Download to read offline


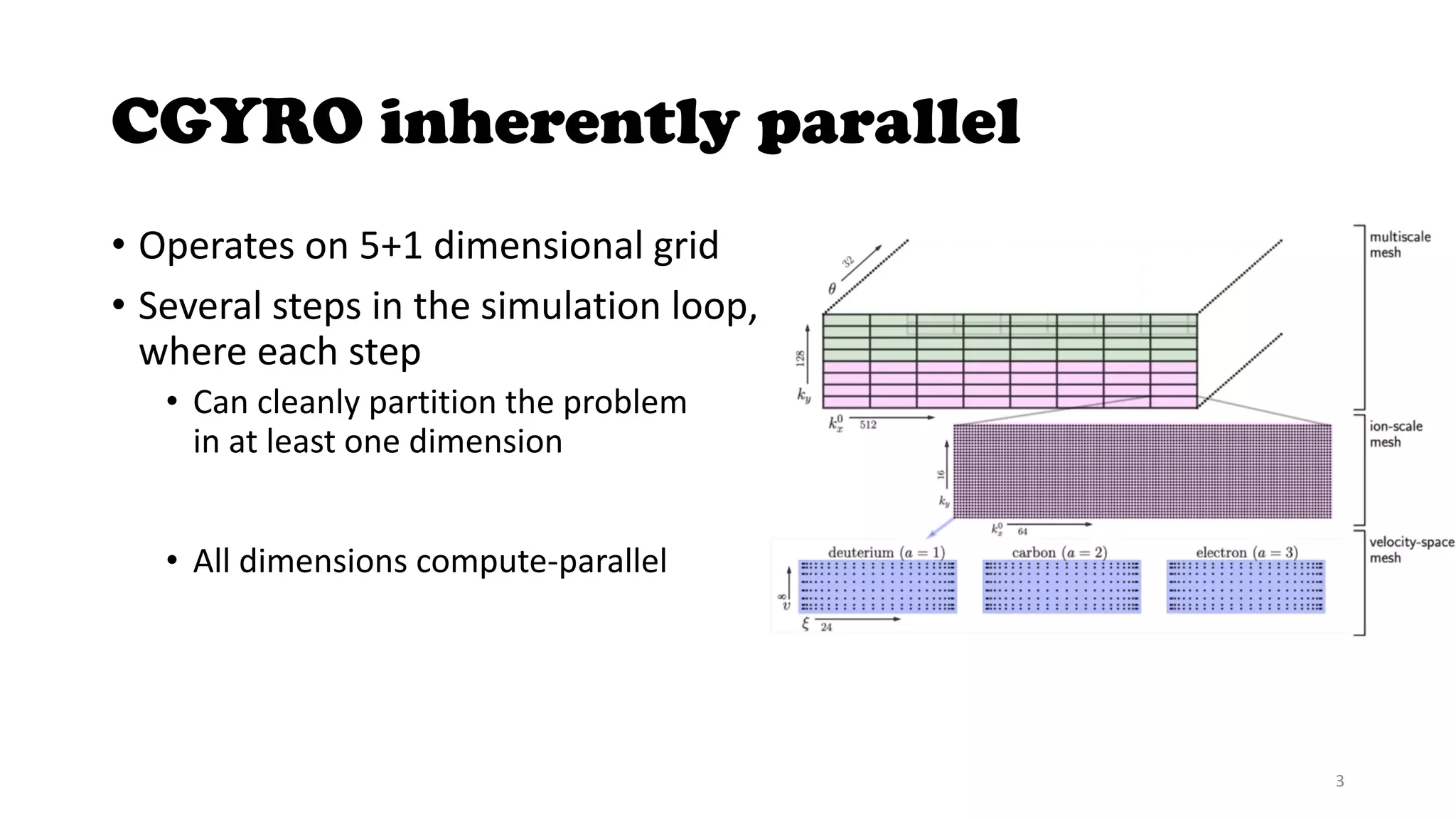

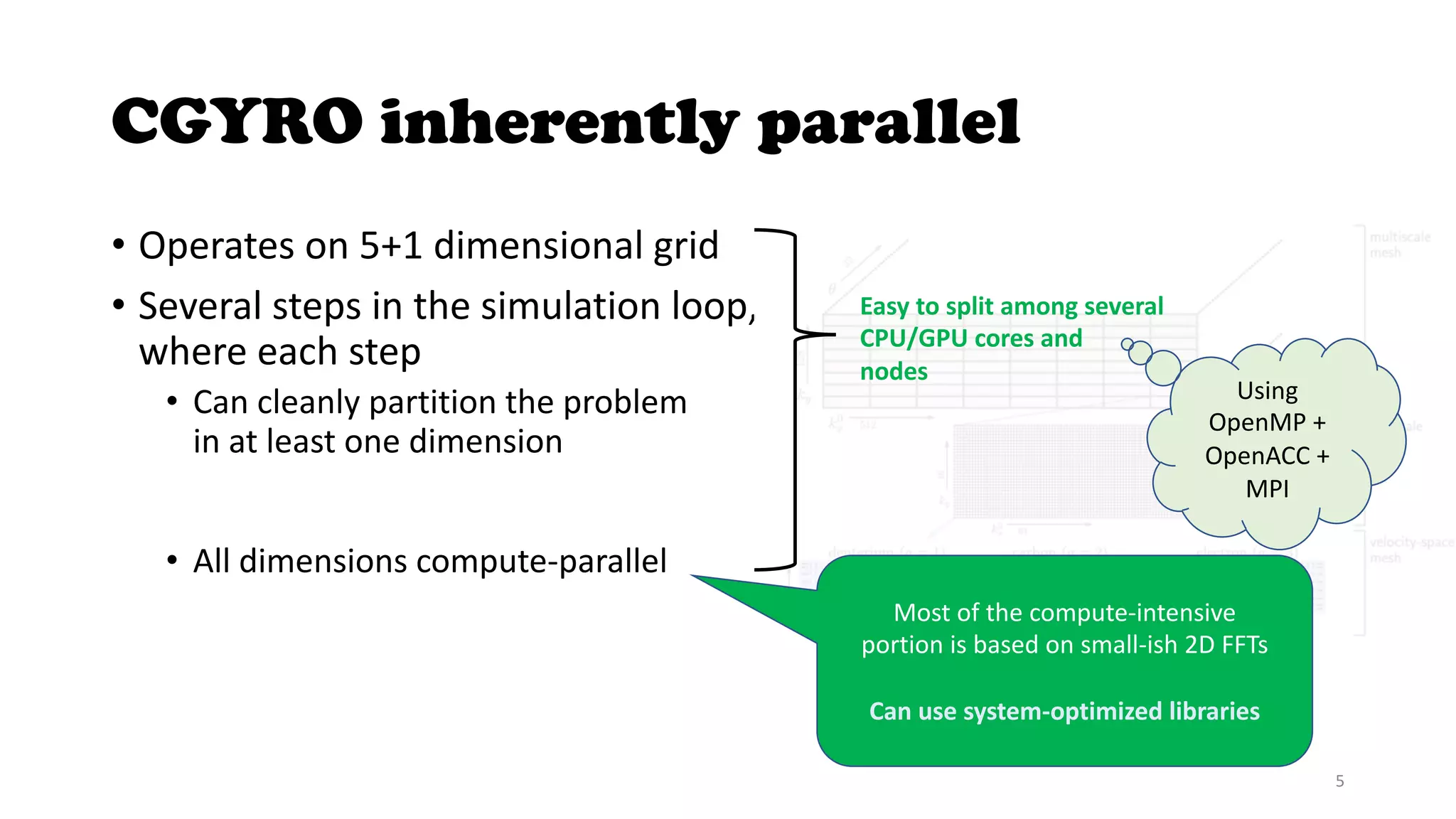
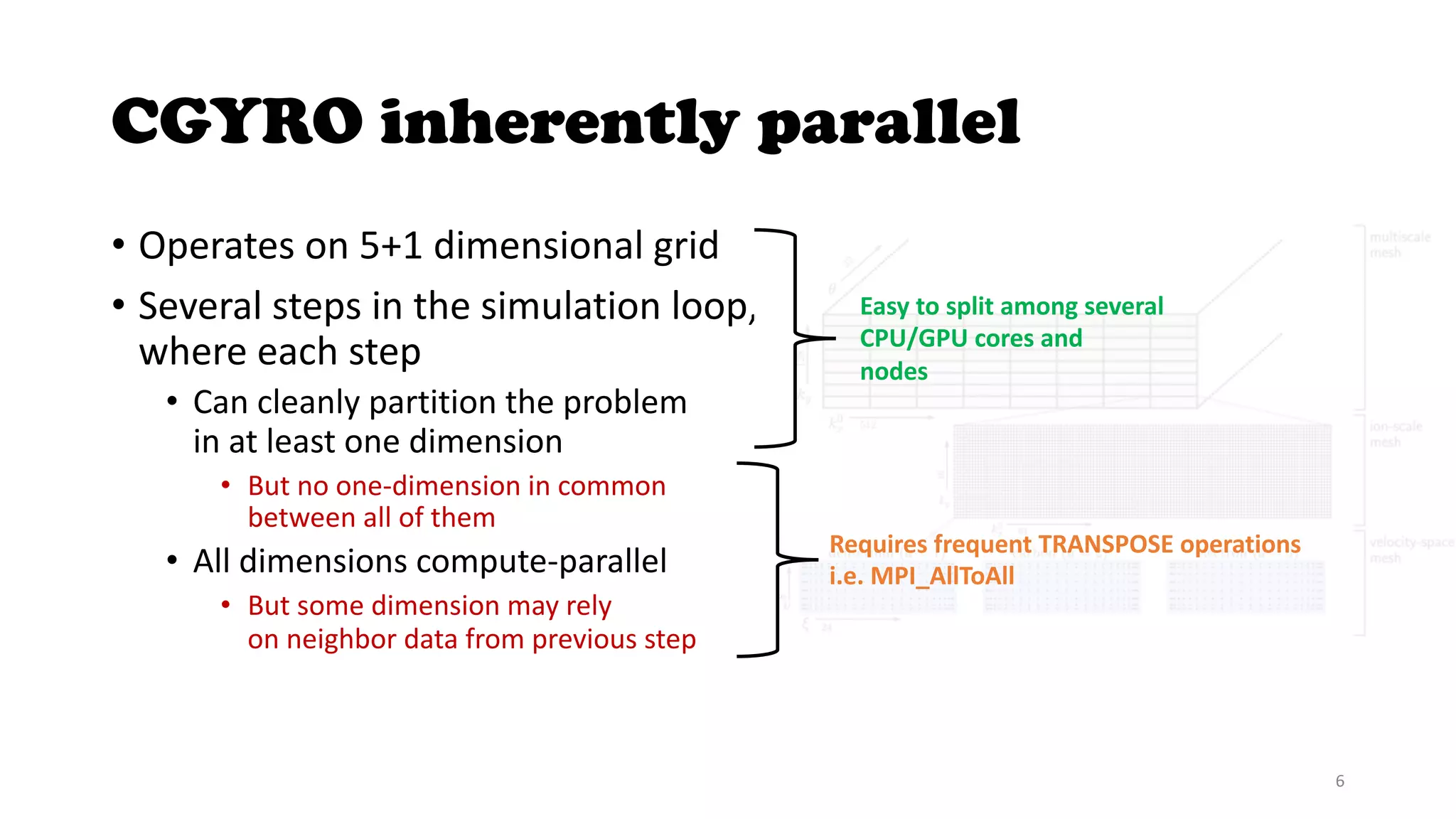
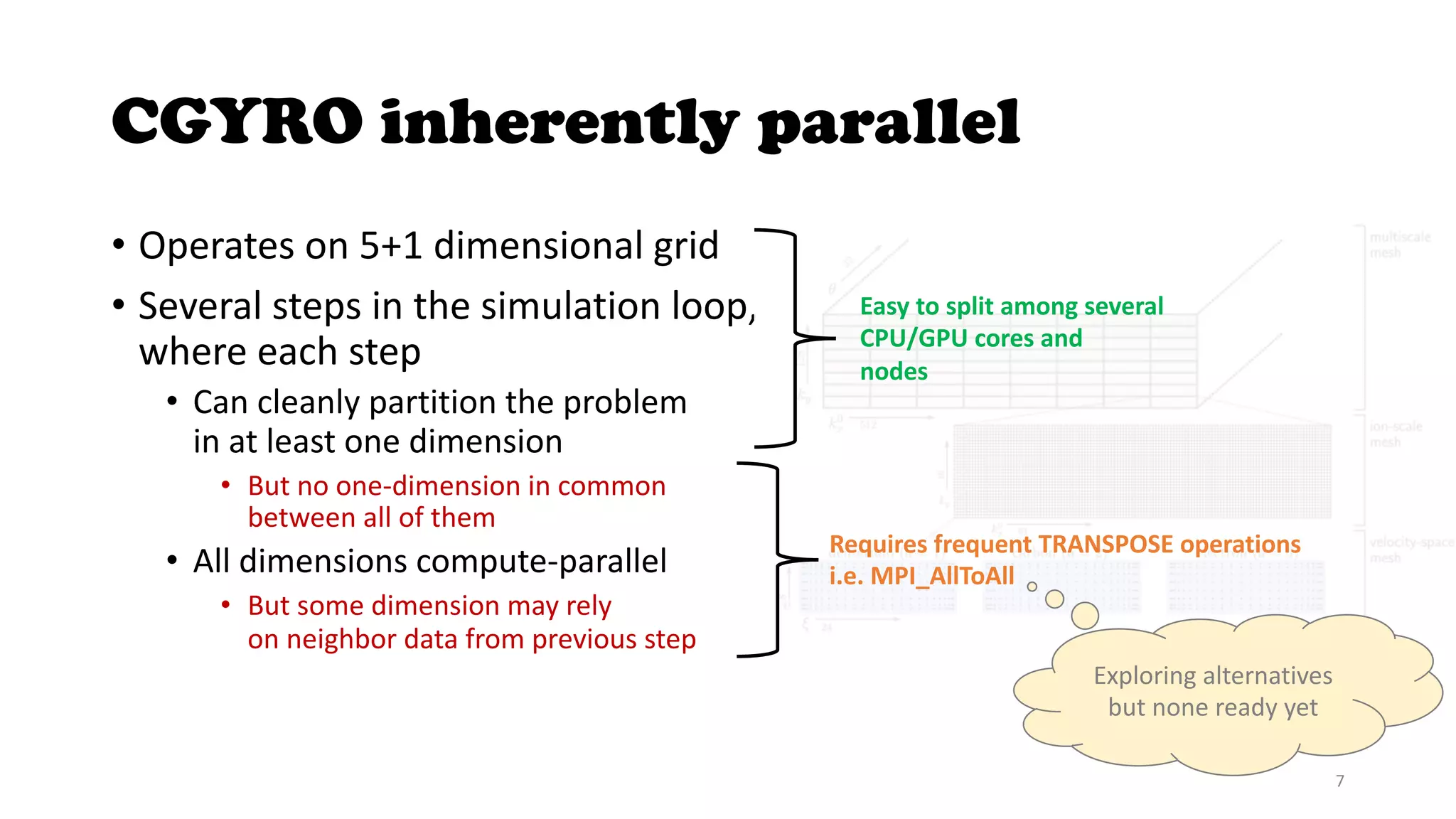






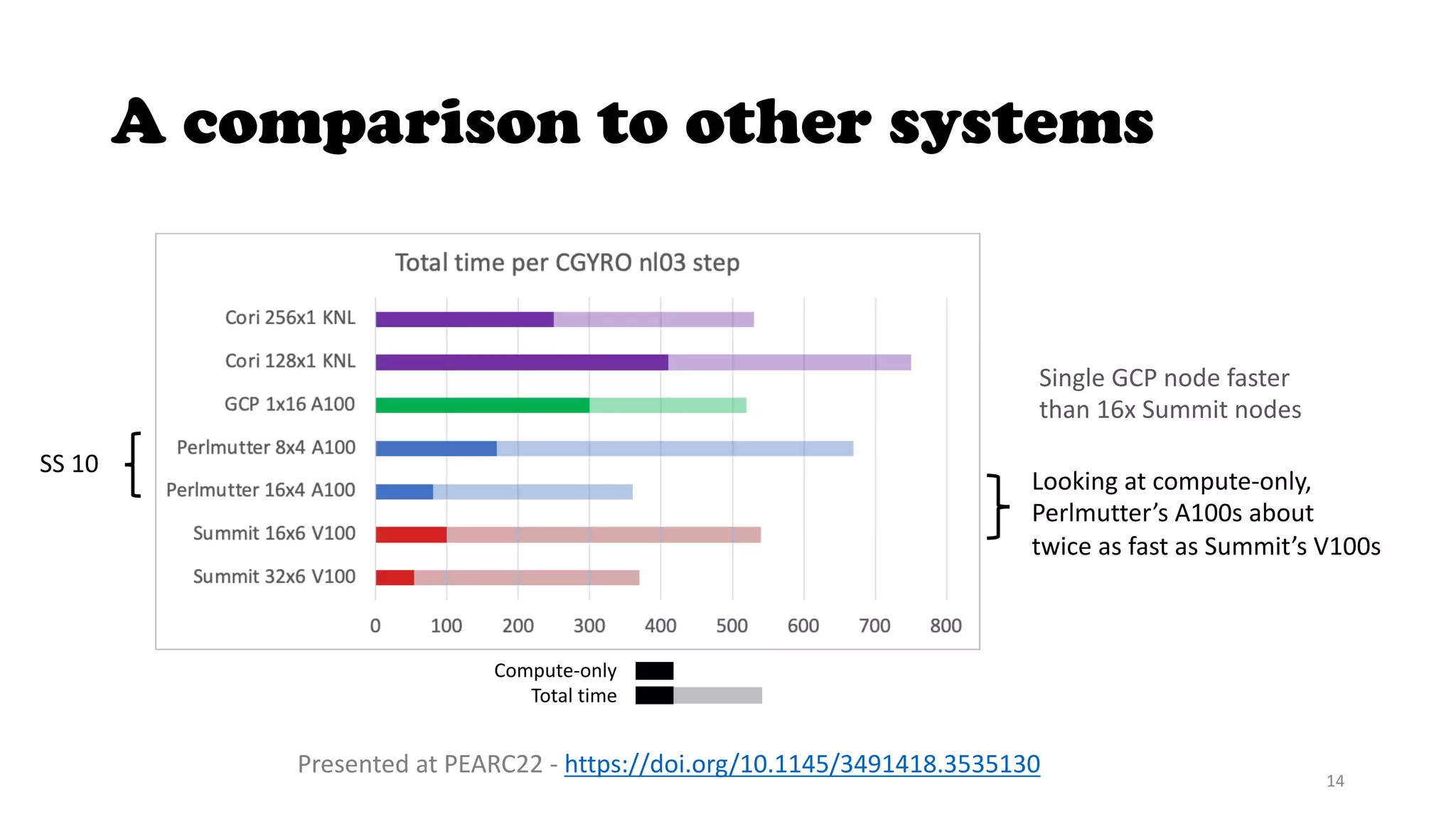



The document discusses the CGYRO simulation tool, which is used for fusion plasma turbulence simulations. CGYRO is optimized for multi-scale simulations and is both memory and compute intensive. It is inherently parallel and uses OpenMP, OpenACC, and MPI for parallelization across CPU and GPU cores. While initial runs on Perlmutter had communication bottlenecks, improved networking with Slingshot 11 has helped increase performance, though it can interfere with MPS. Overall, CGYRO users are pleased with the transition from Cori to Perlmutter, finding it much faster for equivalent hardware.



































































