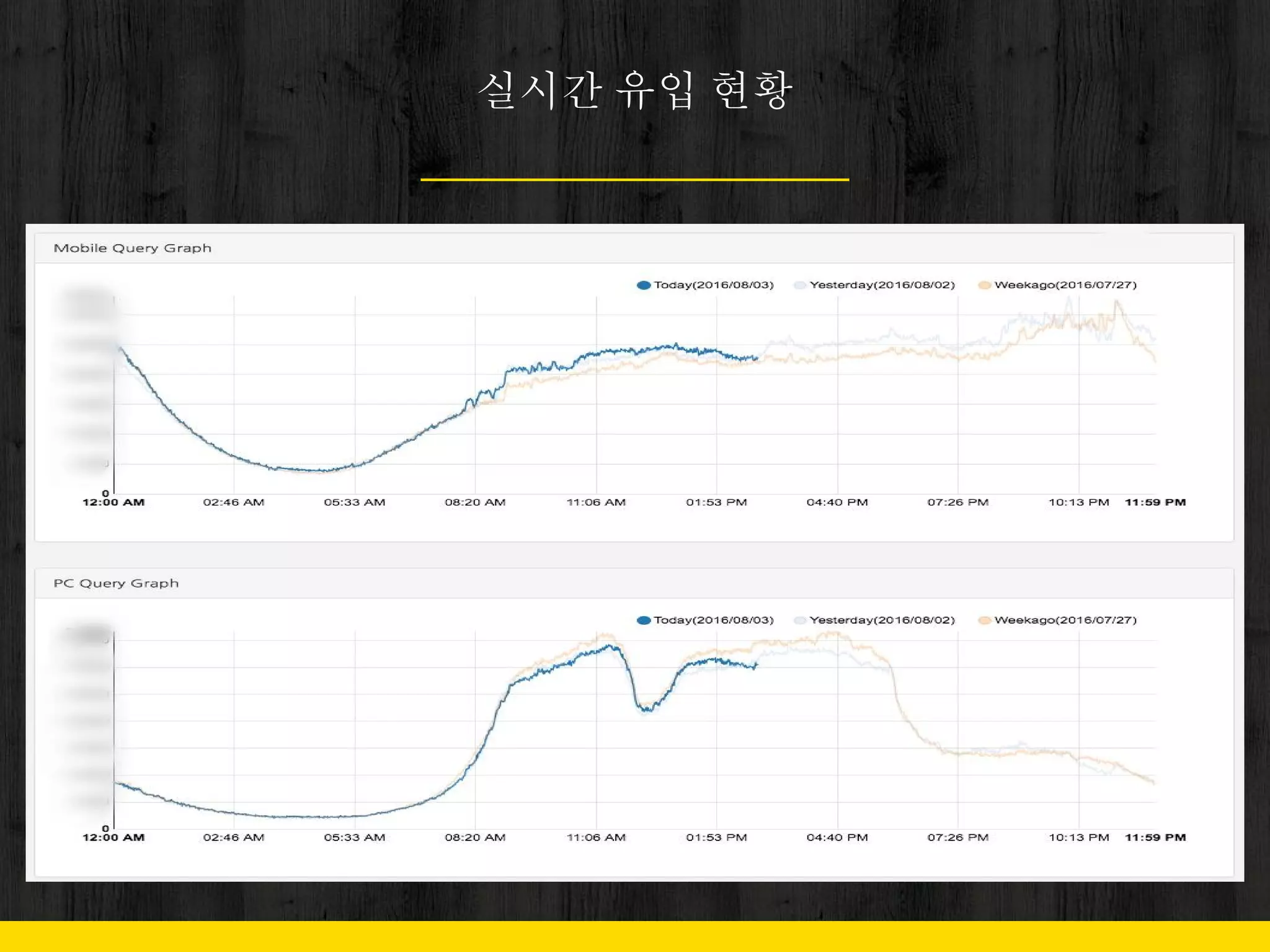
11. 12. 13. 2. 이슈로 인한 트래픽 증가
- 단기 폭증
- 천재지변
- TV 프로그램
- 꾸준히 증가폭 유지
- 연예
- 정치
- 사회
Problem
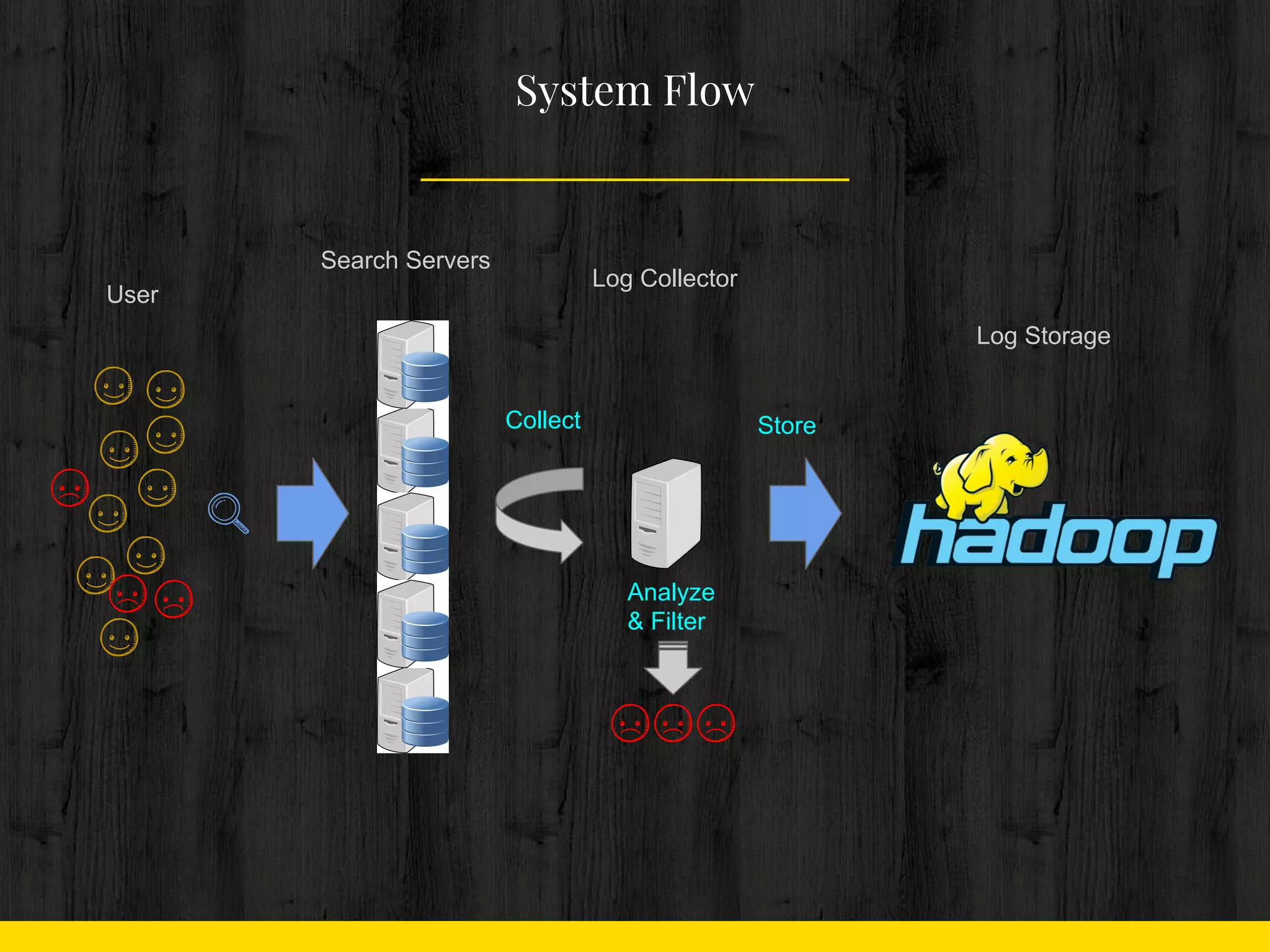
14. 15. 16. 17. 18. 19. 20. 21. 22. ● 할 일
○ 수십대의 서버에서
○ 수메가 바이트의 로그를
○ scp 를 통해 PULL
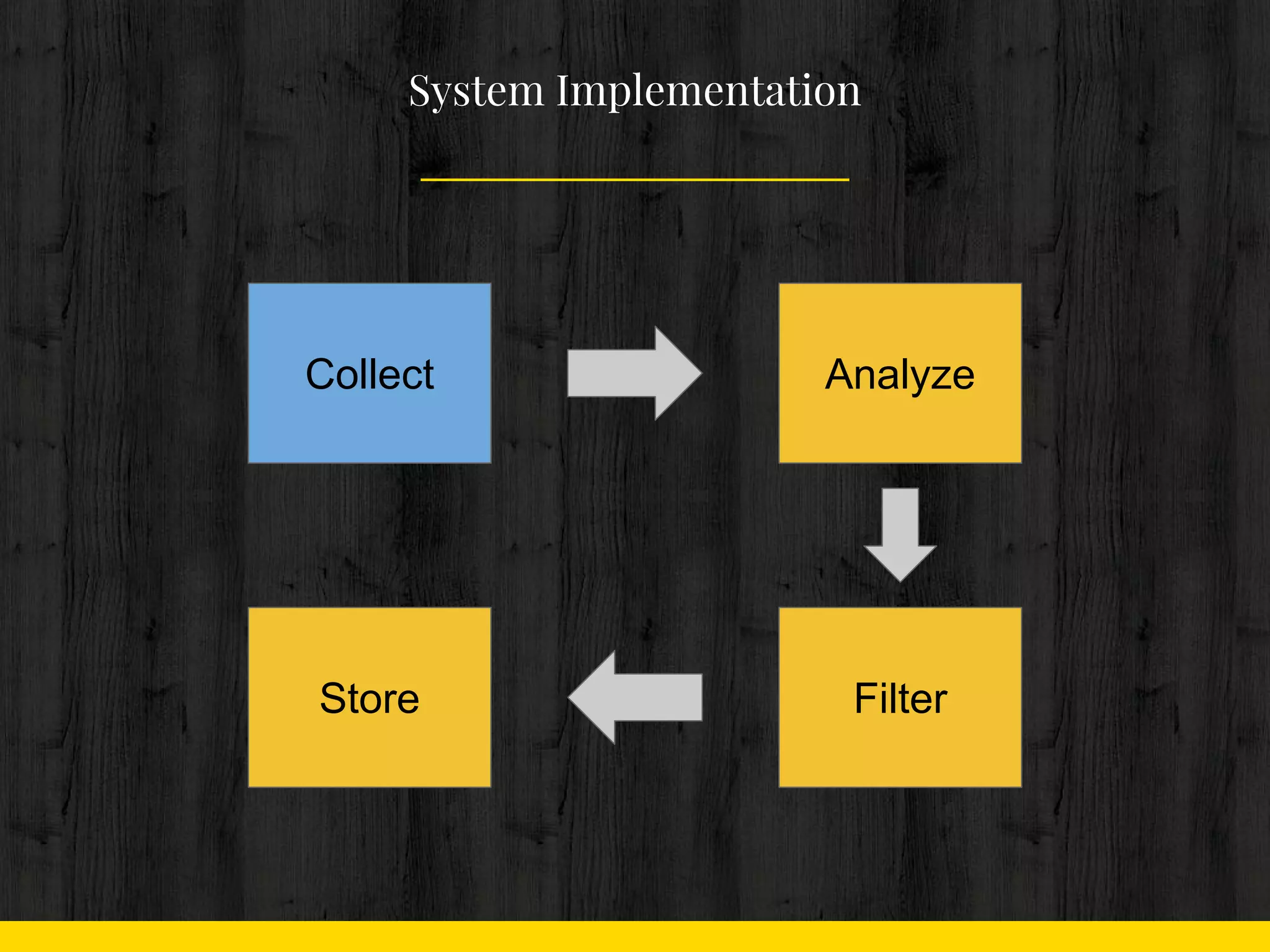
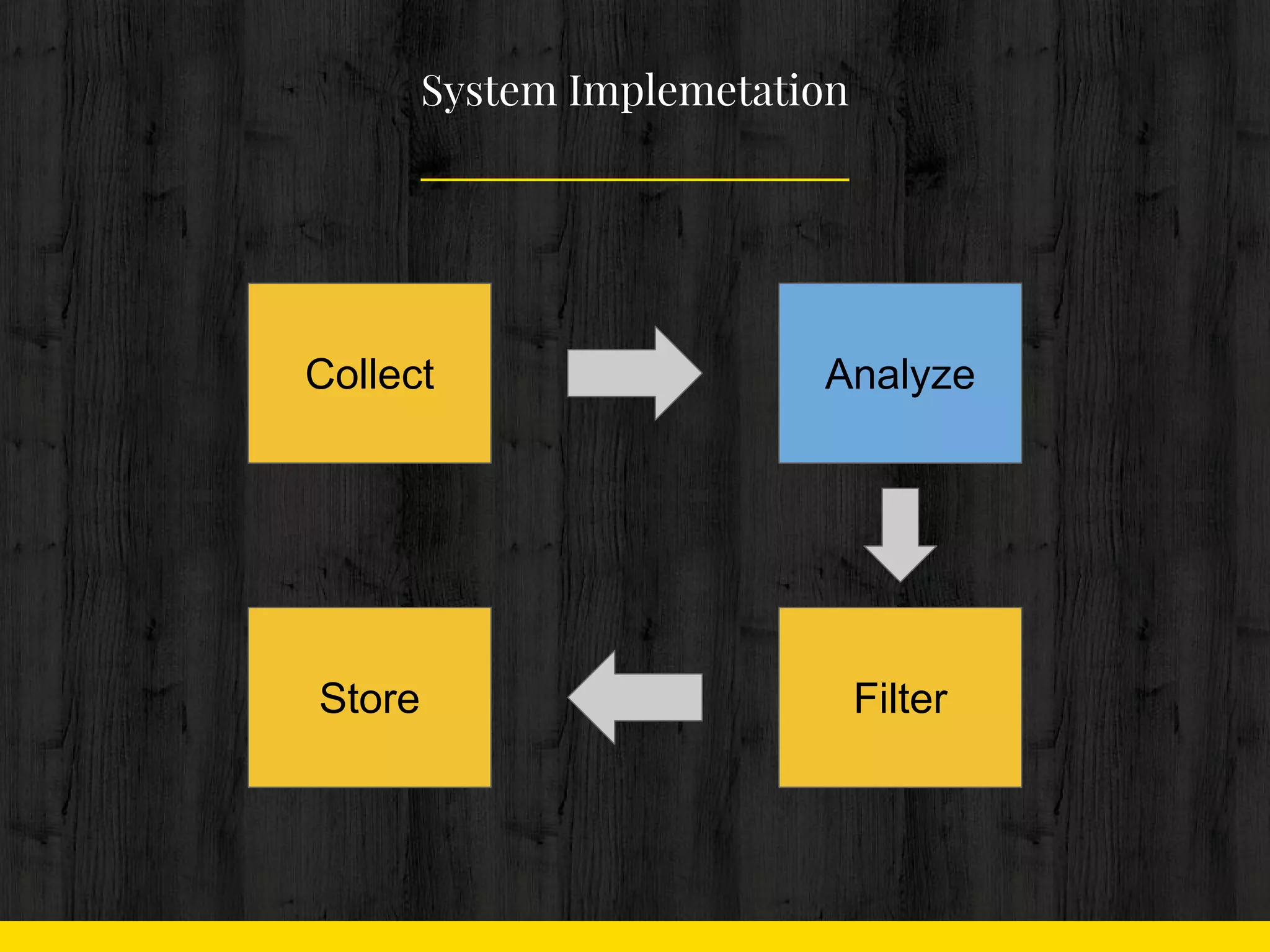
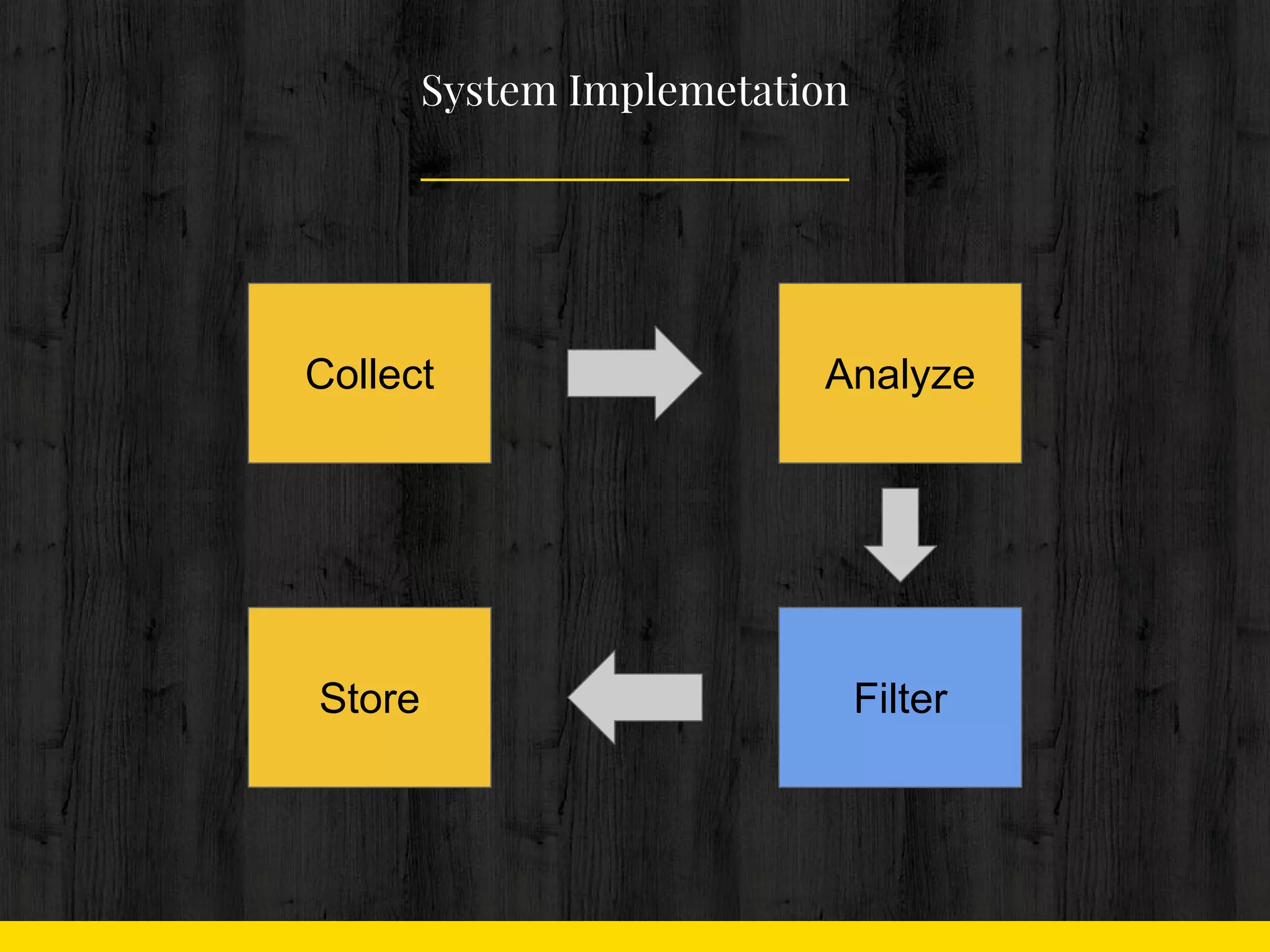
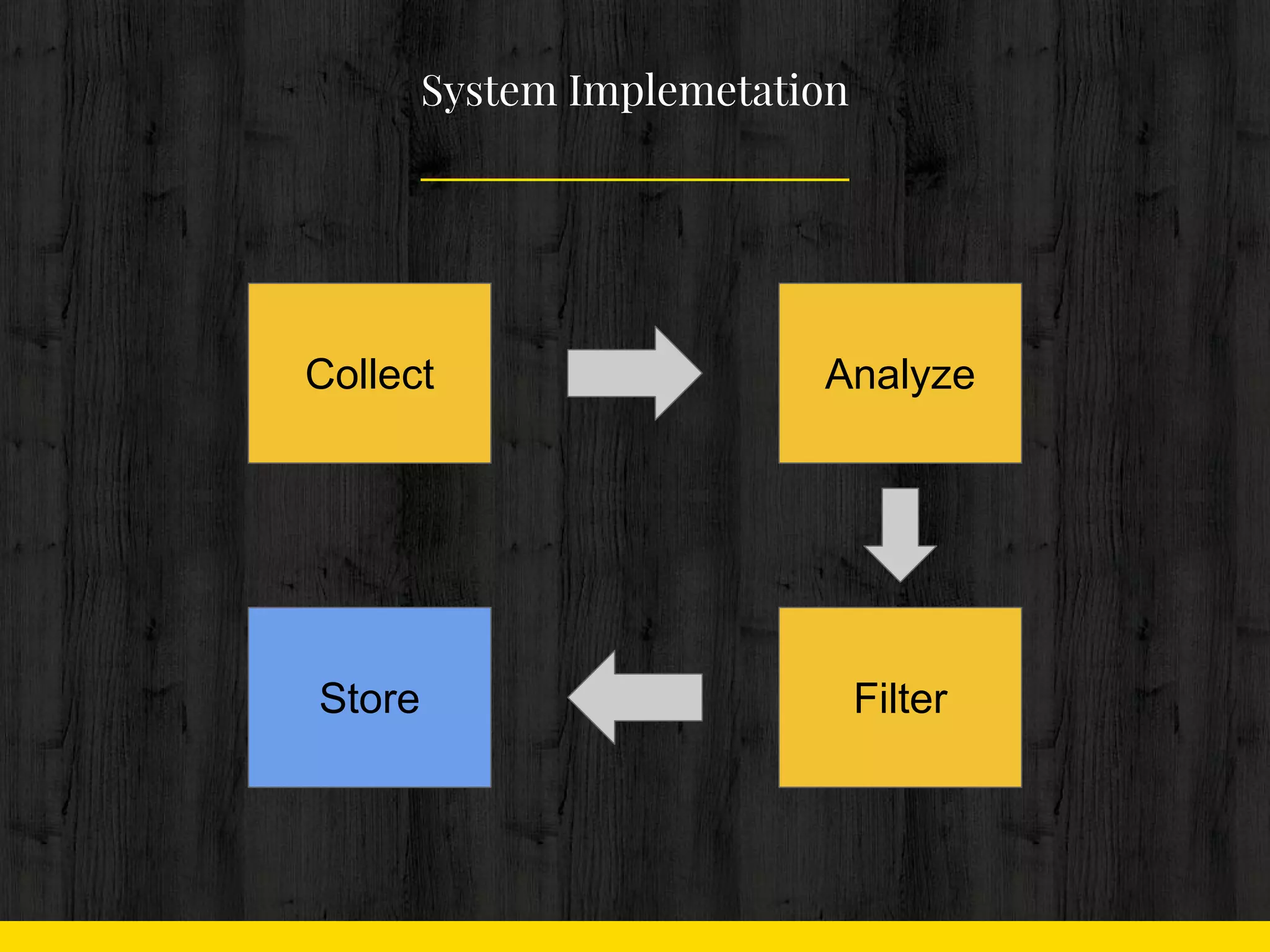
Collect
! scp 채택
- 제일 빠르고 안전.
- 솔루션의 결함을 의심할 필요 없음
- 장애 발생시 복원 작업이 수월
23. ● 가정
○ 서버 : 30대
○ File Size : 300 MByte
○ File Row : 10만
○ 수집 서버 CPU Core : 24개
Collect
24. ● Code
○ pull 은 생략
Collect
SERVERS = ["search-server-dn%d" % index for index in xrange(1, 31)]
[pull(server) for server in SERVERS]
25. 26. 27. ● 속도 개선
○ 하드웨어
■ 세상에서 제일 싼 건 서버 비용
■ 세상에서 제일 비싼 건 당신 연봉
○ 소프트웨어
■ Pycon이니까 이 방법으로 해결해야 함
Collect
28. ● 속도 개선
○ multiprocessing 도입
Collect
import multiprocessing
process_list = [multiprocessing.Process(target=pull, args=(server, )) for
server in SERVERS]
[process.start() for process in process_list]
[process.join() for process in process_list]
[pull(server) for server in SERVERS]
30. ● Java로 했다면..
Collect
public static void main(String[]args){
ArrayList<Thread>threads=new ArrayList<Thread>();
for(int i=0;i<30;i++){
Thread t=new Thread(new Pull(i));
t.start();
threads.add(t);
}
for(int i=0;i<threads.size();i++){
Thread t=threads.get(i);
try{
t.join();
}catch(Exception e){
}
}
}
32. 33. 34. ● 할 일
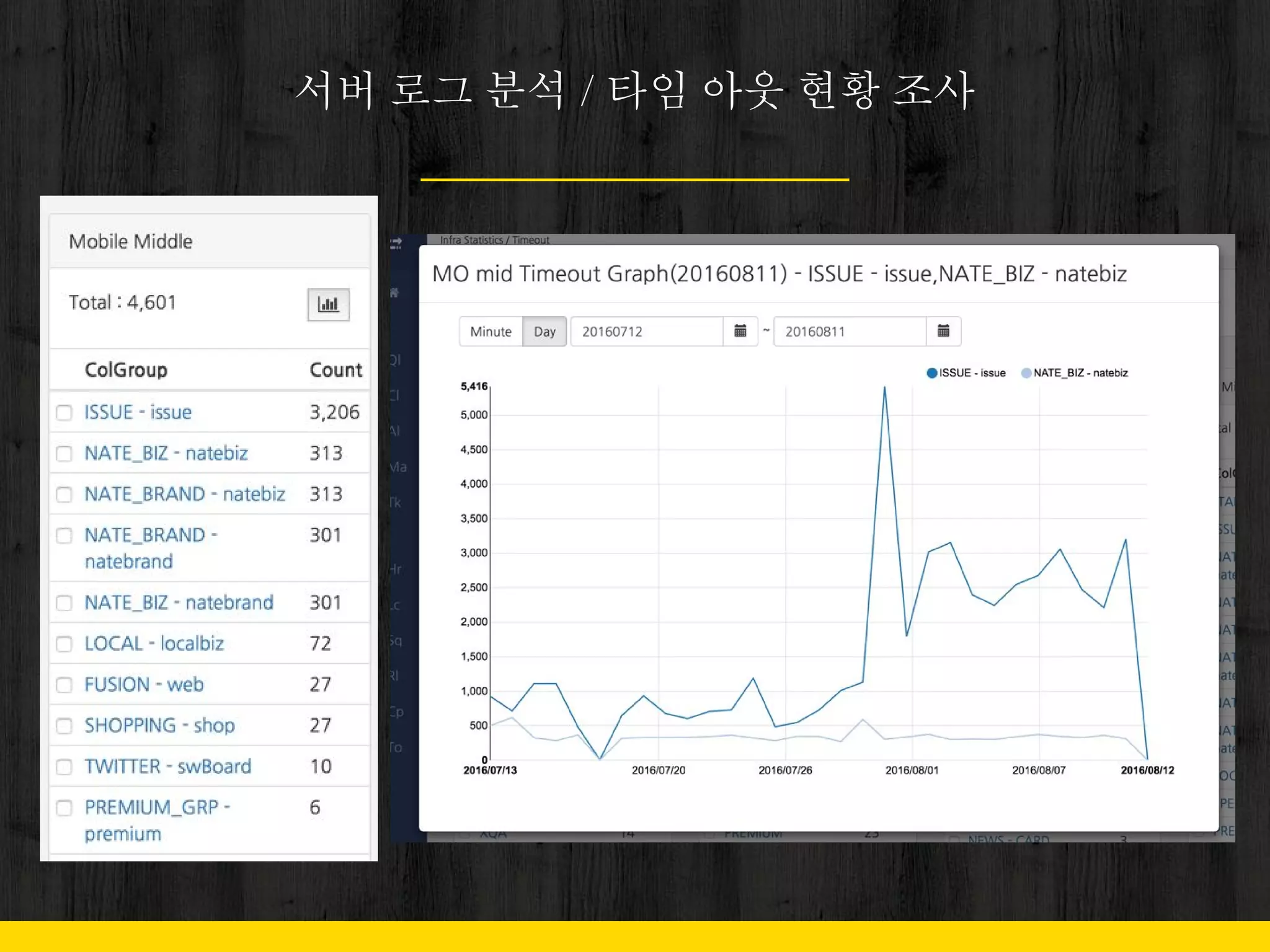
○ 어뷰저 탐색
■ 상위에 Rating 되는 검색어를
극소수의 사용자가 검색
■ Bot에 의한 Crawling
Analyze
35. 36. 37. 38. ● 할 일
○ 앞서 조사한 어뷰저를 제거
○ 정제된 로그는 압축 ( gzip )
■ Network Traffic 최소화
Filter
39. ● Code
Filter
def purify(raw_file_name):
log_file = gzip.open(raw_file_name + ".gz", "w")
abuse_cnt = 0
success_cnt = 0
with open(raw_file_name, "r") as raw:
for line in raw.read().splitlines():
if line in abuse:
abuse_cnt += 1
else:
success_cnt += 1
log_file.write(line)
print "Success : %d, Abuse : %d" % (success_cnt, abuse_cnt)
40. 41. 42. ● 속도 개선
○ multiprocessing 적용
■ 서버별로 받아서, 나뉘어져 있던 파일에
각각 Filtering 적용
■ gzip의 merge하기 쉬운 장점을 이용
■ 1 process -> 30 process
Filter
43. 44. 45. 46. ● 할 일
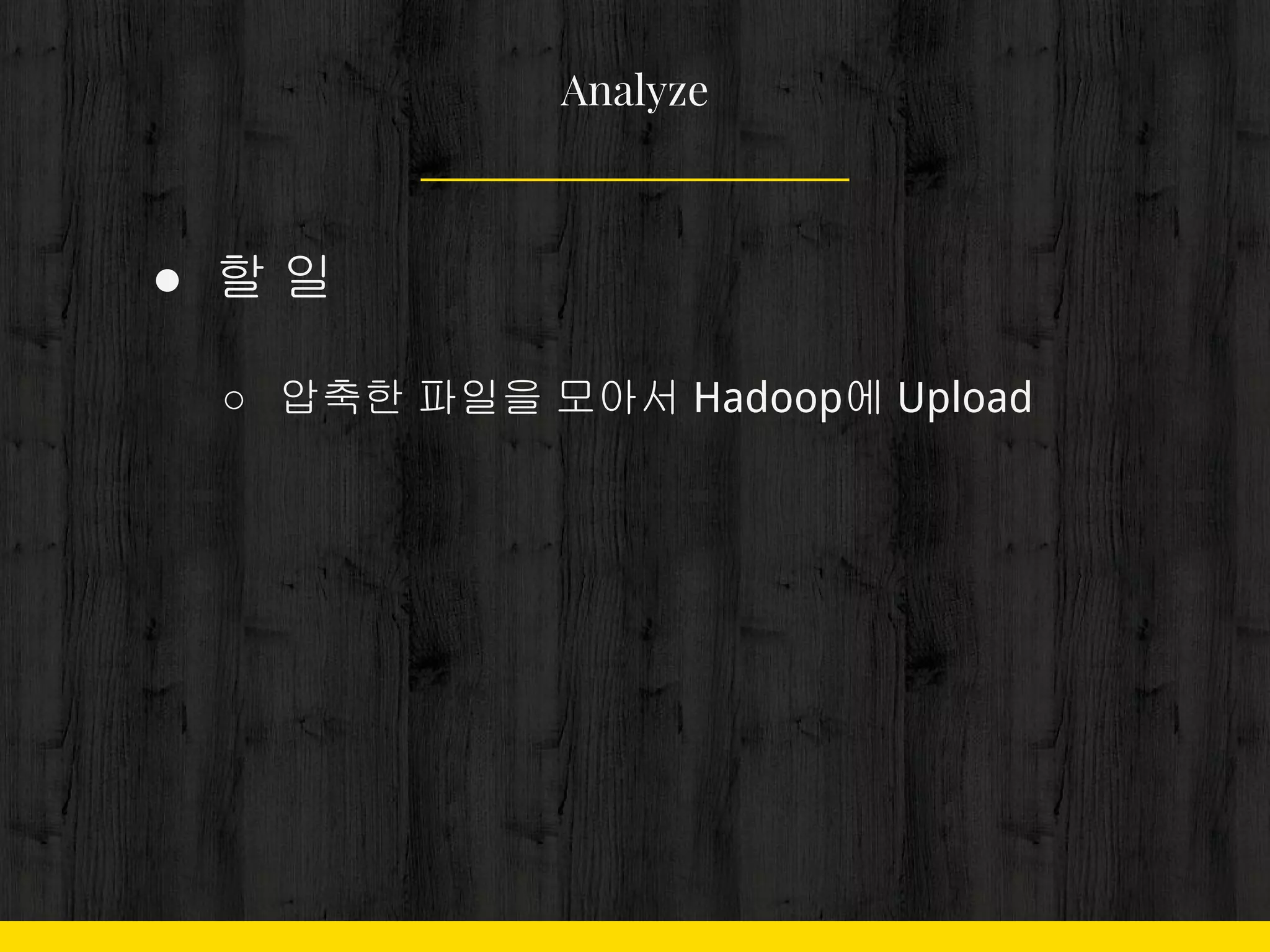
○ 압축한 파일을 모아서 Hadoop에 Upload
Analyze
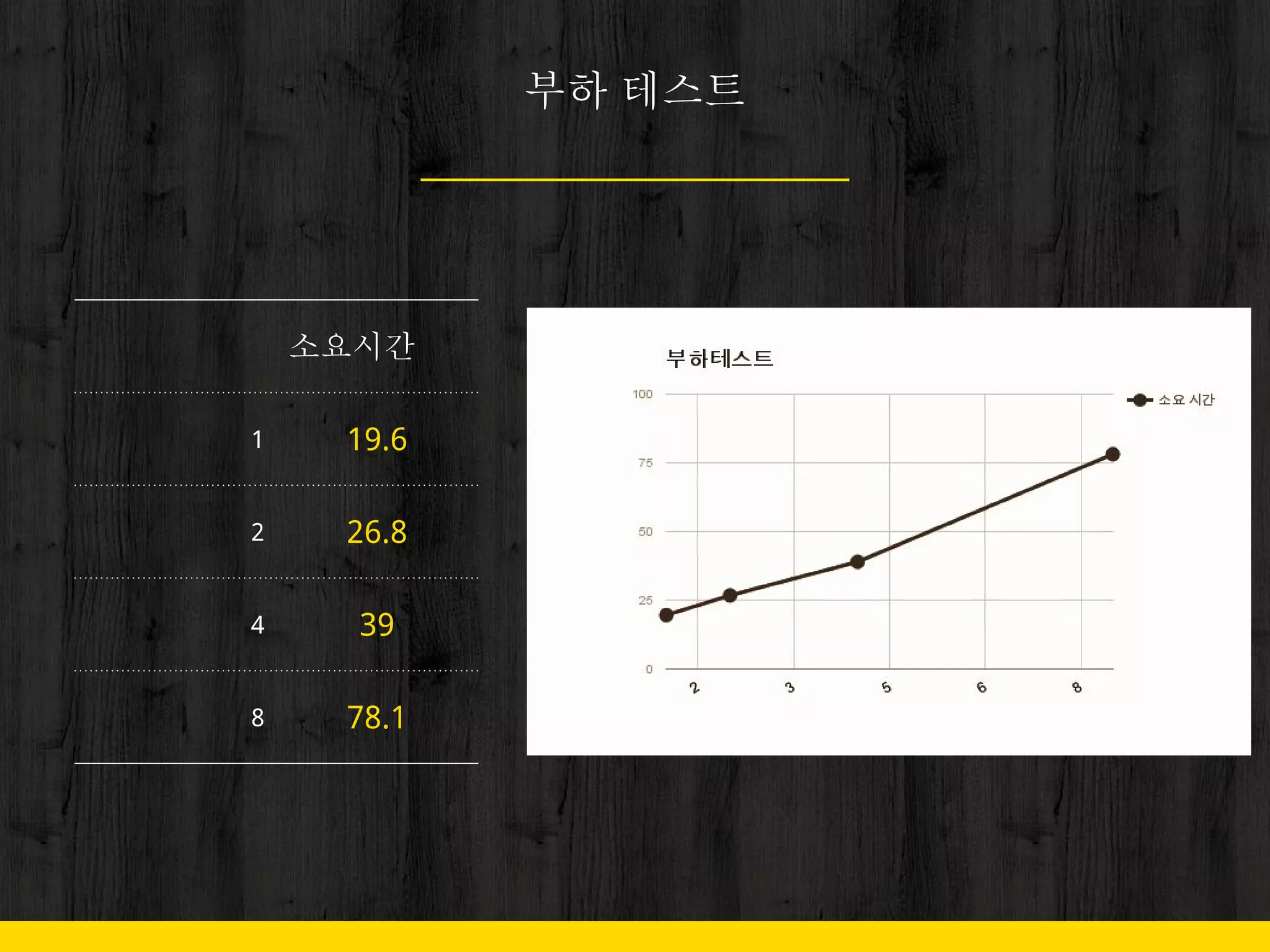
47. 48. 49. 50. 51. 52. 60초가 넘으면
● 로그 정제
○ 사용하지 않는 데이터 제거
○ 사용처에 따라 로그를 분할
● 서버 Upgrade
○ SSD 설치해달라고 조르기
○ 담당할 서버를 나눠서 병렬 처리
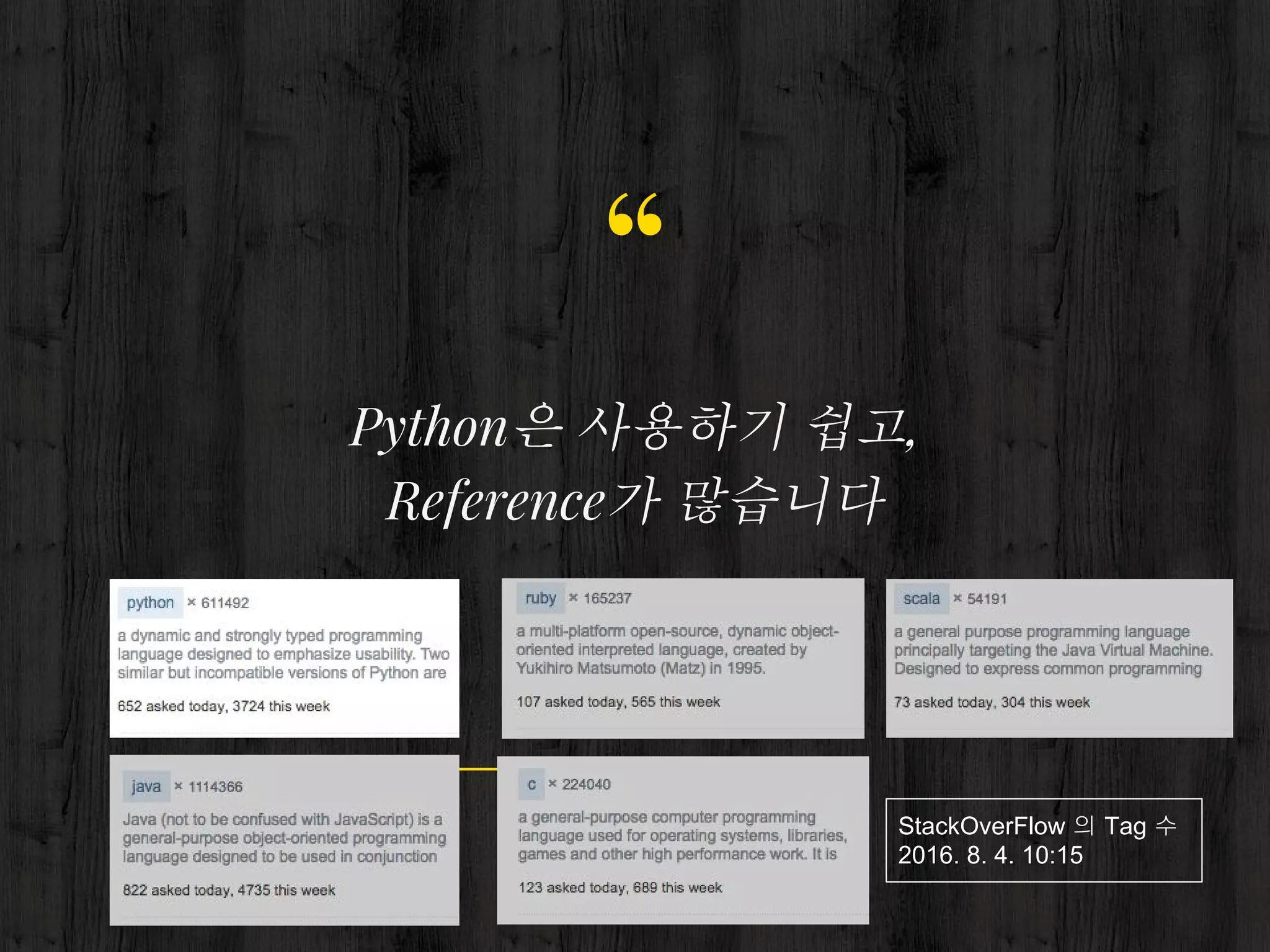
53. 54. Why Python
● 빠른 구현
● 풍부한 라이브러리
● 시스템 커스터마이징
○ 자동 재시도 기능
○ 장애 알림 기능
○ 장애 복구 기능
Impala
1.0.1 (Prod) 출시 : 2013. 6
Impyla
0.7 출시 : 2013. 5
55. Why Python
● vs LogStash, Fluentd
○ 단점
■ Streaming 안함
■ Visualization 안함
■ PetaByte 처리 못함
56. Why Python
● vs LogStash, Fluentd
○ 장점
■ 안정성
● Tool의 bug 걱정 없음
● Pull 방식의 중앙 집중화된 시스템
■ 기능 확장
● RealTime 어뷰징 분석 / 적용
● 각종 Customizing 적용 용이
● 풍부한 Python의 Library를 사용 가능
57. Why Python
● 장애 감소
○ 이전 Version
■ Java로 구성
■ 월 1-2회 장애 발생 ( Traffic )
○ 이후 Version
■ Python 으로 구성
■ 연 2-4회 장애 발생 ( 개발자 실수 )
58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. (private) 예매 가능 확인
● 잔여석 조회 API가 노출된 일부 사이트
● API를 호출, 응답 내용을 파싱
● 잔여석이 1 이상일 때 메신저를 통해 알림
● 명절 때 요긴
69. 70. 71. 72. 73. 74.

















![● Code
○ pull 은 생략
Collect
SERVERS = ["search-server-dn%d" % index for index in xrange(1, 31)]
[pull(server) for server in SERVERS]](https://image.slidesharecdn.com/20160814-102-53-kimdongmoon-160822115246/75/with-Python-24-2048.jpg)



![● 속도 개선
○ multiprocessing 도입
Collect
import multiprocessing
process_list = [multiprocessing.Process(target=pull, args=(server, )) for
server in SERVERS]
[process.start() for process in process_list]
[process.join() for process in process_list]
[pull(server) for server in SERVERS]](https://image.slidesharecdn.com/20160814-102-53-kimdongmoon-160822115246/75/with-Python-28-2048.jpg)

![● Java로 했다면..
Collect
public static void main(String[]args){
ArrayList<Thread>threads=new ArrayList<Thread>();
for(int i=0;i<30;i++){
Thread t=new Thread(new Pull(i));
t.start();
threads.add(t);
}
for(int i=0;i<threads.size();i++){
Thread t=threads.get(i);
try{
t.join();
}catch(Exception e){
}
}
}](https://image.slidesharecdn.com/20160814-102-53-kimdongmoon-160822115246/75/with-Python-30-2048.jpg)








![● Code
Filter
process_list =
[multiprocessing.Process(target=purify,
args=("/pycon/incoming/min_log.%s" % server, ))
for server in SERVERS]
[process.start() for process in process_list]
[process.join() for process in process_list]](https://image.slidesharecdn.com/20160814-102-53-kimdongmoon-160822115246/75/with-Python-43-2048.jpg)























![[135] 오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다.](https://cdn.slidesharecdn.com/ss_thumbnails/35-171016061446-thumbnail.jpg?width=640&height=640&fit=bounds)


![[224]nsml 상상하는 모든 것이 이루어지는 클라우드 머신러닝 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/224nsml-171017024133-thumbnail.jpg?width=640&height=640&fit=bounds)
![[231]운영체제 수준에서의 데이터베이스 성능 분석과 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/231-171017003147-thumbnail.jpg?width=640&height=640&fit=bounds)
![[112]clova platform 인공지능을 엮는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/12clovaplatform-171016022611-thumbnail.jpg?width=640&height=640&fit=bounds)


![[214] data science with apache zeppelin](https://cdn.slidesharecdn.com/ss_thumbnails/241datasciencewithapachezeppelin-150915001420-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![[241] Storm과 Elasticsearch를 활용한 로깅 플랫폼의 실시간 알람 시스템 구현](https://cdn.slidesharecdn.com/ss_thumbnails/83713-150915040003-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[252] 증분 처리 플랫폼 cana 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/225cana-150915052201-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2018] NHN 모니터링의 현재와 미래 for 인프라 엔지니어](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra02-190131073314-thumbnail.jpg?width=640&height=640&fit=bounds)





![[211]대규모 시스템 시각화 현동석김광림](https://cdn.slidesharecdn.com/ss_thumbnails/211-161025004529-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]네트워크 모니터링 시스템(nms)을 지탱하는 기술](https://cdn.slidesharecdn.com/ss_thumbnails/244nms-171017030833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)






![[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









![[2015-05월 세미나] 파이선 초심자의 Openstack](https://cdn.slidesharecdn.com/ss_thumbnails/openstack-150530064311-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[RAG Tutorial] 02. RAG 프로젝트 파이프라인.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/02ragpublish-240714074953-8d0ec793-thumbnail.jpg?width=640&height=640&fit=bounds)

