Download as PDF, PPTX













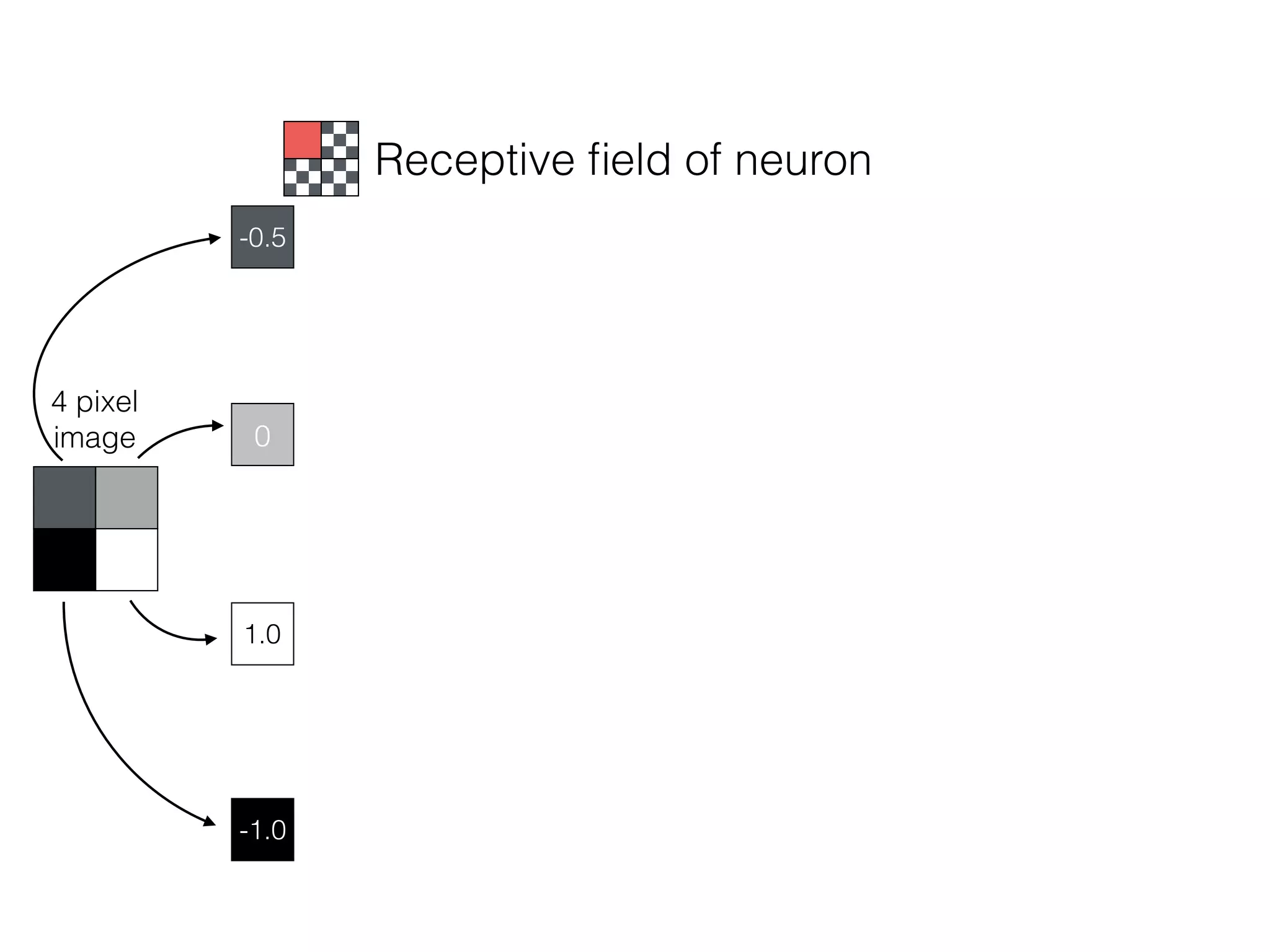
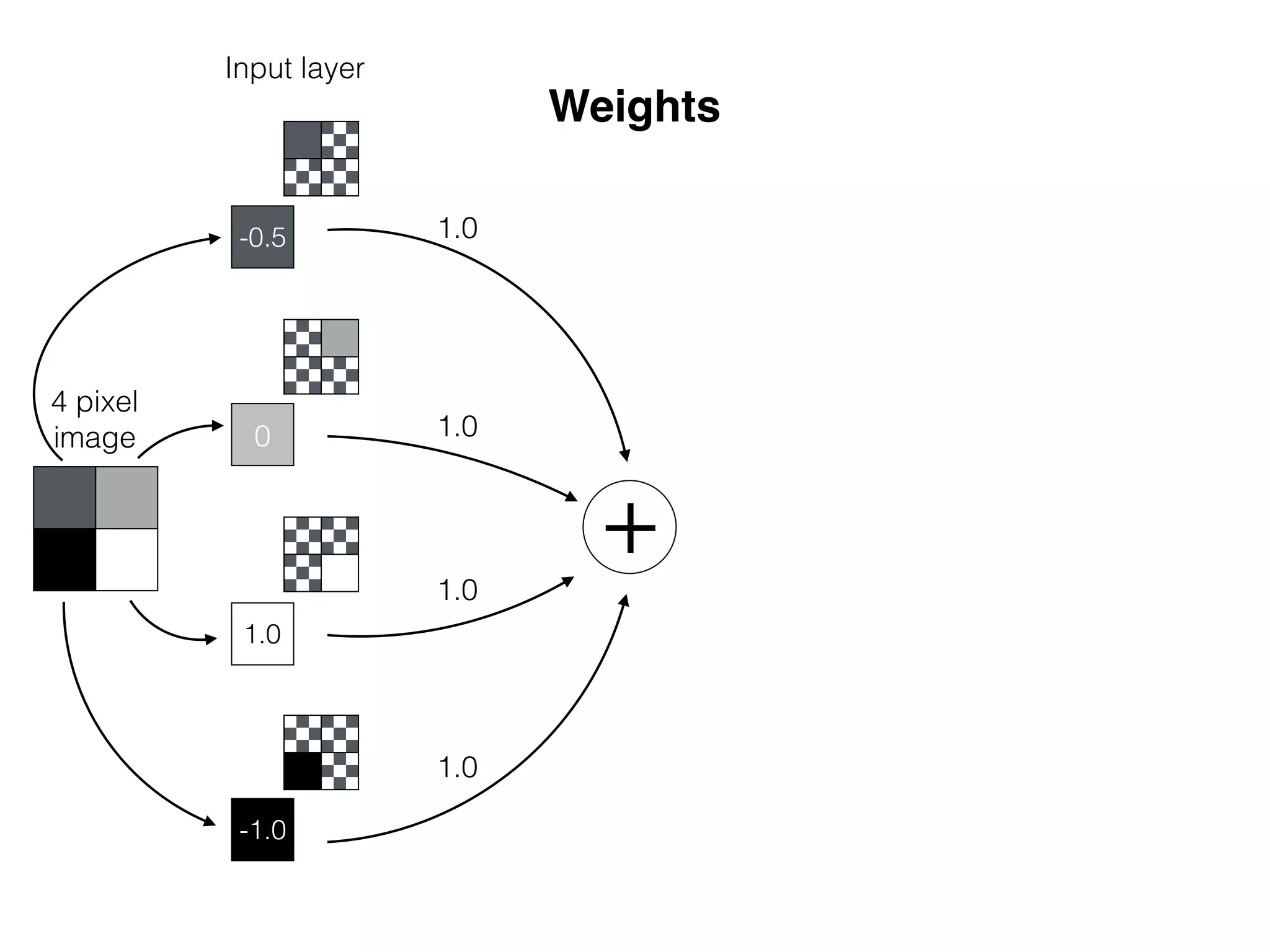
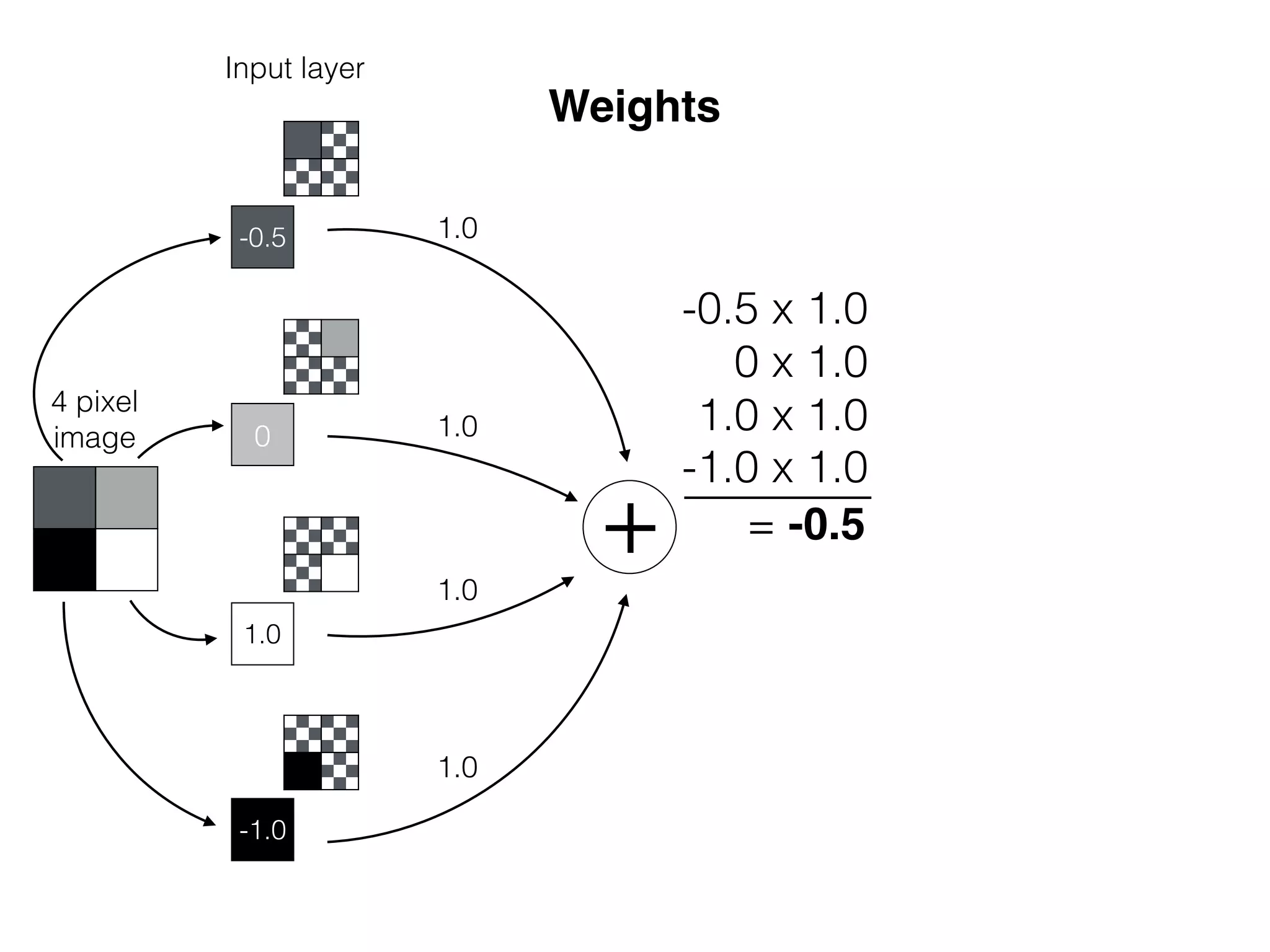

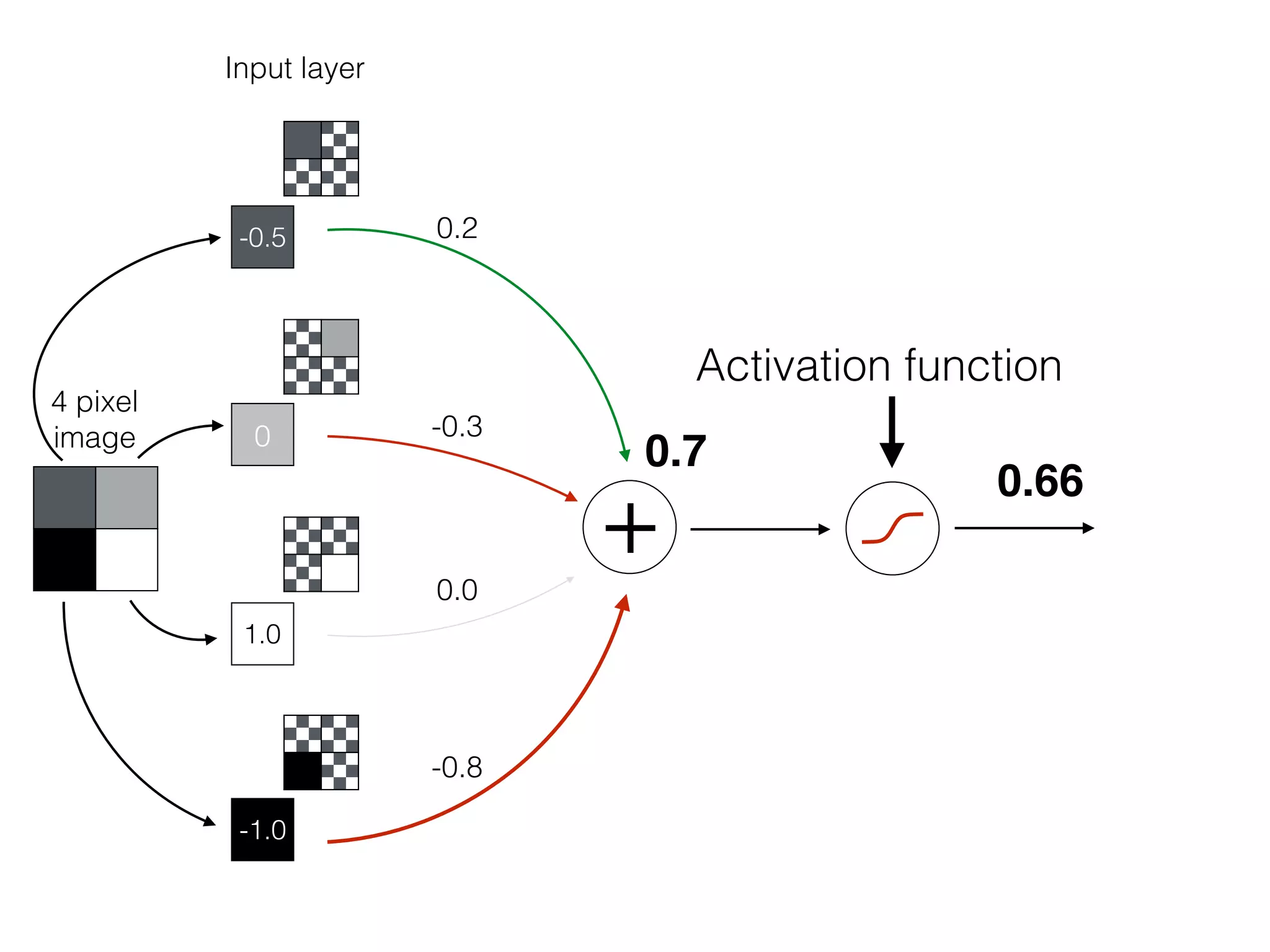
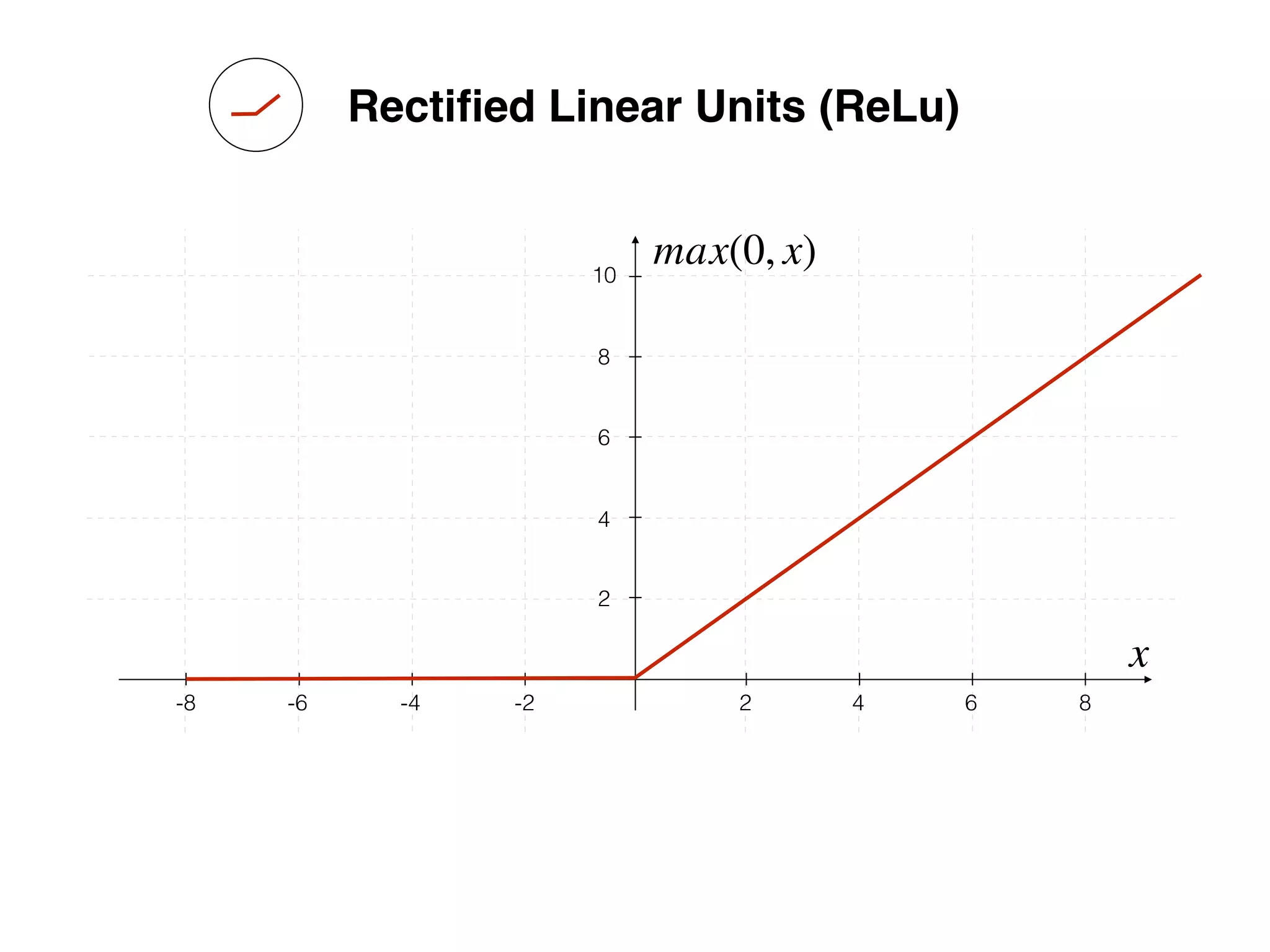
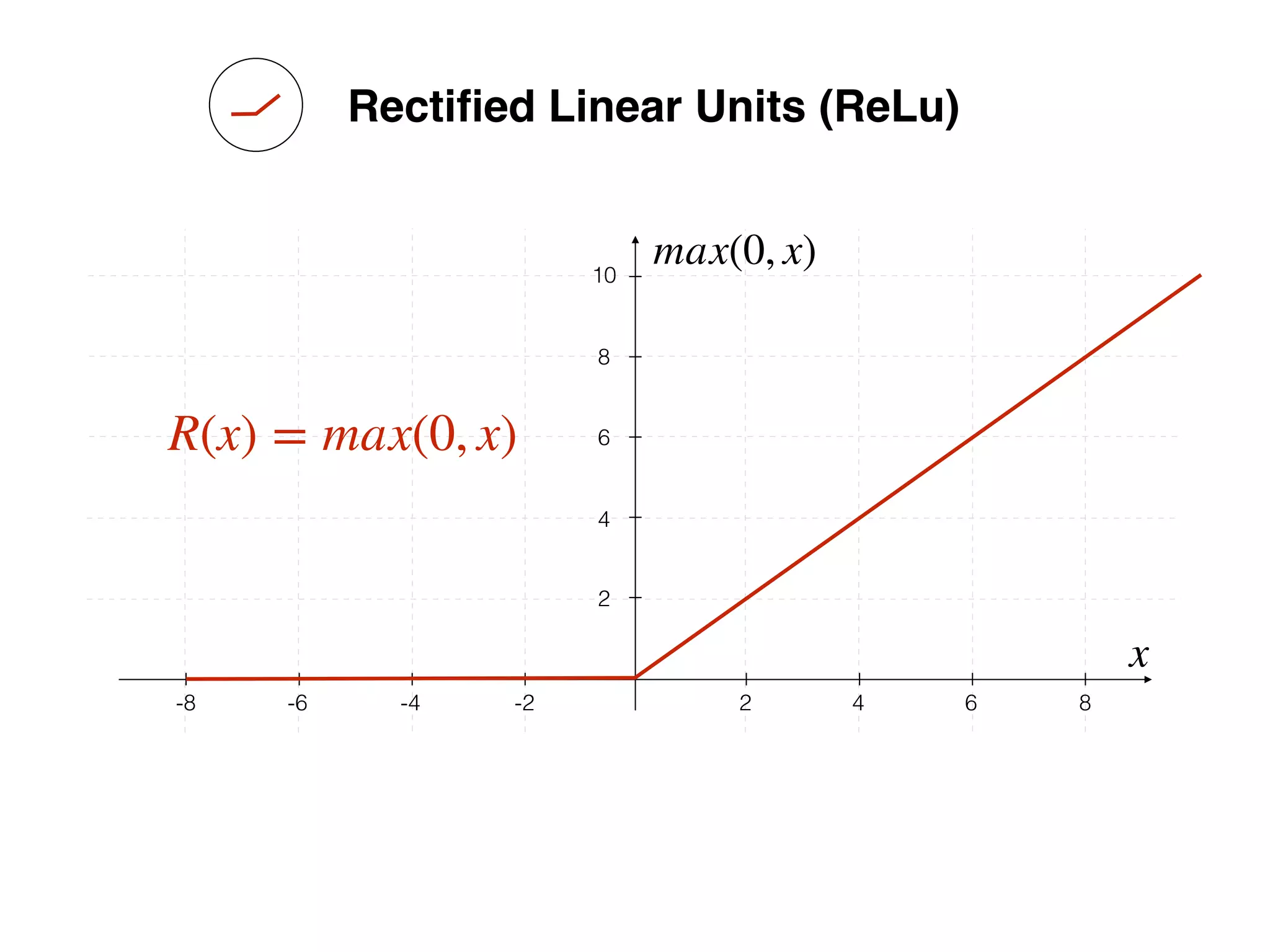
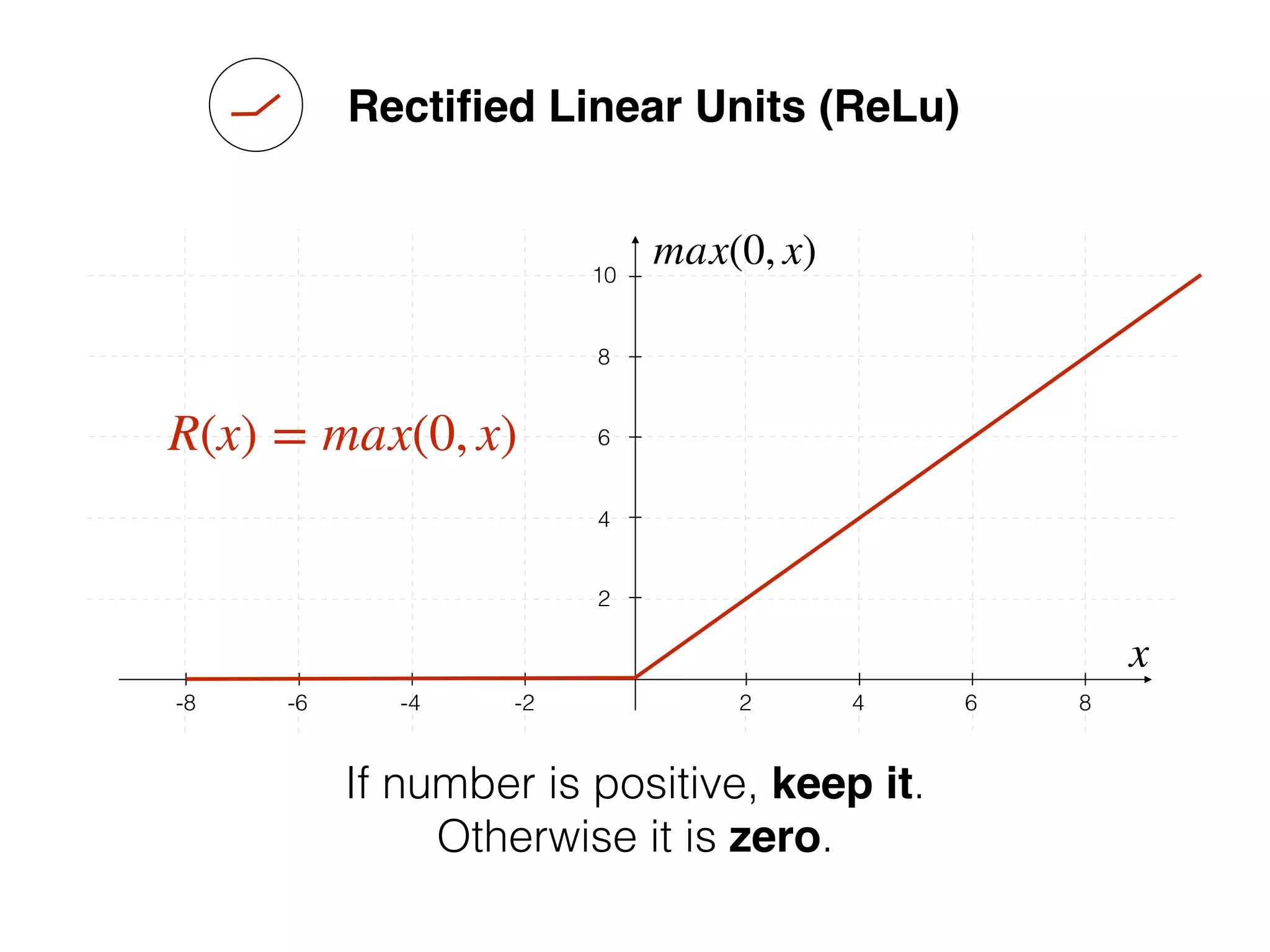
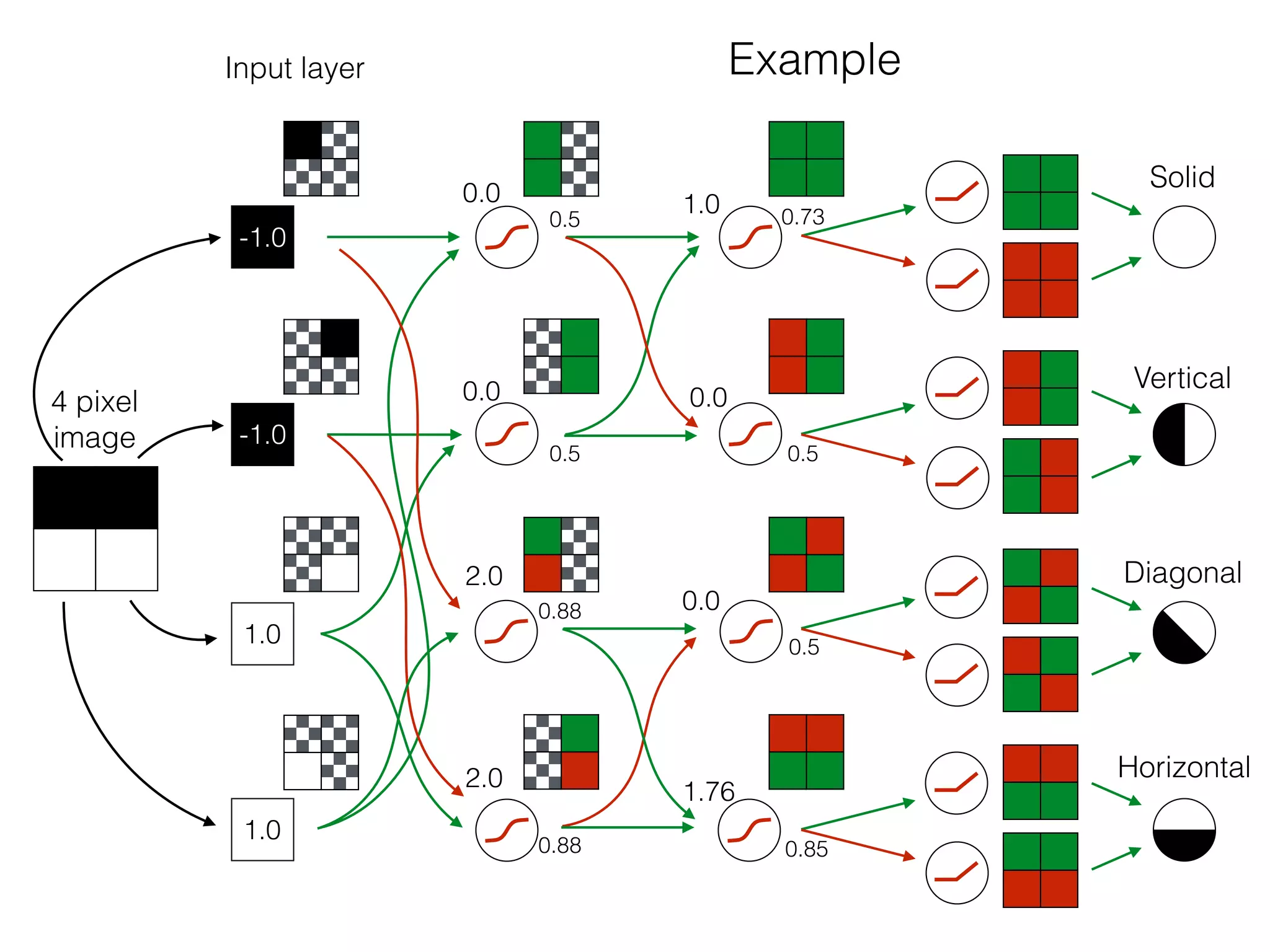
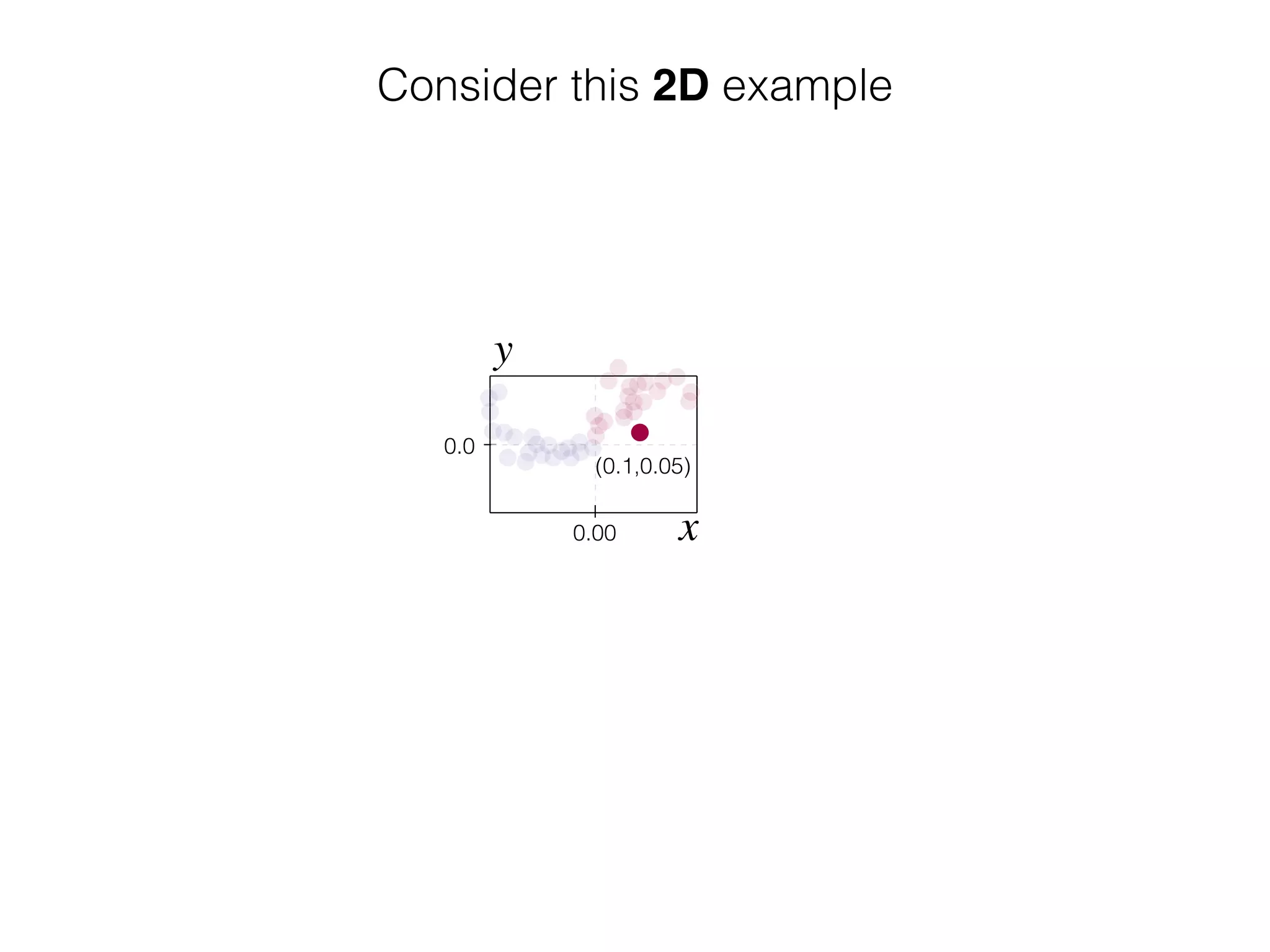
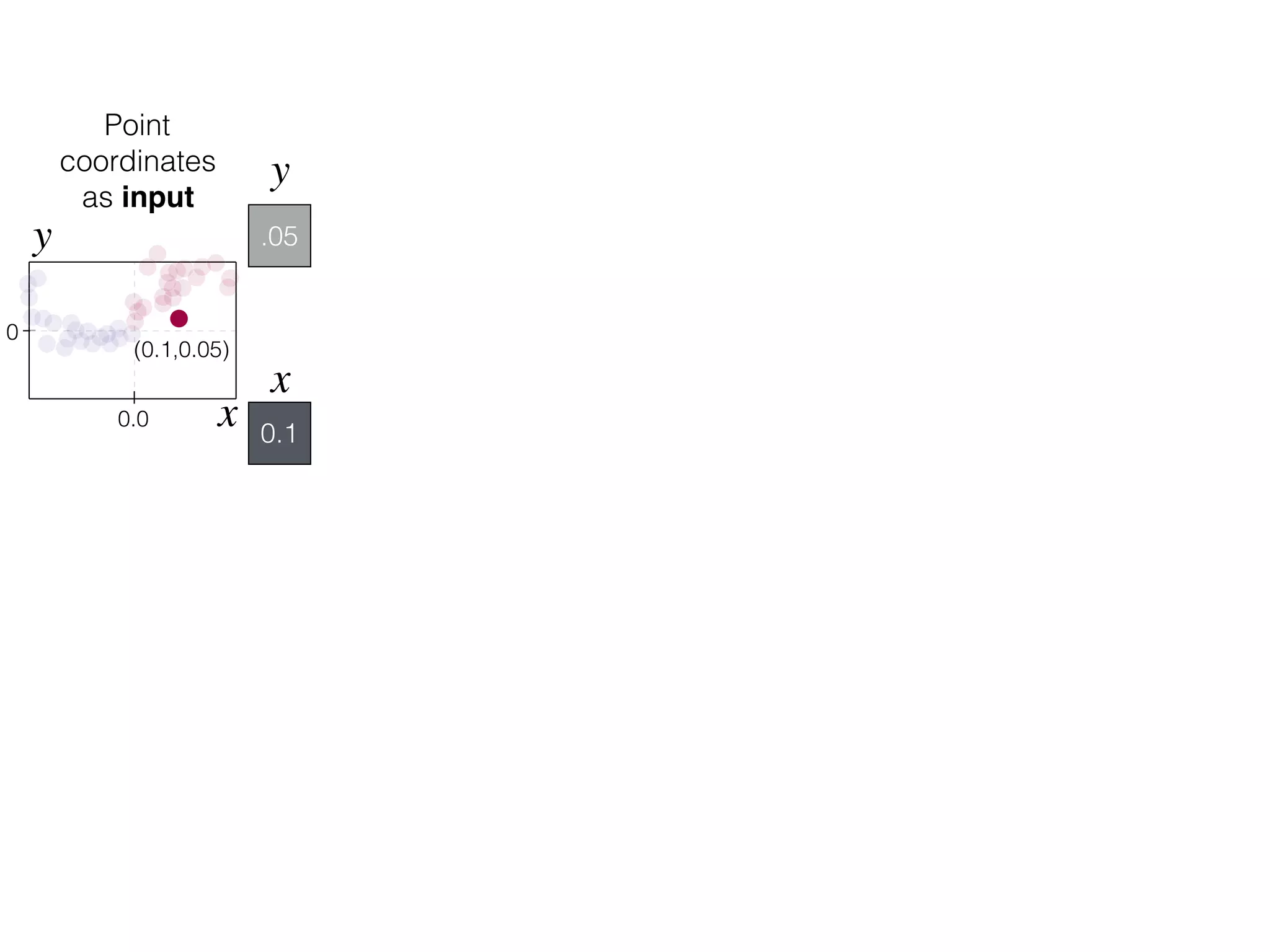
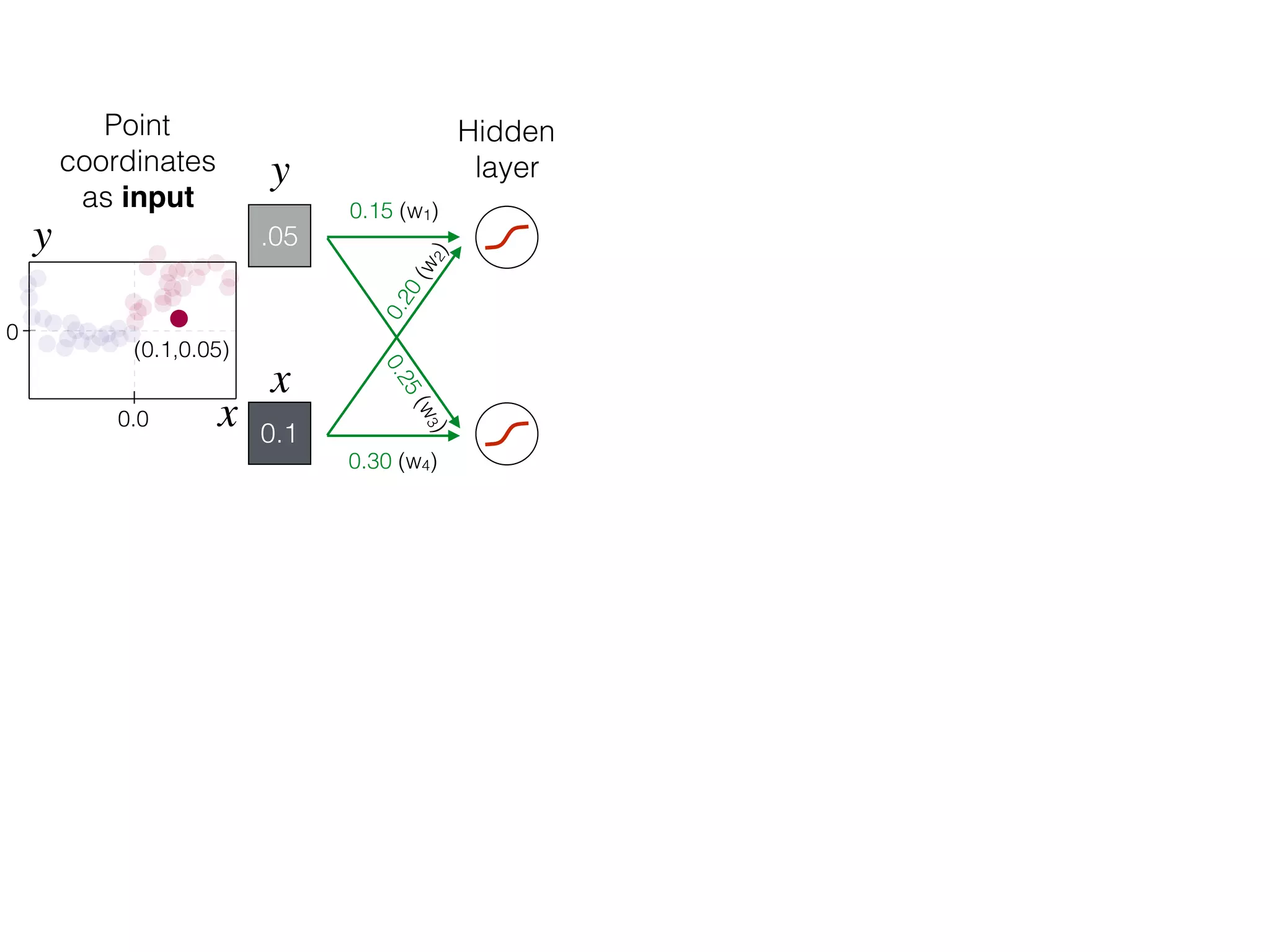
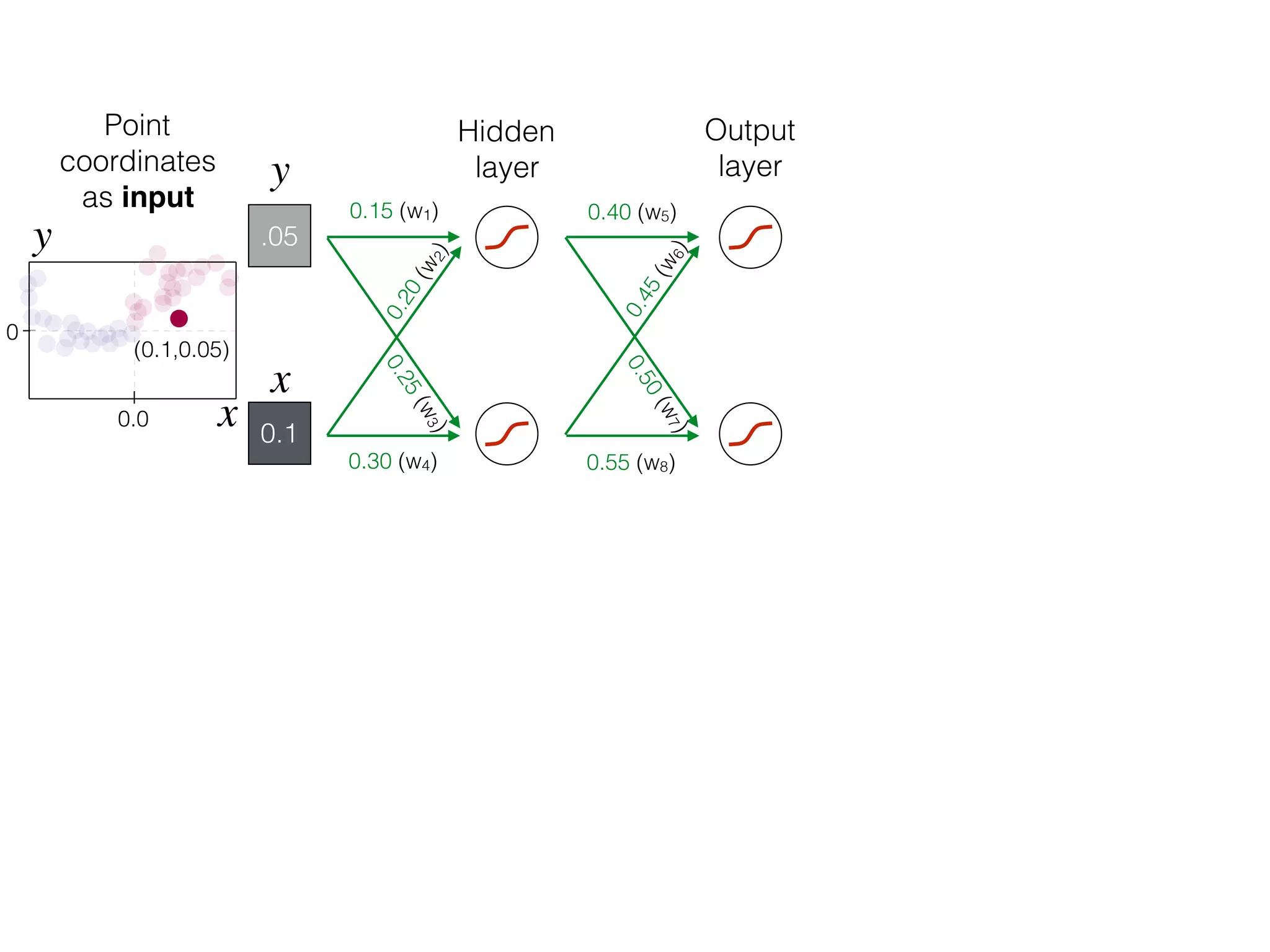
![-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x)
OutputInput
x
w1
sig(w1 * x)
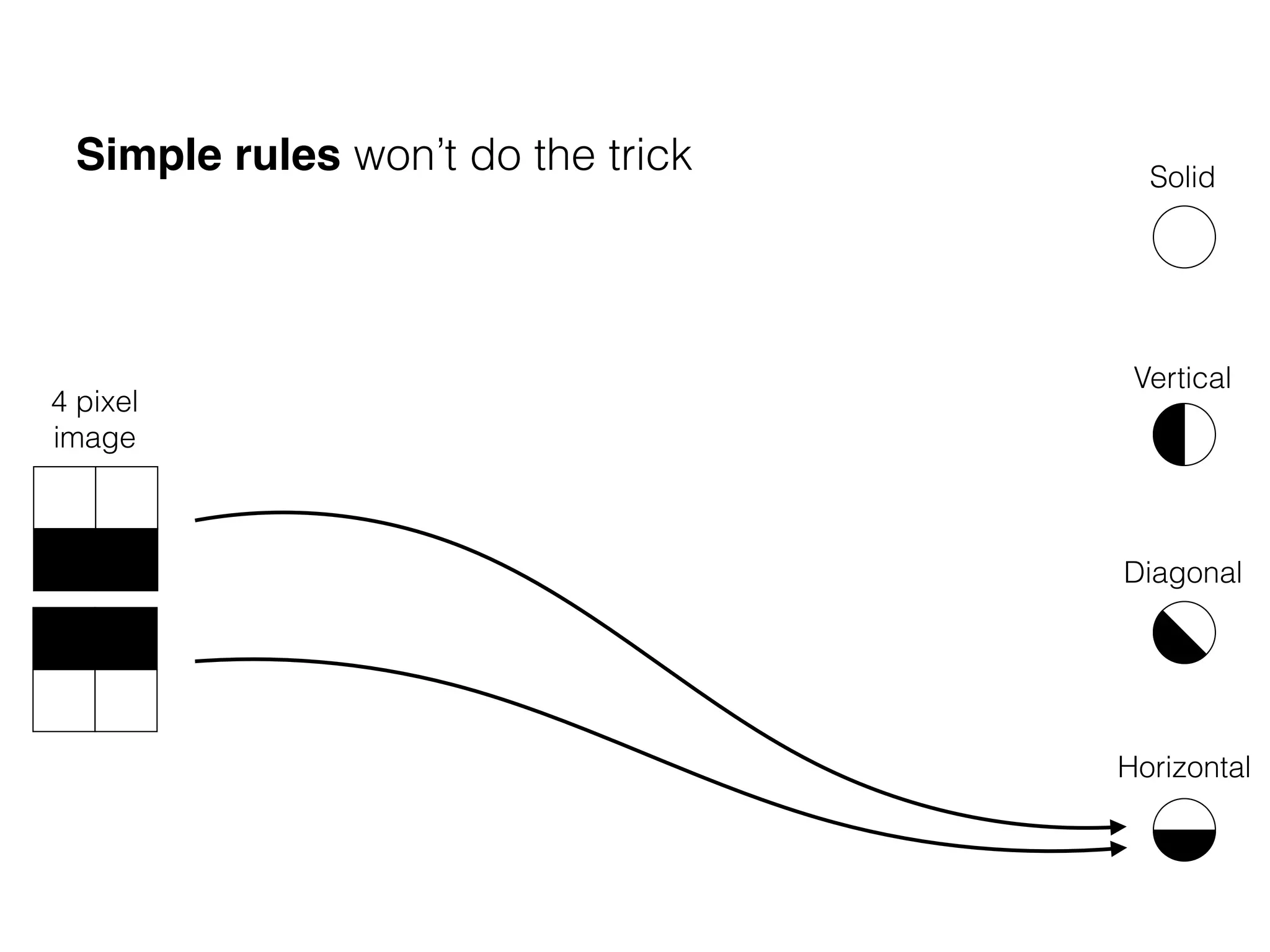
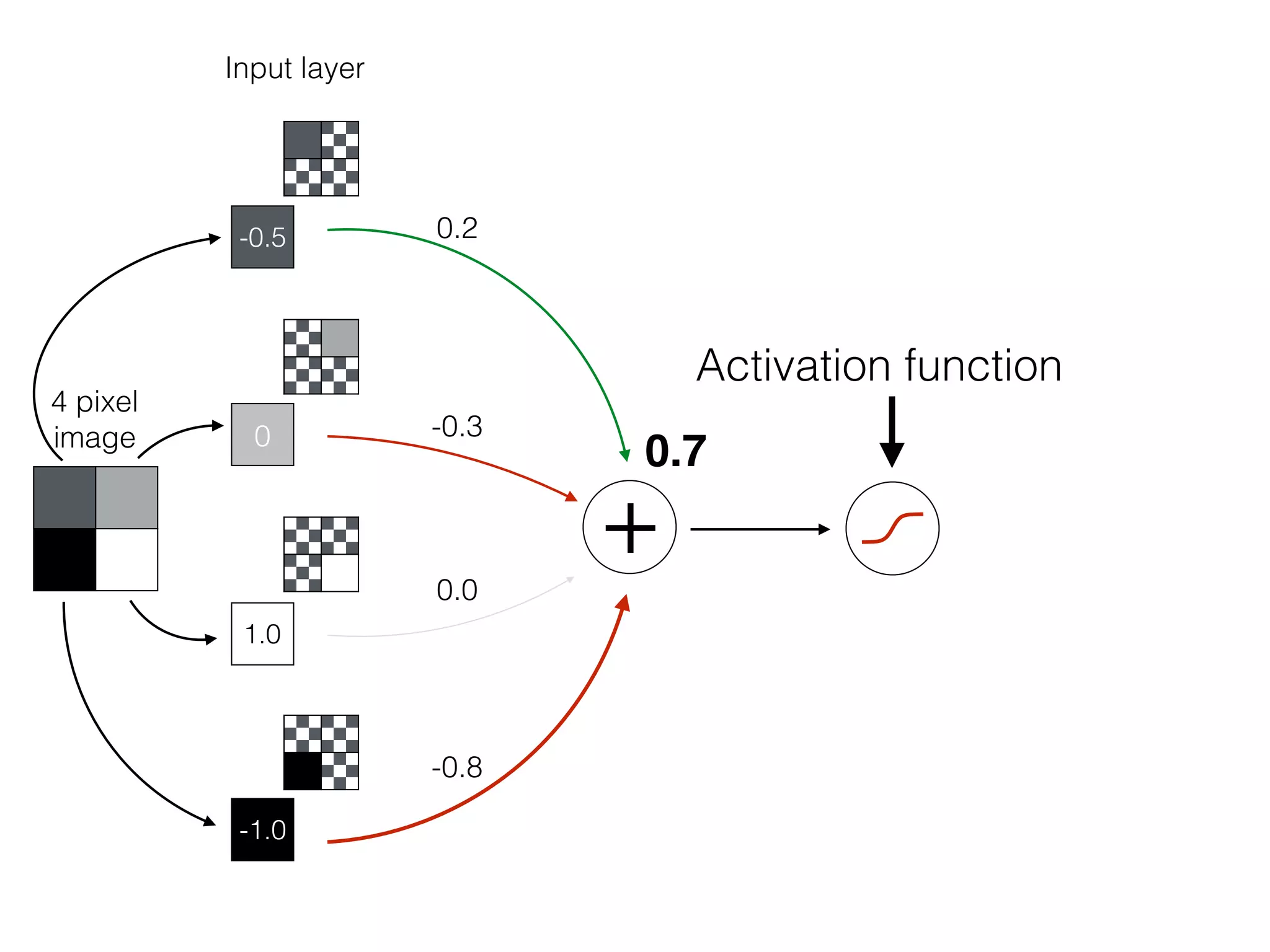
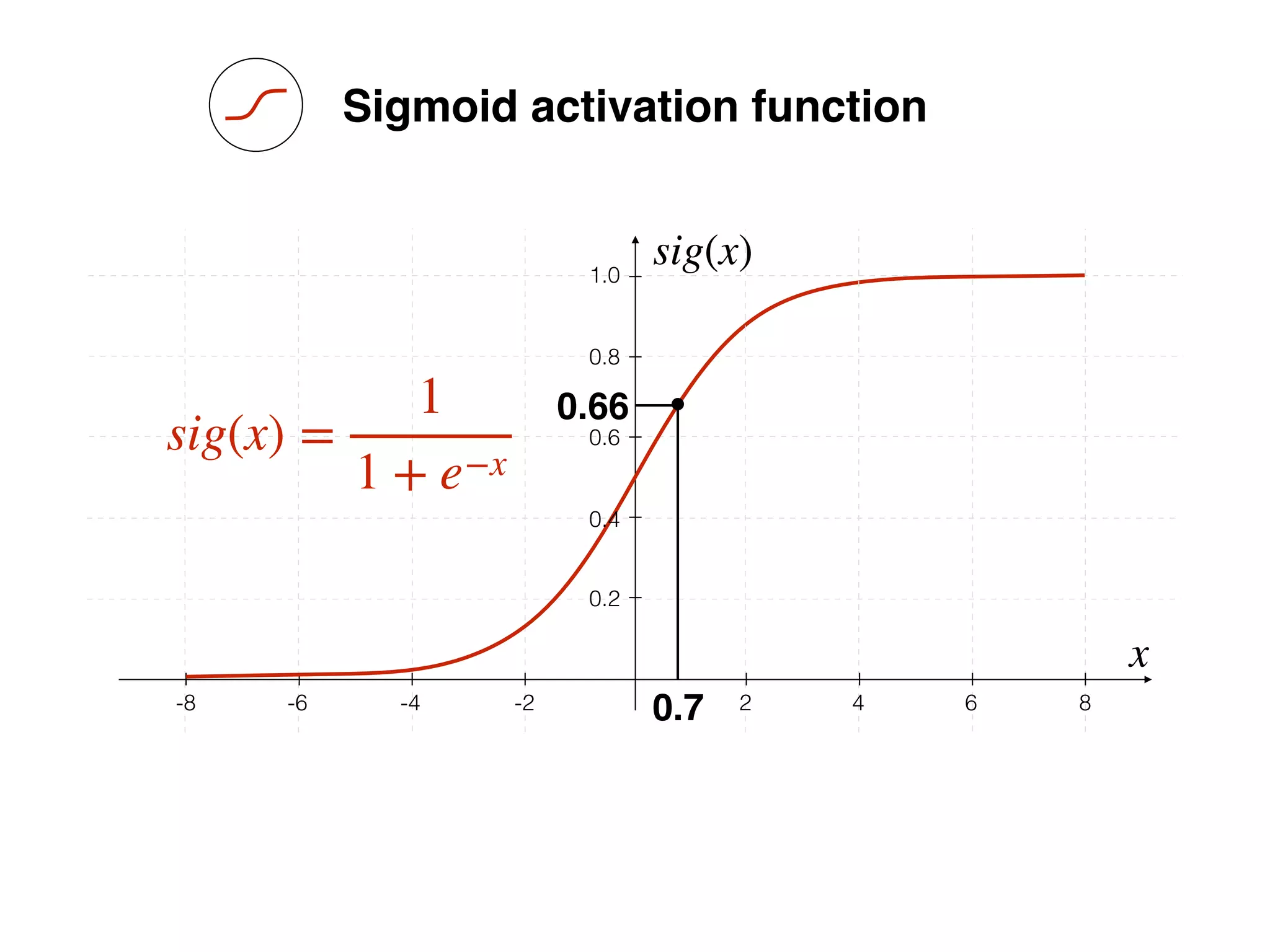
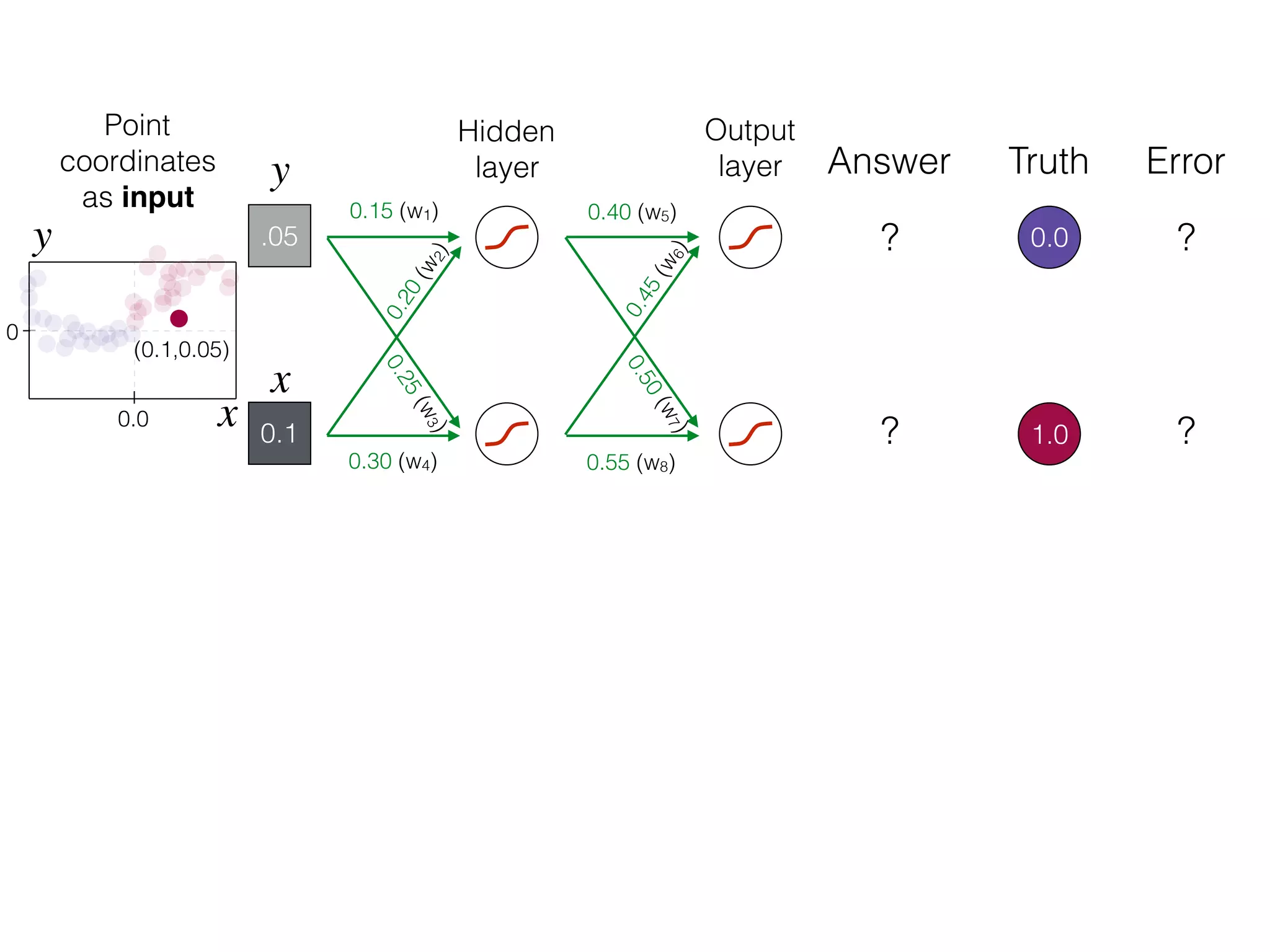
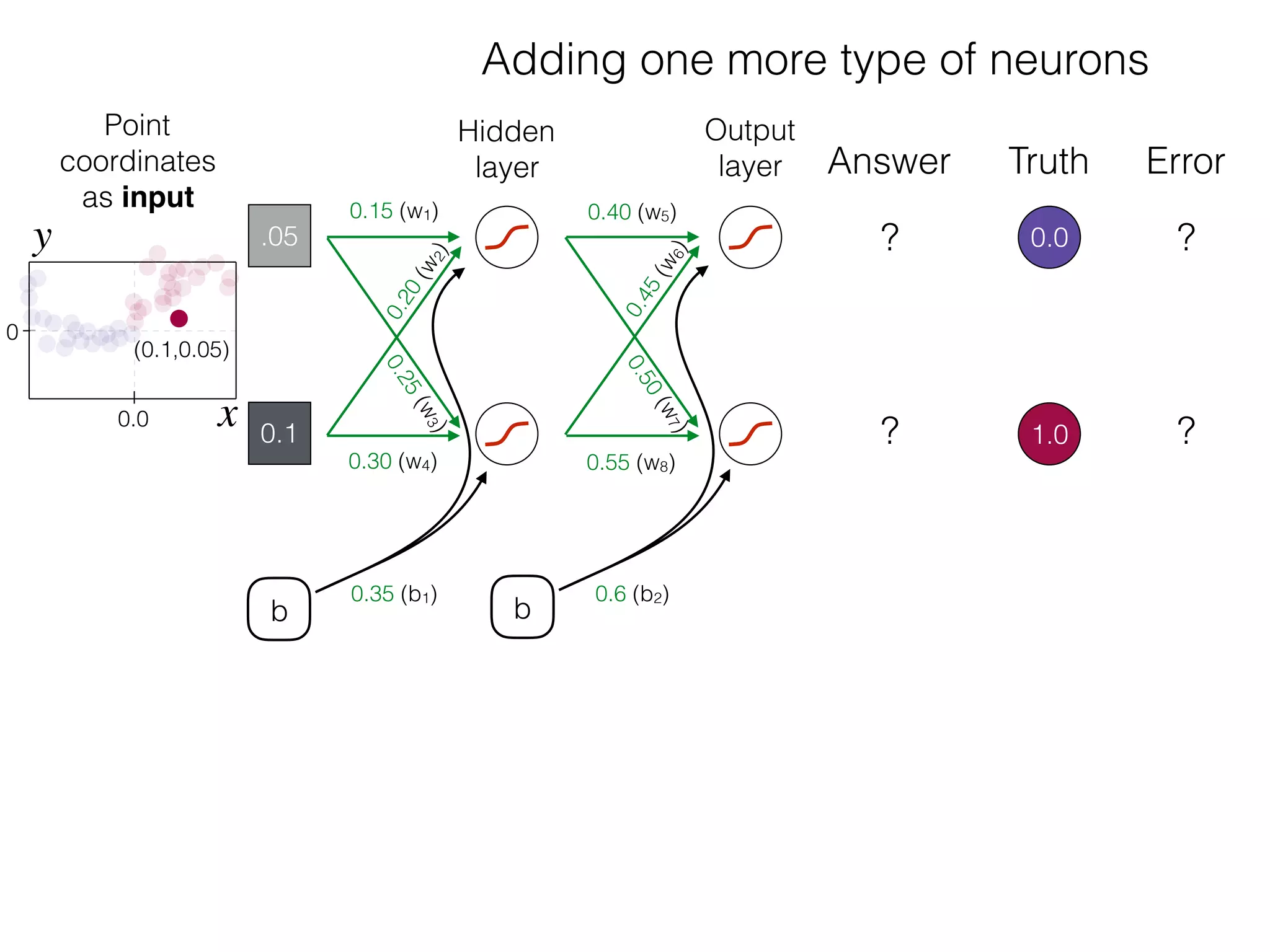
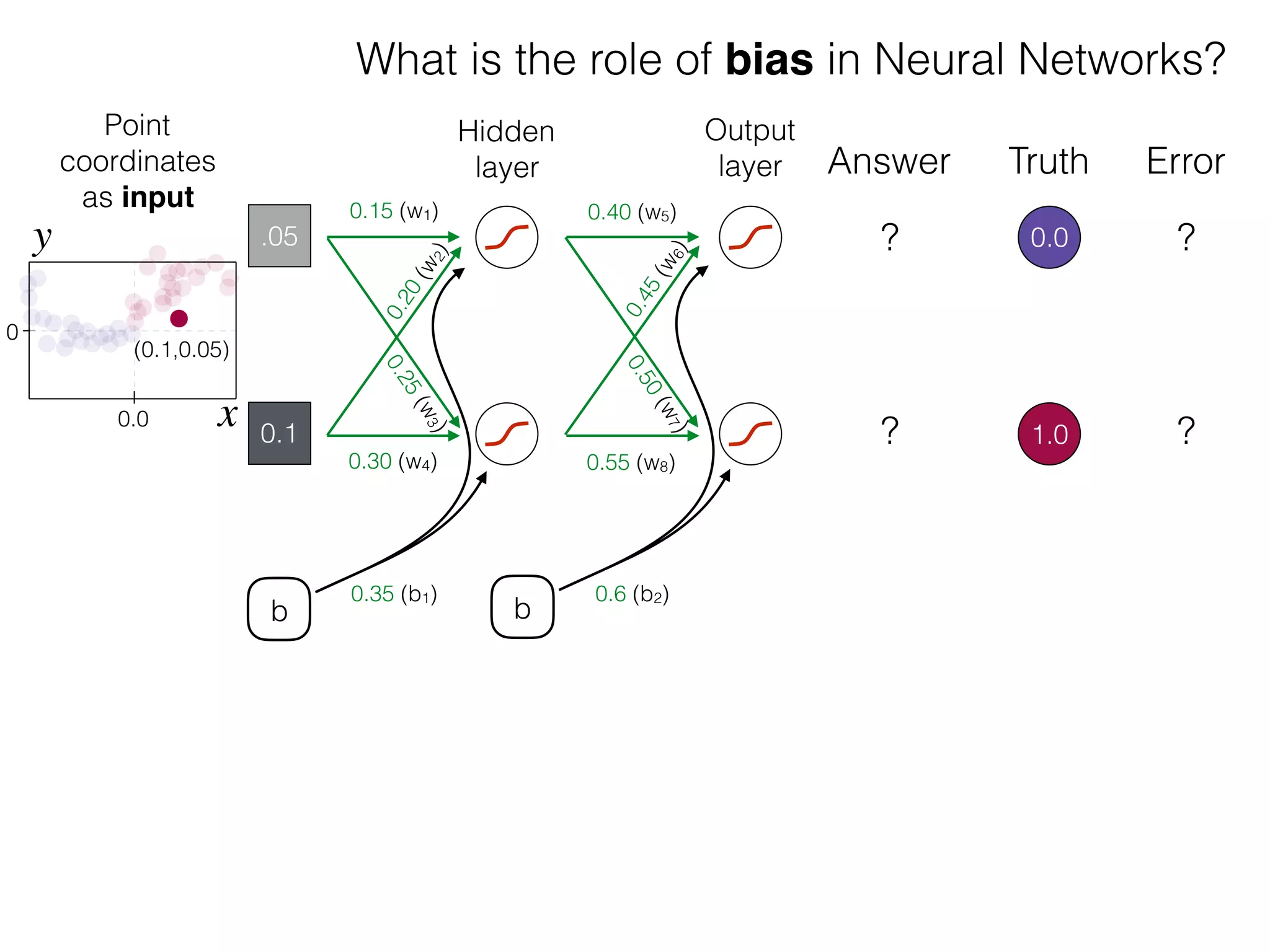
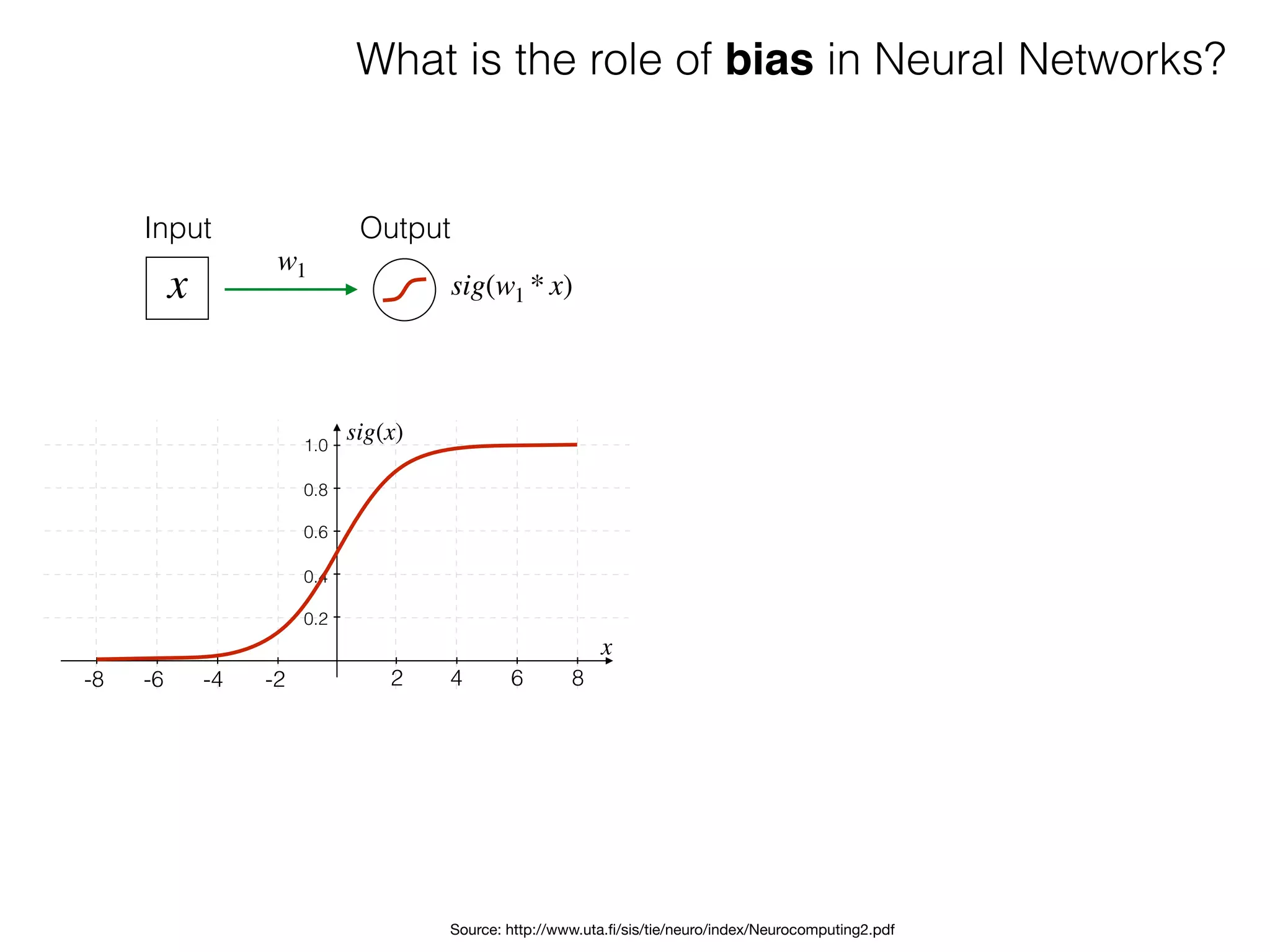
What is the role of bias in Neural Networks?
w1 =[0.5, 1.0, 2.0]
Source: http://www.uta.fi/sis/tie/neuro/index/Neurocomputing2.pdf](https://image.slidesharecdn.com/dllecturegeneral-190728122700/75/Introduction-to-Deep-Learning-95-2048.jpg)
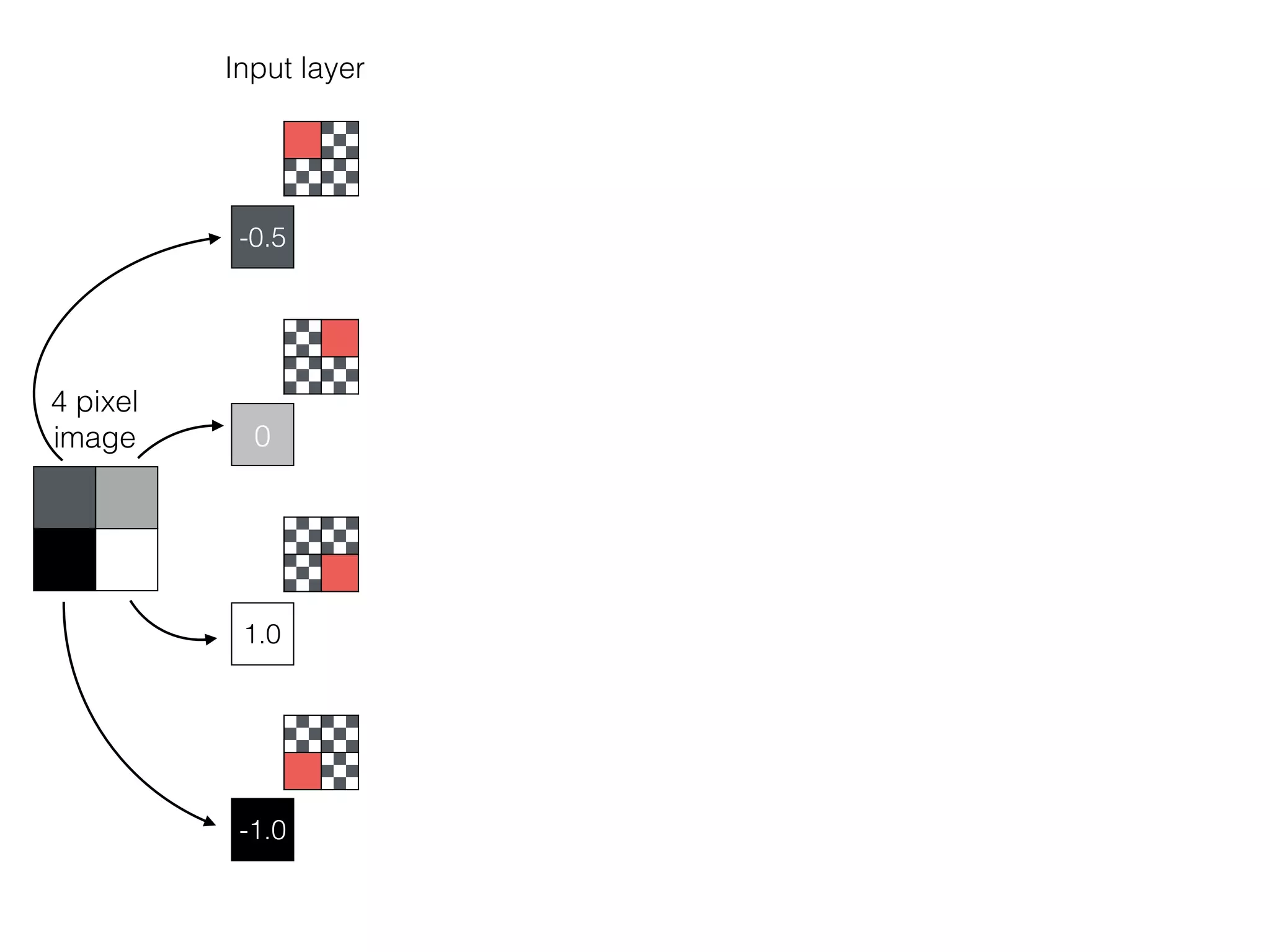
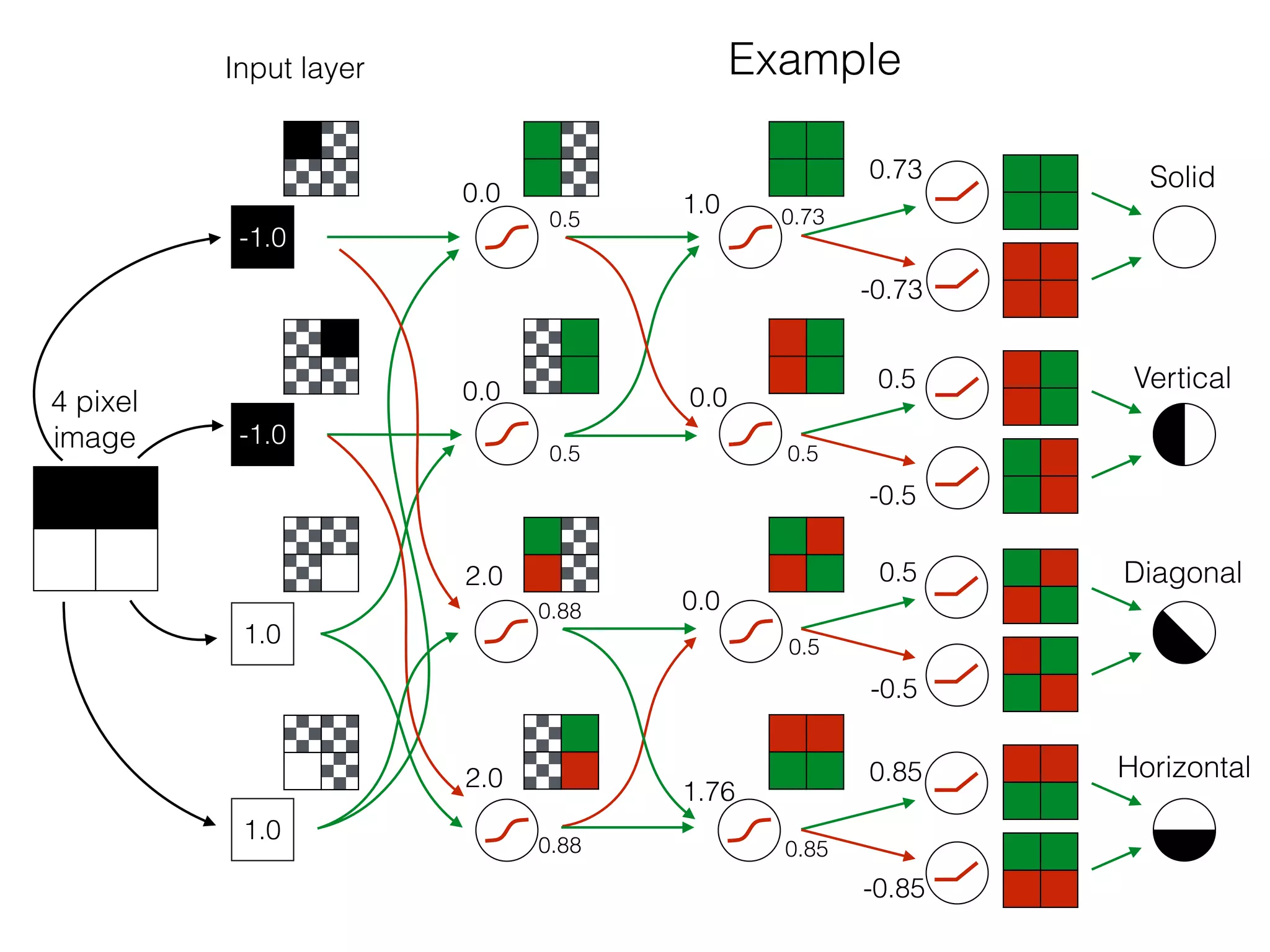
![-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x)
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
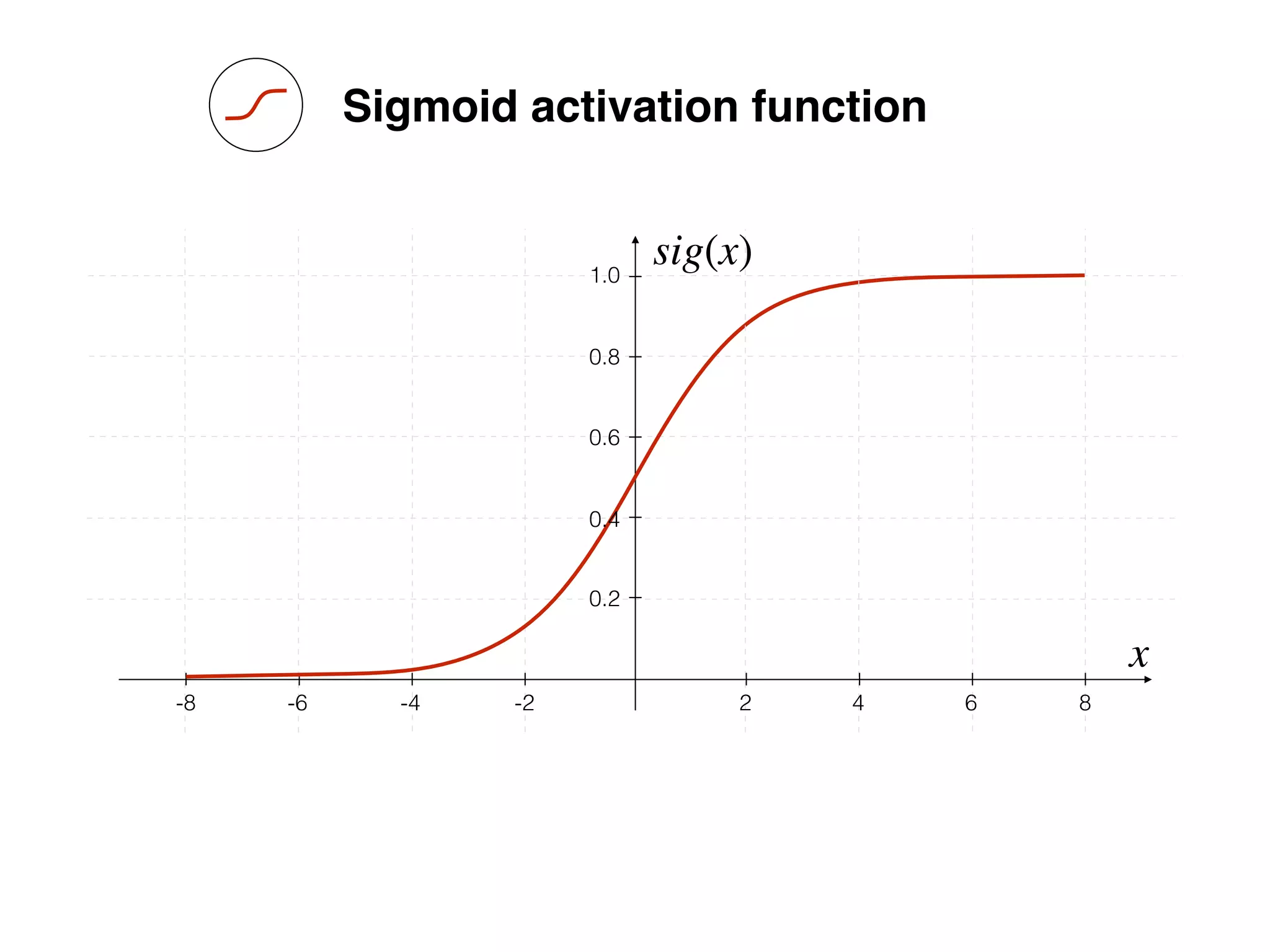
sig(x)
OutputInput
x
w1
sig(w1 * x)
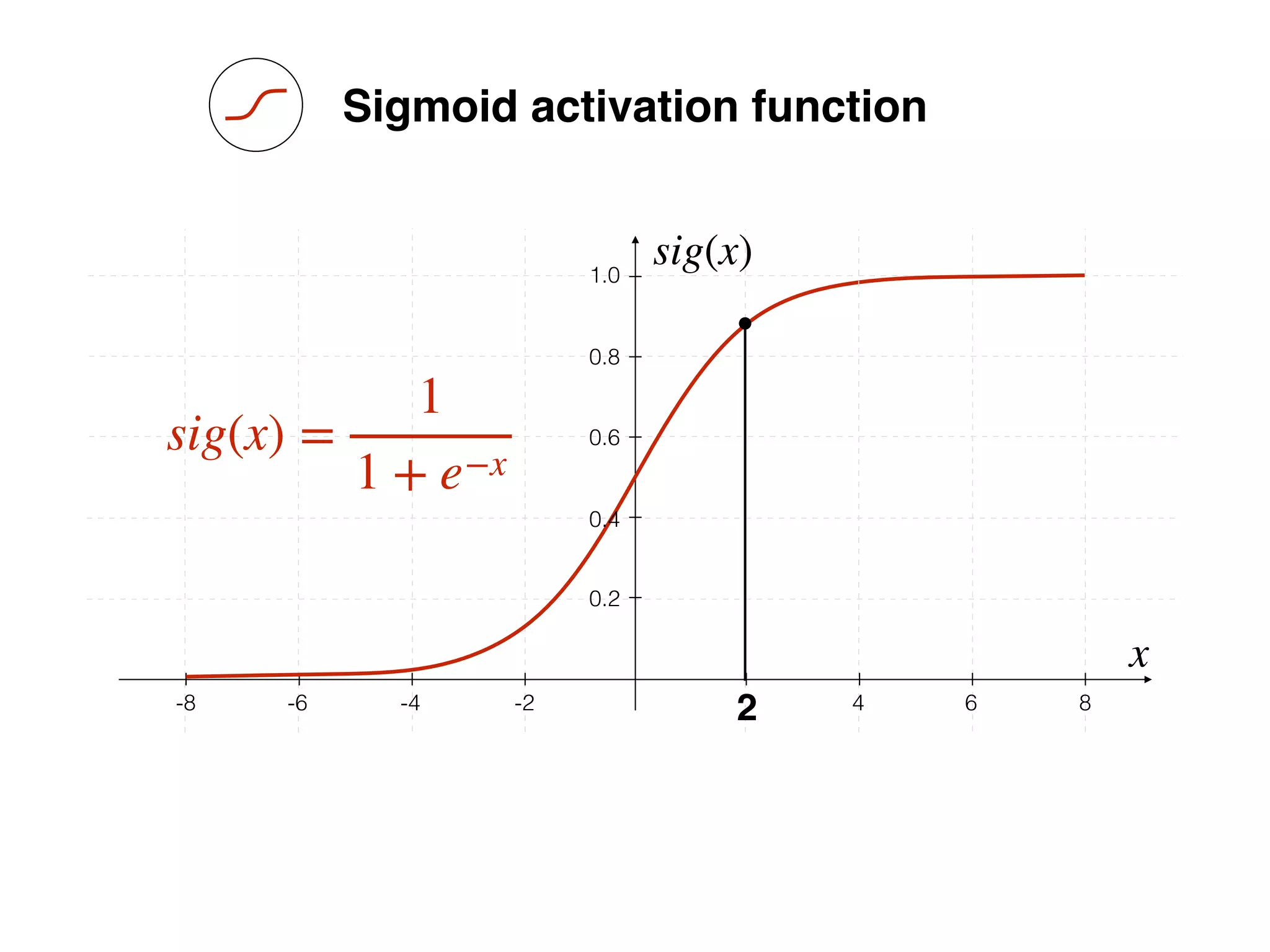
What is the role of bias in Neural Networks?
w1 =[0.5, 1.0, 2.0]
OutputInput
x
w1
sig(w1 * x + b1)
b b1
Source: http://www.uta.fi/sis/tie/neuro/index/Neurocomputing2.pdf](https://image.slidesharecdn.com/dllecturegeneral-190728122700/75/Introduction-to-Deep-Learning-96-2048.jpg)
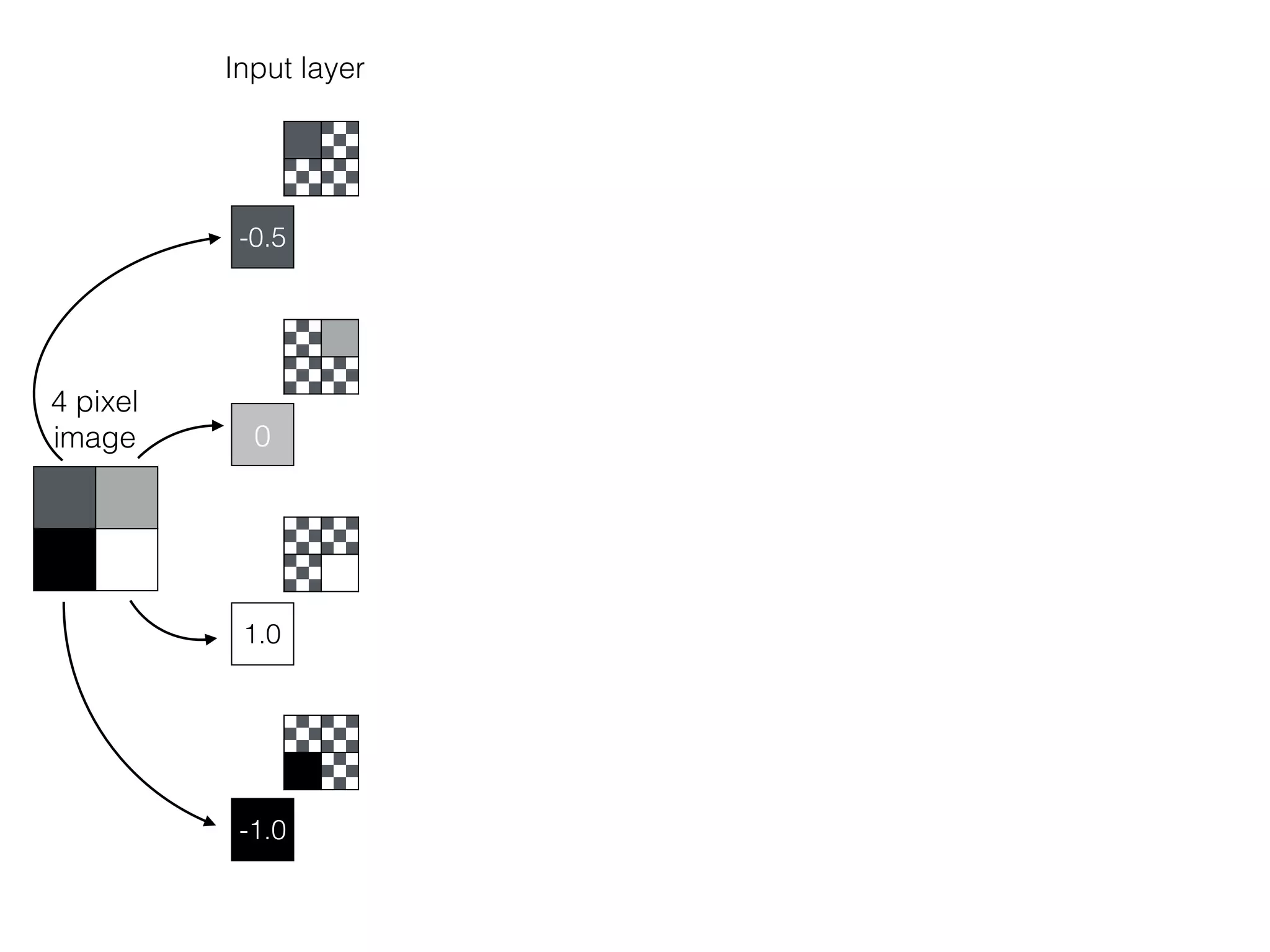
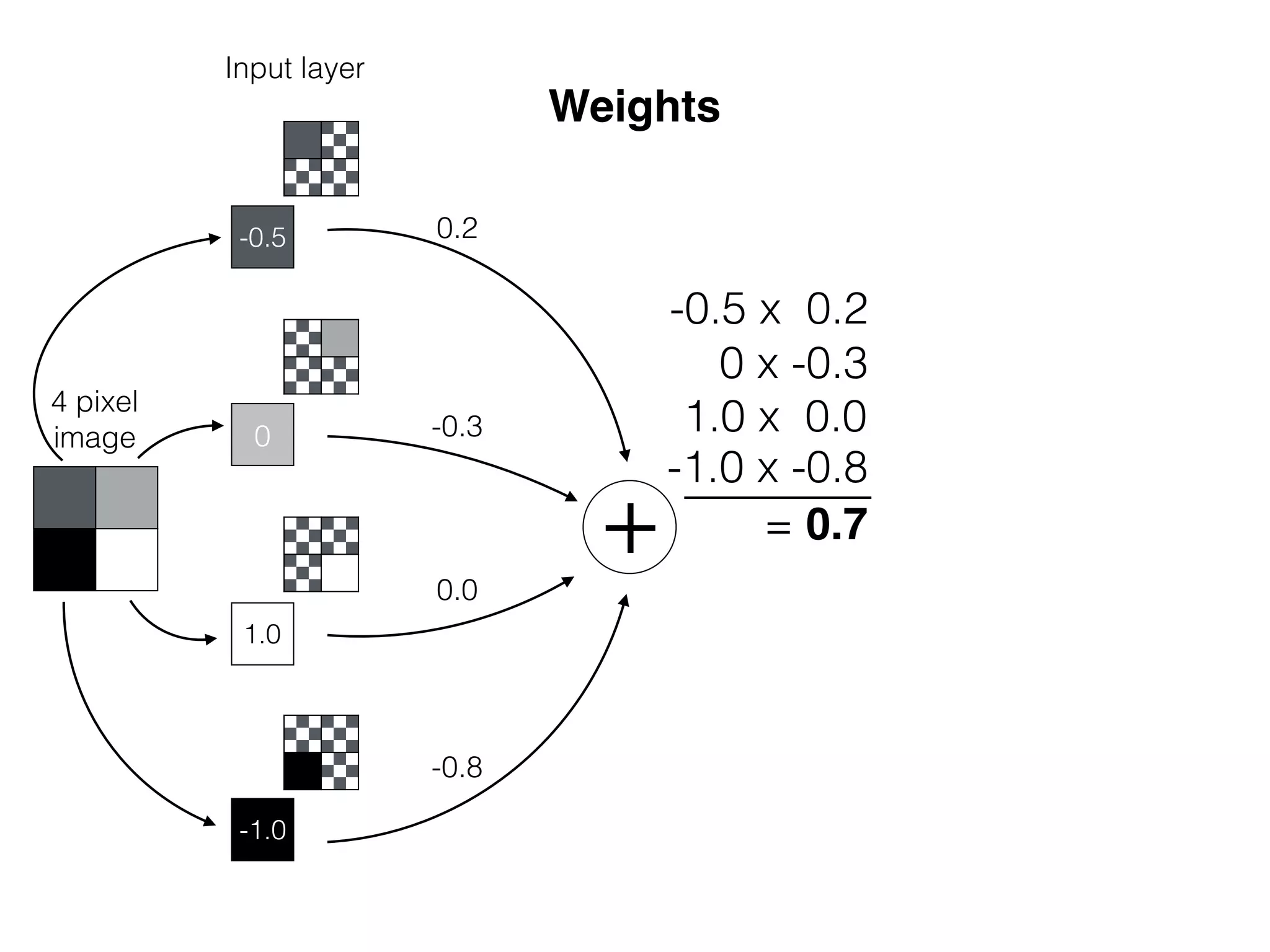
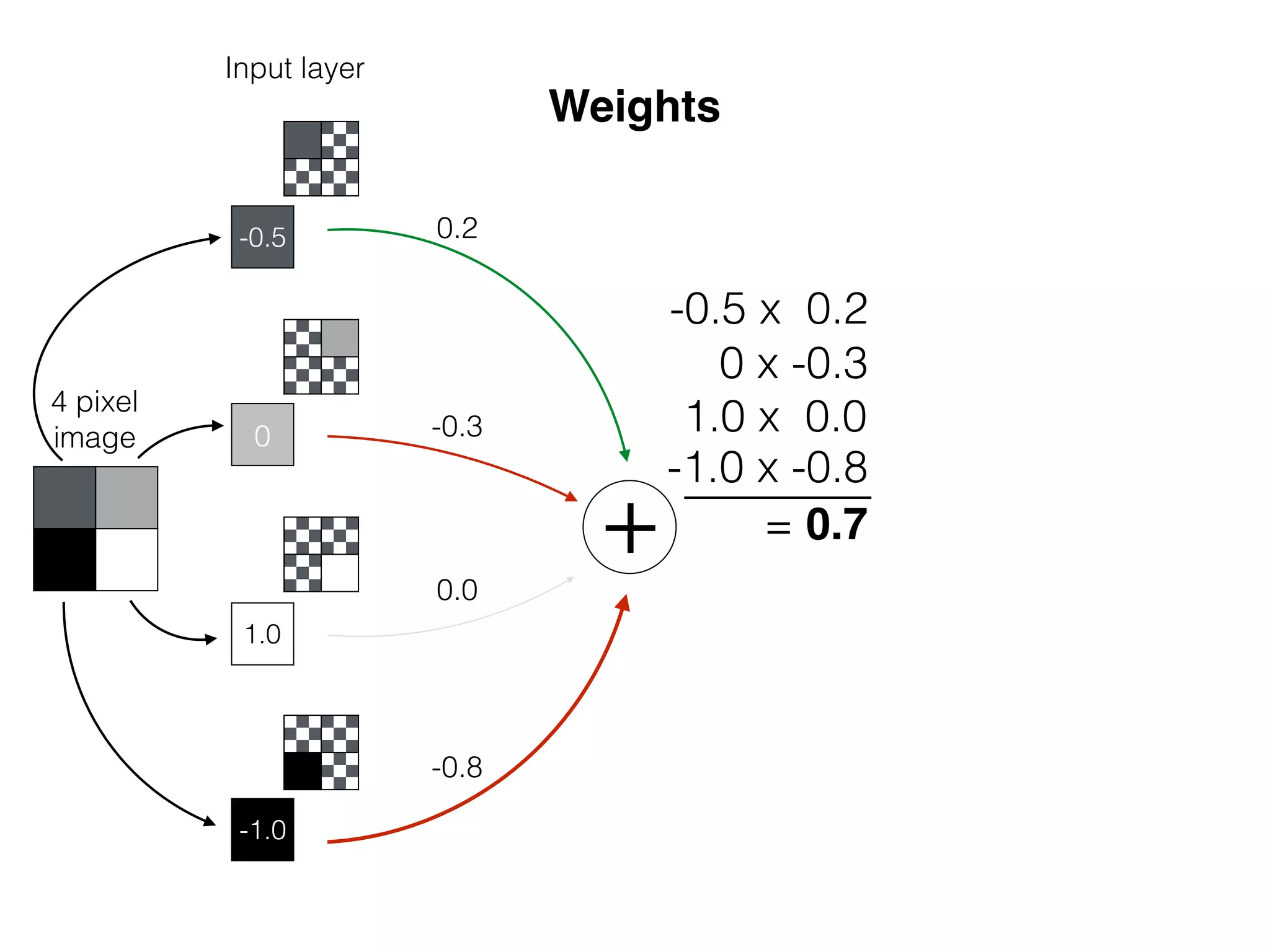
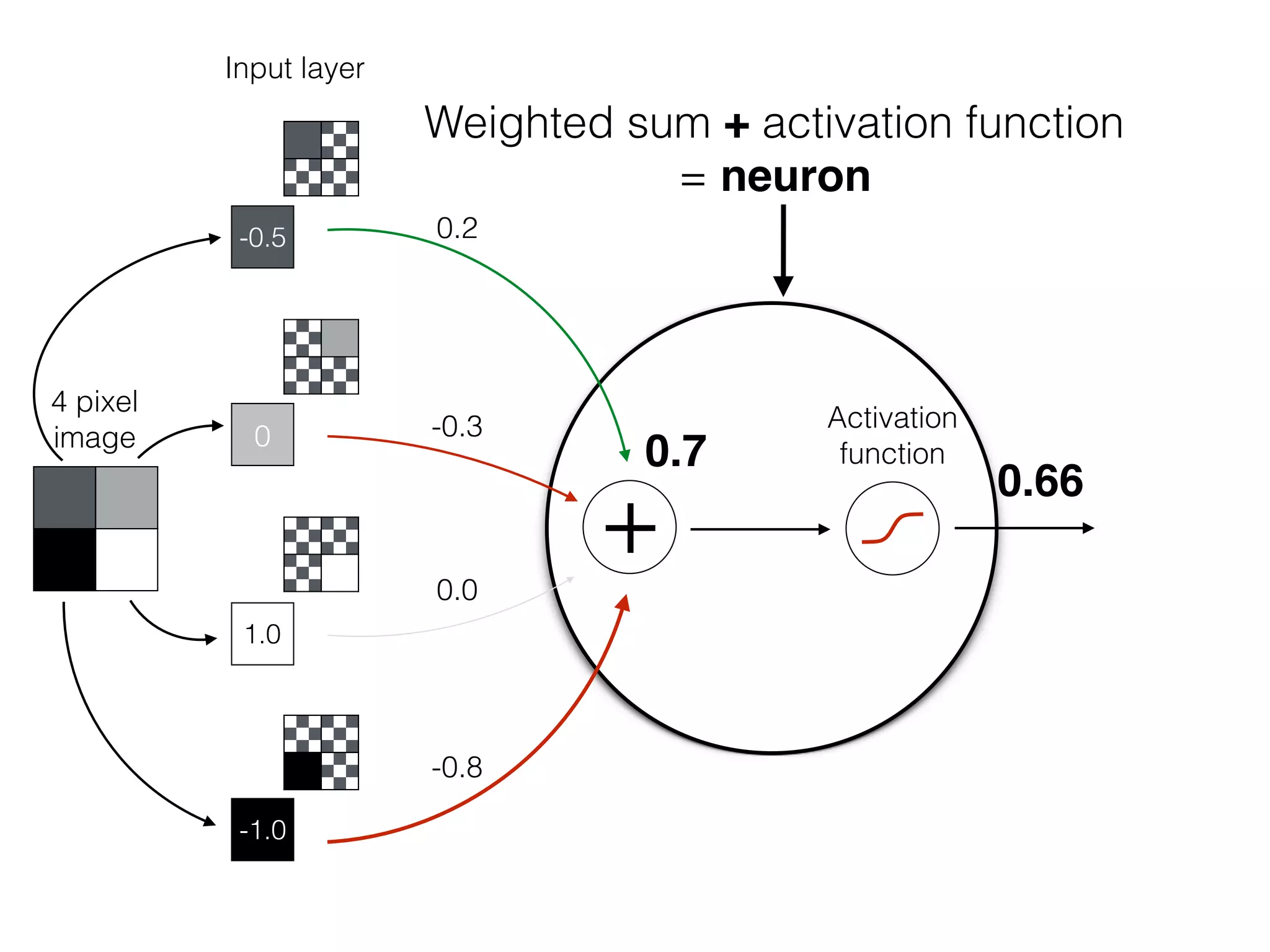
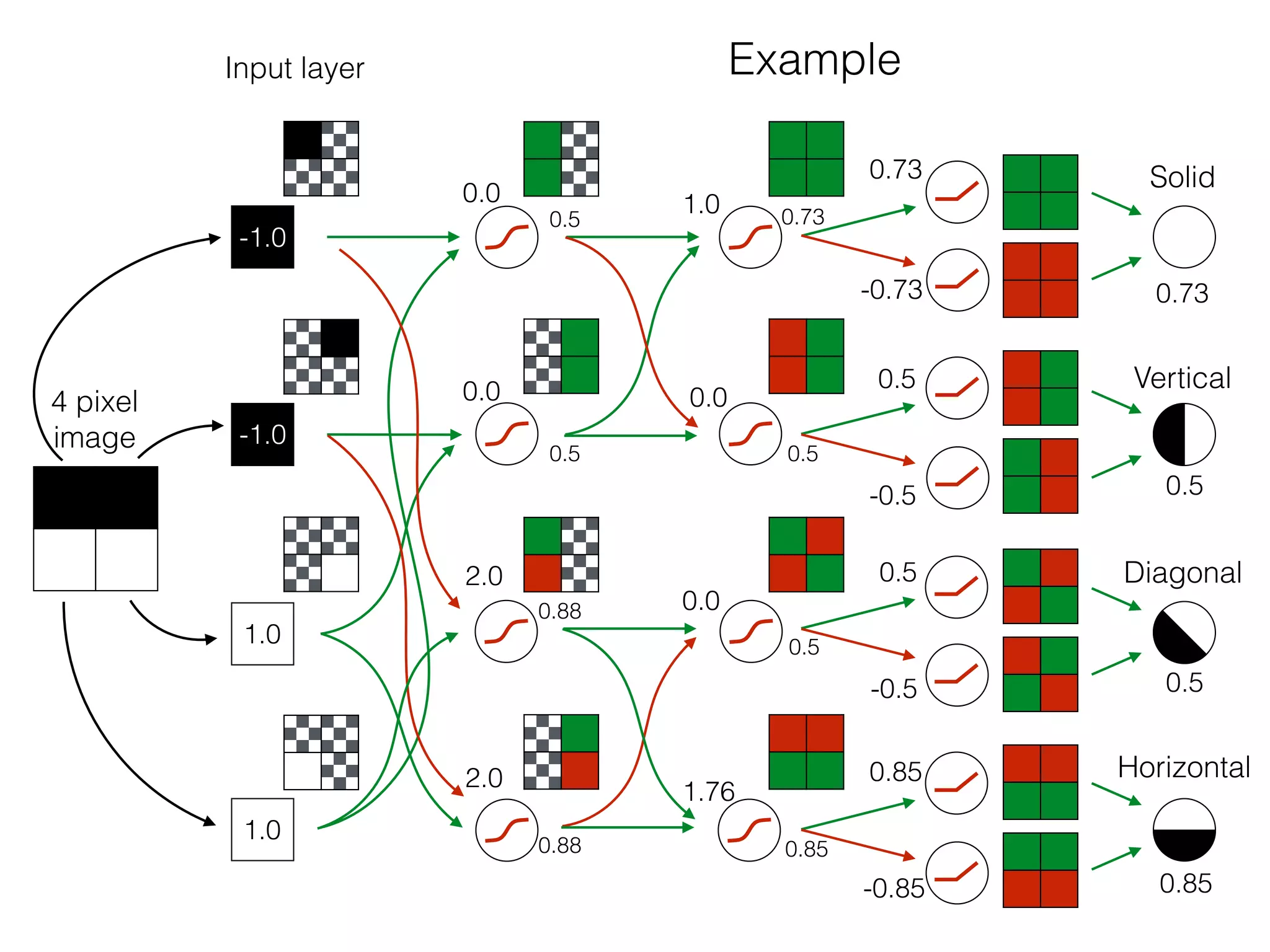
![OutputInput
x
w1
sig(w1 * x)
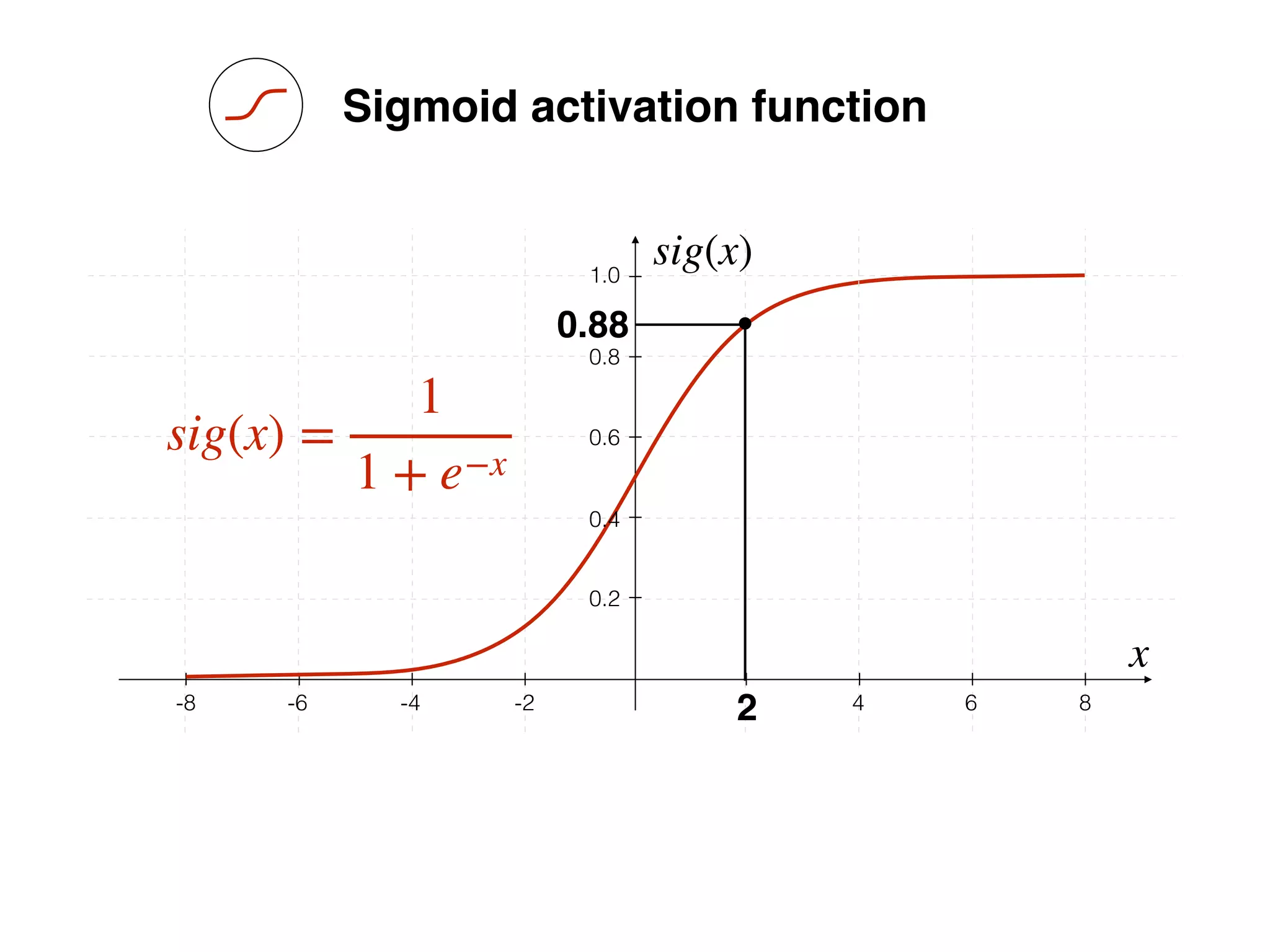
Bias helps to shift the resulting curve
w1 =[0.5, 1.0, 2.0]
OutputInput
x
w1
sig(w1 * x + b1)
b1
= [-4.0, 0.0, 4.0]
b b1
w1=[1.0]
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x + b1)
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x)
b1 b1
Source: http://www.uta.fi/sis/tie/neuro/index/Neurocomputing2.pdf](https://image.slidesharecdn.com/dllecturegeneral-190728122700/75/Introduction-to-Deep-Learning-97-2048.jpg)
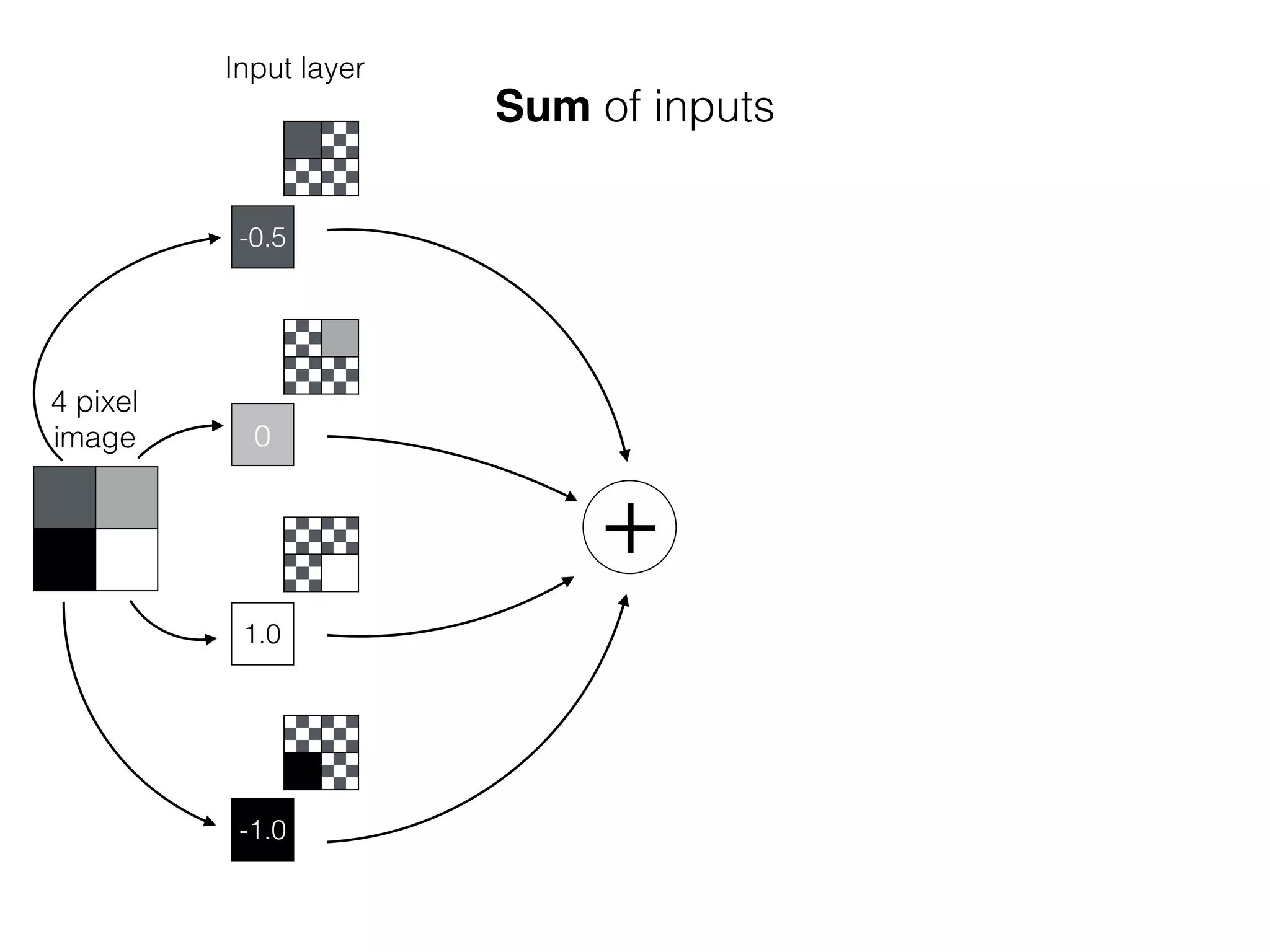
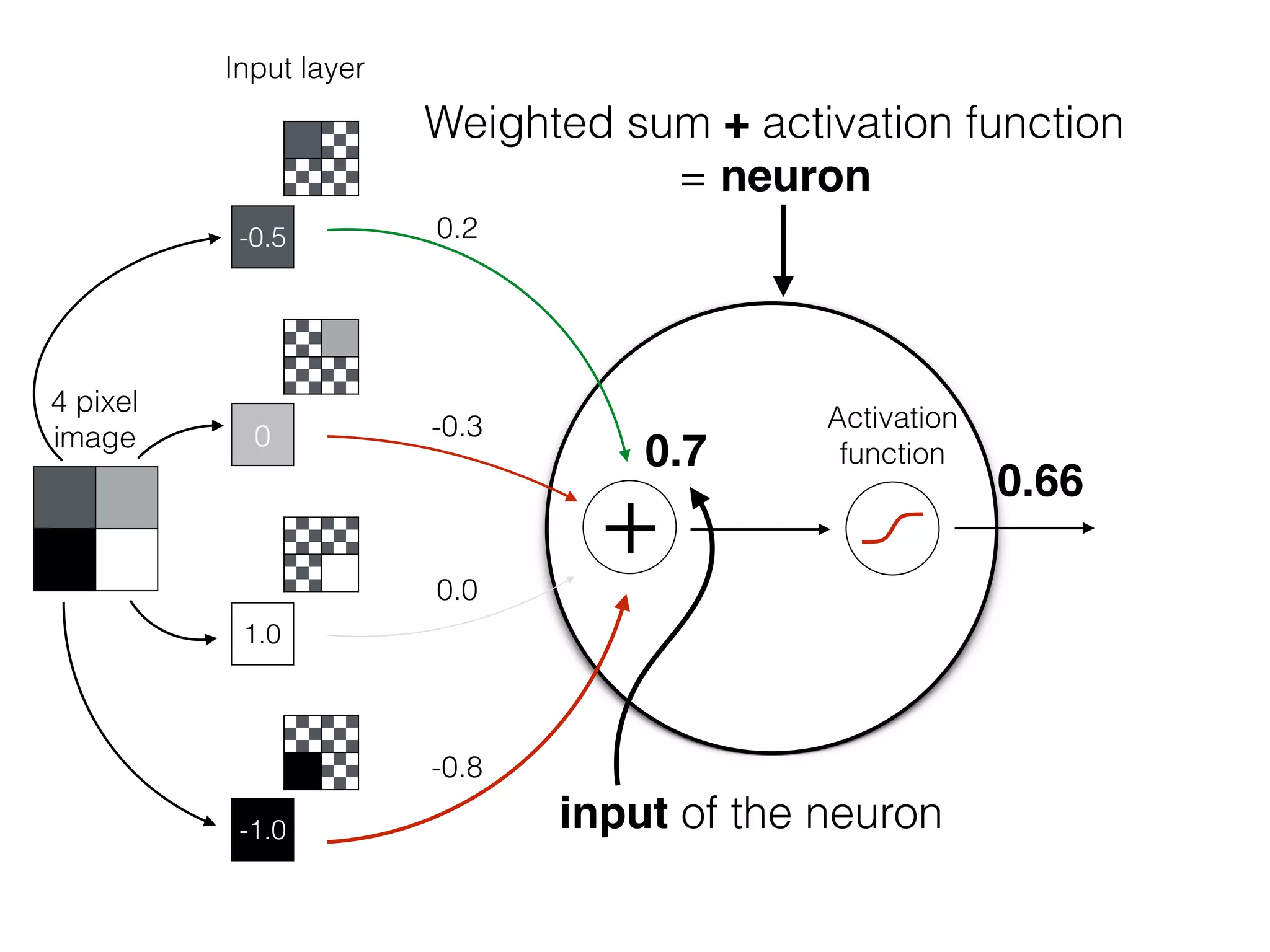
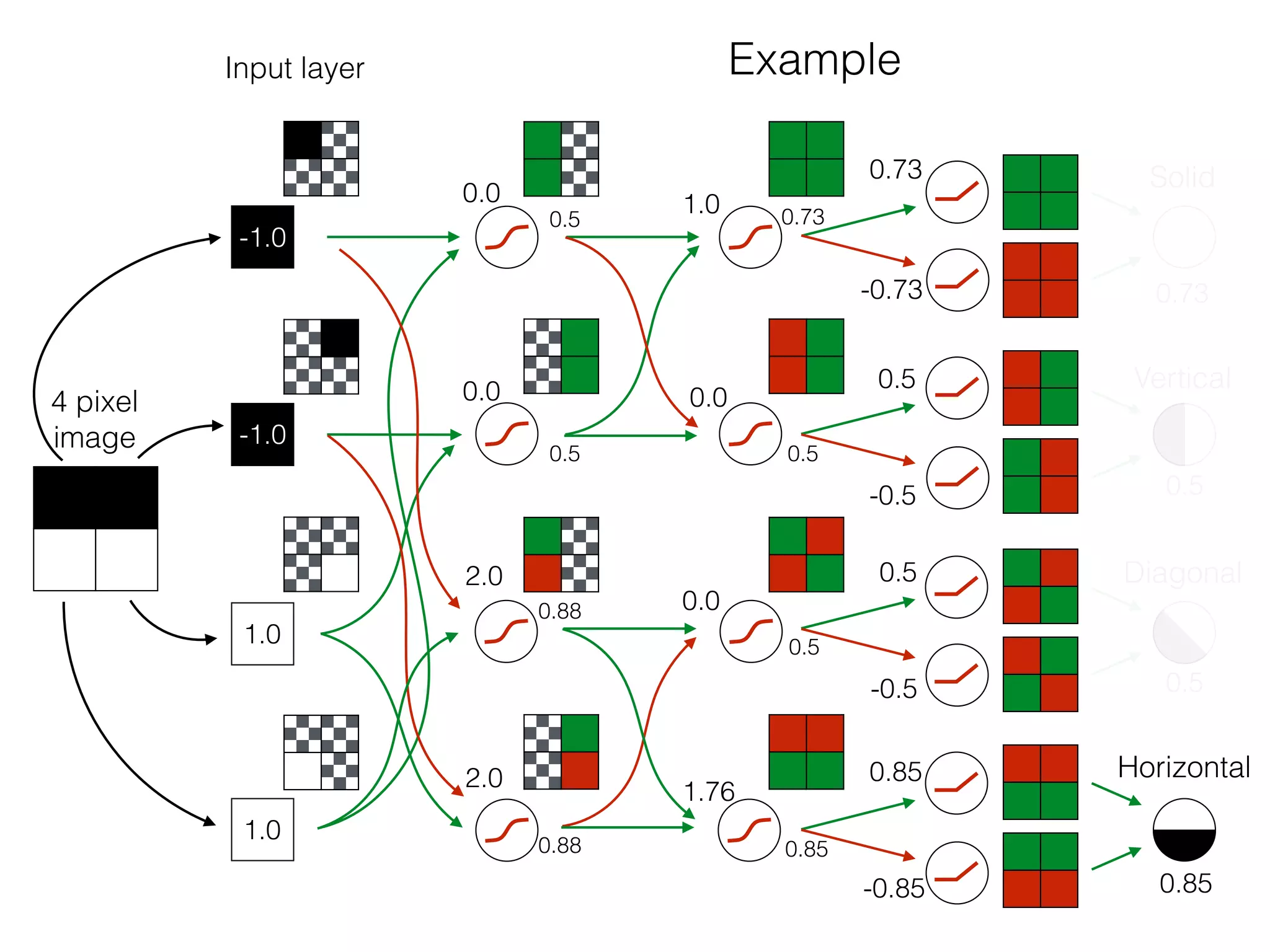
![OutputInput
x
w1
sig(w1 * x)
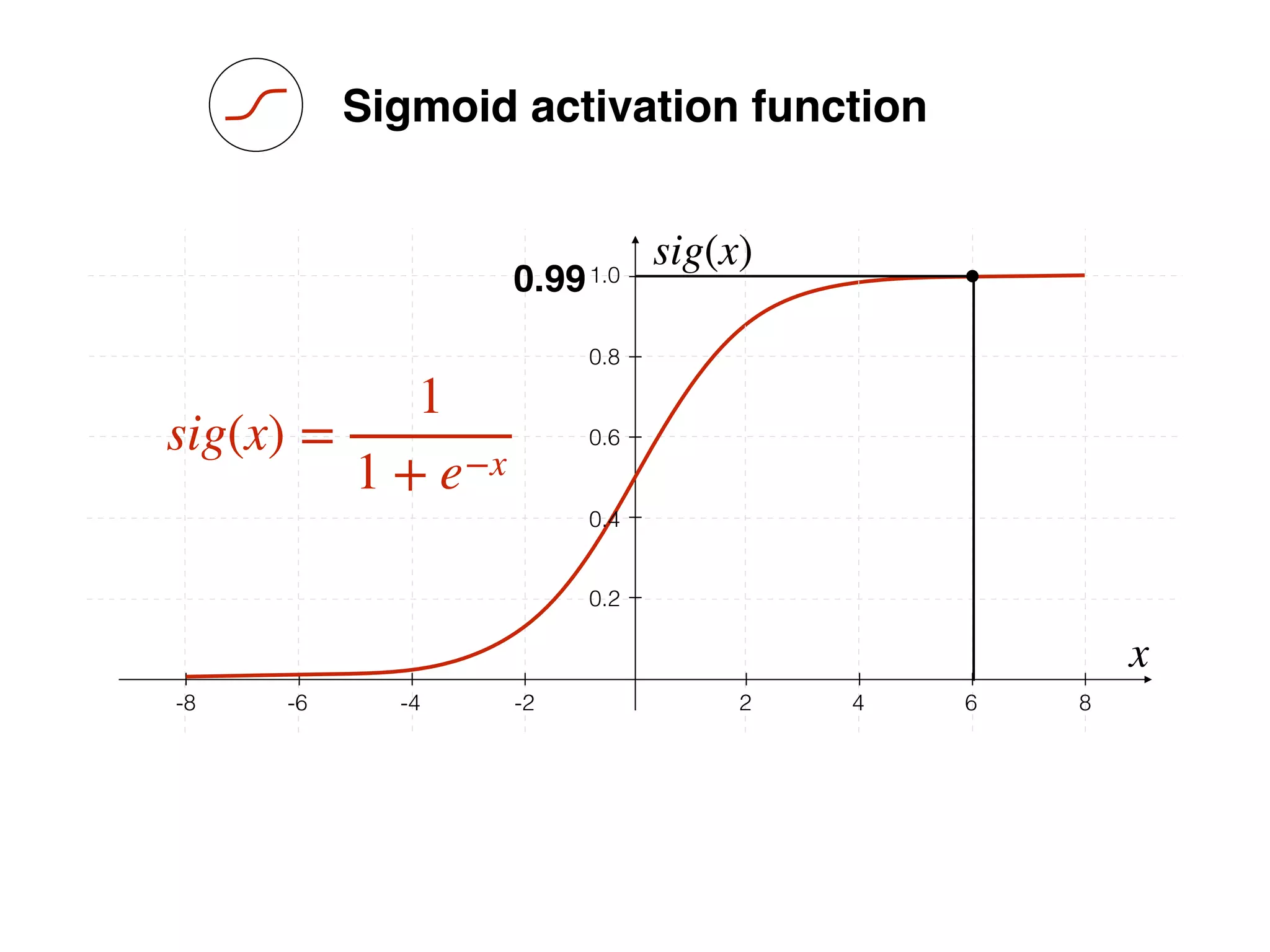
Bias helps to shift the resulting curve
w1 =[0.5, 1.0, 2.0]
OutputInput
x
w1
sig(w1 * x + b1)
b1
= [-4.0, 0.0, 4.0]
b b1
w1=[1.0]
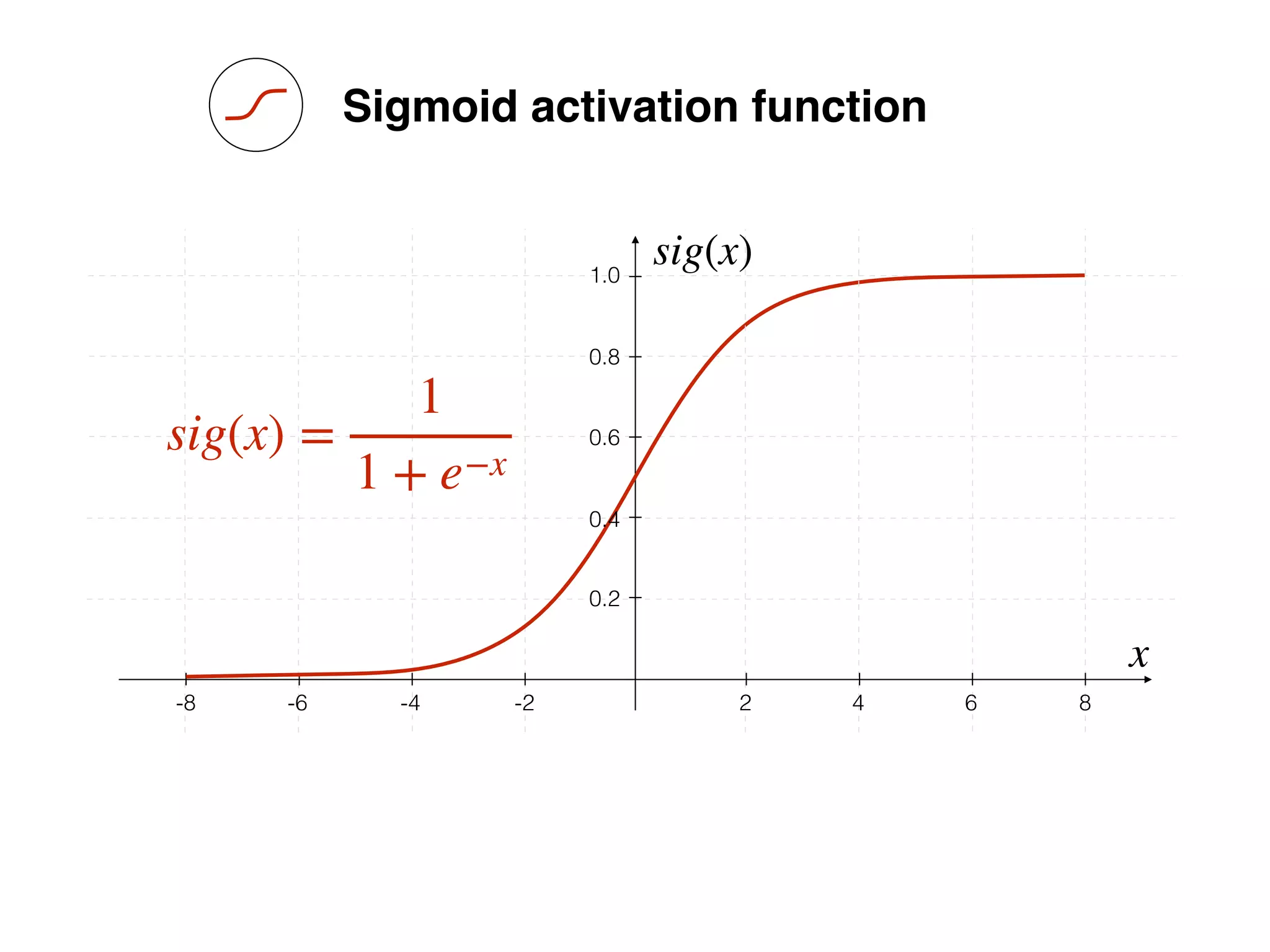
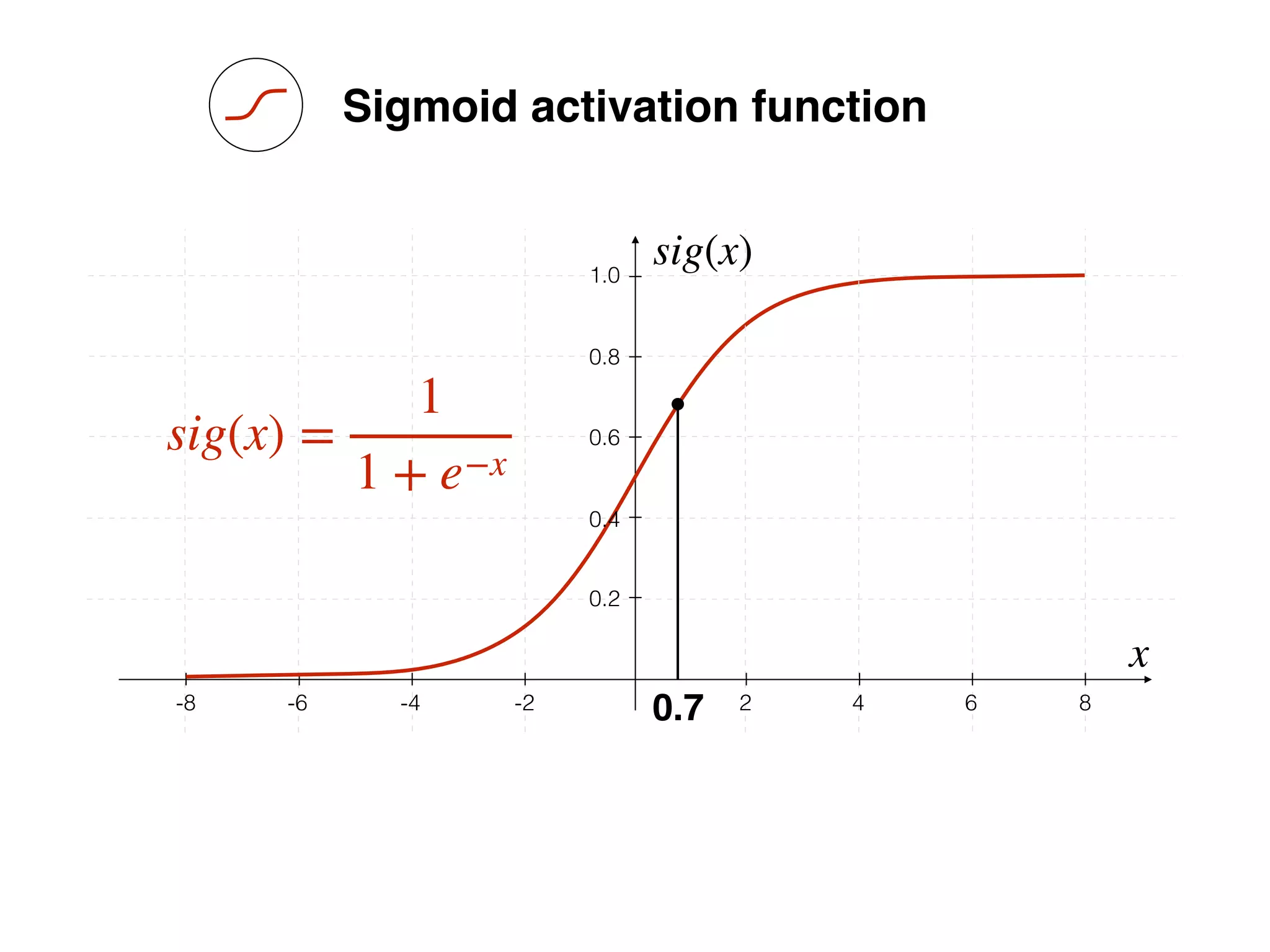
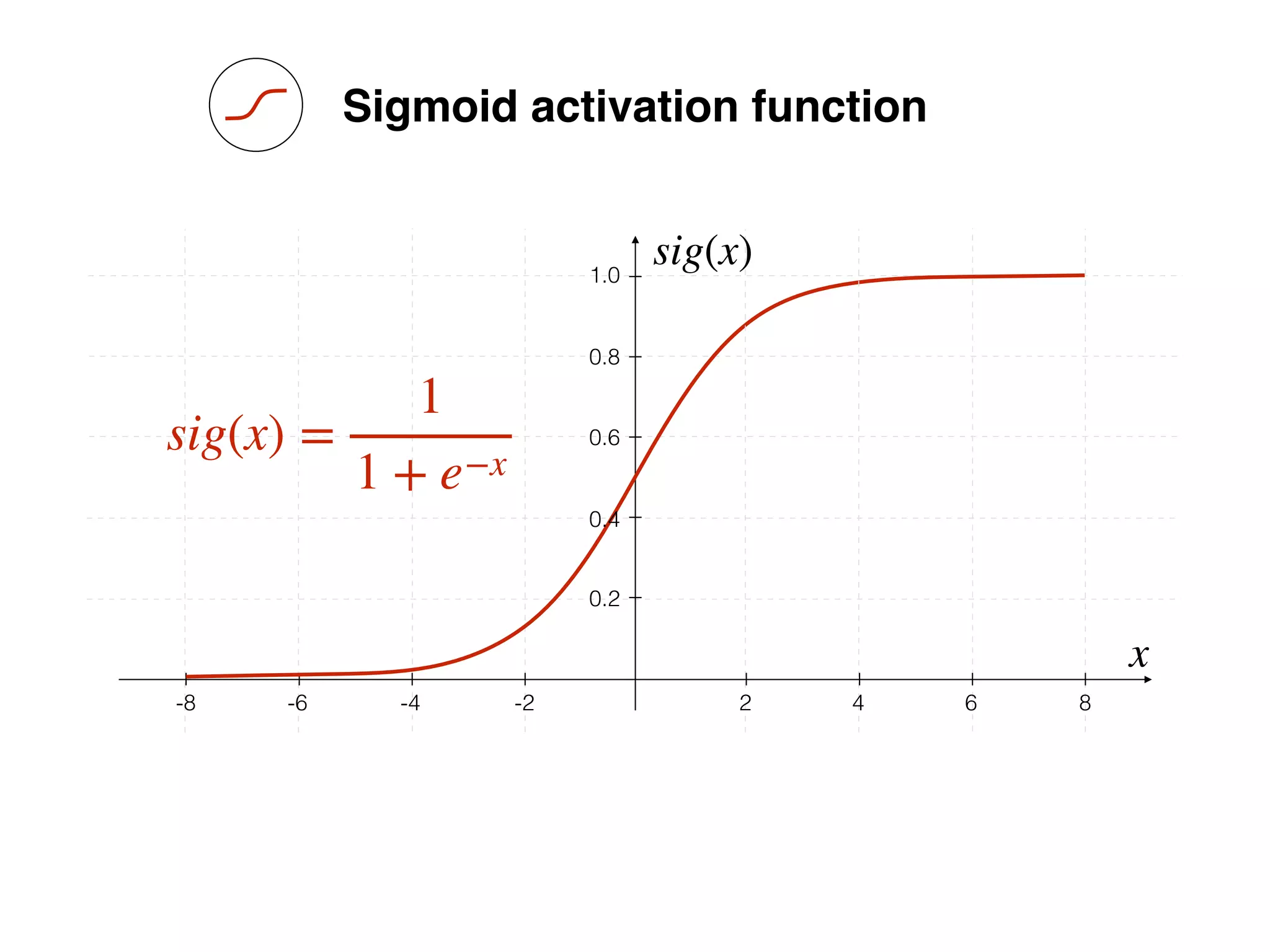
sig(x) =
1
1 + e−x
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x + b1)
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x)
b1 b1
Source: http://www.uta.fi/sis/tie/neuro/index/Neurocomputing2.pdf](https://image.slidesharecdn.com/dllecturegeneral-190728122700/75/Introduction-to-Deep-Learning-98-2048.jpg)
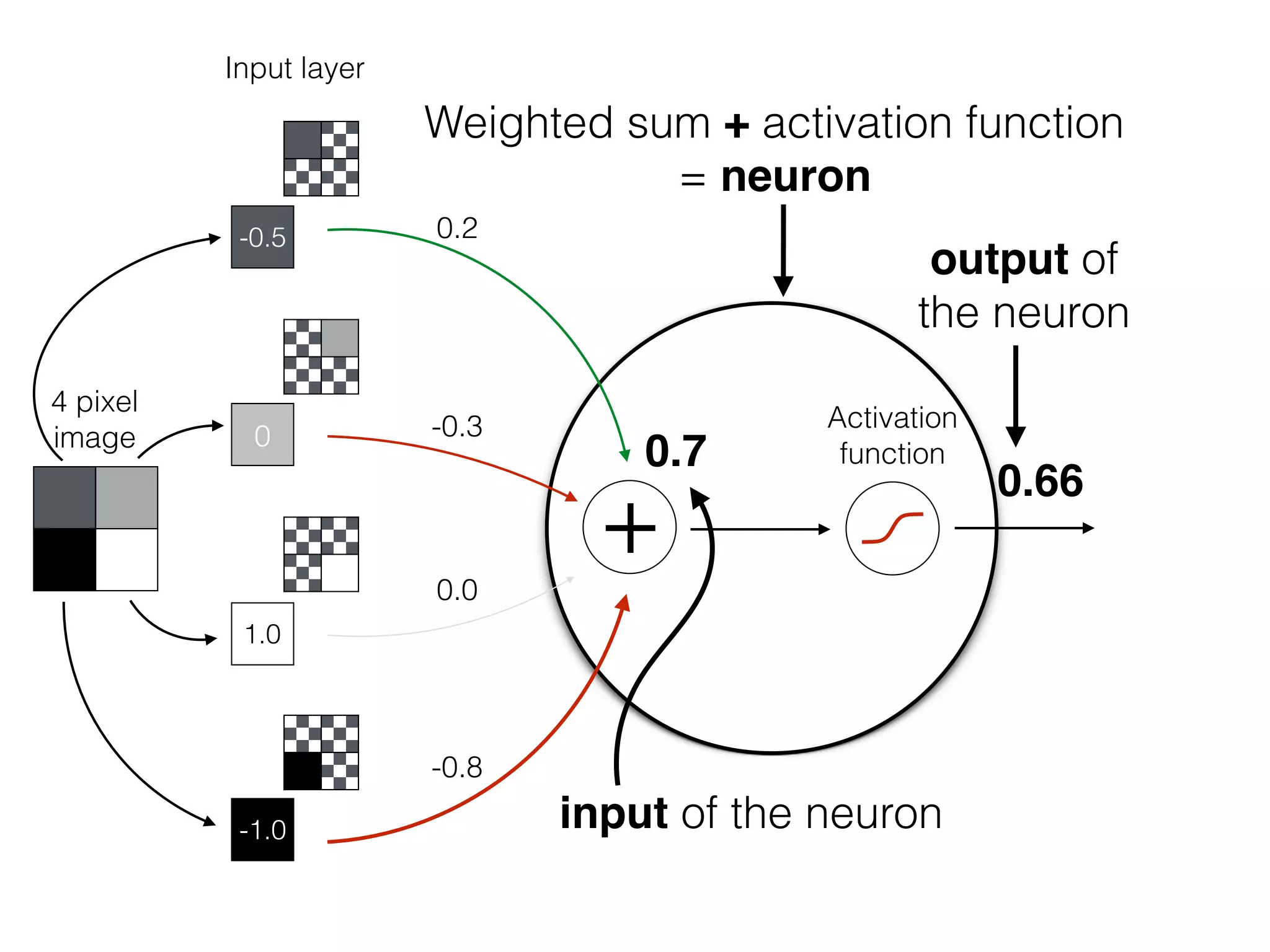
![OutputInput
x
w1
sig(w1 * x)
Bias helps to shift the resulting curve
w1 =[0.5, 1.0, 2.0]
OutputInput
x
w1
sig(w1 * x + b1)
b1
= [-4.0, 0.0, 4.0]
b b1
w1=[1.0]
sig(x) =
1
1 + e−(wx+b)
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x + b1)
-8 -6 -4 -2 2 4 6 8
0.2
0.4
0.6
0.8
1.0
x
sig(w1 * x)
b1 b1
Source: http://www.uta.fi/sis/tie/neuro/index/Neurocomputing2.pdf](https://image.slidesharecdn.com/dllecturegeneral-190728122700/75/Introduction-to-Deep-Learning-99-2048.jpg)
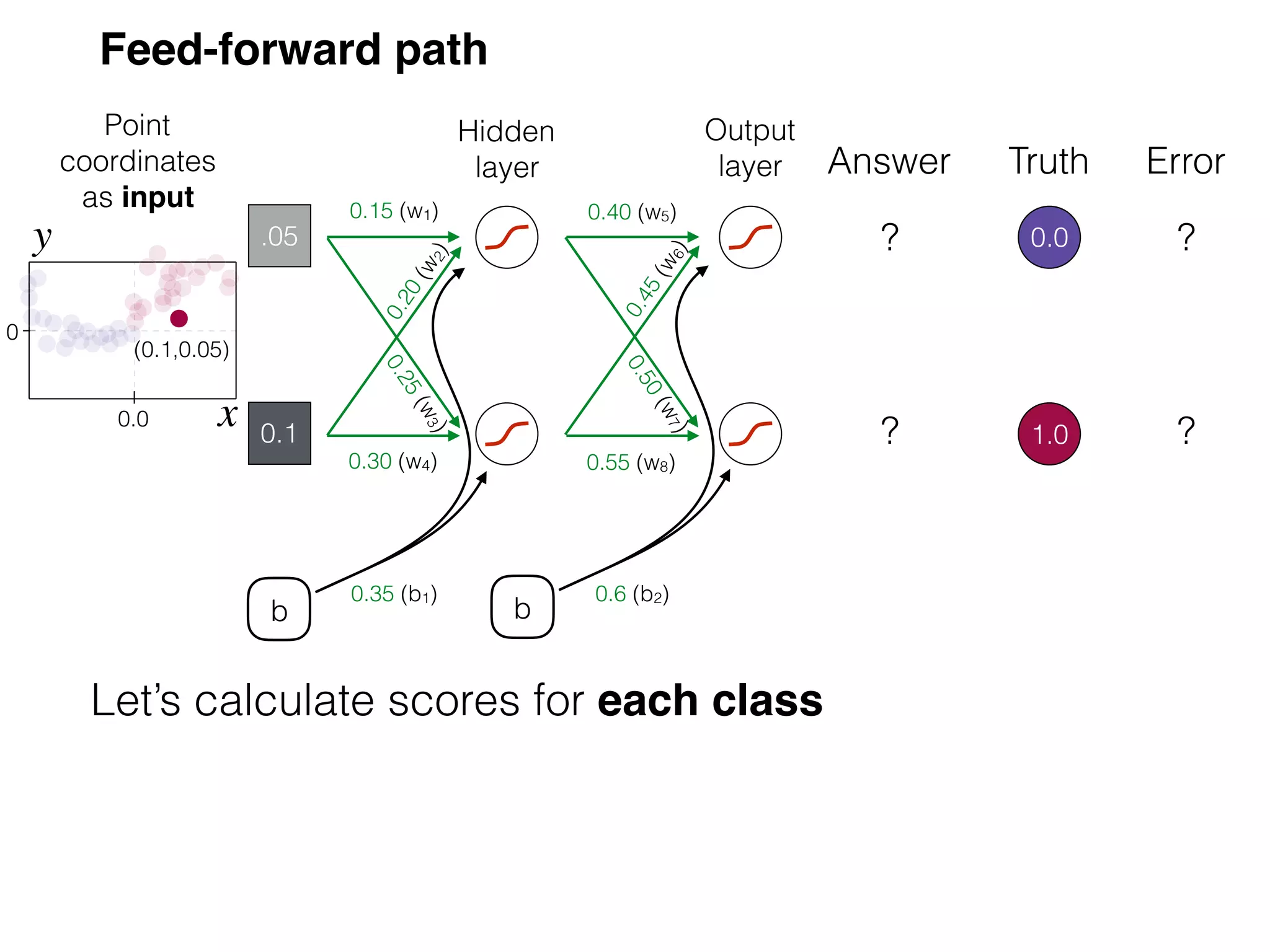
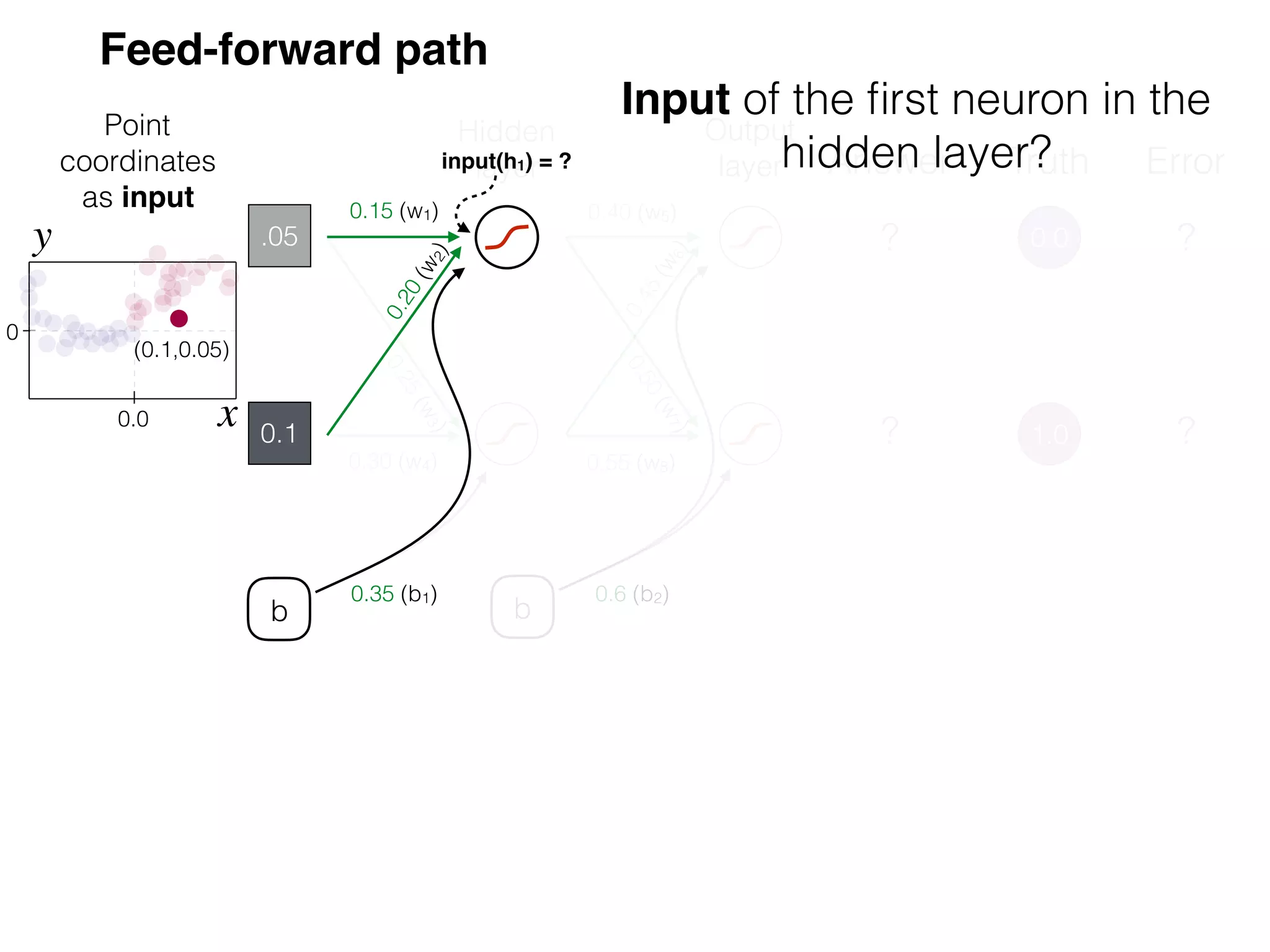
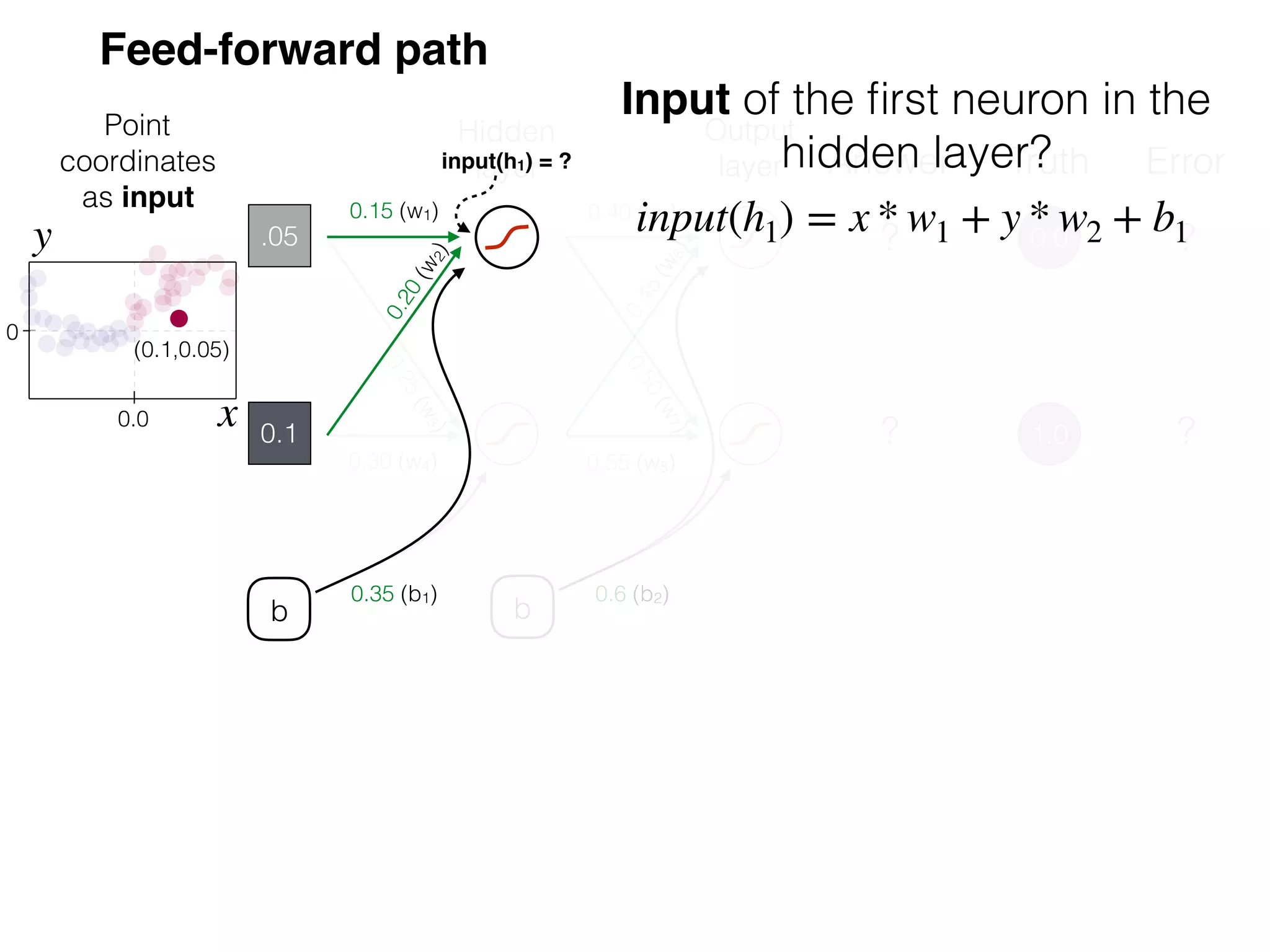
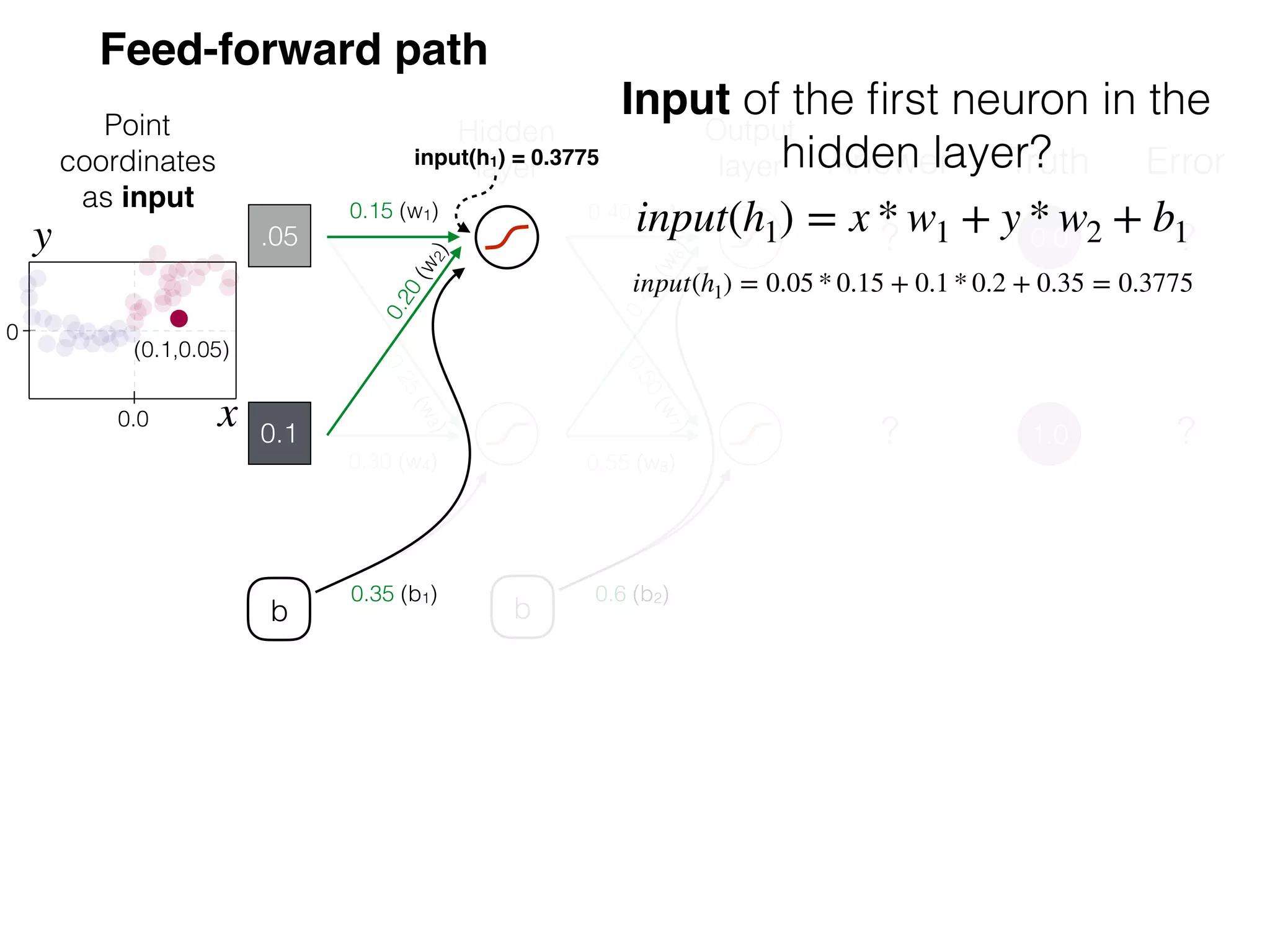
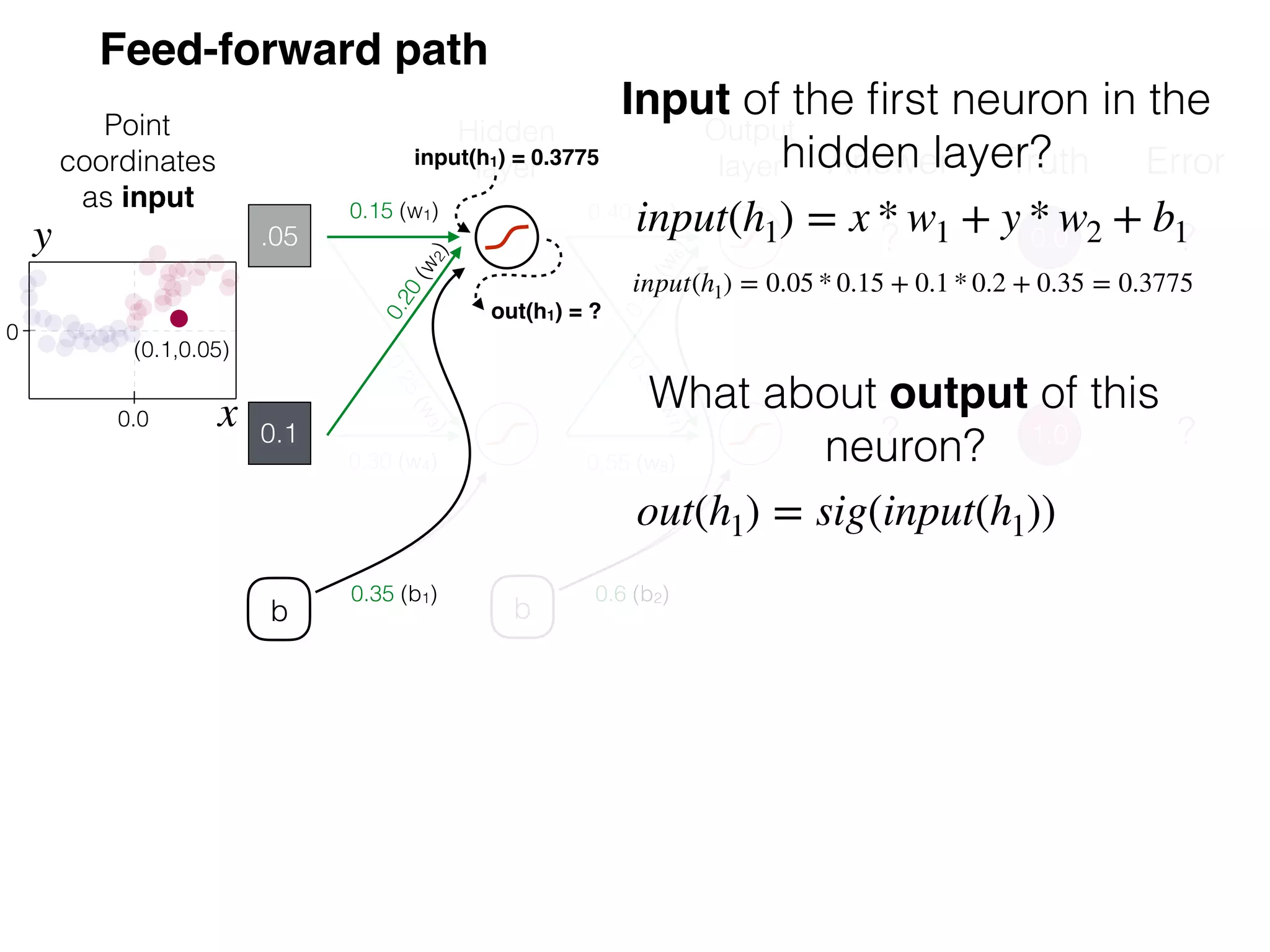
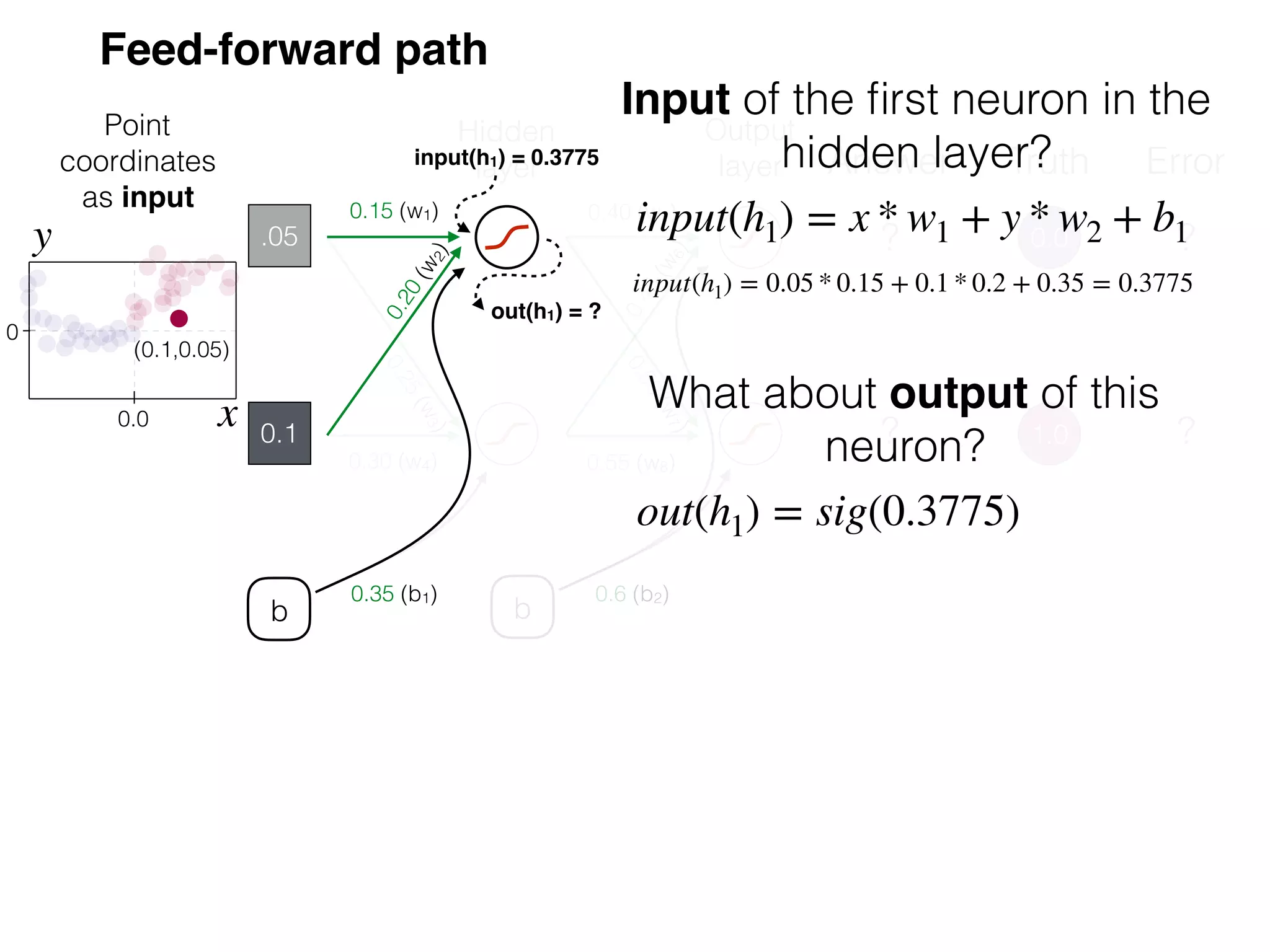
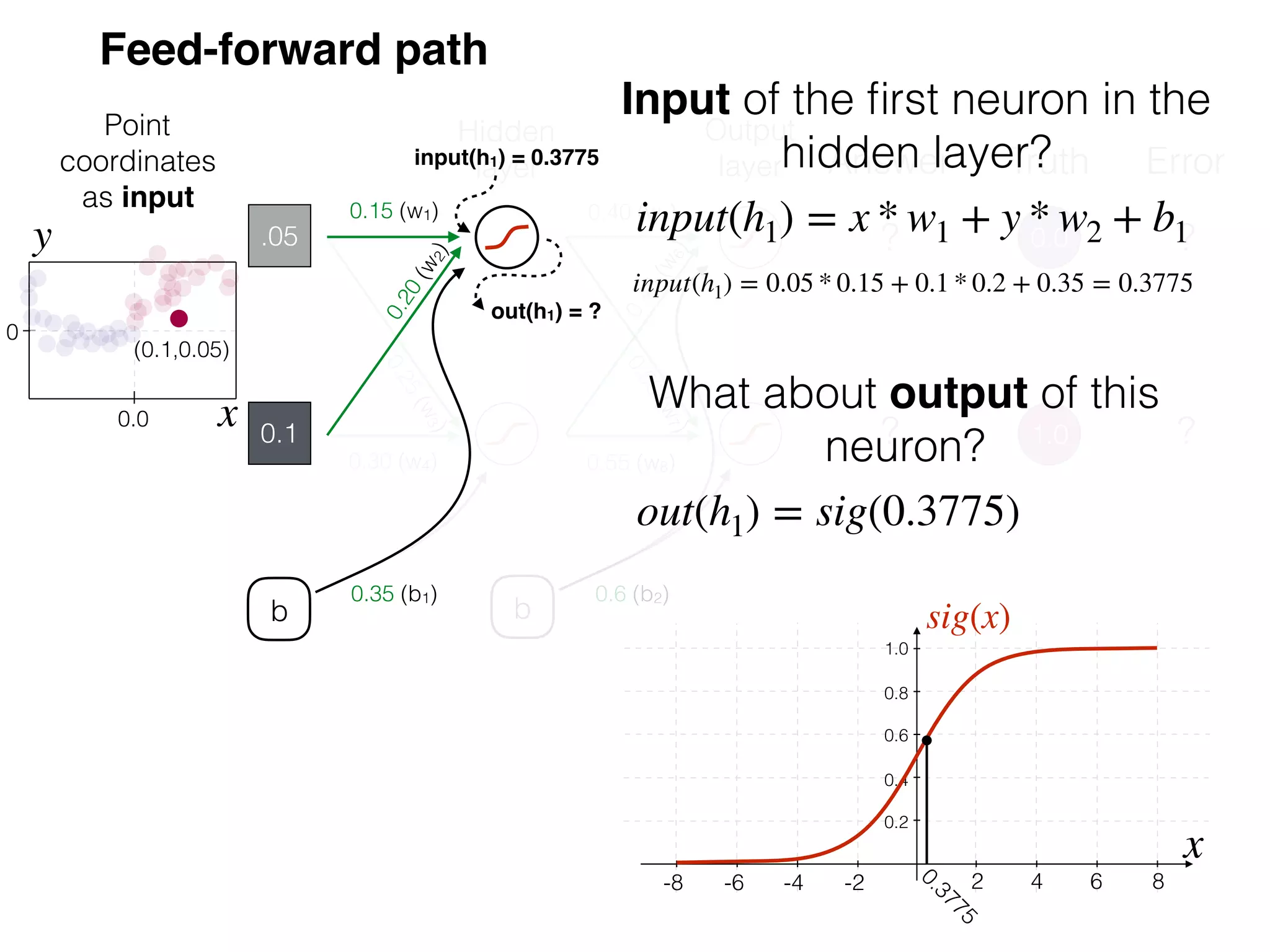
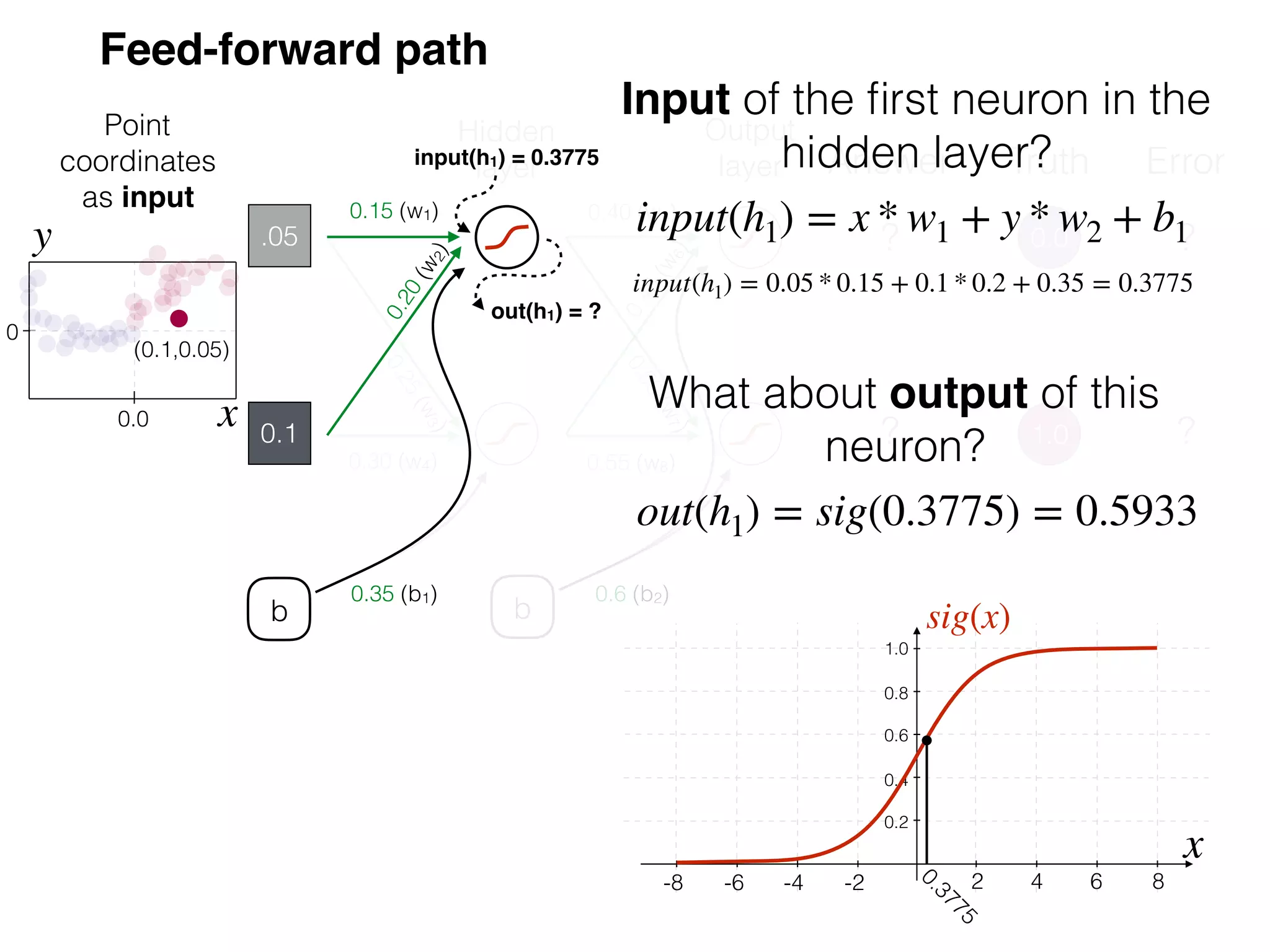
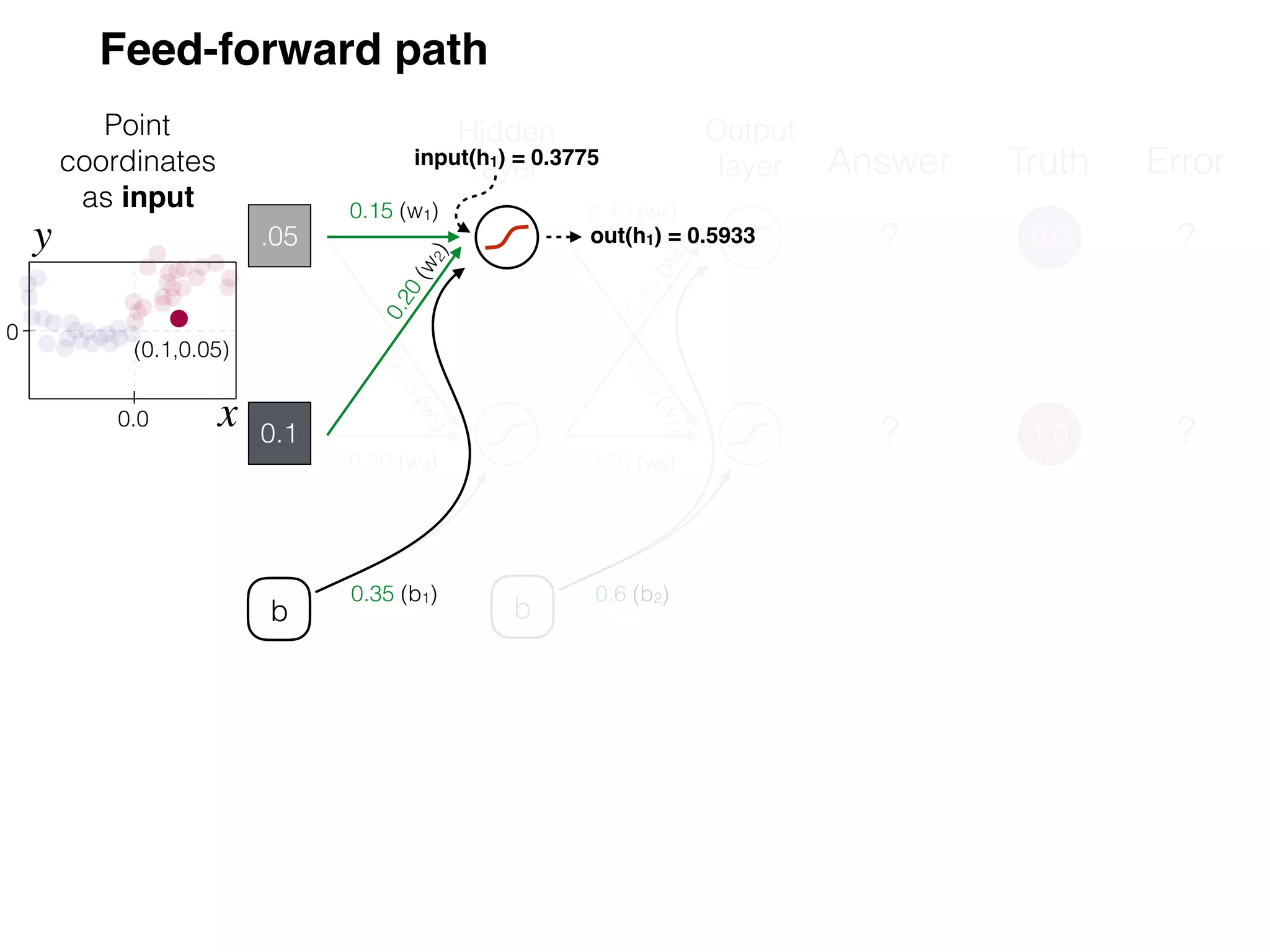
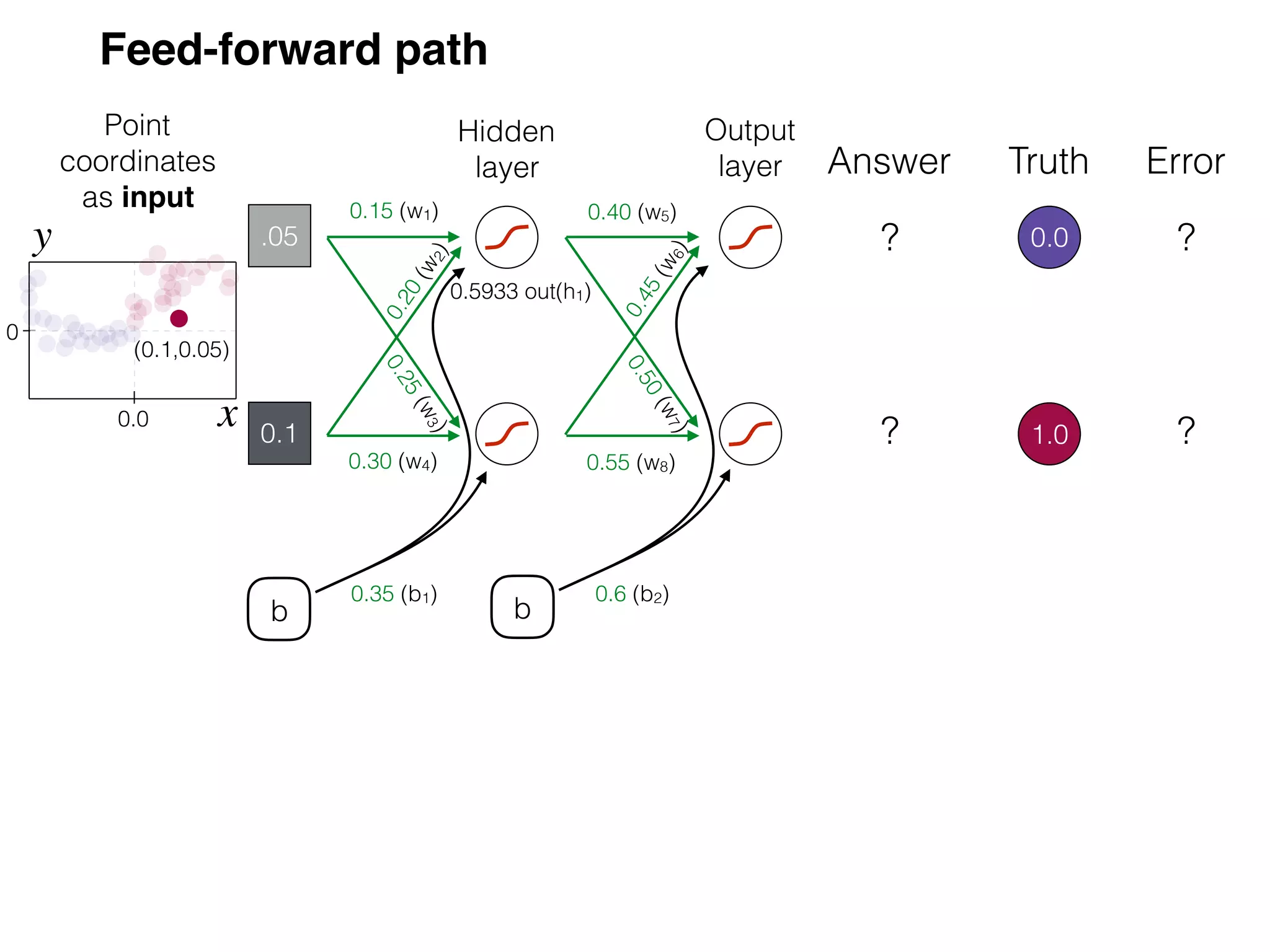
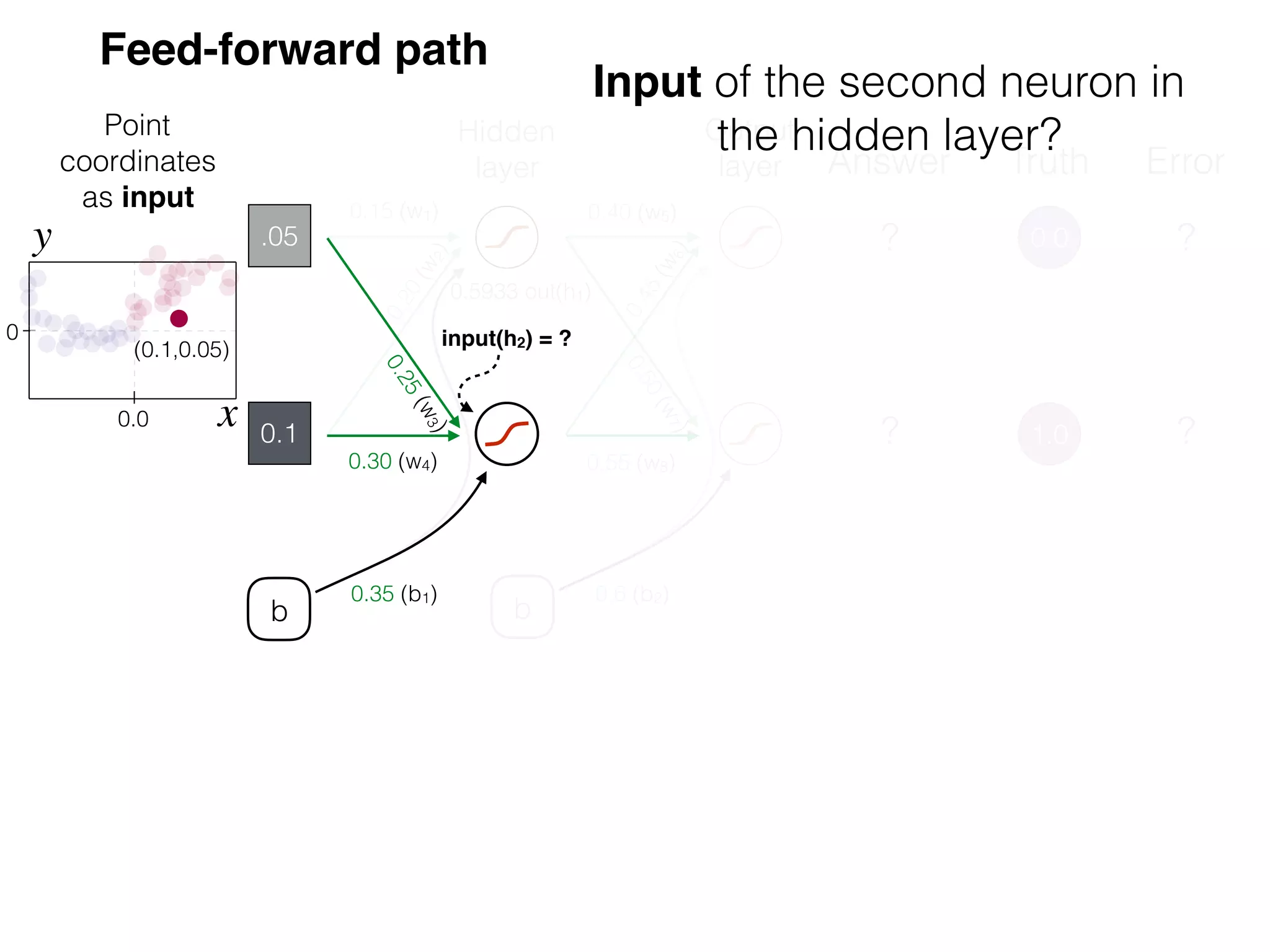
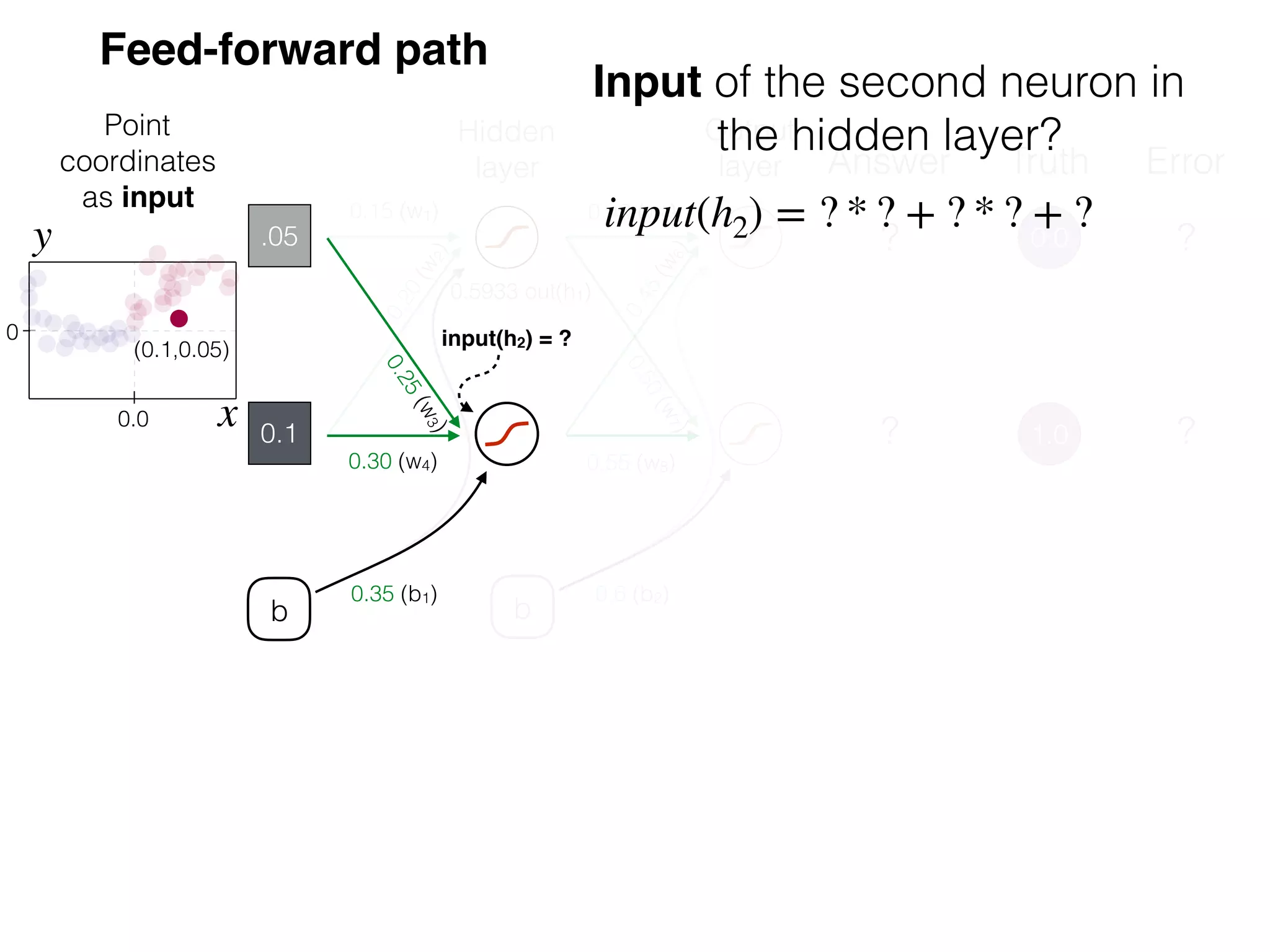
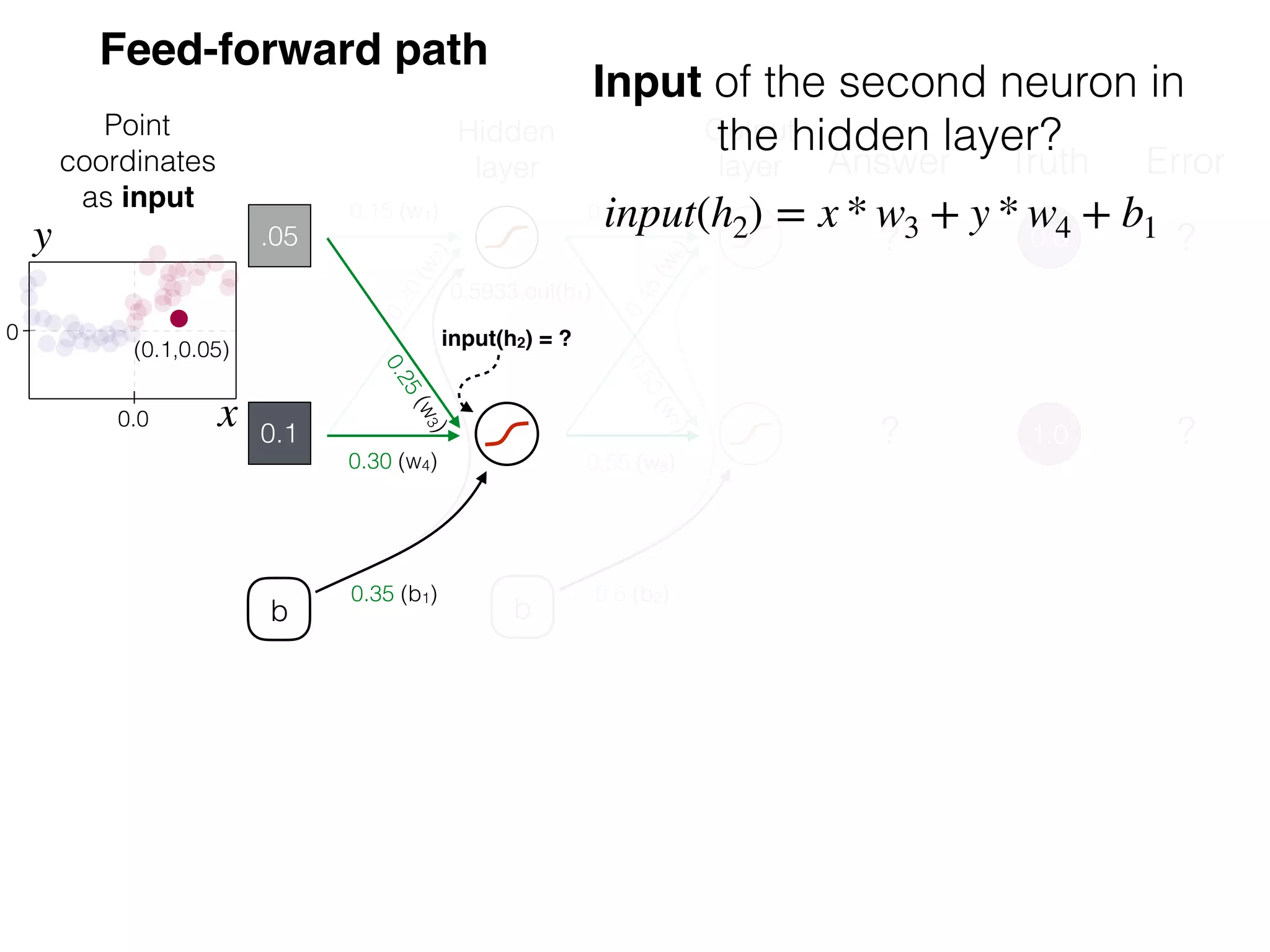
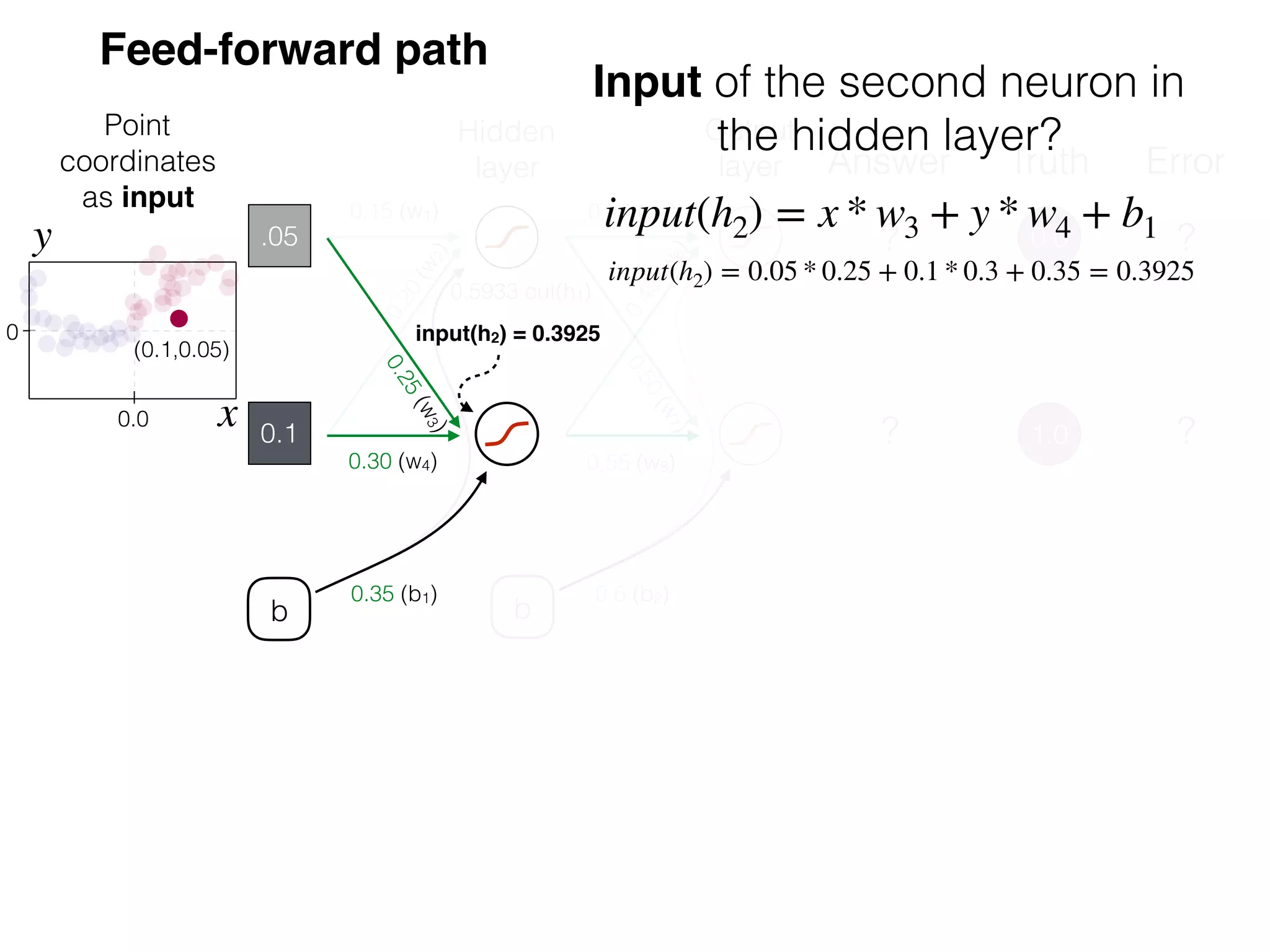
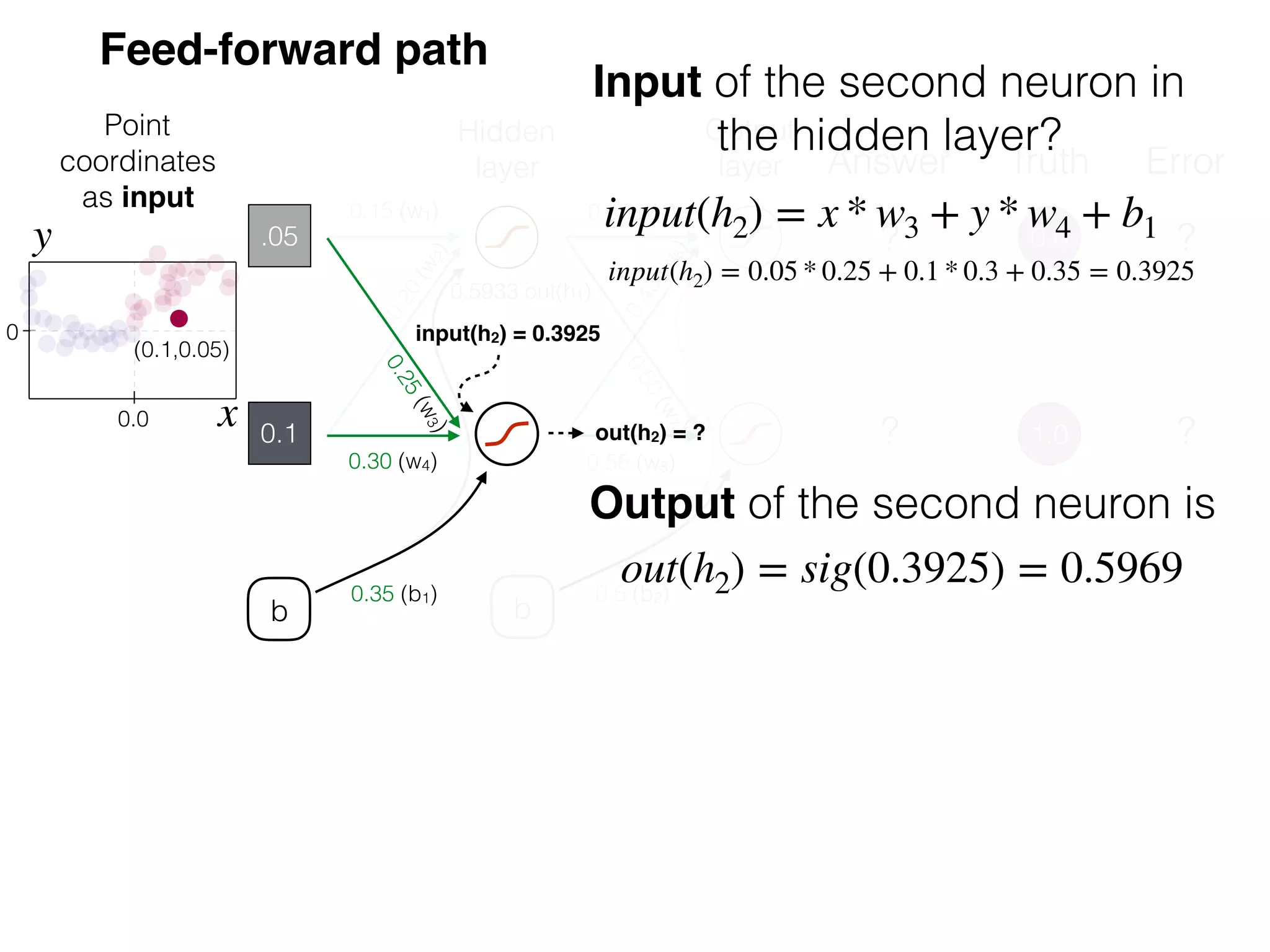
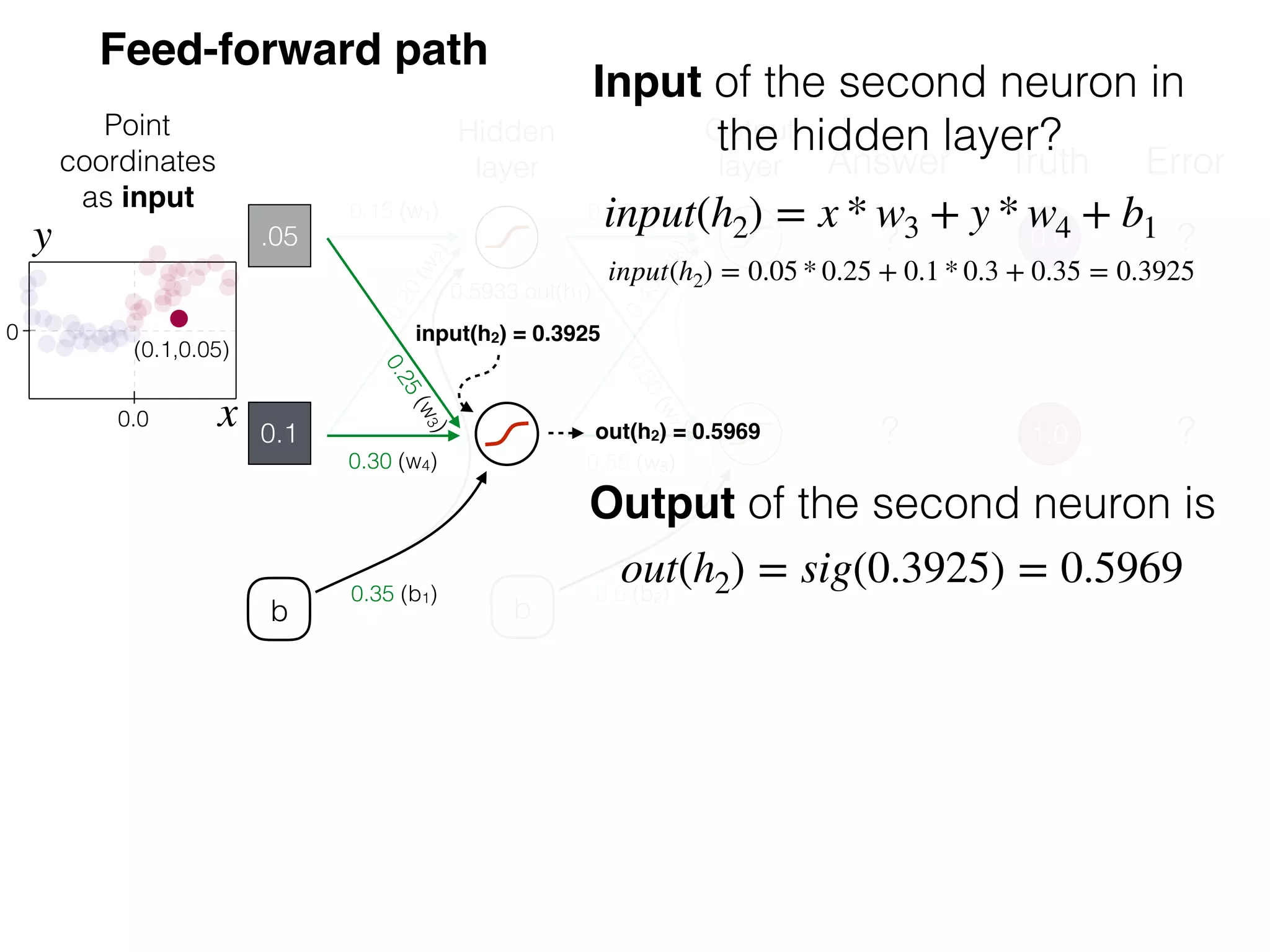
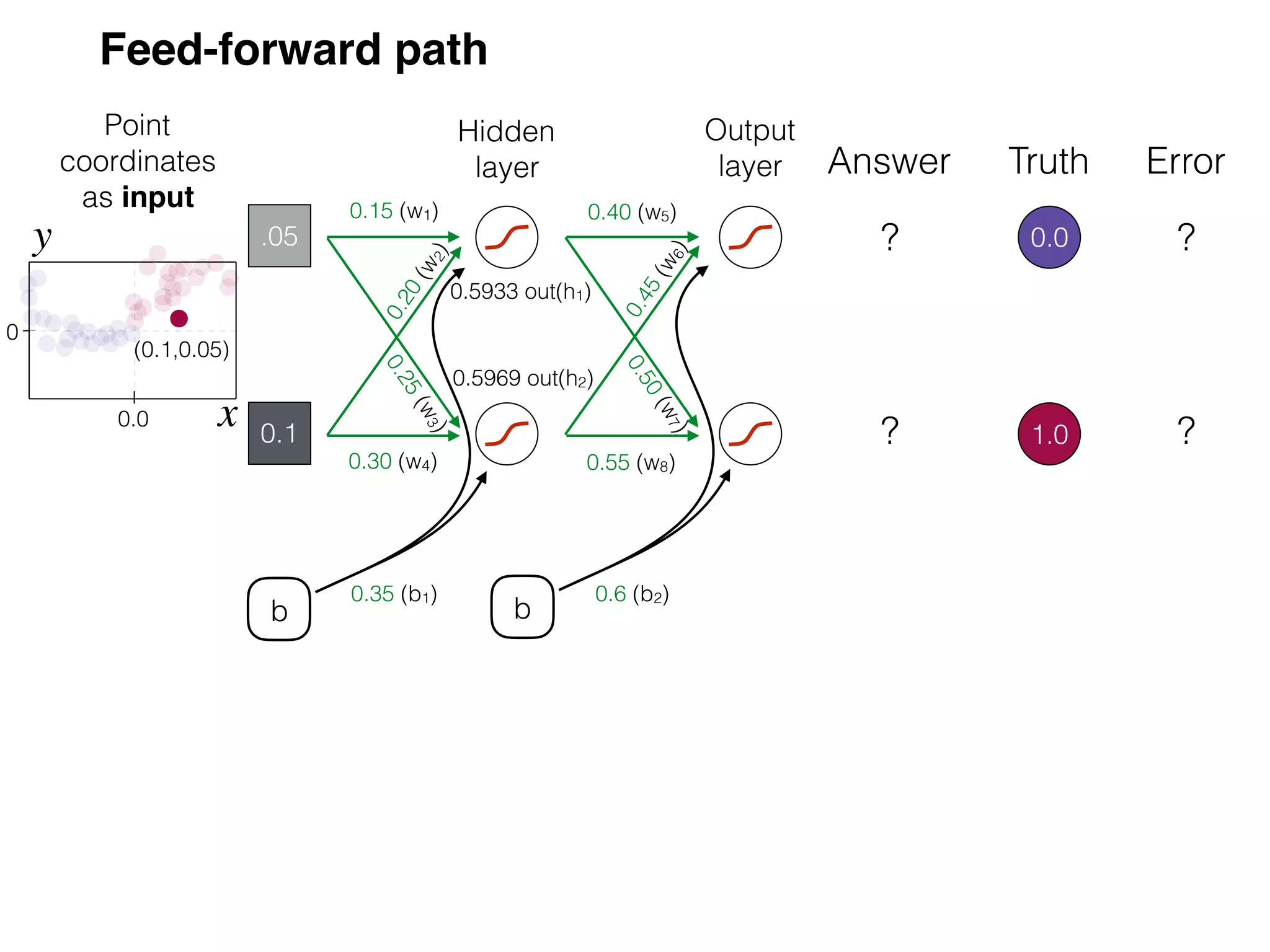
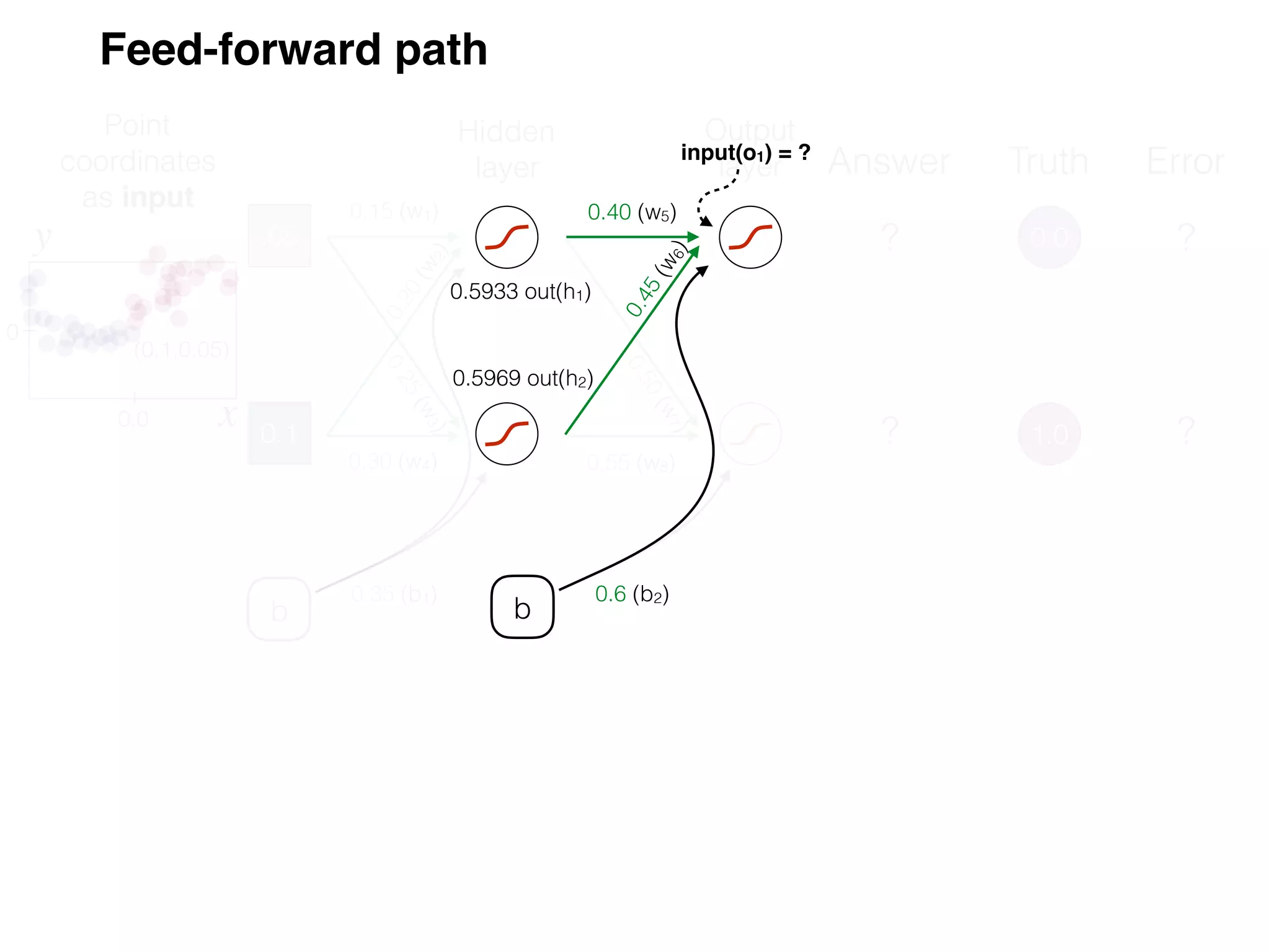
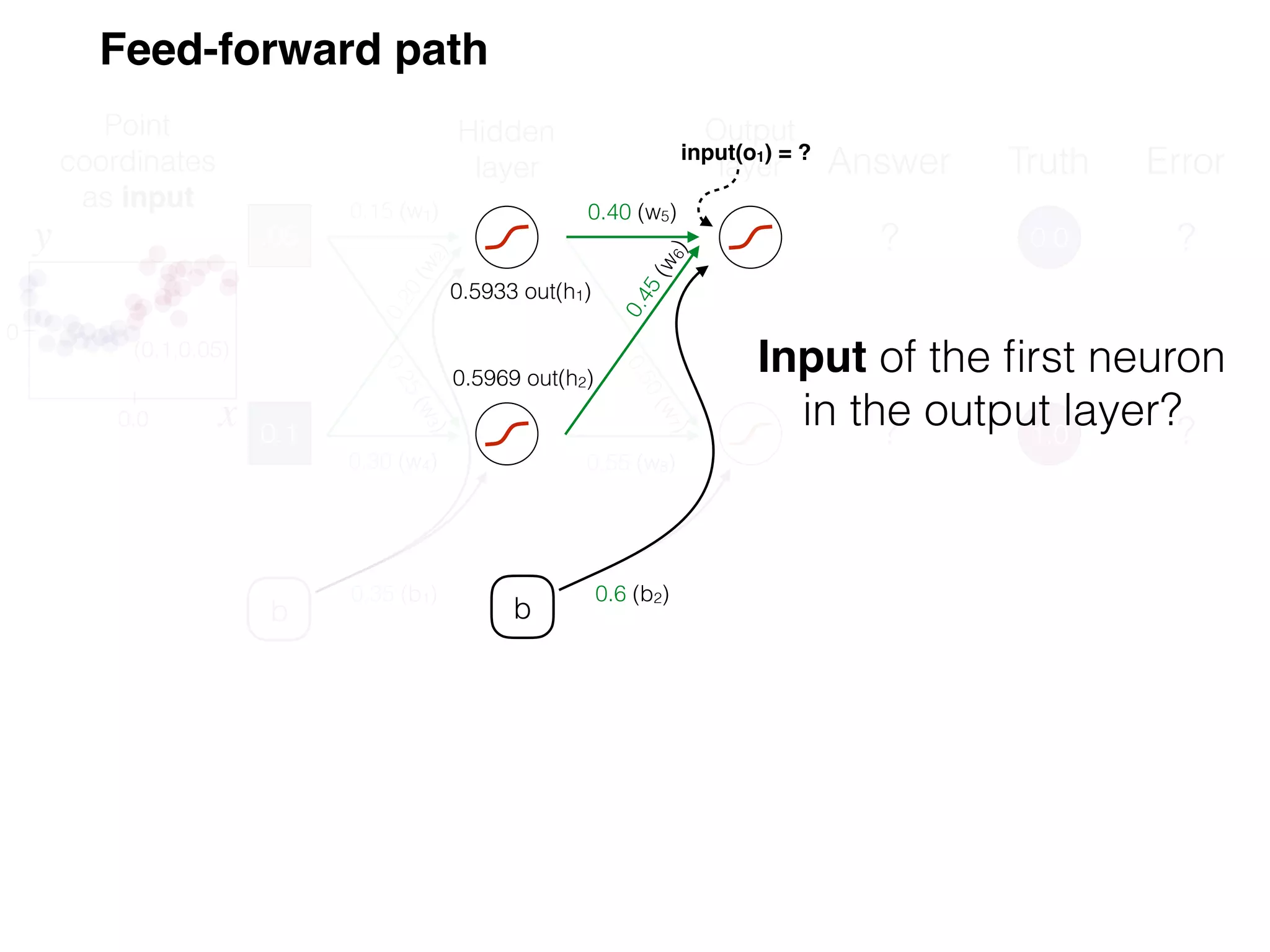
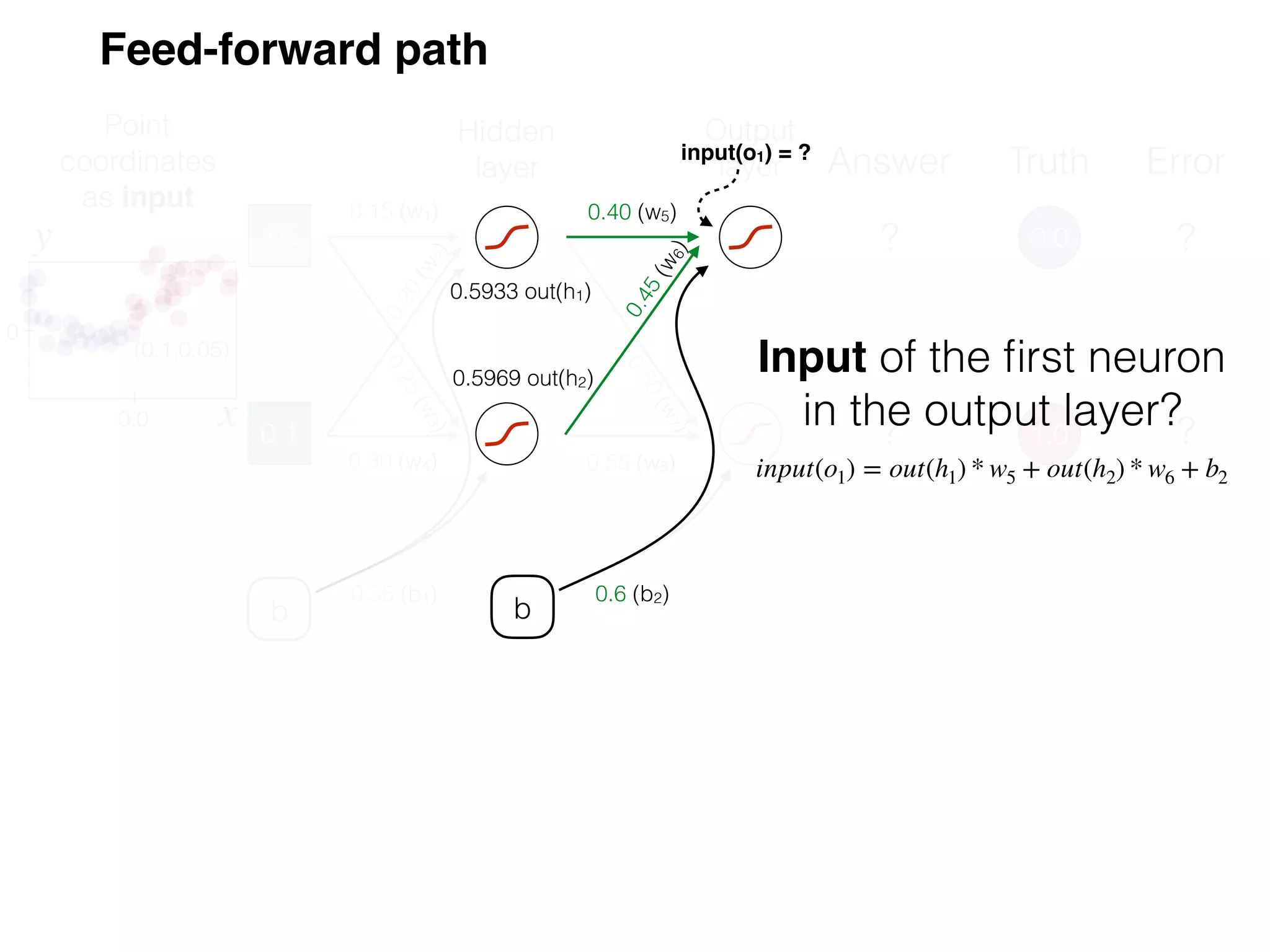
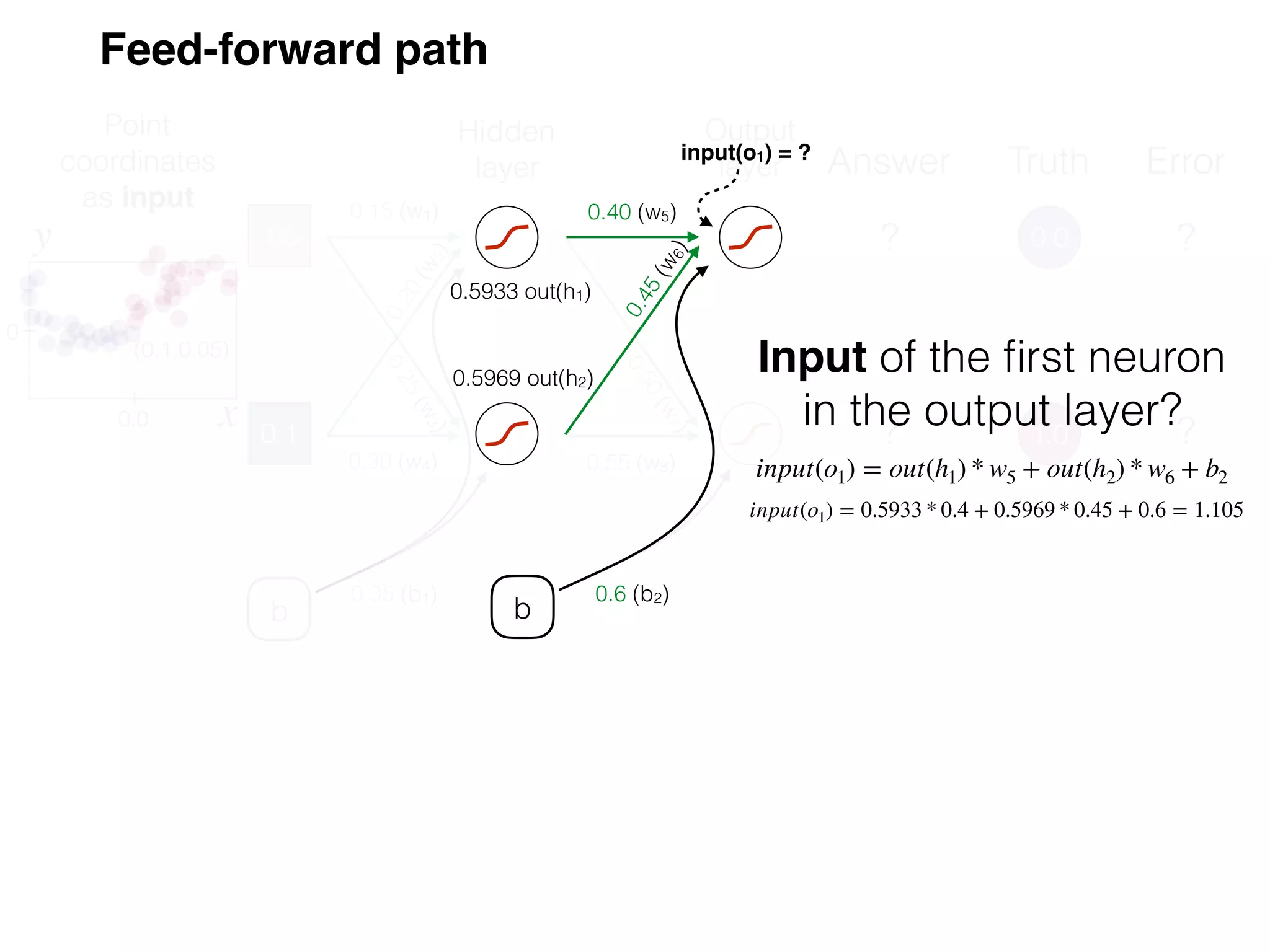
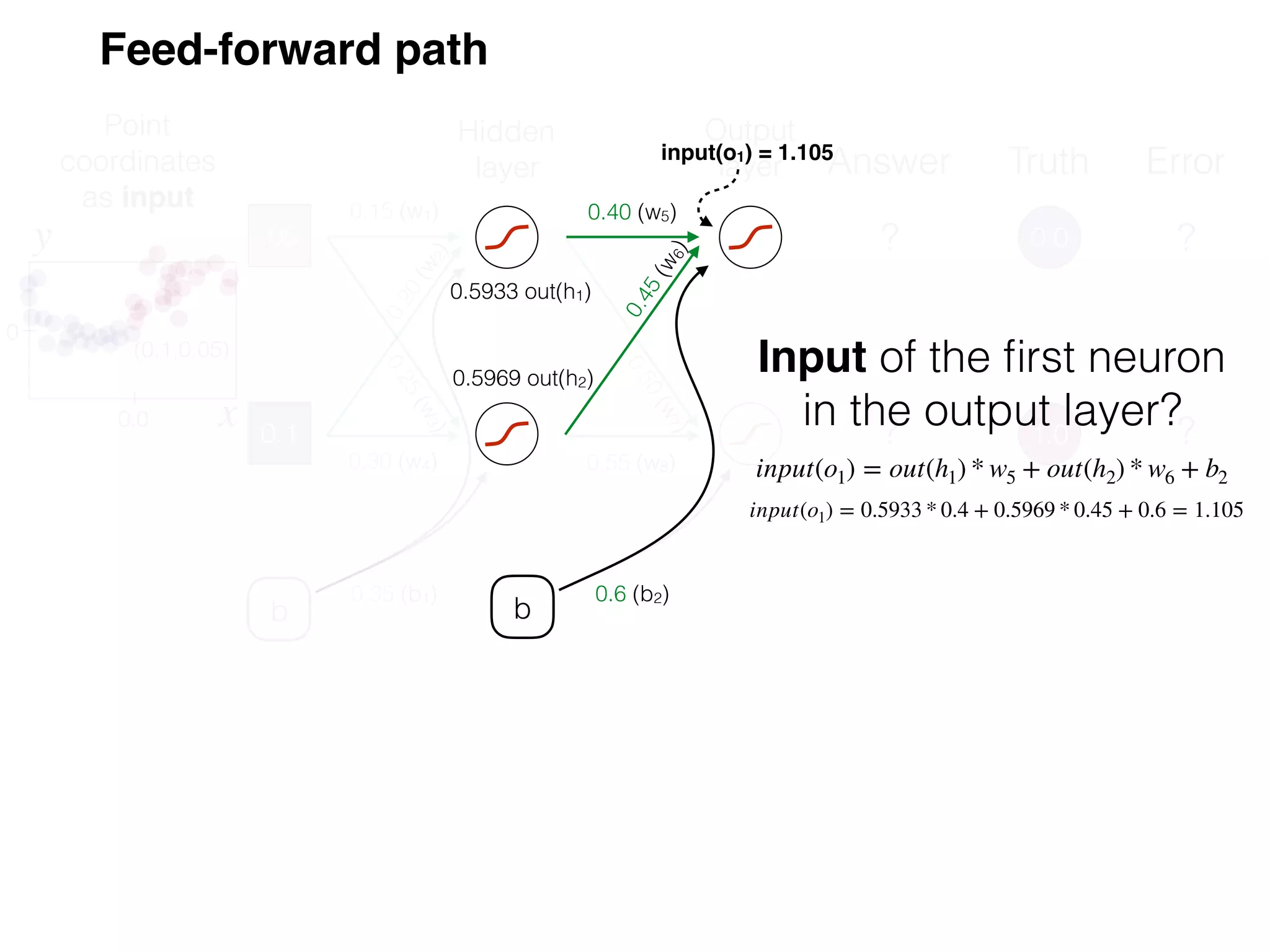
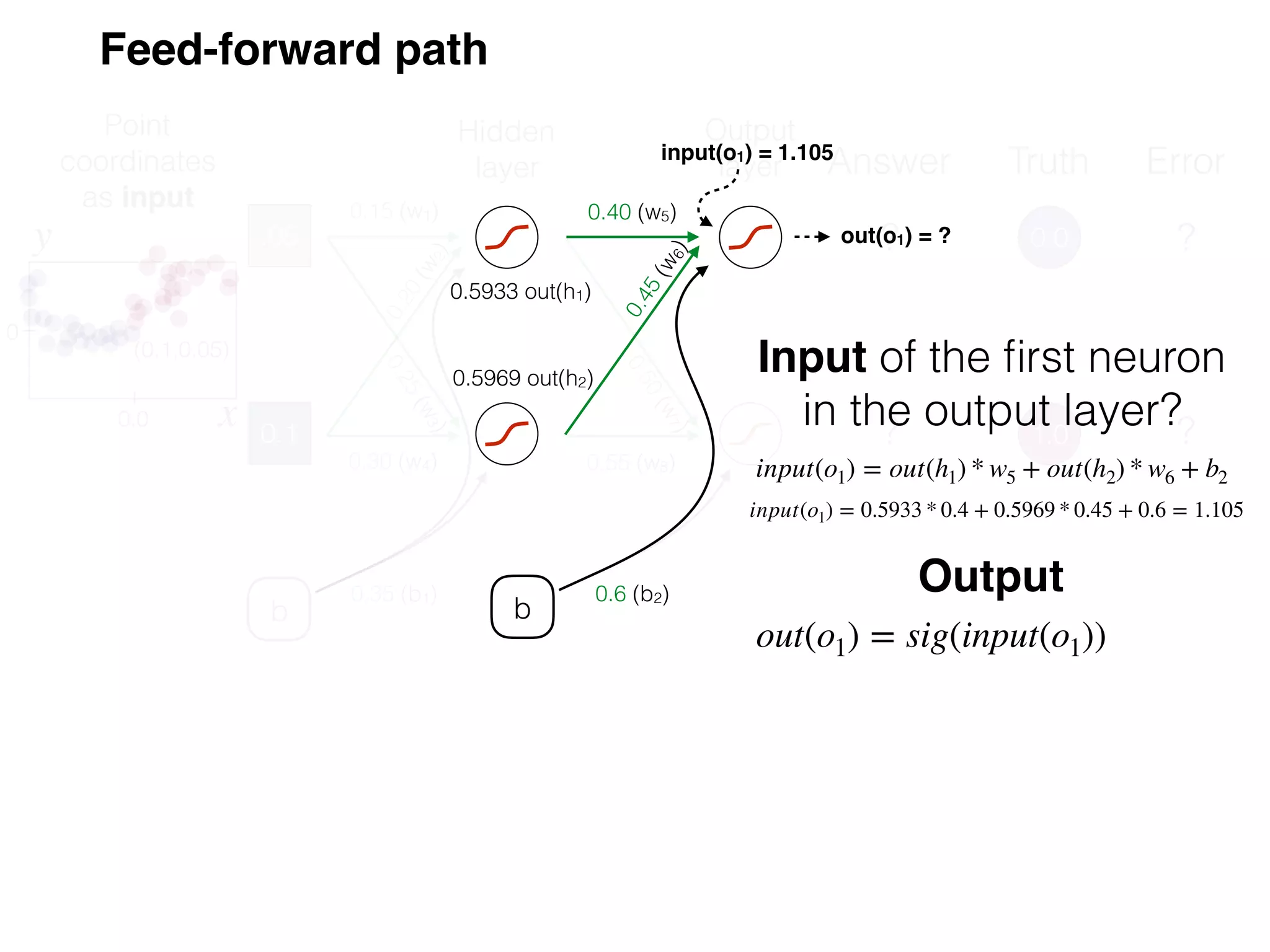
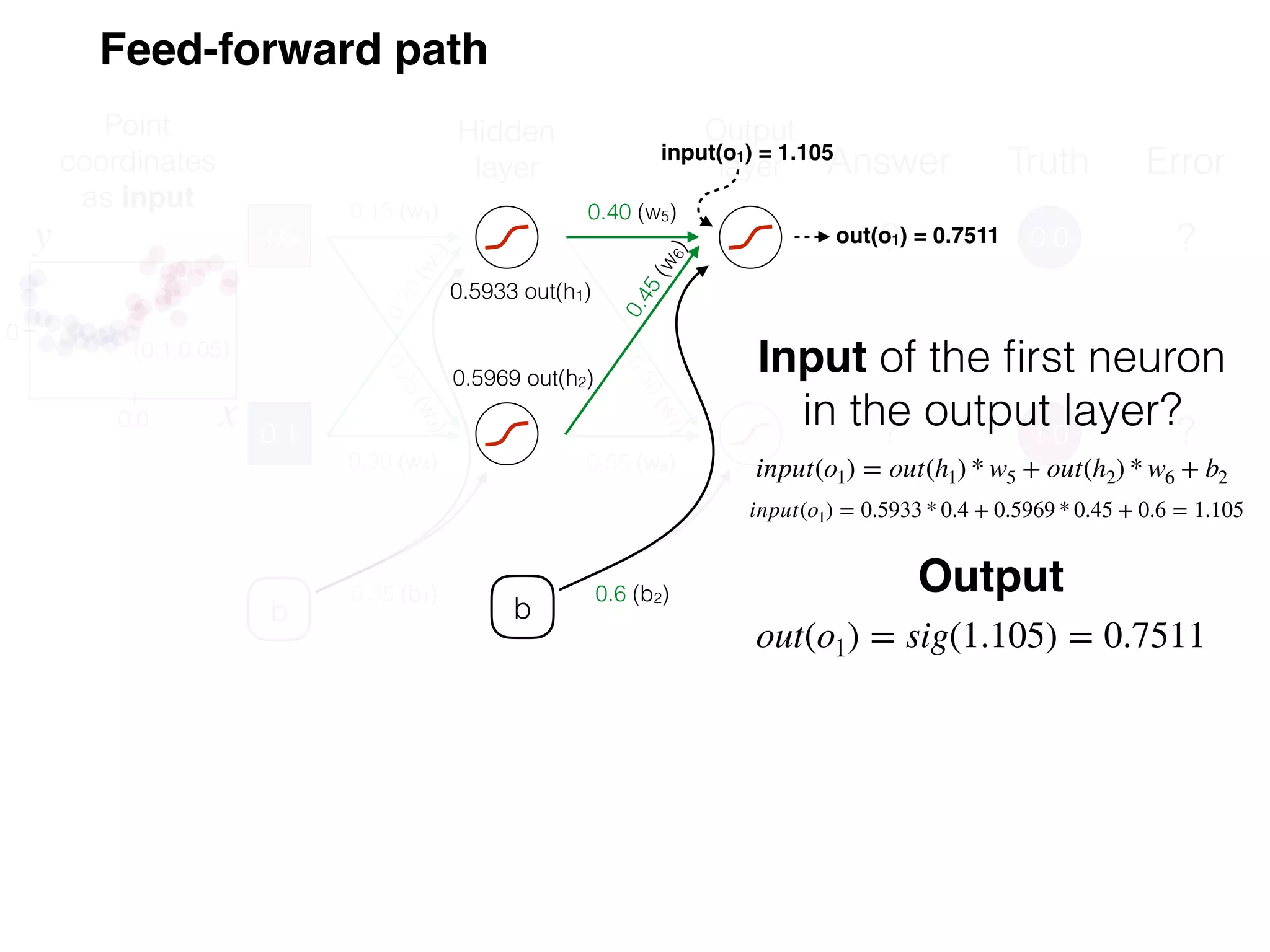
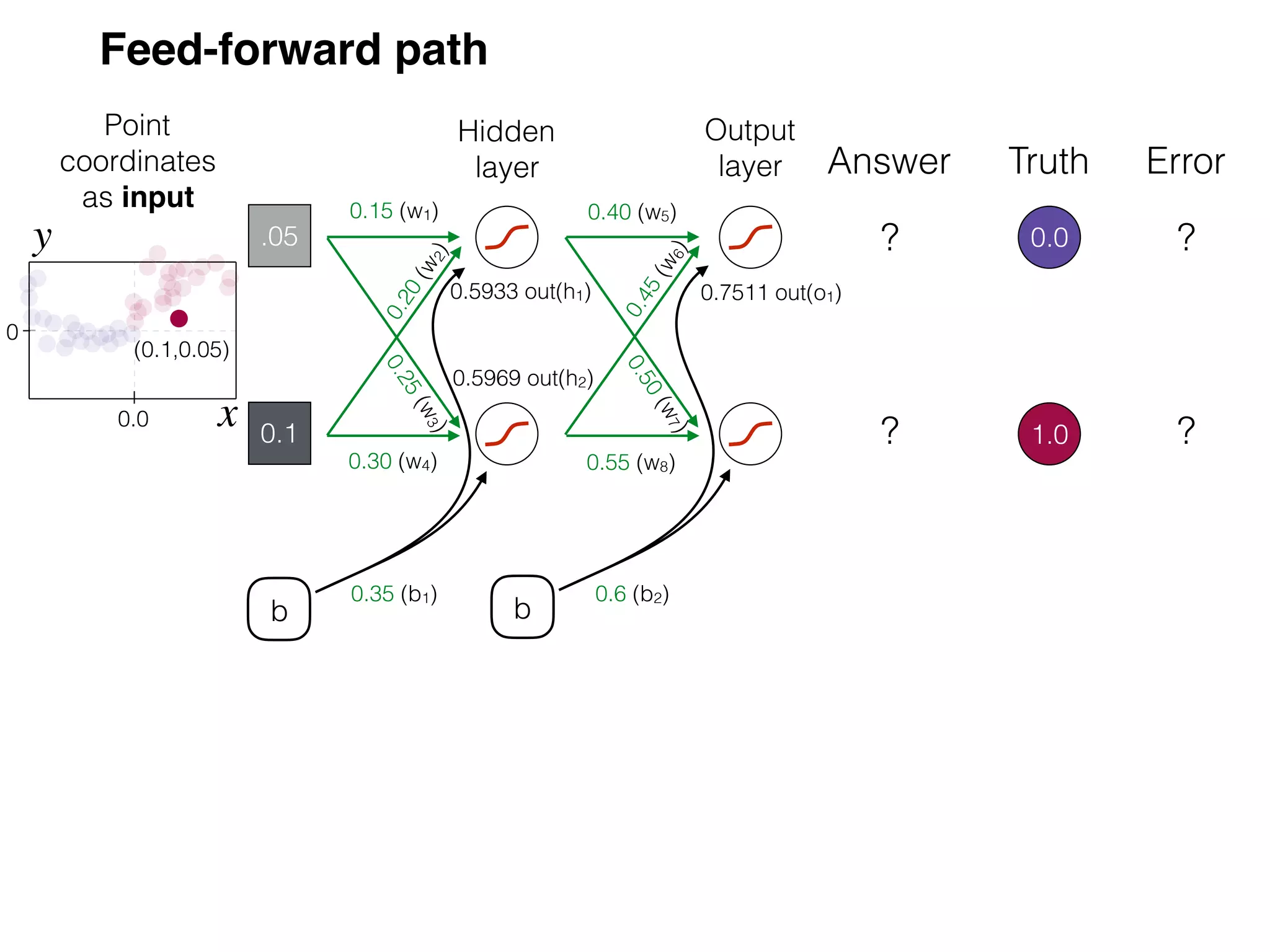
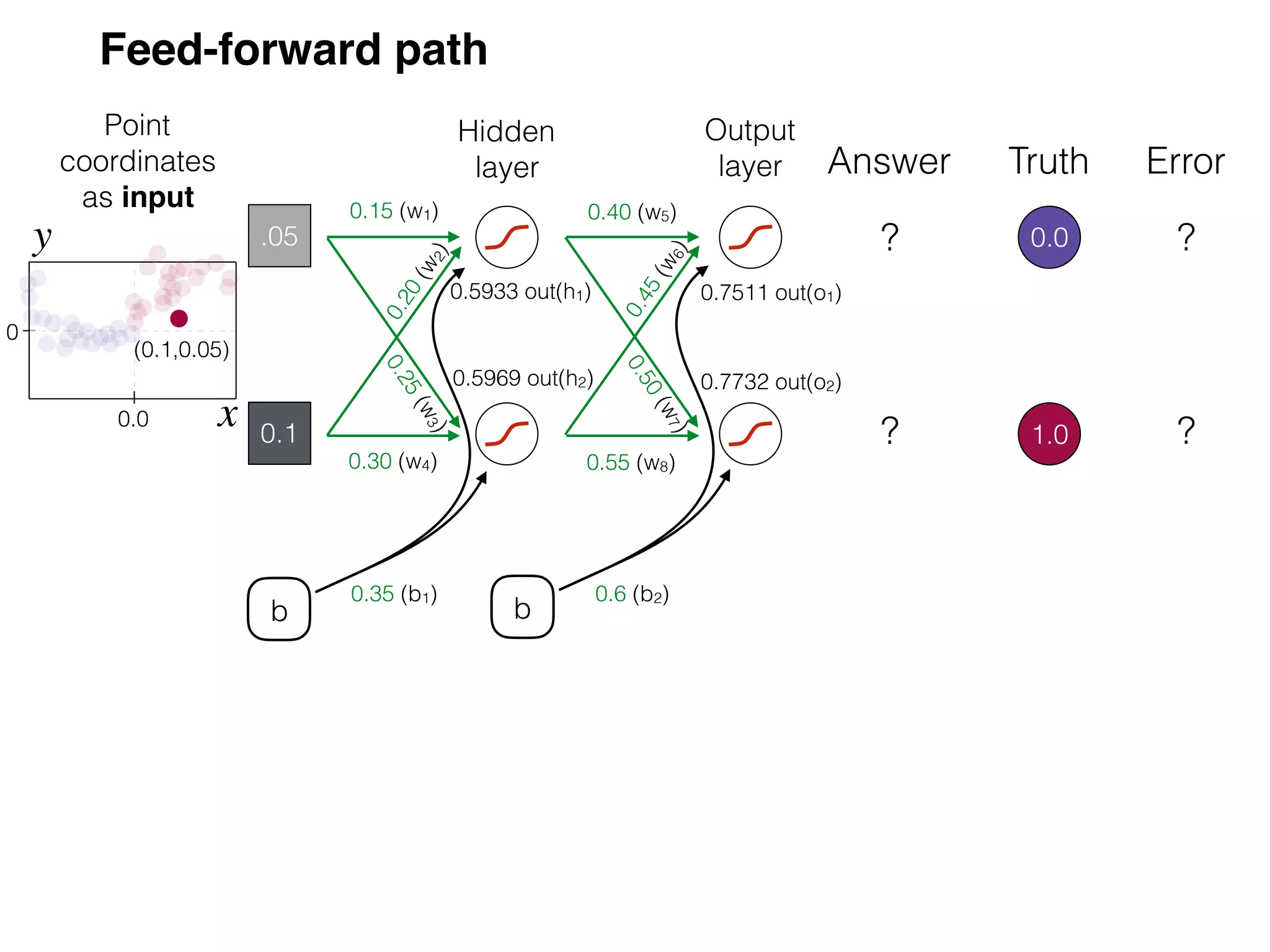
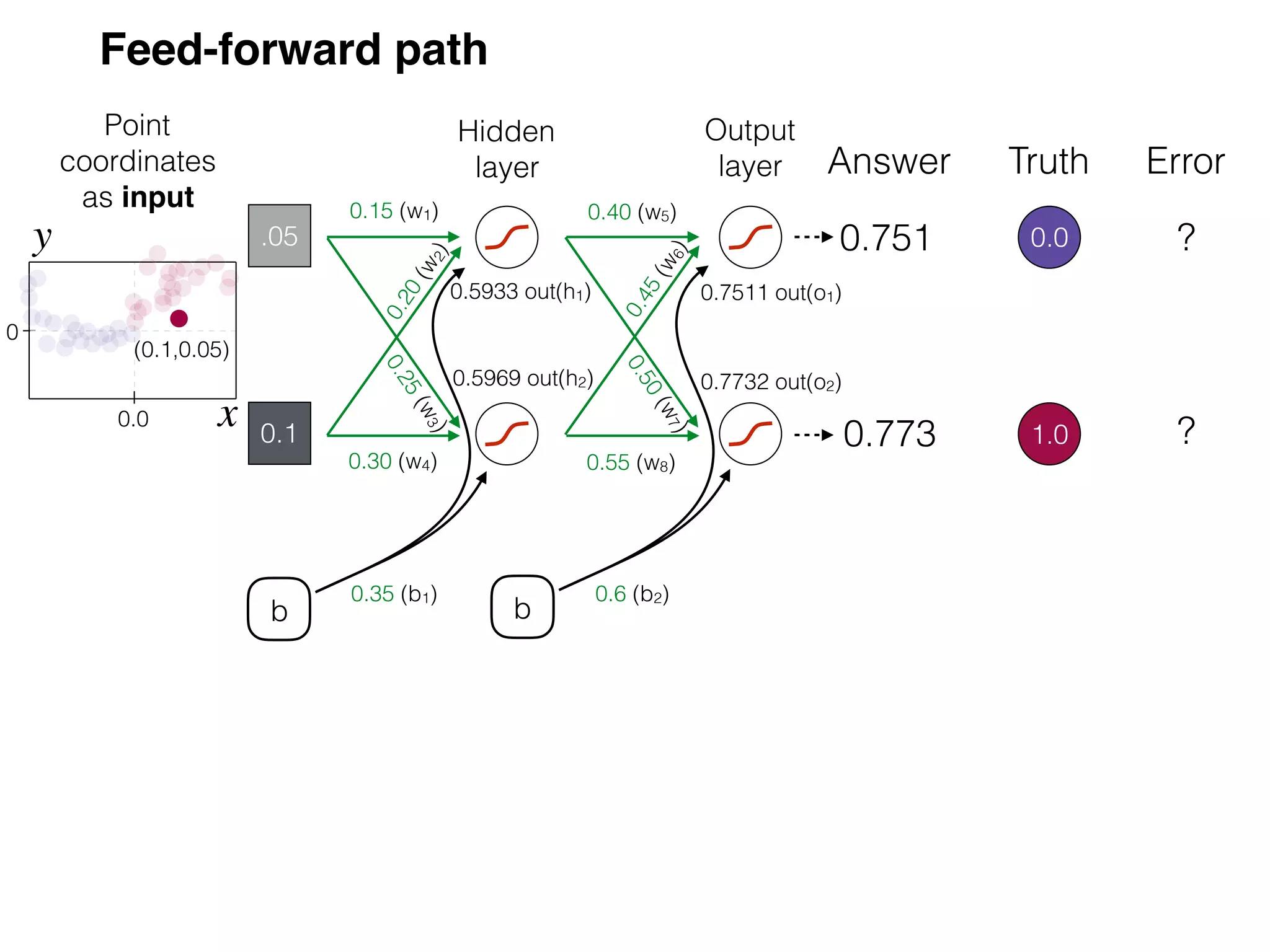
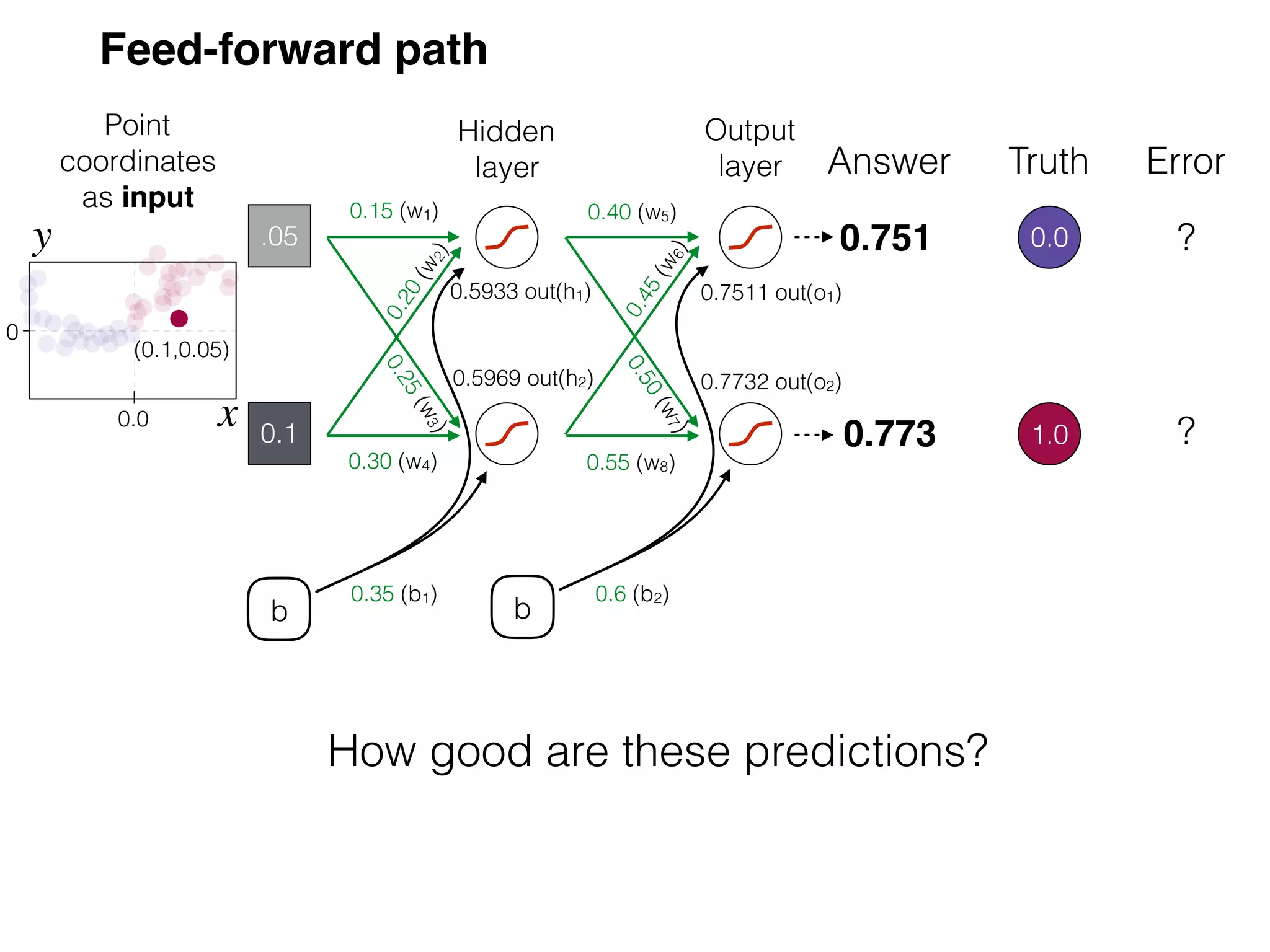







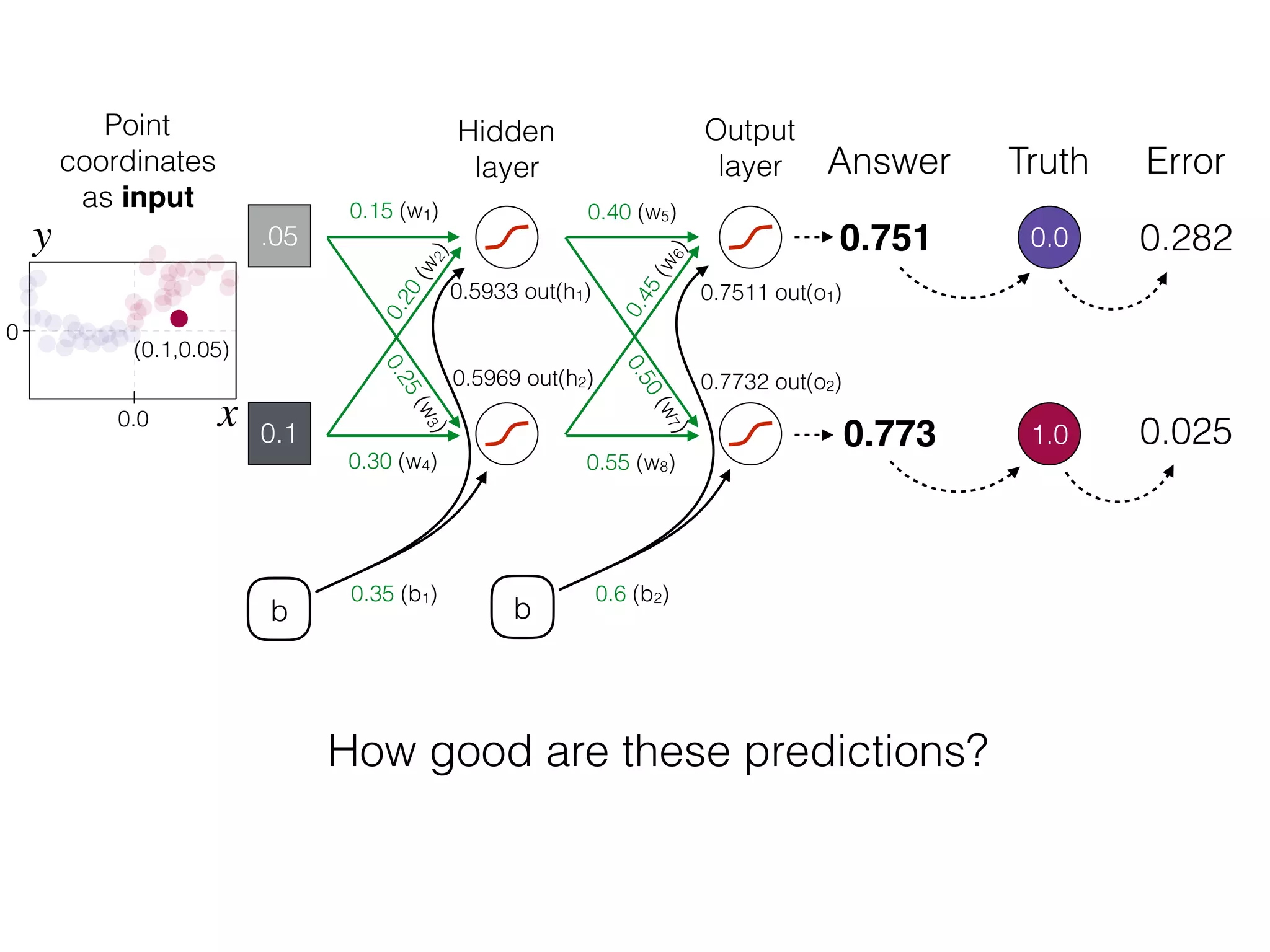
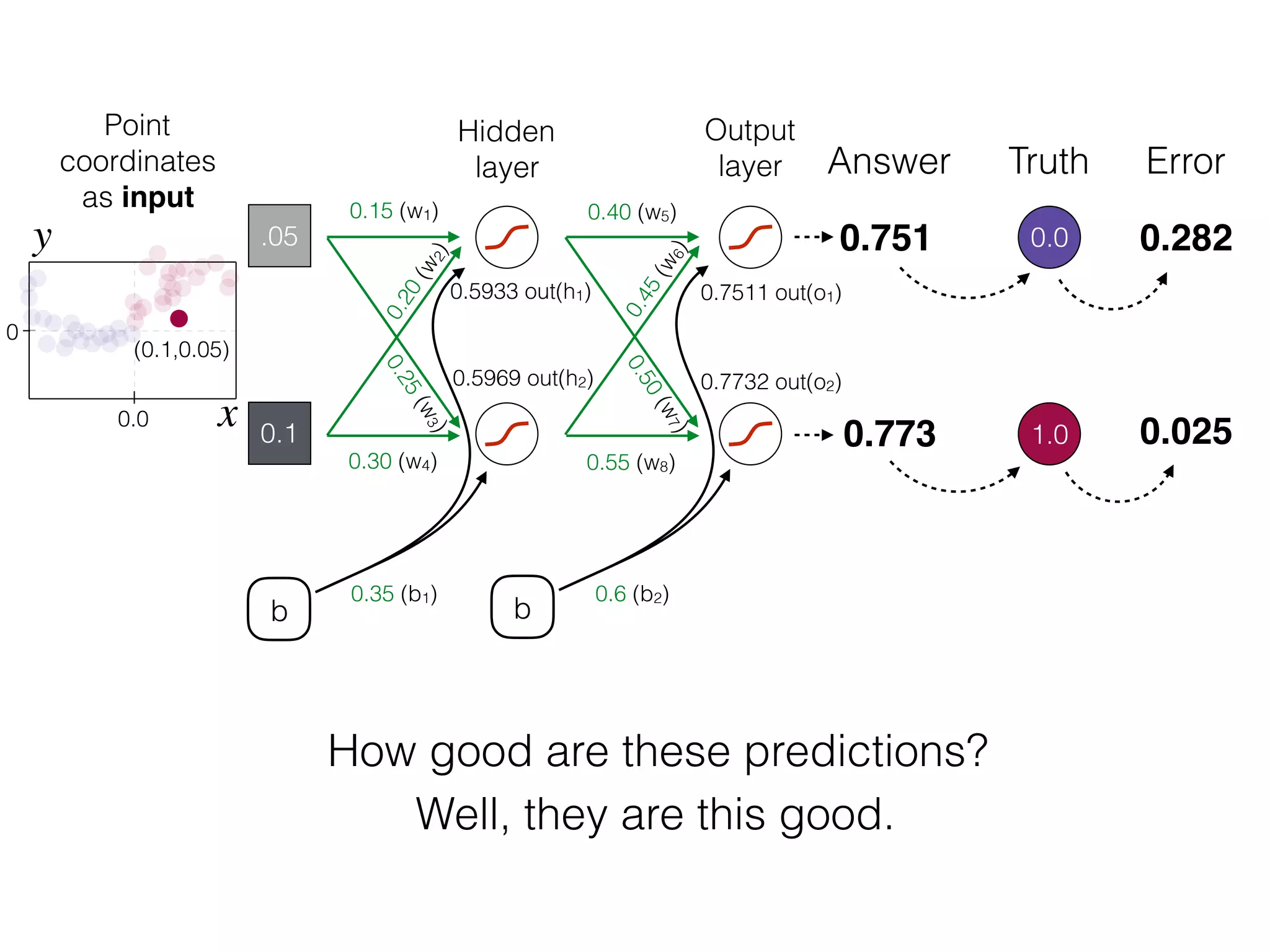
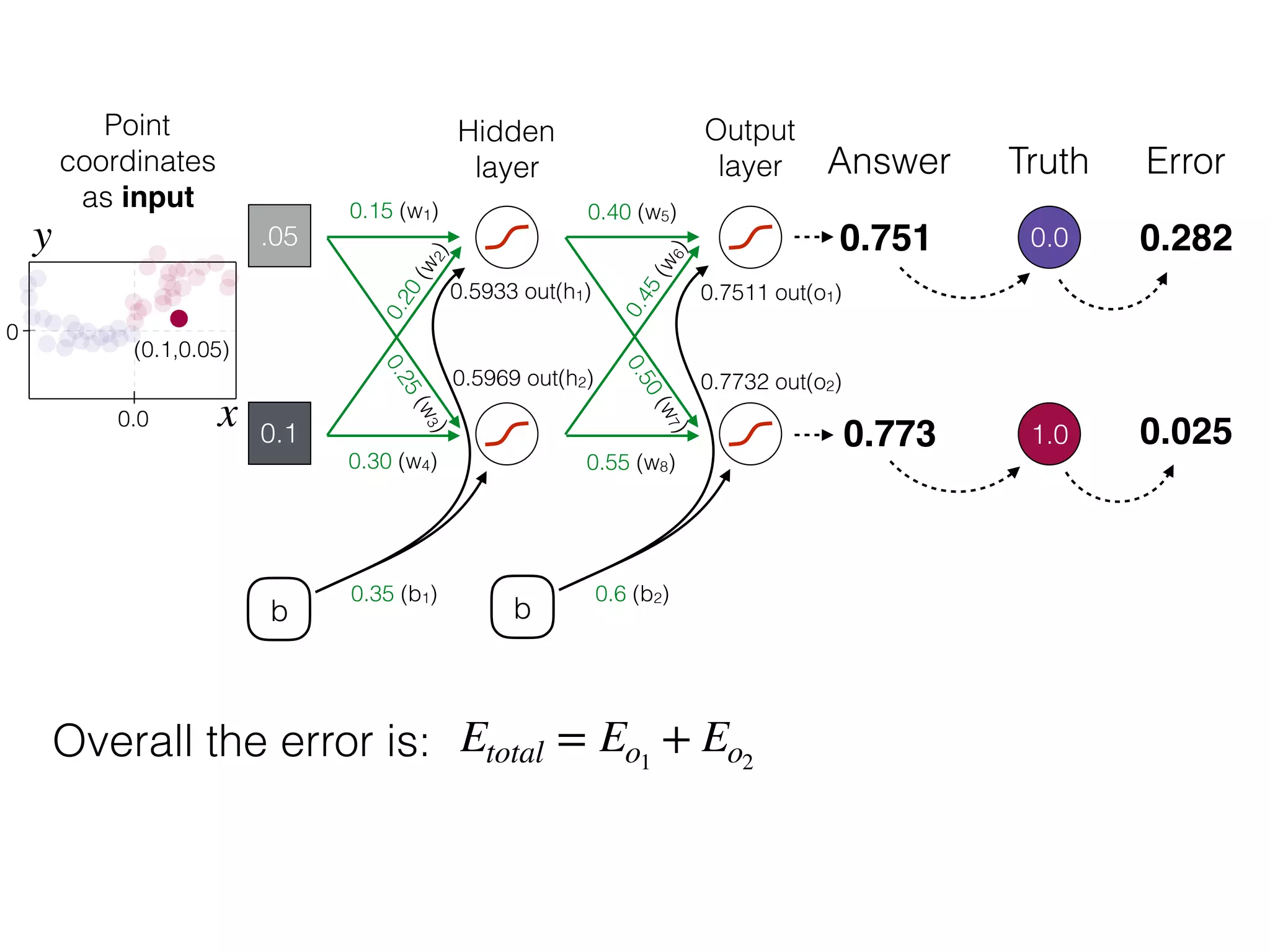
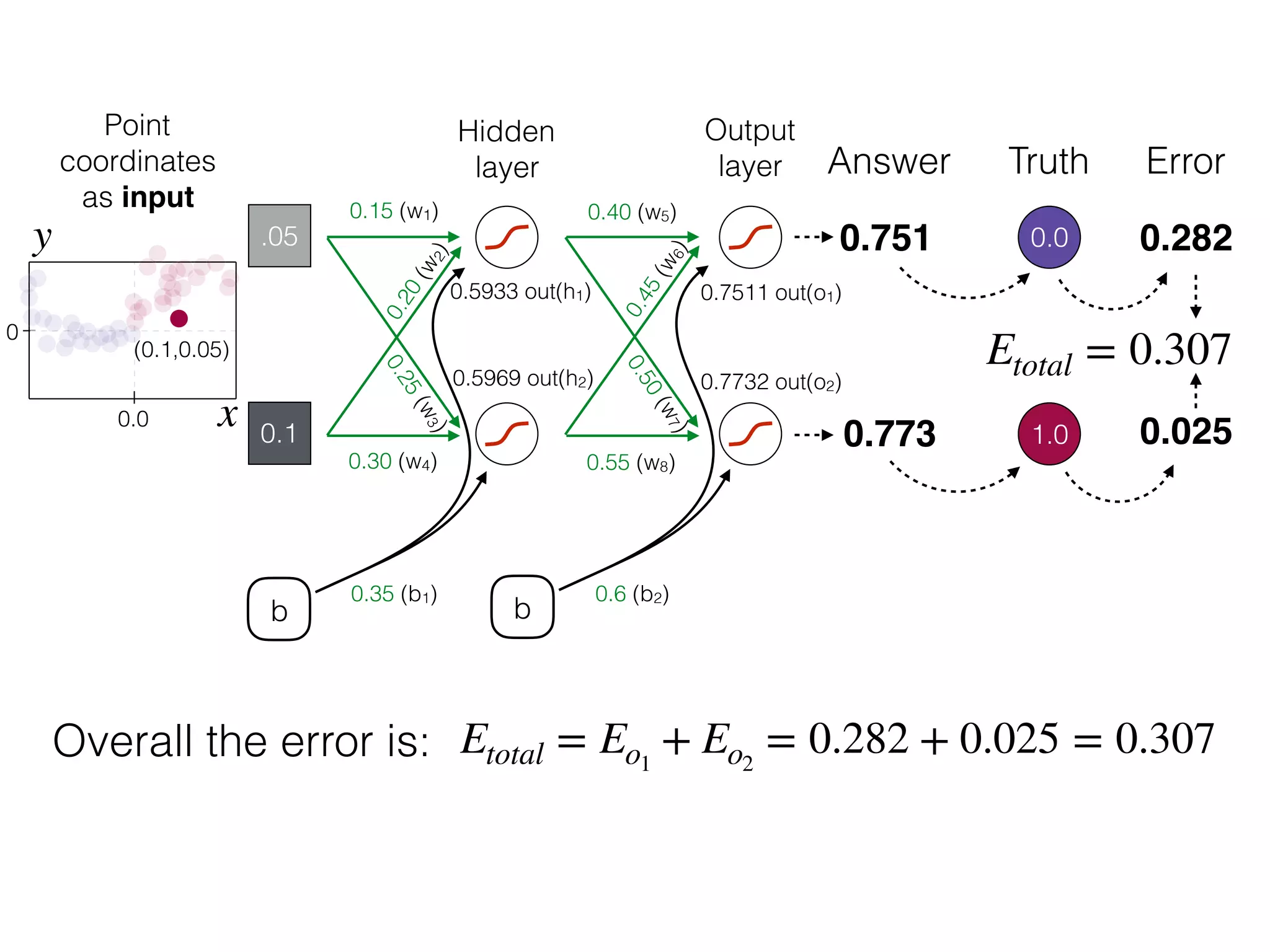
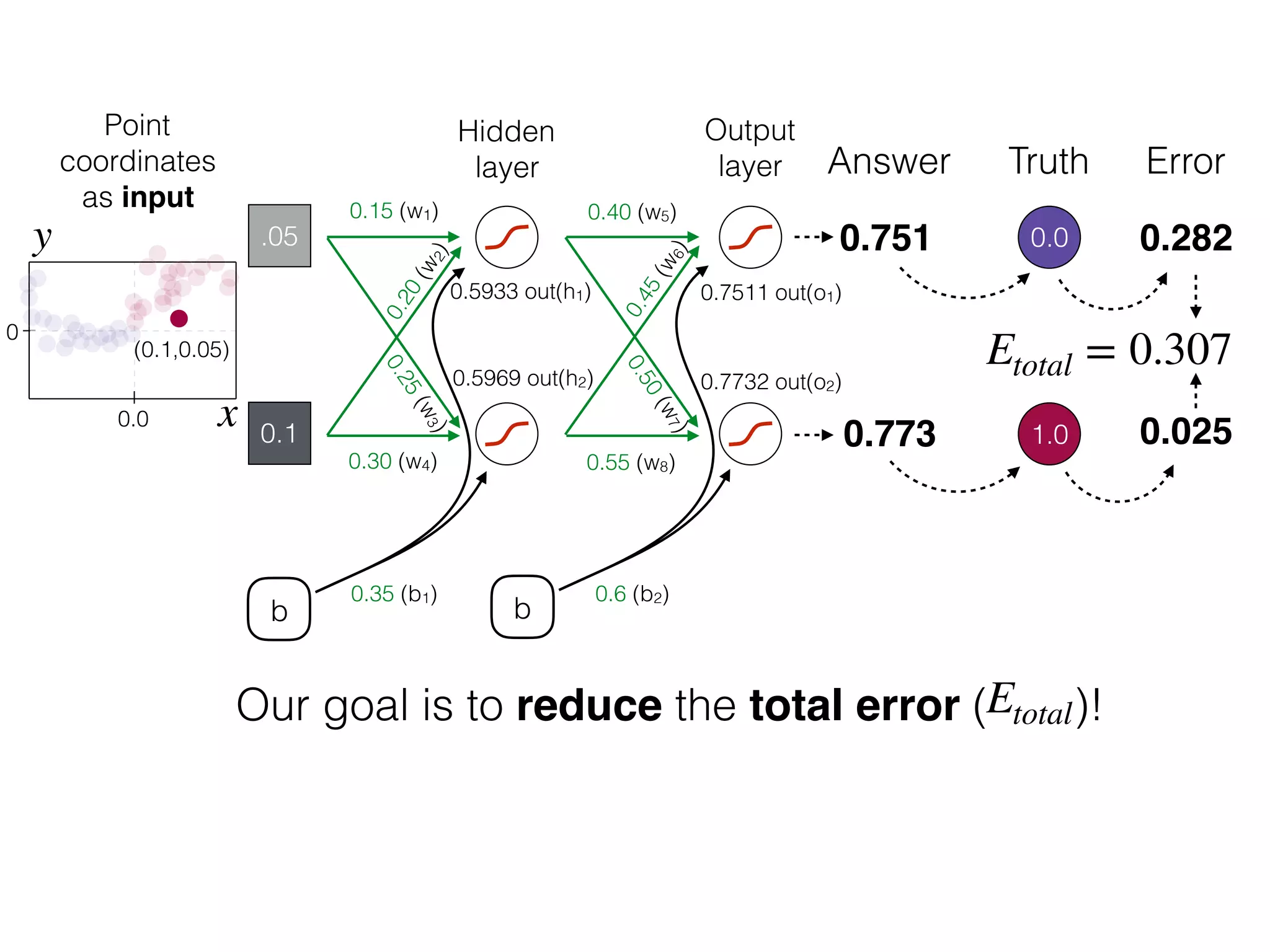
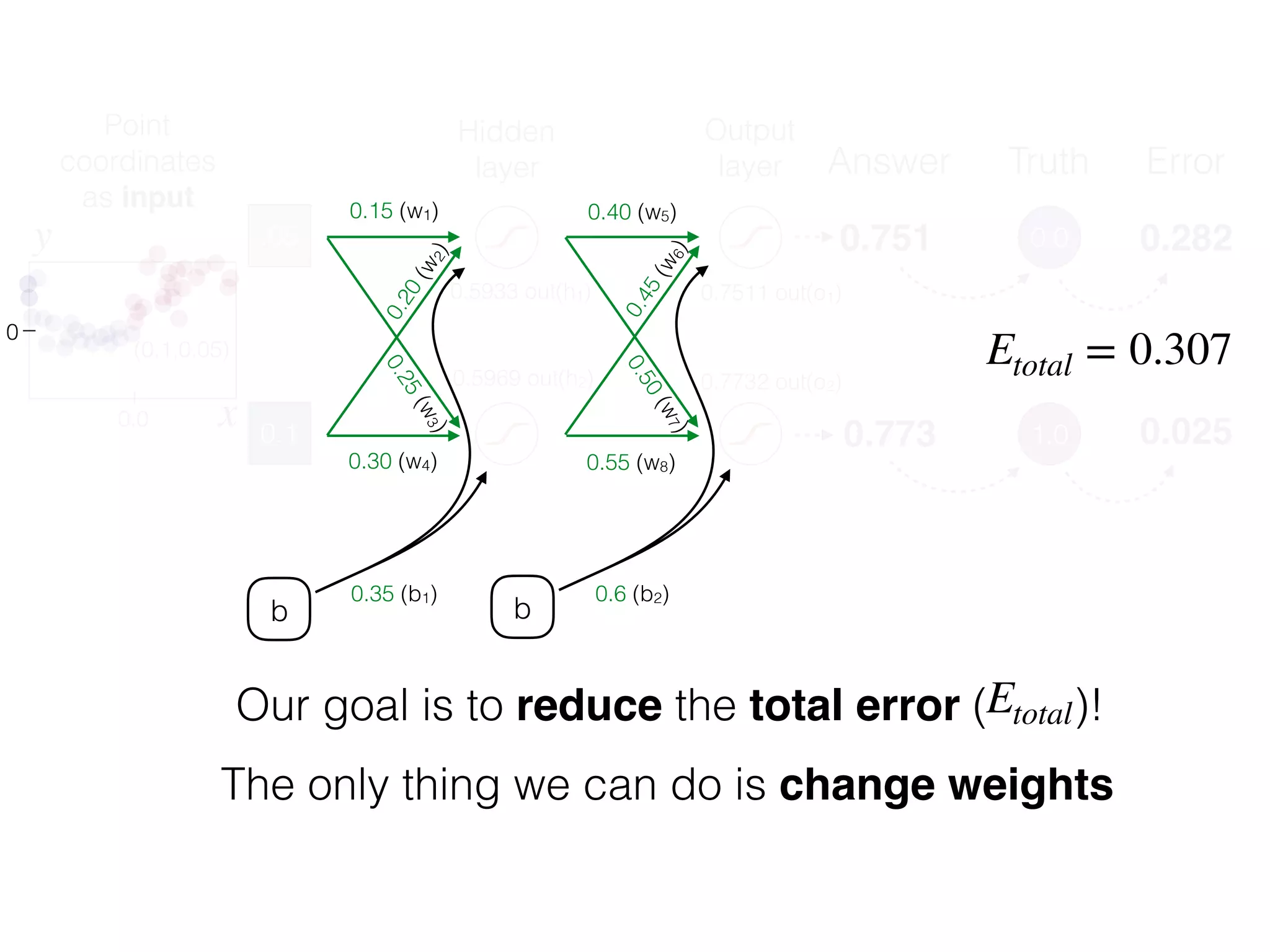






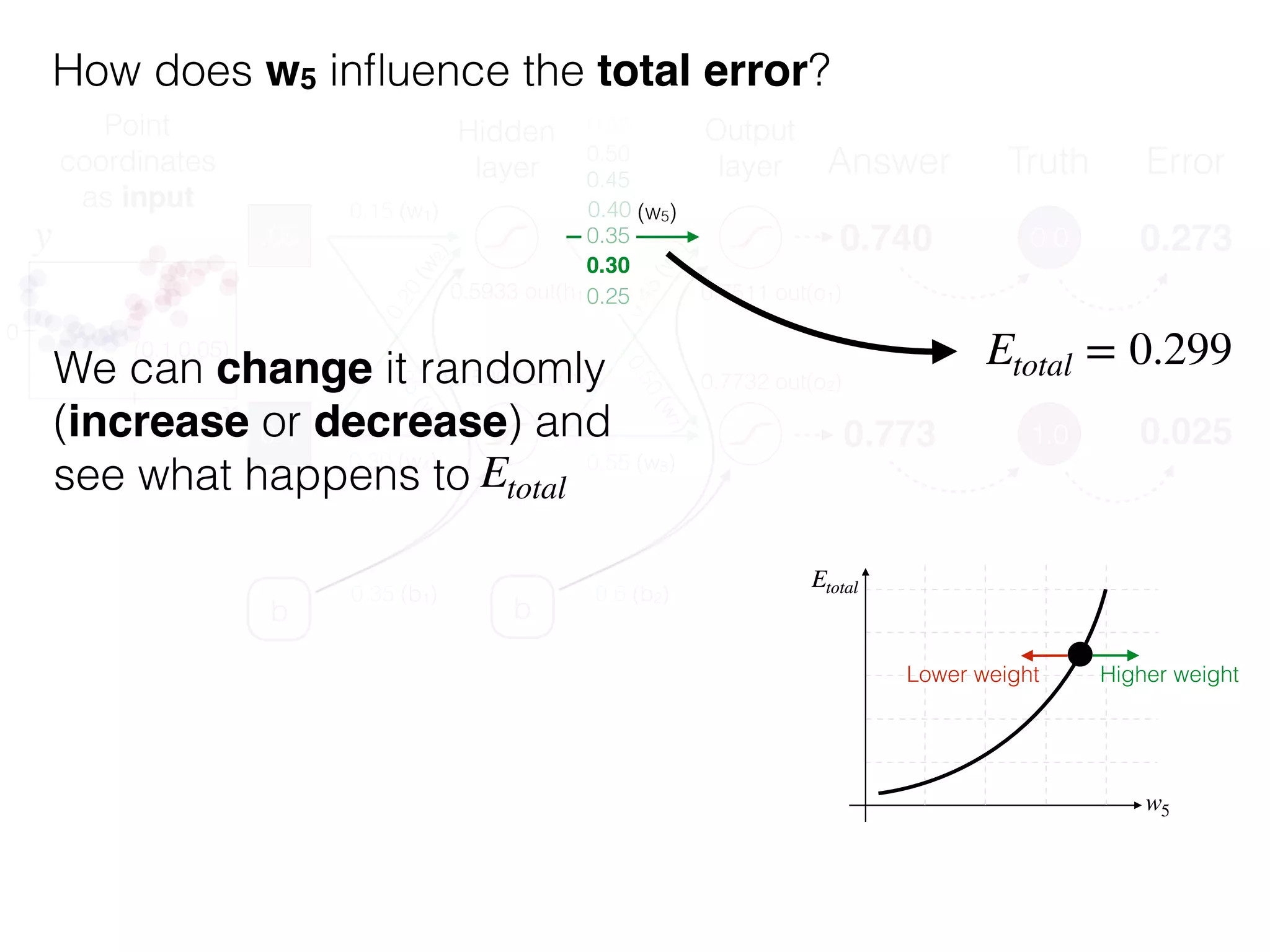
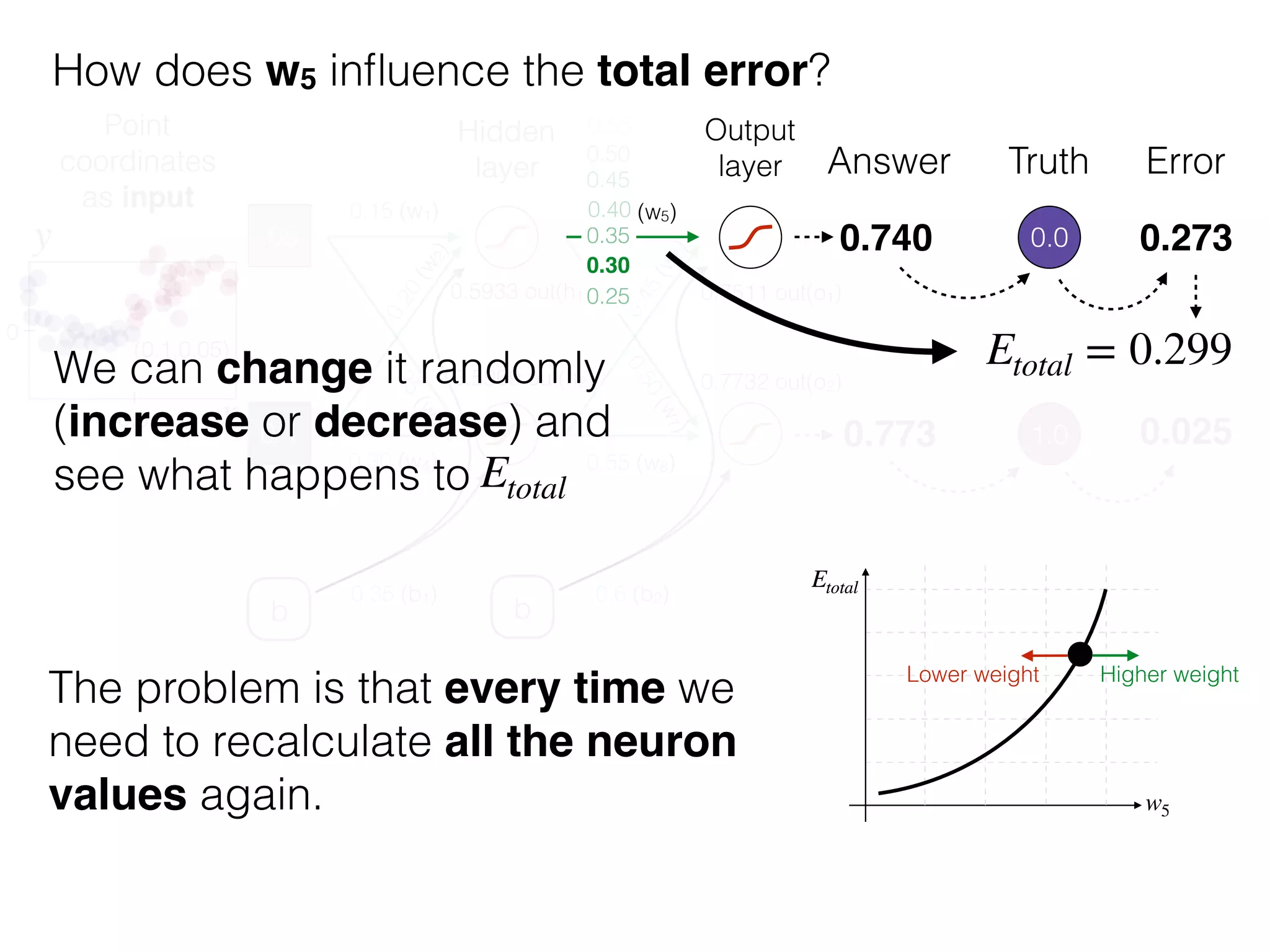
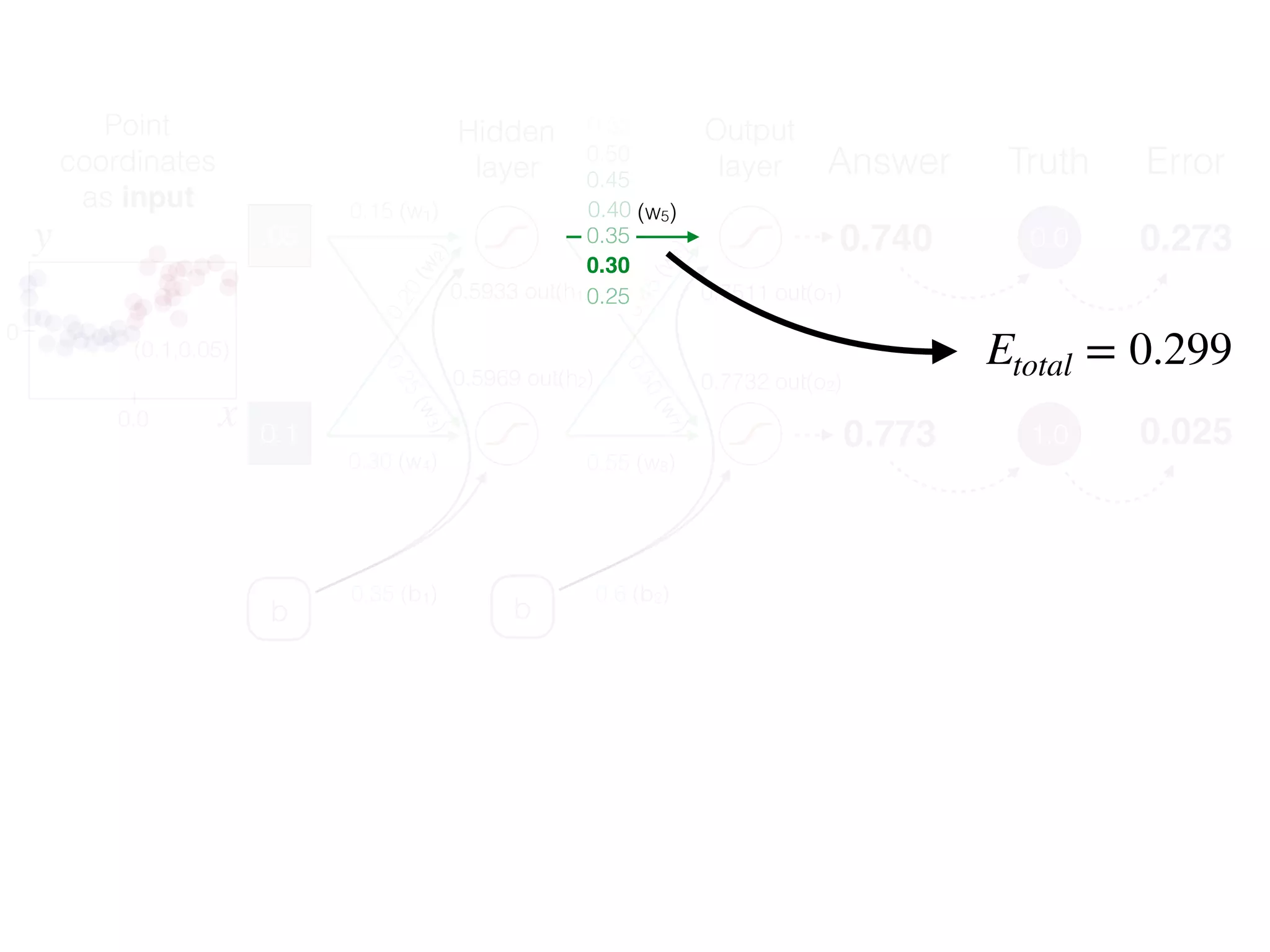
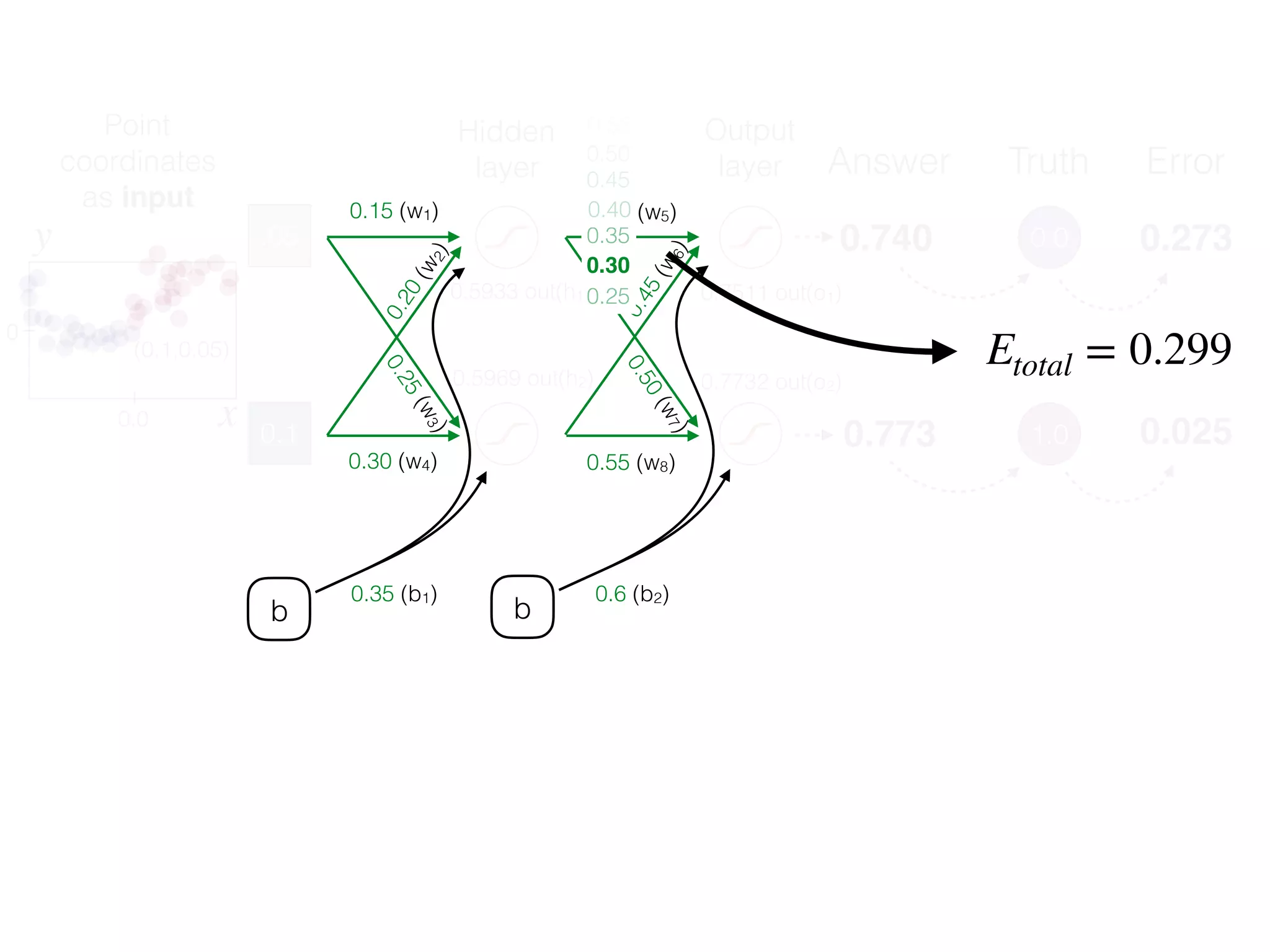
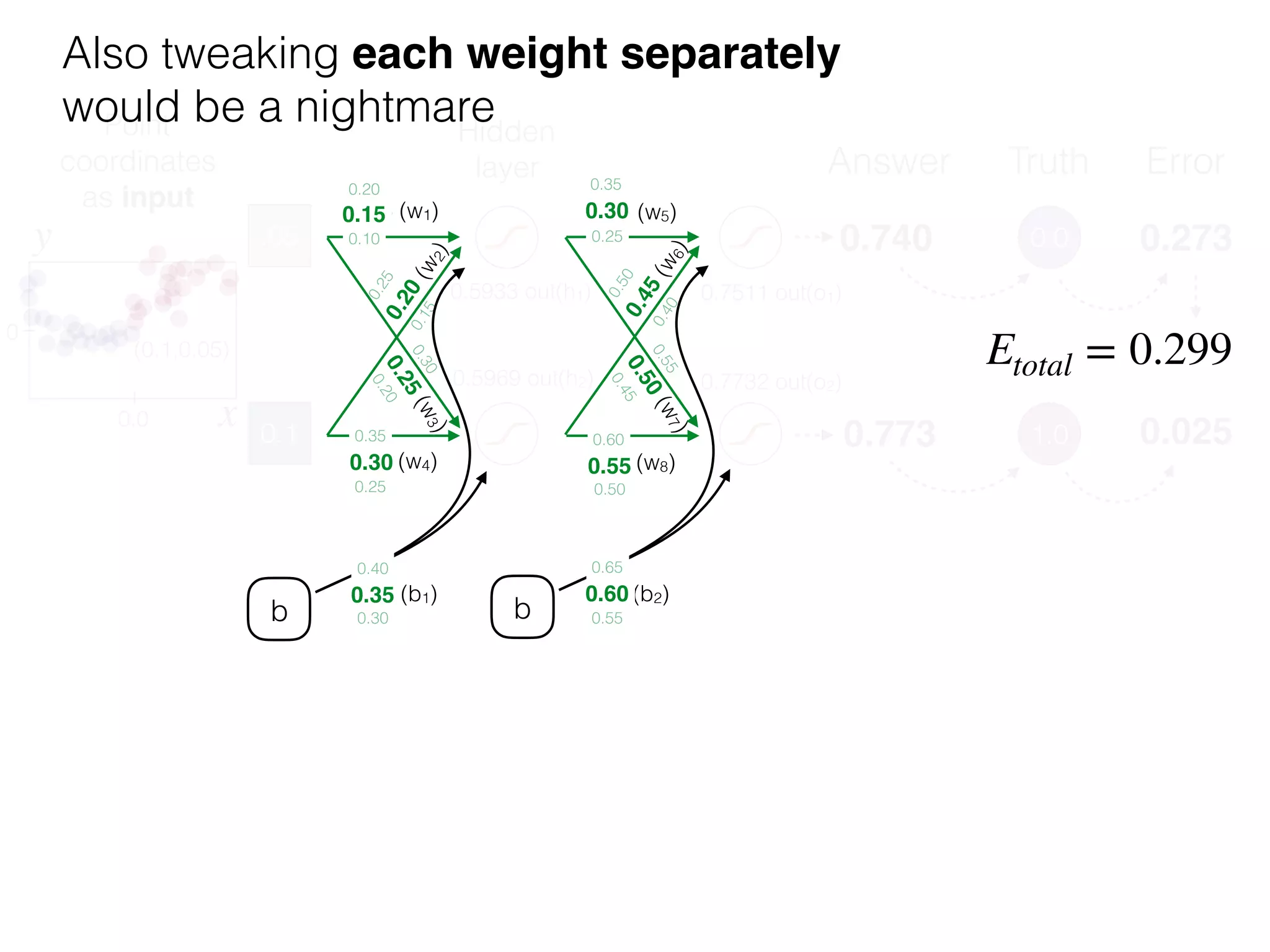
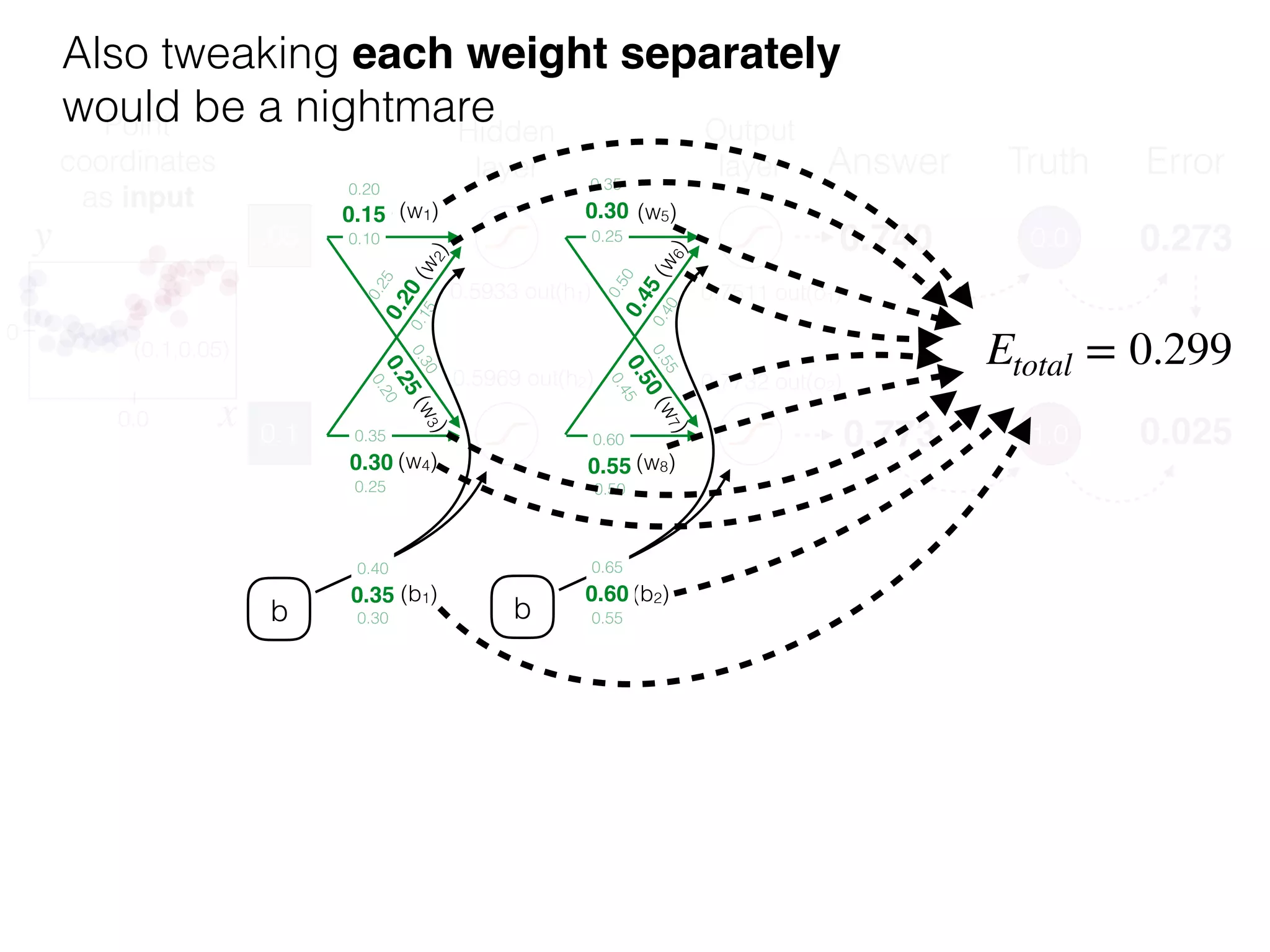
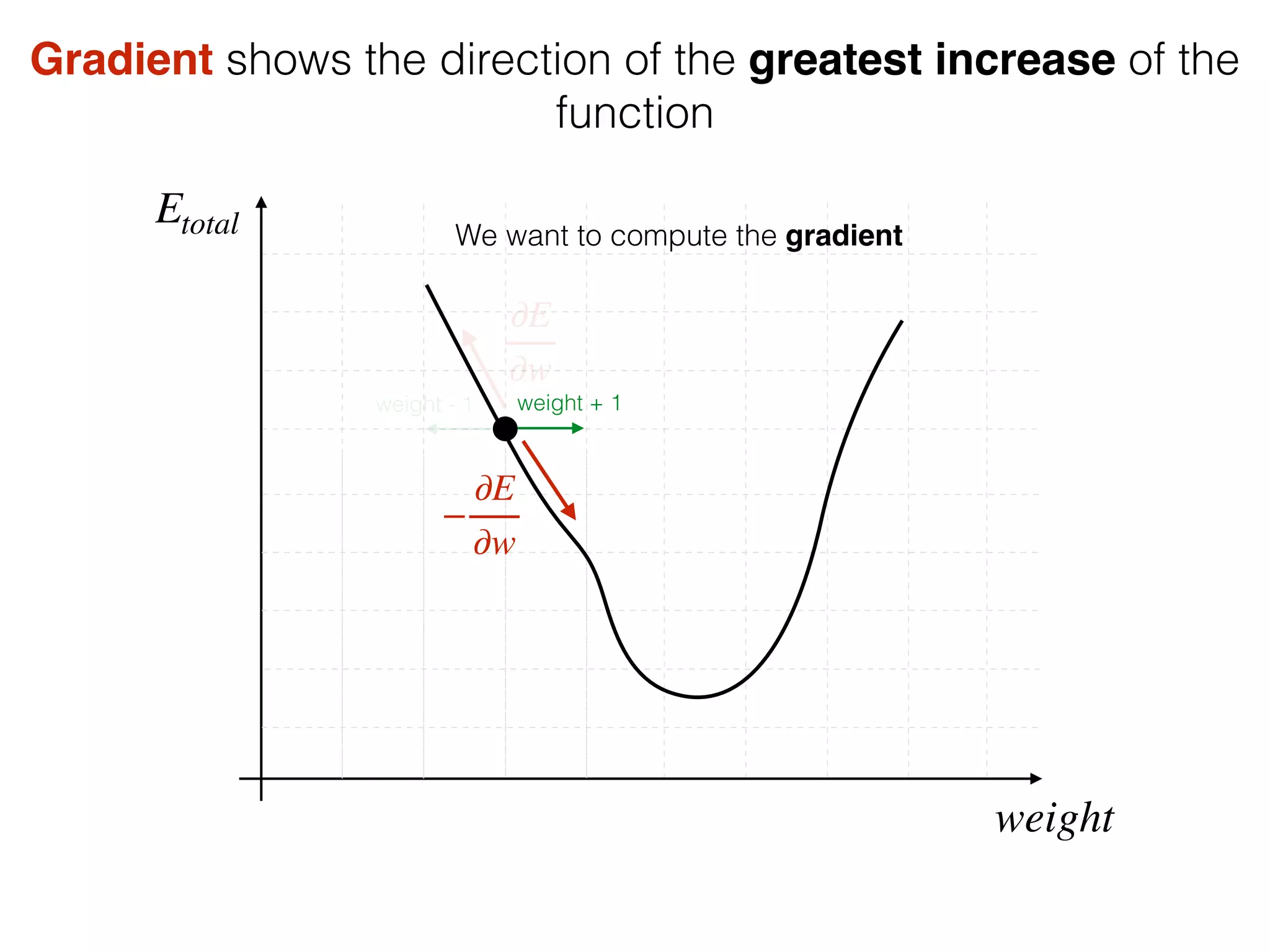
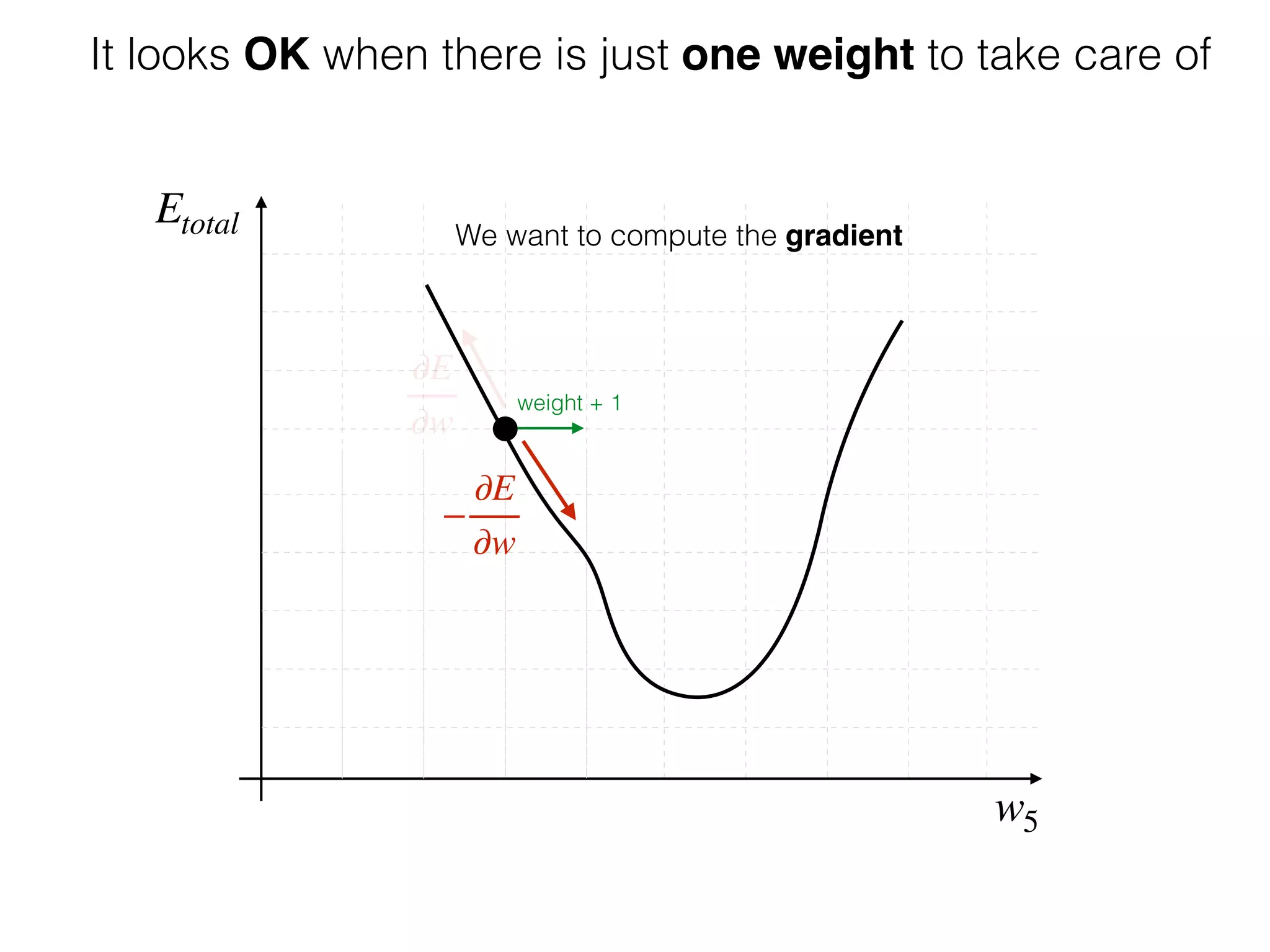
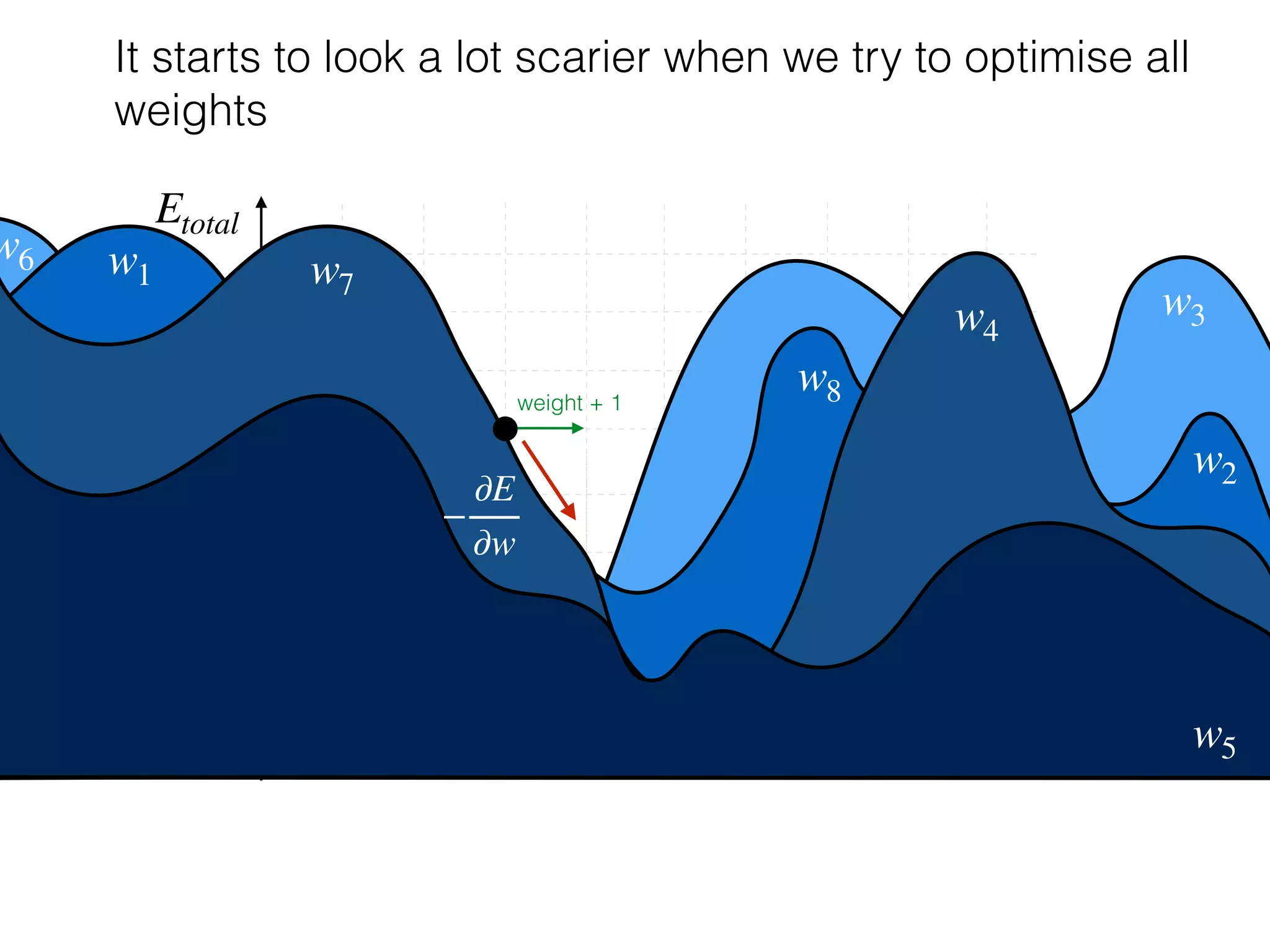
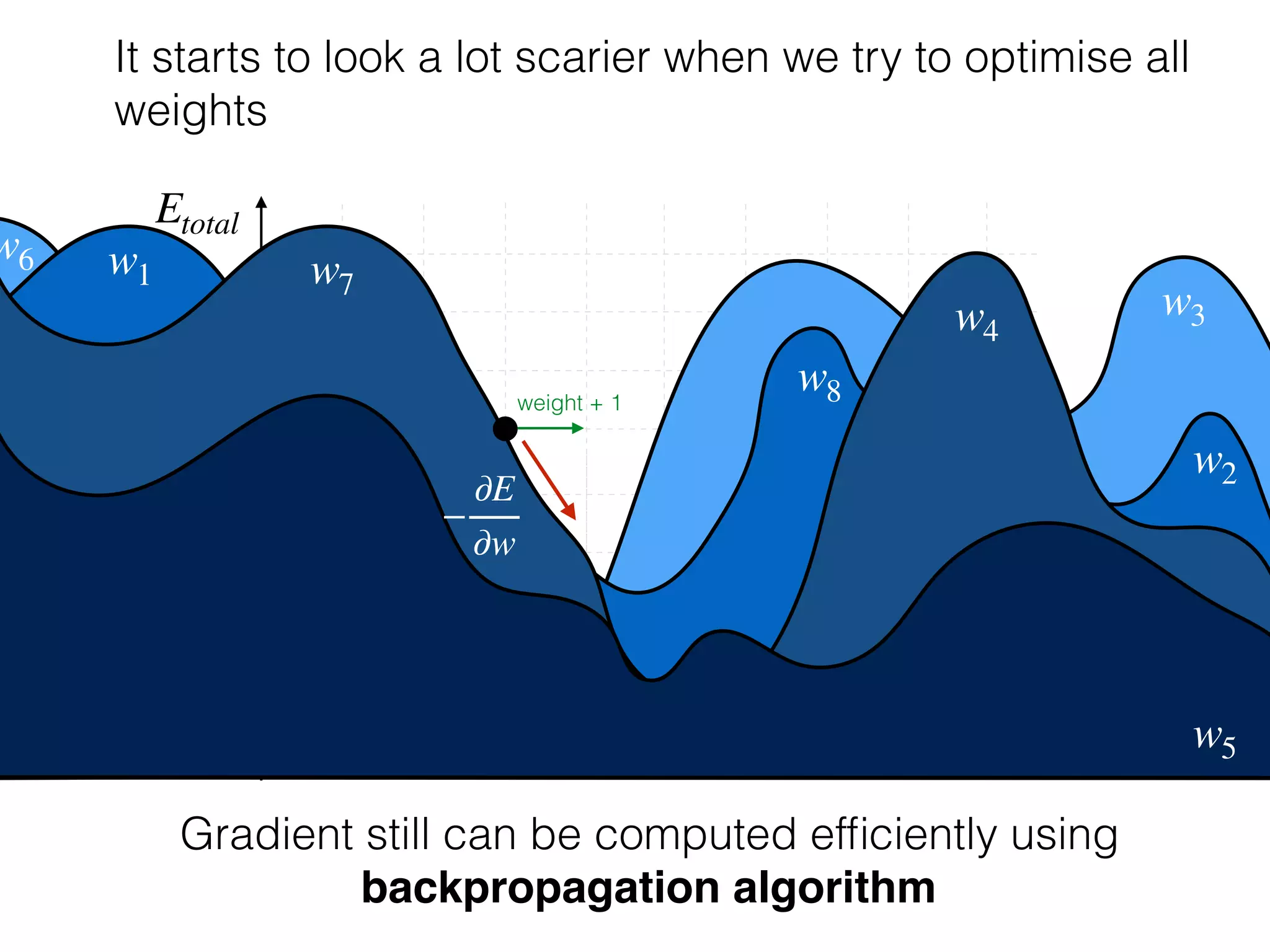


























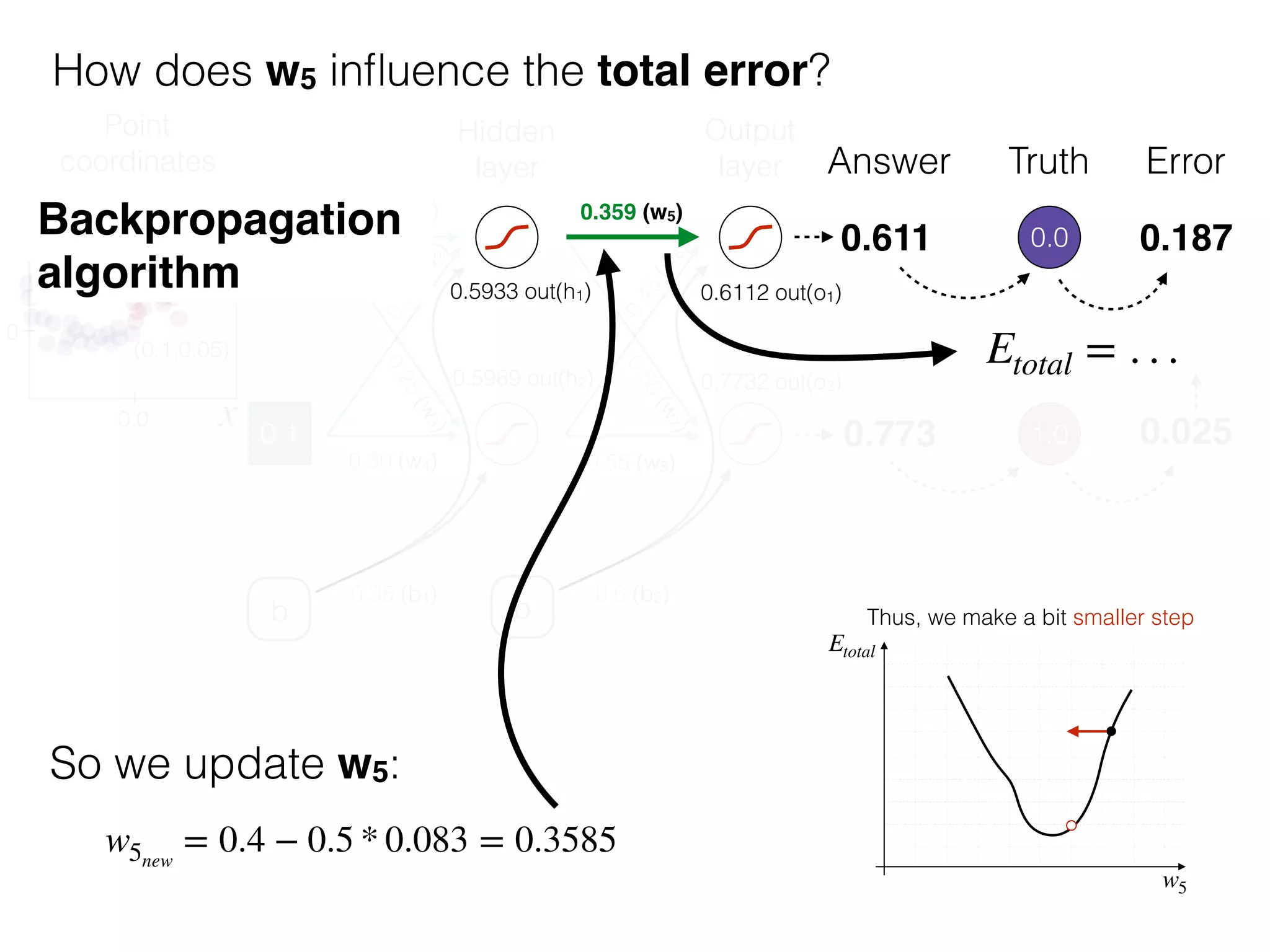
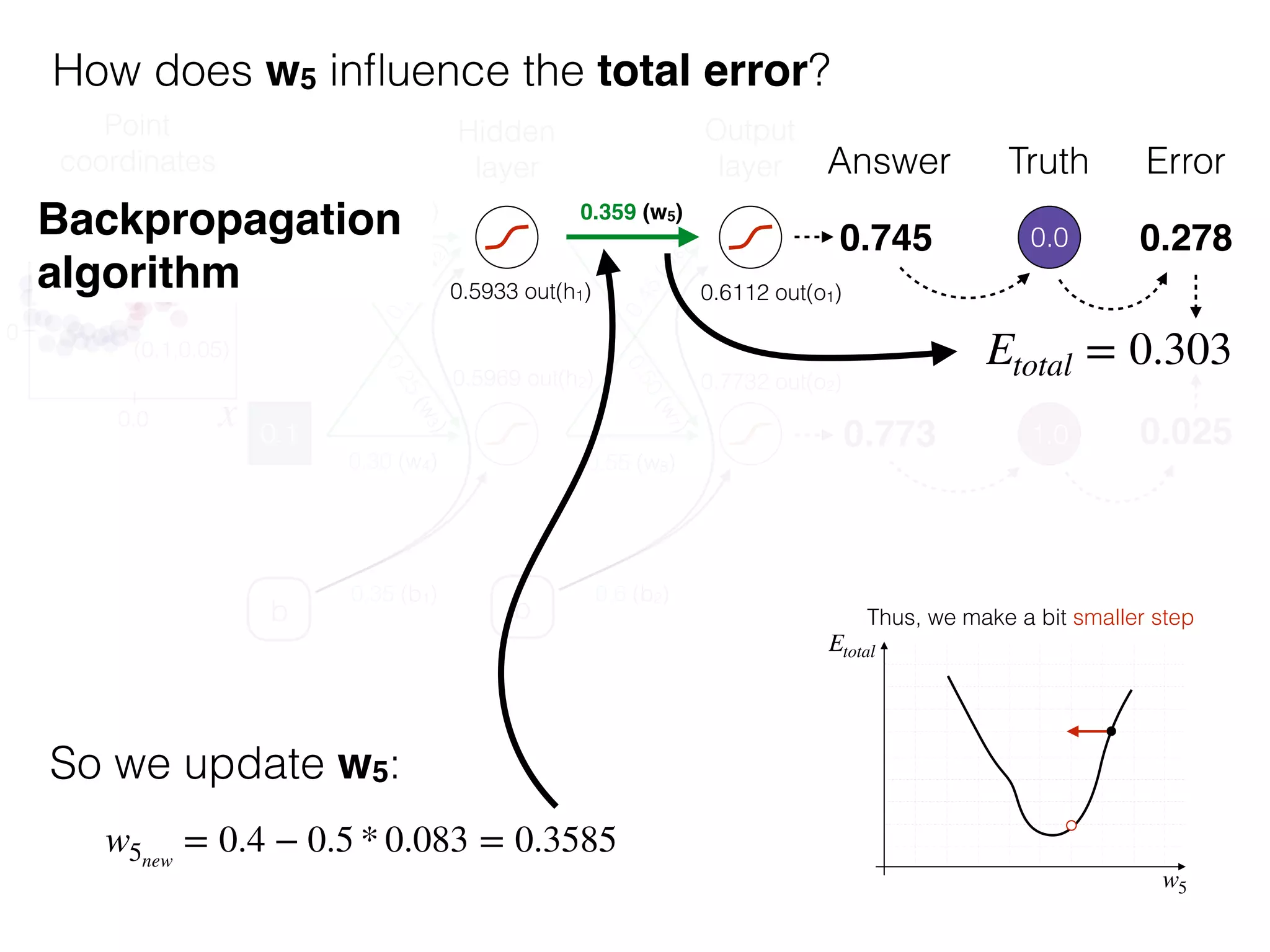


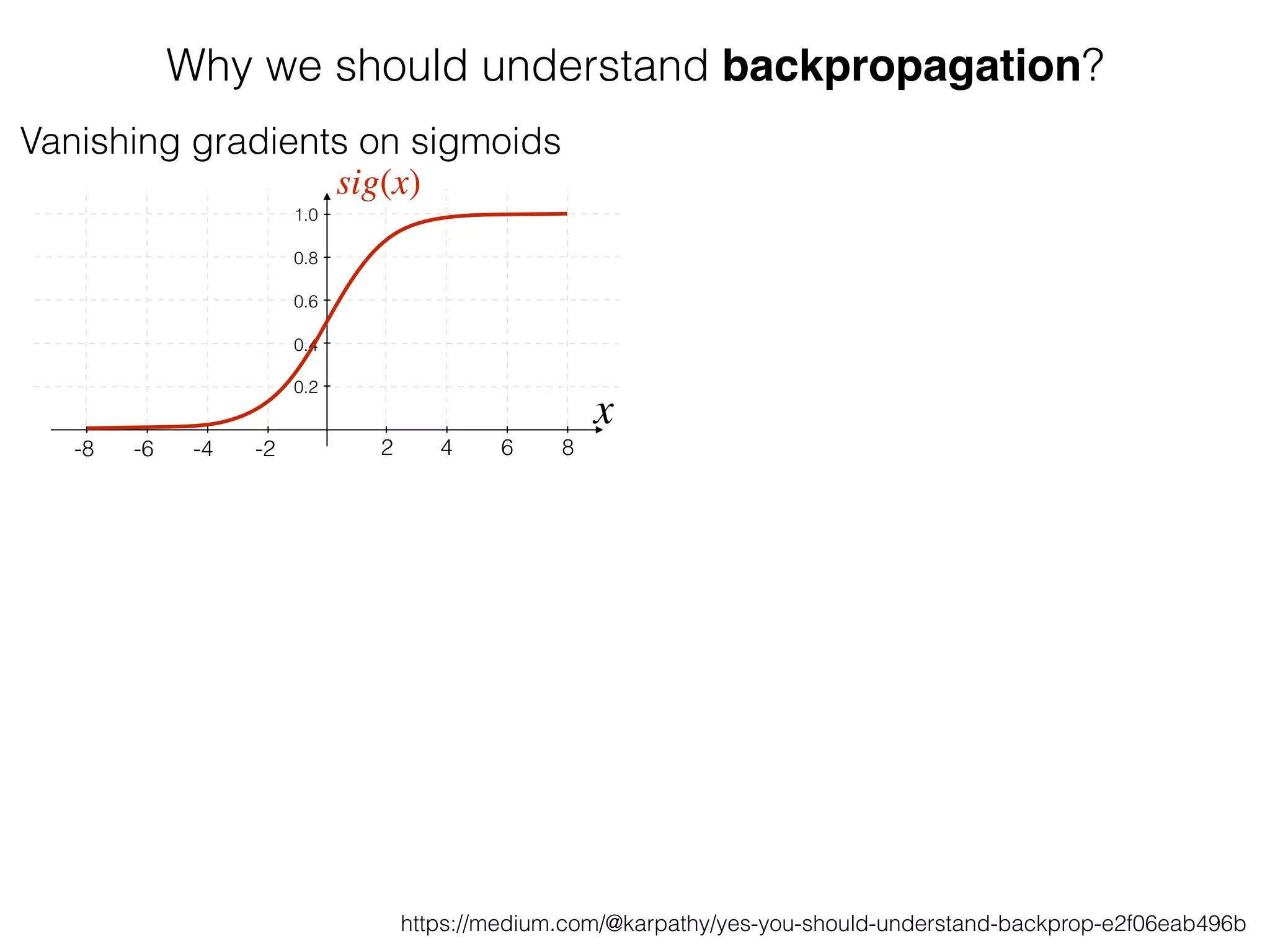
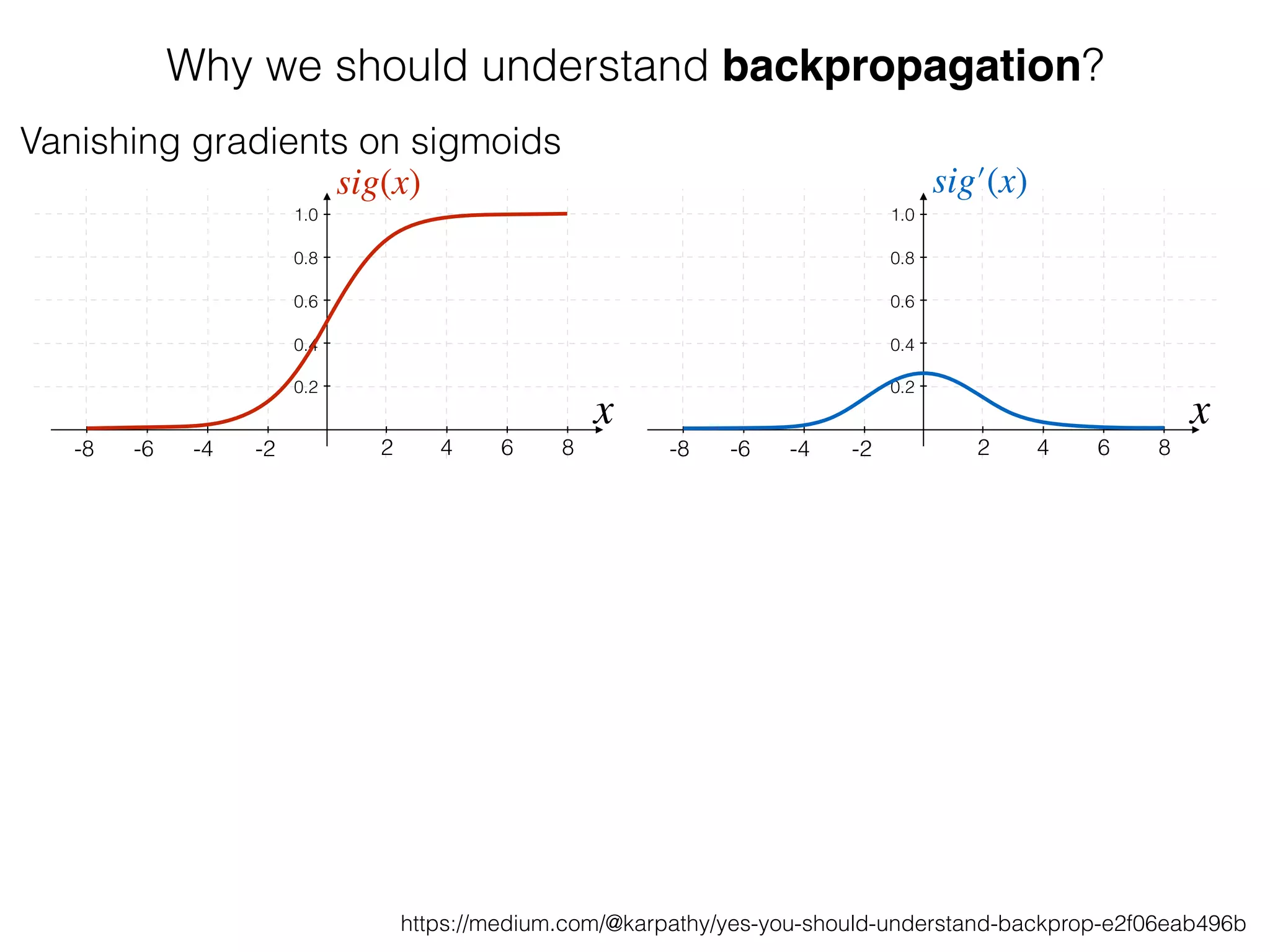
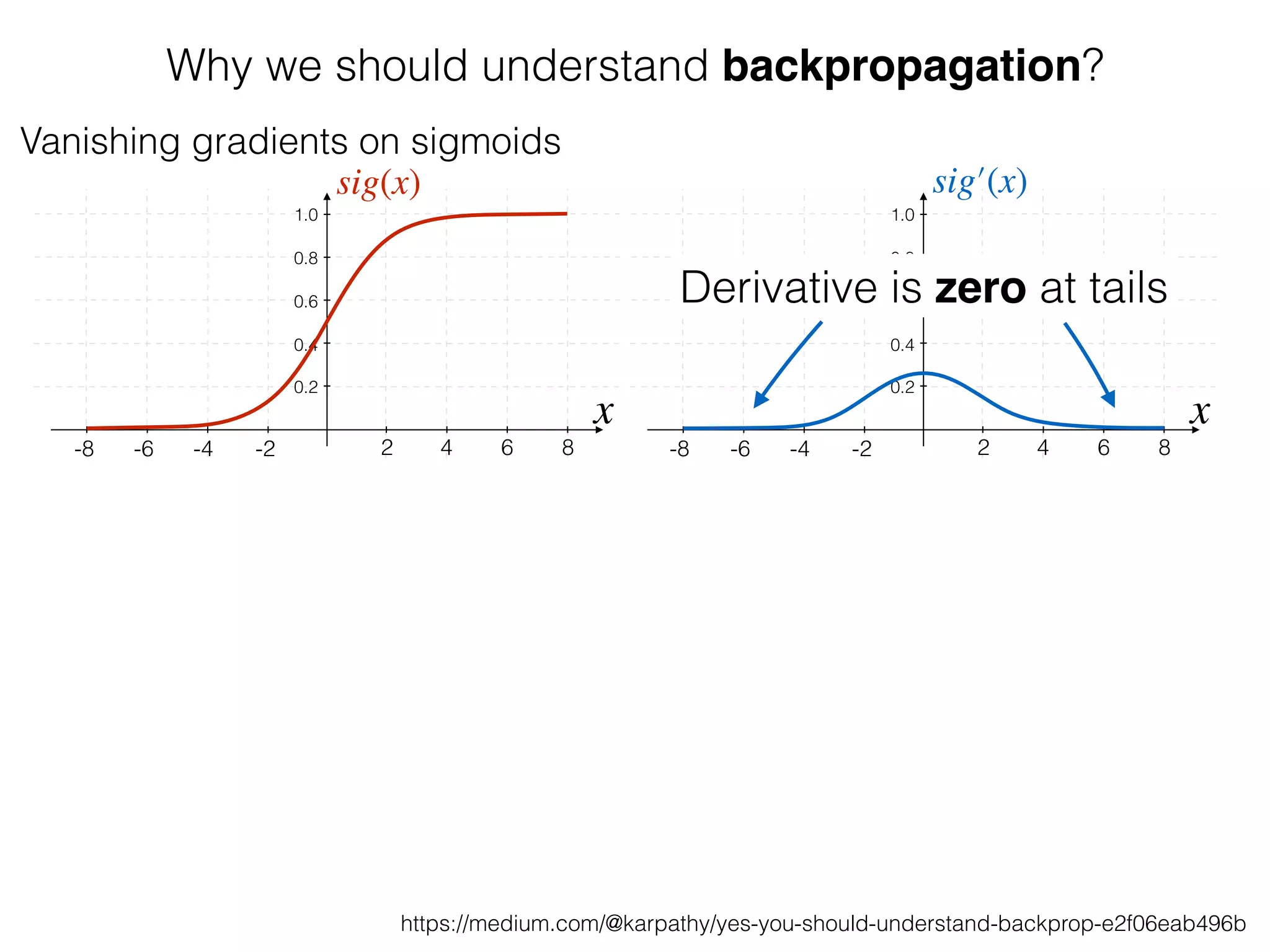
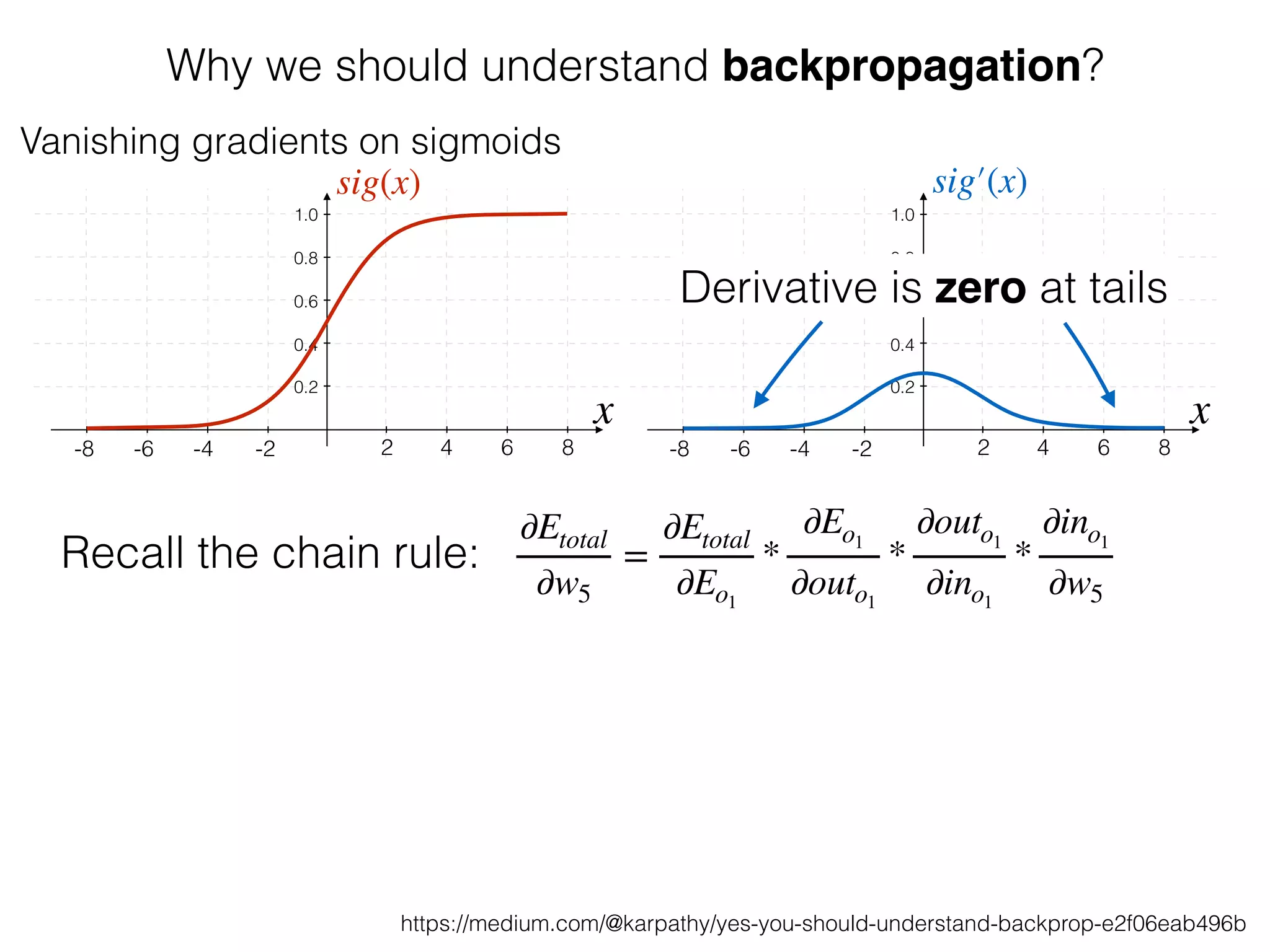
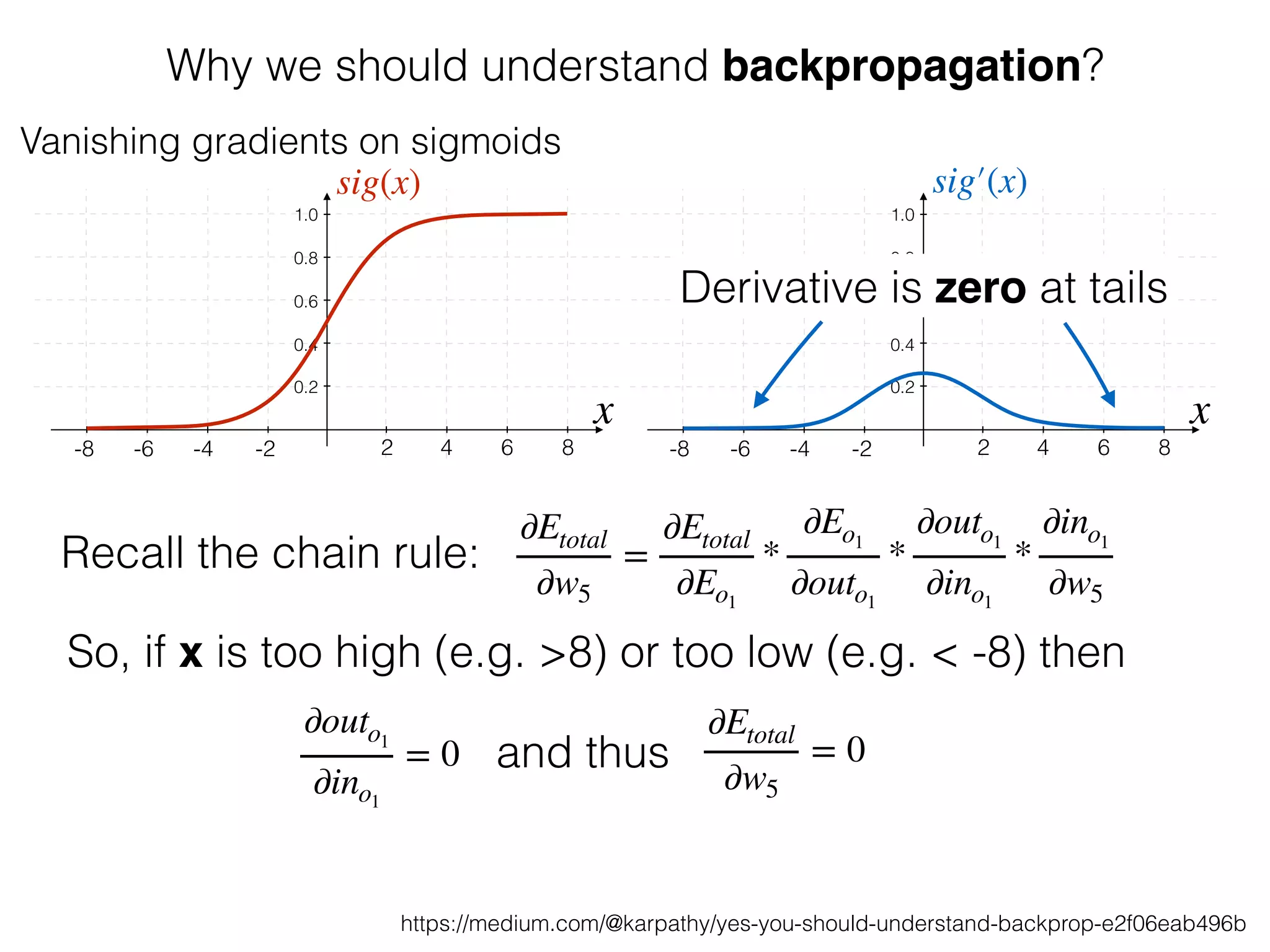
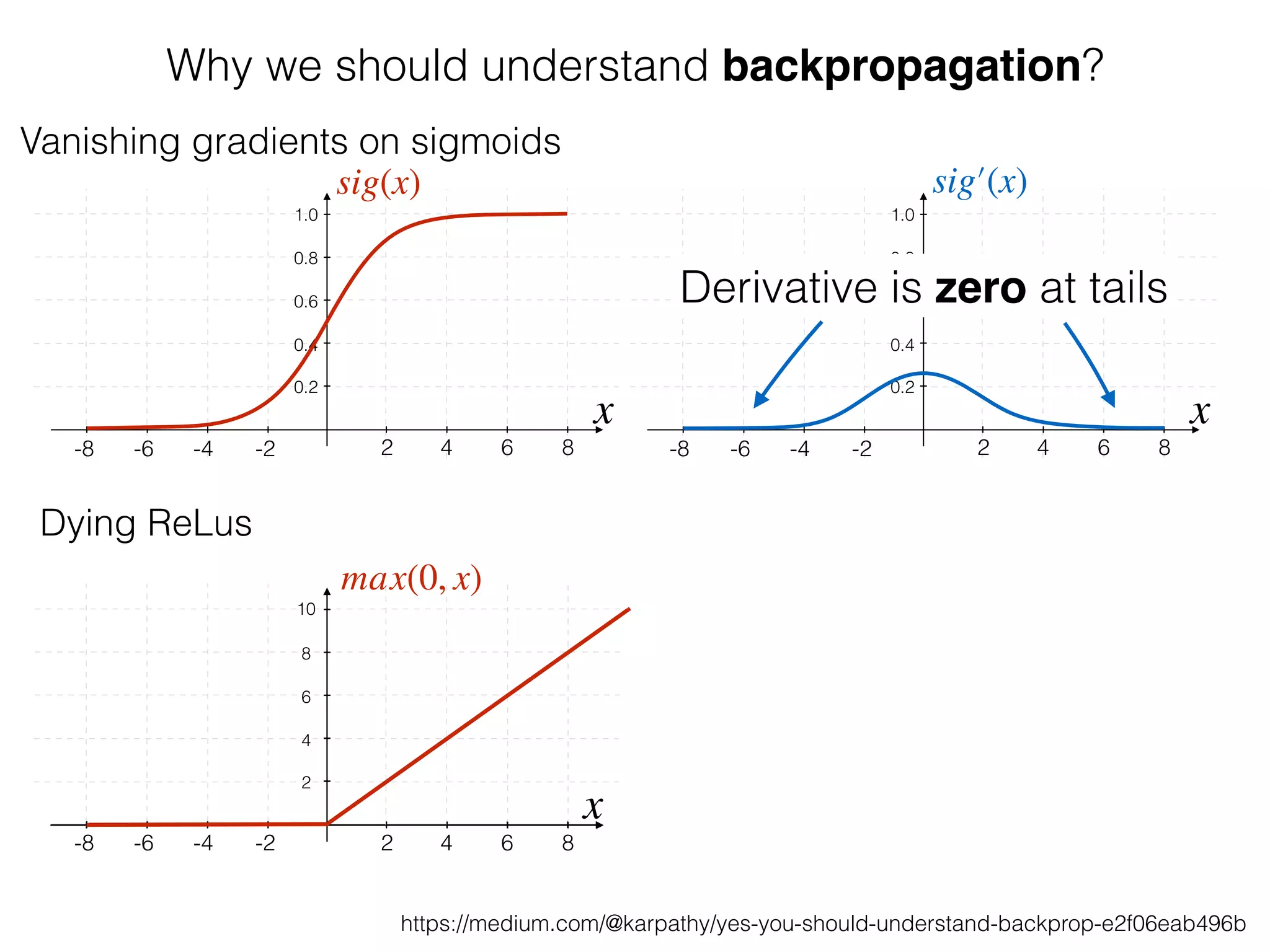
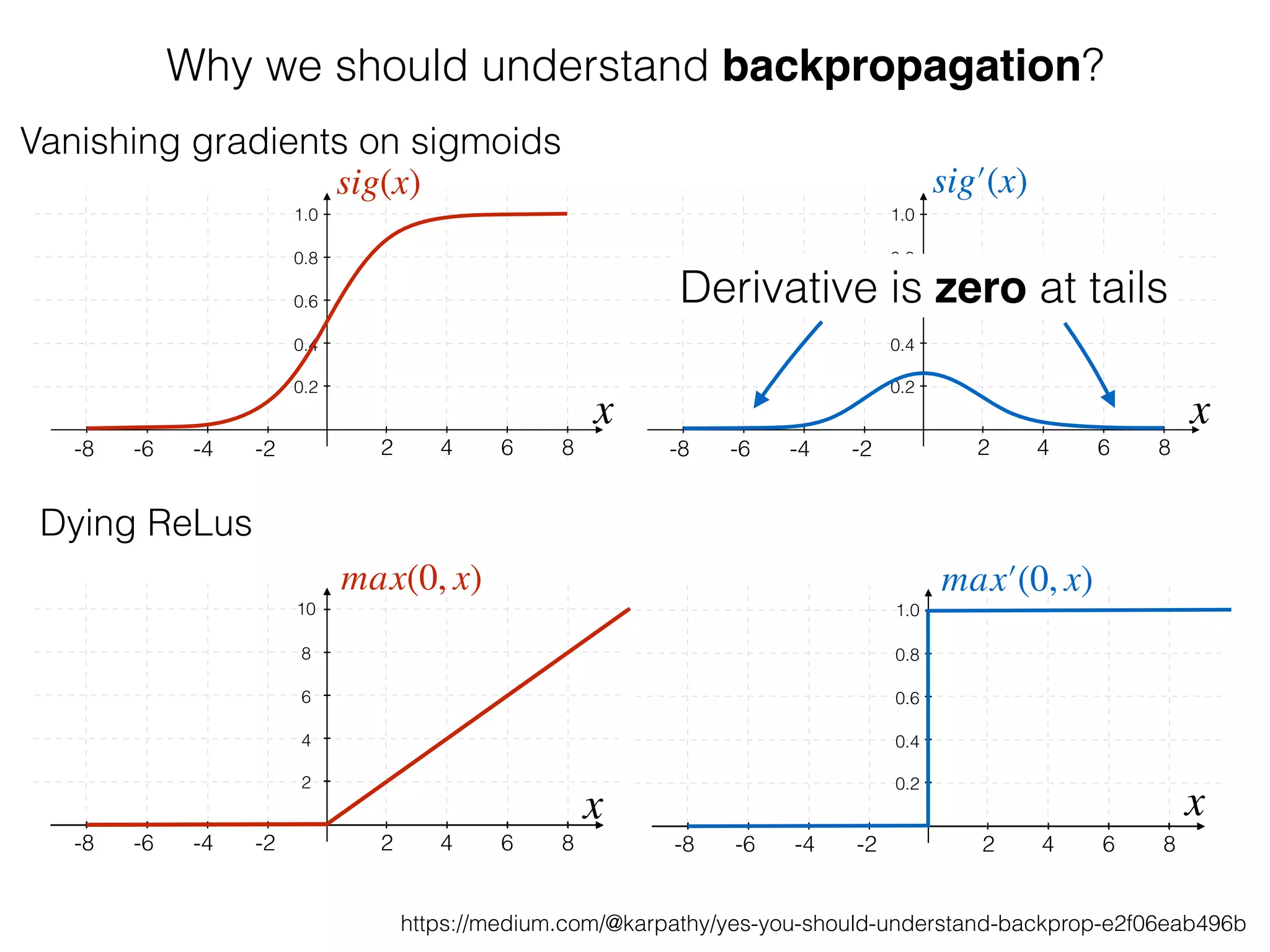
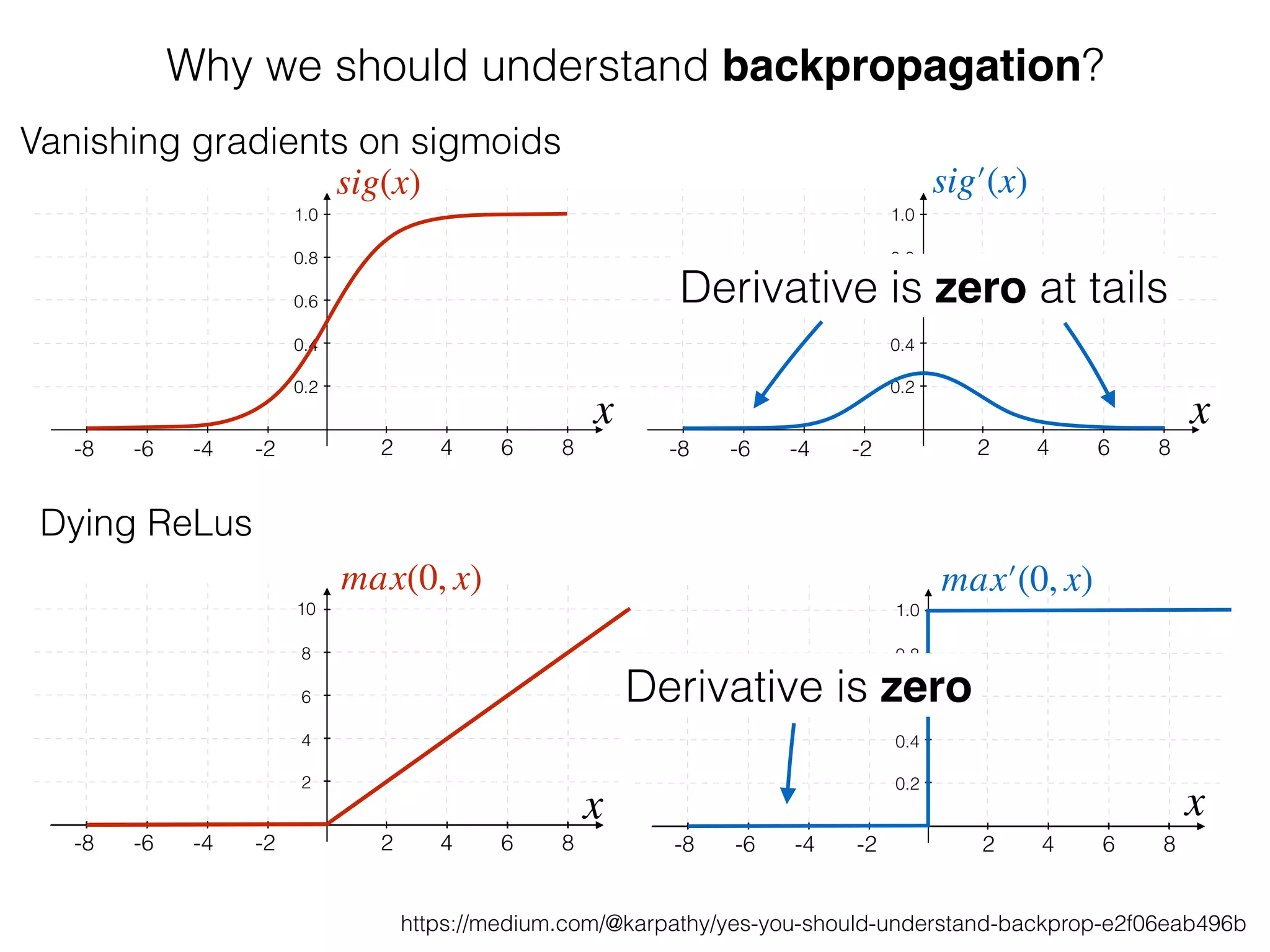


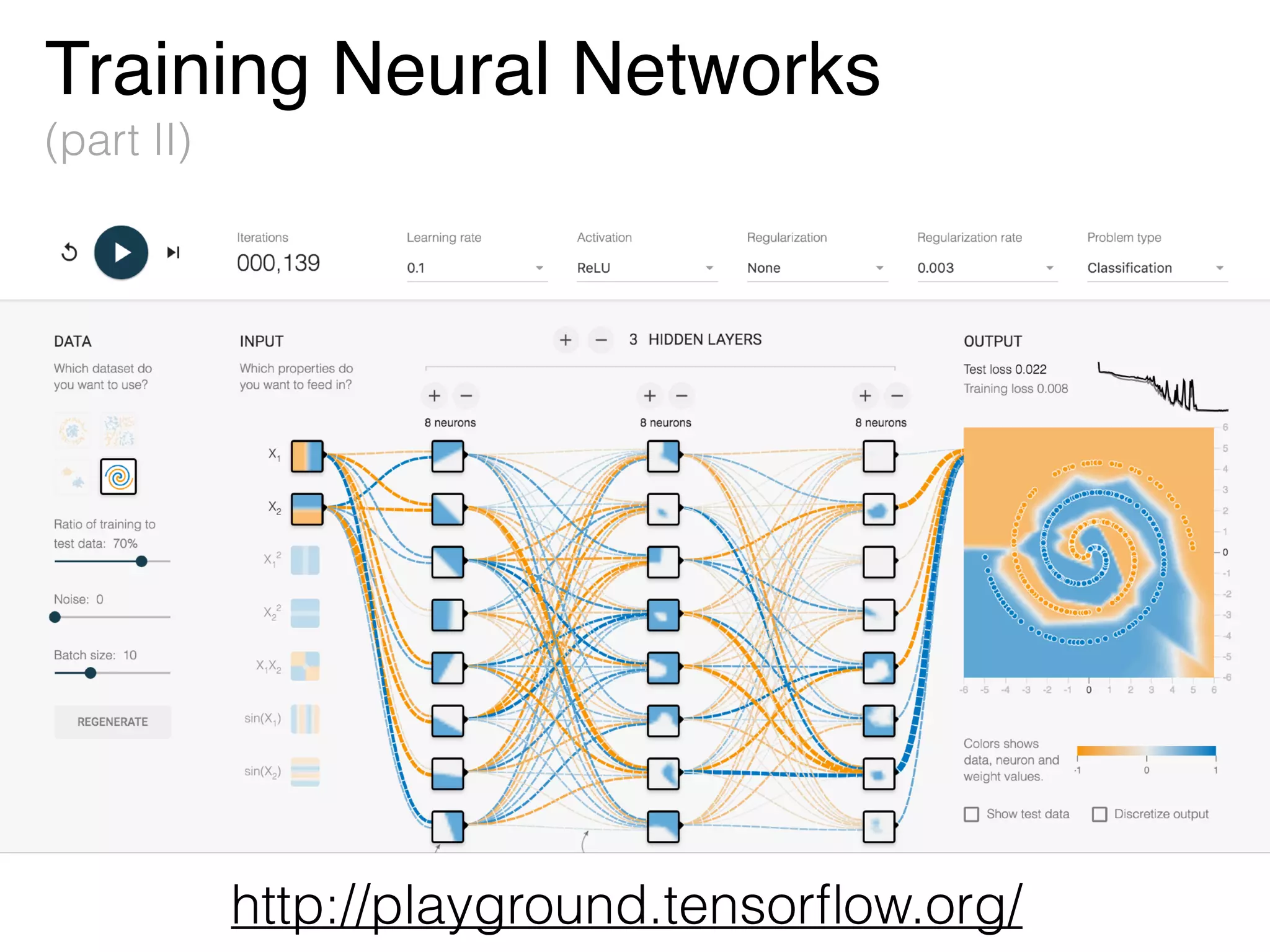






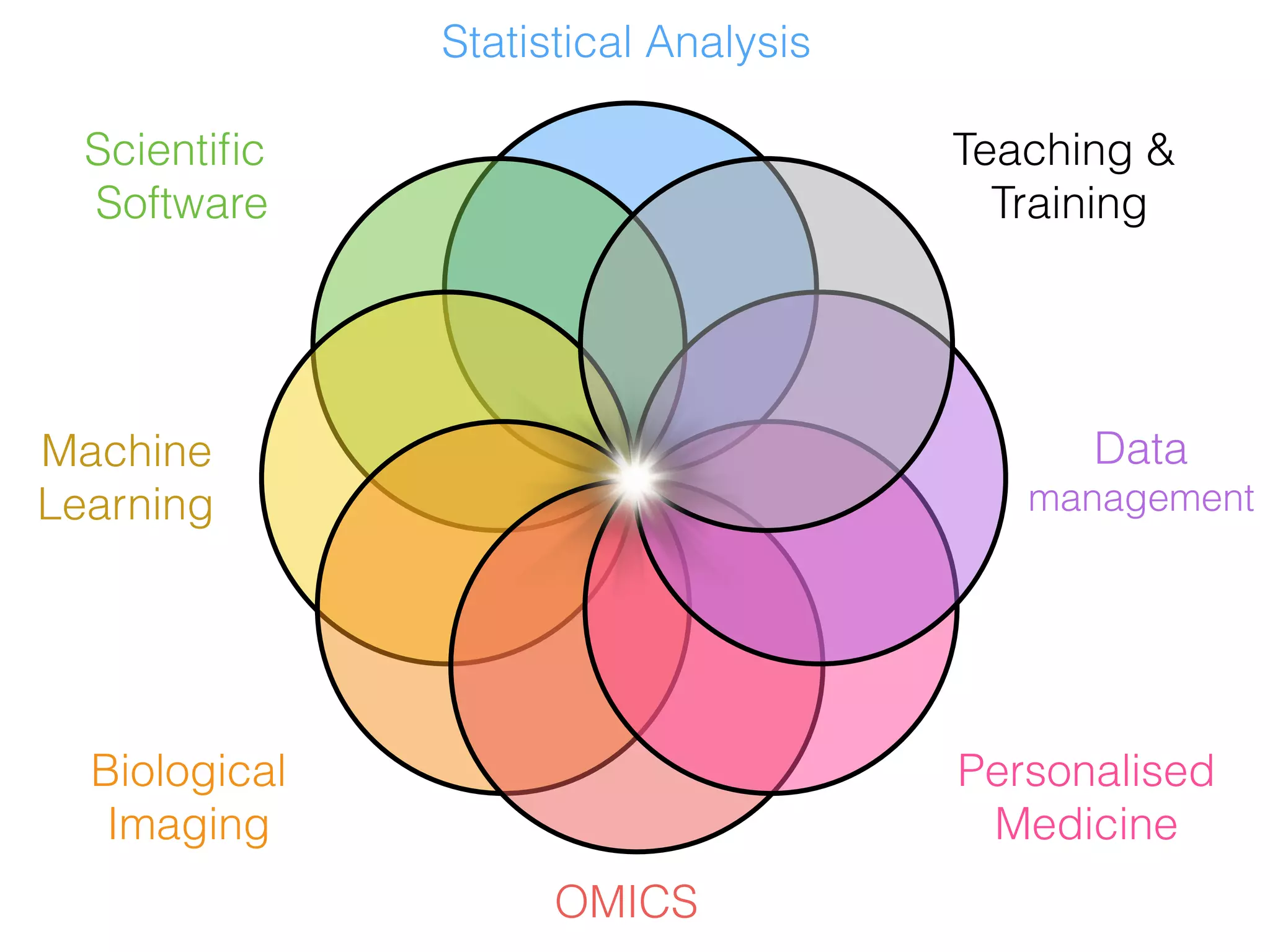
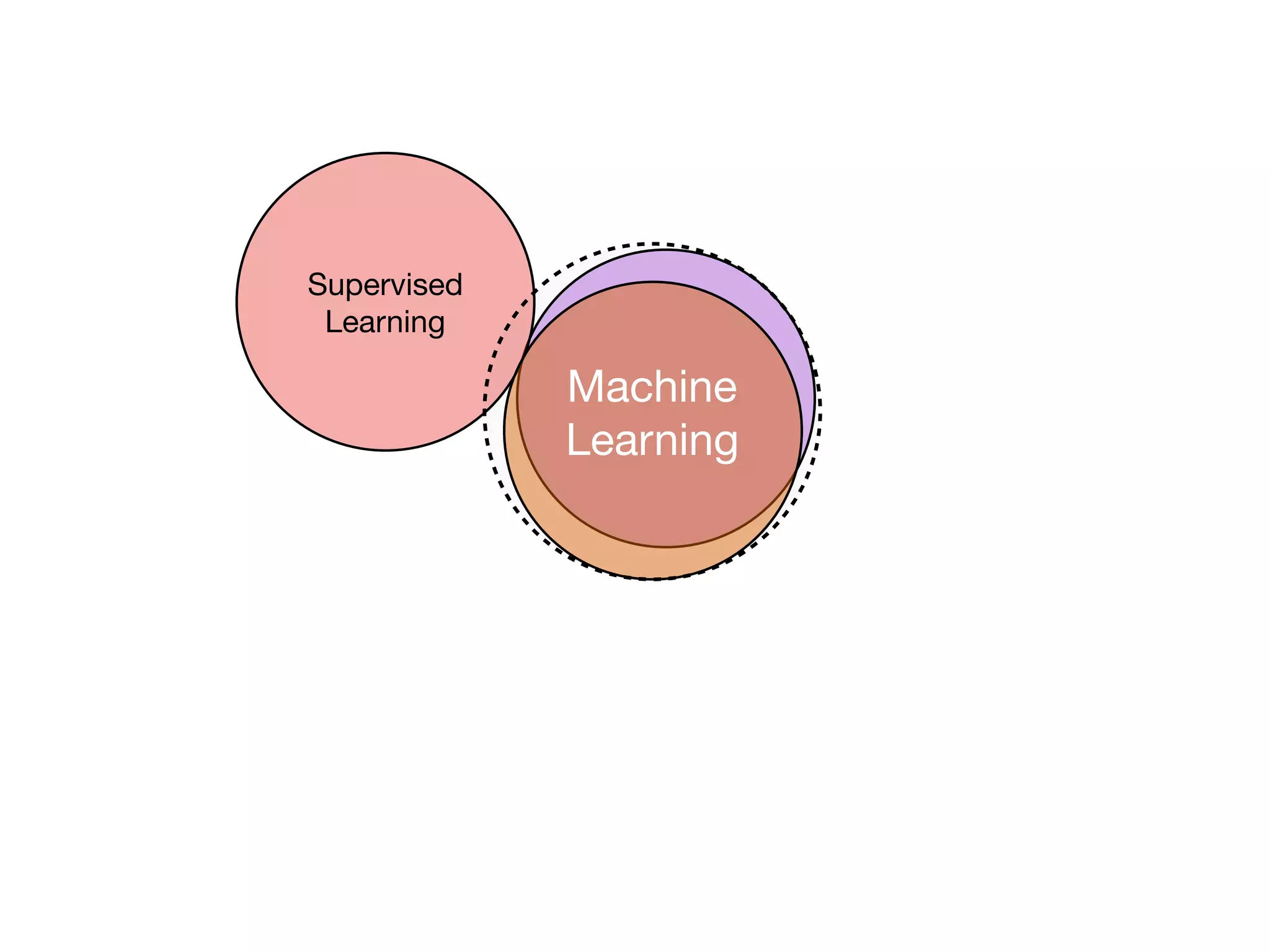
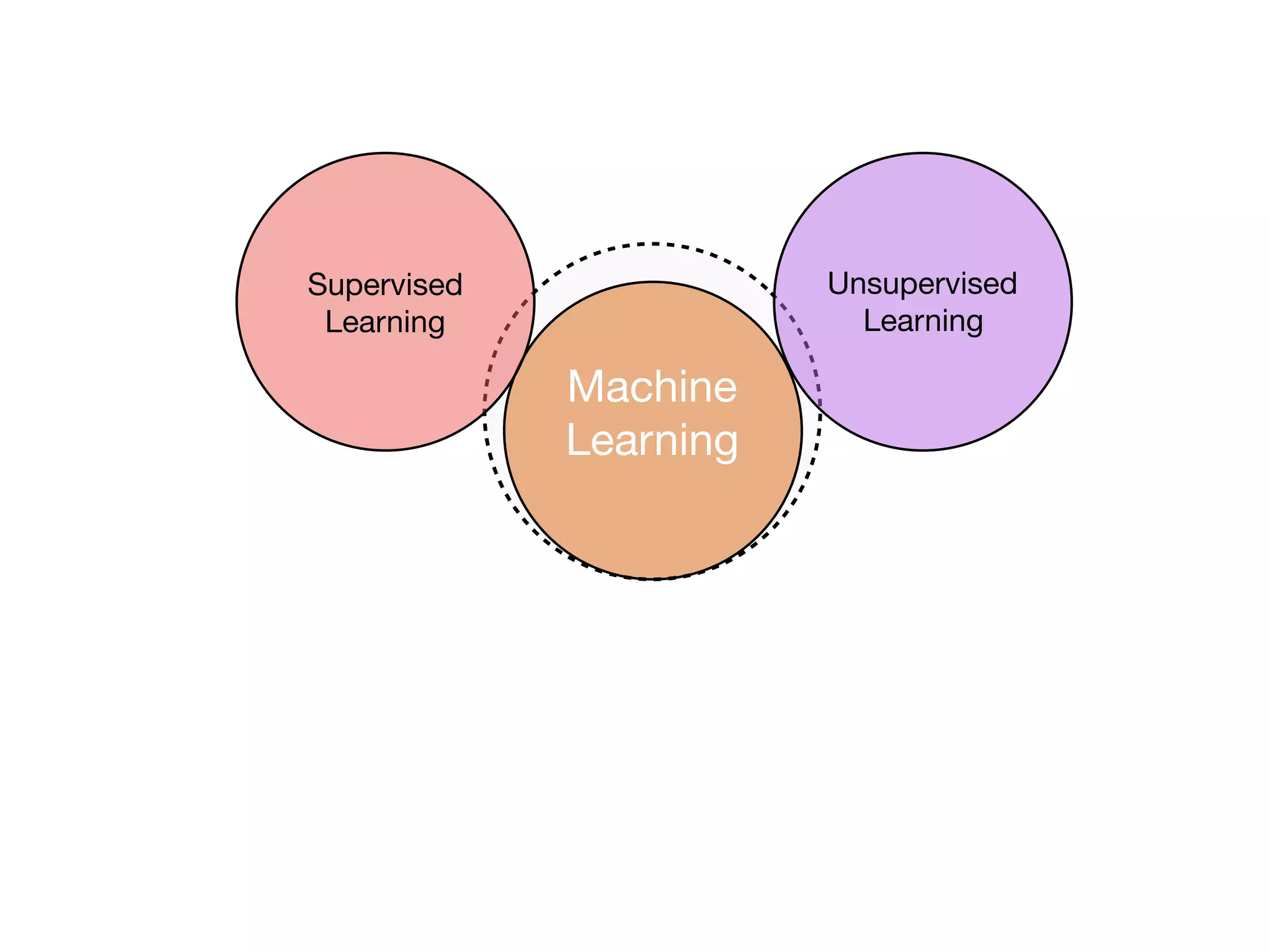
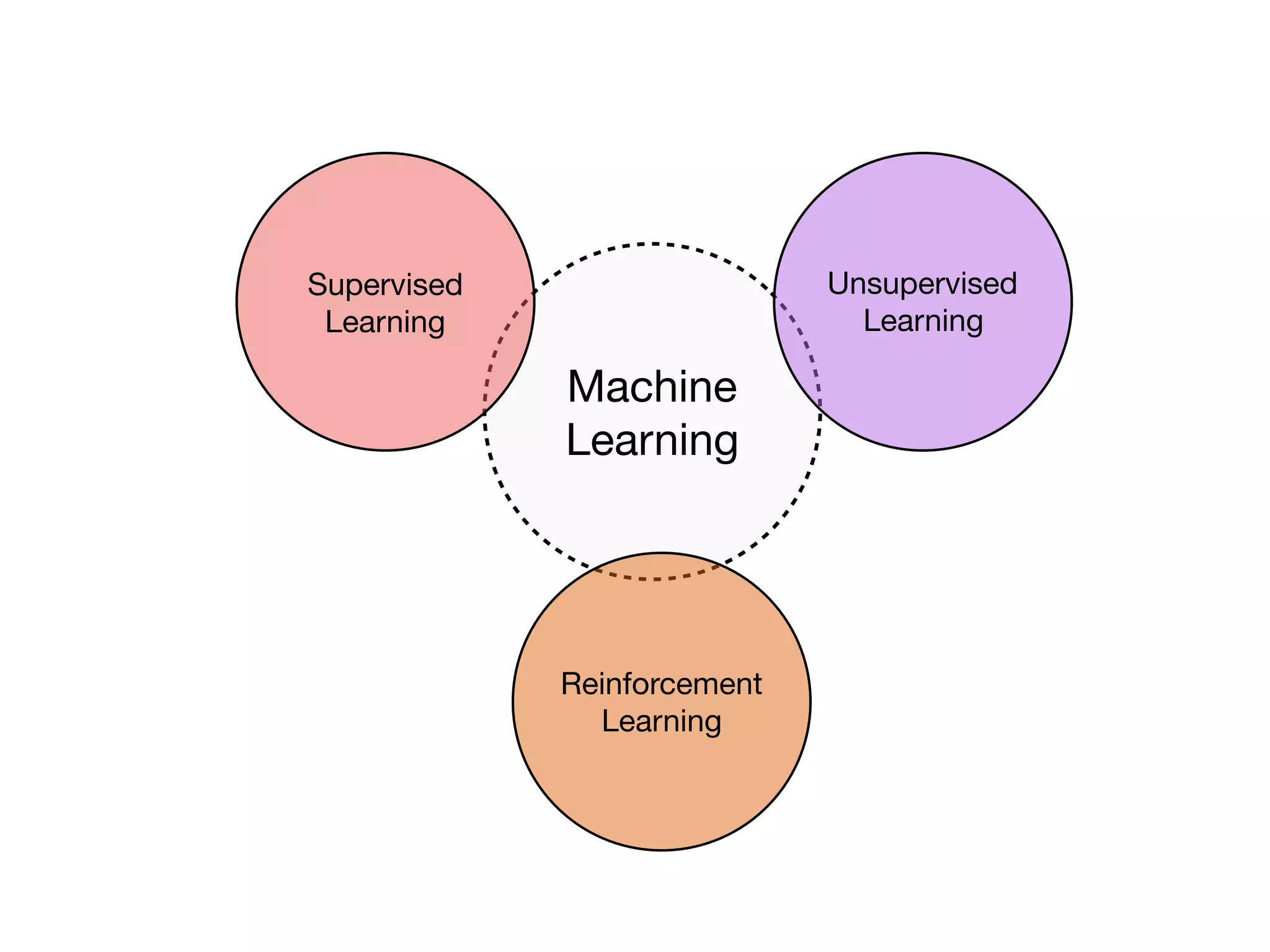
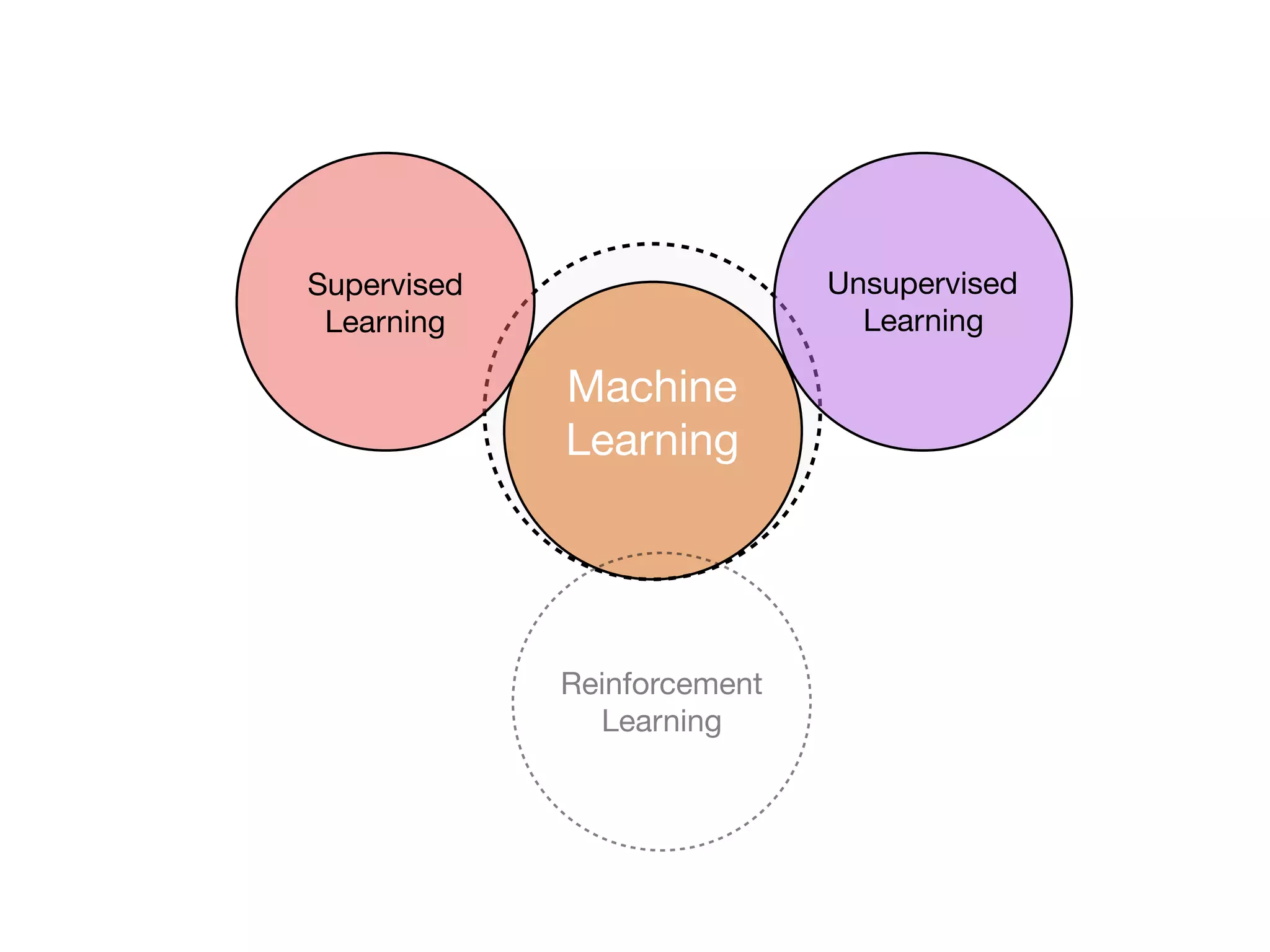
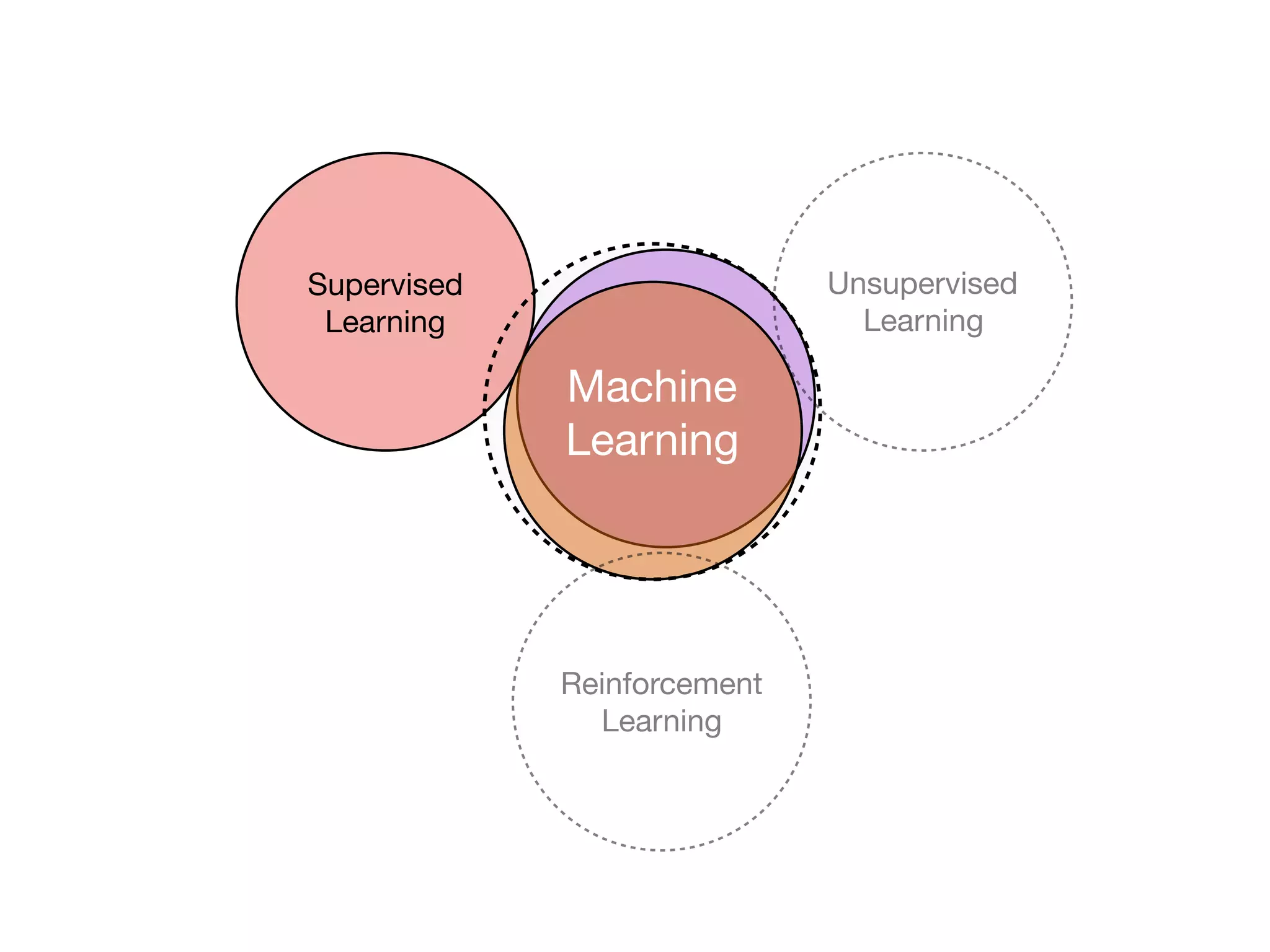
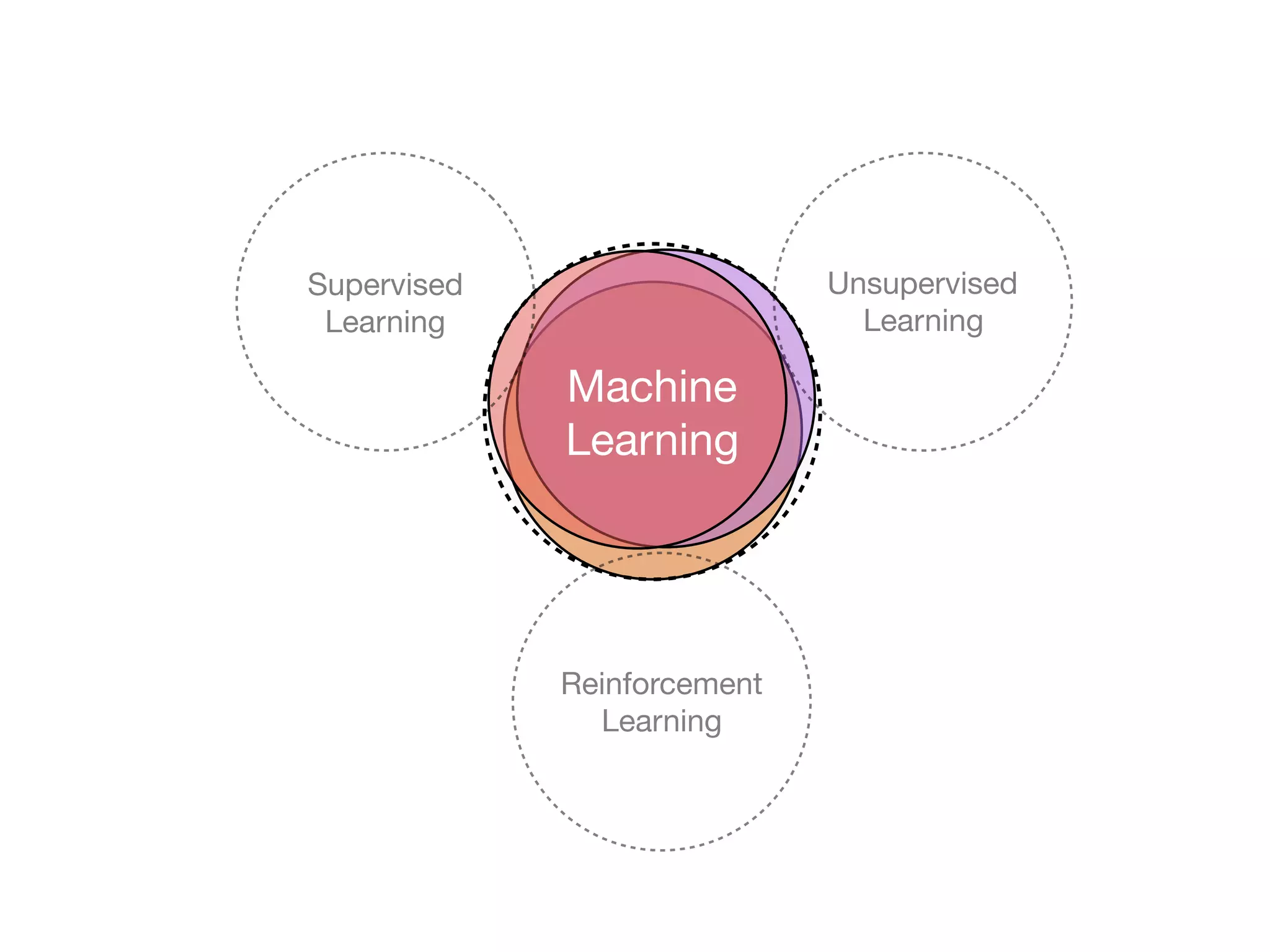
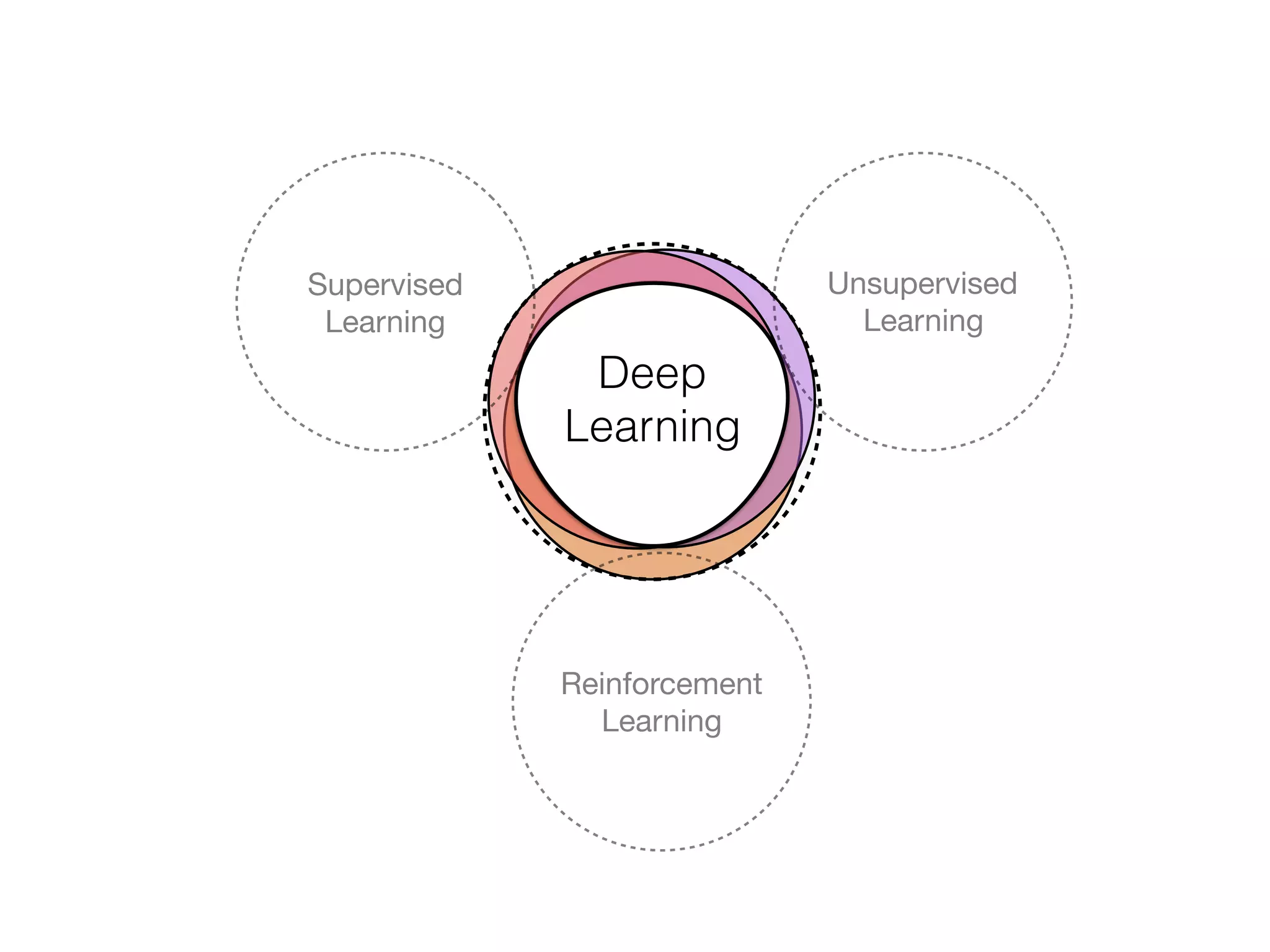
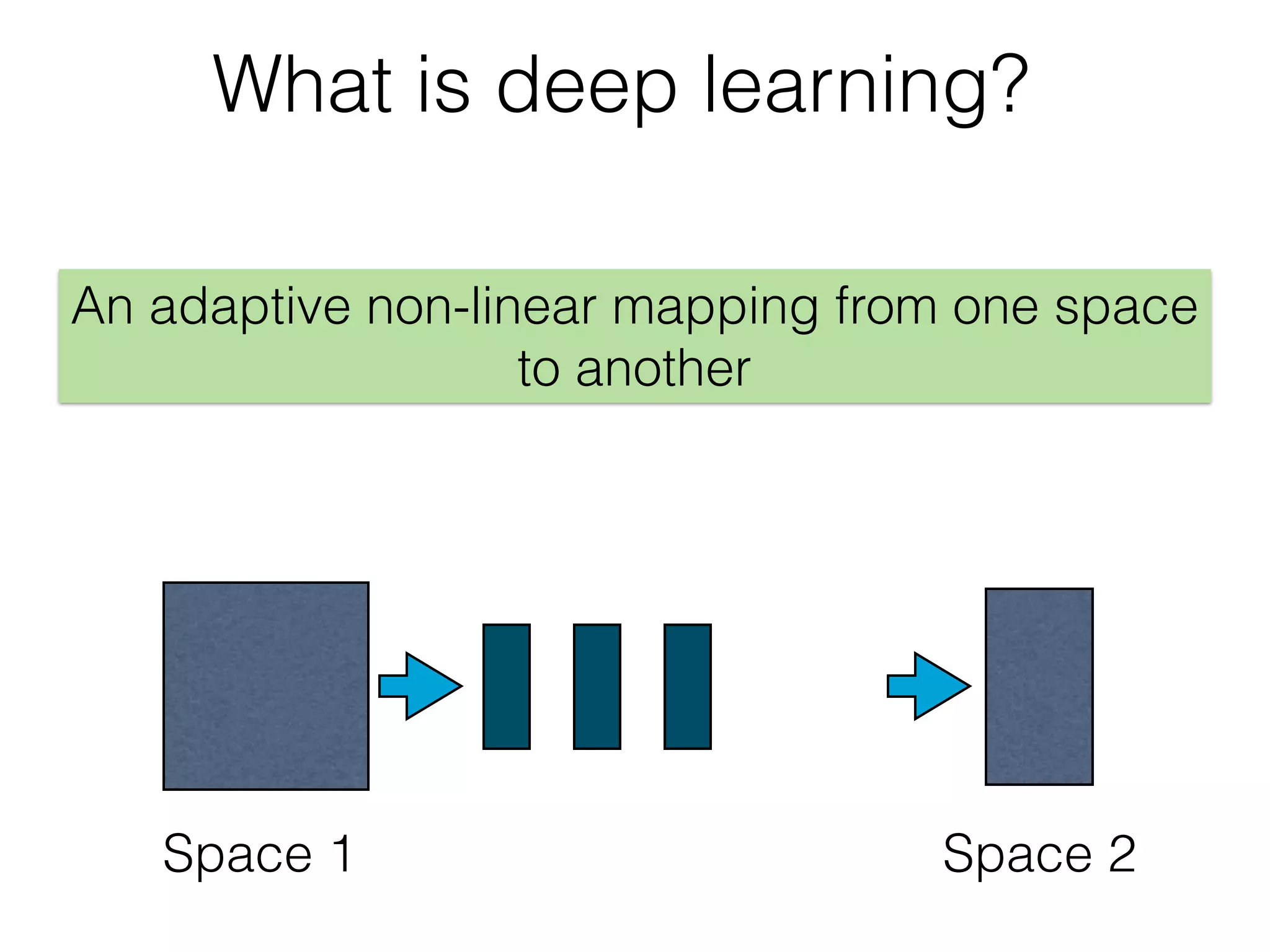
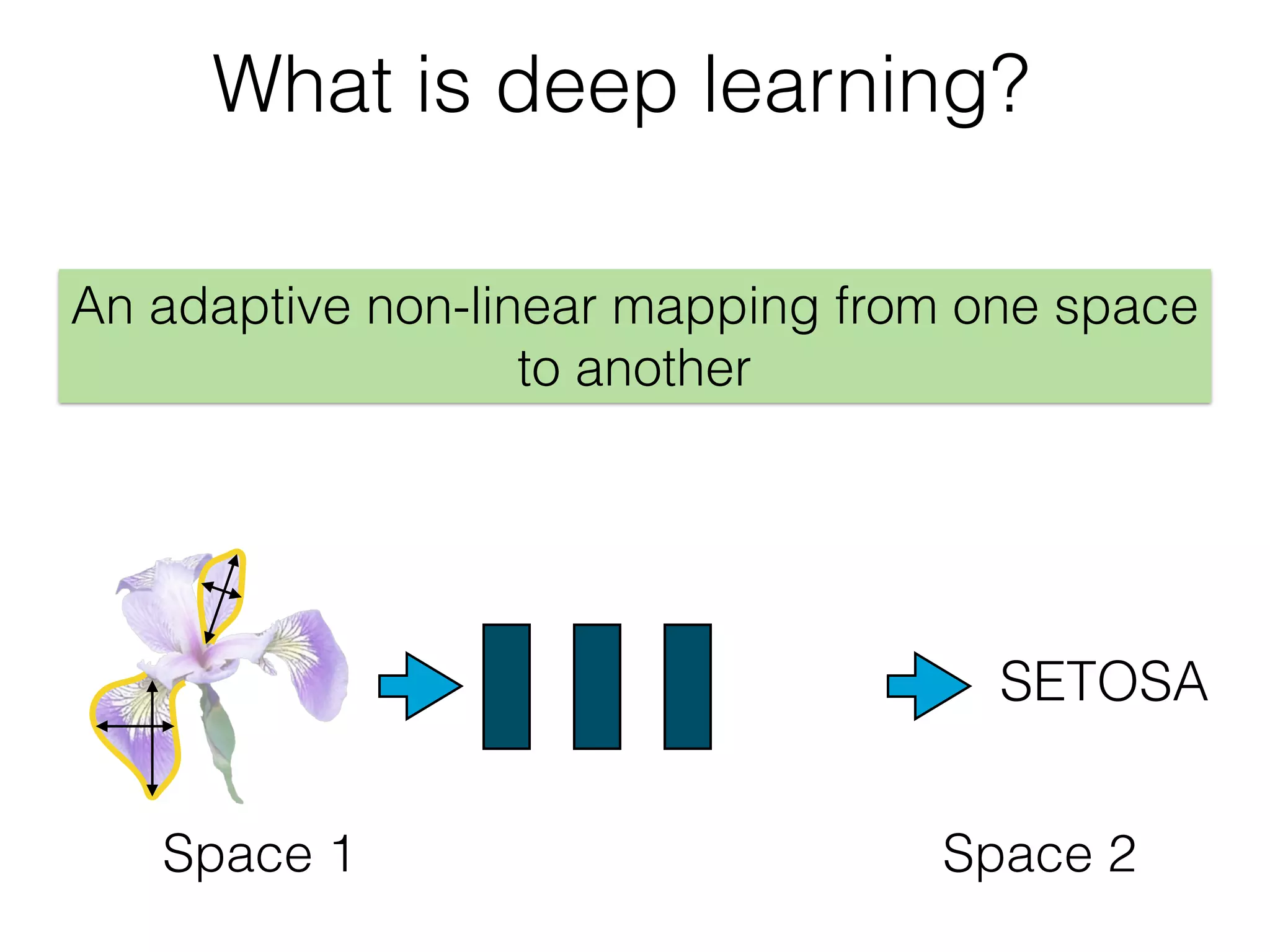
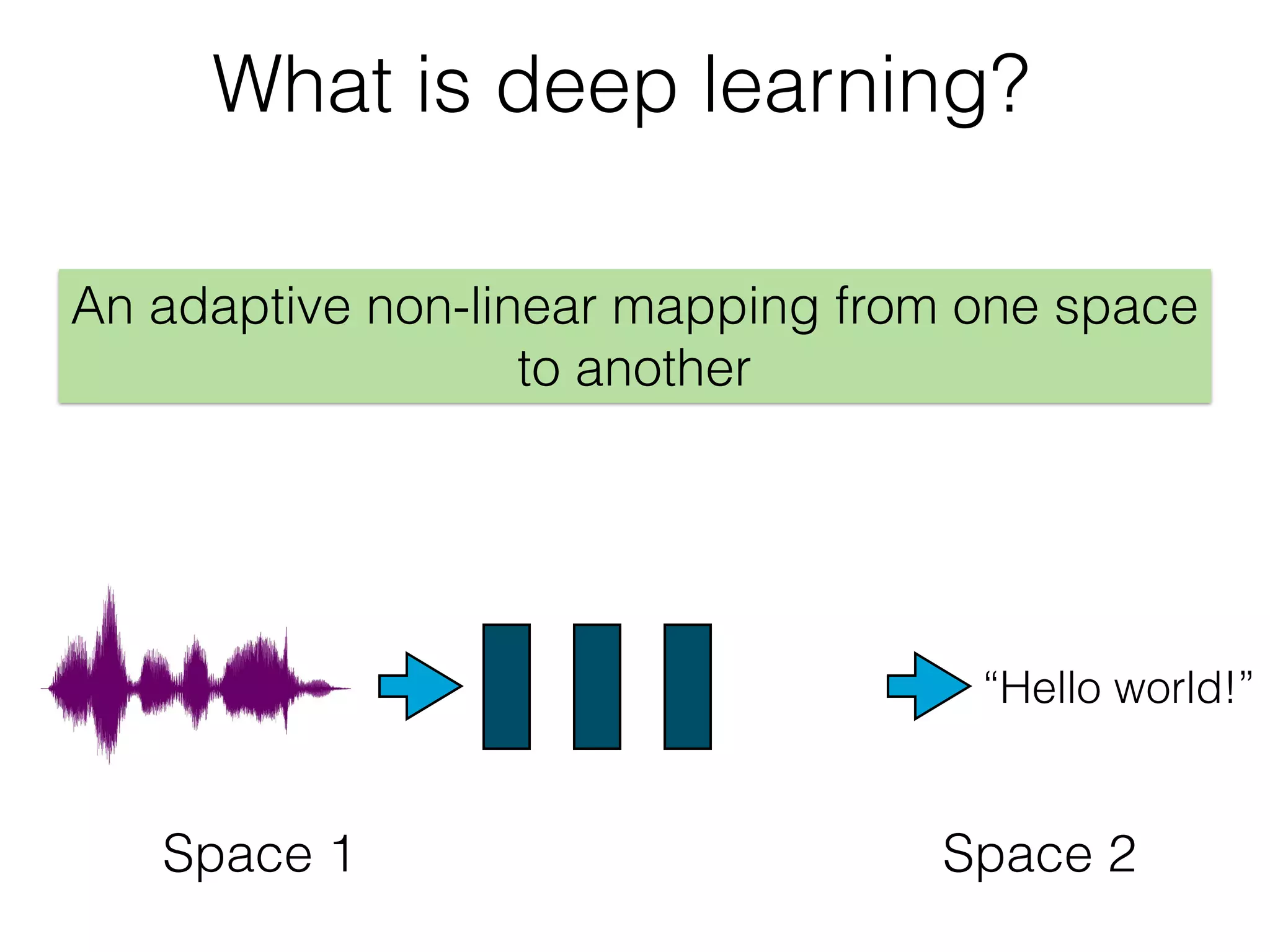
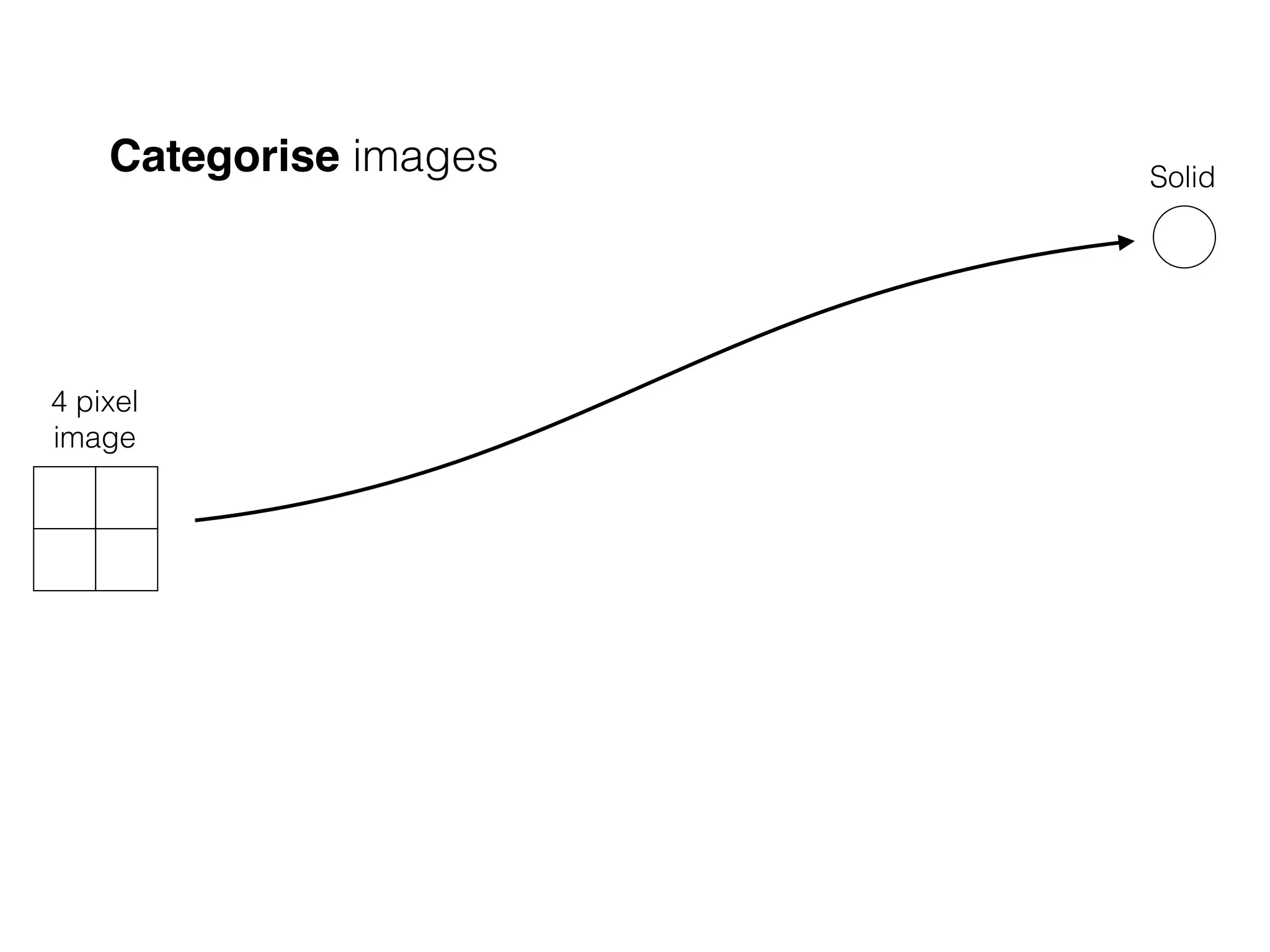
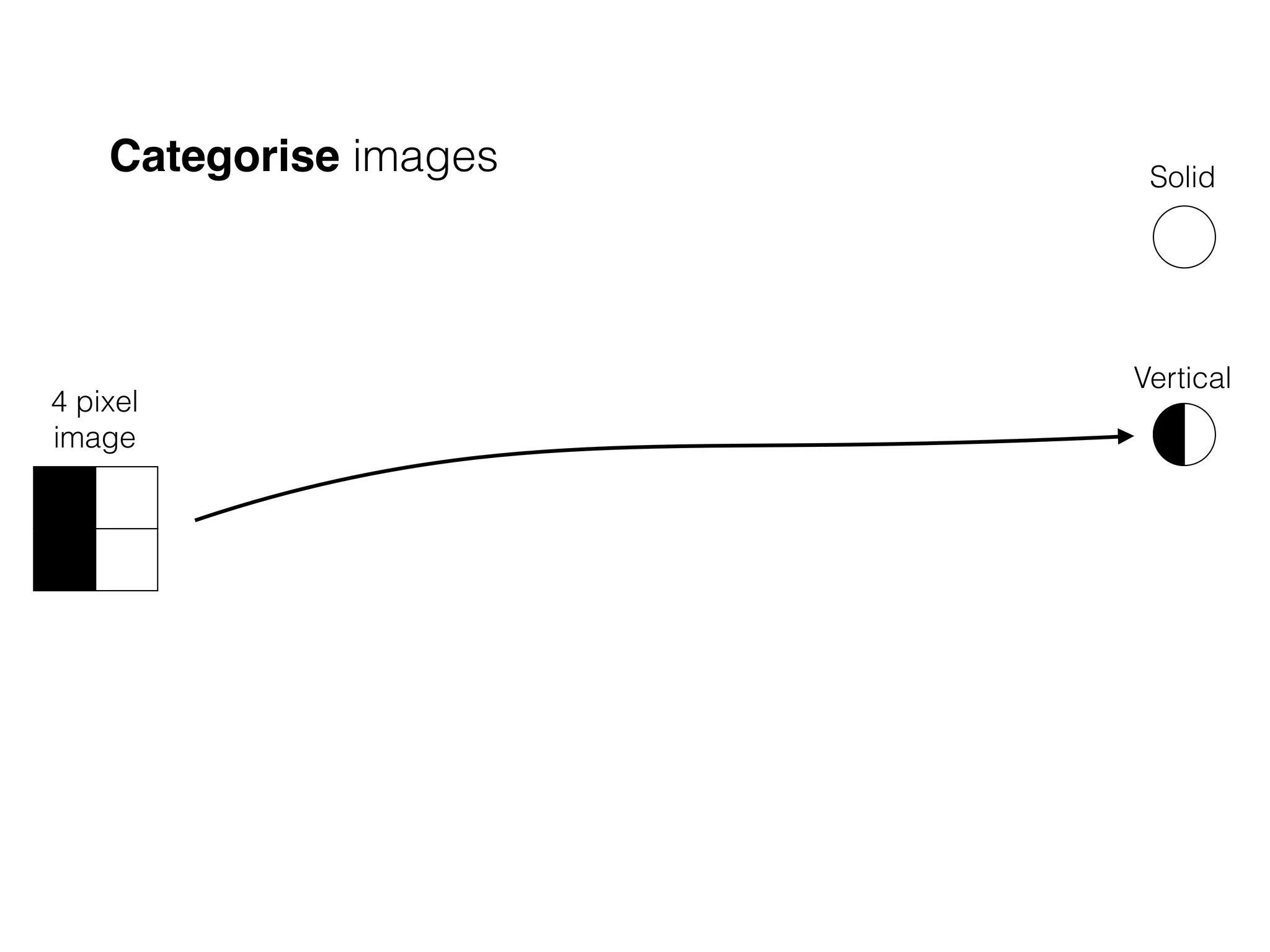
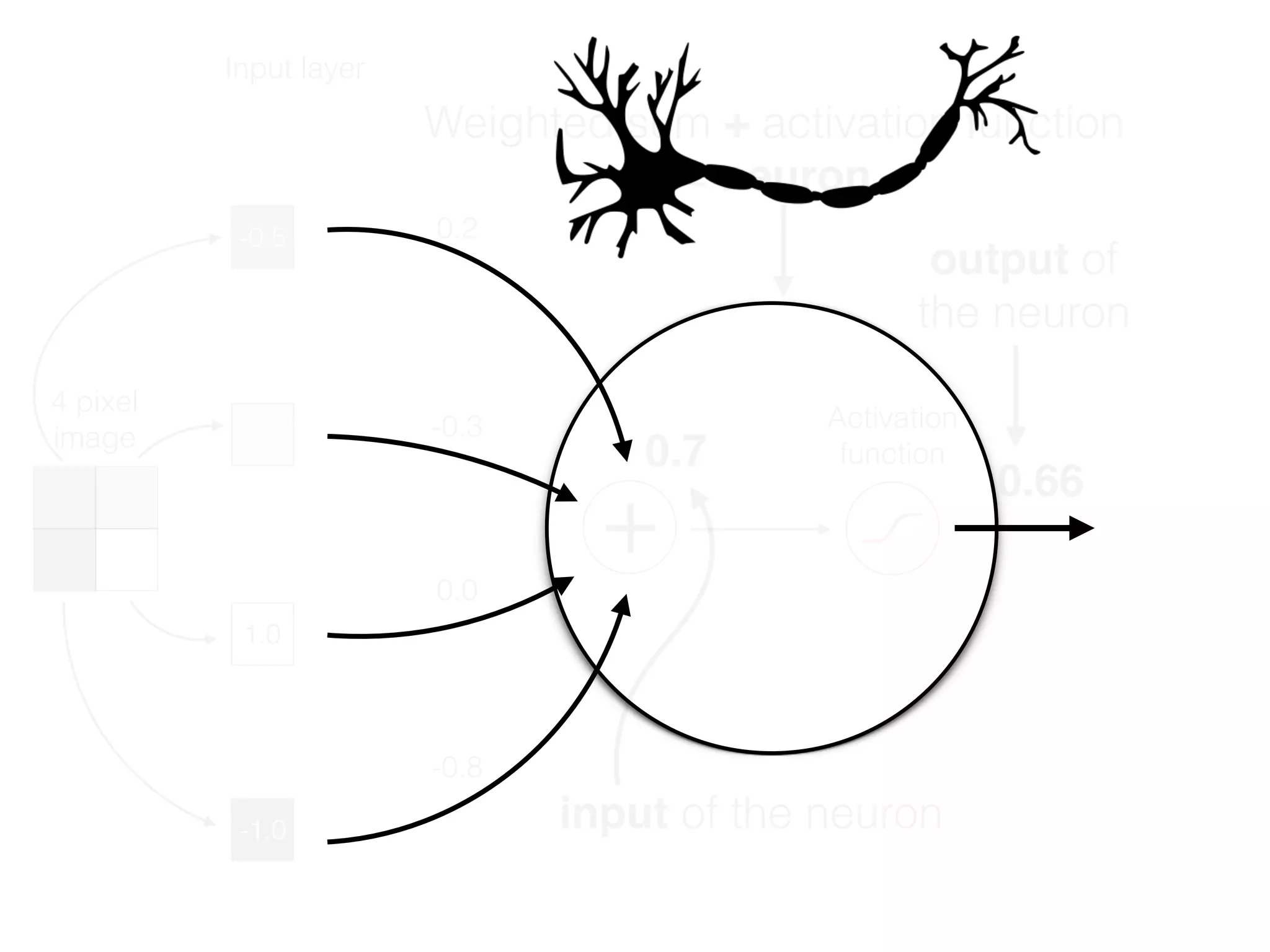
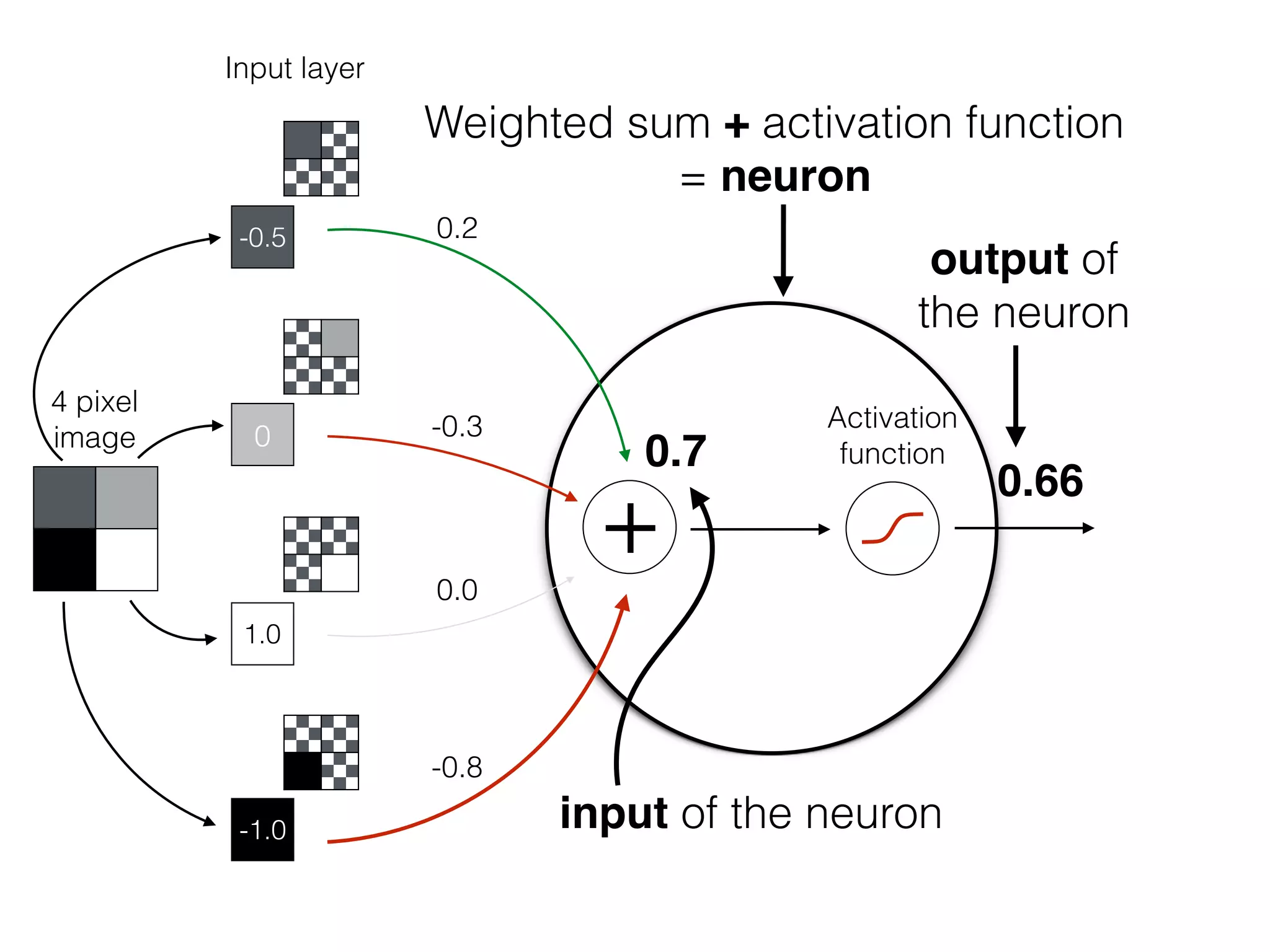
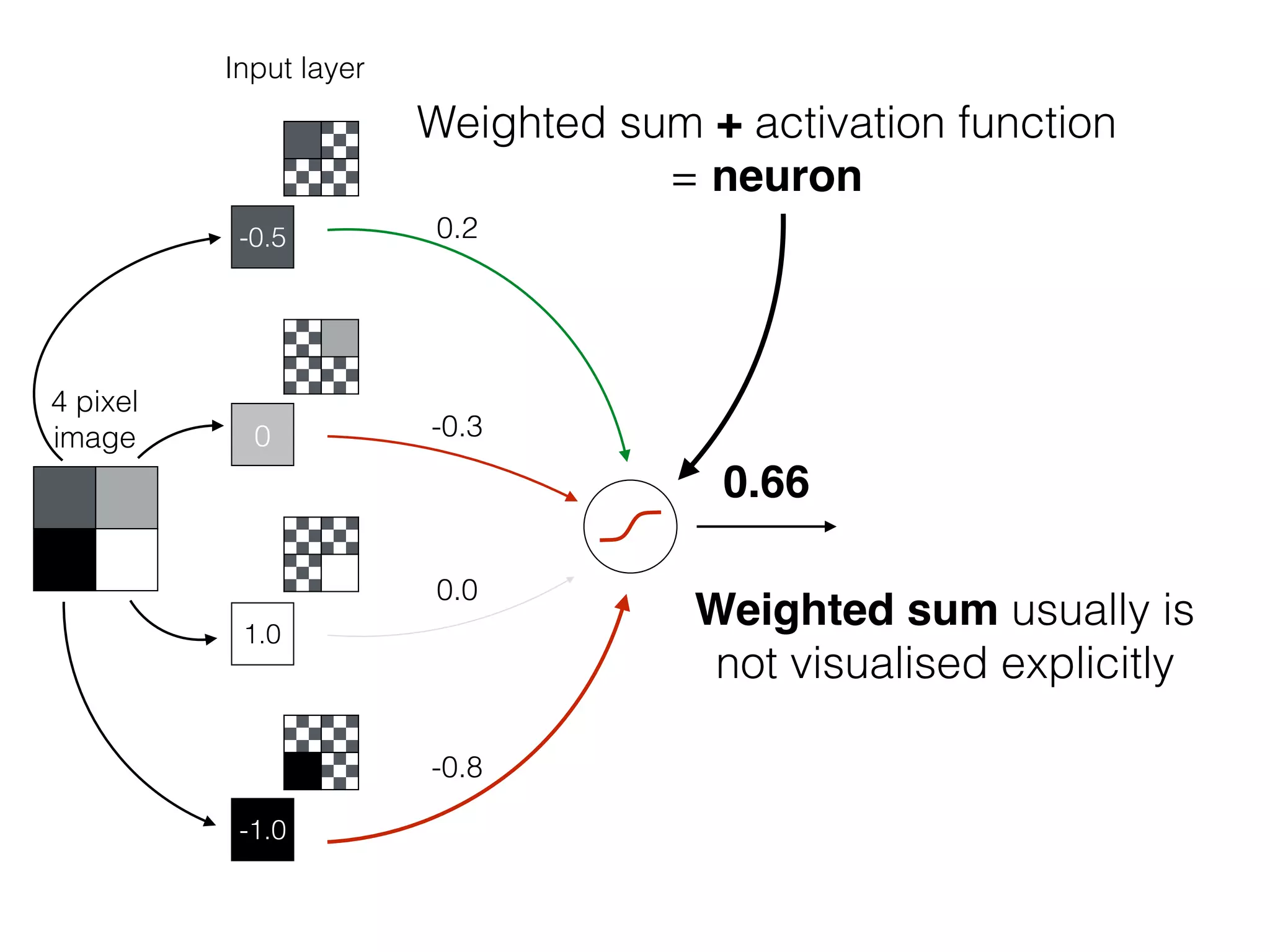
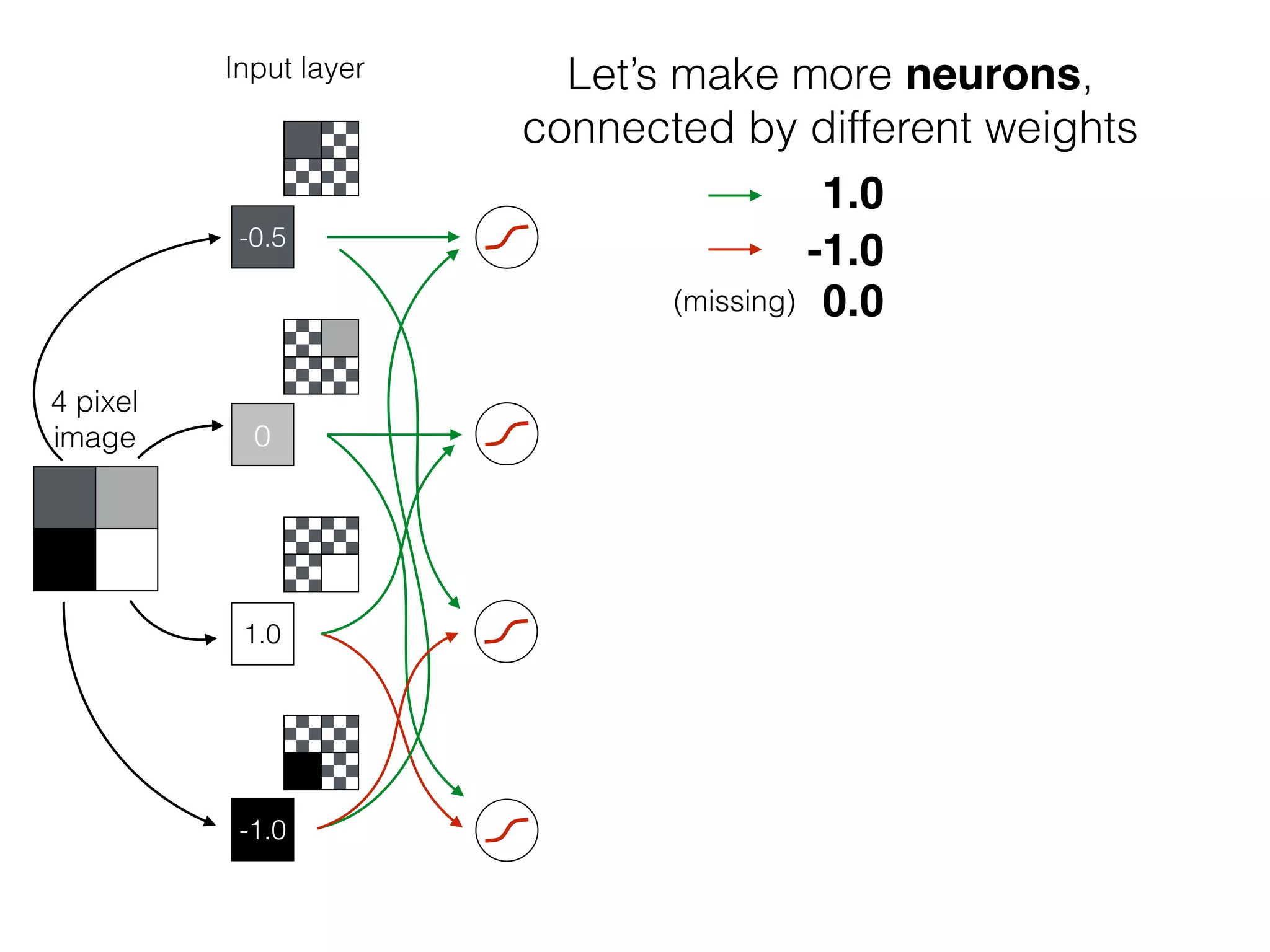
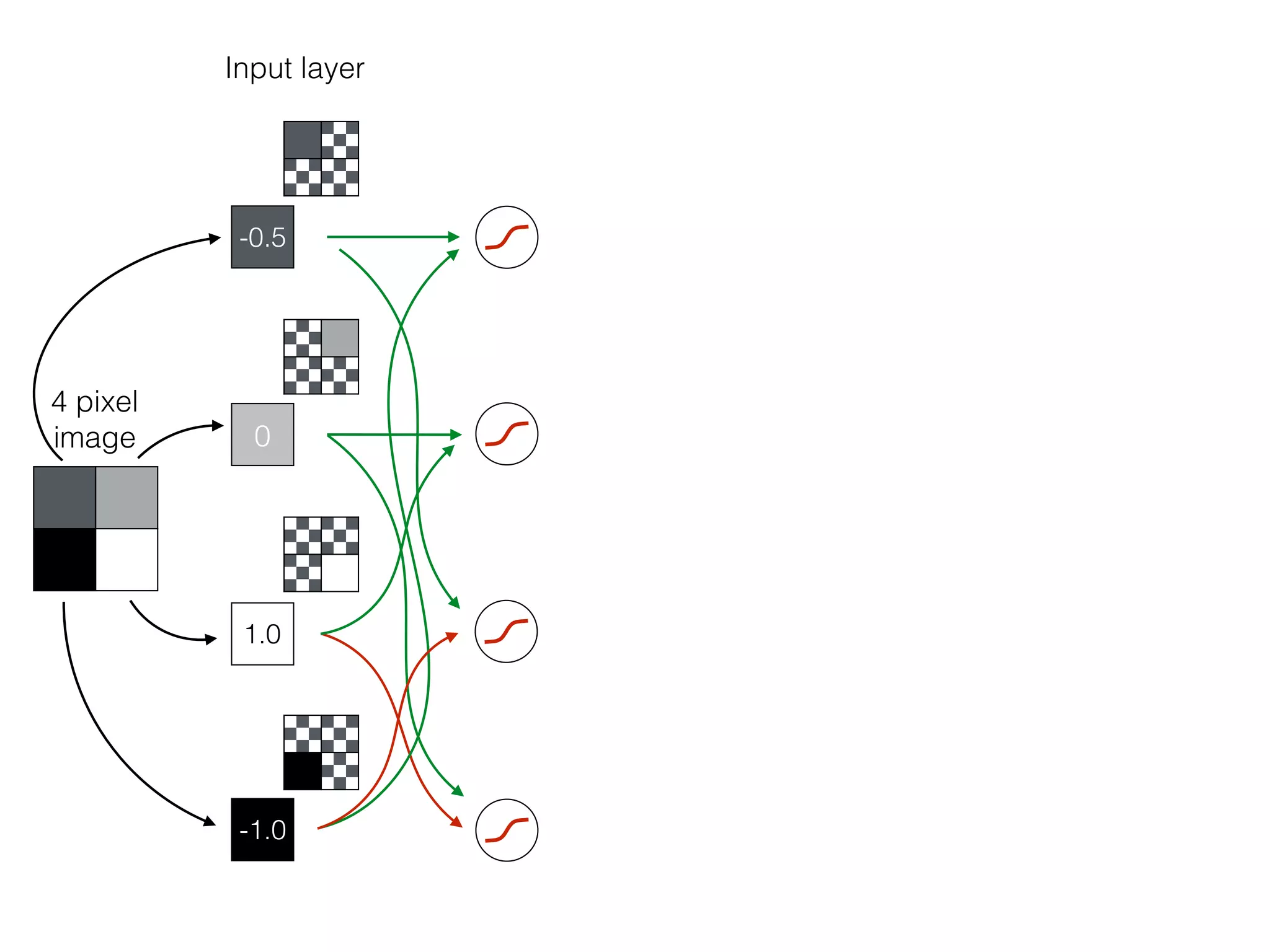
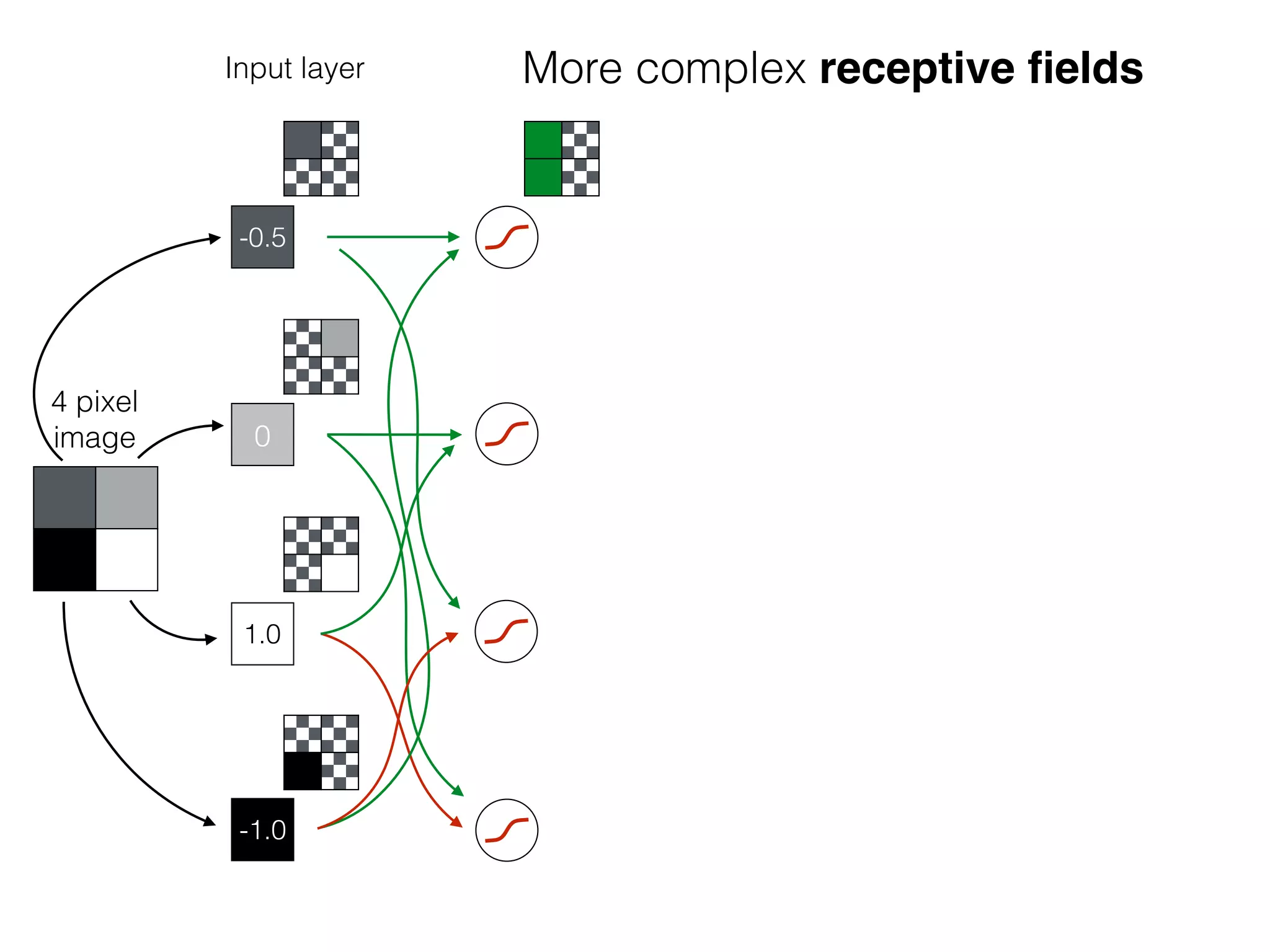
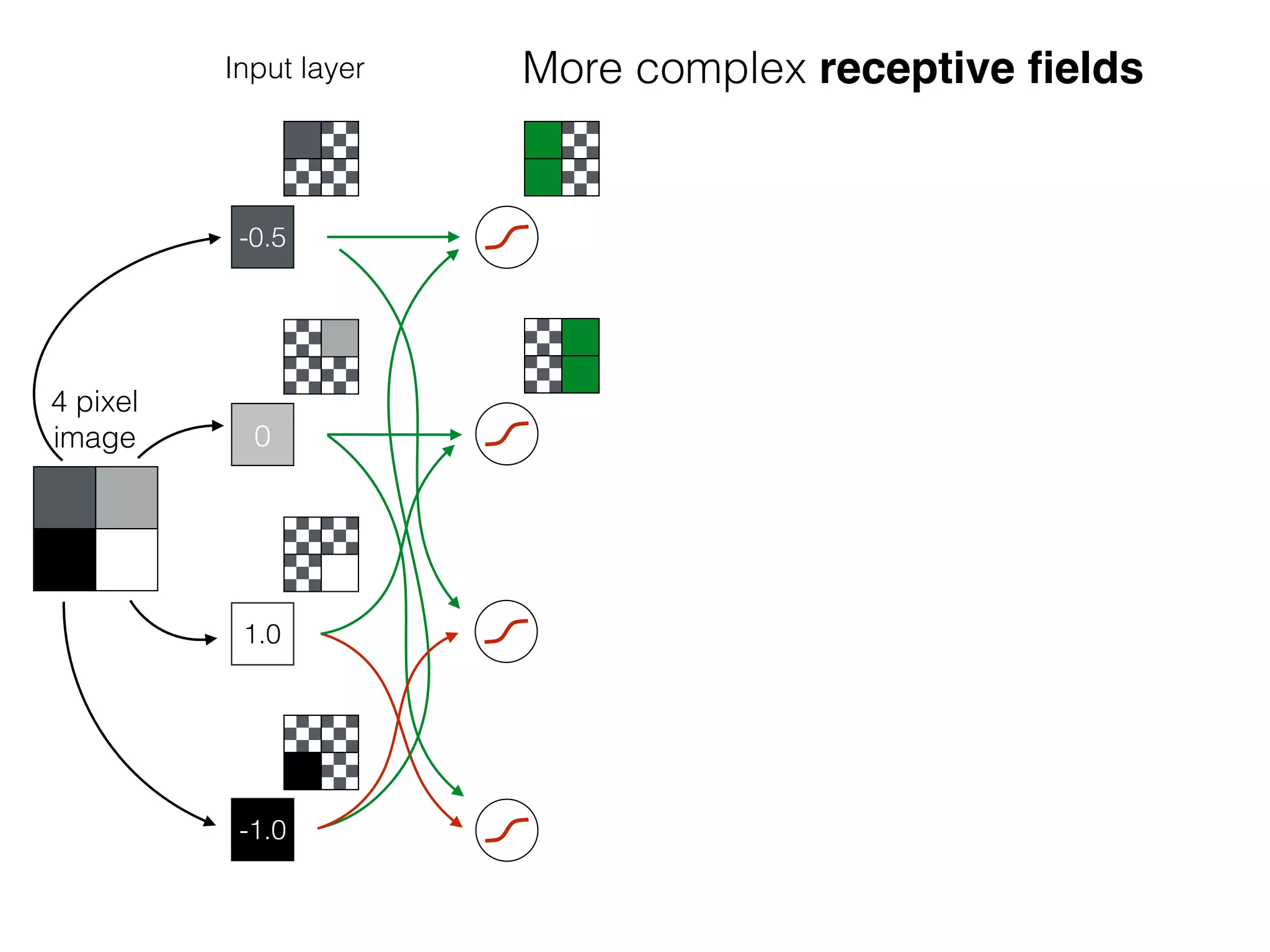
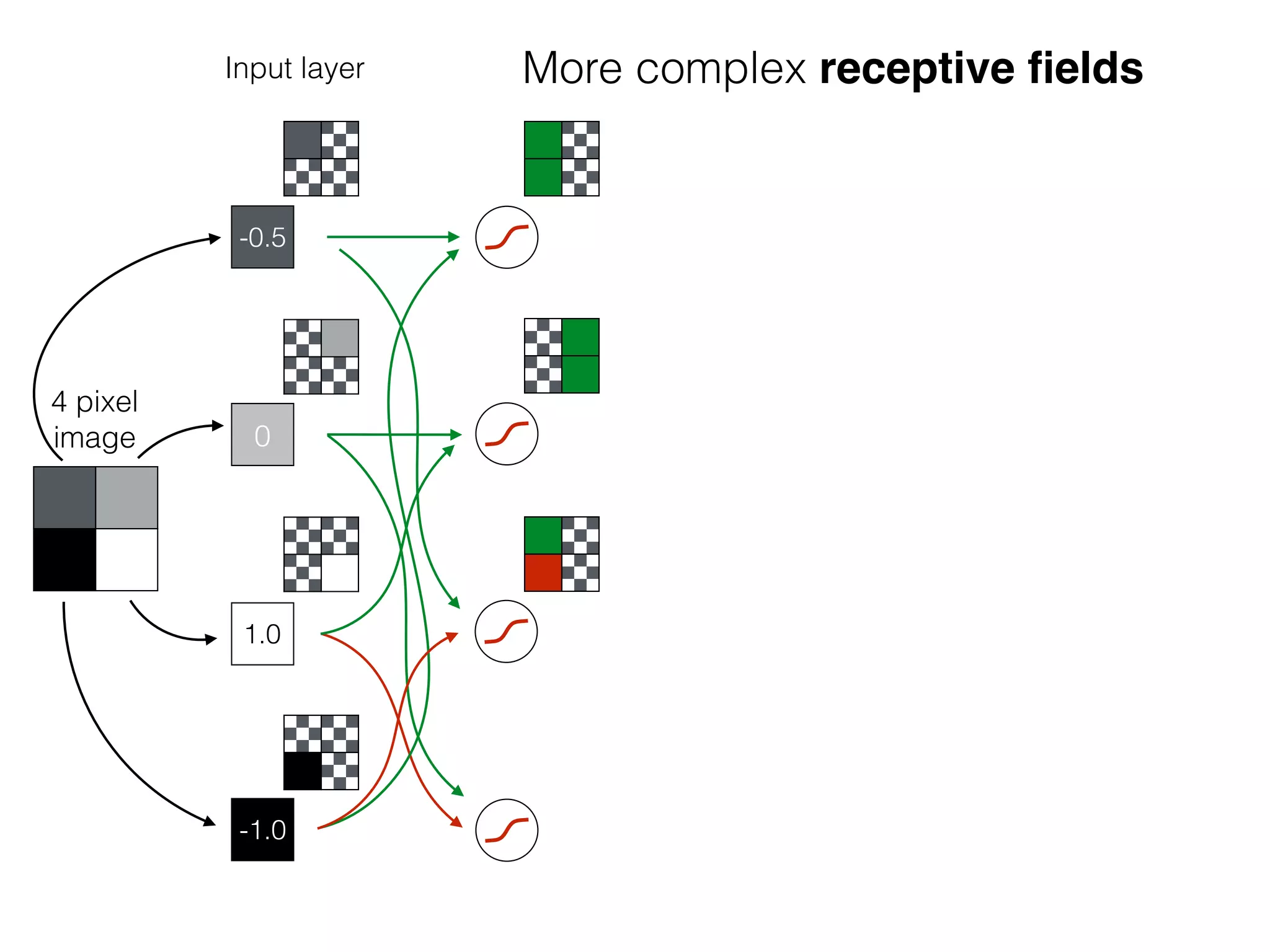
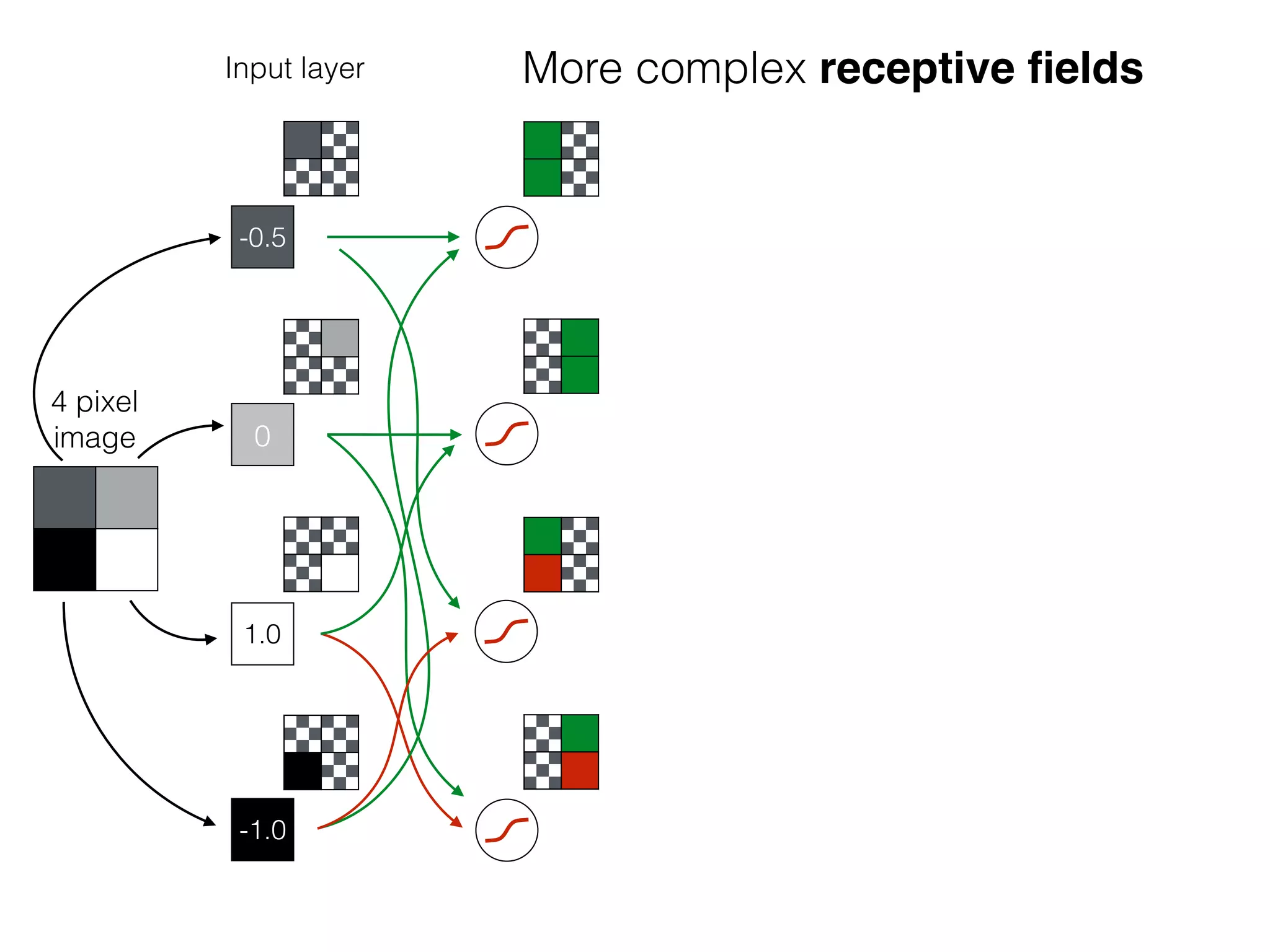
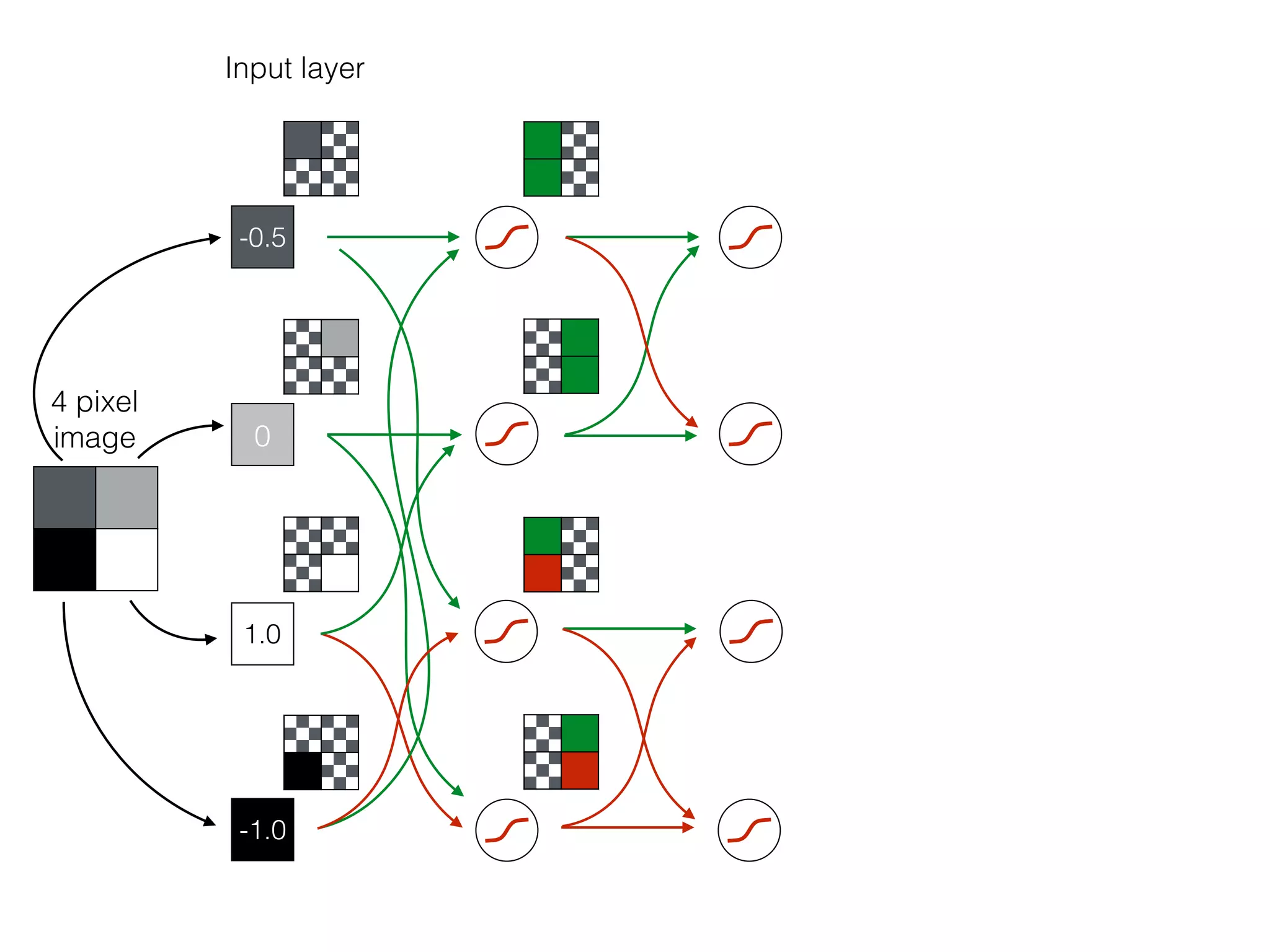
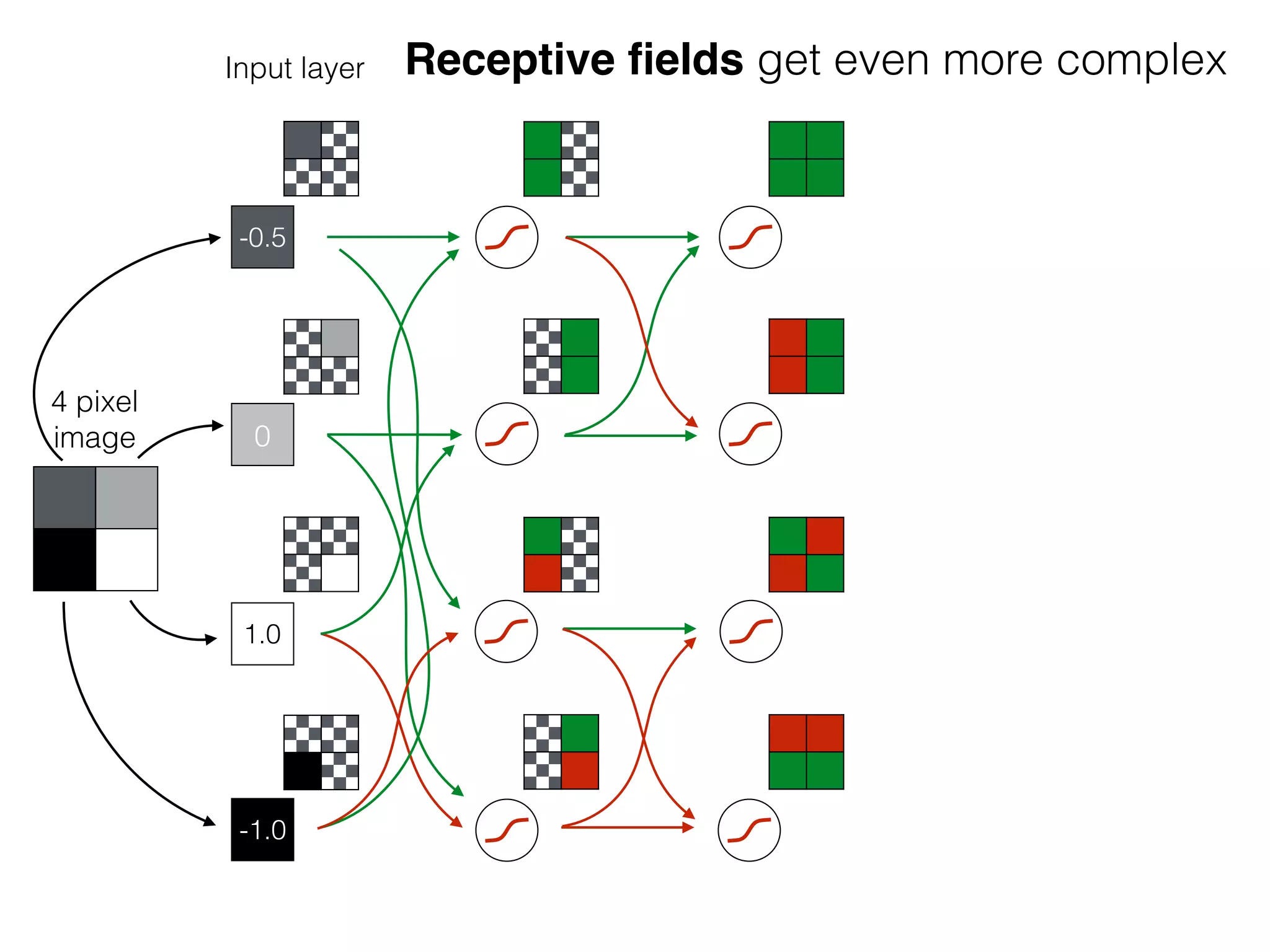
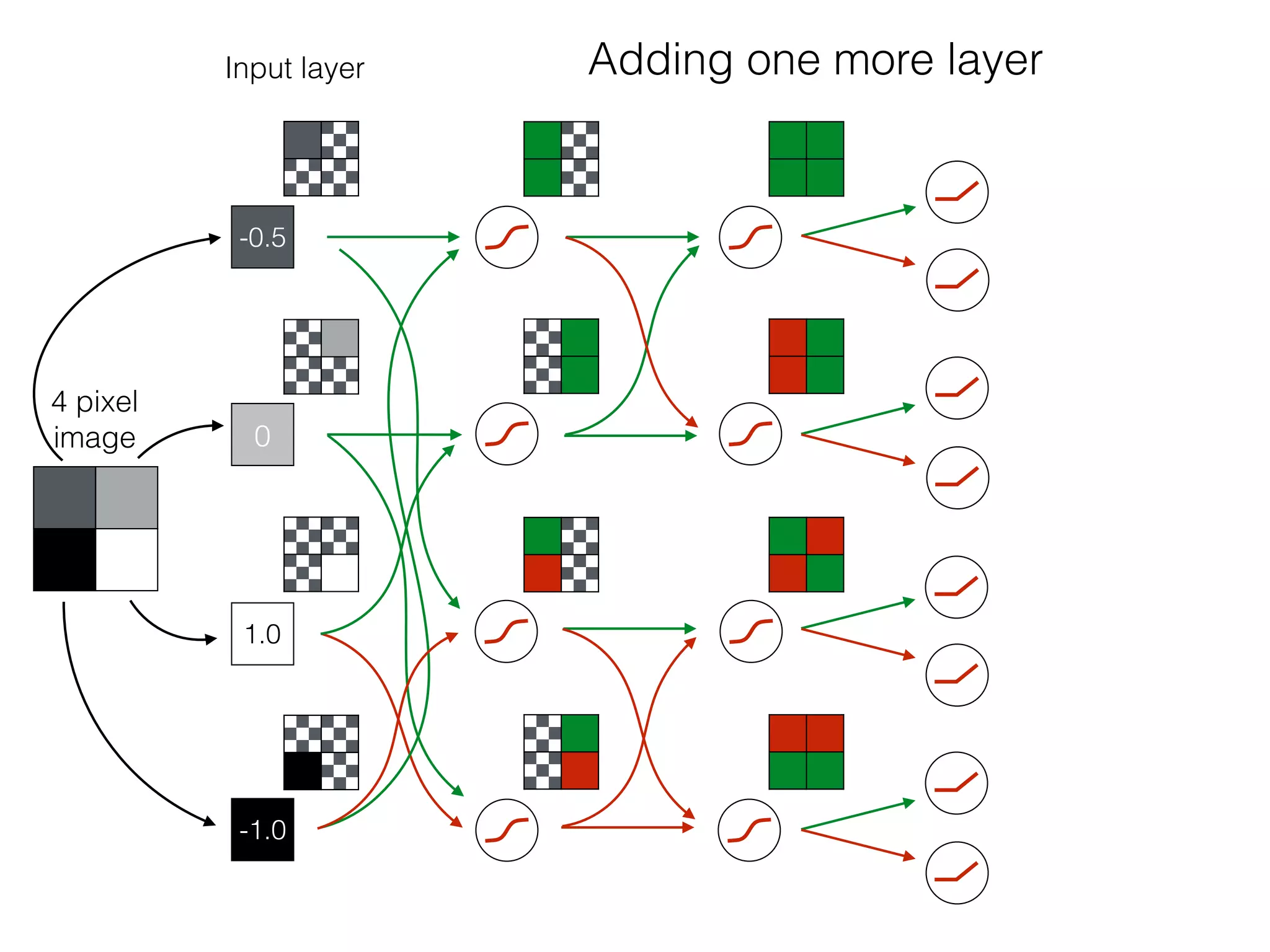
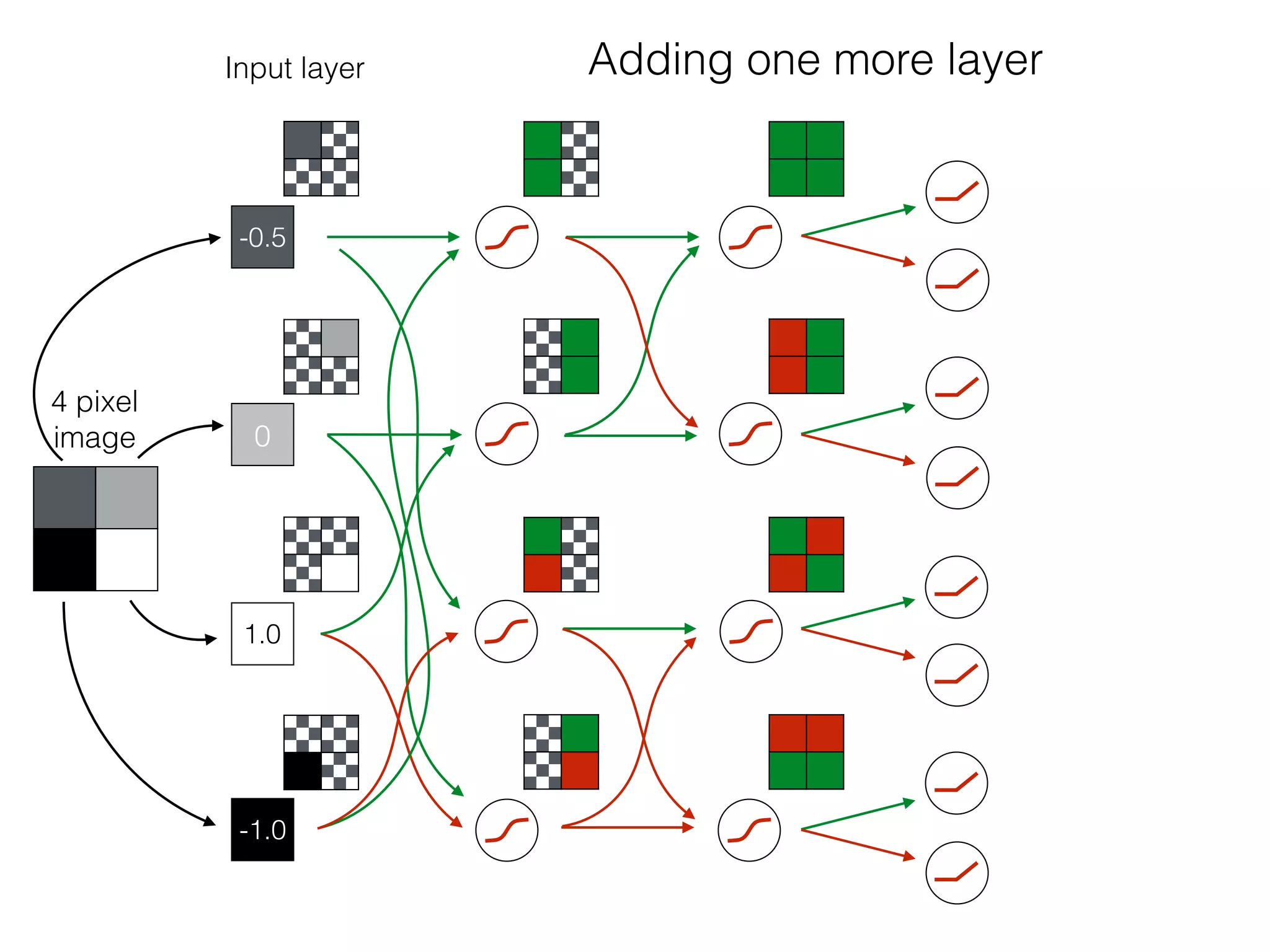
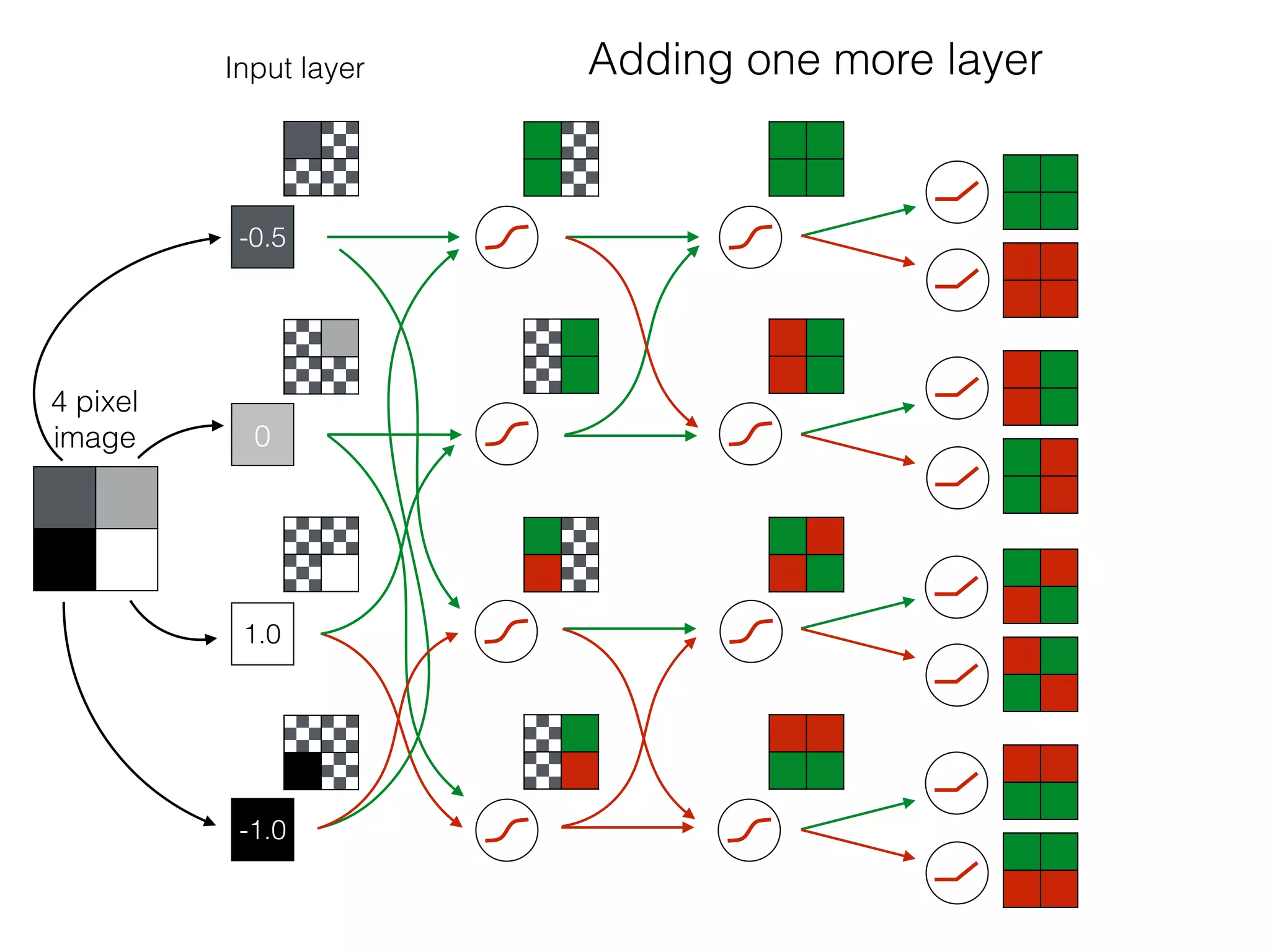
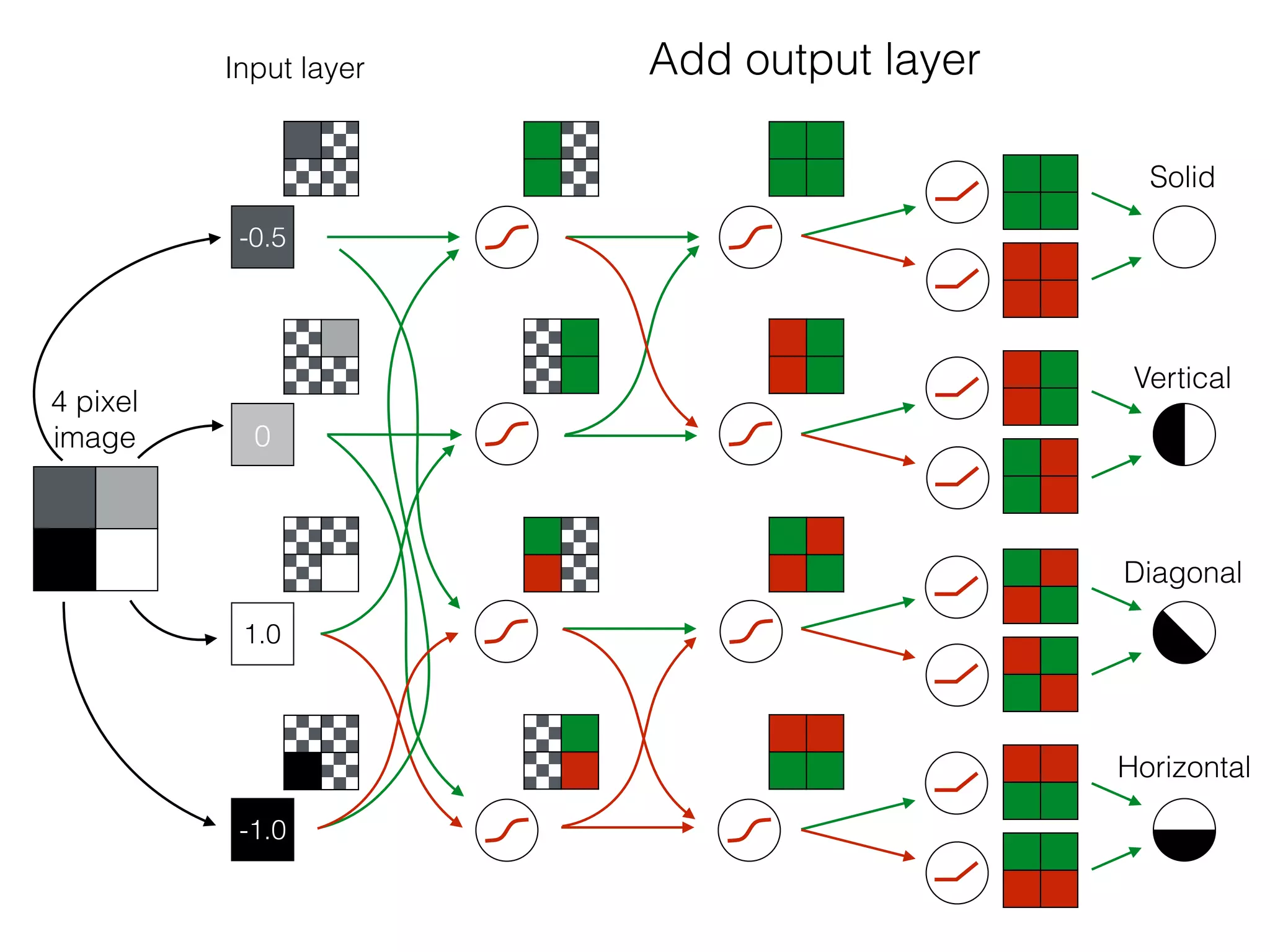
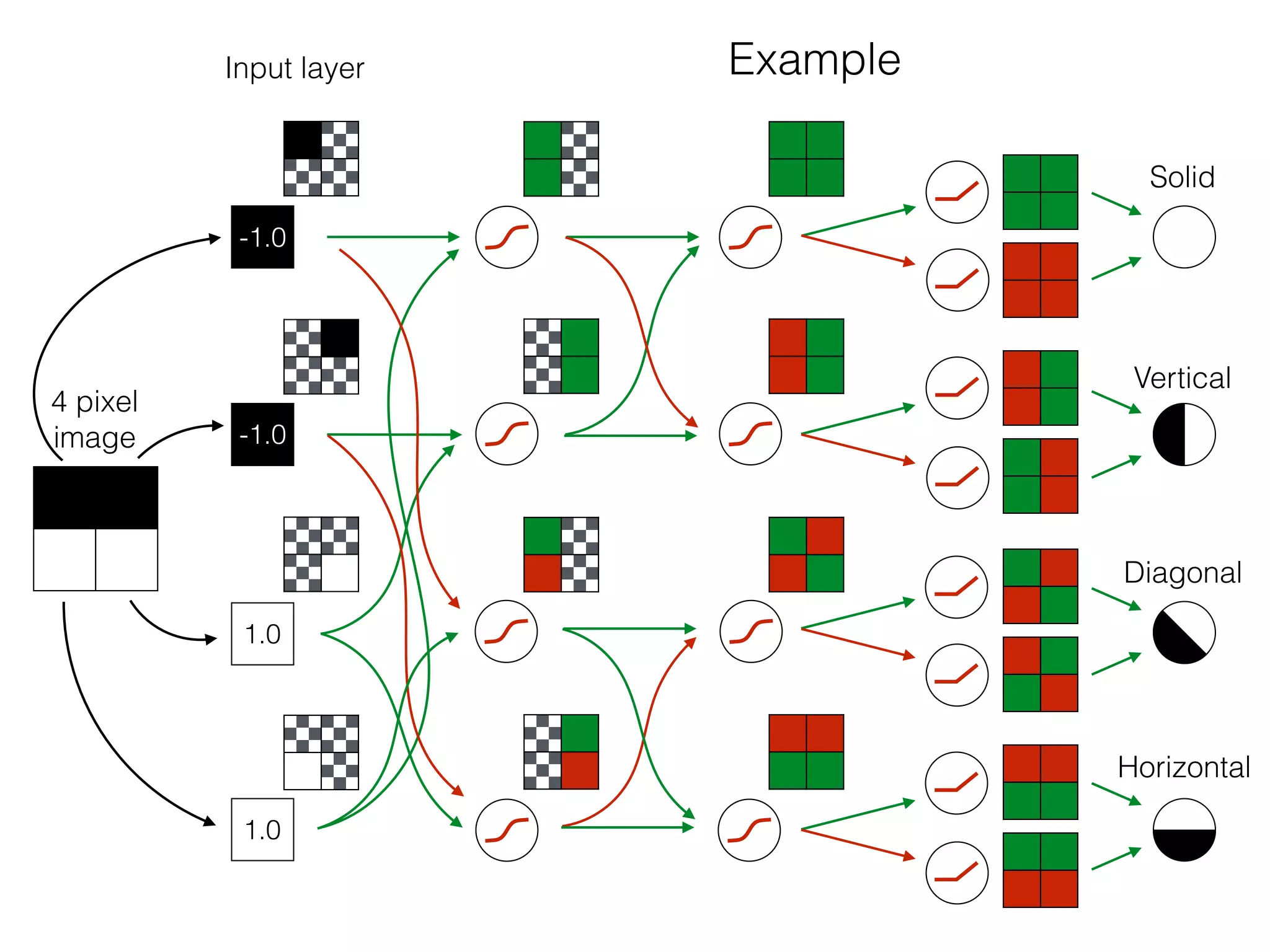
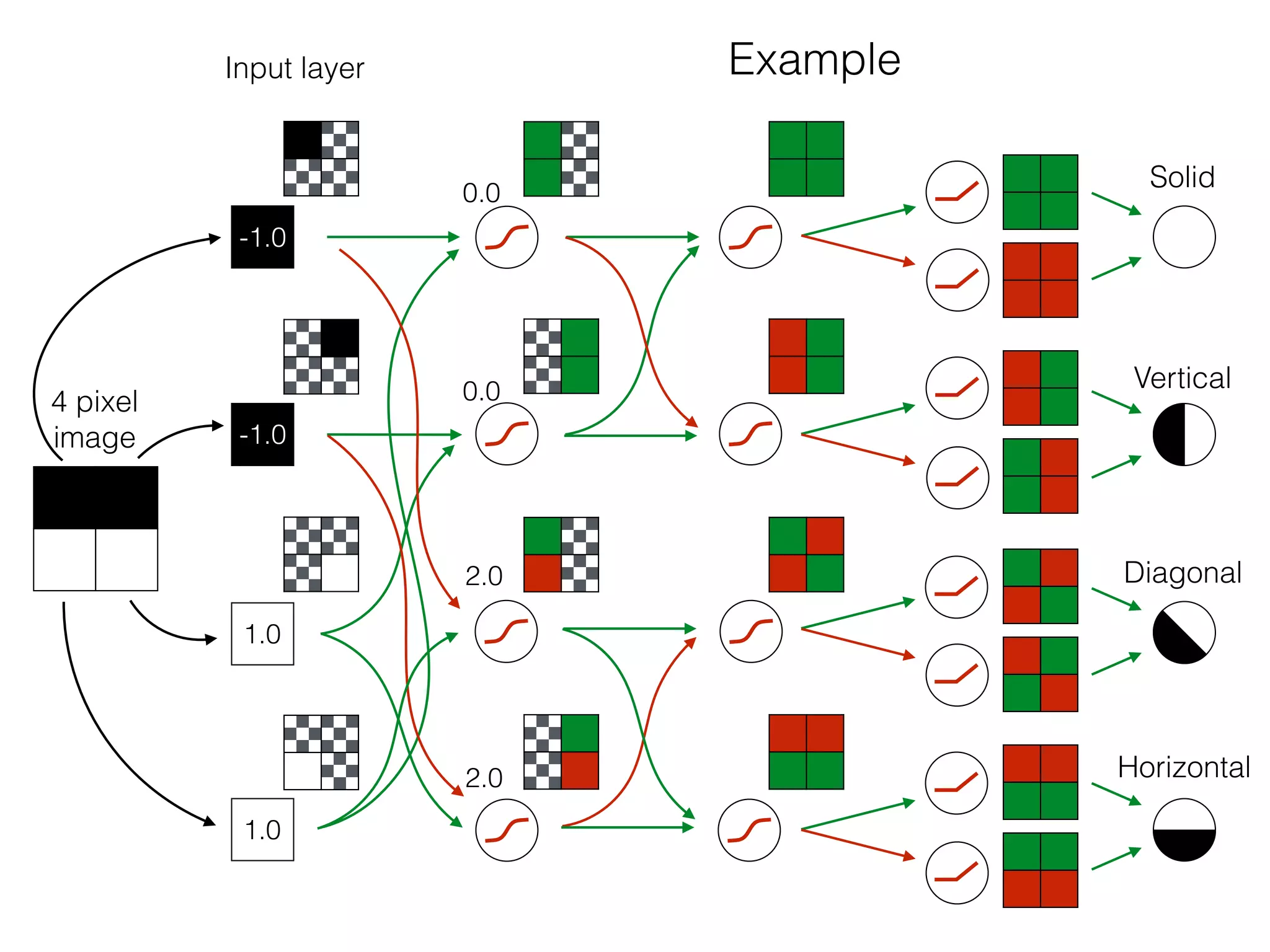
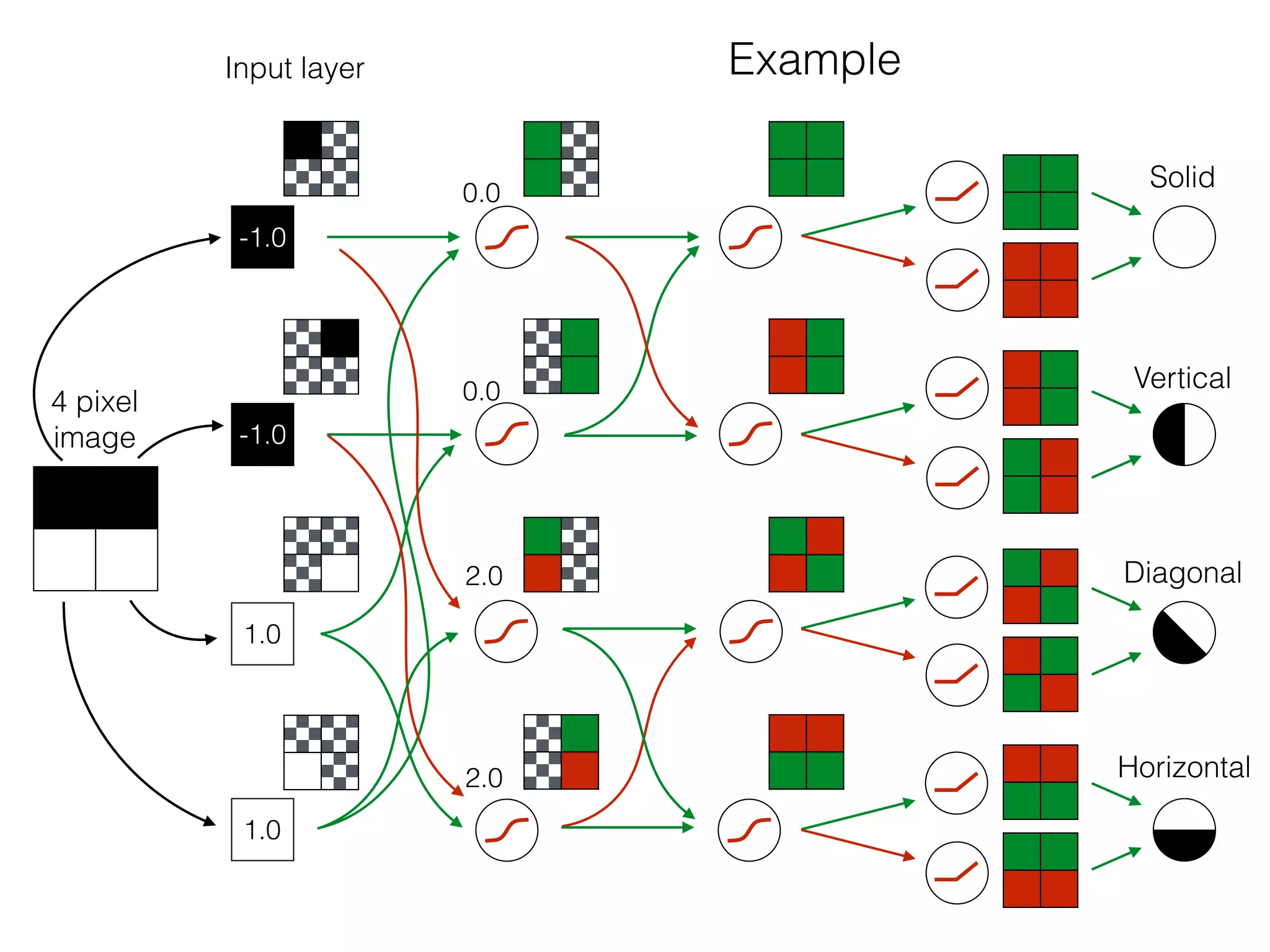
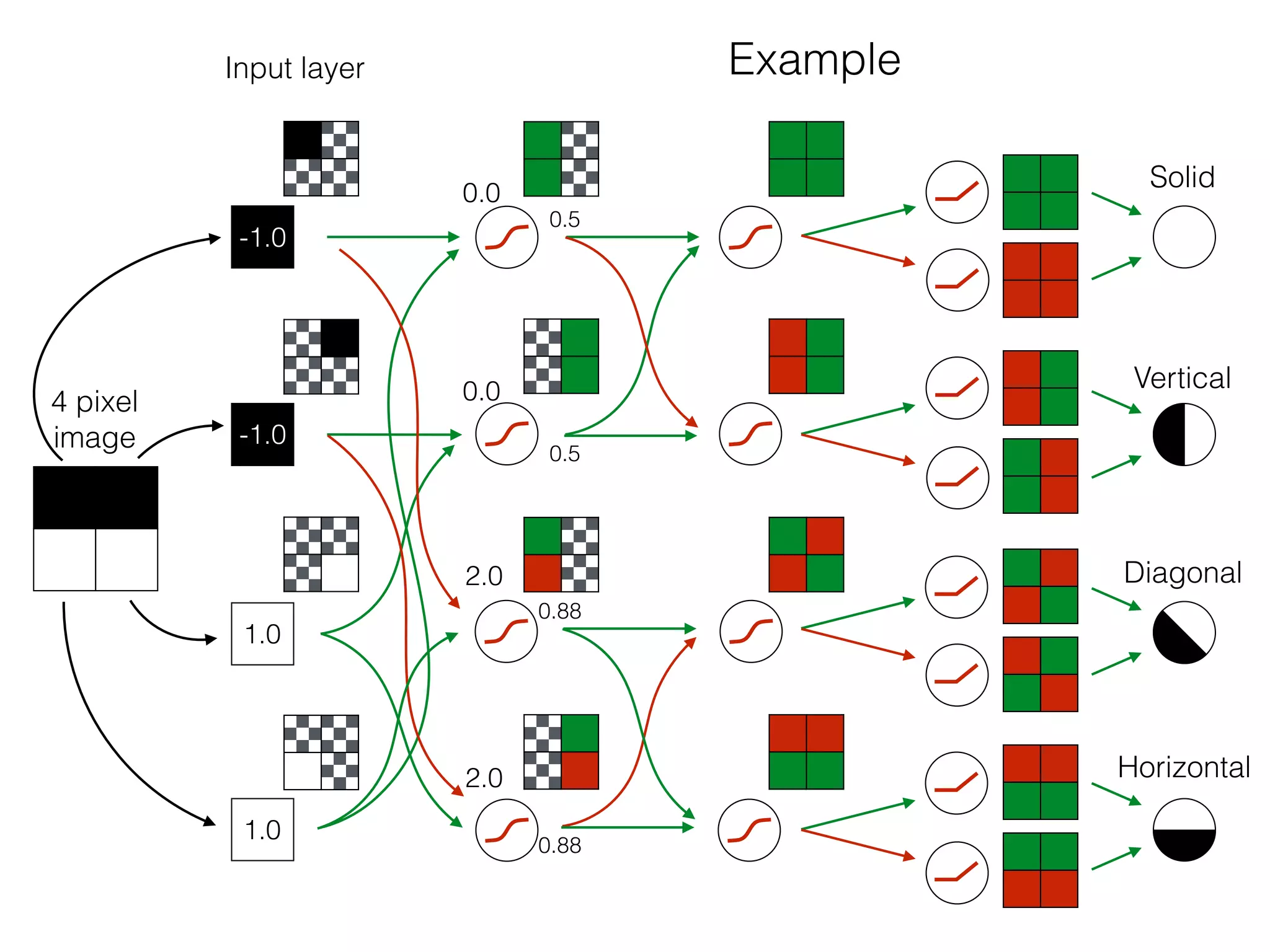
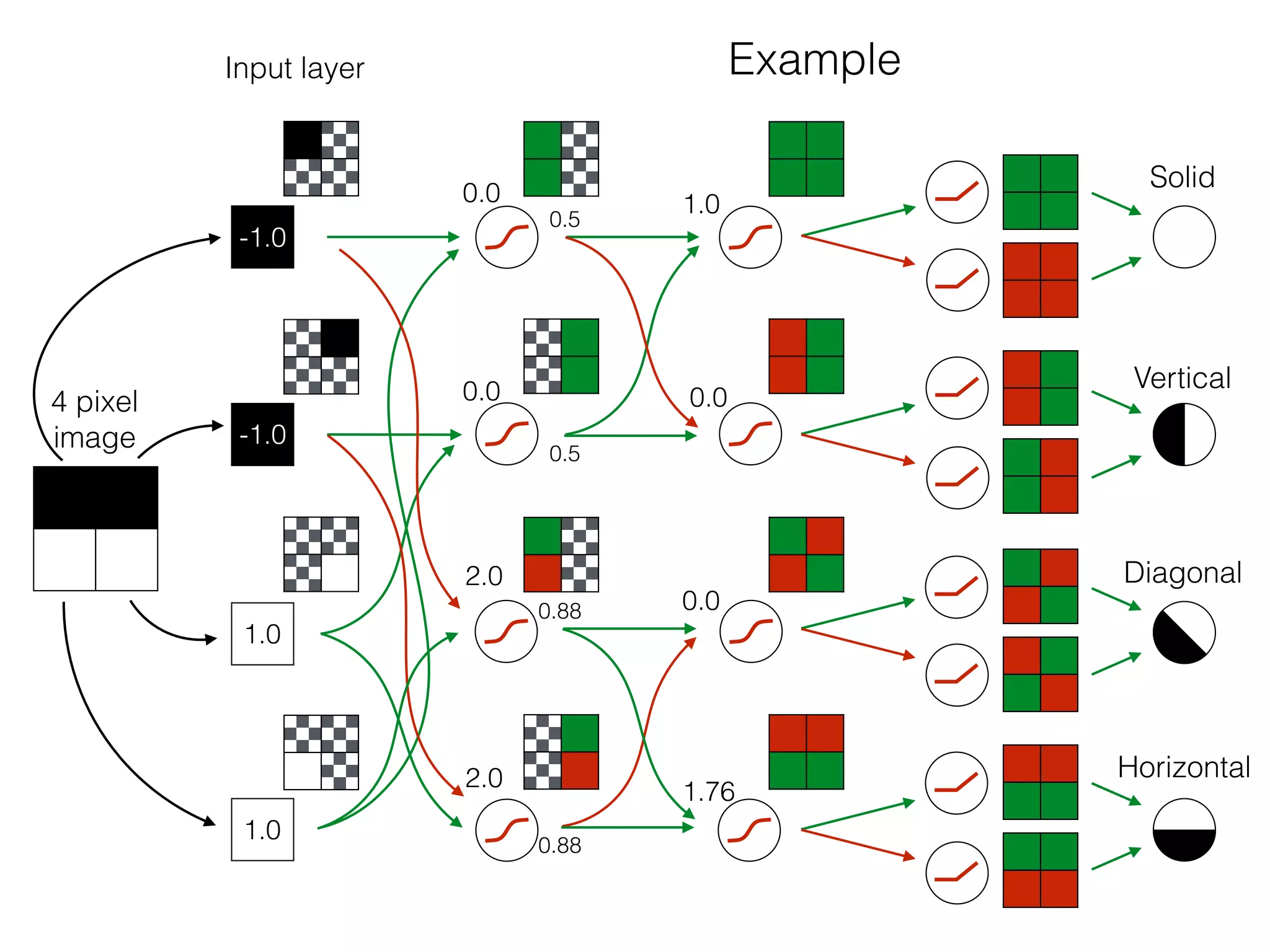
The document is an educational resource on deep learning, covering concepts such as artificial neural networks, supervised and unsupervised learning, and various activation functions like sigmoid and ReLU. It discusses the structure and functioning of neural networks, including input layers, hidden layers, and connections between neurons which contribute to decision-making in tasks such as image classification. The content emphasizes the complexity and adaptability of neural networks in processing various types of data.










































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)