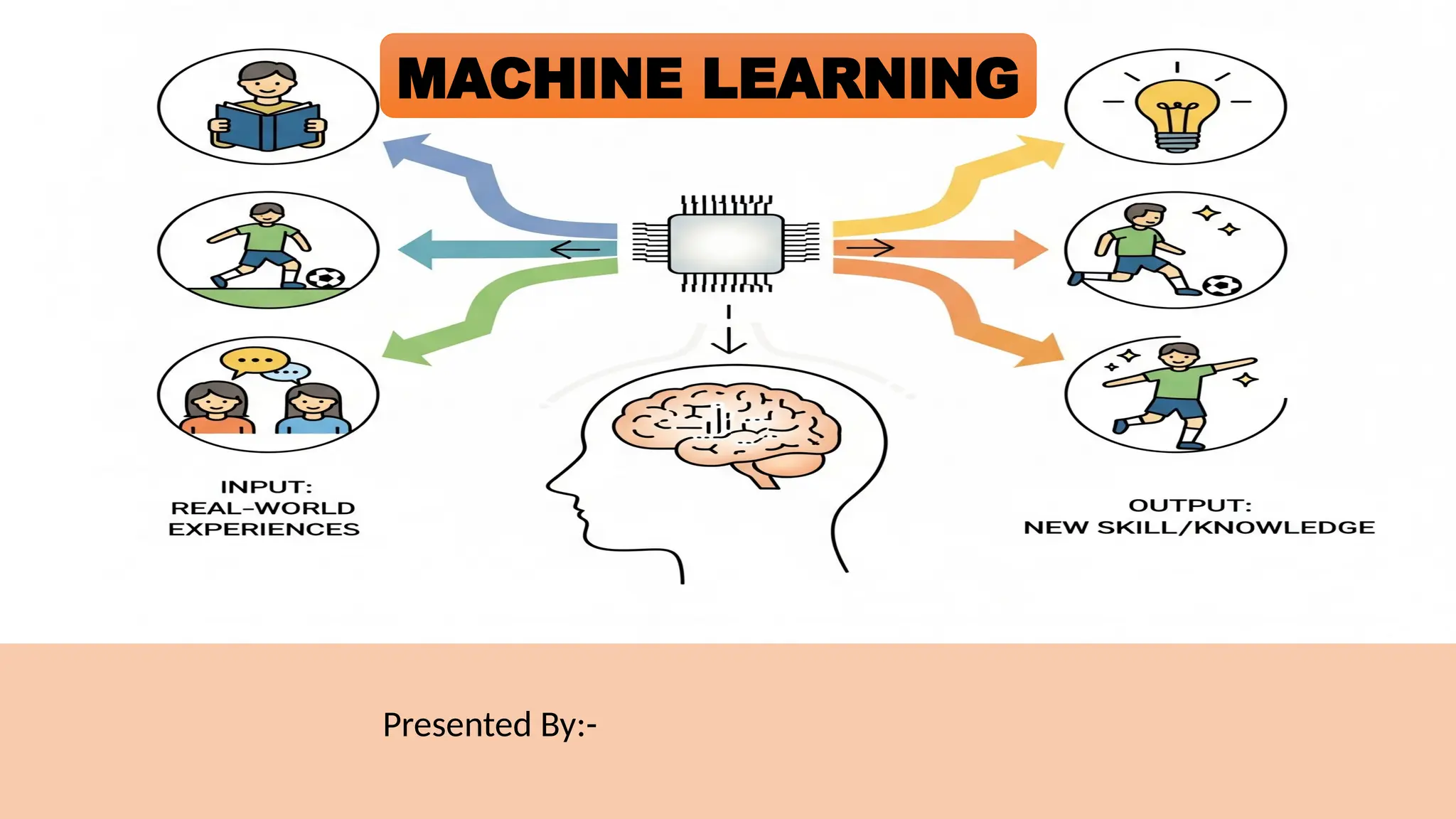
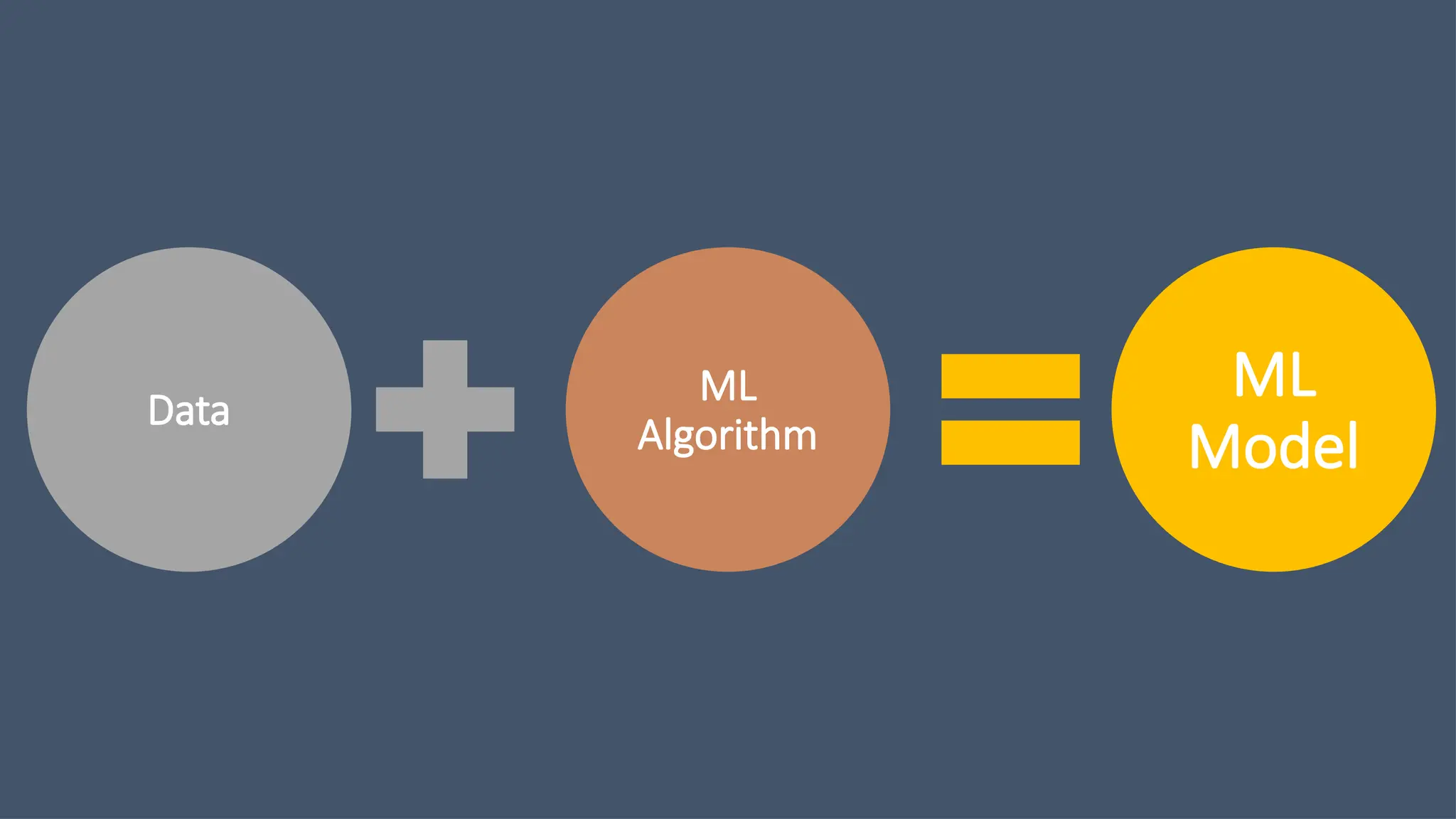
Machine Learning (ML)is a subfield of Artificial Intelligence (AI) that
enables computers to identify patterns, learn from data, and make
predictions or decisions without being explicitly programmed for
every scenario.
MACHINE LEARNING
3.
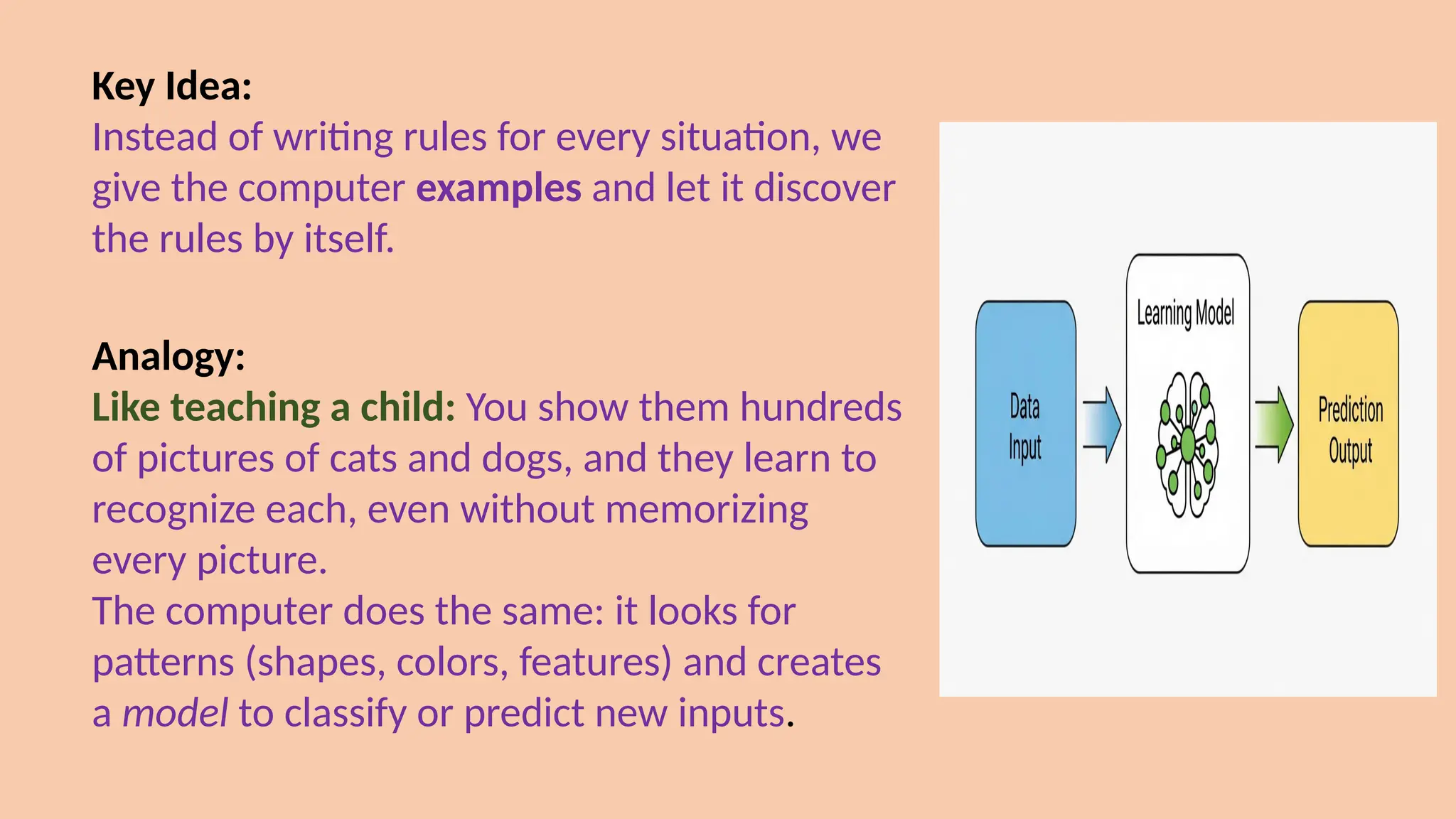
Key Idea:
Instead ofwriting rules for every situation, we
give the computer examples and let it discover
the rules by itself.
Analogy:
Like teaching a child: You show them hundreds
of pictures of cats and dogs, and they learn to
recognize each, even without memorizing
every picture.
The computer does the same: it looks for
patterns (shapes, colors, features) and creates
a model to classify or predict new inputs.
4.
1. Handles MassiveData
• ML can process millions of records in seconds.
• Extracts meaningful insights from structured and unstructured data
(text, images, videos).
2. Improves Decision-Making
• Uses data-driven evidence instead of guesswork.
• Helps businesses, governments, and researchers make smarter, faster,
and more accurate decisions.
3. Adapts and Improves Over Time
• Learns from new data automatically.
• Performance gets better with more training — just like humans
learning from experience.
4. Real-World Examples
• Spam Filters – Gmail’s AI detects unwanted emails.
• Product Recommendations – Amazon, Netflix suggest items based on
your preferences.
• Fraud Detection – Banks identify suspicious transactions in real-time.
WHY MACHINE LEARNING?
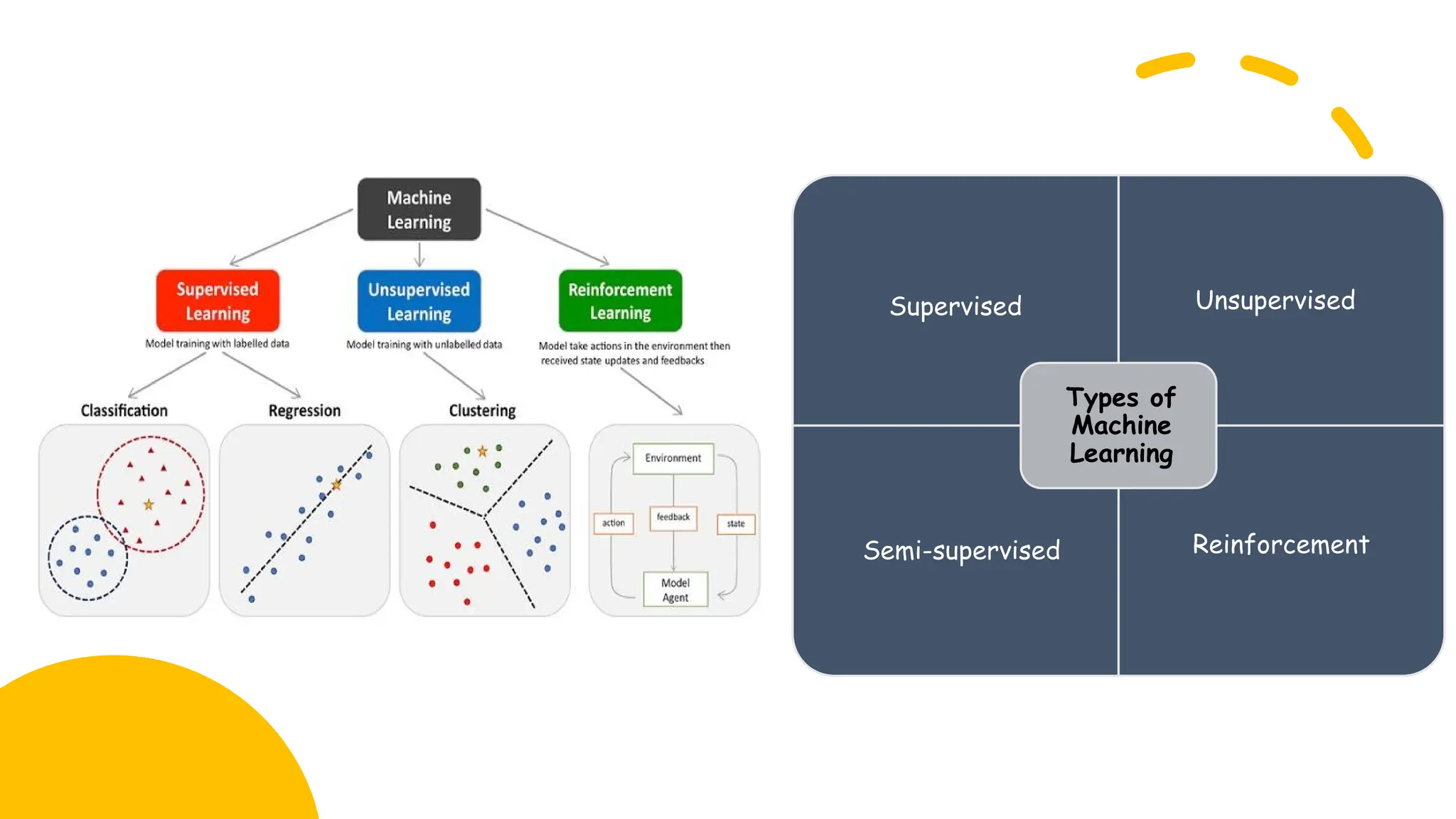
Supervised
• In Supervisedlearning, you train the machine using data
which is well "labeled."
• It means data is already tagged with the correct answer.
• It can be compared to learning which takes place in the
presence of a supervisor or a teacher.
• A supervised learning algorithm learns from labeled
training data, helps you to predict outcomes for
unforeseen data.
• One disadvantage of this learning method is that the
dataset has to be hand-labeled either by a Machine
Learning Engineer or a Data Scientist. This is a very costly
process, especially when dealing with large volumes of
data.
8.
Example
• A personwho have never seen a game of football
in his entire life.
• Learning with a coach.
• A coach explains the rules, show the videos of
football games and clearly labels things. “That’s a
goal keeper, that’s a striker, this is offside, that’s a
goal.”
• After enough labeled examples and corrections,
the person can join a game and play correctly from
the start.
9.
Unsupervised
• Unsupervised Learningis a machine learning
technique in which the users do not need to
supervise the model.
• Instead, it allows the model to work on its
own to discover patterns and information that
was previously undetected.
• It mainly deals with the unlabeled data.
• Unsupervised learning problems are grouped
into clustering and association problems.
• The most basic disadvantage of
any Unsupervised Learning is that
its application spectrum is limited.
10.
Example
• Watching footballwithout guidance
• No one tells him the rules, the name of
the players, or even what the game is
called.
• All he can do is watch carefully noticing
that some players wear red some
blue(finding group and clusters).
• Hey might observe that the players with
gloves stand near the goalposts(finding
pattern).
11.
Reinforcement
• Reinforcement learningis the training of machine learning
models to make a sequence of decisions.
• In this approach, machine learning models are trained to
make a series of decisions based on the rewards and
feedback they receive for their actions.
• The machine learns to achieve a goal in complex and
uncertain situations and is rewarded each time it achieves it
during the learning period.
• Reinforcement learning is different from supervised learning
in the sense that there is no answer available, so the
reinforcement agent decides the steps to perform a task.
• The machine learns from its own experiences when there is
no training data set present.
12.
Example
• Playing withTrial and error.
• He tries kicking the ball if it goes towards the opponent’s
goal, teammates cheer (reward).
• If he accidently kicks it into his own goal, everyone groans
(punish).
• Through trial and error, he learns which action brings
cheers and which brings groans, gradually improving his
play.
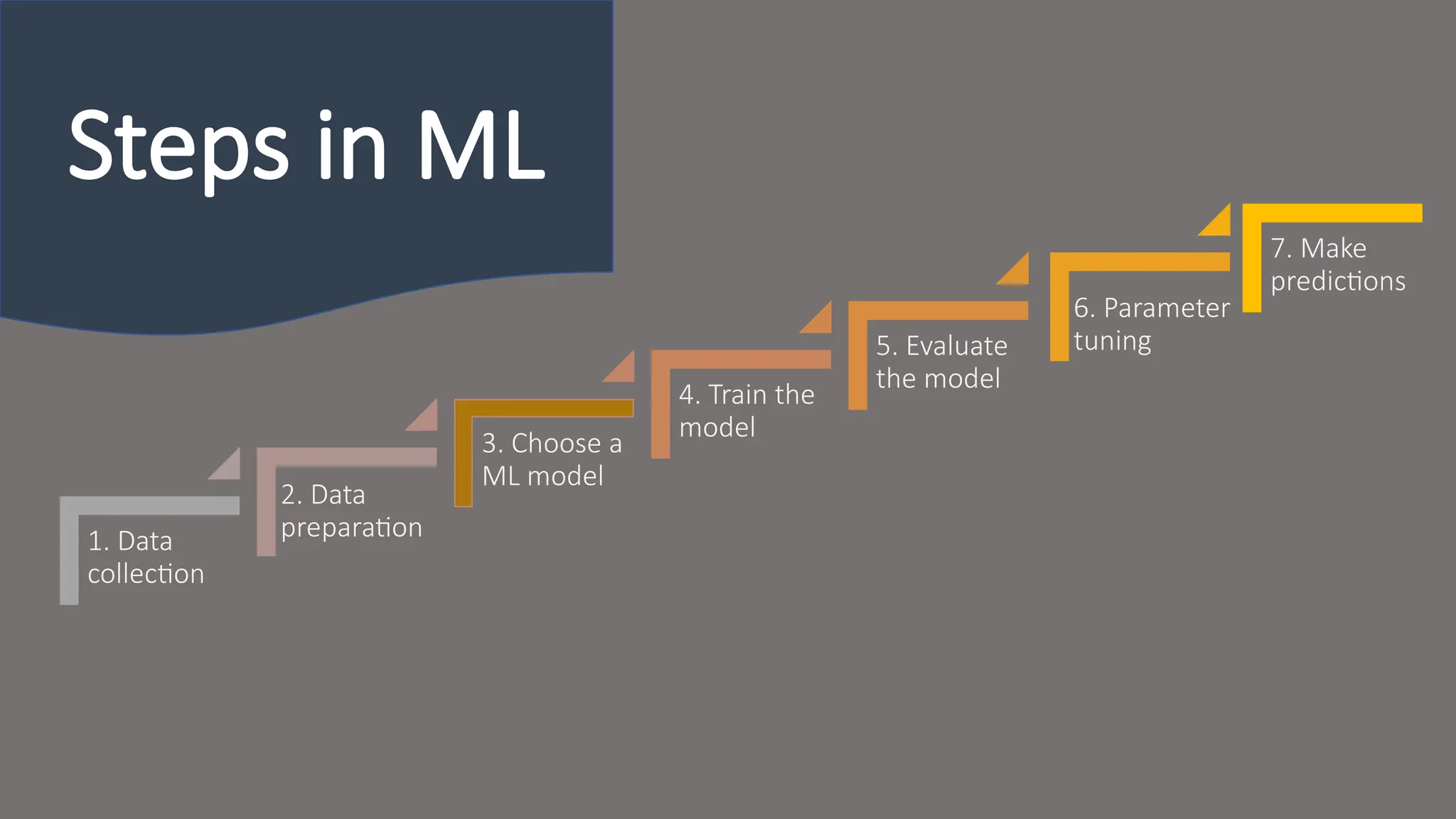
1. Data
collection
Data collectionis the process
of gathering and measuring information
from countless different sources.
This is a critical first step that involves
gathering data from various sources
such as databases, files, and external
repositories.
Before starting the data collection
process, it’s important to articulate the
problem you want to solve with an ML
model.
16.
2. Data
Preparation
Data preparation/pre-processingtechniques
generally refer to the addition, deletion, or
transformation of training set data.
Since the collected data may be in an undesired
format, unorganized, or extremely large, further
steps are needed to enhance its quality. The three
common steps for preprocessing data are
formatting, cleaning, and sampling.
Data preparation (also referred to as
“data preprocessing”) is the process of
transforming raw data so that data scientists and
analysts can run it through machine
learning algorithms to uncover insights or make
predictions.
17.
3. Choose a
MLmodel
Classification:
Random Forest
Decision Tree
Logistic Regression
SVM
Regression:
Linear Regression
Polynomial Regression
Regression Tree
18.
4. Train the
model
Theprocess of training an ML model involves
providing an ML algorithm (that is,
the learning algorithm) with training data to
learn from.
Let's say that you want to train an ML model
to predict if an email is spam or not spam.
You would provide ML model with training
data that contains emails for which you know
the target (that is, a label that tells whether
an email is spam or not spam). Then the
model should be trained by using this data,
resulting in a model that attempts to predict
whether new email will be spam or not
spam.
19.
5. Evaluate
the model
Modelevaluation is a method of assessing the
correctness of models on test data. The test data
consists of data points that have not been seen by
the model before.
There are two methods of evaluating models in
data science, Hold-Out and Cross-Validation.
To avoid overfitting, both methods use a test set
(not seen by the model) to evaluate model
performance.
20.
6. Parameter
Tuning
Each modelhas its own sets of parameters that
need to be tuned to get optimal output.
For every model, our goal is to minimize the error
or say to have predictions as close as possible to
actual values. This is one of the cores or say the
major objective of hyperparameter tuning.
There are following three approaches to
Hyperparameter tuning:
• Manual Search
• Random Search
• Grid Search
21.
7. Make
predictions
“Prediction” refersto the output of an algorithm after
it has been trained on a historical dataset.
Machine learning has two main goals:
prediction and inference.
After you have a model, you can use that model to
generate predictions which means to give your model
the inputs it has never seen before and obtain the
answer the model has predicted.
In addition to making predictions on new data, you can
use machine-learning models to better understand the
relationships between the input features and the
output target which is known as inference.
22.
• Traffic Alerts
•Social Media
• Transportation and Commuting
• Products Recommendations
• Virtual Personal Assistants
• Self Driving Cars
• Dynamic Pricing
• Google Translate
• Online Video Streaming
• Fraud Detection
Applications
Of
ML
































































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)