Downloaded 1,194 times

























![> terragrunt apply
[terragrunt] Acquiring lock for bastion-host in DynamoDB
[terragrunt] Running command: terraform apply
aws_instance.example: Creating...
ami: "" => "ami-0d729a60"
instance_type: "" => "t2.micro”
[...]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
[terragrunt] Releasing lock for bastion-host in DynamoDB
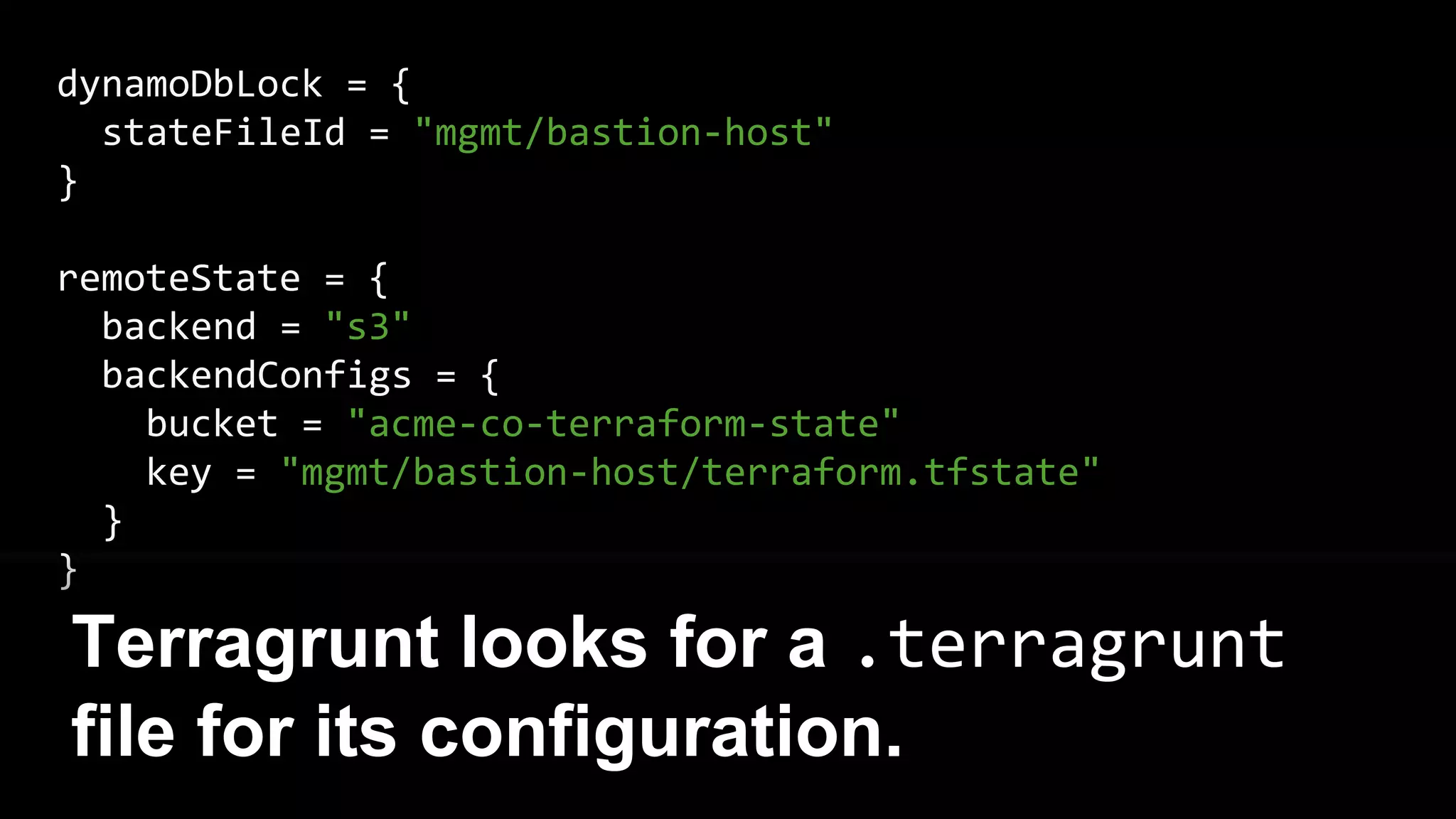
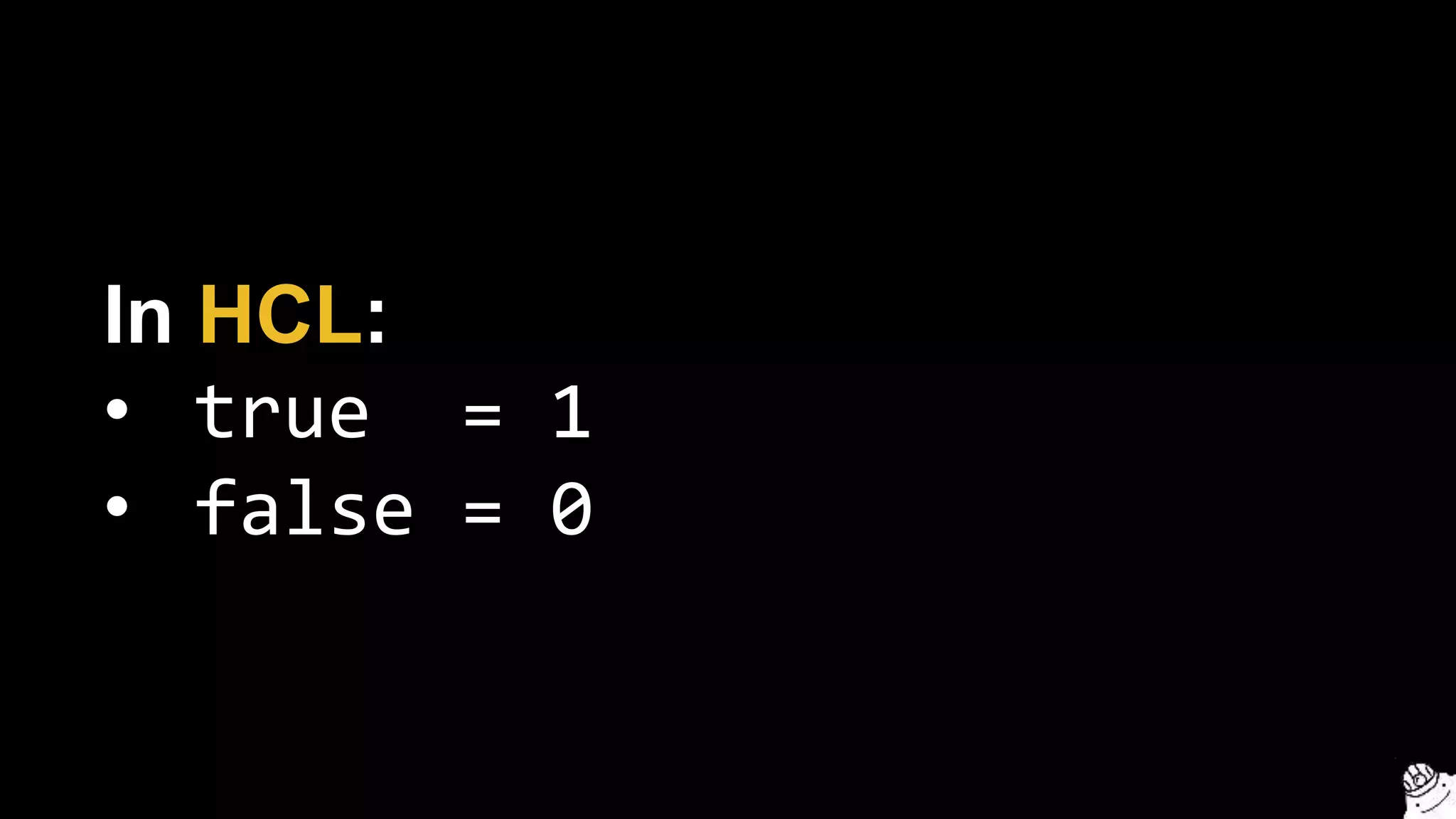
Terragrunt automatically acquires and
releases locks on apply/destroy](https://image.slidesharecdn.com/terraformcomprehensivetraining-09-160921141454/75/Comprehensive-Terraform-Training-37-2048.jpg)








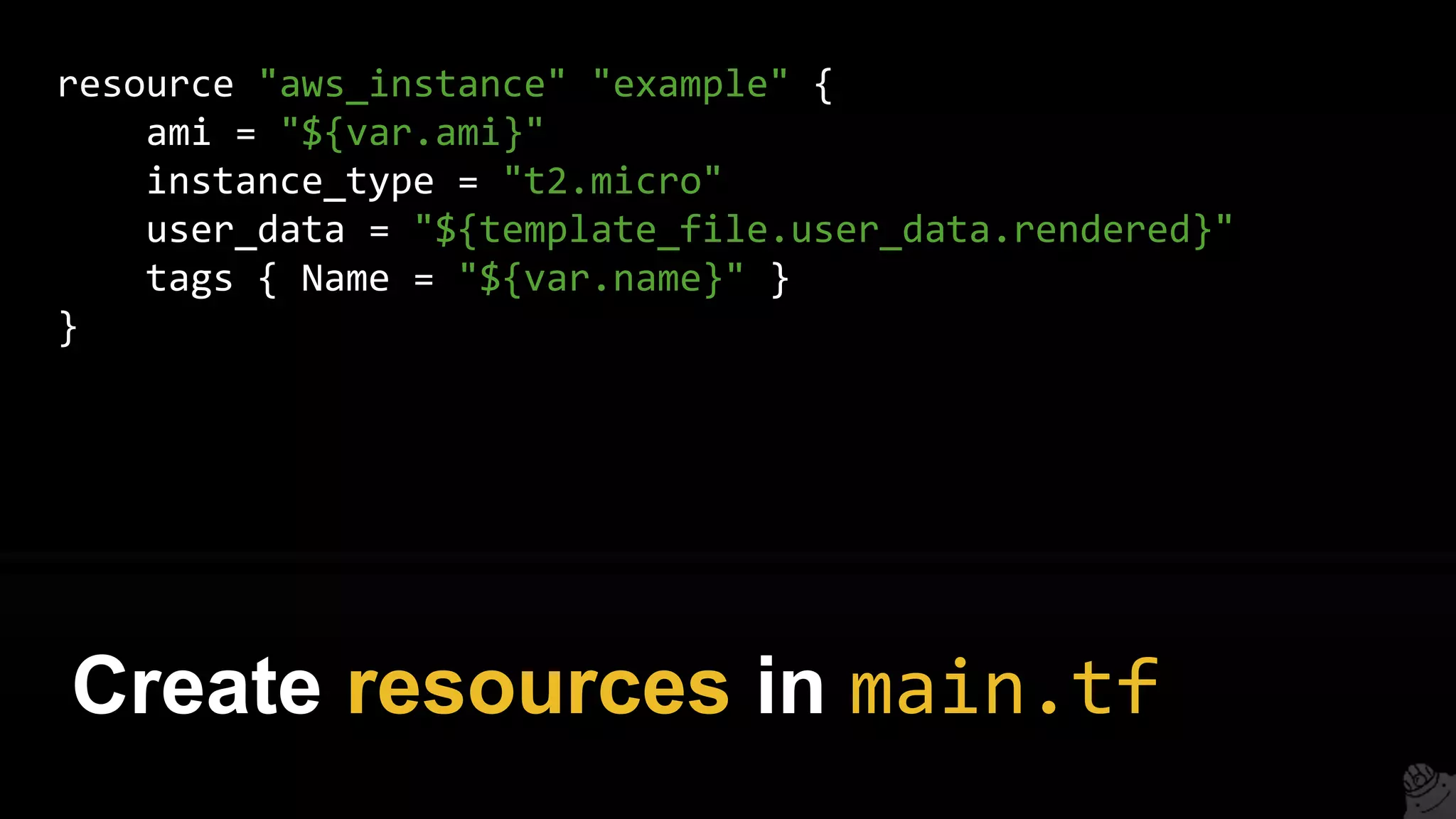




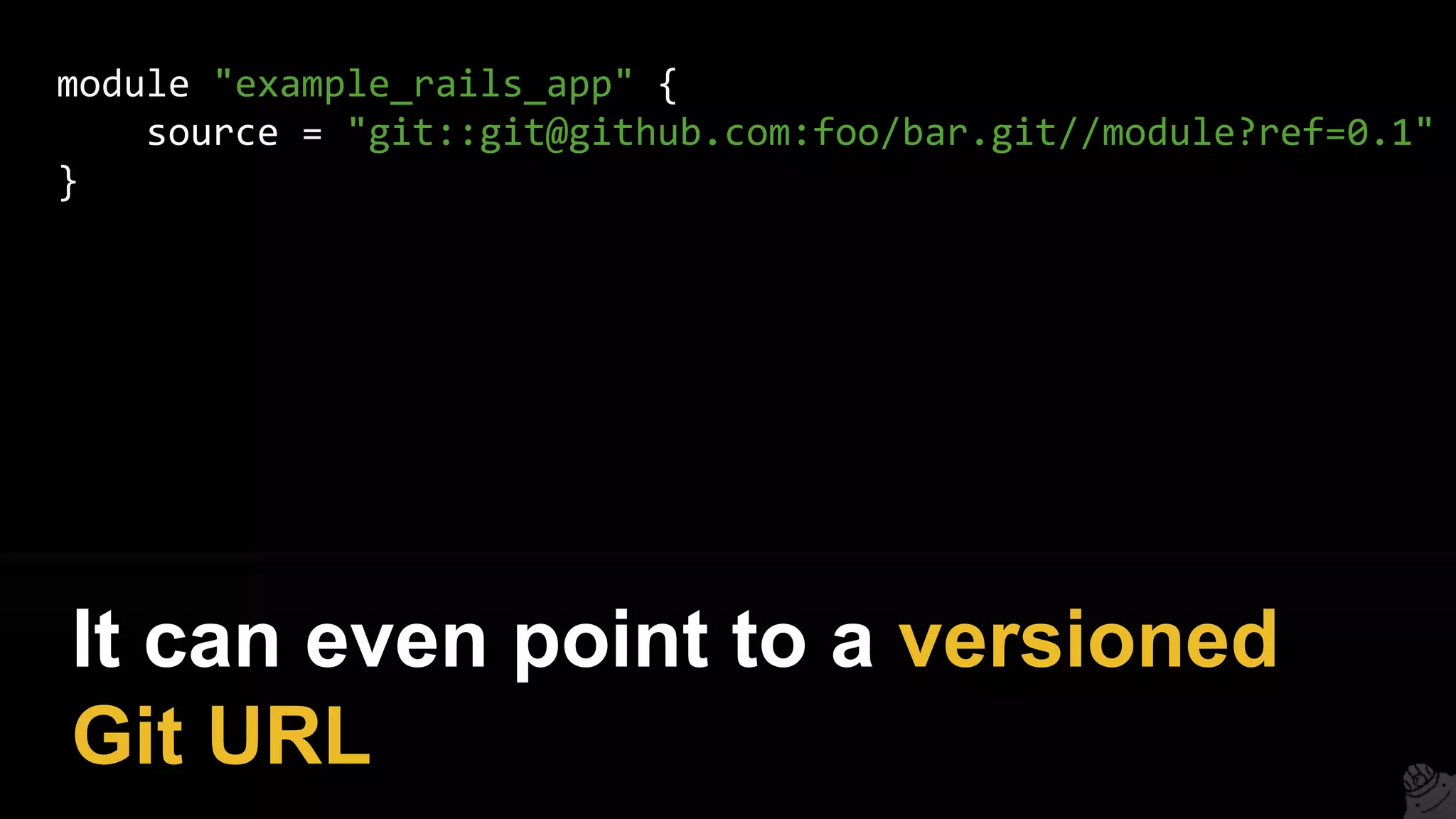


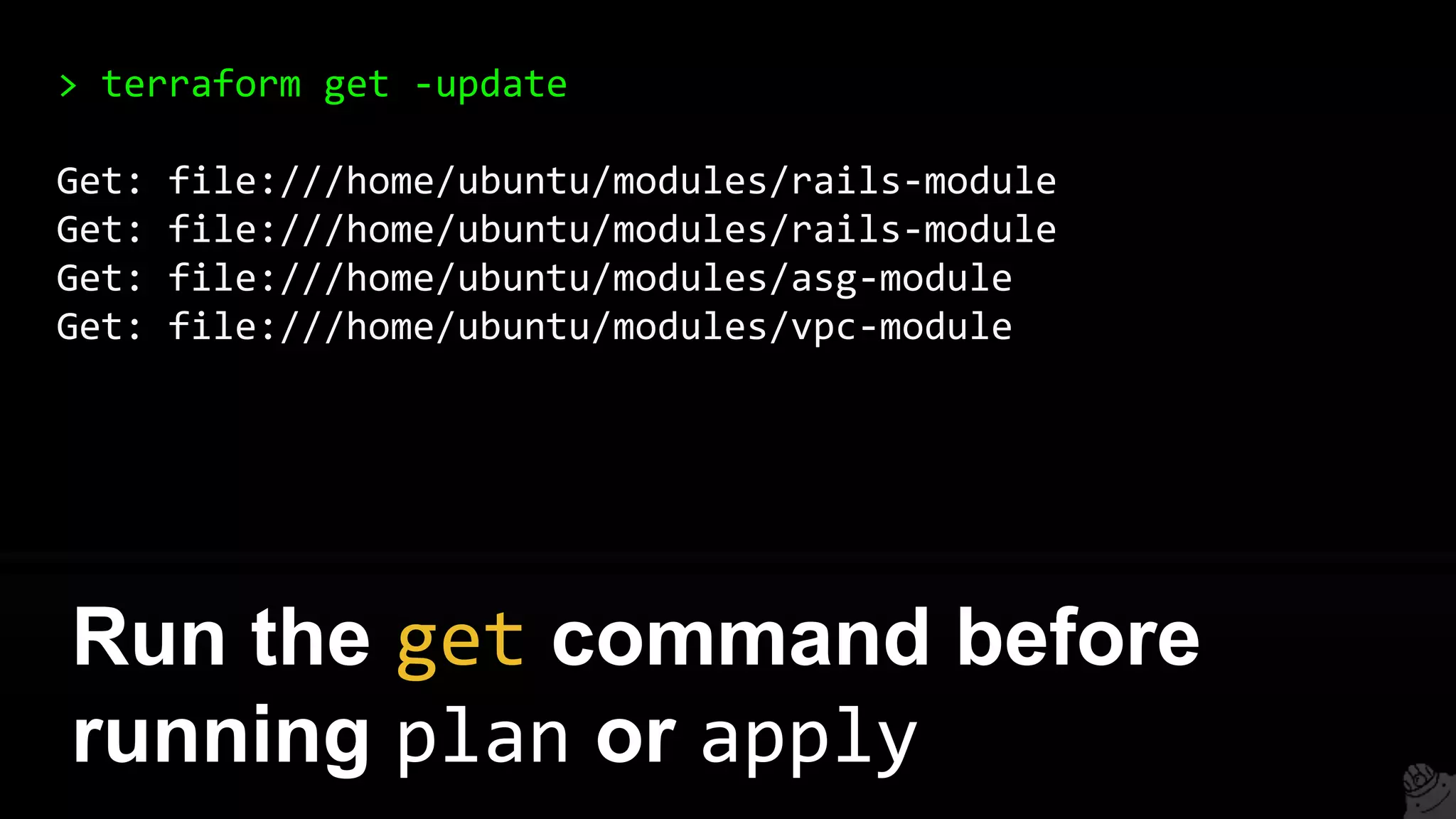









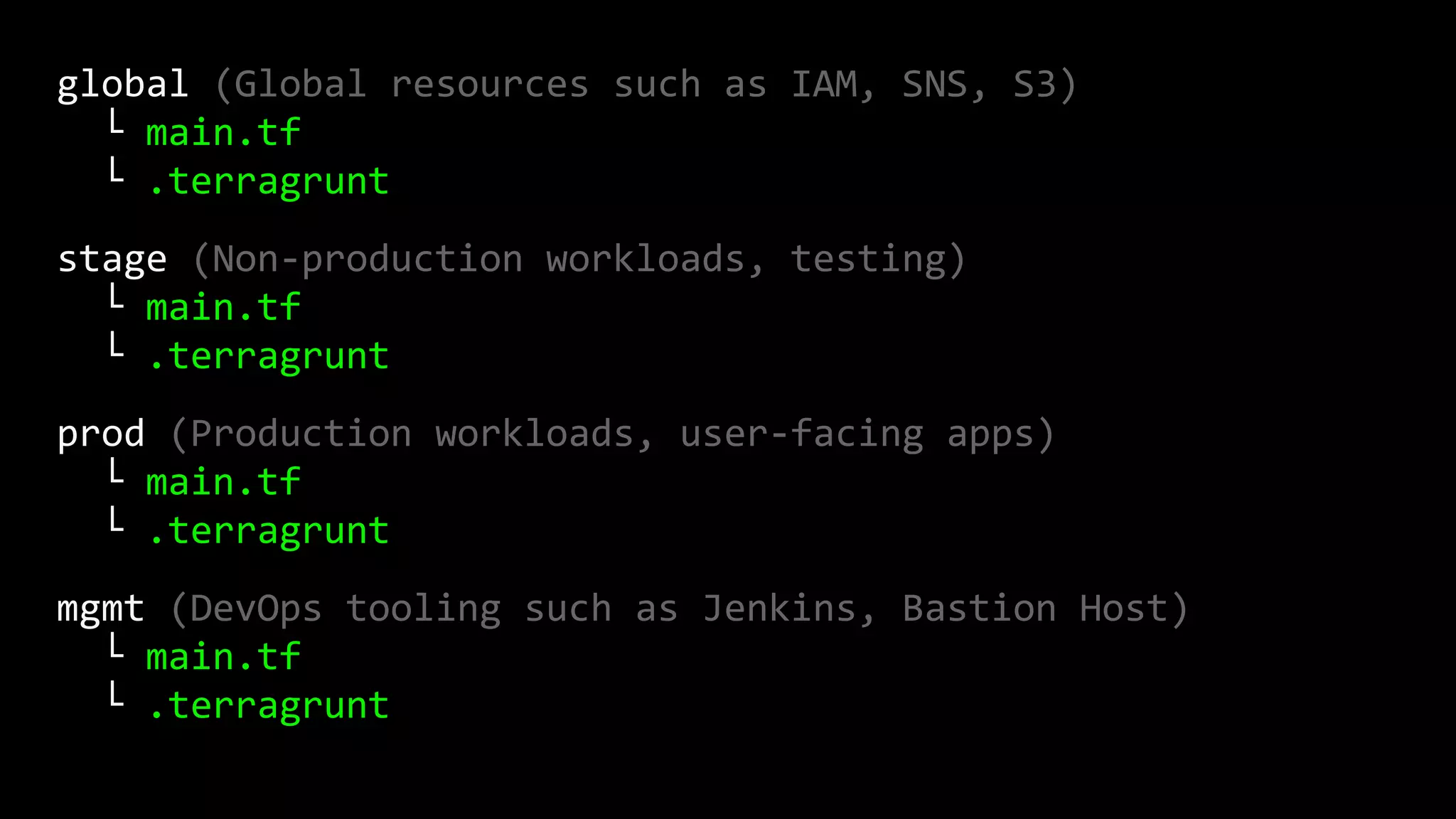
















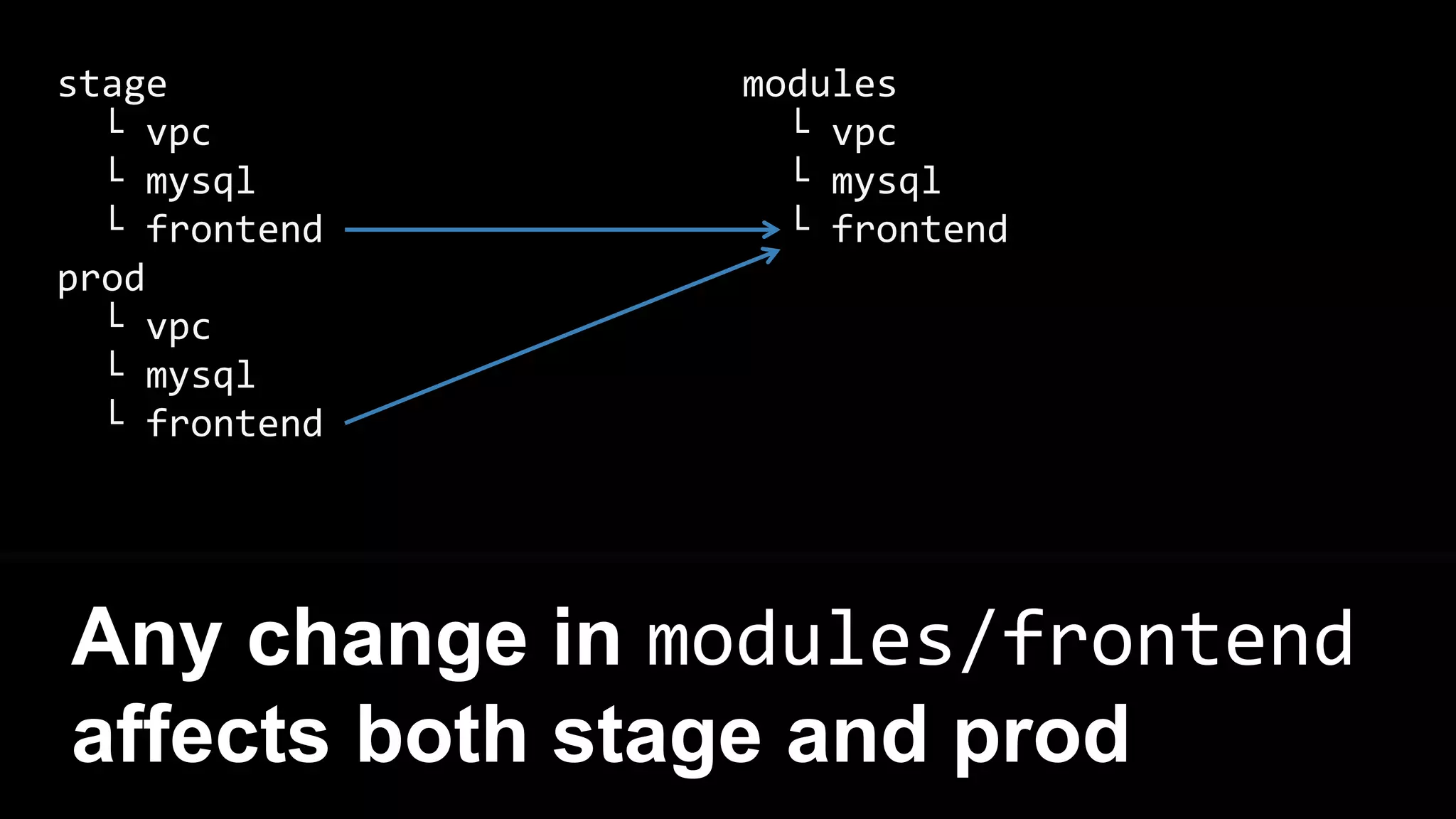

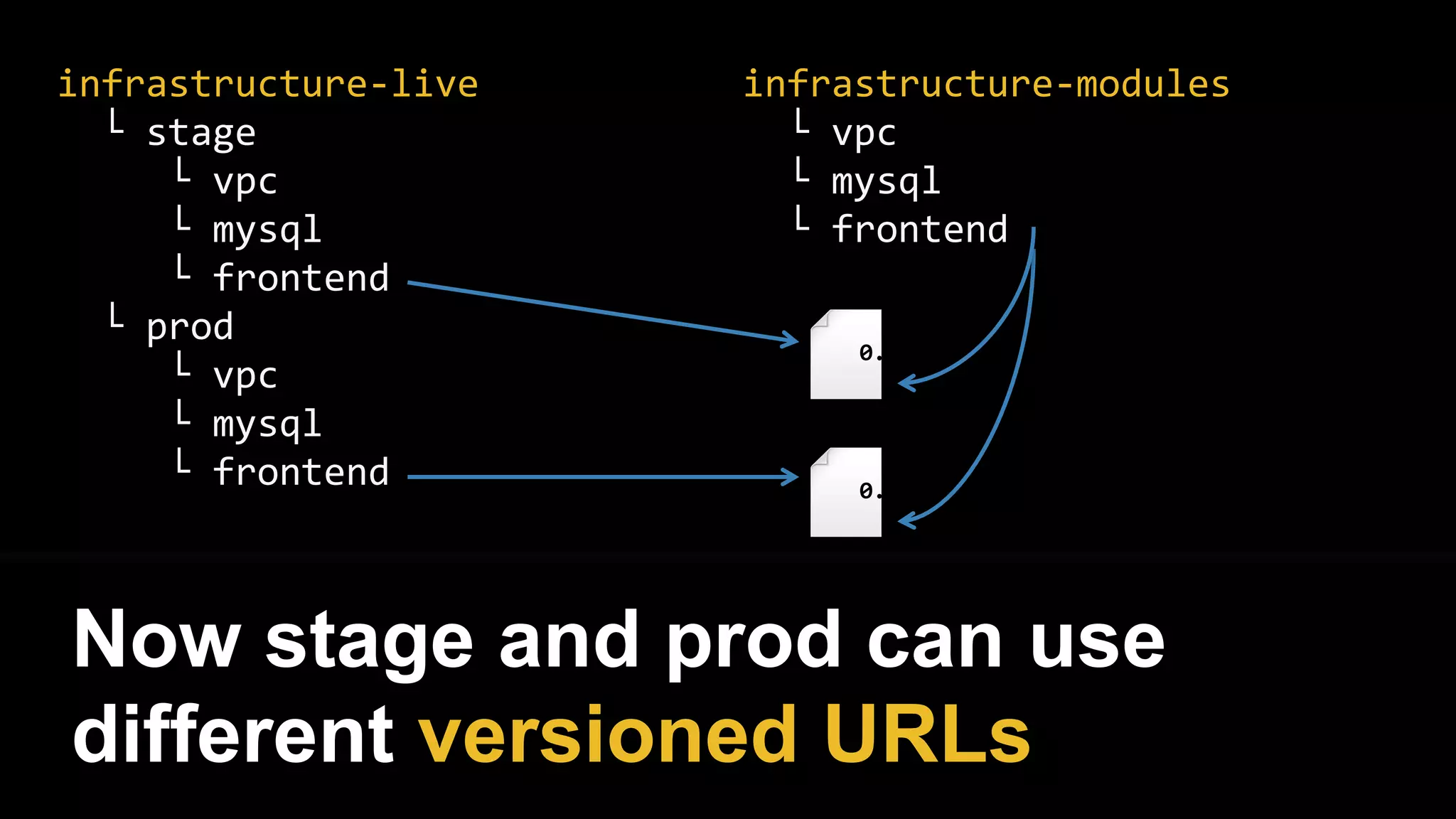




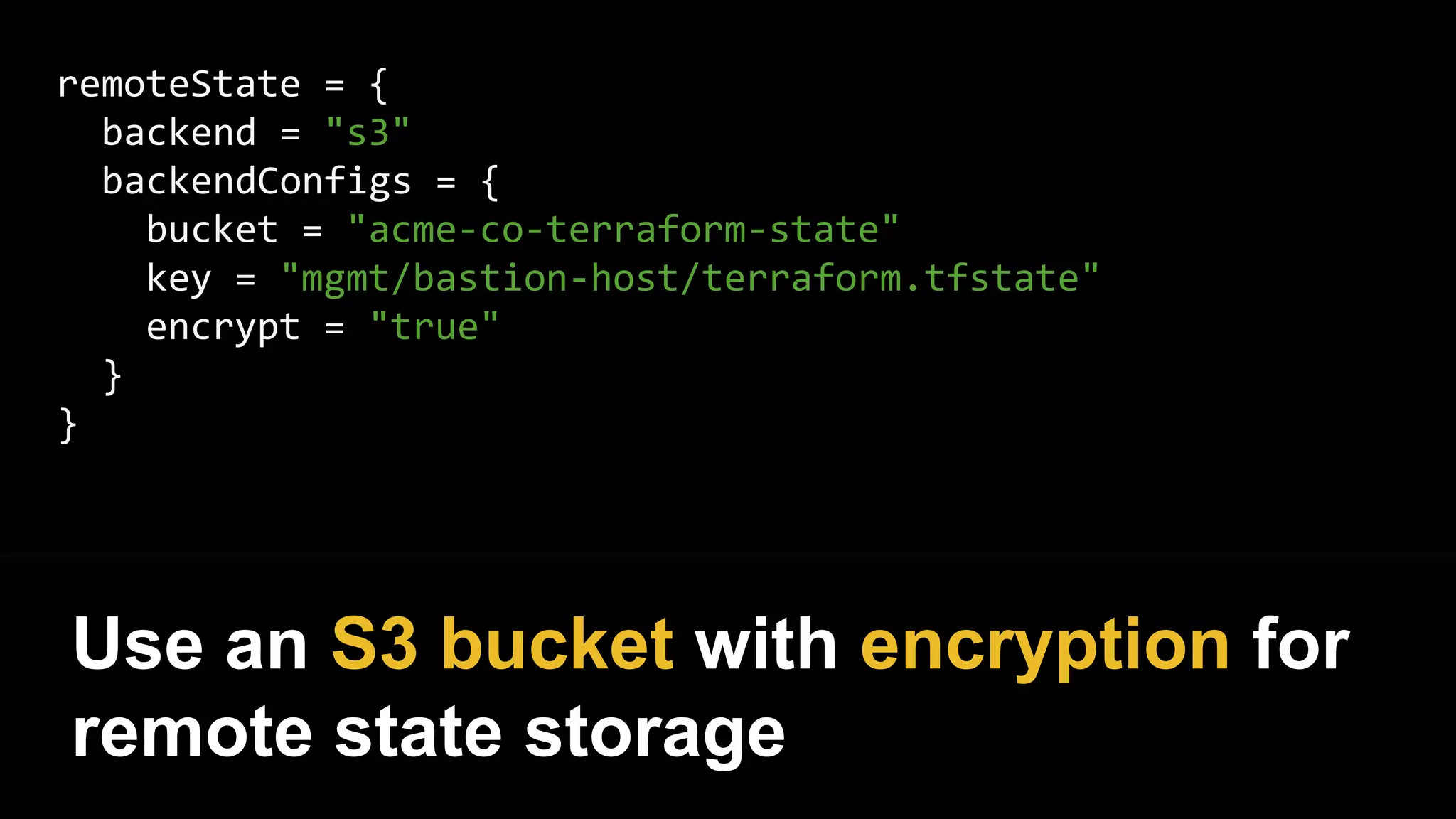
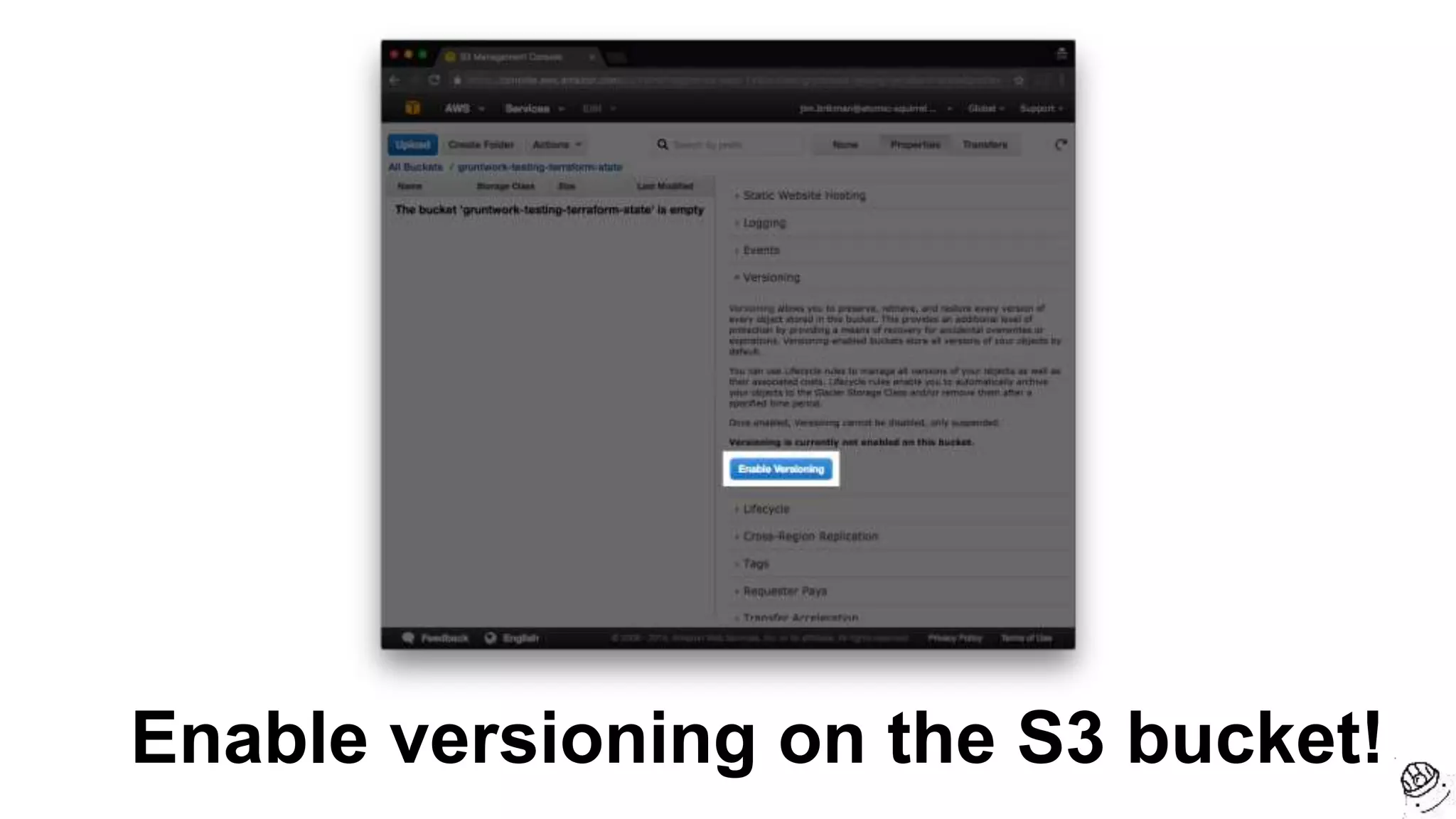








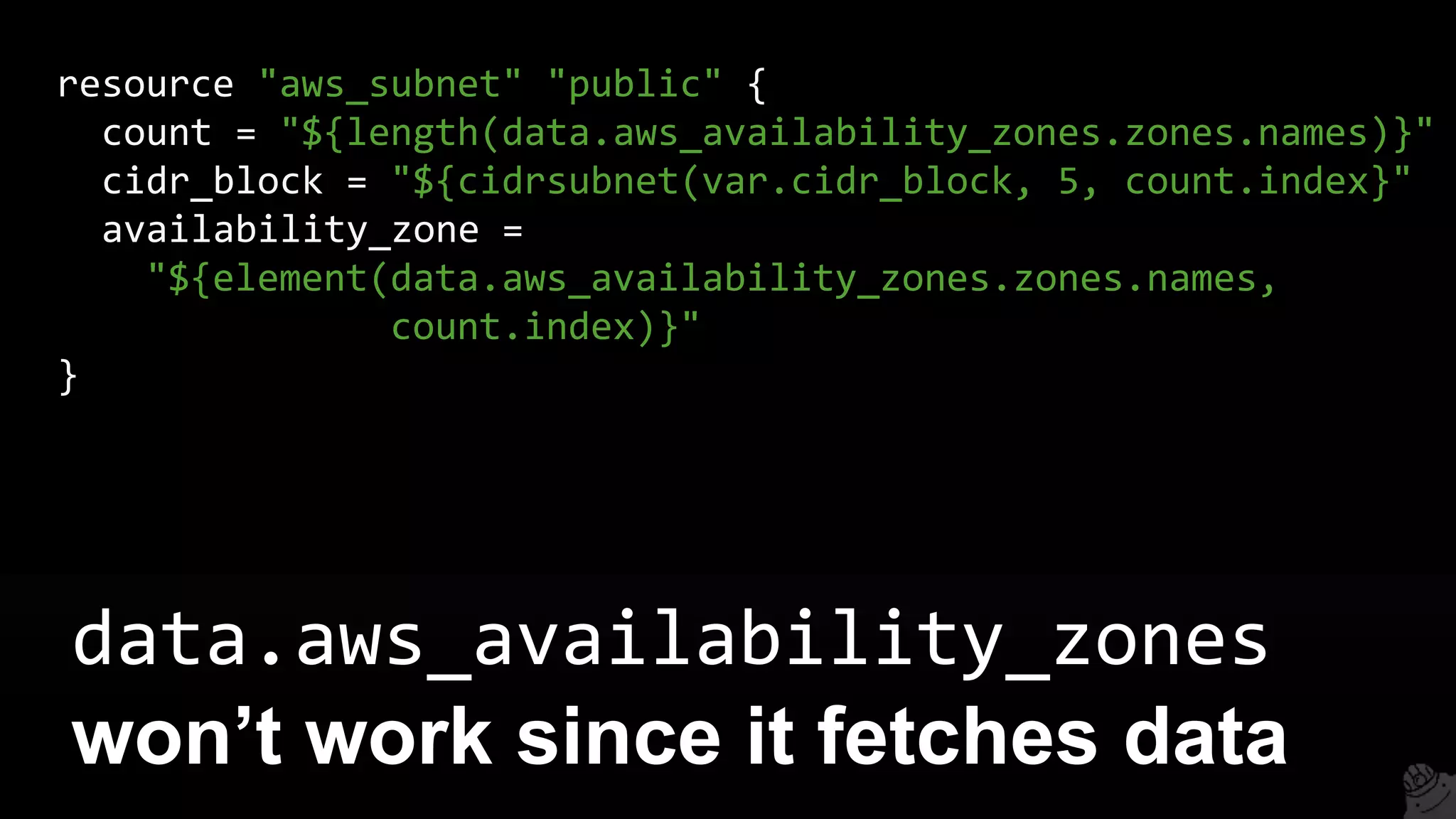
![resource "aws_instance" "example" {
count = 3
ami = "${element(var.amis, count.index)}"
instance_type = "t2.micro"
tags { Name = "${var.name}-${count.index}" }
}
variable "amis" {
type = "list"
default = ["ami-abc123", "ami-abc456", "ami-abc789"]
}
Create three EC2 Instances, each
with a different AMI](https://image.slidesharecdn.com/terraformcomprehensivetraining-09-160921141454/75/Comprehensive-Terraform-Training-103-2048.jpg)
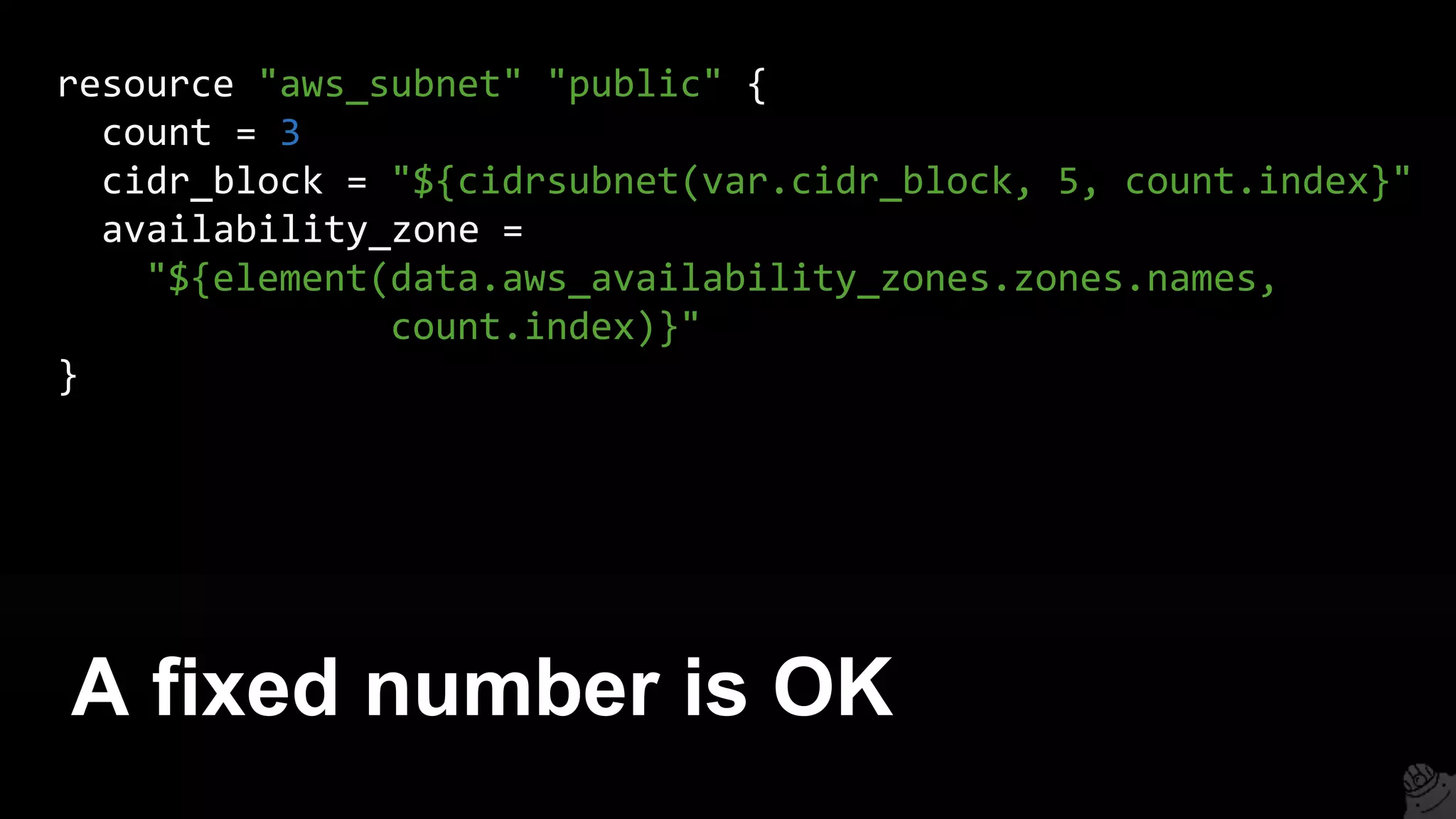
![output "all_instance_ids" {
value = ["${aws_instance.example.*.id}"]
}
output "first_instance_id" {
value = "${aws_instance.example.0.id}"
}
Note: resources with count are
actually lists of resources!](https://image.slidesharecdn.com/terraformcomprehensivetraining-09-160921141454/75/Comprehensive-Terraform-Training-104-2048.jpg)











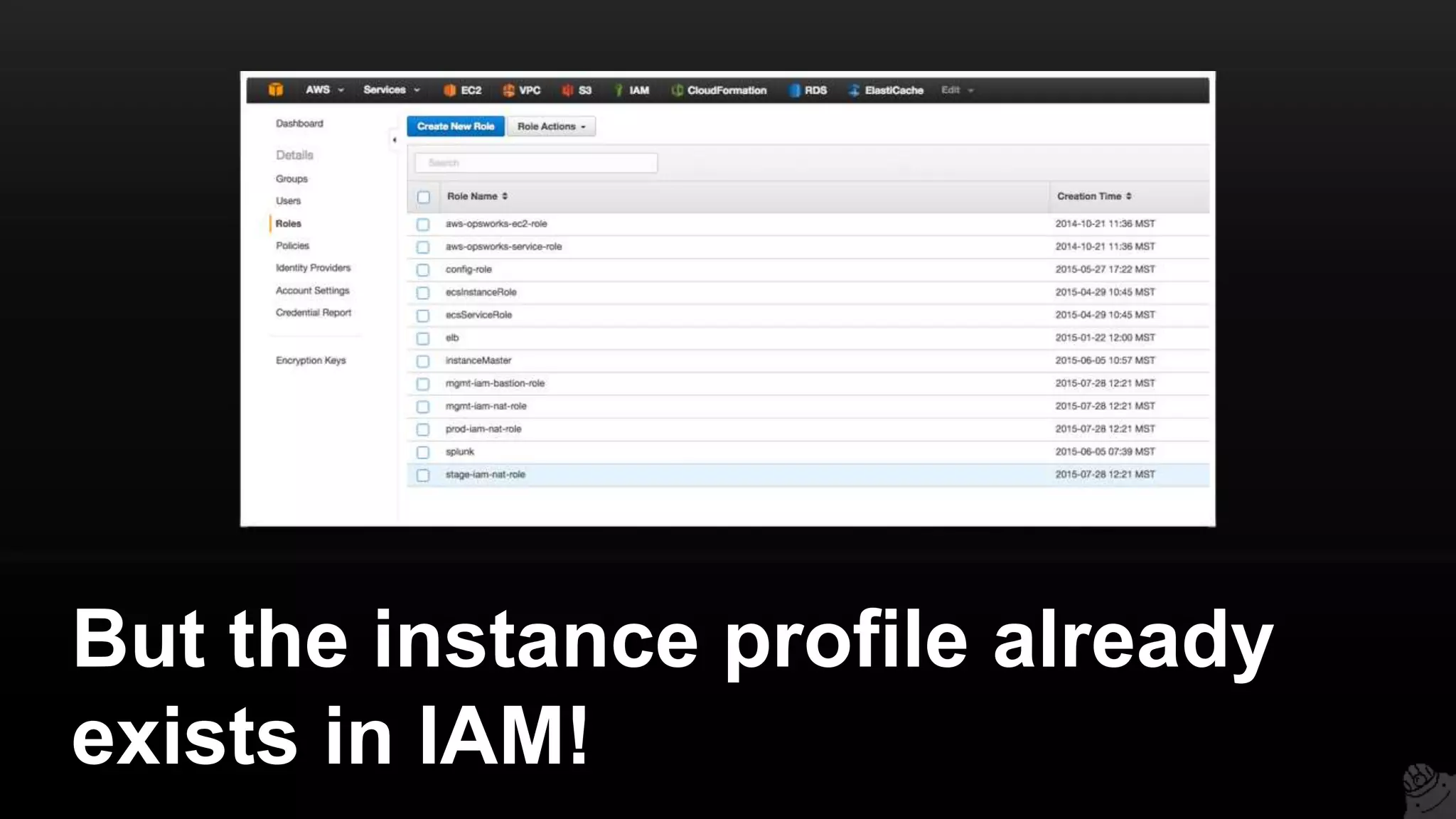
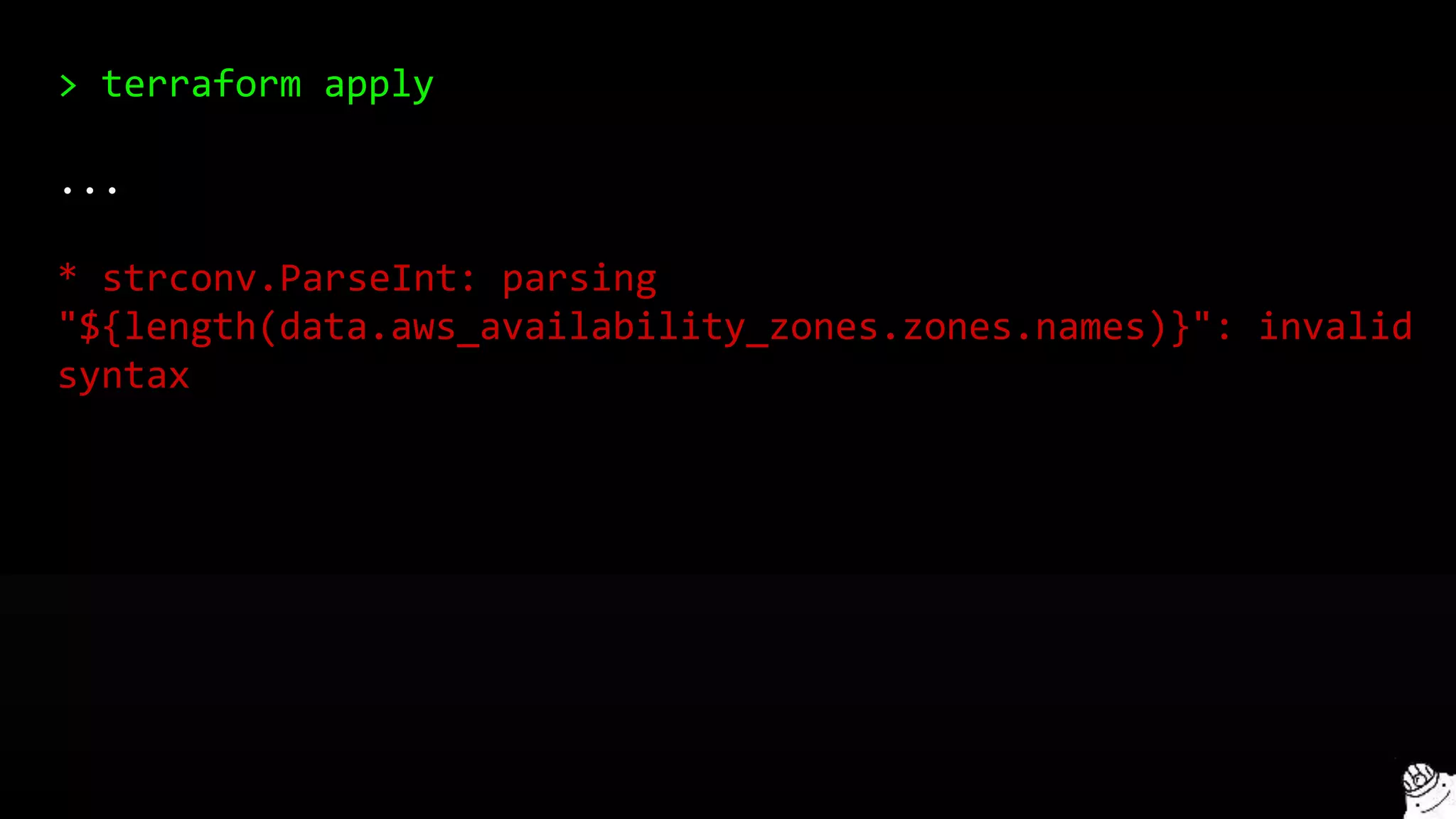
![You get an error
> terraform apply
Error applying plan:
* Error creating IAM role stage-iam-nat-role:
EntityAlreadyExists: Role with name stage-iam-nat-role already
exists
status code: 409, requestId: [e6812c4c-6fac-495c-be9d]](https://image.slidesharecdn.com/terraformcomprehensivetraining-09-160921141454/75/Comprehensive-Terraform-Training-118-2048.jpg)




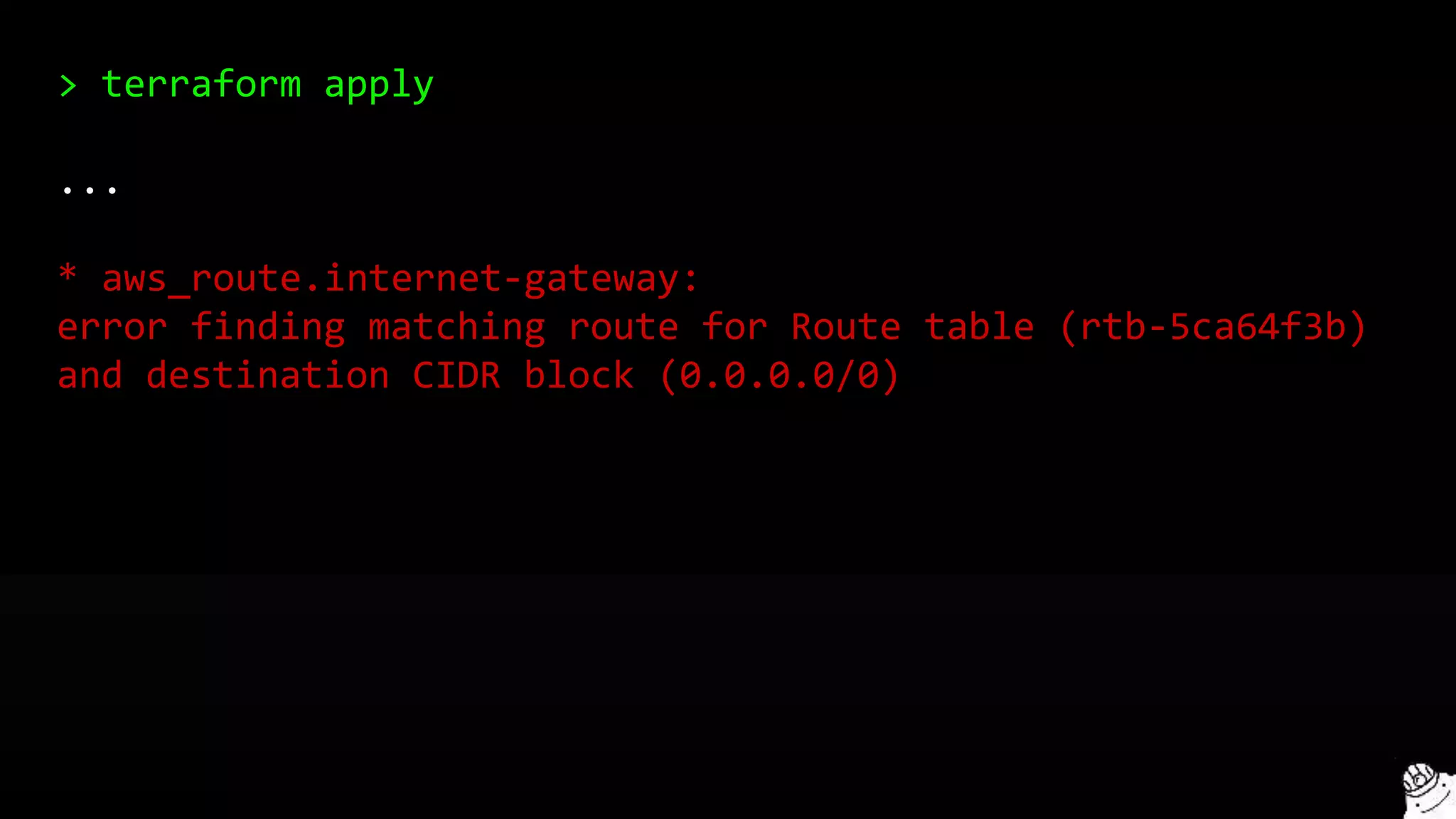
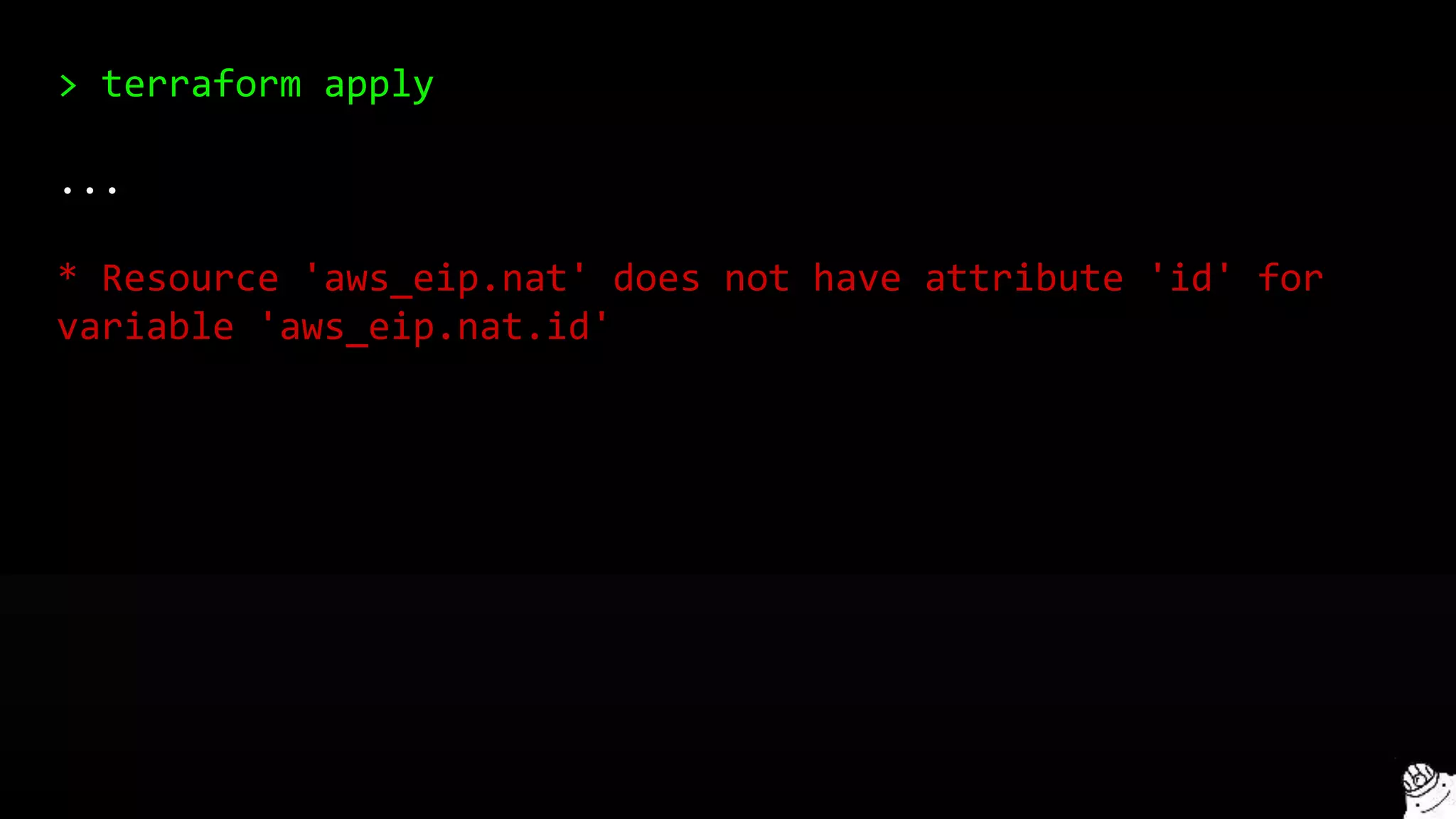
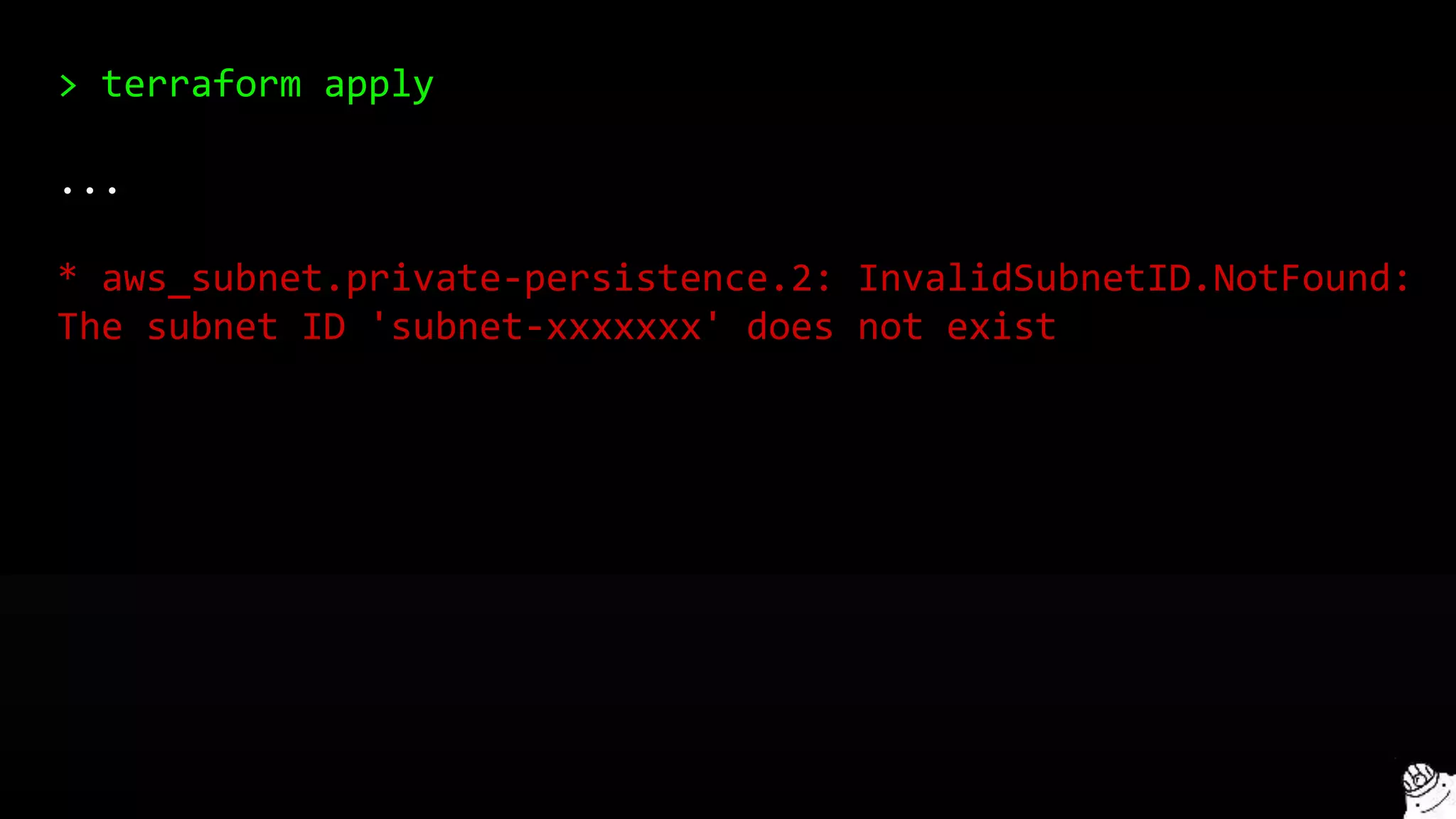
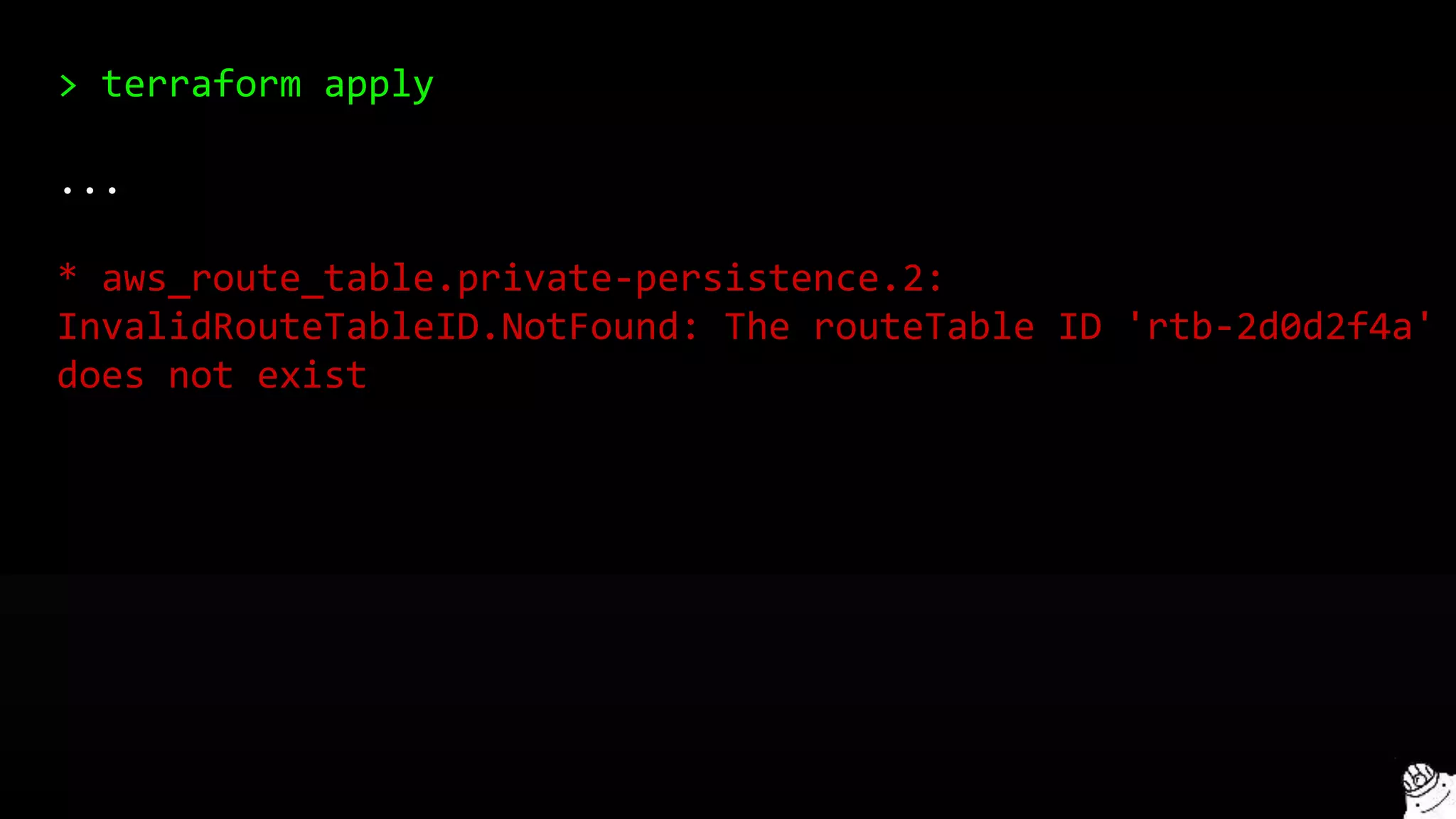
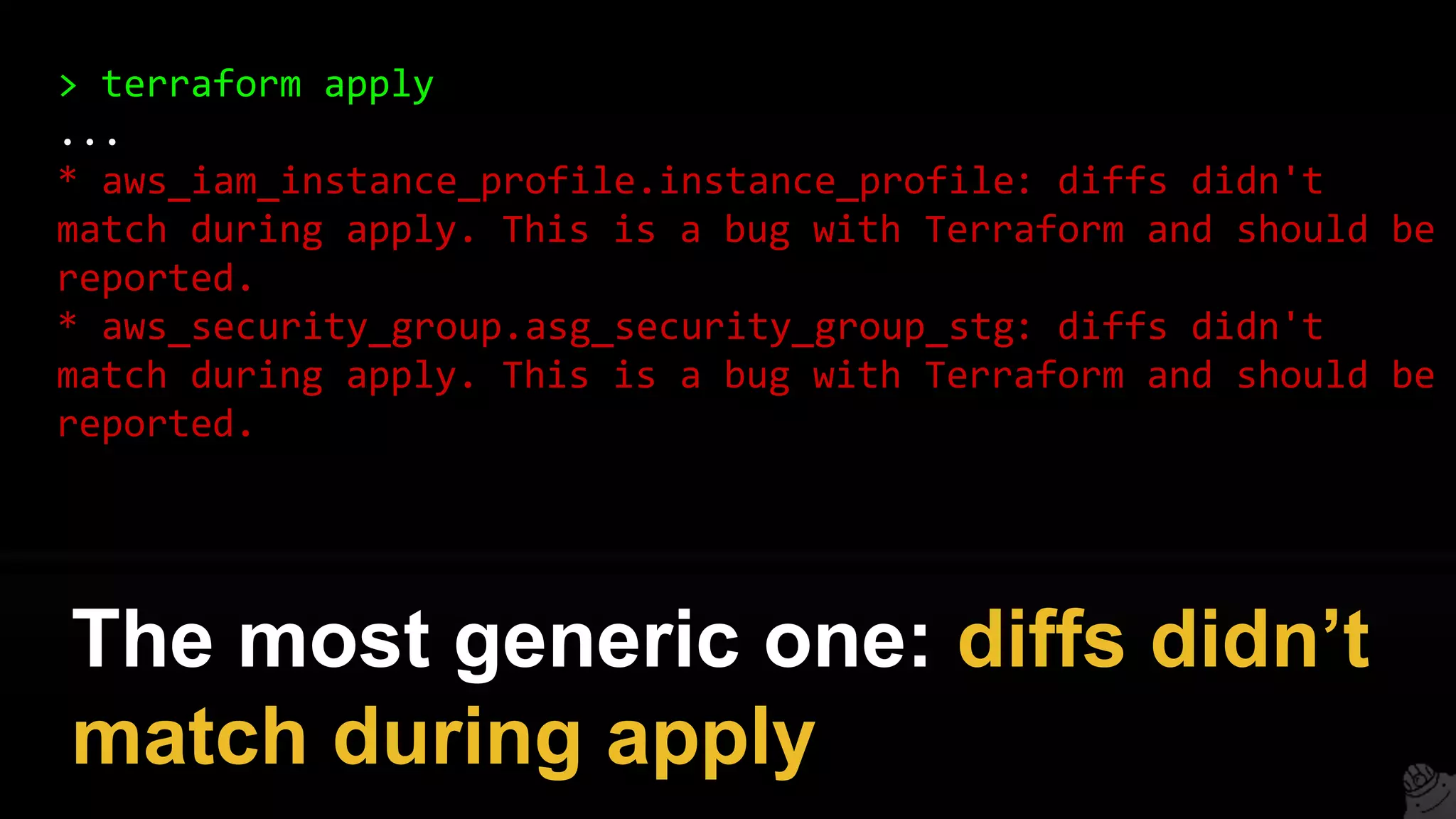






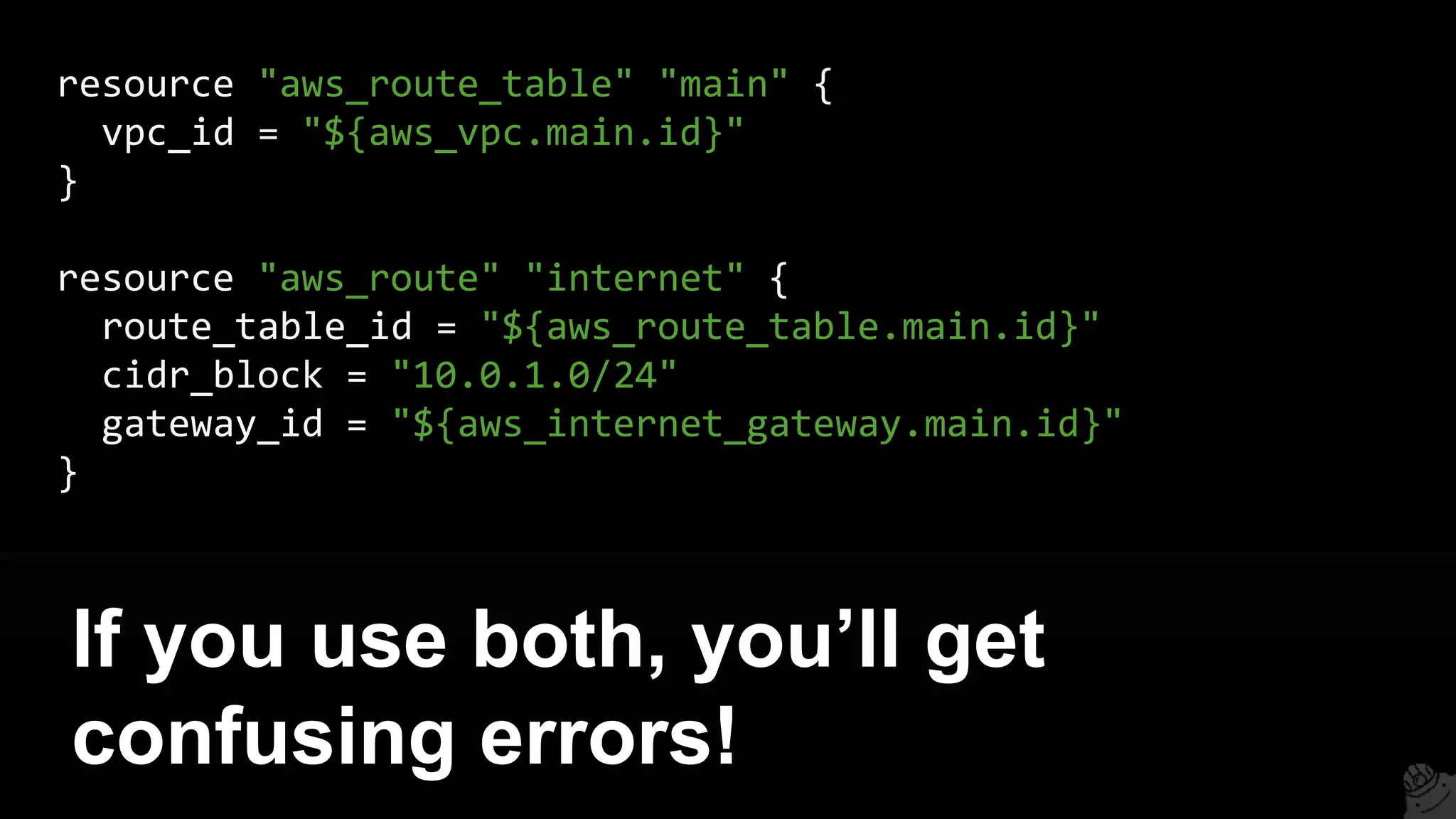











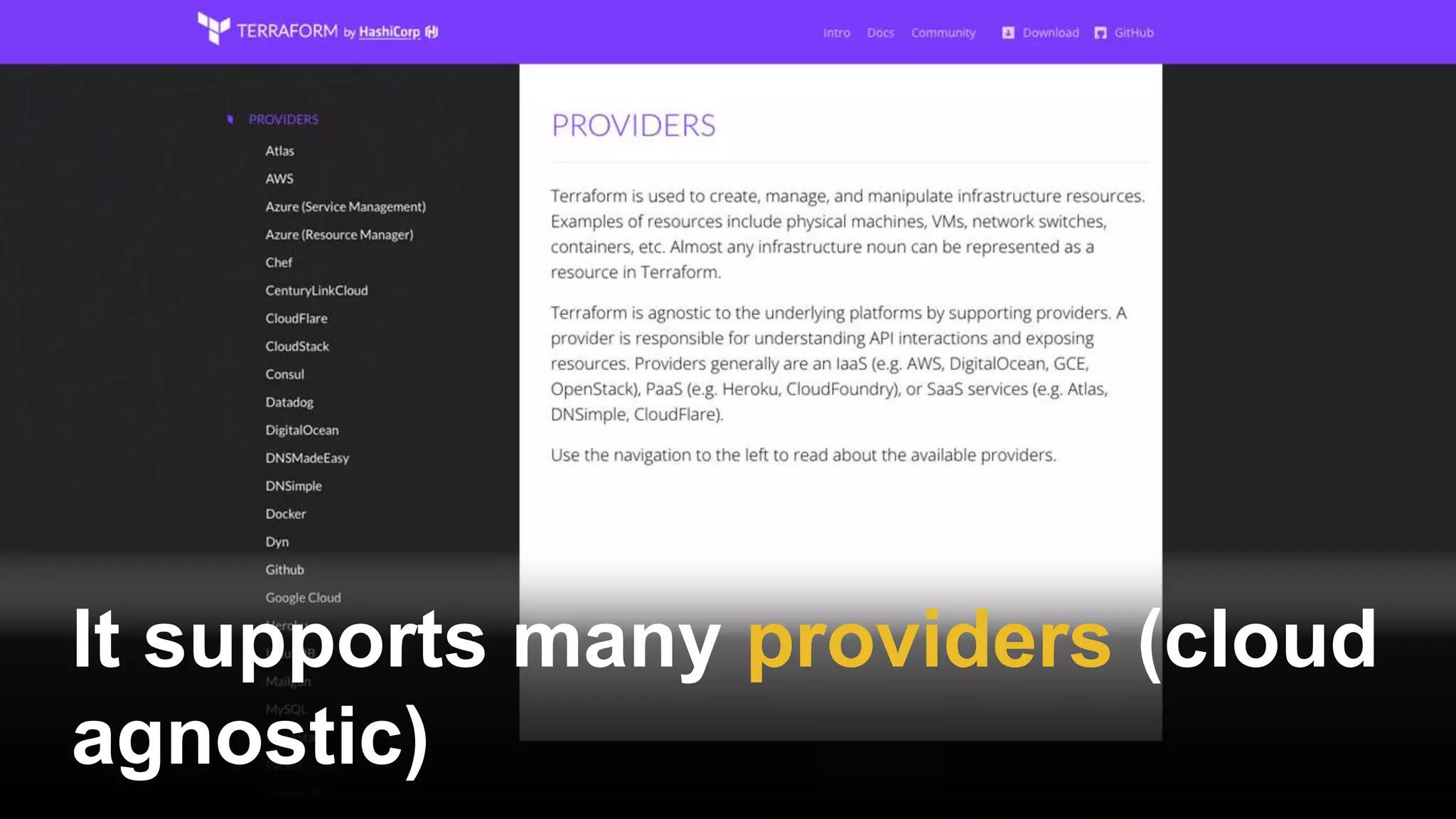
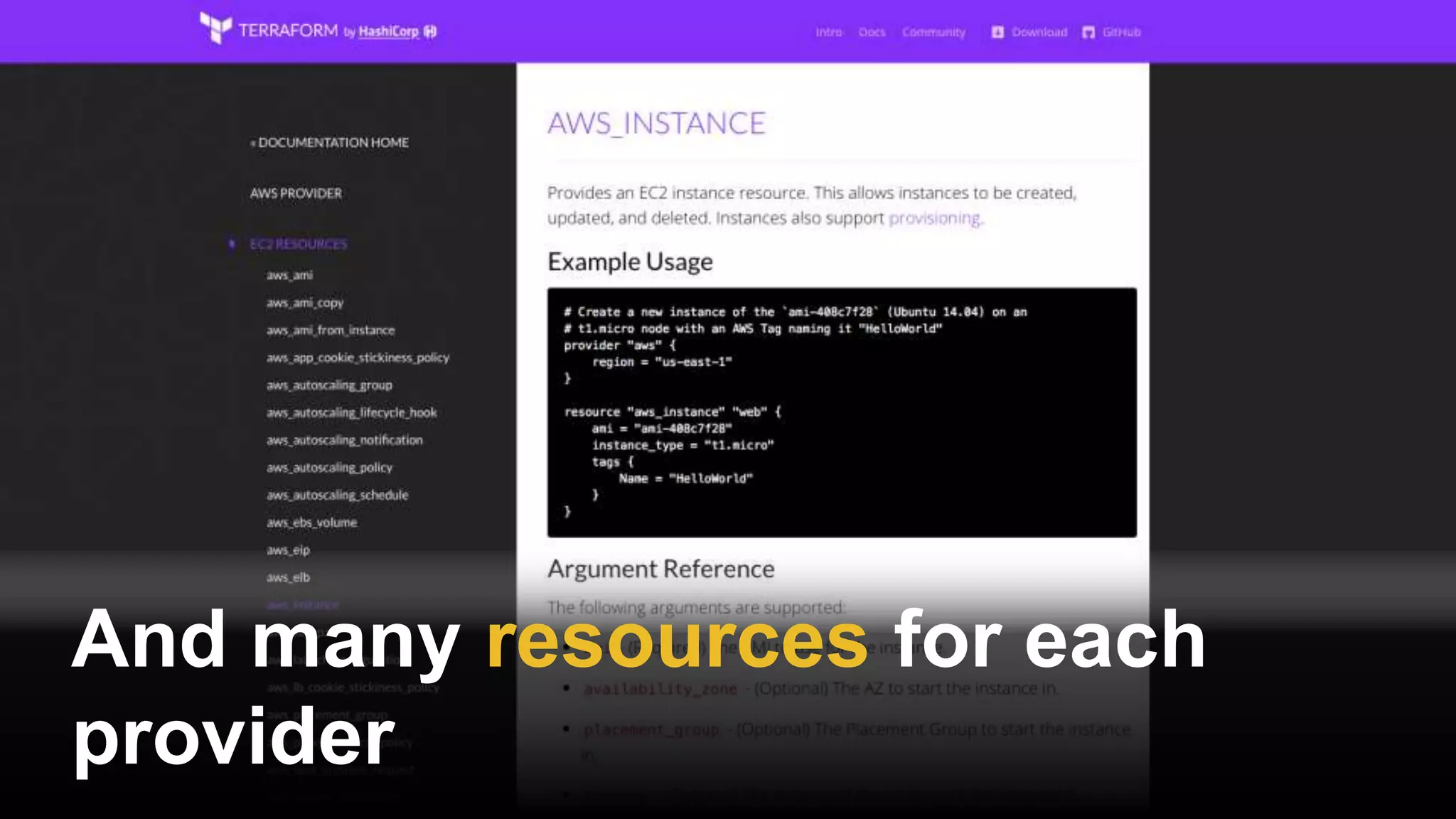
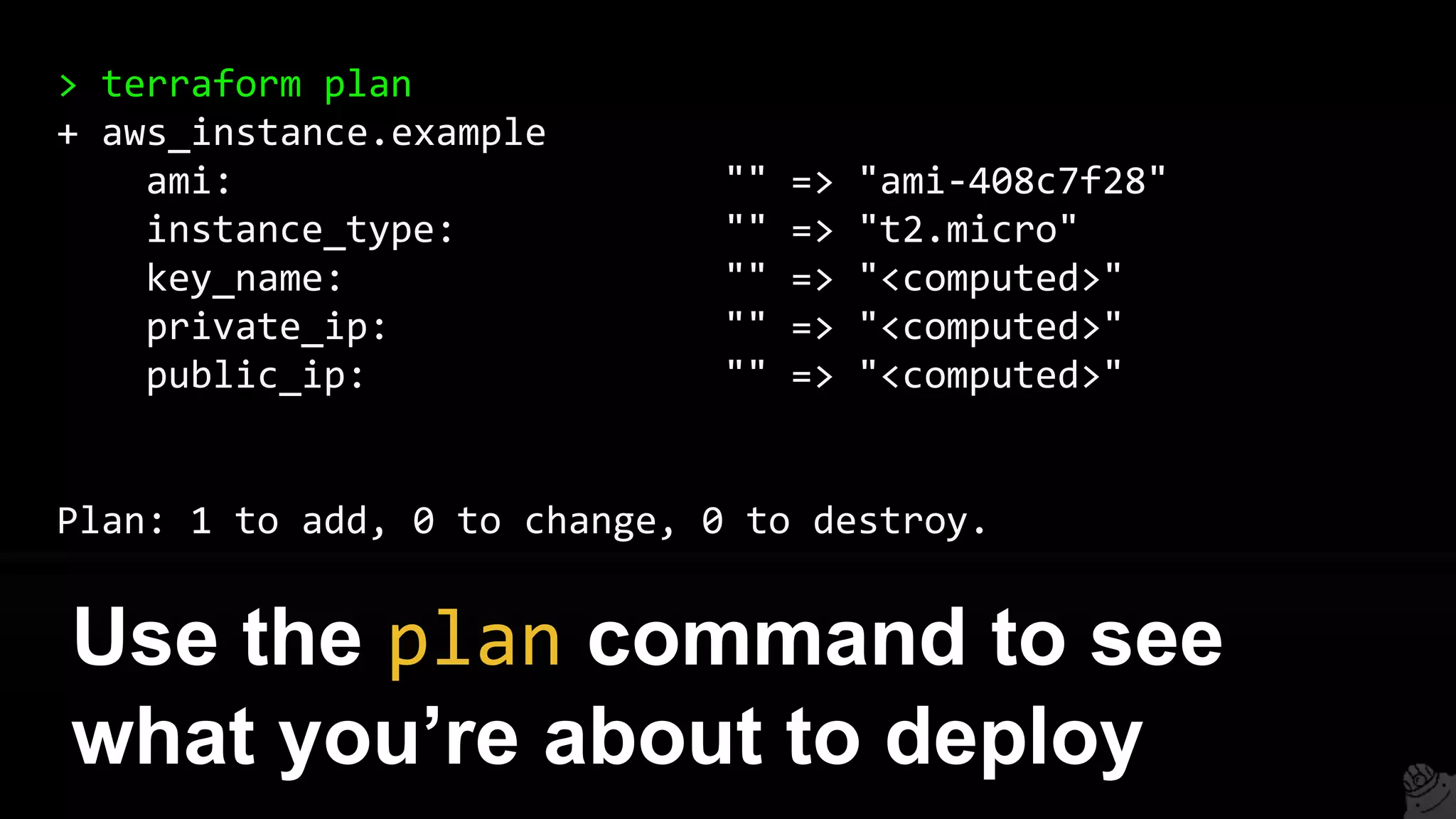
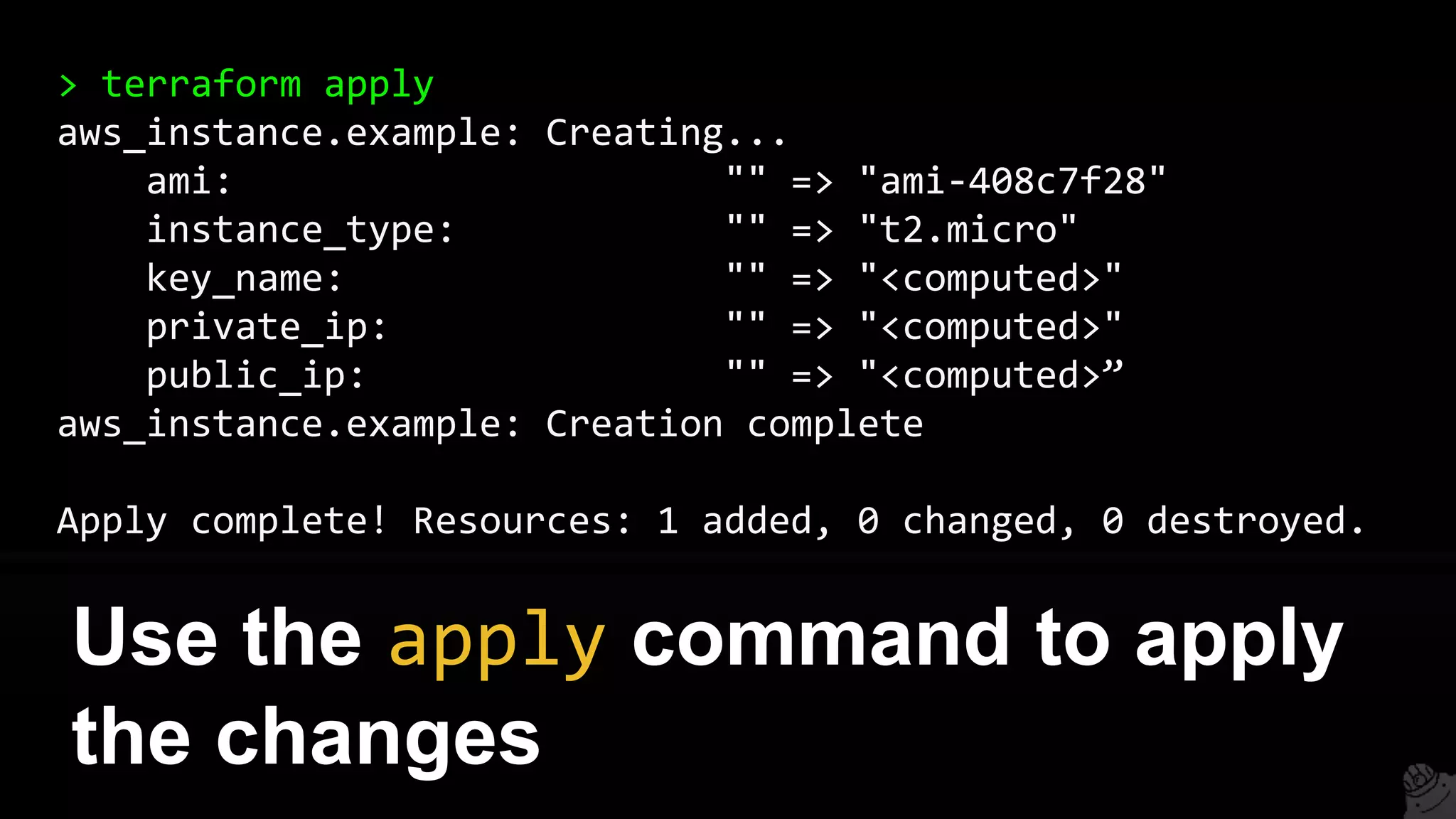
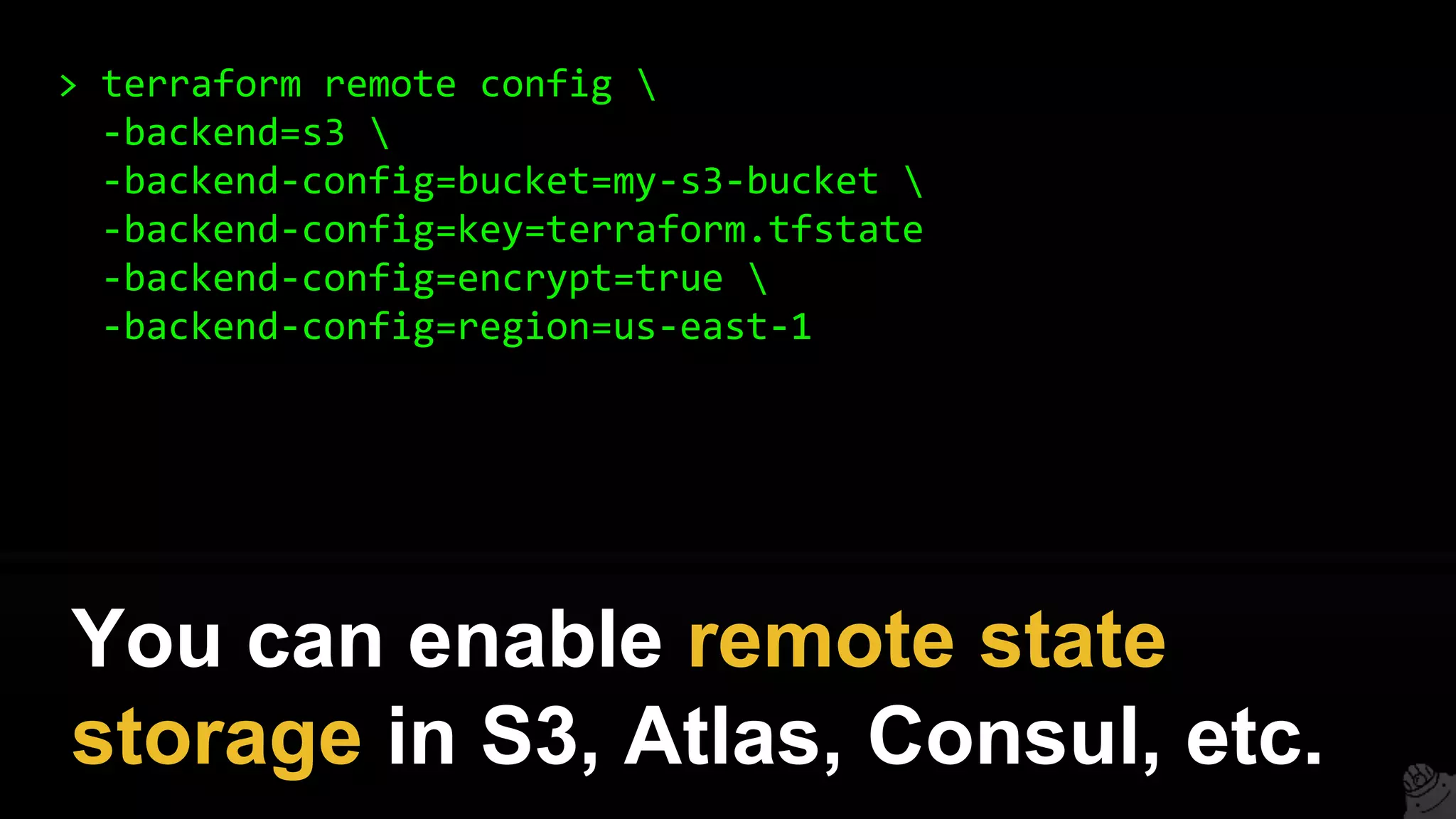
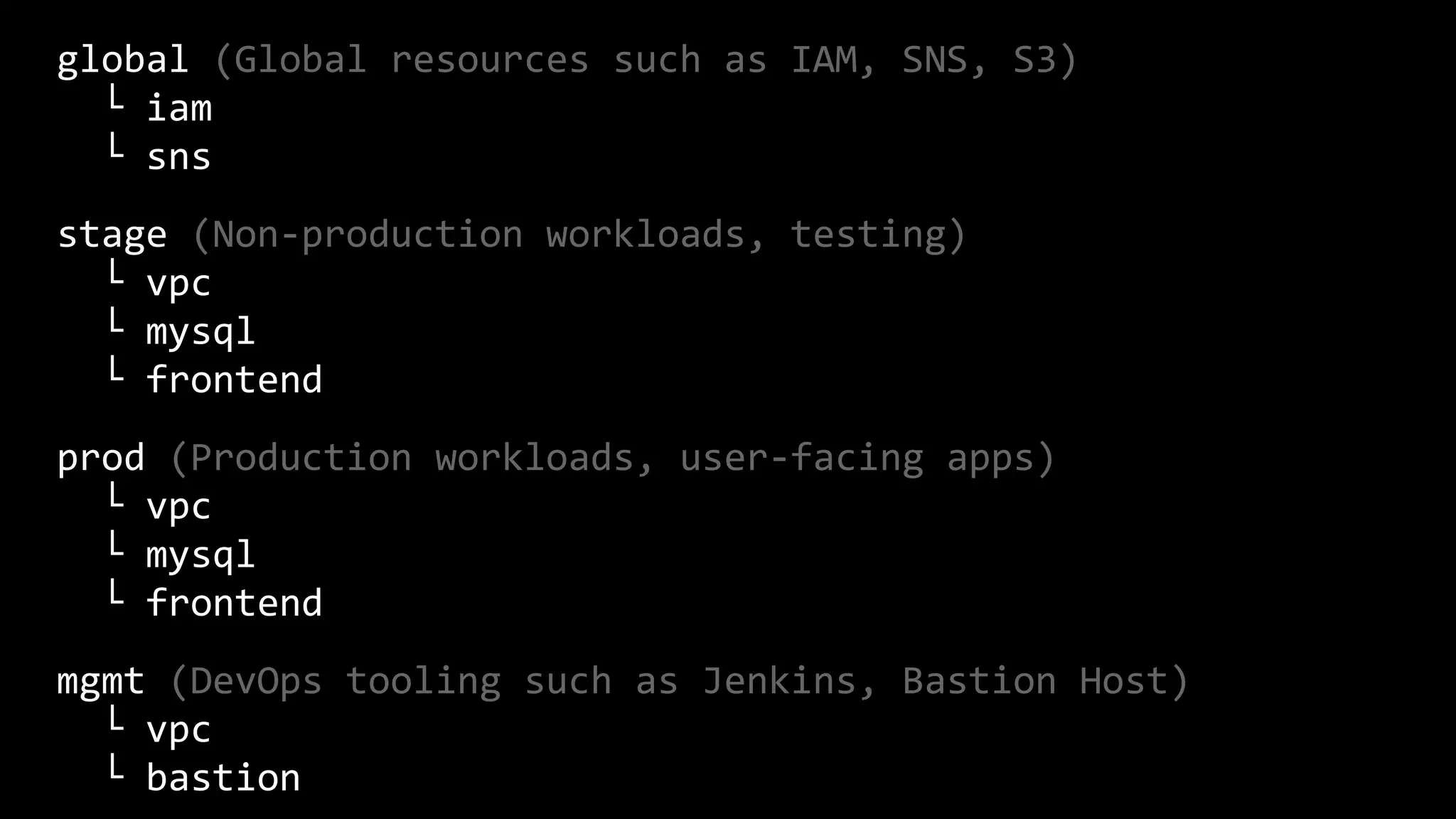
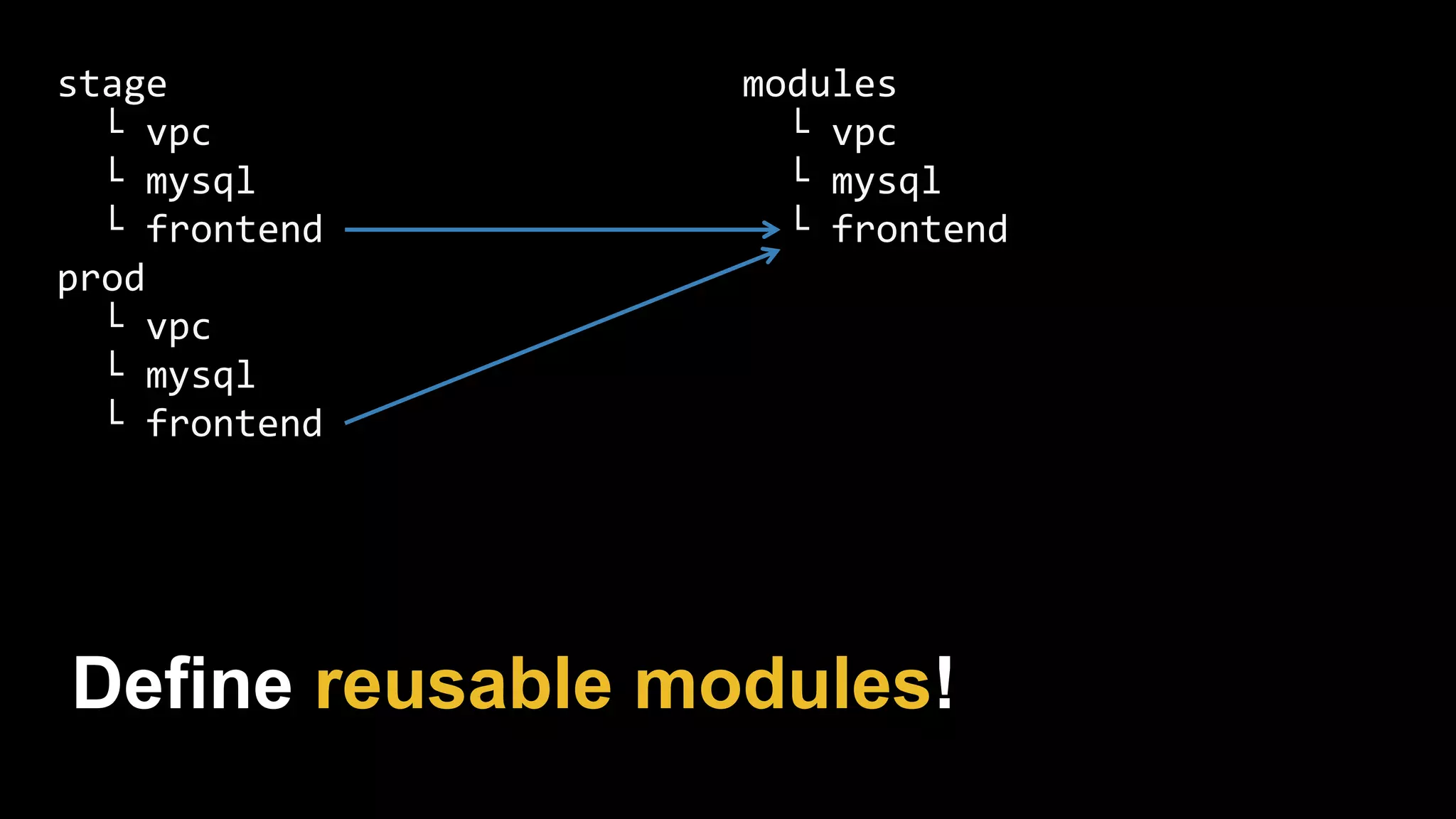
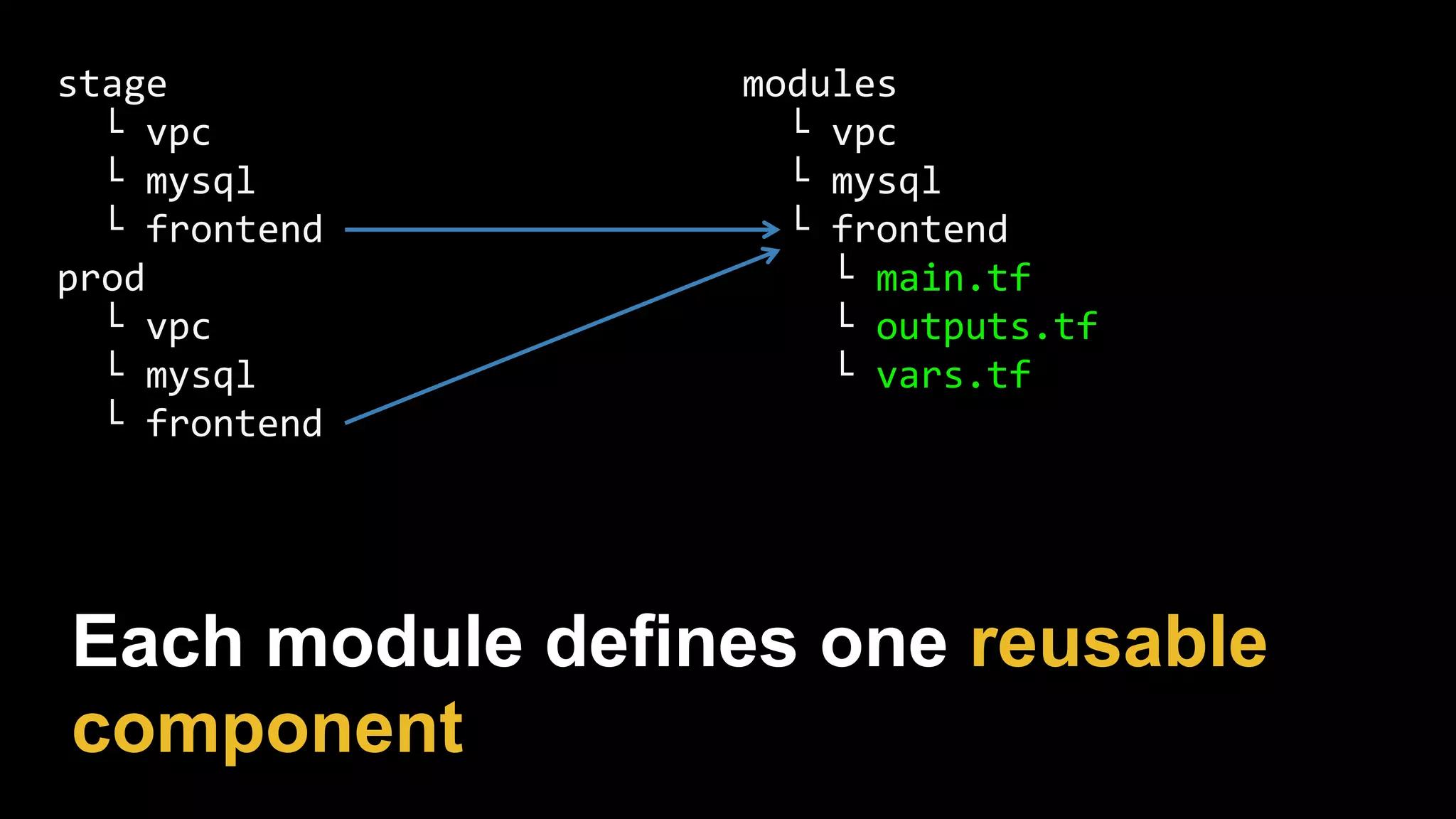
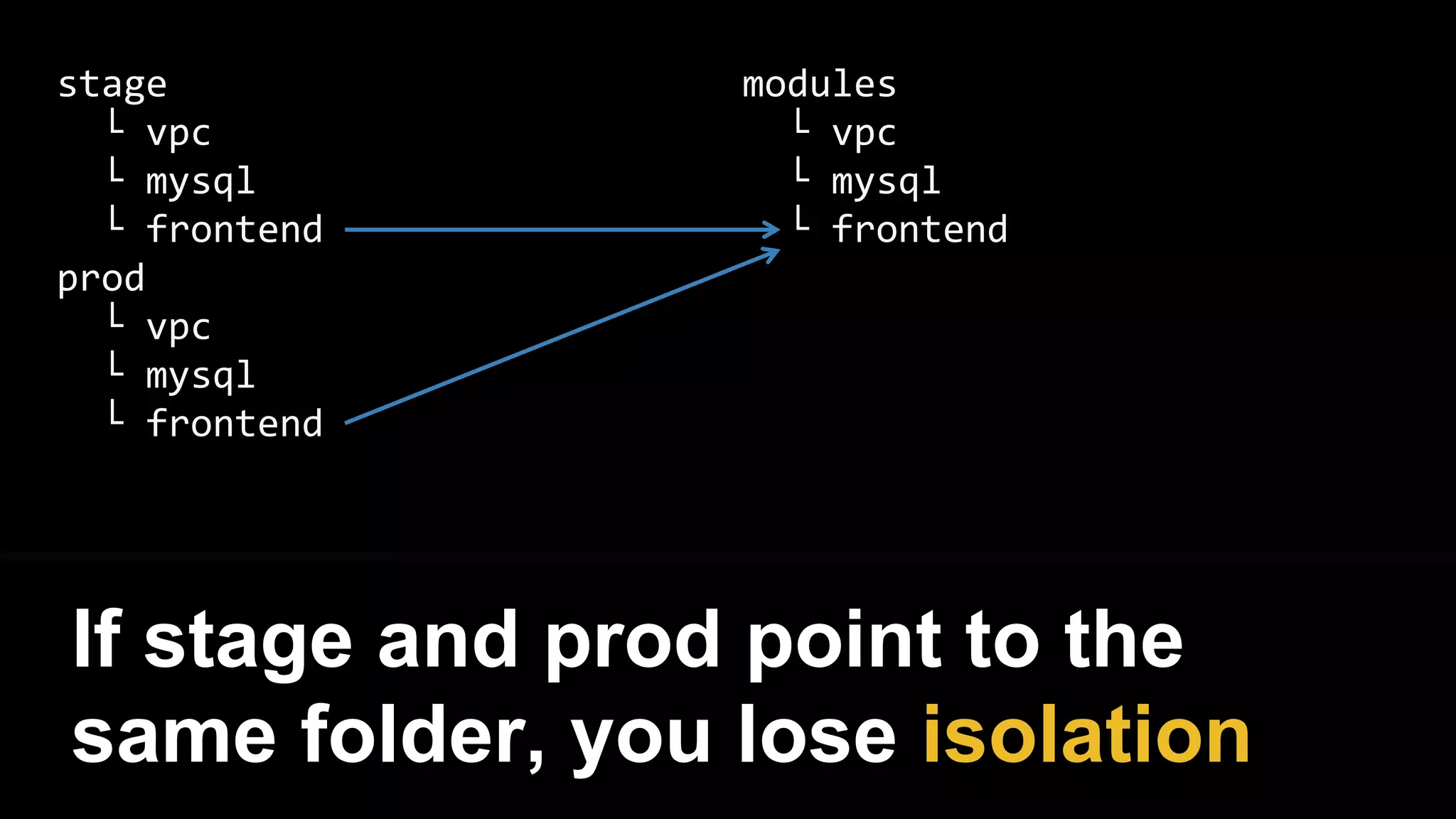
This document provides a comprehensive overview of using Terraform for infrastructure provisioning, detailing its capabilities, including state management, module reusability, and best practices for deploying resources on AWS. It also introduces the Terragrunt tool for enhanced Terraform management, focusing on features like remote state storage, locking, and structured project organization across different environments. The document further explains how to parameterize templates and use loops and conditional statements to manage resources effectively.

































![Hackdays and [in]cubator](https://cdn.slidesharecdn.com/ss_thumbnails/hackdaysandincubator-130211223338-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































































