Downloaded 503 times



![Arrays of Parallel Threads
ALL threads run the same kernel code
Each thread has an ID that’s used to compute
address & make control decisions
Block 0 Block (N -1)
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
… …
unsigned int tid = threadIdx.x + blockIdx.x * blockDim.x; unsigned int tid = threadIdx.x + blockIdx.x * blockDim.x;
int shifted = input_array[tid] + shift_amount; int shifted = input_array[tid] + shift_amount;
if ( shifted > alphabet_max ) if ( shifted > alphabet_max )
shifted = shifted % (alphabet_max + 1); shifted = shifted % (alphabet_max + 1);
output_array[tid] = shifted; output_array[tid] = shifted;
… …
Parallel code Parallel code](https://image.slidesharecdn.com/introductiontocuda-110608080602-phpapp02/75/Introduction-to-CUDA-13-2048.jpg)
![Compiling a CUDA program
C/C++ CUDA float4 me = gx[gtid];
me.x += me.y * me.z;
Application
• Parallel Thread
eXecution (PTX)
– Virtual Machine
NVCC CPU Code and ISA
– Programming
model
Virtual PTX Code – Execution
resources and
state
PTX to Target ld.global.v4.f32 {$f1,$f3,$f5,$f7}, [$r9+0];
mad.f32 $f1, $f5, $f3, $f1;
Compiler
G80 … GPU
Target code](https://image.slidesharecdn.com/introductiontocuda-110608080602-phpapp02/75/Introduction-to-CUDA-14-2048.jpg)
![Example: Block Cypher
void host_shift_cypher(unsigned int *input_array, __global__ void shift_cypher(unsigned int
unsigned int *output_array, unsigned int *input_array, unsigned int *output_array,
shift_amount, unsigned int alphabet_max, unsigned int shift_amount, unsigned int
unsigned int array_length)
alphabet_max, unsigned int array_length)
{
{
for(unsigned int i=0;i<array_length;i++)
unsigned int tid = threadIdx.x + blockIdx.x *
blockDim.x;
{
int shifted = input_array[tid] + shift_amount;
int element = input_array[i];
if ( shifted > alphabet_max )
int shifted = element + shift_amount;
shifted = shifted % (alphabet_max + 1);
if(shifted > alphabet_max)
{
output_array[tid] = shifted;
shifted = shifted % (alphabet_max + 1);
}
}
output_array[i] = shifted;
Int main() {
}
dim3 dimGrid(ceil(array_length)/block_size);
}
dim3 dimBlock(block_size);
Int main() {
shift_cypher<<<dimGrid,dimBlock>>>(input_array,
host_shift_cypher(input_array, output_array,
output_array, shift_amount, alphabet_max,
shift_amount, alphabet_max, array_length);
array_length);
}
}
CPU Program GPU Program](https://image.slidesharecdn.com/introductiontocuda-110608080602-phpapp02/75/Introduction-to-CUDA-15-2048.jpg)




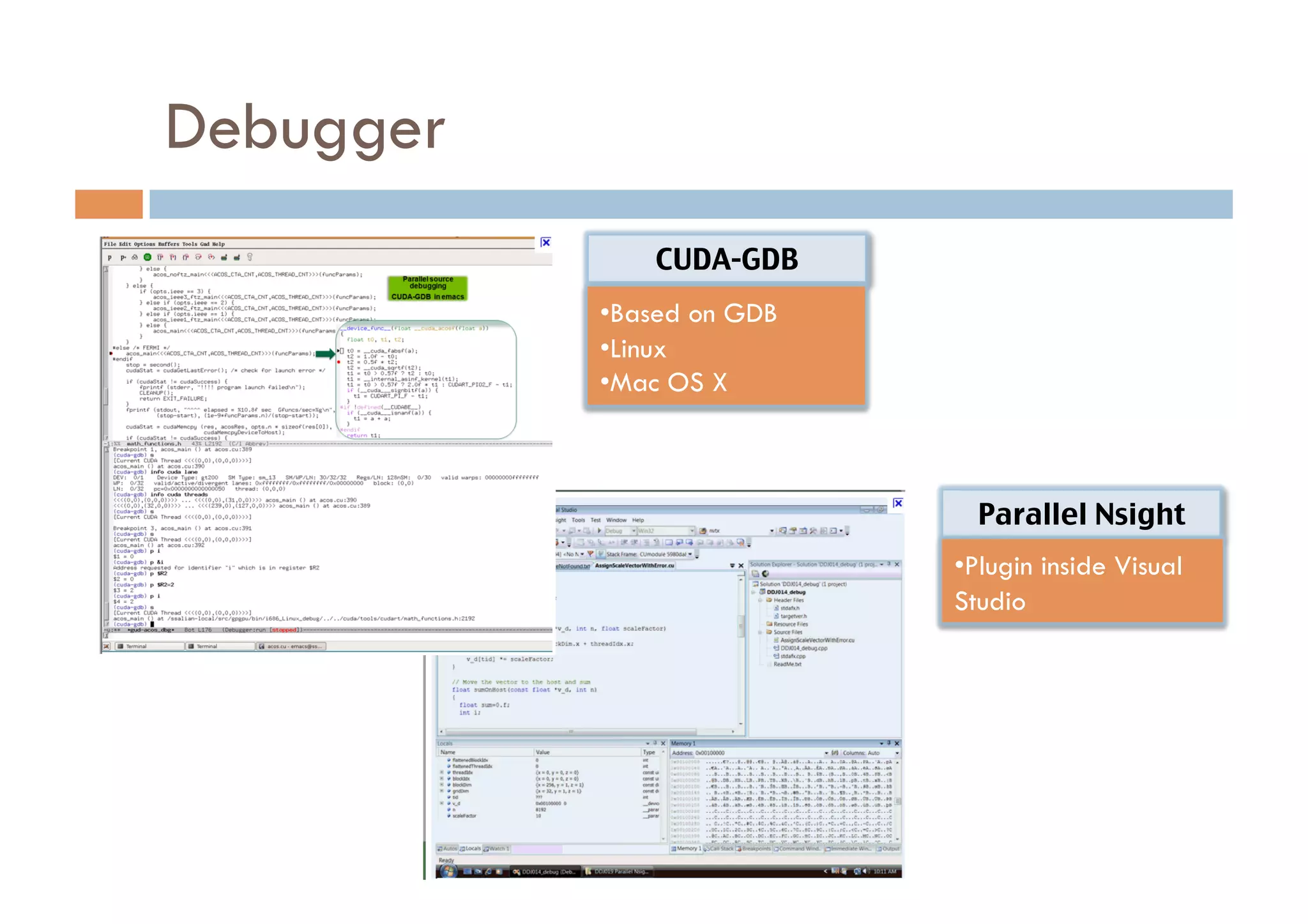
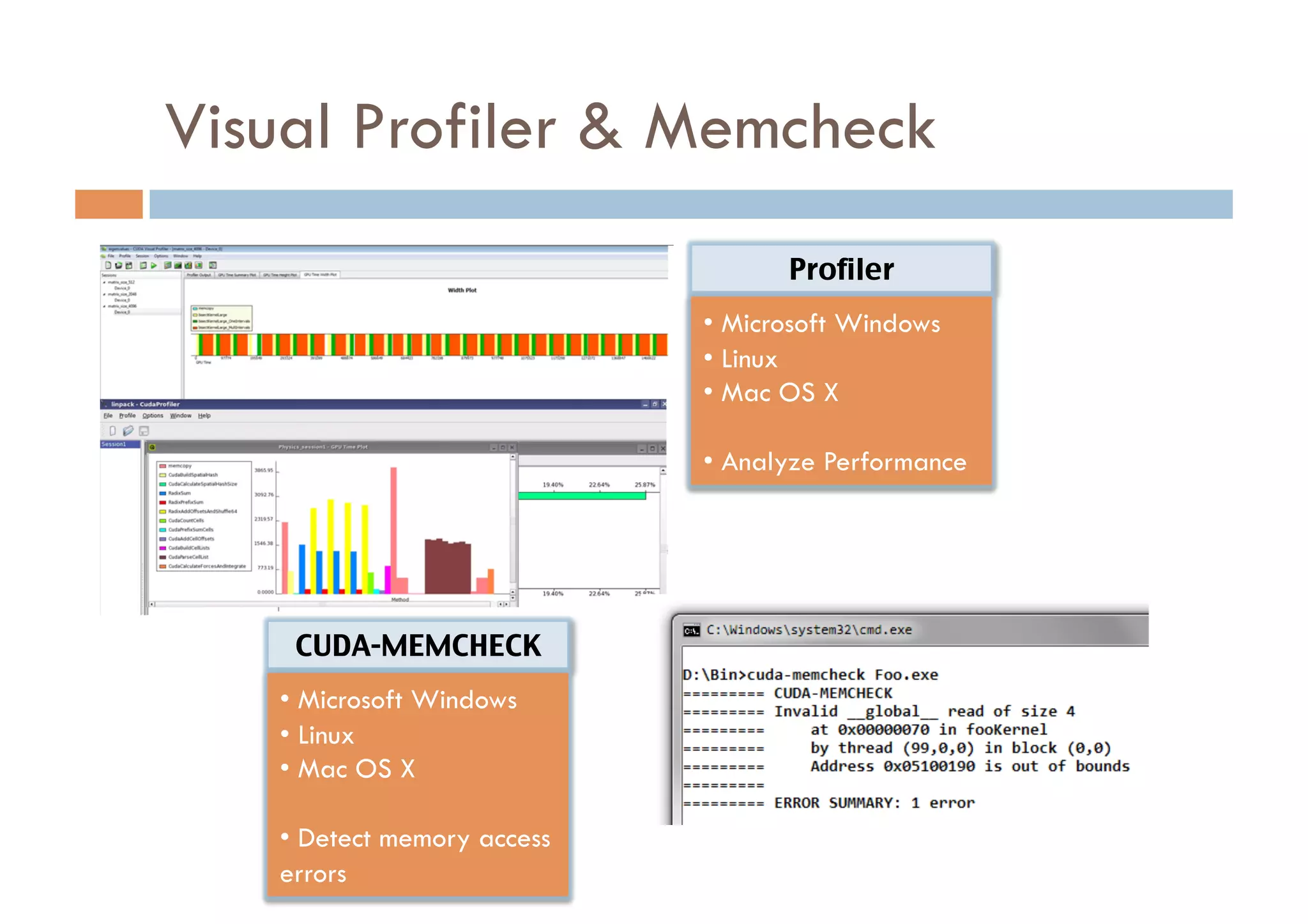







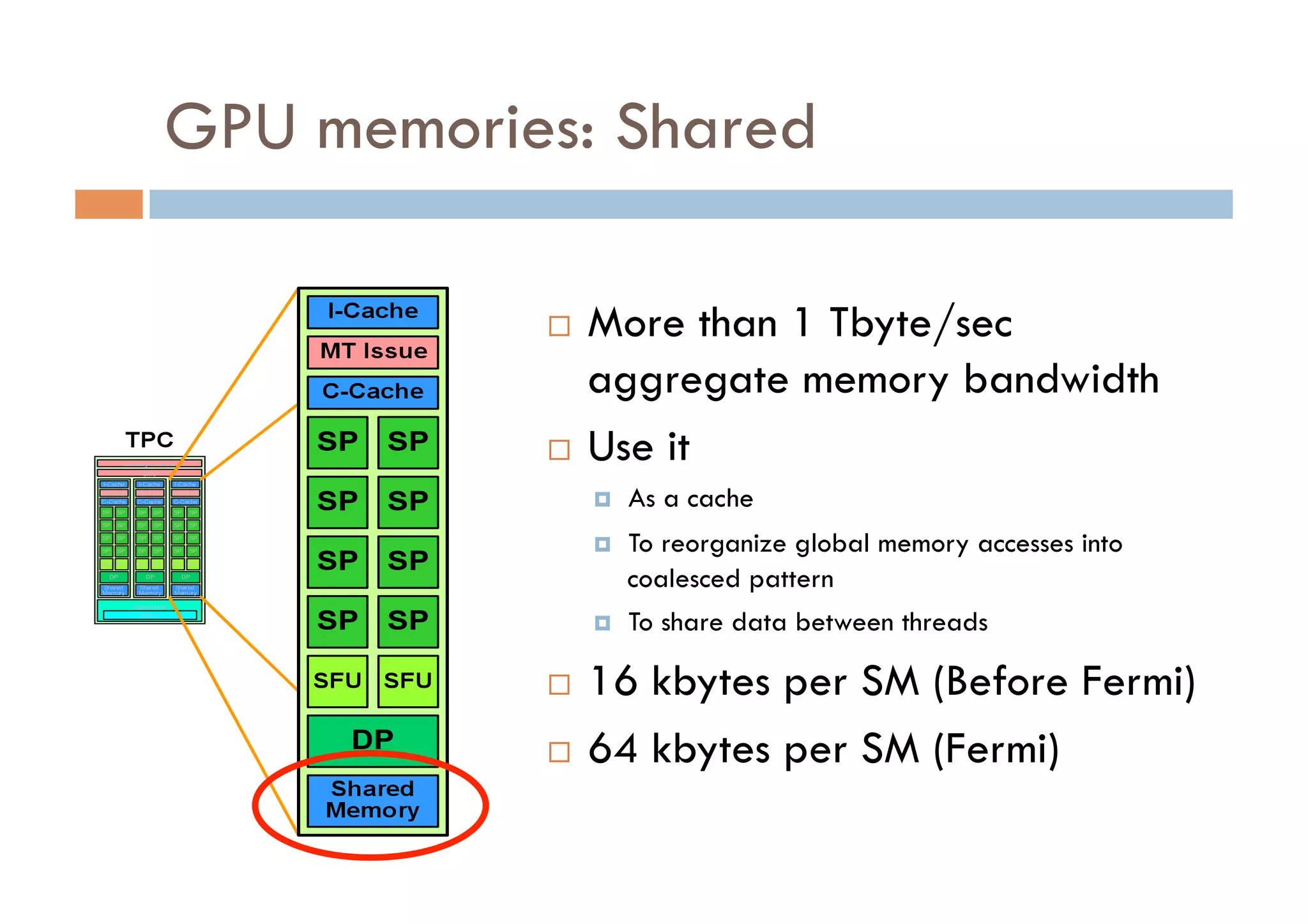
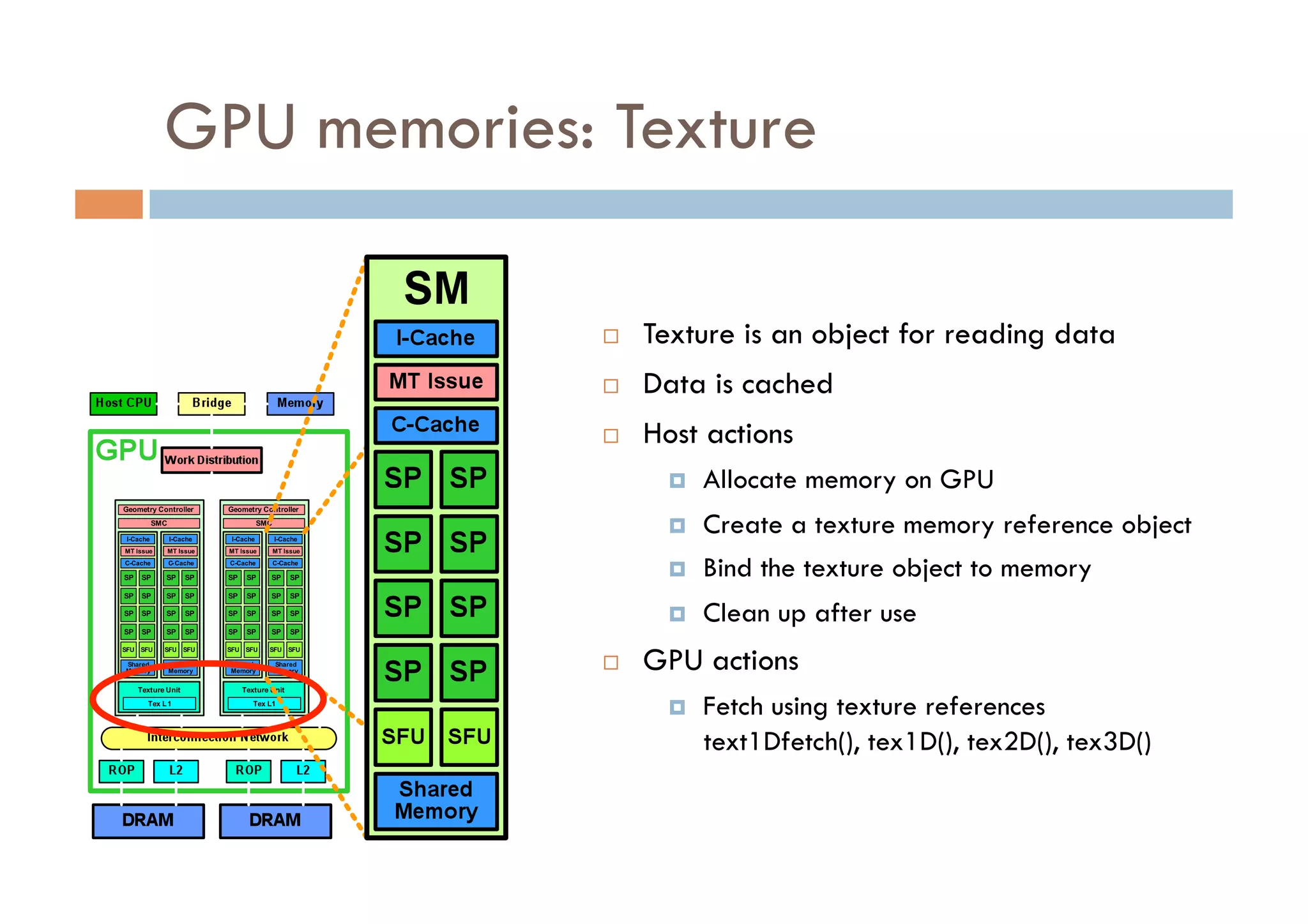
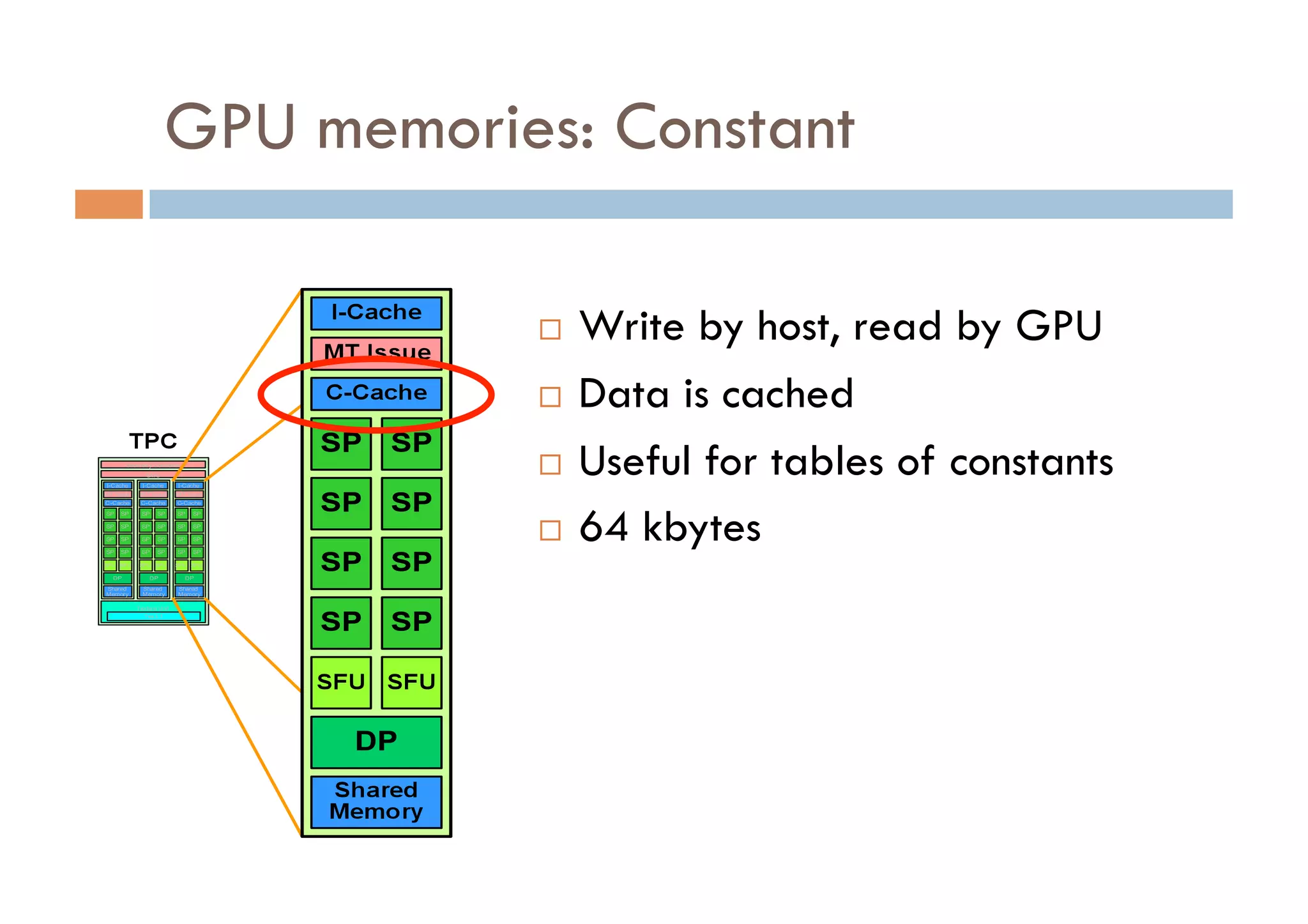

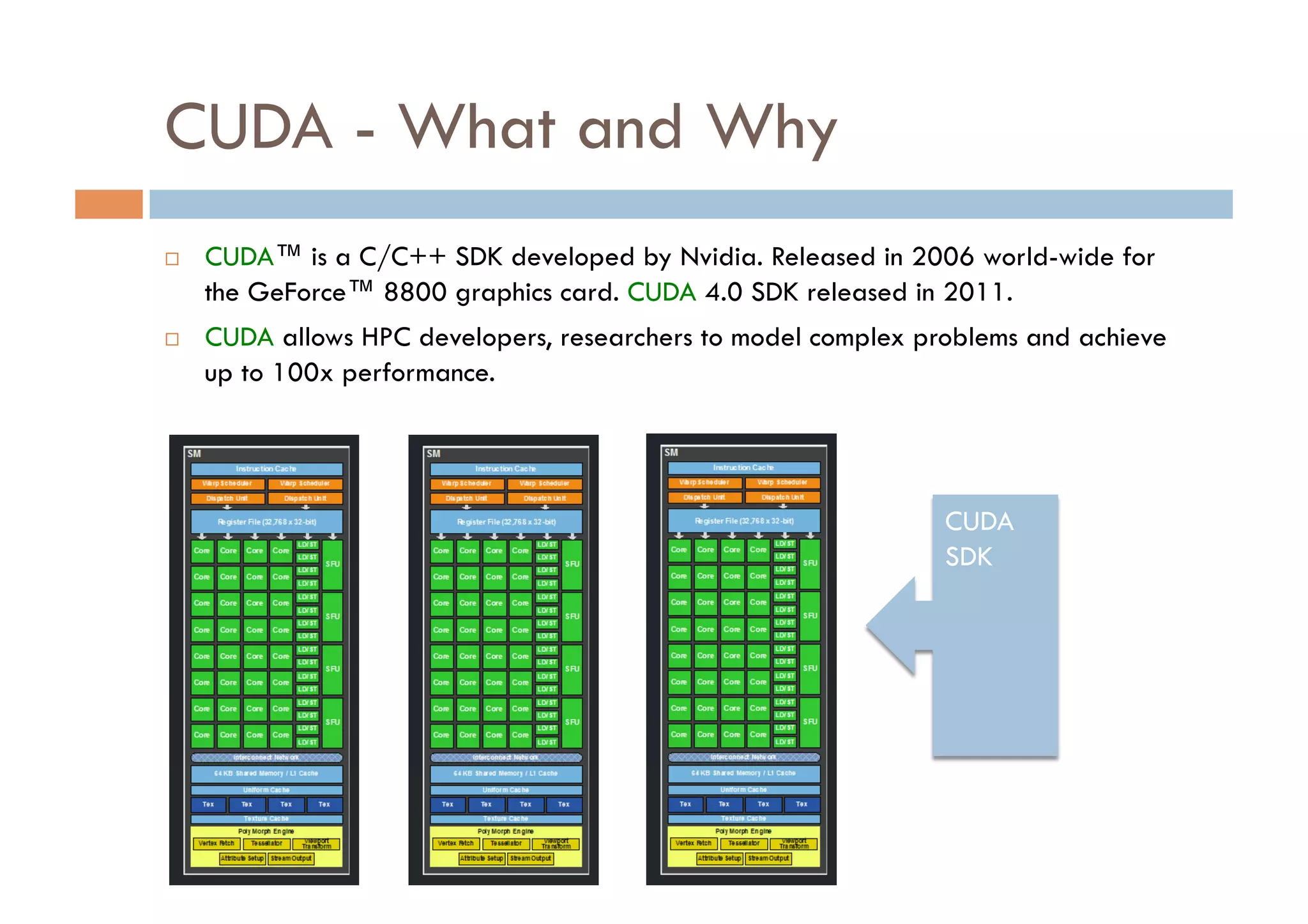
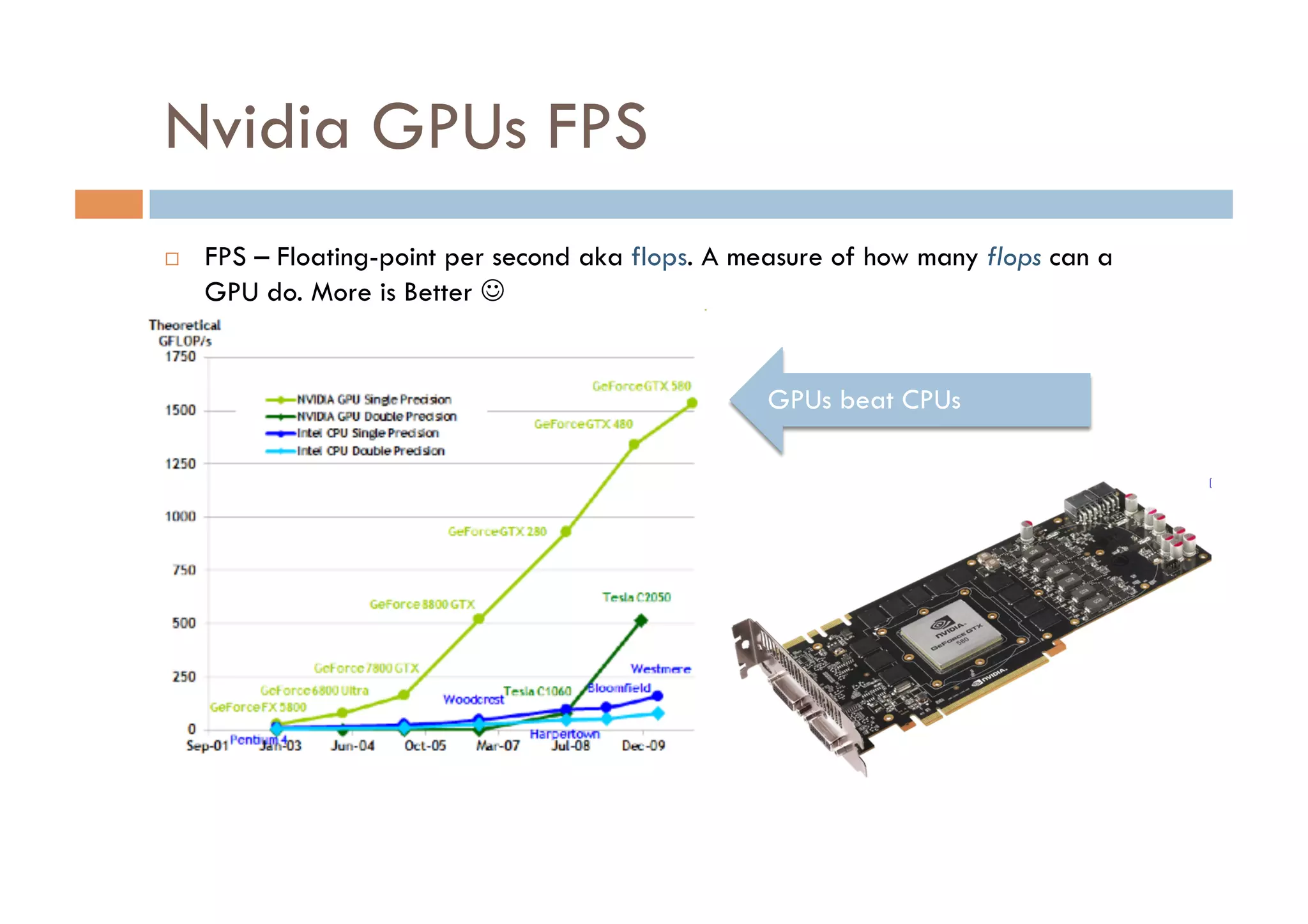
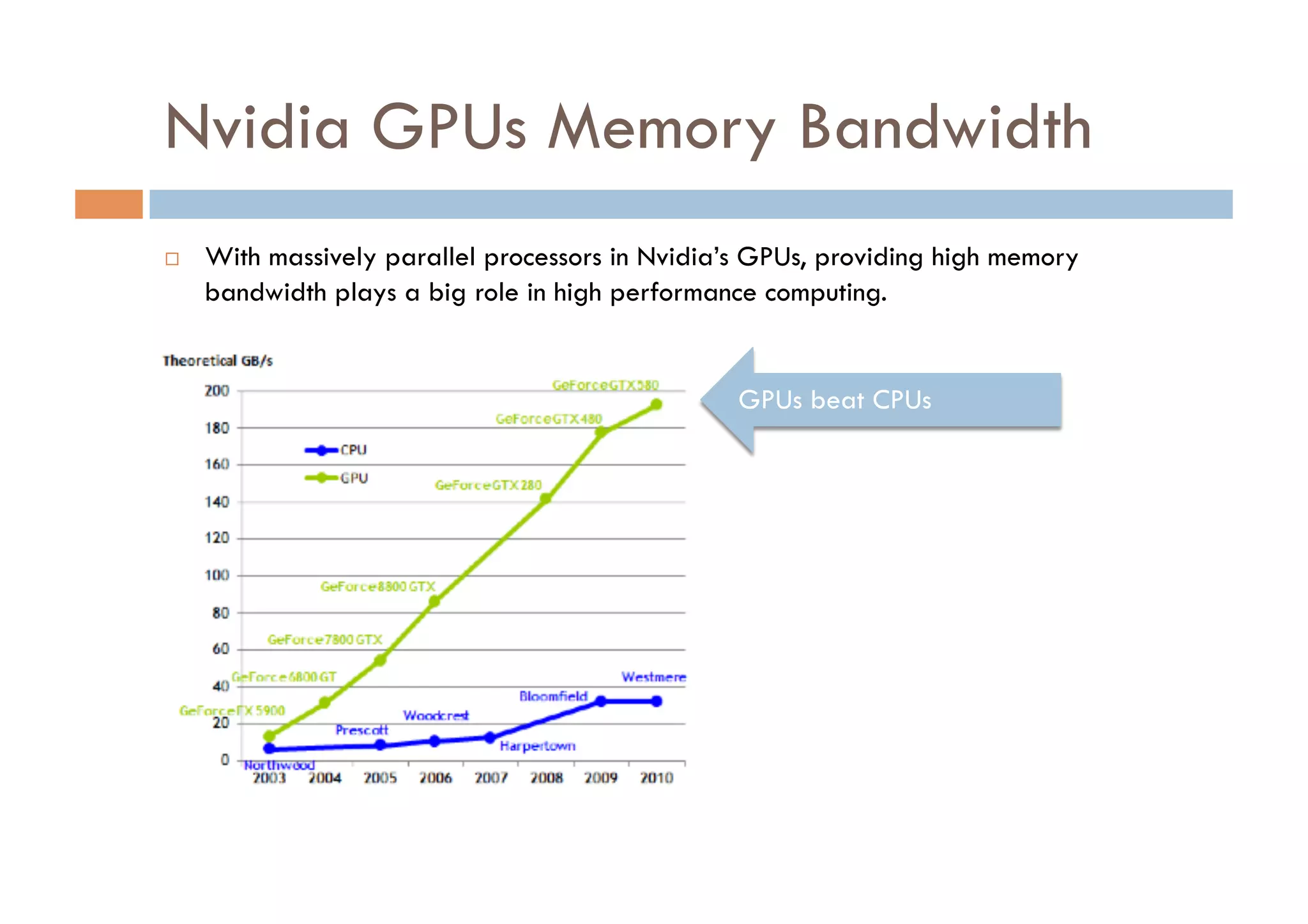
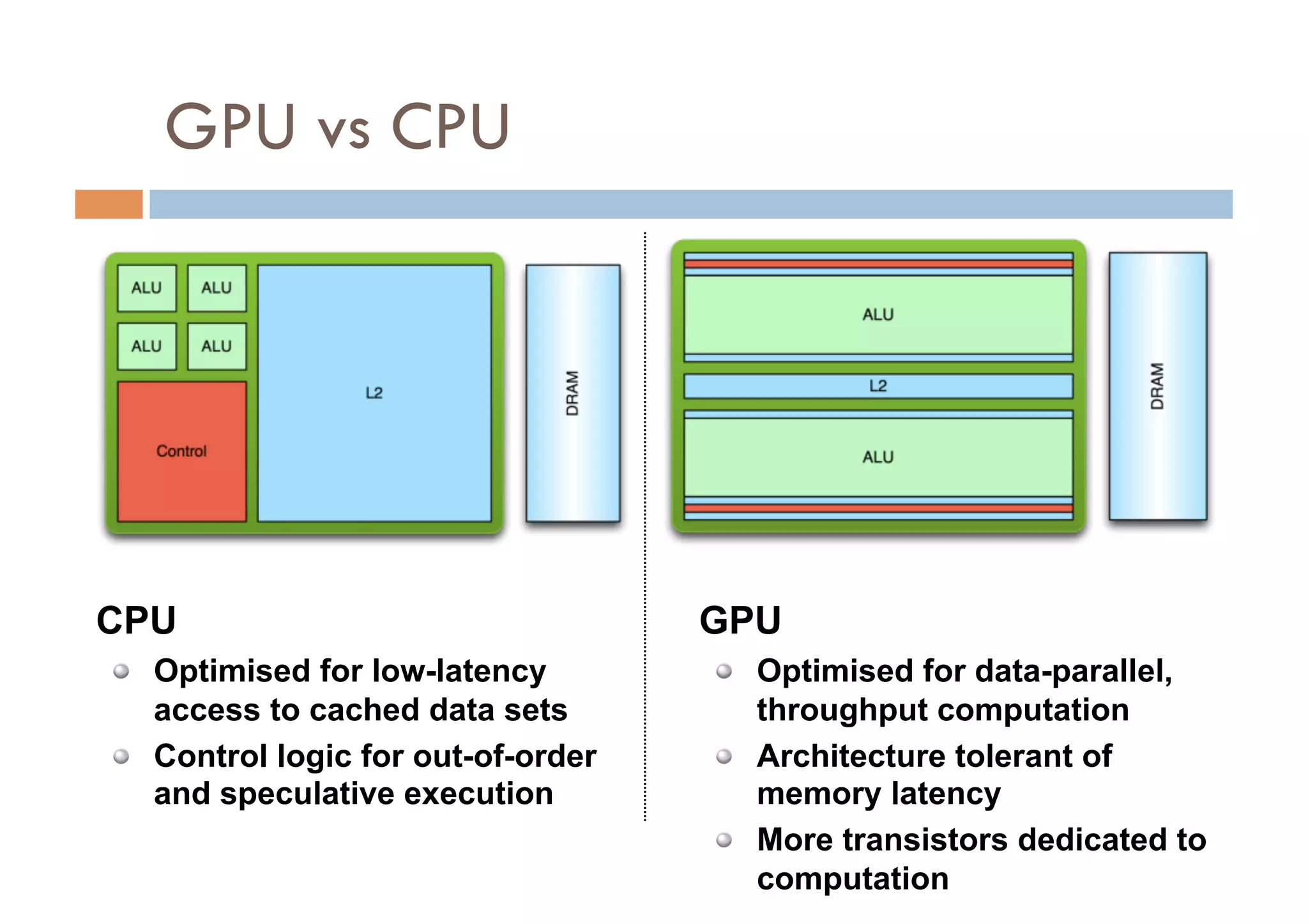
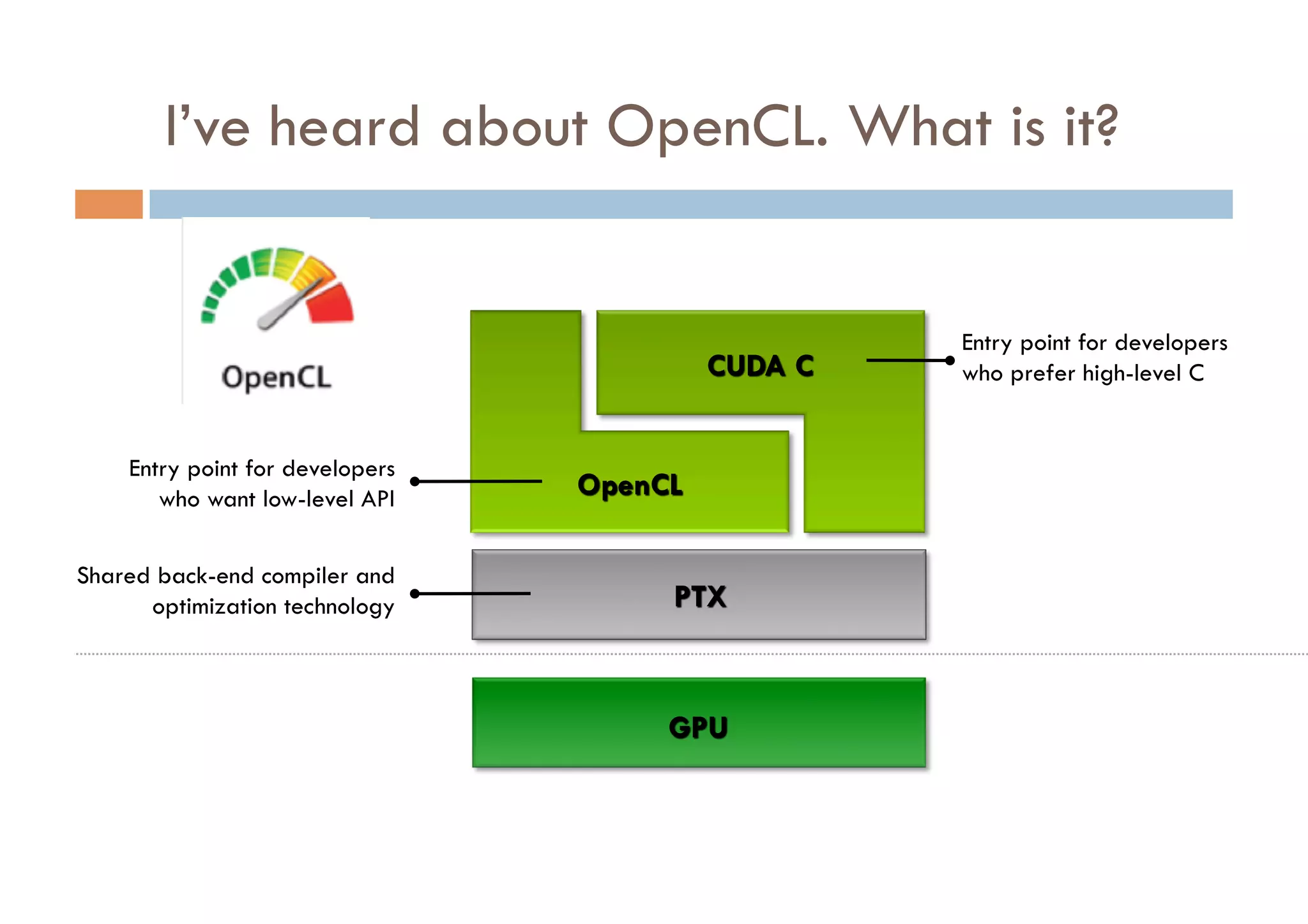
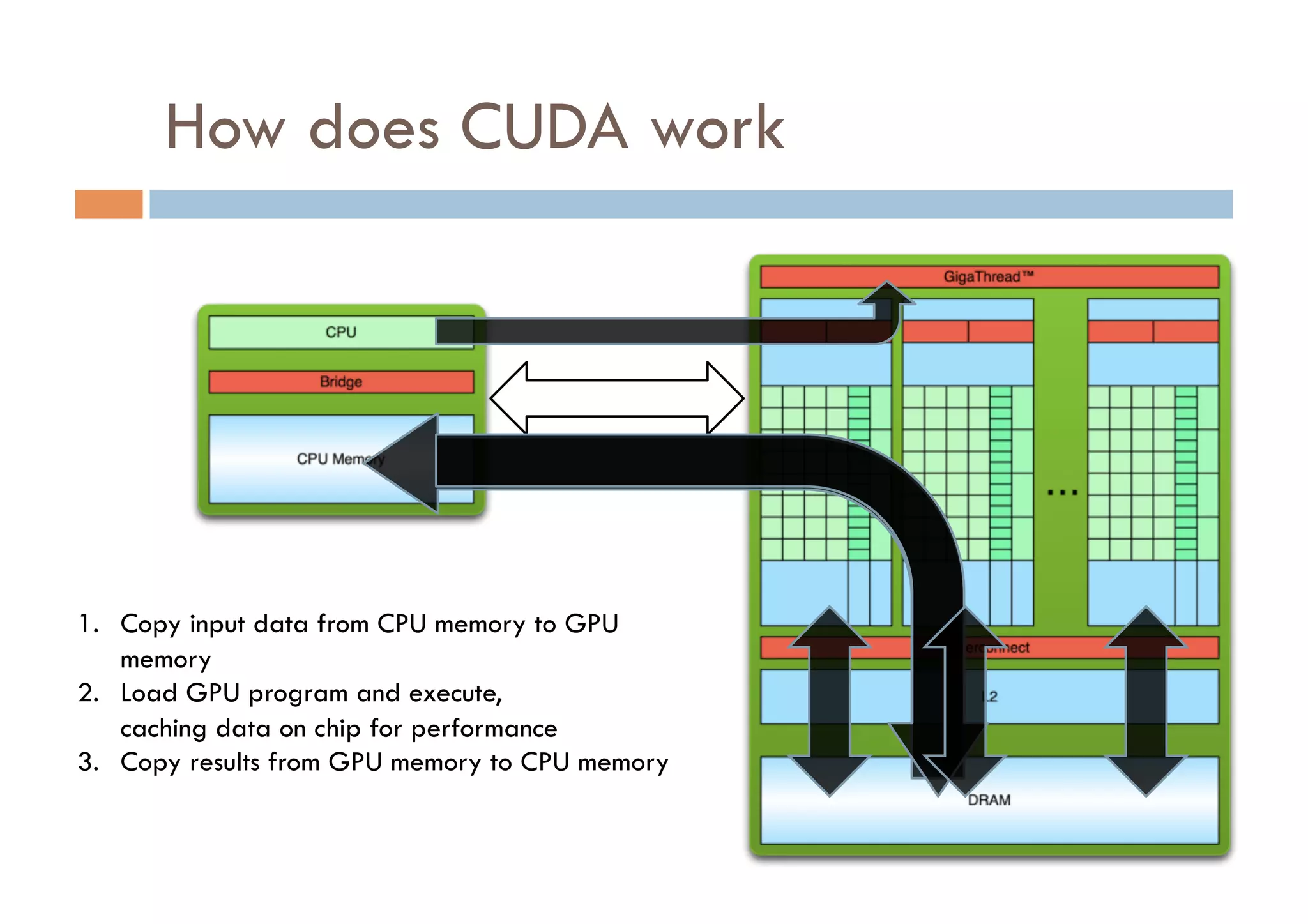
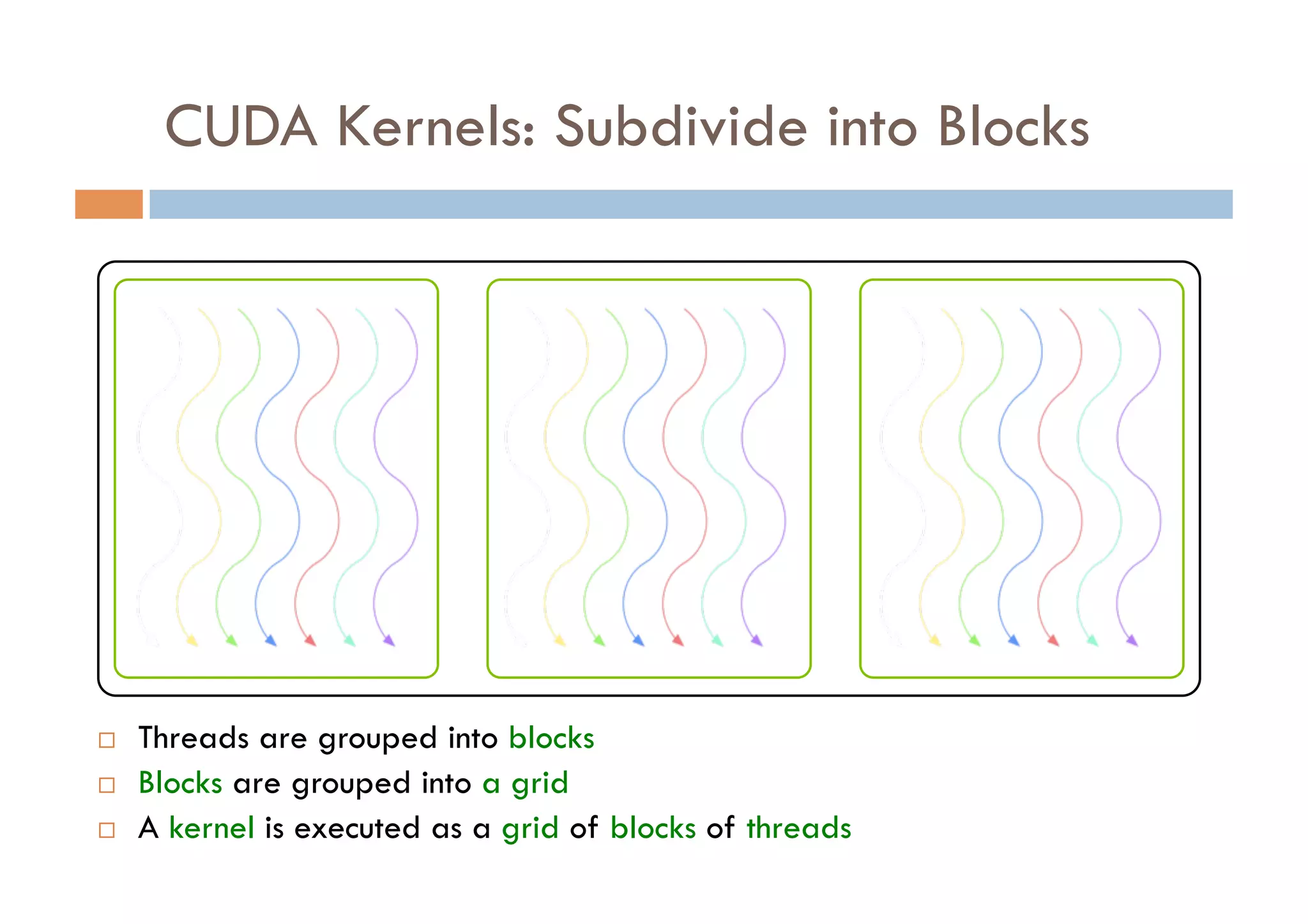
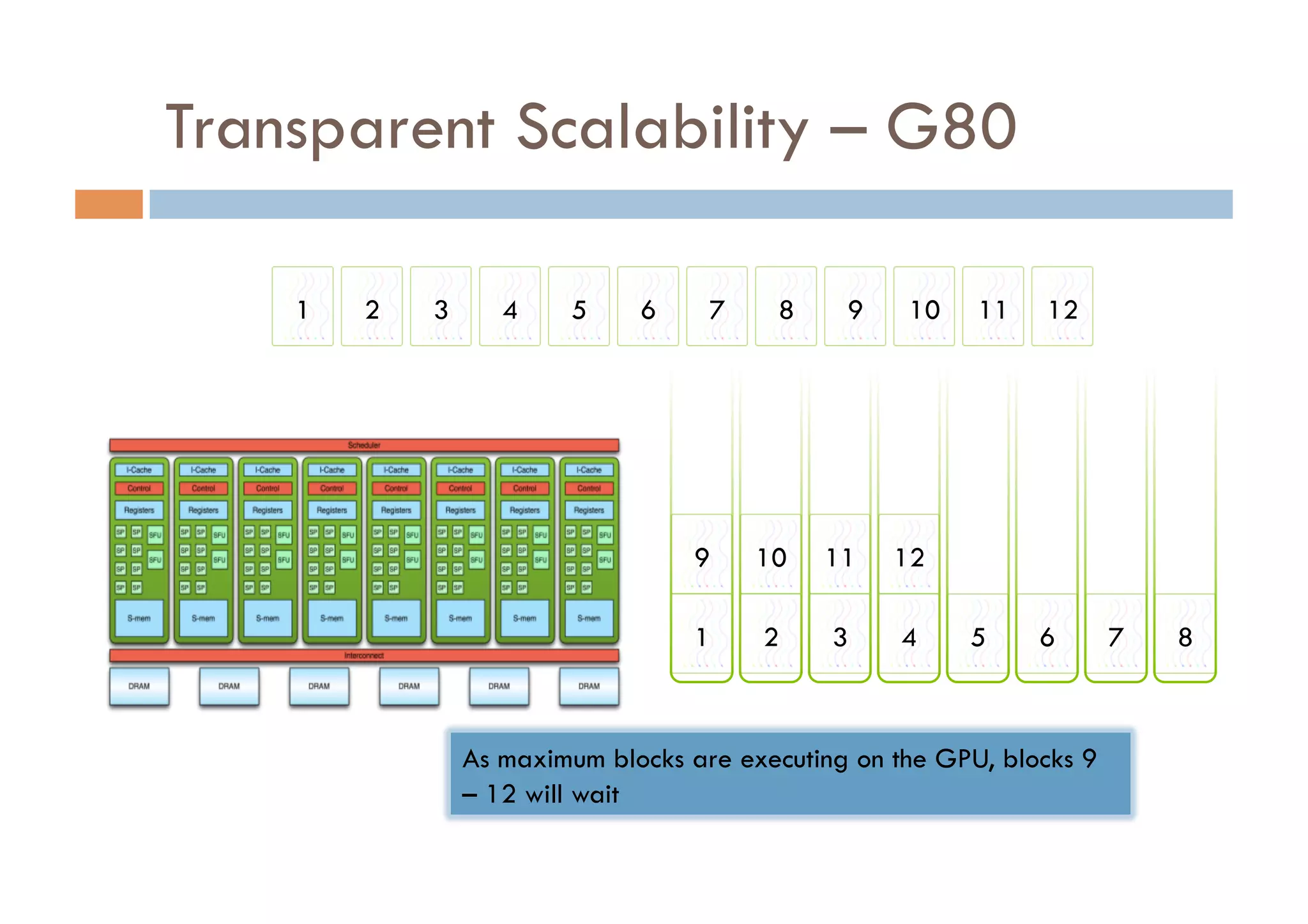
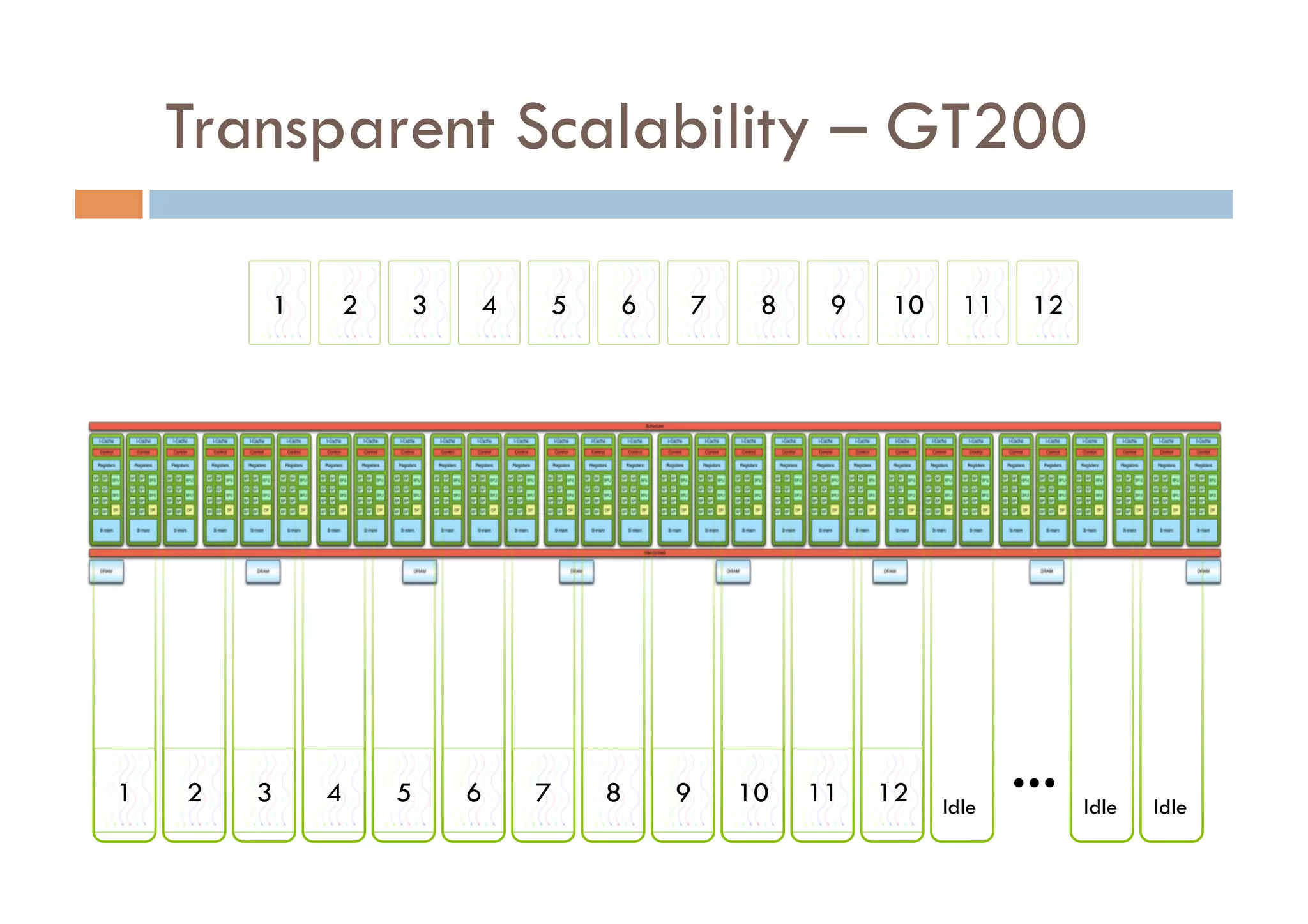
CUDA is a parallel computing platform and programming model developed by Nvidia that allows software developers and researchers to utilize GPUs for general purpose processing. CUDA allows developers to achieve up to 100x performance gains over CPU-only applications. CUDA works by having the CPU copy input data to GPU memory, executing a kernel program on the GPU that runs in parallel across many threads, and copying the results back to CPU memory. Key GPU memories that can be used in CUDA programs include shared memory for thread cooperation, textures for cached reads, and constants for read-only data.






























![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[01][gpu 컴퓨팅을 위한 언어, 도구 및 api] miller languages tools](https://cdn.slidesharecdn.com/ss_thumbnails/01gpuapimillerlanguagestools-110106231409-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







































