15-721 (Spring 2023)
LASTCLASS
We discussed the advantages of the columnar
storage model via PAX for OLAP workloads.
All attributes in a columnar database must be fixed-
length to enable offset addressing.
If the DBMS assumes that its data files are
immutable, it enables several optimization
opportunities.
2
3.
15-721 (Spring 2023)
OBSERVATION
OLTPDBMSs use indexes to find individual tuples
without performing sequential scans.
→ Tree-based indexes (B+Trees) are meant for queries with
low selectivity predicates.
→ Also need to accommodate incremental updates.
But OLAP queries don't necessarily need to find
individual tuples and data files are read-only.
How can we speed up sequential scans?
3
4.
15-721 (Spring 2023)
SEQUENTIALSCAN OPTIMIZATIONS
Data Prefetching
Task Parallelization / Multi-threading
Clustering / Sorting
Late Materialization
Materialized Views / Result Caching
Data Skipping
Data Parallelization / Vectorization
Code Specialization / Compilation
4
5.
15-721 (Spring 2023)
DATASKIPPING
Approach #1: Approximate Queries (Lossy)
→ Execute queries on a sampled subset of the entire table to
produce approximate results.
→ Examples: BlinkDB, Redshift, ComputeDB, XDB, Oracle,
Snowflake, Google BigQuery, DataBricks
Approach #2: Data Pruning (Loseless)
→ Use auxiliary data structures for evaluating predicates to
quickly identify portions of a table that the DBMS can skip
instead of examining tuples individually.
→ DBMS must consider trade-offs between scope vs. filter
efficacy, manual vs. automatic.
5
6.
15-721 (Spring 2023)
DATACONSIDERATIONS
Predicate Selectivity
→ How many tuples will satisfy a query's predicates.
Skewness
→ Whether an attribute has all unique values or contain
many repeated values.
Clustering / Sorting
→ Whether the table is pre-sorted on the attributes accessed
in a query's predicates.
6
15-721 (Spring 2023)
SMALLMATERIALIZED AGGREGATES: A
LIGHT WEIGHT INDEX STRUCTURE FOR
DATA WAREHOUSING
VLDB 1998
ZONE MAPS
Pre-computed aggregates for the attribute values in
a block of tuples. DBMS checks the zone map first
to decide whether it wants to access the block.
→ Originally called Small Materialized Aggregates (SMA)
→ DBMS automatically creates/maintains this meta-data.
Zone Map
val
100
400
280
1400
type
MIN
MAX
AVG
SUM
5
COUNT
Original Data
val
100
200
300
400
400
SELECT * FROM table
WHERE val > 600
8
9.
15-721 (Spring 2023)
SMALLMATERIALIZED AGGREGATES: A
LIGHT WEIGHT INDEX STRUCTURE FOR
DATA WAREHOUSING
VLDB 1998
ZONE MAPS
Pre-computed aggregates for the attribute values in
a block of tuples. DBMS checks the zone map first
to decide whether it wants to access the block.
→ Originally called Small Materialized Aggregates (SMA)
→ DBMS automatically creates/maintains this meta-data.
Zone Map
val
100
400
280
1400
type
MIN
MAX
AVG
SUM
5
COUNT
Original Data
val
100
200
300
400
400
SELECT * FROM table
WHERE val > 600
8
10.
15-721 (Spring 2023)
OBSERVATION
Trade-offbetween scope vs. filter efficacy.
→ If the scope is too large, then the zone maps will be useless.
→ If the scope is too small, then the DBMS will spend too
much checking zone maps.
Zone Maps are only useful when the target
attribute's position and values are correlated.
9
11.
15-721 (Spring 2023)
BITMAPINDEXES
Store a separate Bitmap for each unique value for an
attribute where an offset in the vector corresponds
to a tuple.
→ The ith position in the Bitmap corresponds to the ith tuple
in the table.
Typically segmented into chunks to avoid allocating
large blocks of contiguous memory.
→ Example: One per row group in PAX.
10
MODEL 204 ARCHITECTURE AND PERFORMANCE
HIGH PERFORMANCE TRANSACTION SYSTEMS 1987
12.
15-721 (Spring 2023)
BITMAPINDEXES
11
Compressed Data
Original Data
id
2
1
4
3
7
6
9
8
lit?
Y
Y
N
Y
N
Y
Y
Y
id
2
1
4
3
7
6
9
8
Y
1
1
0
1
0
1
1
1
N
0
0
1
0
1
0
0
0
lit?
13.
15-721 (Spring 2023)
BITMAPINDEXES
11
Compressed Data
Original Data
id
2
1
4
3
7
6
9
8
lit?
Y
Y
N
Y
N
Y
Y
Y
id
2
1
4
3
7
6
9
8
Y
1
1
0
1
0
1
1
1
N
0
0
1
0
1
0
0
0
lit?
14.
15-721 (Spring 2023)
BITMAPINDEXES: EXAMPLE
Take the intersection of three
bitmaps to find matching tuples.
Assume we have 10 million tuples.
43,000 zip codes in the US.
→ 10000000 × 43000 = 53.75GB
This is wasteful because most
entries in the bitmaps will be zeros.
→ Original: 10000000 × 32-bit = 40MB
12
CREATE TABLE customer_dim (
id INT PRIMARY KEY,
name VARCHAR(32),
email VARCHAR(64),
address VARCHAR(64),
zip_code INT
);
SELECT id, email FROM customer_dim
WHERE zip_code IN (15216,15217,15218);
15.
15-721 (Spring 2023)
BITMAPINDEX: DESIGN CHOICES
Encoding Scheme
→ How to represent and organize data in a Bitmap.
Compression
→ How to reduce the size of sparse Bitmaps.
13
16.
15-721 (Spring 2023)
BITMAPINDEX: ENCODING
Approach #1: Equality Encoding
→ Basic scheme with one Bitmap per unique value.
Approach #2: Range Encoding
→ Use one Bitmap per interval instead of one per value.
→ Example: PostgreSQL BRIN
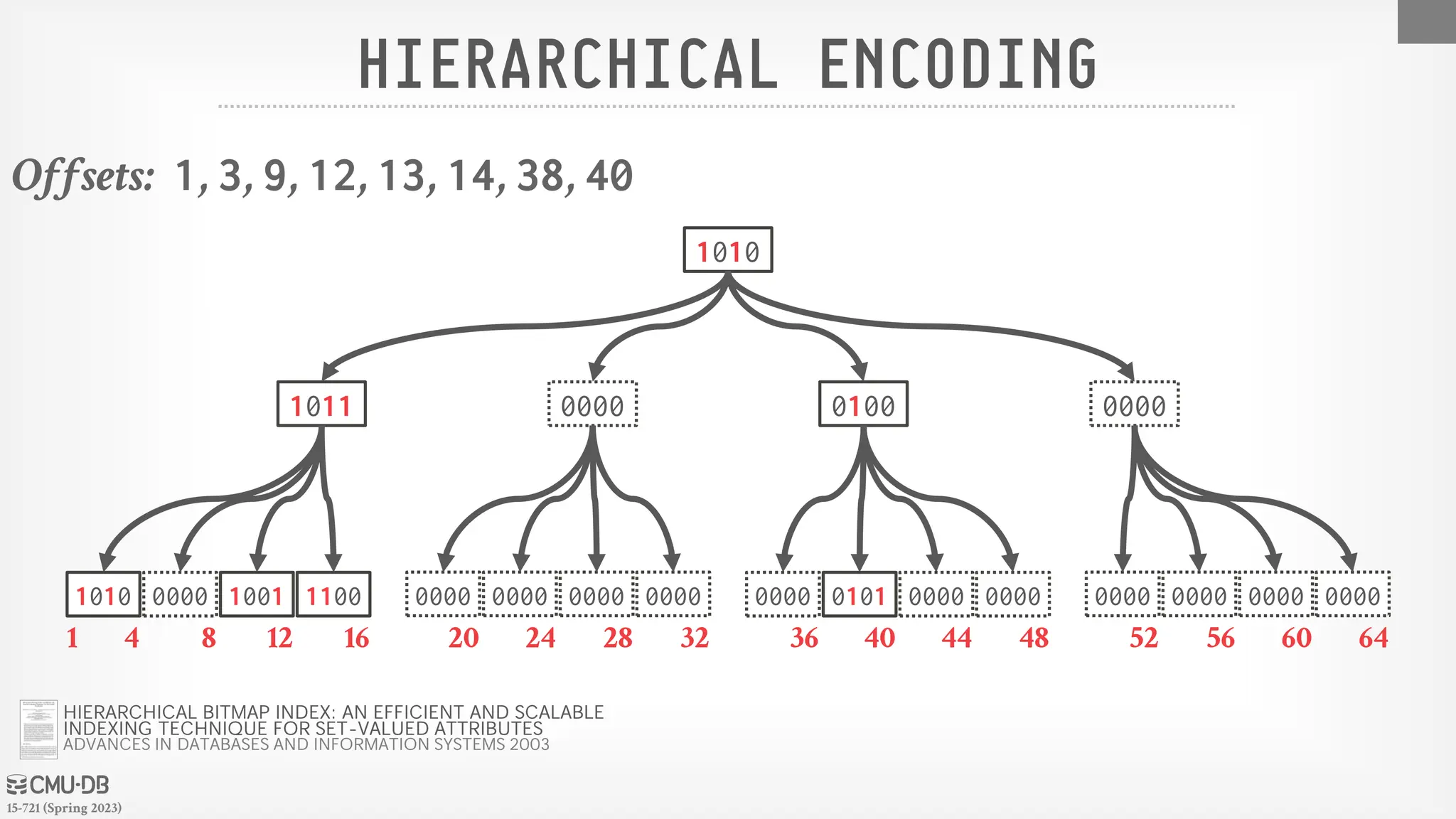
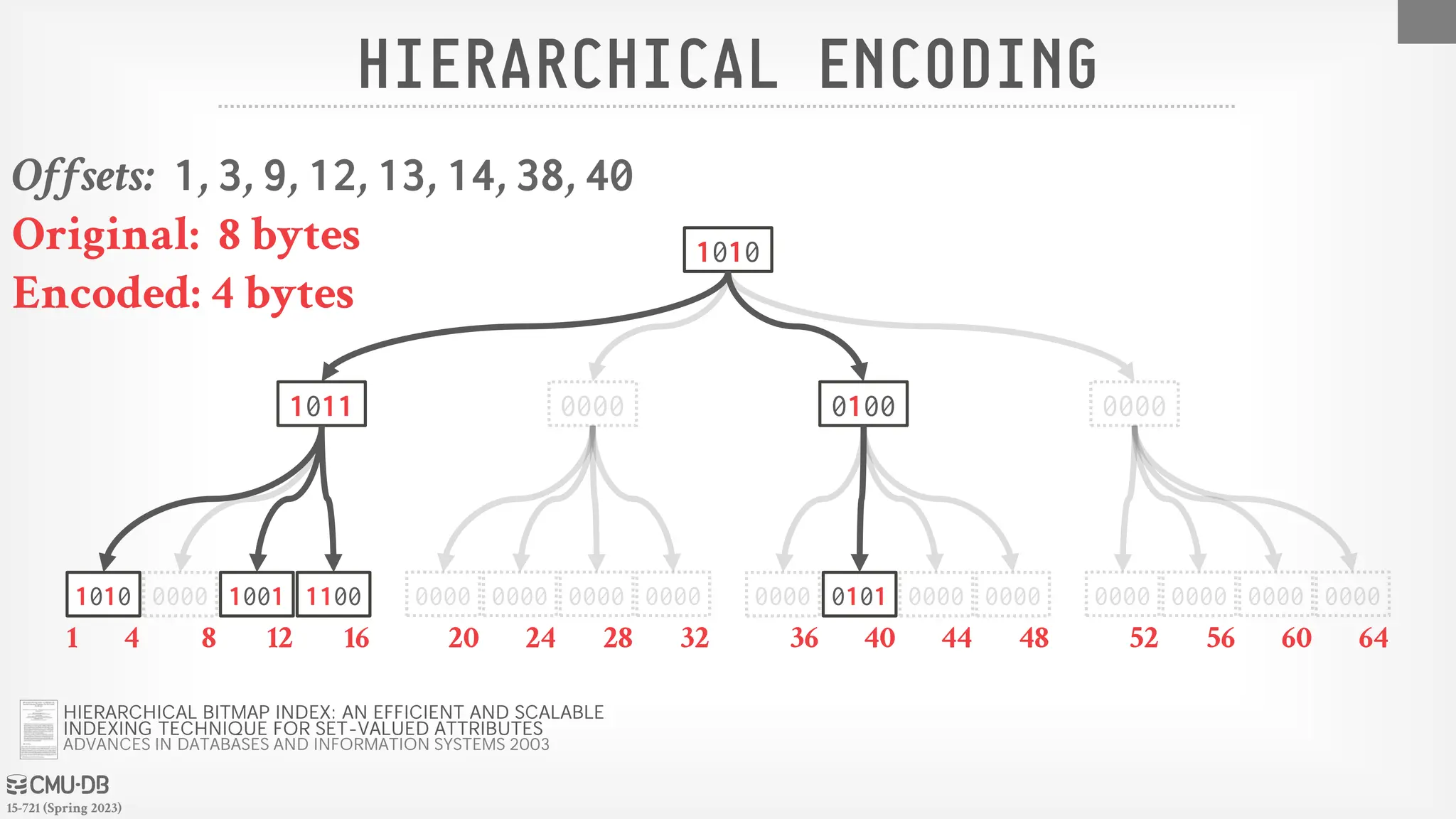
Approach #3: Hierarchical Encoding
→ Use a tree to identify empty key ranges.
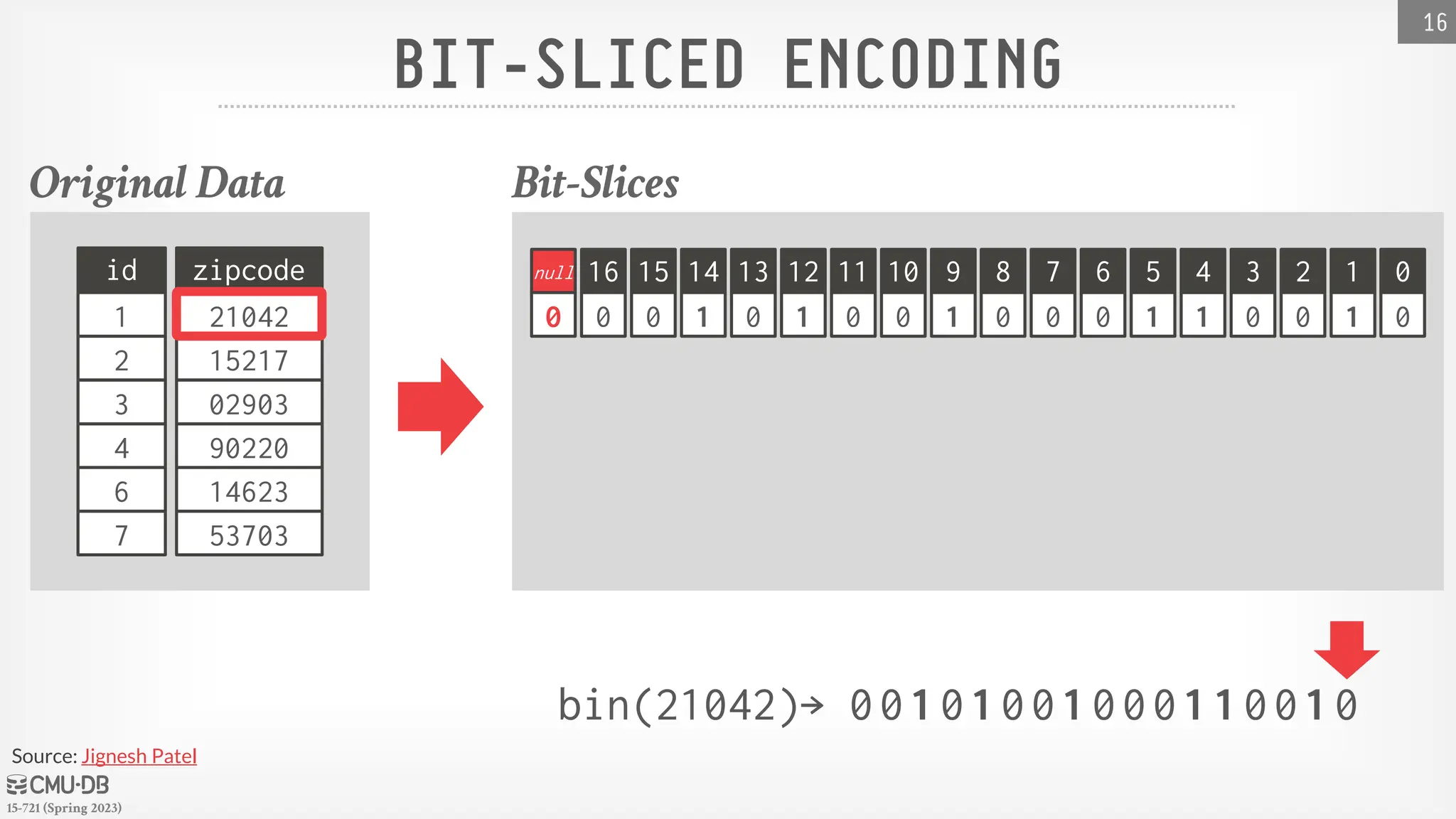
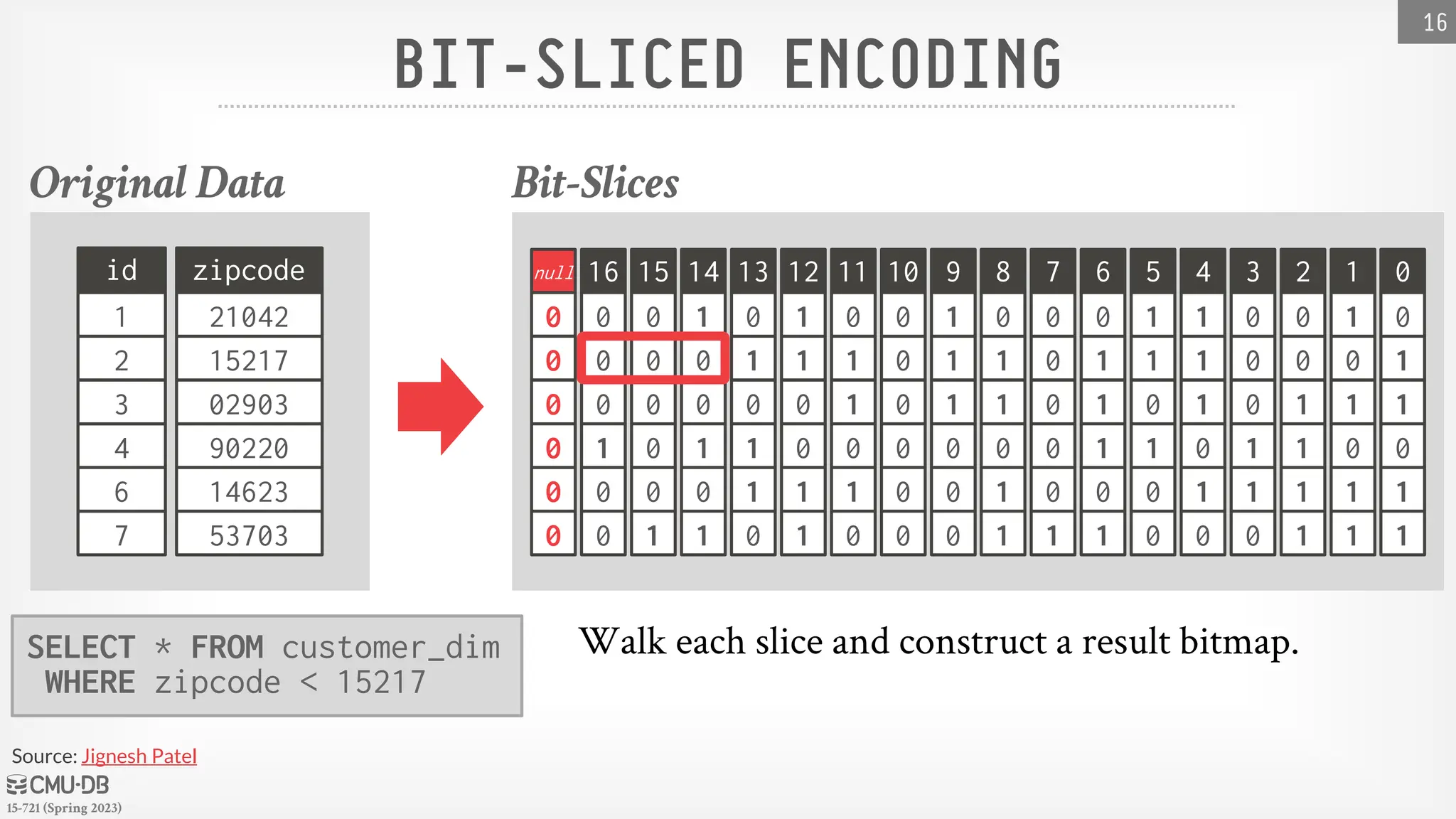
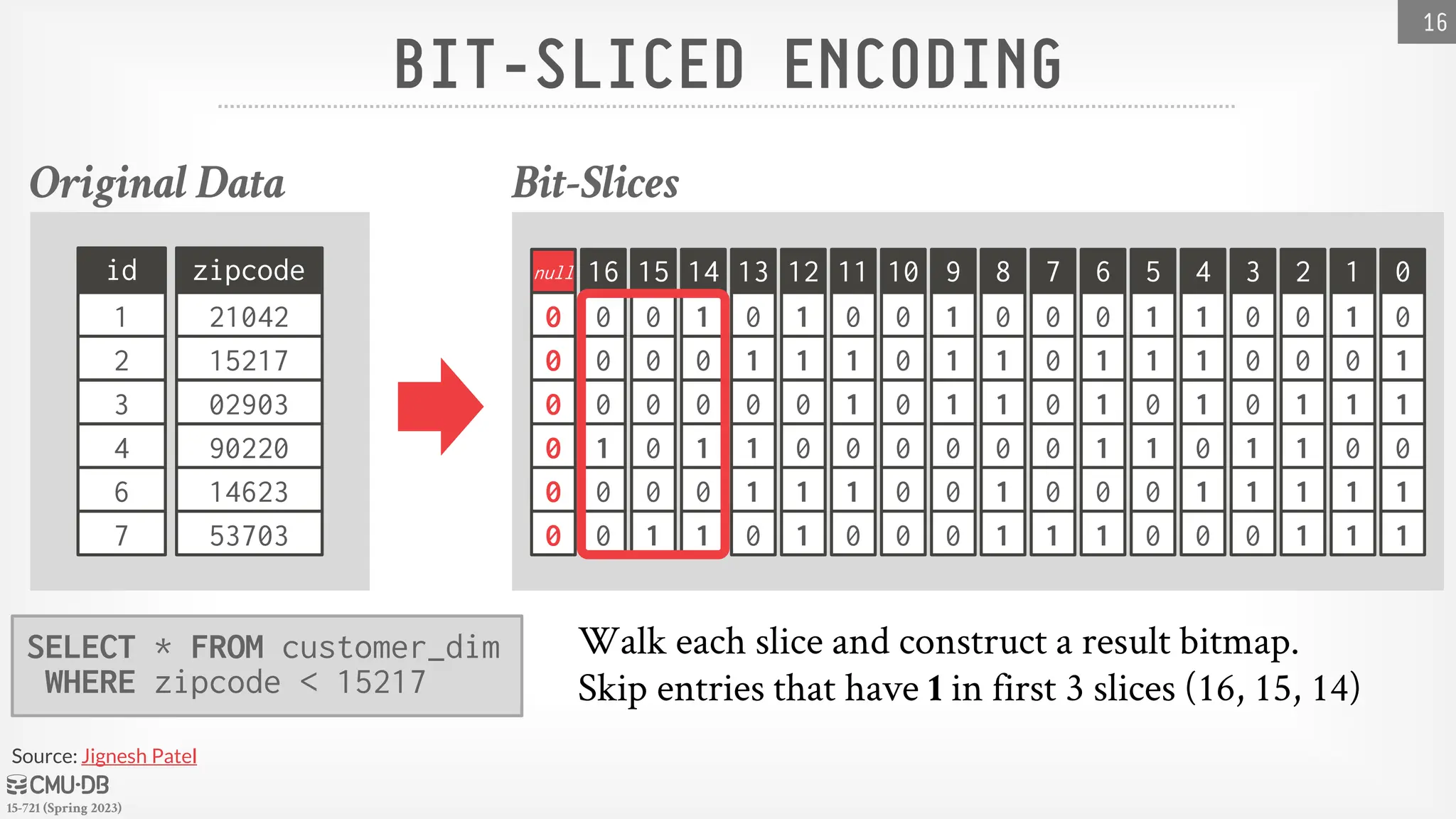
Approach #4: Bit-sliced Encoding
→ Use a Bitmap per bit location across all values.
14
15-721 (Spring 2023)
BIT-SLICEDENCODING
Bit-slices can also be used for efficient aggregate
computations.
Example: SUM(attr) using Hamming Weight
→ First, count the number of 1s in slice17 and multiply the
count by 217
→ Then, count the number of 1s in slice16 and multiply the
count by 216
→ Repeat for the rest of slices…
Intel added POPCNT SIMD instruction in 2008.
17
23.
15-721 (Spring 2023)
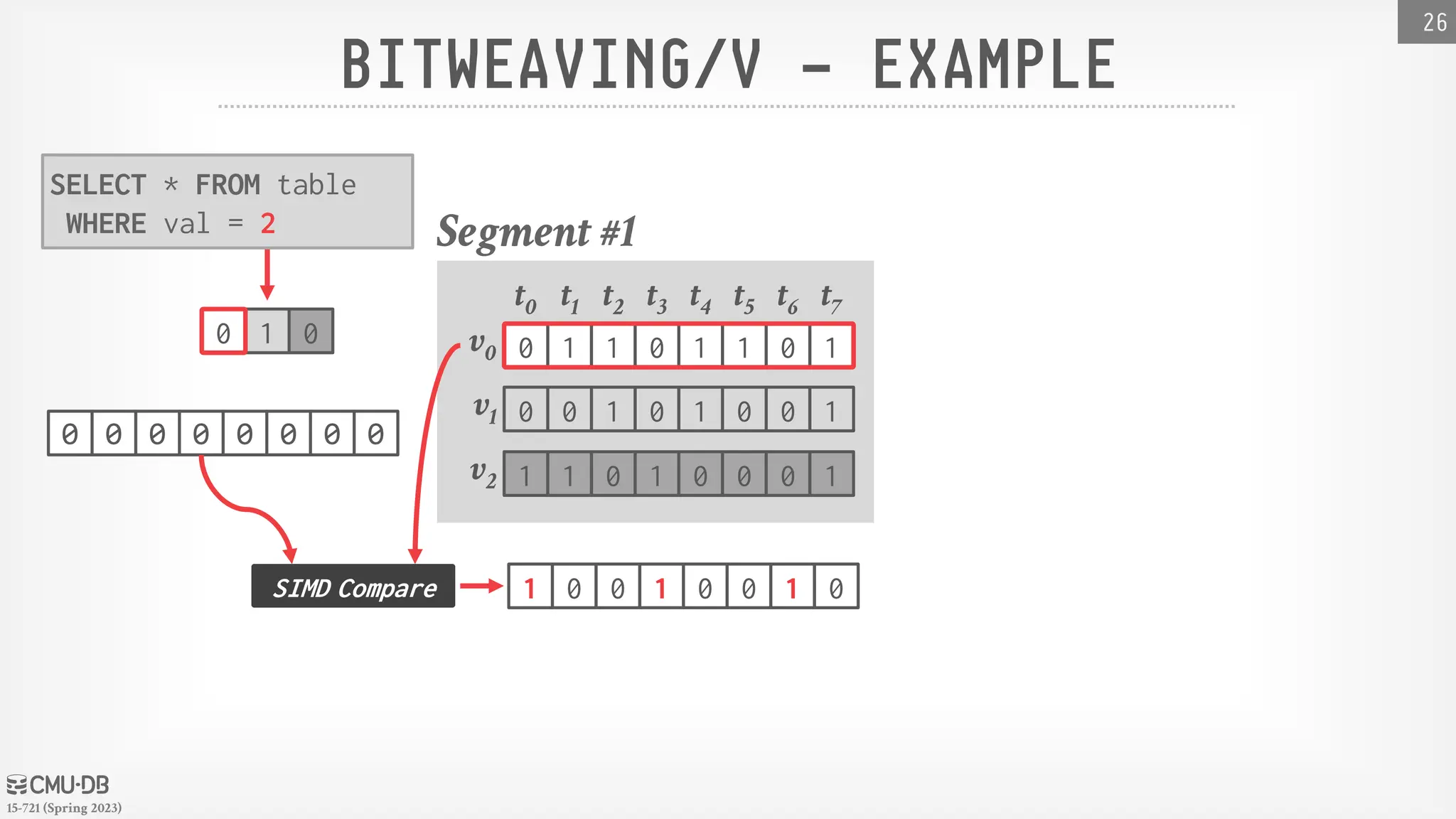
BITWEAVING
Alternativestorage layout for columnar databases
that is designed for efficient predicate evaluation on
compressed data using SIMD.
→ Order-preserving dictionary encoding.
→ Bit-level parallelization.
→ Only require common instructions (no scatter/gather)
Implemented in Wisconsin’s QuickStep engine.
→ Became an Apache Incubator project in 2016 but then died
in 2018.
19
BITWEAVING: FAST SCANS FOR MAIN MEMORY
DATA PROCESSING
SIGMOD 2013
24.
15-721 (Spring 2023)
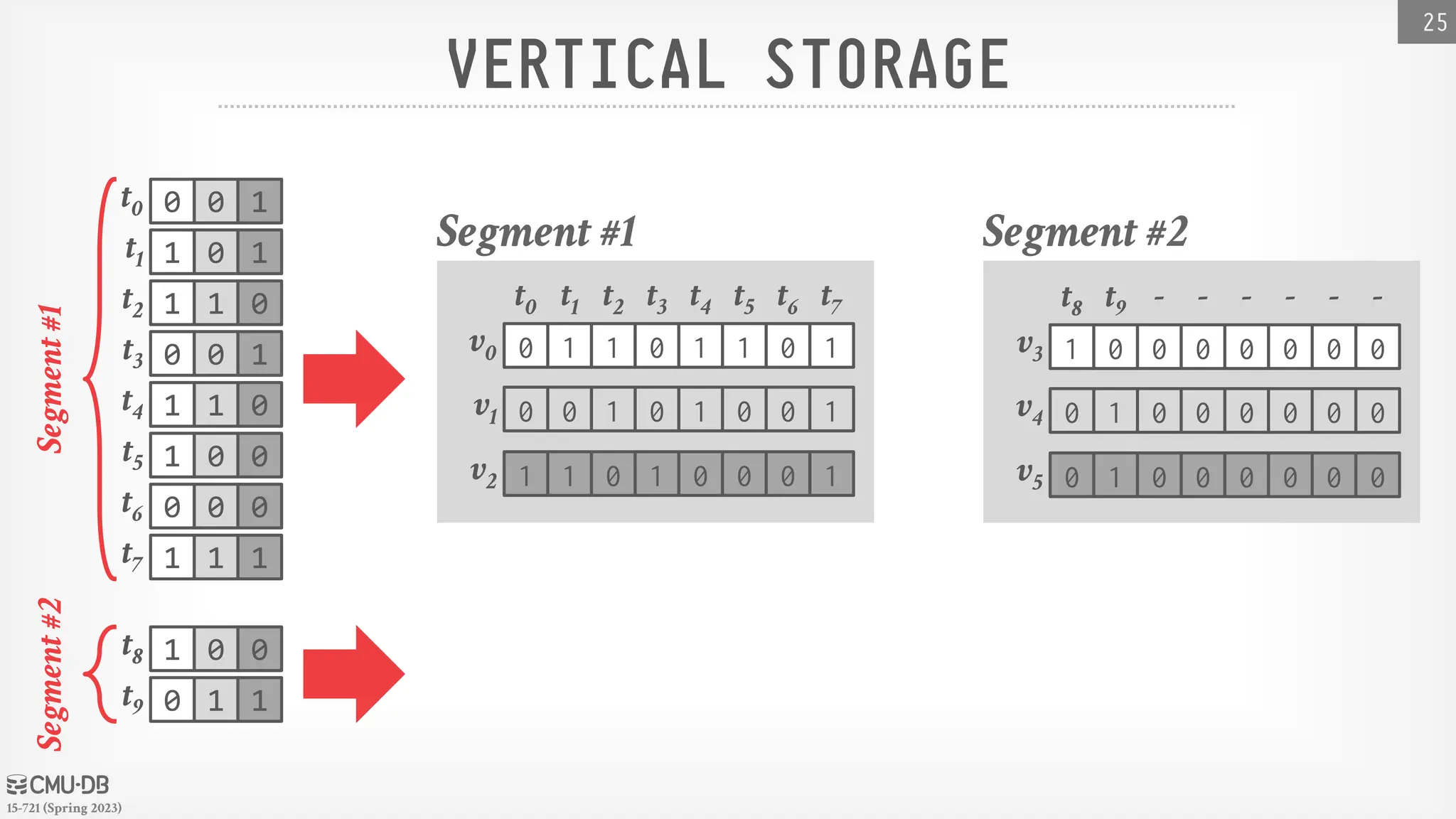
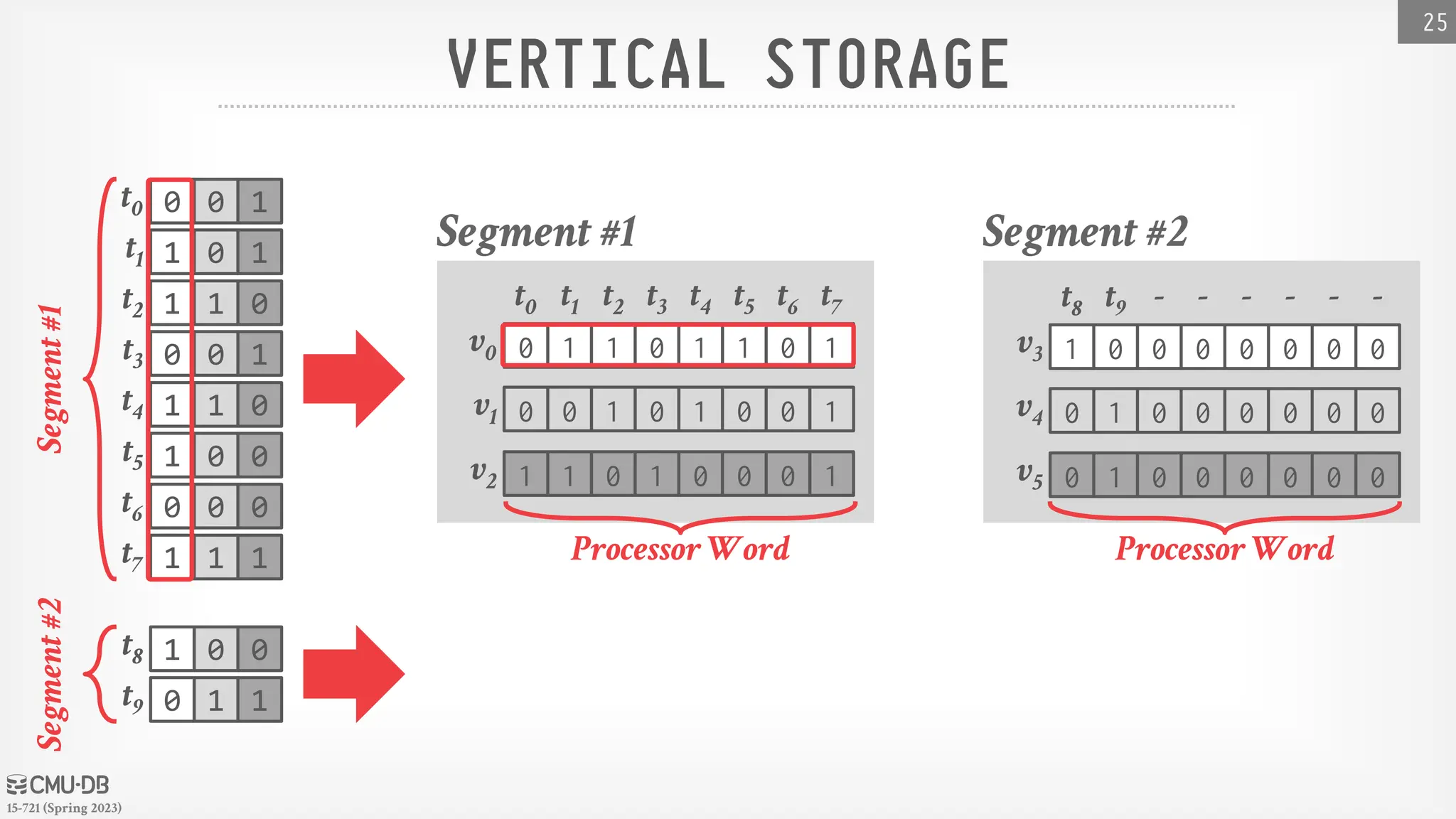
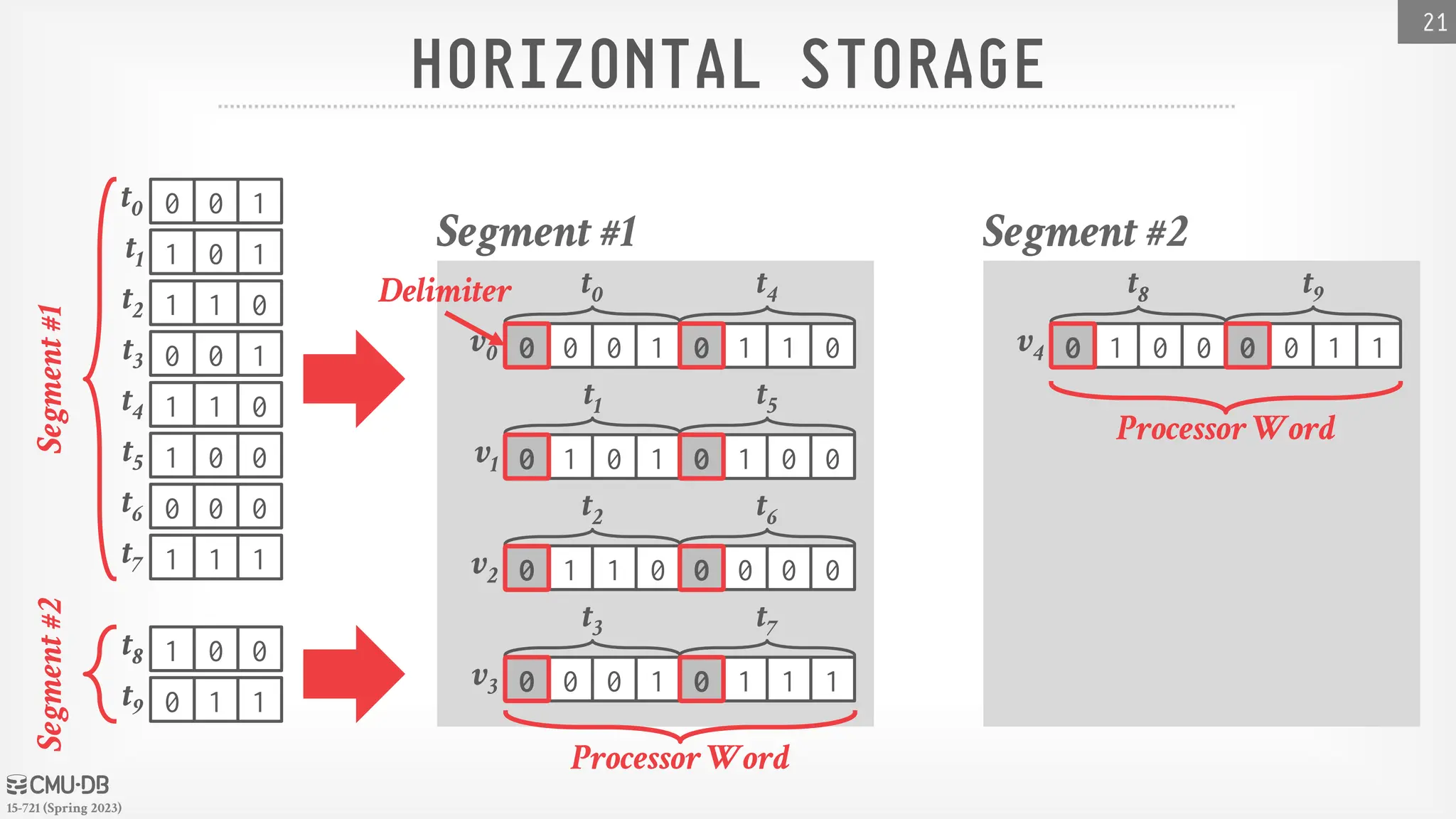
BITWEAVING– STORAGE LAYOUTS
Approach #1: Horizontal
→ Row-oriented storage at the bit-level
Approach #2: Vertical
→ Column-oriented storage at the bit-level
20
15-721 (Spring 2023)
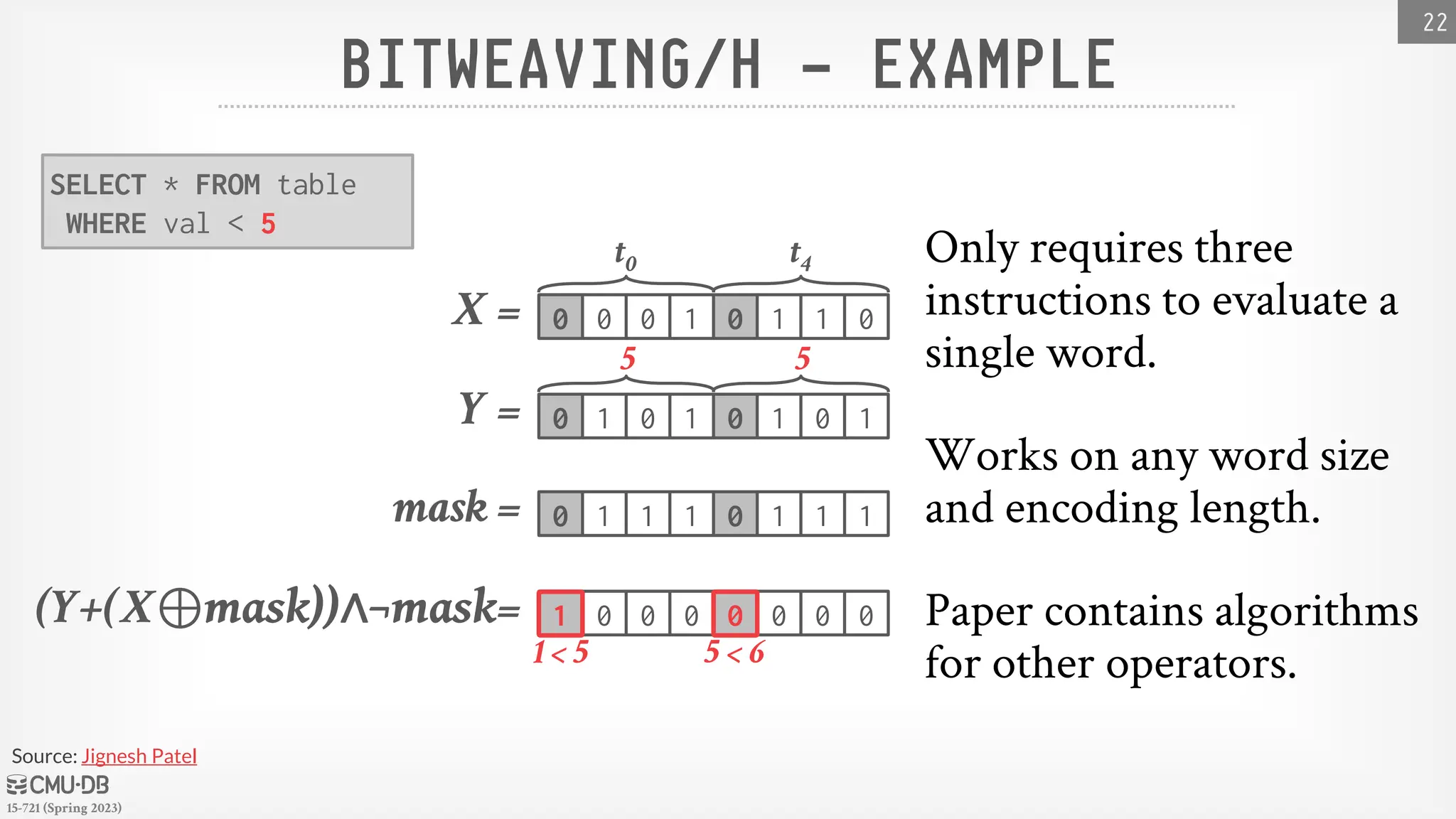
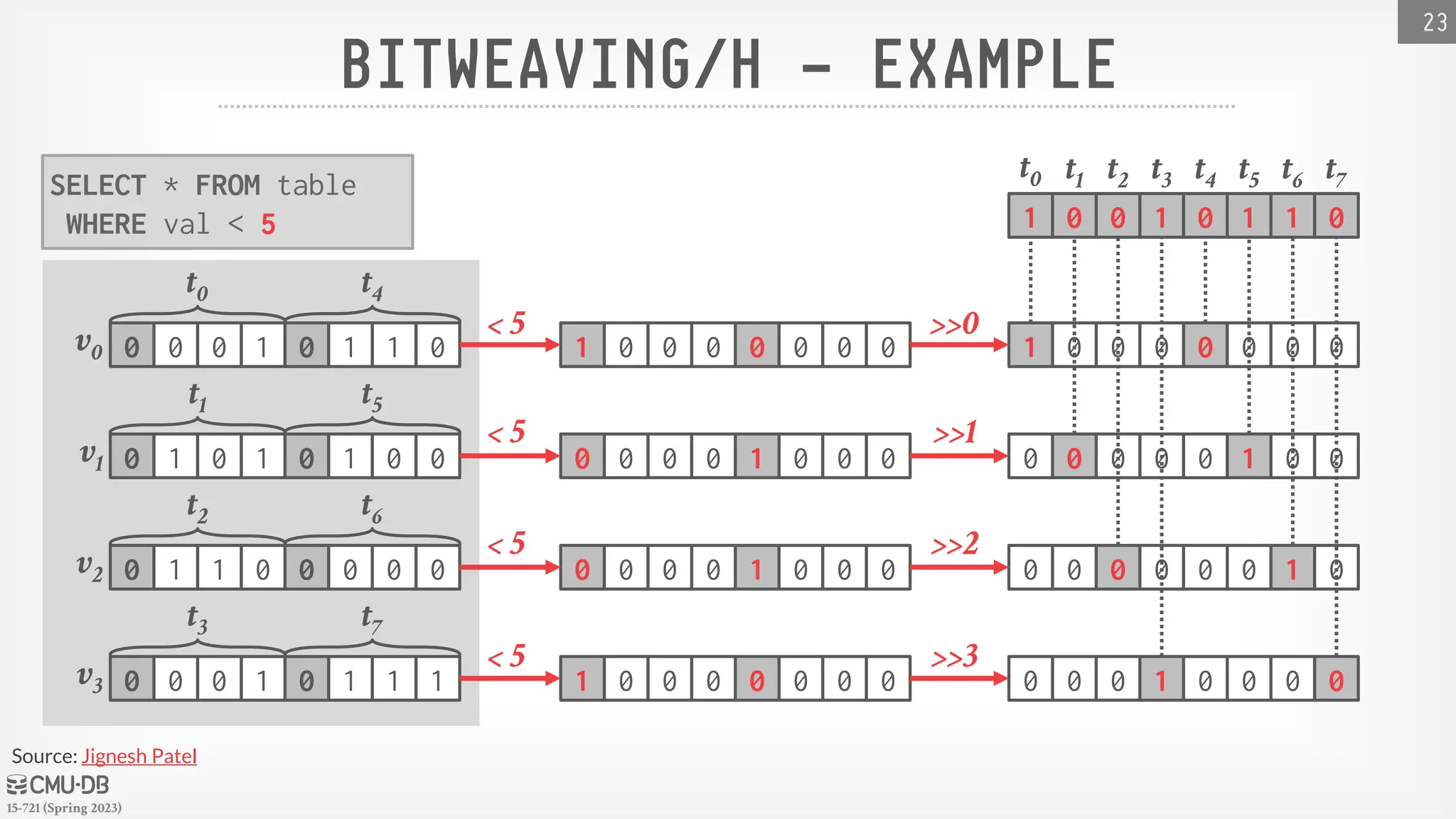
BITWEAVING/H– EXAMPLE
Only requires three
instructions to evaluate a
single word.
Works on any word size
and encoding length.
Paper contains algorithms
for other operators.
SELECT * FROM table
WHERE val < 5
t0 t4
0 0 0 1 0 1 1 0
X =
Y = 0 1 0 1 0 1 0 1
5 5
mask = 0 1 1 1 0 1 1 1
(Y+(X⊕mask))∧¬mask= 1 0 0 0 0 0 0 0
1 < 5 5 < 6
Source: Jignesh Patel
22
15-721 (Spring 2023)
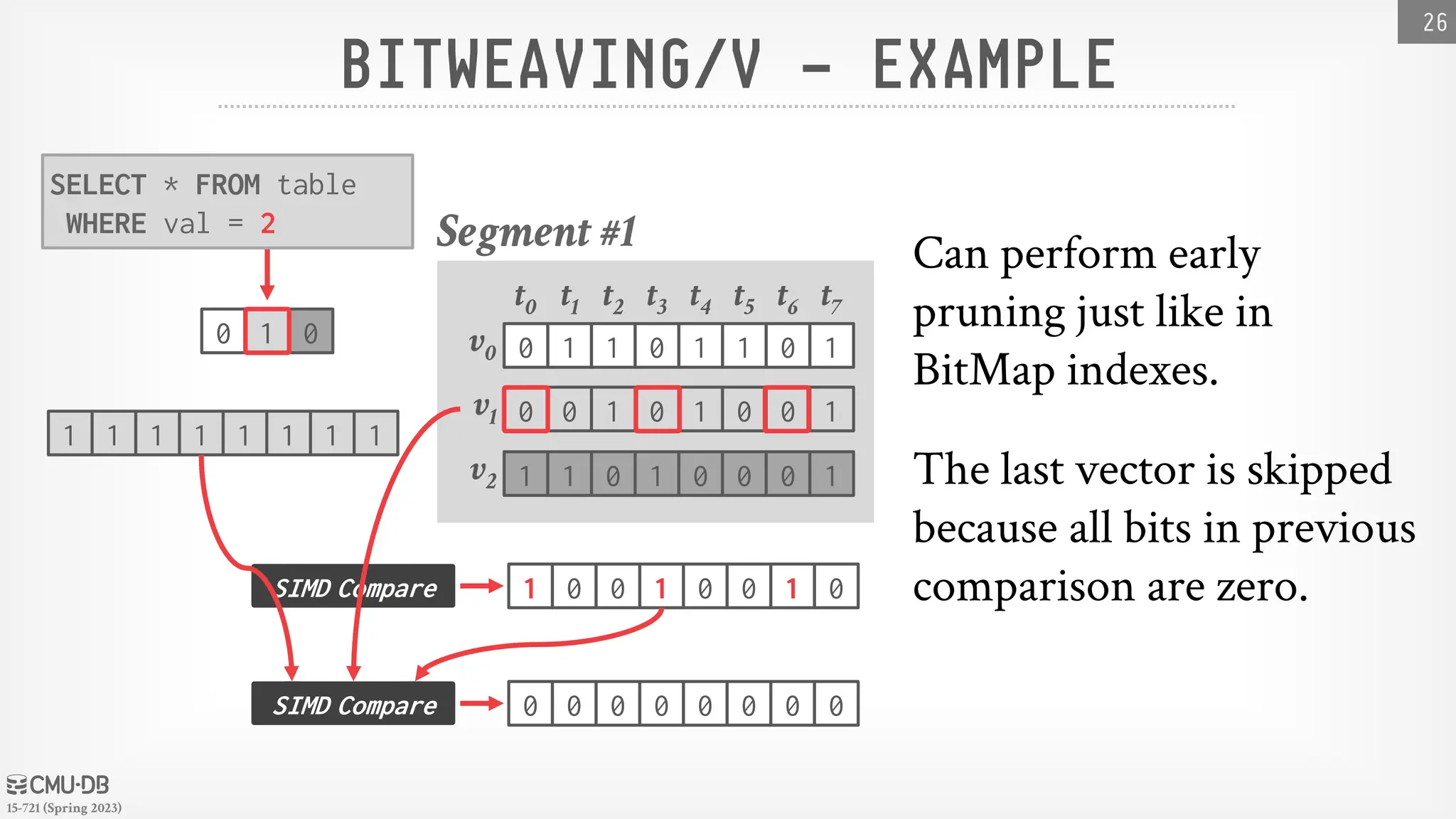
OBSERVATION
Allthe previous Bitmap schemes were about storing
exact/loseless representations of columnar data.
The DBMS could give up some accuracy in
exchange for faster evaluation in the common case.
→ It still must always check the original data to avoid false
positives.
28
37.
15-721 (Spring 2023)
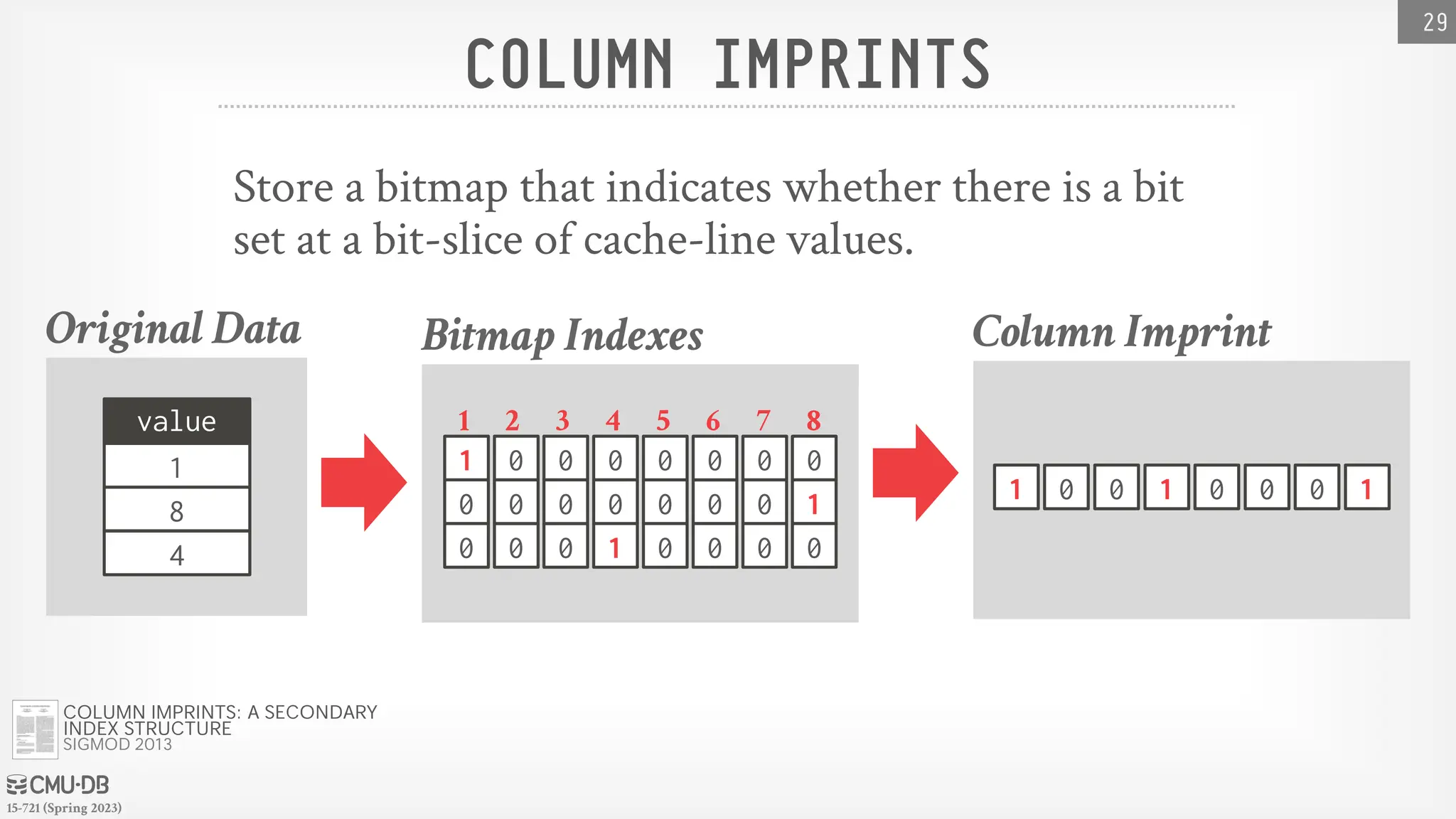
COLUMNIMPRINTS
Store a bitmap that indicates whether there is a bit
set at a bit-slice of cache-line values.
COLUMN IMPRINTS: A SECONDARY
INDEX STRUCTURE
SIGMOD 2013
Original Data
value
8
1
4
Column Imprint
1 0 0 1 0 0 0 1
Bitmap Indexes
1
0
0 0 0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
0
1 2 3 4 5 6 7
0
1
0
8
29
38.
15-721 (Spring 2023)
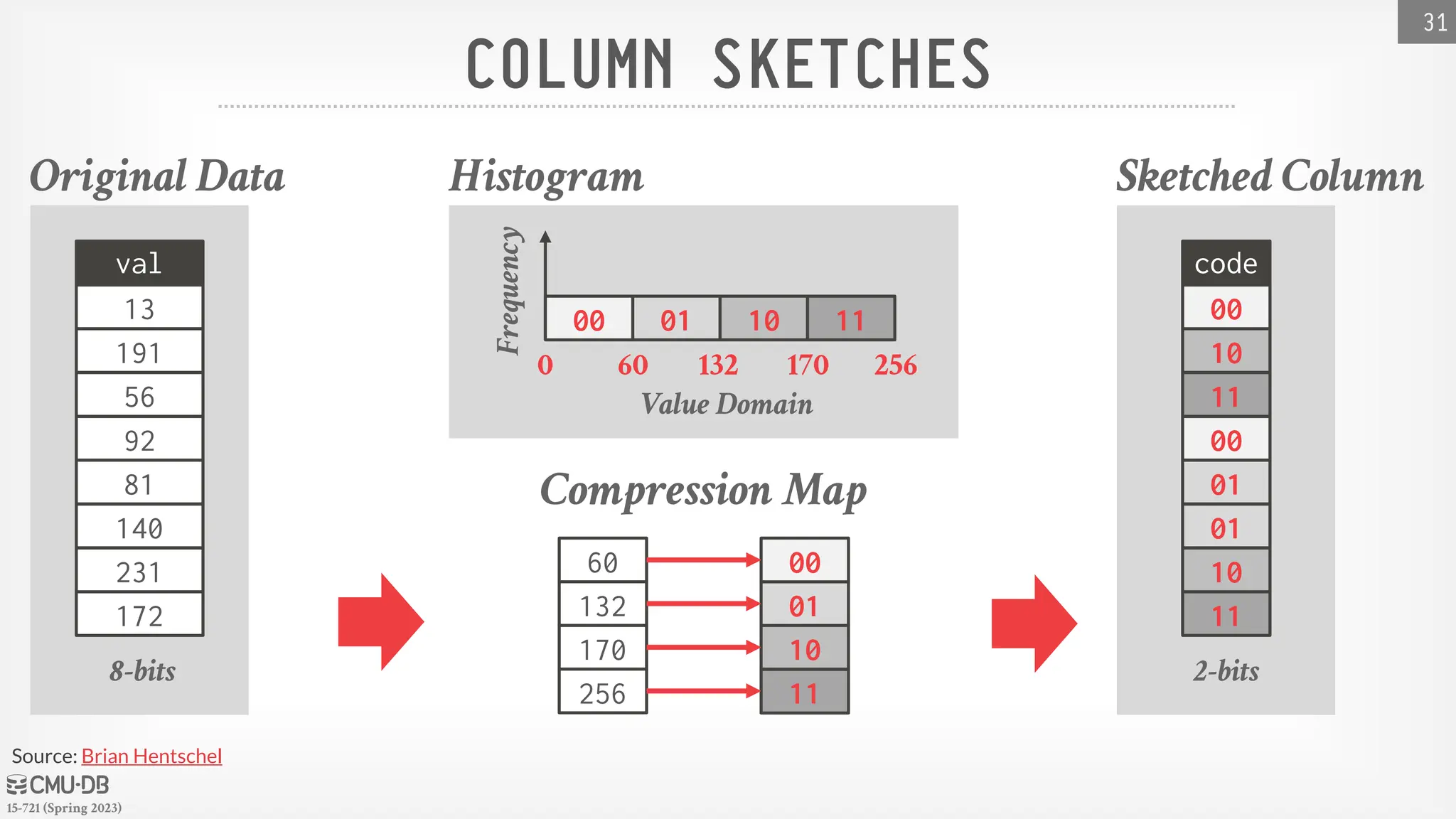
COLUMNSKETCHES
A variation of range-encoded Bitmaps that uses a
smaller sketch codes to indicate that a tuple's value
exists in a range.
DBMS must automatically figure out the best
mapping of codes.
→ Trade-off between distribution of values and compactness.
→ Assign unique codes to frequent values to avoid false
positives.
30
COLUMN SKETCHES: A SCAN ACCELERATOR FOR
RAPID AND ROBUST PREDICATE EVALUATION
SIGMOD 2013
39.
15-721 (Spring 2023)
COLUMNSKETCHES
31
Source: Brian Hentschel
Original Data
val
191
13
92
56
140
81
172
231
8-bits
Sketched Column
code
10
00
00
11
01
01
11
10
2-bits
Histogram
01
00 11
10
0 60 132 170 256
Value Domain
Frequency
01
00
11
10
60
132
170
256
Compression Map
40.
15-721 (Spring 2023)
COLUMNSKETCHES
31
Source: Brian Hentschel
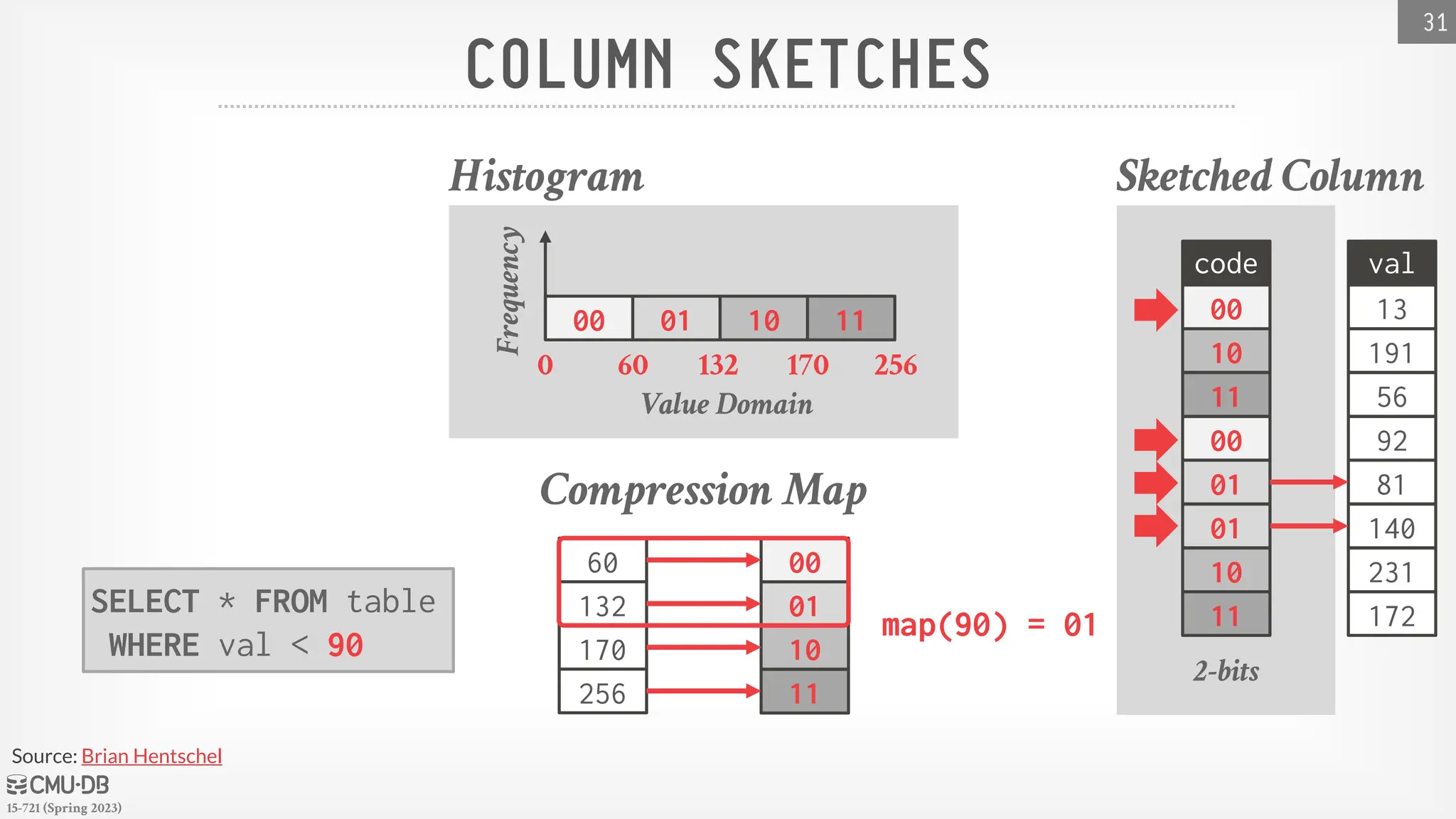
Sketched Column
code
10
00
00
11
01
01
11
10
2-bits
Histogram
01
00 11
10
0 60 132 170 256
Value Domain
Frequency
01
00
11
10
60
132
170
256
Compression Map
SELECT * FROM table
WHERE val < 90
map(90) = 01
val
191
13
92
56
140
81
172
231
41.
15-721 (Spring 2023)
PARTINGTHOUGHTS
Zone Maps are the most widely used method to
accelerate sequential scans.
Bitmap indexes are more common in NSM DBMSs
than columnar OLAP systems.
We’re ignoring multi-dimensional and inverted
indexes…
32
15-721 (Spring 2023)
PROJECT#1 – FOREIGN DATA WRAPPER
You will create a foreign data wrapper
for PostgreSQL for performing simple
scans with predicate pushdown on a
custom columnar data format.
The goal is to get you familiar with
extending Postgres and writing a
simple scan operator.
Due Date: Sunday Feb 26th
34
Prompt: A dramatic renaissance painting of a
scottish terrier riding on top of an African elephant
running through Carnegie Mellon University.
https://15721.courses.cs.cmu.edu/spring2023/project1.html
44.
15-721 (Spring 2023)
PROJECT#1 – TASKS
We provide a simple columnar data file format.
Write a parser for this file that can scan individual
columns and stitching tuples back together.
Integrate it with Postgres as a foreign table.
Add support for predicate evaluation.
35
45.
15-721 (Spring 2023)
DEVELOPMENTHINTS
Write the basic parser code separately first, then
connect it to Postgres.
We recommend completing this project in C++
using PGXS.
→ You can try asking Chi about doing it in Rust but he has
better things to do in his life…
Gradescope is for meant for grading, not
debugging. Write your own local tests.
36
46.
15-721 (Spring 2023)
THINGSTO NOTE
Do not change any file other than the ones that you
submit to Gradescope.
Make sure you fork our version of Postgres.
Post your questions on Piazza or come to TA office
hours.
37
47.
15-721 (Spring 2023)
PLAGIARISMWARNING
Your project implementation must be
your own work.
→ You may not copy source code from other
groups or the web.
Plagiarism will not be tolerated.
See CMU's Policy on Academic
Integrity for additional information.
38




















![15-721 (Spring 2023)
SELECTION VECTOR
SIMD comparison operators produce a bit mask
that specifies which tuples satisfy a predicate.
→ DBMS must convert it into column offsets.
Approach #1: Iteration
Approach #2: Pre-computed Positions Table
tuples = [ ]
for (i=0; i<n; i++) {
if sv[i] == 1
tuples.add(i);
}
1 0 0 1 0 1 1 0
t0 t1 t2 t3 t4 t5 t6 t7
Selection Vector
24](https://image.slidesharecdn.com/04-olapindexes-250408070650-27b99c08/75/OLAP-Indexes-and-Algorithms-CMU-Advanced-Databases-29-2048.jpg)
![15-721 (Spring 2023)
SELECTION VECTOR
SIMD comparison operators produce a bit mask
that specifies which tuples satisfy a predicate.
→ DBMS must convert it into column offsets.
Approach #1: Iteration
Approach #2: Pre-computed Positions Table
1 0 0 1 0 1 1 0
t0 t1 t2 t3 t4 t5 t6 t7
Selection Vector
PAYLOAD
KEY
Positions Table
150
[0,3,5,6]
24](https://image.slidesharecdn.com/04-olapindexes-250408070650-27b99c08/75/OLAP-Indexes-and-Algorithms-CMU-Advanced-Databases-30-2048.jpg)