2
Dependencies along thegenome
In previous classes we assumed every letter in a
sequence is sampled randomly from some
distribution q() over the alpha bet {A,C,T,G}.
This model could suffice for alignment scoring, but it
is not the case in true genomes.
1. There are special subsequences in the genome, like
TATA within the regulatory area, upstream a gene.
2. The pattern CG is less common than expected for
random sampling.
We model such dependencies by Markov chains and
hidden Markov model, which we define next.
3.
3
Finite Markov Chain
Aninteger time stochastic process, consisting of a
domain D of m>1 states {s1,…,sm} and
1. An m dimensional initial distribution vector ( p(s1),.., p(sm)).
2. An m×mtransition probabilities matrix M= (asisj
)
For example, D can be the letters {A, C, T, G}, p(A) the
probability of A to be the 1st
letter in a sequence, and
aAG the probability that G follows A in a sequence.
4.
4
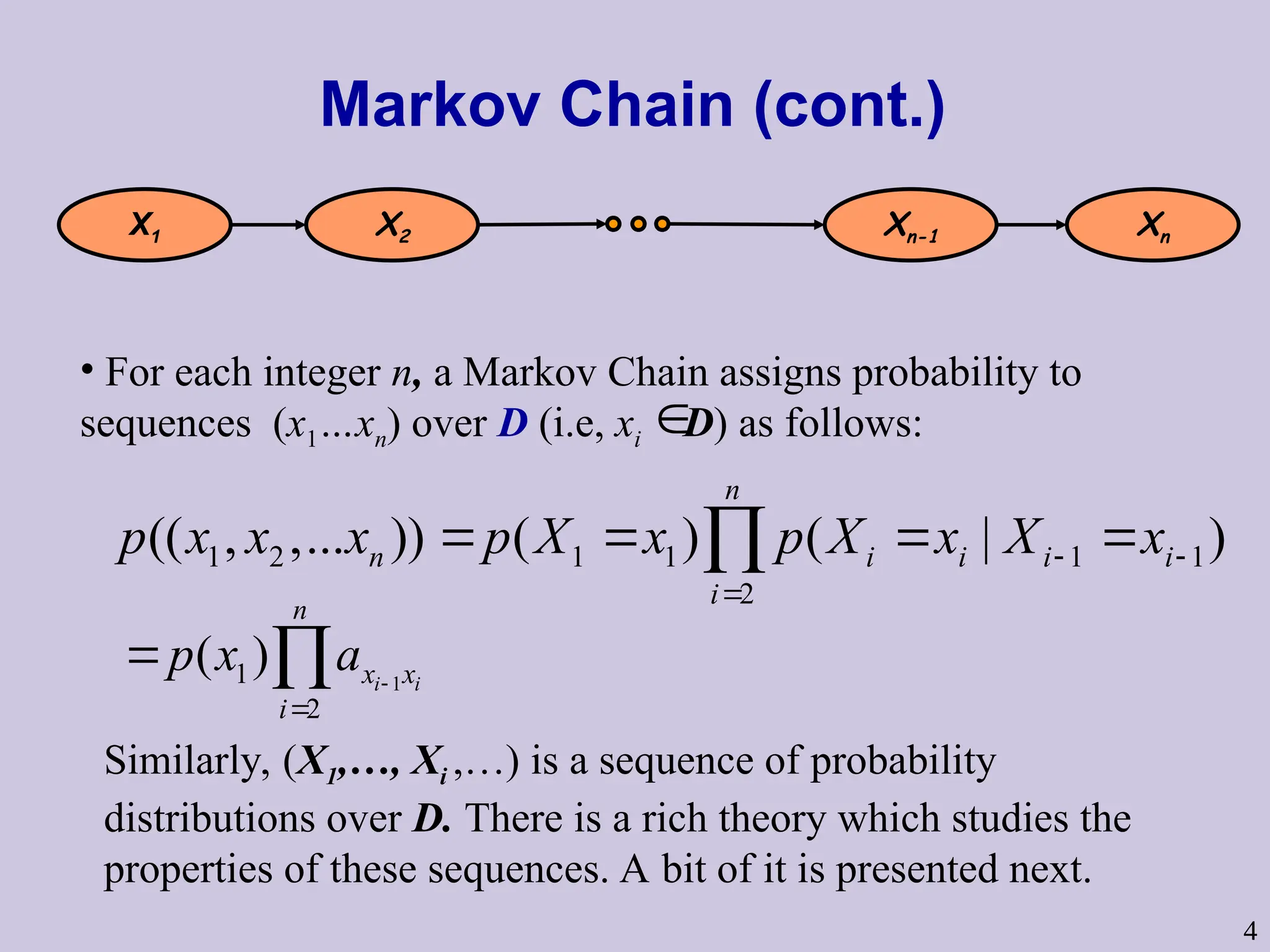
Markov Chain (cont.)
12 1 1 1 1
2
(( , ,... )) ( ) ( | )
n
n i i i i
i
p x x x p X x p X x X x
1
1
2
( ) i i
n
x x
i
p x a
X1 X2 Xn-1 Xn
• For each integer n, a Markov Chain assigns probability to
sequences (x1…xn) over D (i.e, xi D) as follows:
Similarly, (X1,…, Xi ,…) is a sequence of probability
distributions over D. There is a rich theory which studies the
properties of these sequences. A bit of it is presented next.
5.
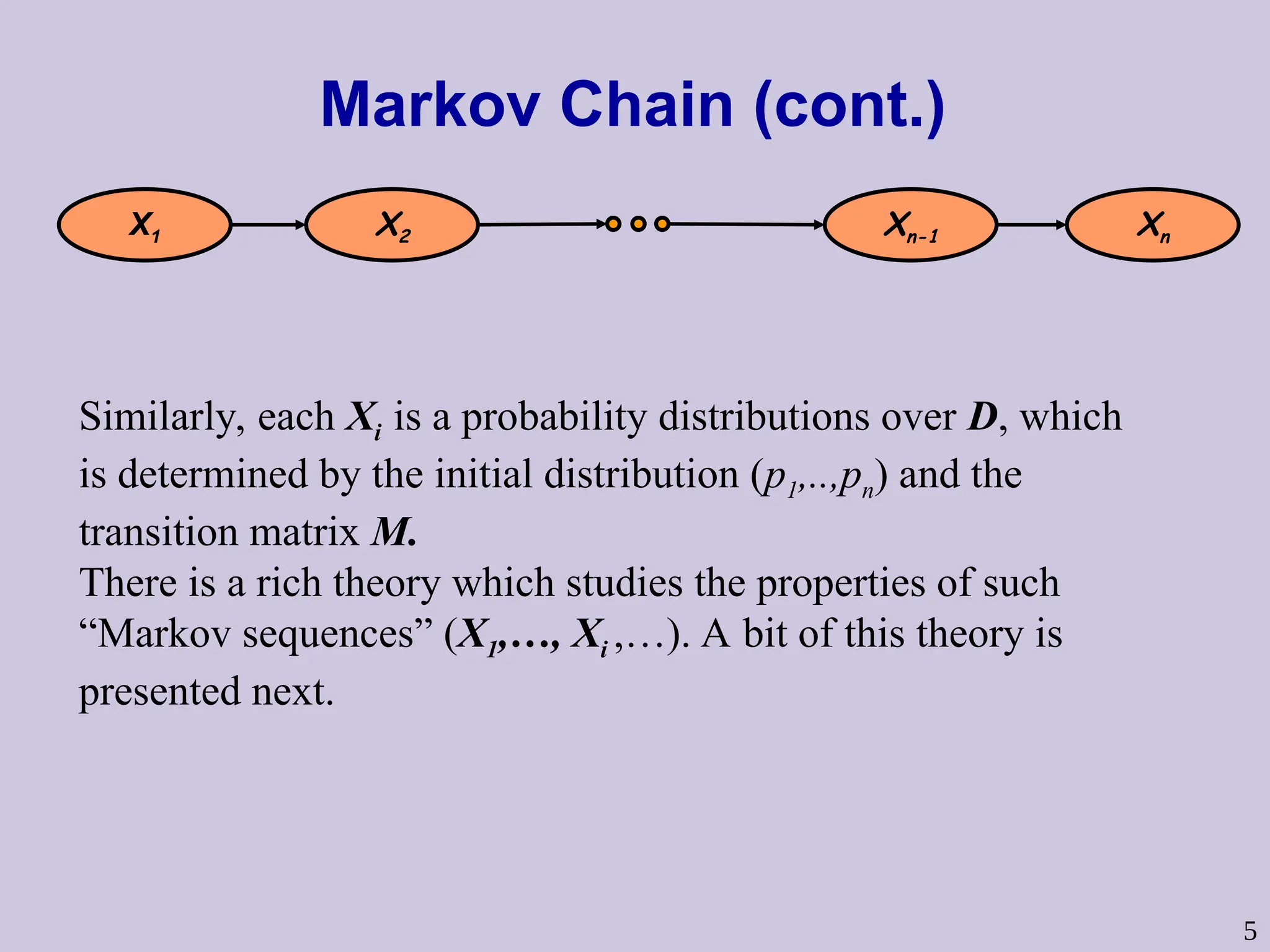
5
Markov Chain (cont.)
X1X2 Xn-1 Xn
Similarly, each Xi is a probability distributions over D, which
is determined by the initial distribution (p1,..,pn) and the
transition matrix M.
There is a rich theory which studies the properties of such
“Markov sequences” (X1,…, Xi ,…). A bit of this theory is
presented next.
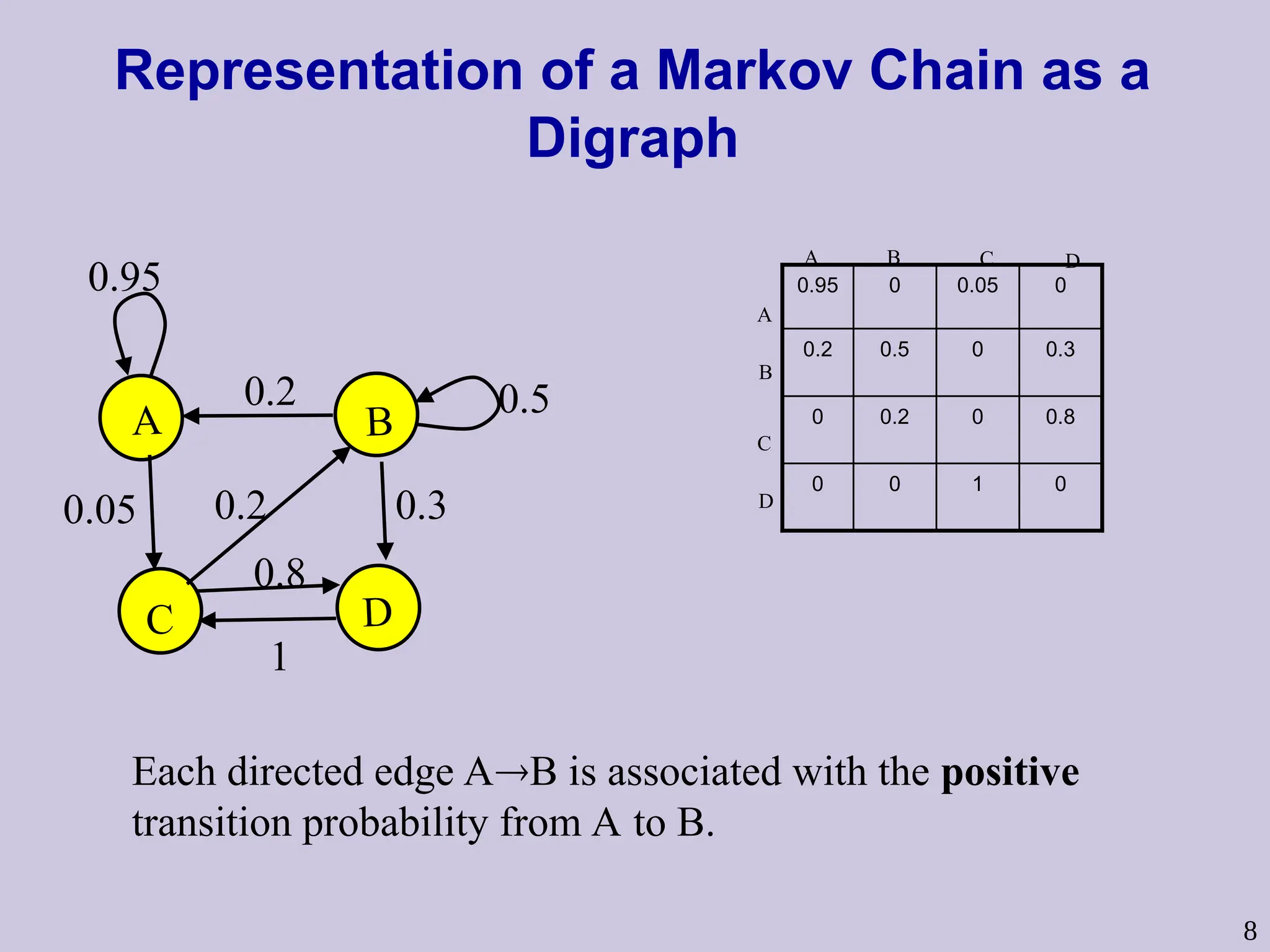
8
Representation of aMarkov Chain as a
Digraph
Each directed edge AB is associated with the positive
transition probability from A to B.
A B
C D
0.2
0.3
0.5
0.05
0.95
0.2
0.8
1
0
1
0
0
0.8
0
0.2
0
0.3
0
0.5
0.2
0
0.05
0
0.95
A B
B
A
C
C
D
D
9.
9
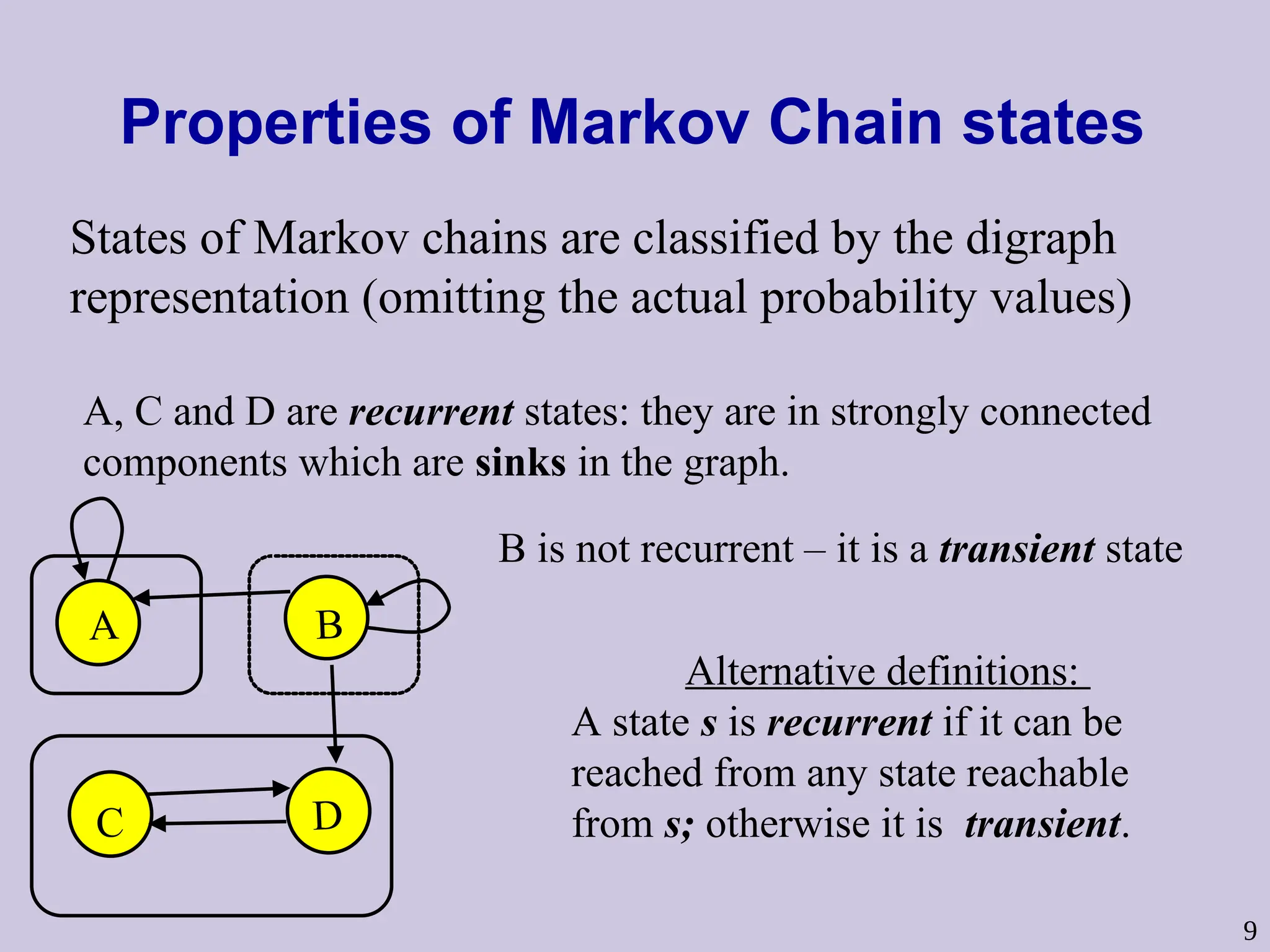
Properties of MarkovChain states
A B
C D
States of Markov chains are classified by the digraph
representation (omitting the actual probability values)
A, C and D are recurrent states: they are in strongly connected
components which are sinks in the graph.
B is not recurrent – it is a transient state
Alternative definitions:
A state s is recurrent if it can be
reached from any state reachable
from s; otherwise it is transient.
10.
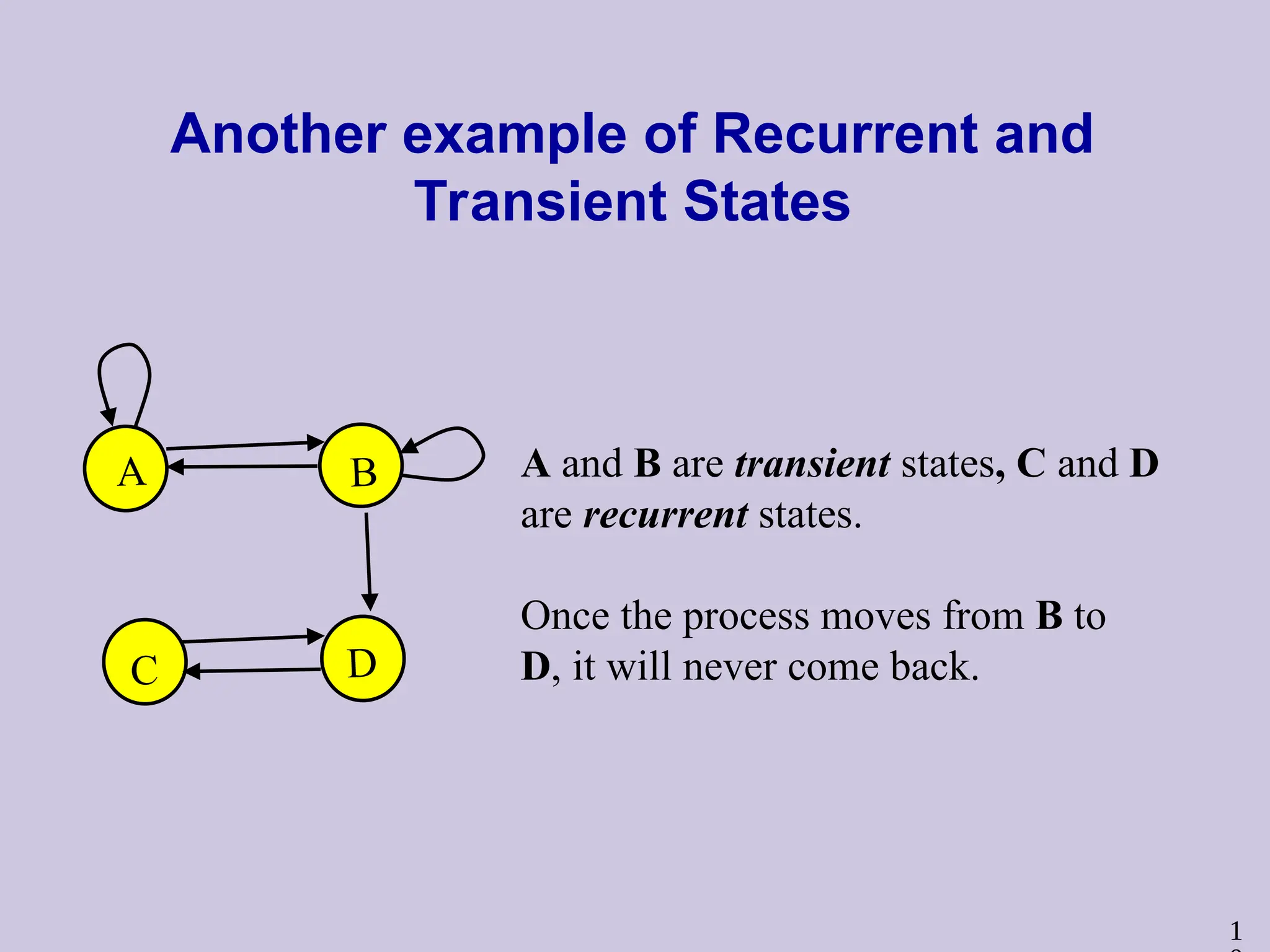
1
Another example ofRecurrent and
Transient States
A B
C D
A and B are transient states, C and D
are recurrent states.
Once the process moves from B to
D, it will never come back.
11.
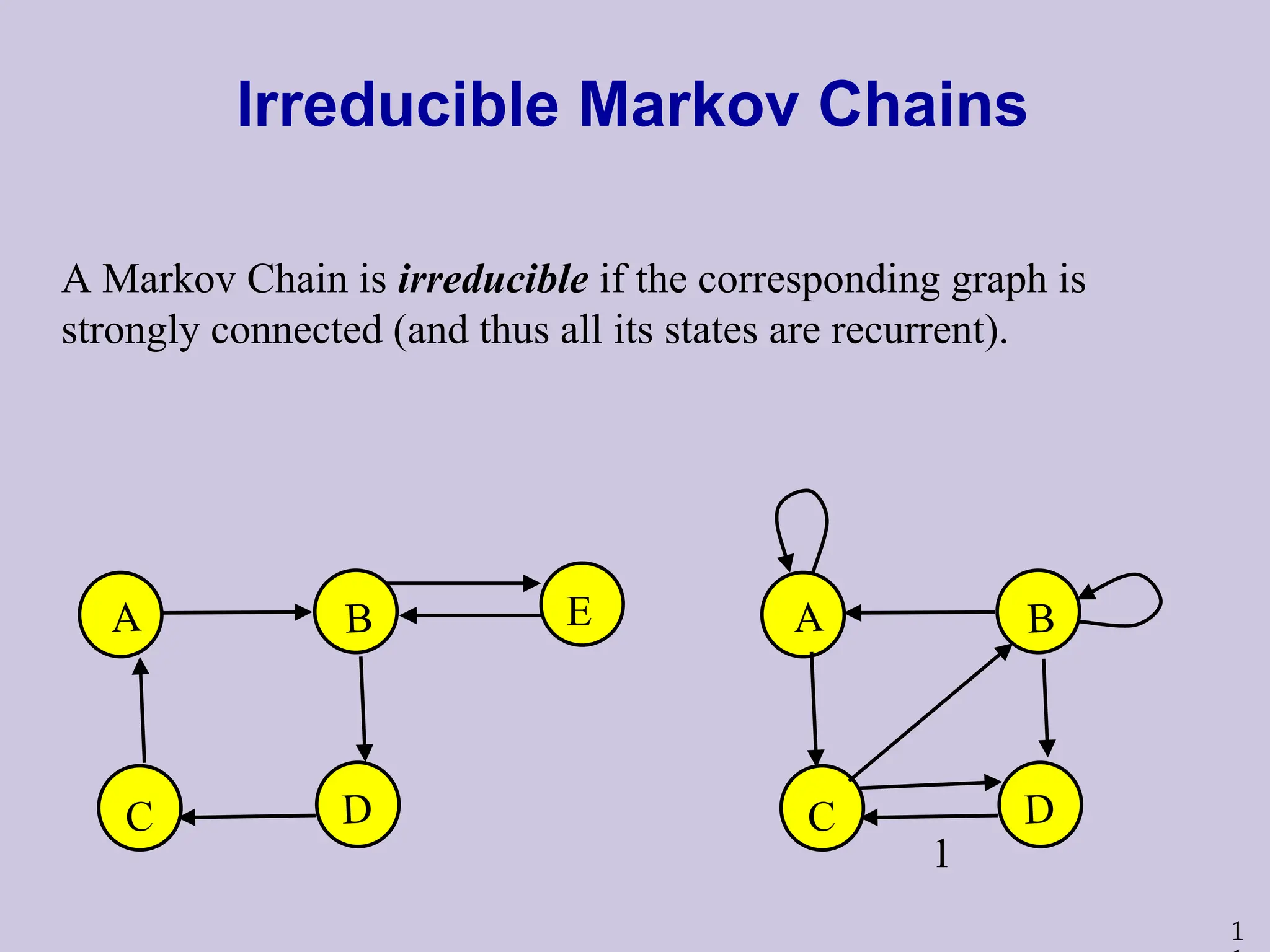
1
Irreducible Markov Chains
AMarkov Chain is irreducible if the corresponding graph is
strongly connected (and thus all its states are recurrent).
A B
C D
1
A B
C D
E
12.
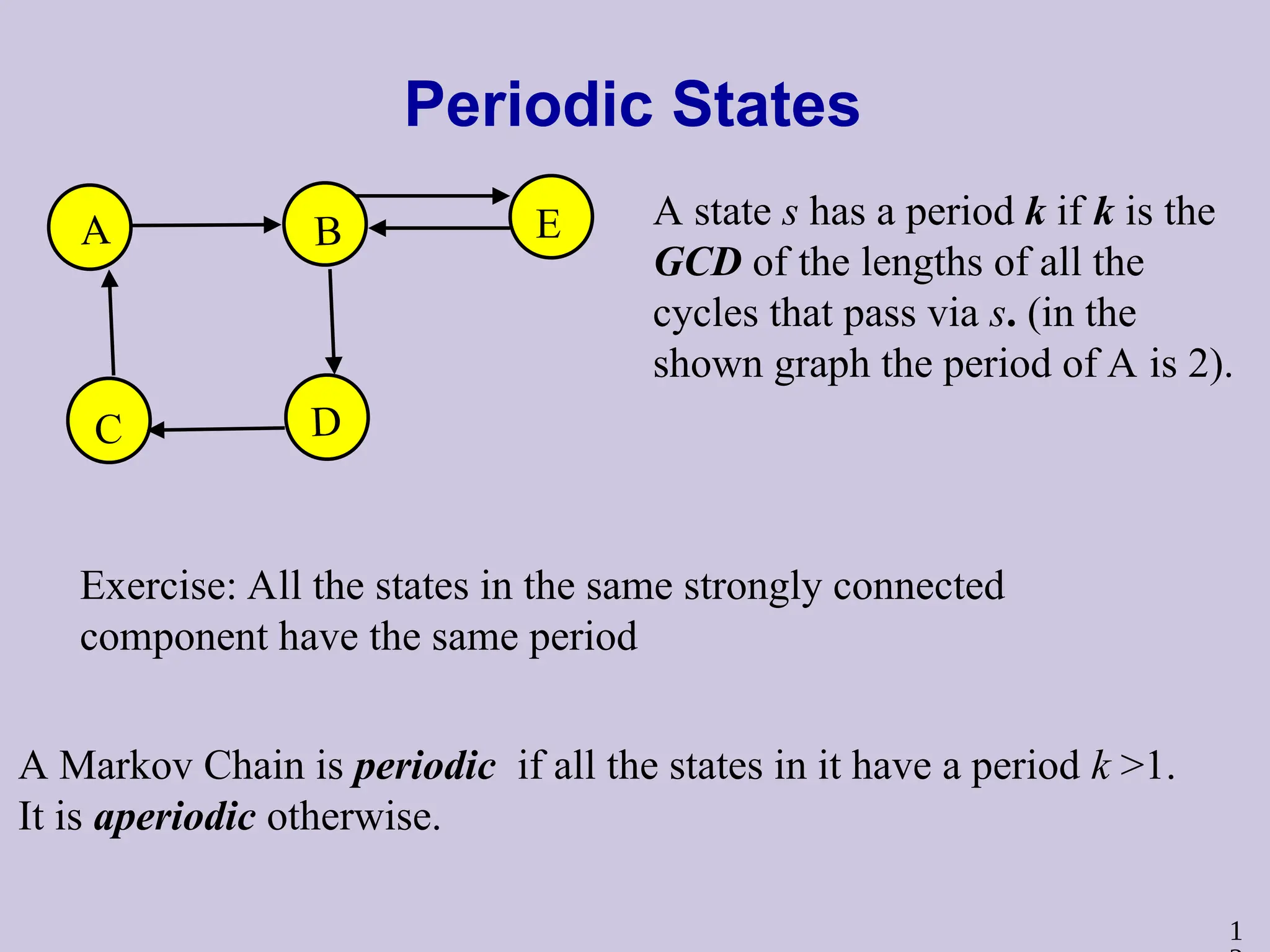
1
Periodic States
A states has a period k if k is the
GCD of the lengths of all the
cycles that pass via s. (in the
shown graph the period of A is 2).
A B
C D
E
A Markov Chain is periodic if all the states in it have a period k >1.
It is aperiodic otherwise.
Exercise: All the states in the same strongly connected
component have the same period
13.
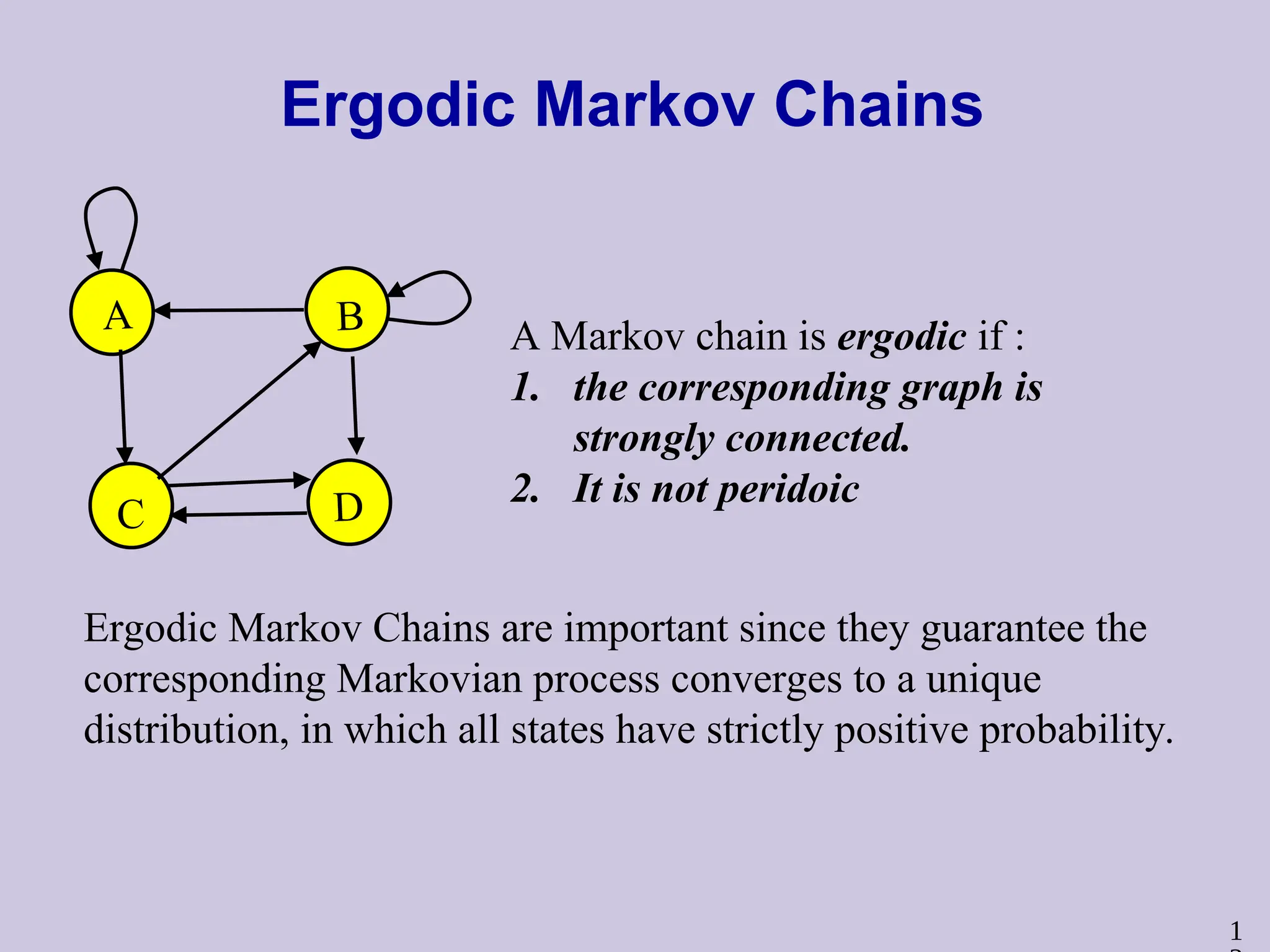
1
Ergodic Markov Chains
AB
C D
A Markov chain is ergodic if :
1. the corresponding graph is
strongly connected.
2. It is not peridoic
Ergodic Markov Chains are important since they guarantee the
corresponding Markovian process converges to a unique
distribution, in which all states have strictly positive probability.
14.
1
Stationary Distributions forMarkov
Chains
Let M be a Markov Chain of m states, and let V = (v1,…,vm) be a
probability distribution over the m states
V = (v1,…,vm) is stationary distribution for M if VM=V.
(ie, if one step of the process does not change the distribution).
V is a stationary distribution
V is a left (row) Eigenvector of M with Eigenvalue 1.
15.
1
Stationary Distributions fora Markov
Chain M
Exercise: A stochastic matrix always has a real left Eigenvector
with Eigenvalue 1 (hint: show that a stochastic matrix has a
right Eigenvector with Eigenvalue 1. Note that the left
Eigenvalues of a Matrix are the same as the right Eiganvlues).
[It can be shown that the above Eigenvector V can be non-
negative. Hence each Markov Chain has a stationary
distribution.]
16.
1
“Good” Markov chains
AMarkov Chains is good if the distributions Xi , as i∞:
(1) converge to a unique distribution, independent of the initial
distribution.
(2) In that unique distribution, each state has a positive
probability.
The Fundamental Theorem of Finite Markov Chains:
A Markov Chain is good the corresponding graph is
ergodic.
We will prove the part, by showing that non-ergodic Markov
Chains are not good.
17.
1
Examples of
“Bad” MarkovChains
A Markov chains is not “good” if either :
1. It does not converge to a unique
distribution.
2. It does converge to u.d., but some states
in this distribution have zero probability.
18.
1
Bad case 1:Mutual Unreachabaility
A B
C D
In case a), the sequence will stay at A forever.
In case b), it will stay in {C,D} for ever.
Fact 1: If G has two states which are unreachable from each
other, then {Xi} cannot converge to a distribution which is
independent on the initial distribution.
Consider two initial distributions:
a) p(X1=A)=1 (p(X1 = x)=0 if x≠A).
b) p(X1= C) = 1
19.
1
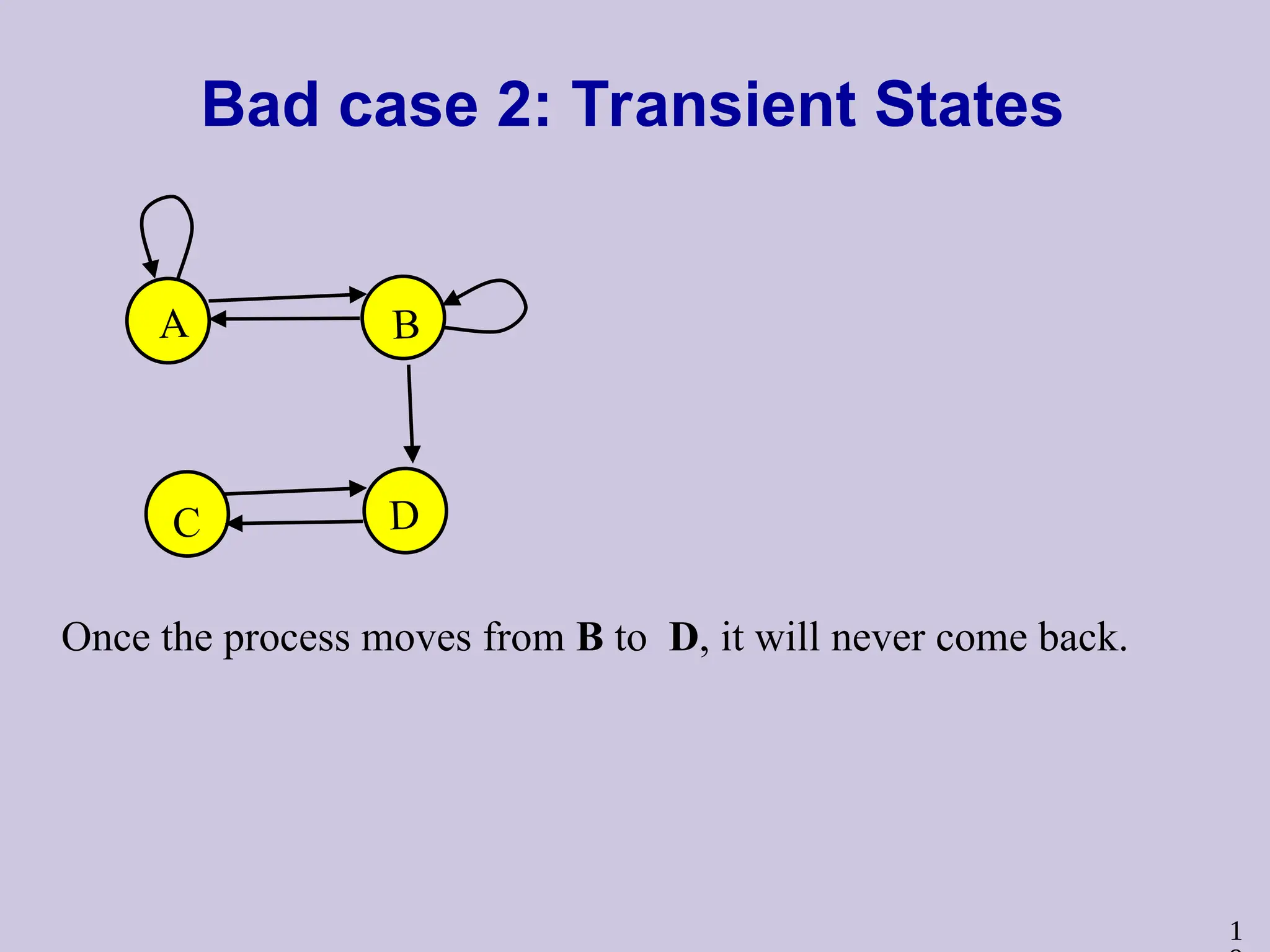
Bad case 2:Transient States
A B
C D
Once the process moves from B to D, it will never come back.
20.
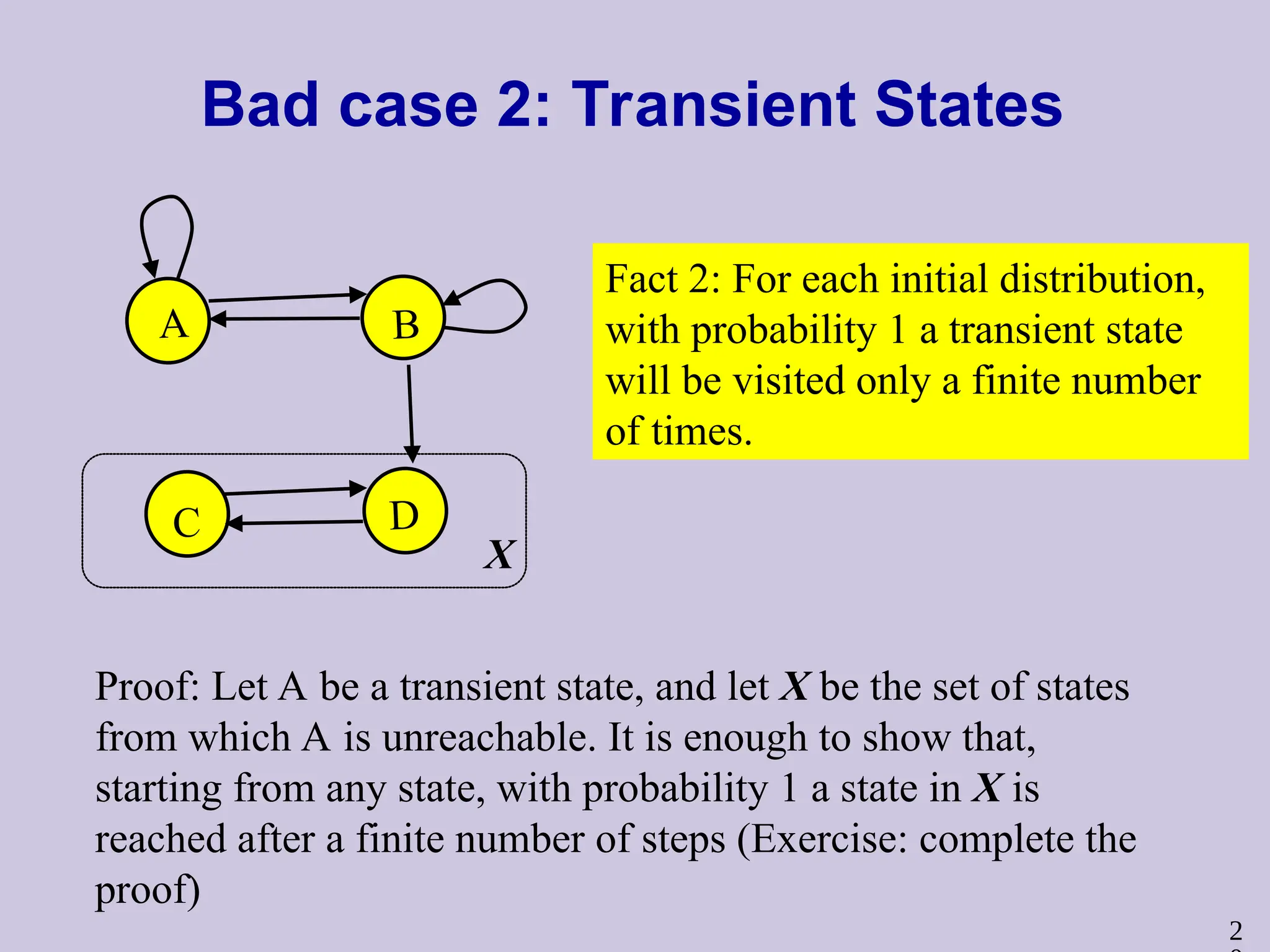
2
Bad case 2:Transient States
A B
C D
Fact 2: For each initial distribution,
with probability 1 a transient state
will be visited only a finite number
of times.
Proof: Let A be a transient state, and let X be the set of states
from which A is unreachable. It is enough to show that,
starting from any state, with probability 1 a state in X is
reached after a finite number of steps (Exercise: complete the
proof)
X
2
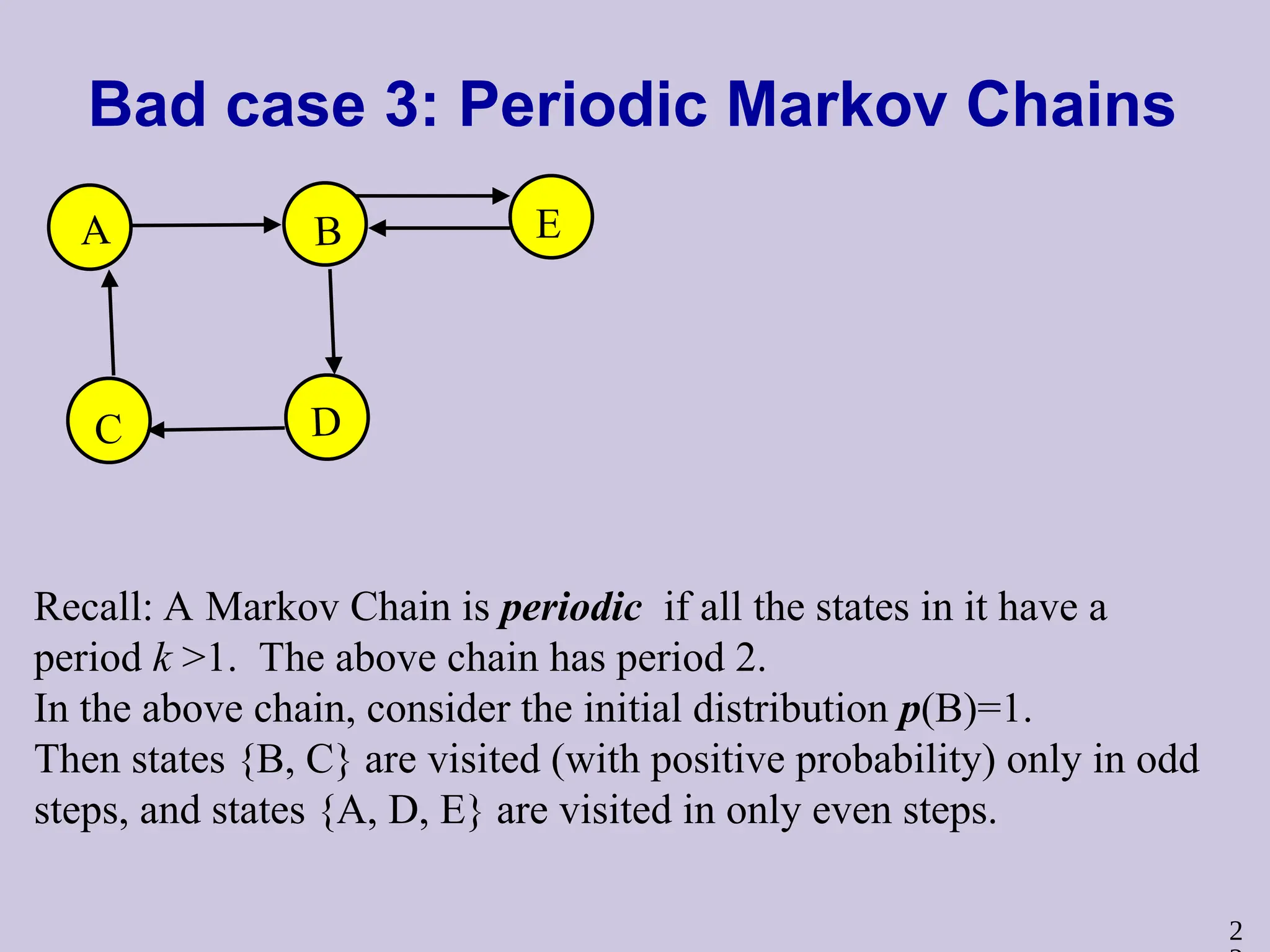
Bad case 3:Periodic Markov Chains
A B
C D
E
Recall: A Markov Chain is periodic if all the states in it have a
period k >1. The above chain has period 2.
In the above chain, consider the initial distribution p(B)=1.
Then states {B, C} are visited (with positive probability) only in odd
steps, and states {A, D, E} are visited in only even steps.
23.
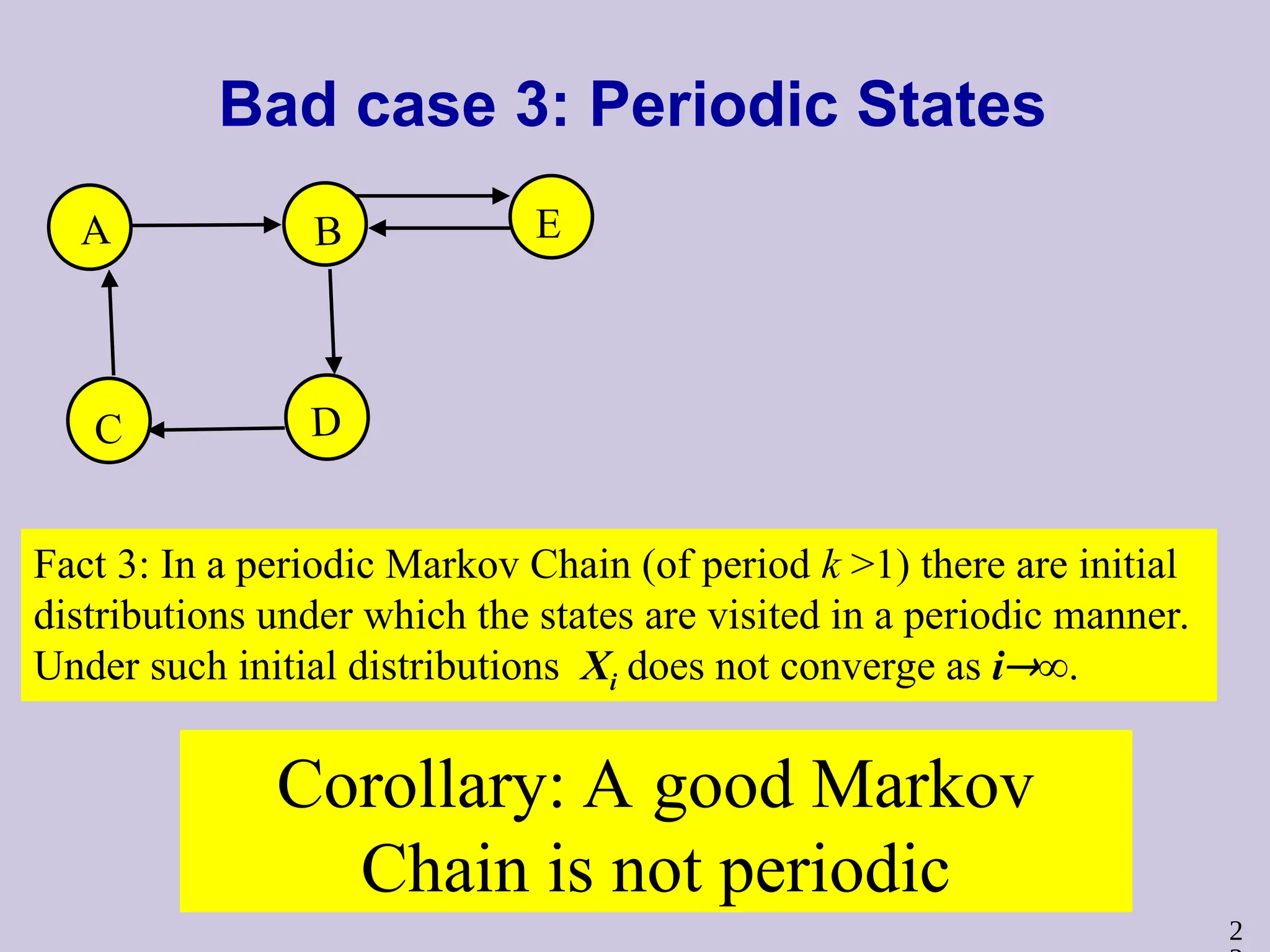
2
Bad case 3:Periodic States
A B
C D
E
Fact 3: In a periodic Markov Chain (of period k >1) there are initial
distributions under which the states are visited in a periodic manner.
Under such initial distributions Xi does not converge as i∞.
Corollary: A good Markov
Chain is not periodic
24.
2
The Fundamental Theoremof Finite Markov
Chains:
If a Markov Chain is ergodic, then
1. It has a unique stationary distribution vector V > 0, which is an
Eigenvector of the transition matrix.
2. For any initial distribution, the distributions Xi , as i∞,
converges to V.
We have proved that non-ergodic Markov Chains are not
good. A proof of the other part (based on Perron-Frobenius
theory) is beyond the scope of this course:
25.
2
Use of MarkovChains in Genome search:
Modeling CpG Islands
In human genomes the pair CG often transforms to
(methyl-C) G which often transforms to TG.
Hence the pair CG appears less than expected from
what is expected from the independent frequencies
of C and G alone.
Due to biological reasons, this process is sometimes
suppressed in short stretches of genomes such as in
the start regions of many genes.
These areas are called CpG islands (p denotes “pair”).
26.
2
Example: CpG Island(Cont.)
We consider two questions (and some variants):
Question 1: Given a short stretch of genomic data, does
it come from a CpG island ?
Question 2: Given a long piece of genomic data, does
it contain CpG islands in it, where, what length ?
We “solve” the first question by modeling strings with
and without CpG islands as Markov Chains over the
same states {A,C,G,T} but different transition
probabilities:
27.
2
Example: CpG Island(Cont.)
The “+” model: Use transition matrix A+
= (a+
st),
Where:
a+
st = (the probability that t follows s in a CpG
island)
The “-” model: Use transition matrix A-
= (a-
st),
Where:
a-
st = (the probability that t follows s in a non
CpG island)
28.
2
Example: CpG Island(Cont.)
With this model, to solve Question 1 we need to decide
whether a given short sequence of letters is more likely
to come from the “+” model or from the “–” model.
This is done by using the definitions of Markov Chain,
in which the parameters are determined by known data
and the log odds-ratio test.
29.
2
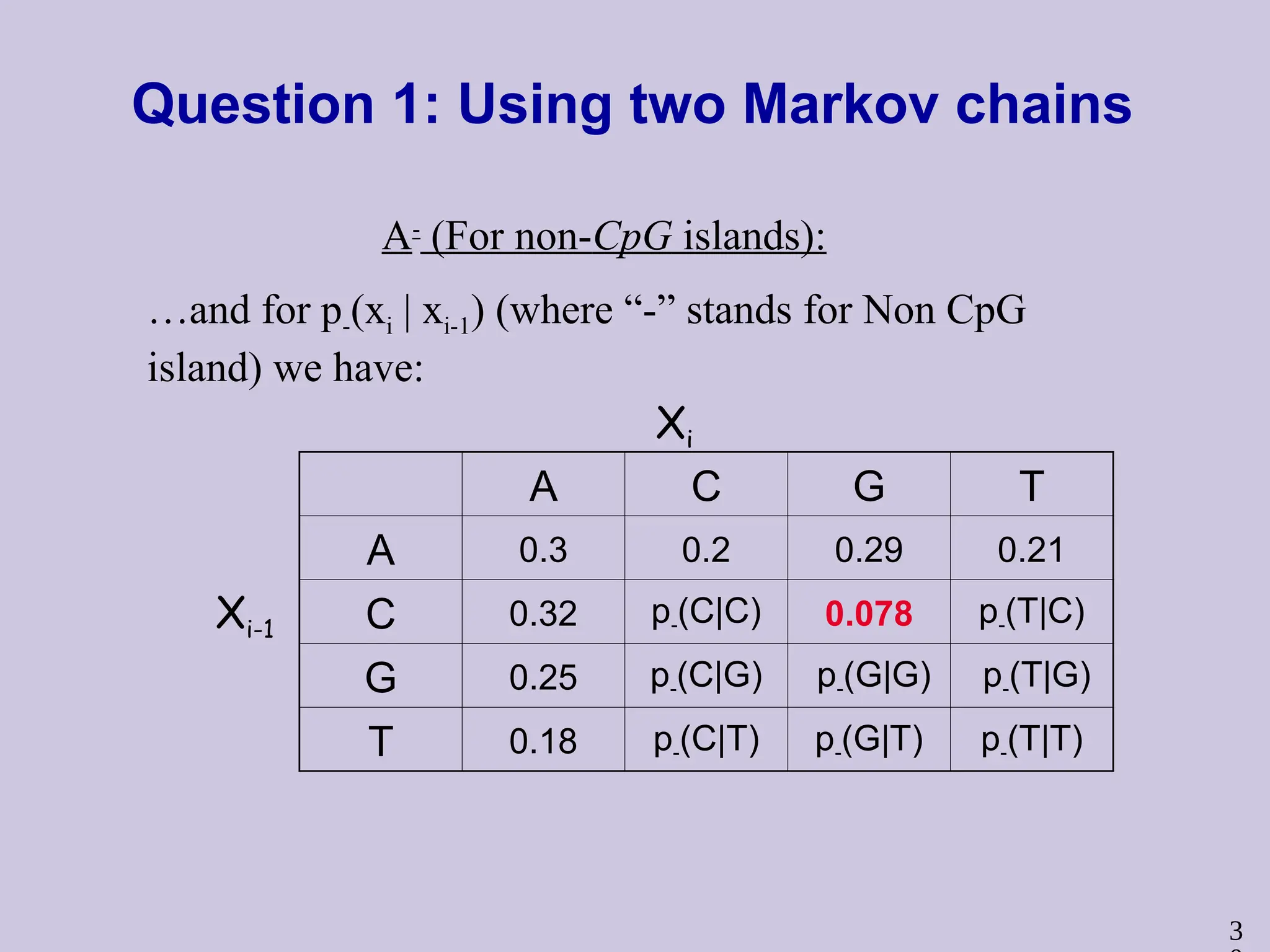
Question 1: Usingtwo Markov chains
A+
(For CpG islands):
Xi-1
Xi
A C G T
A 0.18 0.27 0.43 0.12
C 0.17 p+(C | C) 0.274 p+(T|C)
G 0.16 p+(C|G) p+(G|G) p+(T|G)
T 0.08 p+(C |T) p+(G|T) p+(T|T)
We need to specify p+(xi | xi-1) where + stands for CpG
Island. From Durbin et al we have:
(Recall: rows must add up to one; columns need not.)
30.
3
Question 1: Usingtwo Markov chains
A-
(For non-CpG islands):
Xi-1
Xi
A C G T
A 0.3 0.2 0.29 0.21
C 0.32 p-(C|C) 0.078 p-(T|C)
G 0.25 p-(C|G) p-(G|G) p-(T|G)
T 0.18 p-(C|T) p-(G|T) p-(T|T)
…and for p-(xi | xi-1) (where “-” stands for Non CpG
island) we have:
31.
3
Discriminating between thetwo models
Given a string x=(x1….xL), now compute the ratio
If RATIO>1, CpG island is more likely.
Actually – the log of this ratio is computed:
X1 X2 XL-1 XL
1
0
1
1
0
1
model)
(
model)
(
RATIO L
i
i
i
L
i
i
i
x
x
p
x
x
p
p
p
)
|
(
)
|
(
|
|
x
x
Note: p+(x1|x0) is defined for convenience as p+(x1).
p-(x1|x0) is defined for convenience as p-(x1).
32.
3
Log Odds-Ratio test
Takinglogarithm yields
If logQ > 0, then + is more likely (CpG island).
If logQ < 0, then - is more likely (non-CpG island).
i i
i
i
i
L
L
)
|x
(x
p
)
|x
(x
p
)
|
...x
p(x
)
|
...x
p(x
Q
1
1
1
1
log
log
log
33.
3
Where do theparameters (transition-
probabilities) come from ?
Learning from complete data, namely, when the label is given and
every xi is measured:
Source: A collection of sequences from CpG islands, and a
collection of sequences from non-CpG islands.
Input: Tuples of the form (x1, …, xL, h), where h is + or -
Output: Maximum Likelihood parameters (MLE)
Count all pairs (Xi=a, Xi-1=b) with label +, and
with label -, say the numbers are Nba,+ and Nba,- .
34.
3
Maximum Likelihood Estimate(MLE) of
the parameters (using labeled data)
The needed parameters are:
P+(x1), p+ (xi | xi-1), p-(x1), p-(xi | xi-1)
The ML estimates are given by:
Using MLE is justified when we have a large sample. The numbers appearing in
the text book are based on 60,000 nucleotides. When only small samples are
available, Bayesian learning is an attractive alternative.
X1 X2 XL-1 XL
x
x
a
N
N
a
X
p
,
,
)
( 1 Where Nx,+ is the number of times letter x
appear in CpG islands in the dataset.
x
bx
ba
i
i
N
N
b
X
a
X
p
,
,
)
|
( 1
Where Nbx,+ is the number of times letter
x appears after letter b in CpG islands in
the dataset.
35.
3
Question 2: FindingCpG Islands
Given a long genomic string with possible CpG
Islands, we define a Markov Chain over 8 states, all
interconnected (hence it is ergodic):
C+
T+
G+
A+
C-
T-
G-
A-
The problem is that we don’t know
the sequence of states which are
traversed, but just the sequence of
letters.
Therefore we use here Hidden Markov Model
36.
3
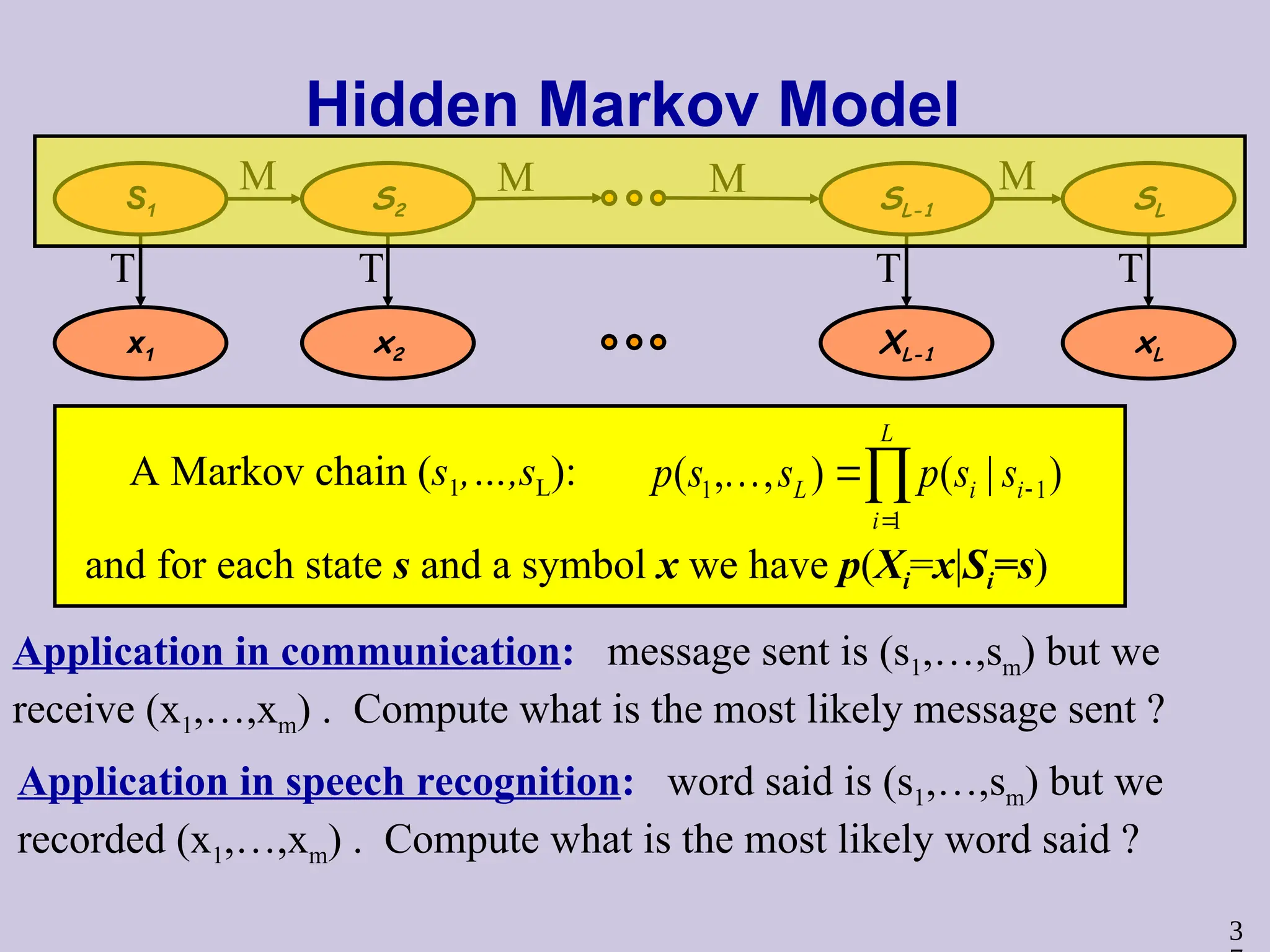
Hidden Markov Model
11
1
( , , ) ( | )
L
L i i
i
p s s p s s
A Markov chain (s1,…,sL):
and for each state s and a symbol x we have p(Xi=x|Si=s)
Application in communication: message sent is (s1,…,sm) but we
receive (x1,…,xm) . Compute what is the most likely message sent ?
Application in speech recognition: word said is (s1,…,sm) but we
recorded (x1,…,xm) . Compute what is the most likely word said ?
S1 S2 SL-1 SL
x1 x2 XL-1 xL
M M M M
T
T
T
T
37.
3
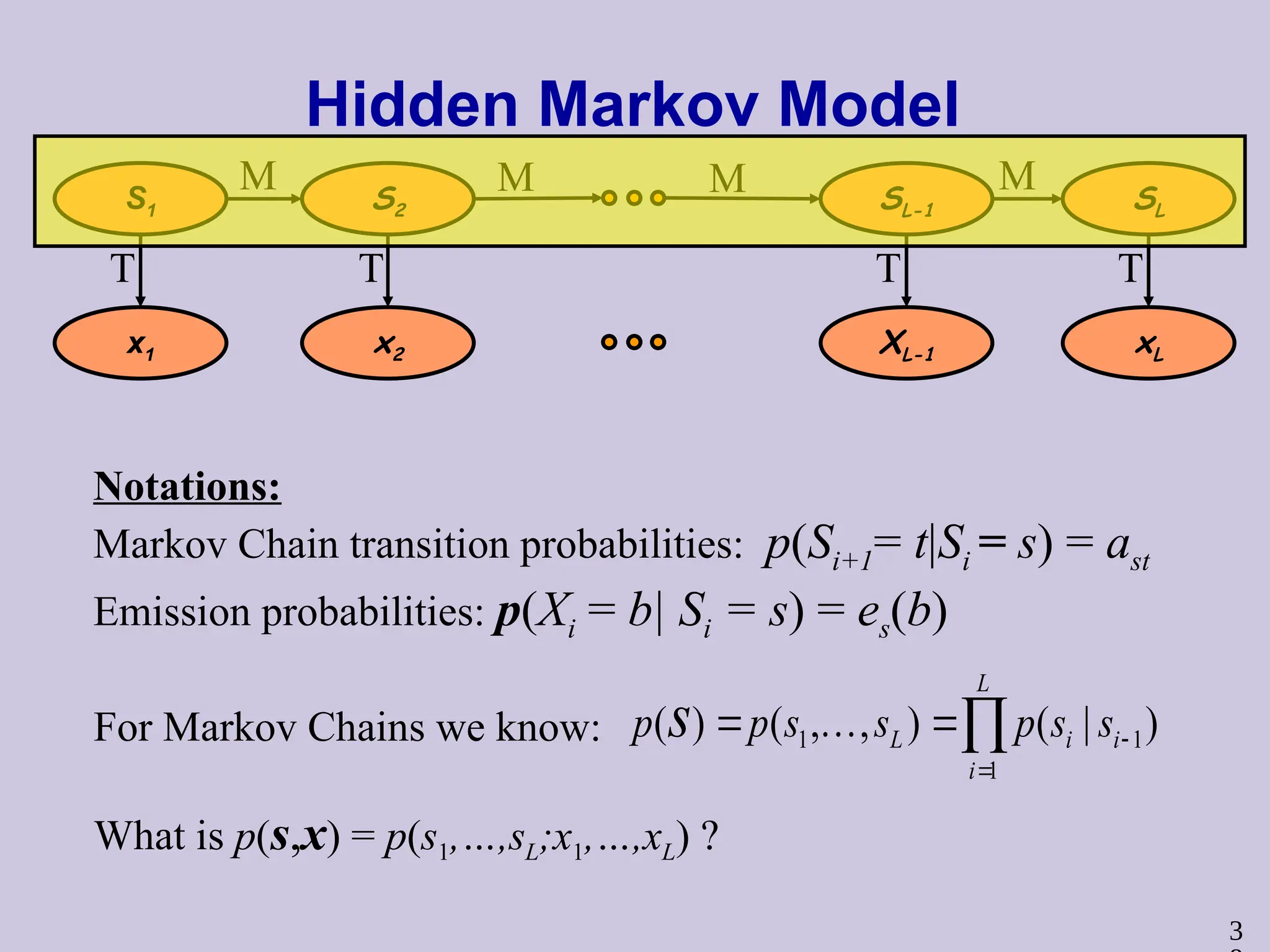
Hidden Markov Model
Notations:
MarkovChain transition probabilities: p(Si+1= t|Si = s) = ast
Emission probabilities: p(Xi = b| Si = s) = es(b)
S1 S2 SL-1 SL
x1 x2 XL-1 xL
M M M M
T
T
T
T
For Markov Chains we know:
What is p(s,x) = p(s1,…,sL;x1,…,xL) ?
1 1
1
( ) ( , , ) ( | )
L
L i i
i
p p s s p s s
s
38.
3
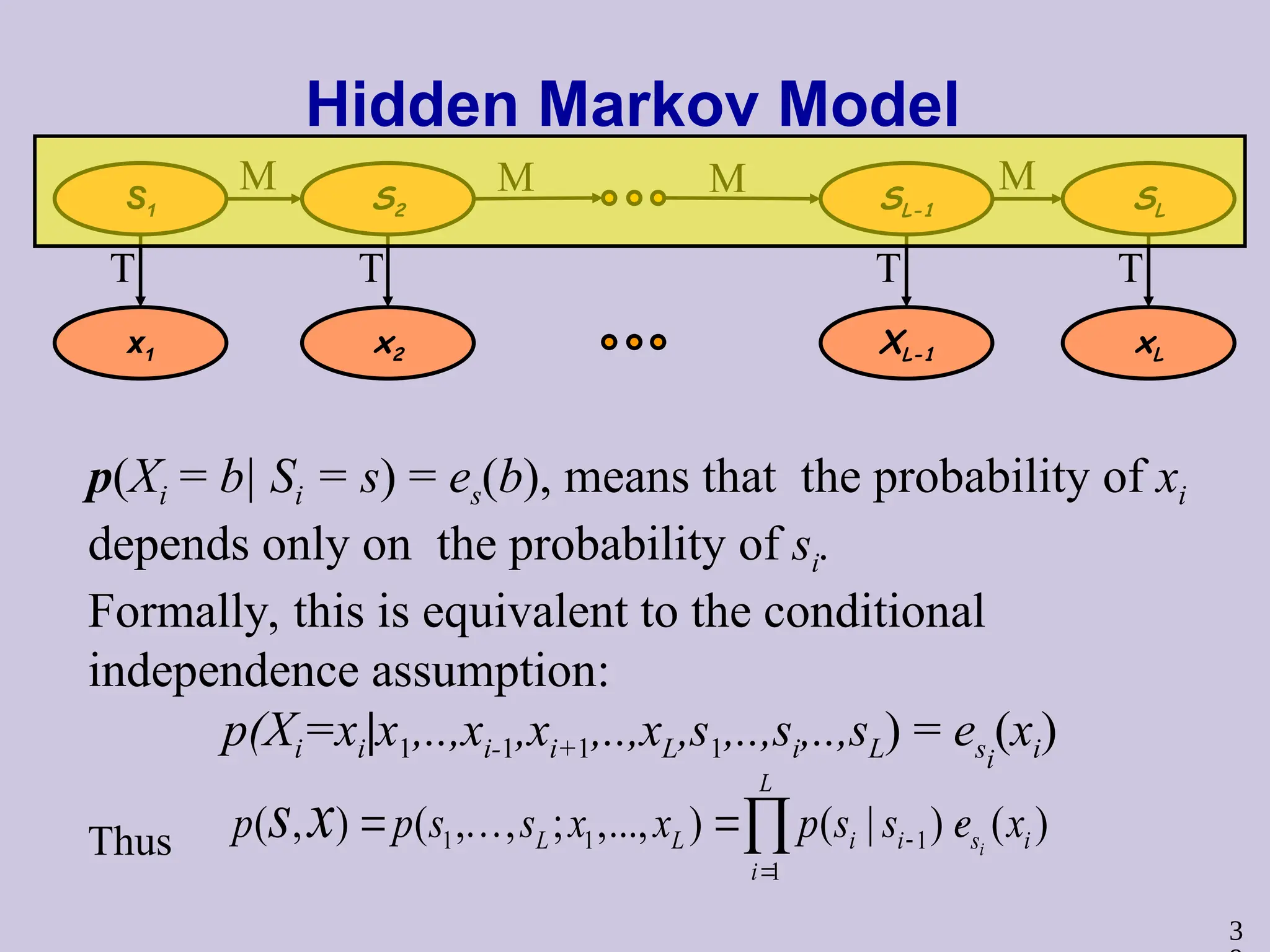
Hidden Markov Model
p(Xi= b| Si = s) = es(b), means that the probability of xi
depends only on the probability of si.
Formally, this is equivalent to the conditional
independence assumption:
p(Xi=xi|x1,..,xi-1,xi+1,..,xL,s1,..,si,..,sL) = esi
(xi)
S1 S2 SL-1 SL
x1 x2 XL-1 xL
M M M M
T
T
T
T
1 1 1
1
( , ) ( , , ; ,..., ) ( | ) ( )
i
L
L L i i s i
i
p p s s x x p s s e x
s x
Thus






![1
Stationary Distributions for a Markov
Chain M
Exercise: A stochastic matrix always has a real left Eigenvector
with Eigenvalue 1 (hint: show that a stochastic matrix has a
right Eigenvector with Eigenvalue 1. Note that the left
Eigenvalues of a Matrix are the same as the right Eiganvlues).
[It can be shown that the above Eigenvector V can be non-
negative. Hence each Markov Chain has a stationary
distribution.]](https://image.slidesharecdn.com/class05-m-251210145853-a8dbca64/75/Markov-chain-presentation-class05-m-ppt-15-2048.jpg)













































![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)