Downloaded 107 times


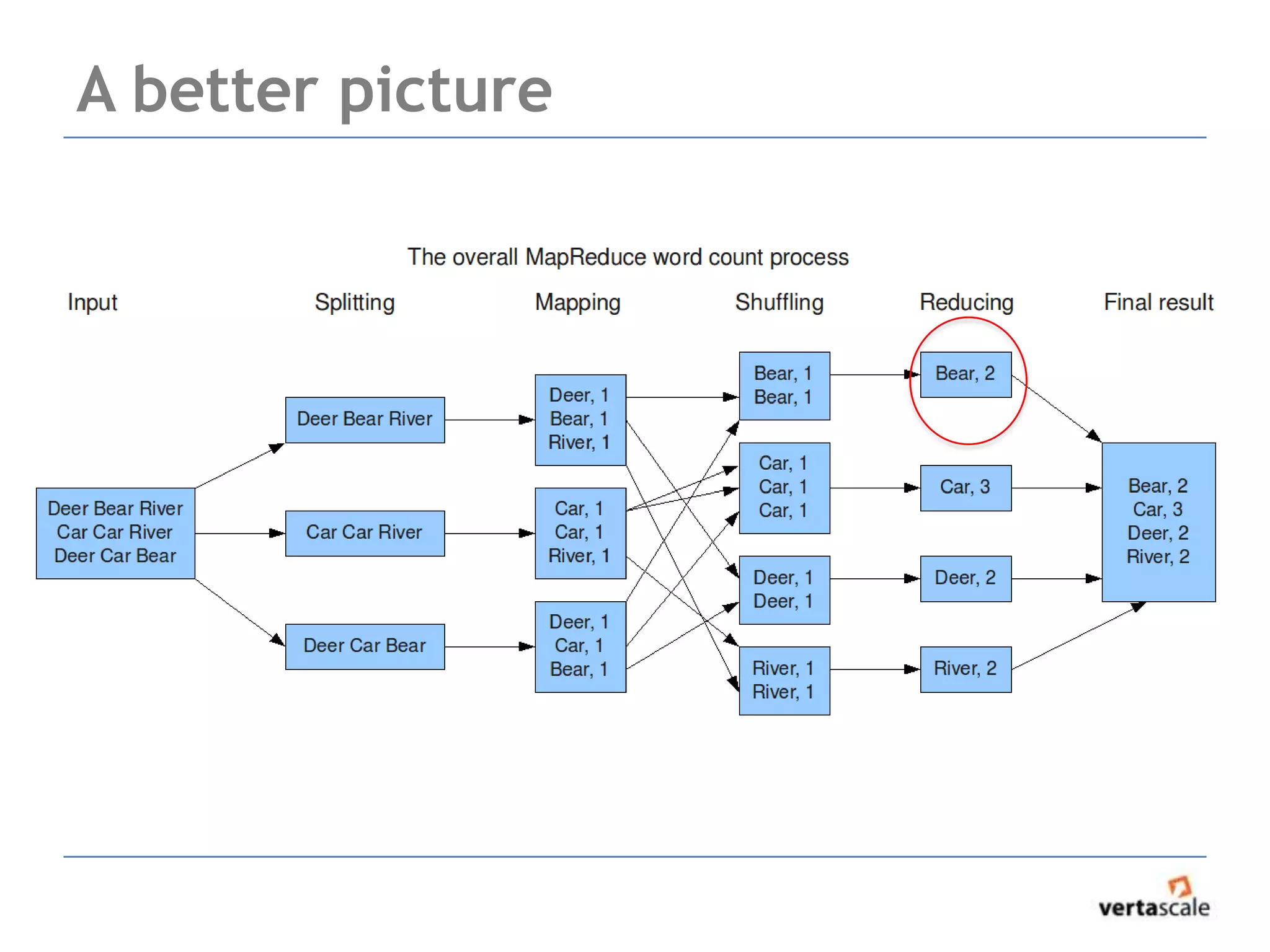


![Reducer Group Iterators
• Reducer groups values together by key
• Your code will iterate over the values, emit reduced
result
Bear:[1,1] Bear:2
• Hadoop reducer value iterators return THE SAME
OBJECT each next(). Object is “reused” to reduce
garbage collection load
• Beware of “reused” objects (this is a VERY common
cause of long and confusing debugs)
• Cause for concern: you are emitting an object with
non-primitive values. STALE “reused object” state from
previous value.](https://image.slidesharecdn.com/real-timehadoopmapreduceintro-130213103724-phpapp01/75/Real-time-hadoop-mapreduce-intro-8-2048.jpg)


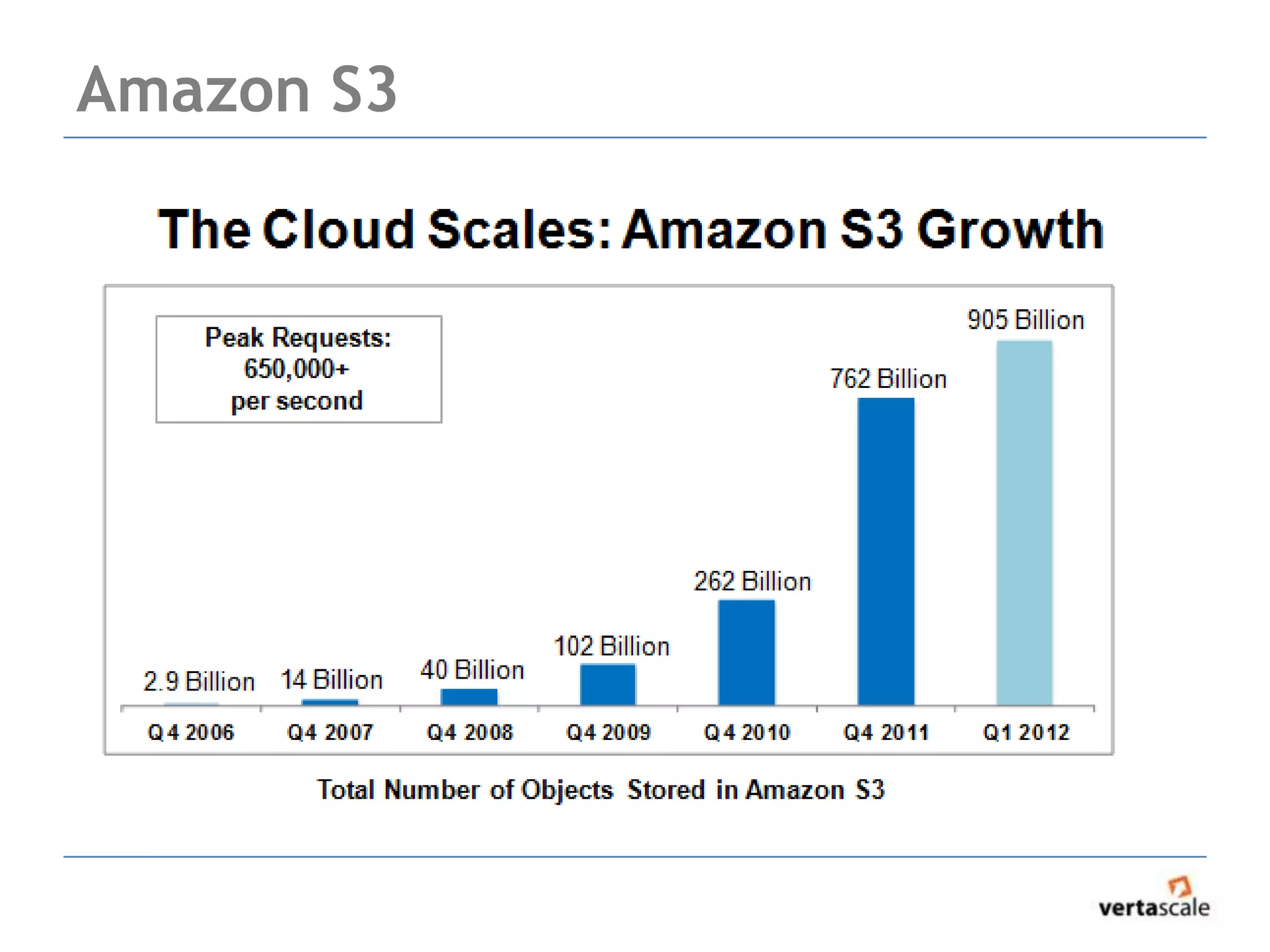
![HDFS performance characteristics
• HDFS was designed for high throughput, not low
seek latency
• best-case configurations have shown HDFS to
perform 92K/s random reads
[http://hadoopblog.blogspot.com/]
• Personal experience: HDFS very robust. Fault
tolerance is “real”. I’ve unplugged machines
and never lost data.](https://image.slidesharecdn.com/real-timehadoopmapreduceintro-130213103724-phpapp01/75/Real-time-hadoop-mapreduce-intro-14-2048.jpg)







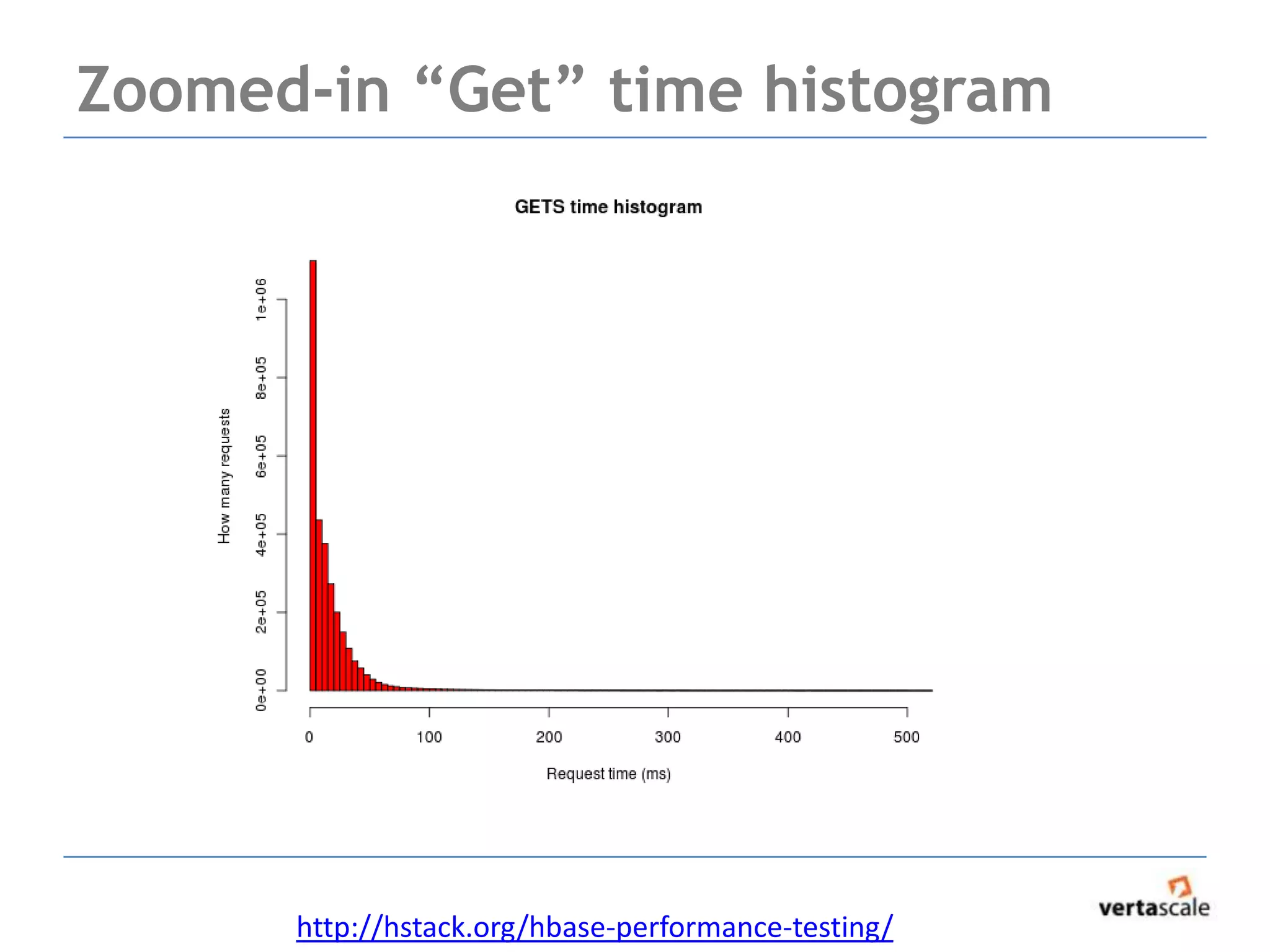












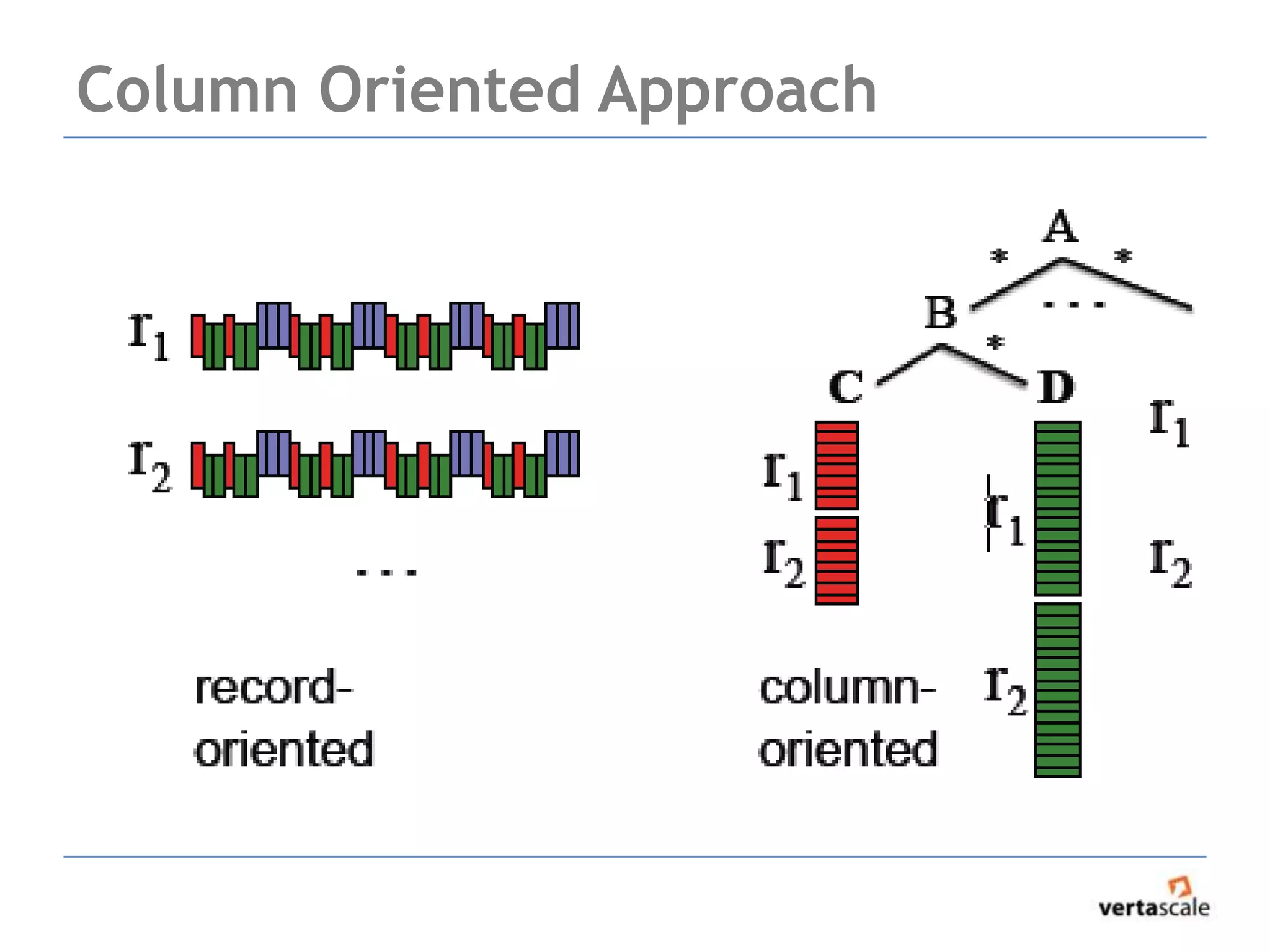
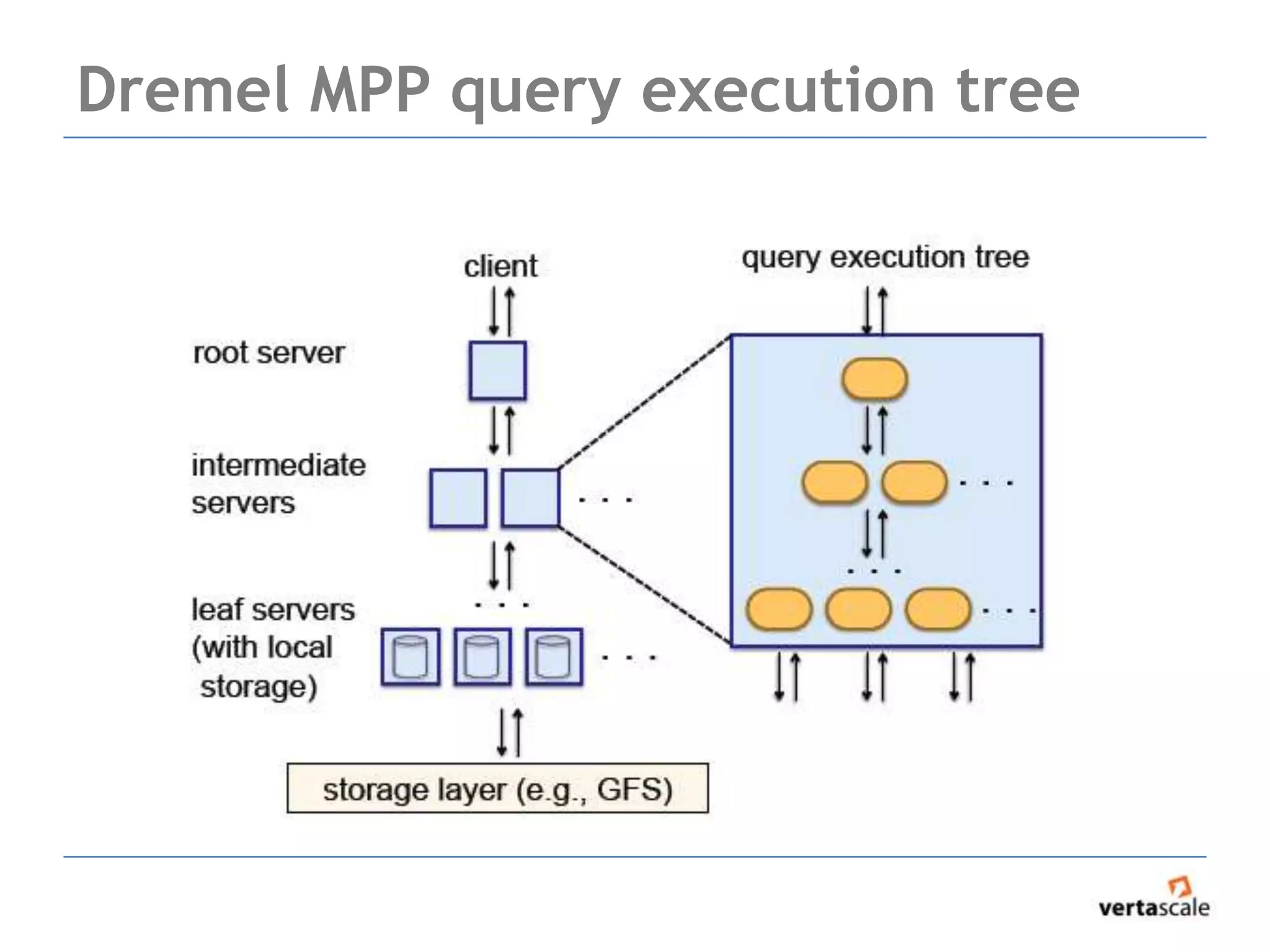
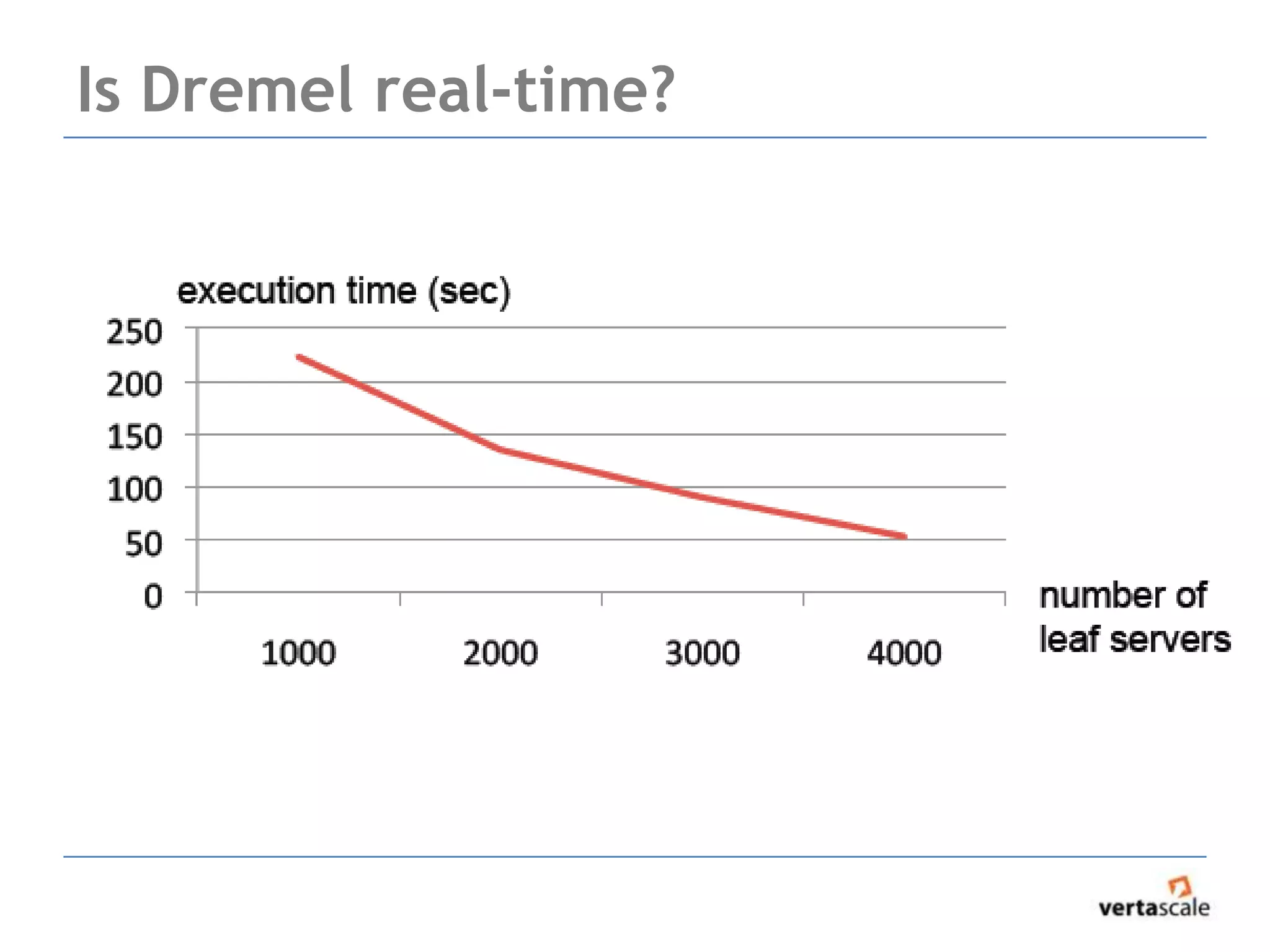




The document provides a comprehensive overview of Hadoop and its ecosystem, focusing on key components such as MapReduce, HDFS, and HBase, while discussing challenges and considerations for real-time data access. It highlights the complexity of debugging MapReduce jobs and the limitations of traditional approaches in handling big data, emphasizing the need for faster time-to-answer solutions. Additionally, it introduces alternative architectures like Apache Drill and Spark, aimed at improving data analysis and processing efficiency.















































