Download to read offline






![Grammars and Parsing
$ less Grammar/Grammar
...
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcde
async_stmt: ASYNC (funcdef | with_stmt | for_stmt)
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
while_stmt: 'while' test ':' suite ['else' ':' suite]
for_stmt: 'for' exprlist 'in' testlist ':' suite ['else' ':' suite]
...
Parsing: Given an input string, determine/guess
grammar production rules to generate it](https://image.slidesharecdn.com/pyconde2016-poweredbypython1-161107154324/75/Powered-by-Python-PyCon-Germany-2016-13-2048.jpg)

![Word2Vec
● Map words to vectors
● “Step up” from
bag-of-words model
● ‘Cats’ and ‘dogs’ should
be similar - because they
occur in similar contexts
>>> m["python"]
array([-0.1351, -0.1040,
-0.0823, -0.0287, 0.3709,
-0.0200, -0.0325, 0.0166,
0.3312, -0.0928, -0.0967,
-0.0199, -0.2498, -0.4445,
-0.0445,
# ...](https://image.slidesharecdn.com/pyconde2016-poweredbypython1-161107154324/75/Powered-by-Python-PyCon-Germany-2016-15-2048.jpg)
![Fun with Word2Vec
>>> # trained from 100k meetup descriptions!
>>> m = gensim.models.Word2Vec.load("data/word2vec")
>>> m.most_similar(positive=["python"])[:3]
[(u'javascript', 0.83), (u'php', 0.82), (u'django', 0.81)]
>>> m.doesnt_match(["python", "c++", "javascript"])
'c++'
>>> m.most_similar(positive=["ladies"])[:3]
[(u'girls', 0.81), (u'mamas', 0.74), (u'gals', 0.73)]](https://image.slidesharecdn.com/pyconde2016-poweredbypython1-161107154324/75/Powered-by-Python-PyCon-Germany-2016-16-2048.jpg)


![class MyTask(luigi.Task):
def output(self):
return luigi.Target("/to/make/this/file")
def requires(self):
return [
INeedThisTask(),
AndAlsoThisTask("with_some arg")
]
def run(self):
# ... then ...
# I do this to make it!](https://image.slidesharecdn.com/pyconde2016-poweredbypython1-161107154324/75/Powered-by-Python-PyCon-Germany-2016-20-2048.jpg)


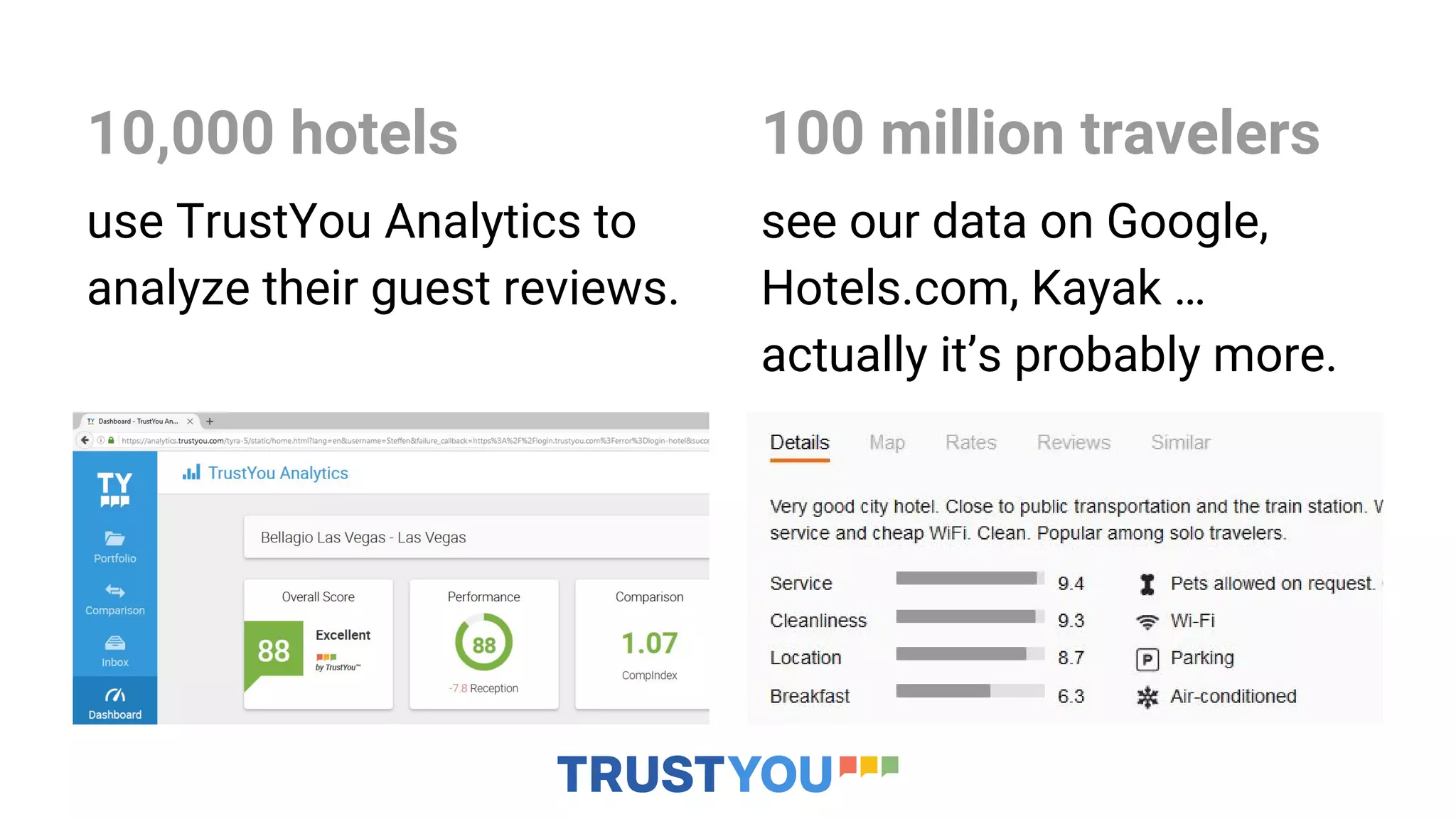
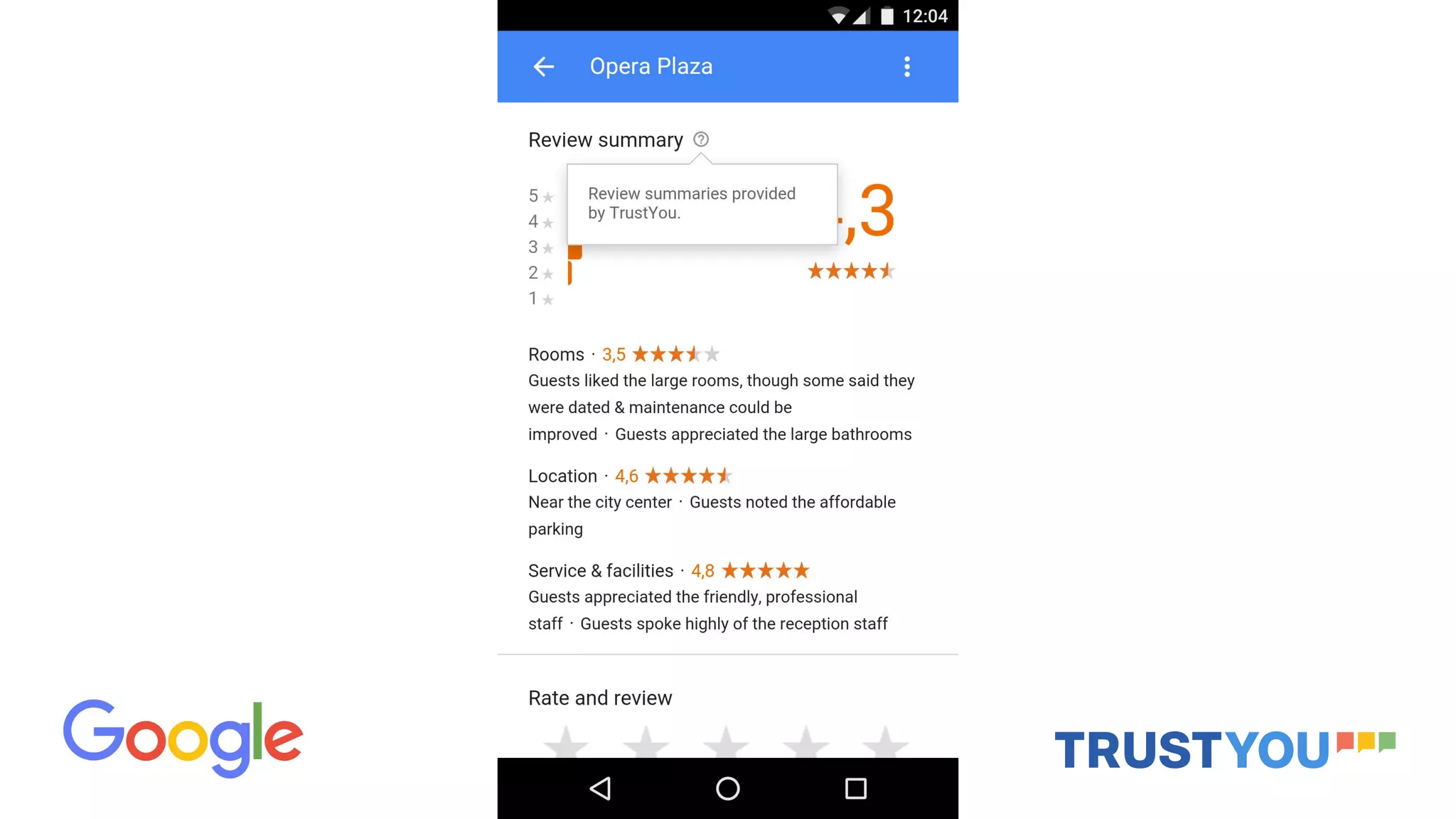
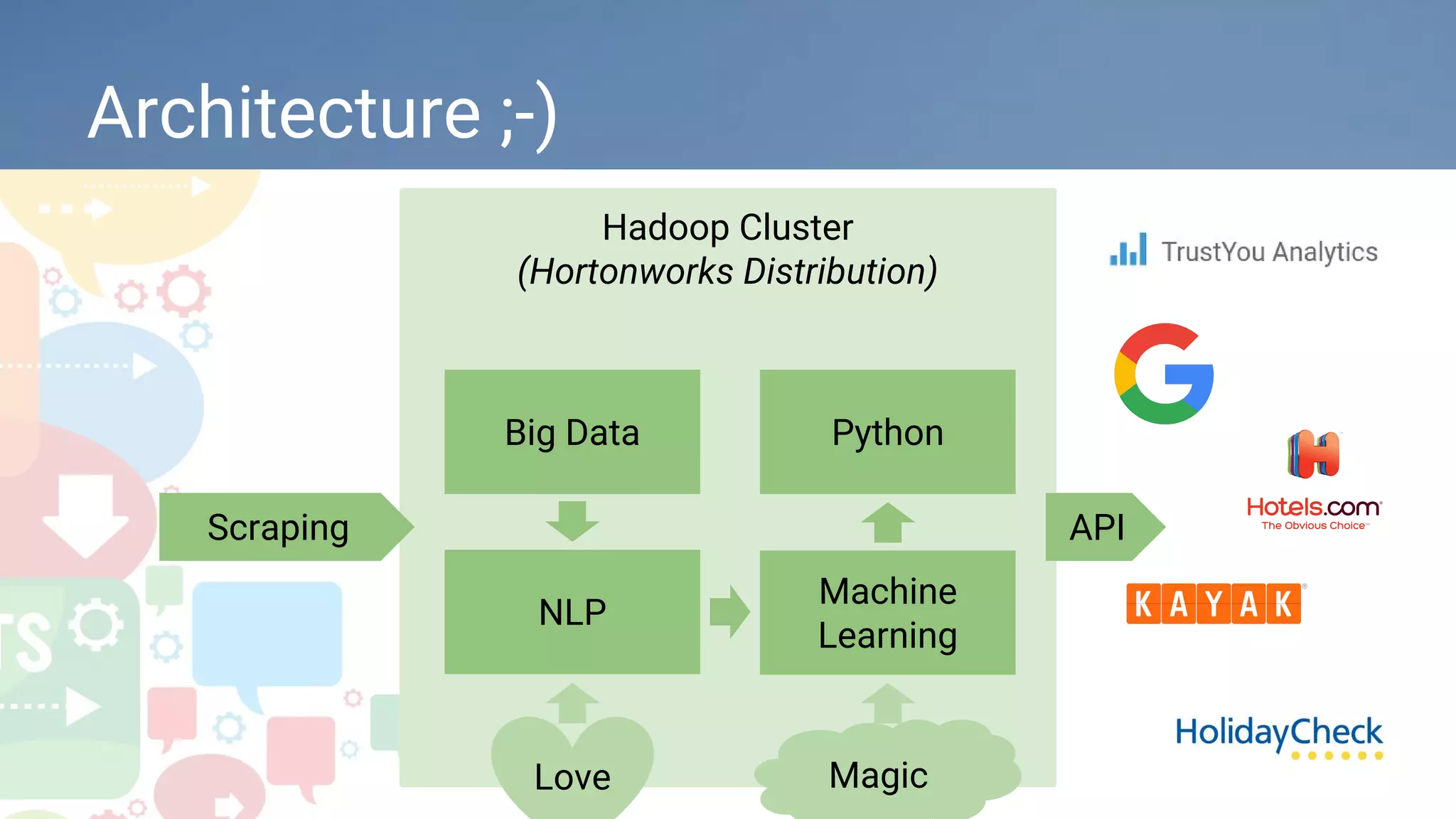
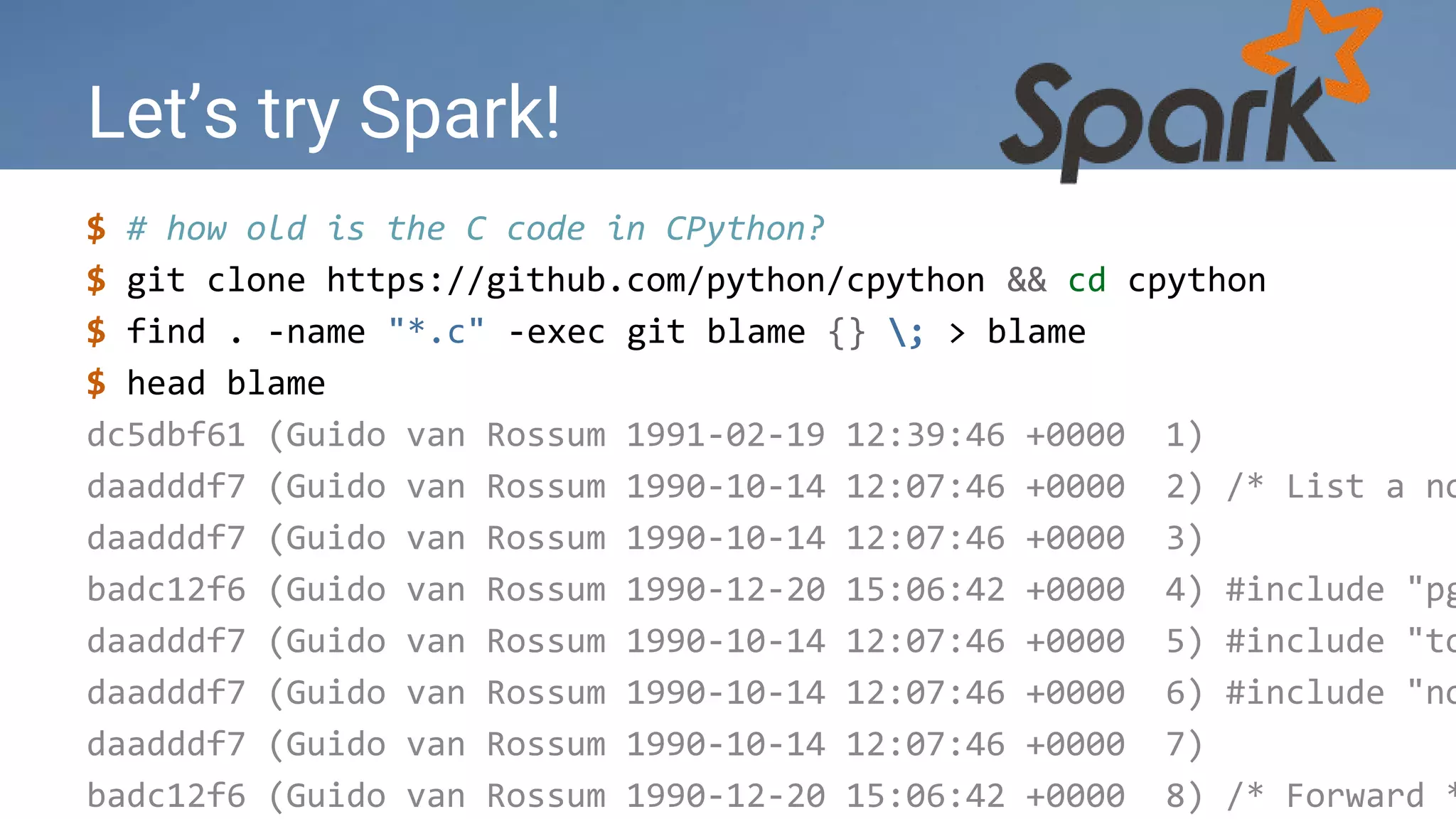
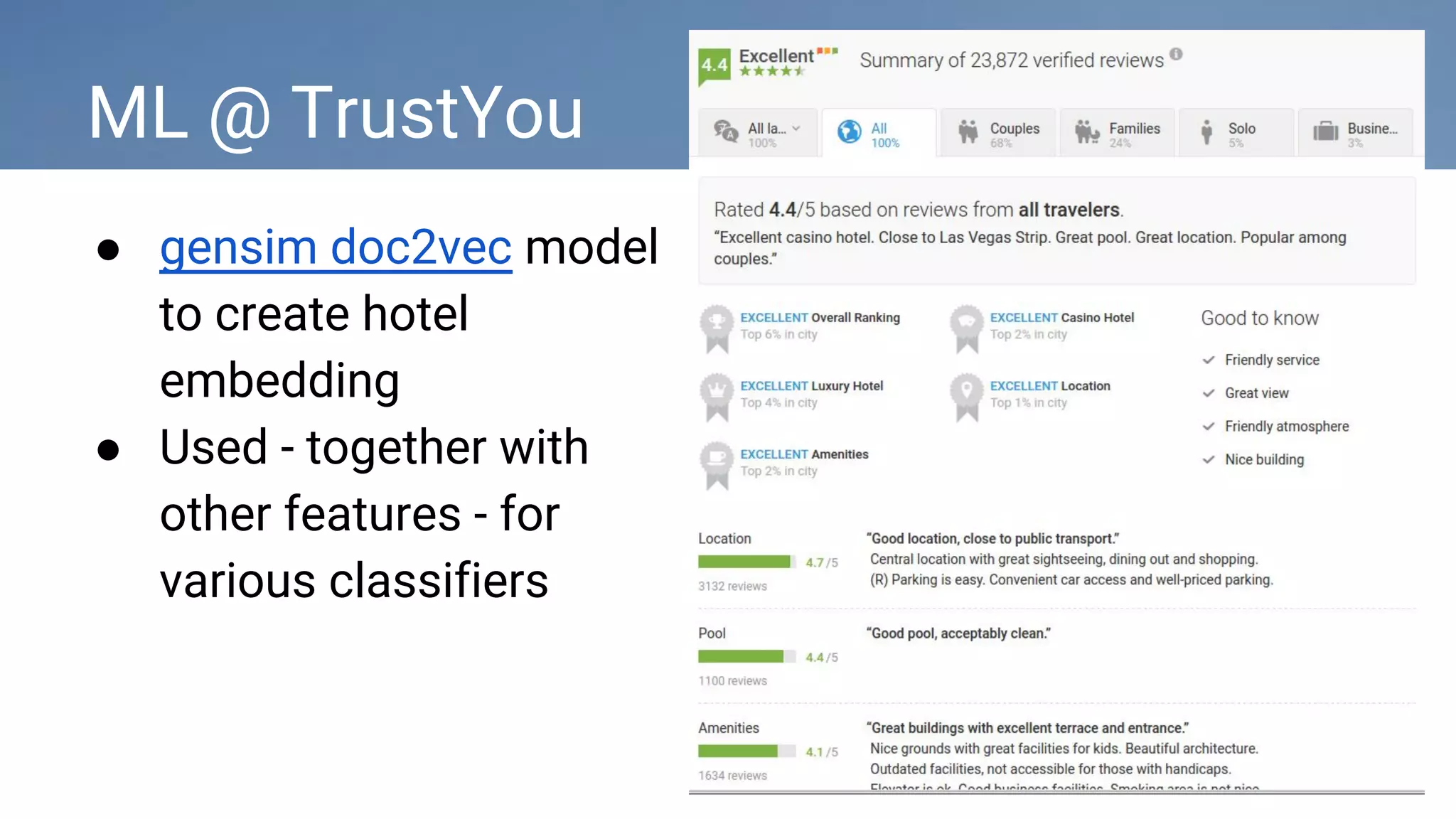
The document discusses how TrustYou uses Python and machine learning techniques like word embeddings and document classification to analyze over 100 million hotel reviews and provide summarizations to travelers. It also provides an overview of TrustYou's architecture, which uses Hadoop and Spark to process large amounts of review data and power their analytics using Python libraries for natural language processing and machine learning. The company is hiring data engineers and web developers to continue expanding their platform.










































































