Download to read offline









![• Linear data access is the best you can do to
help hardware prefetching
• Processor recognizes pattern and preload data for next iterations
beforehand
Vec4D in[SIZE]; // Offset from origin
float ChebyshevDist[SIZE]; // Chebyshev distance from origin
for (auto i = 0; i < SIZE; ++i)
{
ChebyshevDist[i] = Max(in[i].x, in[i].y, in[i].z, in[i].w);
}
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-12-2048.jpg)








![struct FooBonus
{
float fooBonus;
float otherData[15];
};
// For every character…
// Assume we have array<FooBonus> structs;
float Sum{0.0f};
for (auto i = 0; i < SIZE; ++i)
{
Actor->Total += FooArray[i].fooBonus;
}
Example of poor data layout:
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-23-2048.jpg)
![• 64 byte offset between loads
• Each is on separate cache line
• 60 from 64 bytes are wasted
addss xmm6,dword ptr [rax-40h]
addss xmm6,dword ptr [rax]
addss xmm6,dword ptr [rax+40h]
addss xmm6,dword ptr [rax+80h]
addss xmm6,dword ptr [rax+0C0h]
addss xmm6,dword ptr [rax+100h]
addss xmm6,dword ptr [rax+140h]
addss xmm6,dword ptr [rax+180h]
add rax,200h
cmp rax,rcx
jl main+0A0h
*MSVC loves x8 loop unrolling
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-24-2048.jpg)

![Cold fields
struct FooBonus
{
MiscData* otherData;
float fooBonus;
};
struct MiscData
{
float otherData[15];
};
Optimizing for data cache
+ 4 bytes for memory alignment on 64bit](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-26-2048.jpg)
![• 12 byte offset
• Much less bandwidth is wasted
• Can do better?!
addss xmm6,dword ptr [rax-0Ch]
addss xmm6,dword ptr [rax]
addss xmm6,dword ptr [rax+0Ch]
addss xmm6,dword ptr [rax+18h]
addss xmm6,dword ptr [rax+24h]
addss xmm6,dword ptr [rax+30h]
addss xmm6,dword ptr [rax+3Ch]
addss xmm6,dword ptr [rax+48h]
add rax,60h
cmp rax,rcx
jl main+0A0h
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-27-2048.jpg)
![• Maybe no need to make a pointer to the cold fields?
• Make use of Structure of Arrays
• Store and index different arrays
struct FooBonus
{
float fooBonus;
};
struct MiscData
{
float otherData[15];
};
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-28-2048.jpg)
![• 100% bandwidth utilization
• If everything is 64byte aligned
addss xmm6,dword ptr [rax-4]
addss xmm6,dword ptr [rax]
addss xmm6,dword ptr [rax+4]
addss xmm6,dword ptr [rax+8]
addss xmm6,dword ptr [rax+0Ch]
addss xmm6,dword ptr [rax+10h]
addss xmm6,dword ptr [rax+14h]
addss xmm6,dword ptr [rax+18h]
add rax,20h
cmp rax,rcx
jl main+0A0h
Optimizing for data cache](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-29-2048.jpg)




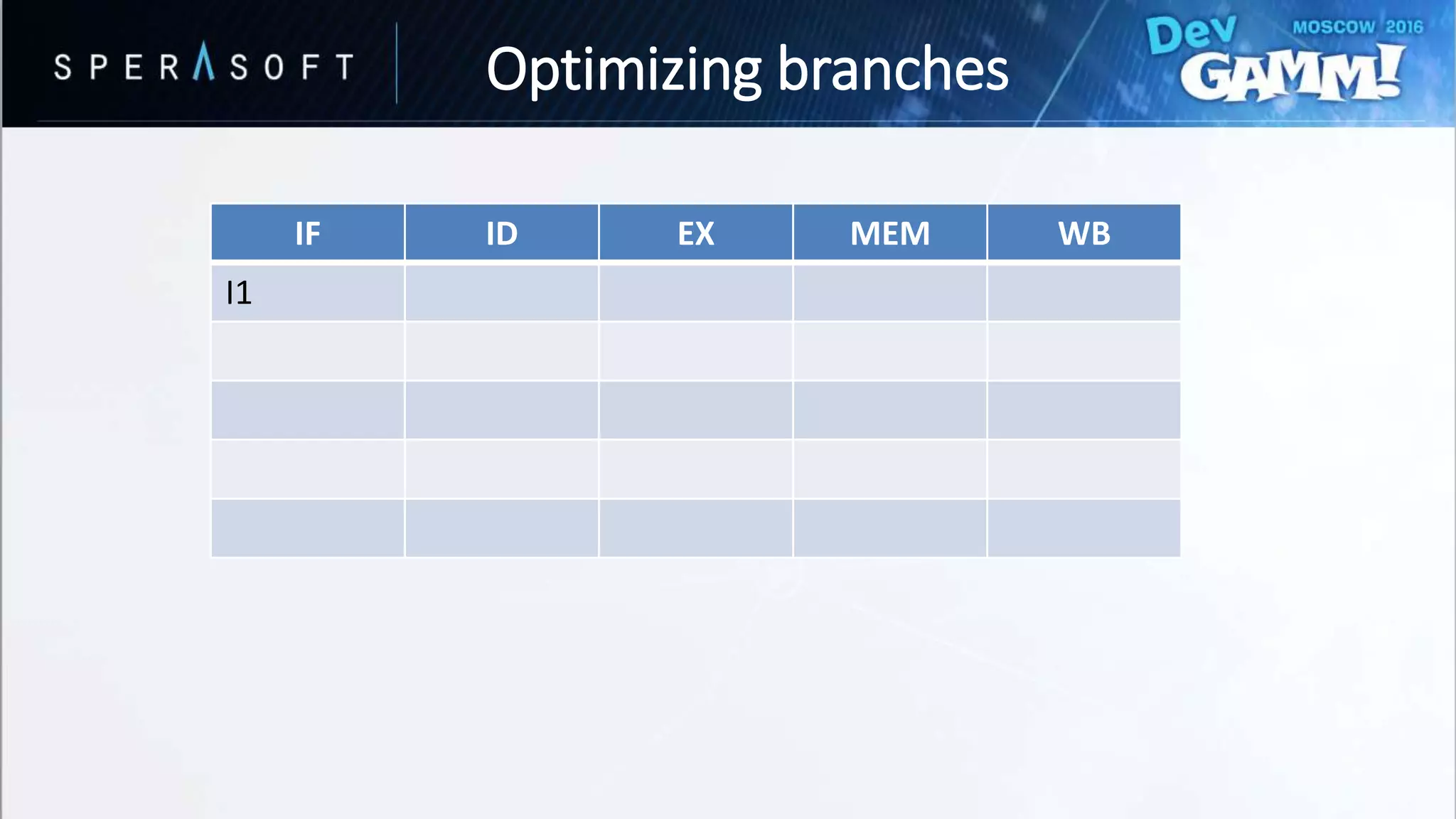
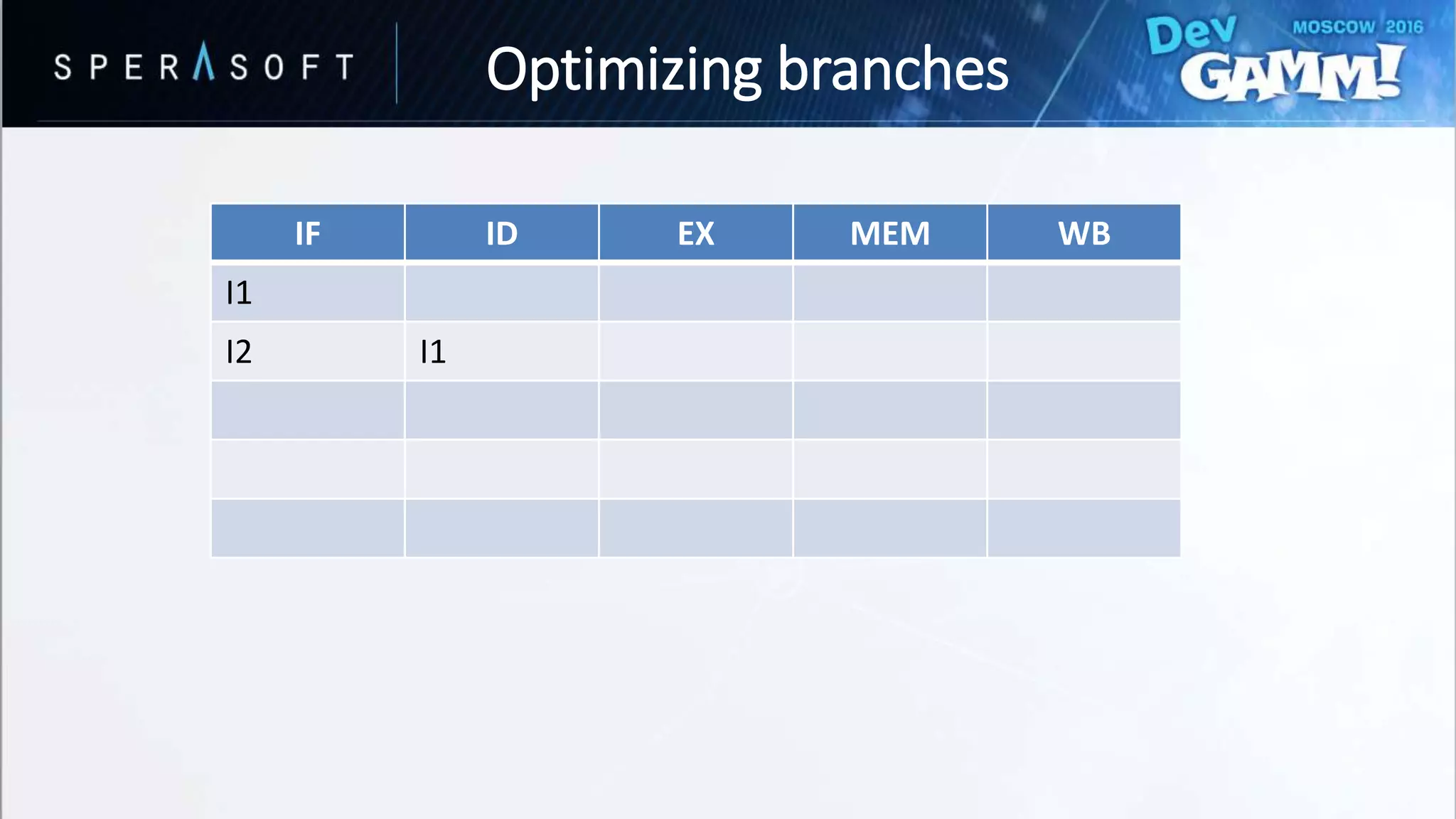
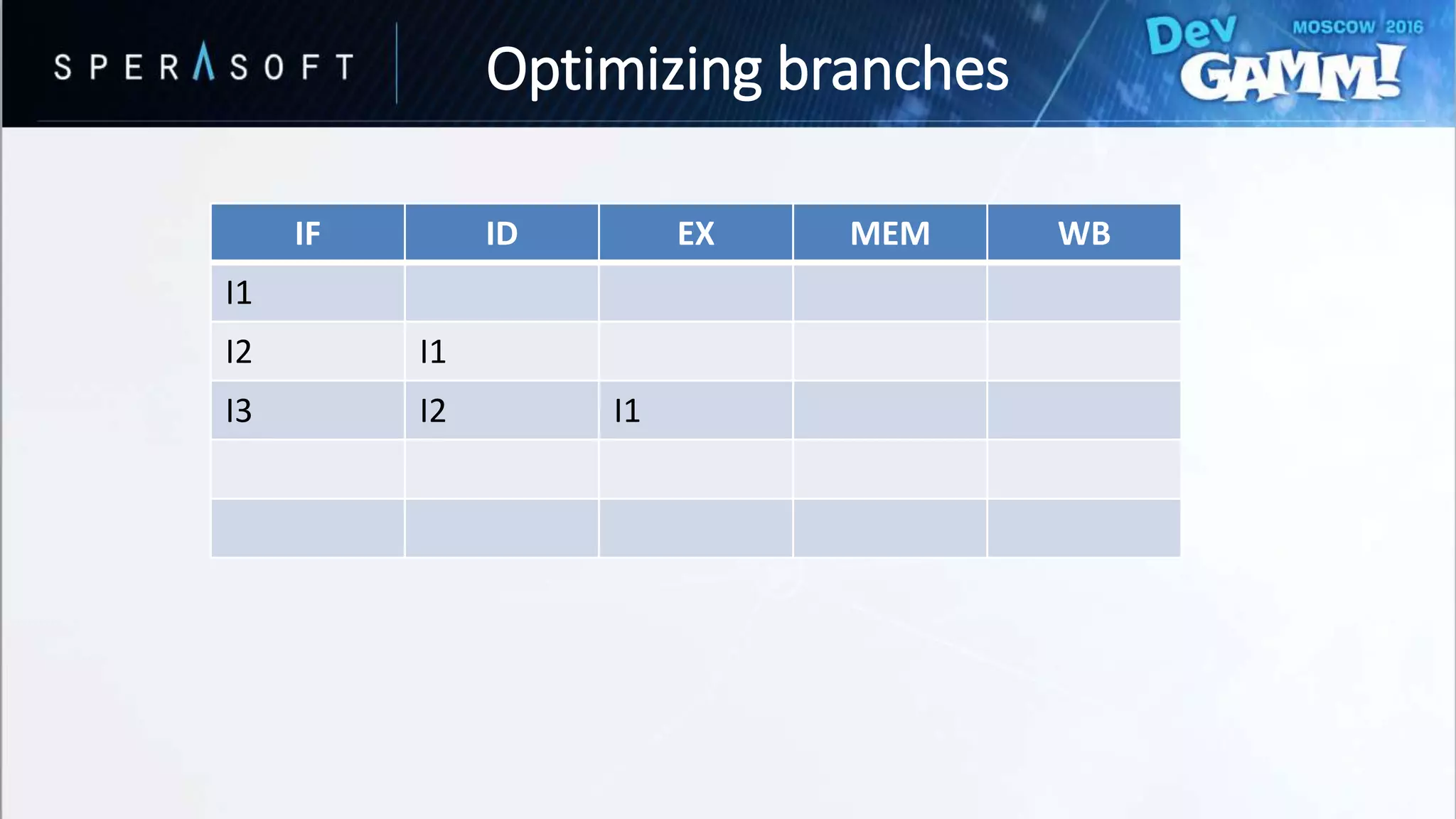
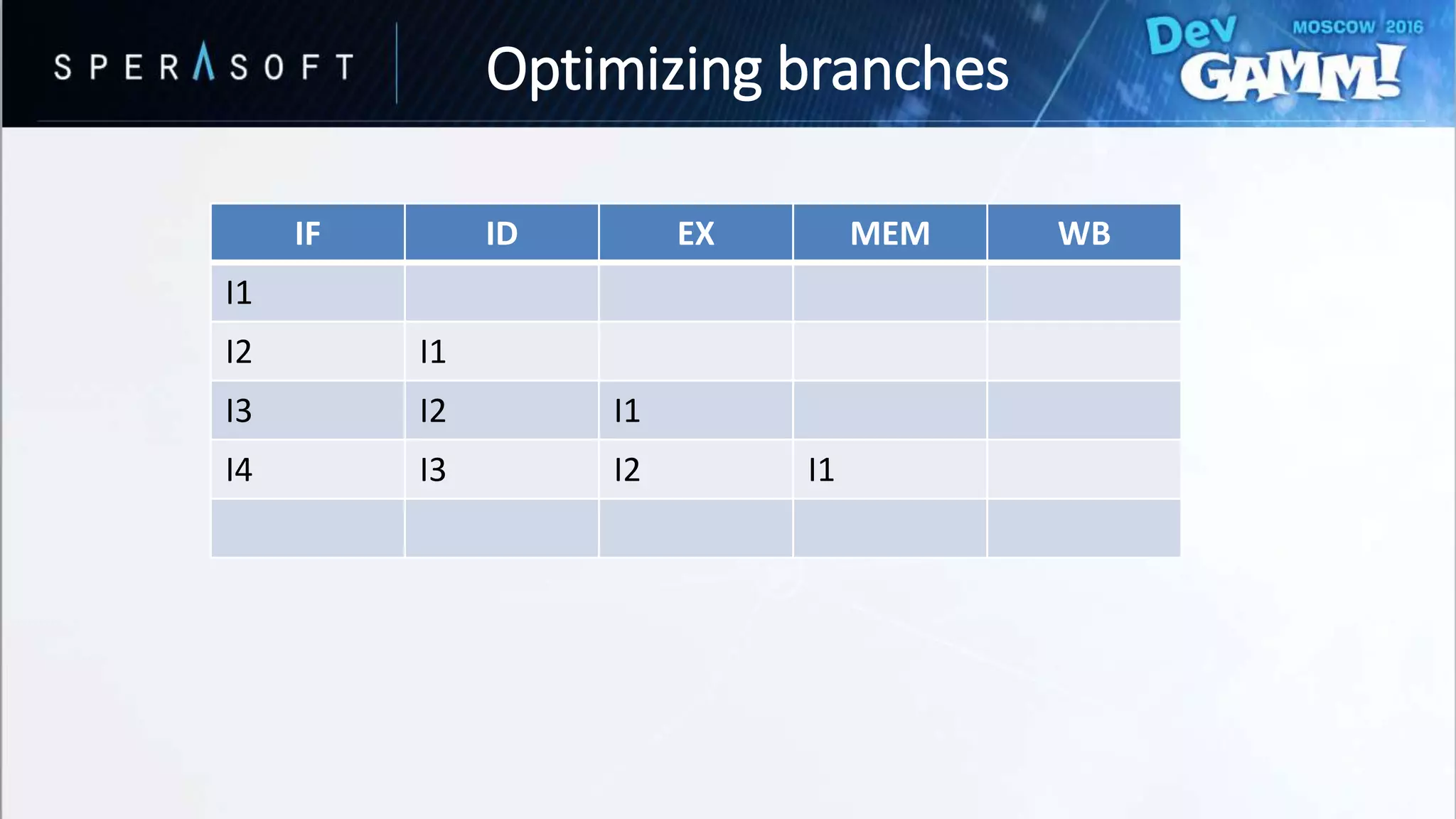
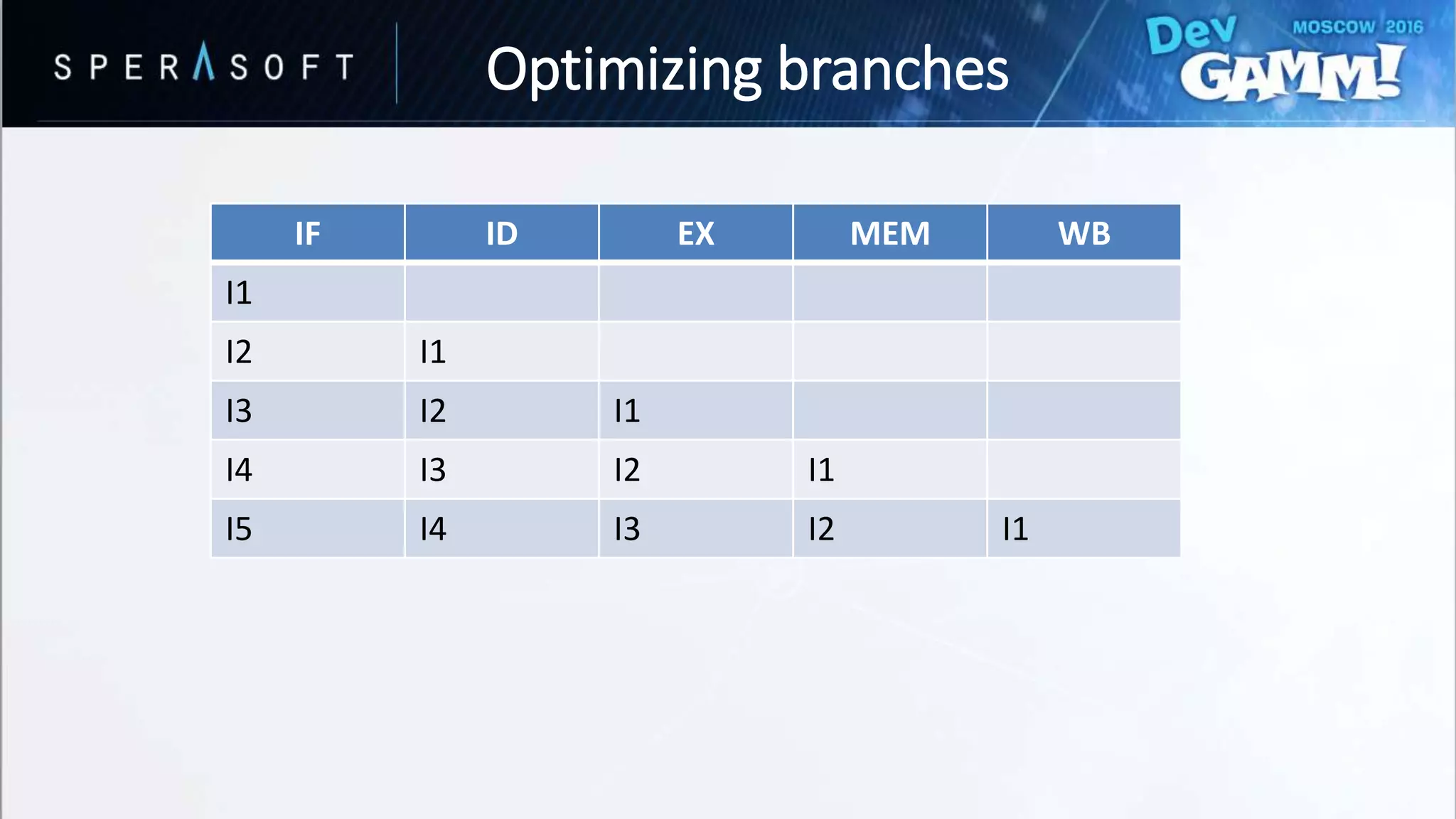







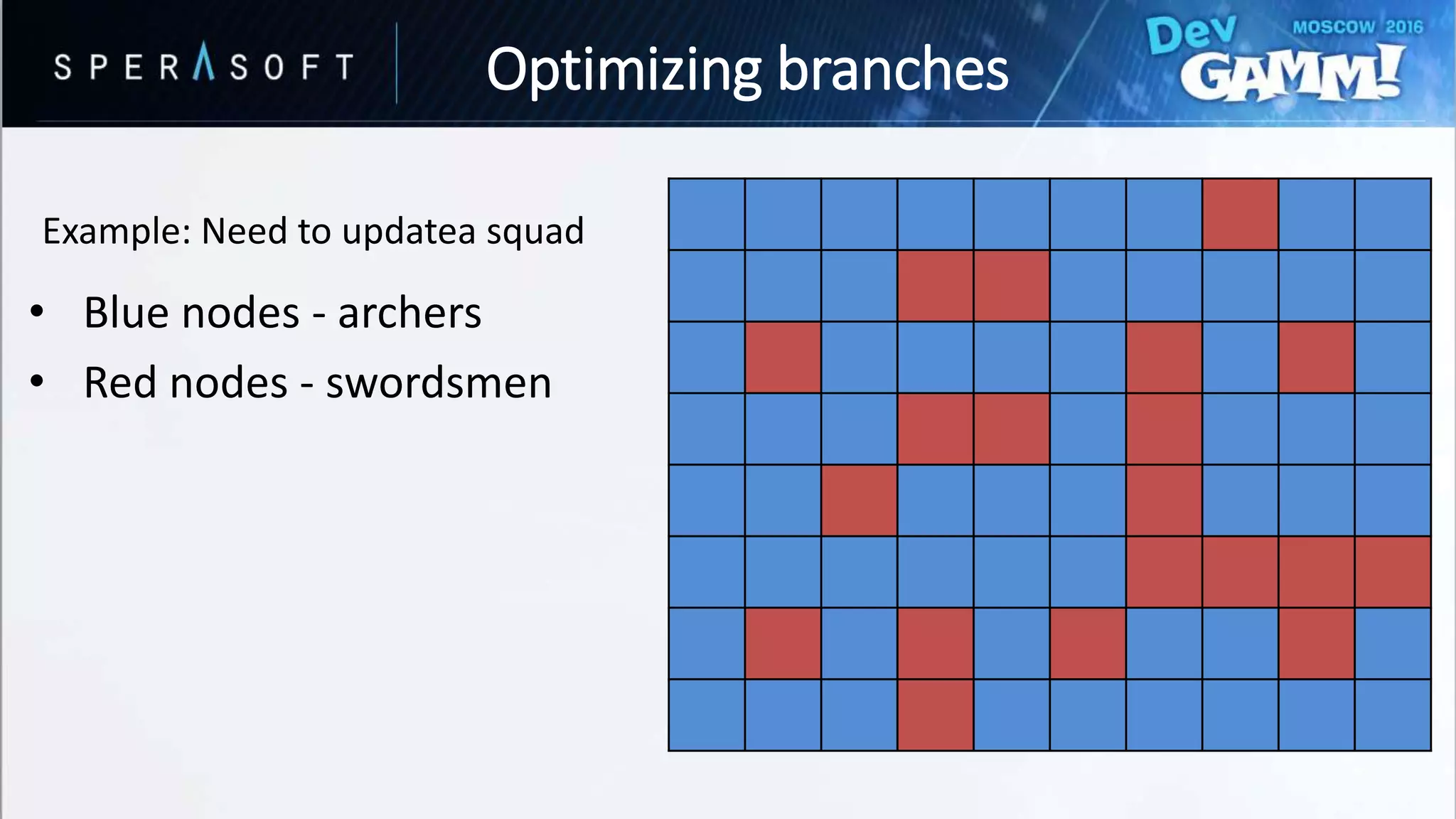
![struct CombatActor
{
// Data…
EUnitType Type; //ARCHER or SWORDSMAN
};
struct Squad
{
CombatActor Units[SIZE][SIZE];
};
void UpdateArmy(const Squad& squad)
{
for (auto i = 0; i < SIZE; ++i)
for (auto j = 0; j < SIZE; ++j)
{
const auto & Unit = squad.Units[i][j];
switch (Unit.Type)
{
case EElementType::ARCHER:
// Process archer
break;
case EElementType::SWORDSMAN:
// Process swordsman
break;
default:
// Handle default
break;
}
}
}
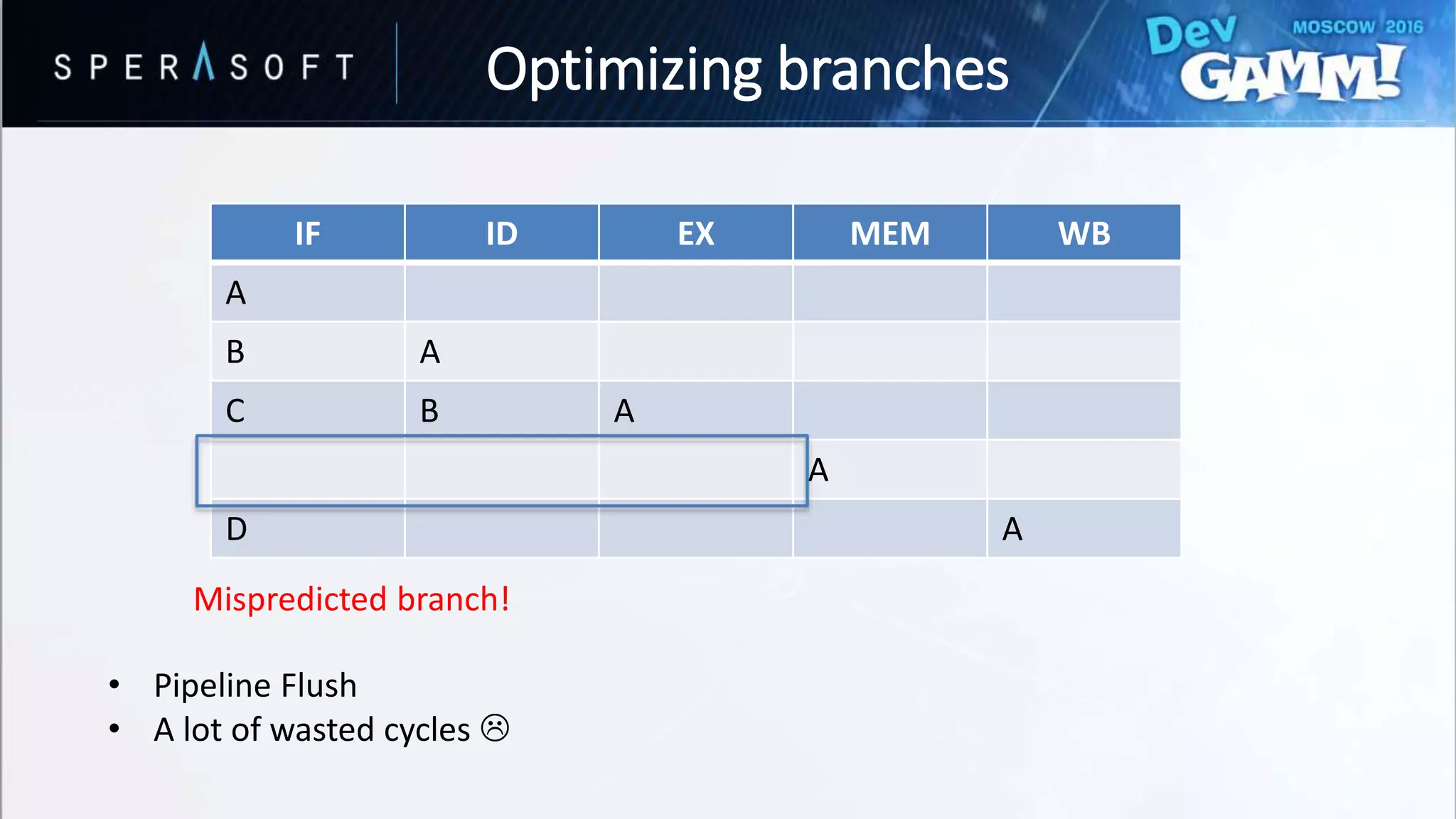
• Branching every iteration?
• Bad performance for hard-to-predict branches
Optimizing branches](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-49-2048.jpg)
![struct CombatActor
{
// Data…
EUnitType Type; //ARCHER or SWORDSMAN
};
struct Squad
{
CombatActor Archers[A_SIZE];
CombatActor Swordsmen[S_SIZE];
};
void UpdateArchers(const Squad & squad)
{
// Just iterate and process, no branching here
// Update archers
}
• Split! And process separately
• No branching in processing methods
• + Better utilization of I-cache!
void UpdateSwordsmen(const Squad & squad)
{
// Just iterate and process, no branching here
// Update swordsmen
}
Optimizing branches](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-50-2048.jpg)

![; function prologue
cmp dword ptr [data], 0
je END
; set of some ALU instructions…
;…
END:
; function epilogue
; function prologue
cmp dword ptr [data], 0
jne COMP
jmp END
COMP:
; set of some ALU instructions…
;…
END:
; function epilogue
• Imagine cmp dword ptr [data], 0 – likely to evaluate to “false”
• Prefer predicted not taken
Predicted not taken Predicted taken
Optimizing branches](https://image.slidesharecdn.com/devgammoptimizationtricksevgenymuralev-161003150120/75/Code-and-Memory-Optimisation-Tricks-52-2048.jpg)






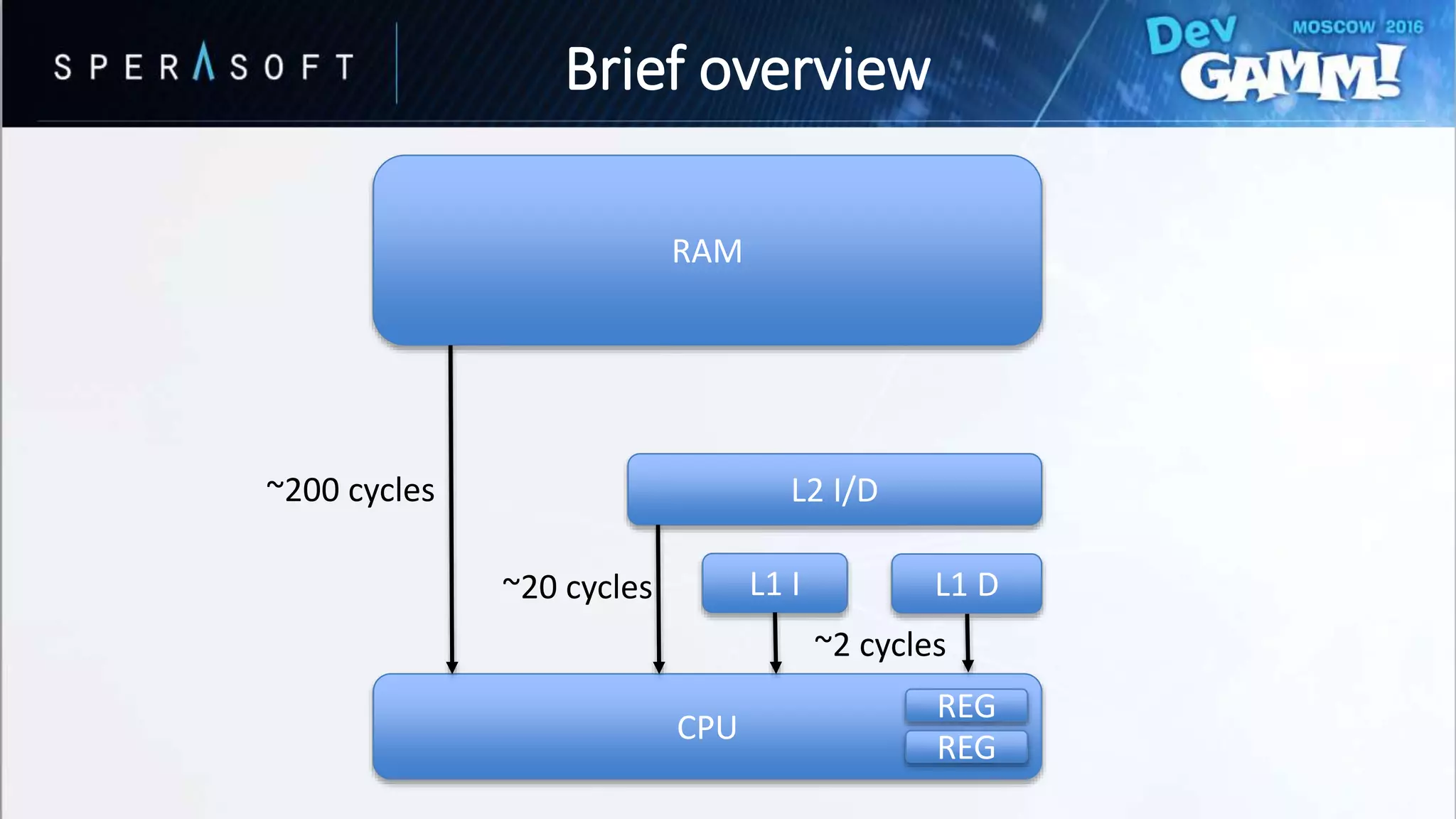
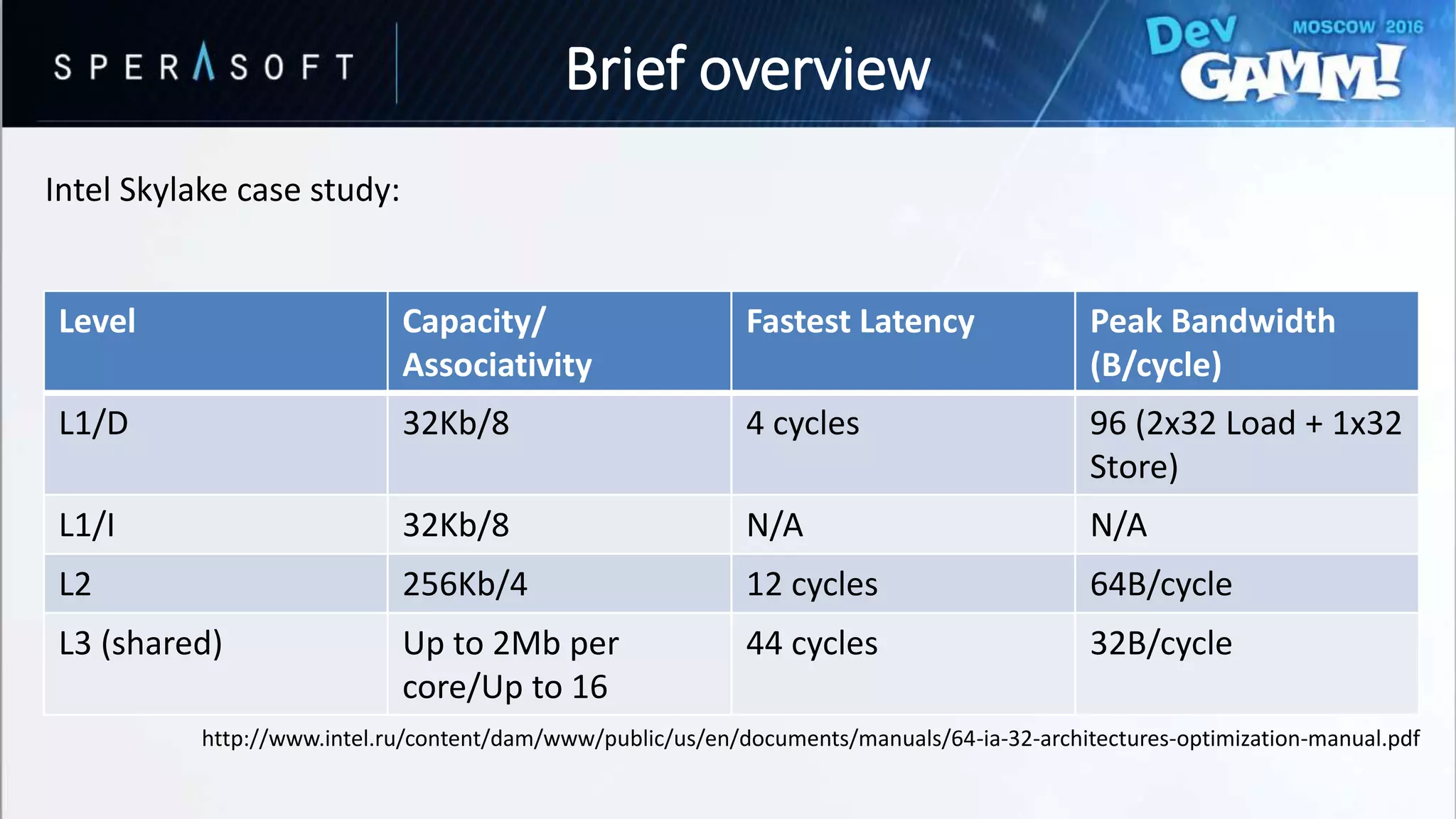
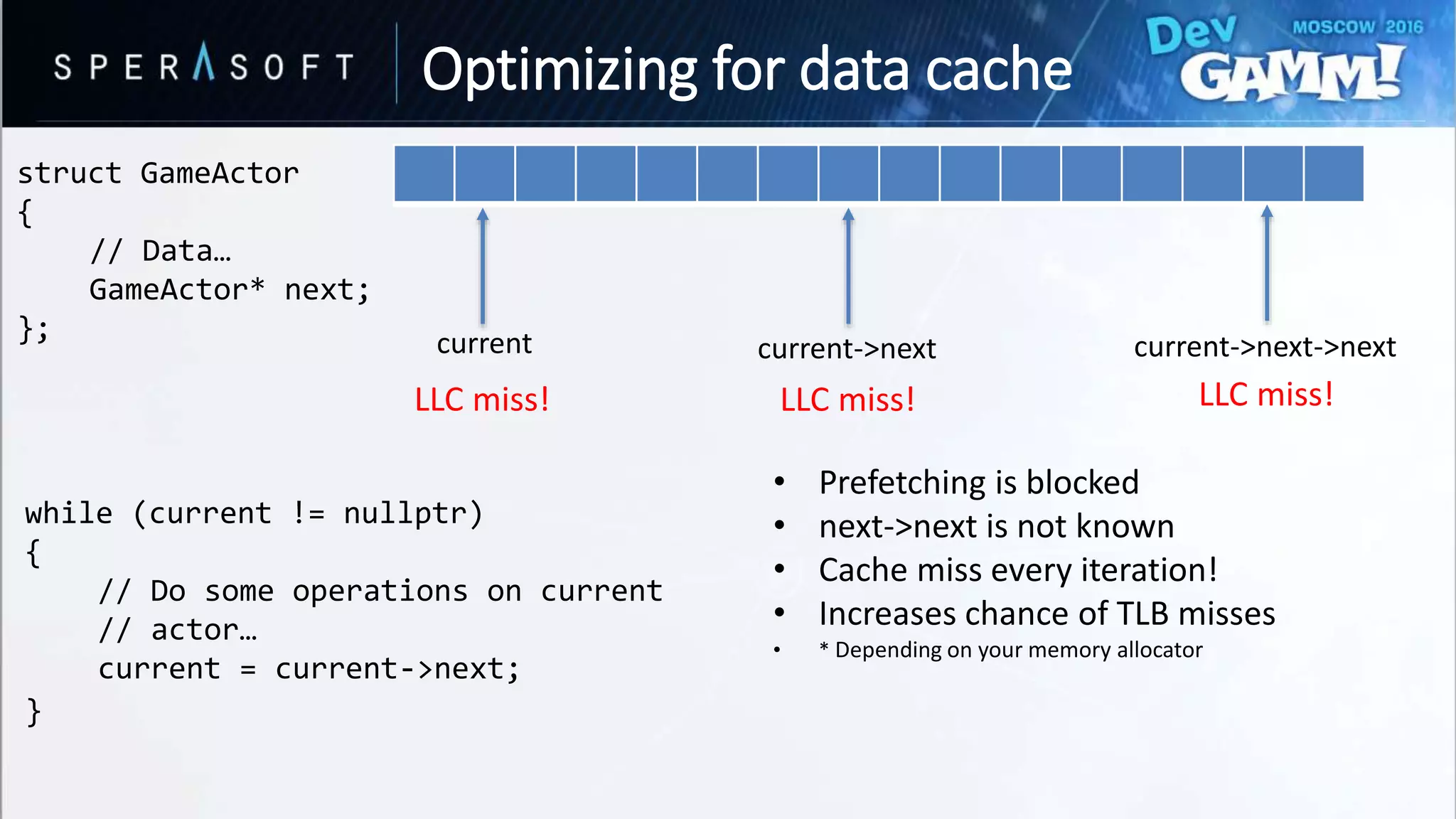
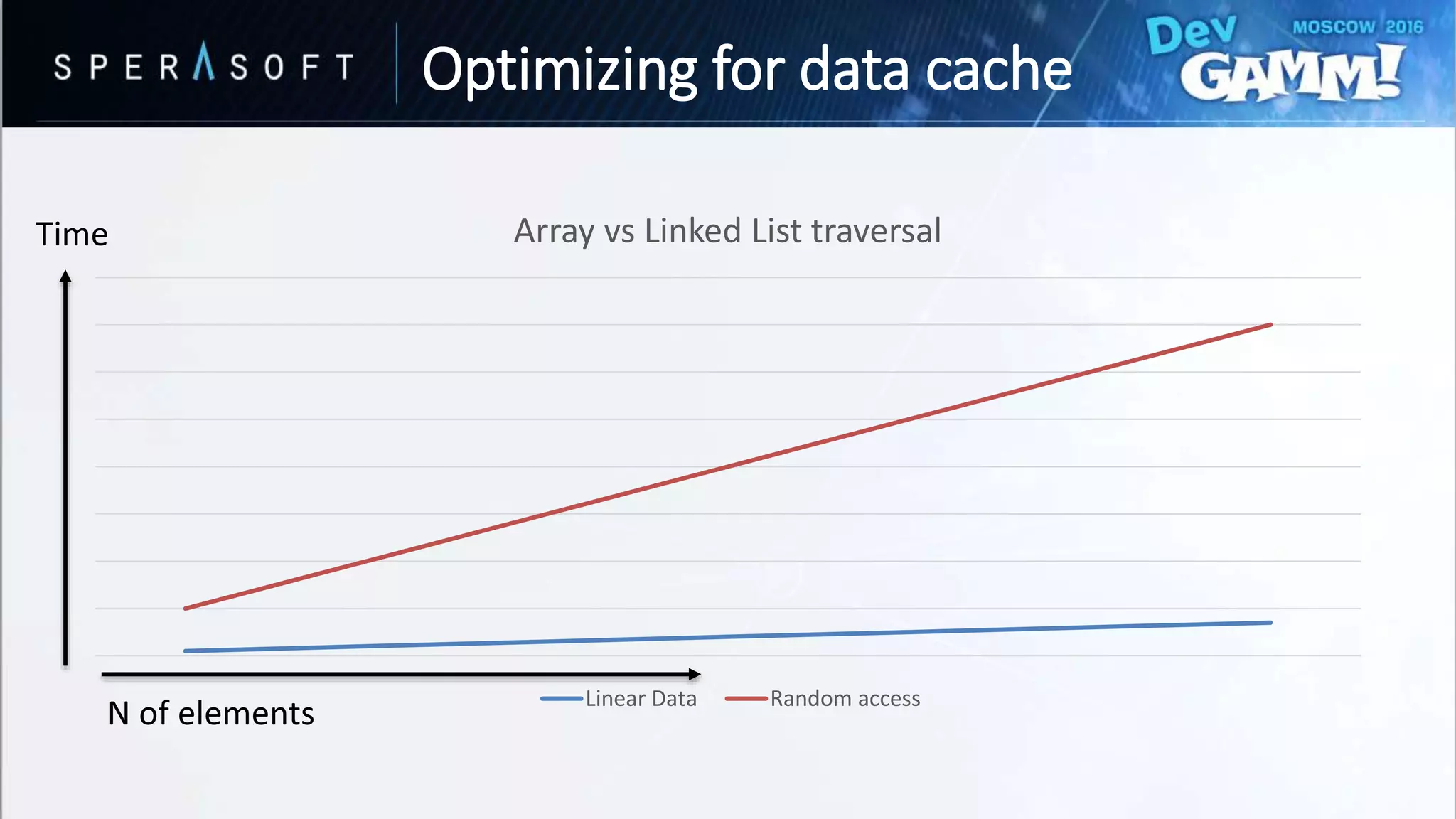
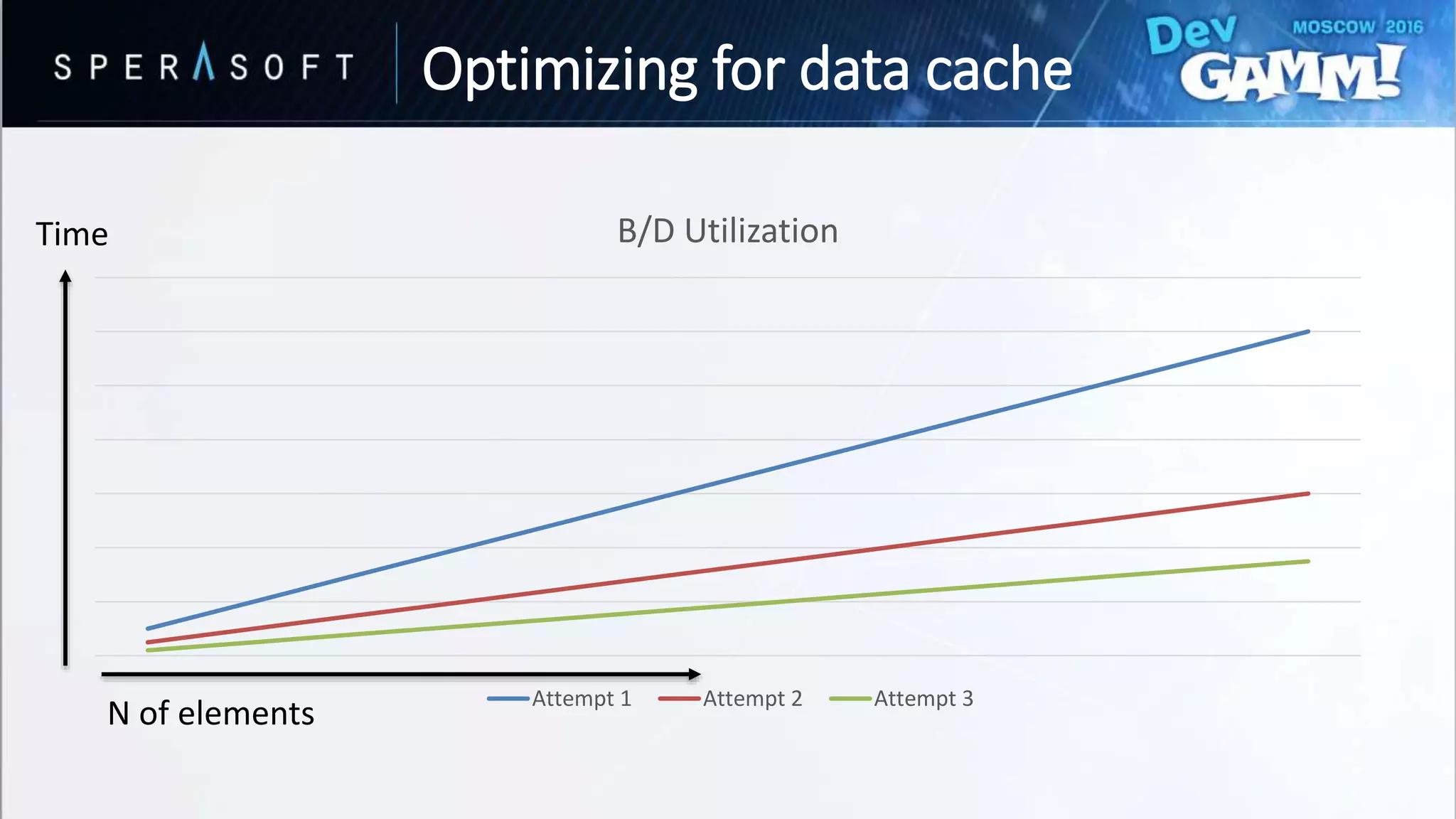
This document discusses code and memory optimization techniques for software engineers developing AAA game titles. It begins with an introduction to the speaker and provides an overview of hardware architecture including CPU registers, caches, and memory access times. The bulk of the document focuses on optimizing for data caches through techniques like improving data layout, prefetching, and utilizing cache lines efficiently. It also discusses optimizing branches through removing branches, computing both paths, and splitting data to avoid branches. Resources for further reading are provided.













![Java on arm theory, applications, and workloads [dev5048]](https://cdn.slidesharecdn.com/ss_thumbnails/javaonarm-theoryapplicationsandworkloadsdev5048-181028011435-thumbnail.jpg?width=640&height=640&fit=bounds)









































































