















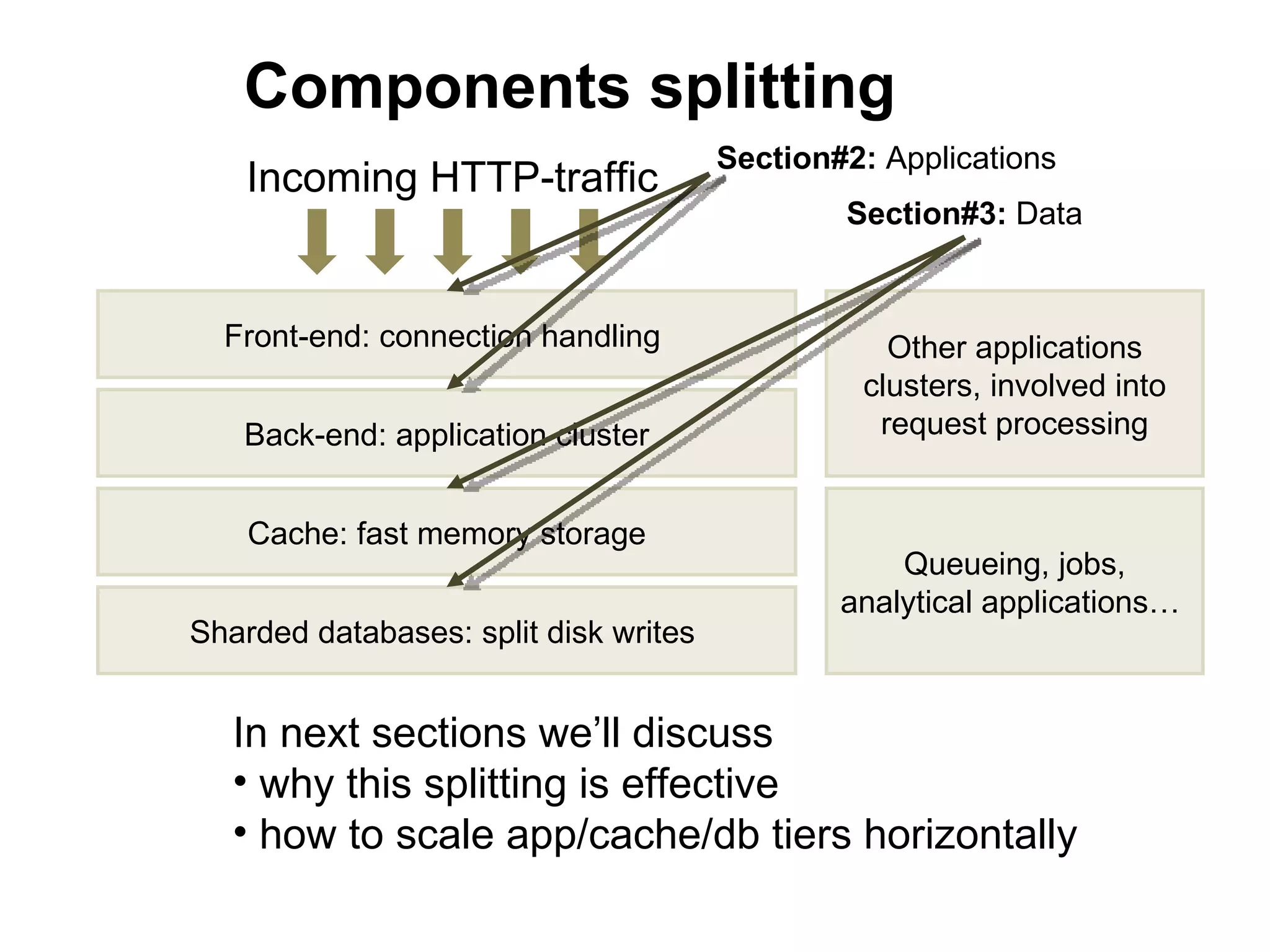






![[front/back]end
• What does web-server do?
• Executes script code
• Serves client
• Hey, does cook talk to restaurant
customers?
• These tasks are different, split to
frontend/backend
• nginx + Apache with mod_php, mod_perl,
mod_python
• nginx + FCGI (for example, php-fpm)](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-29-2048.jpg)
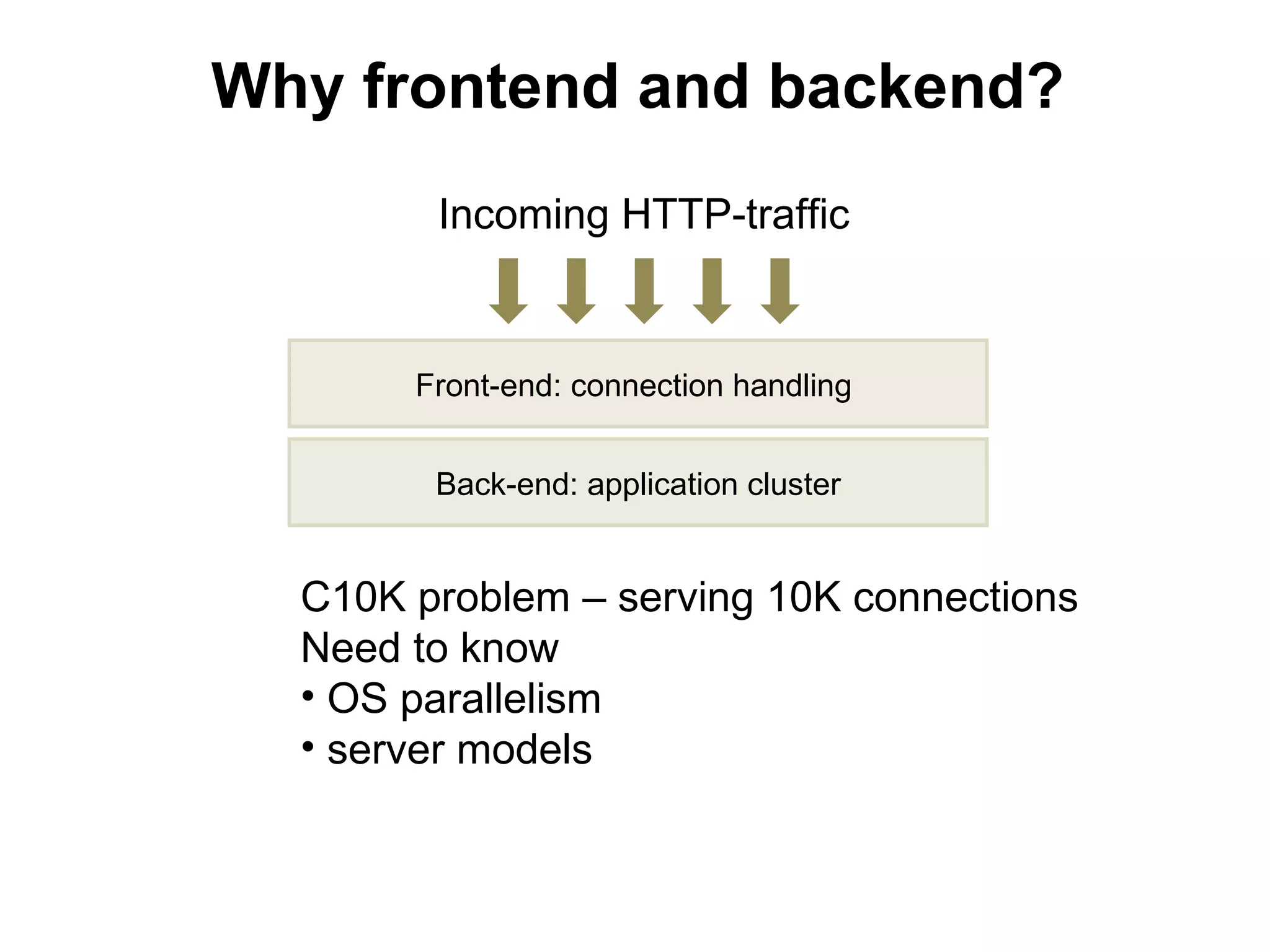
![[front/back]end
Heavy-weight server (HWS)
Light-weight server (LWS)
Apache
mod_php,
nginx mod_perl,
mod_python
FastCGI
«fast» and «slow» clients static content;
can do simple
scripting (SSI, perl) dynamic content](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-30-2048.jpg)
![[front/back]end: scaling
B • homogeneous tiers
(maintenance)
F
• round-robin balancing
B (weighted, WRRB)
• WRRB means there’s no
SLB F “state”
B • key to simplest horizontal
scaling:
6)don’t store any “state” on the
box
7)weak coupling
F B](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-31-2048.jpg)


![nginx: fastcgi
upstream backend {
server www1.lan:8080 weight=2;
server www2.lan:8080;
}
server {
location / {
fastcgi_index index.phtml;
fastcgi_param [param] [value]
...
fastcgi_pass backend;
}
}](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-35-2048.jpg)

























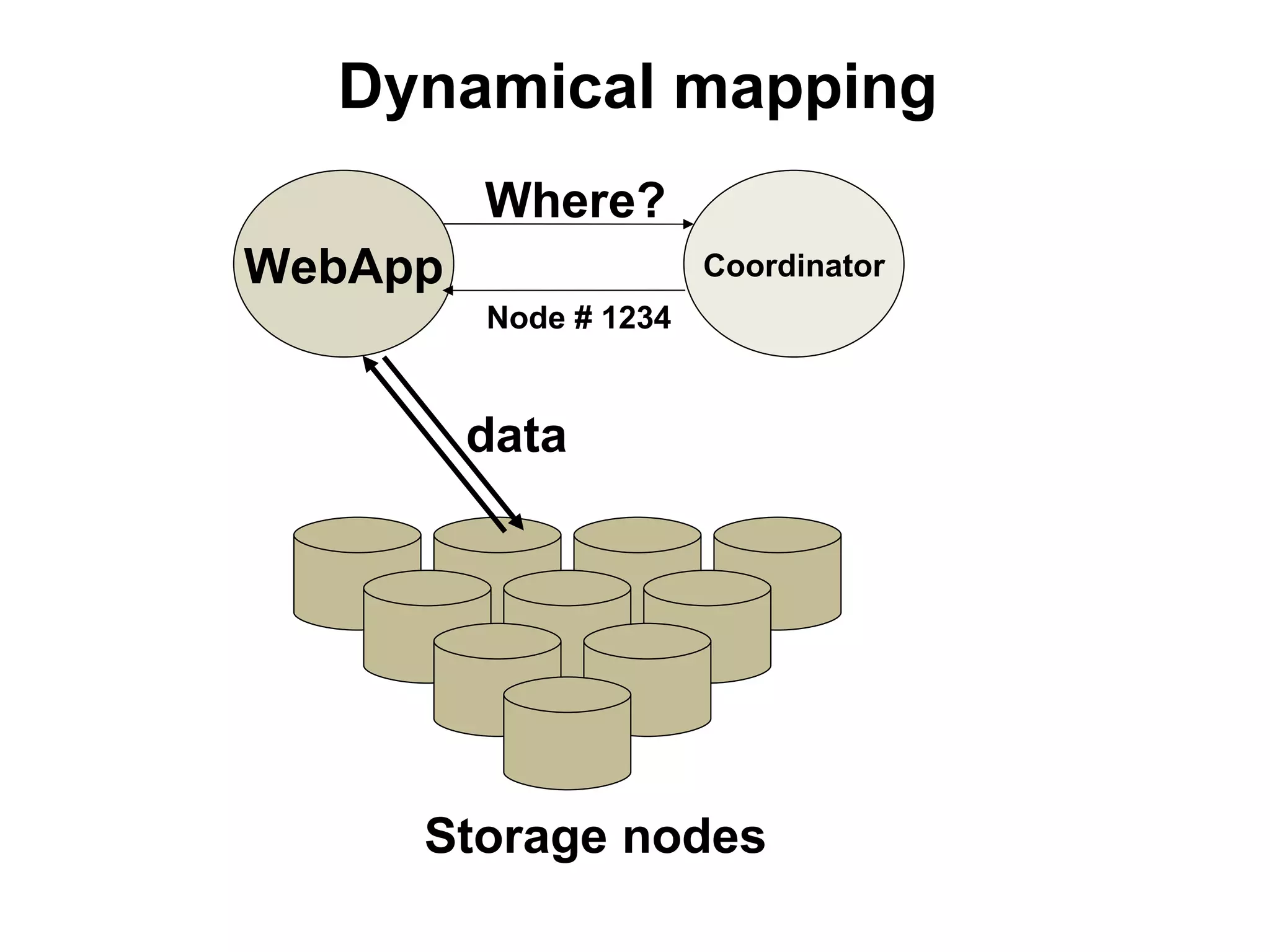
![Mapping data to shard
• primary attribute: user_id, document_id …
• unmanaged: id -> hash%N -> server
• better: virtual buckets
• id -> hash%N -> bucket -> [C] -> server
• buckets: user -> bucket is determined by formula
• best, “dynamical”: user -> bucket can be configurable
• “dynamical”: id -> [C1] -> bucket -> [C2] -> server
• configuration: C1 – “dynamical”, C2 – almost static](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-64-2048.jpg)



















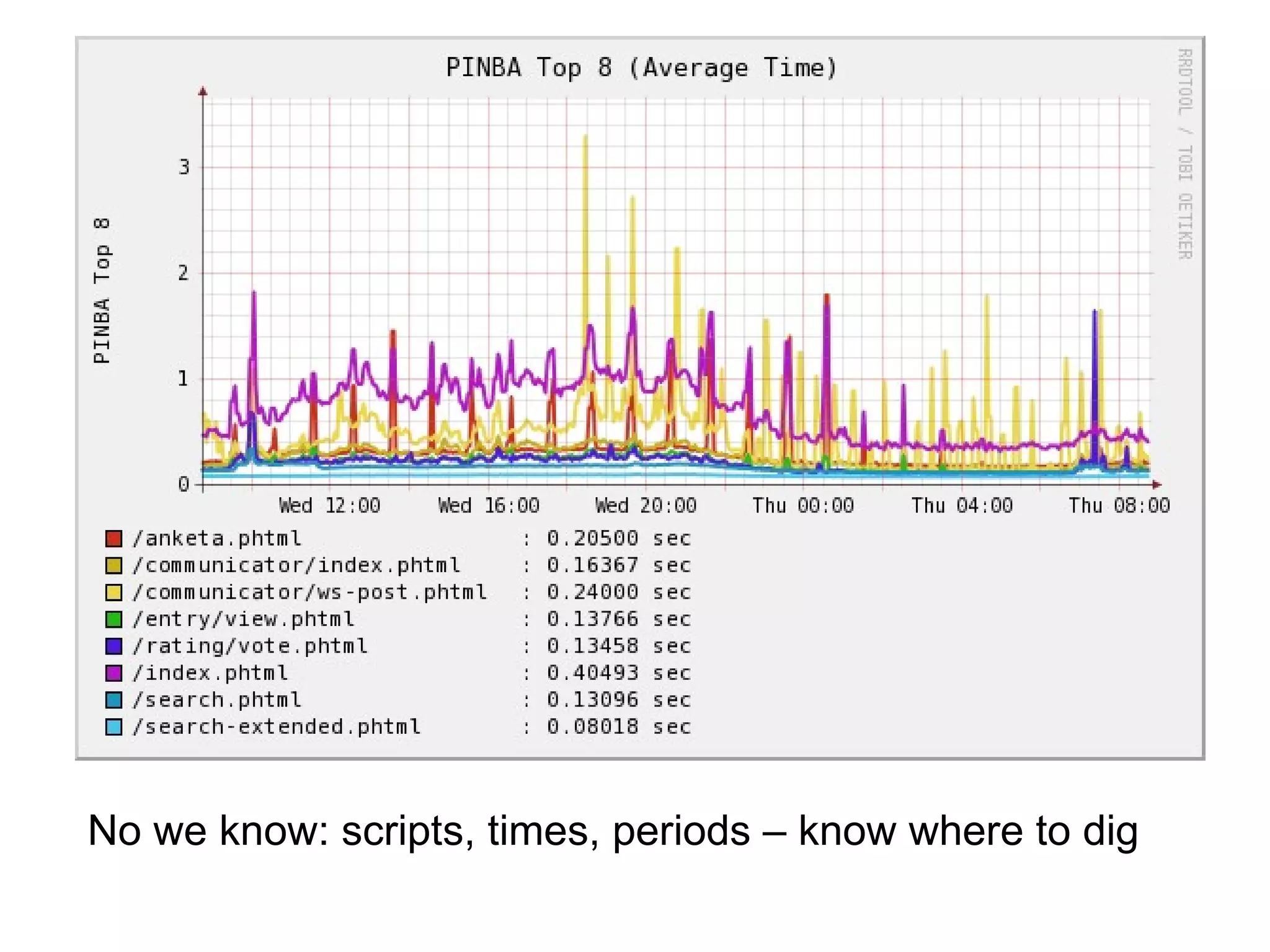
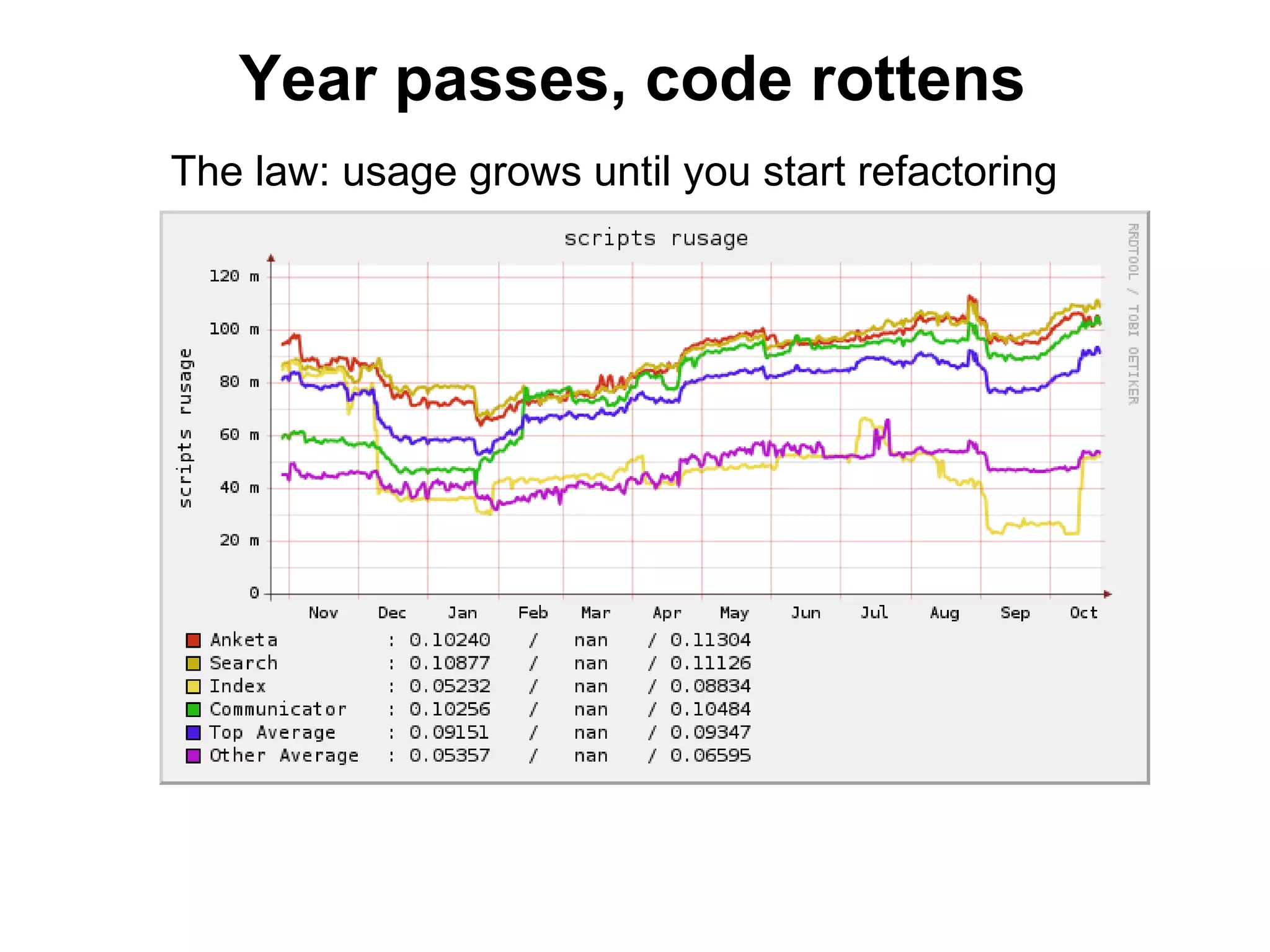
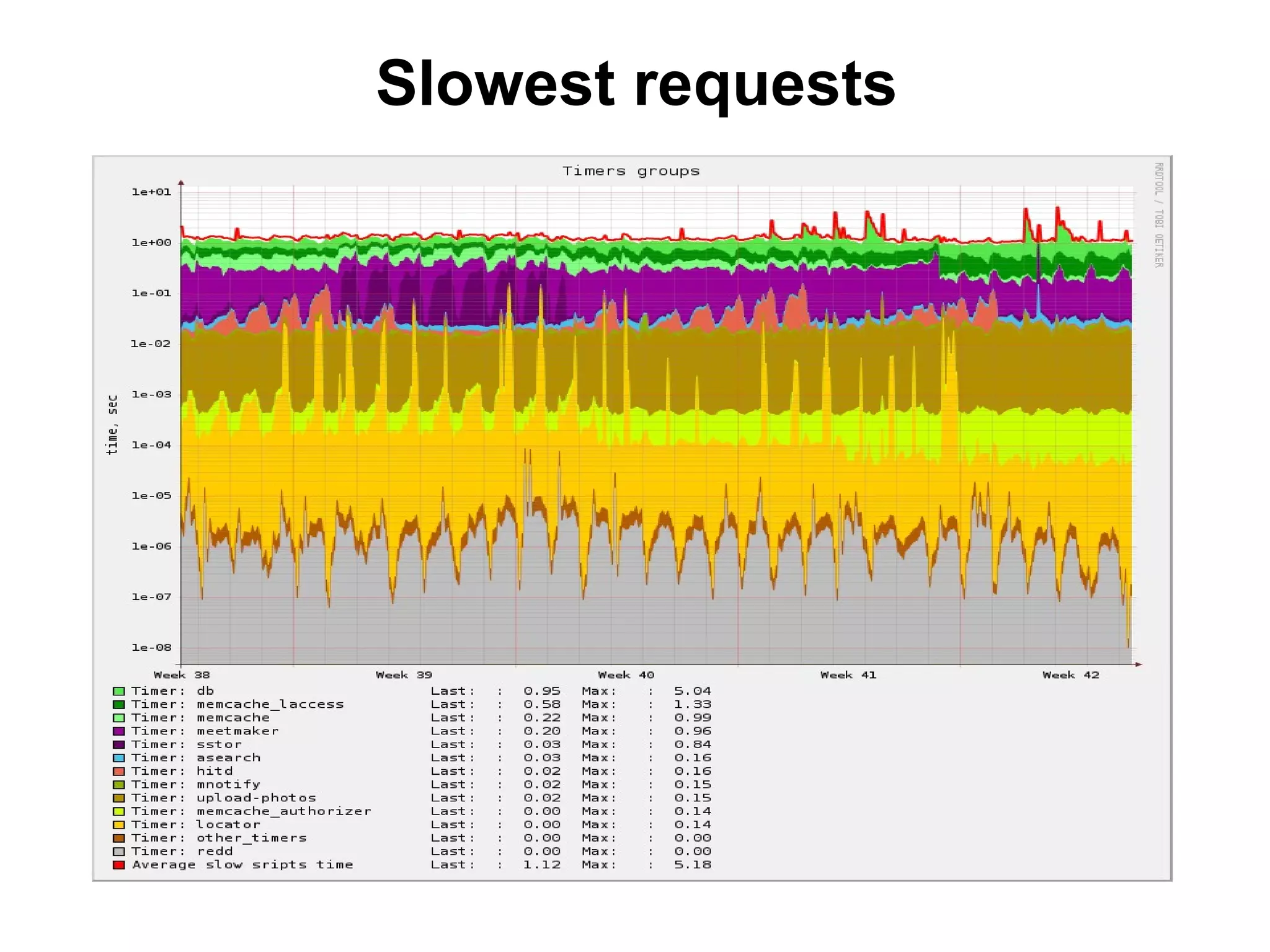

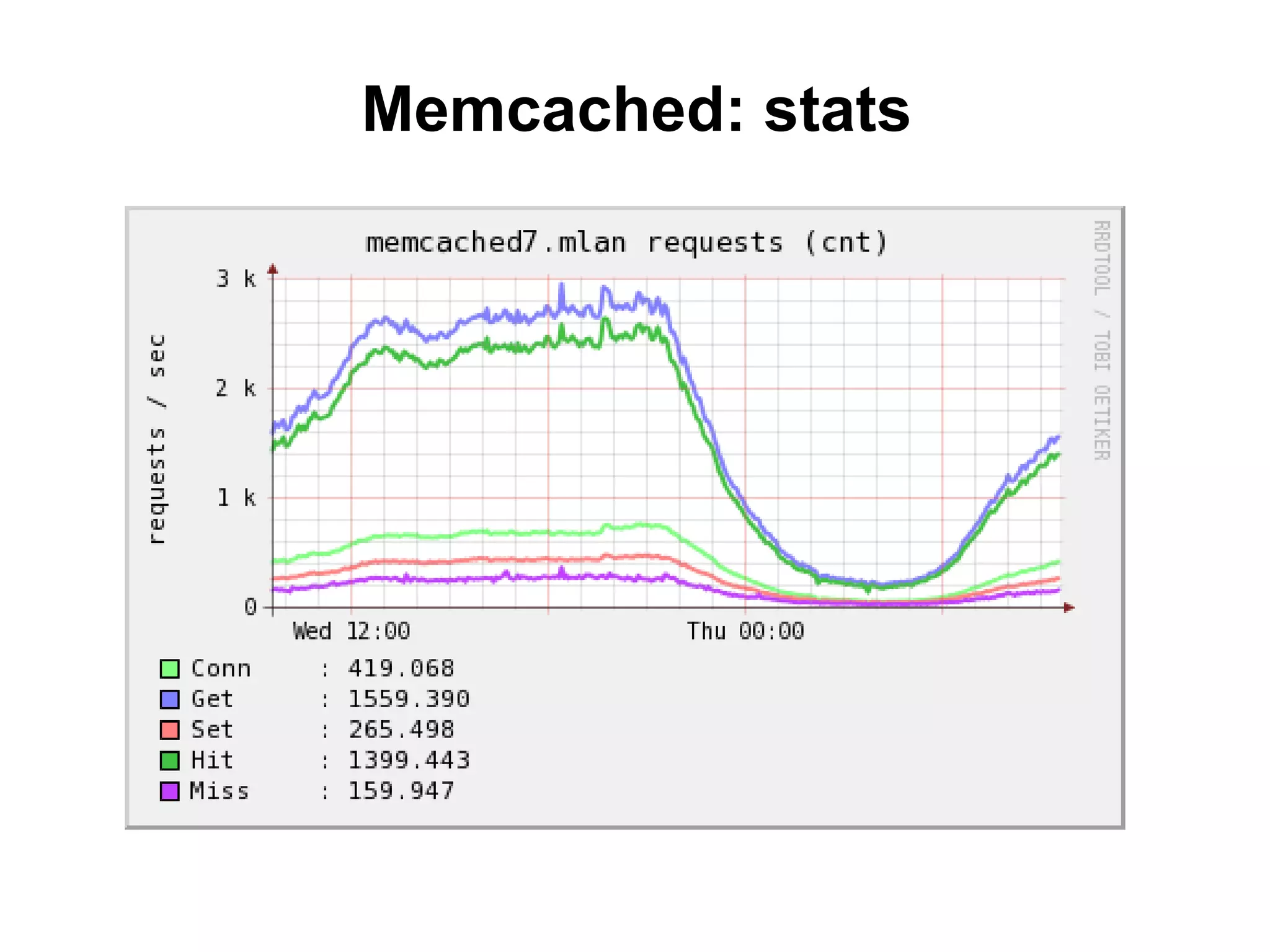
![Cachedump (1/4)
17th slab = 128 K
stats cachedump 17
ITEM uin_search_ZHJhZ29uXzIwMDM0QGhvdG1haWwuY29t [65470
b; 1272983719 s]
ITEM uin_search_YW5nZWw1dHJpYW5hZEBob3RtYWlsLmNvbQ==
[65529 b; 1272974774 s]
ITEM unreaded_contacts_count_55857620 [83253 b; 1272498369 s]
ITEM antispam_gui_1676698422010-04-17 [83835 b; 1271677328 s]
ITEM antispam_gui_1708317782010-04-15 [123400 b; 1271523593 s]
ITEM psl_24139020 [65501 b; 1271335111 s]
END](https://image.slidesharecdn.com/devconf2012-tutorial-rybak-120616042113-phpapp01/75/Large-scale-projects-development-scaling-LAMP-95-2048.jpg)








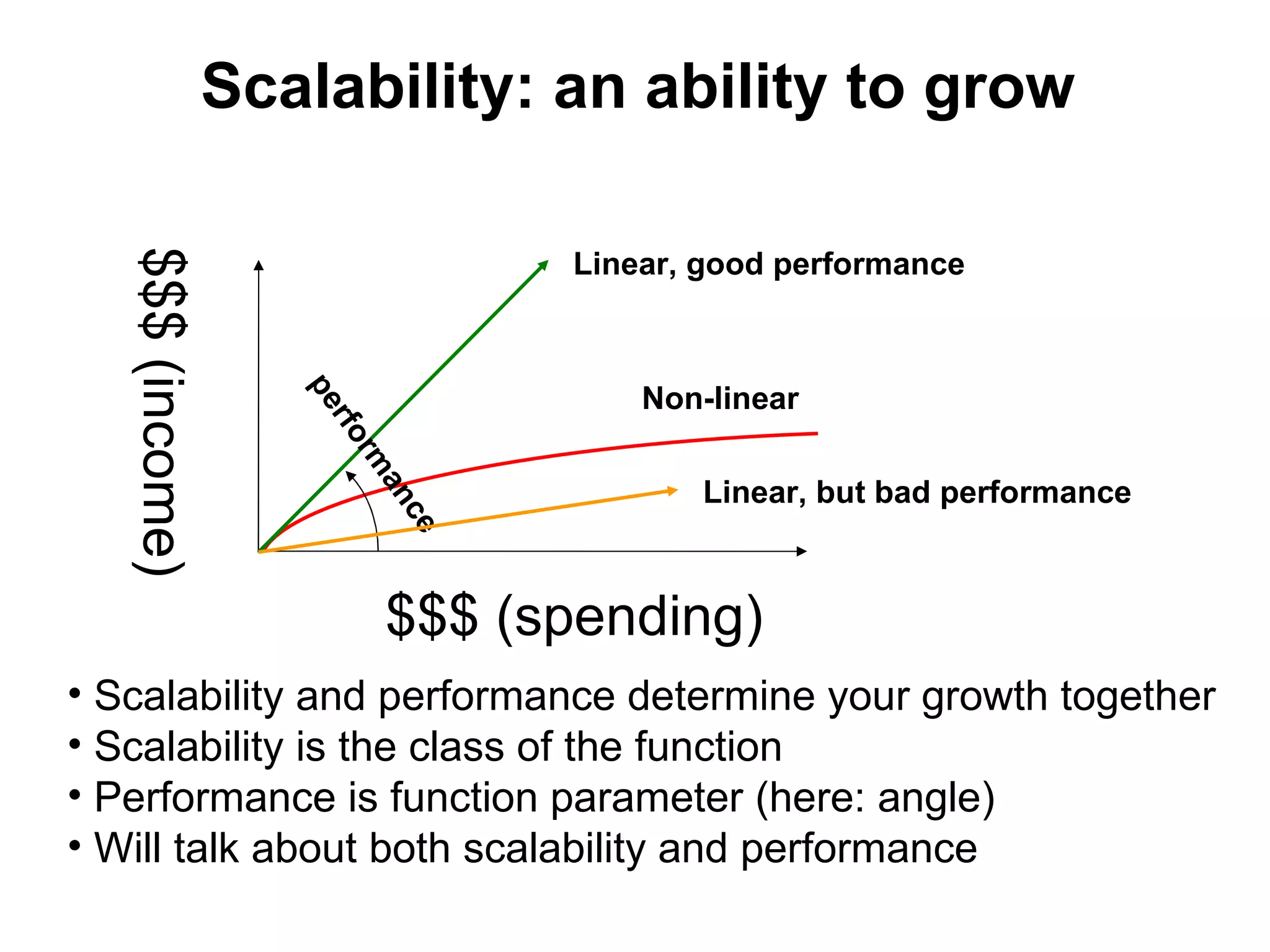
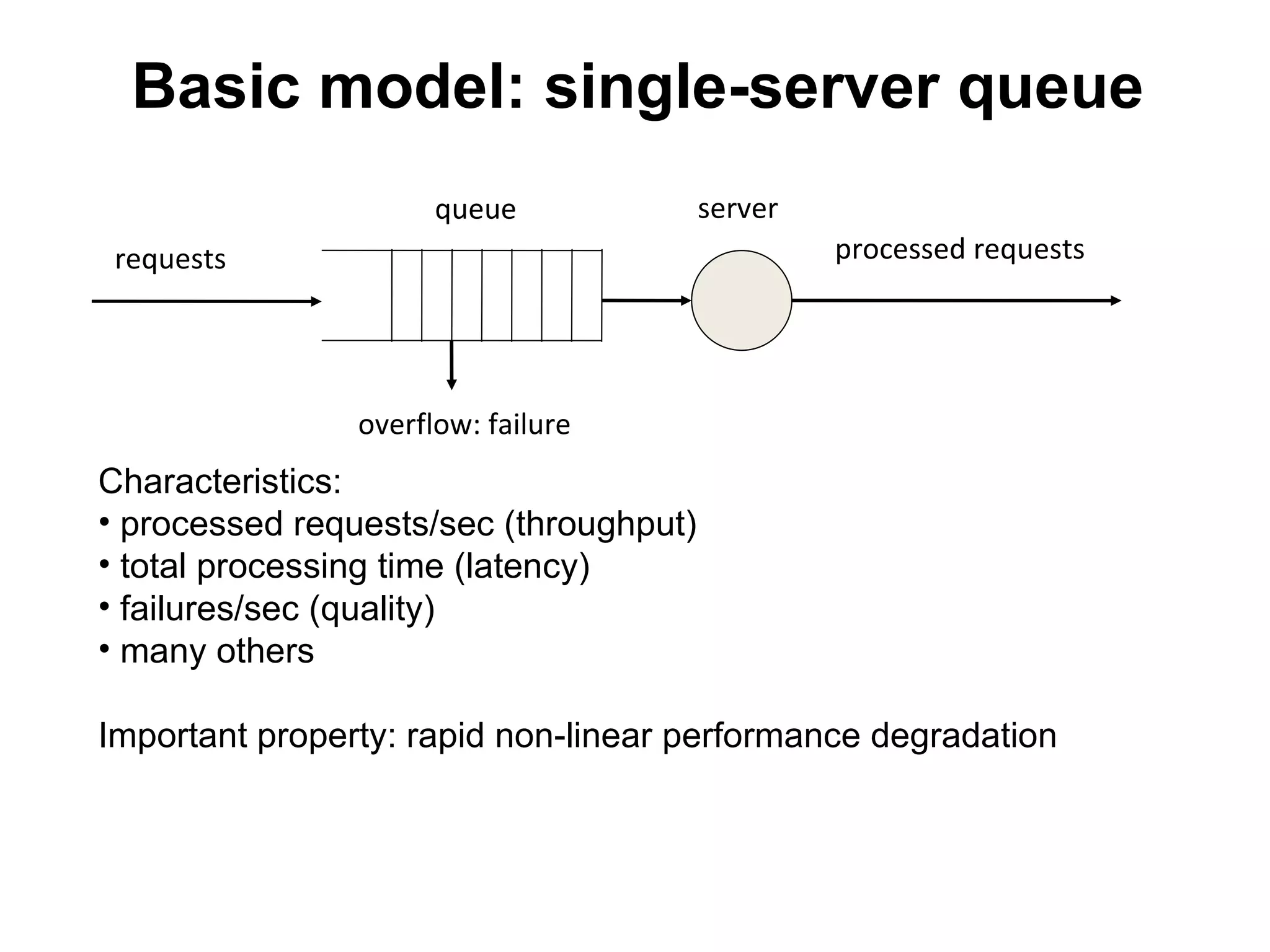
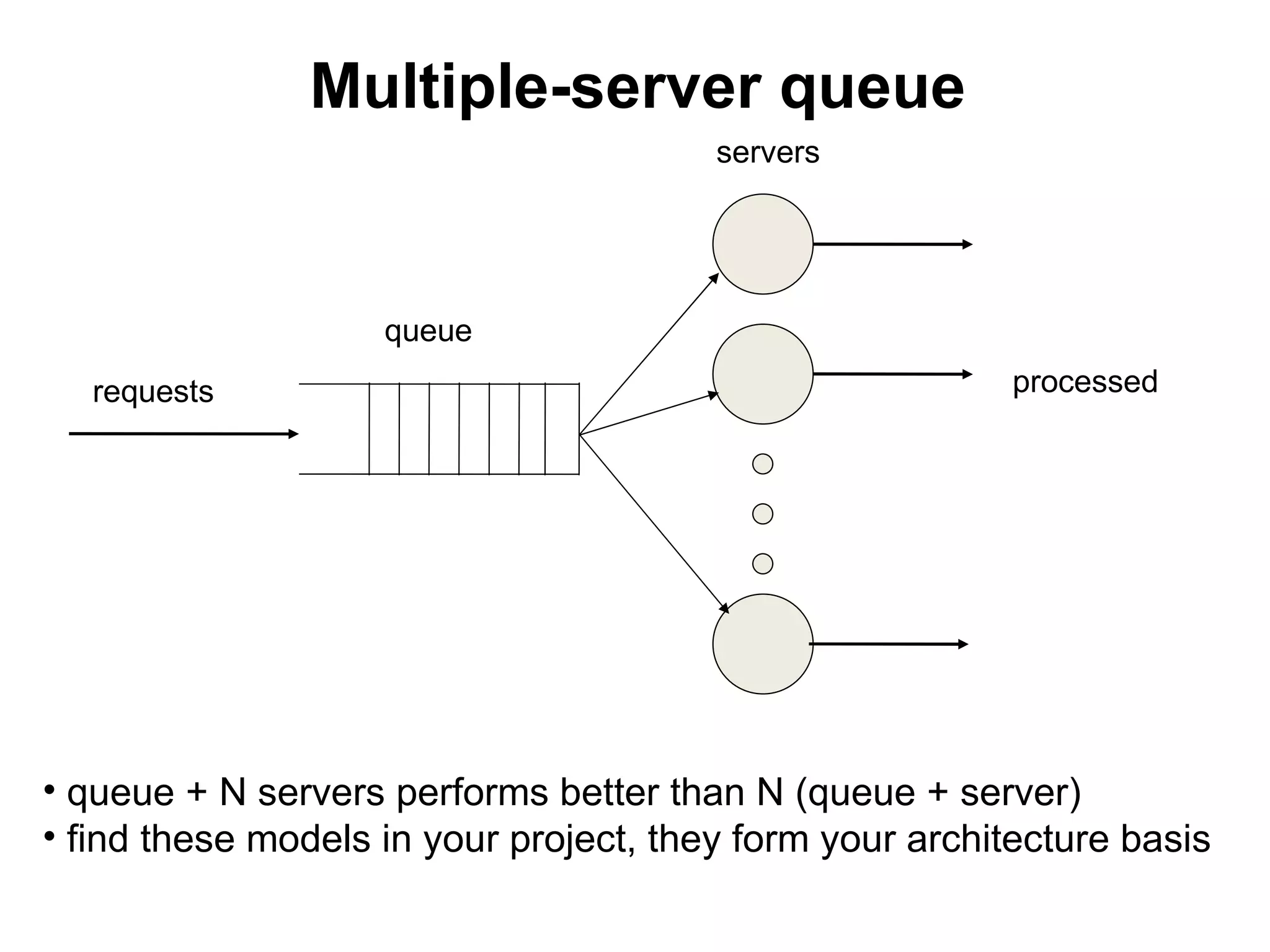
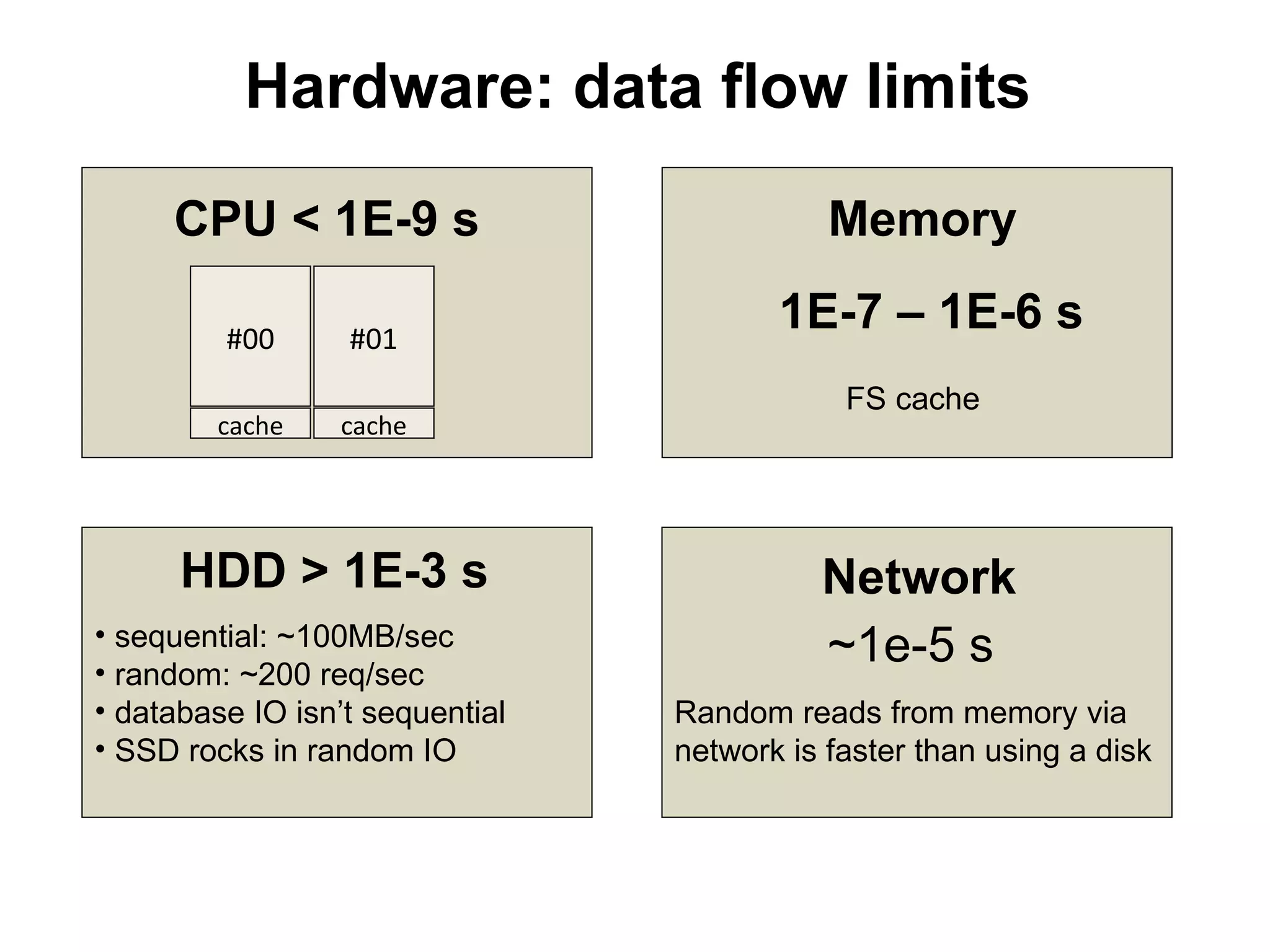
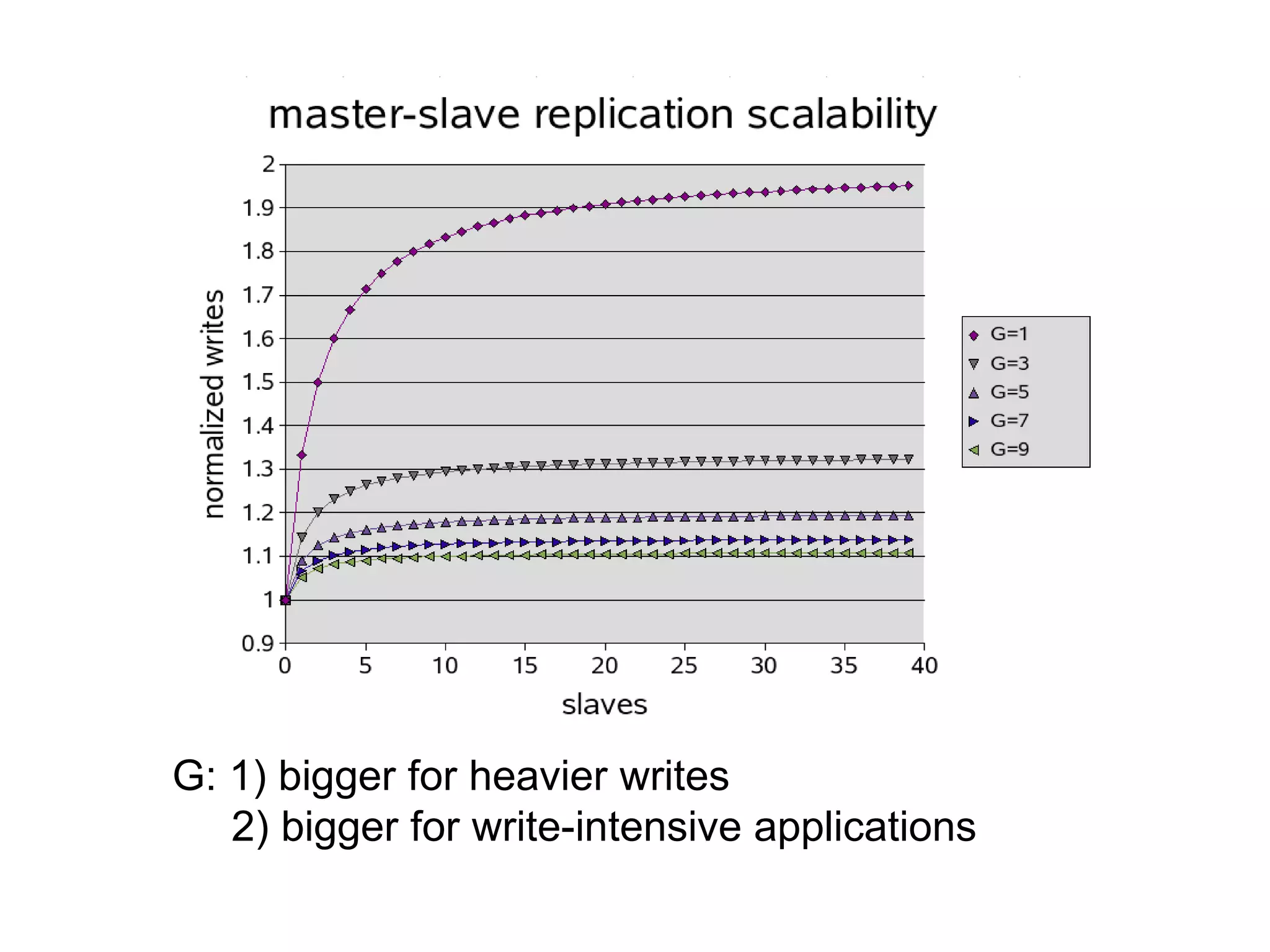
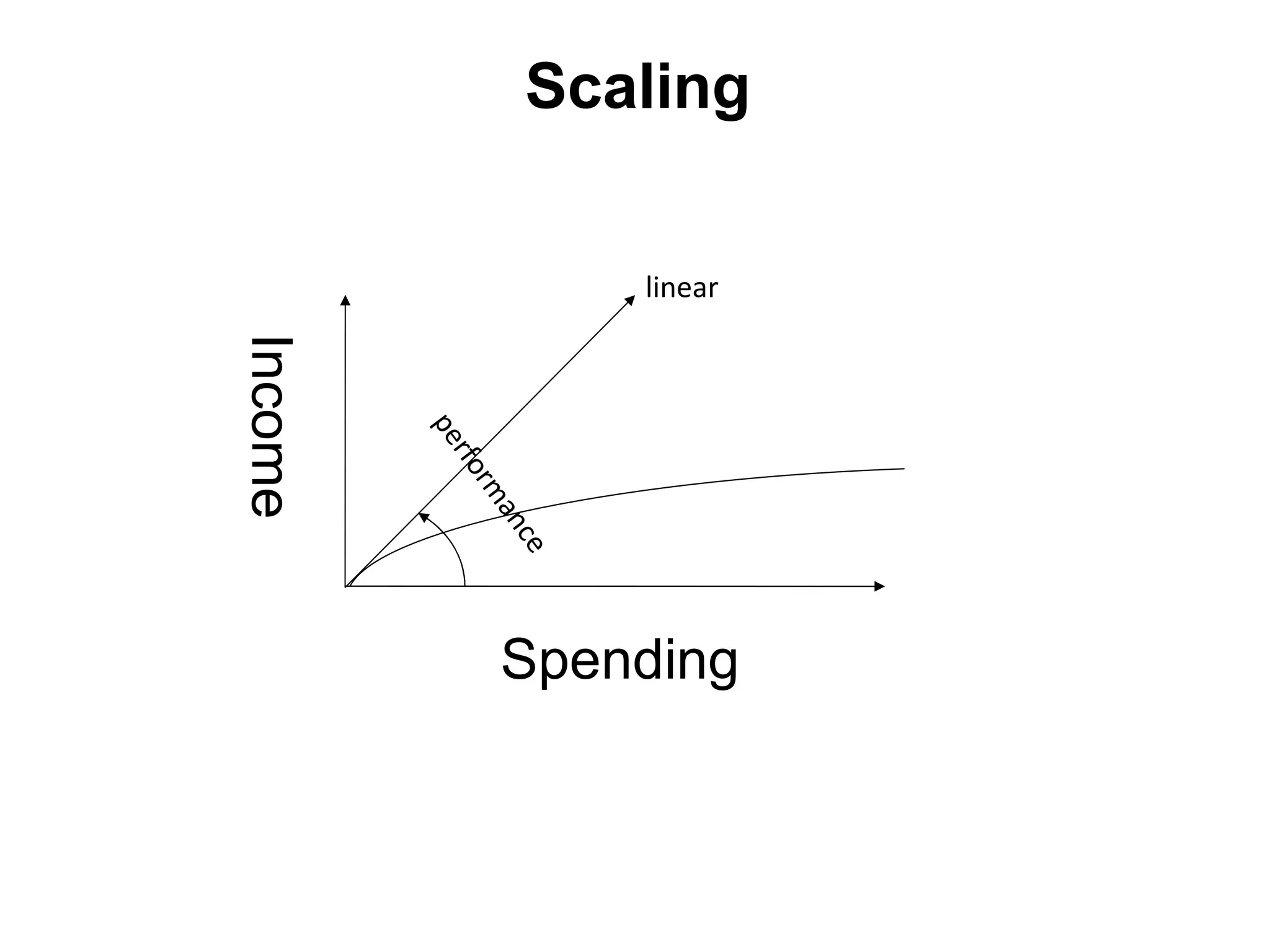
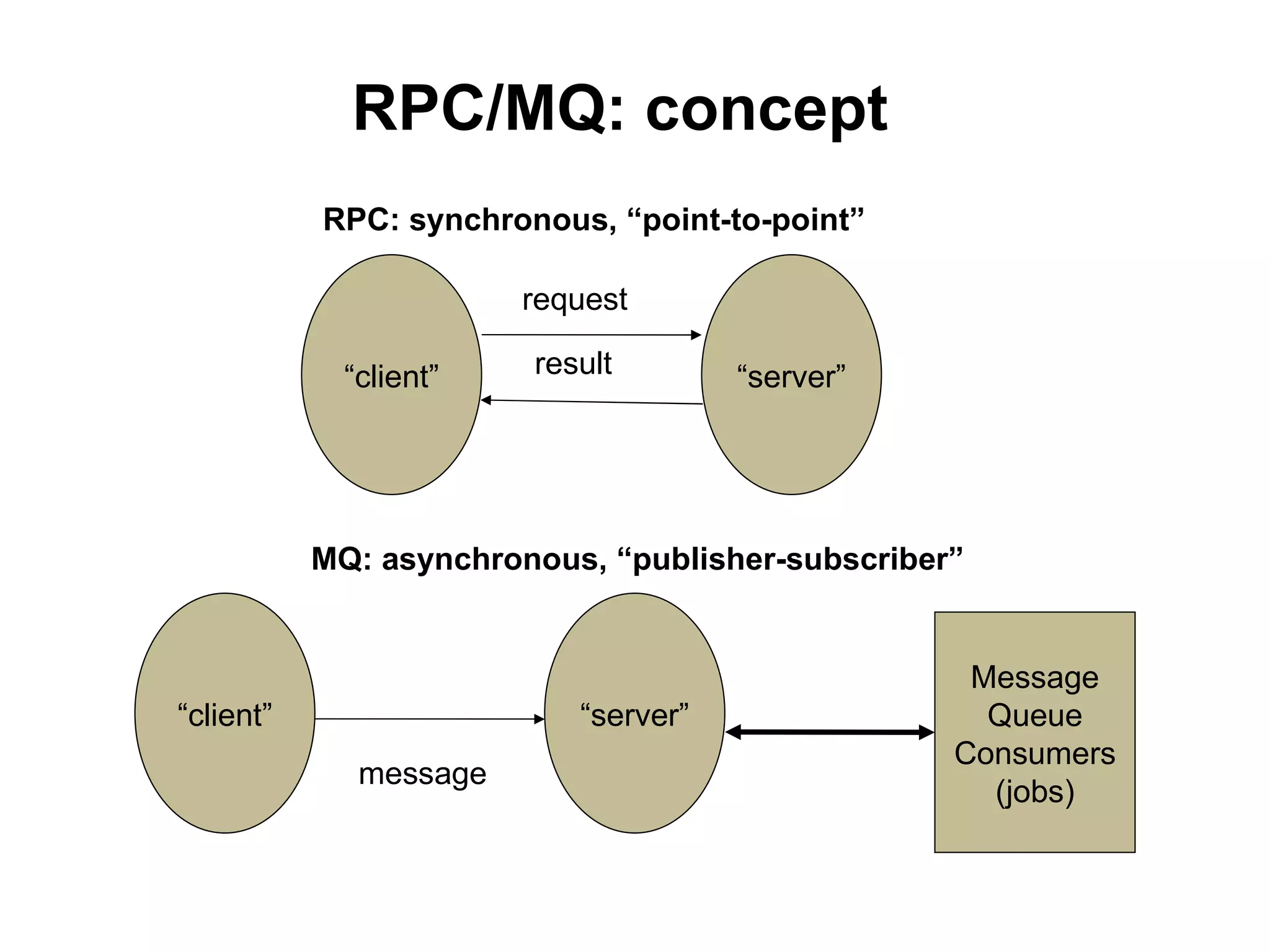
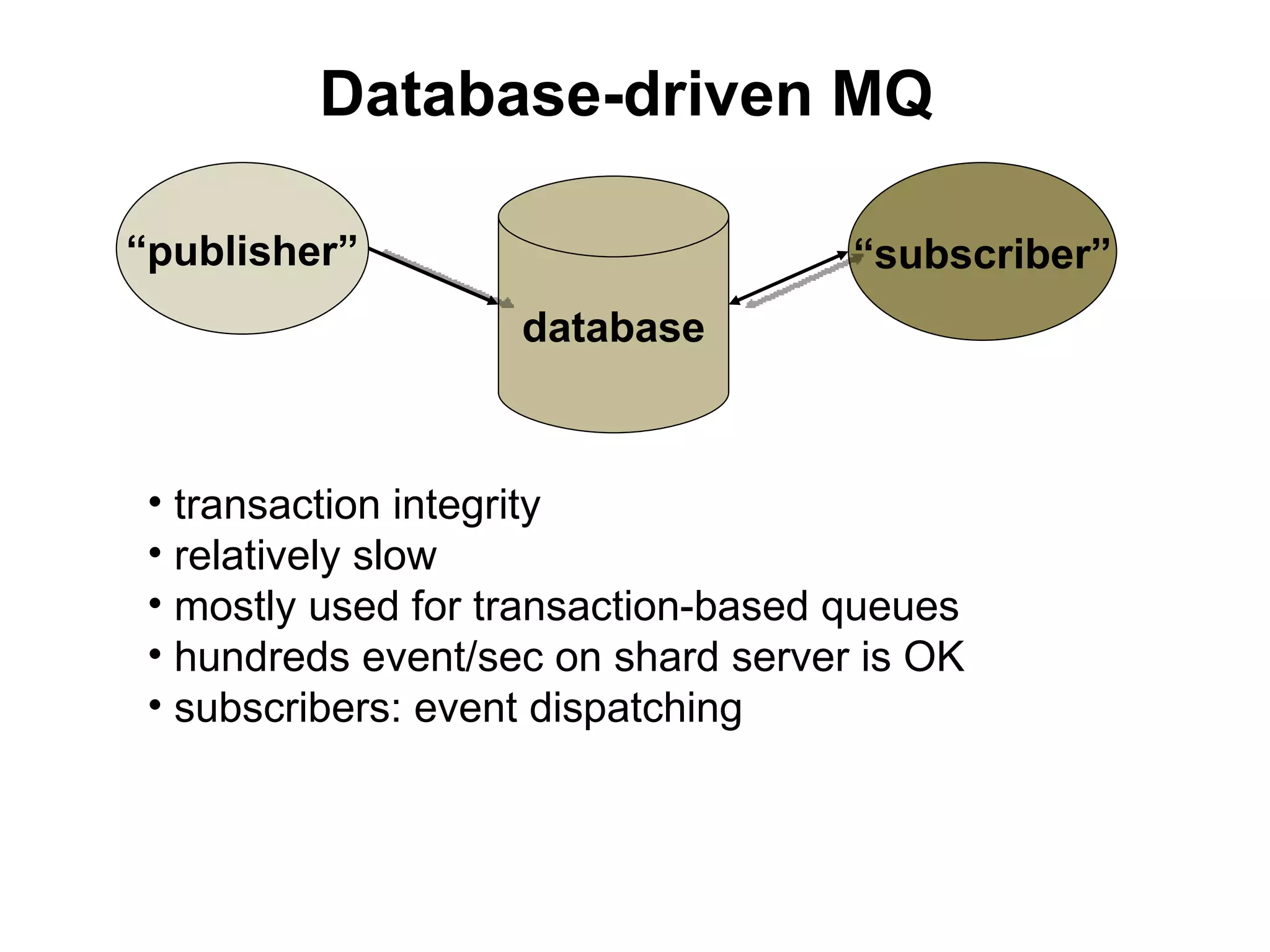
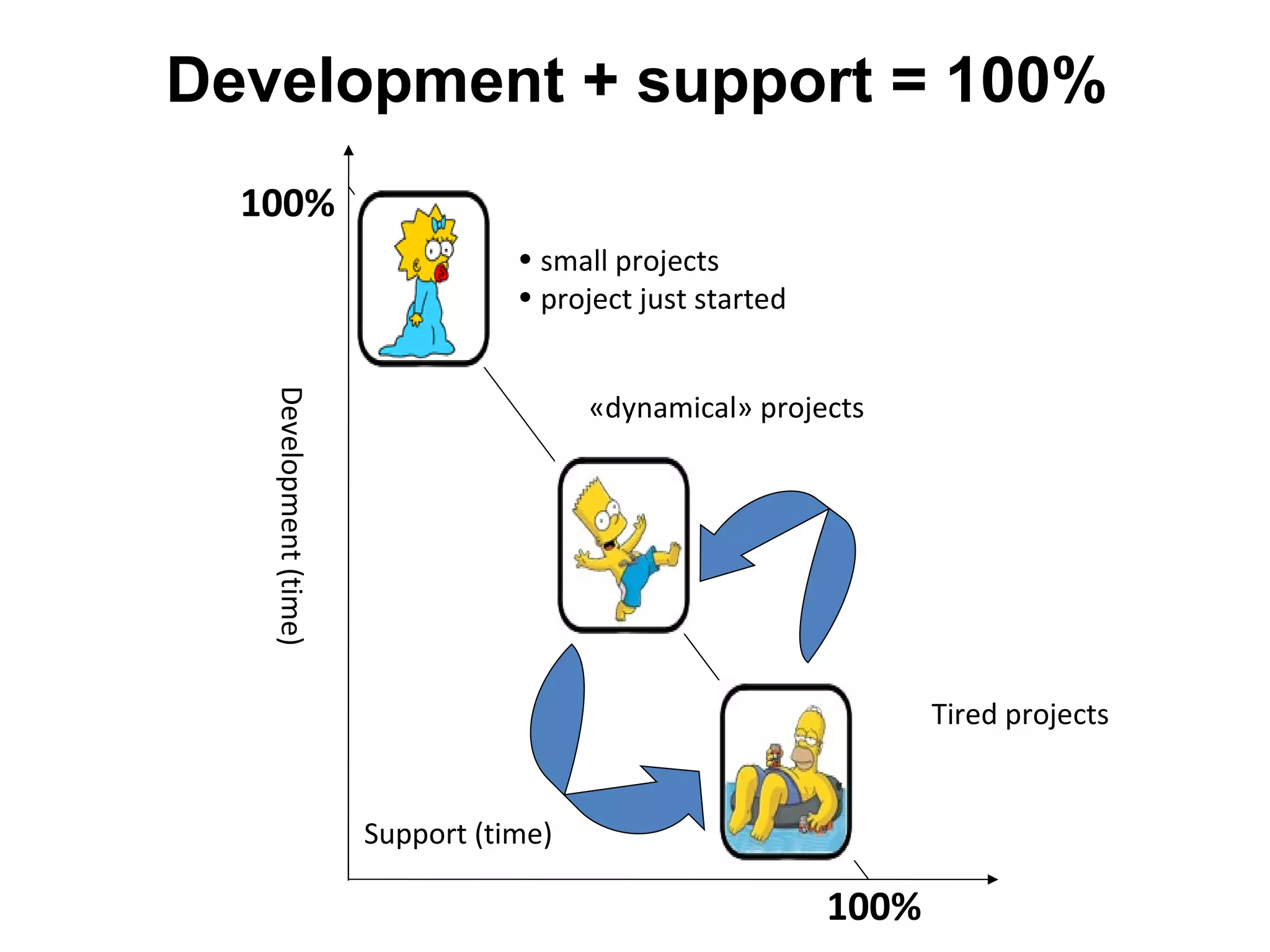
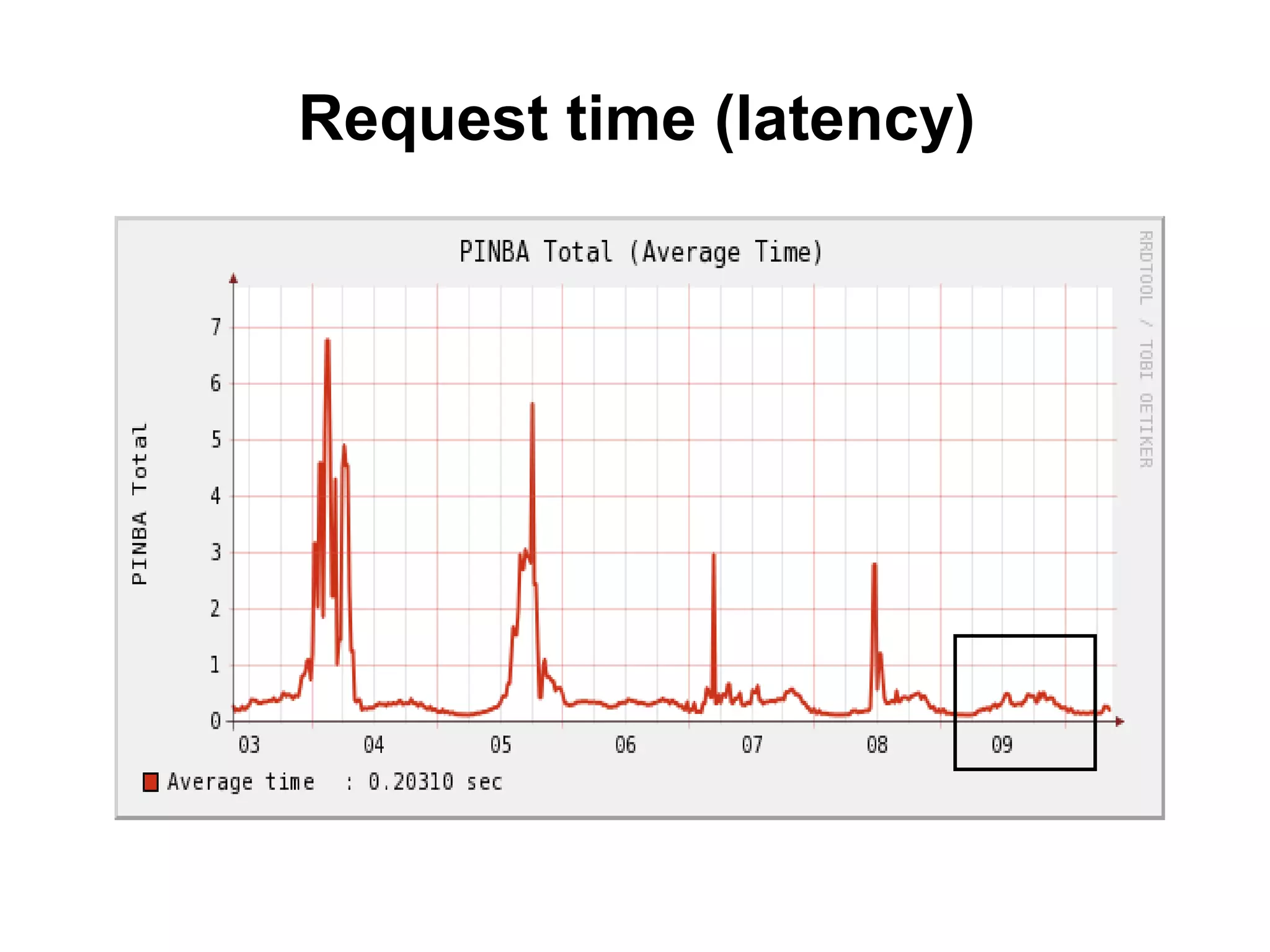
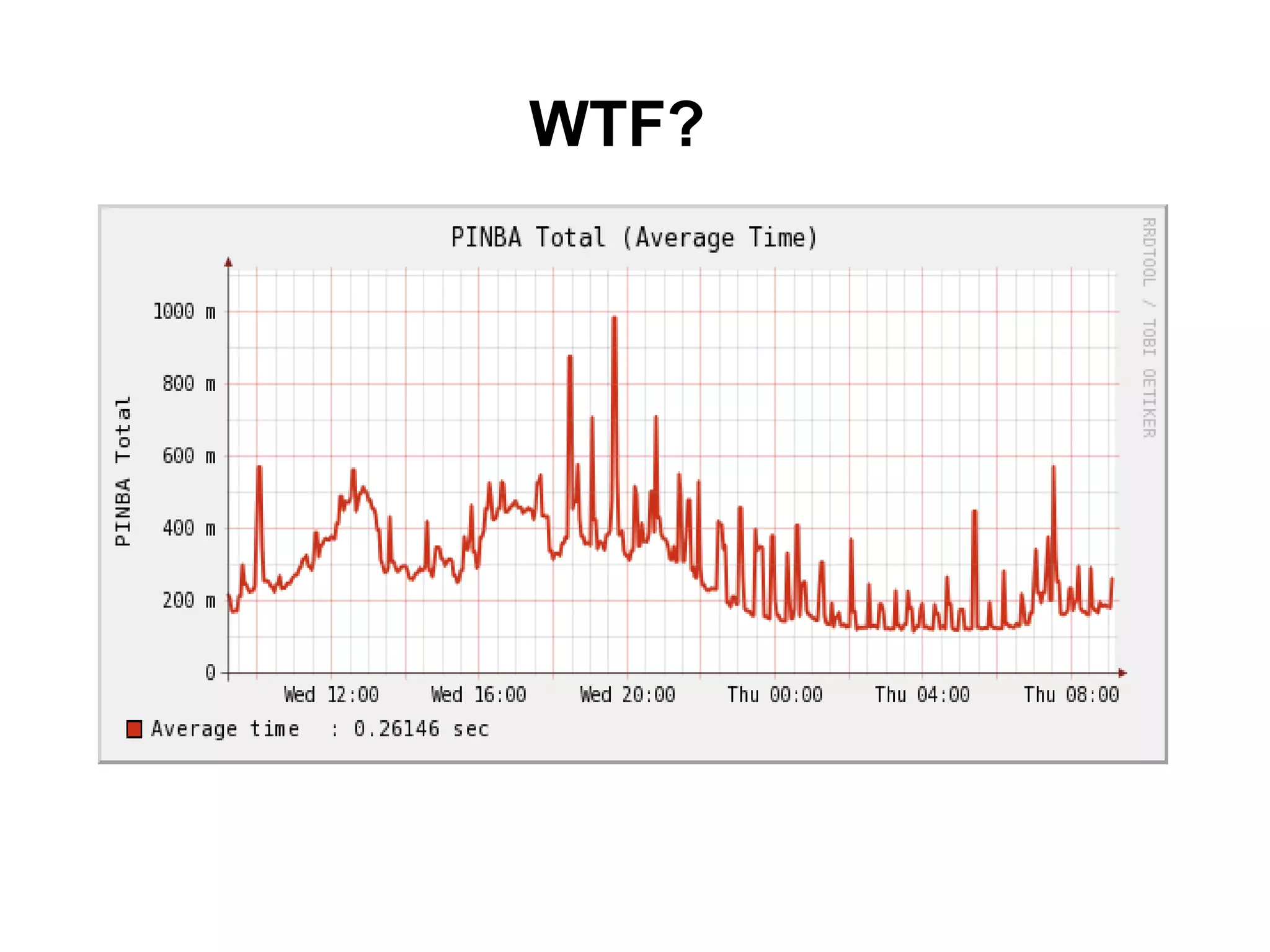
The tutorial by Alexey Rybak discusses the fundamentals of large-scale project development and system design, highlighting the importance of understanding scalability, performance, and effective component coupling. It covers various technical aspects including web/application layers, queues, caching strategies, database performance, and sharding for data distribution. The tutorial emphasizes practical approaches to managing architecture for high availability and reliability in large systems.
























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









