Introduction to MachineLearning
• Introduction to Machine Learning: Evolution of Machine Learning,
Paradigms for ML, learning by Rote, Learning by Induction,
Reinforcement Learning, Types of Data, Stages in Machine Learning.
• CRISP-Model: CRISP-DM framework.
3.
Introduction to MachineLearning
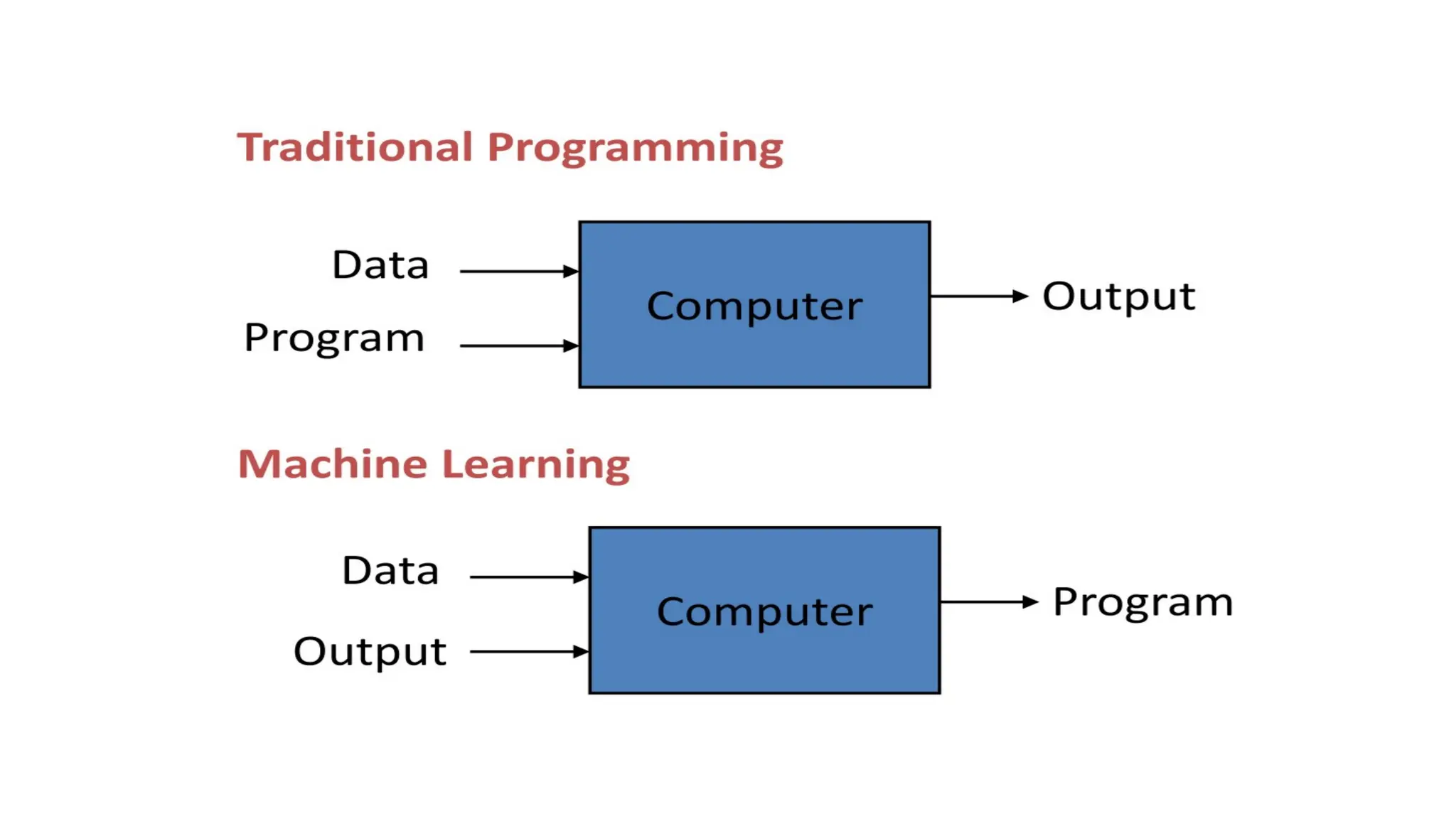
• Machine learning (ML) is a subset of artificial intelligence (AI) that
focuses on enabling systems to learn from data and make decisions or
predictions without being explicitly programmed. Rather than
following predetermined rules, ML algorithms allow computers to
recognize patterns, make inferences, and improve their performance
over time through experience.
4.
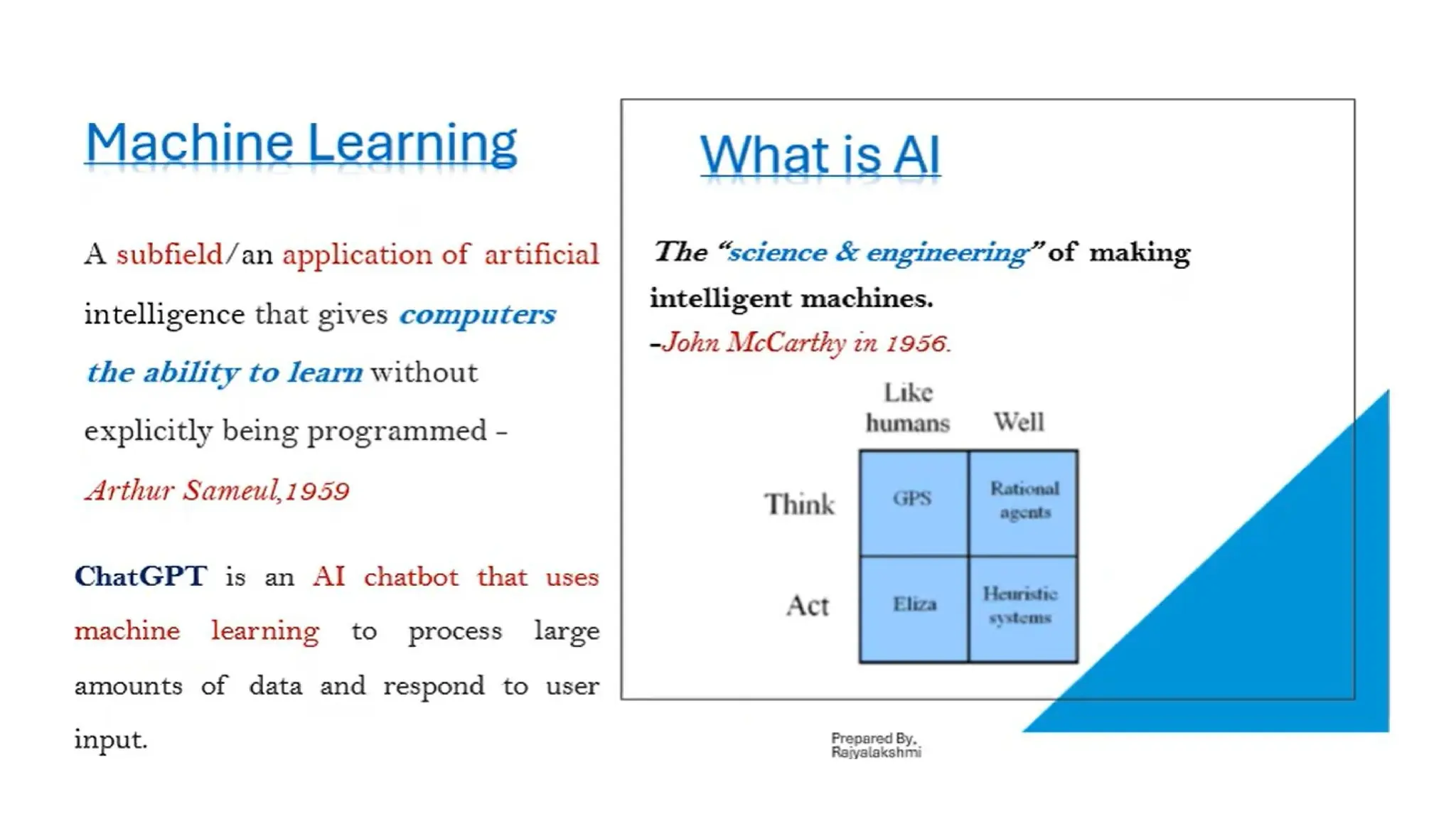
What is MachineLearning?
• Machine learning refers to the field of study that gives computers the
ability to learn from data, identify patterns, and make decisions with
minimal human intervention. This involves using algorithms to analyze
and model data to make predictions or decisions.
7.
When Do WeUse Machine Learning?
• ML is used when:
• Human expertise does not exist (navigating on Mars)
• Humans can’t explain their expertise (speech recognition)
• Models must be customized (personalized medicine)
• Models are based on huge amounts of data (genomics)
10.
1. Solving ComplexBusiness Problems
• Traditional programming struggles with tasks like image recognition,
natural language processing (NLP), and medical diagnosis. ML,
however, thrives by learning from examples and making predictions
without relying on predefined rules.
• Example Applications:
• Image and speech recognition in healthcare.
• Language translation and sentiment analysis.
11.
2. Handling LargeVolumes of Data
• With the internet’s growth, the data generated daily is immense. ML
effectively processes and analyzes this data, extracting valuable
insights and enabling real-time predictions.
• Use Cases:
• Fraud detection in financial transactions.
• Social media platforms like Facebook and Instagram predicting
personalized feed recommendations from billions of interactions.
12.
3. Automate RepetitiveTasks
• ML automates time-intensive and repetitive tasks with precision,
reducing manual effort and error-prone systems.
• Examples:
• Email Filtering: Gmail uses ML to keep your inbox spam-free.
• Chatbots: ML-powered chatbots resolve common issues like order
tracking and password resets.
• Data Processing: Automating large-scale invoice analysis for key
insights.
13.
4. Personalized UserExperience
• ML enhances user experience by tailoring recommendations to
individual preferences. Its algorithms analyze user behavior to deliver
highly relevant content.
• Real-World Applications:
• Netflix: Suggests movies and TV shows based on viewing history.
• E-Commerce: Recommends products you’re likely to purchase.
14.
5. Self Improvementin Performance
• ML models evolve and improve with more data, making them smarter
over time. They adapt to user behavior and refine their performance.
• Examples:
• Voice Assistants (e.g., Siri, Alexa): Learn user preferences, improve
voice recognition, and handle diverse accents.
• Search Engines: Refine ranking algorithms based on user interactions.
• Self-Driving Cars: Enhance decision-making using millions of miles of
data from simulations and real-world driving.
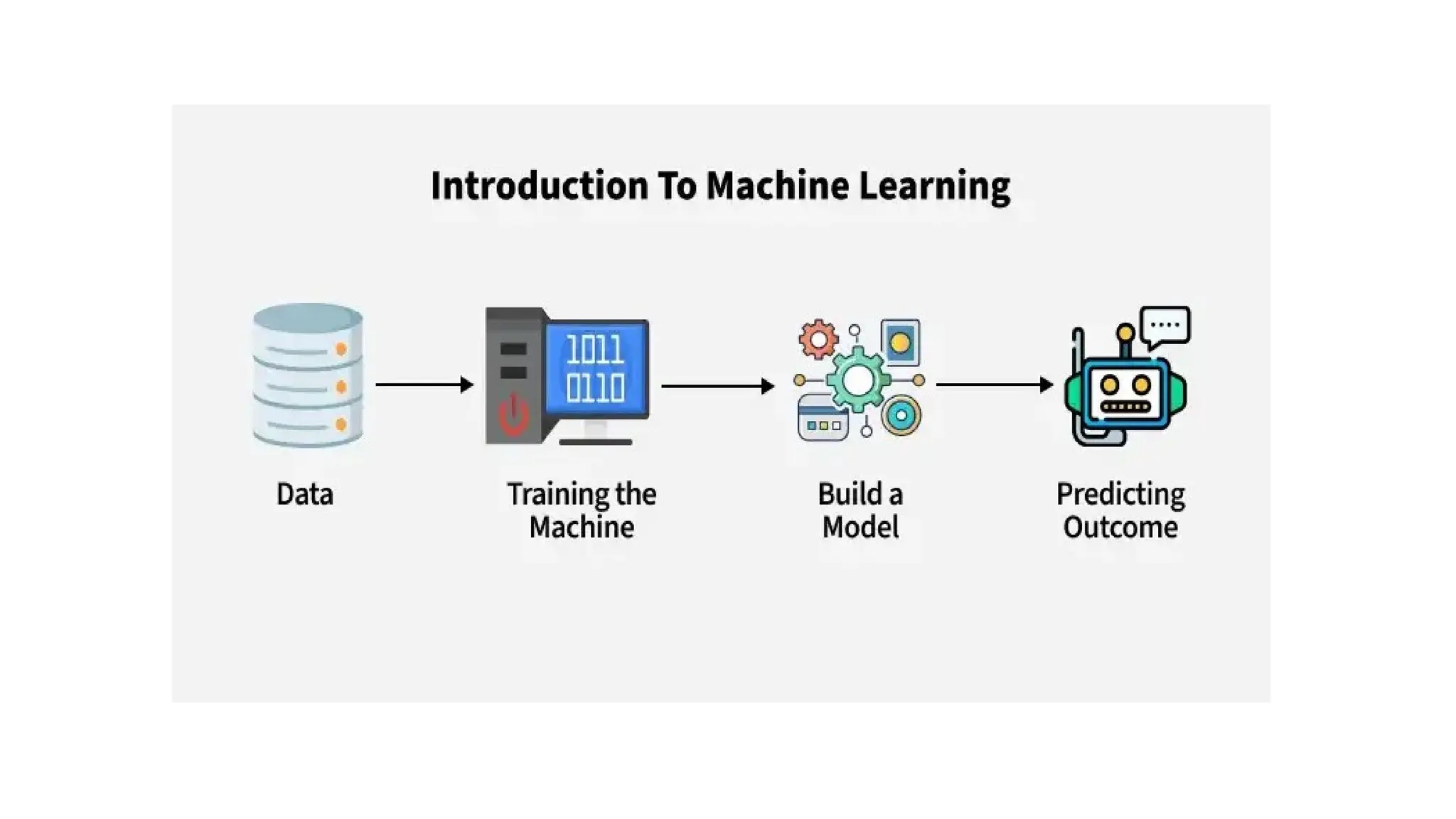
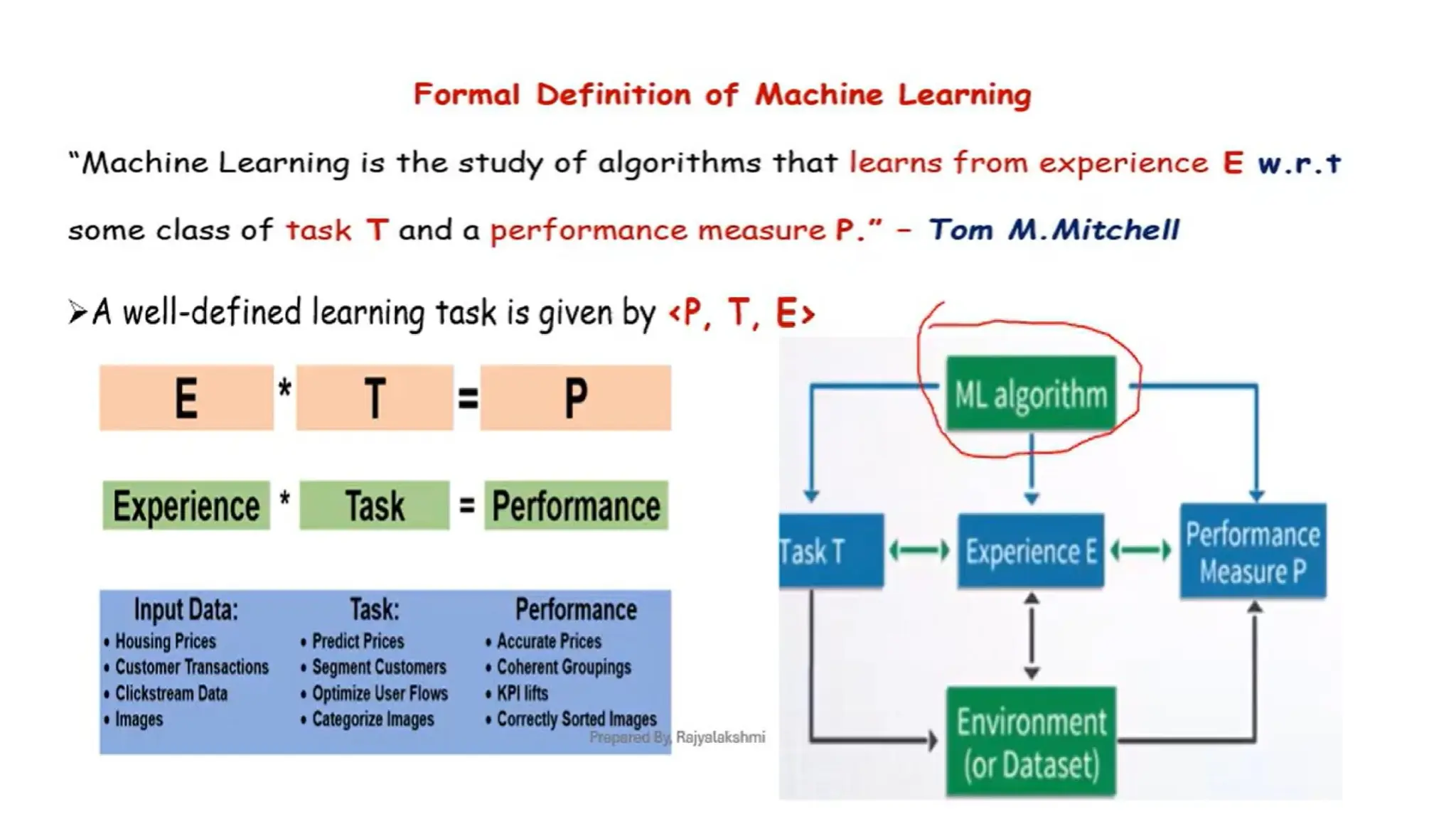
A machine “learns”by recognizing patterns and improving its
performance on a task based on data, without being explicitly
programmed.
17.
• Data Input:Machines require data (e.g., text, images, numbers) to
analyze.
• Algorithms: Algorithms process the data, finding patterns or
relationships.
• Model Training: Machines learn by adjusting their parameters based on
the input data using mathematical models.
• Feedback Loop: The machine compares predictions to actual outcomes
and corrects errors (via optimization methods like gradient descent).
• Experience and Iteration: Repeating this process with more data
improves the machine’s accuracy over time.
• Evaluation and Generalization: The model is tested on unseen data to
ensure it performs well on real-world tasks.
18.
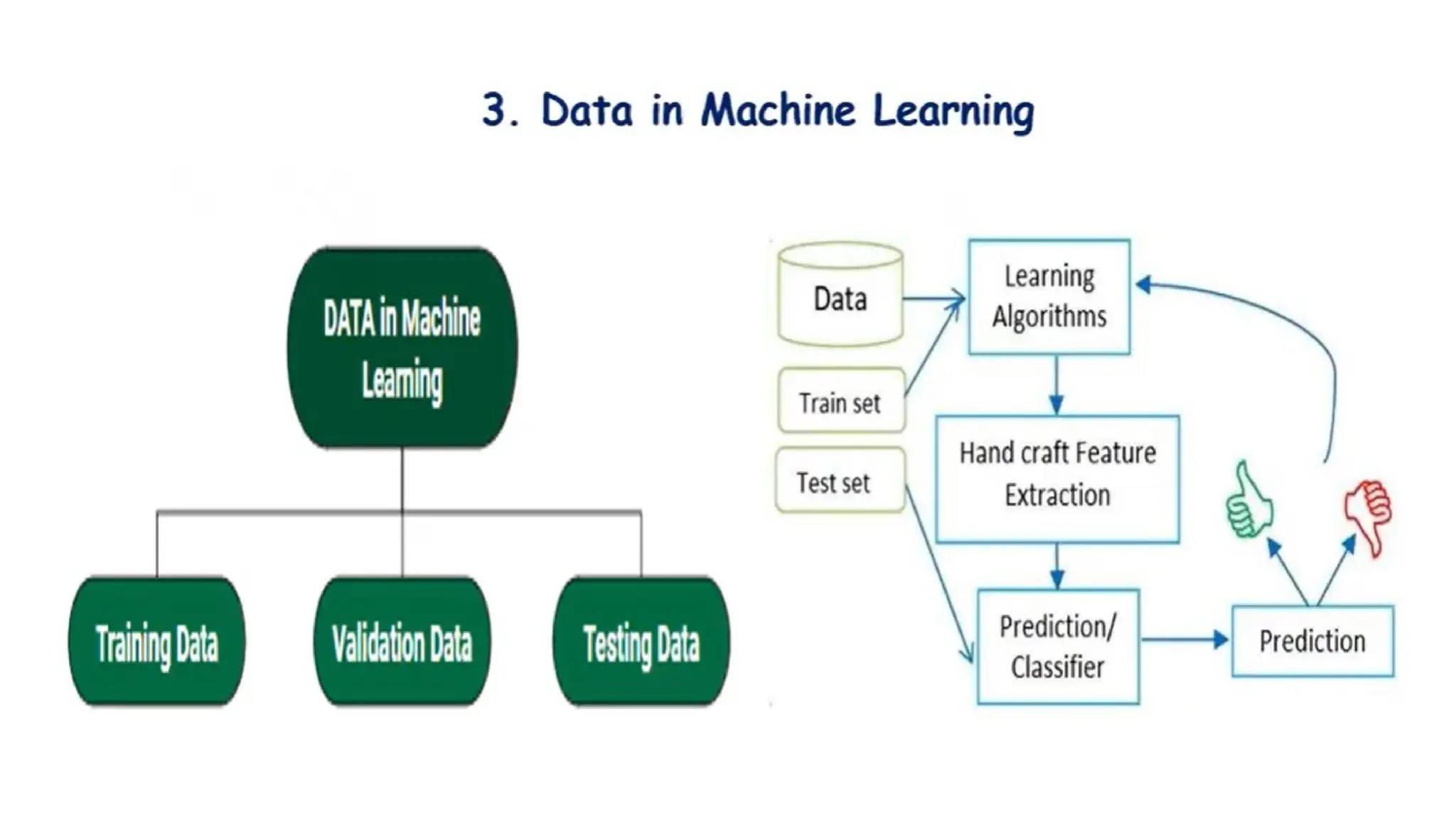
Importance of Datain Machine Learning
• Data is the foundation of machine learning (ML). Without quality data, ML
models cannot learn, perform, or make accurate predictions.
• Data provides the examples from which models learn patterns and
relationships.
• High-quality and diverse data improves model accuracy and generalization.
• Data ensures models understand real-world scenarios and adapt to practical
applications.
• Features derived from data are critical for training models.
• Separate datasets for validation and testing assess how well the model
performs on unseen data.
• Data fuels iterative improvements in ML models through feedback loops.
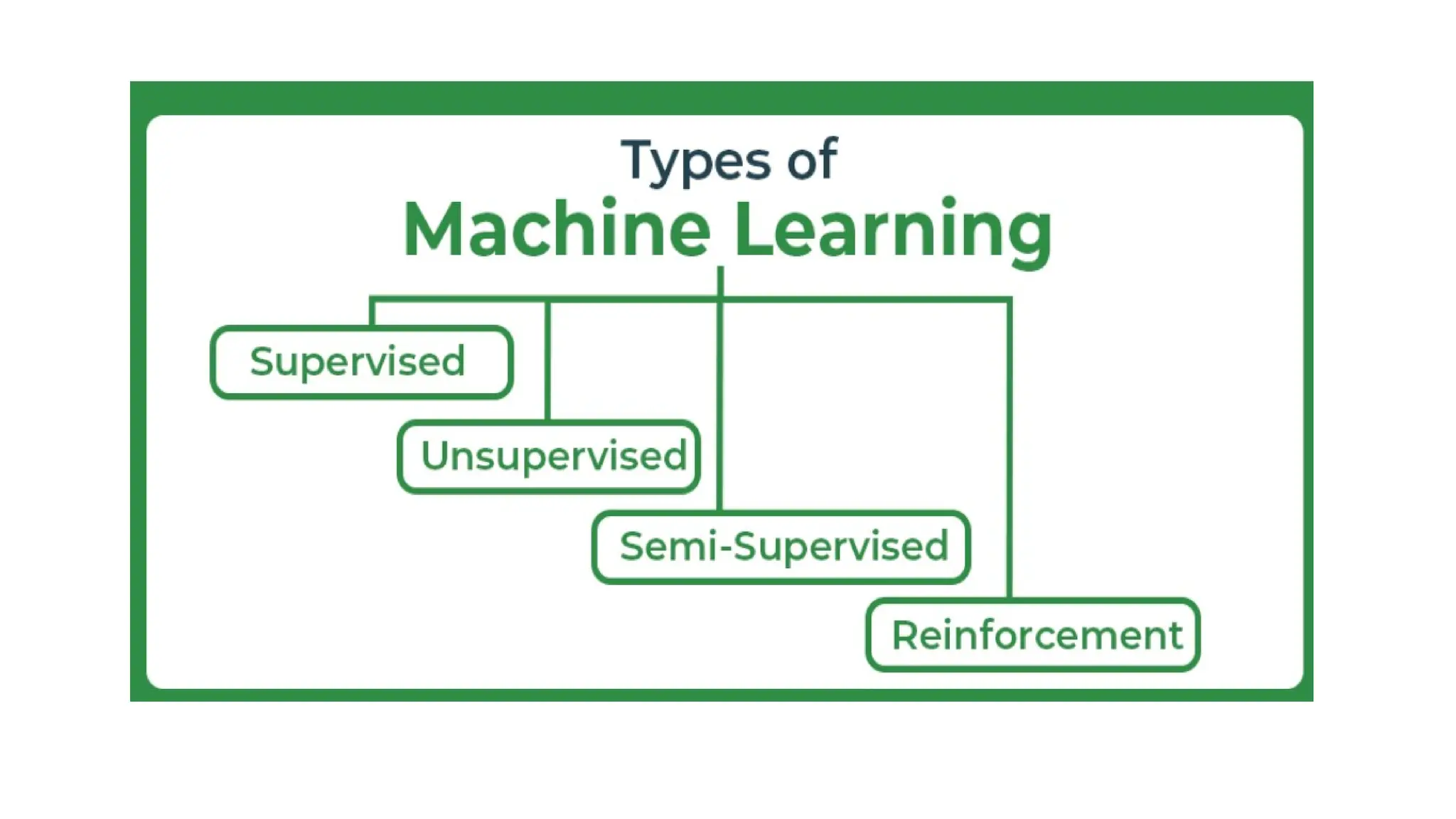
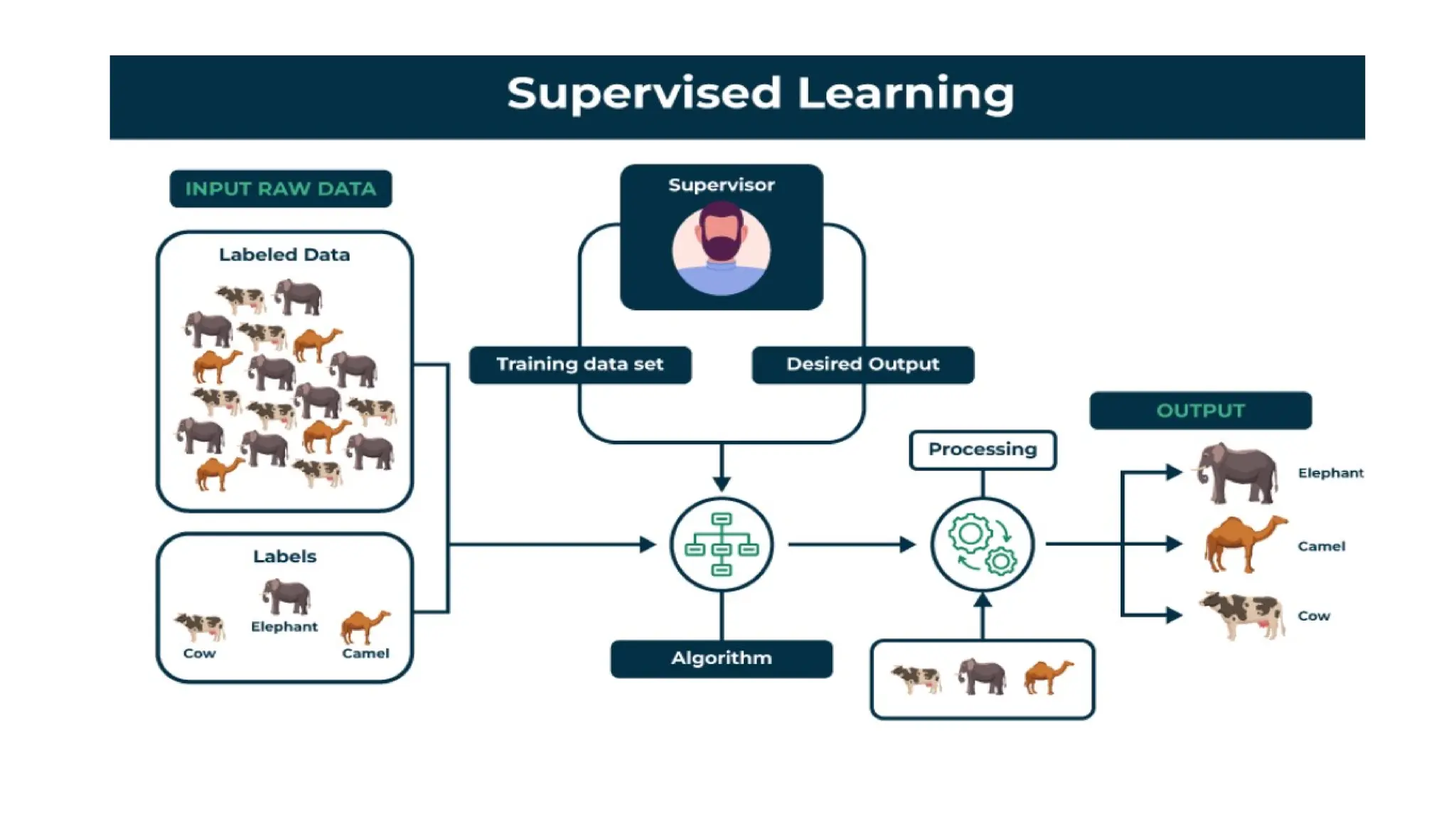
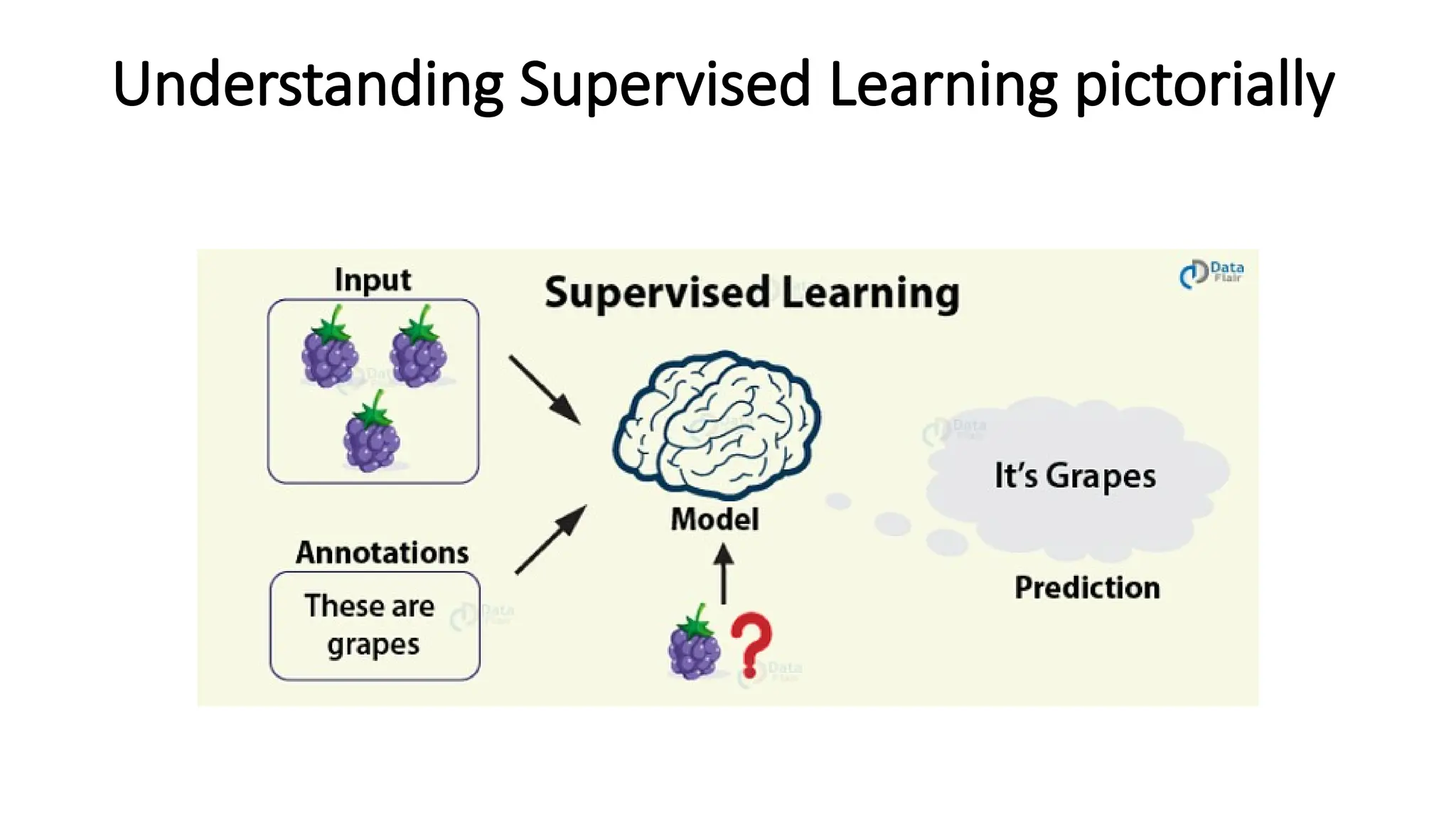
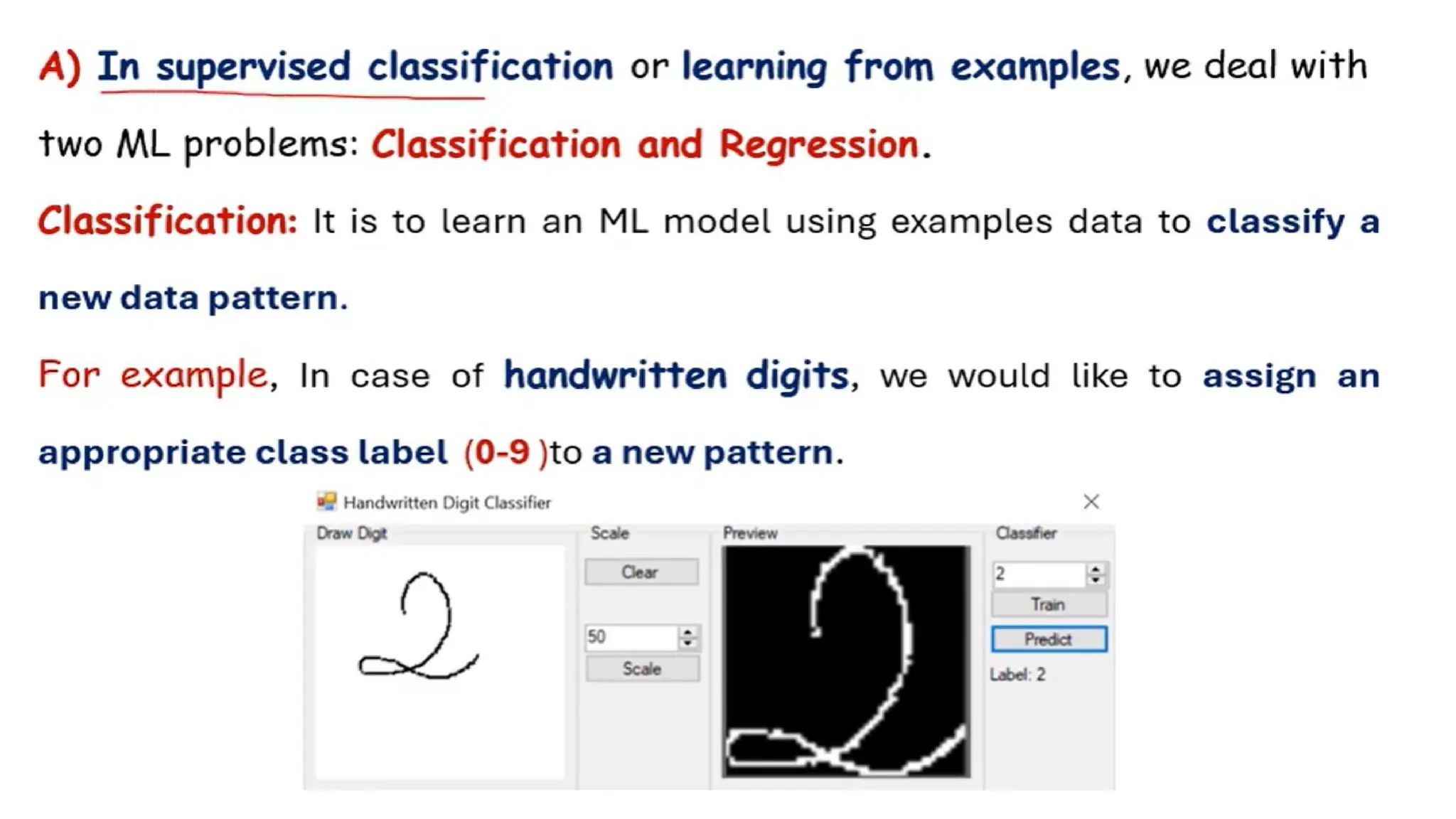
Supervised learning
• Supervisedlearning is a type of machine learning where a model is
trained on labeled data—meaning each input is paired with the correct
output. The model learns by comparing its predictions with the actual
answers provided in the training data.
• Both classification and regression problems are supervised learning
problems.
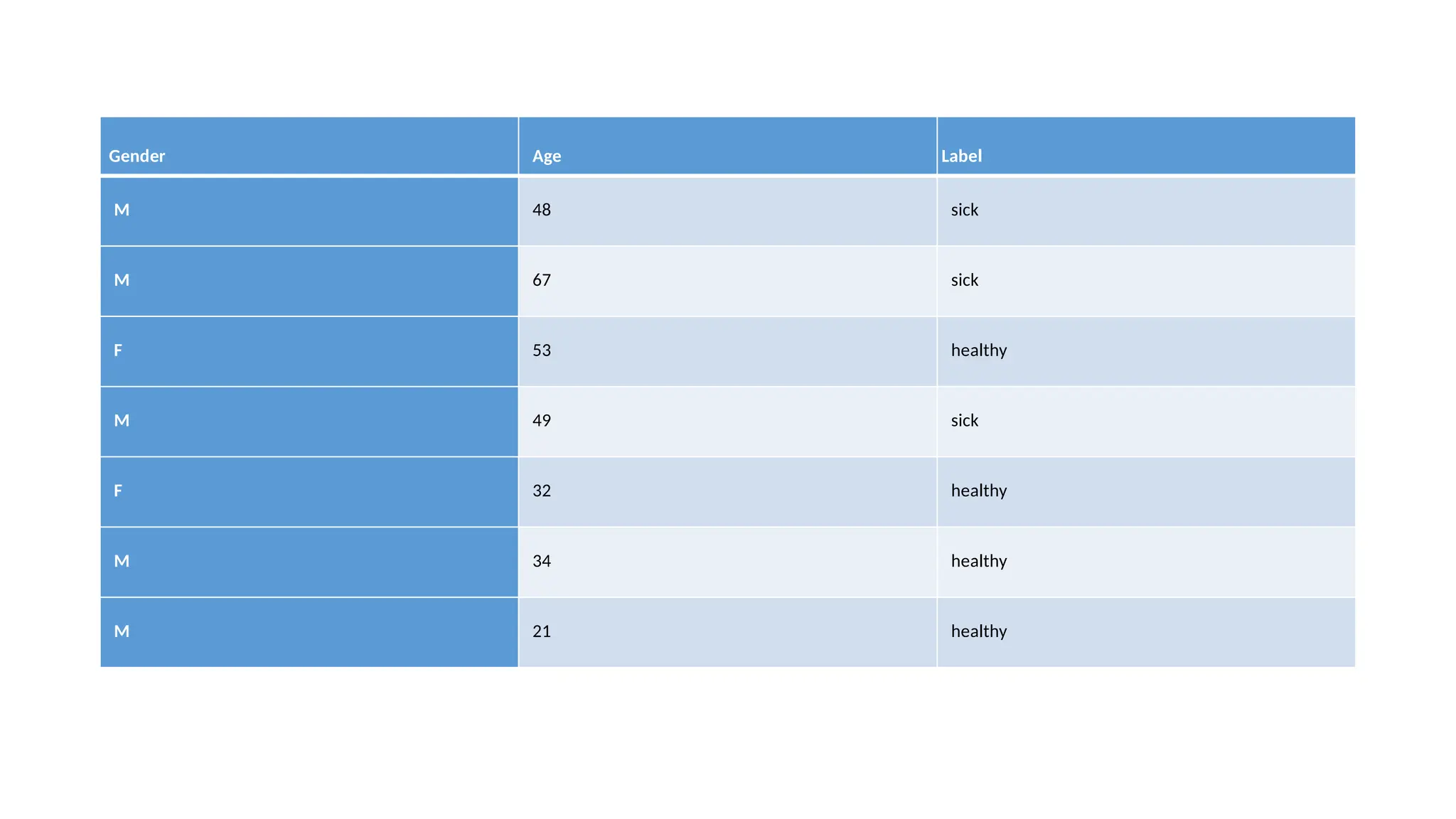
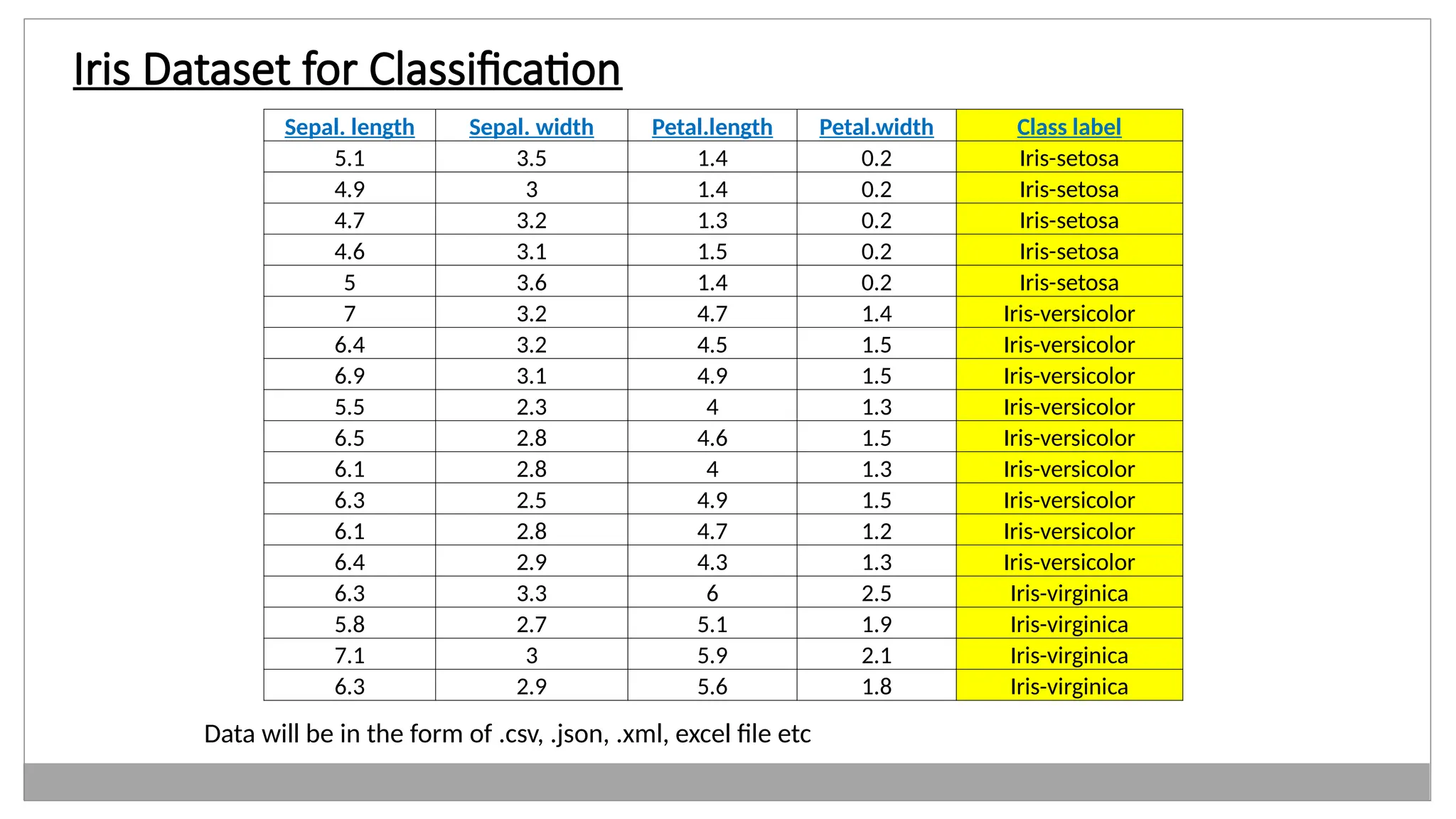
• Example: Consider the following data regarding patients entering a clinic.
The data consists of the gender and age of the patients and each patient
is labeled as “healthy” or “sick”.
23.
Gender Age Label
M48 sick
M 67 sick
F 53 healthy
M 49 sick
F 32 healthy
M 34 healthy
M 21 healthy
24.
In this example,supervised learning is to use this labeled data to train a
model that can predict the label (“healthy” or “sick”) for new patients
based on their gender and age. For instance, if a new patient (e.g.,
Male, 50 years old) visits the clinic, the model can classify whether the
patient is “healthy” or “sick” based on the patterns it learned during
training.
26.
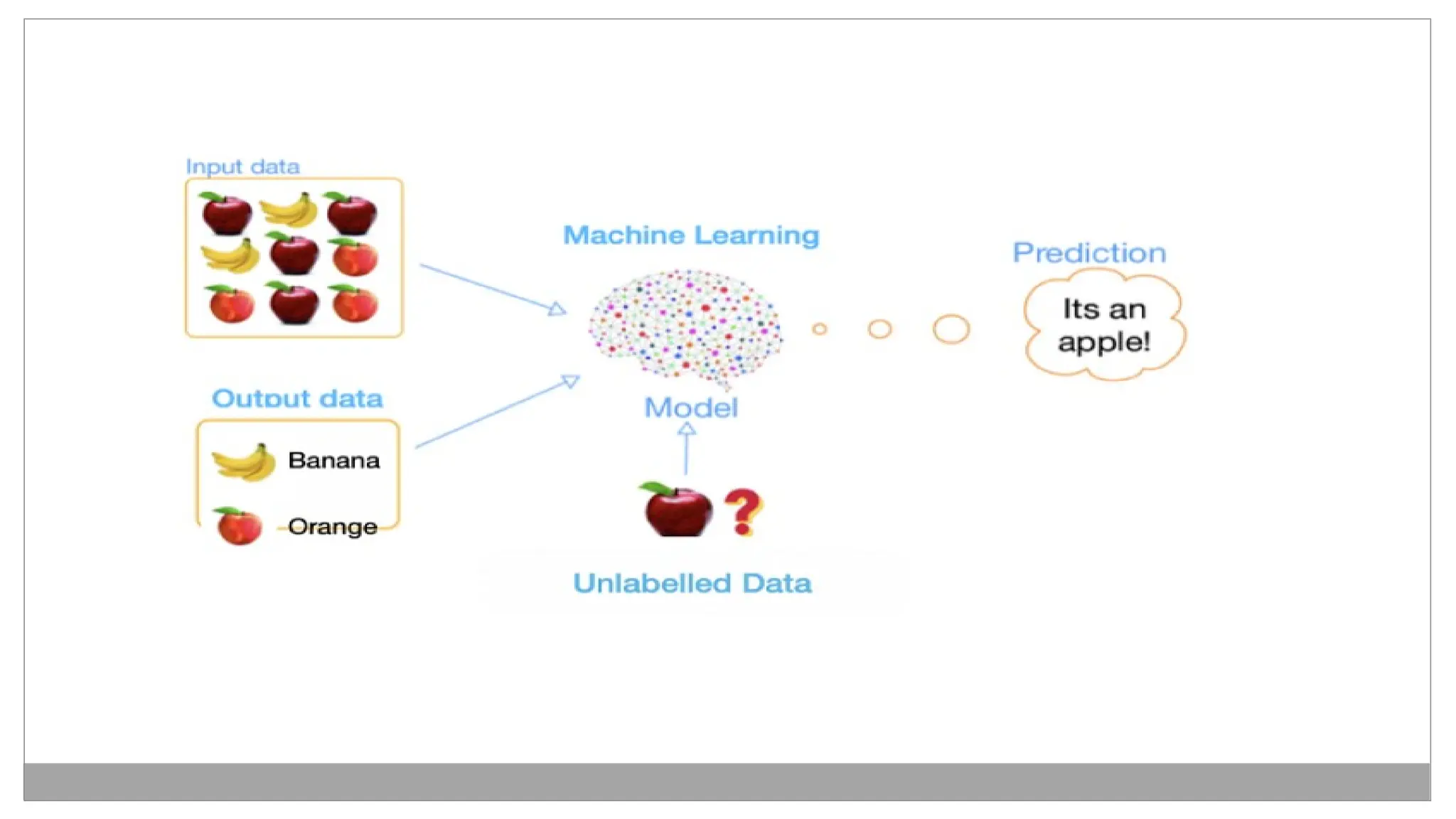
• Example: Considera scenario where you have to build an image
classifier to differentiate between cats and dogs. If you feed the
datasets of dogs and cats labelled images to the algorithm, the
machine will learn to classify between a dog or a cat from these
labeled images. When we input new dog or cat images that it has
never seen before, it will use the learned algorithms and predict
whether it is a dog or a cat. This is how supervised learning works,
and this is particularly an image classification.
27.
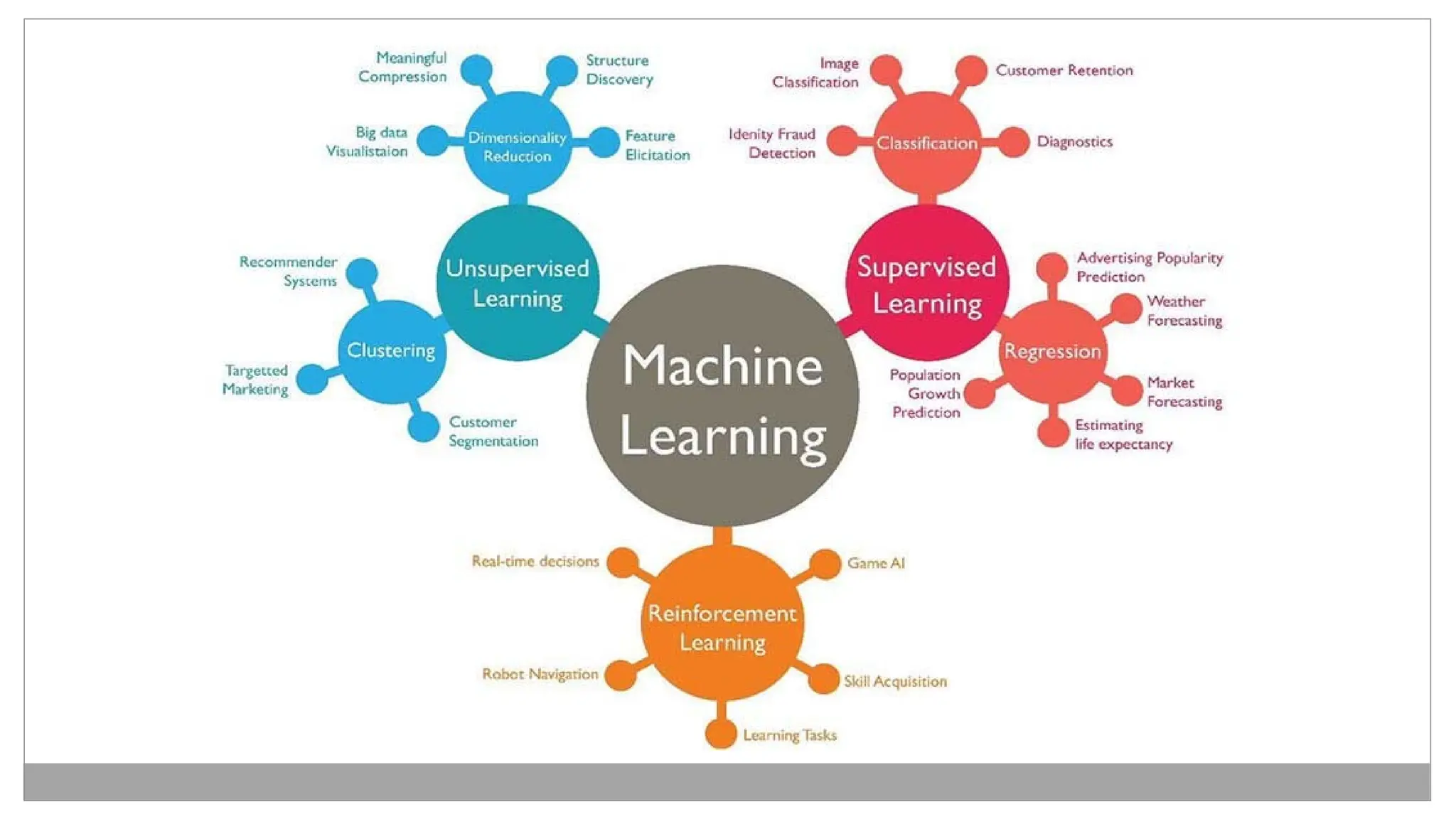
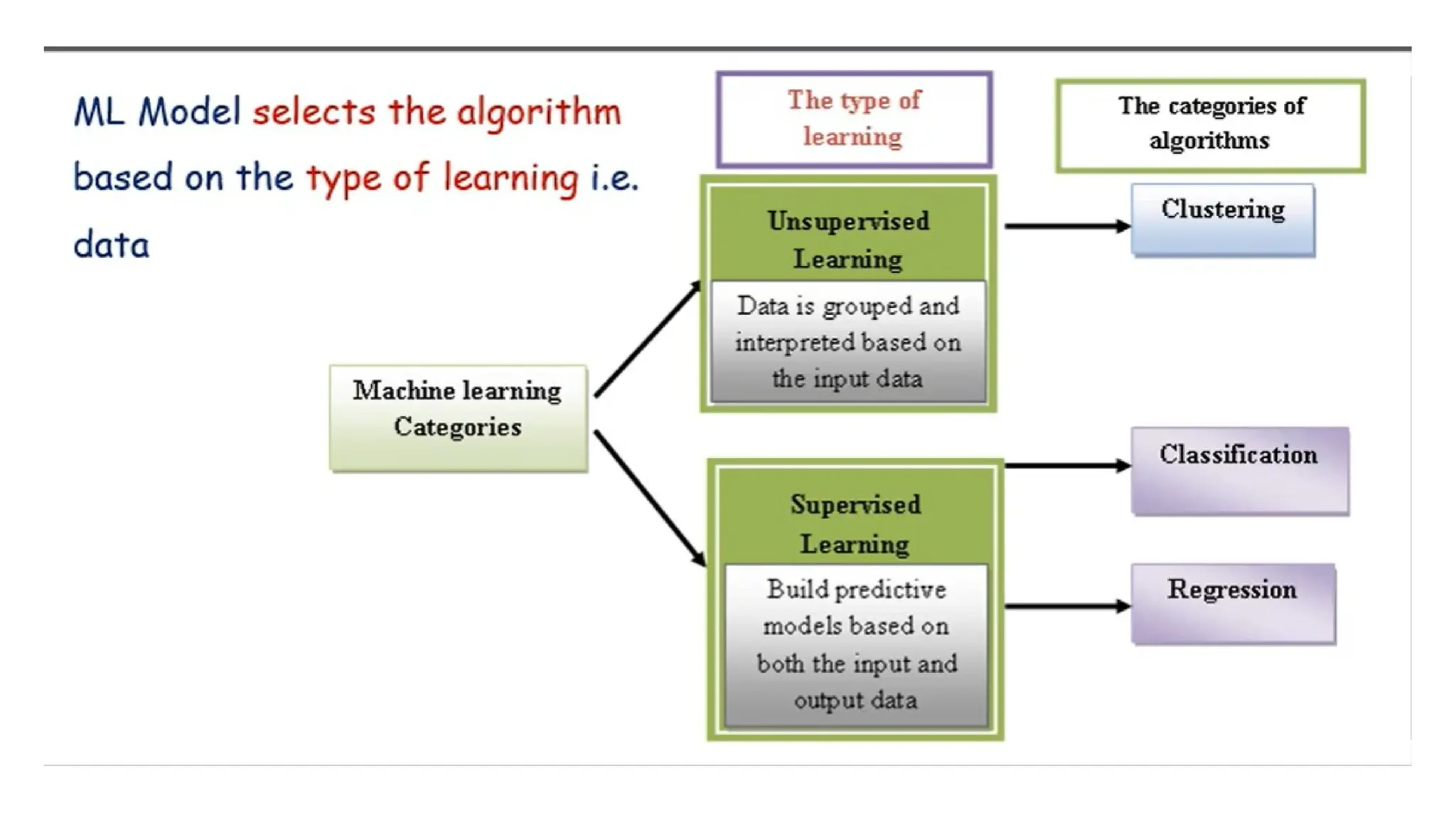
• There aretwo main categories of supervised learning that are
mentioned below:
• Classification
• Regression
Types of Supervisedlearning
Classification separates the data, Regression fits the data
32.
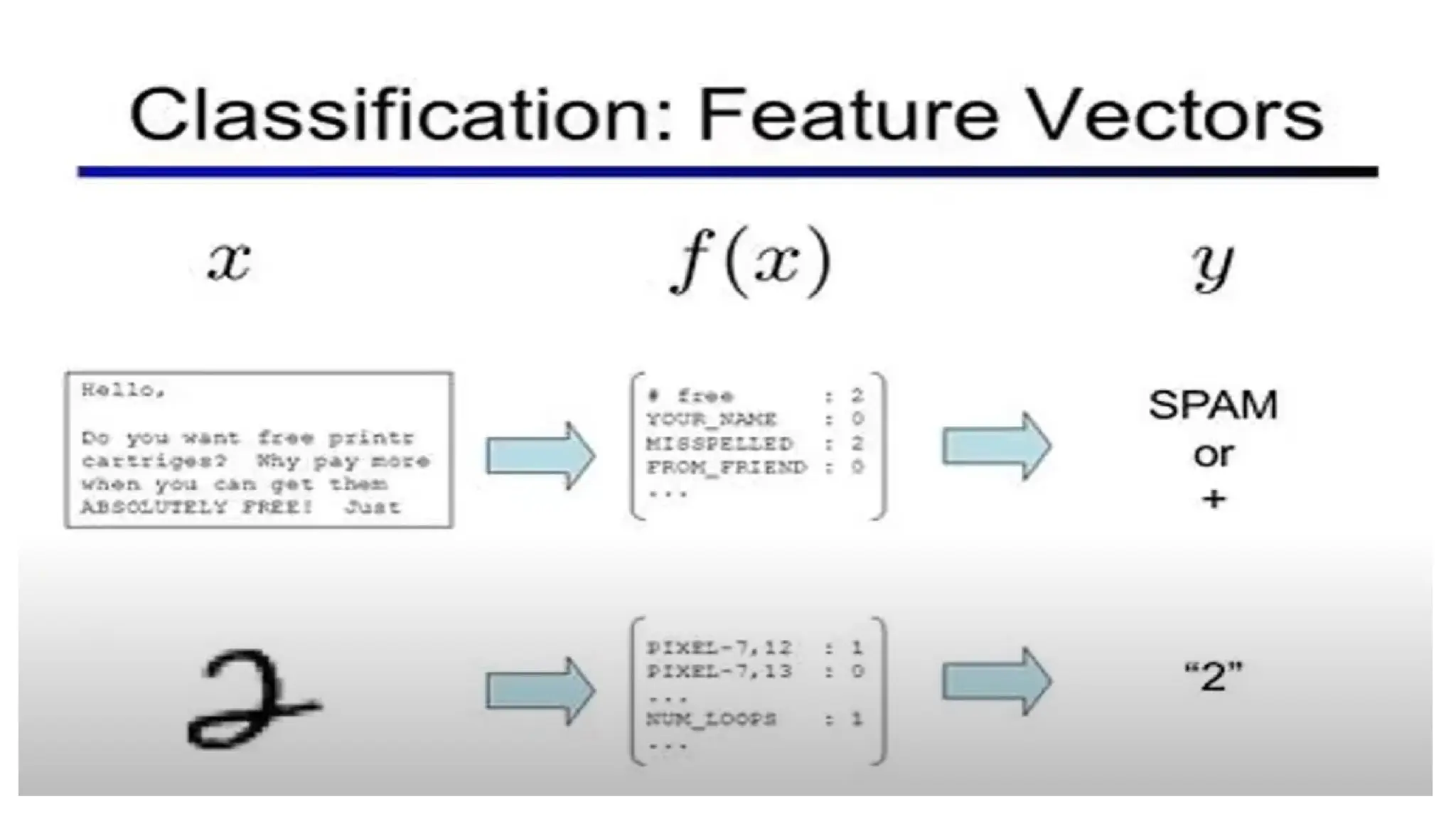
Classification
This is atype of problem where we predict the categorical response value where the data can be
separated into specific “classes” (ex: we predict one of the values in a set of values).
Some examples are :
1. This mail is spam or not?
2. Will it rain today or not?
3. Is this picture a cat or not?
Basically ‘Yes/No’ type questions called binary classification.
Other examples are :
4. This mail is spam or important or promotion?
5. Is this picture a cat or a dog or a tiger?
This type is called multi-class classification.
Regression
This is atype of problem where we need to predict the continuous response value (ex : above we
predict number which can vary from infinity to +infinity)
Some examples are
1. What is the price of house in Durg?
2. What is the value of the stock?
3. What can the temperature tomorrow?
etc… there are tons of things we can predict if we wish.
Classification
• Classification dealswith predicting categorical target variables, which
represent discrete classes or labels. For instance, classifying emails as spam or
not spam, or predicting whether a patient has a high risk of heart disease.
Classification algorithms learn to map the input features to one of the
predefined classes.
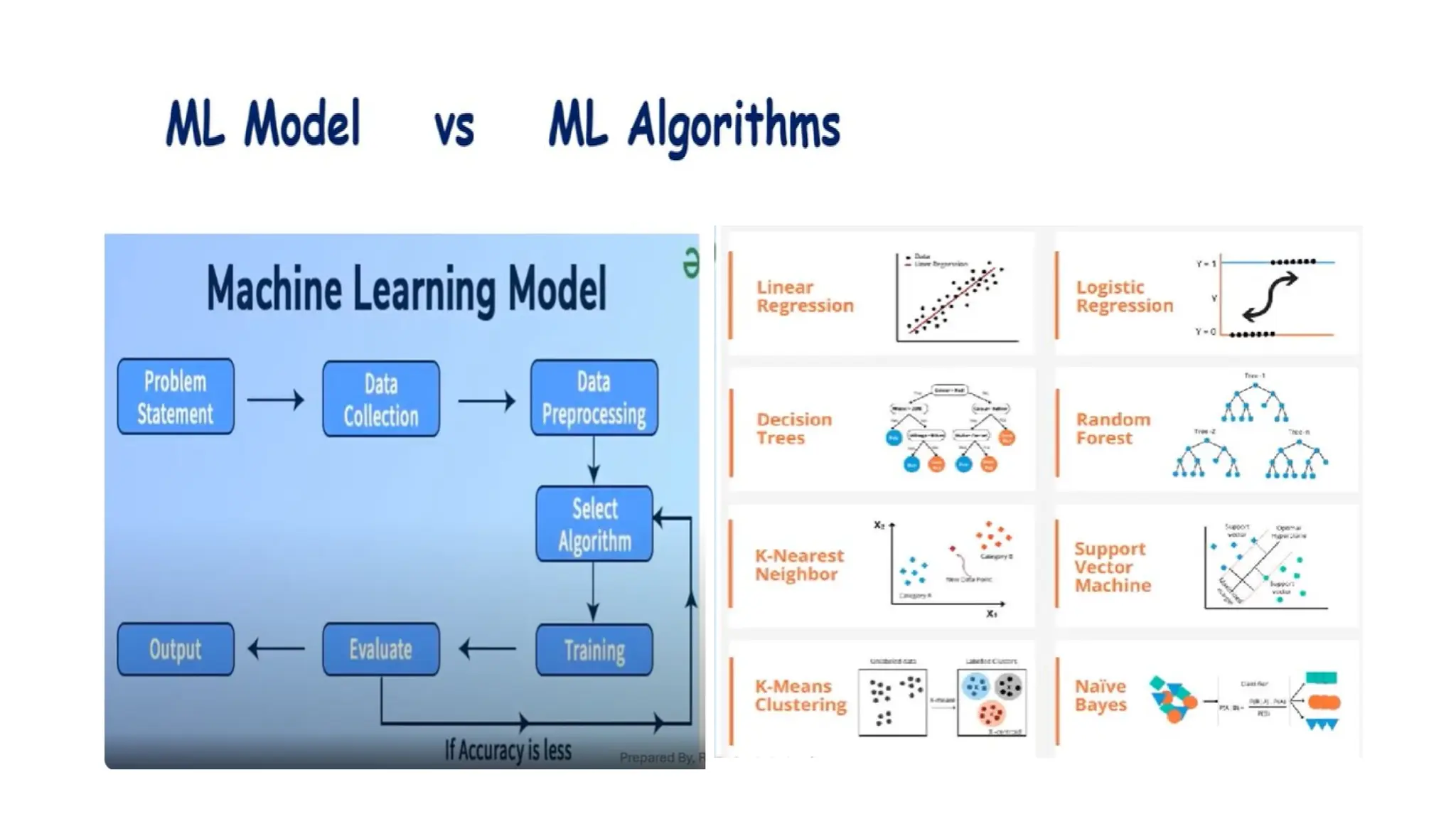
• Here are some classification algorithms:
Logistic Regression
Support Vector Machine
Random Forest
Decision Tree
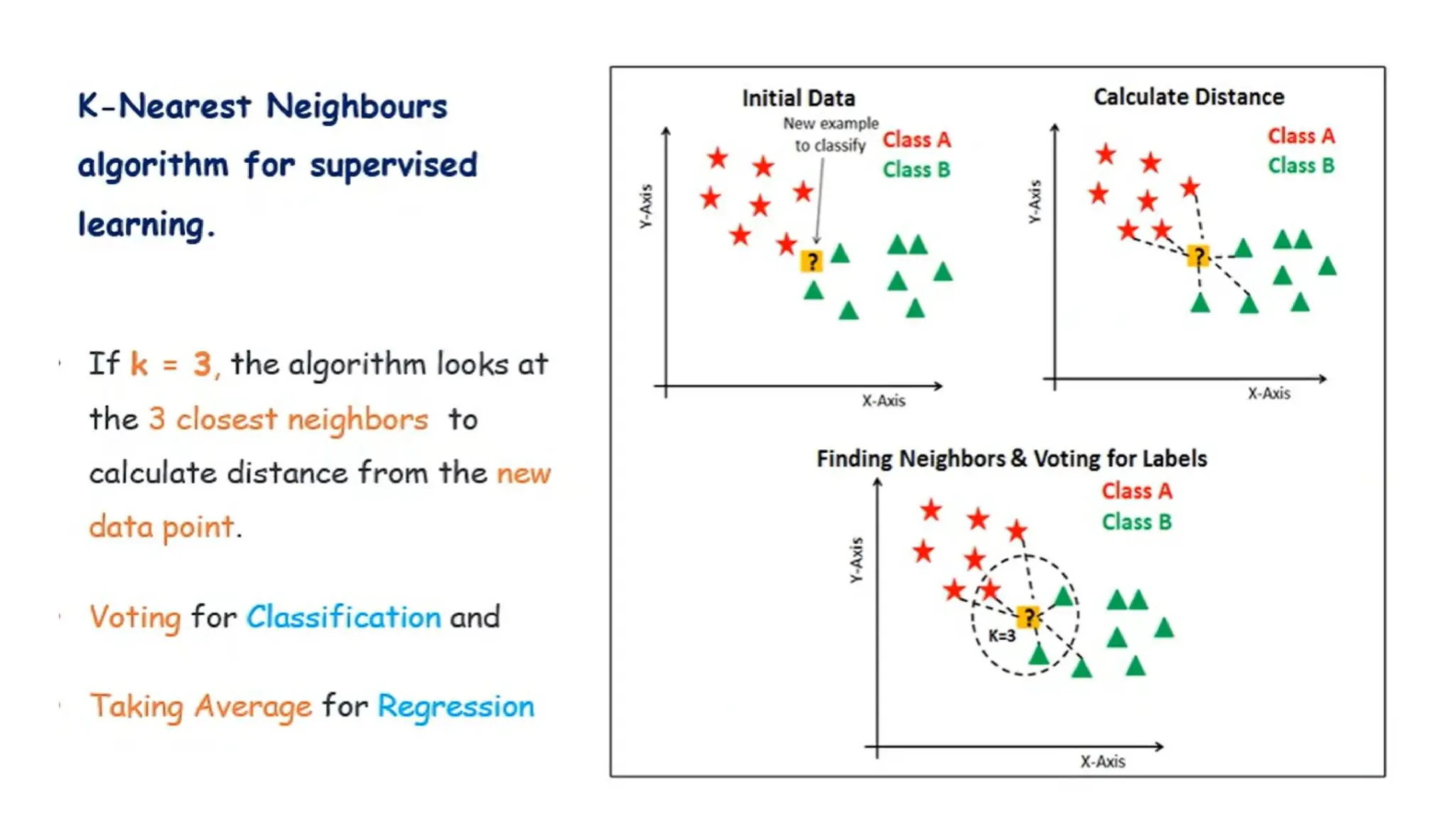
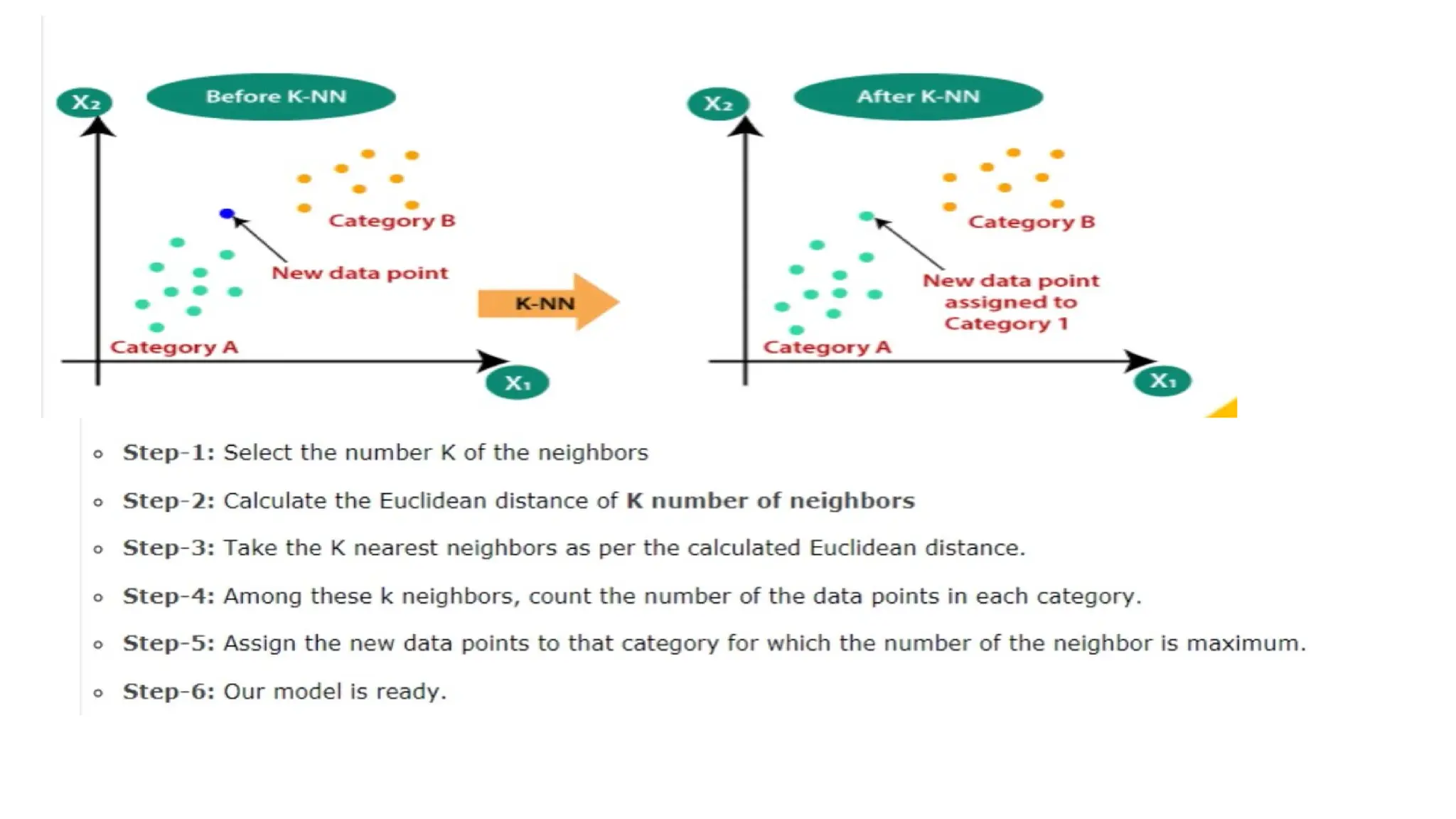
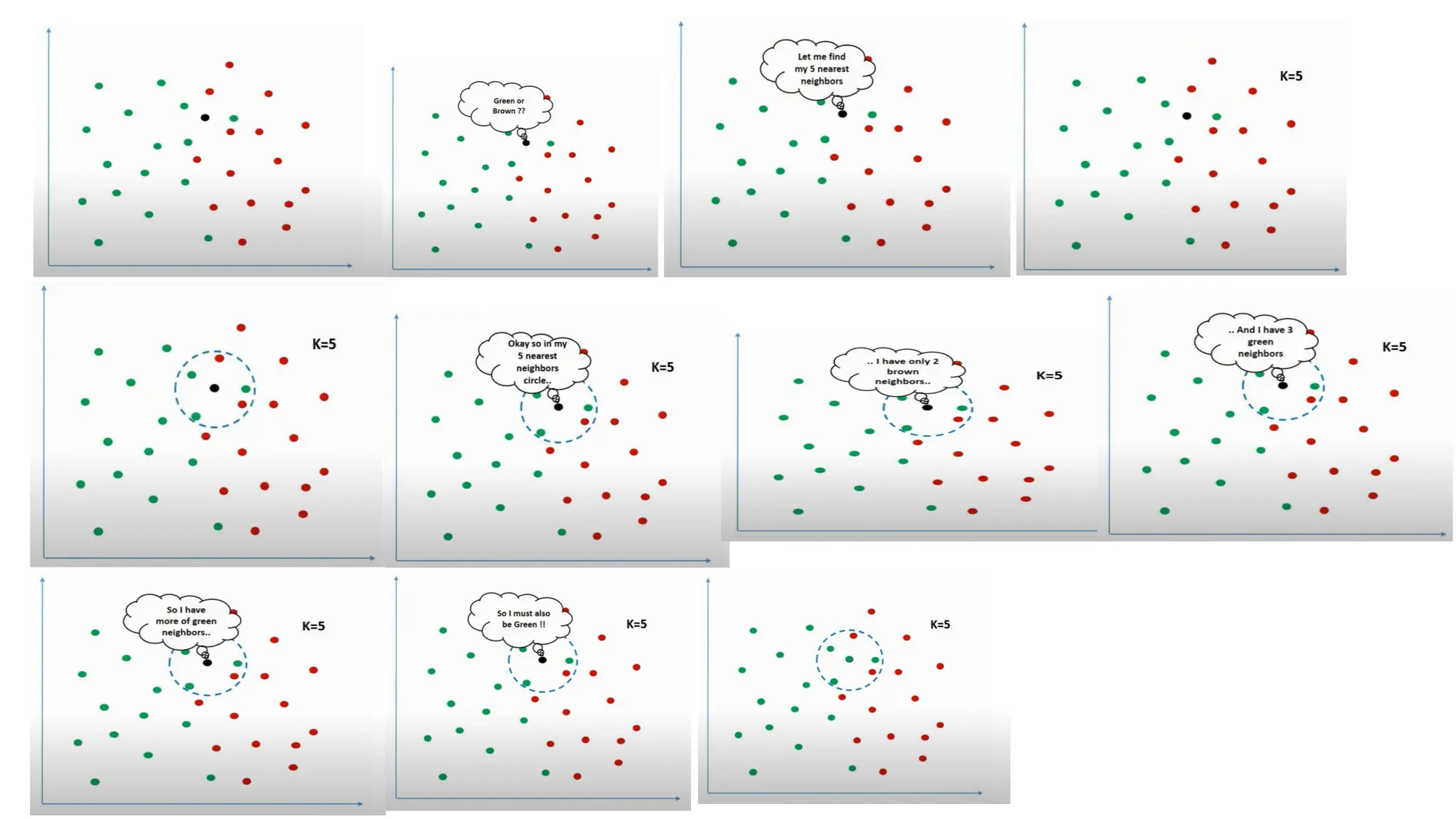
K-Nearest Neighbors (KNN)
Naive Bayes
37.
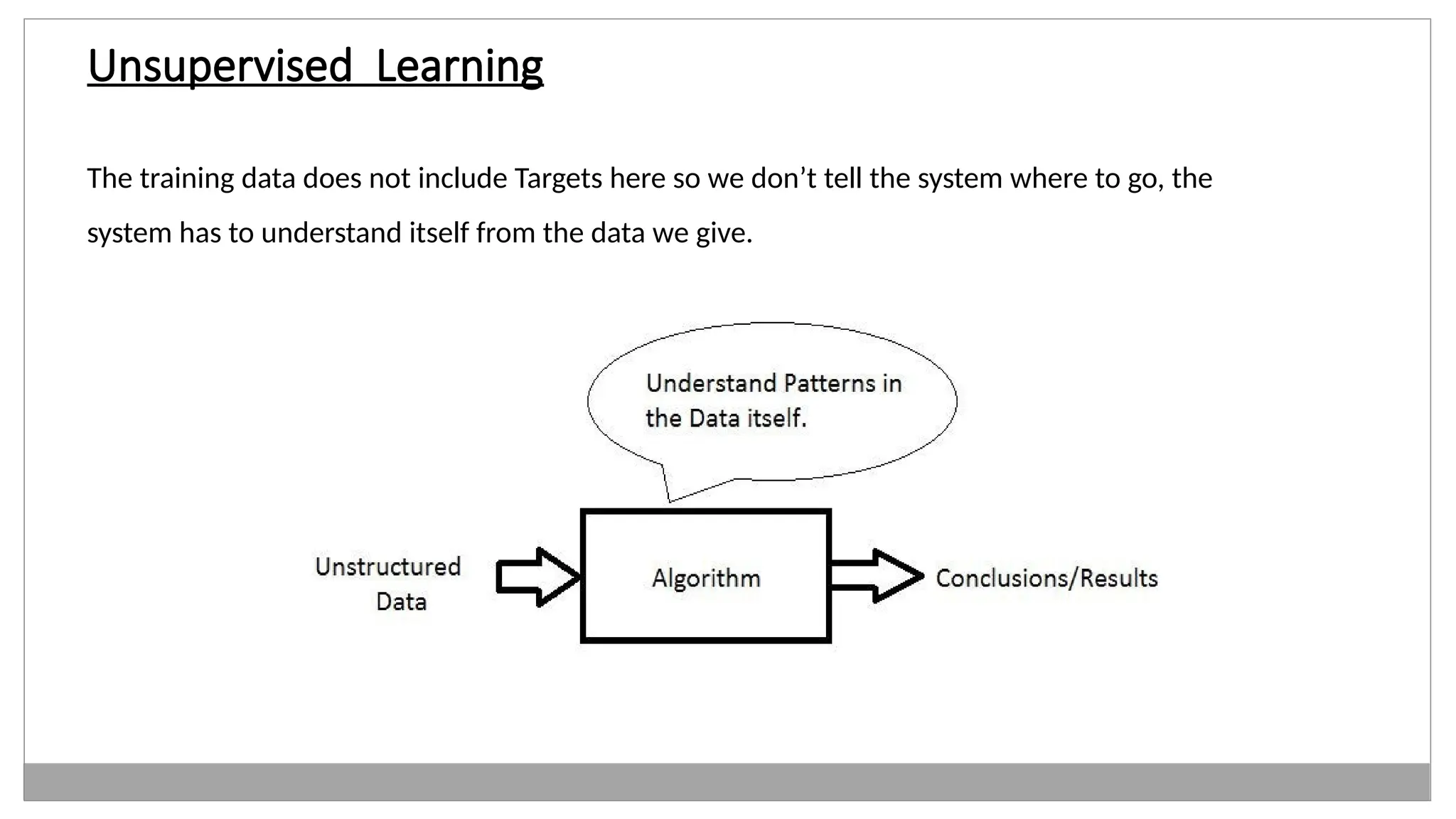
Unsupervised Learning
The trainingdata does not include Targets here so we don’t tell the system where to go, the
system has to understand itself from the data we give.
39.
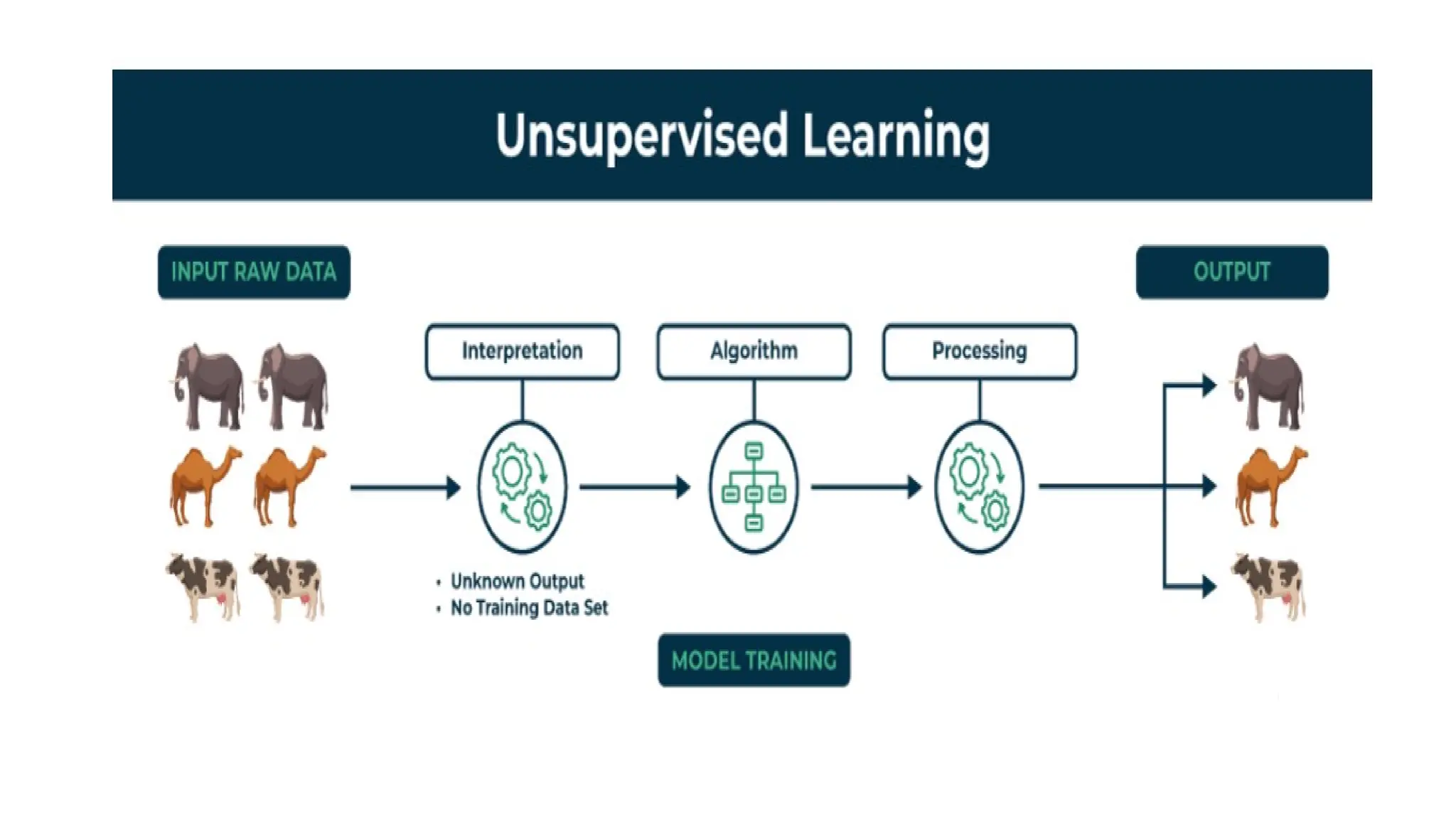
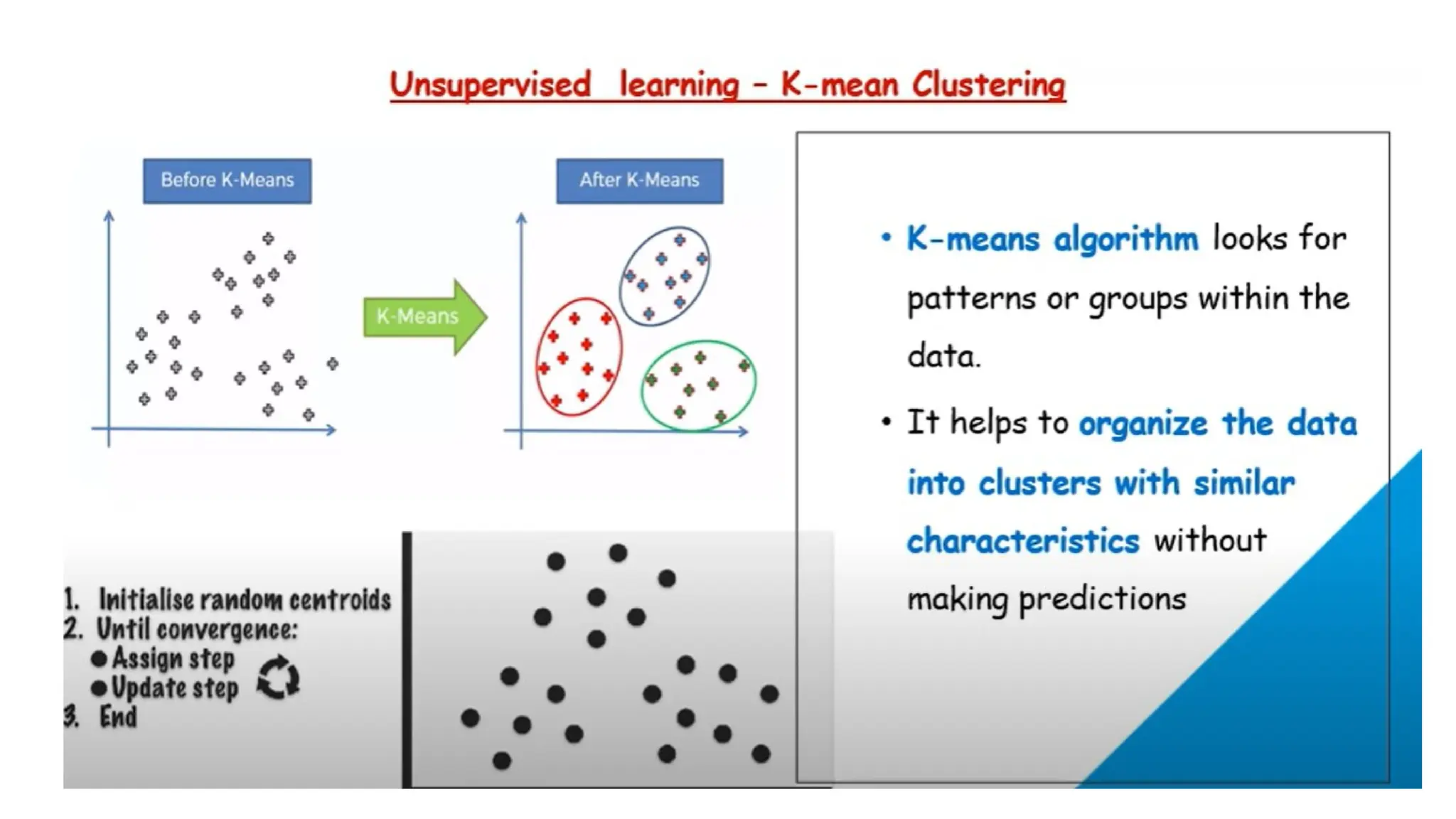
2. Unsupervised learning:
Unsupervisedlearning algorithms draw inferences from datasets
consisting of input data without labeled responses. In unsupervised
learning algorithms, classification or categorization is not included in
the observations.
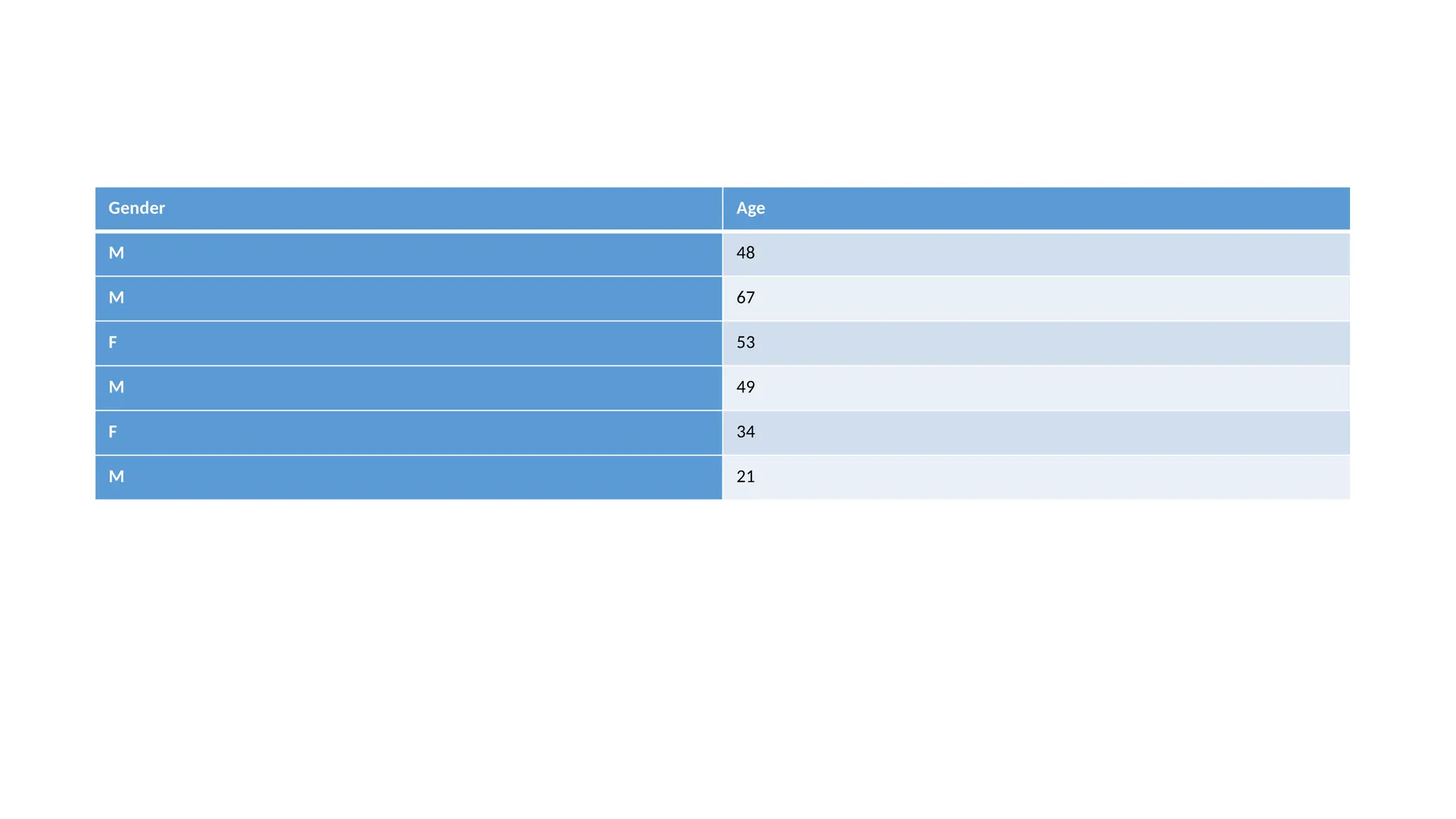
Example: Consider the following data regarding patients entering a
clinic. The dataset includes unlabeled data, where only the gender and
age of the patients are available, with no health status labels.
• Here, unsupervisedlearning technique will be used to find patterns or
groupings in the data such as clustering patients by age or gender. For
example, the algorithm might group patients into clusters, such as
“younger healthy patients” or “older patients,” without prior
knowledge of their health status.
43.
Example: Consider thatyou have a dataset that contains information
about the purchases you made from the shop. Through clustering, the
algorithm can group the same purchasing behavior among you and
other customers, which reveals potential customers without predefined
labels. This type of information can help businesses get target
customers as well as identify outliers.
There are two main categories of unsupervised learning that are
mentioned below:
• Clustering
• Association
45.
Clustering
This is atype of problem where we group similar things together. It is similar to multi class
classification but here we don’t provide the labels, the system understands from data itself and
cluster the data.
Some examples are :
1. Given news articles, cluster into different types of news
2. Given a set of tweets, cluster based on content of tweet
3. Given a set of images, cluster them into different objects
Of the followingexamples, which learning you make use of
3. Given a database of customer data, automatically discover market
segments and group customers into different market segments.
1. Given email labeled as spam/not spam, learn a spam filter.
2. Given a set of news articles found on the web, group them into set of
articles about the same story.
4. Given a dataset of patients diagnosed as either having diabetes or not,
learn to classify new patients as having diabetes or not.
Ans 1: Supervised Learning - Classification
Ans 2: Unsupervised Learning - Clustering
Ans 3: Unsupervised Learning - Clustering
Ans 4: Supervised Learning - Classification
48.
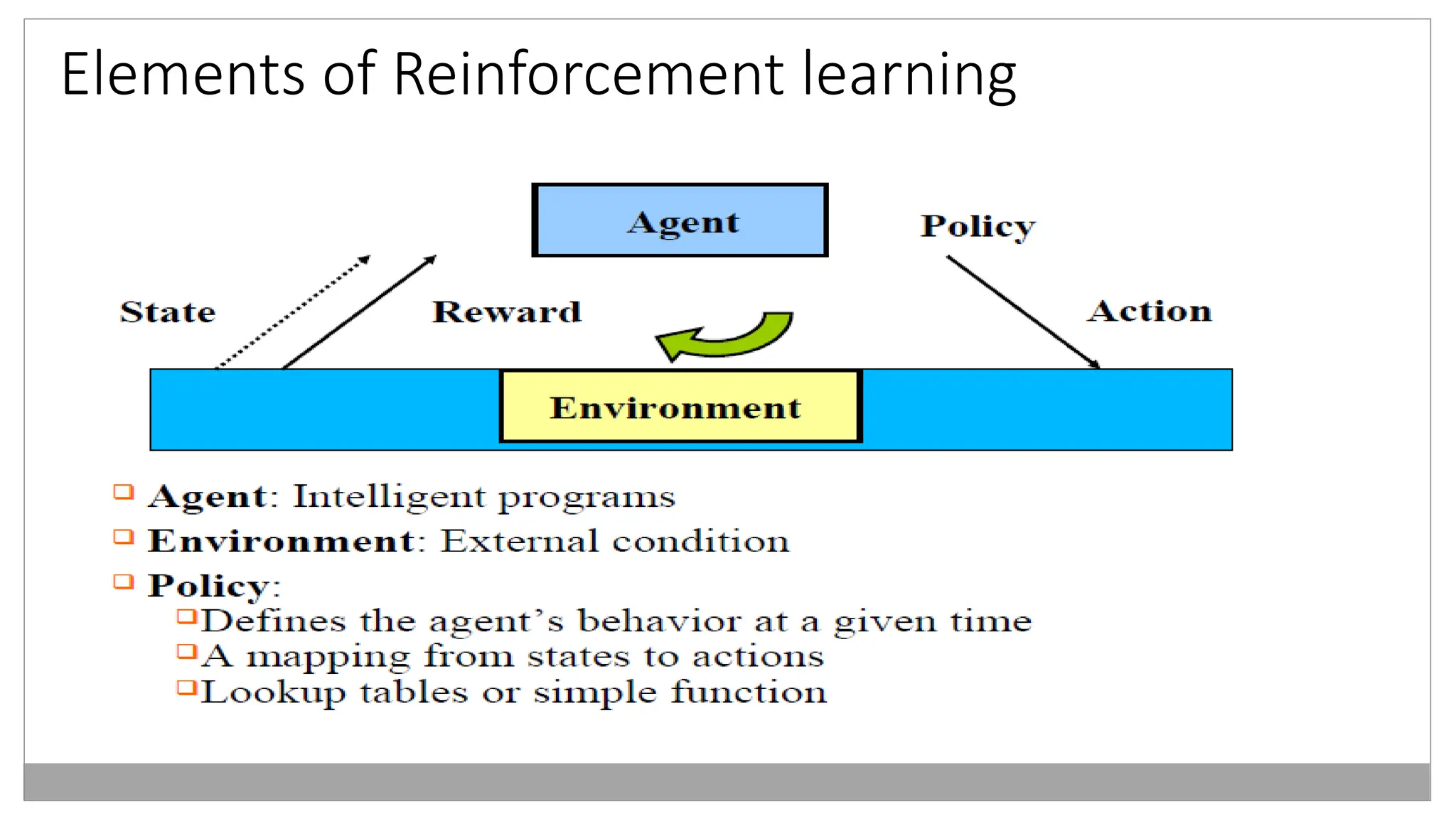
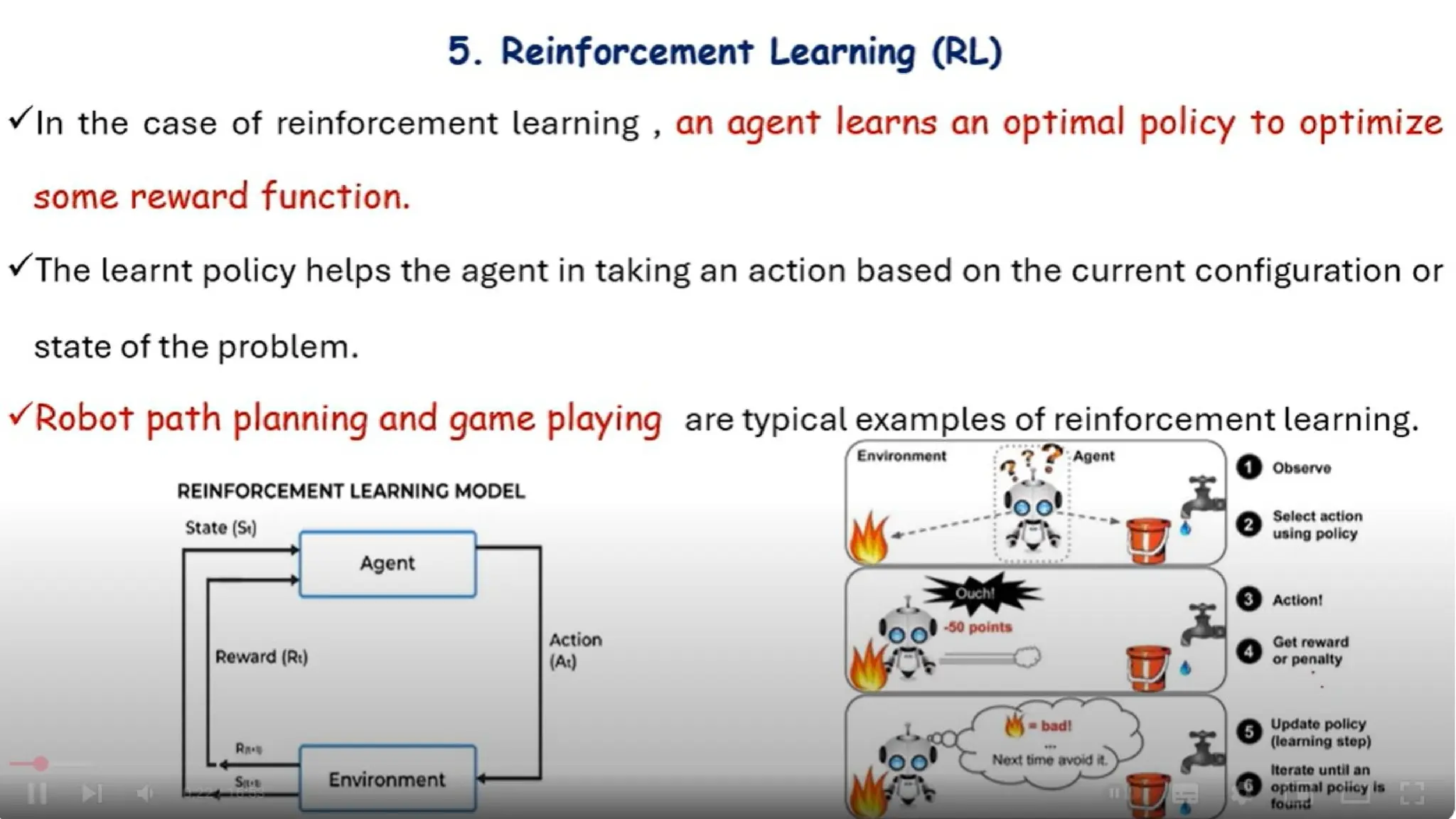
Reinforcement learning
Meaning ofReinforcement:
Occurrence of an event, in the proper relation to a response, that tends to increase the
probability that the response will occur again in the same situation.
Reinforcement learning is the problem faced by an
• agent that learns behavior through trial-and-error interactions with a dynamic
environment.
• Reinforcement Learning is learning how to act in order to maximize a numerical
reward.
49.
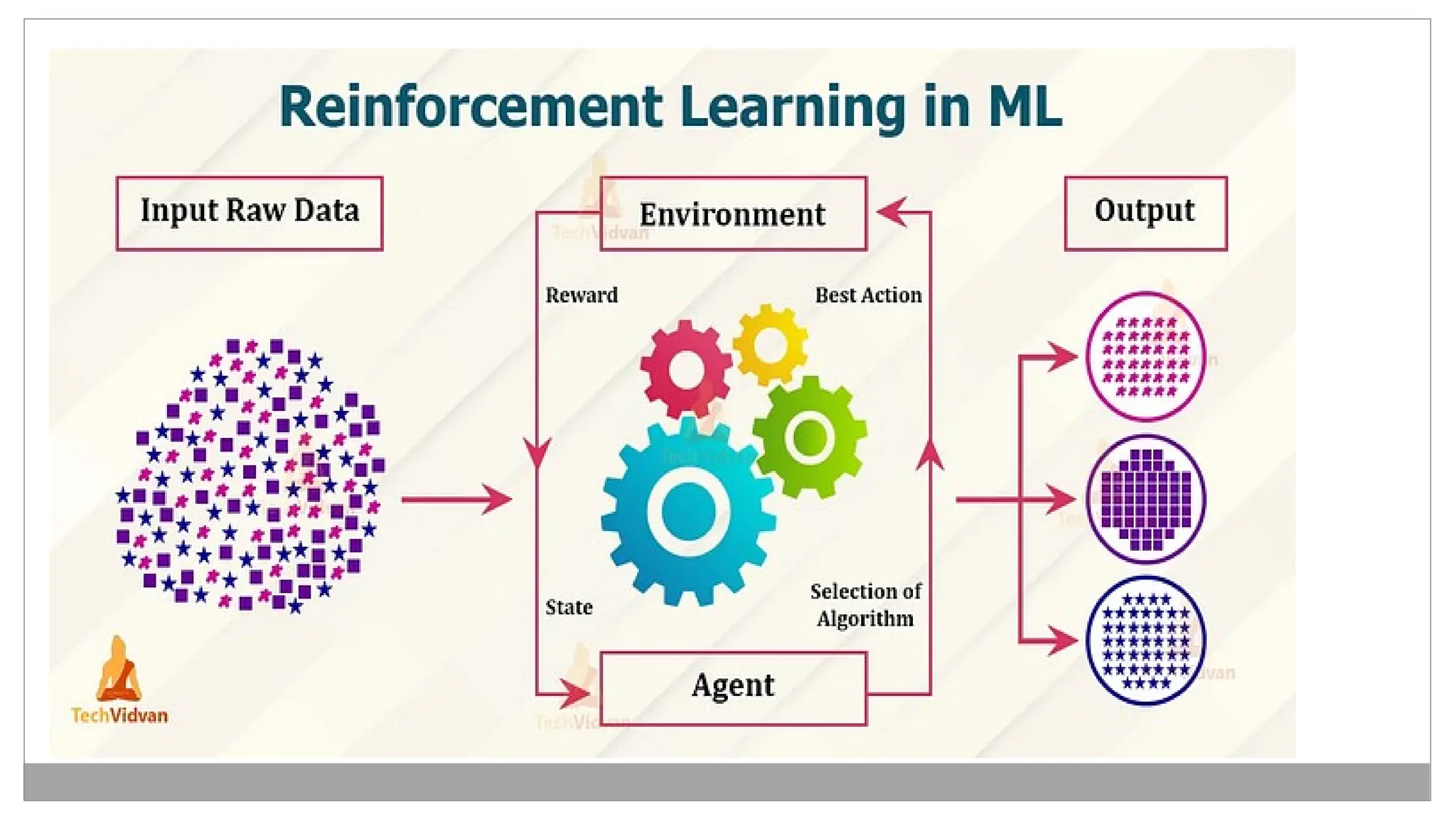
Reinforcement Learning (RL)is a type of machine learning where an agent
learns how to behave in an environment by performing actions and receiving
feedback (rewards or penalties).
RL Learning Process:
1.Initialize the agent.
2.Observe the current state.
3.Take an action based on the current policy.
4.Receive a reward and move to a new state.
5.Update the policy using the received reward.
6.Repeat until optimal policy is learned.
50.
Using reinforcement learning,the goal of learning in this case is to train the dog (agent) to complete
a task within an environment, which includes the surroundings of the dog as well as the trainer. First,
the trainer issues a command or cue, which the dog observes (observation). The dog then responds
by taking an action. If the action is close to the desired behavior, the trainer will likely provide a
reward, such as a food treat or a toy; otherwise, no reward will be provided
51.
Reinforcement learning
Examples:
• Arobot cleaning my room and recharging its battery
• Robot-soccer
• How to invest in shares
• Modeling the economy through rational agents
• Learning how to fly a helicopter
• Scheduling planes to their destinations
Semi-Supervised Learning
• Semi-supervisedlearning is a type of machine learning that falls in
between supervised and unsupervised learning.
• It is a method that uses a small amount of labeled data and a large amount
of unlabeled data to train a model.
• The goal of semi-supervised learning is to learn a function that can
accurately predict the output variable based on the input variables, similar
to supervised learning.
• However, unlike supervised learning, the algorithm is trained on a dataset
that contains both labeled and unlabeled data.
56.
Semi-supervised learning strikesa balance by combining a small amount
of labelled data with a larger pool of unlabeled data. This approach
leverages the benefits of both supervised and unsupervised learning
paradigms, making it a cost-effective and efficient method for training
models when the labeled data is limited.
58.
Benefits of MachineLearning
Enhanced Efficiency and Automation: ML automates repetitive tasks, freeing up
human resources for more complex work. It also streamlines processes, leading to
increased efficiency and productivity.
Data-Driven Insights: ML can analyze vast amounts of data to identify patterns and
trends that humans might miss. This allows for better decision-making based on real-
world data.
Improved Personalization: ML personalizes user experiences across various
platforms. From recommendation systems to targeted advertising, ML tailors content
and services to individual preferences.
Advanced Automation and Robotics: ML empowers robots and machines to perform
complex tasks with greater accuracy and adaptability. This is revolutionizing fields
like manufacturing and logistics.
59.
Challenges of MachineLearning
Data Bias and Fairness: ML algorithms are only as good as the data they are
trained on. Biased data can lead to discriminatory outcomes, requiring careful data
selection and monitoring of algorithms.
Security and Privacy Concerns: As ML relies heavily on data, security breaches
can expose sensitive information. Additionally, the use of personal data raises
privacy concerns that need to be addressed.
Interpretability and Explainability: Complex ML models can be difficult to
understand, making it challenging to explain their decision-making processes. This
lack of transparency can raise questions about accountability and trust.
Job Displacement and Automation: Automation through ML can lead to job
displacement in certain sectors. Addressing the need for retraining and reskilling the
workforce is crucial.
60.
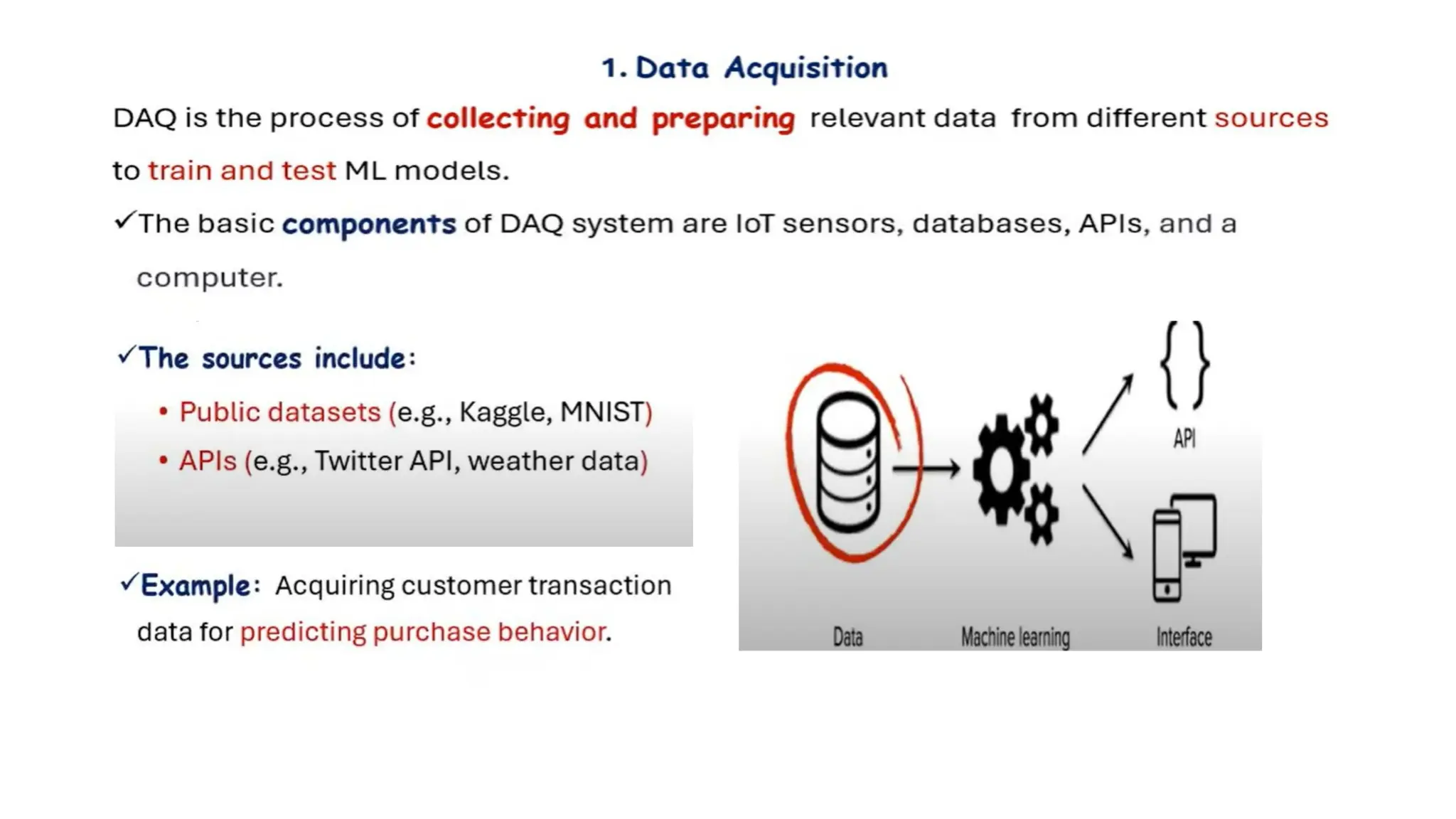
Where can Iget datasets?
• Kaggle Datasets - https://www.kaggle.com/datasets
• Amazon data sets - https://registry.opendata.aws/
• UCI Machine Learning Repository-
https://archive.ics.uci.edu/ml/datasets.html
Many more…..
Prepare your Datasets OR you can get data from
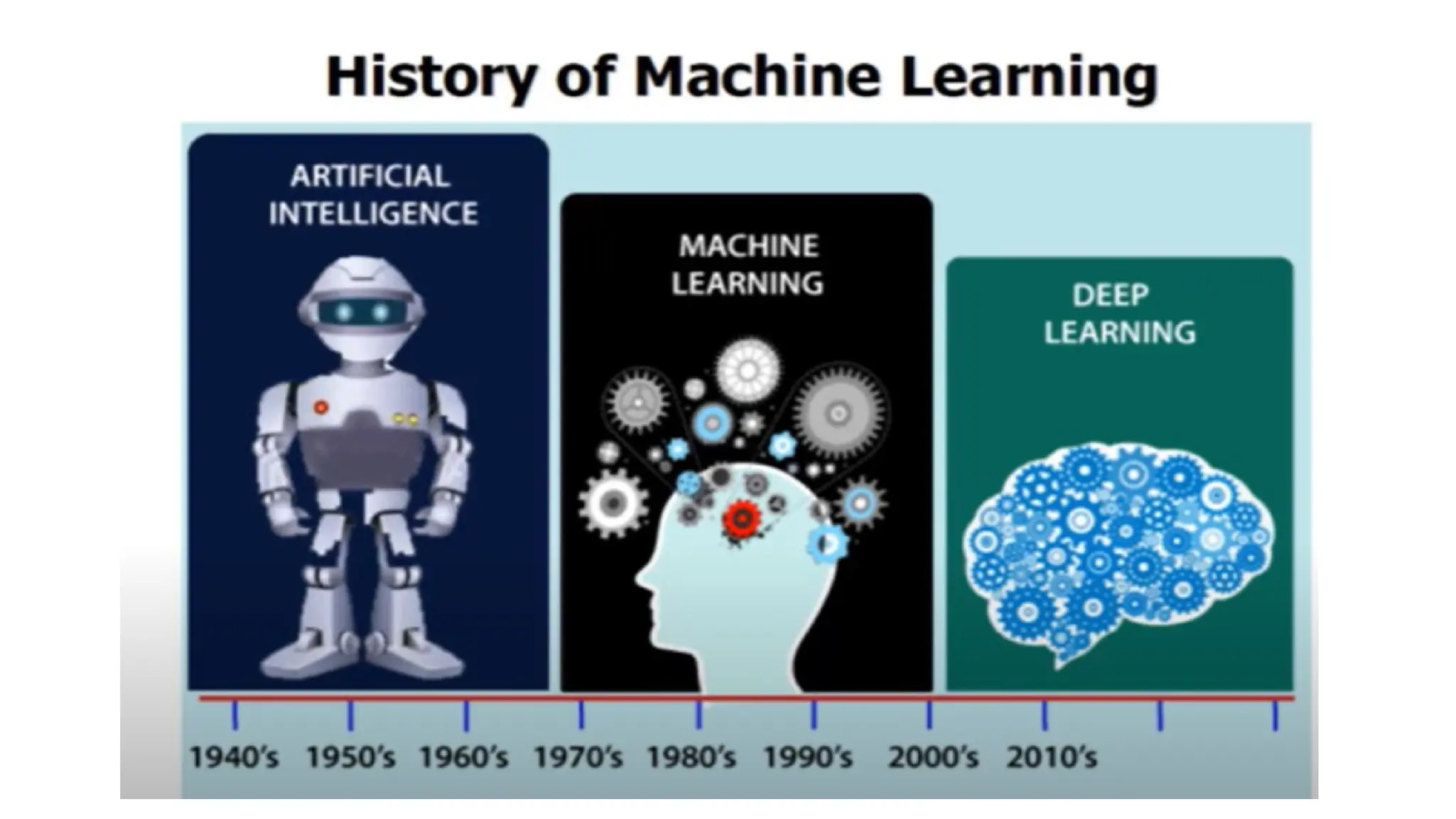
Evolution of MachineLearning
1. Early Foundations (1940s–1950s)
The roots of machine learning can be traced back to the early days of
computing and artificial intelligence (AI):
Turing's Work (1936-1937): The British mathematician Alan Turing
laid the groundwork for theoretical computing with the concept of the
Turing machine
Neural Networks and Perceptrons (1950s): In the 1950s, early work on
neural networks began with the creation of the Perceptron by Frank
Rosenblatt.
70.
2. Symbolic AIand Rule-Based Systems (1950s–1970s)
Rule-based AI: During the 1950s to 1970s, AI research was dominated by
symbolic approaches. Early ML Algorithms: Researchers began exploring
algorithms like decision trees and clustering methods, though the field was
still in its infancy
71.
3. The AIWinter (1970s–1990s)
Despite early successes, progress in AI and machine learning slowed
significantly during this period due to limited computational resources and
overly optimistic expectations:
•Challenges in Data and Computing: The limitations of computers at the
time, both in terms of memory and processing power, constrained the
development of more advanced ML algorithms. Additionally, AI and
machine learning models struggled to perform well in real-world, noisy data
scenarios.
•AI Winter: This term refers to a period of reduced funding and interest in
AI research during the late 1970s to early 1990s, as results from early ML
models did not live up to expectations.
72.
4. Revival andStatistical Learning (1990s–2000s)
The 1990s saw a resurgence in machine learning, driven by the development of statistical
methods, the increase in computational power, and the availability of larger datasets:
Introduction of Support Vector Machines (SVMs): In the 1990s, algorithms like
SVMs were developed, offering powerful methods for classification tasks
Bayesian Networks and Probabilistic Models: Researchers developed new
approaches based on probabilistic reasoning.
Neural Networks and Backpropagation: While neural networks had been explored
earlier, the backpropagation algorithm in the 1980s (further developed in the 1990s)
enabled multi-layer networks to learn more complex patterns and drove interest in deep
learning.
Reinforcement Learning: The concept of learning by interacting with an environment
and maximizing rewards.
73.
5. Data-Driven Approachesand Deep Learning (2010s–Present)
The 2010s saw significant breakthroughs in machine learning, particularly in the area of deep learning:
Big Data:.
Rise of Deep Learning: Deep learning :
o ImageNet Breakthrough (2012): The ImageNet competition marked a pivotal moment when
deep learning models, especially convolutional neural networks (CNNs), drastically
outperformed traditional machine learning algorithms in image classification tasks. This
achievement sparked widespread interest in deep learning.
Natural Language Processing (NLP) and Transformer Models: In the field of NLP, algorithms
like Word2Vec and later transformers (such as BERT and GPT) revolutionized language
understanding and generation, allowing machines to achieve human-level performance on tasks like
translation, question answering, and text generation.
Reinforcement Learning Advancements: Reinforcement learning, notably through deep Q-learning
(DeepMind's AlphaGo playing Go), reached new heights, solving complex decision-making
problems.
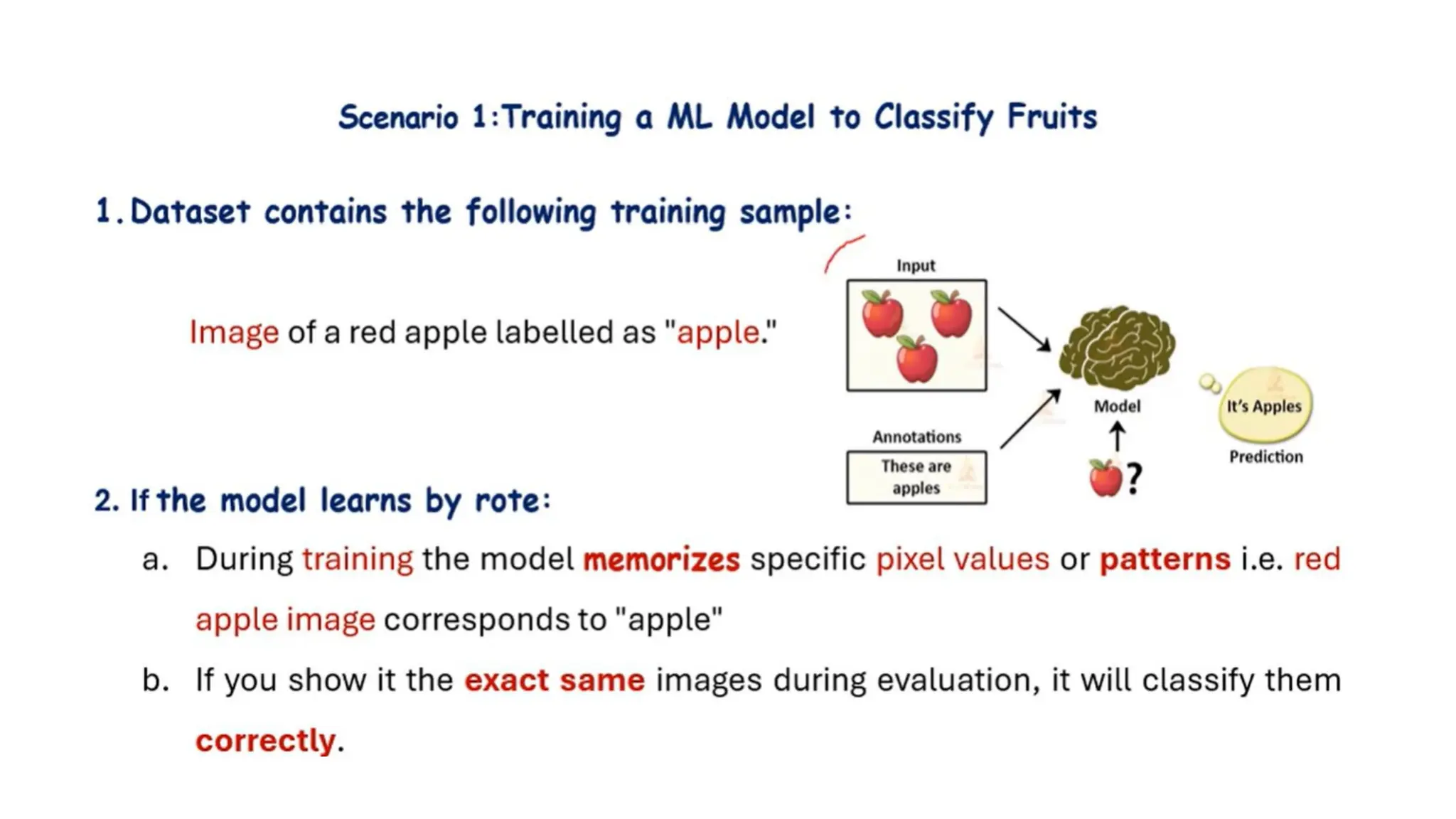
Learning by Rote
Definition:Learning by rote means memorizing data exactly as it is
presented.
No Generalization: The system does not try to find patterns or infer
rules from the data. It just stores what it has seen.
Limitation: If a new input is slightly different from the stored one, the
system cannot handle it.
79.
Example in MachineLearning:
Suppose a system is trained with these data pairs:
•Input: "cat" → Output: "animal"
•Input: "apple" → Output: "fruit"
If you then give it:
•Input: "dog" → It gives no output (since it has not seen "dog" before).
This shows rote learning: only exact matches are recognized.
80.
Why It’s NotSufficient in ML:
•Machine learning aims to generalize from training data.
•Modern ML models (like neural networks) learn patterns and can predict
outputs for unseen inputs.
•Rote learning fails in real-world tasks like:
• Image recognition
• Language understanding
• Forecasting and prediction
81.
What is Learningby Deduction?
Learning by deduction is a logical reasoning process where new knowledge is inferred
from already known facts using logical rules.
It follows the top-down approach:
General Rule(s) → Specific Conclusion
•Deduction: The ground is wet.
•Fact: It is raining now.
•Rule: If it rains, the ground gets wet.
85.
What is Learningby Abudction?
Learning by Abduction is a type of reasoning often used in Artificial Intelligence and
logic-based learning. It involves forming a hypothesis(T/F) that explains a given
observation. Unlike deduction (deriving specifics from a general rule) or induction
(generalizing from examples), abduction starts with an observation and tries to find
the best explanation for it.
Example in AI/ML:
Scenario:
•Observation: The road is wet.
•Hypothesis: It must have rained.
•Reasoning: If it had rained, the road would be wet. The road is wet. So maybe it rained.
This is abductive reasoning — choosing the most plausible explanation, even if it’s not guaranteed to be
true.
86.
What is Learningby Induction?
Inductive learning is the process of generalizing rules or patterns from specific examples or
observations.
Induction = Specific → General
Learning from examples-Supervised Learning
Learning from observations-Unsupervised Learning
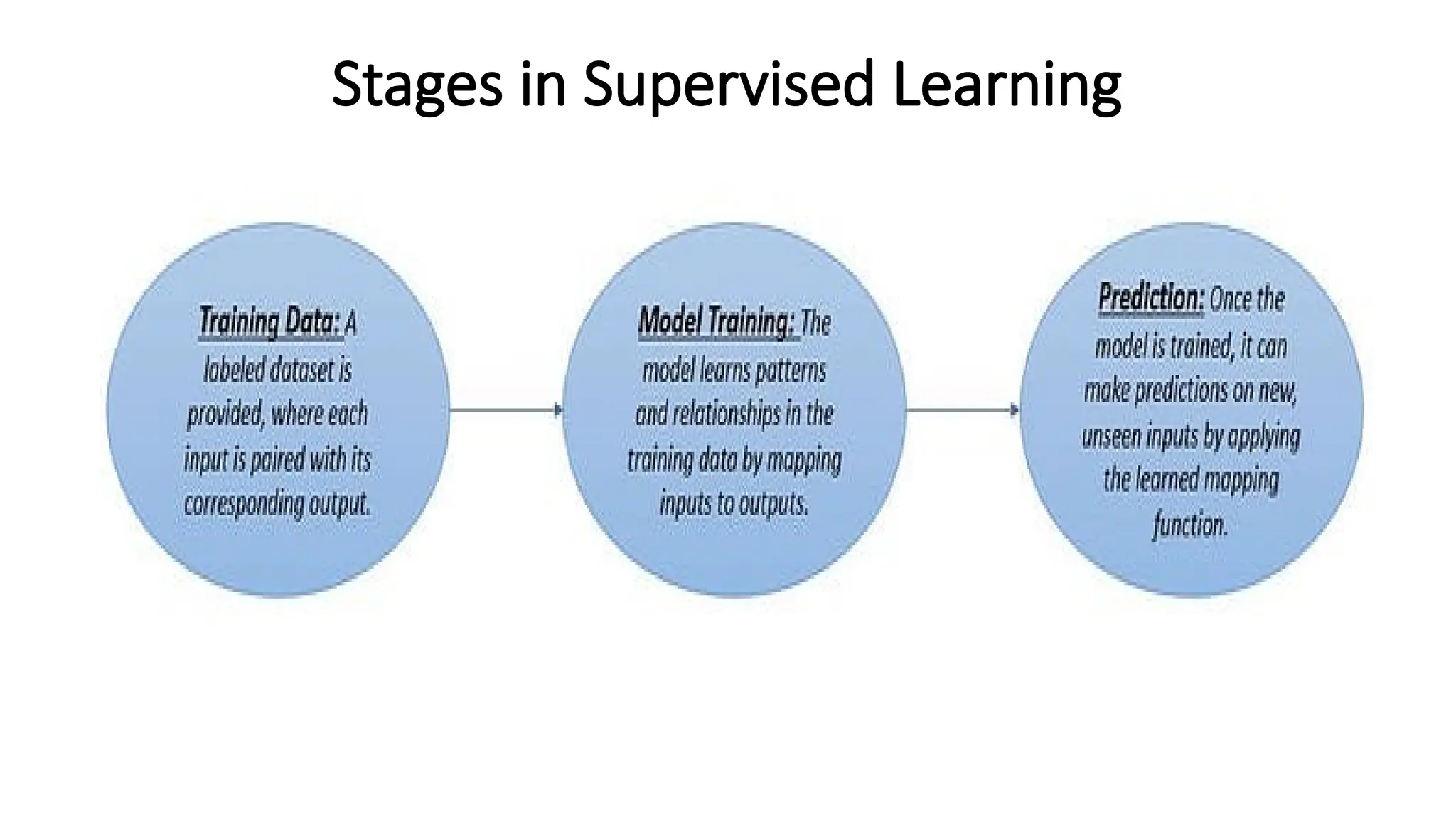
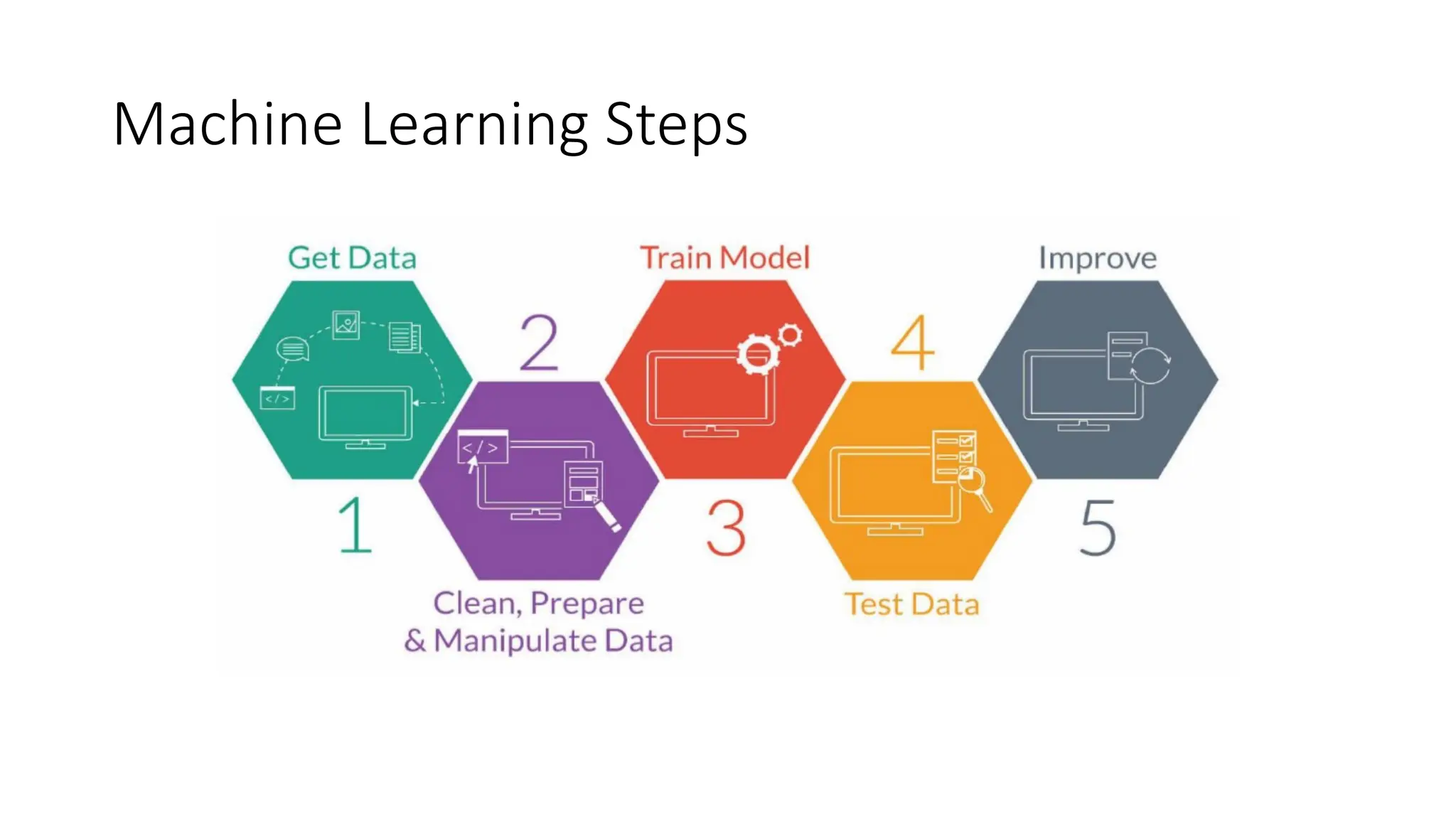
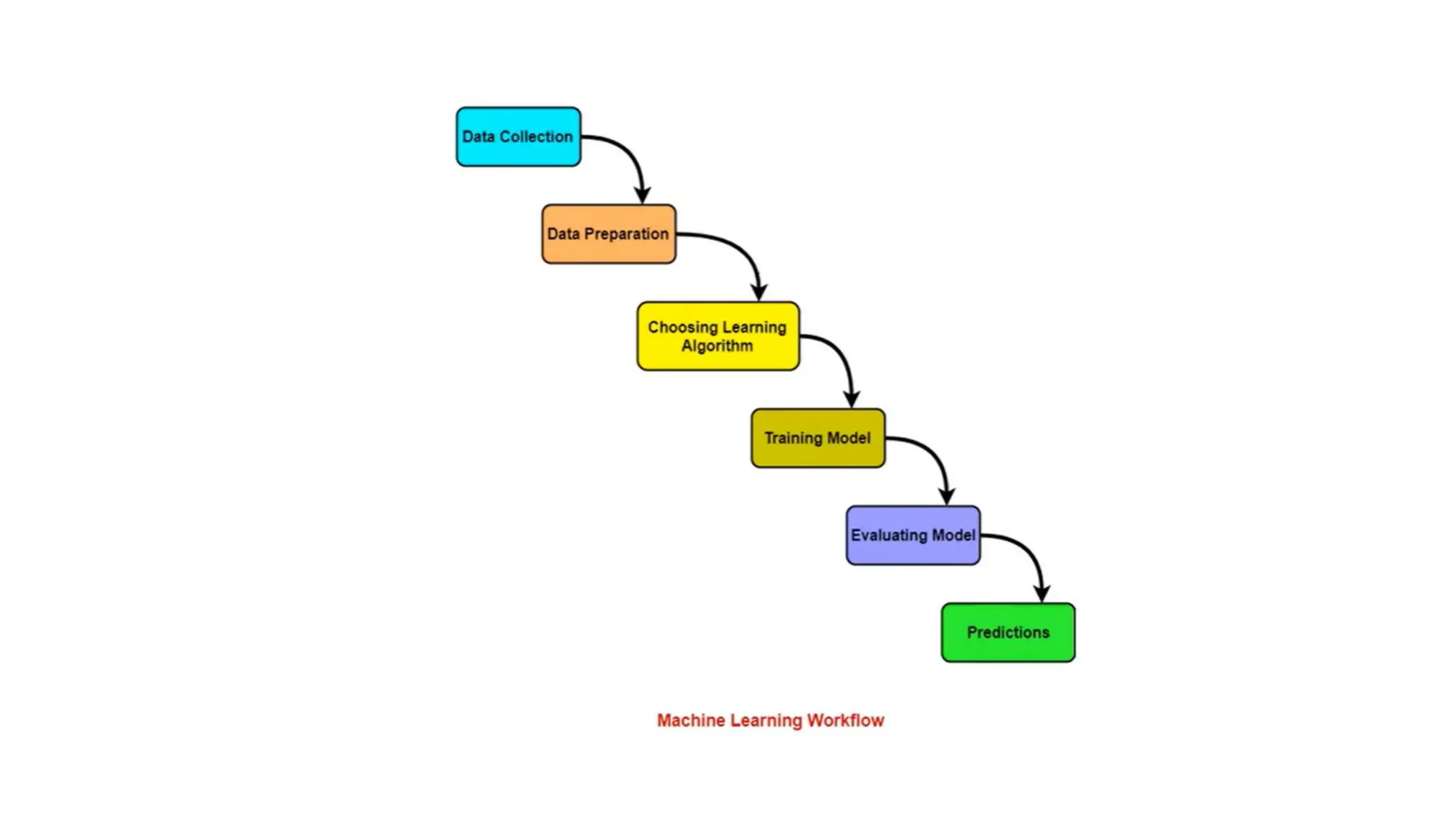
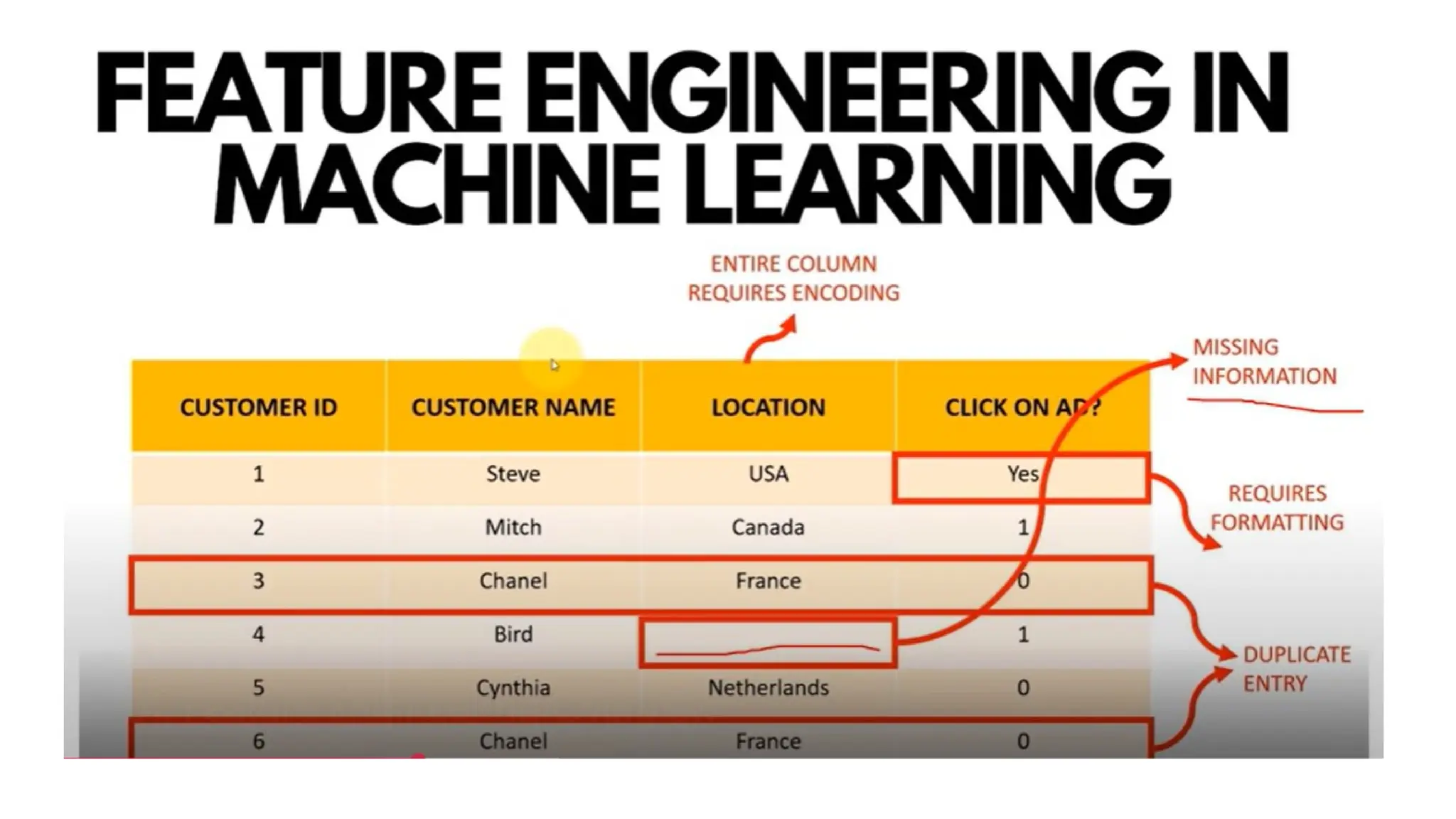
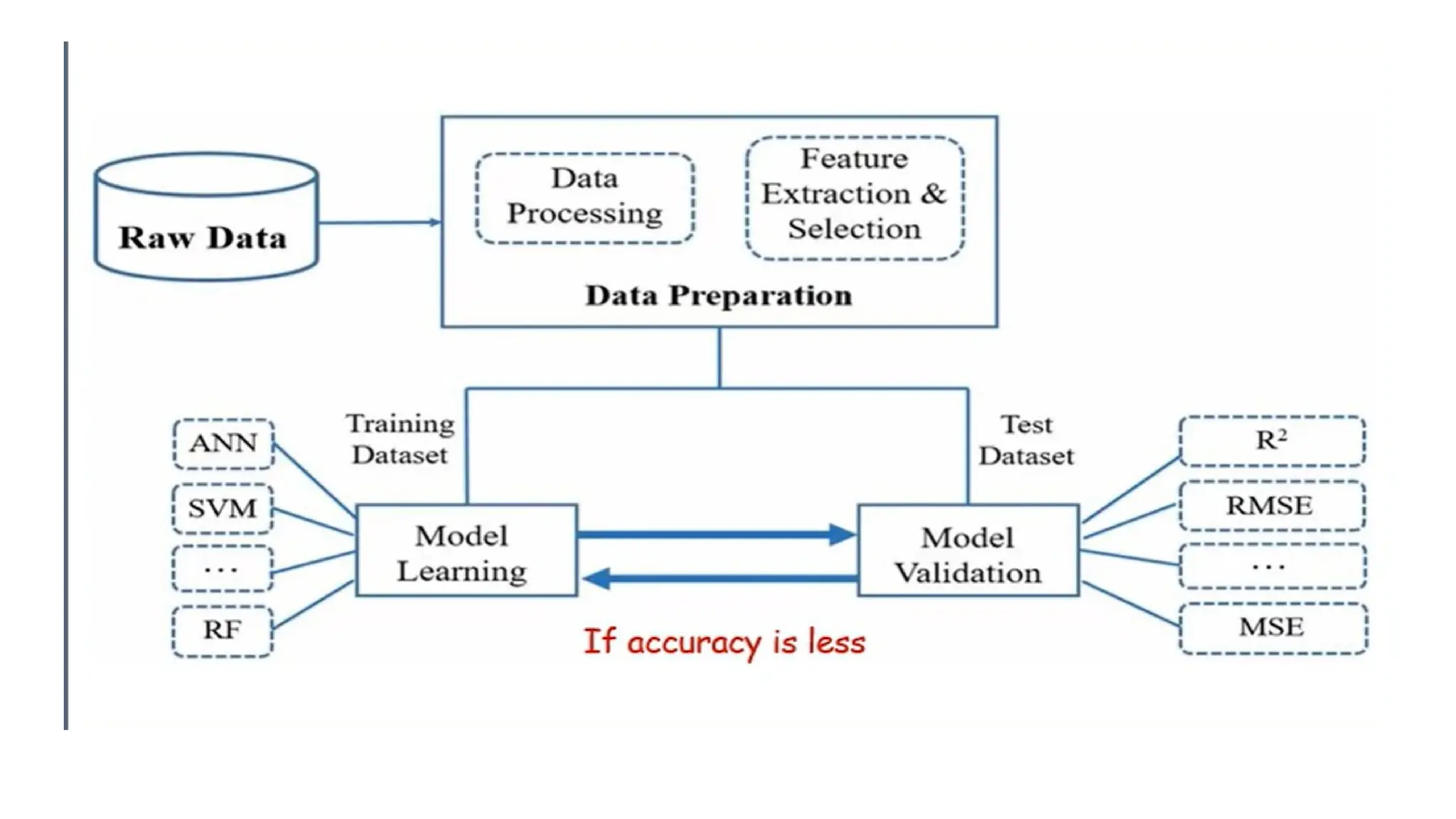
1. Data Collection:Gathering the relevant data for the problem you're solving.
2. Data Preprocessing: Cleaning and preparing the data for modeling, including handling
missing values, normalizing, and encoding categorical variables.
3. Model Selection: Choosing the appropriate machine learning algorithm.
4. Training the Model: Feeding the training data into the model to allow it to learn from
the data.
5. Evaluation: Assessing the model's performance using metrics like accuracy, precision,
recall, or mean squared error (for regression).
6. Hyper parameter Tuning: Adjusting the model parameters for optimal performance.
7. Deployment: Integrating the trained model into a real-world application.
128.
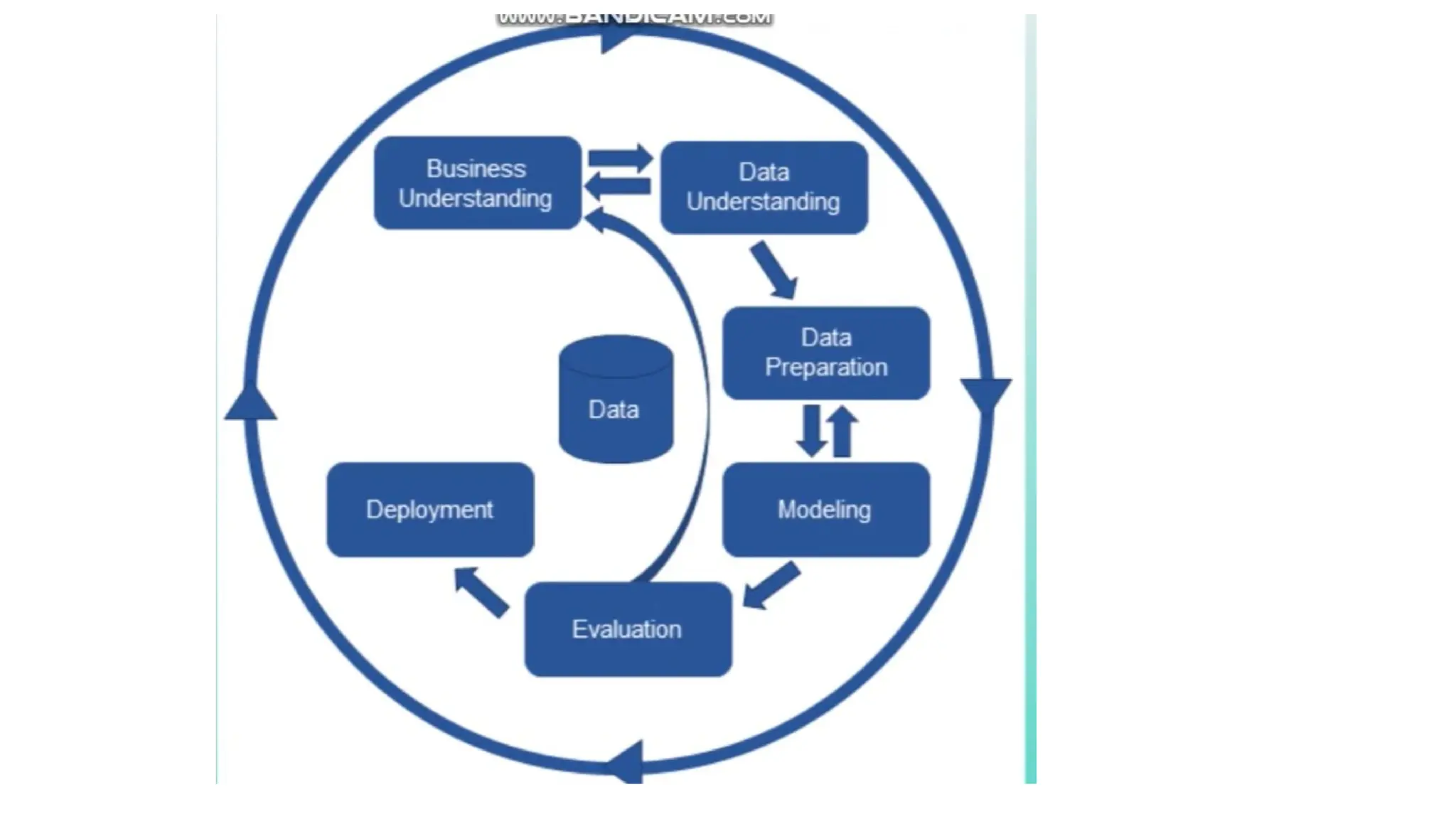
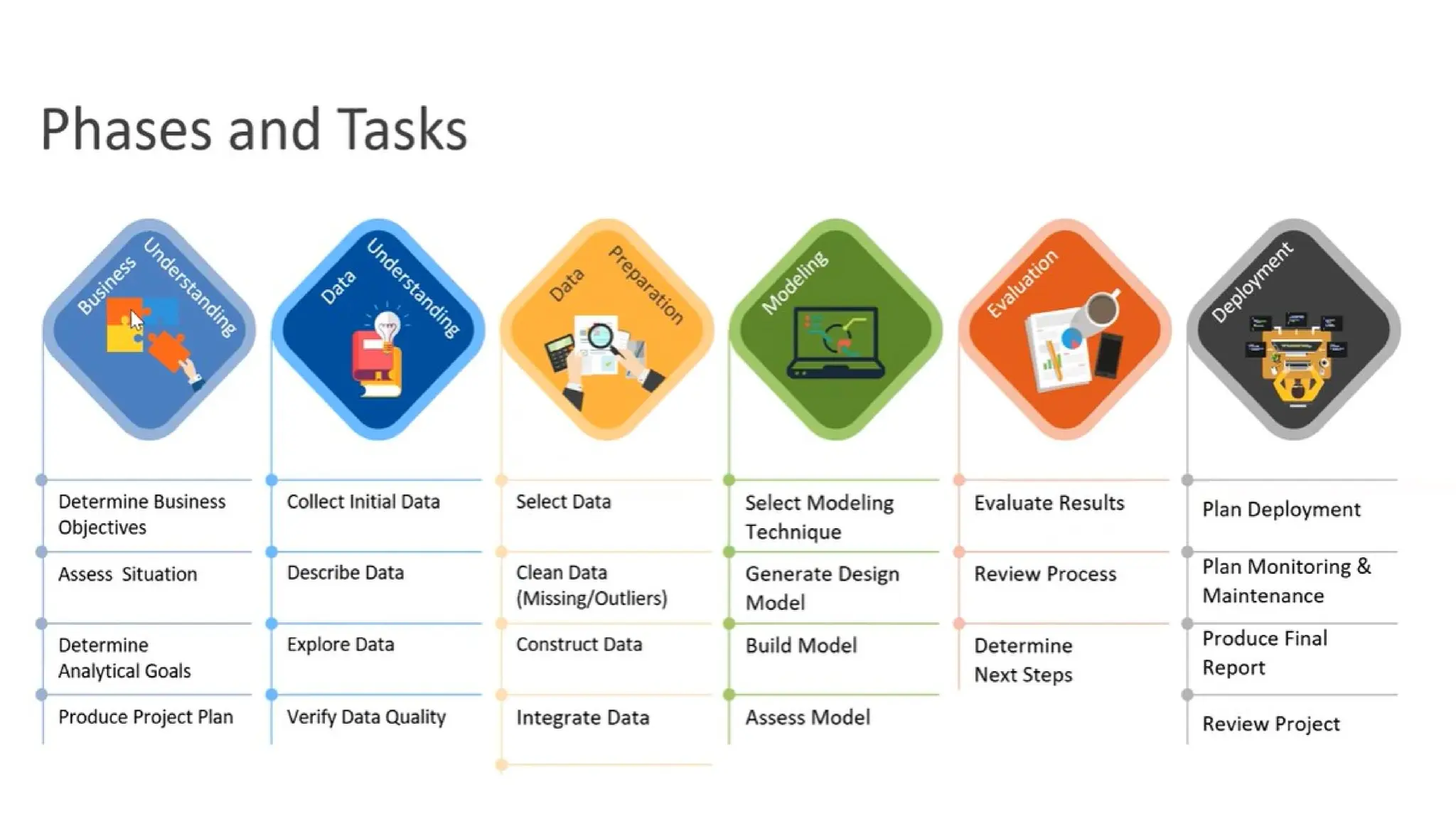
CRISP-DM
• CRISP DMis a data mining technology or a methodology or a process
that helps you or provides you a blueprint to conduct a data mining
project.
• C-CROSS
• I-INDUSTY
• S-STANDARD
• P-PROCESS
• It was implemented in 1996.
133.
BUSINESS UNDERSTANDING
• Convertbusiness objective into
data mining tasks
• determine business objective,
where we focus on what is my
true goal of my project
• Assess the situation-assumptions
we need to make
• Set objectives for a team
• Specific outlines and also specify
timelines
134.
DATA UNDERSTANDING
• Createhypothesis with the
hidden information that we have
collected.
• Examine the data
• First findings
• Missing attributes, spelling
mistakes
1. Which ofthe following is not a type of machine learning paradigm?
A. Supervised Learning
B. Reinforcement Learning
C. Inductive Learning
D. Internet Learning
2. Which learning method is based on memorization without understanding?
A. Learning by Induction
B. Learning by Rote
C. Learning by Deduction
D. Learning by Reinforcement
3. Learning by Induction involves:
A. Remembering examples
B. Deriving general rules from specific examples
C. Learning from rewards
D. Guessing outcomes randomly
4. Which of the following is true for Reinforcement Learning?
A. Uses labeled data
B. Learns from direct supervision
C. Learns from interaction with the environment and rewards
D. Uses only unsupervised data
140.
5. Which ofthe following is an example of supervised
learning?
A. K-means clustering
B. Q-learning
C. Decision Trees
D. PCA (Principal Component Analysis)
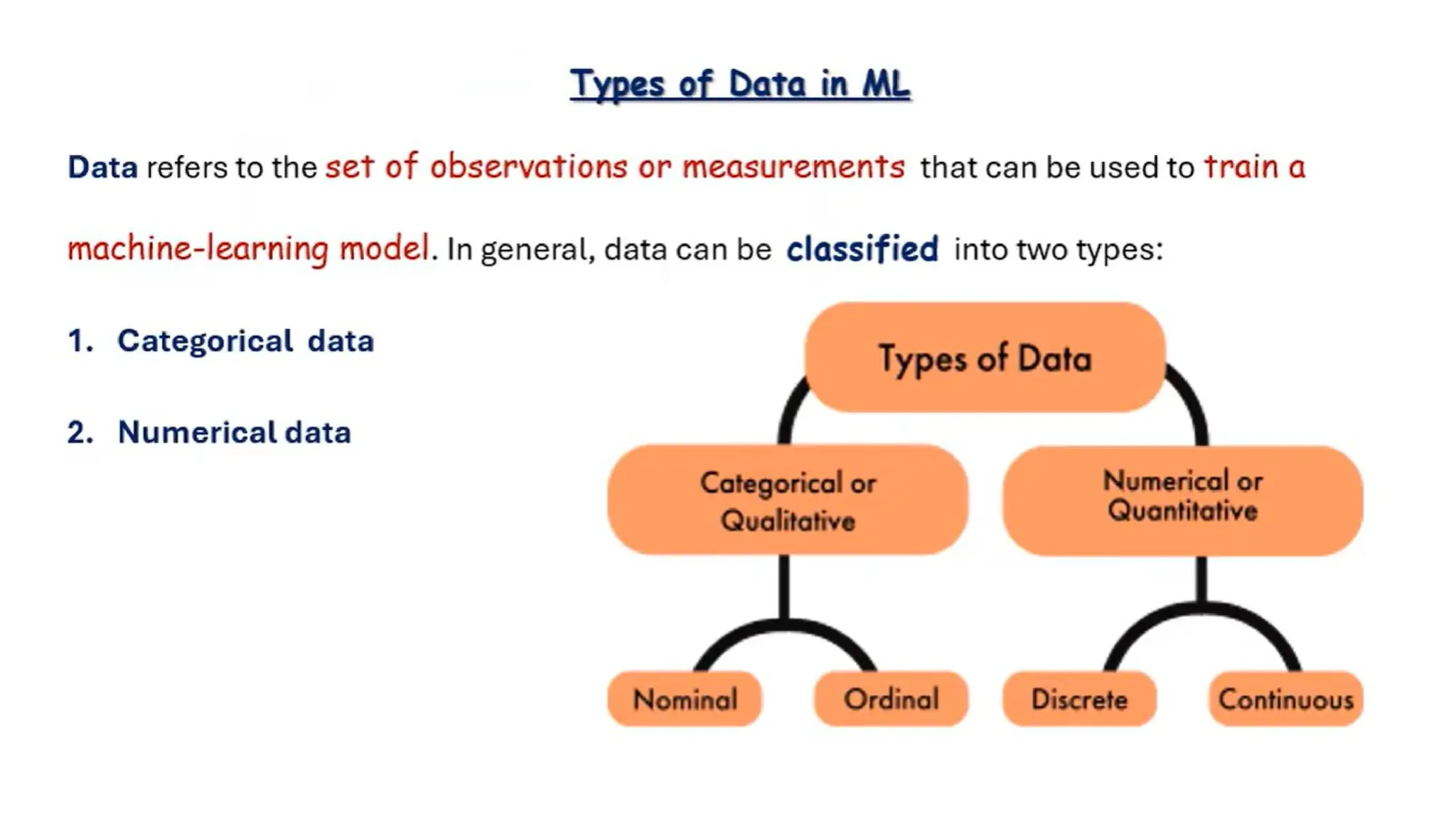
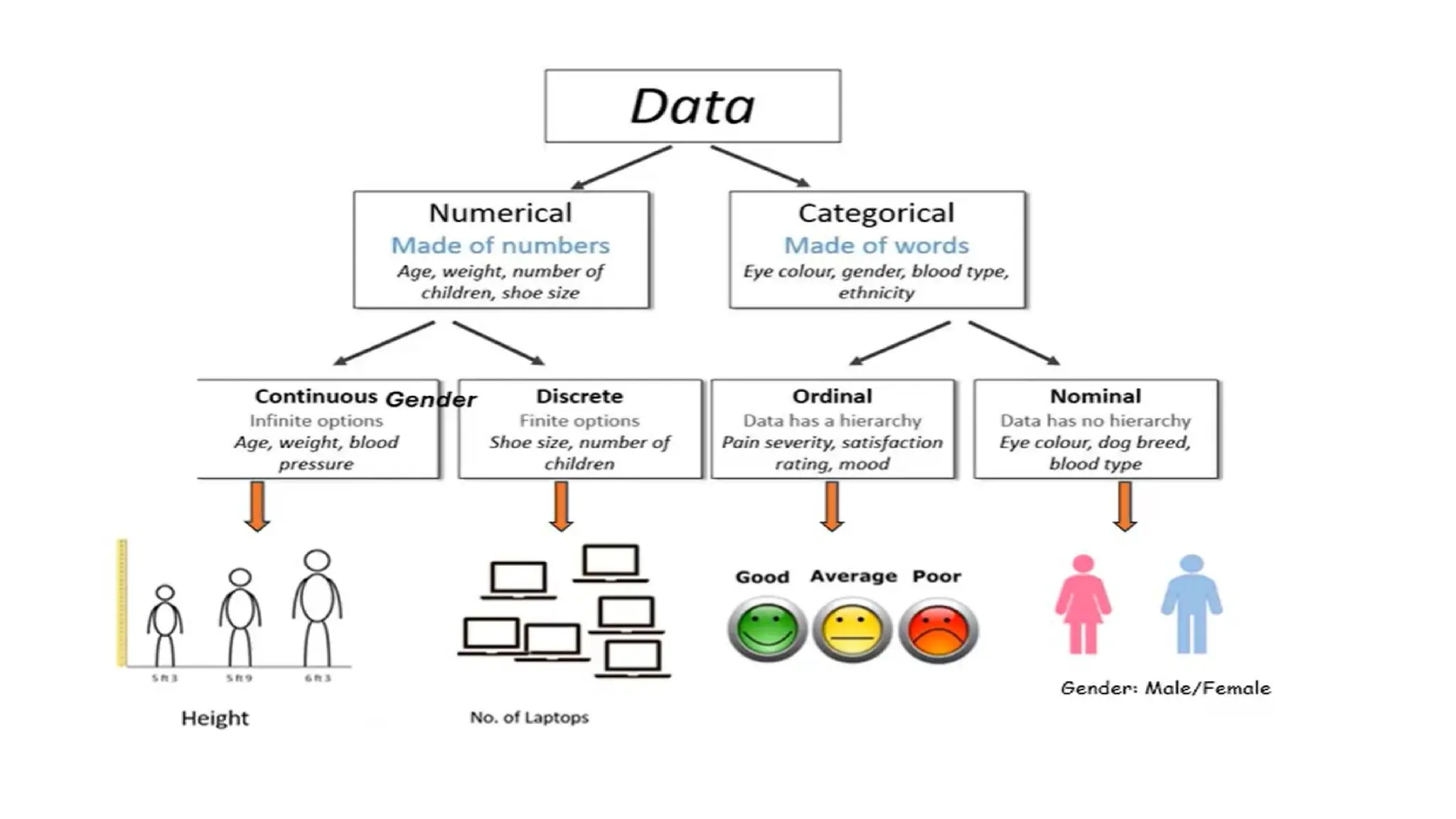
6. Which of the following is a type of categorical data?
A. Height
B. Weight
C. Gender
D. Temperature
7. Quantitative data refers to:
A. Descriptive categories
B. Numerical values
C. Audio or video formats
D. None of the above
141.
8. Which isthe correct first step in a machine learning project?
A. Model Evaluation
B. Data Preprocessing
C. Problem Understanding
D. Model Deployment
9. Which step involves splitting data into training and testing sets?
A. Data Collection
B. Data Preprocessing
C. Model Building
D. Model Evaluation
10. What does CRISP-DM stand for?
A. Common Research in Scientific Processes - Data Mining
B. Cross Industry Standard Process for Data Mining
C. Common Review Standard Procedure for Data Mining
D. Certified Research In Statistics and Programming - Data
Mining
142.
11. Which phasein CRISP-DM includes understanding the business objectives?
A. Data Preparation
B. Evaluation
C. Business Understanding
D. Data Understanding
12. In CRISP-DM, what comes after ‘Data Understanding’?
A. Deployment
B. Evaluation
C. Modeling
D. Data Preparation
13. Machine Learning is a subfield of:
A. Data Entry
B. Artificial Intelligence
C. Database Management
D. Software Engineering
14. Which of the following best defines machine learning?
A. Hard-coding rules to perform a task
B. Teaching computers to play games
C. Systems that learn from data and improve performance
D. Writing large software programs
143.
15. Which ofthese is an example of unsupervised learning?
A. Classification
B. Regression
C. Clustering
D. Logistic Regression
16. Which paradigm of machine learning uses labeled input
and output pairs?
A. Unsupervised Learning
B. Reinforcement Learning
C. Supervised Learning
D. Deep Learning
17. Which of the following is not a type of learning in machine
learning?
A. Supervised Learning
B. Rote Learning
C. Reinforcement Learning
D. Visual Learning
144.
18. Which learningparadigm mimics trial-and-error behavior?
A. Rote Learning
B. Unsupervised Learning
C. Reinforcement Learning
D. Transfer Learning
19. Learning by Rote is mostly used in:
A. Robotic learning
B. Human memorization without reasoning
C. Pattern recognition
D. Statistical modeling
20. Which type of learning uses logical reasoning from specific
to general?
A. Deduction
B. Rote
C. Induction
D. Observation
21. Reinforcement learning involves:
A. Supervision from teacher data
B. Rewards and punishments
C. Using clustering algorithms
D. Predefined outputs
145.
22. Ordinal datais:
A. Data with no meaningful order
B. Numerical but not measurable
C. Categorical with meaningful order
D. Real-time streaming data
23. Which data type is most suitable for regression analysis?
A. Nominal
B. Ordinal
C. Numerical (Continuous)
D. Binary
24. Which is not a common stage in ML development?
A. Data Collection
B. Data Understanding
C. Model Repair
D. Model Deployment
25. Model evaluation is primarily done to:
A. Collect more data
B. Prepare for training
C. Test model accuracy and performance
D. Choose a software tool
146.
26. What isthe final stage of CRISP-DM?
A. Modeling
B. Evaluation
C. Data Preparation
D. Deployment
27. In CRISP-DM, data modeling is done after:
A. Data Collection
B. Data Understanding
C. Data Preparation
D. Deployment
28. Which step includes checking if the model meets business goals?
A. Data Understanding
B. Modeling
C. Evaluation
D. Business Understanding
147.
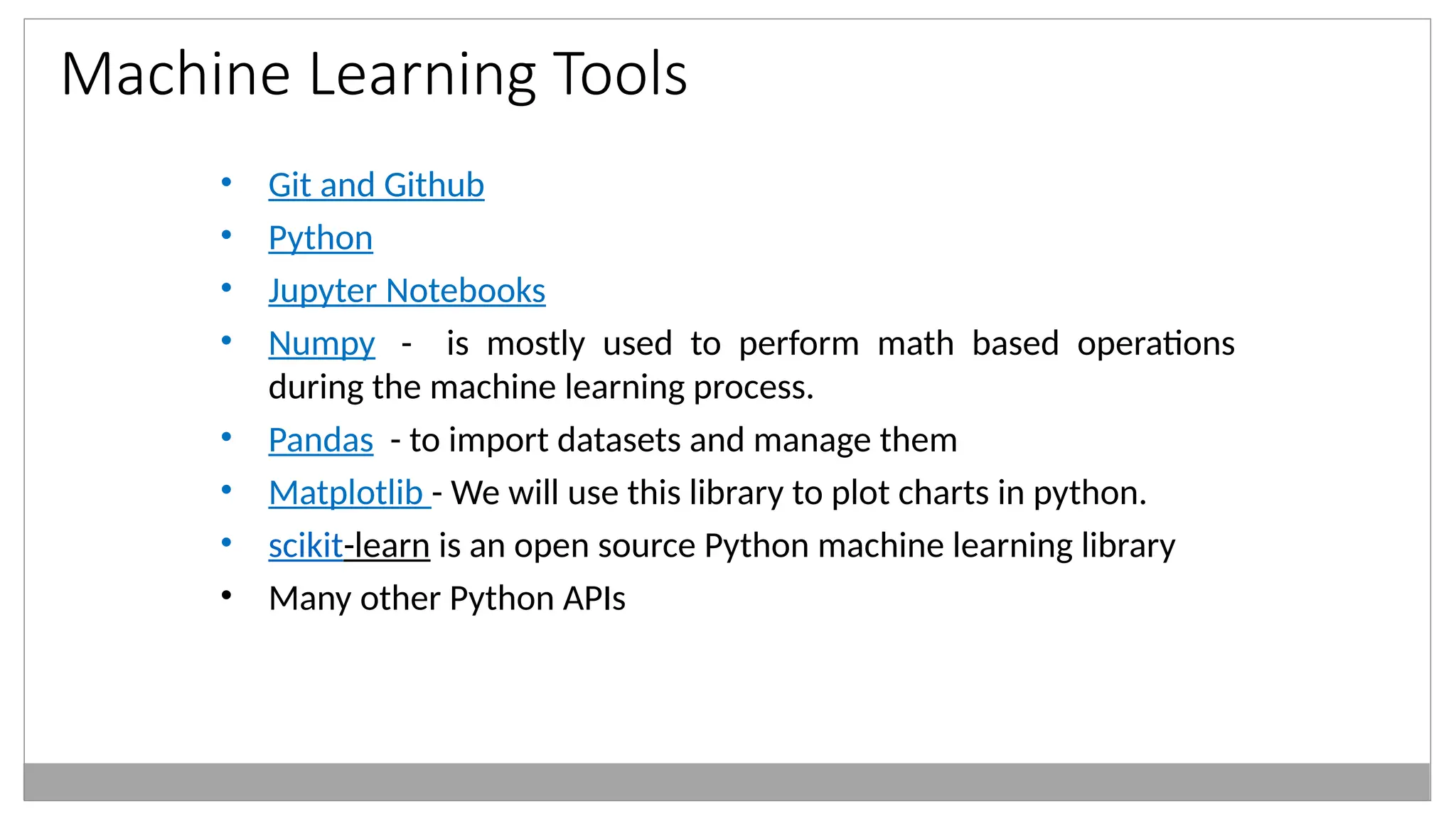
Machine Learning Tools
•Git and Github
• Python
• Jupyter Notebooks
• Numpy - is mostly used to perform math based operations
during the machine learning process.
• Pandas - to import datasets and manage them
• Matplotlib - We will use this library to plot charts in python.
• scikit-learn is an open source Python machine learning library
• Many other Python APIs
Editor's Notes
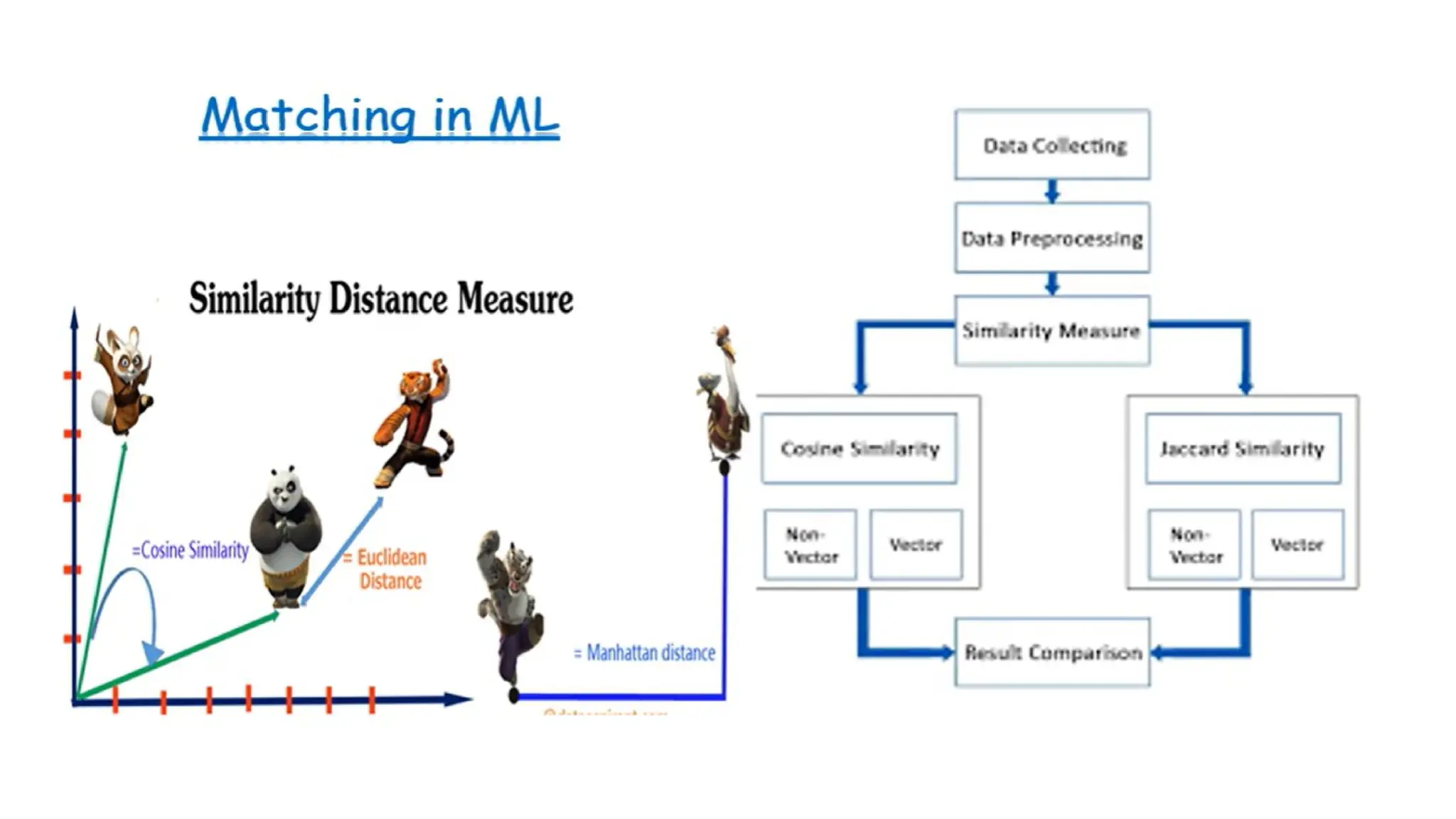
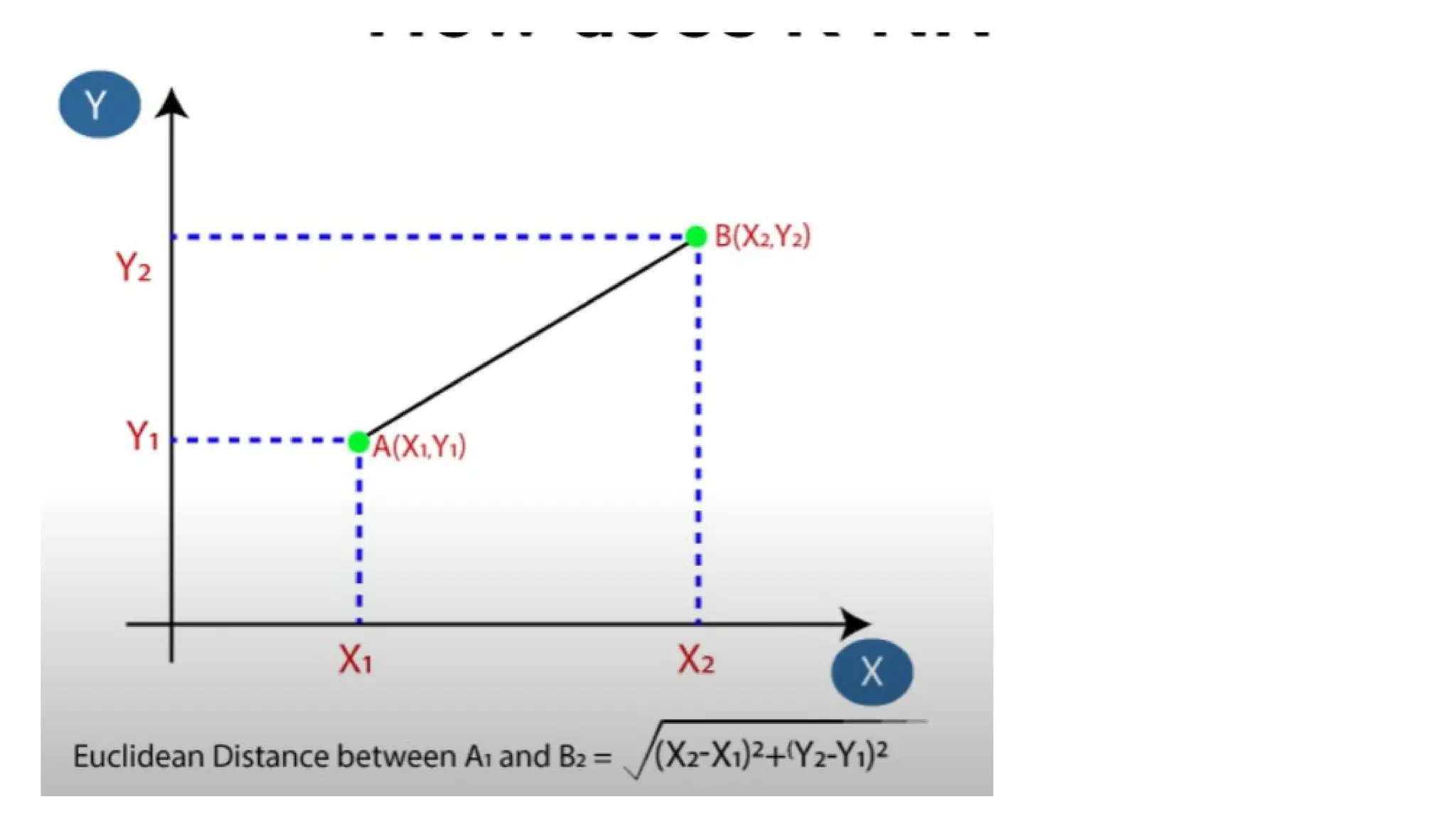
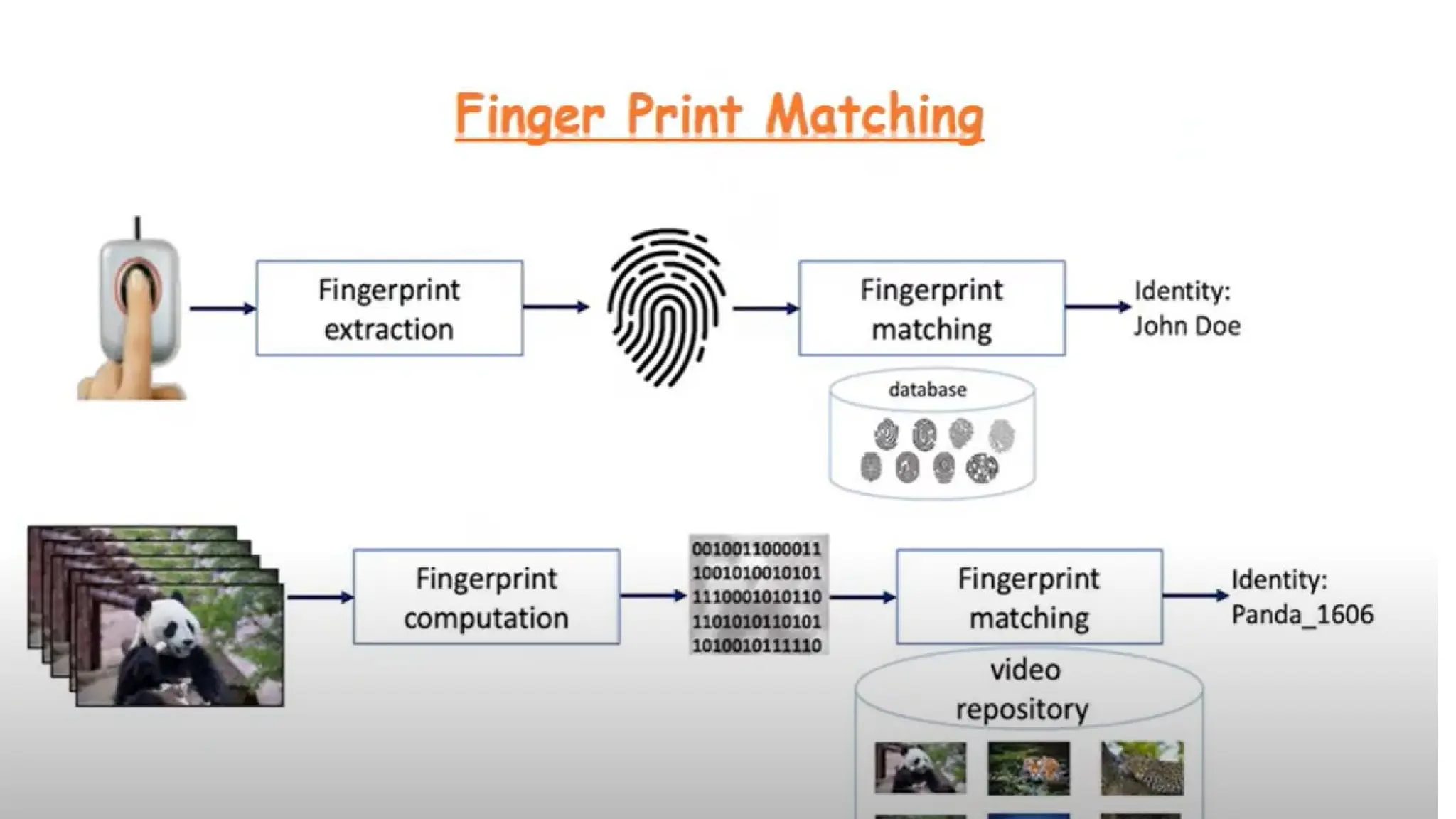
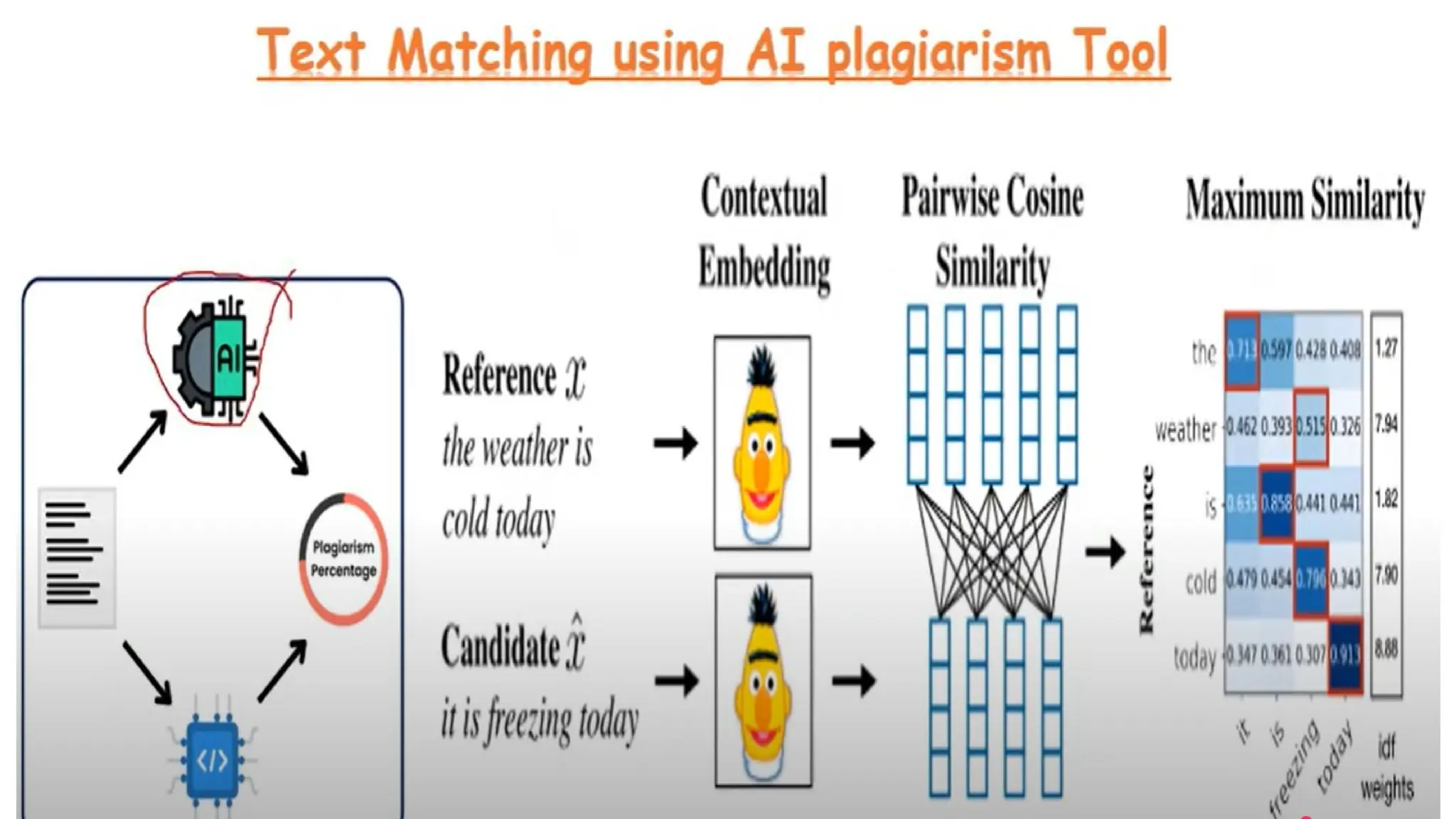
#99 Calculate the % of similarity in fingerprint through mathematical formulas:
Euclidean distance : when two data points lying in the same straight line the machine will calculate shortest path
Cosine similarity : when two data points are separated by angle theta the similarity measure using is cosine similarity
#100 Proximity measures, in data analysis and machine learning, are mathematical techniques used to quantify the similarity or dissimilarity between data objects.
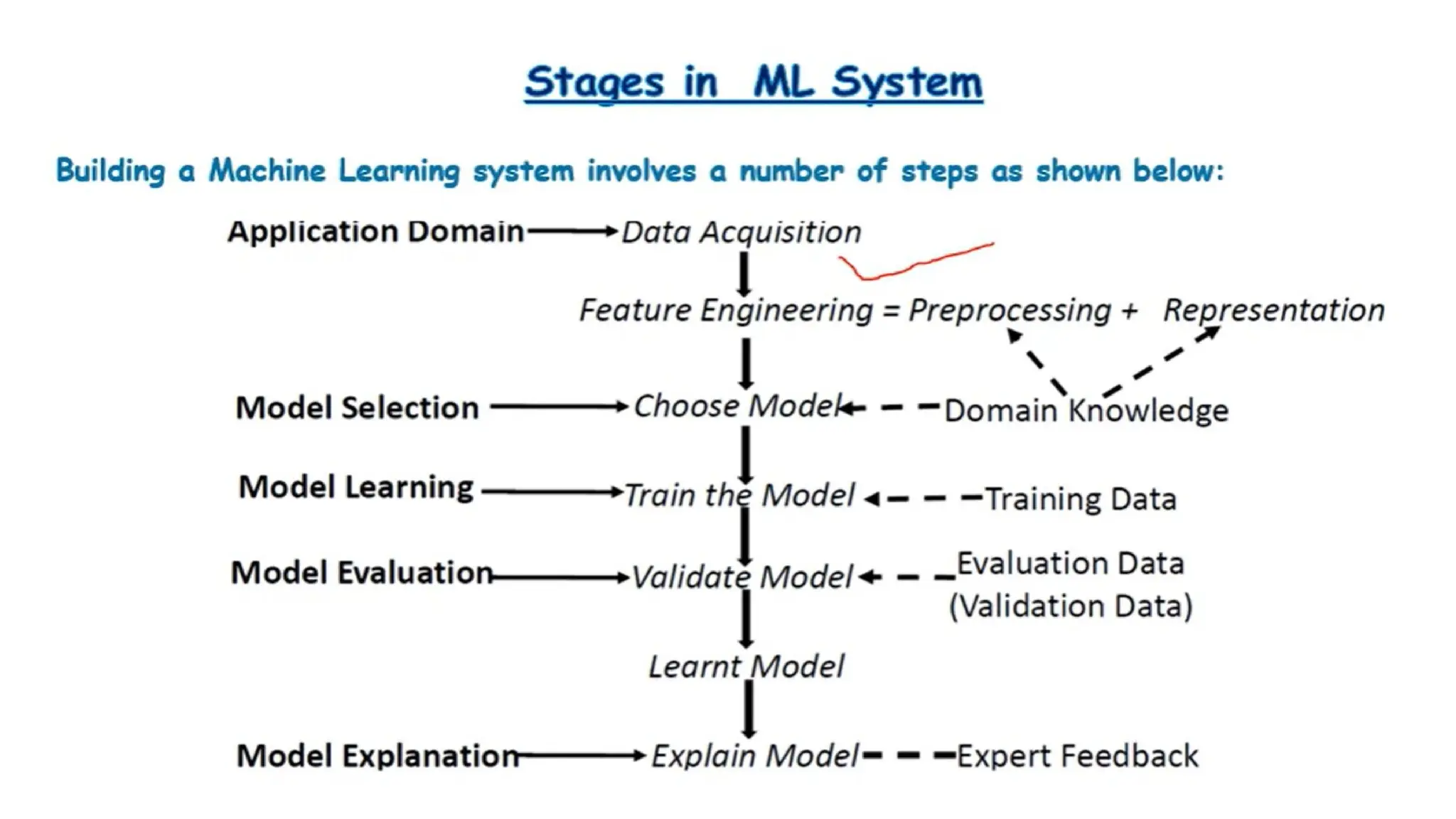
#114 Feature engineering : extracting features
Preprocessing: unwanted noise remove
Model selection : choose algorithm by itself based on the type of data
Evaluation data: % of accuracy
Tain the model: tuning the model










































































































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)








































