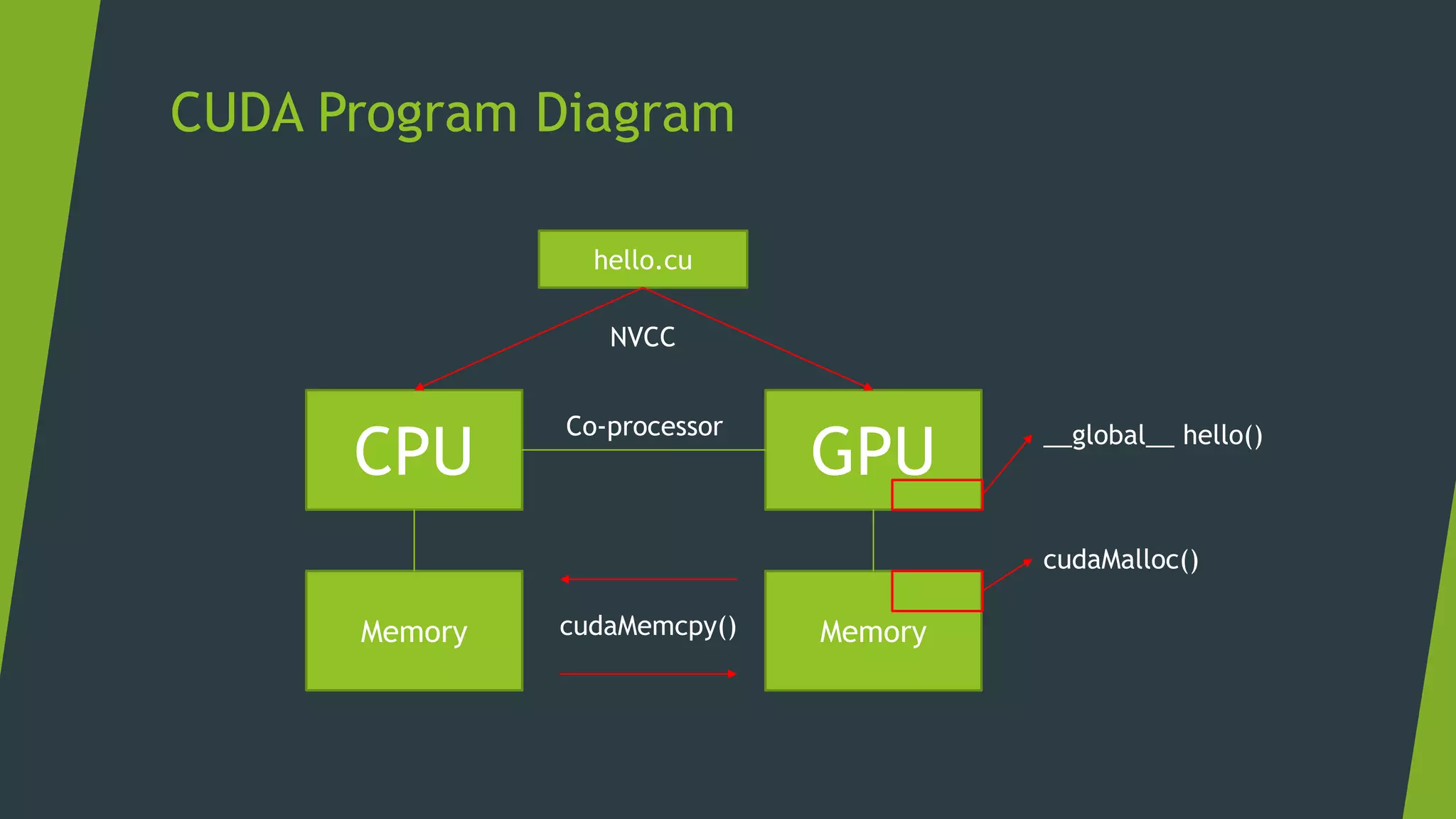
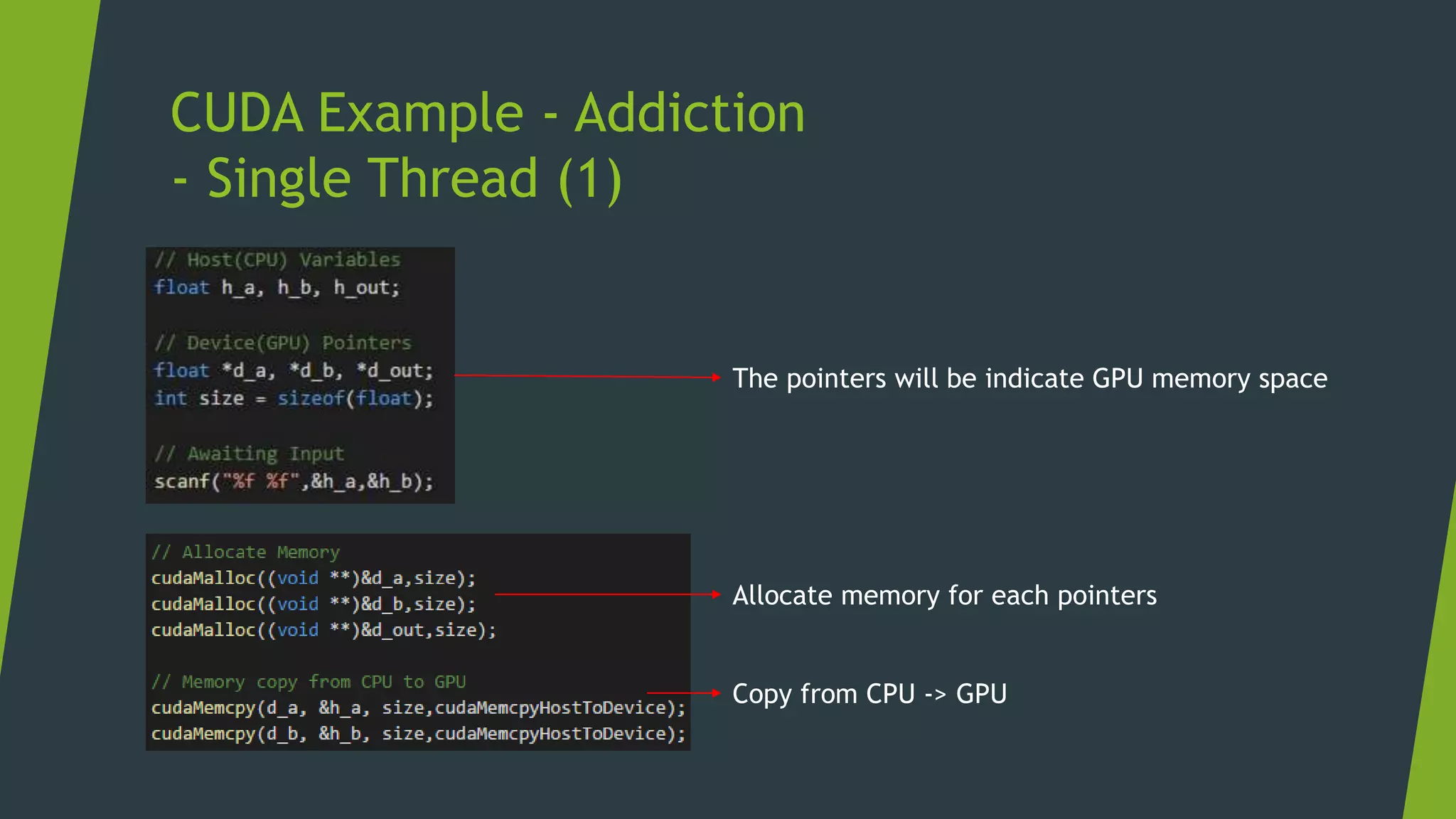
GPUs are specialized for enormous small tasks in parallel, while CPUs are optimized for few huge tasks sequentially. The typical procedure for a CUDA program includes: 1) allocating memory on the GPU, 2) copying data from CPU to GPU, 3) launching kernels on the GPU, and 4) copying results back to the CPU. Measuring GPU performance focuses on throughput or tasks processed per hour rather than latency of each task.




![Measuring Performance
CPU – Latency
How long does it take for a work
GPU - Throughput
How many tasks per hour
Data Size : 4.5[GB]
Assume that …
CPU can process 2 tasks at the time and each core processes 200 [MB/h]
GPU can process 40 tasks at the time and each core processes 50 [MB/h]
Latency
CPU : 4500/200 [MB/h] = 22.5 [Hours]
GPU : 4500/50 [MB/h] = 90 [Hours]
Throughput
CPU : 2[Tasks]/22.5[Hours] = 0.089[Tasks/Hour]
GPU : 40[Tasks]/90[Hours] = 0.445[Tasks/Hour]
Better !
Better !](https://image.slidesharecdn.com/cudaweek1-180706064509/75/GPU-Accelerated-Parallel-Computing-5-2048.jpg)






![cuCUDAn
- Implementation
idx Value
0 0
1 1
2 2
3 3
4 4
… …
99 99
idx Value
0 0
1 1
2 2
3 3
4 4
… …
99 99
X T[0] T[1] T[2] T[3] T[…] T[99]
B[0] 0 0 0 0 … 0
B[1] 0 1 2 3 … 99
B[2] 0 2 4 6 … 198
B[3] 0 3 6 9 … 297
B[…] … … … … … …
B[99] 0 99 198 297 … 9801
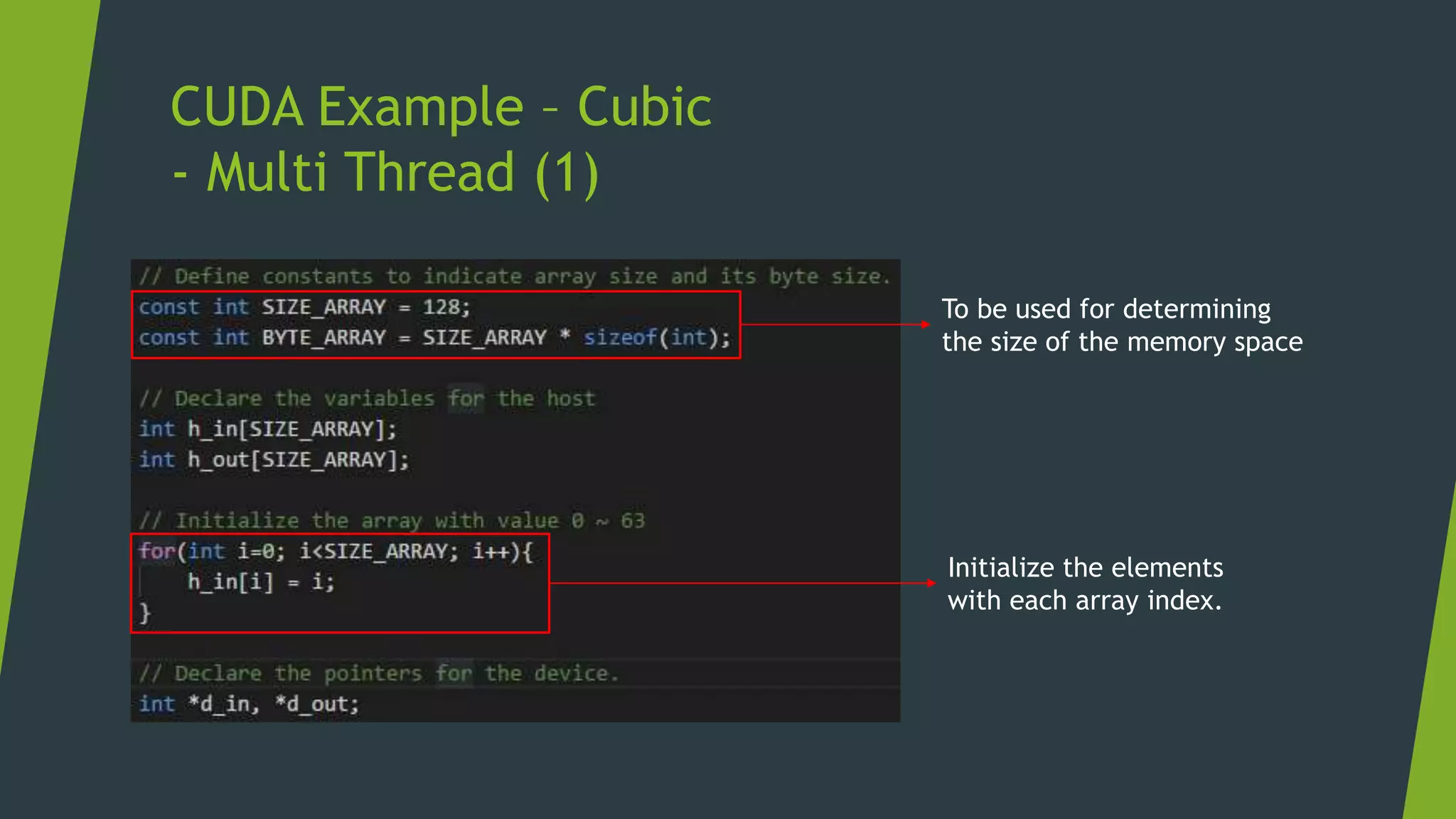
blockDim.x
Limitation : Maximum 512/1024 threads for a block.](https://image.slidesharecdn.com/cudaweek1-180706064509/75/GPU-Accelerated-Parallel-Computing-15-2048.jpg)
![cuCUDAn
- Implementation
dim(d_out) = [100 * 100]
Using 1D-Matrix instead of 2D-Matrix](https://image.slidesharecdn.com/cudaweek1-180706064509/75/GPU-Accelerated-Parallel-Computing-16-2048.jpg)


![cuCUDAn
- Result
……
Multiplication in each threads.
※ Total : 10,000 Threads
Elapsed time : 7.168 [μs]](https://image.slidesharecdn.com/cudaweek1-180706064509/75/GPU-Accelerated-Parallel-Computing-19-2048.jpg)



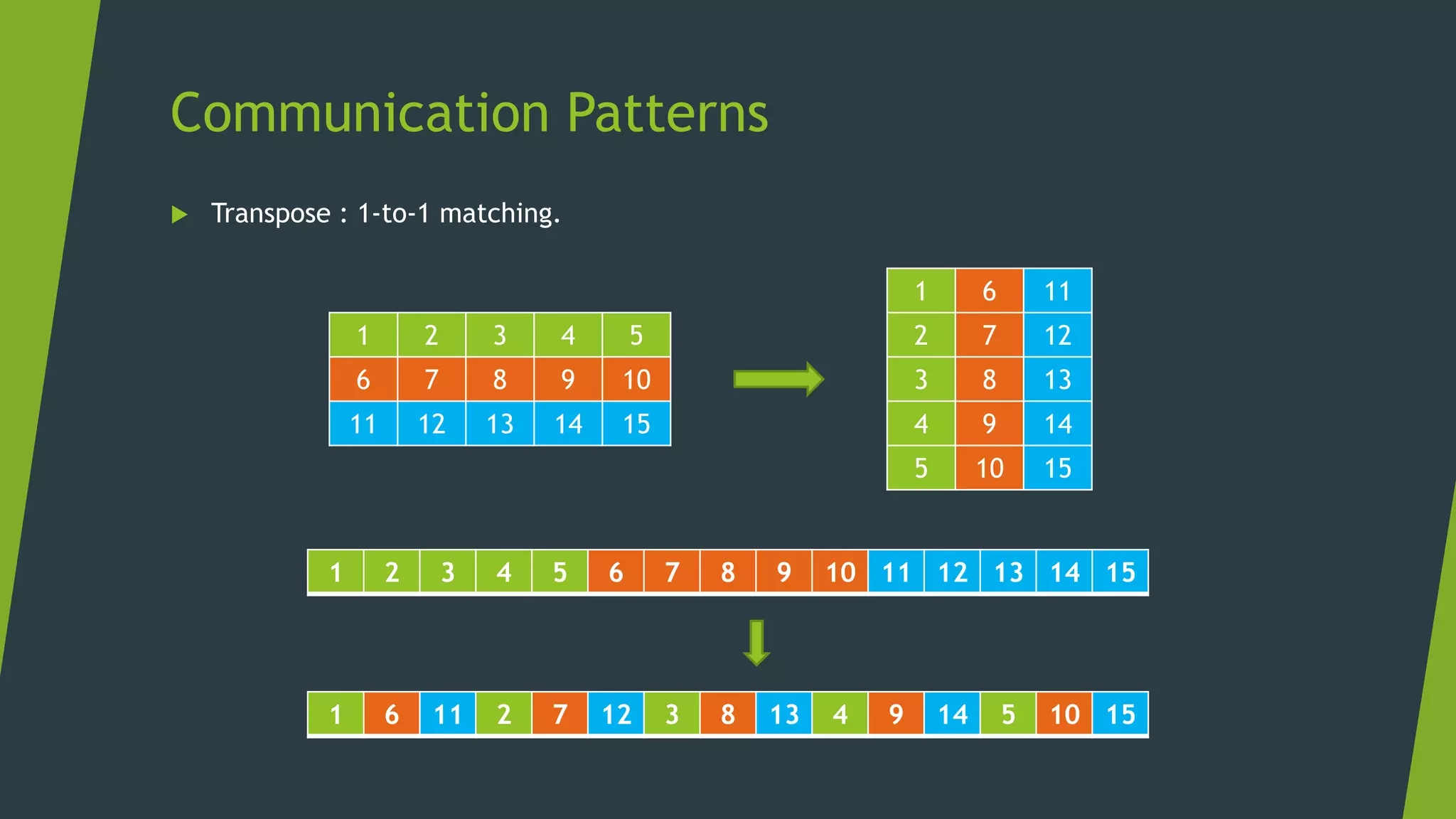
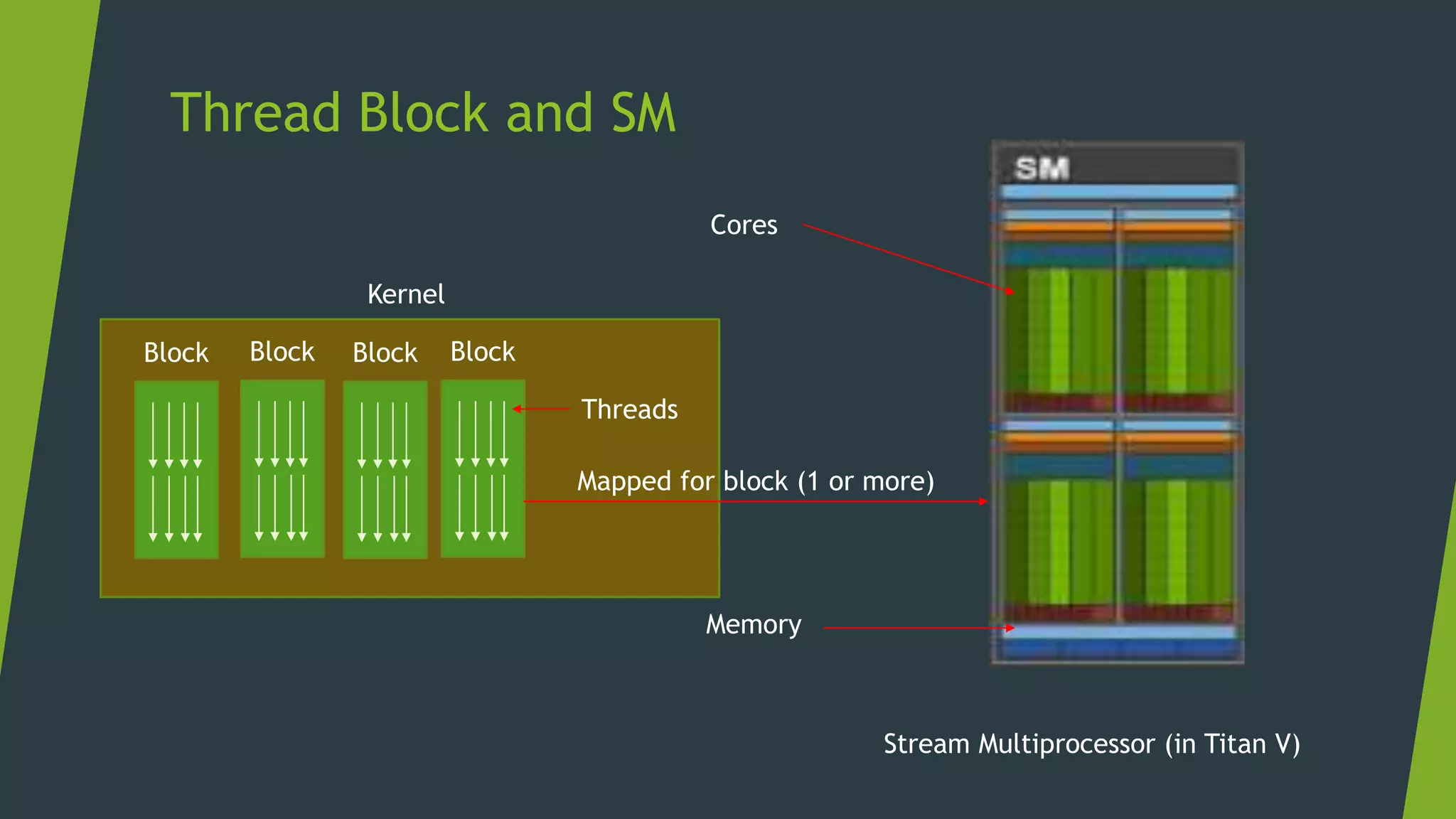
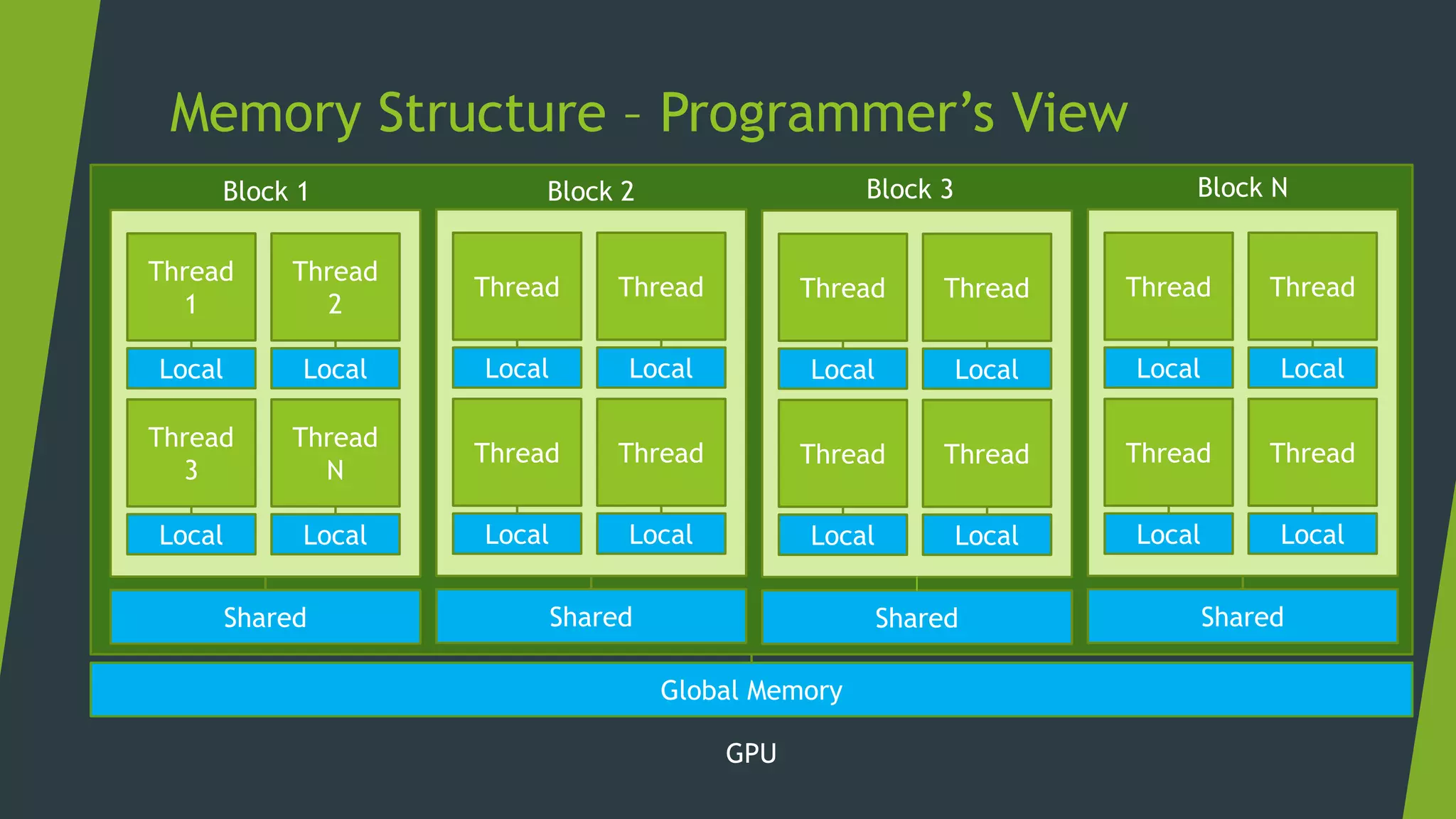
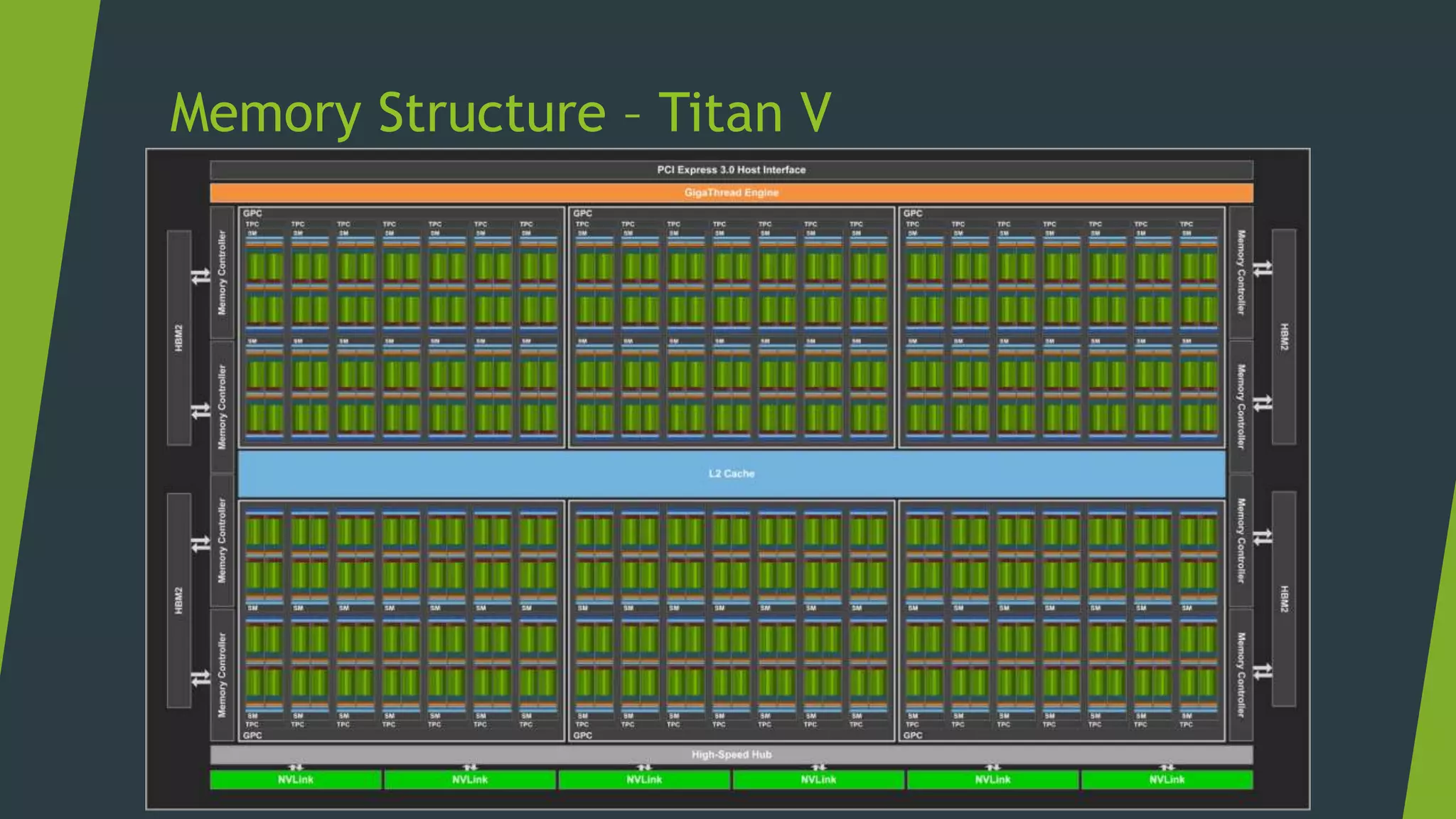

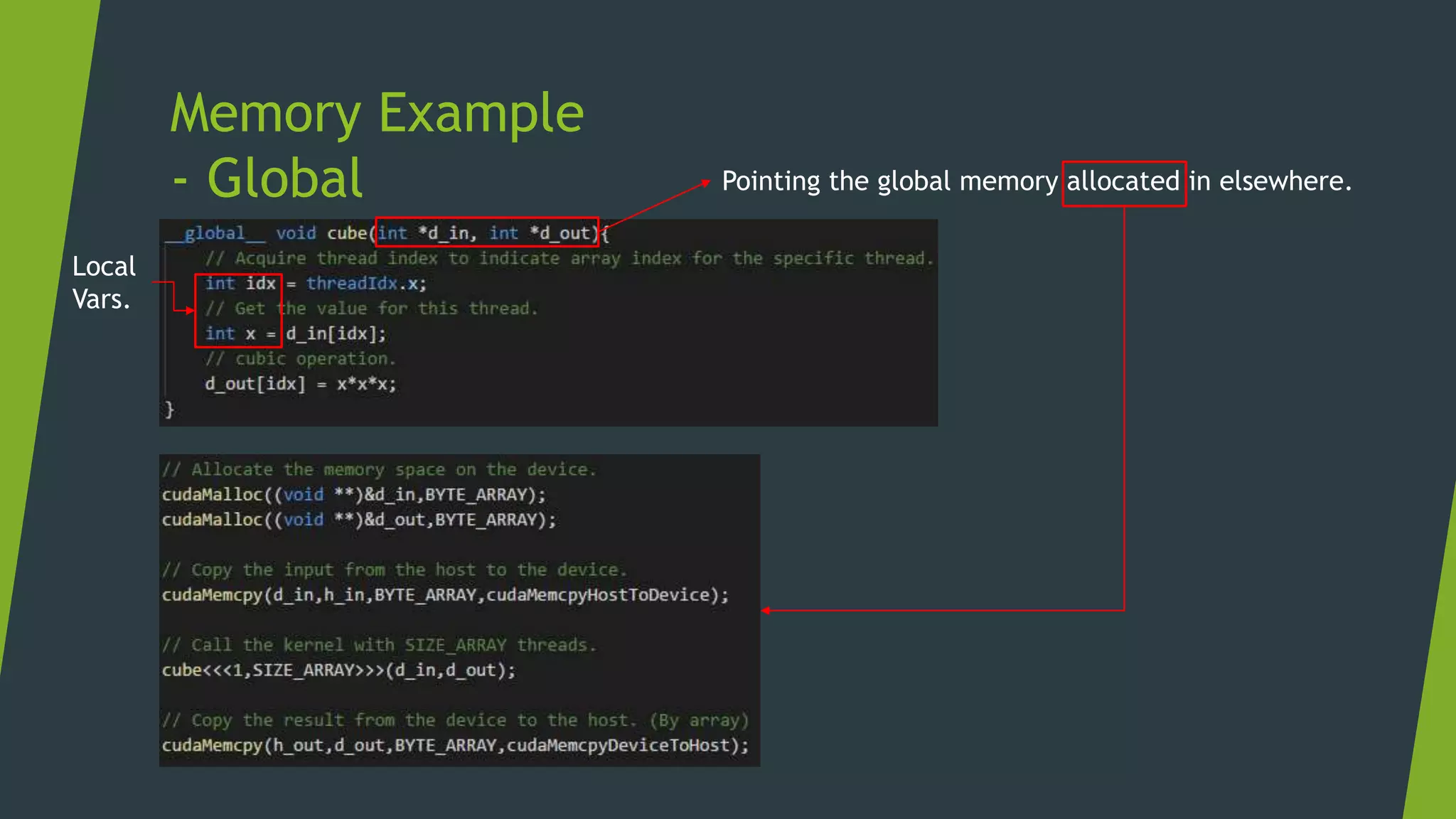
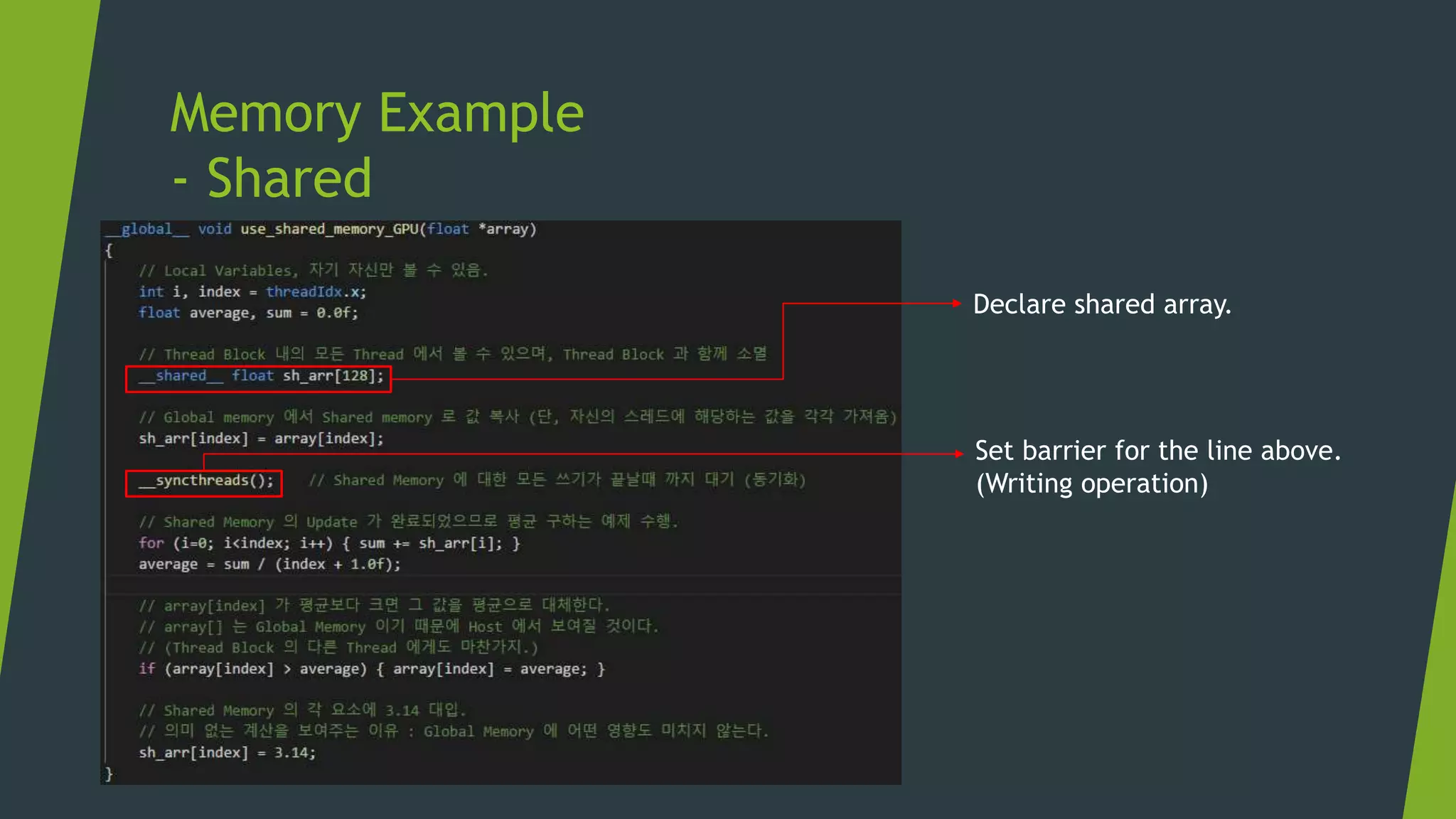

![Memory Management Strategies
Maximize arithmetic intensity
Maximize compute operations per thread
Minimize time spent on memory per thread
Move frequently-accessed data to fast memory
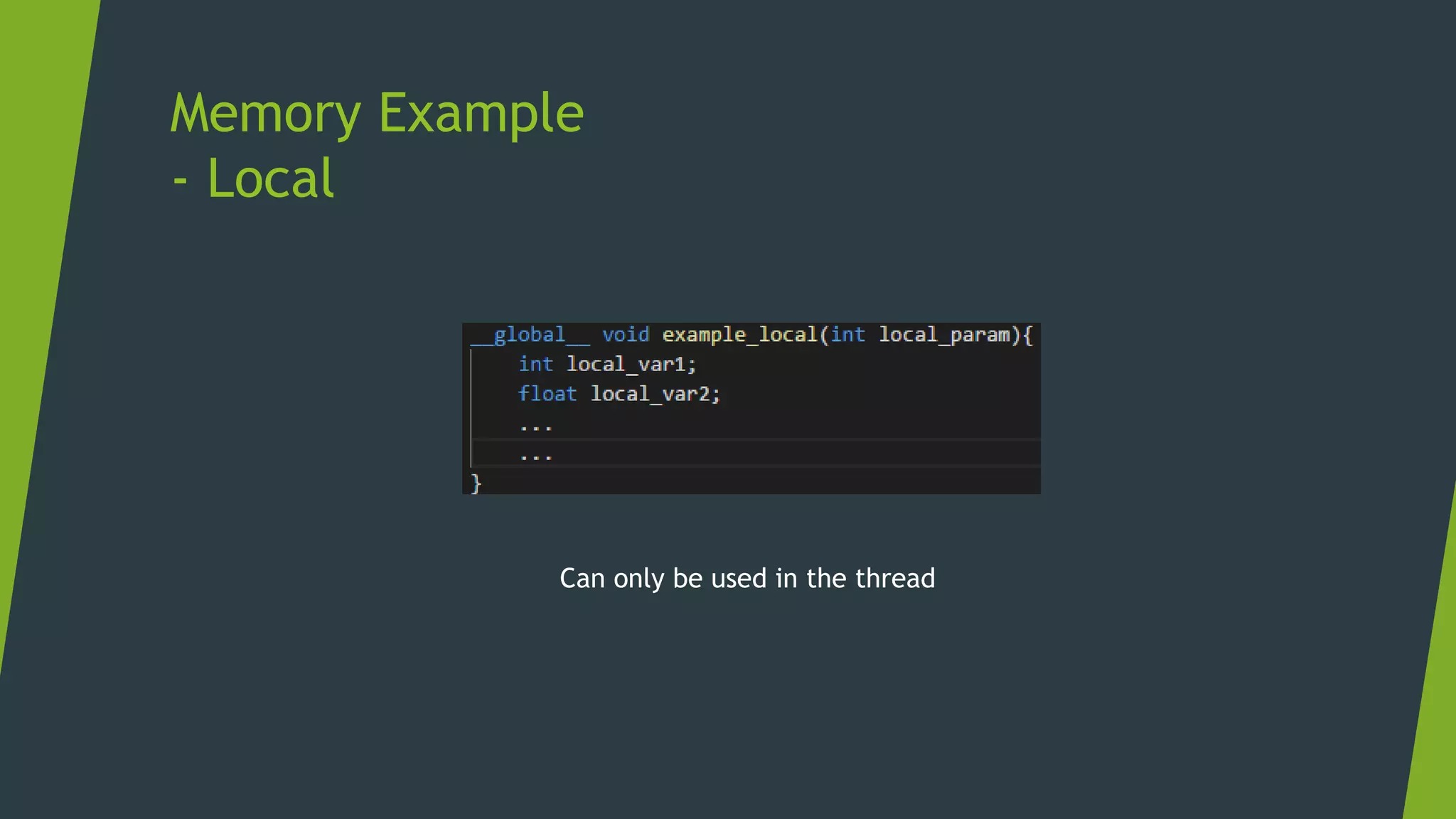
Local
Shared
Global
Host
[Access Speed from Core]](https://image.slidesharecdn.com/cudaweek1-180706064509/75/GPU-Accelerated-Parallel-Computing-36-2048.jpg)