Download as PDF, PPTX





























![Typing?
• Defining APIs
• Rubyists (including me) MAY be using:
[string, integer, boolean, string, ...]
• Rubyists (including me) MAY be using:
{"time": unix_time (but sometimes float)}
• Explicit definition makes nothing bad in designing APIs
• Json schema or something others may help us...](https://image.slidesharecdn.com/rubykaigi2017storagesystems-170920042448/75/Ruby-and-Distributed-Storage-Systems-36-2048.jpg)








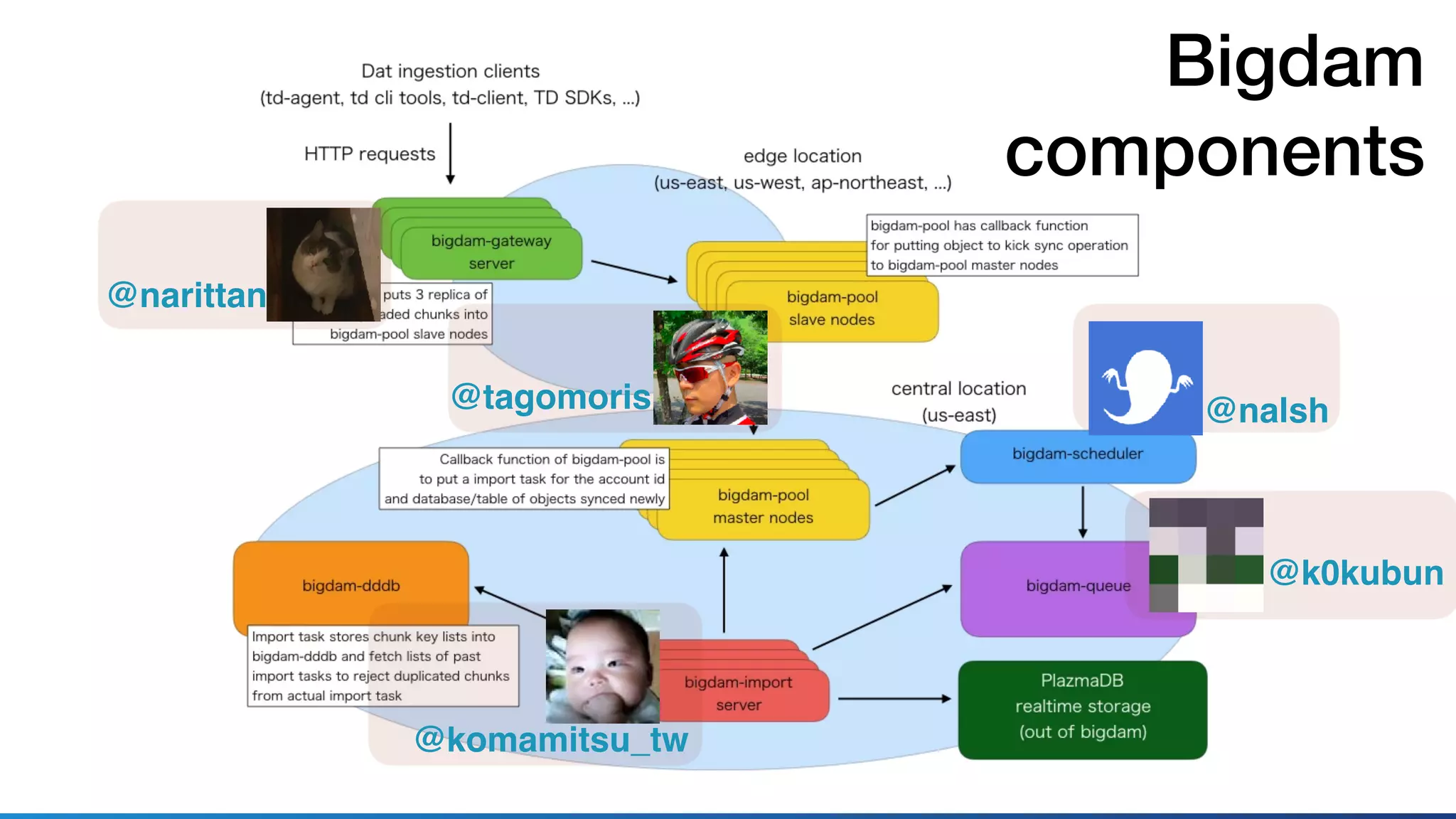
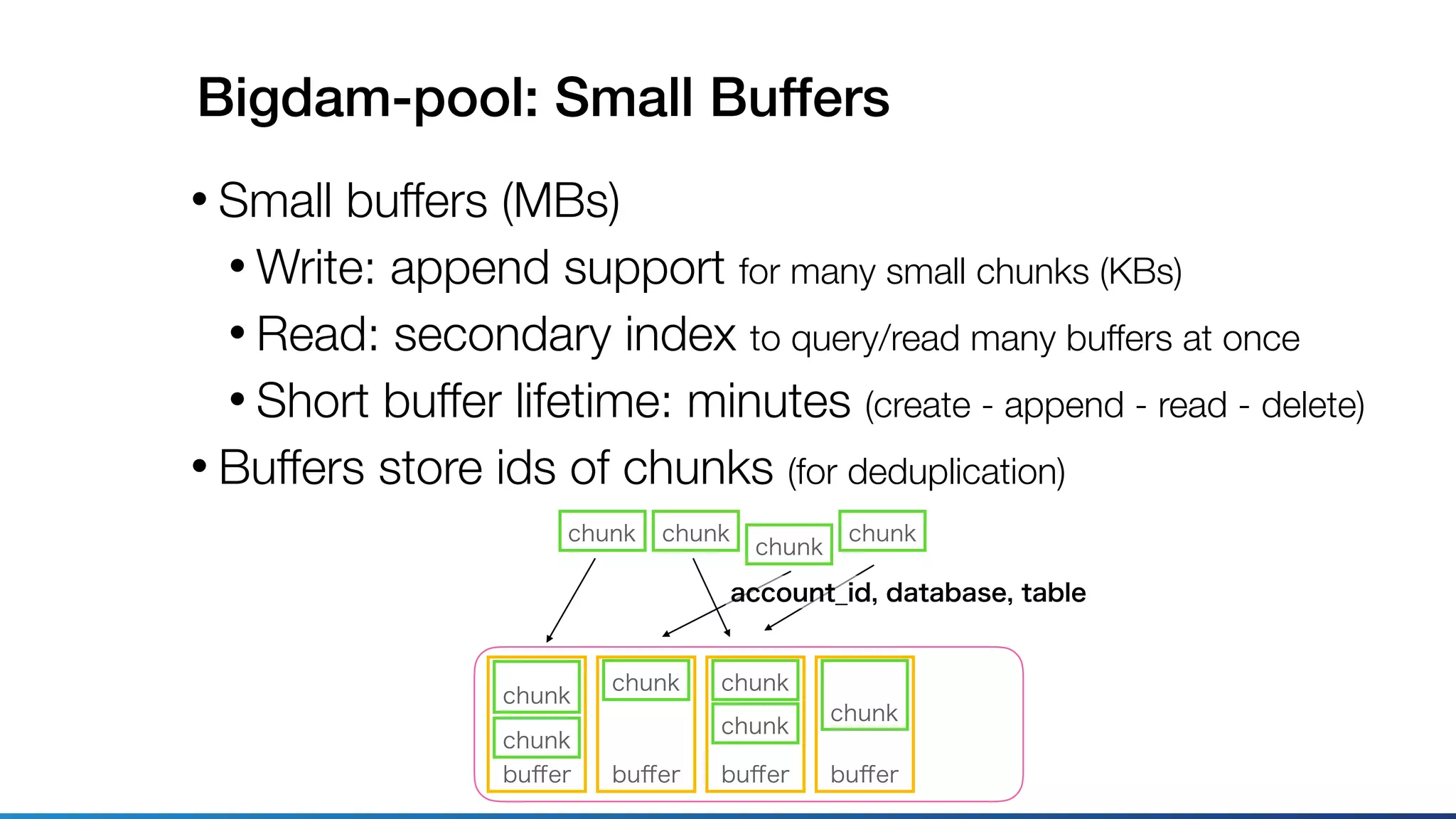
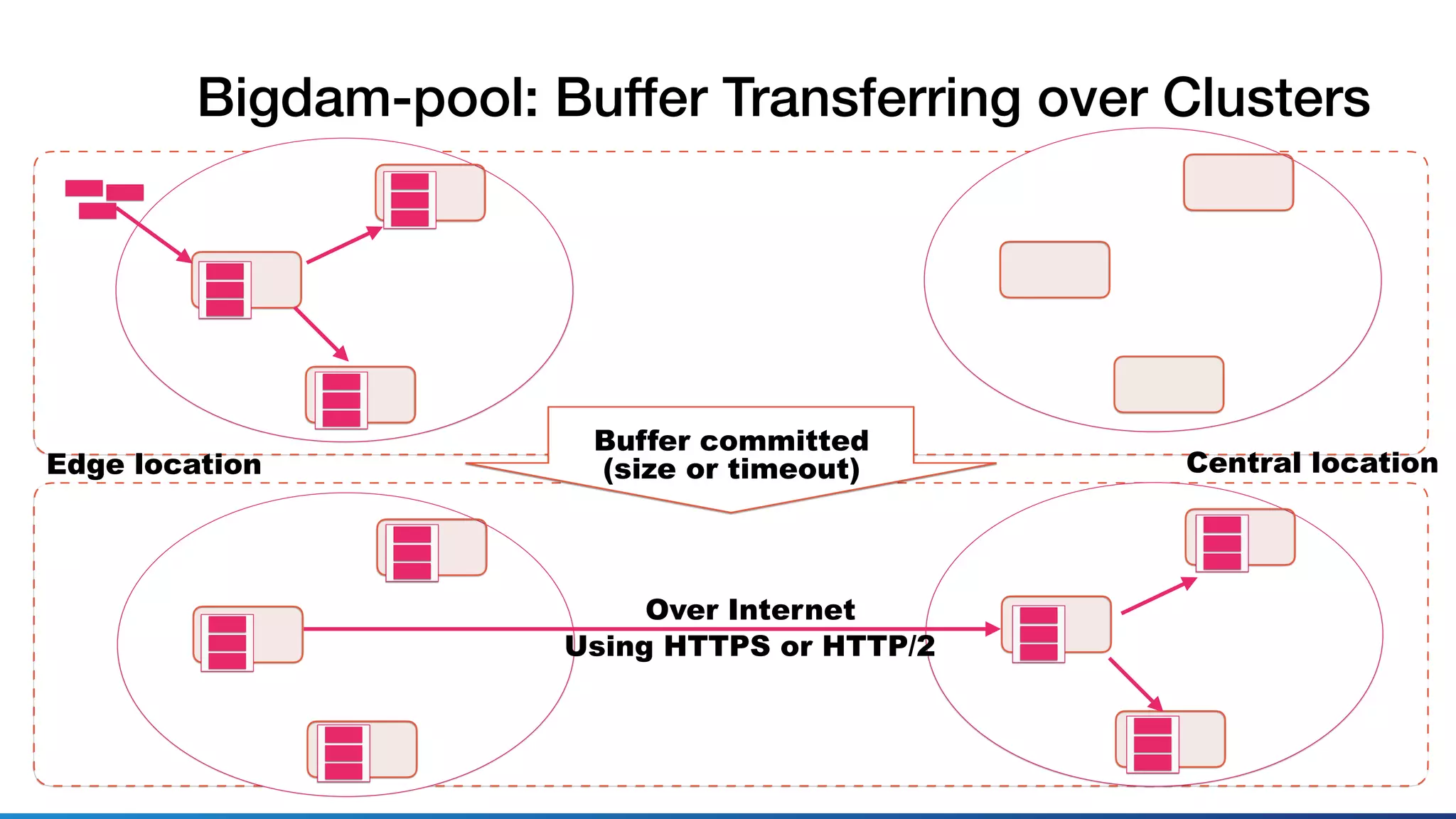
This document discusses using Ruby for distributed storage systems. It describes components like Bigdam, which is Treasure Data's new data ingestion pipeline. Bigdam uses microservices and a distributed key-value store called Bigdam-pool to buffer data. The document discusses designing and testing Bigdam using mocking, interfaces, and integration tests in Ruby. It also explores porting Bigdam-pool from Java to Ruby and investigating Ruby's suitability for tasks like asynchronous I/O, threading, and serialization/deserialization.































































































