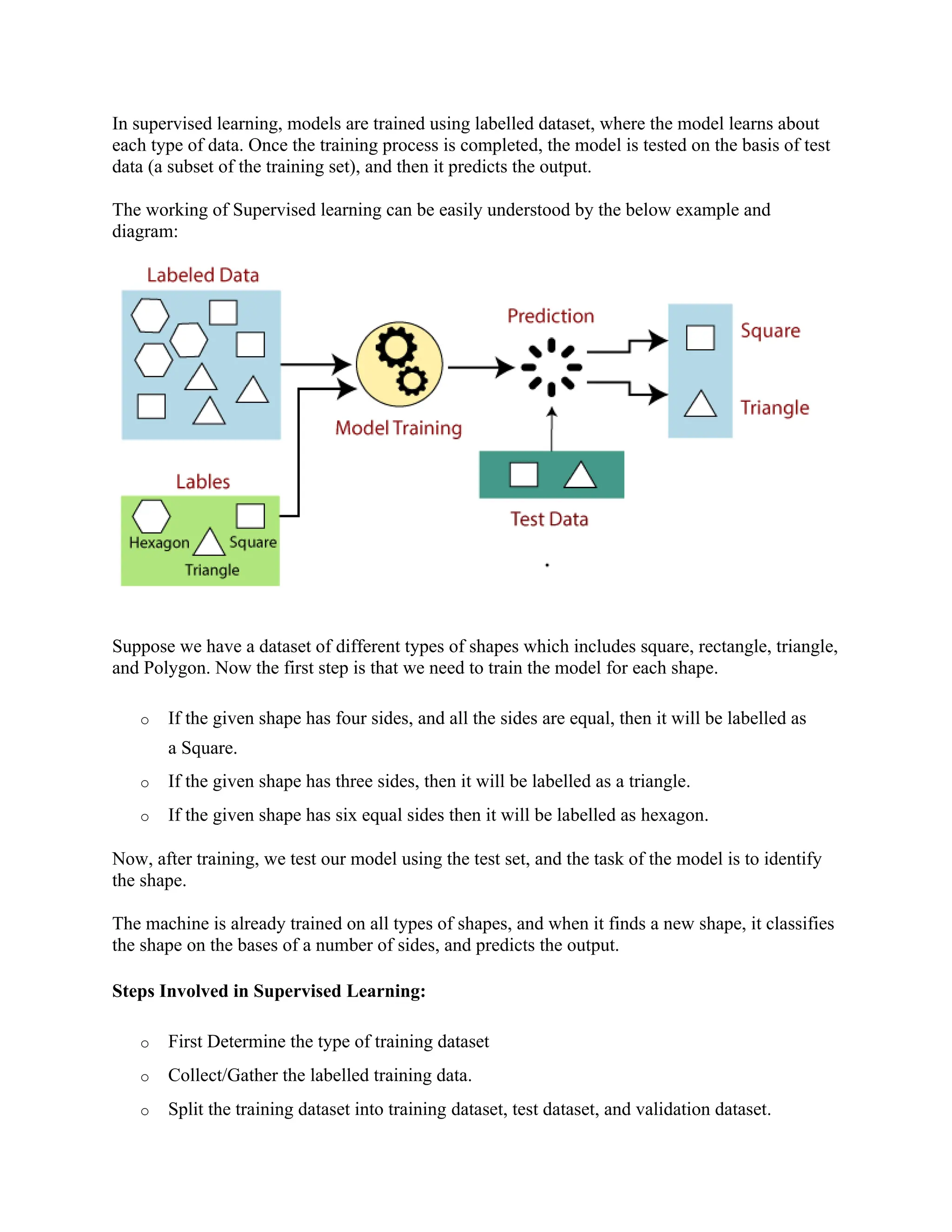
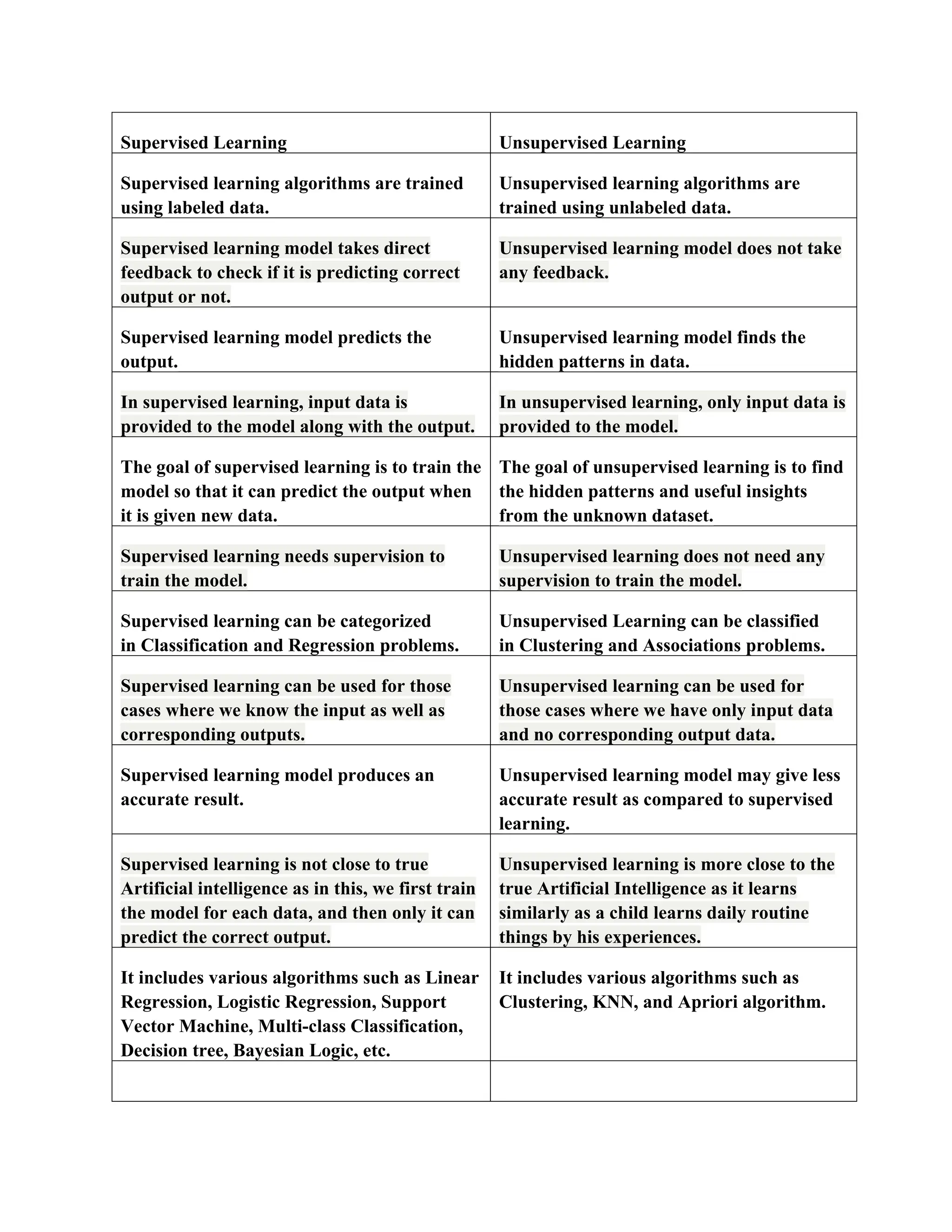
Machine learning is a subset of artificial intelligence that enables computers to automatically learn from past data, improving their performance and making predictions without explicit programming. It encompasses various approaches, including supervised, unsupervised, and reinforcement learning, with applications in image recognition, fraud detection, and recommendation systems. The performance of machine learning algorithms is highly dependent on the quality and quantity of data provided, making it essential for solving complex tasks and uncovering patterns in large datasets.