Download as PDF, PPTX














![IA
VS
Rasterizer
PS
Output
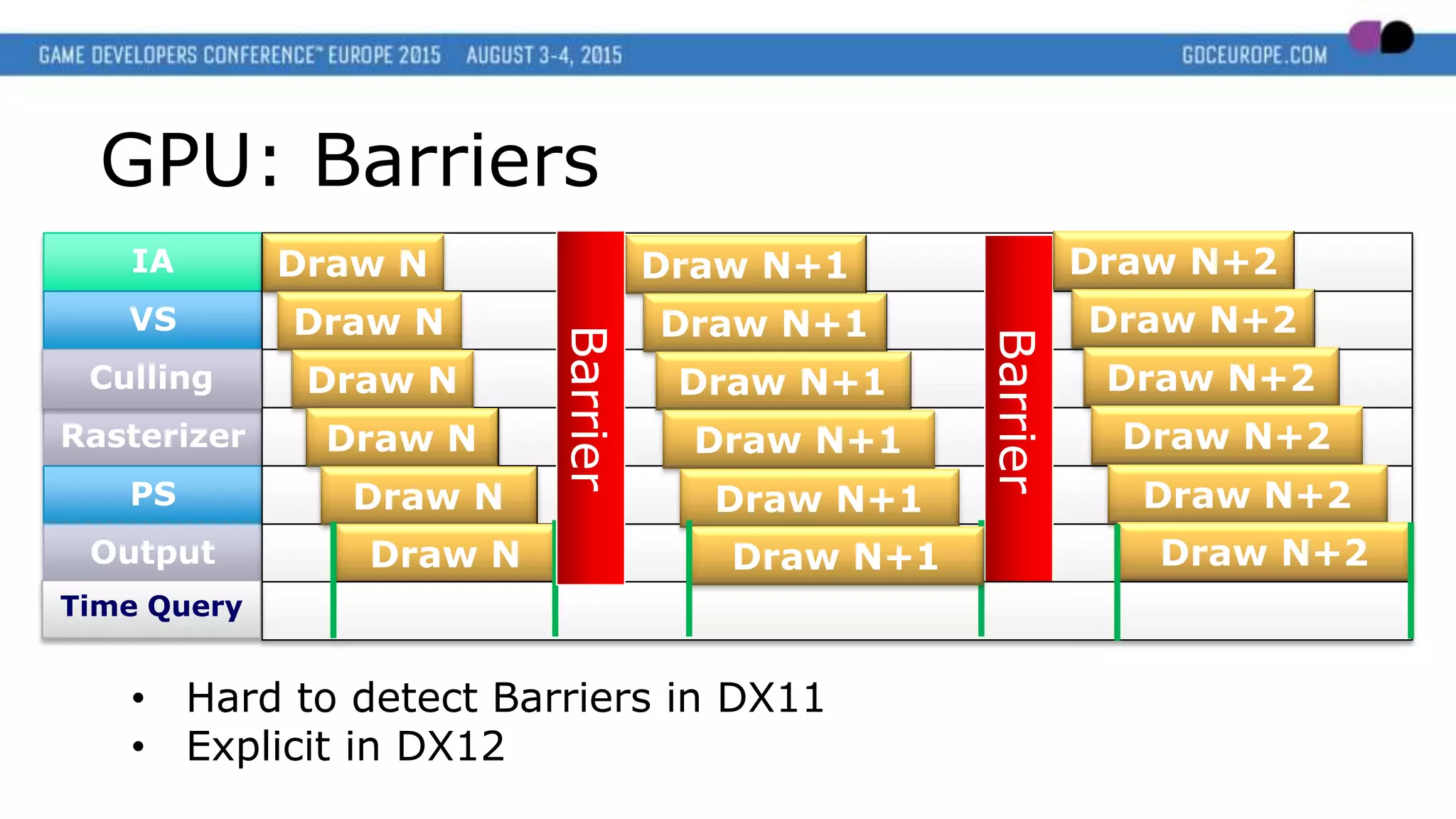
GPU: Barriers
• Batch them!
• [DX12] In the future split barriers may help
Culling
Draw N
Draw N
Draw N
Draw N
Draw N
Draw N
Time Query
Draw N+2
Draw N+2
Draw N+2
Draw N+2
Draw N+2
Draw N+2DoubleBarrier
Draw N+1
Draw N+1
Draw N+1
Draw N+1
Draw N+1
Draw N+1](https://image.slidesharecdn.com/hodesstephandirectx12andvulkan-150820145027-lva1-app6892/75/DX12-Vulkan-Dawn-of-a-New-Generation-of-Graphics-APIs-20-2048.jpg)






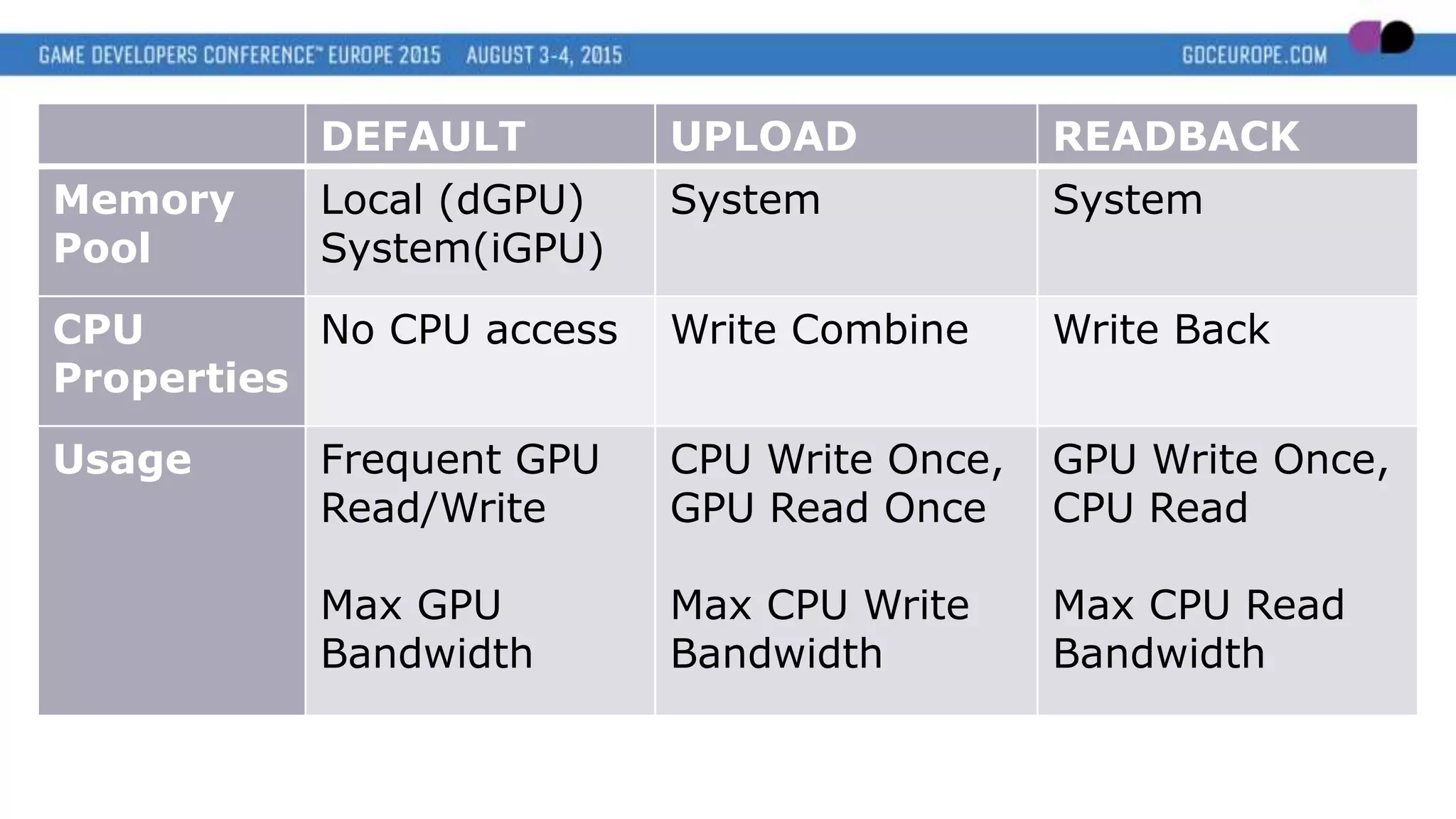

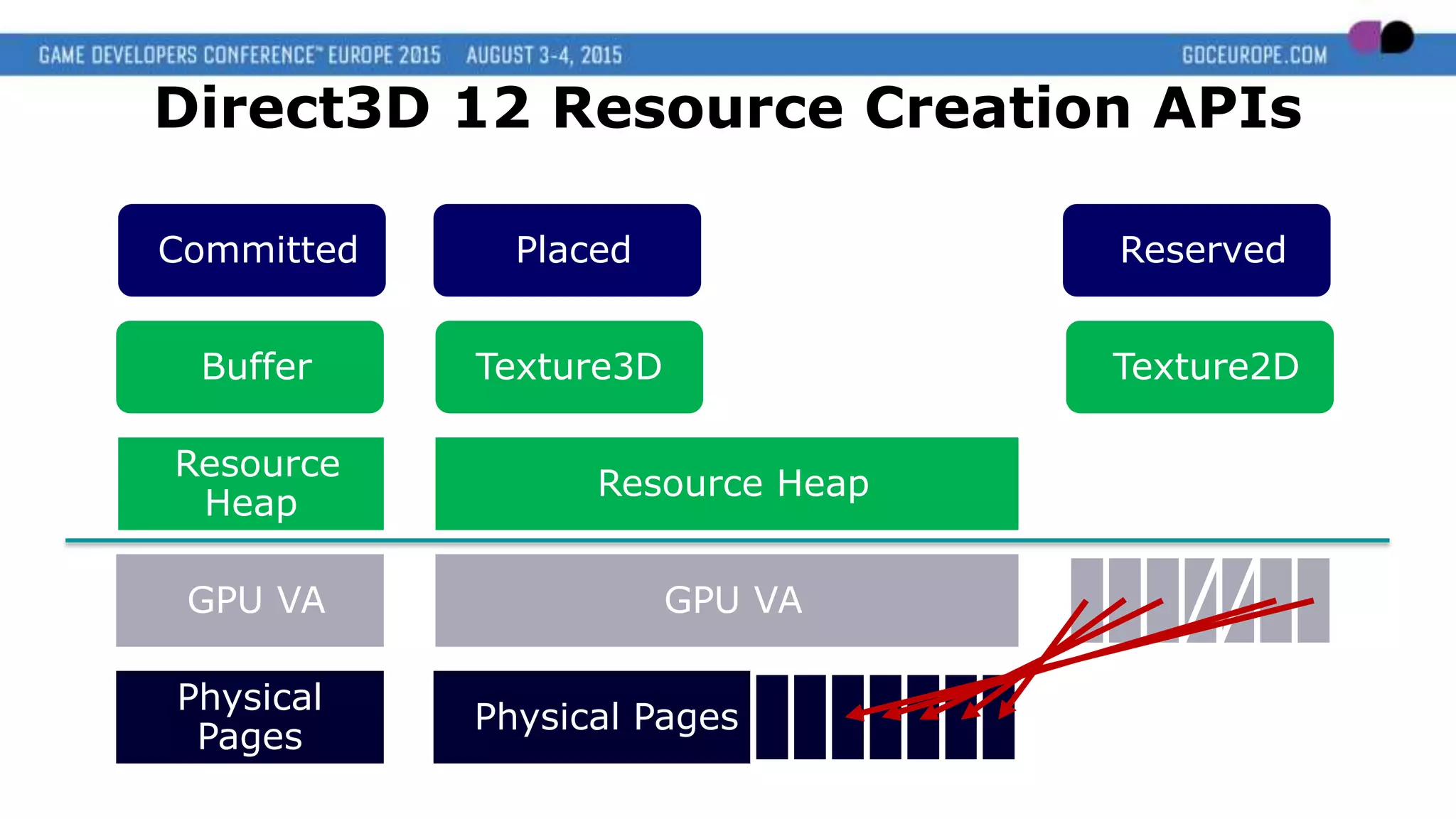


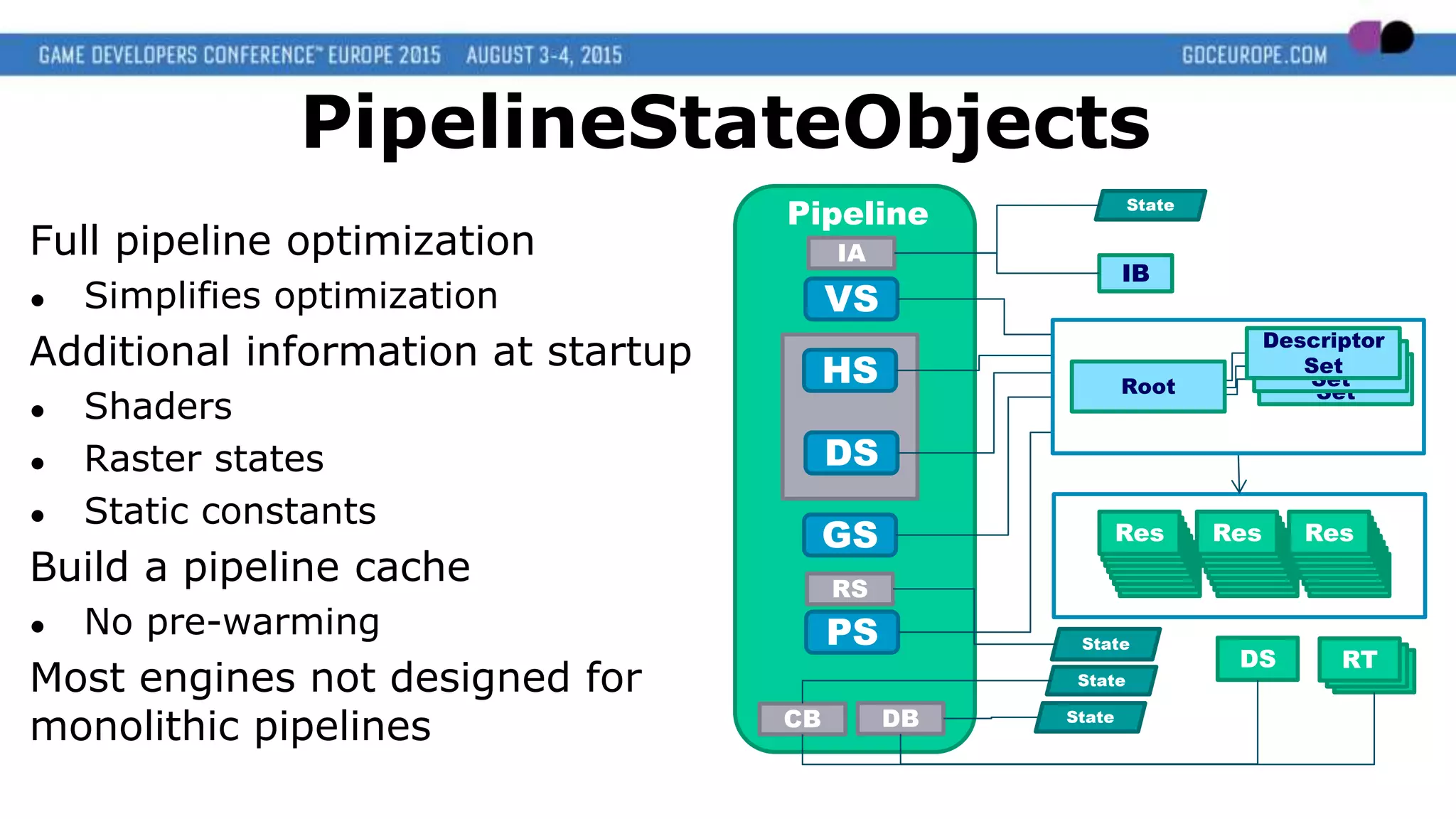


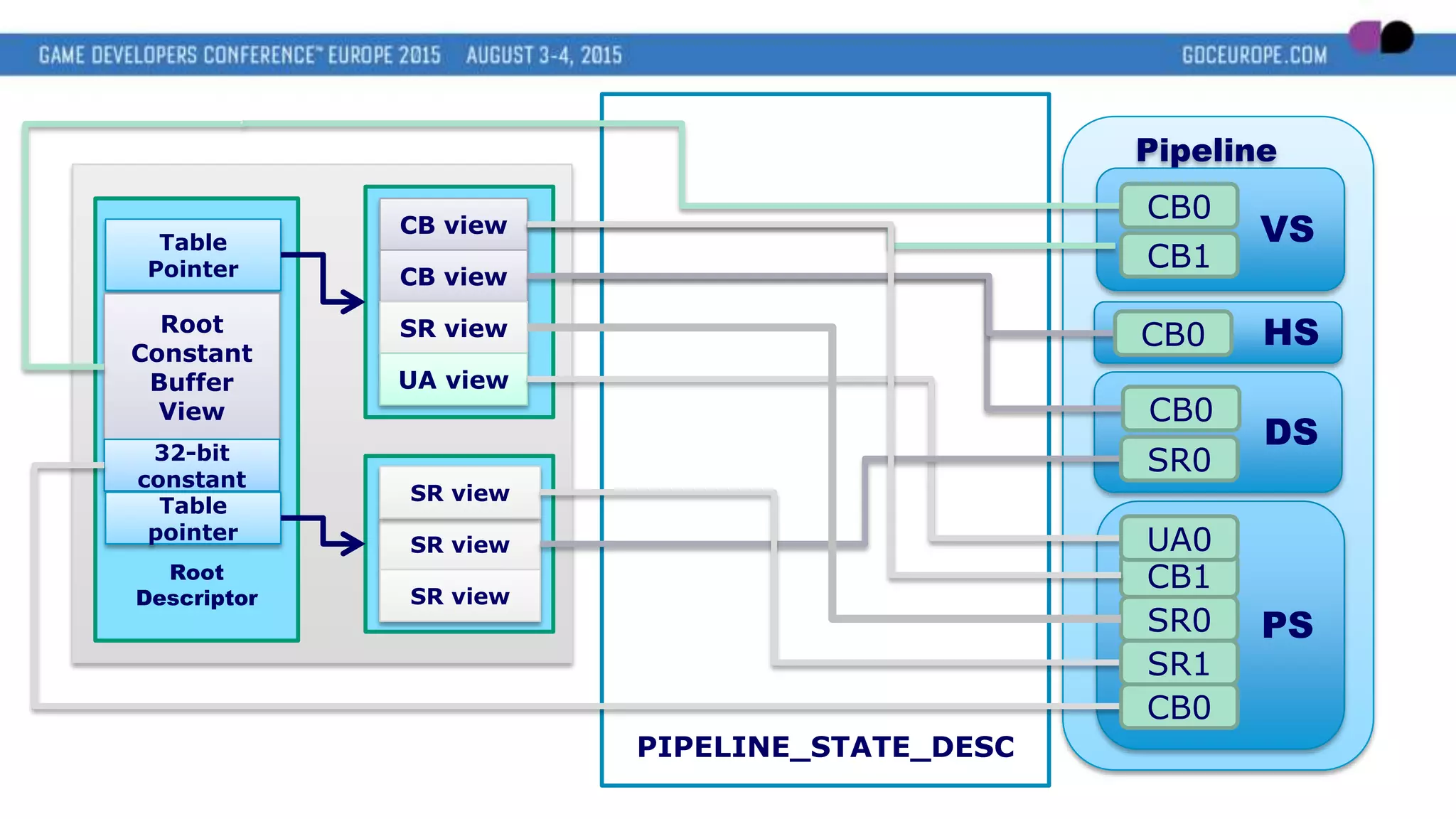



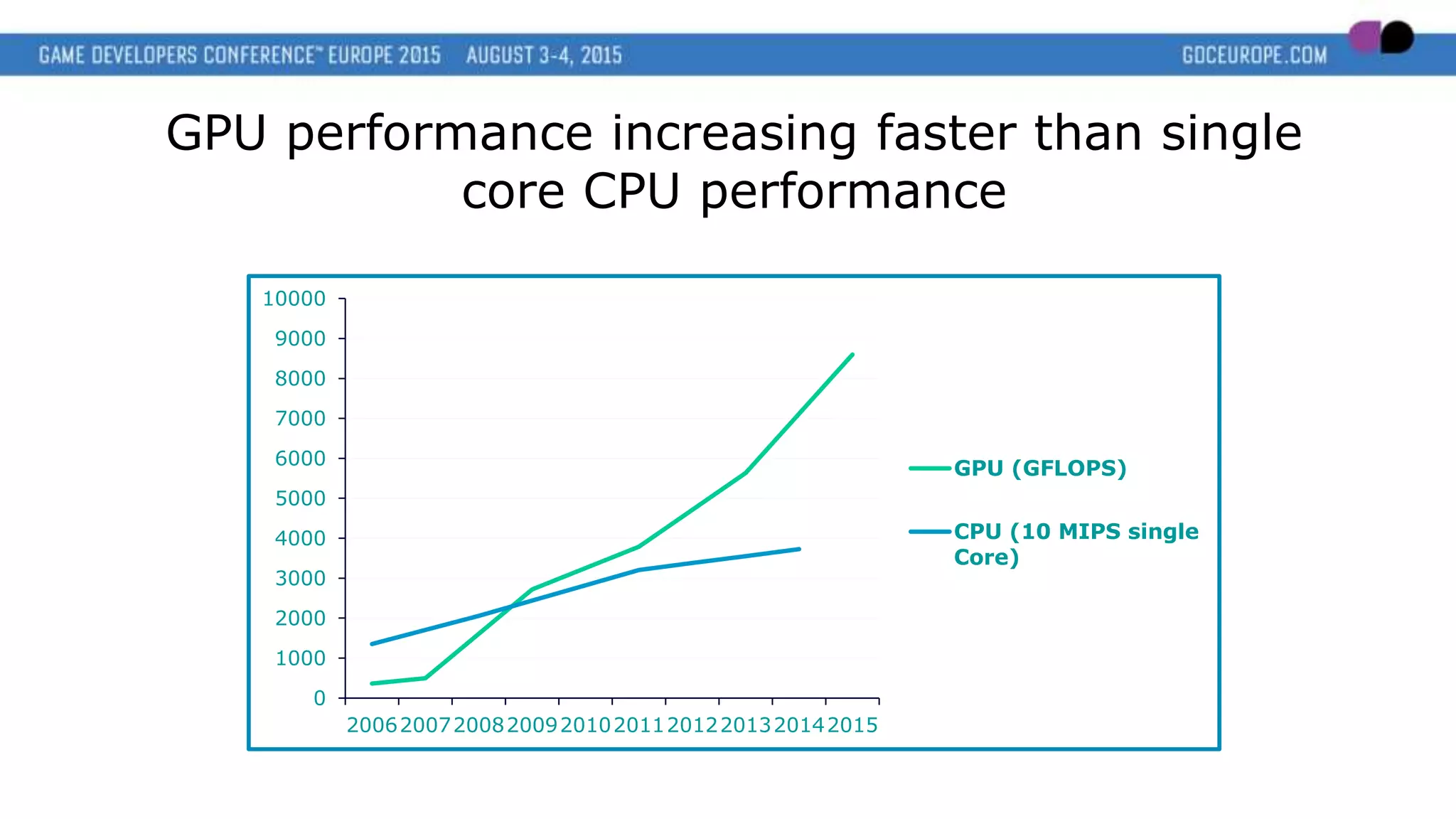
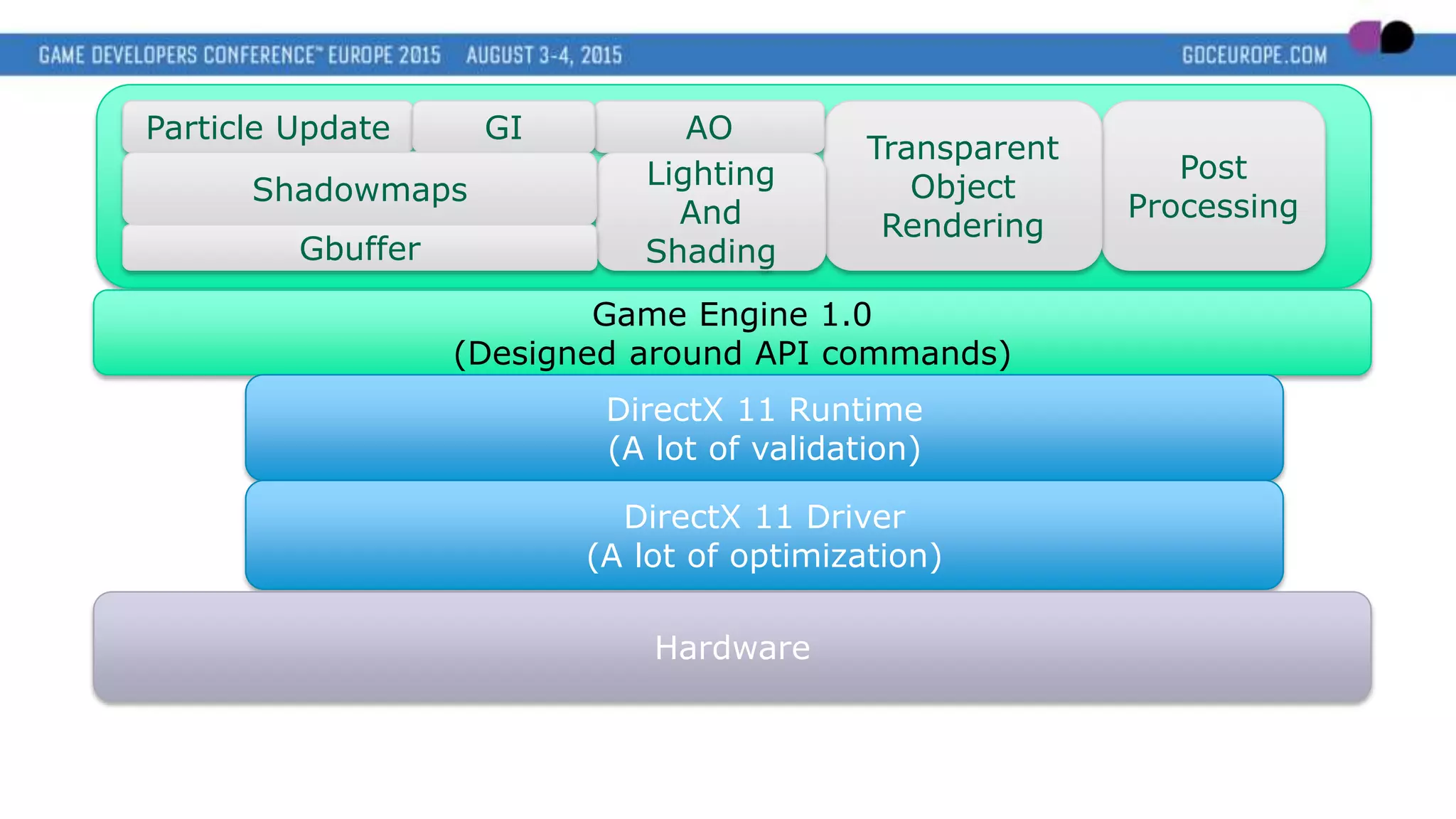
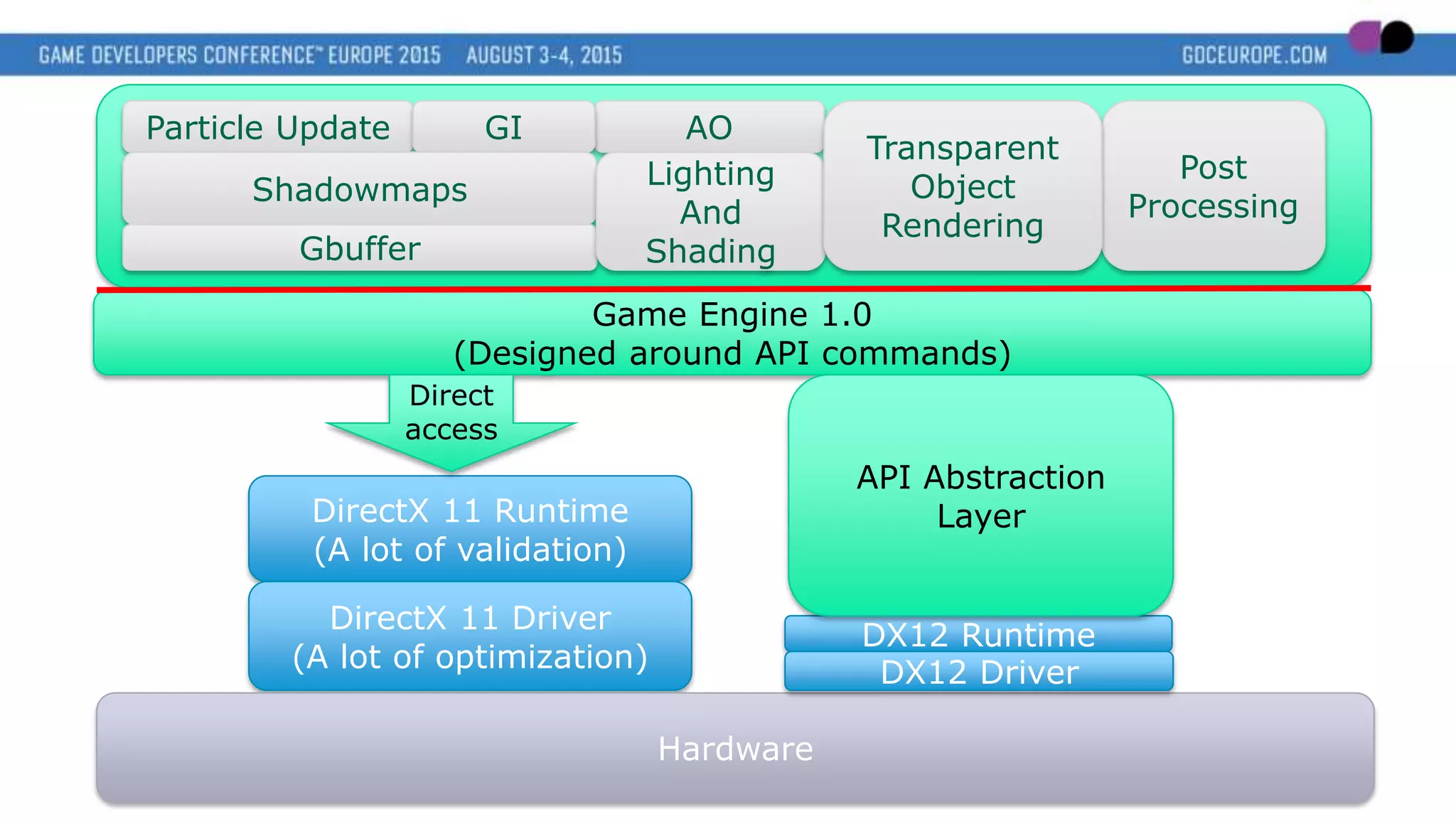
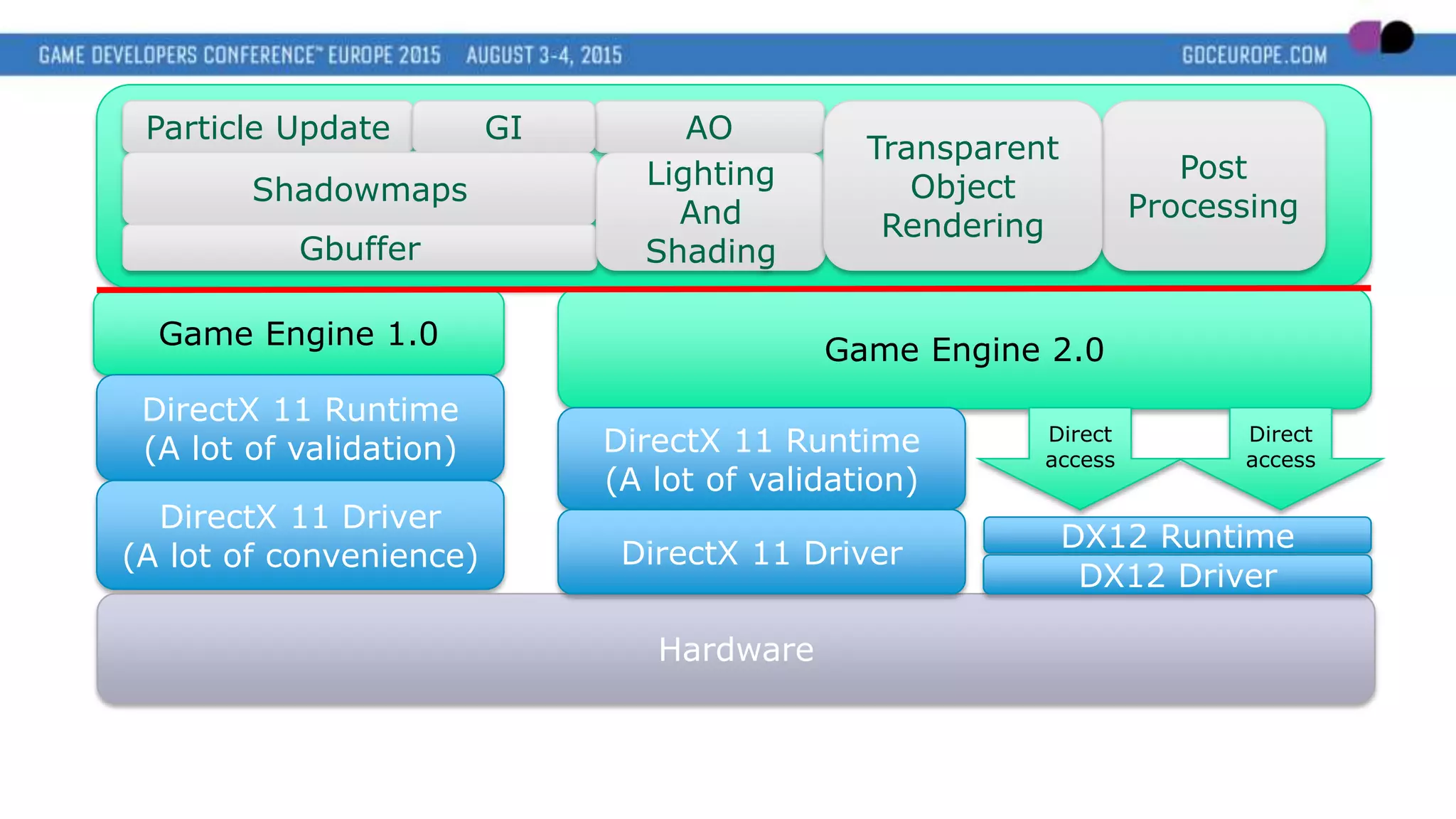
This document discusses new graphics APIs like DX12 and Vulkan that aim to provide lower overhead and more direct hardware access compared to earlier APIs. It covers topics like increased parallelism, explicit memory management using descriptor sets and pipelines, and best practices like batching draw calls and using multiple asynchronous queues. Overall, the new APIs allow more explicit control over GPU hardware for improved performance but require following optimization best practices around areas like parallelism, memory usage, and command batching.

![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[1023 박민수] 깊이_버퍼_그림자_1](https://cdn.slidesharecdn.com/ss_thumbnails/10231-101028122527-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































