Download as PDF, PPTX






![Add and contains on bitset
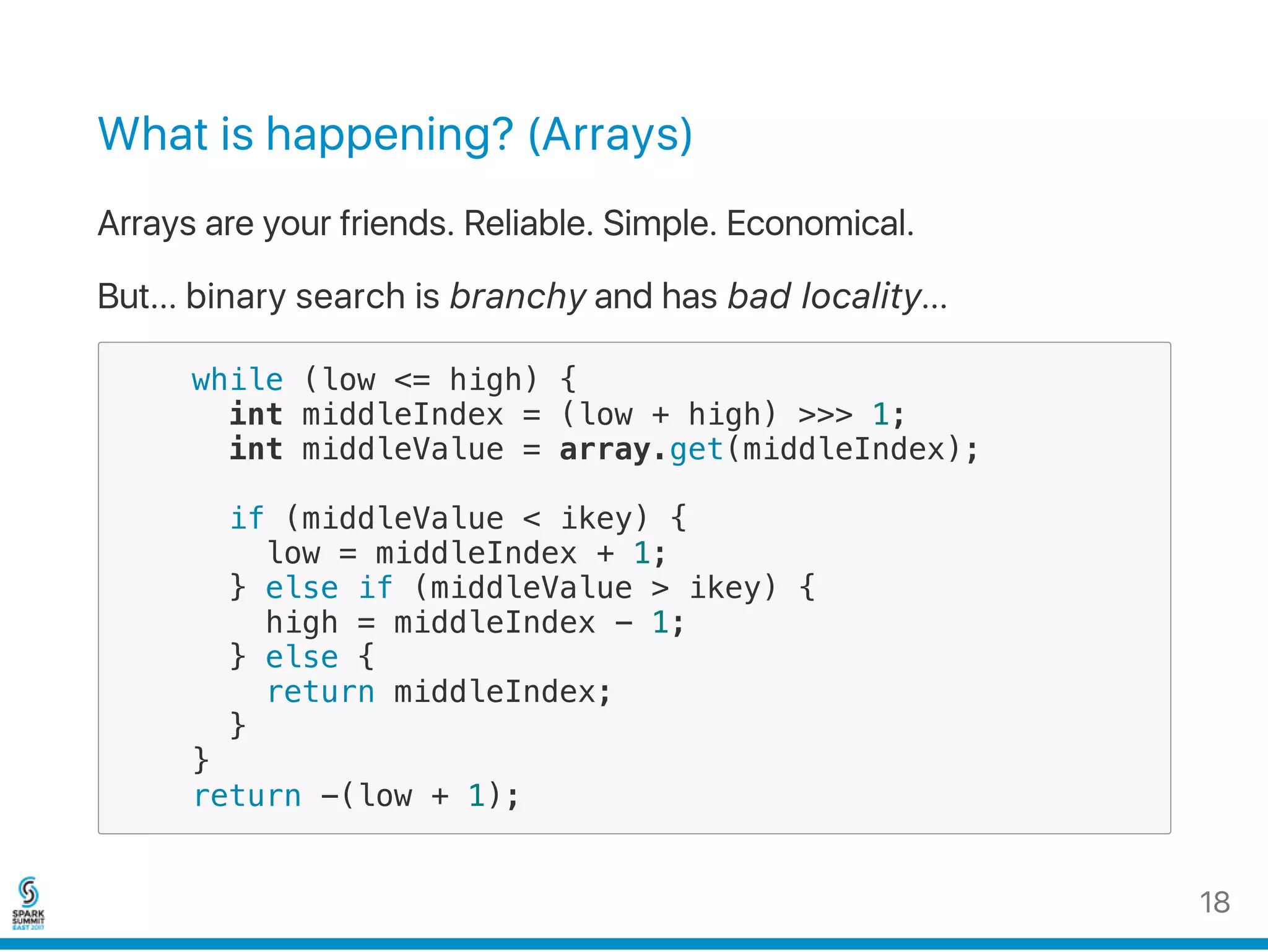
Most of the processors work on 64‑bit words.
Given index x , the corresponding word index is x/64 and within‑
word bit index is x % 64 .
add(x) {
array[x / 64] |= (1 << (x % 64))
}
contains(x) {
return array[x / 64] & (1 << (x % 64))
}
8](https://image.slidesharecdn.com/fastindexes-170207222837/75/Engineering-fast-indexes-8-2048.jpg)
![How fast can you set bits in a bitset?
Very fast! Roughly three instructions (on x64)...
index = x / 64 -> a single shift
mask = 1 << ( x % 64) -> a single shift
array[ index ] |- mask -> a logical OR to memory
(Or can use BMI's bts .)
On recent x64 can set one bit every ≈ 1.65 cycles (in cache)
Recall : Modern processors are superscalar (more than one
instruction per cycle)
9](https://image.slidesharecdn.com/fastindexes-170207222837/75/Engineering-fast-indexes-9-2048.jpg)

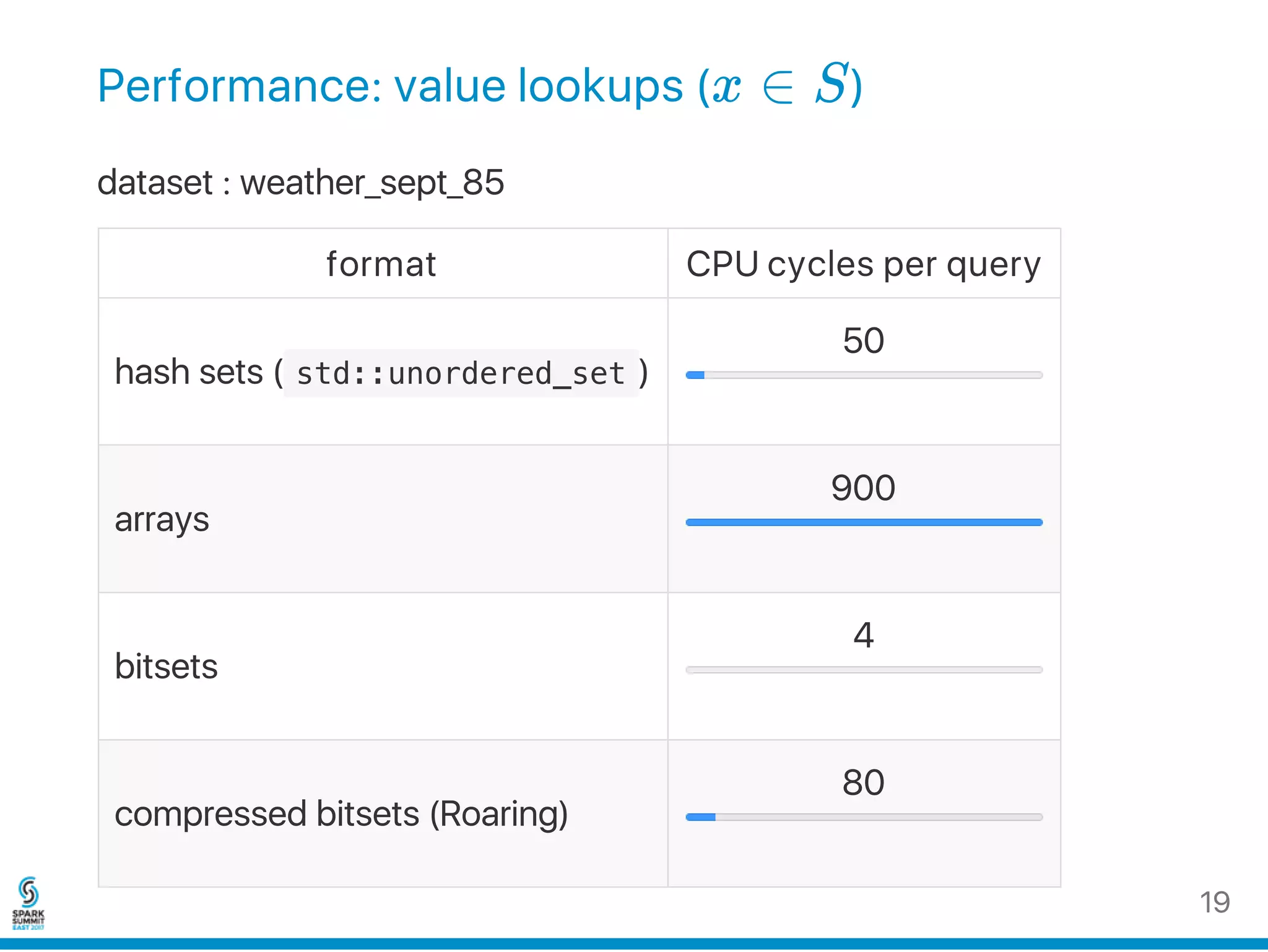
![Bitsets are efficient: in practice
for i in [0...n]
out[i] = A[i] & B[i]
Recent x64 processors can do this at a speed of ≈ 0.5 cycles per
pair of input 64‑bit words (in cache) for n = 1024 .
0.5
memcpy runs at ≈ 0.3 cycles.
0.3
11](https://image.slidesharecdn.com/fastindexes-170207222837/75/Engineering-fast-indexes-11-2048.jpg)








![Hybrid Model
Decompose 32‑bit space into
16‑bit spaces (chunk).
Given value x, its chunk index is x ÷ 2 (16 most significant bits).
For each chunk, use best container to store least 16 significant bits:
a sorted array ({1,20,144})
a bitset (0b10000101011)
a sequences of sorted runs ([0,10],[15,20])
That's Roaring!
Prior work: O'Neil's RIDBit + BitMagic
16
22](https://image.slidesharecdn.com/fastindexes-170207222837/75/Engineering-fast-indexes-22-2048.jpg)





The document discusses innovations in integer set data structures, particularly focusing on roaring bitmaps, which are used by various major platforms like Apache Spark and Netflix. It compares the efficiency and performance of different data structures, including hash sets, bitsets, and compressed bitsets, highlighting their strengths and weaknesses in various scenarios. The document also emphasizes the importance of memory usage and processing speed in handling sets of integers for applications in databases and search engines.


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

