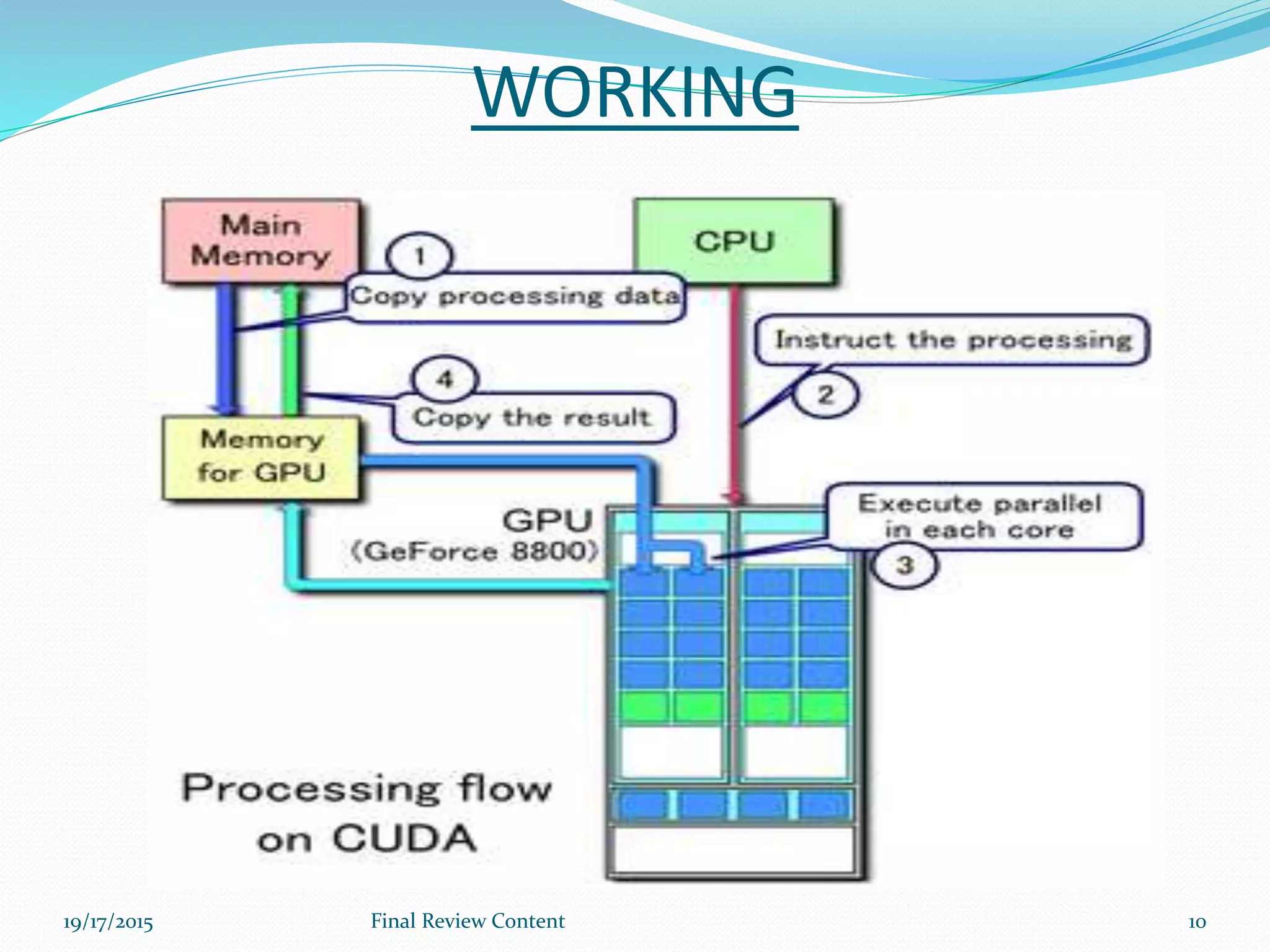
The document discusses graphics processing units (GPUs) and general-purpose GPU (GPGPU) computing. It explains that GPUs were originally designed for computer graphics but can now be used for general computations through GPGPU. The document outlines CUDA and MPI frameworks for programming GPGPU applications and discusses how GPGPU provides highly parallel processing that is much faster than traditional CPUs. Example applications mentioned include molecular dynamics, bioinformatics, and high performance computing.



































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
