Download to read offline













![A Simple Program
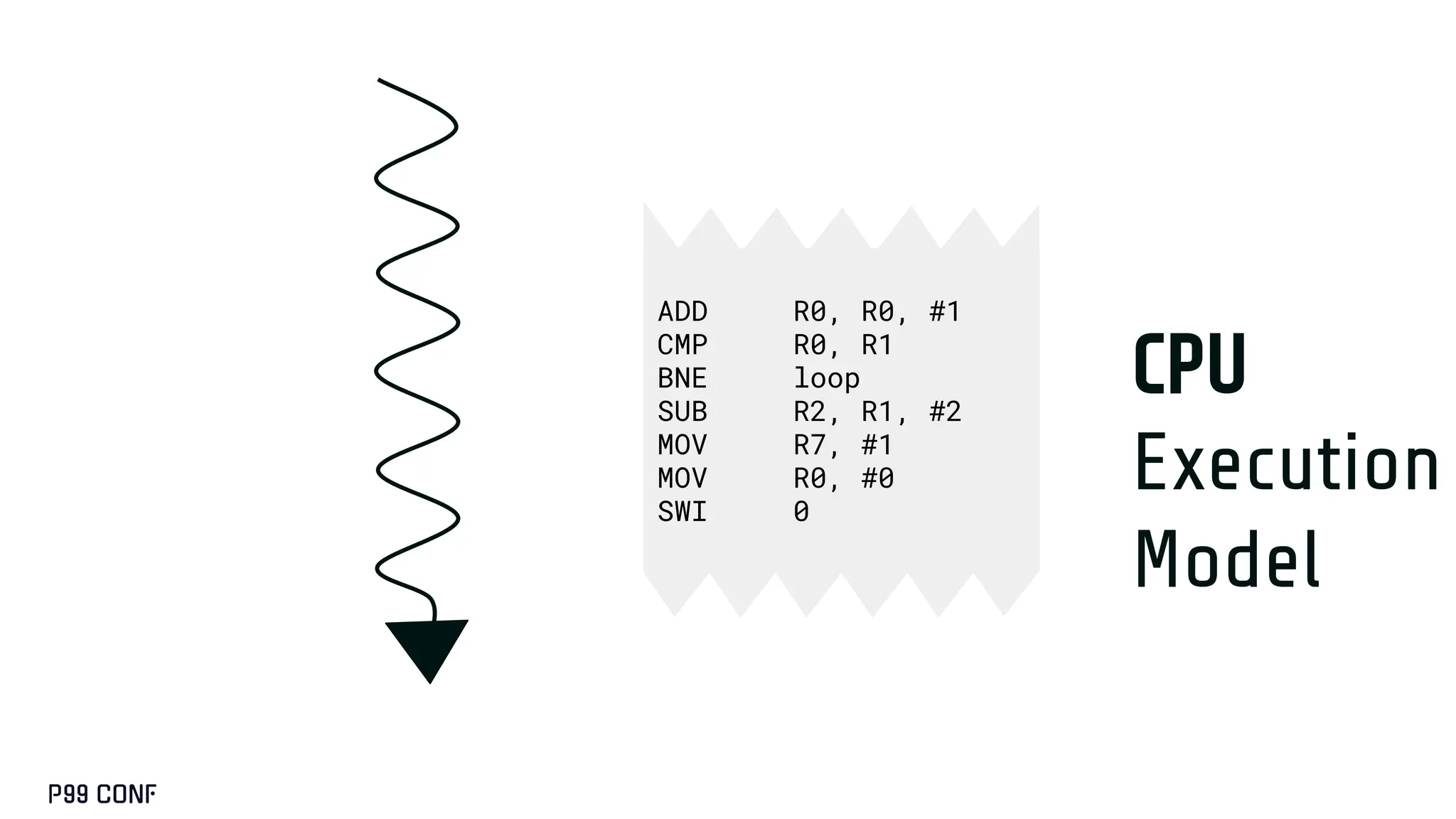
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-44-2048.jpg)
![A Simple Program
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-45-2048.jpg)
![A Simple Program
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-46-2048.jpg)
![A Simple Program
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-47-2048.jpg)
![A Simple Program
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-48-2048.jpg)
![A Simple Program
__global__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-49-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-50-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-51-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-52-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-53-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-54-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-55-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-56-2048.jpg)
![A Simple Program
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-57-2048.jpg)
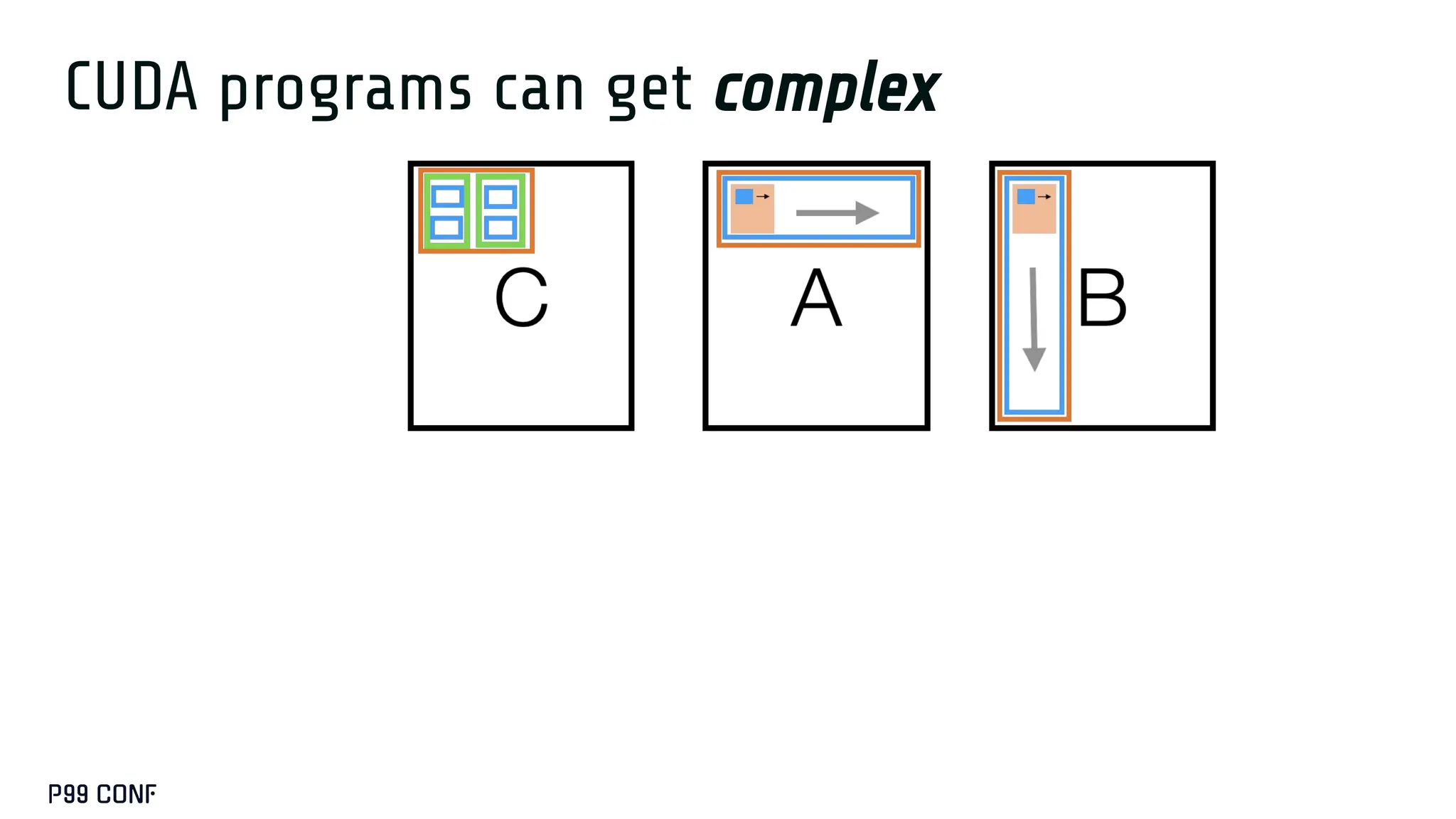
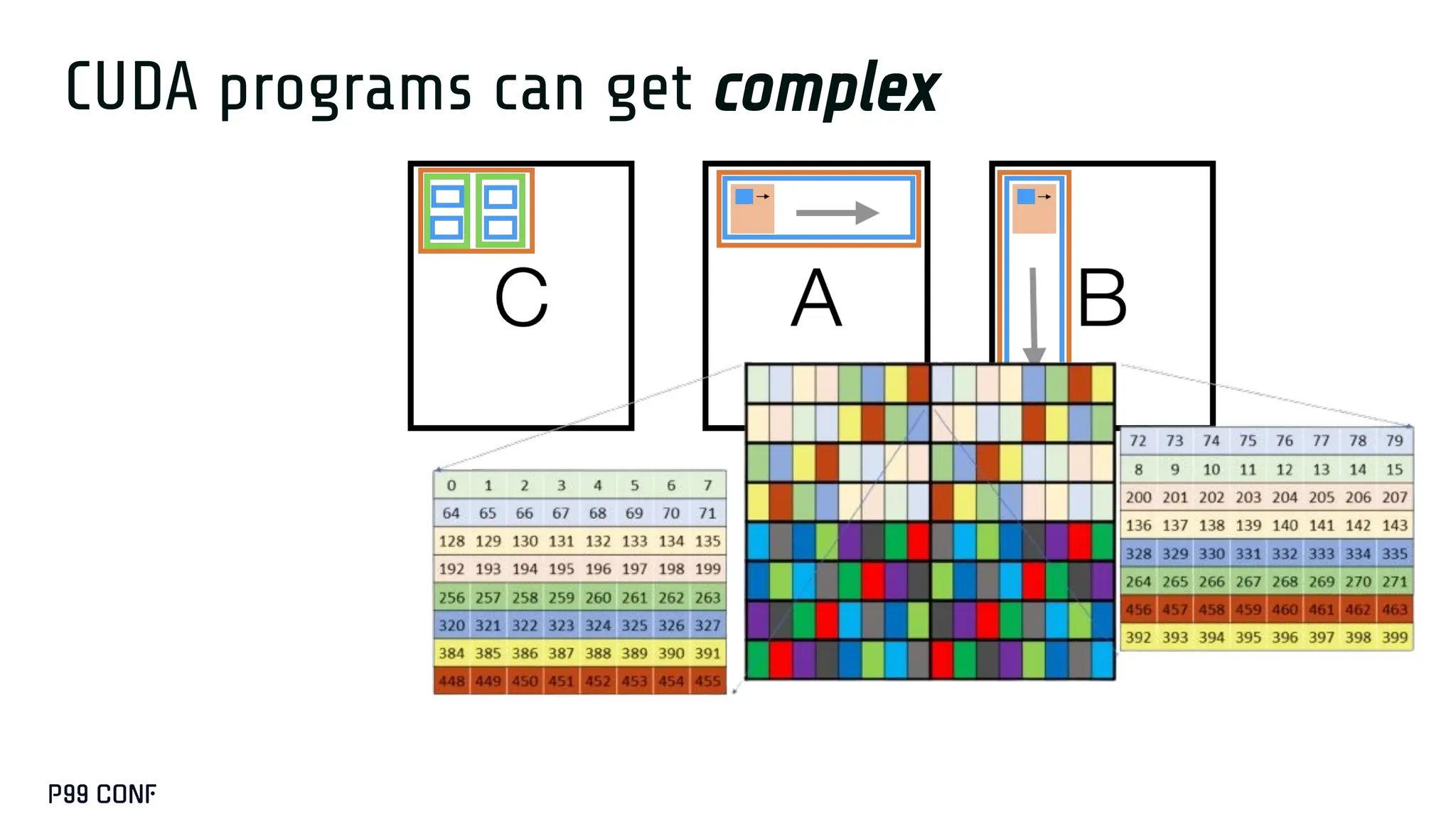
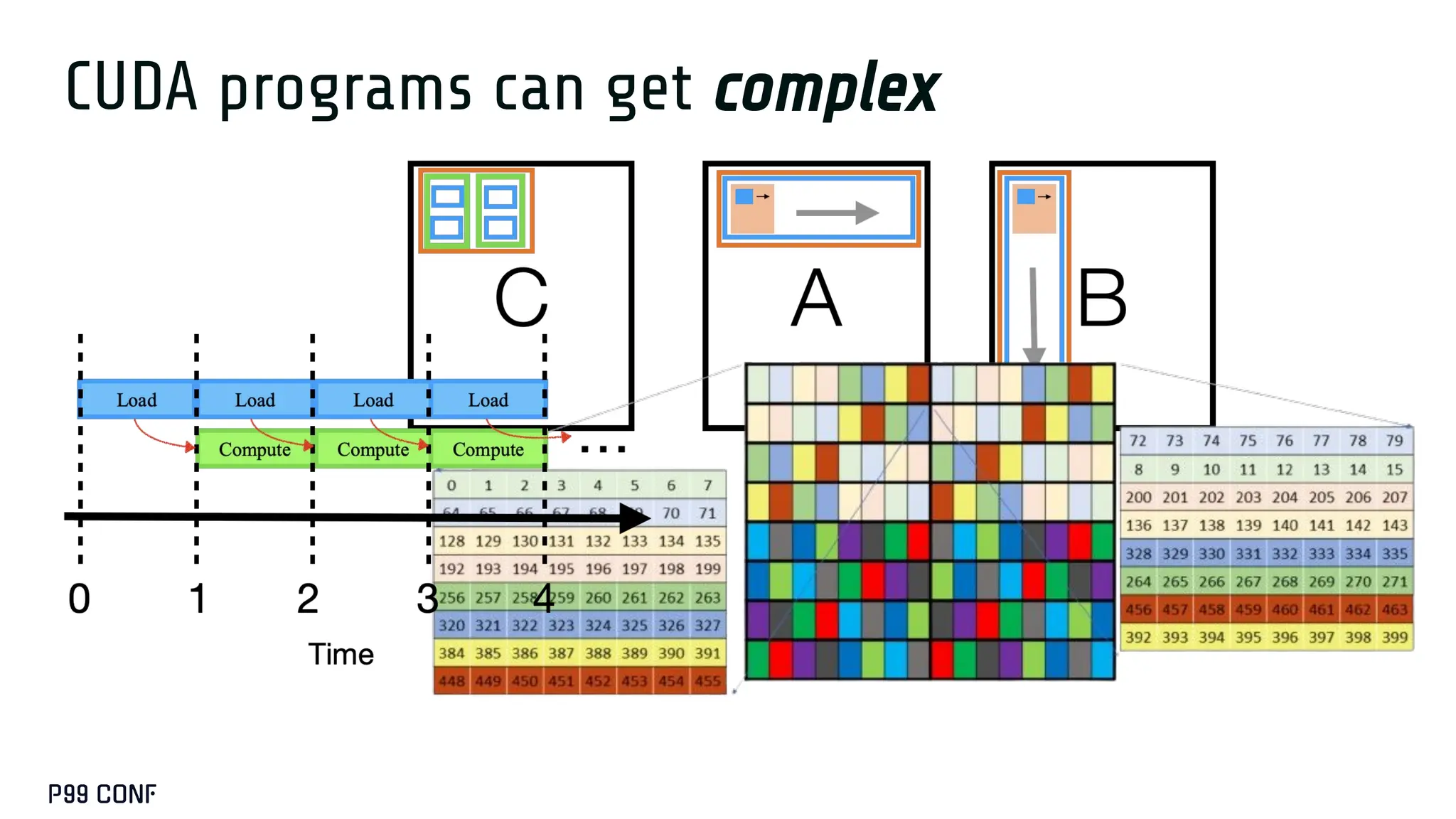
![H A
__global__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a
A nonsensical
program](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-62-2048.jpg)



![Our first program
__device__ void add_1(const float *a, float *b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
int offset = (blockIdx.x*blockDim.x+threadIdx.x);
a += offset; // Move to the thread’s position
b += offset; // Move to the thread’s position
if (offset < N){
b[i] = a[i] + 1;
}}}}
1
a
b
+
… …
…](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-66-2048.jpg)
![__device__ void add_1(const float* a,float* b, int N){
for(blockIdx.x;blockIdx.x<gridDim.x;blockIdx.x++){
for(threadIdx.x;threadIdx.x<blockDim.x;threadIdx.x++){
extern __shared__ float smem[];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int tid = threadIdx.x;
// Load with circular shift
if (idx < N) {
int ld_idx = blockIdx.x* blockDim.x
+ ((tid + 1) % blockDim.x);
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = a[ld_idx];
__syncthreads();
b[idx] = smem[tid] + 1.0f;
}}}
… …
…
S H A R E D
b
a
Our second program](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-67-2048.jpg)


![Spot the difference
__device__ void add_1(const float *a, float *b, int N);
__device__ void add_1(const float *a, float *b, int N);
#1
#2
a += offset;
b += offset;
if (offset < N){
b[i] = a[i] + 1;
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = ...
__syncthreads();
b[idx] = smem[tid] + 1.0f;](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-70-2048.jpg)
![Spot the difference
__device__ void add_1(const float *a, float *b, int N);
__device__ void add_1(const float *a, float *b, int N);
#1
#2
a += offset;
b += offset;
if (offset < N){
b[i] = a[i] + 1;
if (load_idx < N)
smem[(tid + 1) % blockDim.x] = ...
__syncthreads();
b[idx] = smem[tid] + 1.0f;
Cannot trust the implementation
from looking at the interface](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-71-2048.jpg)




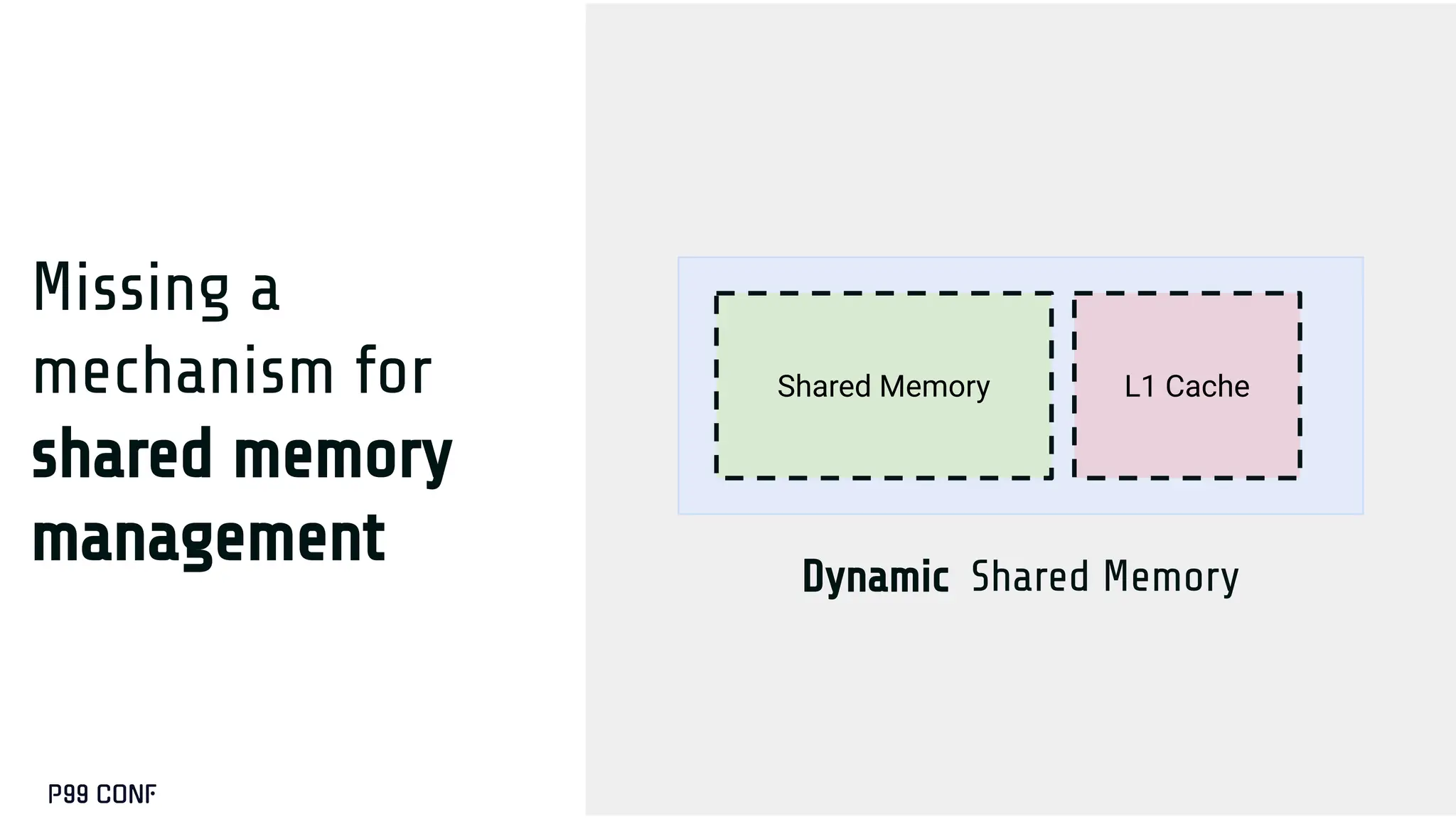
![Missing a
mechanism for
shared memory
management
__device__ void foo_shared()
{
extern __shared__ char smem[];
float* a_smem = (float*)smem;
float* b_smem = (float*)smem + A_SIZE * 4;
…
}](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-77-2048.jpg)
![Missing a
mechanism for
shared memory
management
__device__ void foo_shared()
{
extern __shared__ char smem[];
float* a_smem = (float*)smem;
float* b_smem = (float*)smem + A_SIZE * 4;
…
foo_local(a_smem, b_mem);
}](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-78-2048.jpg)
![Missing a
mechanism for
shared memory
management
No malloc/free!
__device__ void foo_shared()
{
extern __shared__ char smem[];
float* a_smem = (float*)smem;
float* b_smem = (float*)smem + A_SIZE * 4;
…
foo_local(a_smem, b_mem);
}](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-79-2048.jpg)
![Memory hierarchy
is implicit in the
program
__device__ void foo_local(float * a, float * b)
{
}
__device__ void foo_shared()
{
extern __shared__ char smem[];
float* a_smem = (float*)smem;
float* b_smem = (float*)smem + A_SIZE * 4;
…
foo_local(a_smem, b_mem);
}](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-80-2048.jpg)
![Memory hierarchy
is implicit in the
program
__device__ void foo_shared()
{
extern __shared__ char smem[];
float* a_smem = (float*)smem;
float* b_smem = (float*)smem + A_SIZE * 4;
…
foo_local(a_smem, b_mem);
}
__device__ void foo_local(float * a, float * b)
{
a[0] = threadIdx.x + b[0];
}](https://image.slidesharecdn.com/take2-251209191012-727b945c/75/GPUS-and-How-to-Program-Them-by-Manya-Bansal-81-2048.jpg)








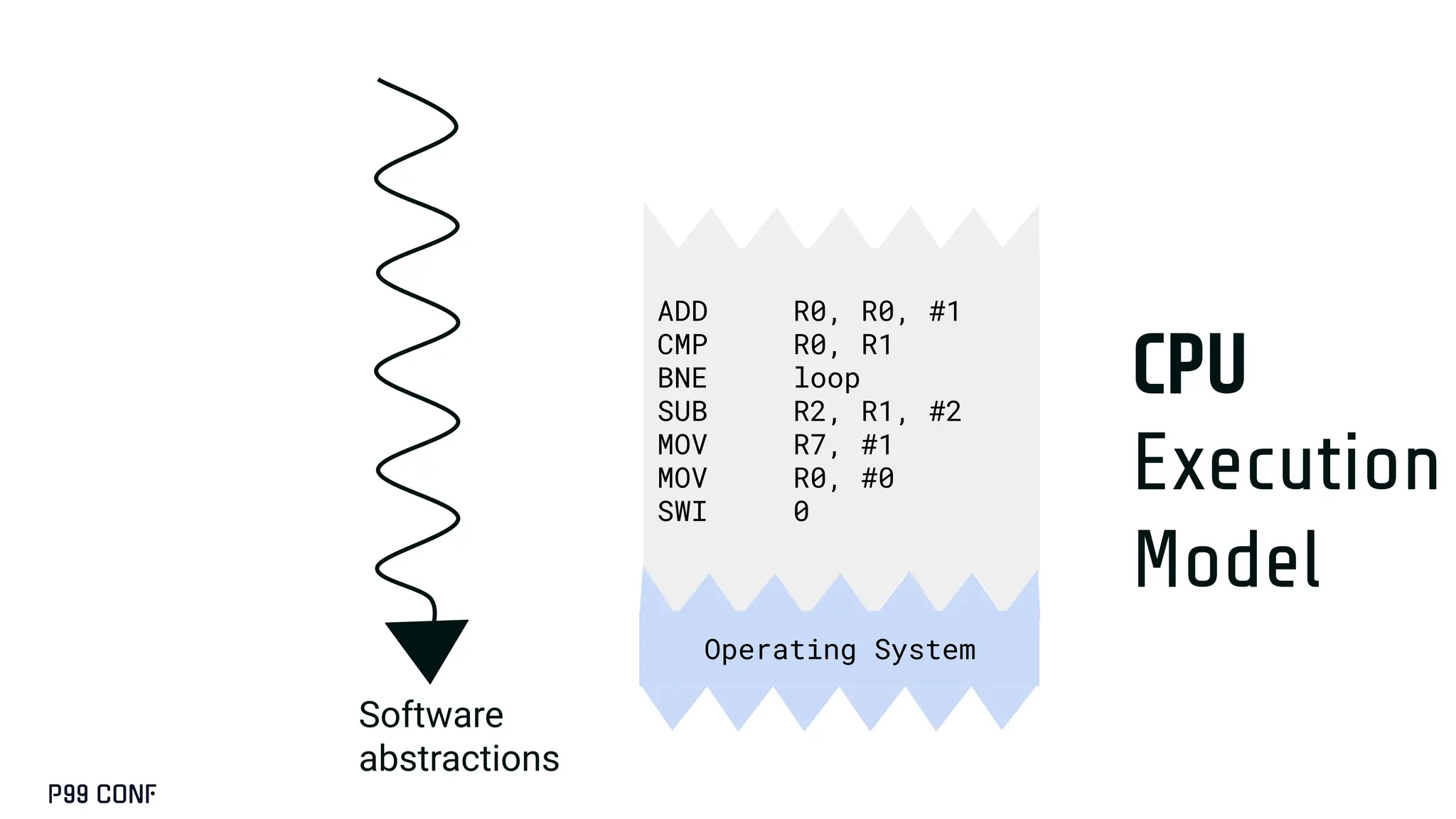
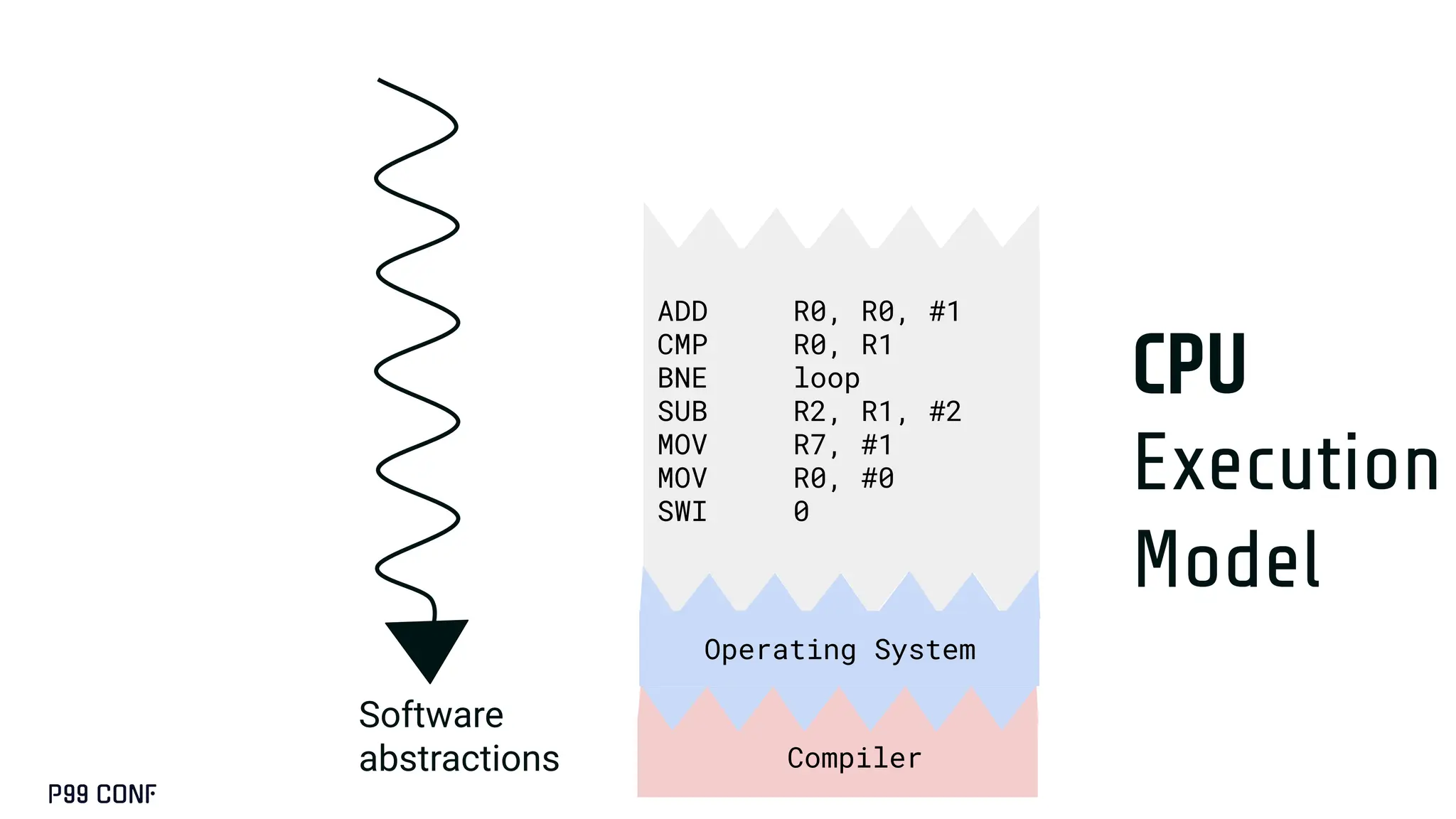
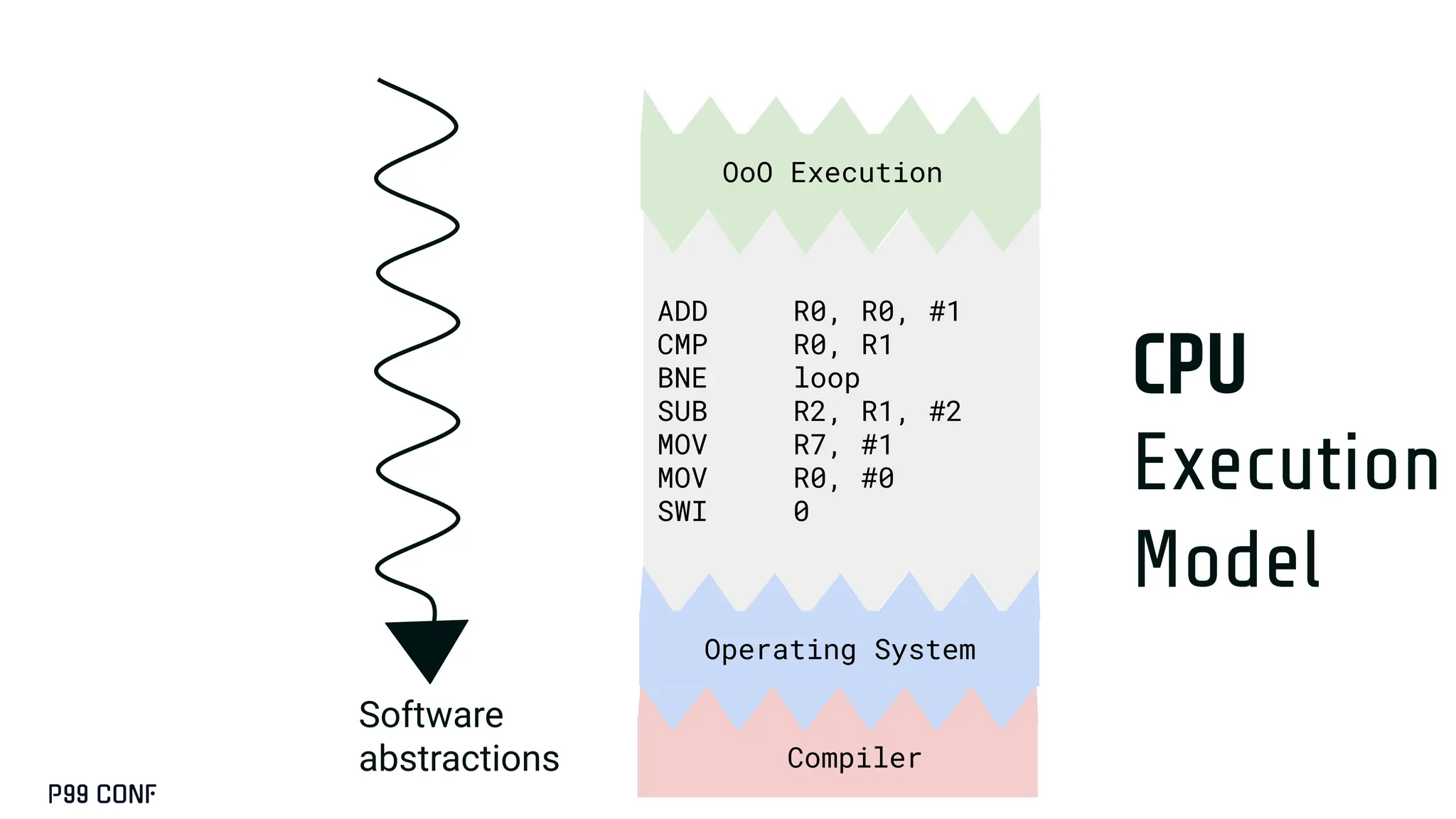
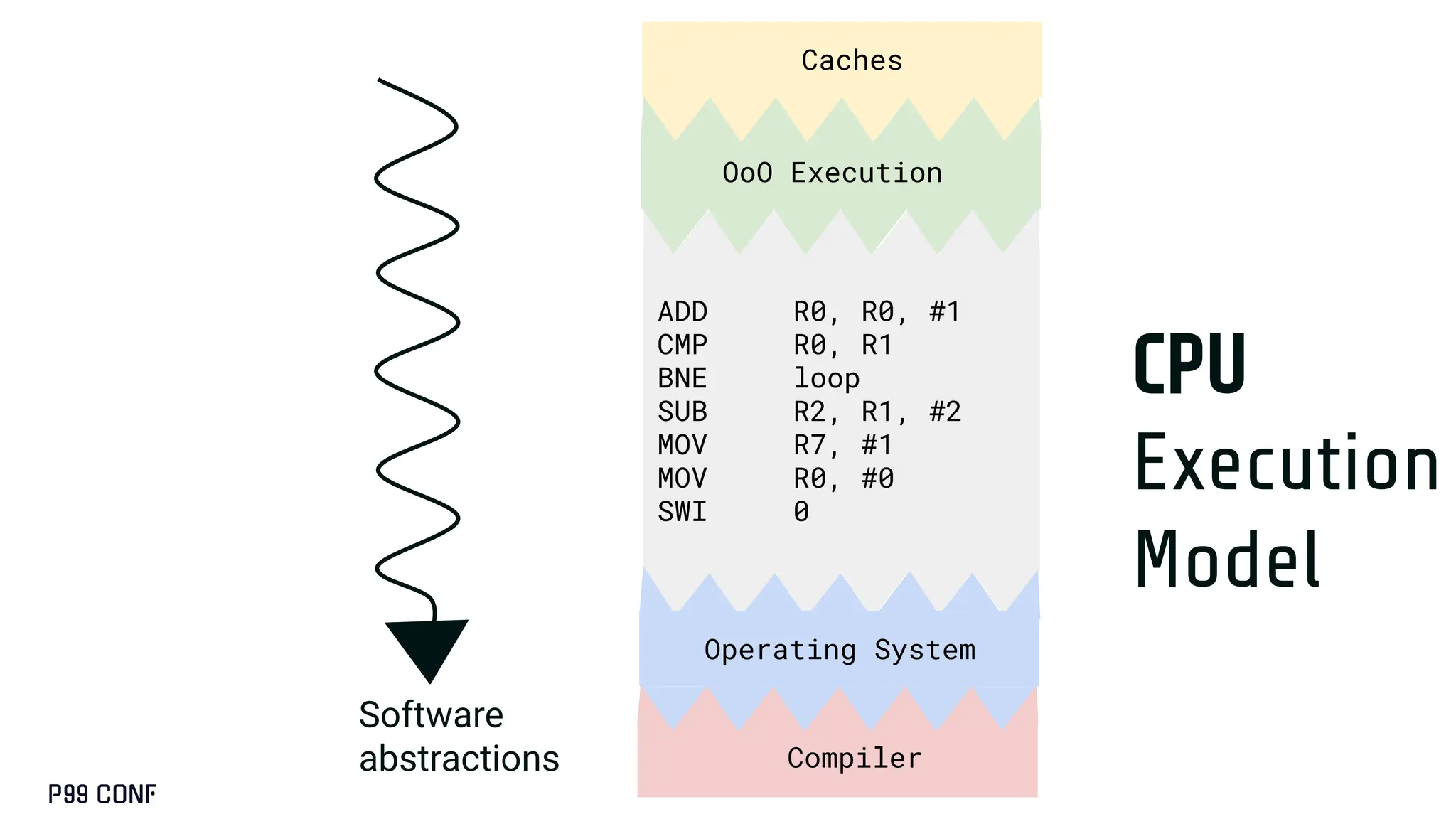
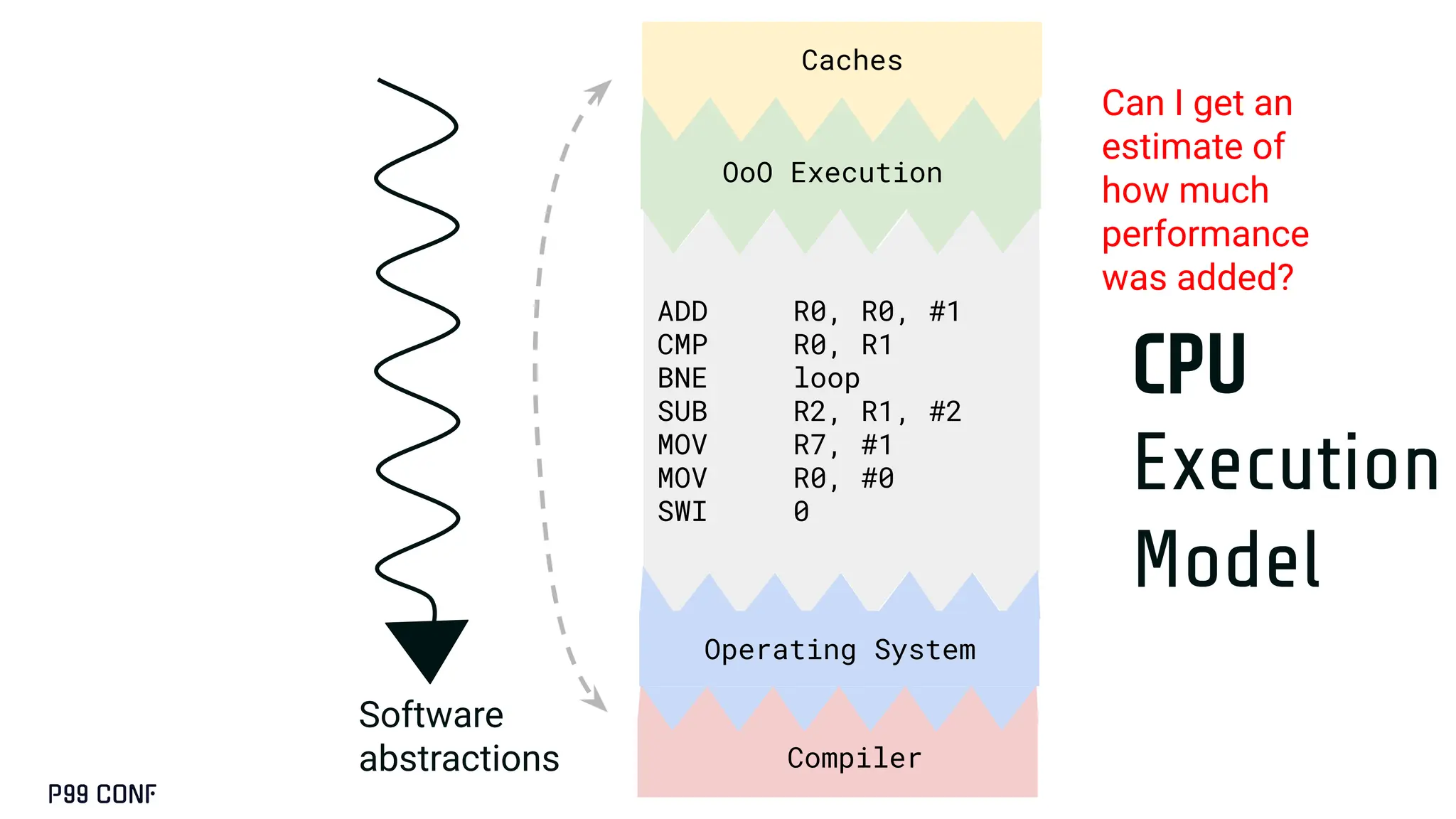
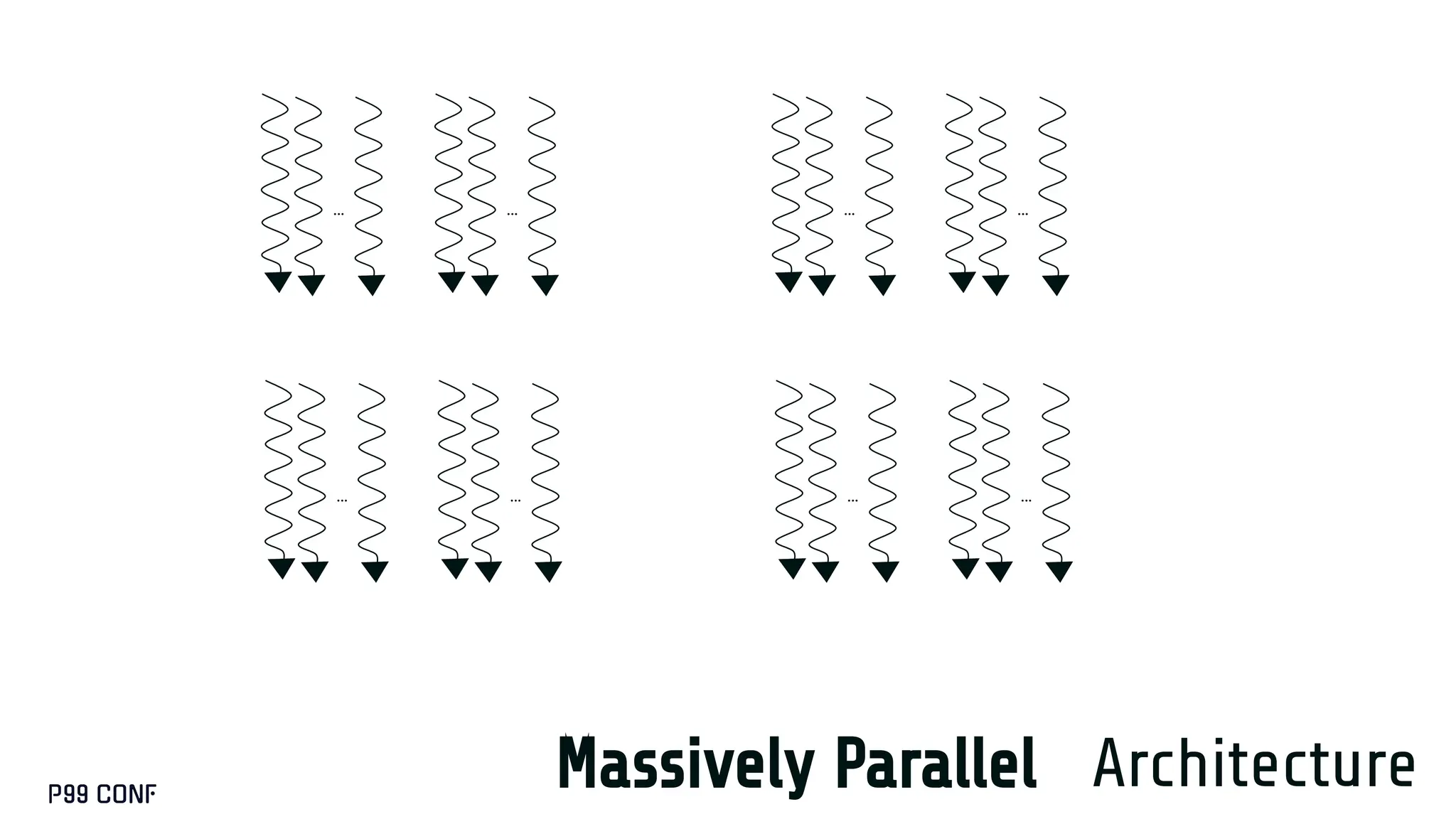
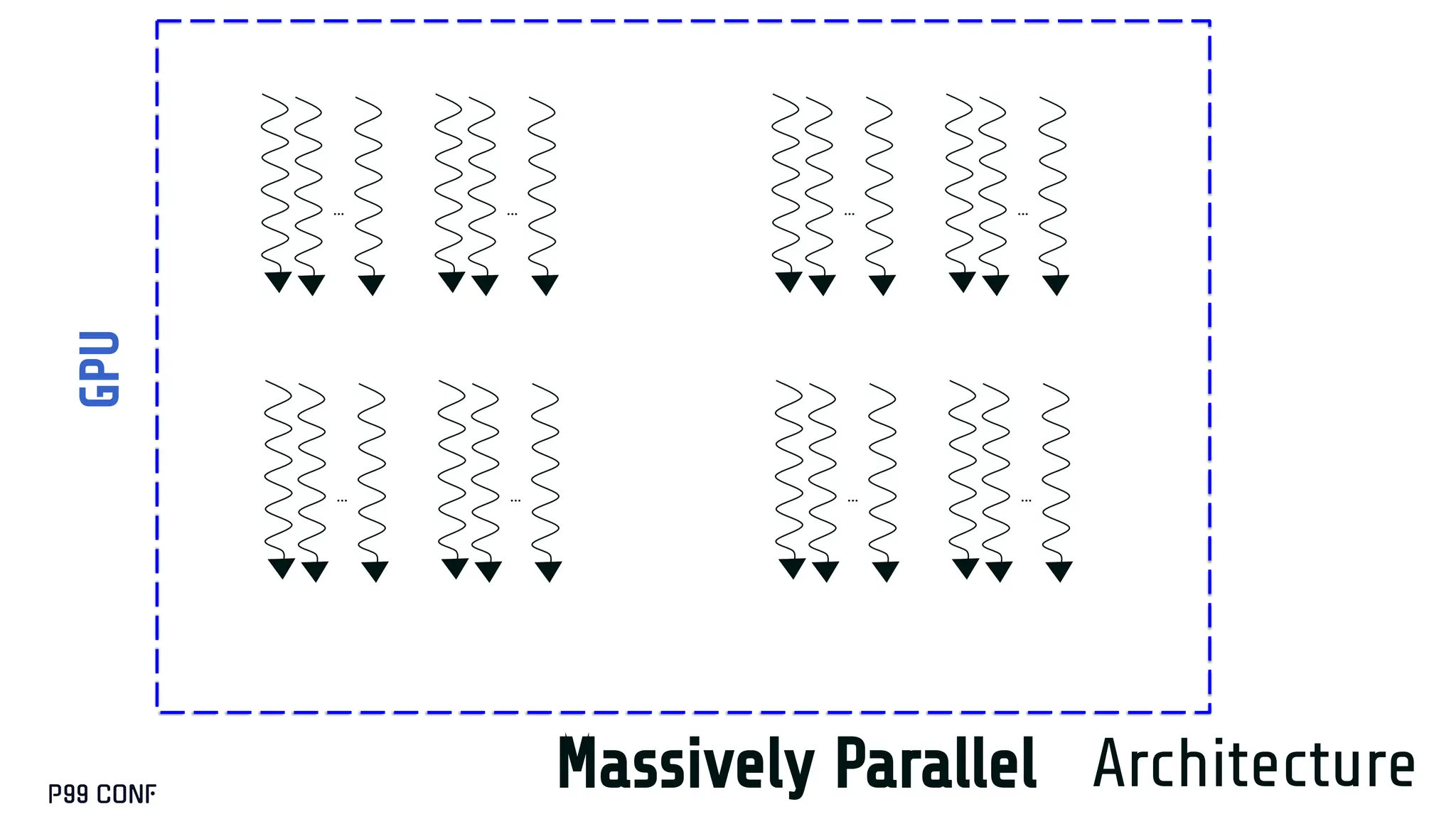
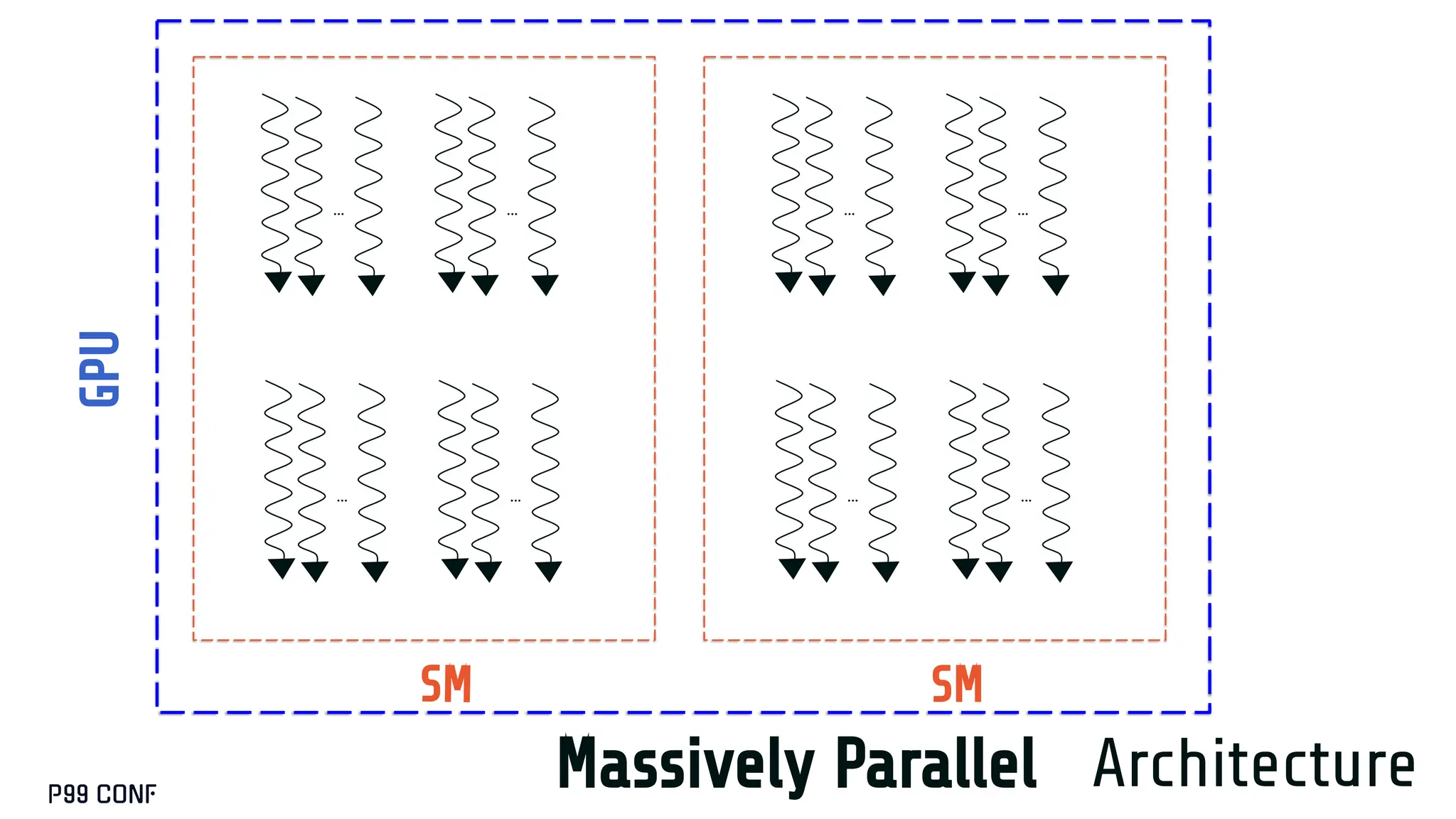
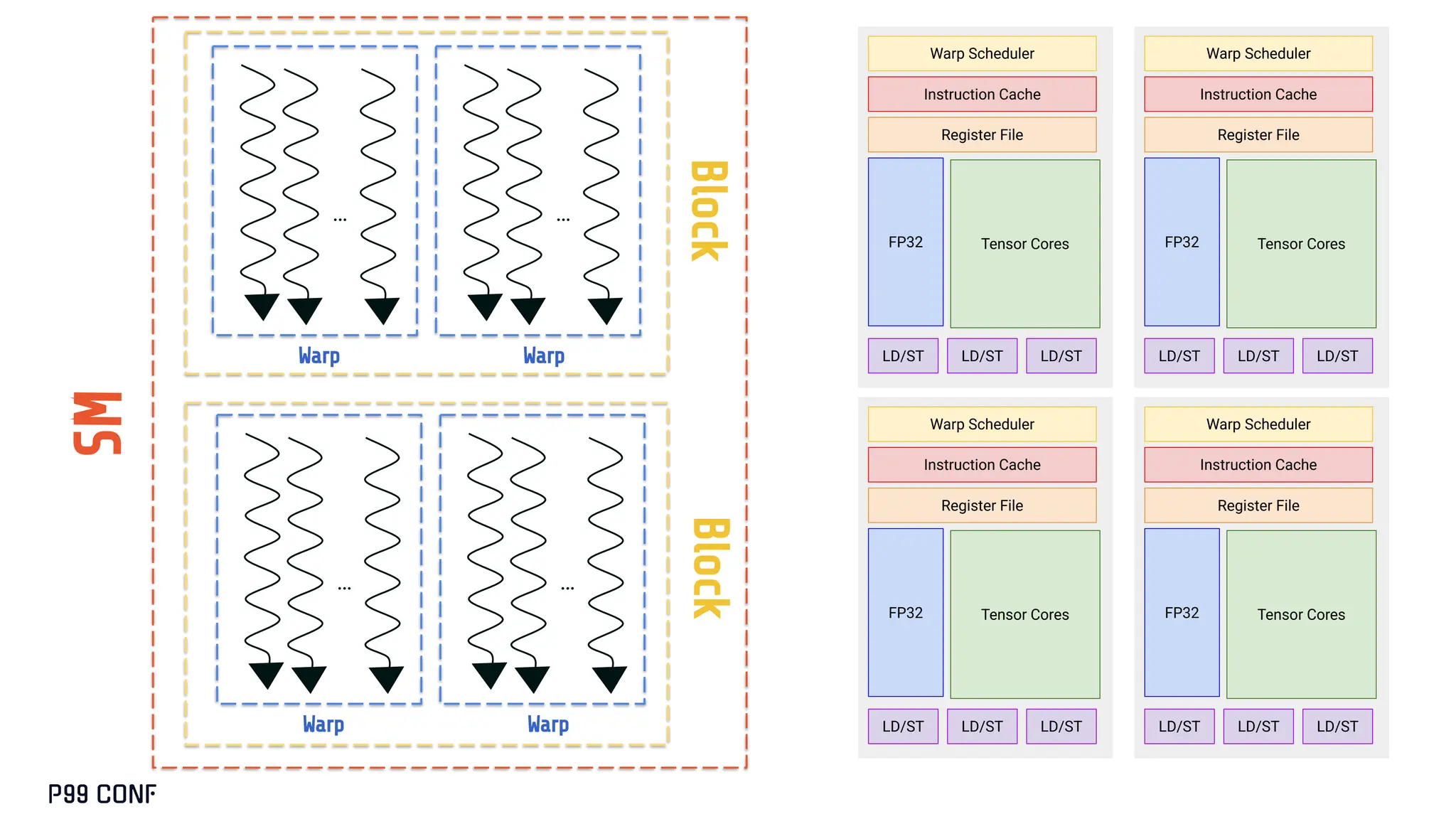
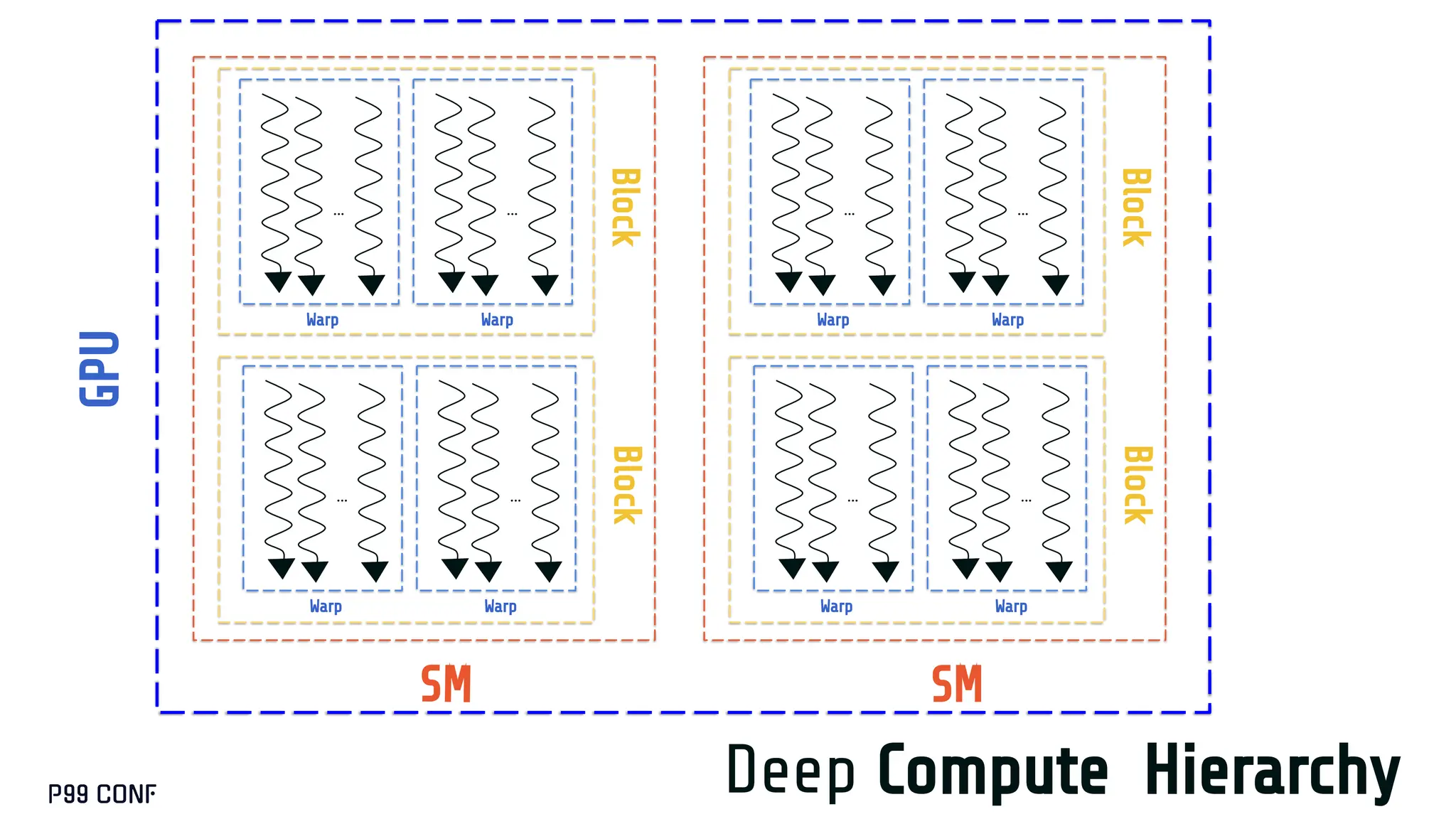
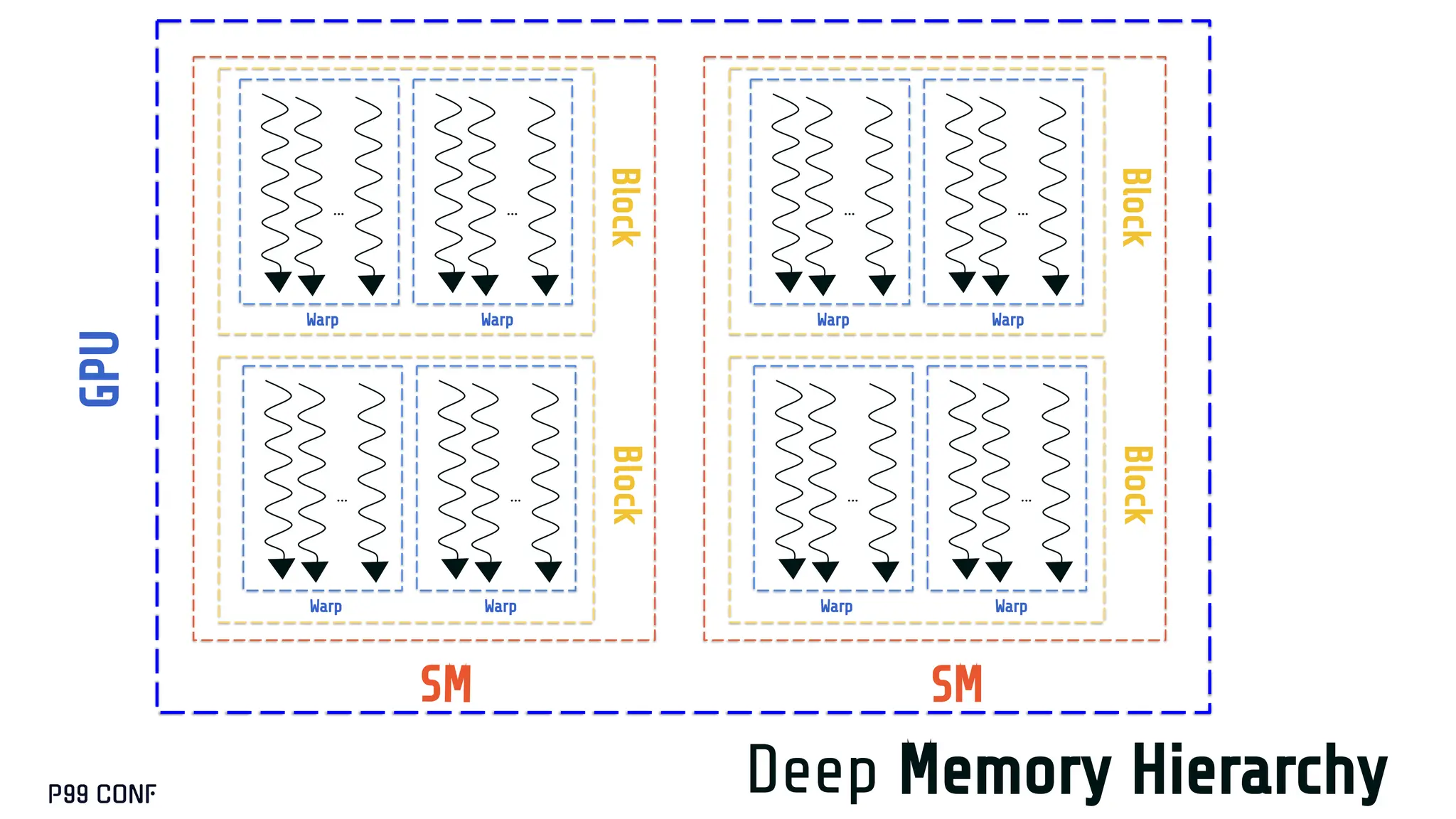
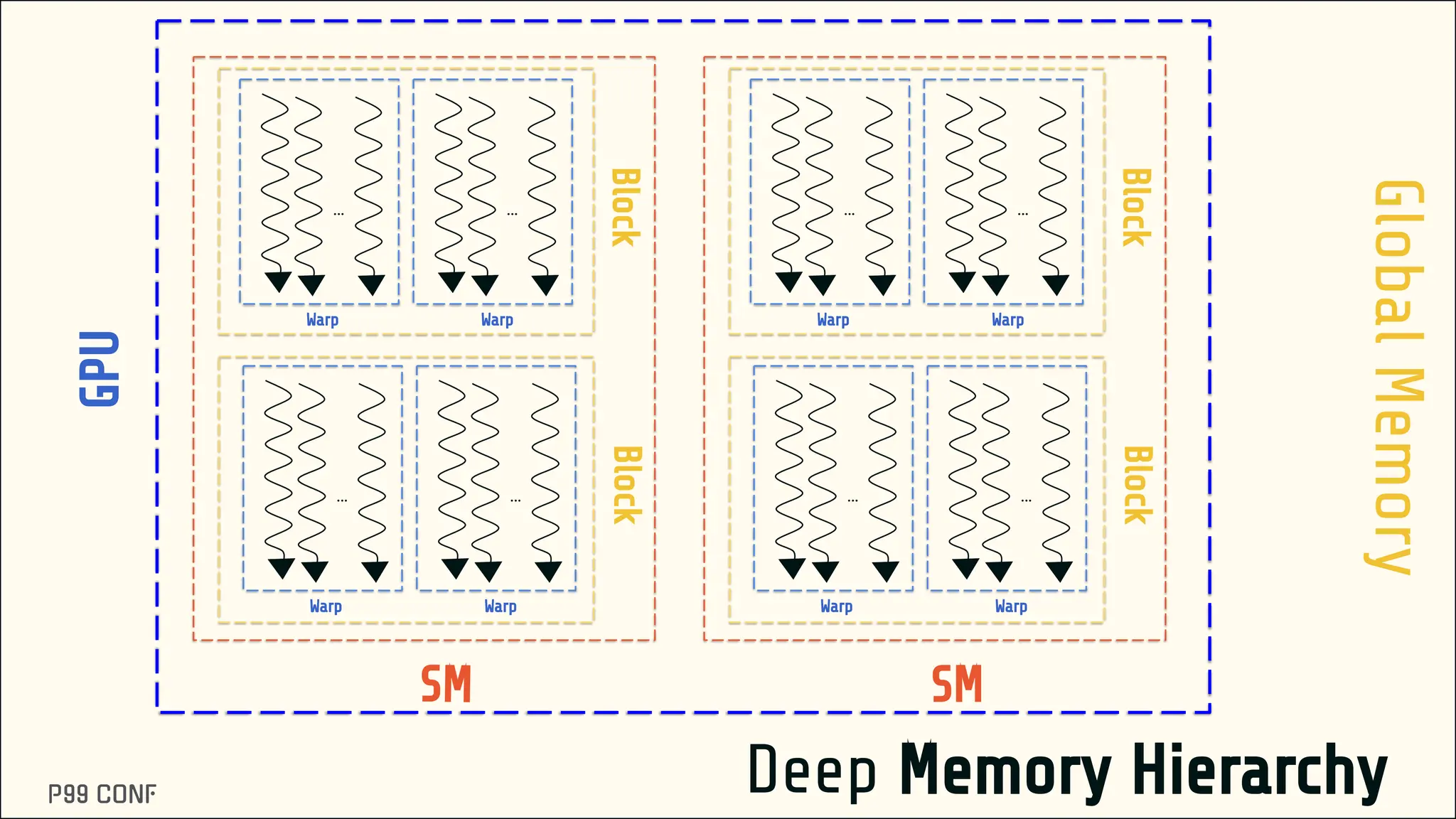
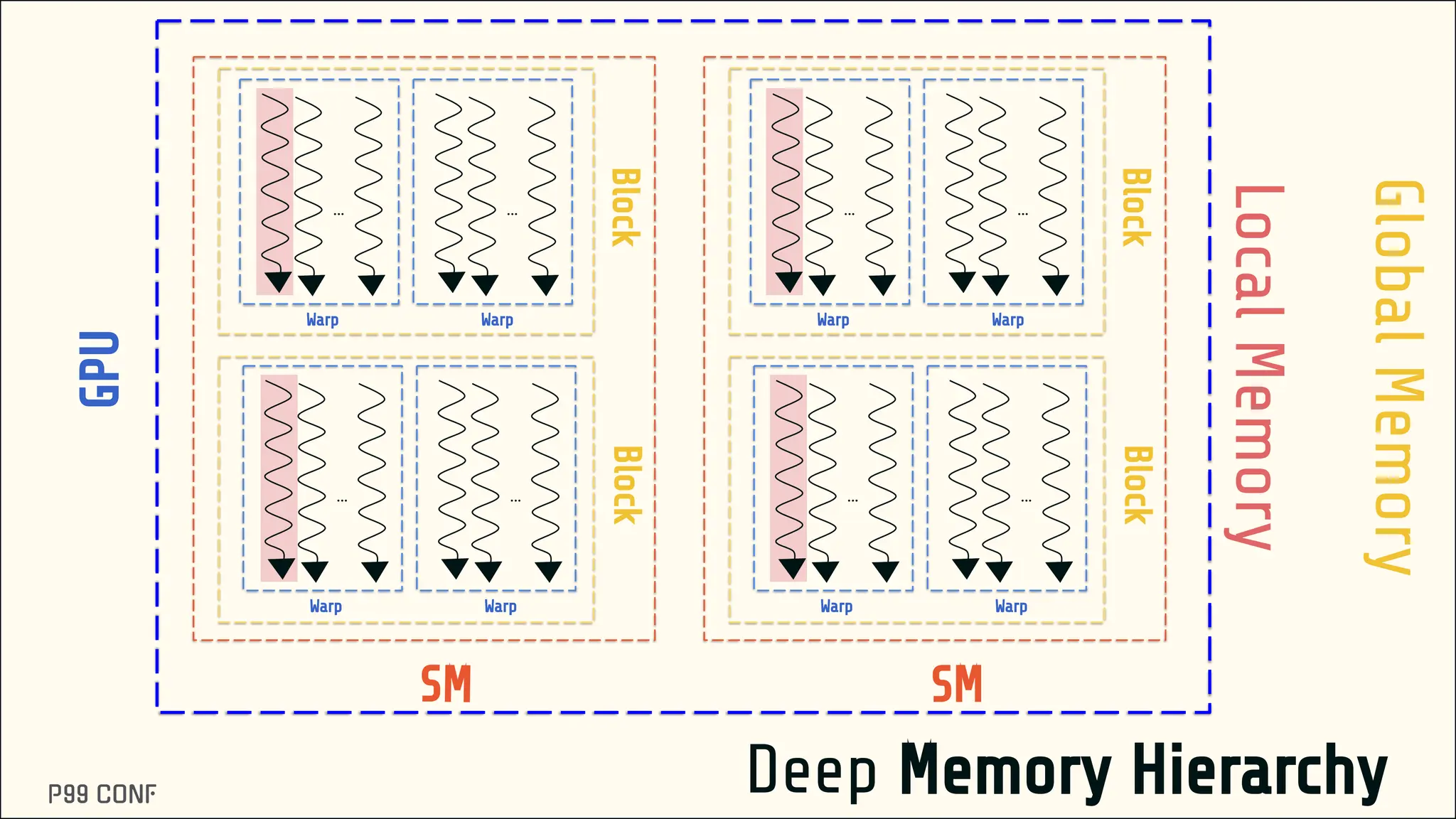
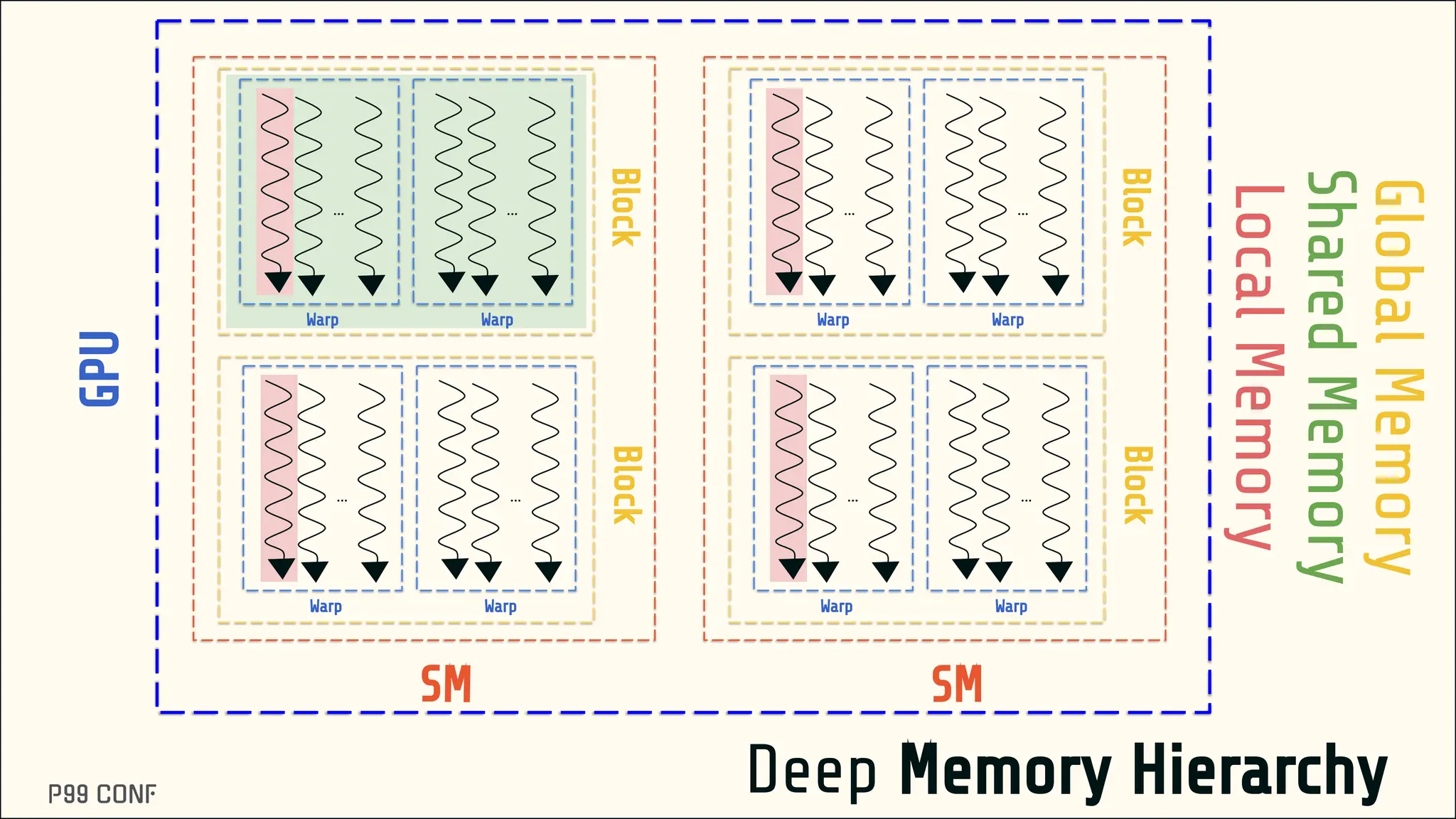
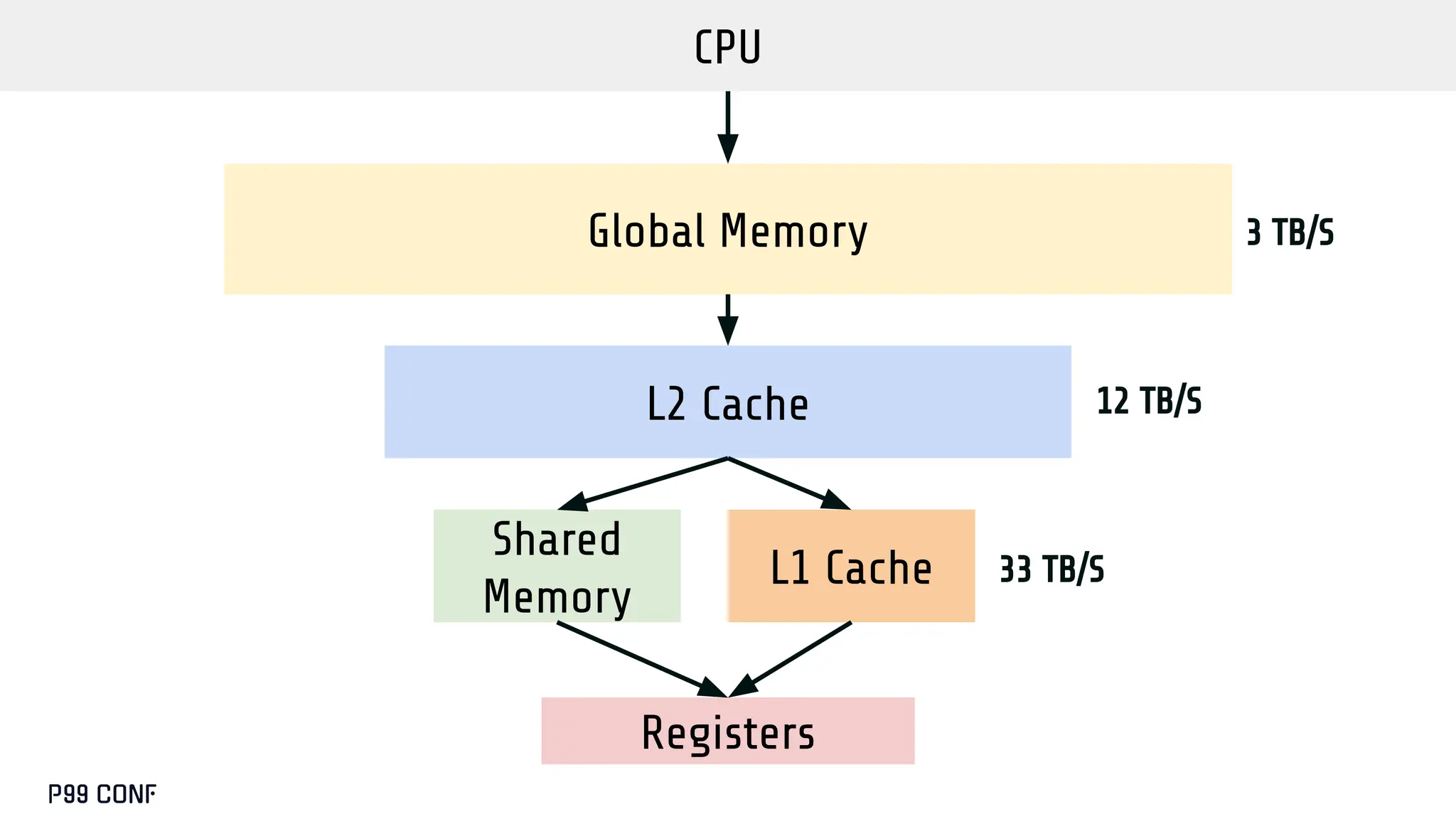
CUDA, designed as an extension to C++, preserves its familiar abstractions. However, unlike CPU programming --- where compilers and runtime systems abstract away most hardware concerns --- writing CUDA code requires developers to manually map computations onto the GPU’s parallel execution and memory hierarchy, while respecting the fundamental constraints of the hardware. In this talk, I’ll discuss where this model breaks down and why an alternative low-level language is needed for productive, compositional GPU programming.


























![[05][cuda 및 fermi 최적화 기술] hryu optimization](https://cdn.slidesharecdn.com/ss_thumbnails/05cudafermihryuoptimization-110106231451-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)







































