Downloaded 16 times


























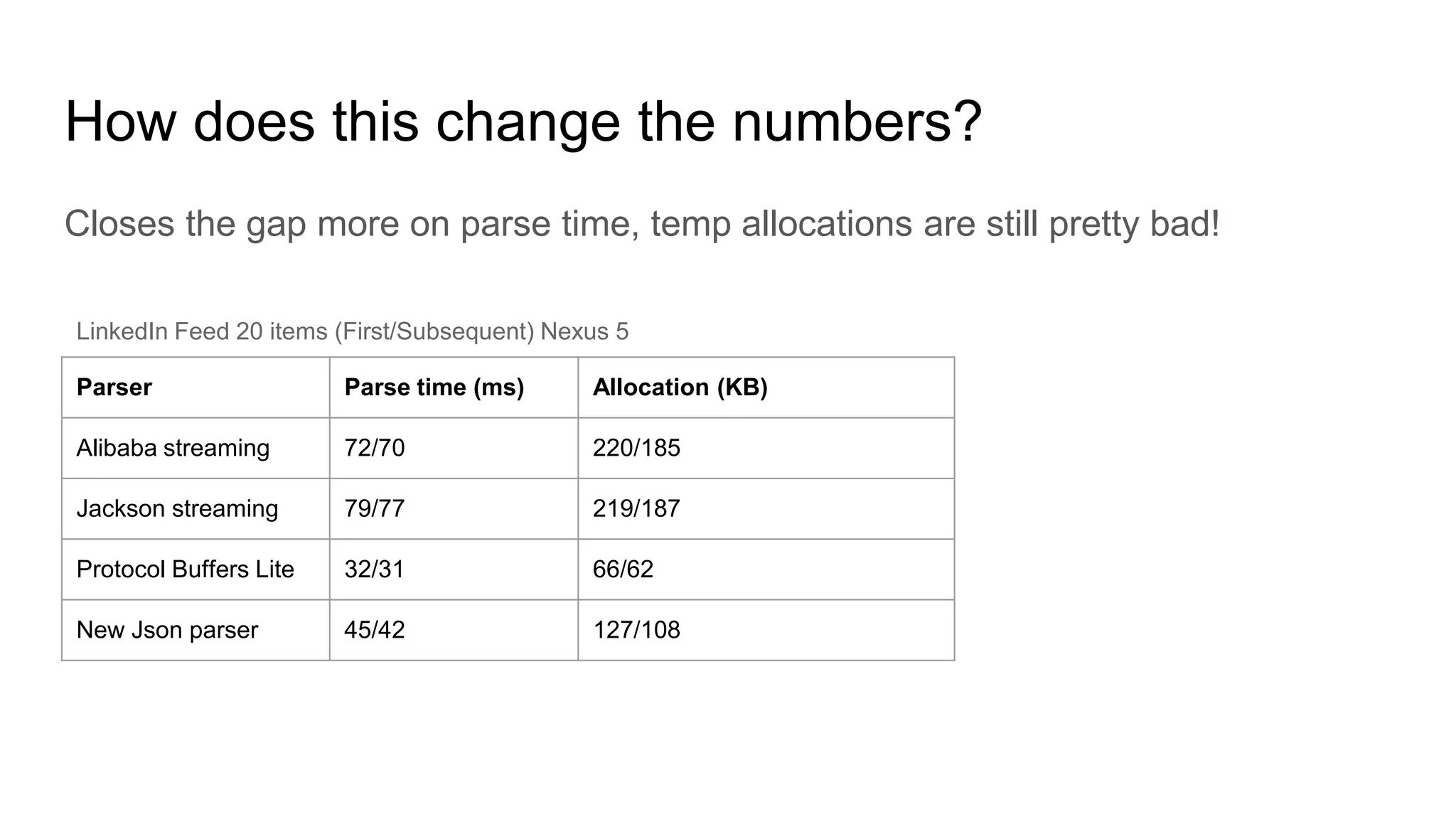




![UTF-8 decoding revised
int c = inputStream.read();
switch (UTF_8_LOOKUP_TABLE[c]) {
case 0: // read 1 byte char;
break;
case 2: // read 2 byte char;
break;
case 3: // read 3 byte char;
break;
case 4: // read 4 byte char;
break;
default: // handle error;
break;
}
1 branch, 1 comparison computation per char](https://image.slidesharecdn.com/screamingfastjsonparsing-170608024211/75/Screaming-fast-json-parsing-on-Android-39-2048.jpg)





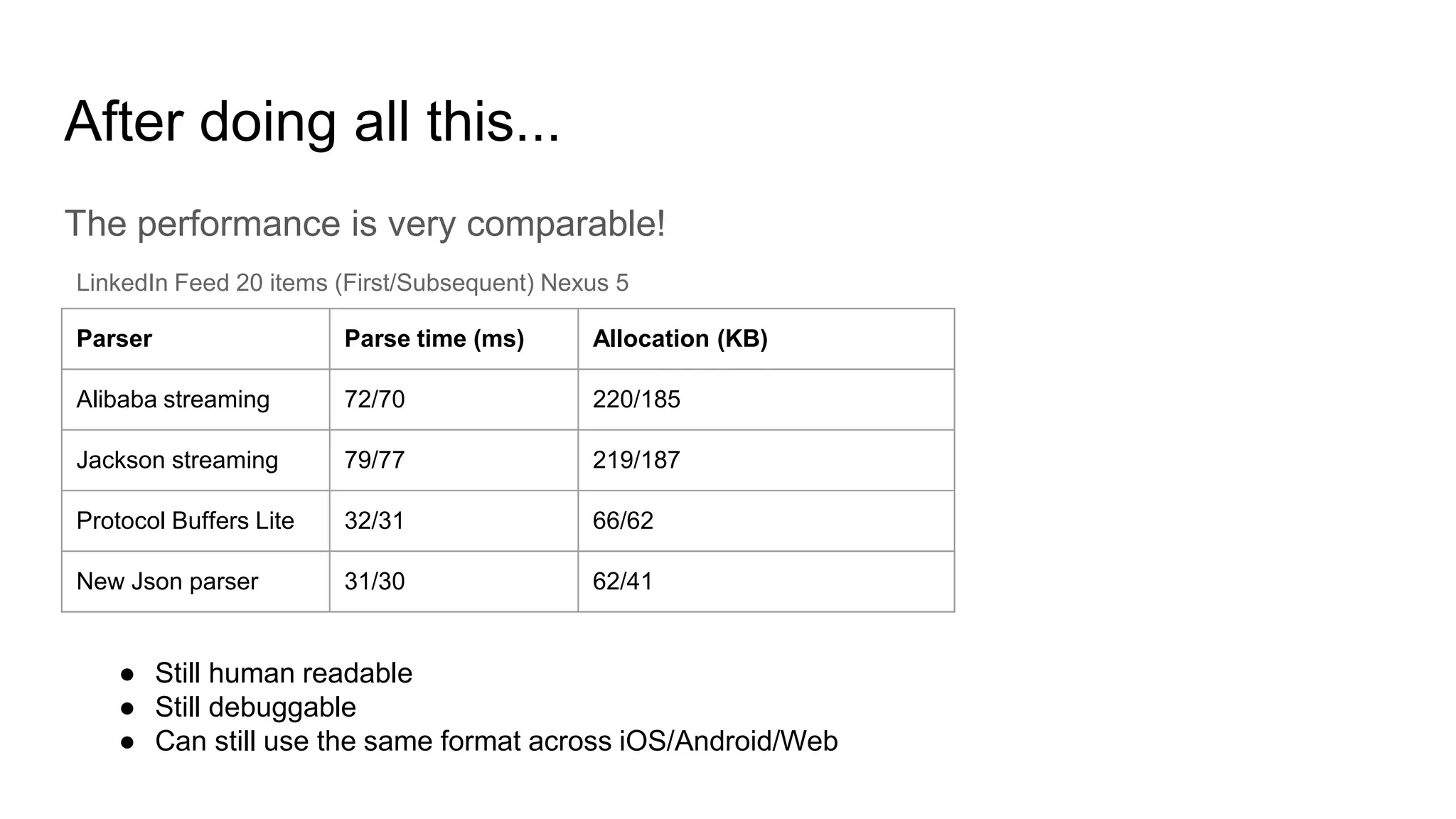






This document discusses techniques for improving JSON parsing performance on Android. It begins by introducing the author and describing LinkedIn's mobile app ecosystem. It then analyzes factors that affect JSON parsing like memory usage and parsing approaches. The document evaluates various JSON parsing libraries and binary formats. It proposes optimizations like using code generation, streaming parsing, removing JSON key comparisons via a trie, and leveraging known data schemas to further optimize parsing. Profiling revealed additional gains from eliminating byte to char conversions and temporary string allocations during parsing. The goal is to close the performance gap with highly optimized binary parsers.