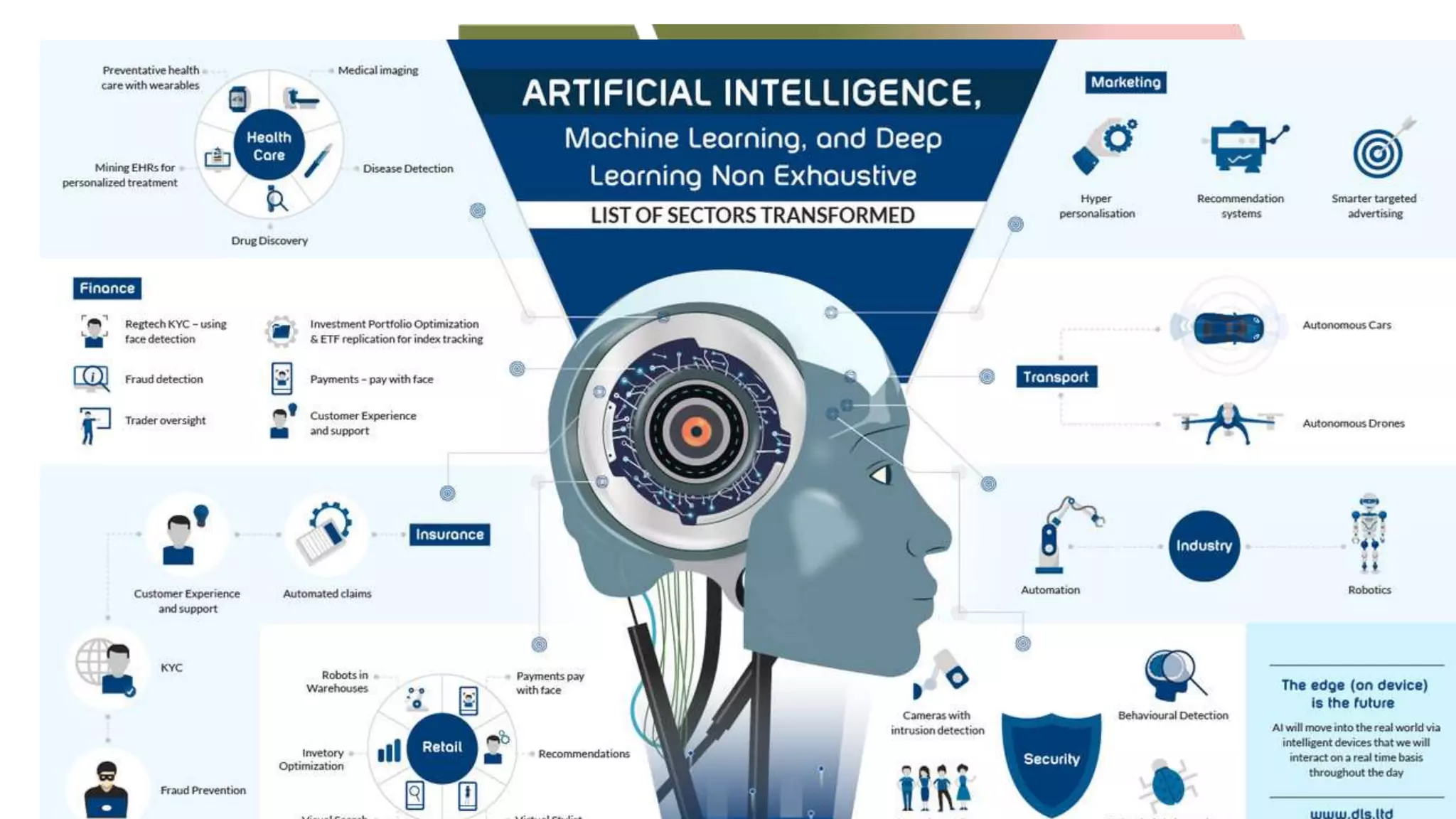
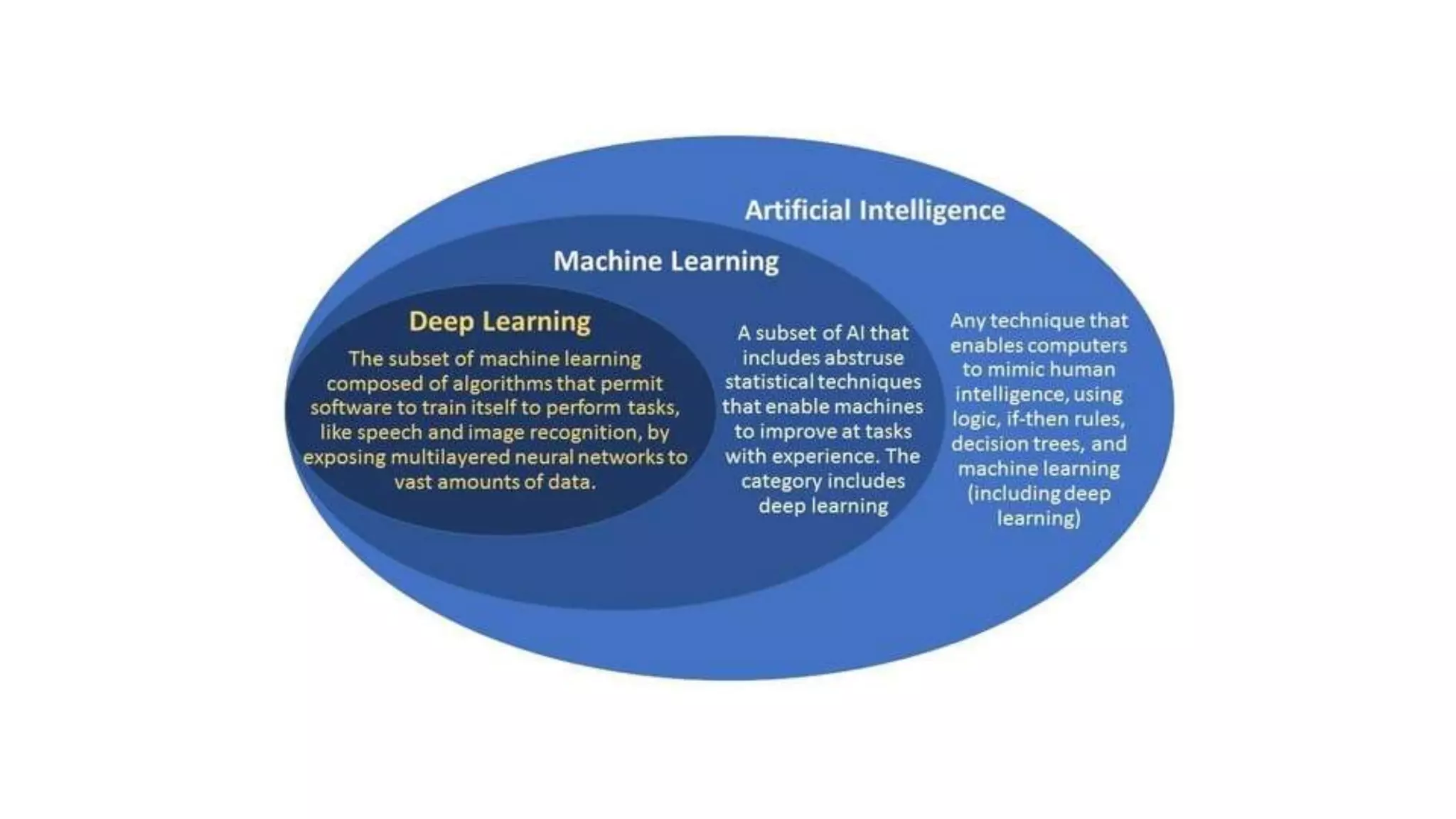
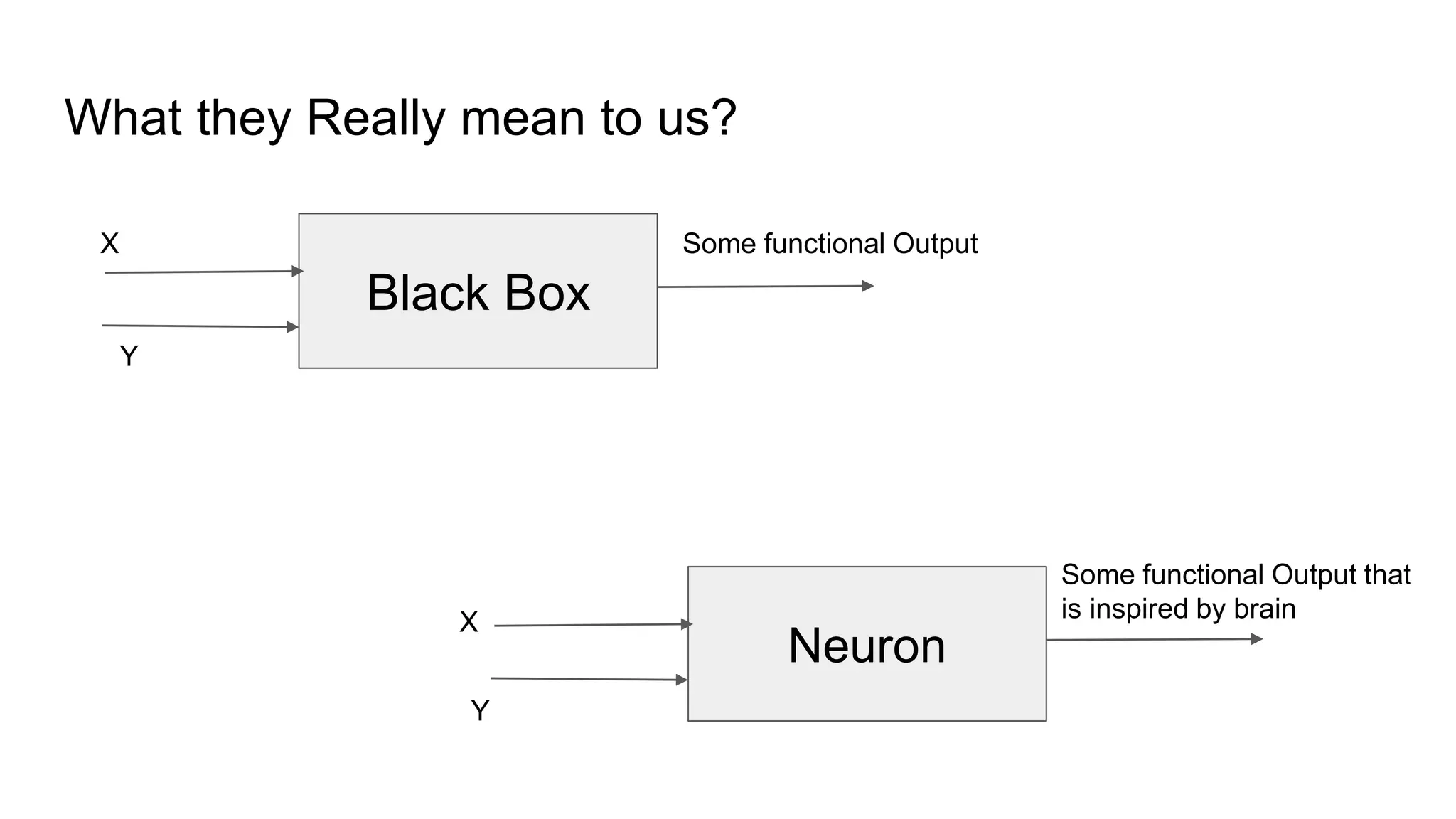
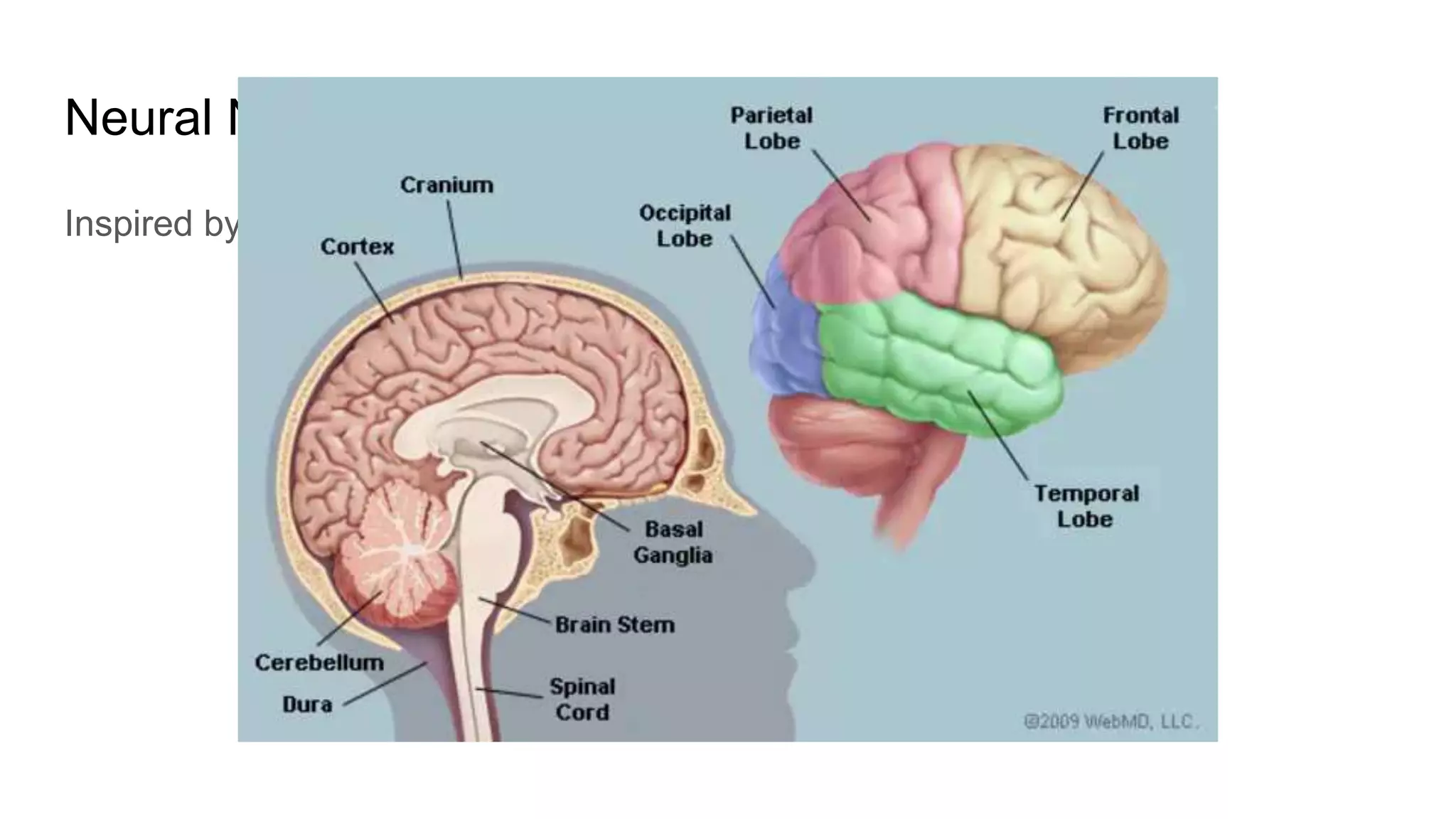
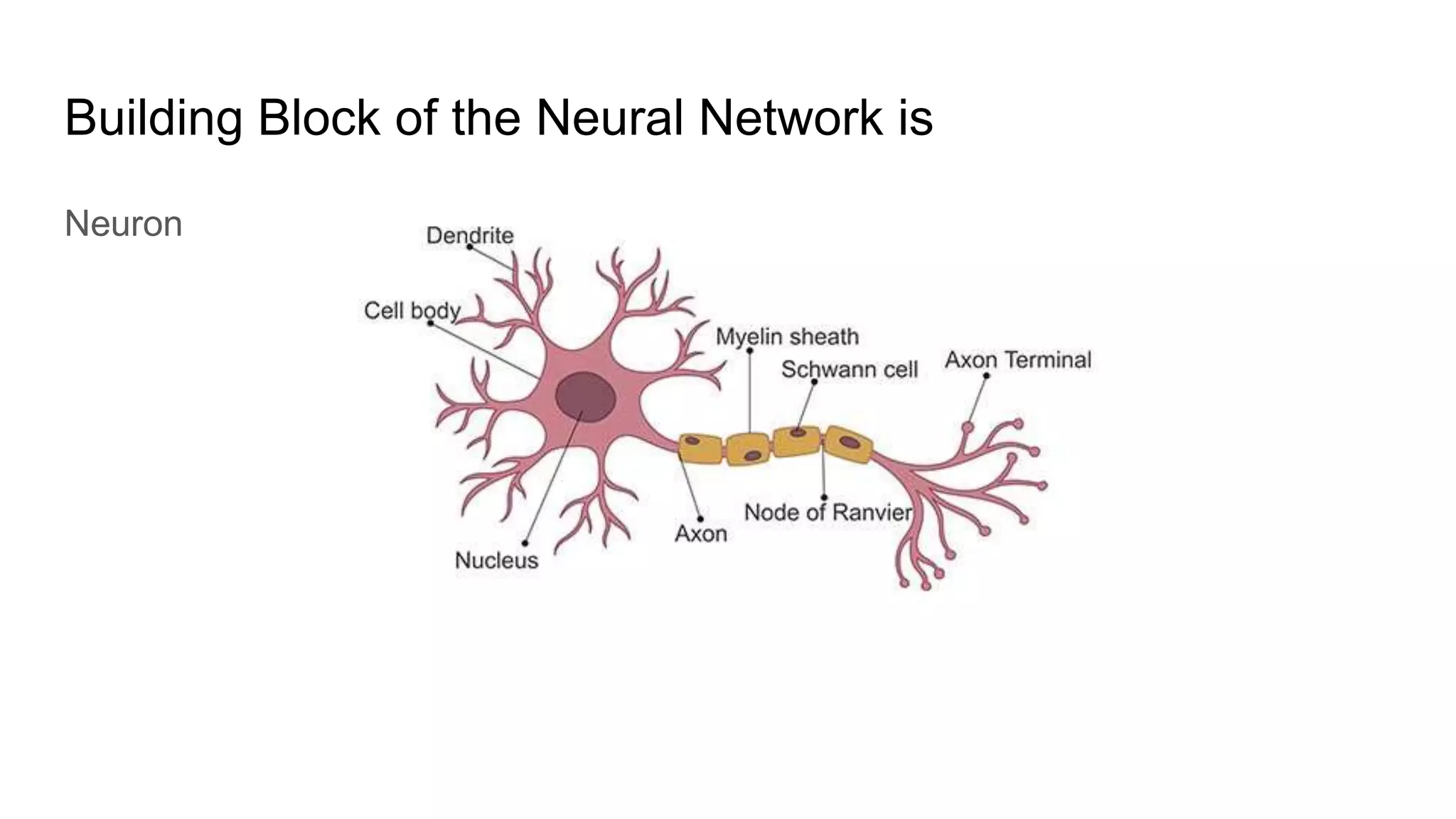
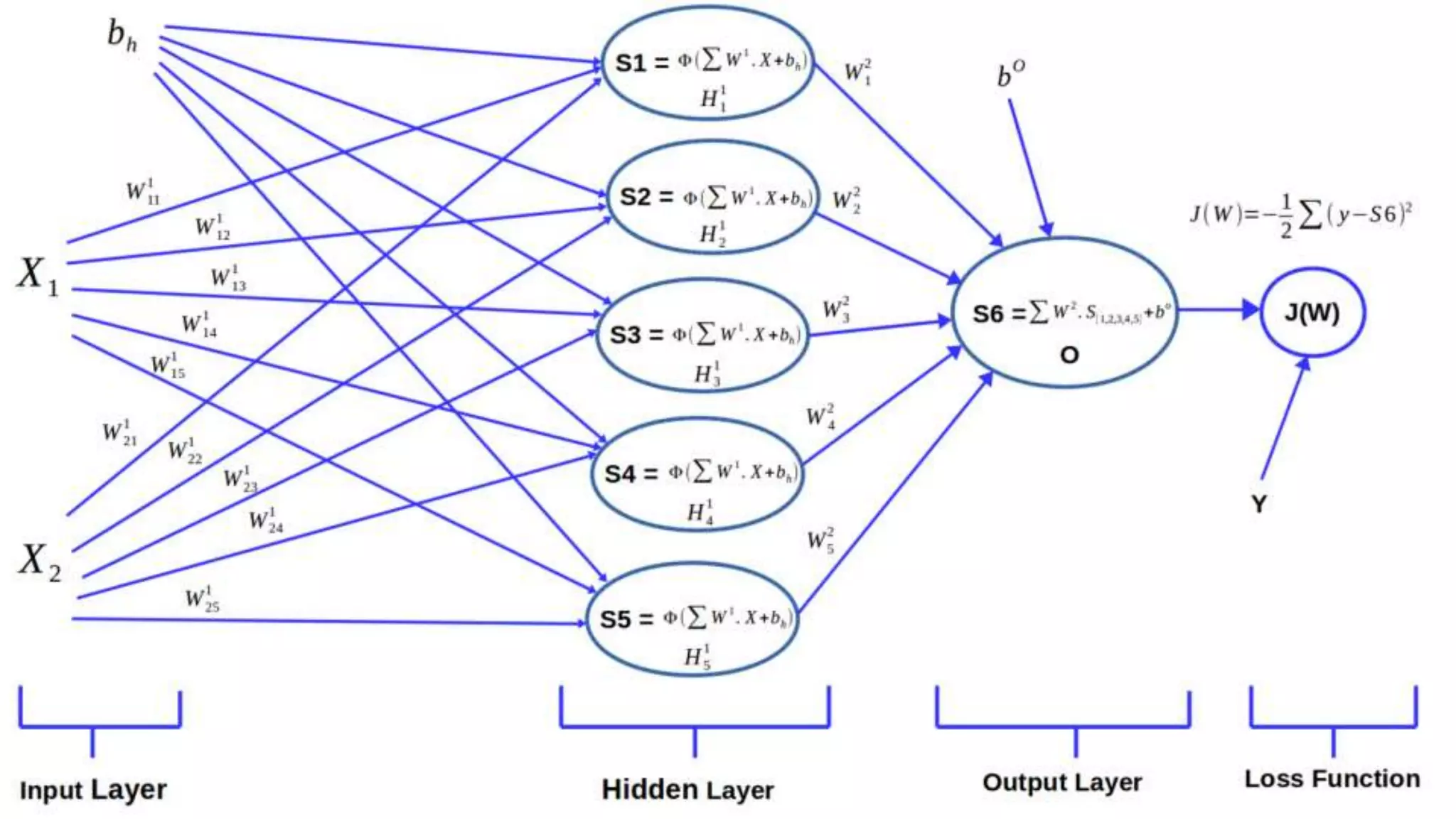
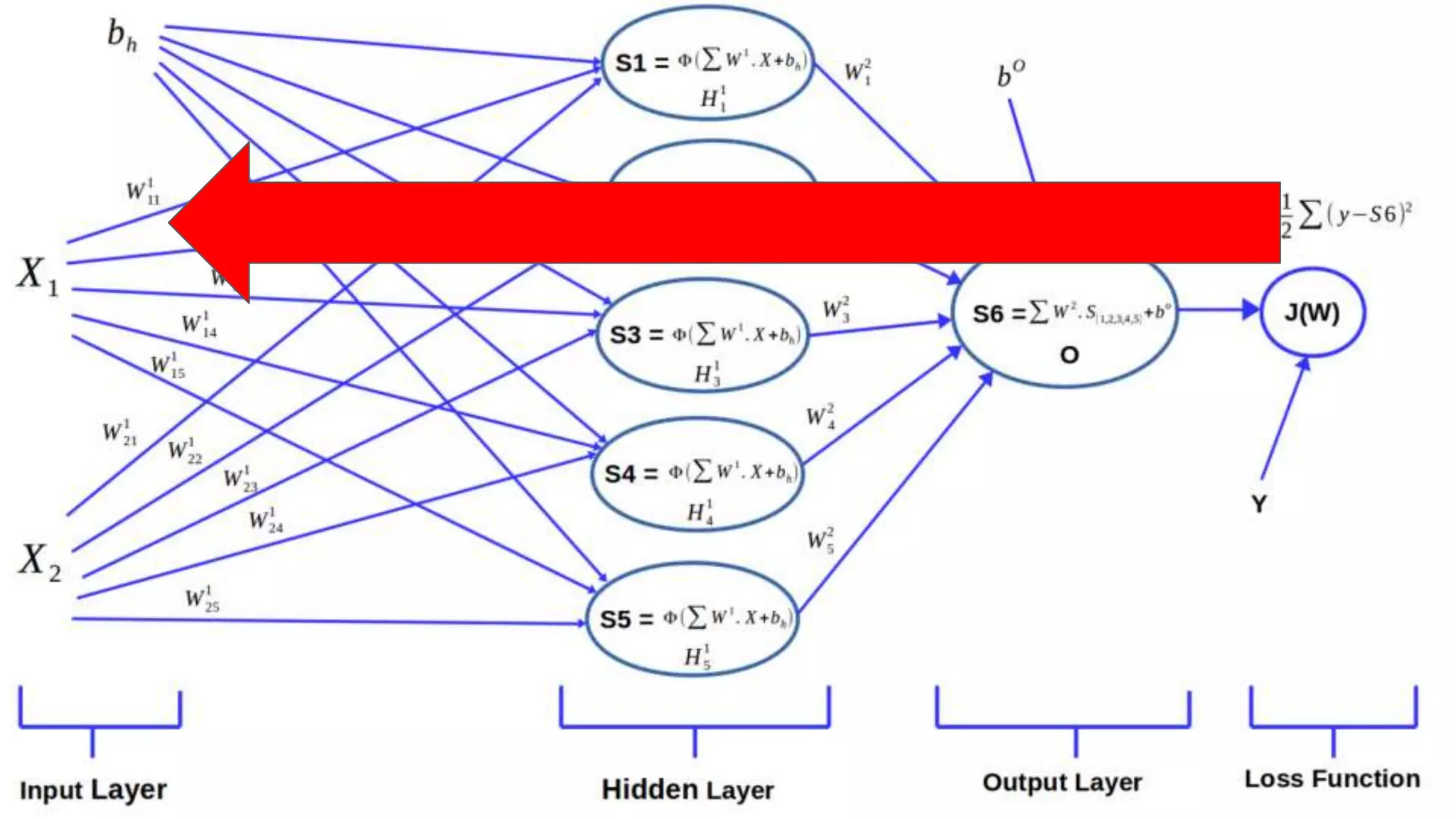
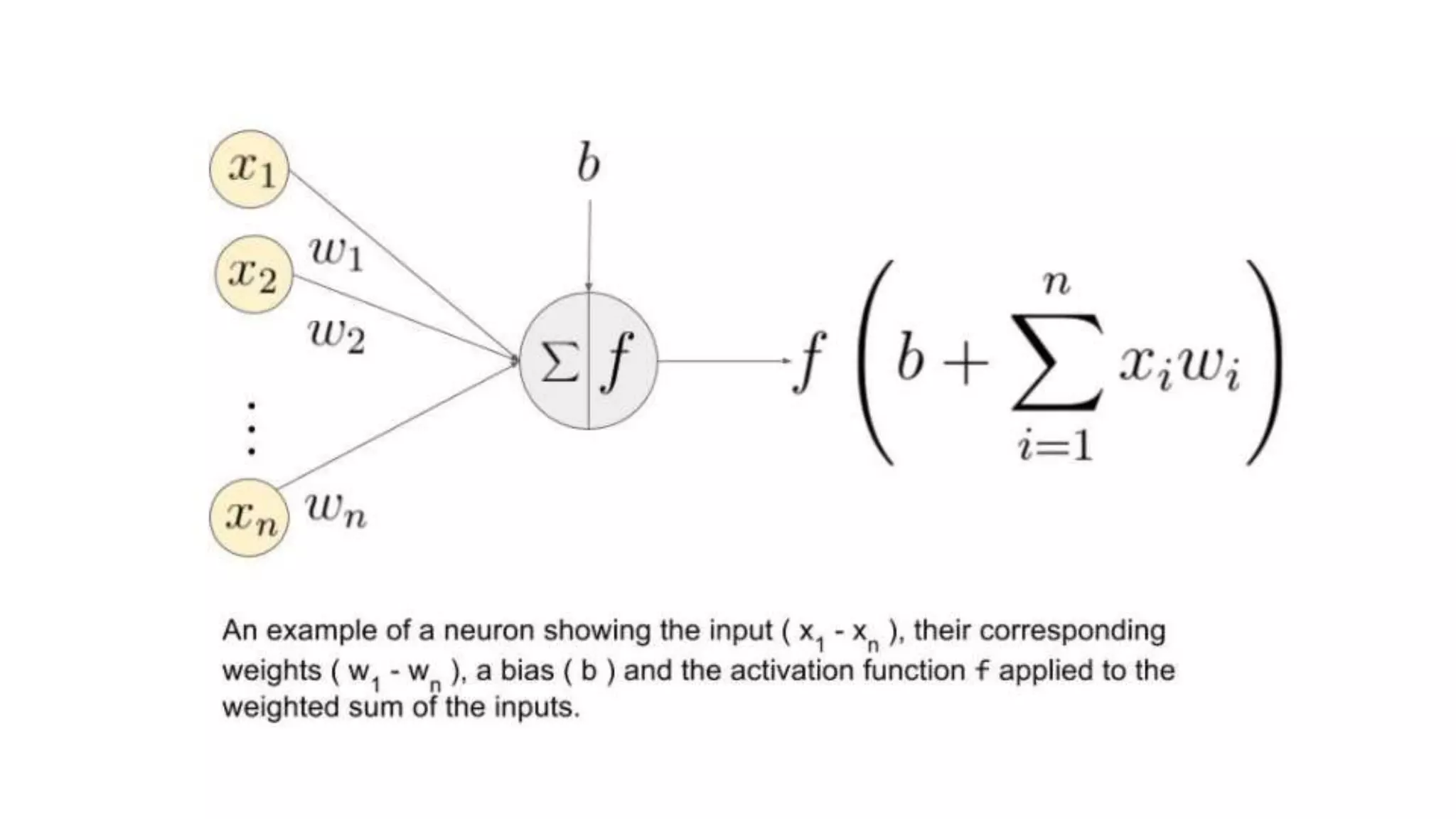
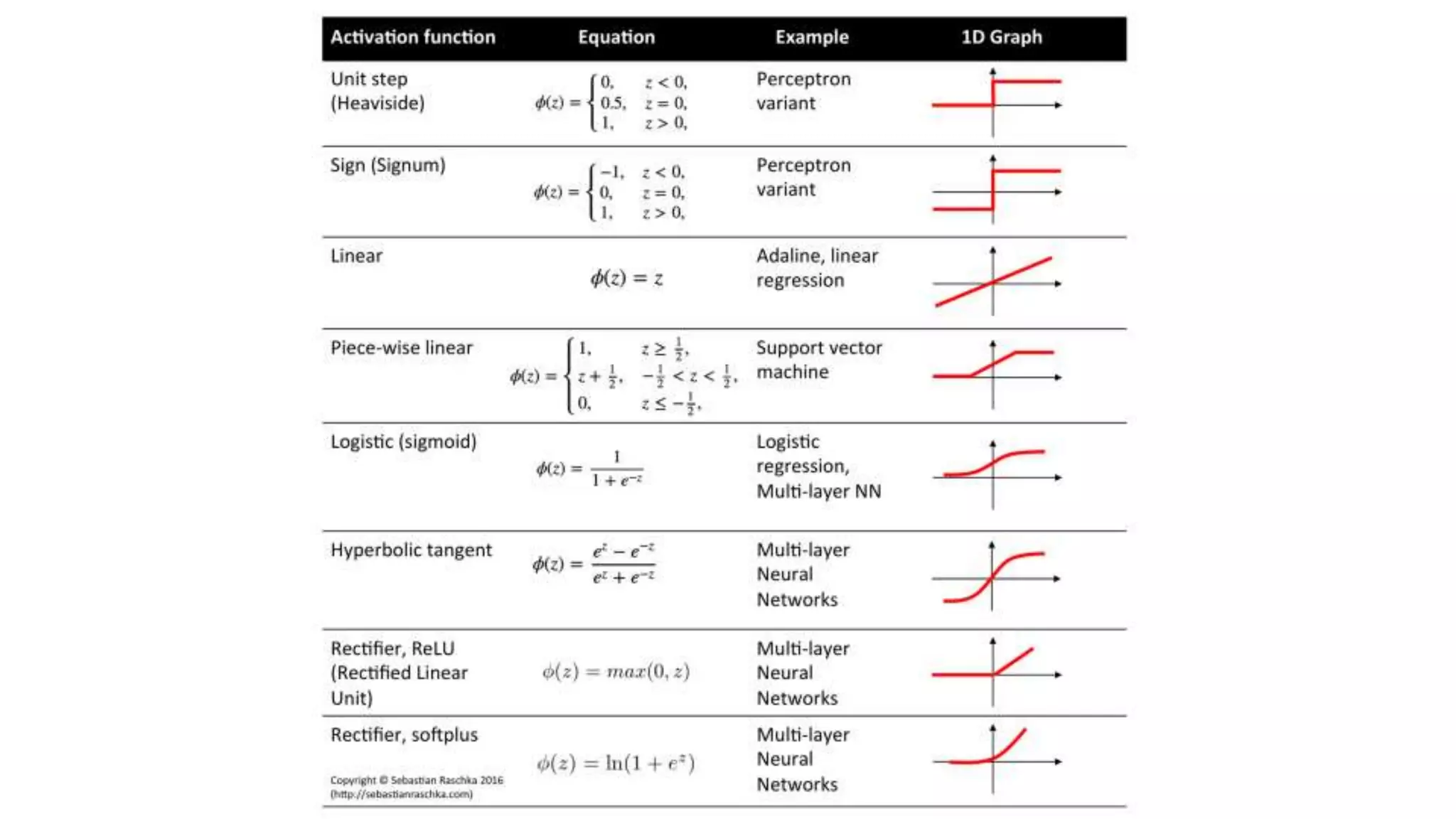
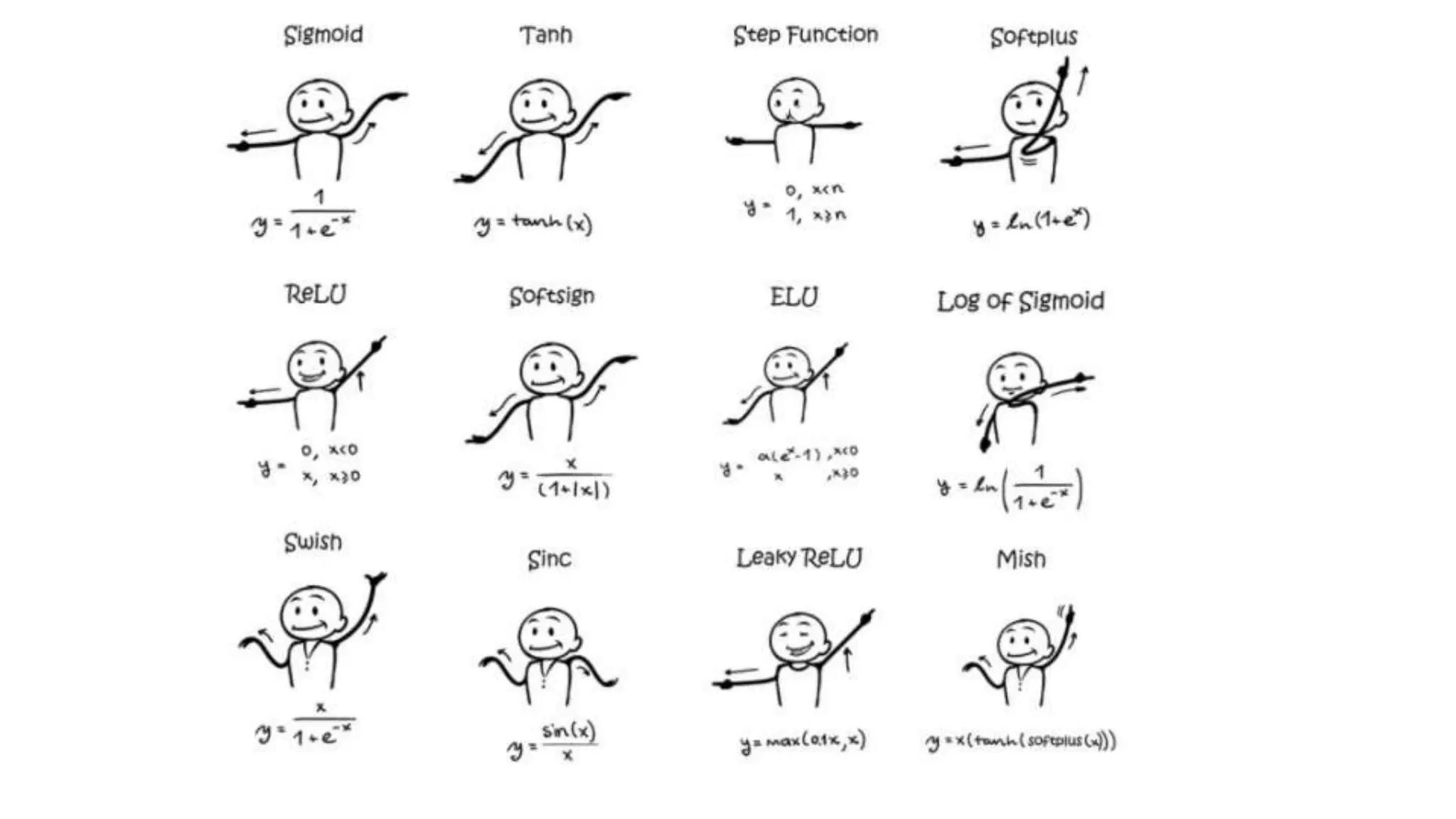
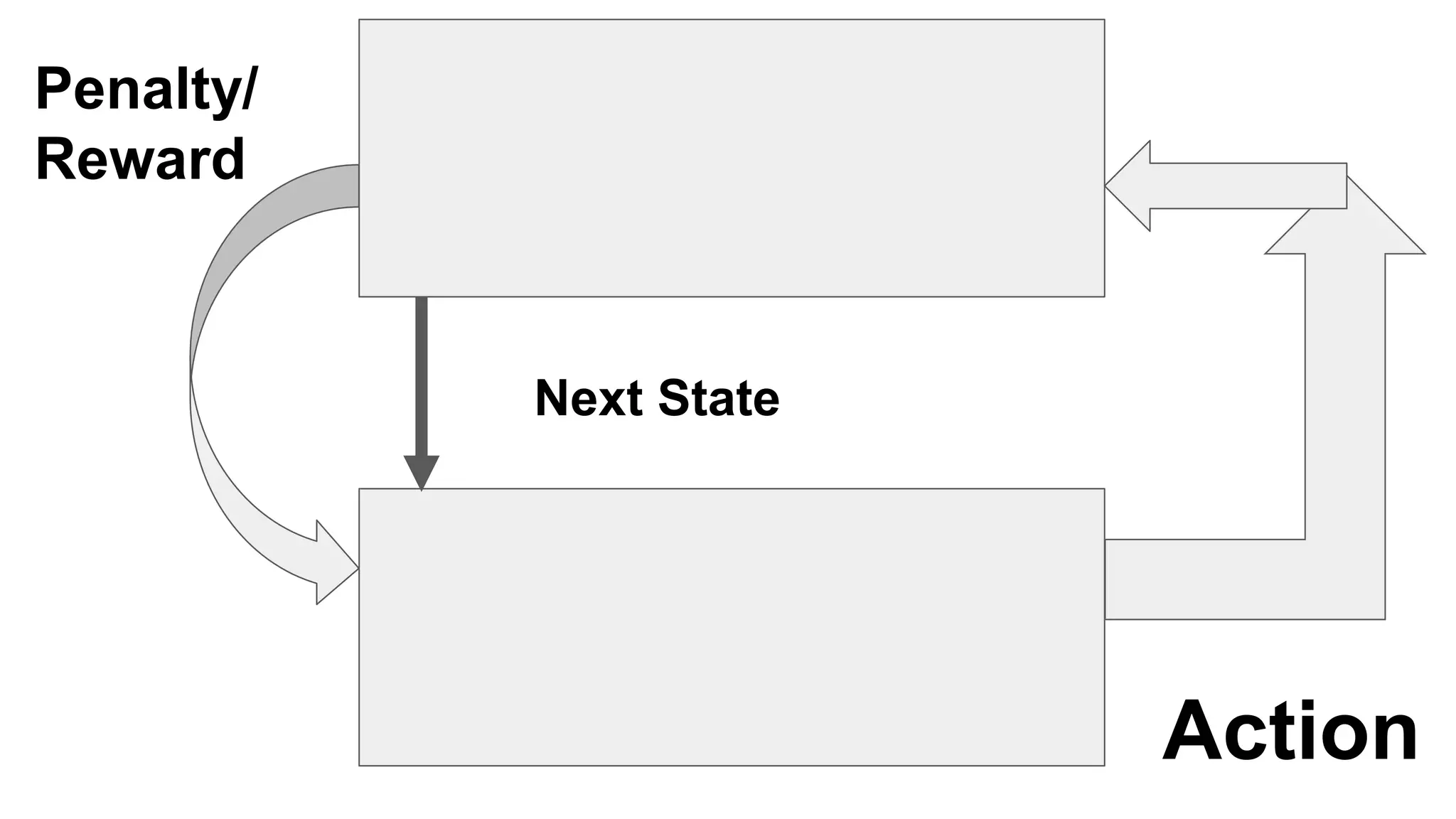
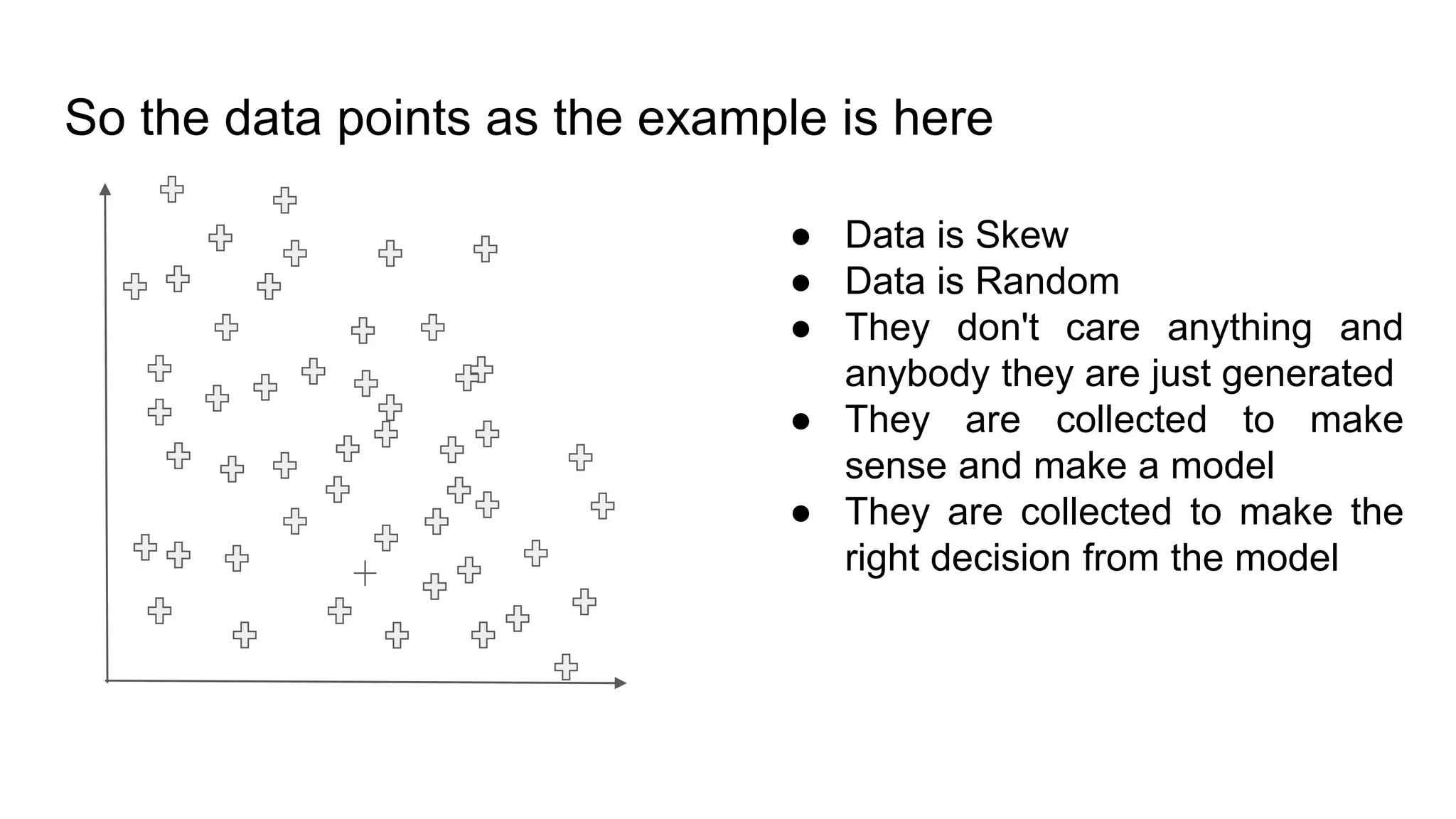
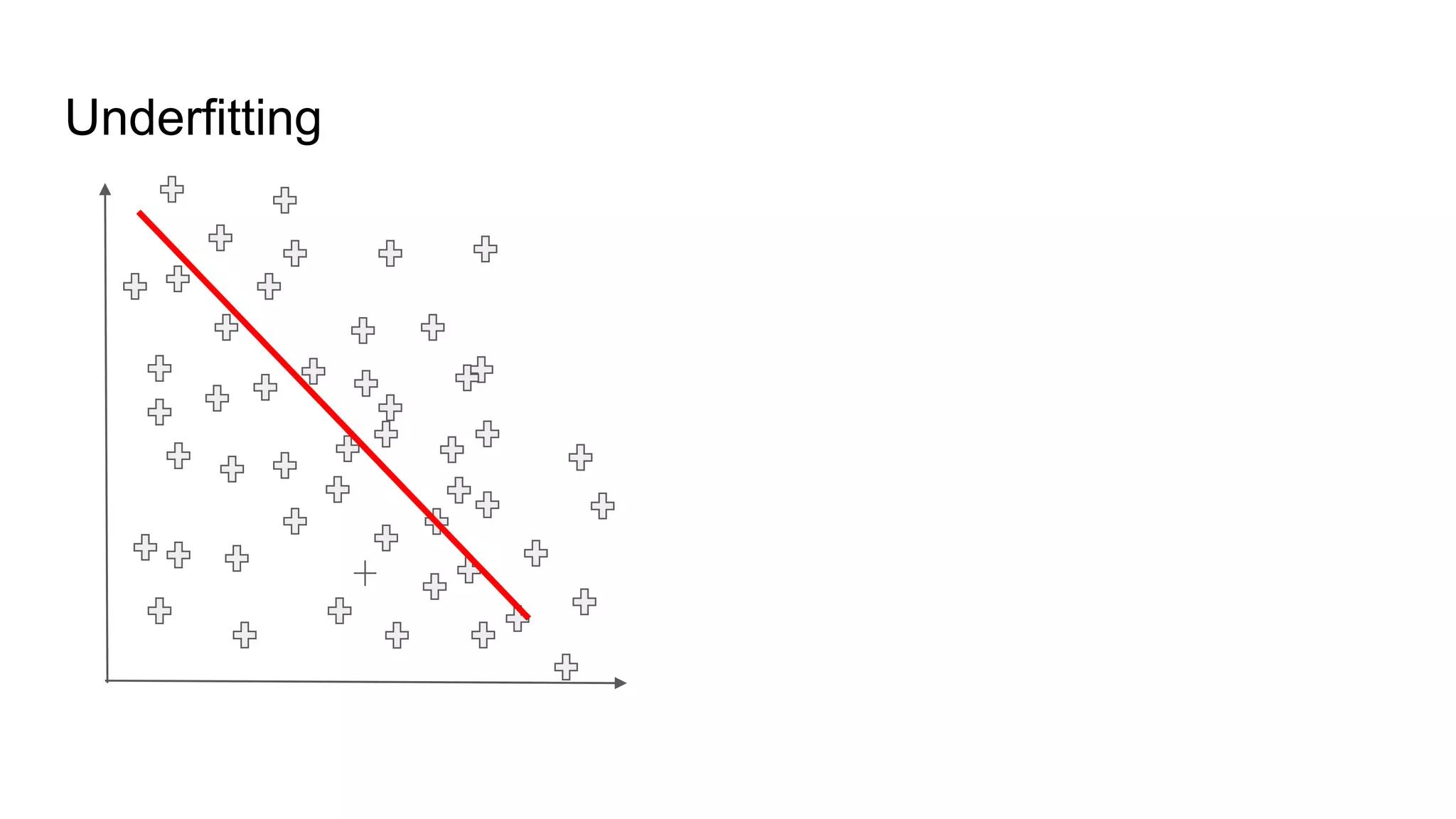
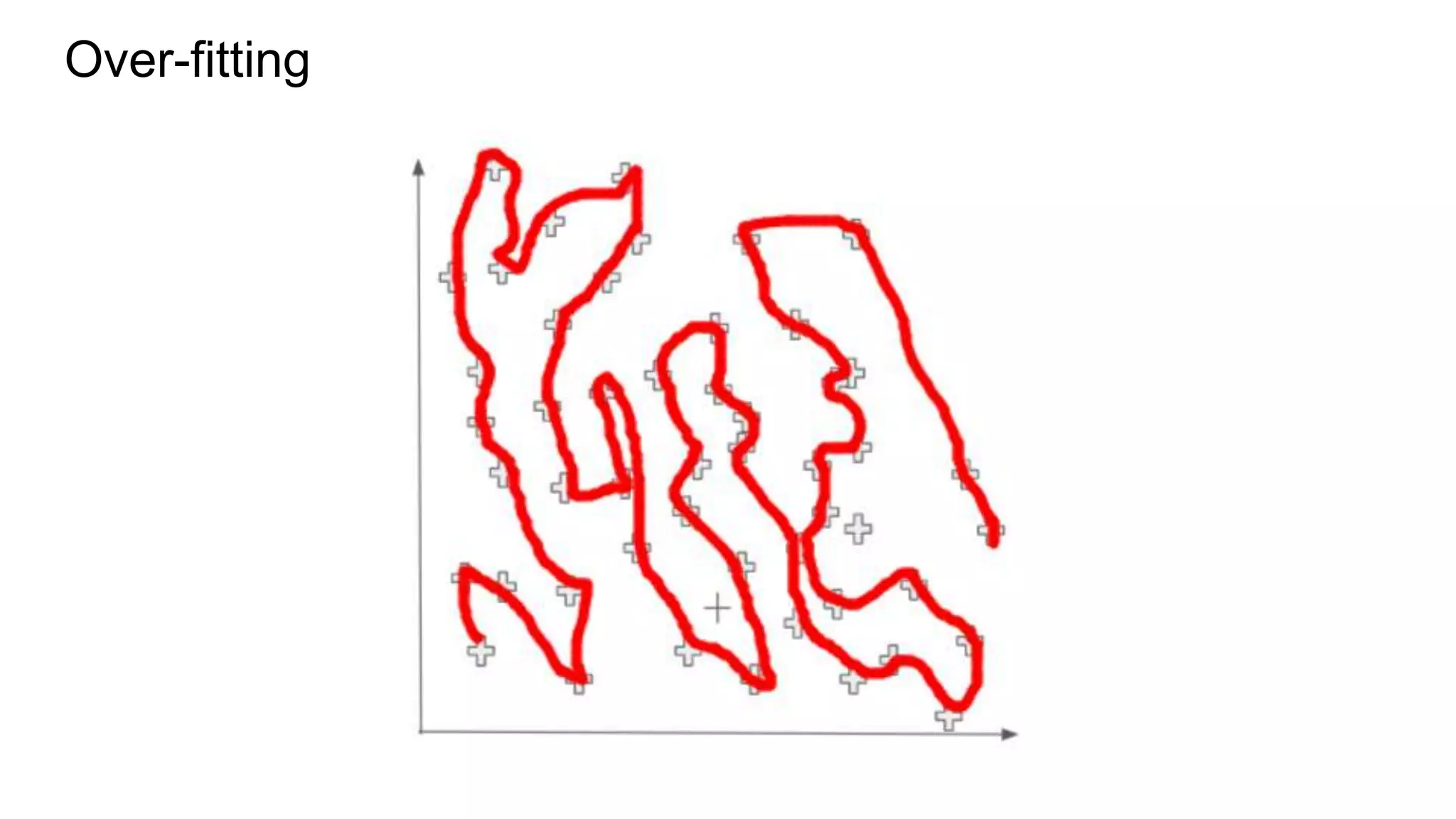
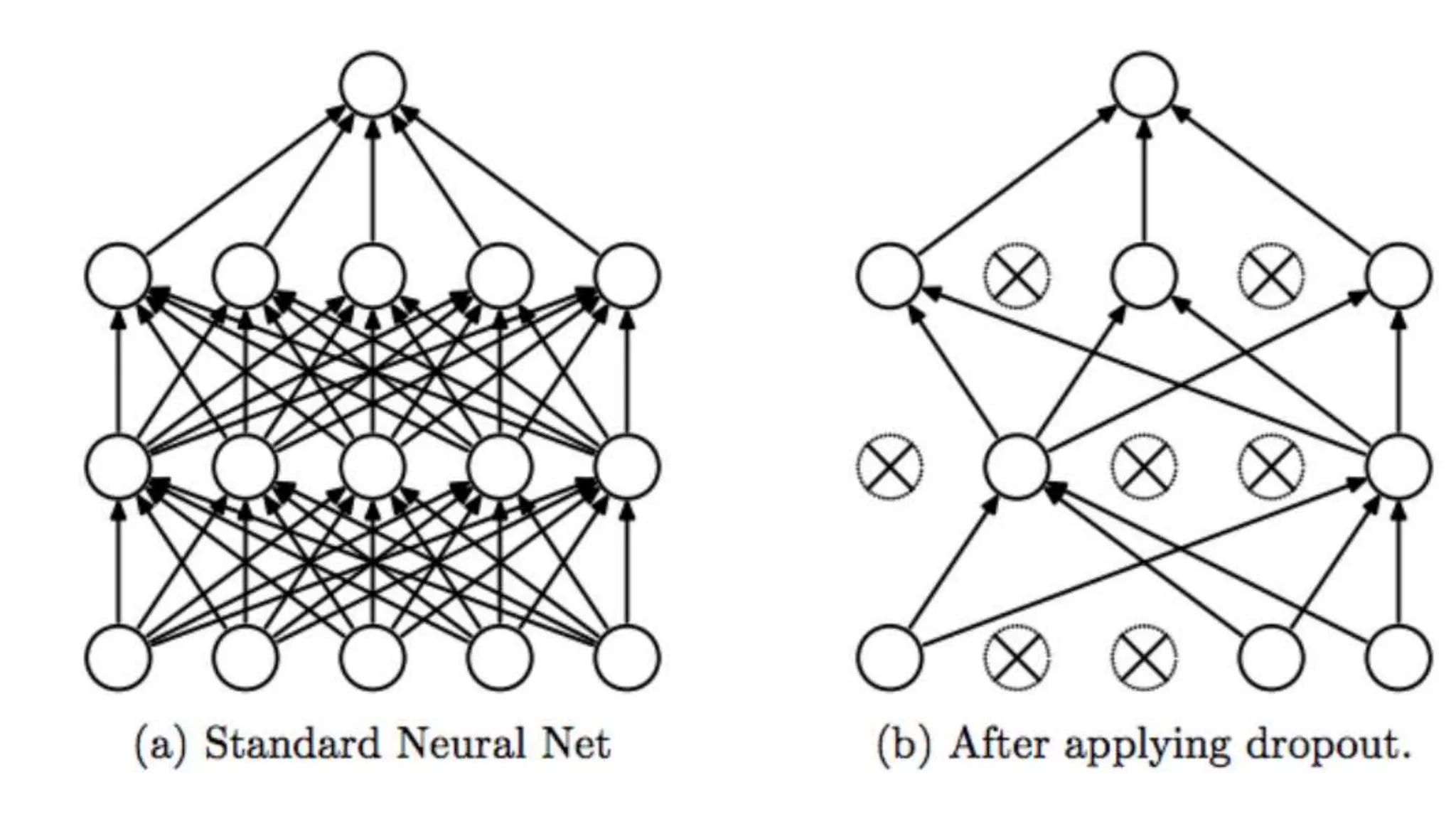
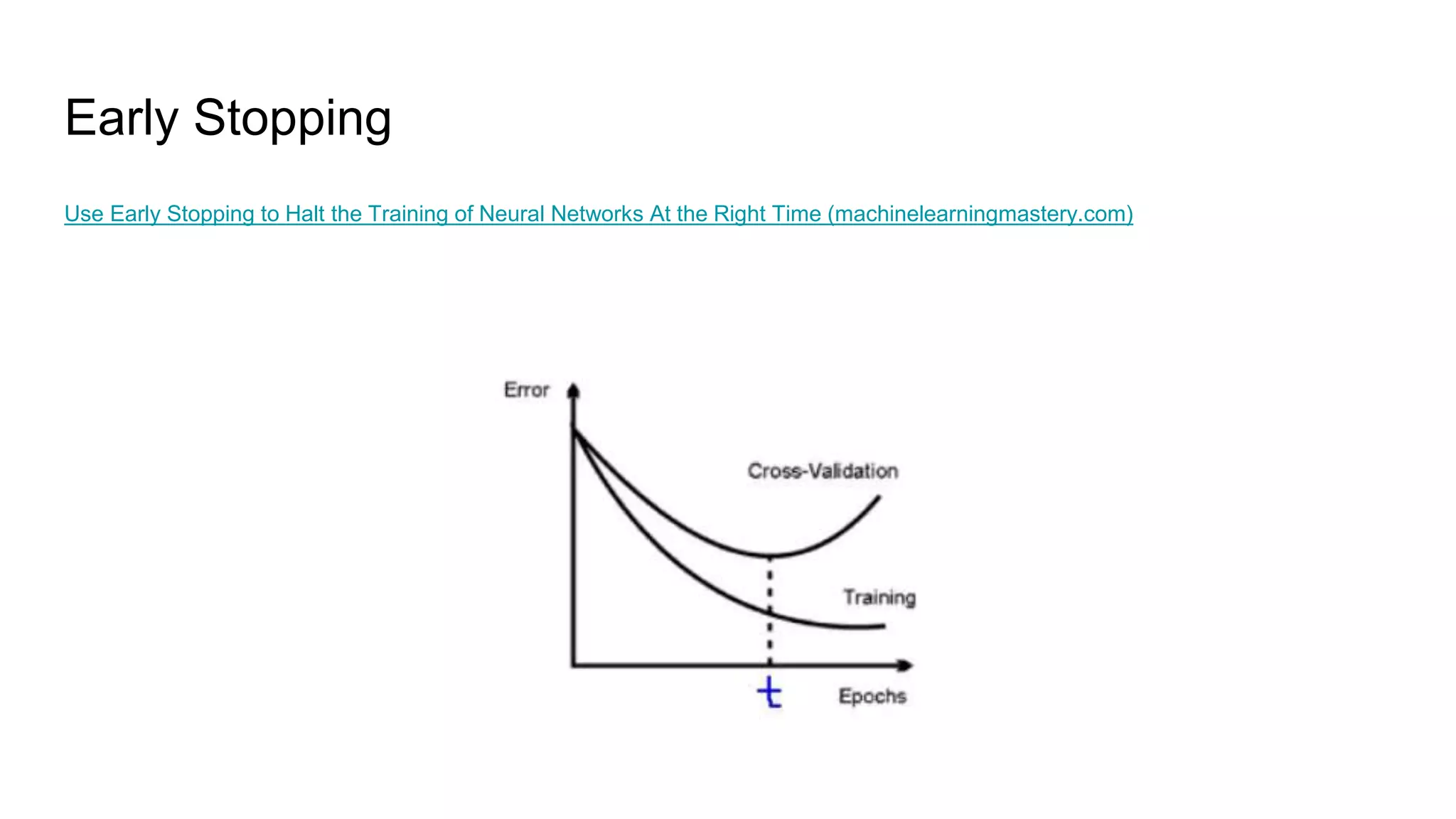
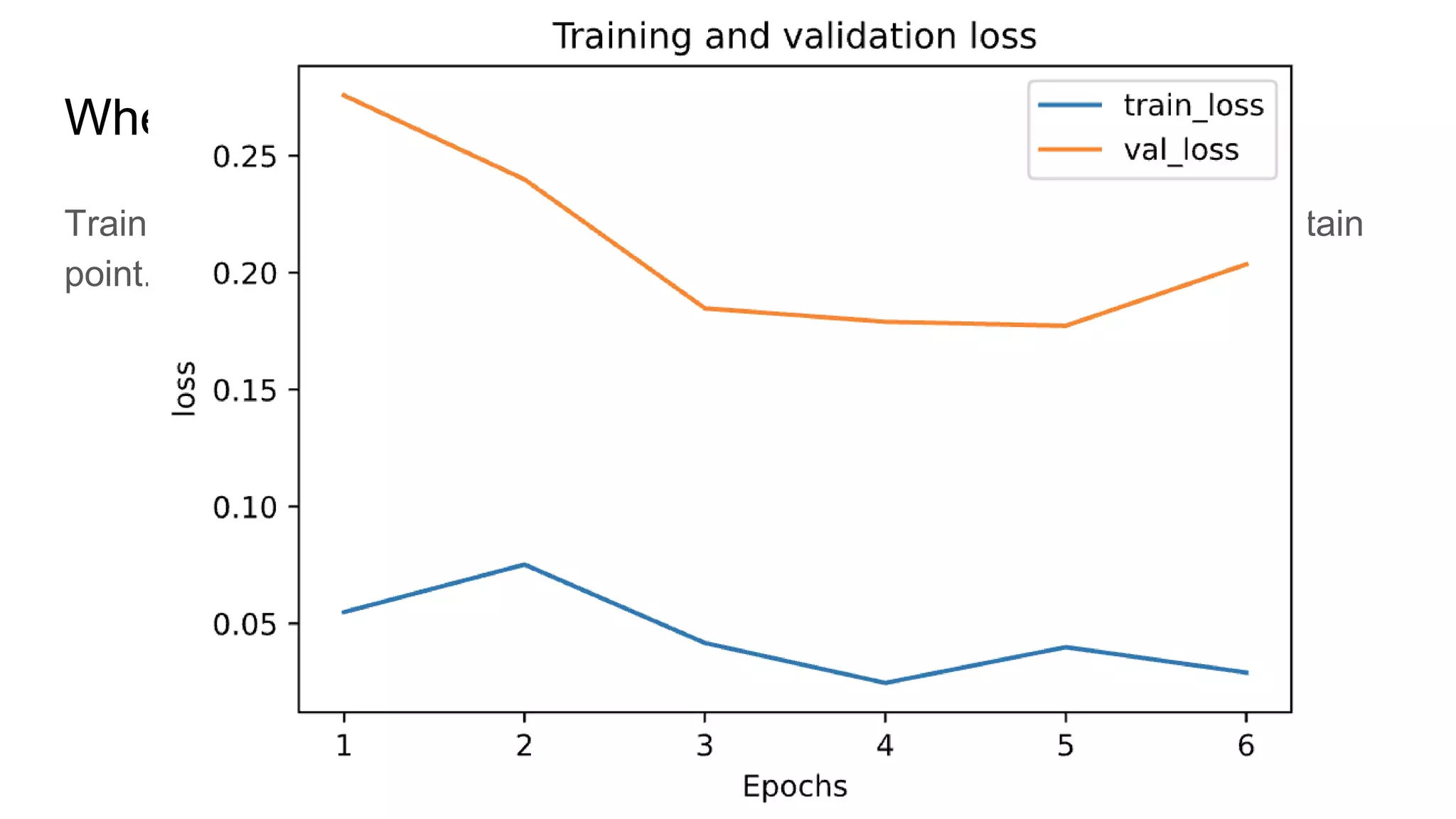
This document provides an overview of deep learning concepts including neural networks, supervised and unsupervised learning, and key terms. It explains that deep learning uses neural networks with many hidden layers to learn features directly from raw data. Supervised learning algorithms learn from labeled examples to perform classification or regression on unseen data. Unsupervised learning finds patterns in unlabeled data. Key terms defined include neurons, activation functions, loss functions, optimizers, epochs, batches, and hyperparameters.

































































































































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)














