Download as PDF, PPTX








![More nodes, higher probability of failure in system.
Possible problems with nodes:
Node stopped (and will not be back);
Node was down small amount of time (and we should bring it
back to operation);
Network partitions (avoid split-brain).
If we want to survive network partitions than we can have not more
than [N/2] - 1 failures.
HA/autofailover
13](https://image.slidesharecdn.com/distributedpostgres-160518144919/75/Distributed-Postgres-13-2048.jpg)





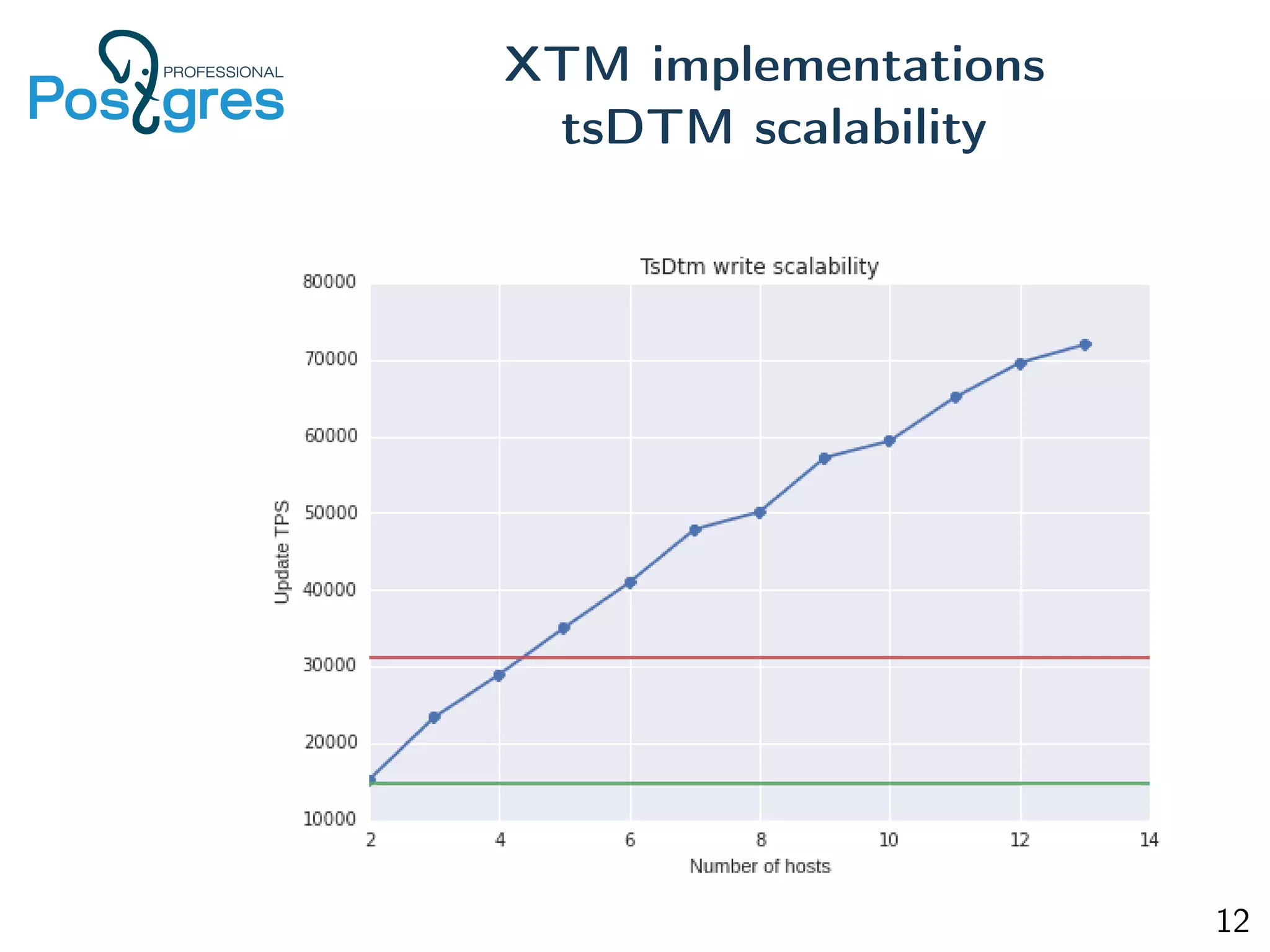
This document discusses distributed Postgres including multi-master replication, distributed transactions, and high availability/auto failover. It explores existing implementations like Postgres-XC and proposes a transaction manager API and time-stamp based approach to enable distributed transactions without a central bottleneck. The document also outlines a multimaster implementation built on logical replication, a transaction replay pool, and Raft-based storage for failure handling and distributed deadlocks. Performance is approximately half of standalone Postgres with the same read speeds and capabilities for node recovery and network partition handling.













































































