Download to read offline















![Loop Parallel
If each iteration in a loop only depends on that
iteration results + read only data, each iteration
can run in a different thread
As it’s based on data, also called data parallelism
int[] A = .. int[] B = .. int[] C = ..
for (int i; i<N; i++){
C[i] = F(A[i], B[i])
}
19](https://image.slidesharecdn.com/08-solutionpatterns-240108065305-2aa120a8/75/Solution-Patterns-for-Parallel-Programming-19-2048.jpg)
![Which for These are Loop Parallel?
int[] A = .. int[] B = .. int[] C = ..
for (int i; i<N; i++){
C[i] = F(A[i], B[i-1])
}
int[] A = .. int[] B = .. int[] C = ..
for (int i; i<N; i++){
C[i] = F(A[i], C[i-1])
}
20](https://image.slidesharecdn.com/08-solutionpatterns-240108065305-2aa120a8/75/Solution-Patterns-for-Parallel-Programming-20-2048.jpg)





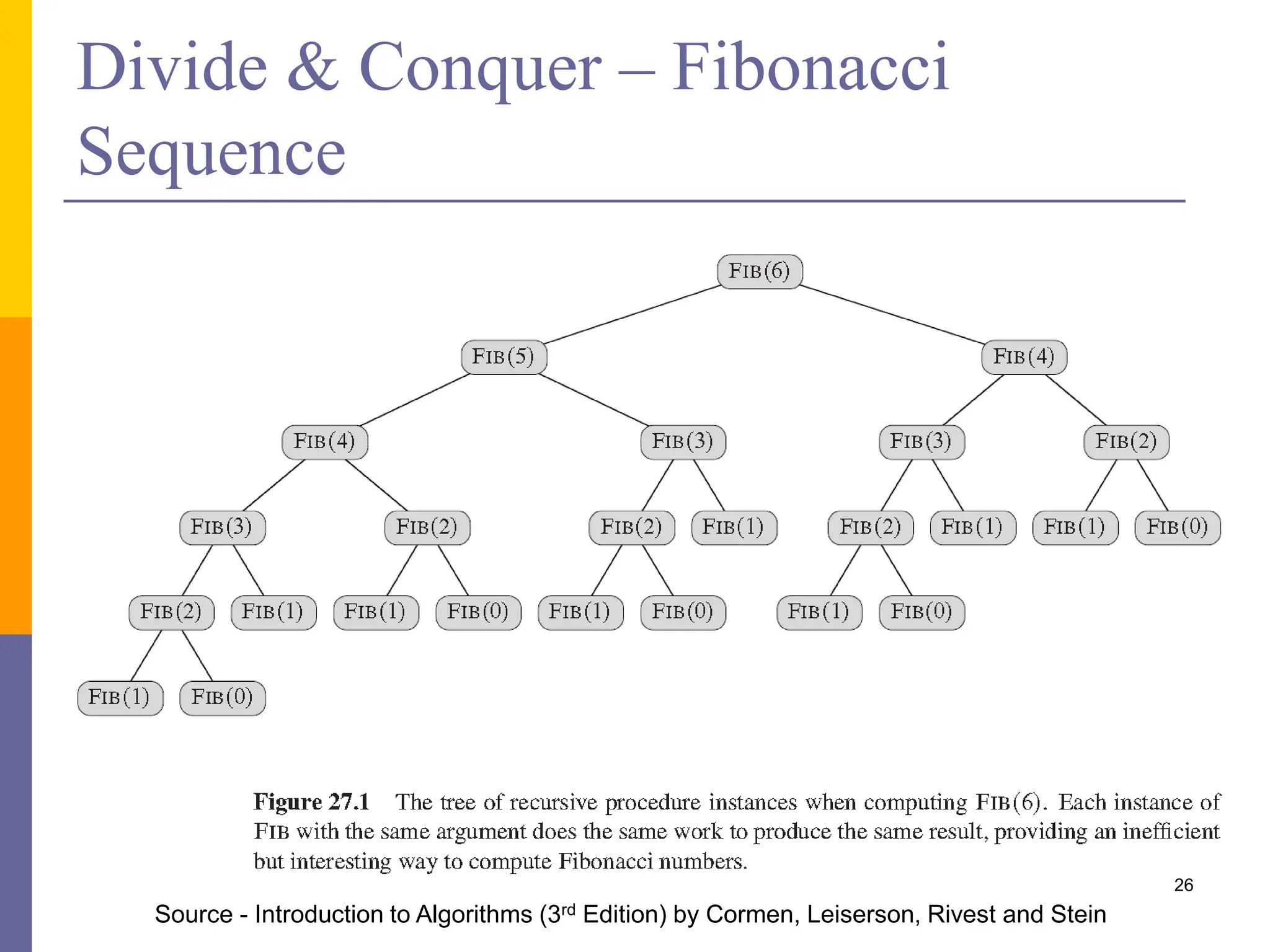
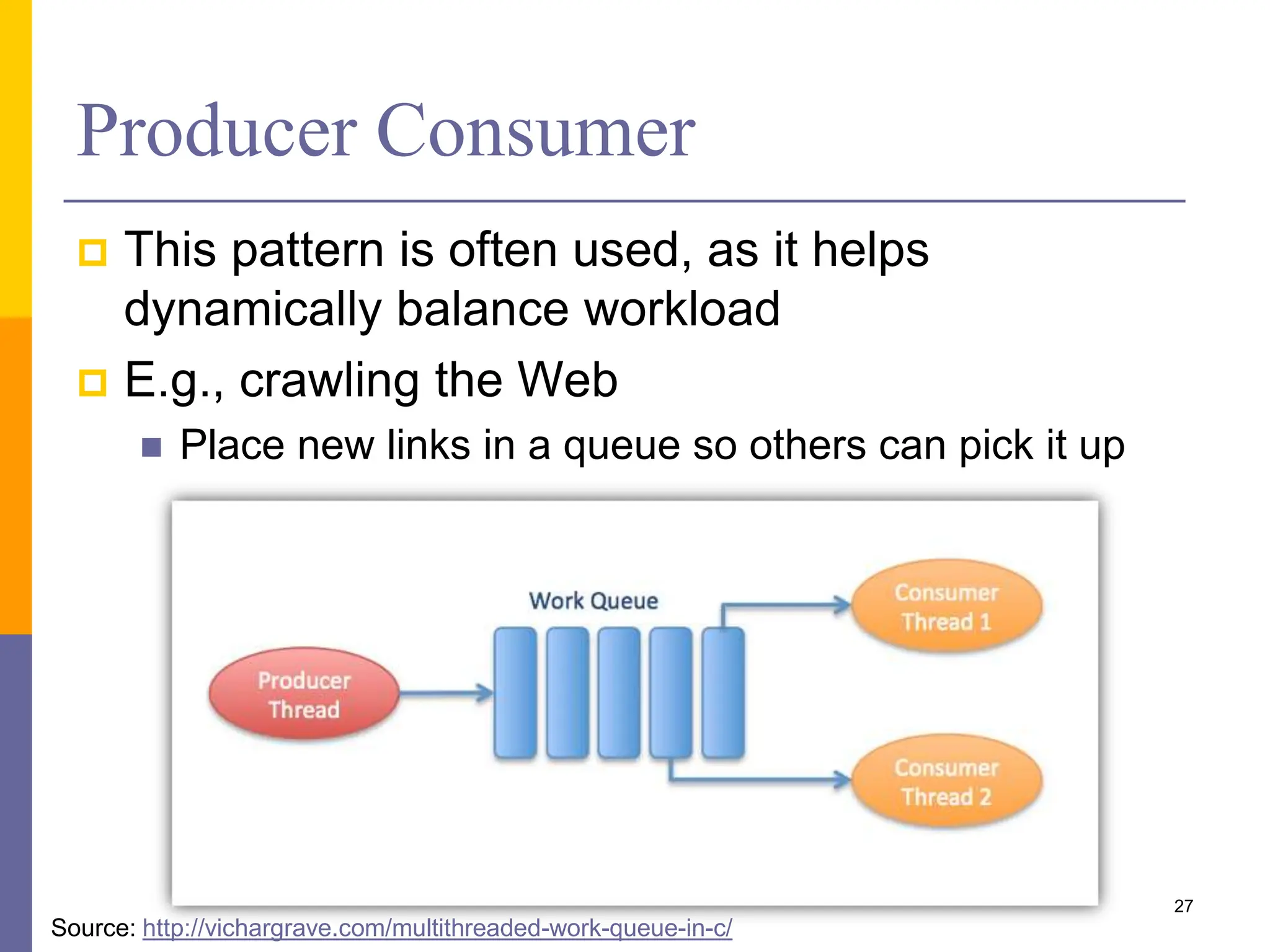

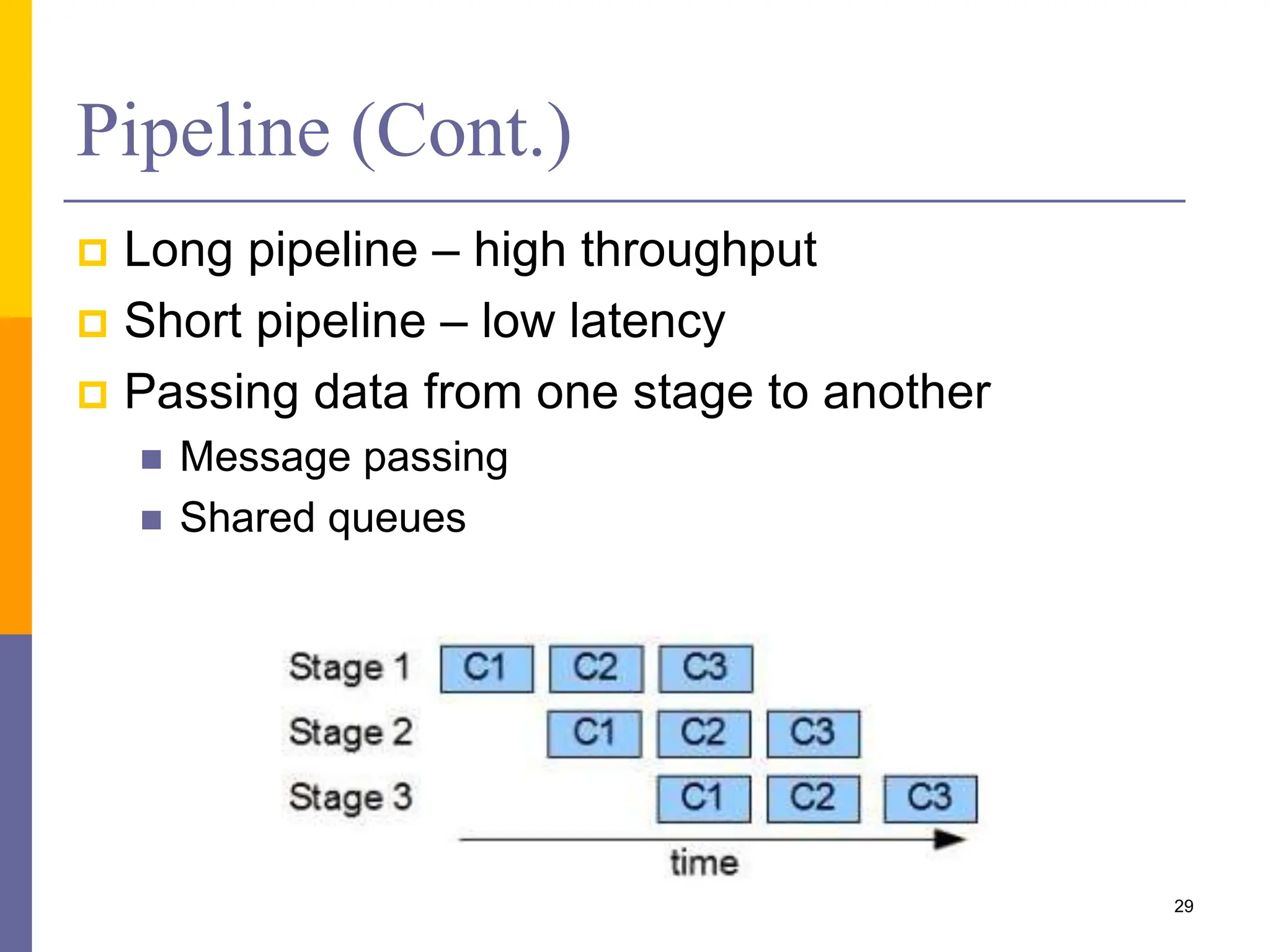

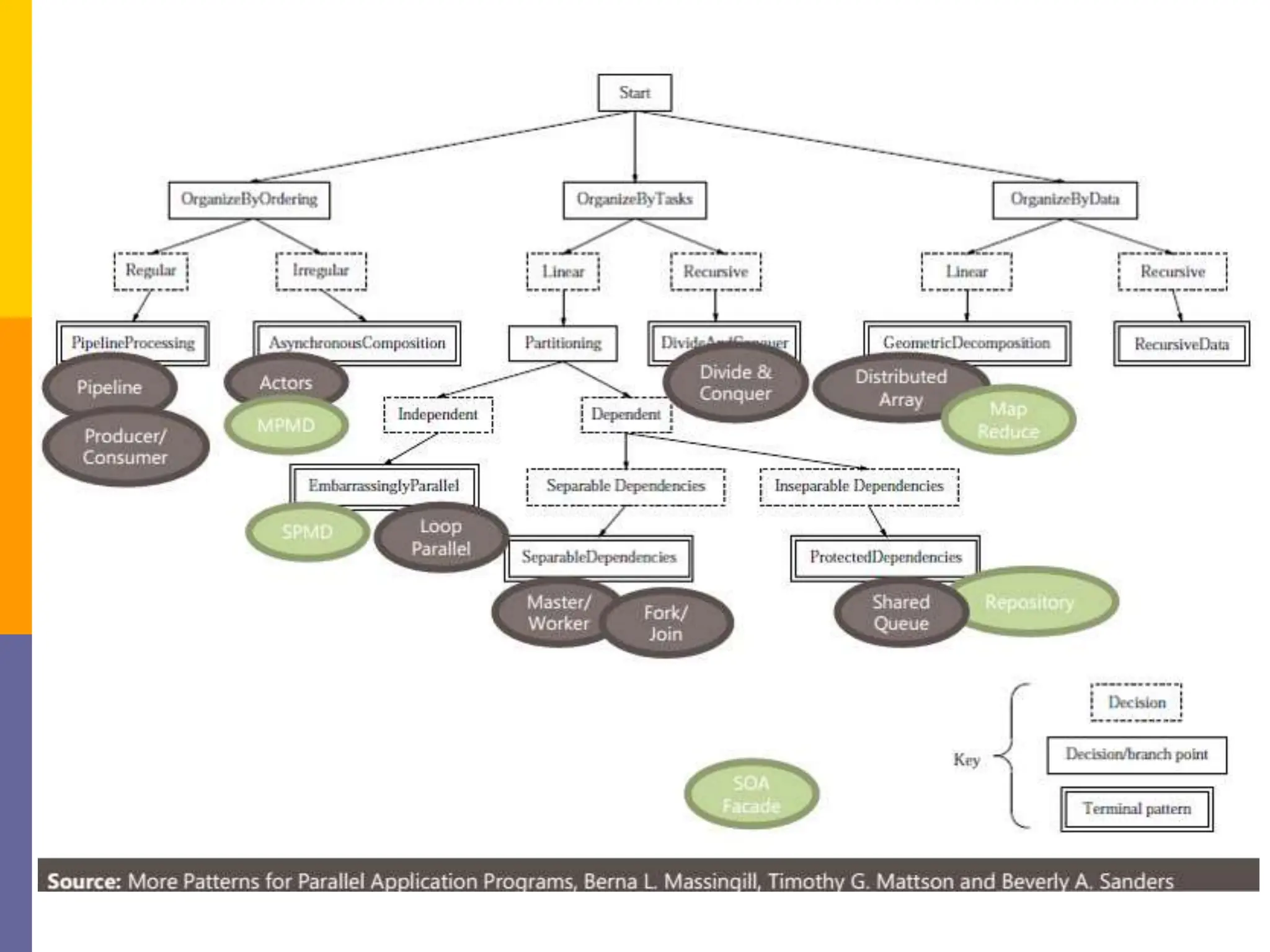

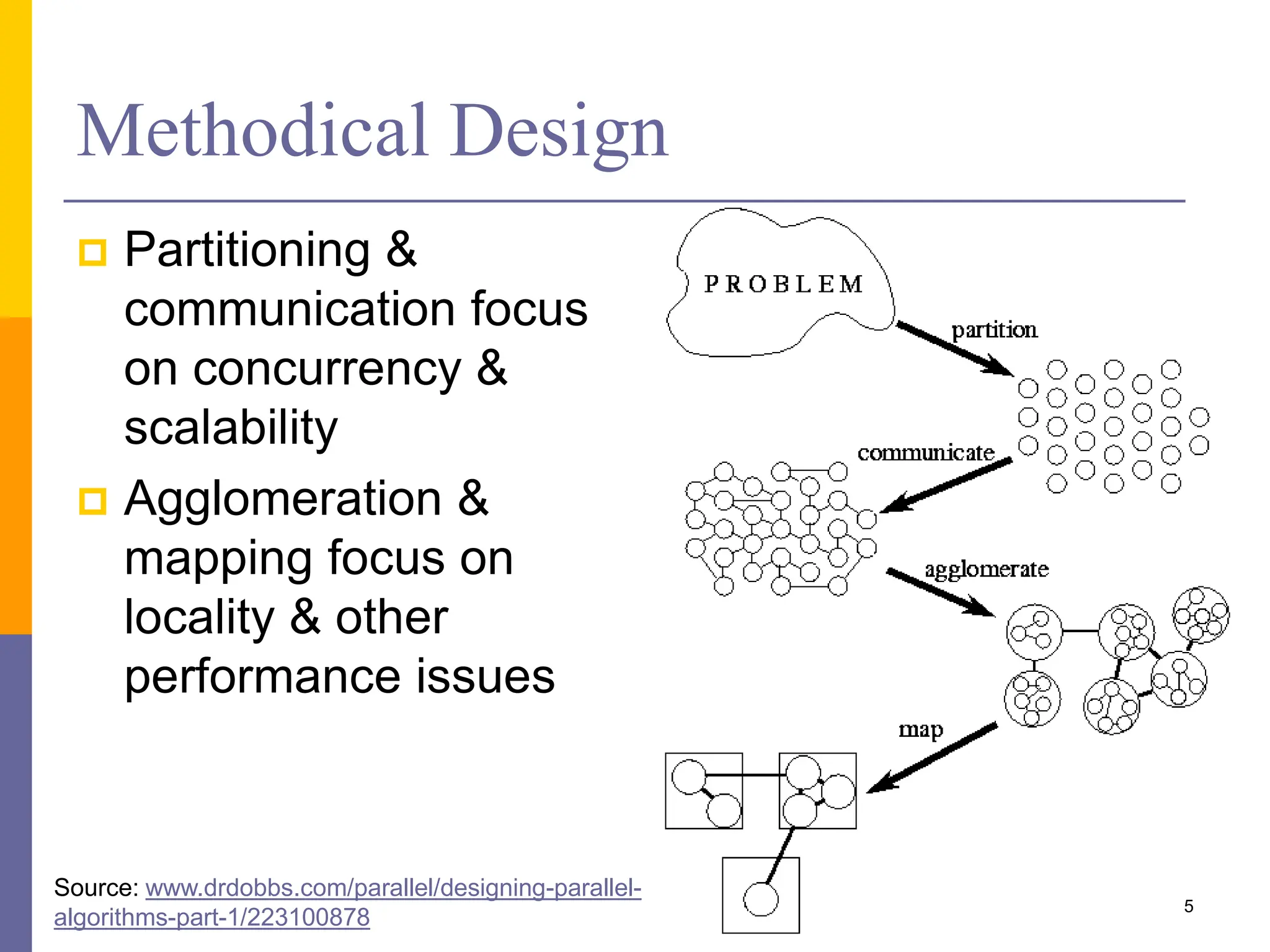
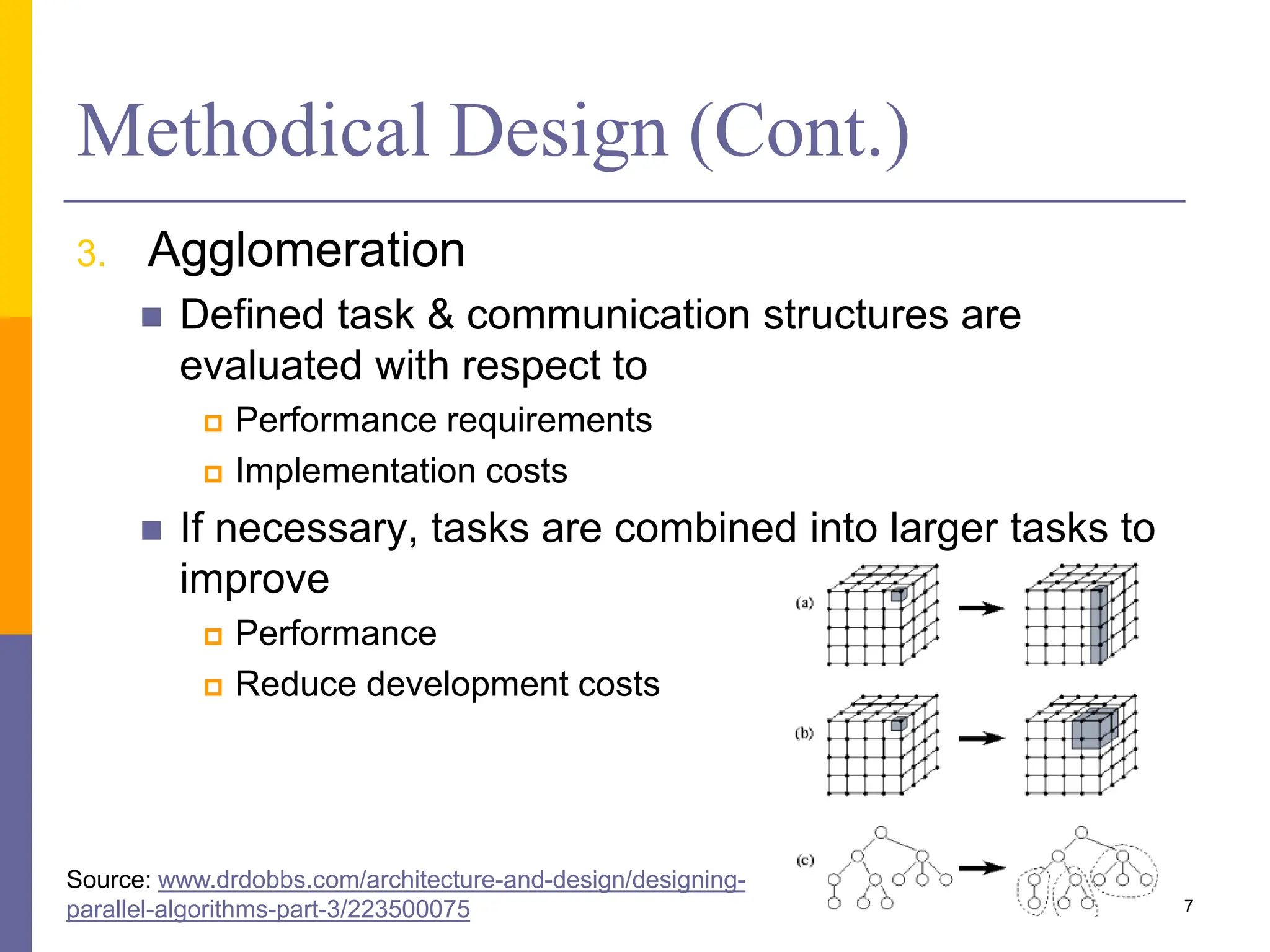
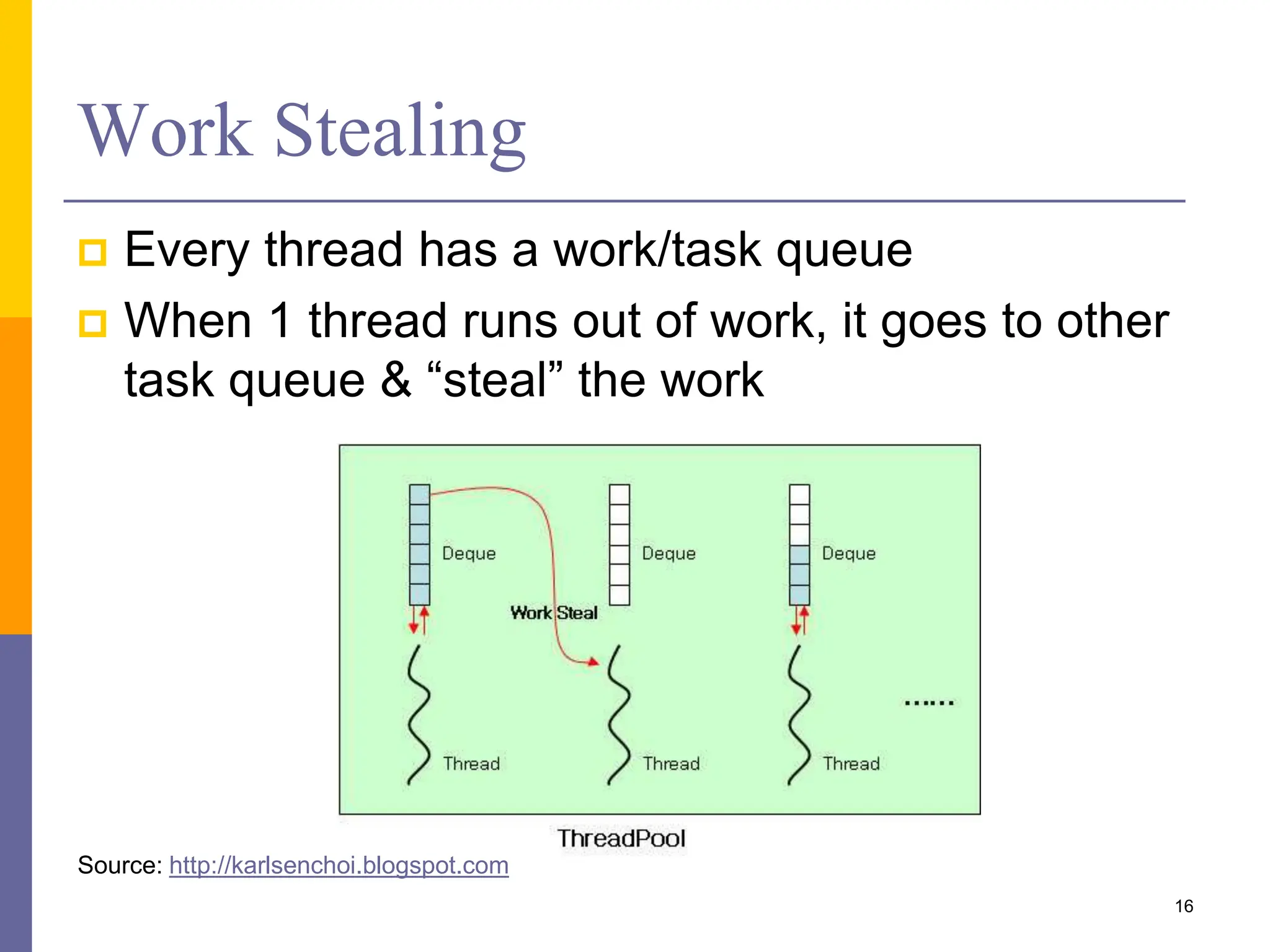
The document presents various solution patterns for parallel programming, focusing on designing algorithms that leverage concurrency and scalability. Key strategies discussed include partitioning, communication, and mapping of tasks while addressing efficiency and load balancing through methods like task queues and work stealing. Several specific patterns such as loop parallelism, fork/join, divide and conquer, and producer/consumer are highlighted, along with considerations for asynchronous agents.



































































