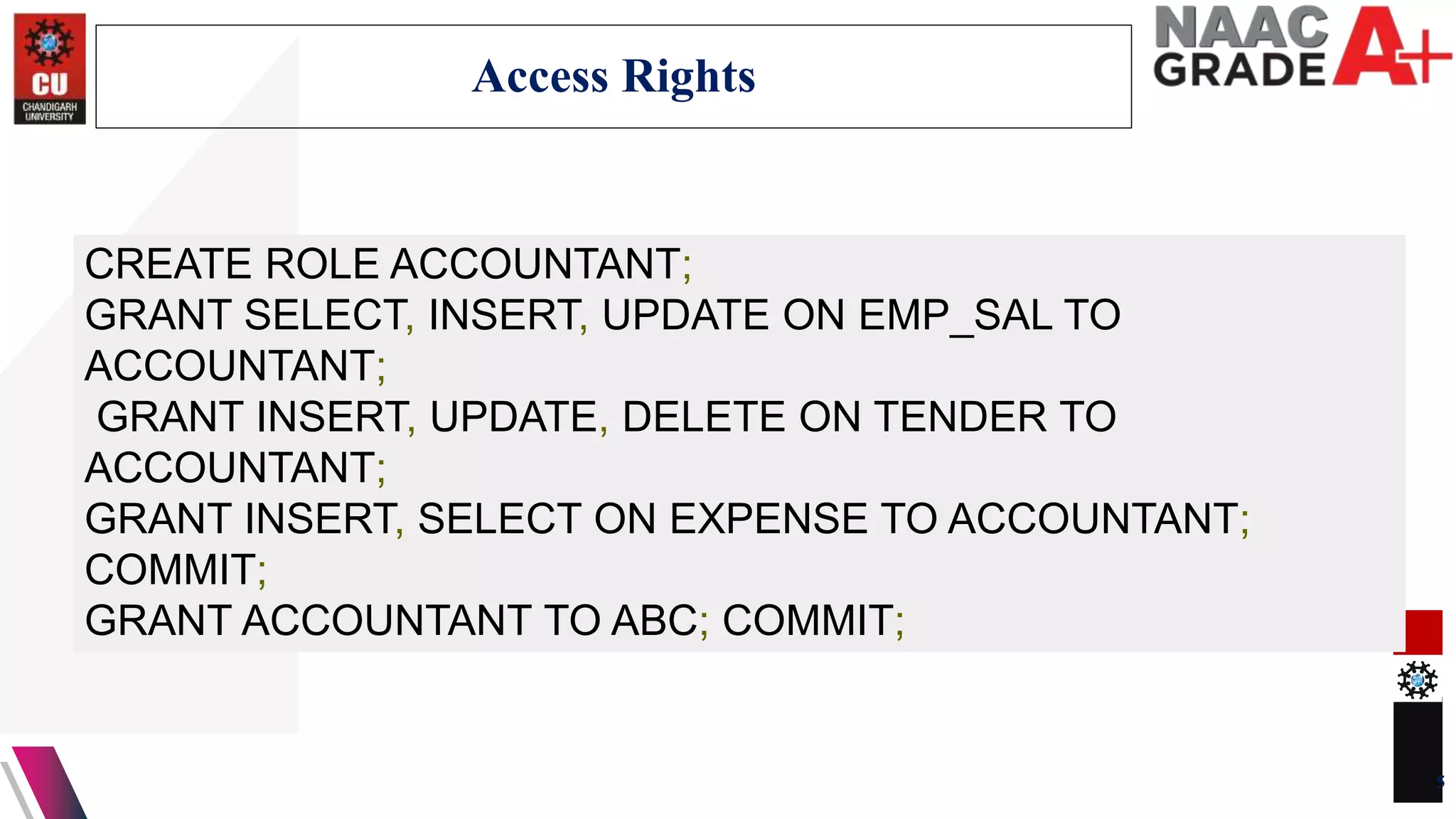
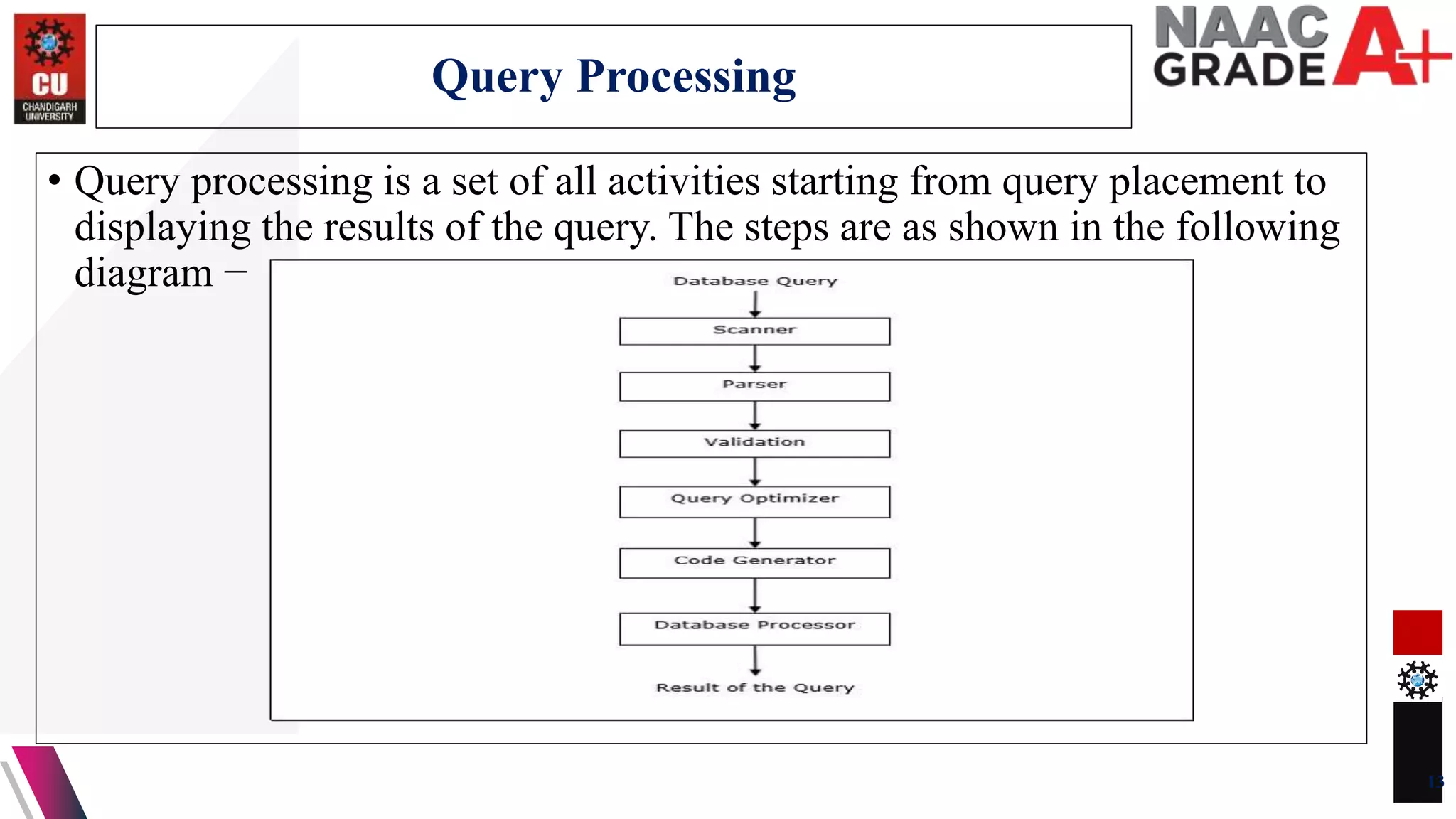
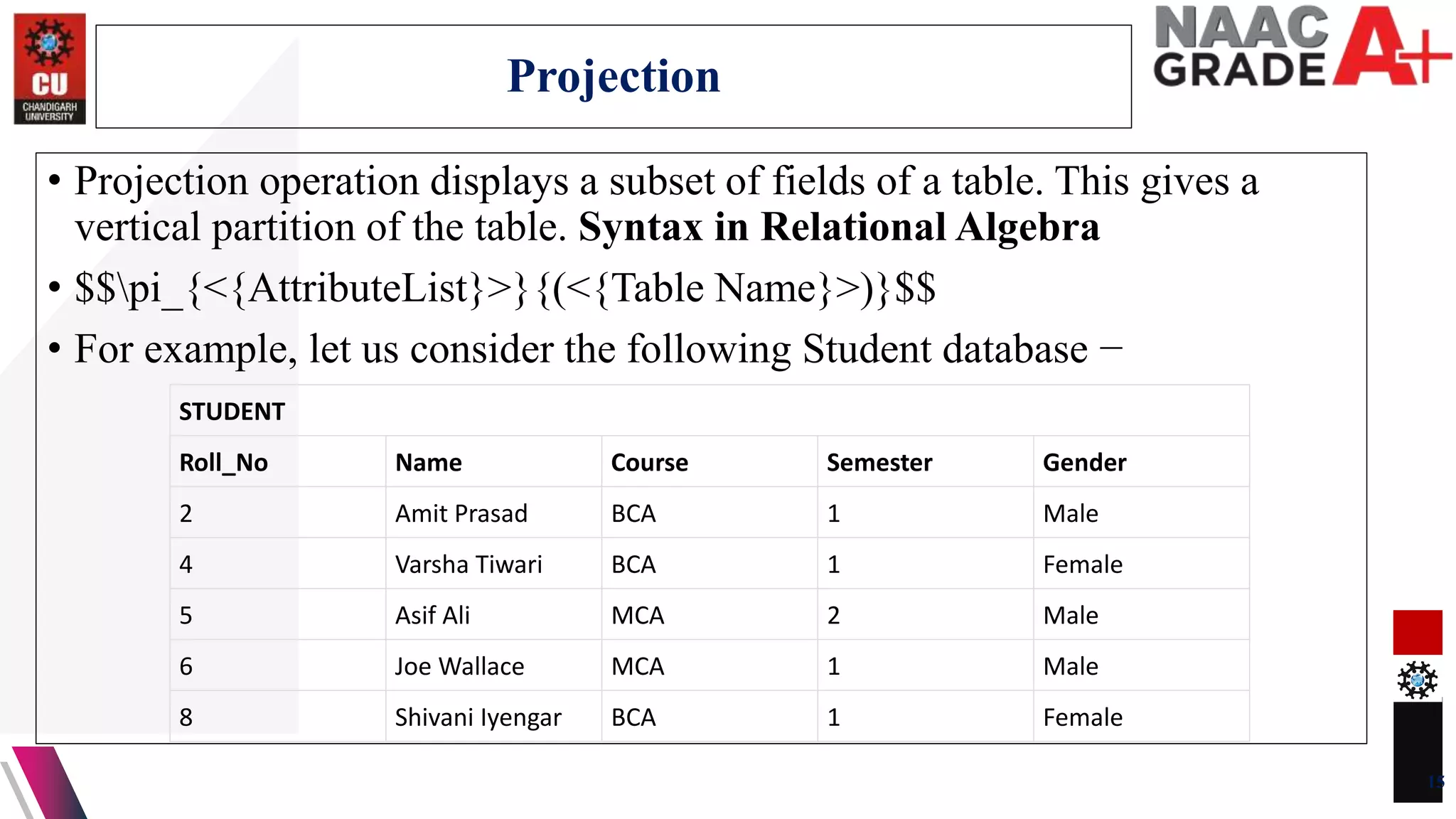
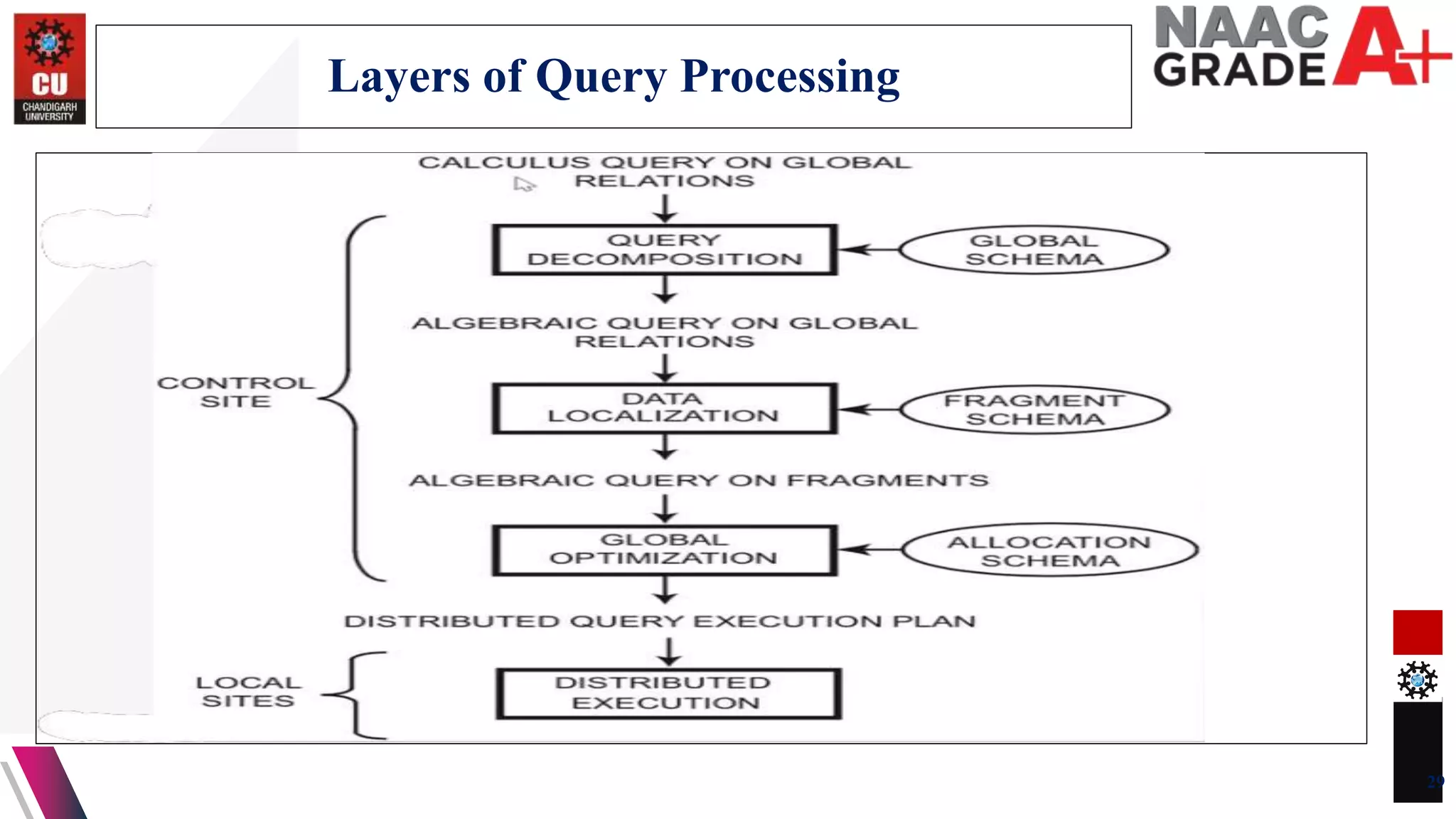
The document discusses database control and its three dimensions - authentication, access rights, and integrity constraints. It provides details on how authentication controls access to client computers and database software. It describes how access rights can be assigned through roles to users in distributed environments. It also explains the different types of integrity constraints - data type, entity, and referential integrity constraints - and provides SQL examples to define them for tables.