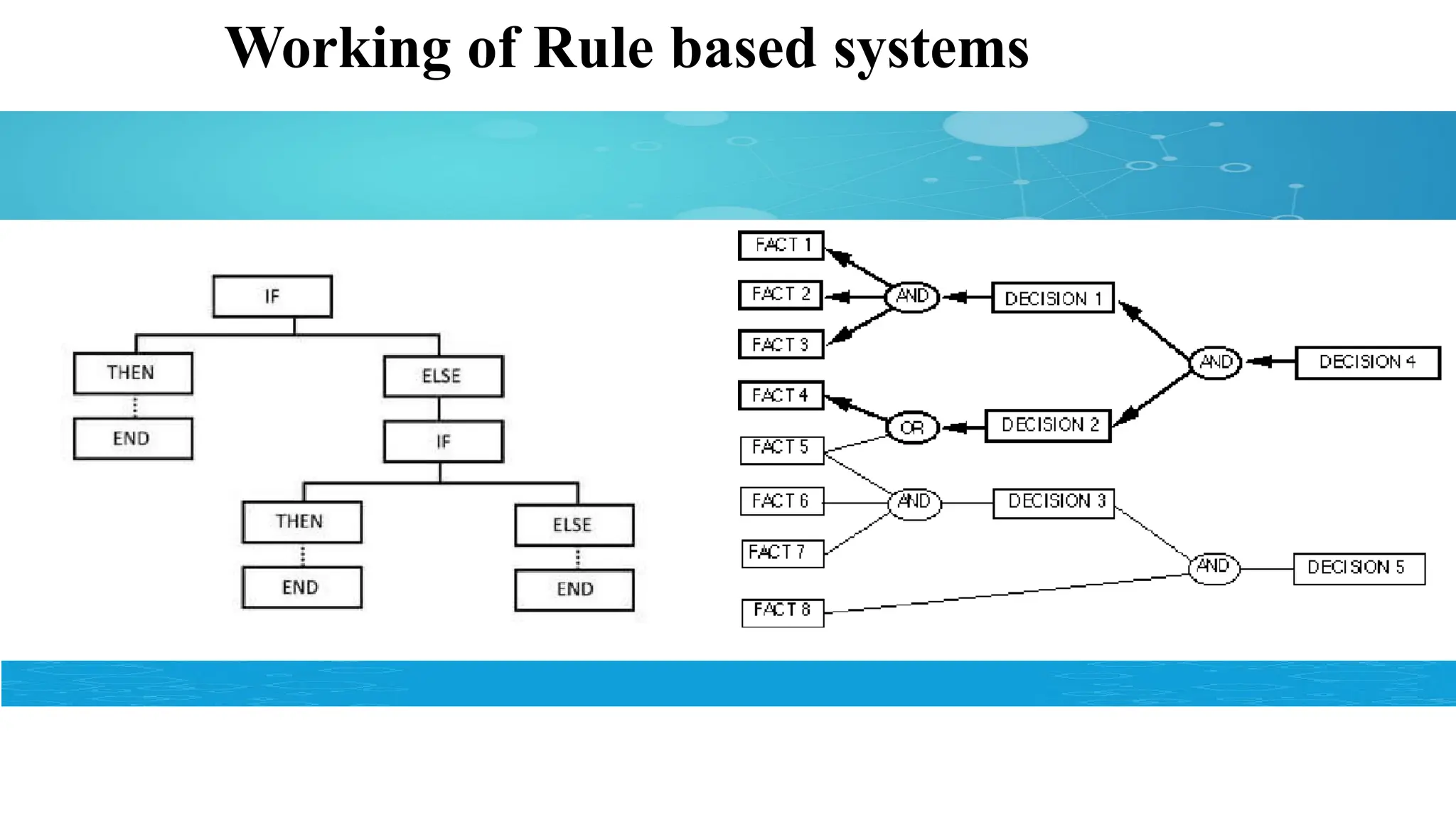
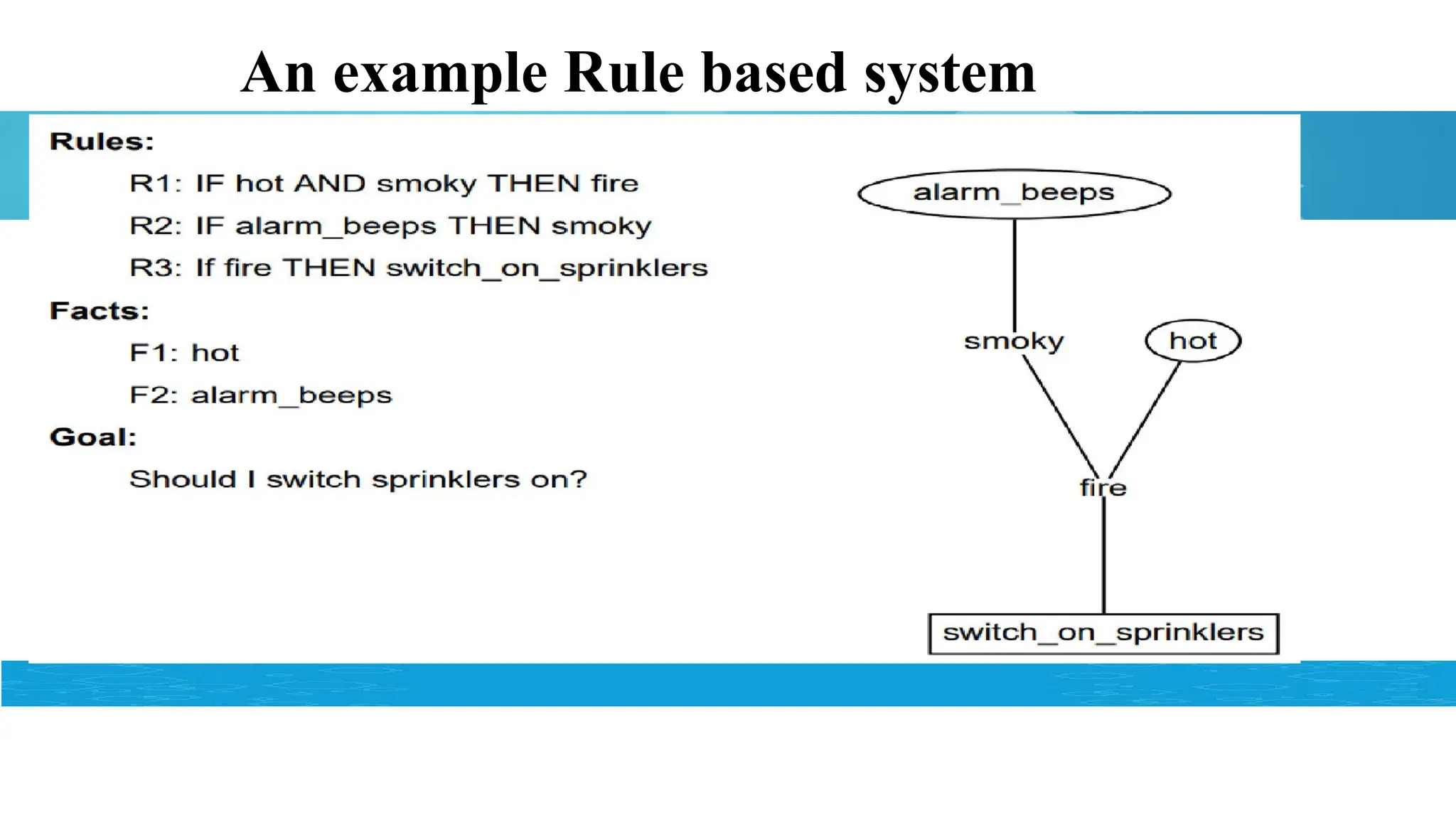
Limitations of Rules-BasedSystems
In other words: Why use machine learning?
It takes lot of time to list out all the rules
Changing rules is tedious
As the list of rules grows, it becomes too difficult to manage and has
a lot of redundancies.
The person who wrote the initial rules for you leaves, and you have
to spend time and resources to catch up on the long list of rules.
8.
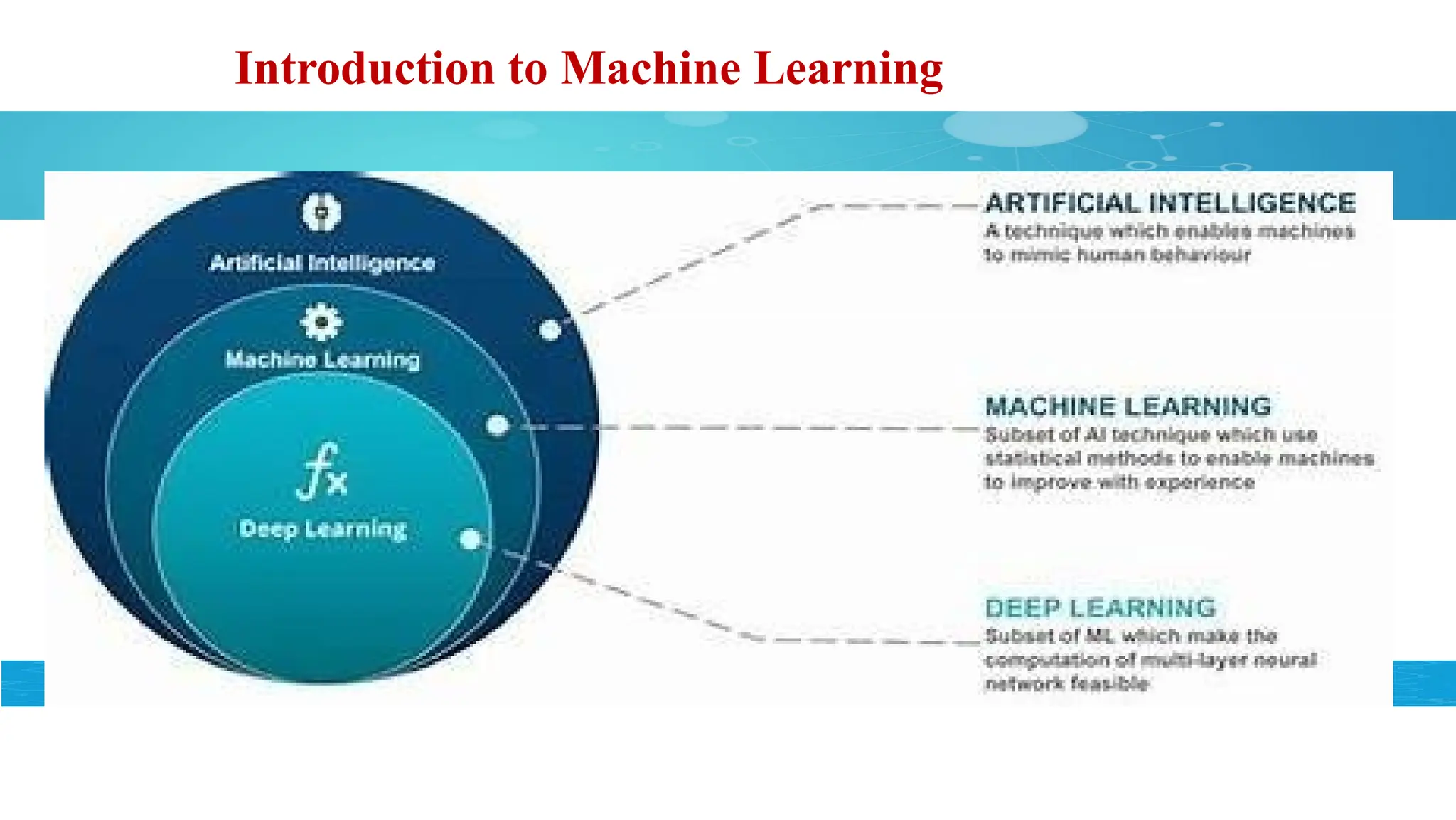
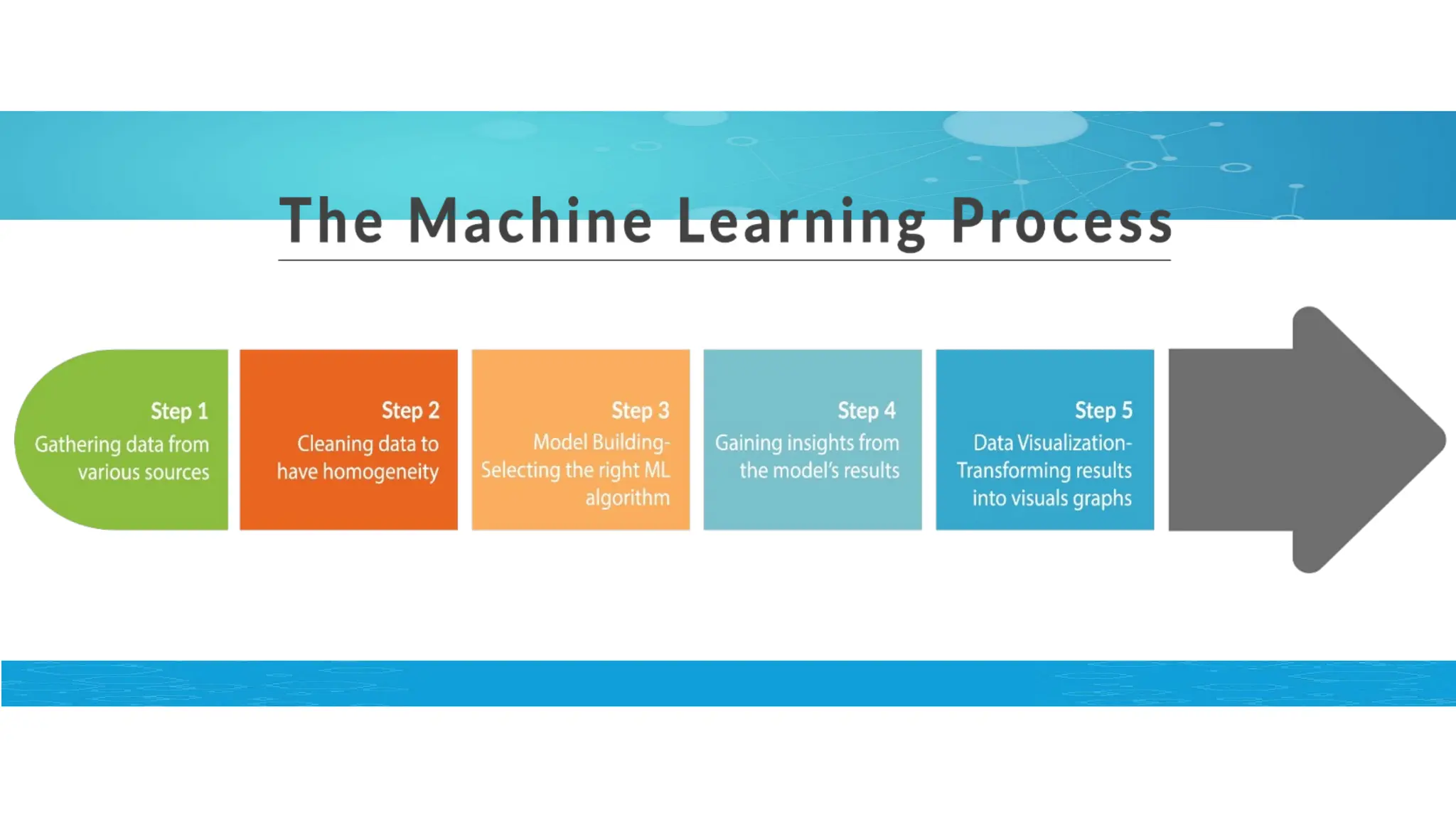
Introduction to MachineLearning
*Machine Learning (ML) is the scientific study of algorithms and statistical
models that computer systems use in order to perform a specific task by
relying on patterns and inference instead of explicit instructions.
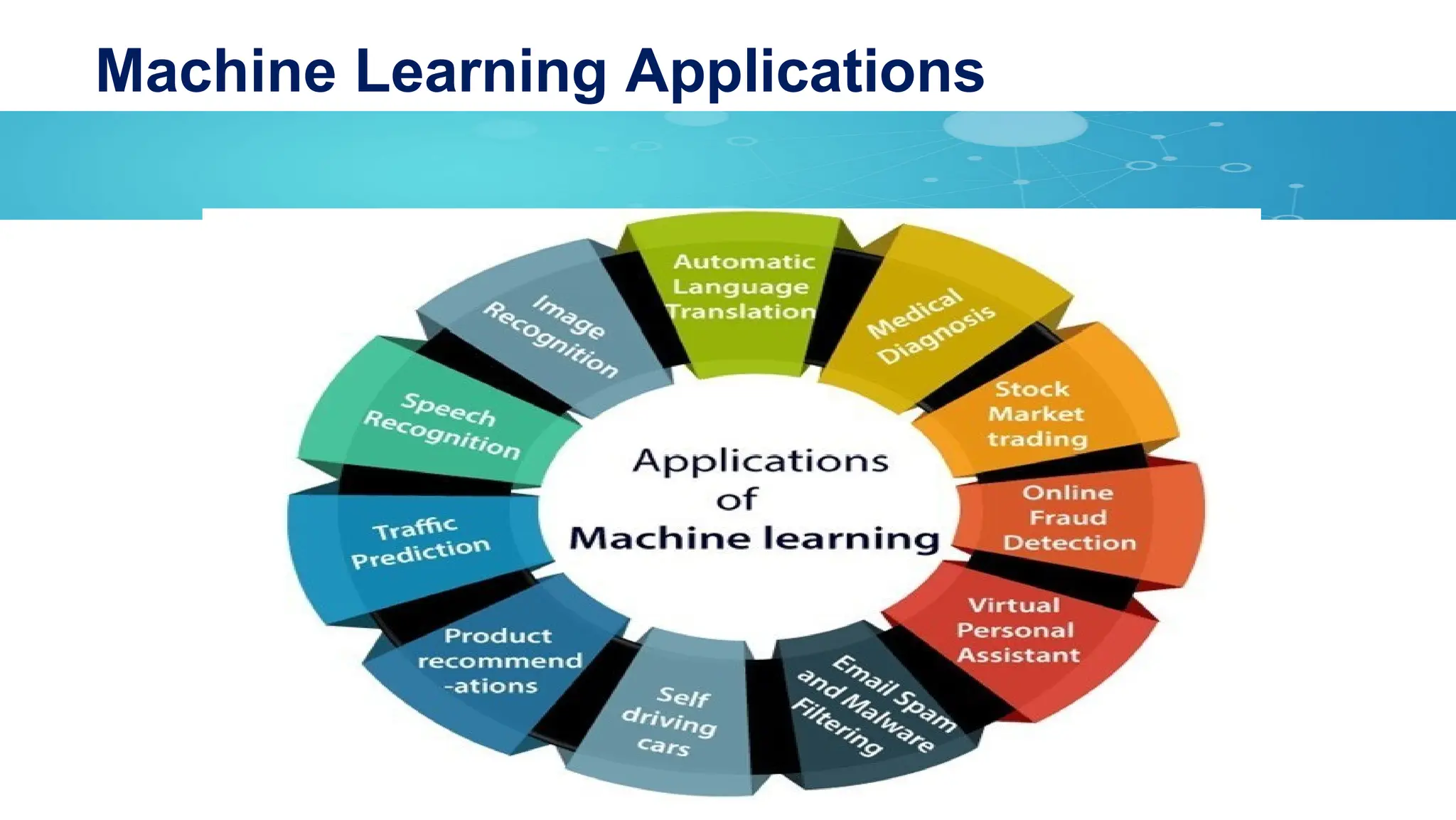
*ML algorithms are used in a wide variety of applications, such as
computer vision (CV), data mining, natural language processing (NLP),
etc.
9.
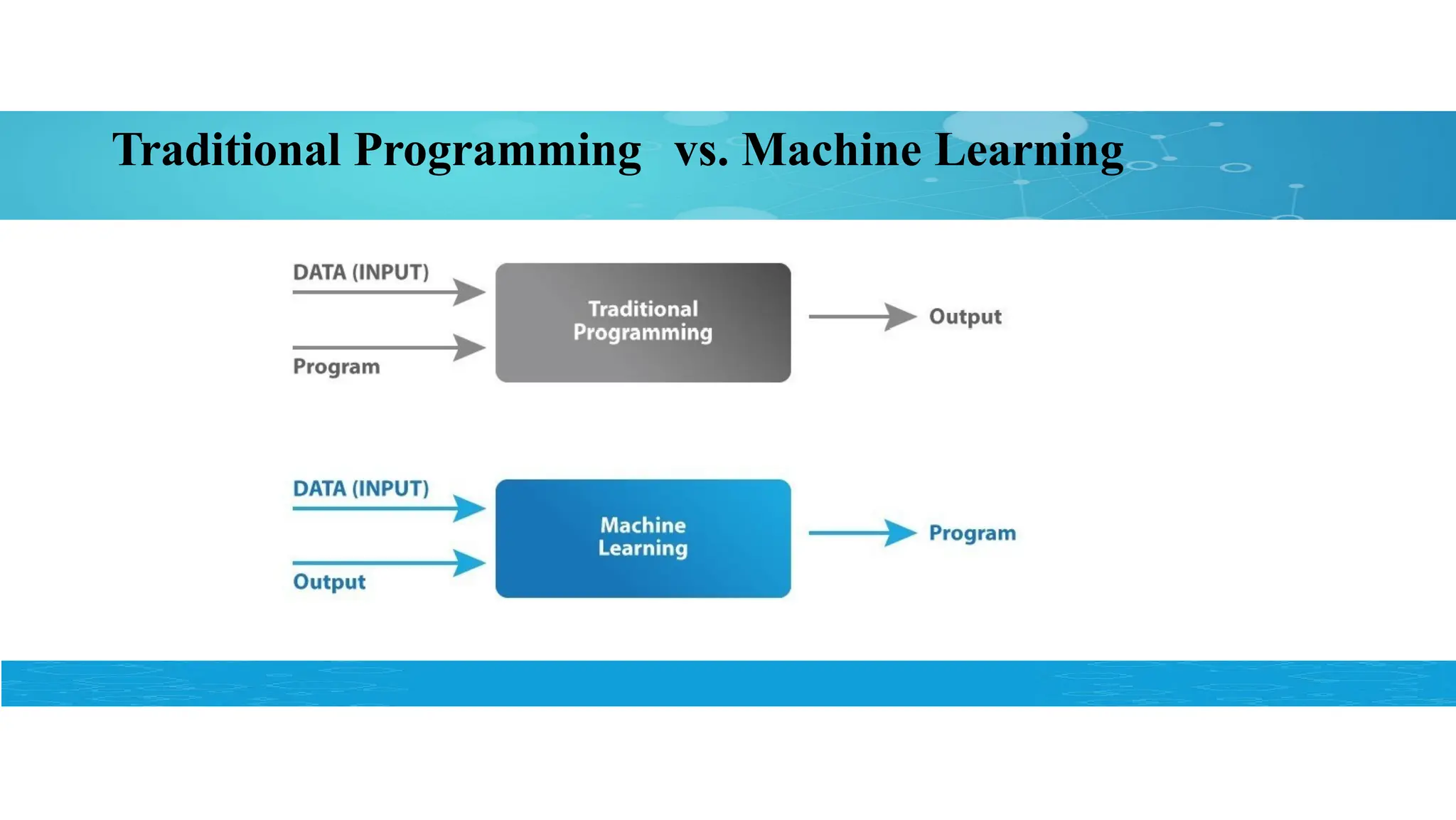
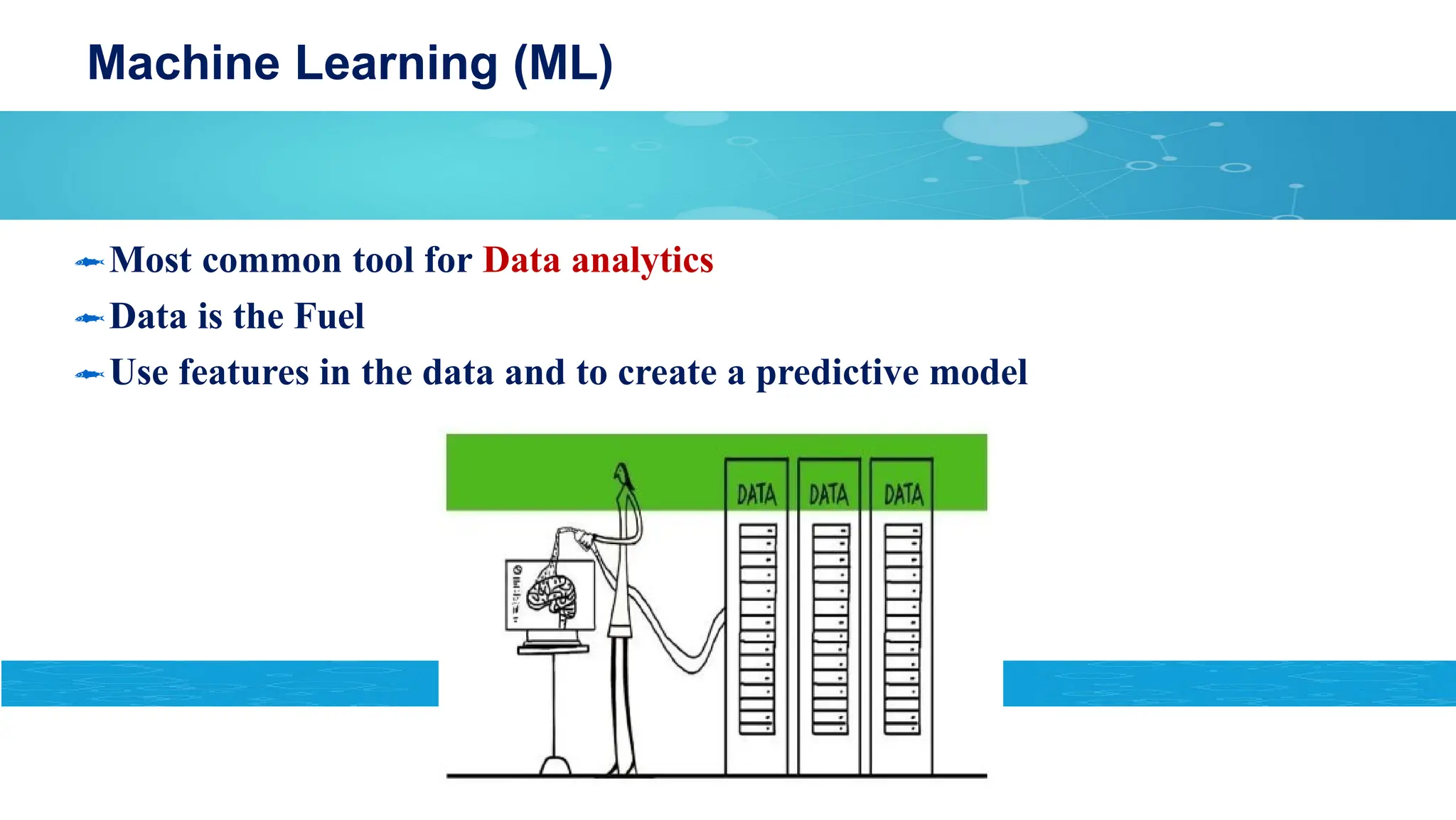
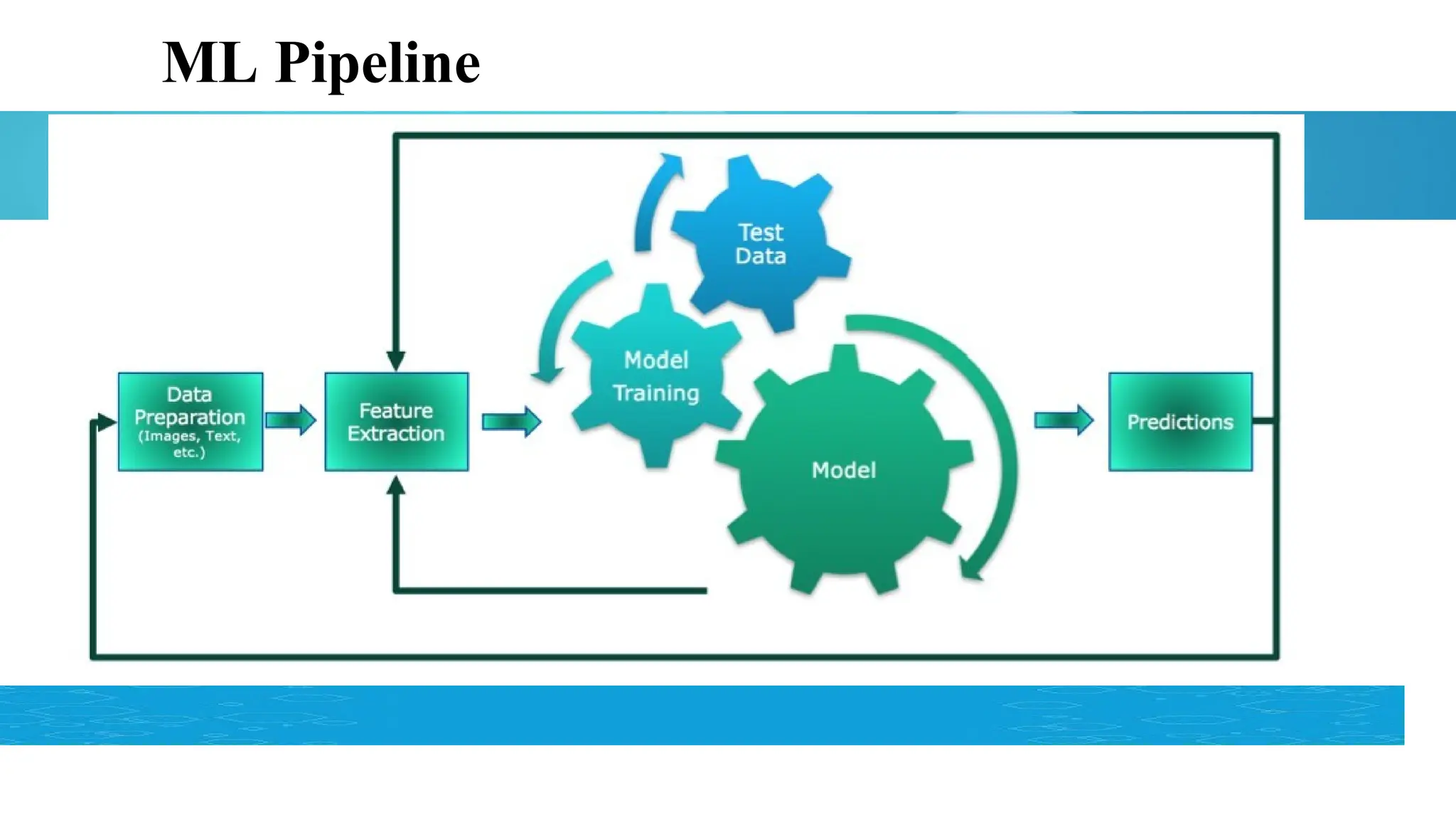
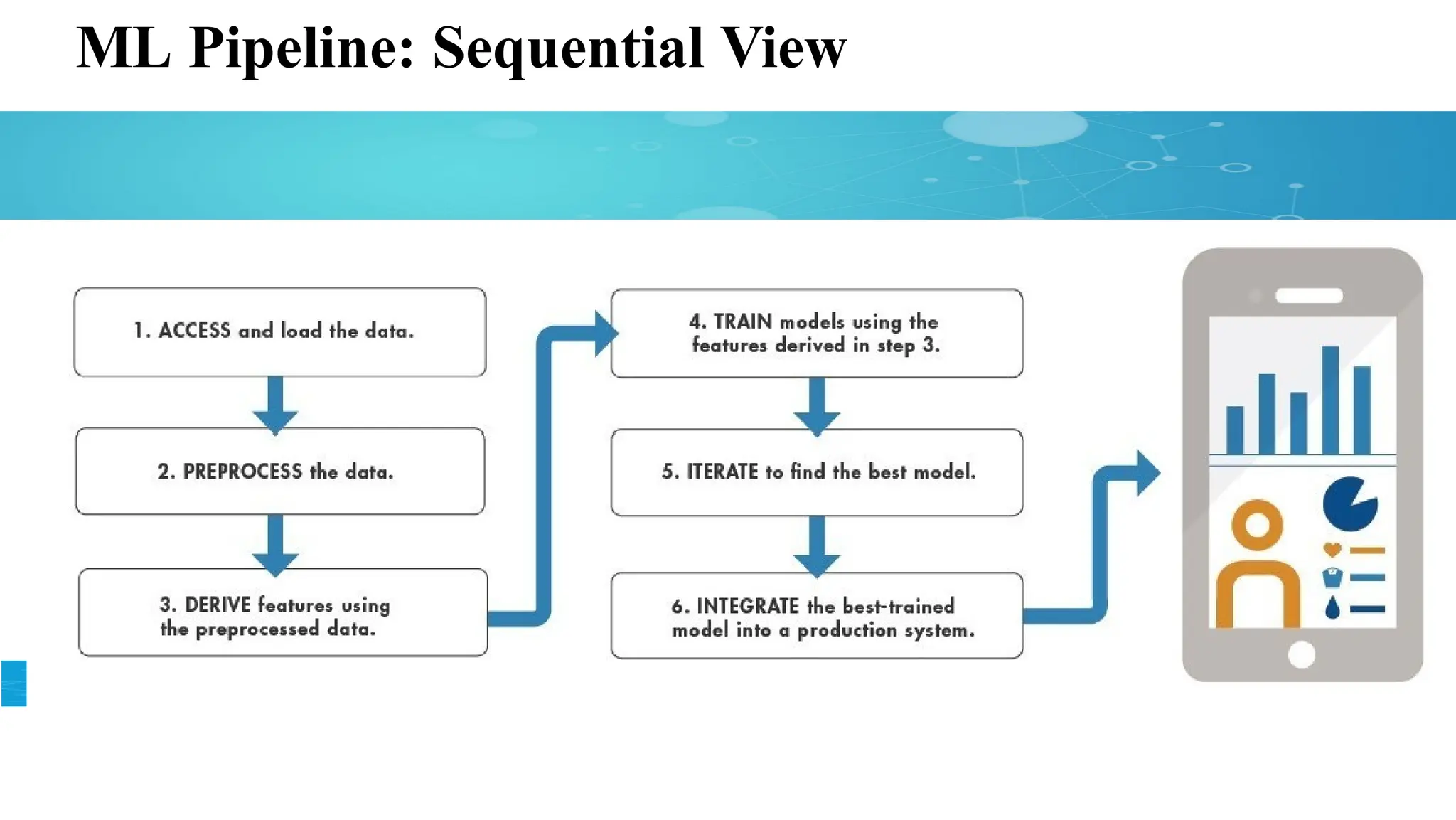
Machine Learning (ML)
ML refers to the ability of computers to learn without being
explicitly Programmed.
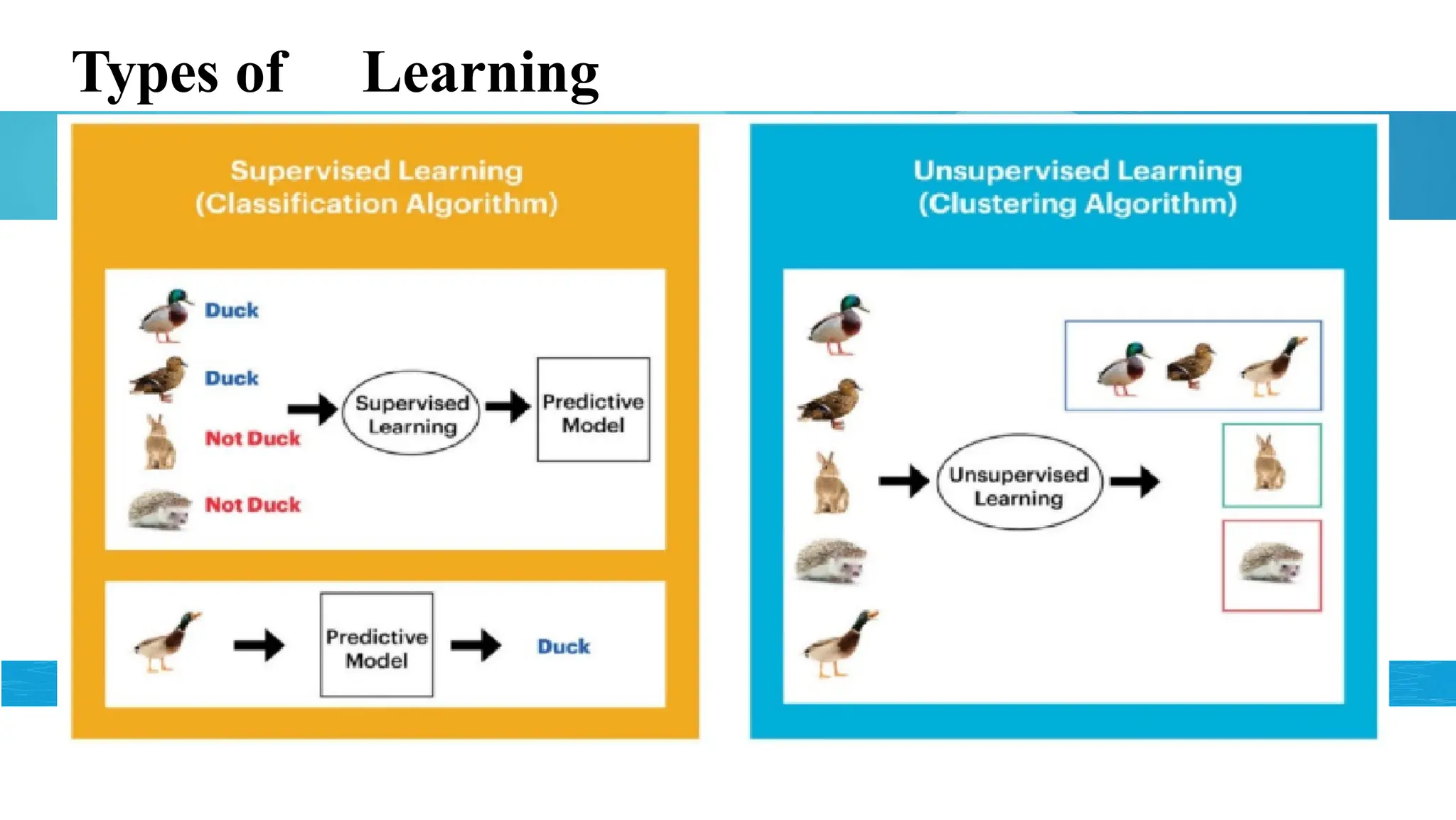
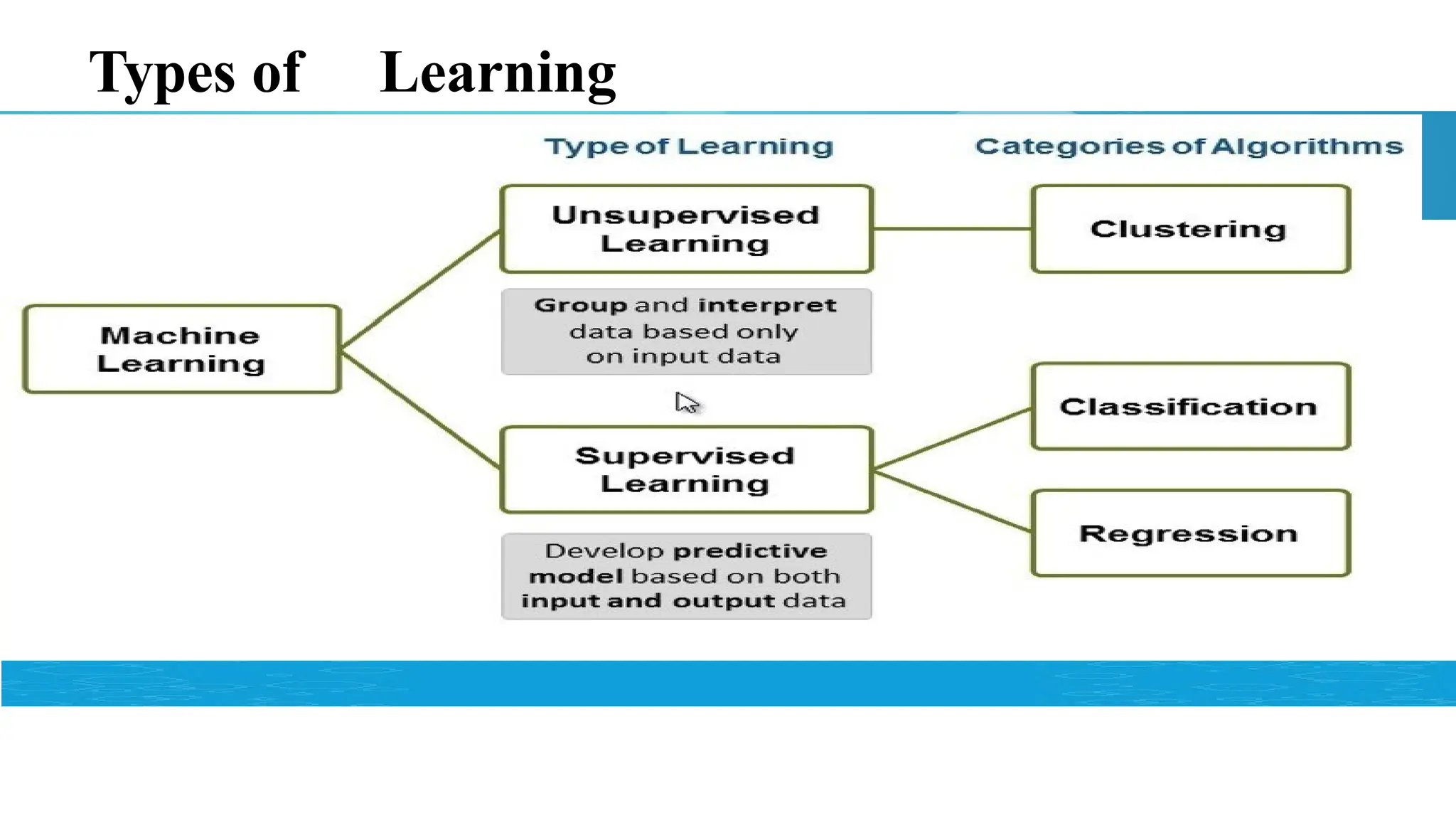
Classification vs Regressionvs Clustering
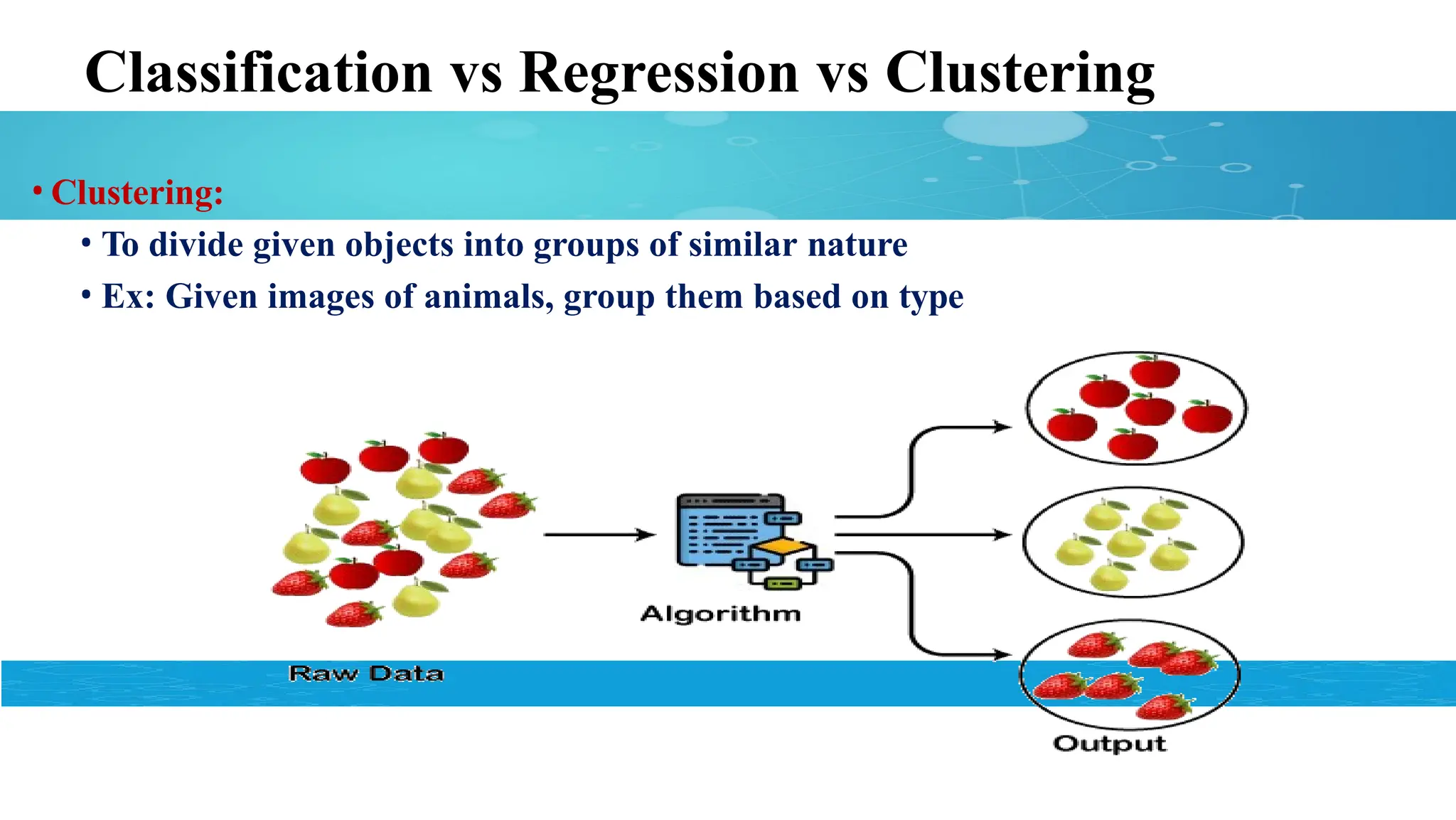
• Clustering:
• To divide given objects into groups of similar nature
• Ex: Given images of animals, group them based on type
22.
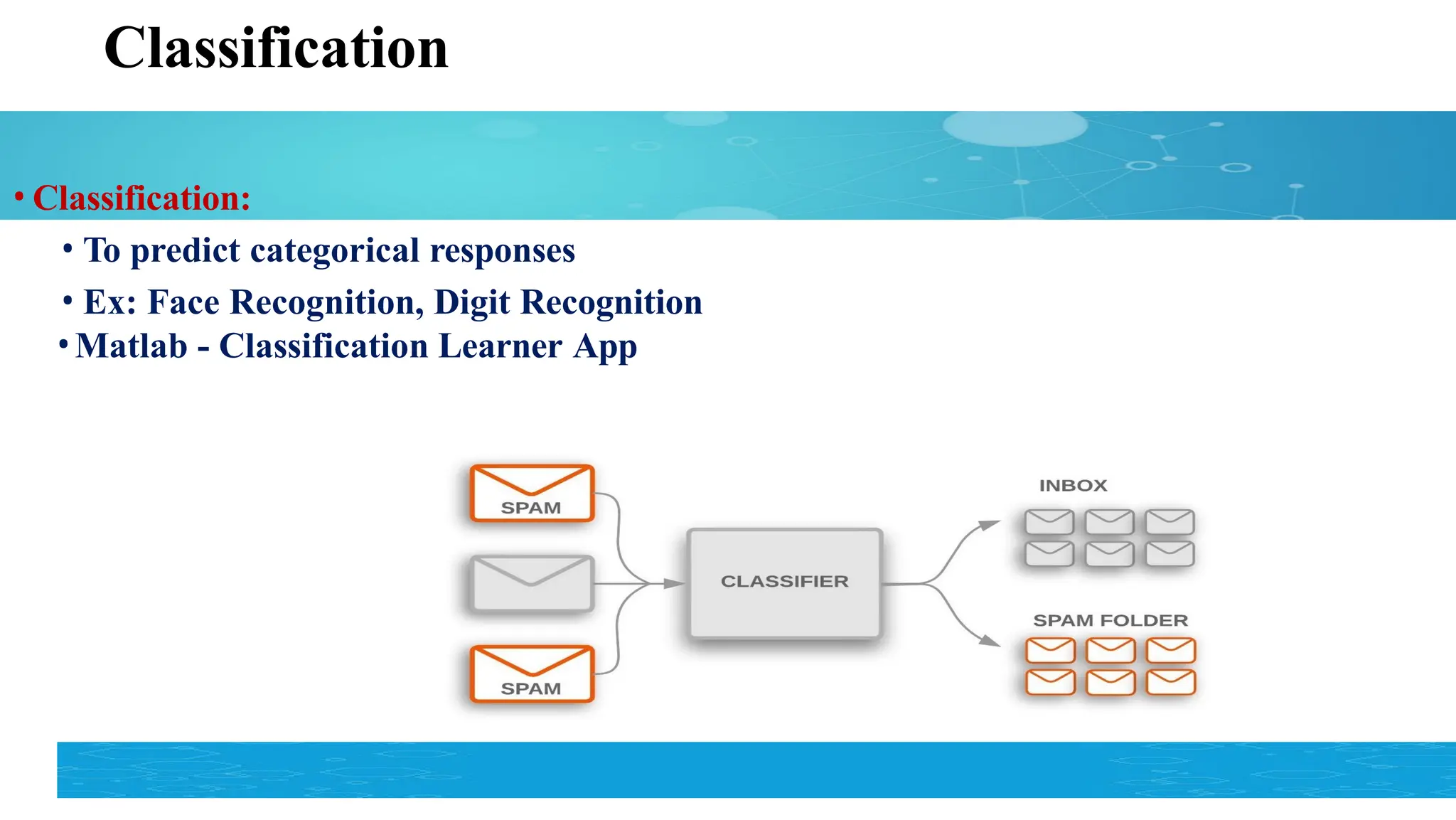
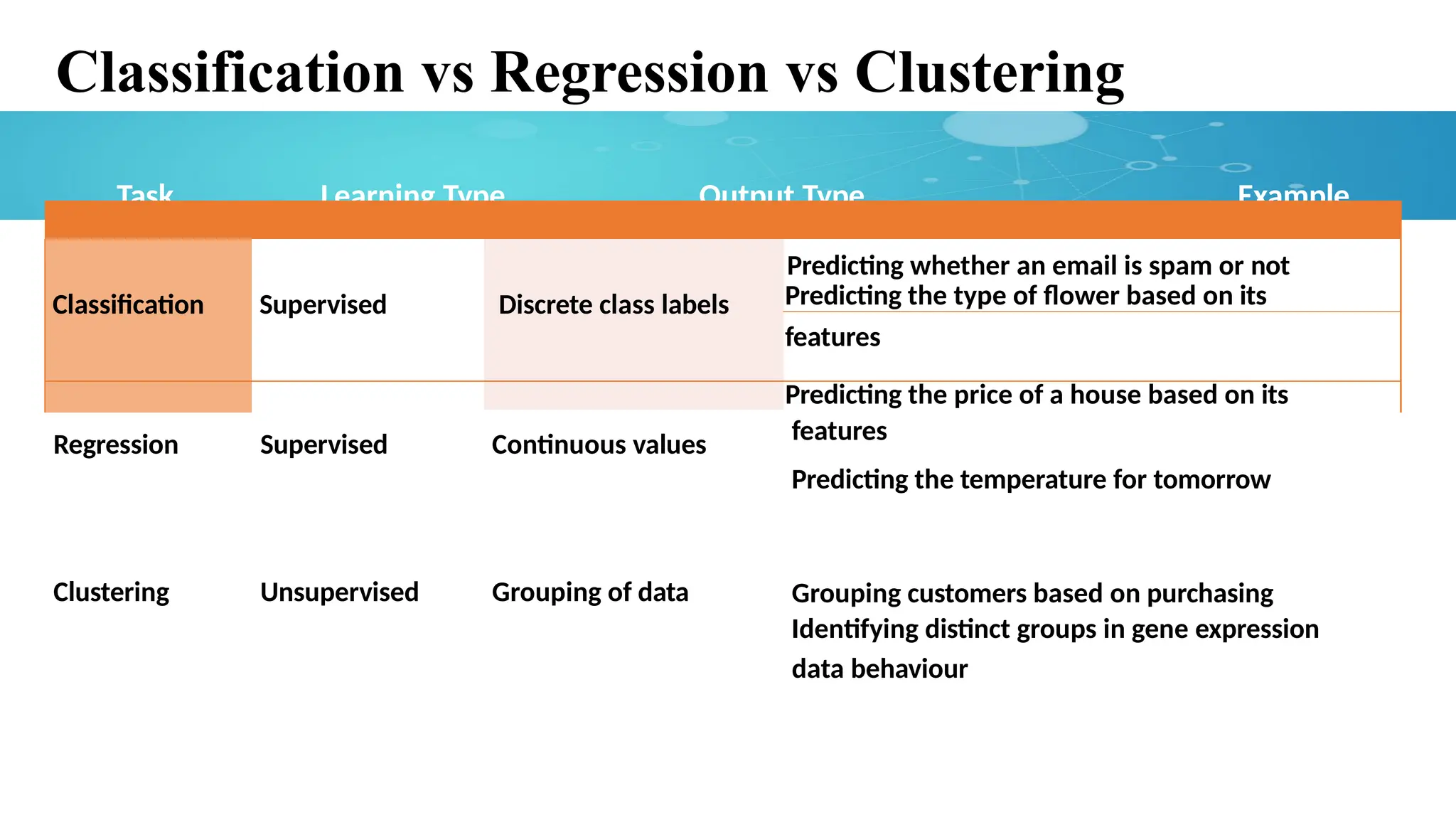
Classification vs Regressionvs Clustering
Task Learning Type Output Type Example
Classification Supervised Discrete class labels
Predicting whether an email is spam or not
Predicting the type of flower based on its
features
Predicting the price of a house based on its
Regression Supervised Continuous values features
Predicting the temperature for tomorrow
Clustering Unsupervised Grouping of data Grouping customers based on purchasing
Identifying distinct groups in gene expression
data behaviour
23.
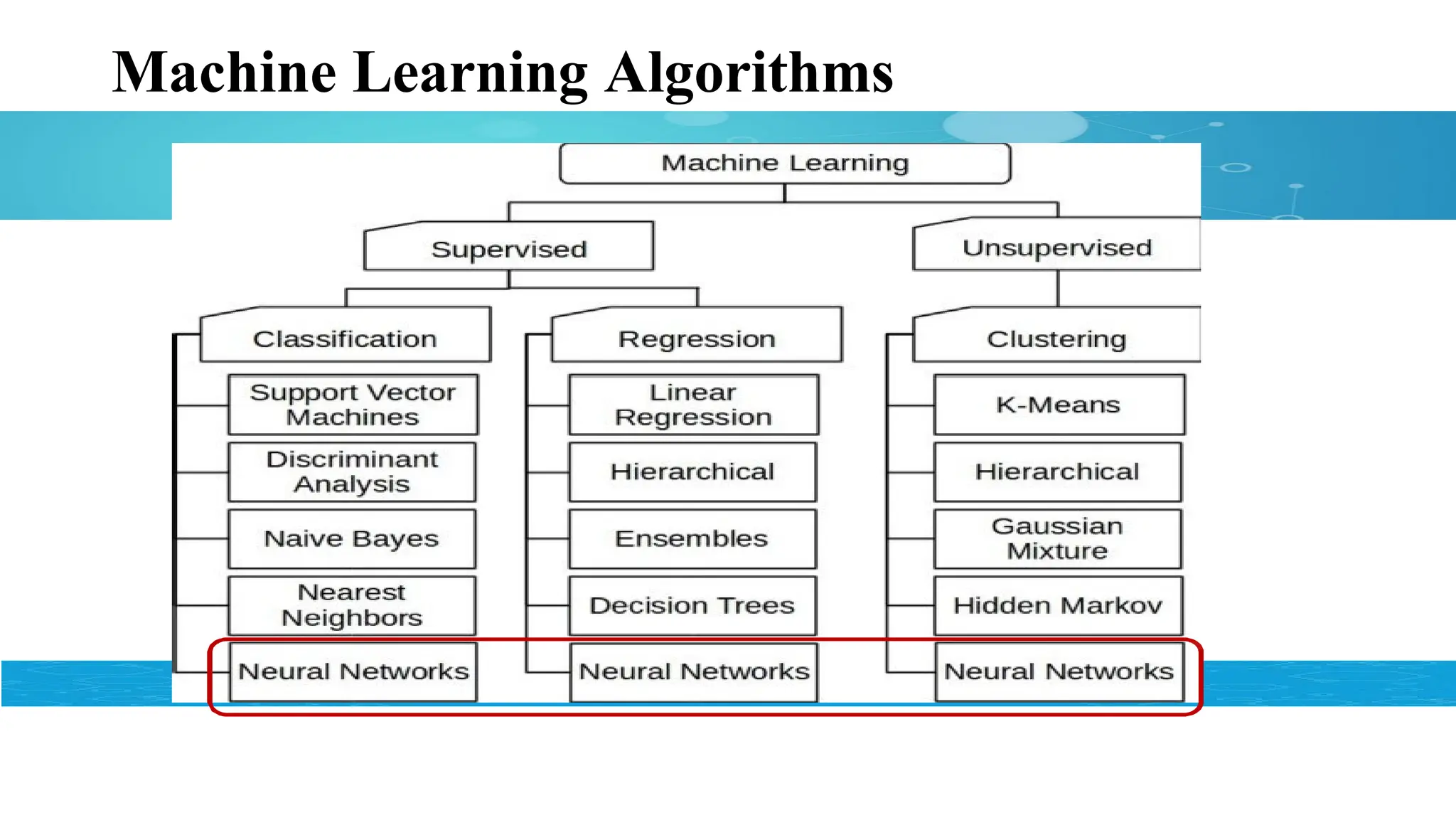
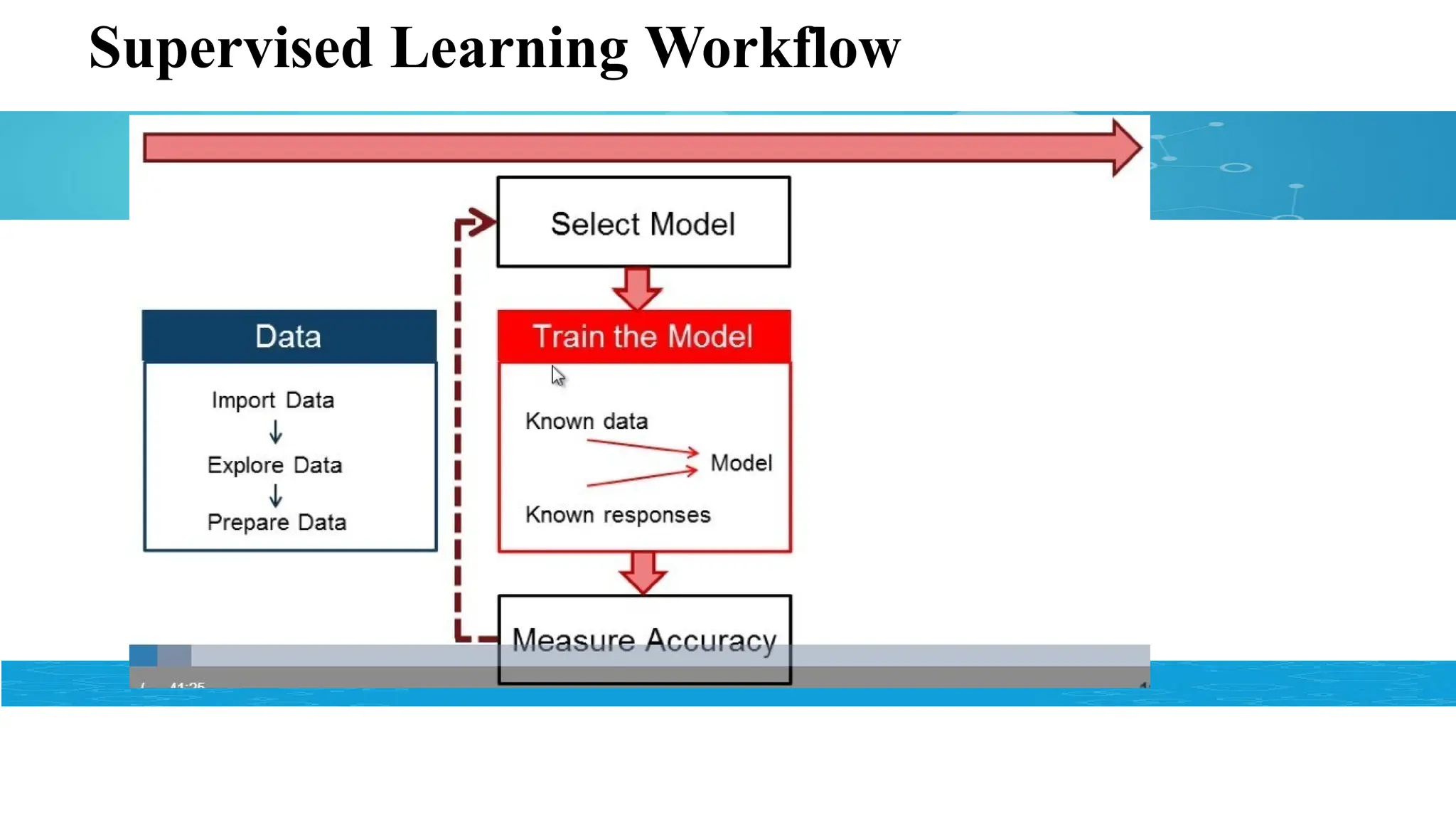
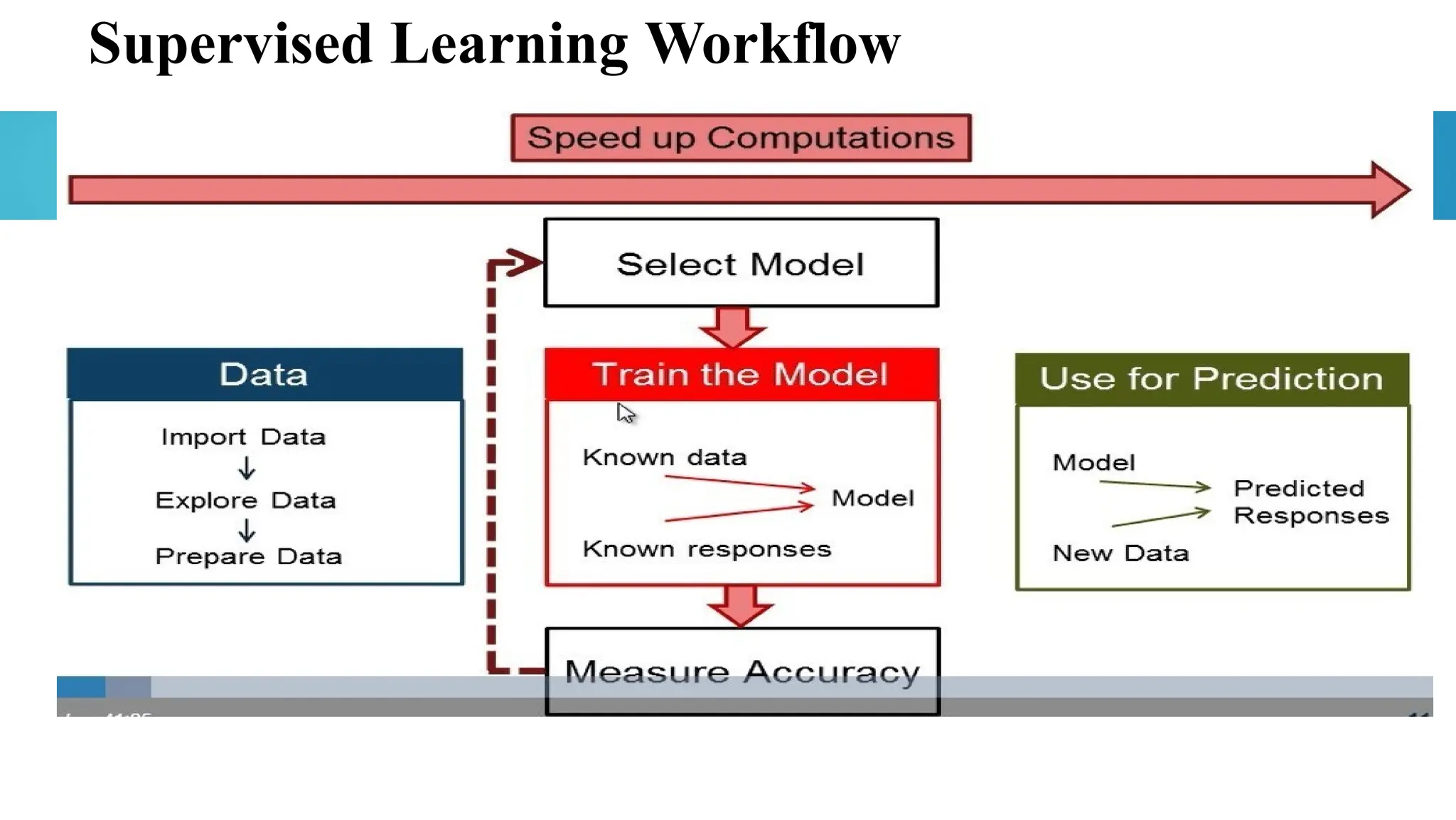
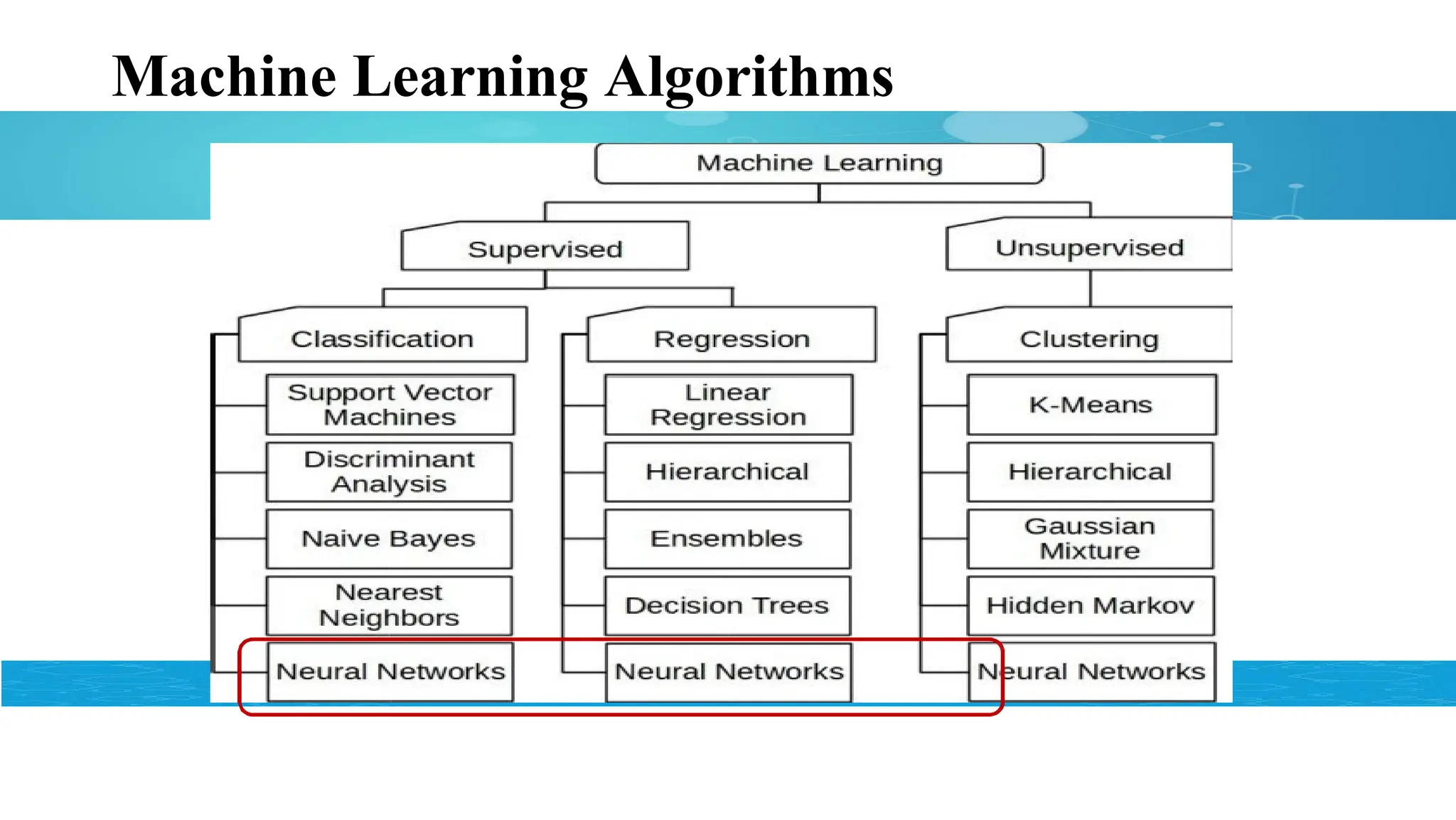
Standard Supervised Learningalgorithms
• Classification Algorithms:
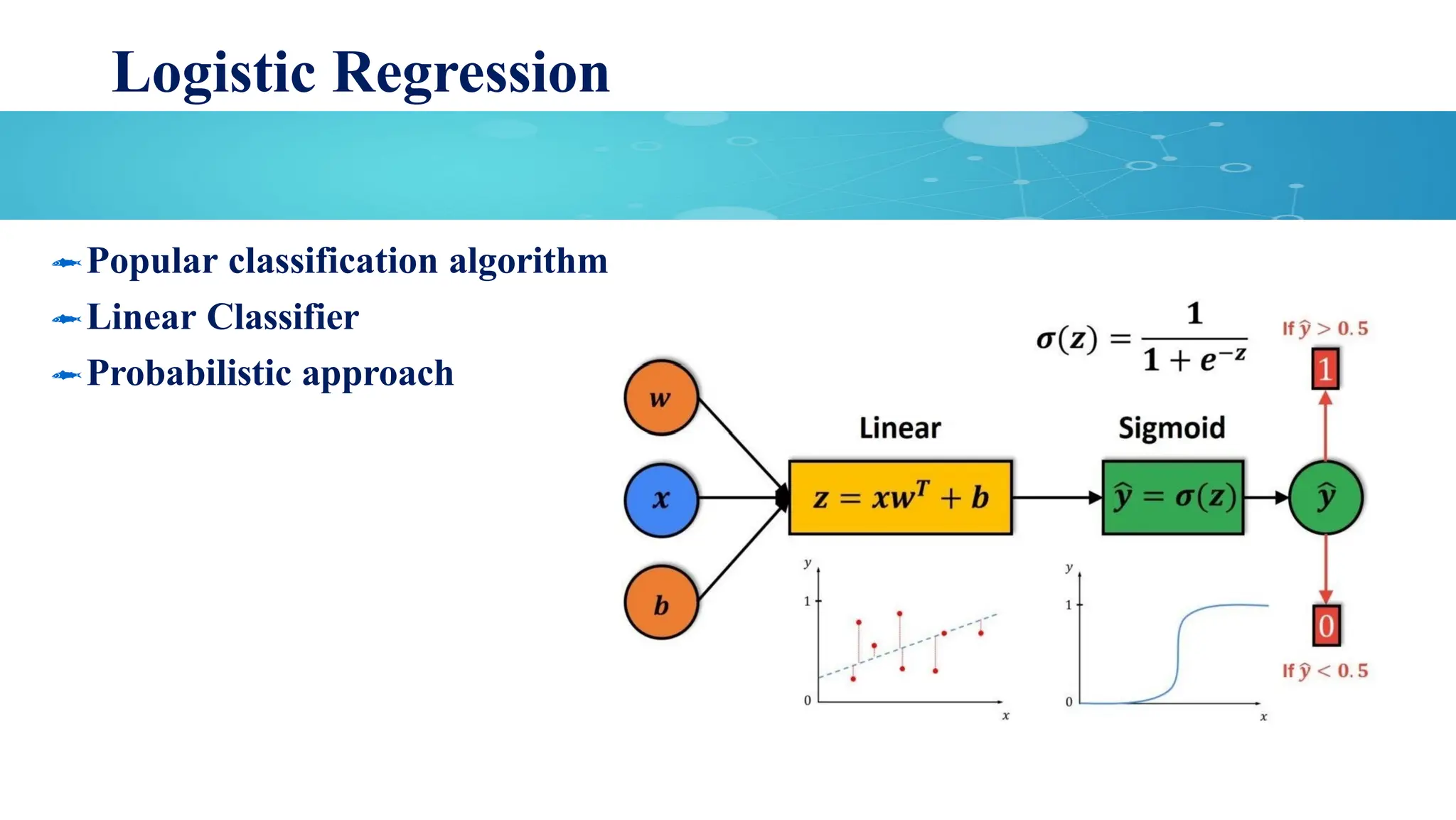
Logistic Regression
K-Nearest Neighbors
Decision Trees
Naïve Baye’s Classifier
Support Vector Machines
Neural Network Models
• Regression Algorithms:
Linear Regression
Polynomial Regression
Decision tree Regression
Support Vector Regression
Neural Network Models
24.
Standard Clustering algorithms
Partitioningbased Clustering:
K-Means, K-medoids
Density based Clustering:
DBSCAN
Hierarchical Clustering:
Agglomerative, Divisive
Graph Clustering:
Spectral Clustering
When Should YouUse Machine Learning?
To solve a complex task or problem involving:
A large amount of data and lots of variables,
No existing formula or equation
Machine learning is a good option:
Hand-written rules and equations are too complex. Ex:
Face recognition and speech recognition
⮚ The rules of a task are constantly changing. Ex: Fraud
detection from transaction records
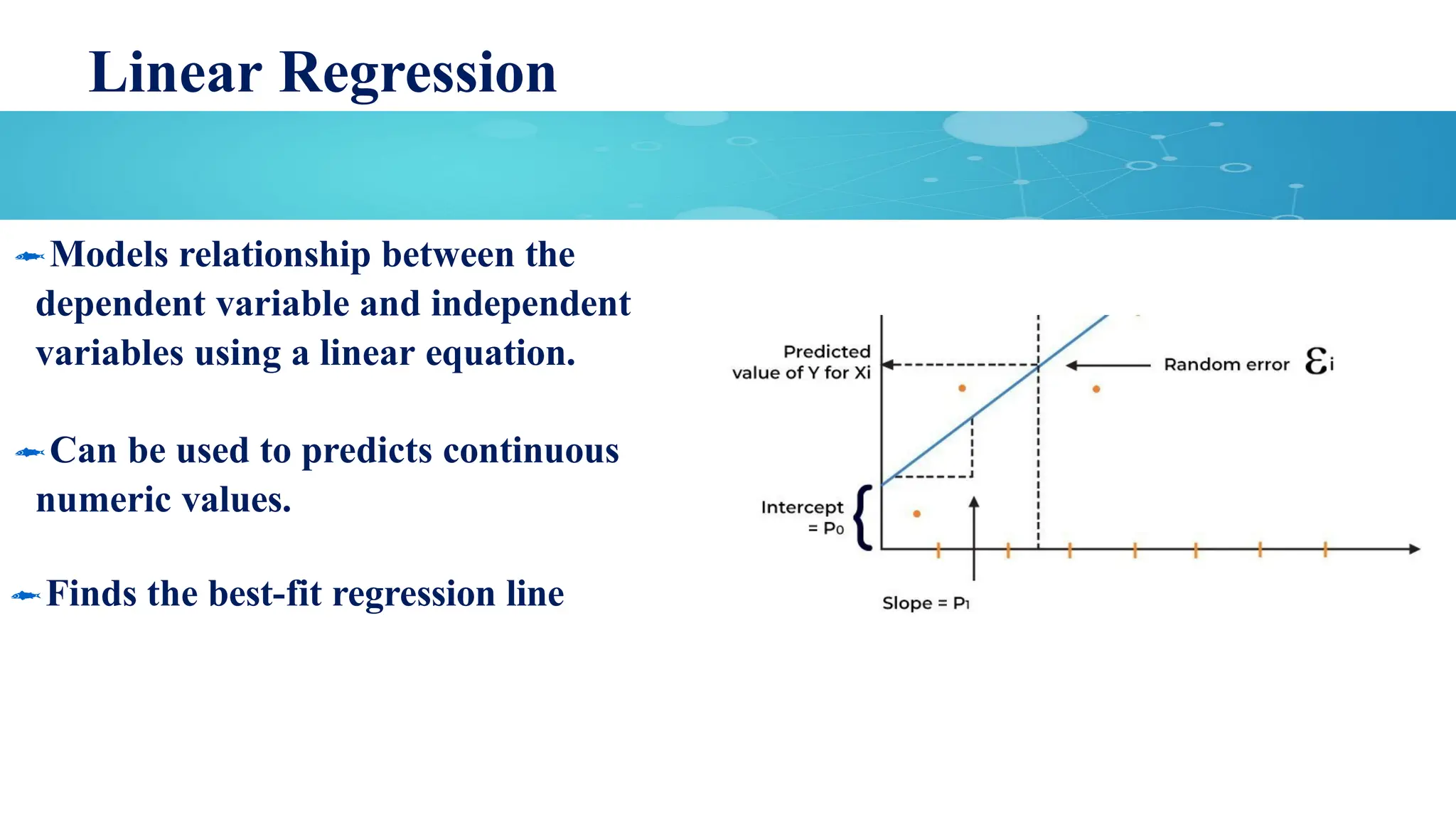
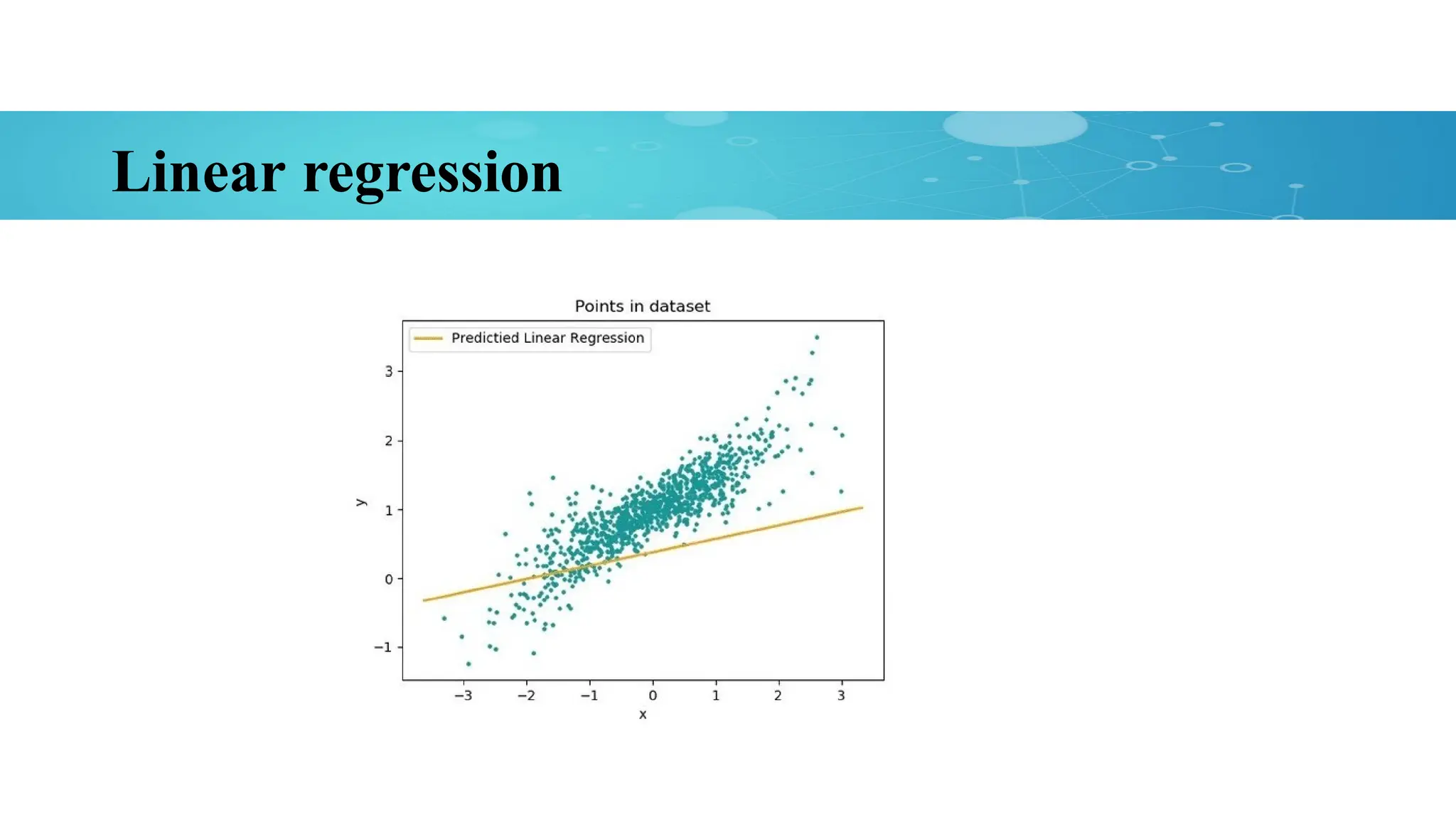
Linear Regression
Models relationshipbetween the
dependent variable and independent
variables using a linear equation.
Can be used to predicts continuous
numeric values.
Finds the best-fit regression line
K-Nearest Neighbourhood Approach
Suitablefor both Classification and Regression
Simple non-parametric approach
Doe not involve any training
Identifies K Nearest Neighbors (NN)
Majority voting for classification
Average of the NN for Regression
36.
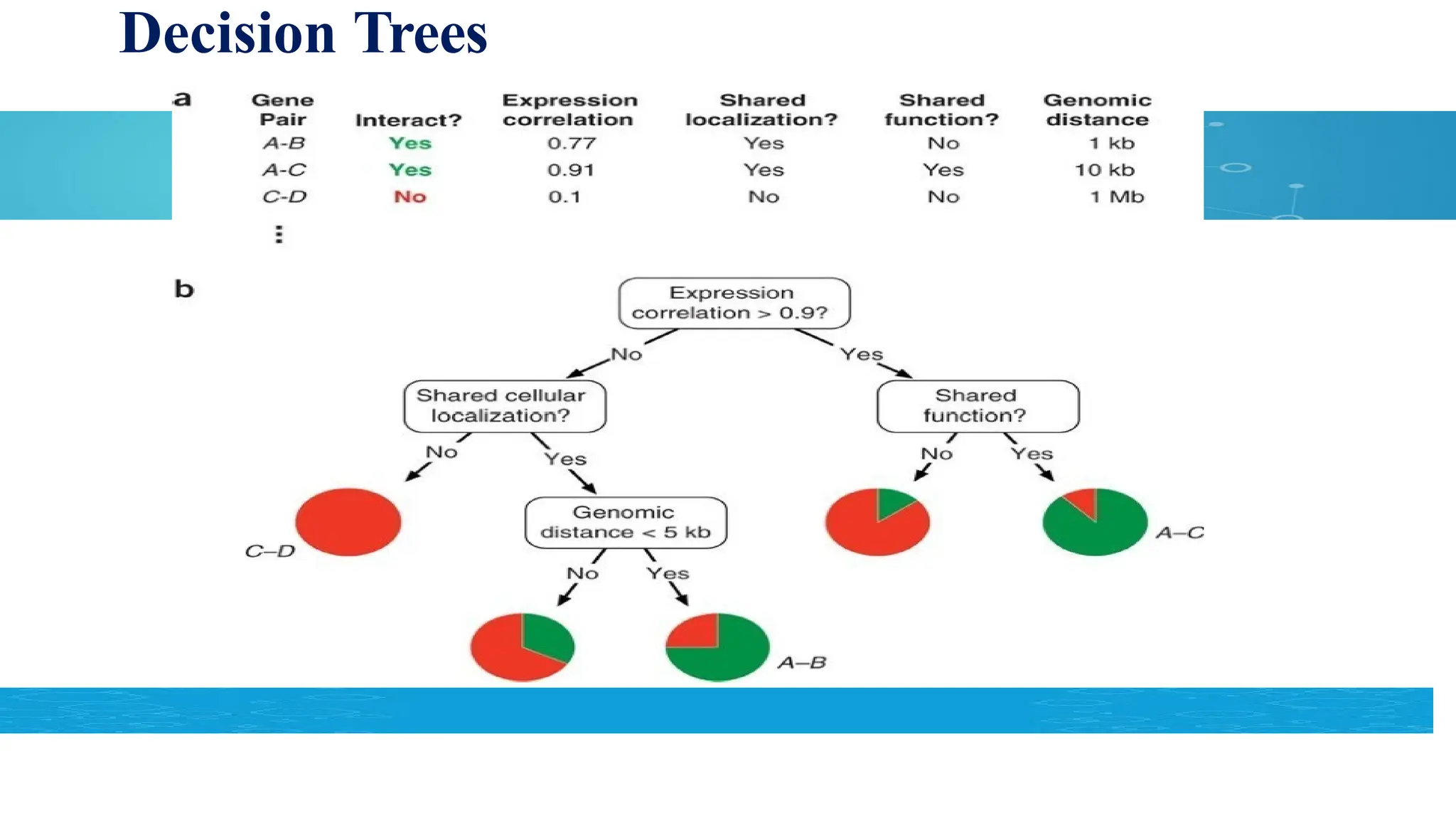
Decision Trees
Used forboth classification and regression tasks.
A tree-like structure is generated based on training data
Each internal node represents a feature or attribute
Each branch represents a decision rule
Each leaf represents predicted value.
Decision Trees recursively partition data on feature values to make predictions.
Easy to interpret and visualize
Can handle both numerical and categorical features
Support Vector Machines
Canbe used for classification and regression
Support Vector Classification (SVC):
⮚Used for Binary Classification task
⮚Logistic regression finds a possible separating
hyper plane
⮚SVM Finds optimal Hyperplane
⮚Handles linearly separable as well as non-
linearly separable data by using kernel
functions
39.
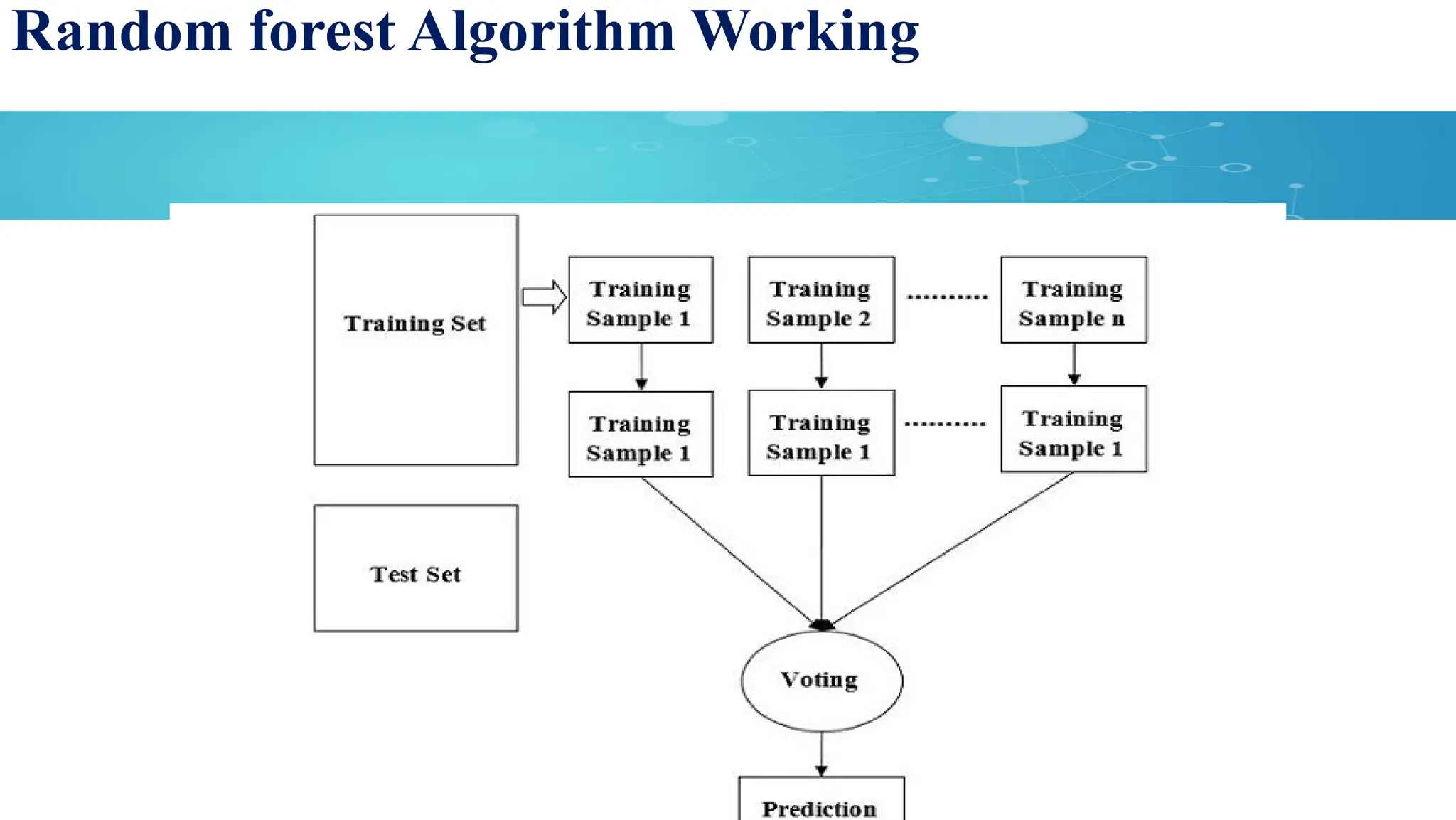
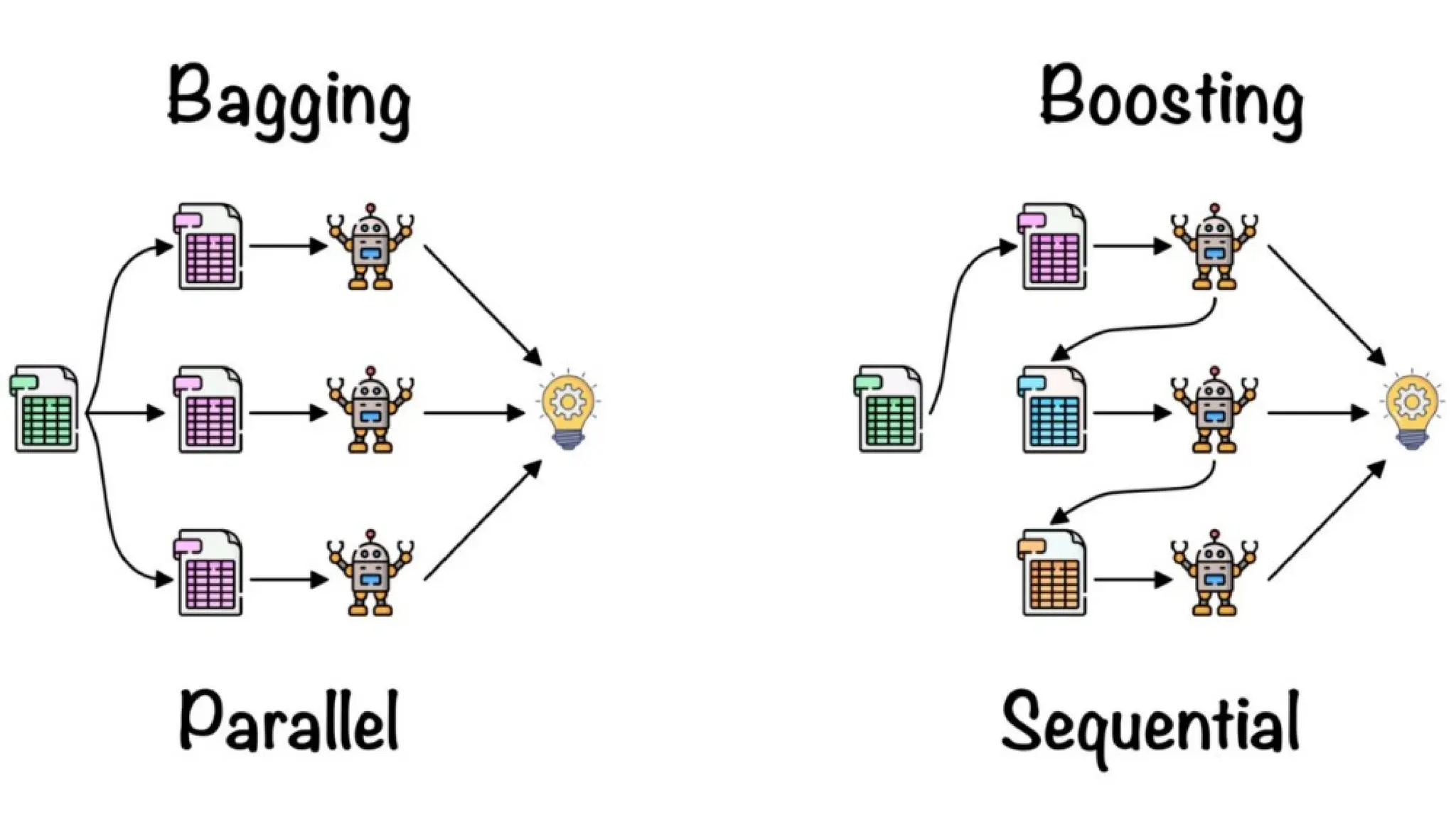
Random Forest Algorithm
Random forests is an supervised learning algorithm.
Random forests is an ensemble learning Technique.
Ensemble techniques: combination of multiple models is known as
Ensemble.
• Bagging
• Boosting