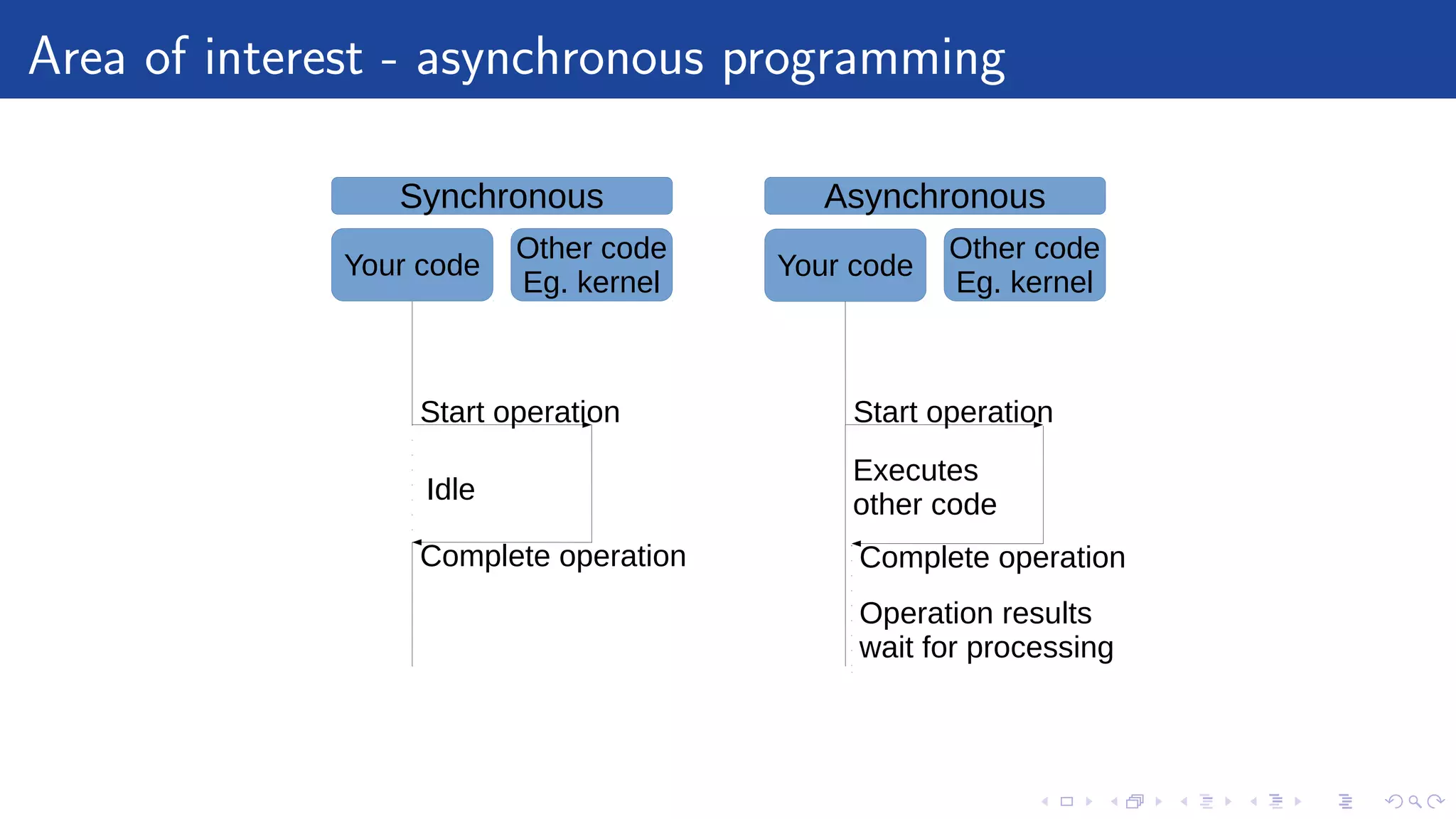
The document discusses different approaches to asynchronous programming, focusing on callbacks, promises, and coroutines. It outlines the limitations of callbacks, the advantages of promises in structuring code and flow control, and the benefits of coroutines for readability and error handling. Each approach is illustrated with examples to highlight their pros and cons in handling asynchronous operations.








![Maintenance is hell
https://en.wikipedia.org/wiki/Scribe#/media/File:Escribano.jpg [1]](https://image.slidesharecdn.com/kamilwiteckiasynchronousyetreadablecode-170418105117/75/Kamil-witecki-asynchronous-yet-readable-code-9-2048.jpg)























![Approach #2: flow control
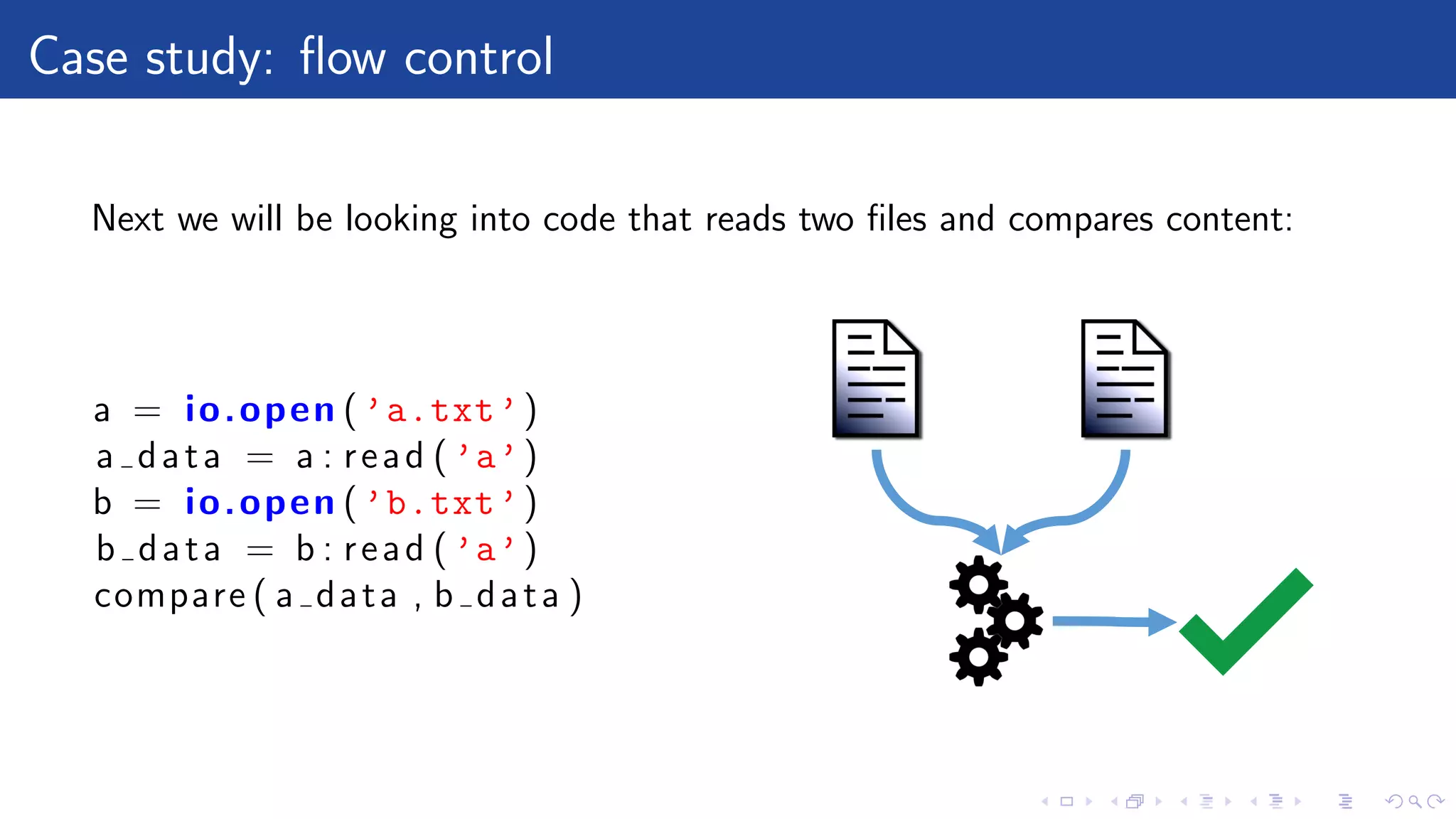
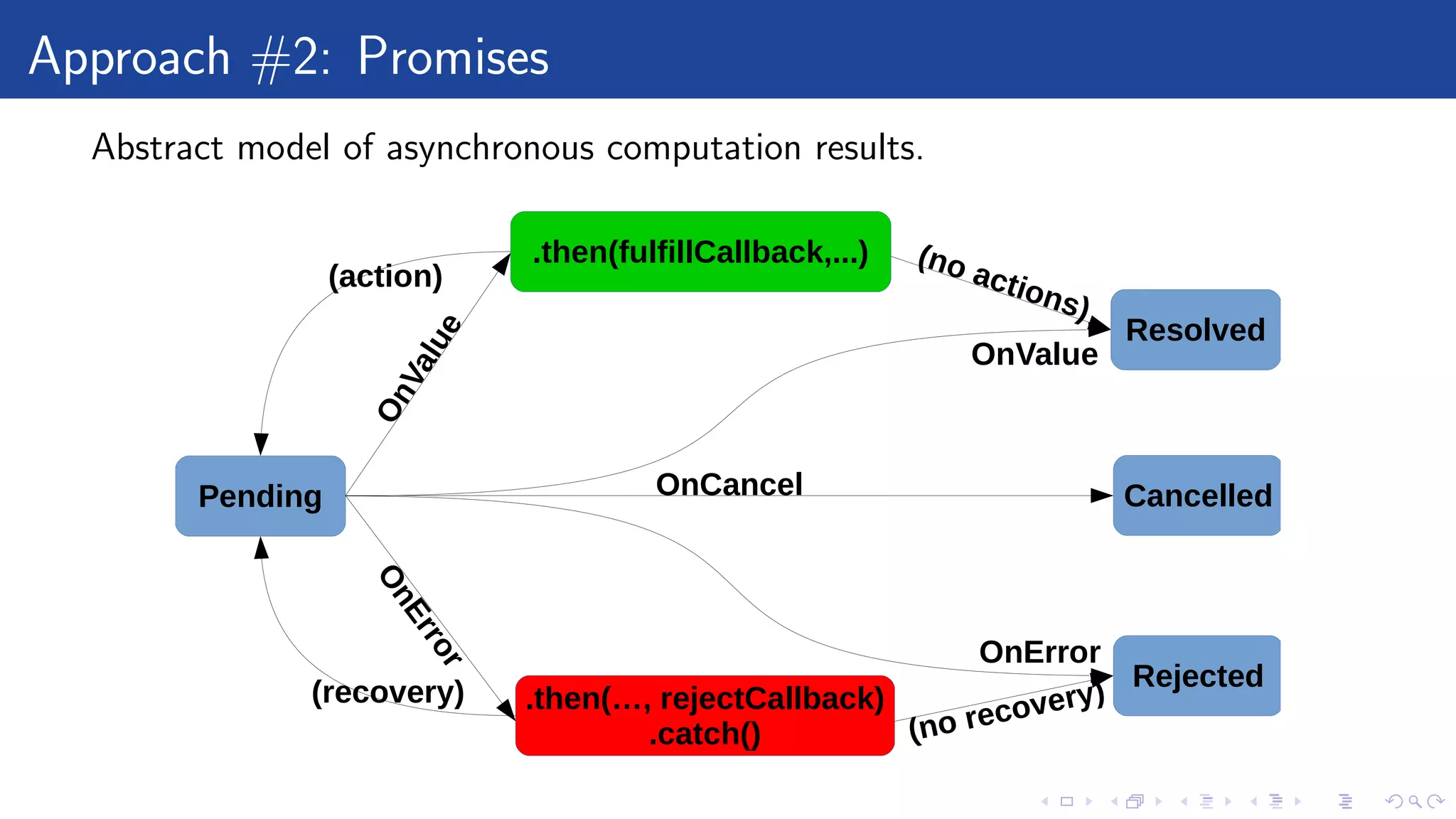
Promises are abstract model of computation. Therefore it is possible to build
flow control with them. For example:
c(a(paramsOfA), b(paramsOfB))
becomes:
l o c a l a = f s . readAsync ("a.txt")
l o c a l b = f s . readAsync ("b.txt")
d e f e r r e d . a l l ({a , b } ) : next ( function ( r e s u l t s )
return c ( r e s u l t s [ 0 ] , r e s u l t s [ 1 ] )
end )](https://image.slidesharecdn.com/kamilwiteckiasynchronousyetreadablecode-170418105117/75/Kamil-witecki-asynchronous-yet-readable-code-38-2048.jpg)


![Approach #2: What about callstacks? II
Still not so good:
Unhandled r e j e c t i o n TypeError : path must be a s t r i n g
at TypeError ( n a t i v e )
at Object . f s . s t a t ( f s . j s : 7 8 3 : 1 1 )
at Object . t r y C a t c h e r ( node modules b l u e b i r d j s r e l e a s e u t i l . j s : 1 6 : 2 3 )
at Object . r e t [ as statAsync ] ( e v a l at <anonymous> ( node modules b l u e b i r d j s r e l e a s e p r o m i s i f y . j s : 1 8 4 : 1 2 ) , <a
at t e s t . j s : 5 : 1 3
at t r y C a t c h e r ( node modules b l u e b i r d j s r e l e a s e u t i l . j s : 1 6 : 2 3 )
at Promise . settlePromiseFromHandler ( node modules b l u e b i r d j s r e l e a s e promise . j s : 5 0 9 : 3 1 )
at Promise . s e t t l e P r o m i s e ( node modules b l u e b i r d j s r e l e a s e promise . j s : 5 6 6 : 1 8 )
at Promise . s e t t l e P r o m i s e 0 ( node modules b l u e b i r d j s r e l e a s e promise . j s : 6 1 1 : 1 0 )
at Promise . s e t t l e P r o m i s e s ( node modules b l u e b i r d j s r e l e a s e promise . j s : 6 9 0 : 1 8 )
at Promise . f u l f i l l ( node modules b l u e b i r d j s r e l e a s e promise . j s : 6 3 5 : 1 8 )
at node modules b l u e b i r d j s r e l e a s e nodeback . j s : 4 2 : 2 1
at FSReqWrap . oncomplete ( f s . j s : 9 5 : 1 5 )
test.js:4-5
function b( f i l e ) { return function ()
{ return f s . statAsync ( f i l e )}}](https://image.slidesharecdn.com/kamilwiteckiasynchronousyetreadablecode-170418105117/75/Kamil-witecki-asynchronous-yet-readable-code-41-2048.jpg)







![Approach #3: Coroutines
http://www.boost.org/doc/libs/1 60 0/libs/coroutine/doc/html/coroutine/intro.html [2]](https://image.slidesharecdn.com/kamilwiteckiasynchronousyetreadablecode-170418105117/75/Kamil-witecki-asynchronous-yet-readable-code-49-2048.jpg)



![Approach #3: What about callstacks? II
> l u v i t . exe c o r o u t i n e s . lua
deps / coro−f s . lua : 4 4 : bad argument #1 to ’ f s s t a t ’
( s t r i n g expected , got f u n c t i o n )
stack traceback :
t e s t . lua : 1 0 : in f u n c t i o n <t e s t . lua :10>
[C ] : in f u n c t i o n ’ f s s t a t ’
deps / coro−f s . lua : 4 4 : in f u n c t i o n ’ bug ’
t e s t . lua : 4 : in f u n c t i o n ’ bug ’
t e s t . lua : 8 : in f u n c t i o n <t e s t . lua :6>
[C ] : in f u n c t i o n ’ x p c a l l ’
t e s t . lua : 6 : in f u n c t i o n <t e s t . lua :6>
coroutines.lua:6,8
coroutine.wrap ( function () xpcall ( function ()
bug ()](https://image.slidesharecdn.com/kamilwiteckiasynchronousyetreadablecode-170418105117/75/Kamil-witecki-asynchronous-yet-readable-code-53-2048.jpg)


























![[FT-11][suhorng] “Poor Man's” Undergraduate Compilers](https://cdn.slidesharecdn.com/ss_thumbnails/poormansundergraduatecompilers-140421081114-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![Empty Base Class Optimisation, [[no_unique_address]] and other C++20 Attributes](https://cdn.slidesharecdn.com/ss_thumbnails/emptybaseattributespublic-200727061030-thumbnail.jpg?width=640&height=640&fit=bounds)











































