Downloaded 29 times





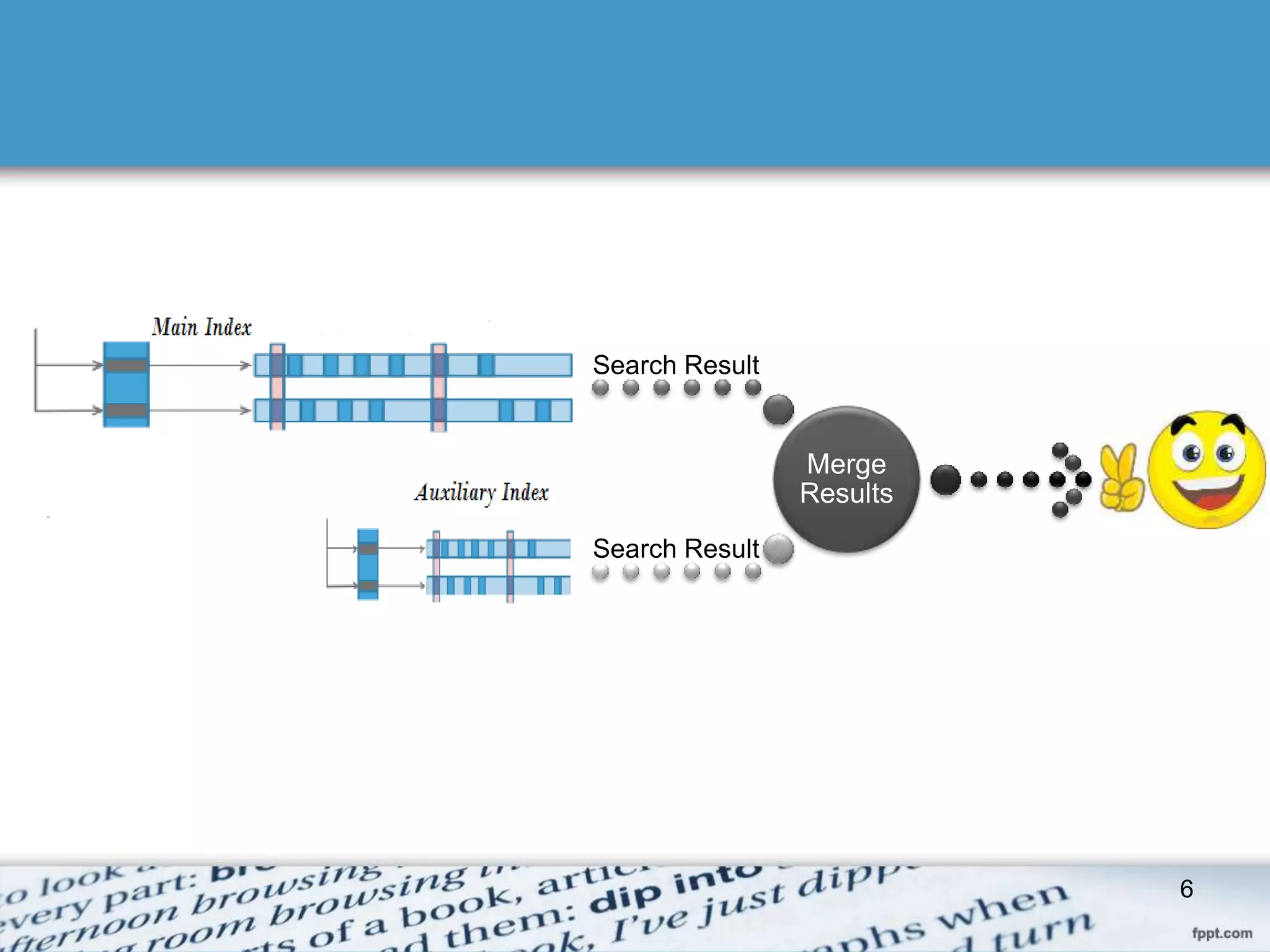










The document discusses different approaches to dynamic indexing in information retrieval systems. The simplest approach maintains a main index and auxiliary index, with new documents added to the auxiliary index and merged periodically into the main index. An alternative logarithmic merge approach maintains multiple indexes at increasing sizes, merging them in a logarithmic fashion. While more efficient for indexing, the logarithmic approach requires merging multiple indexes for query processing. Large search engines use dynamic indexing with both incremental changes and periodic full rebuilds of the main index.



























































































