Download to read offline



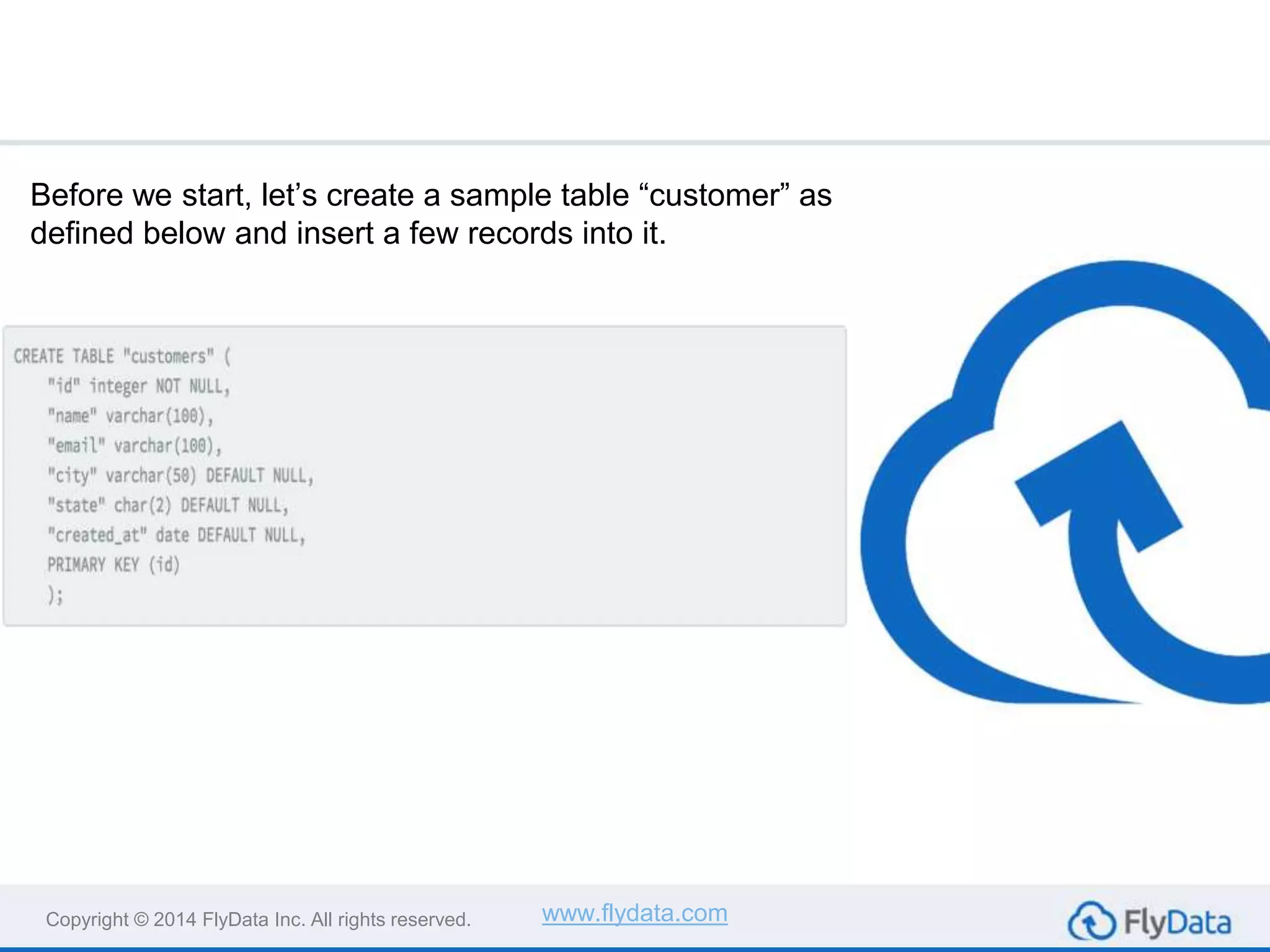
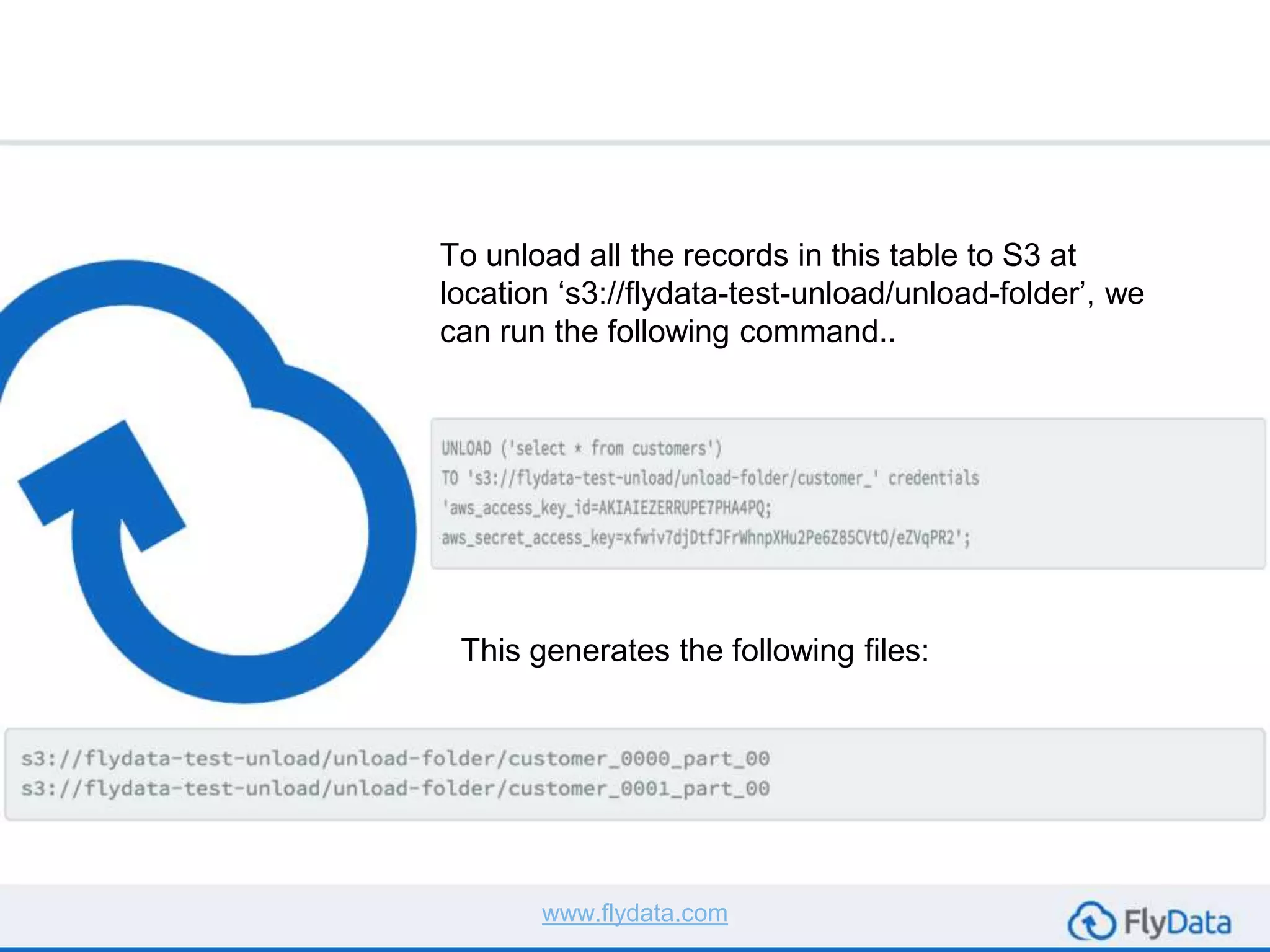
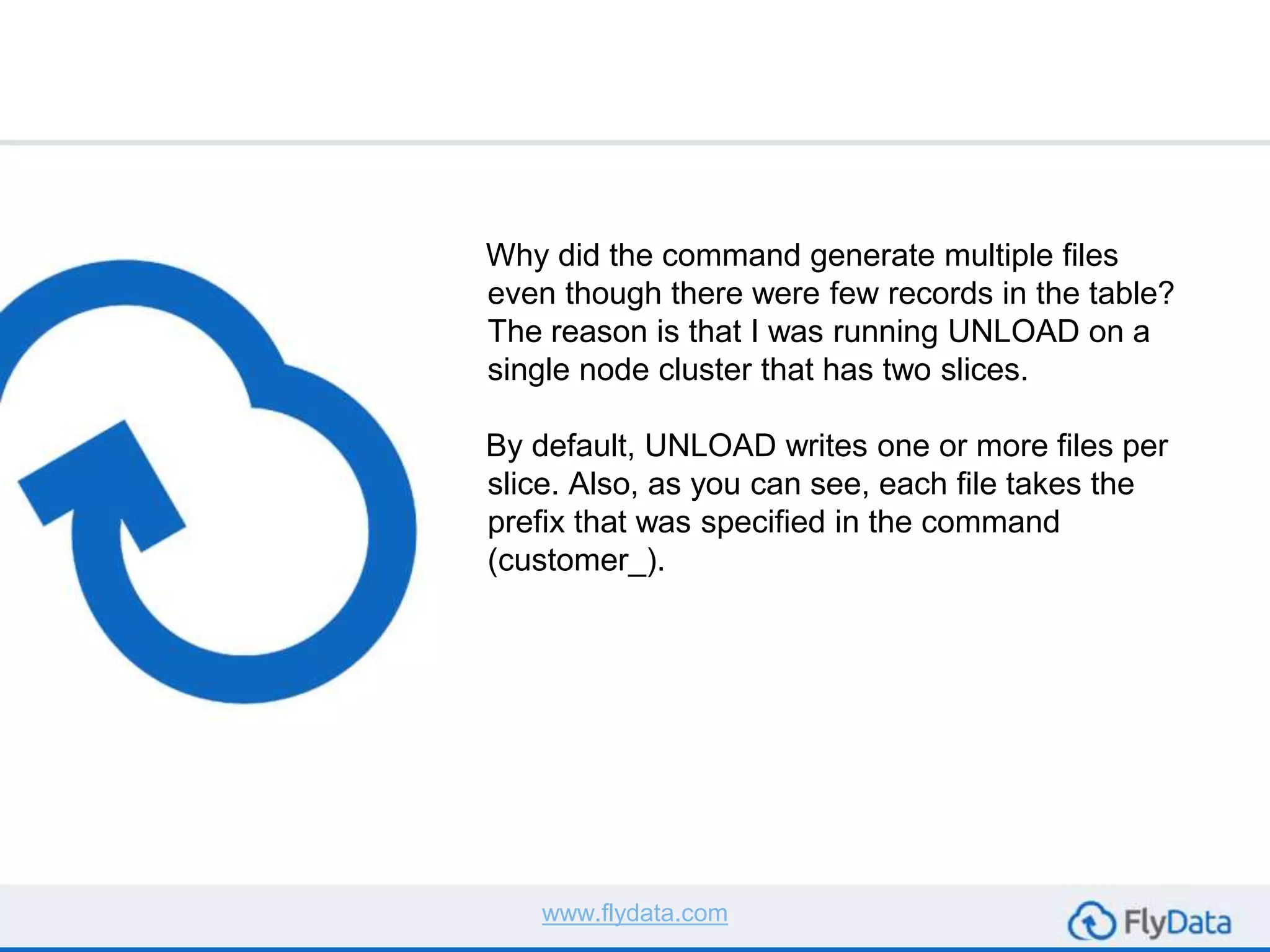
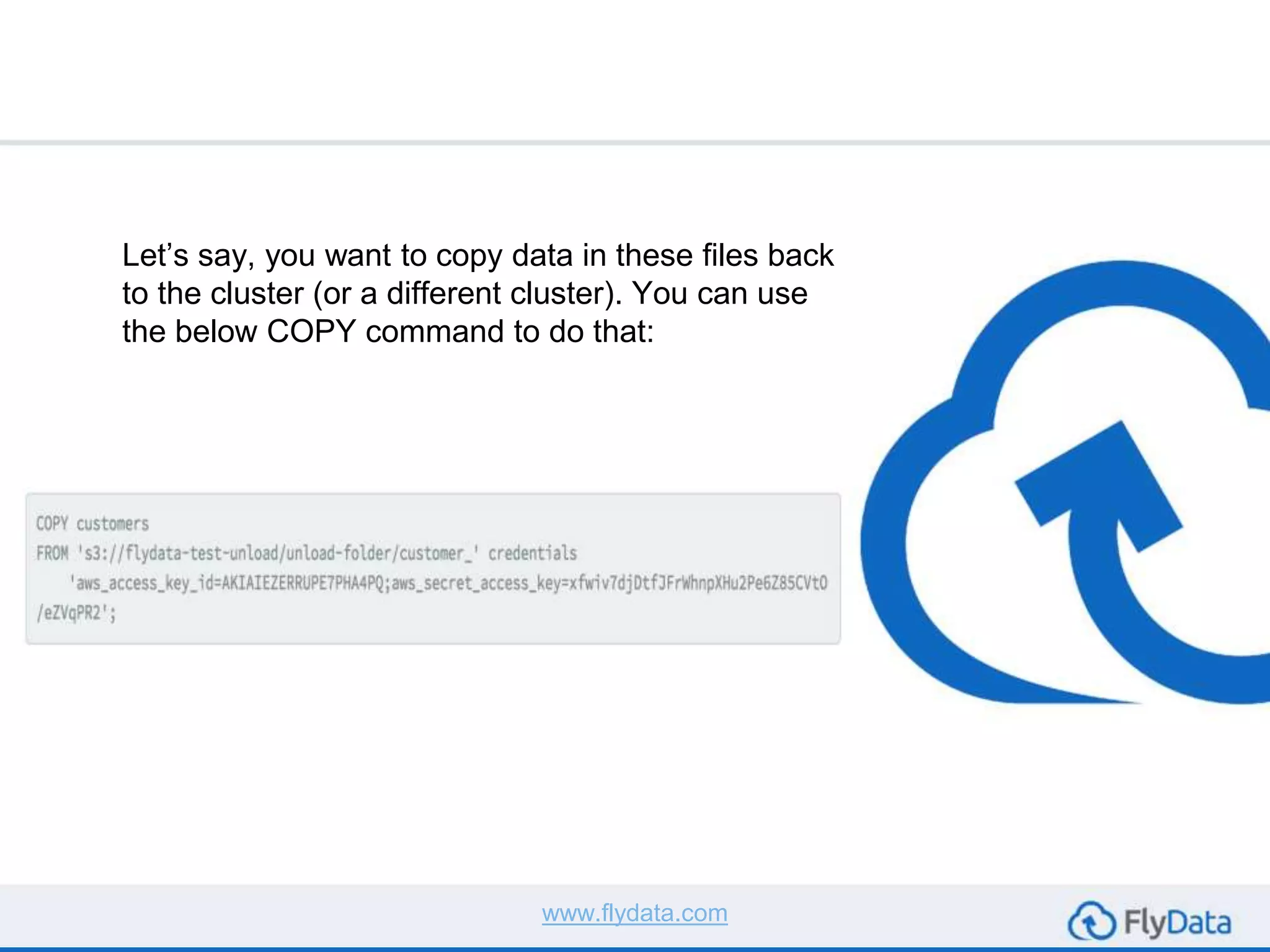


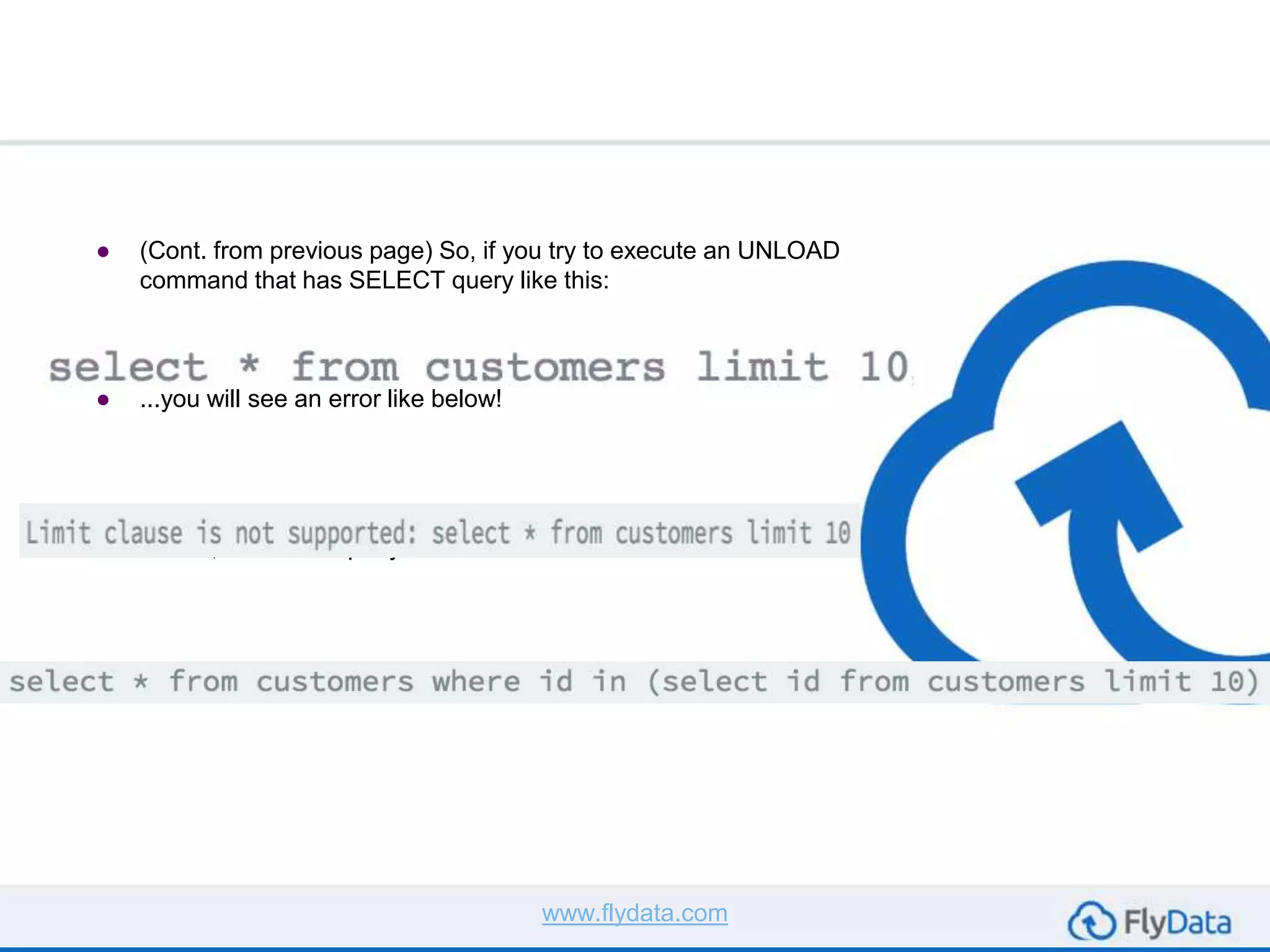


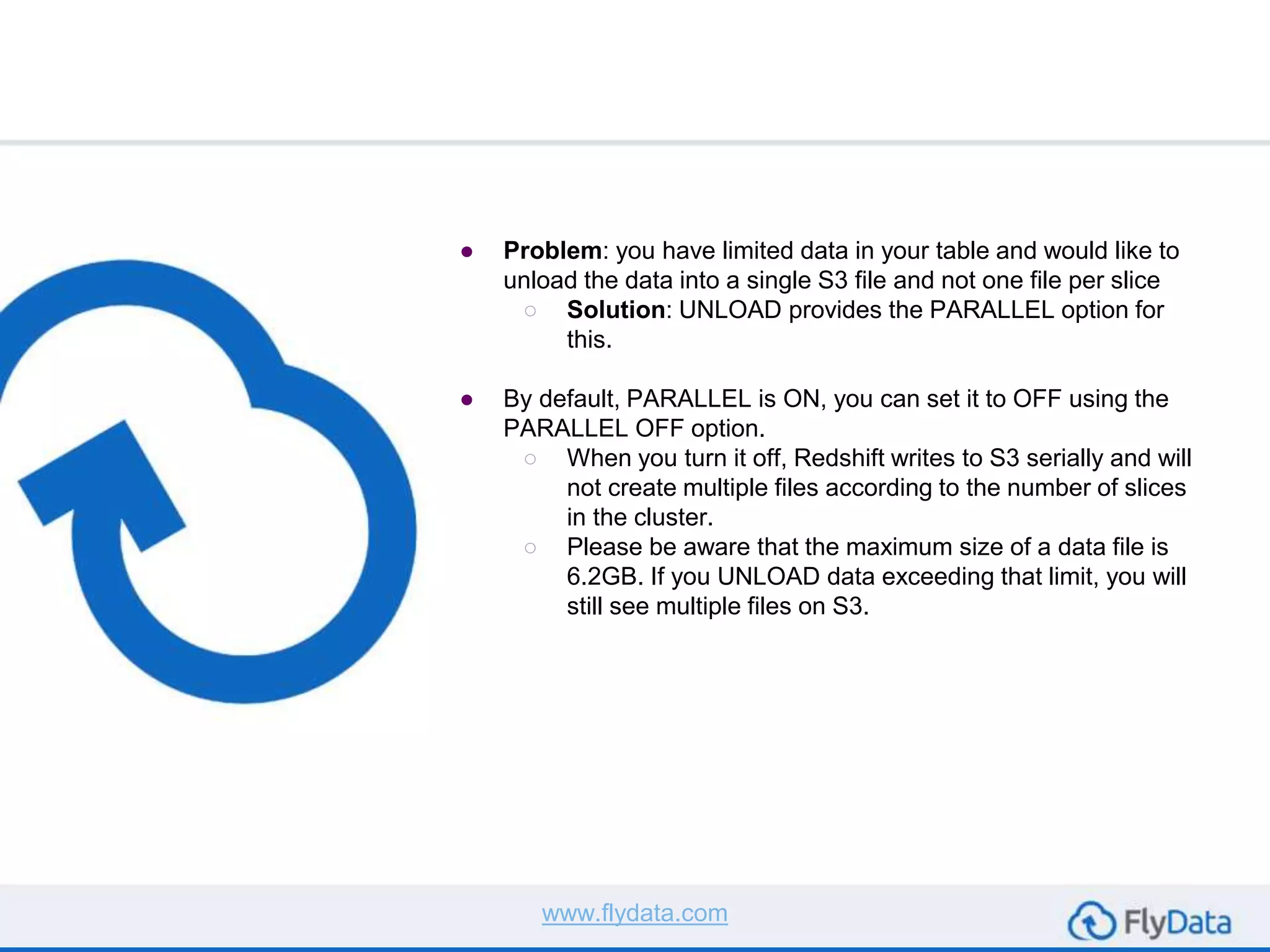
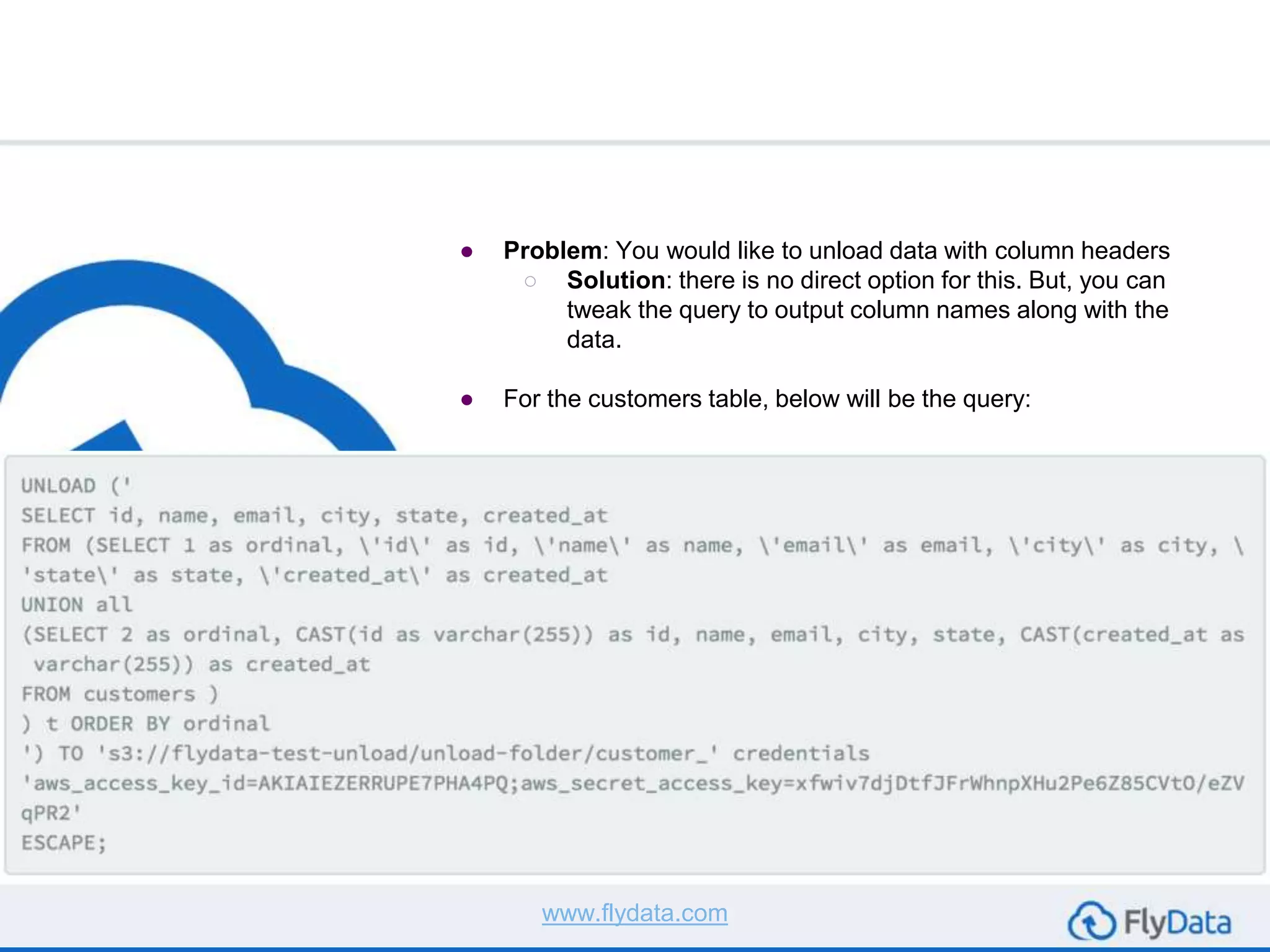



The document provides guidance on using the unload command in Amazon Redshift to extract data from Redshift tables to S3, offering multiple reasons for doing so, such as data transformation and migration. It outlines important considerations, commands, and best practices to follow when executing data unload operations, including handling delimiters, file sizes, and overwriting existing data. It concludes by emphasizing testing with sample data and consulting AWS documentation for additional options.





































