Downloaded 63 times








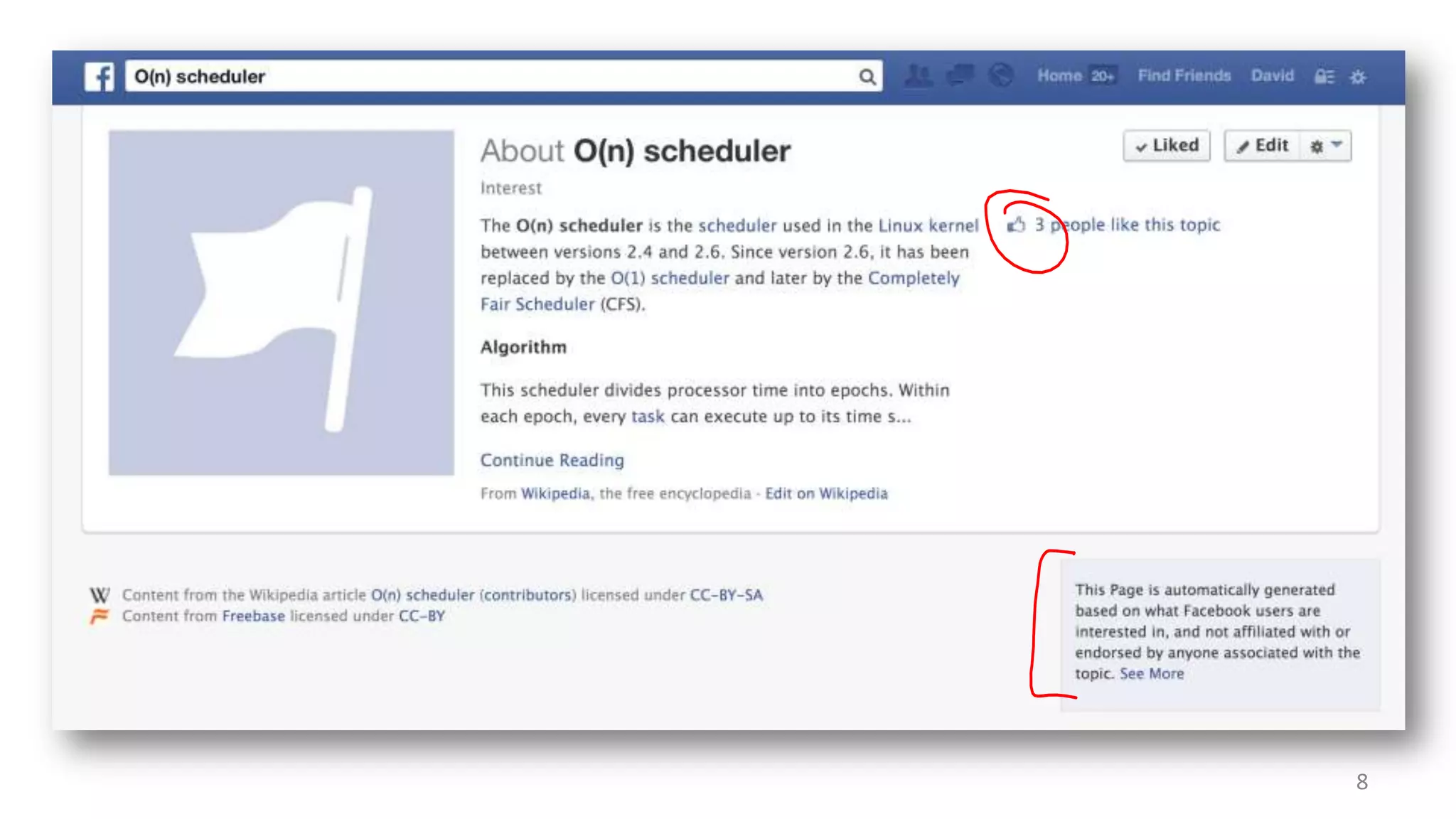

![Linux 2.6 Scheduler
(2003-2007)
struct runqueue {
struct prioarray *active;
struct prioarray *expired;
struct prioarray arrays[2];
140 different queues (for
};
each processor)
struct prioarray {
0-99 for “real time” processes
int nr_active; /* # Runnable */
100-139 for “normal” processes unsigned long bitmap[5];
struct list_head queue[140];
Bit vector of ready-to-run
};
Scheduler picks first process from highest-priority queue with a ready process
10](https://image.slidesharecdn.com/class12-inked-140304131029-phpapp02/75/Scheduling-in-Linux-and-Web-Servers-11-2048.jpg)






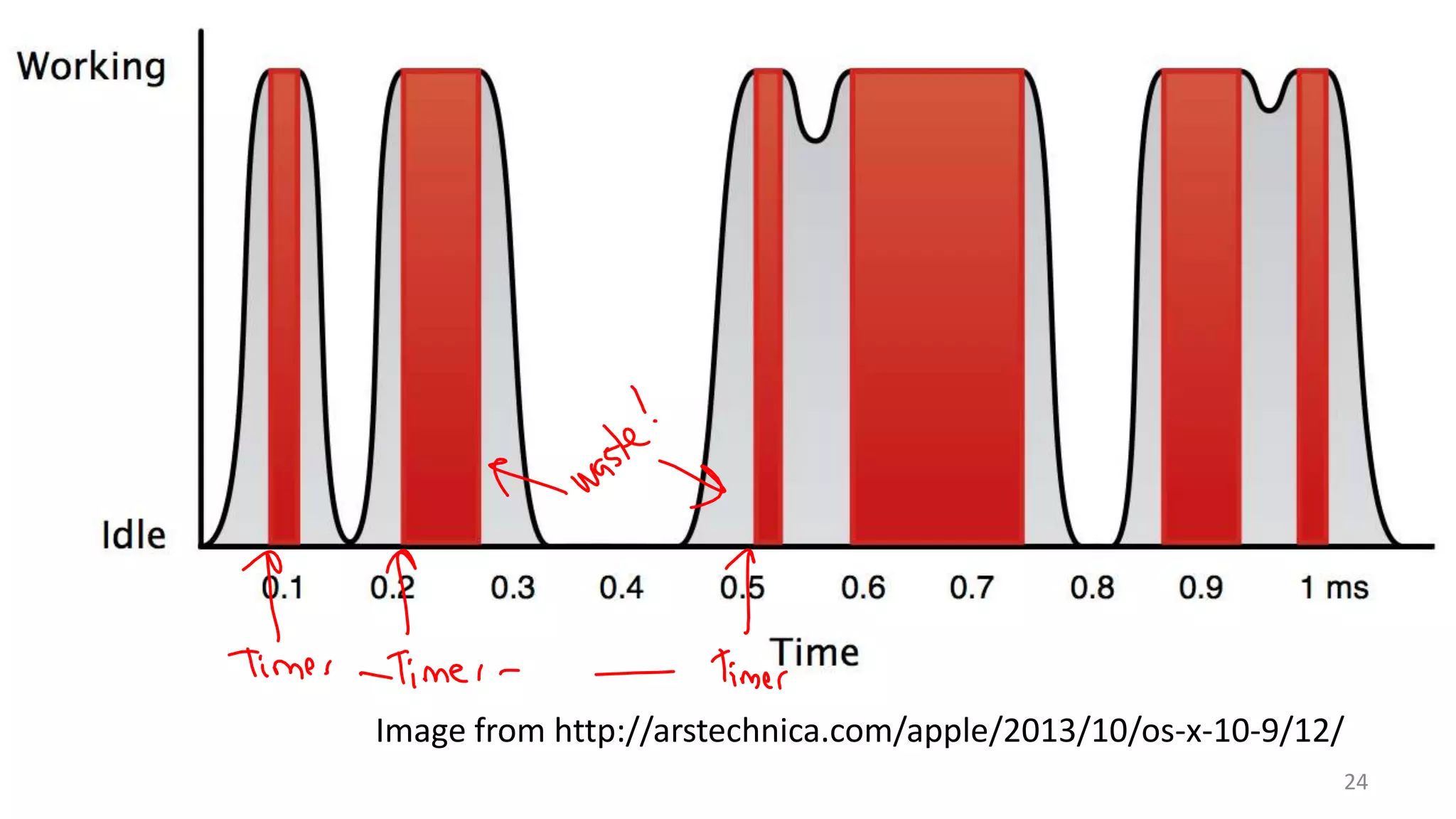
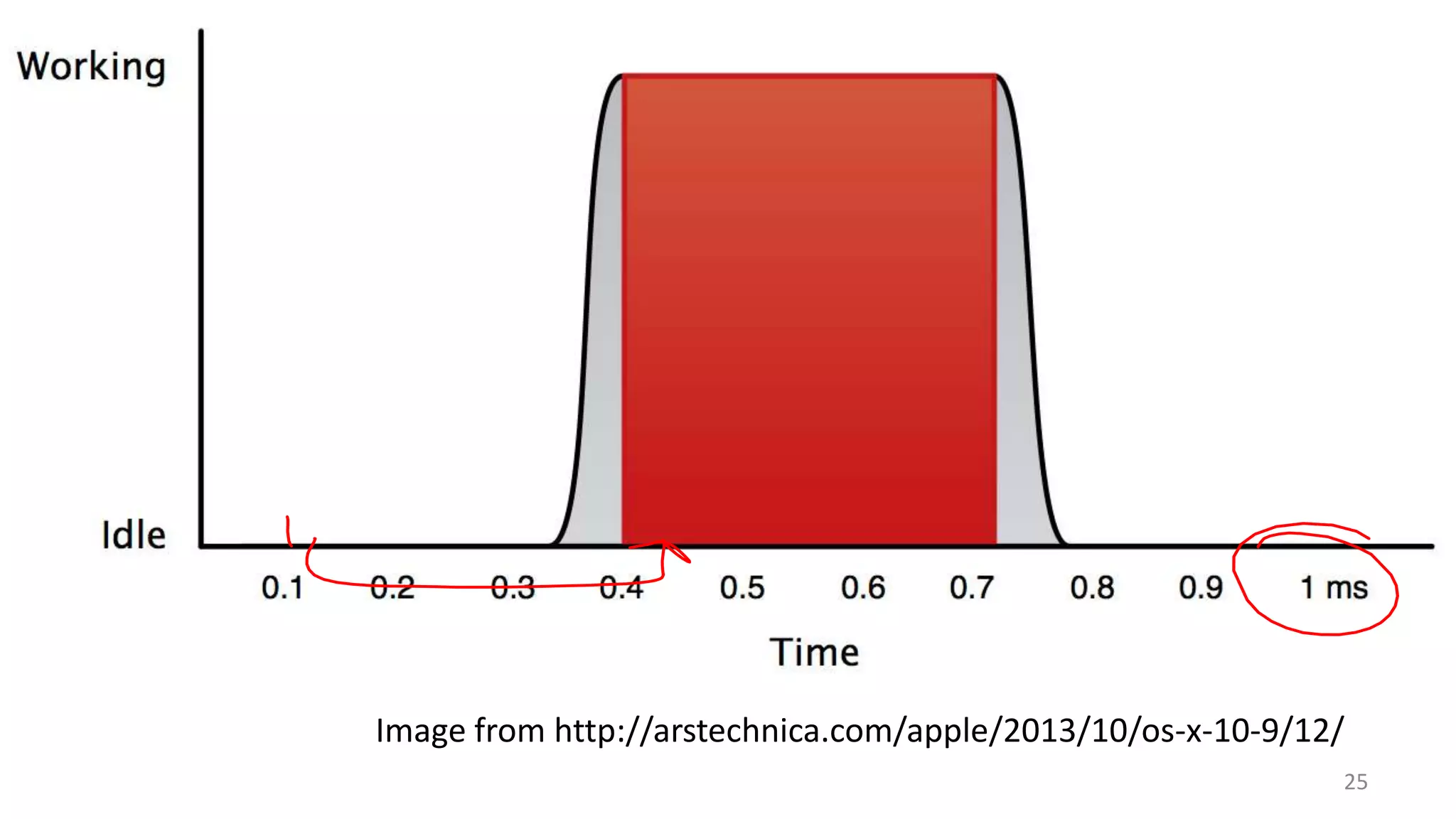
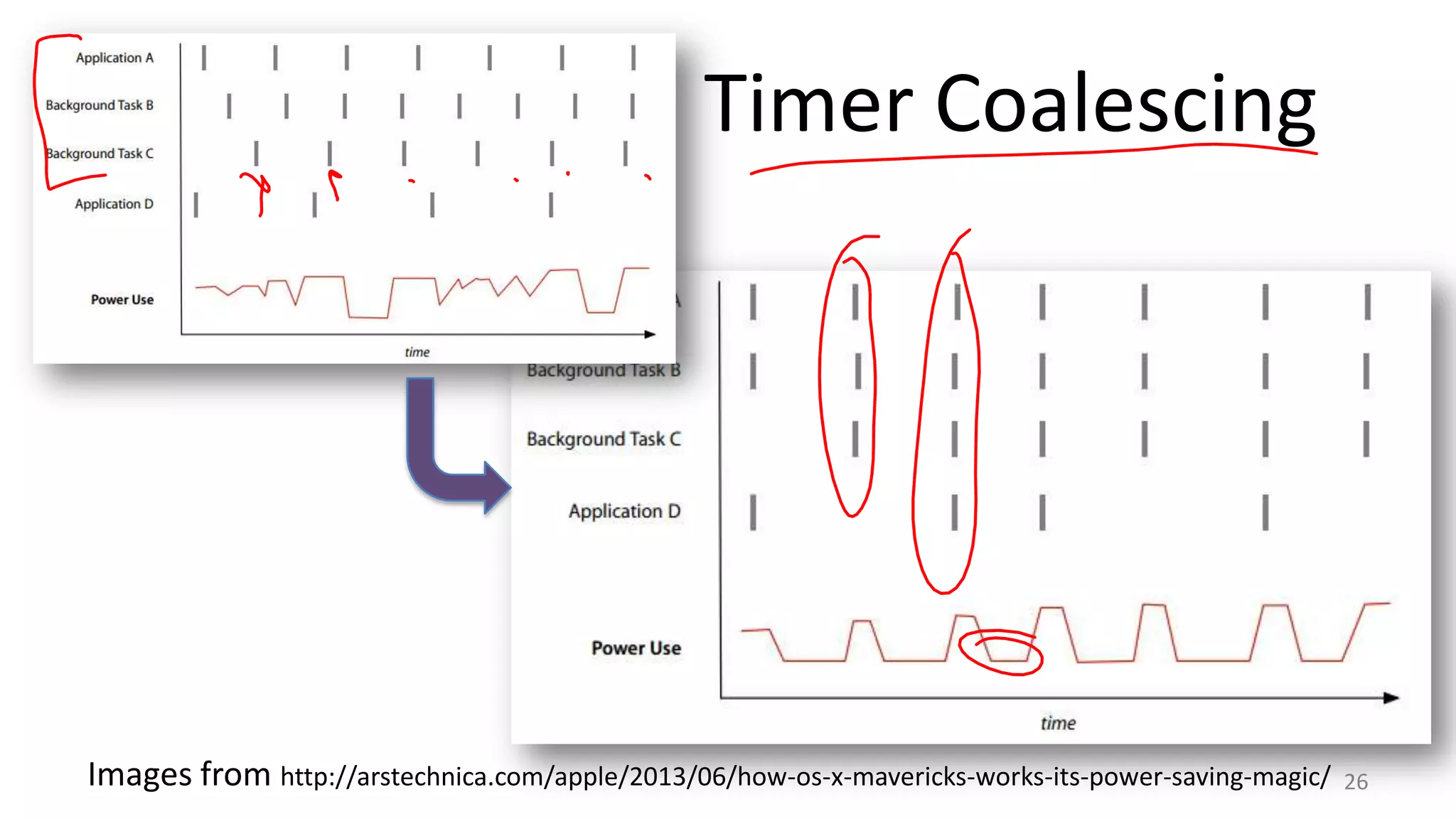


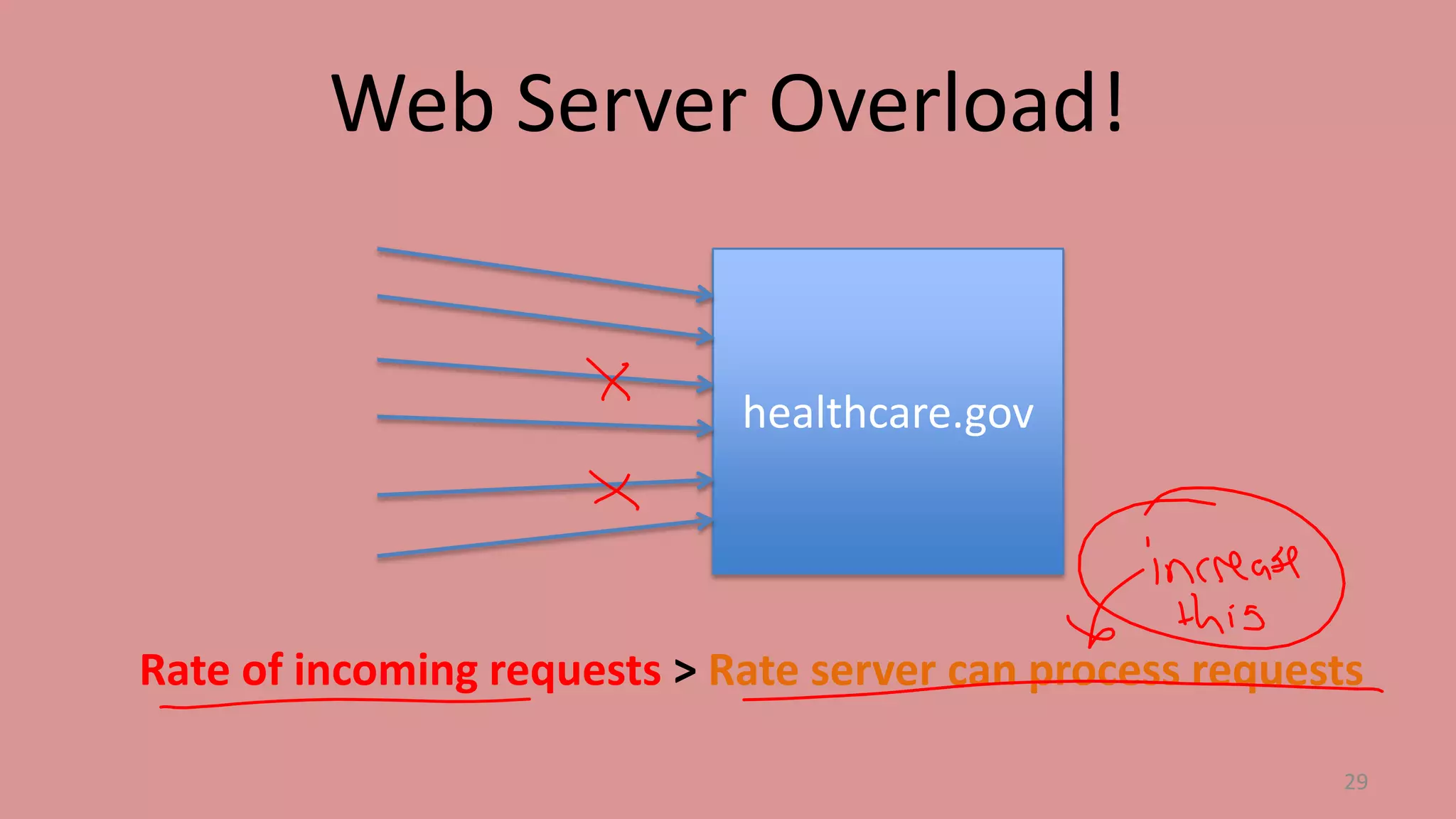










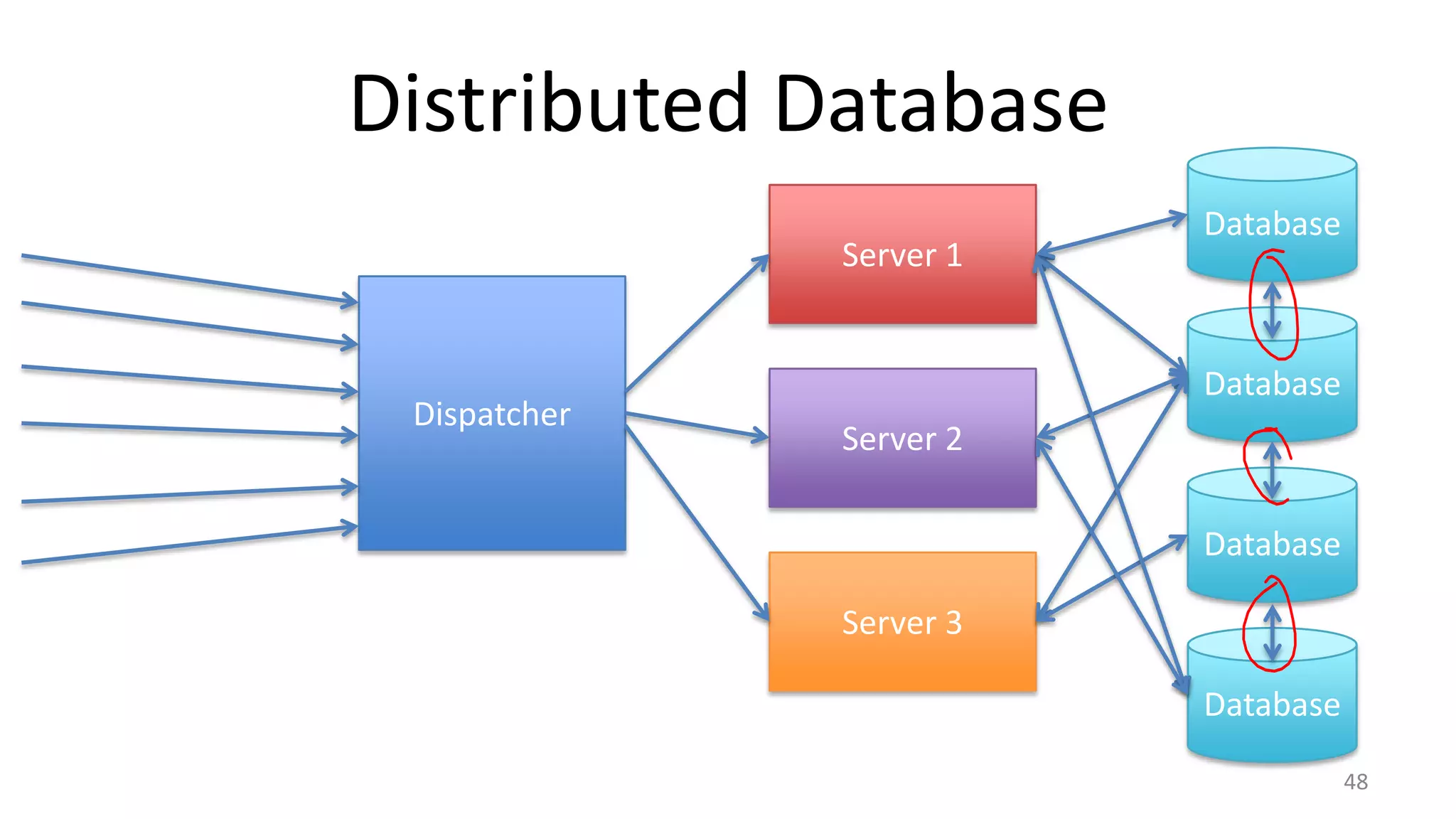
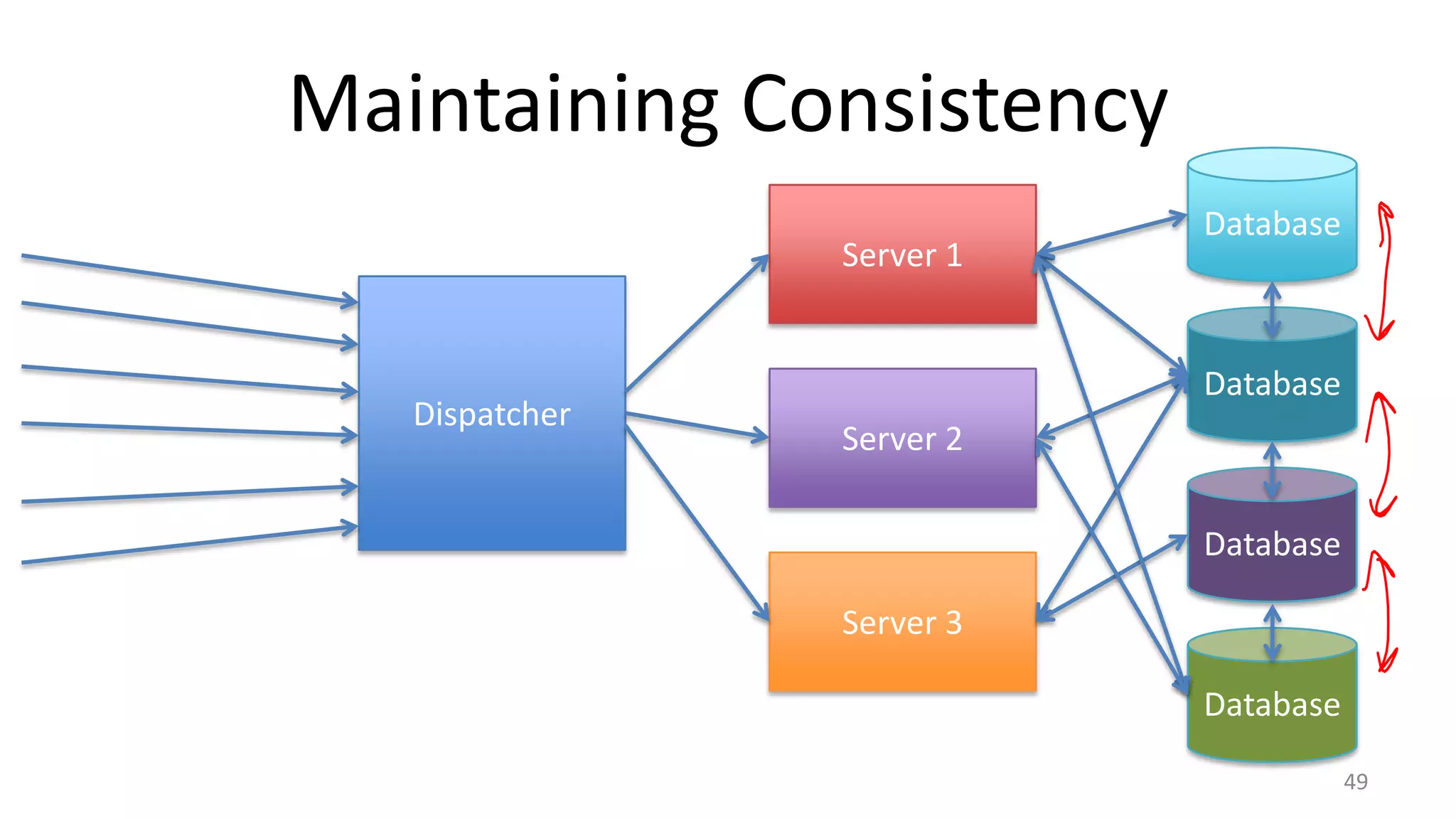

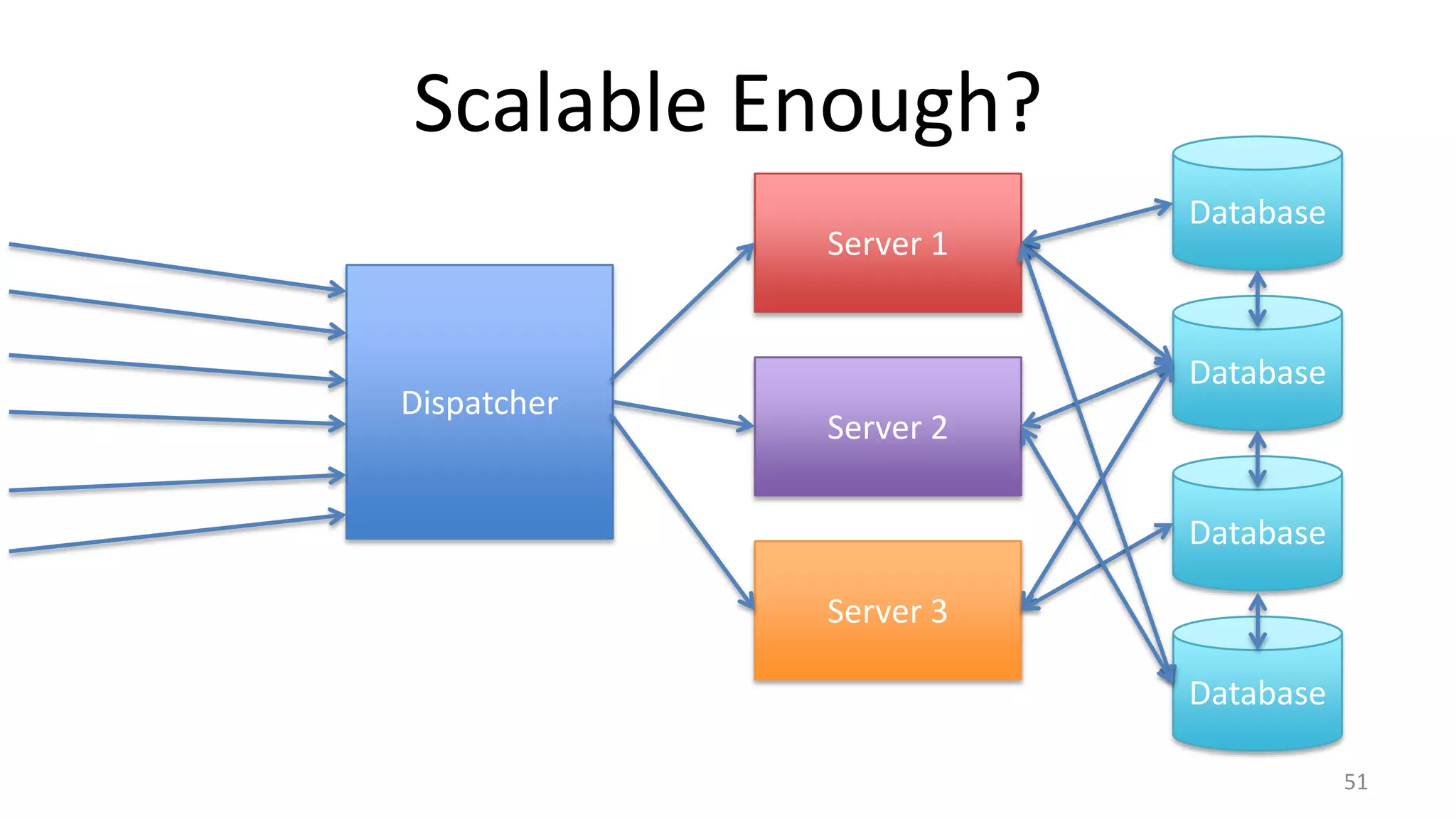
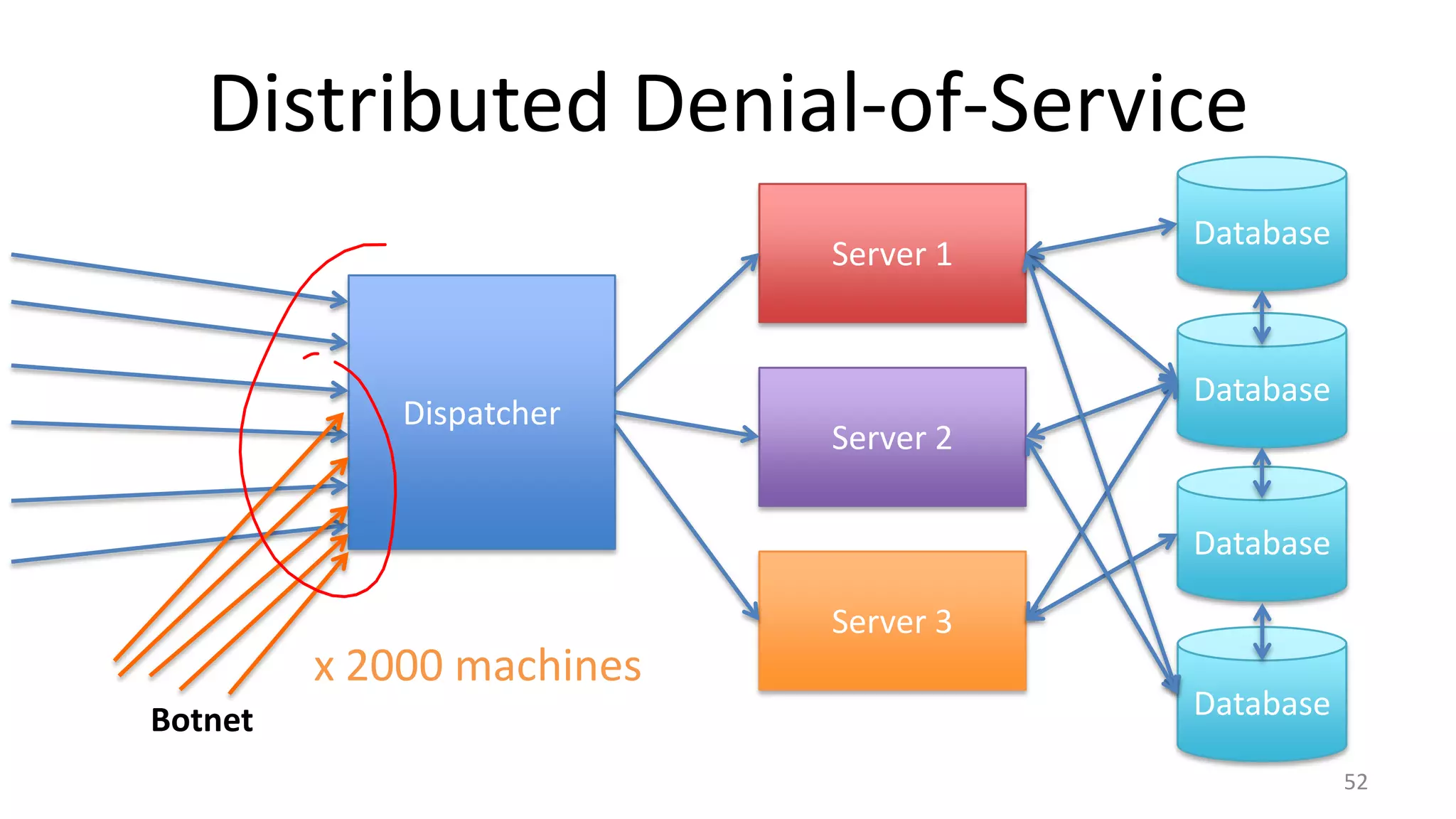

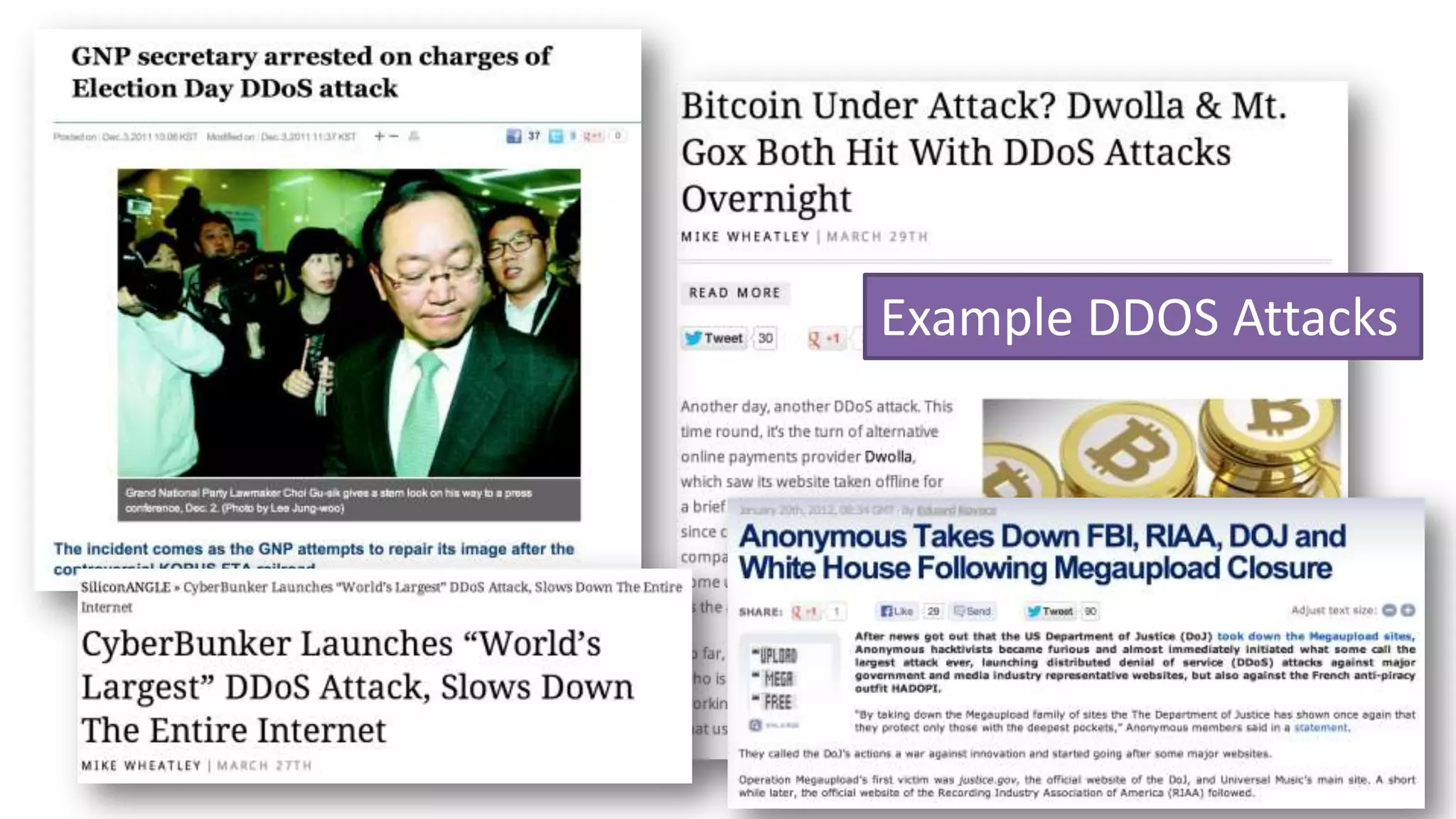


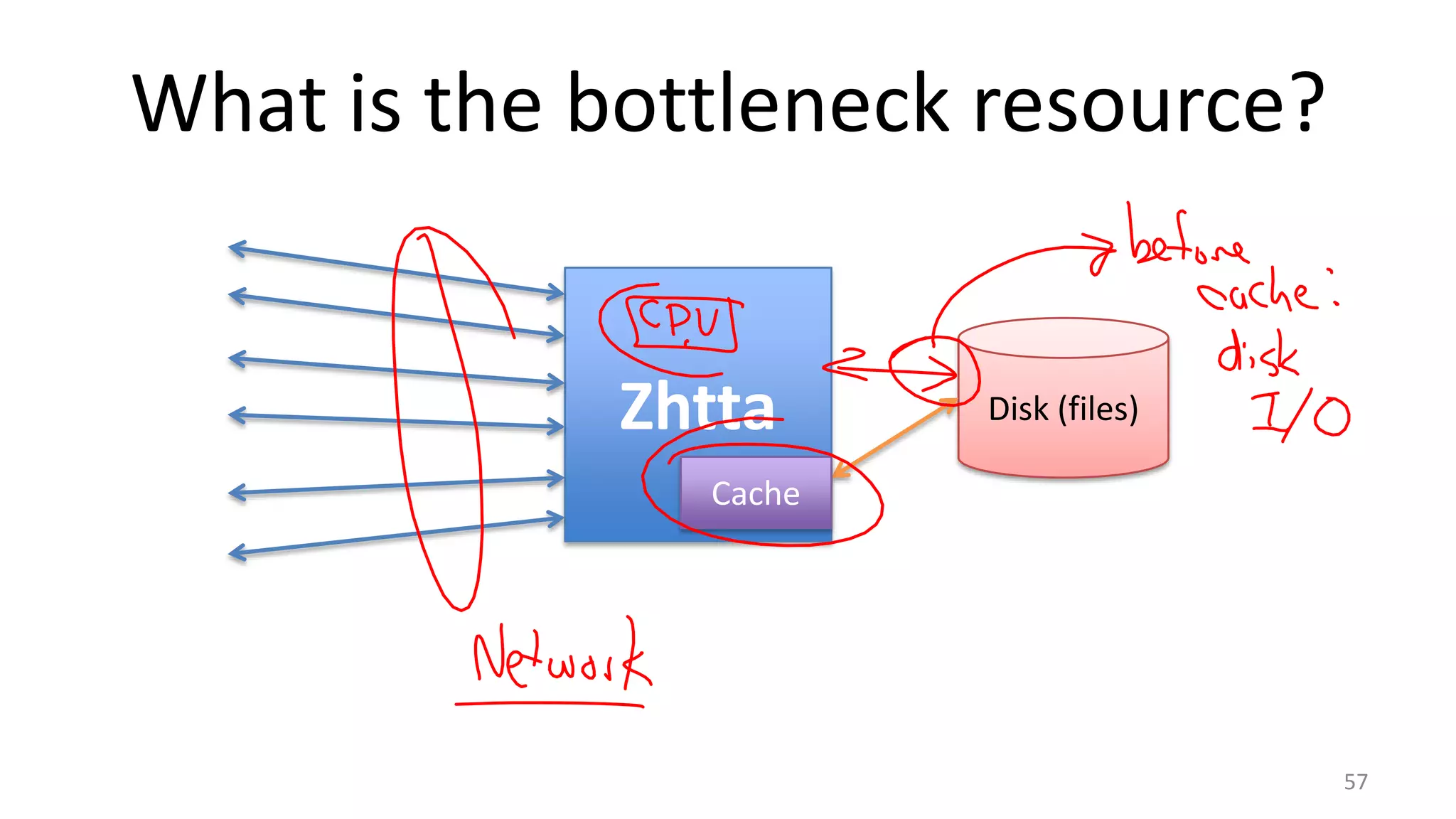
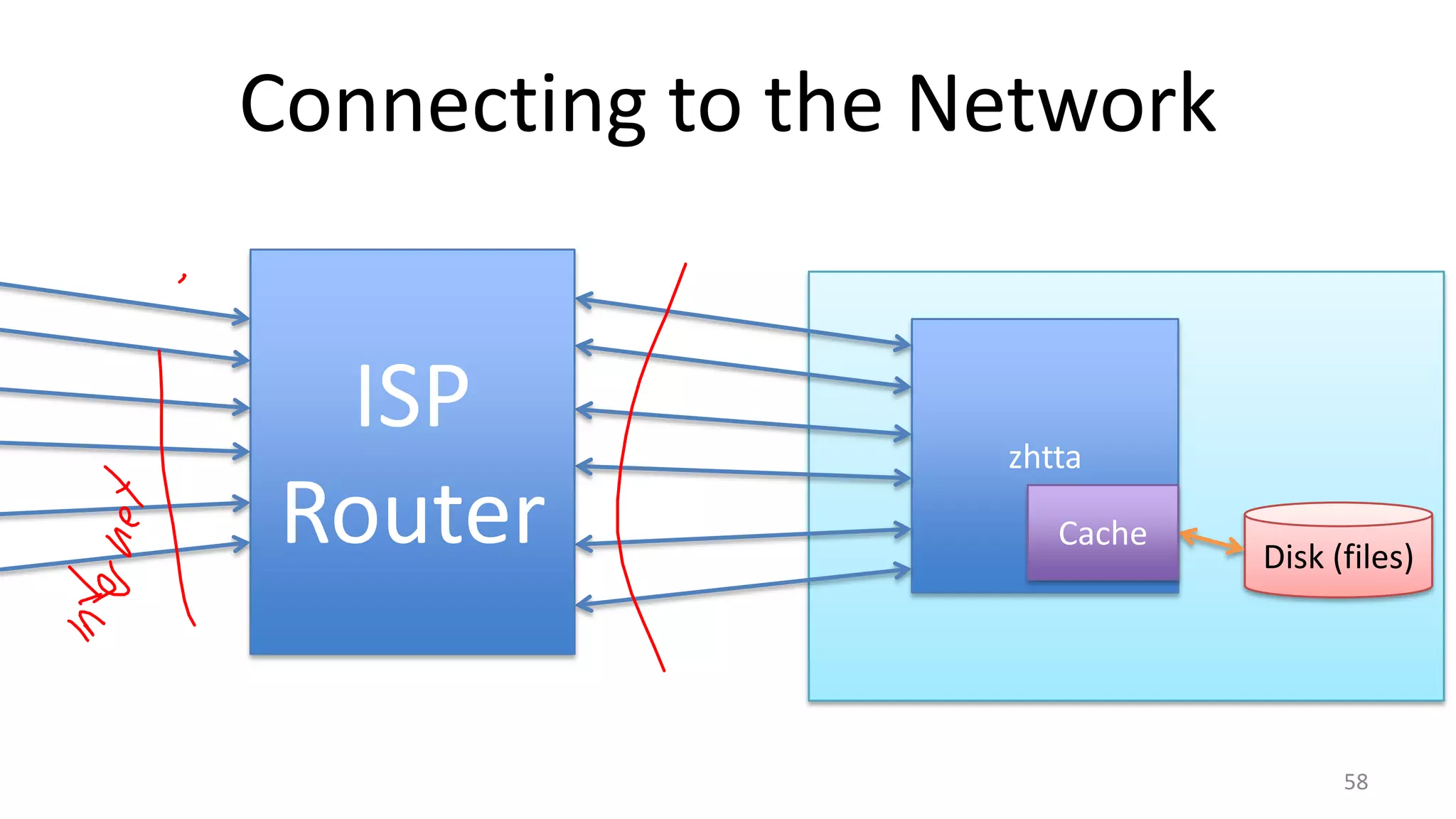
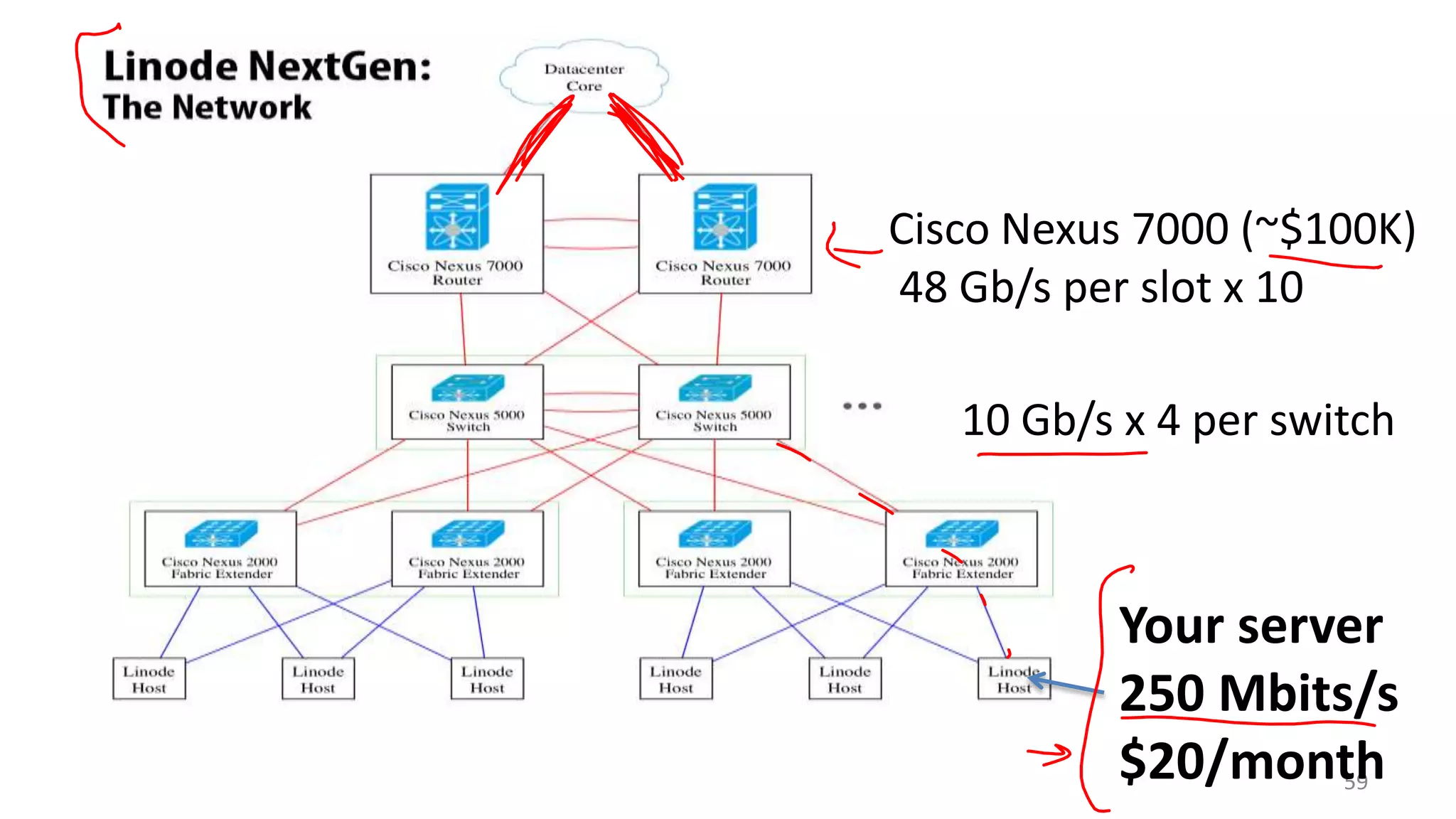



The document discusses scheduling mechanisms in Linux from its early versions to recent developments, outlining process types, priority handling, and improvements in the Linux scheduler. It also addresses challenges faced by web servers, notably in handling overload situations like those experienced by healthcare.gov, proposing strategies such as content simplification, caching, and increased server capacity. Lastly, it emphasizes the importance of monitoring and measuring performance to optimize scheduling policies and resources effectively.























































































