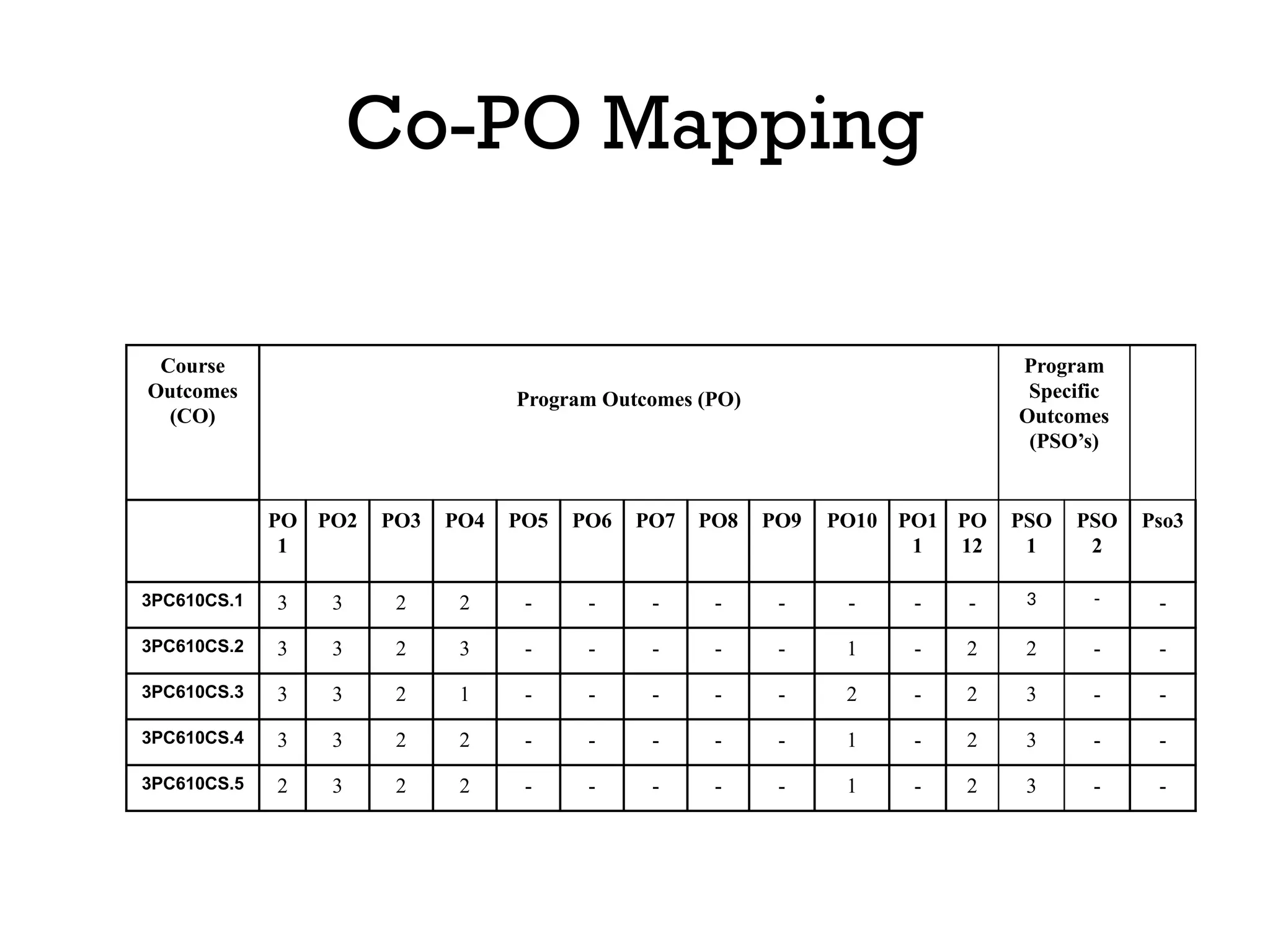
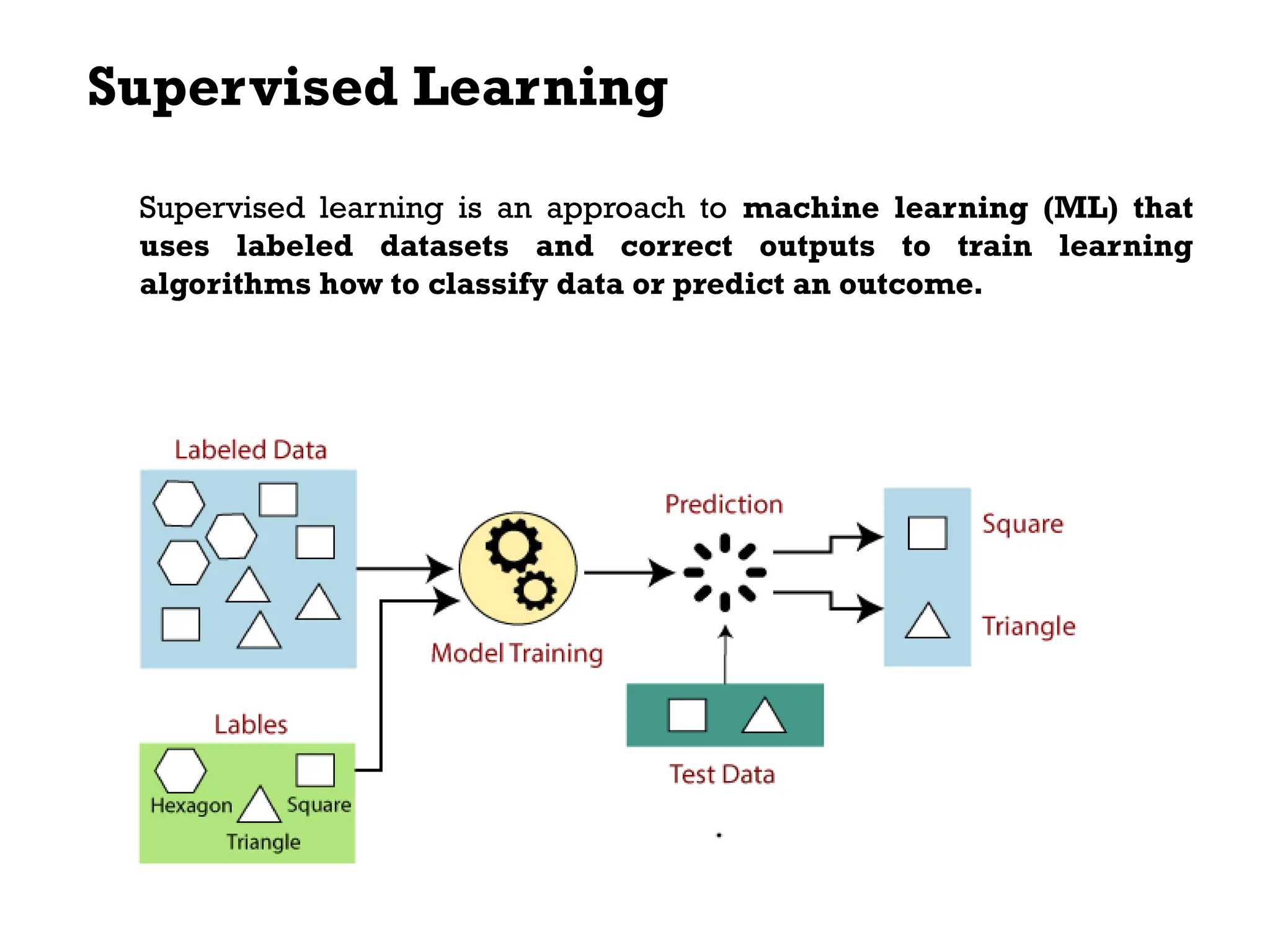
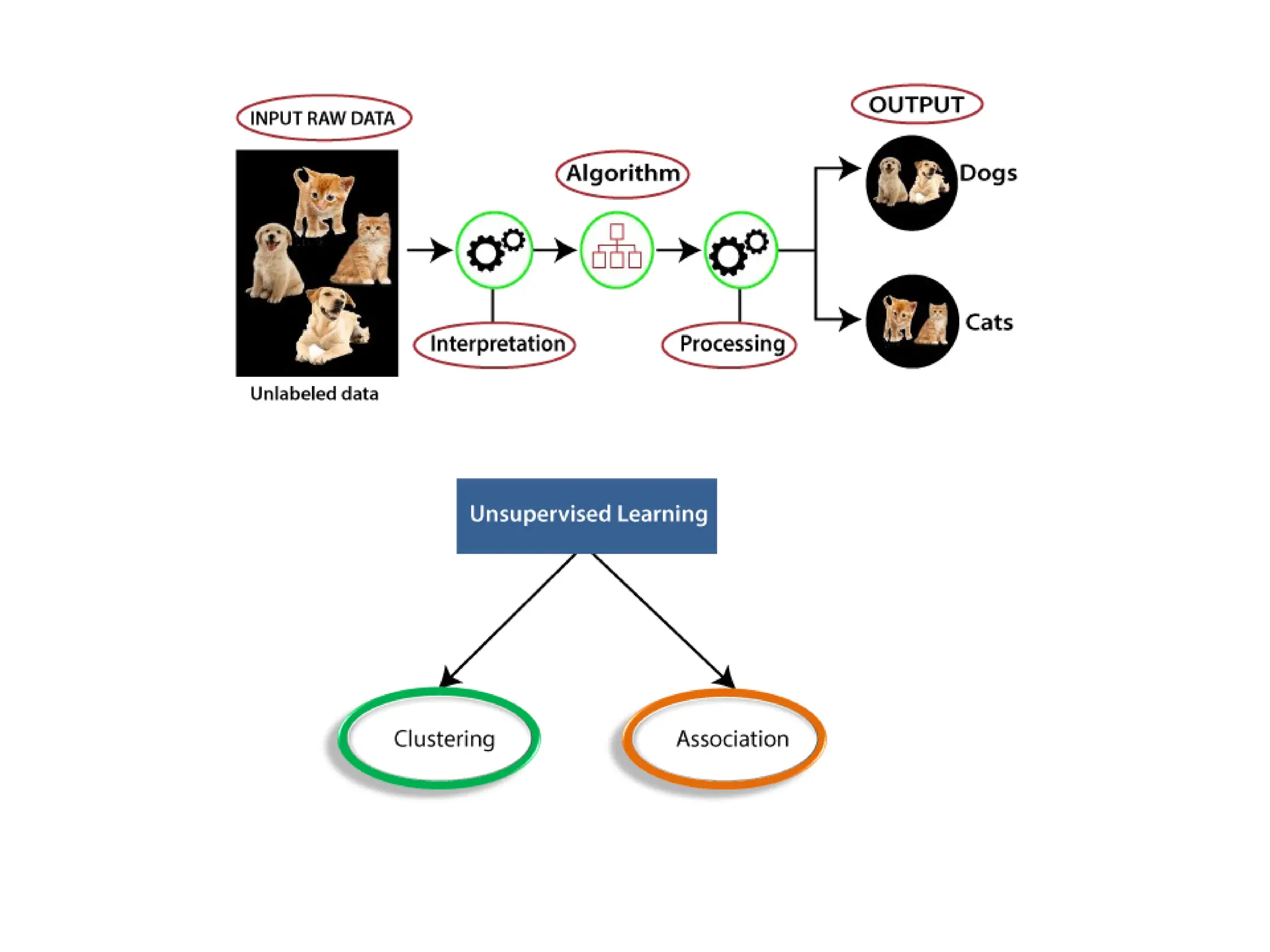
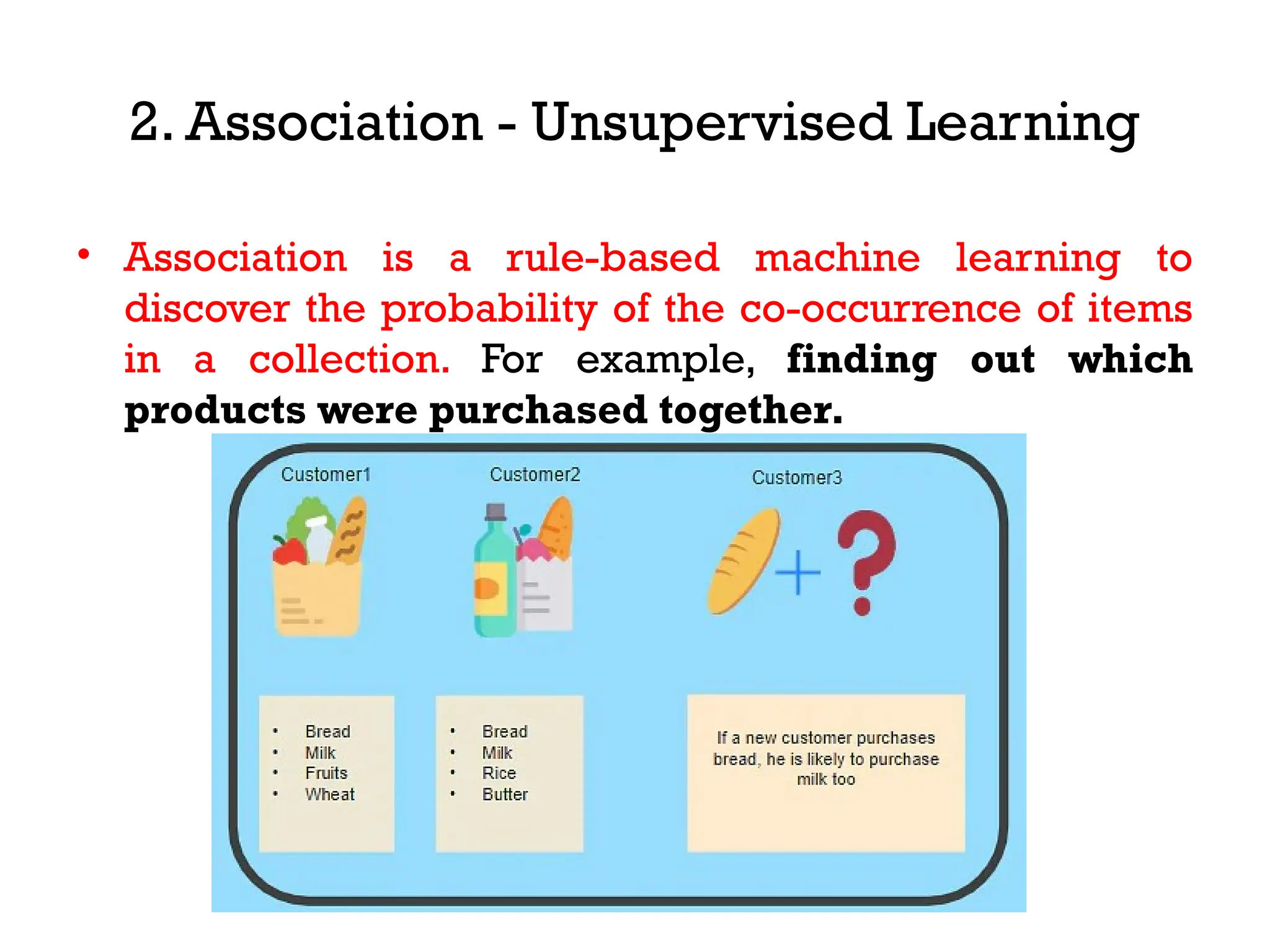
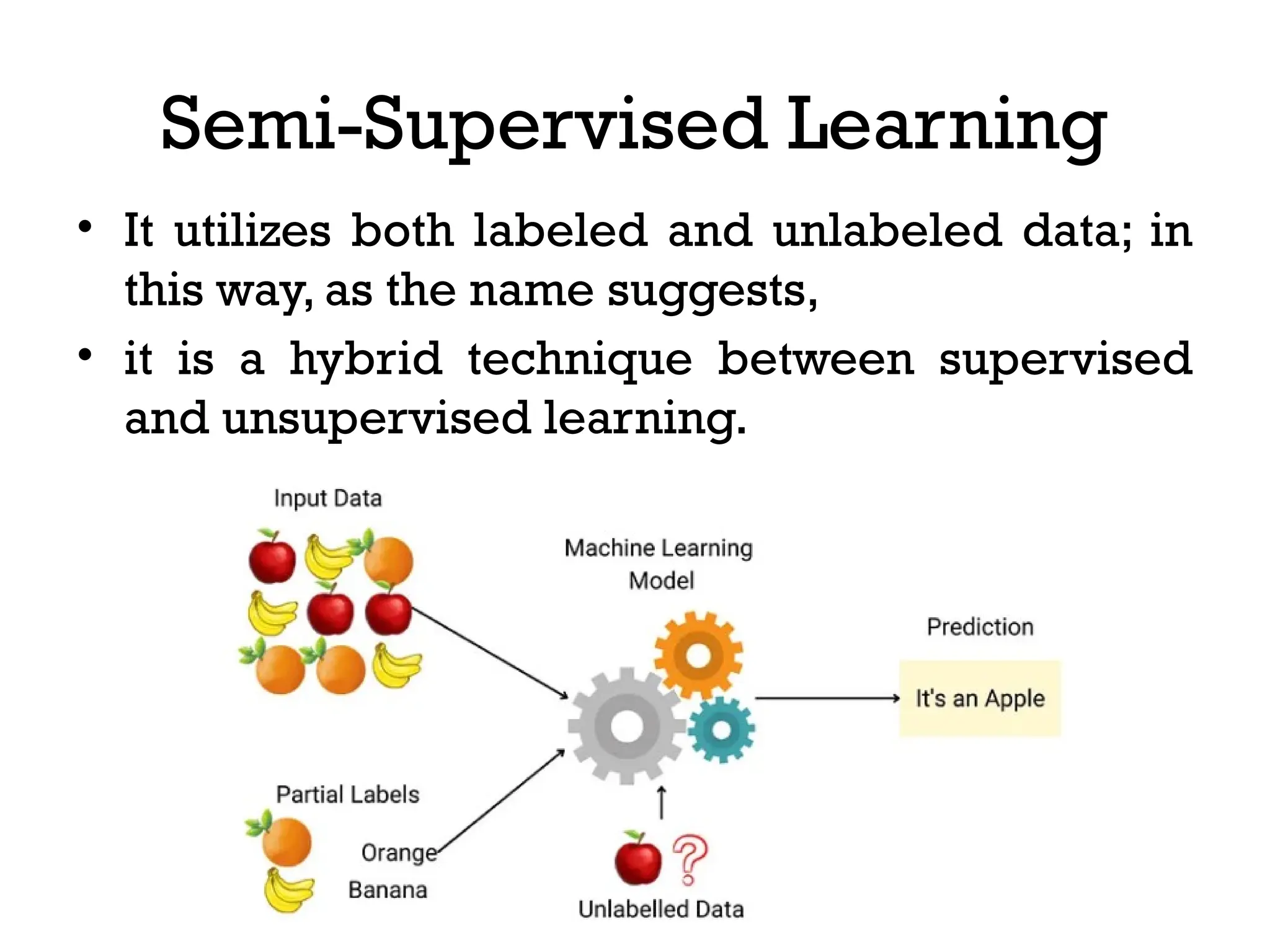
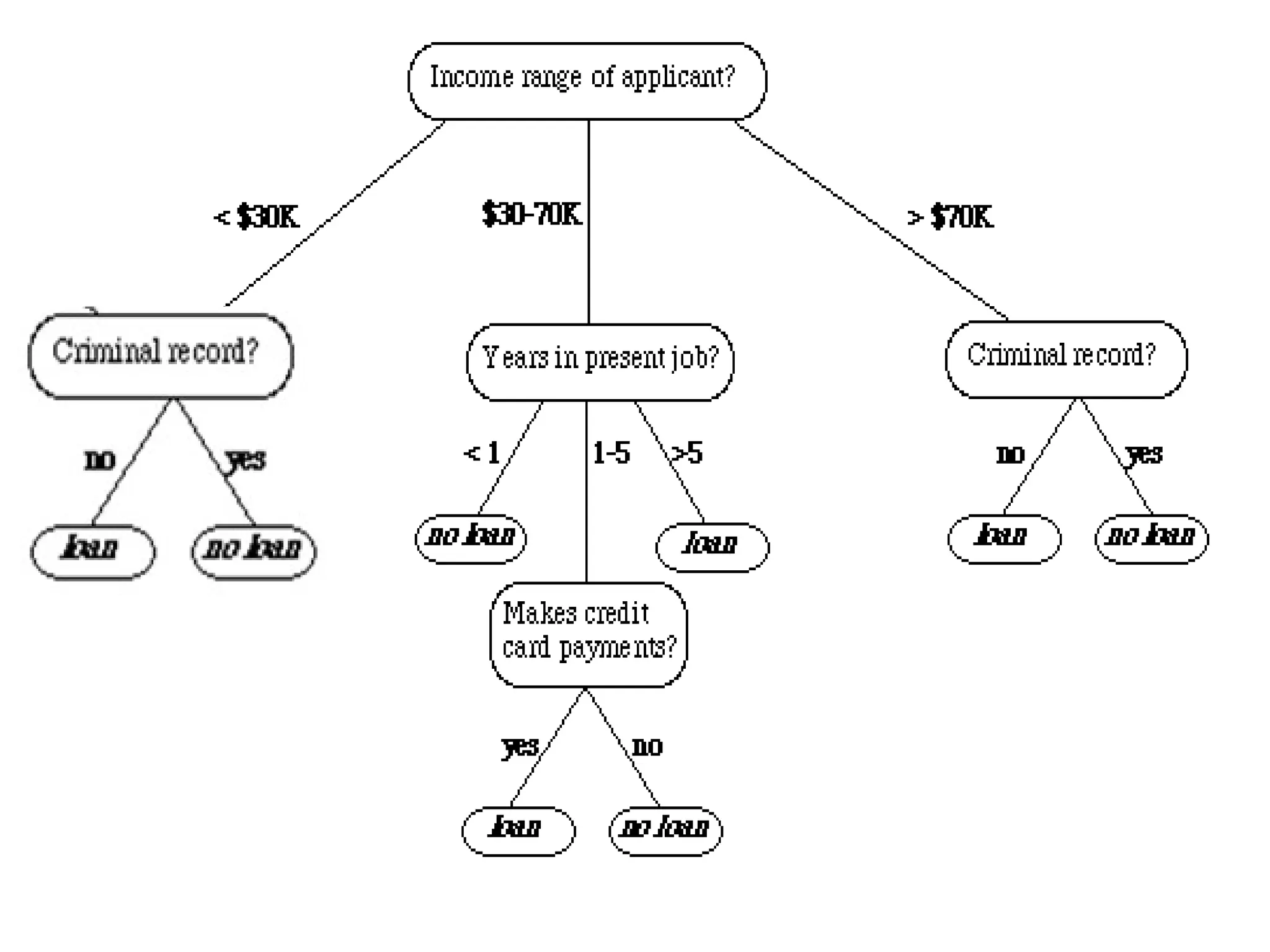
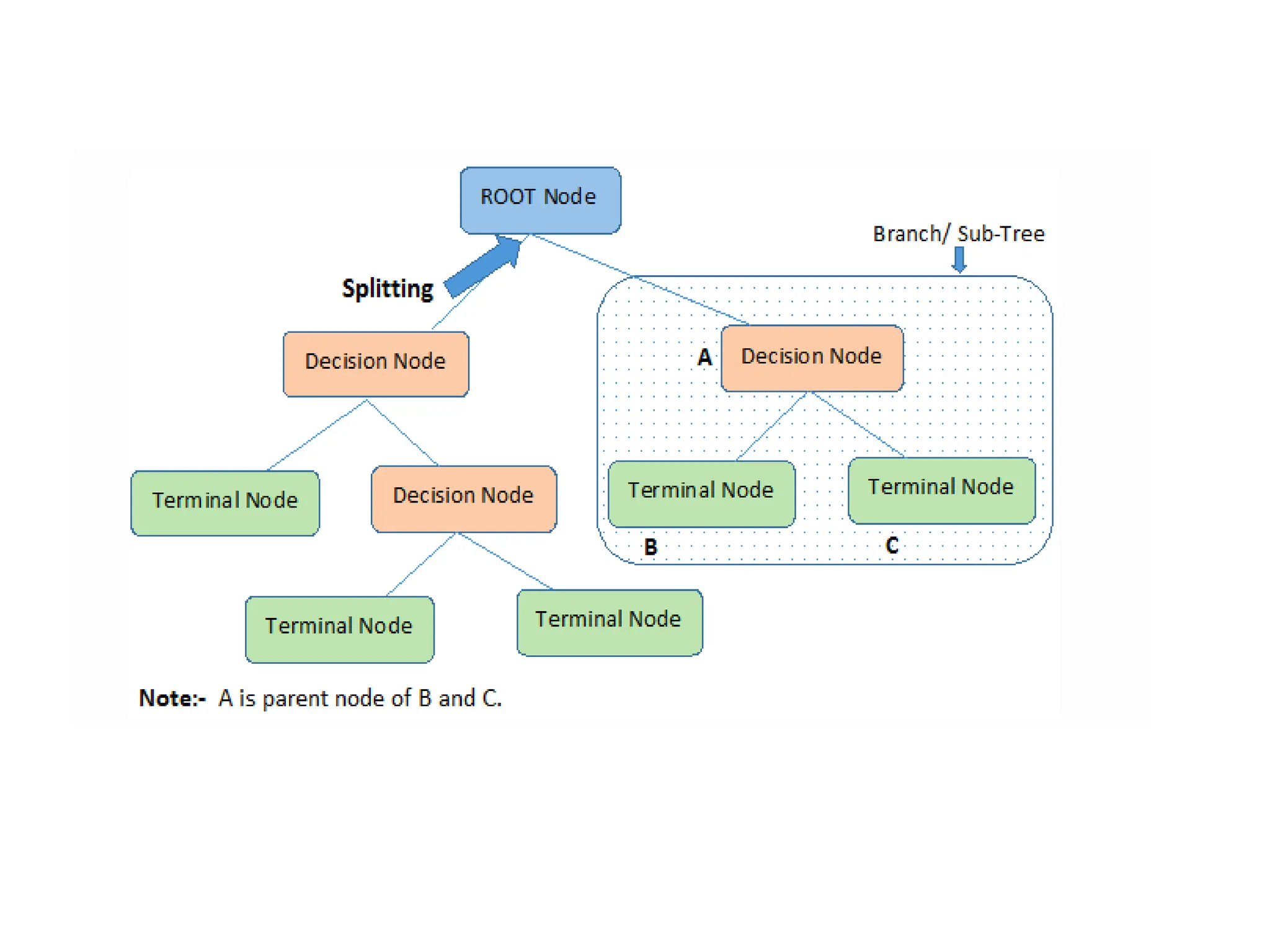
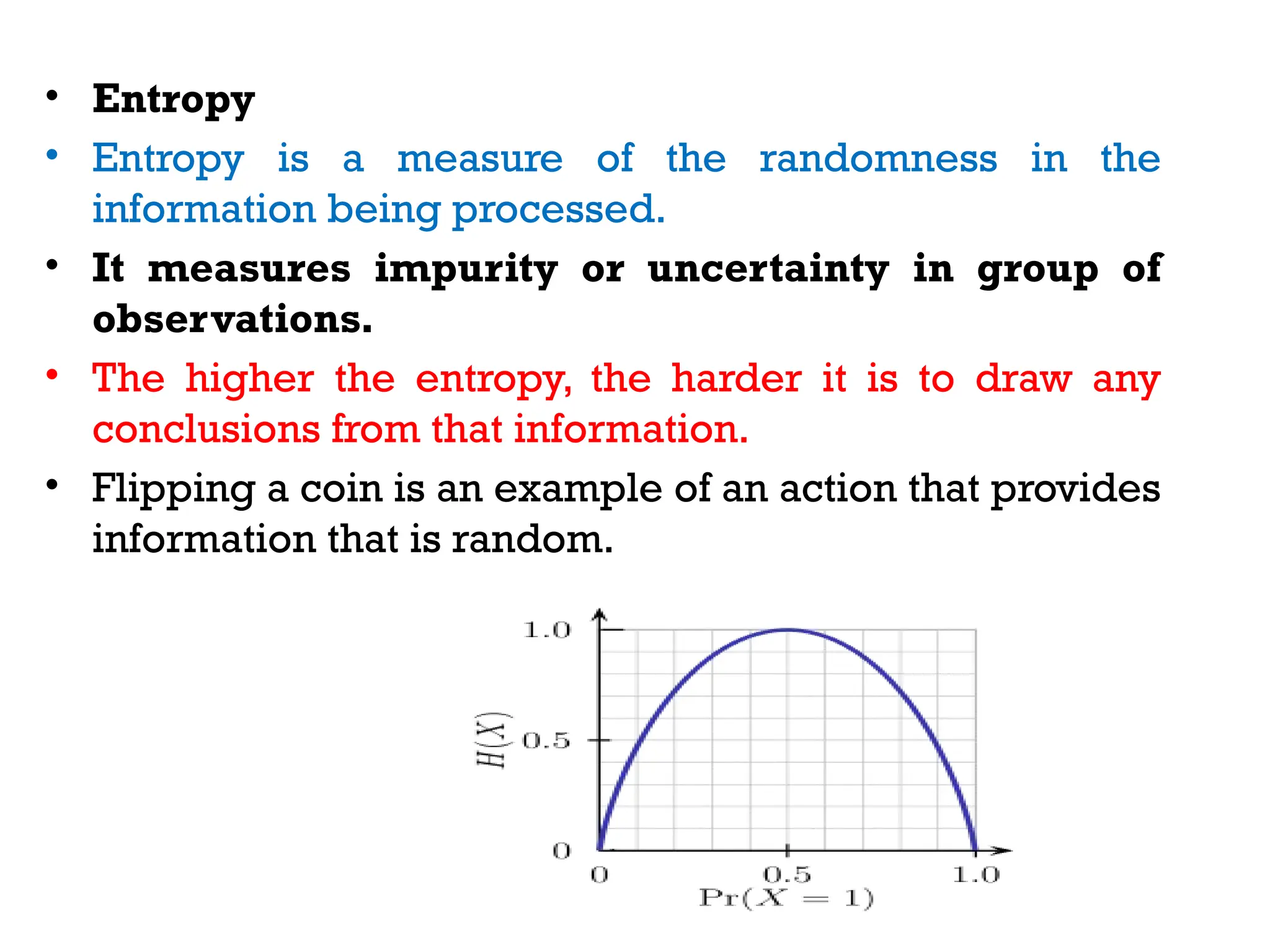
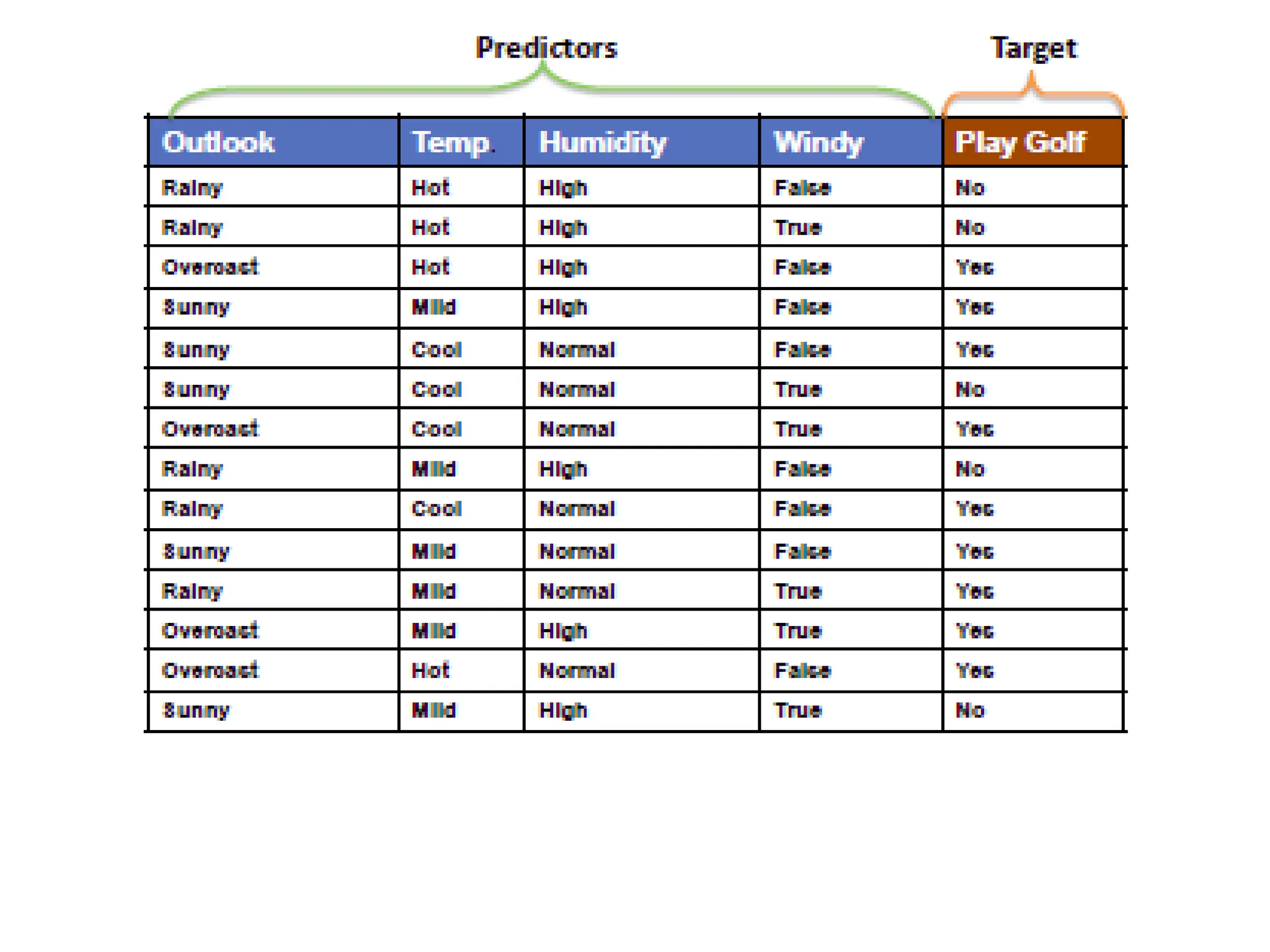
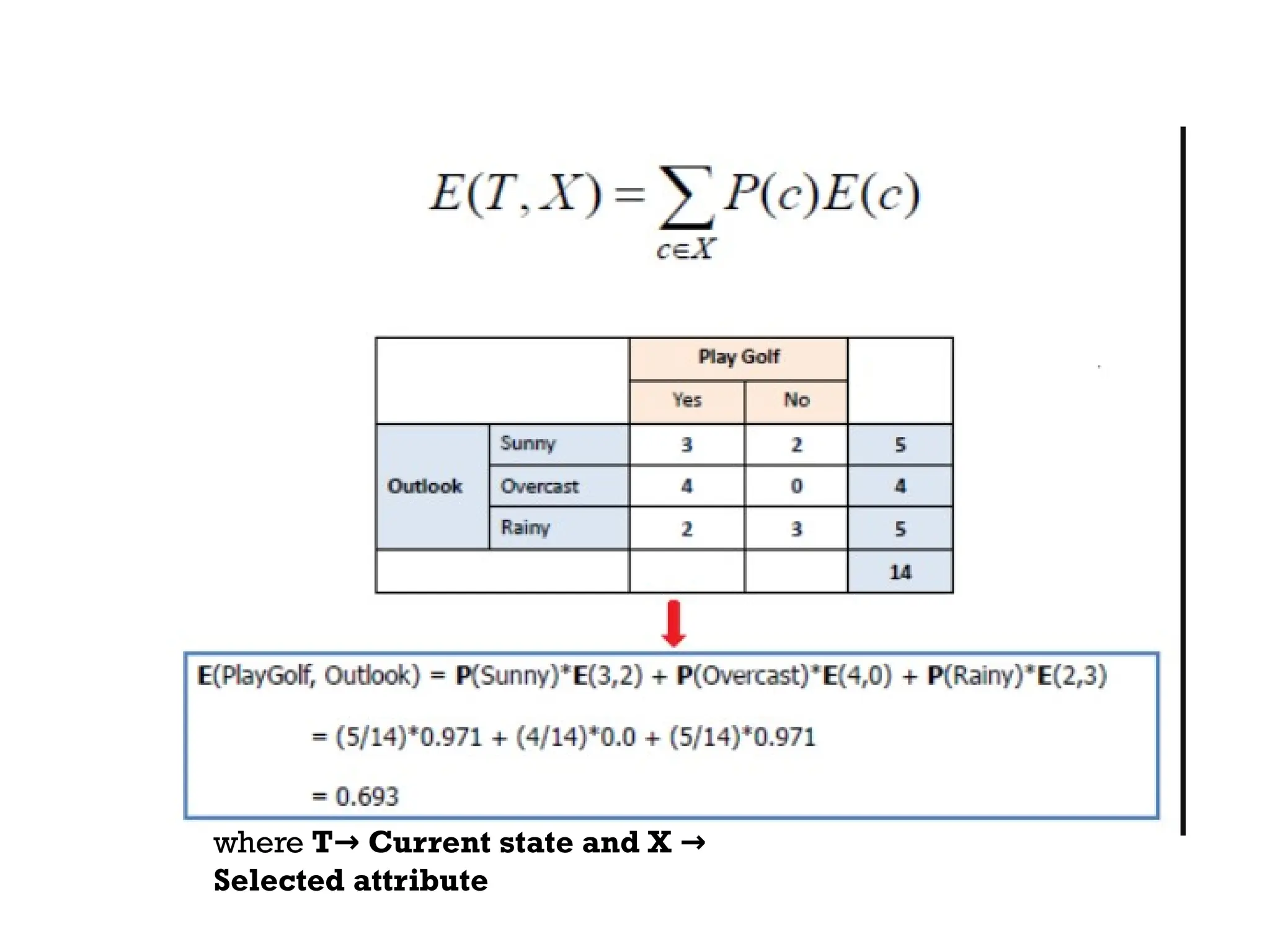
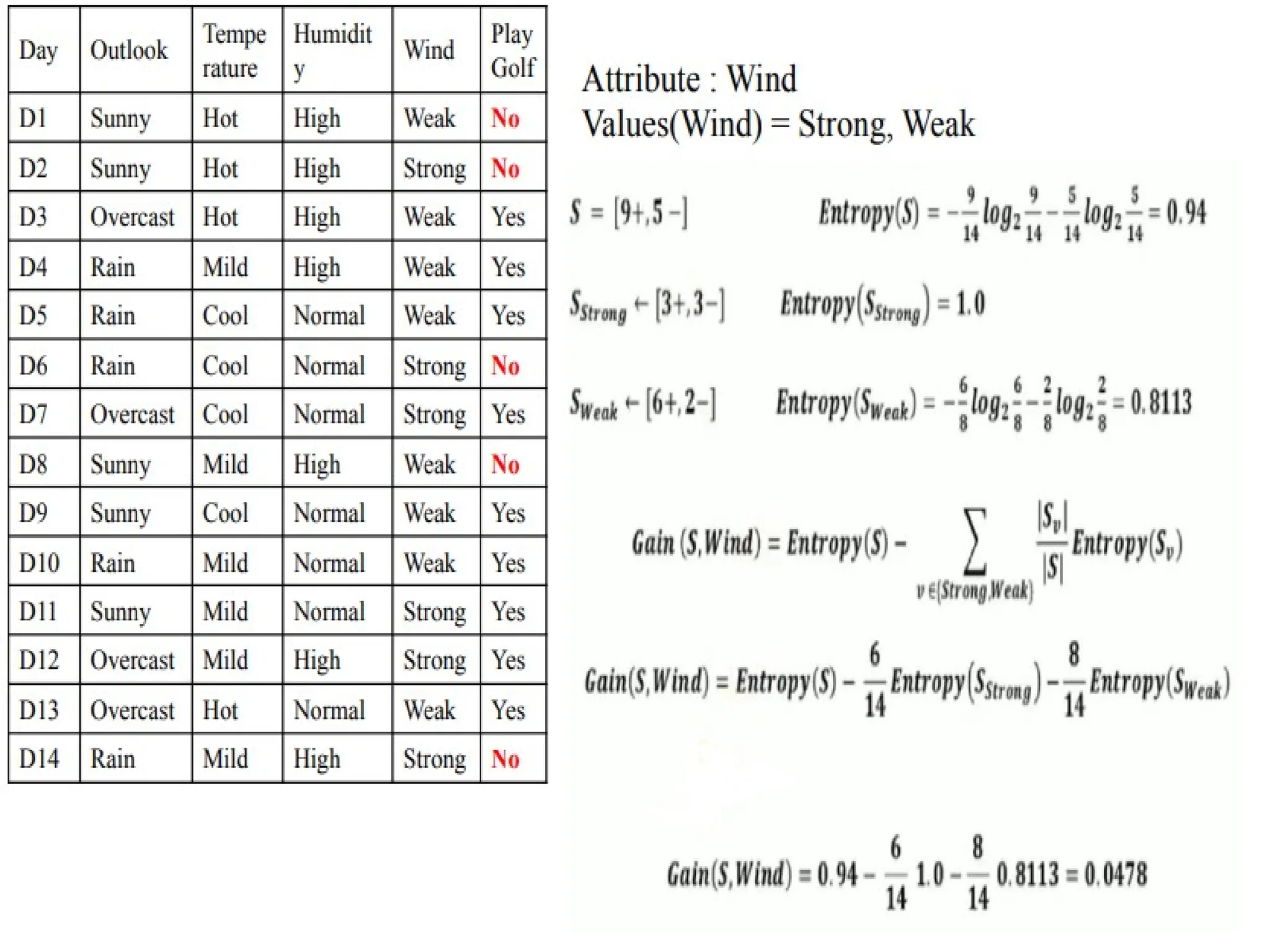
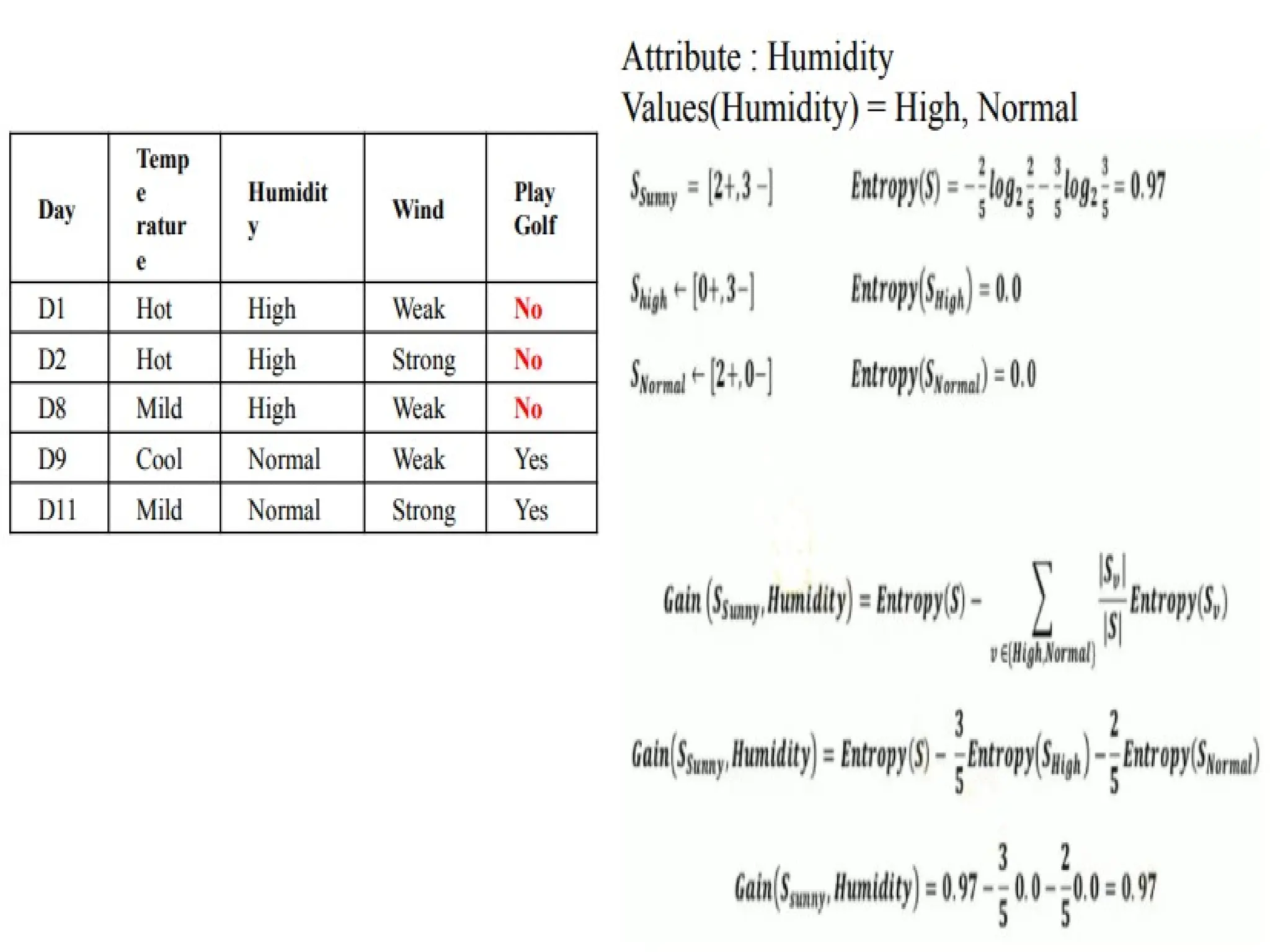
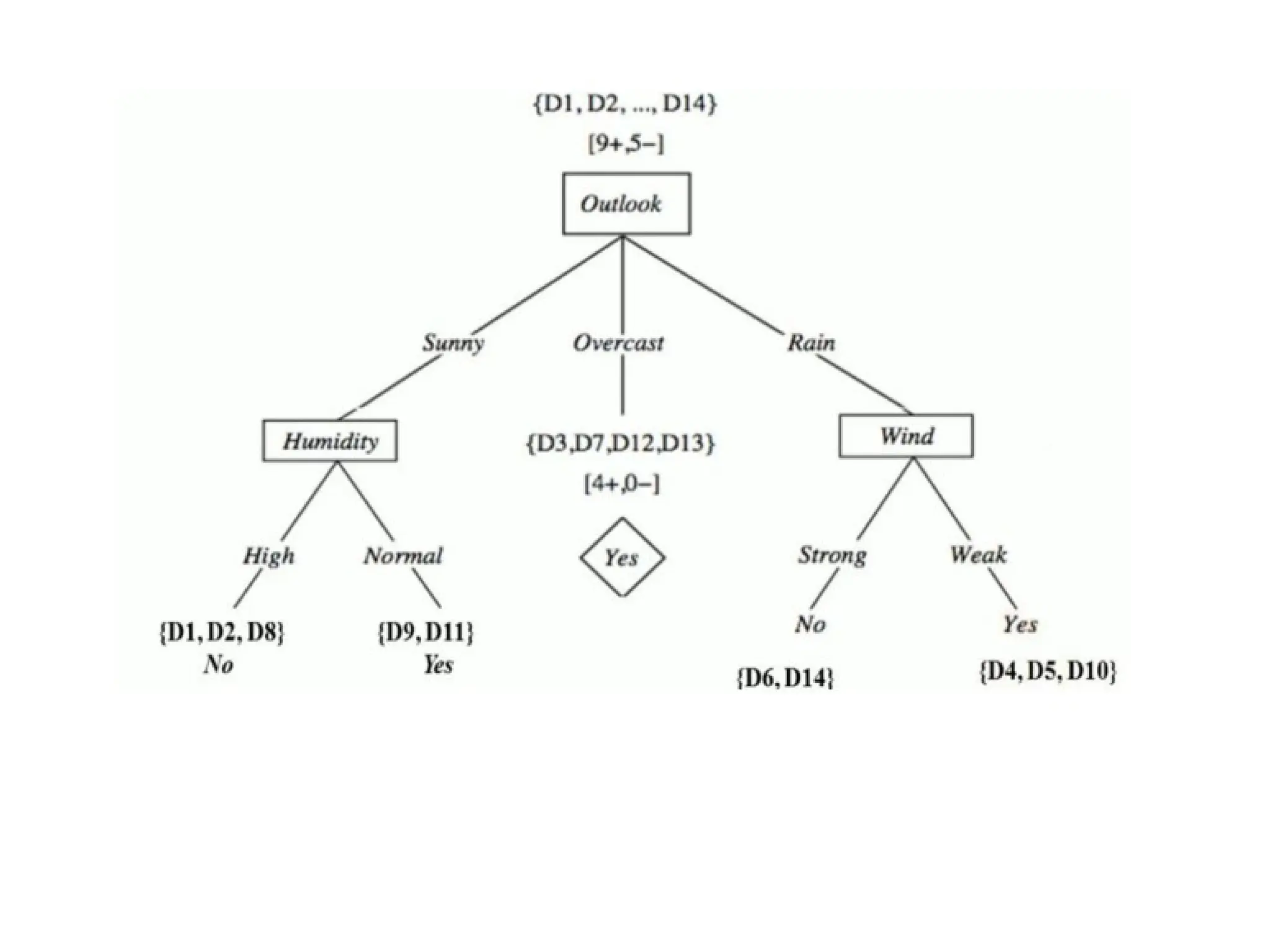
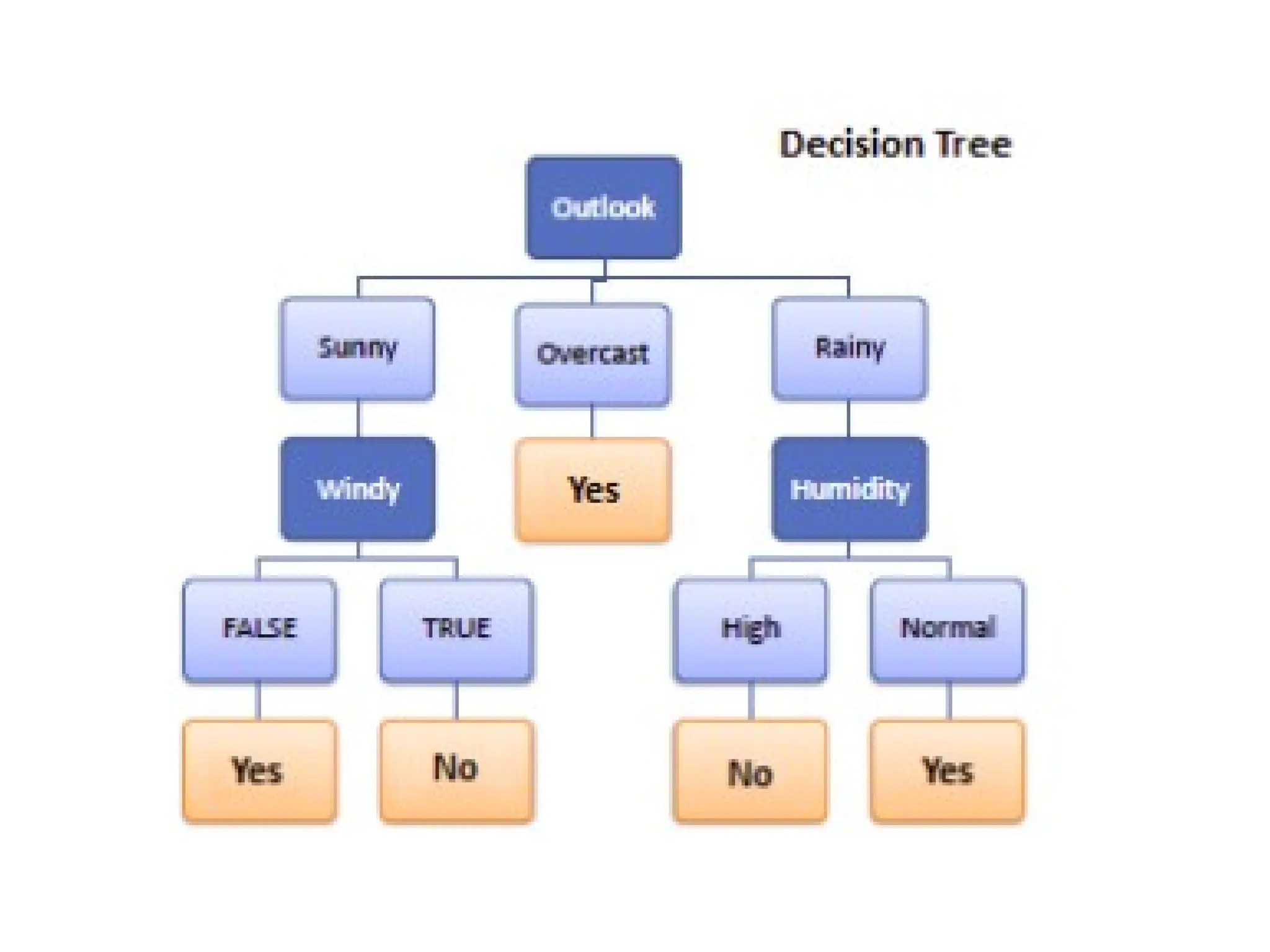
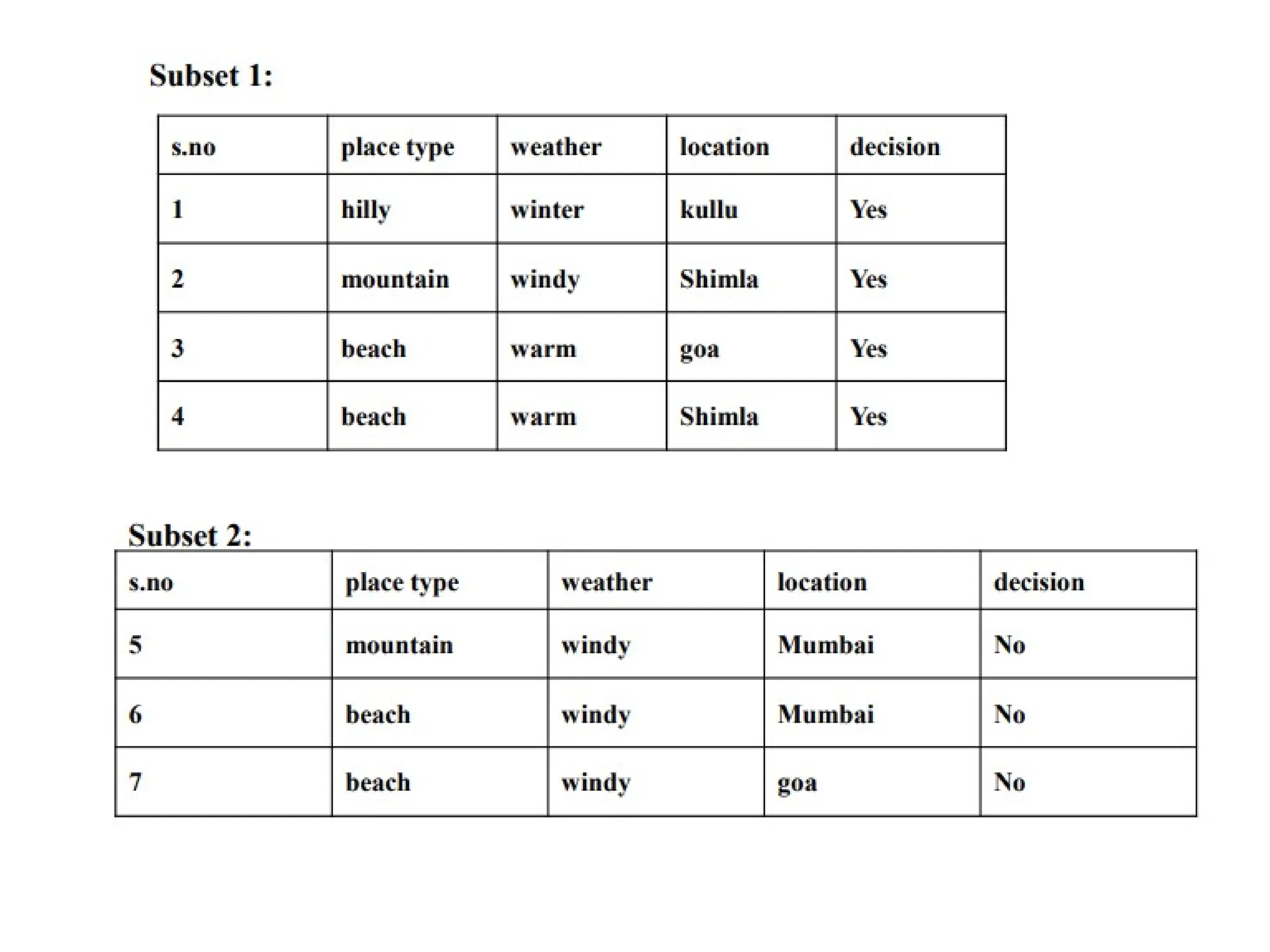
The document outlines the vision and mission of an educational institute and its computer science department, focusing on ethical engineering and innovative professional development. It discusses the objectives and outcomes of a machine learning course, emphasizing the importance of understanding various learning algorithms, including supervised, unsupervised, and reinforcement learning. Practical applications of machine learning in fields such as finance, healthcare, and retail are highlighted, alongside the significance of algorithms for predicting outcomes and insights from data.