Downloaded 179 times









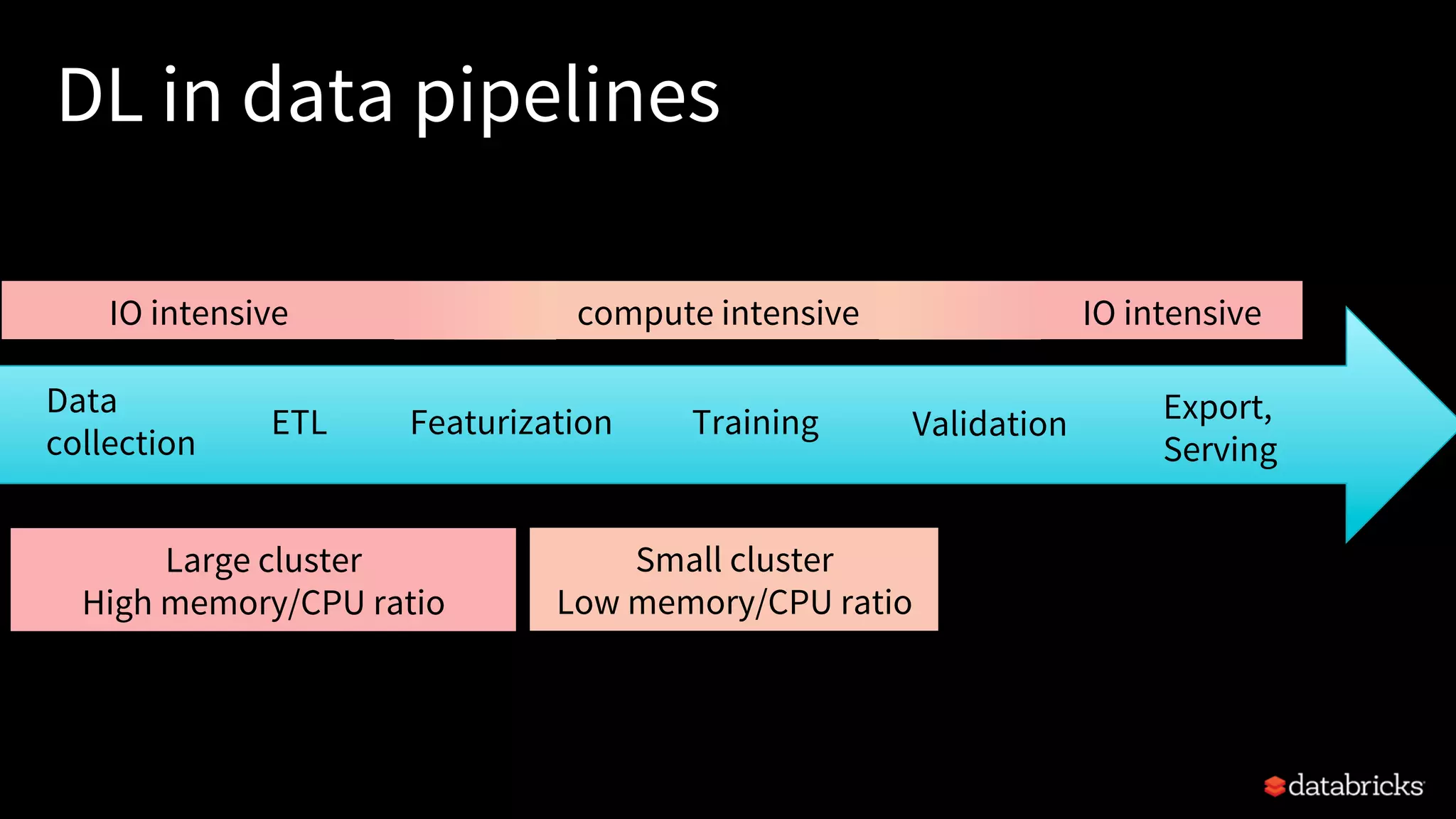

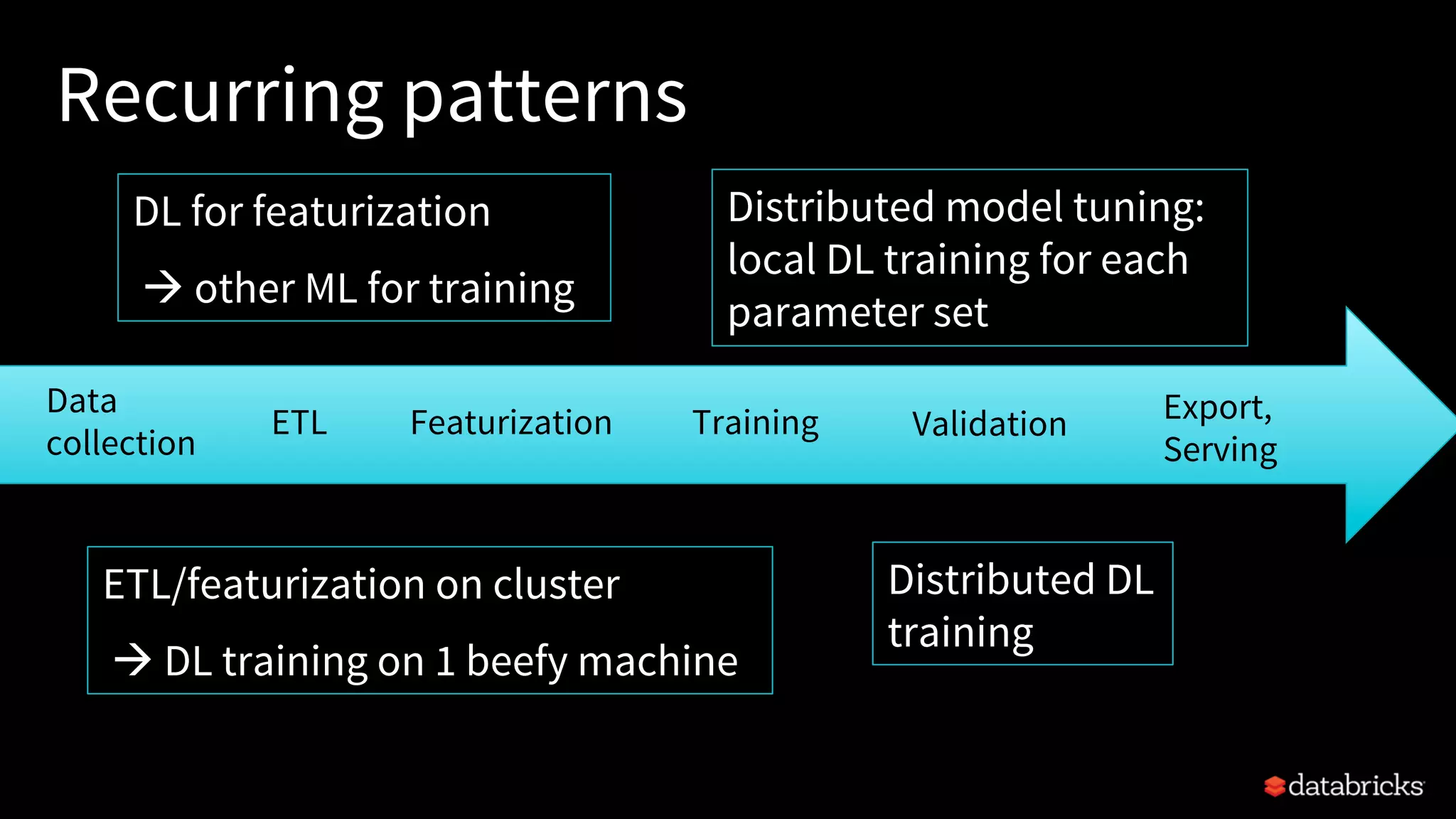











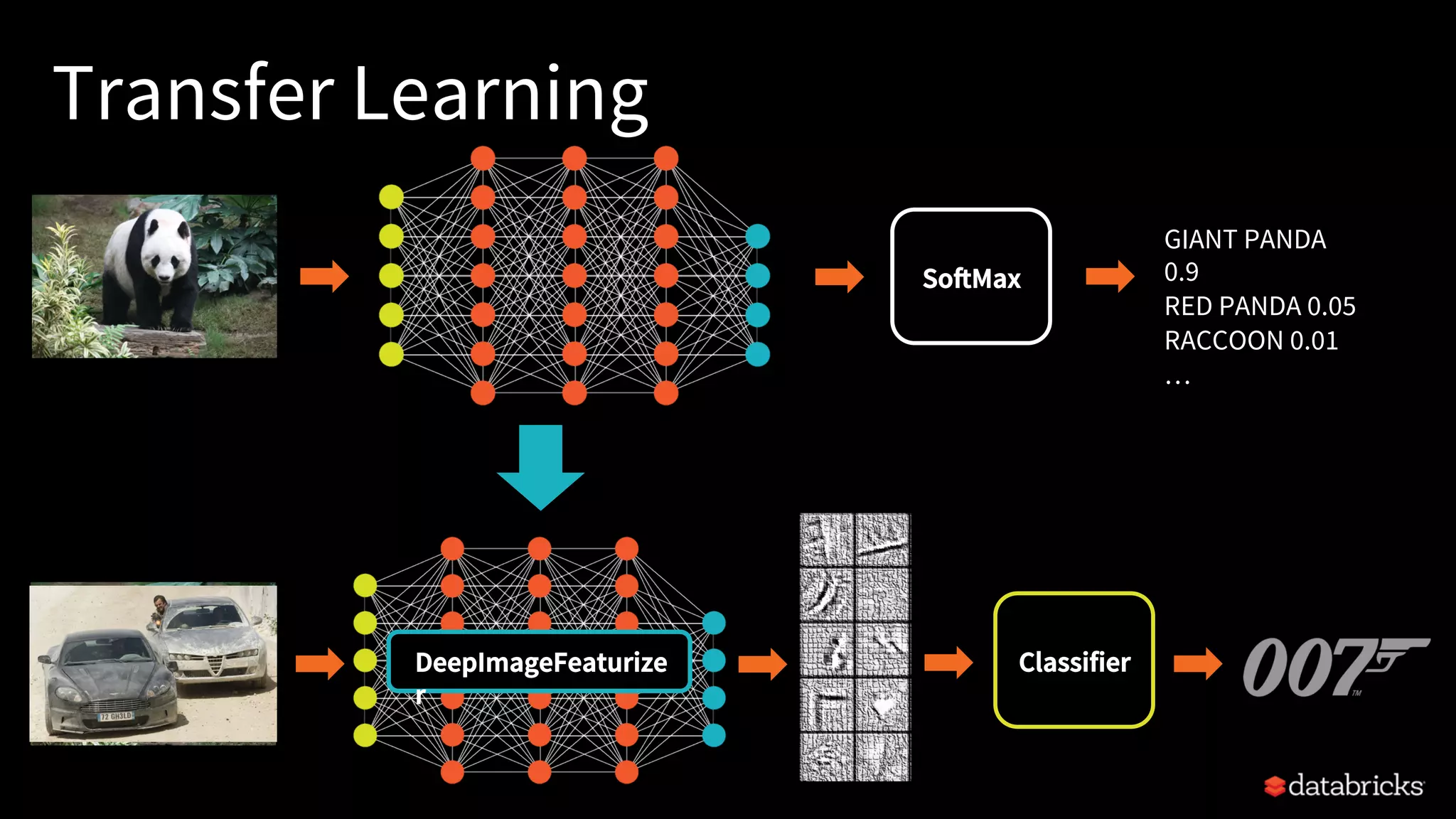






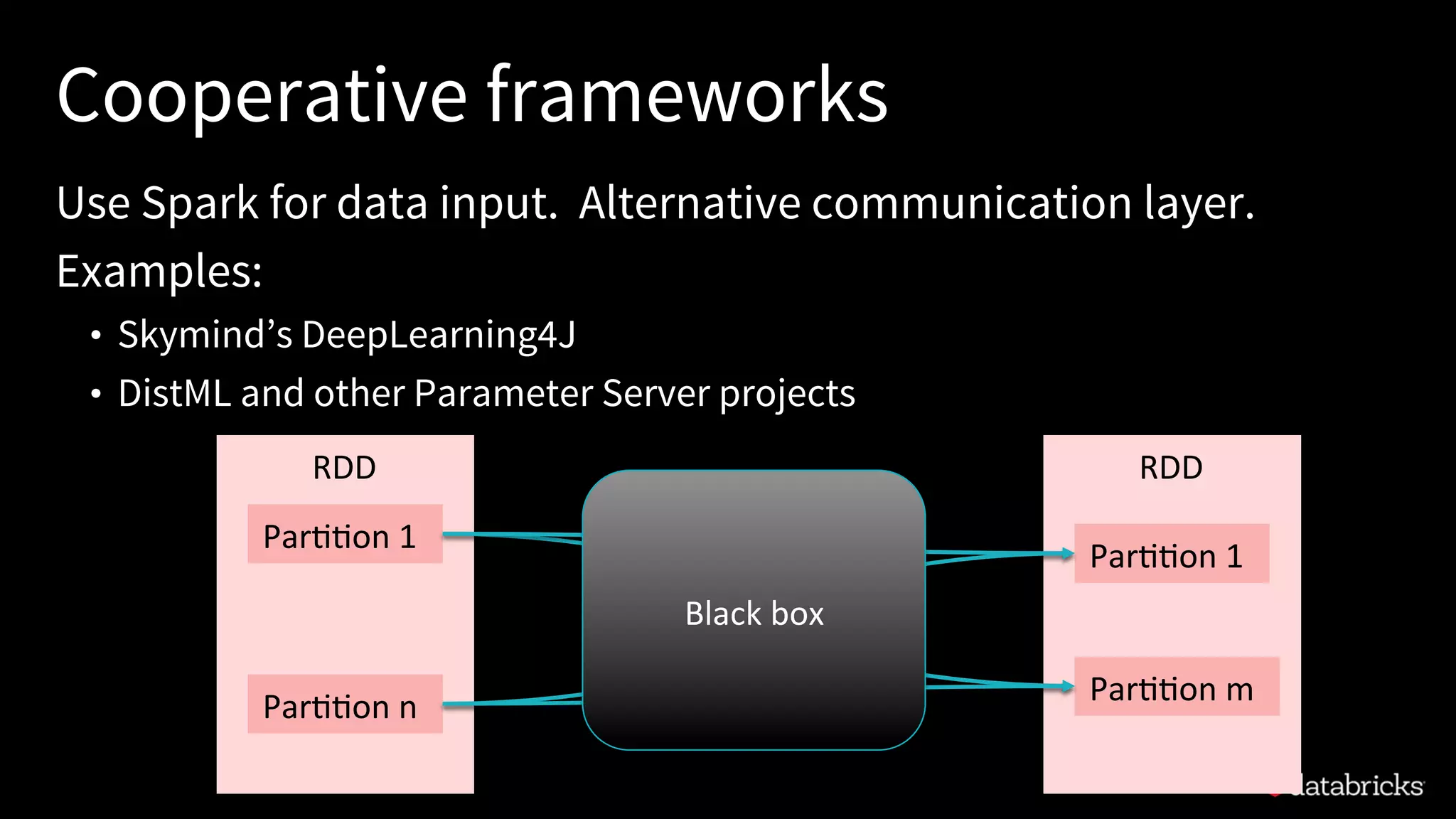








The document discusses integrating deep learning libraries with Apache Spark, highlighting various frameworks such as TensorFlow, Keras, and MXNet that can be utilized within the Spark environment. It emphasizes the development of a deep learning pipeline API to streamline processes like featurization and model training, aiming for easier integration and scalability. The talk outlines challenges pertaining to communication patterns, flexible cluster deployments, and the importance of proper resource management in deep learning applications.























































































