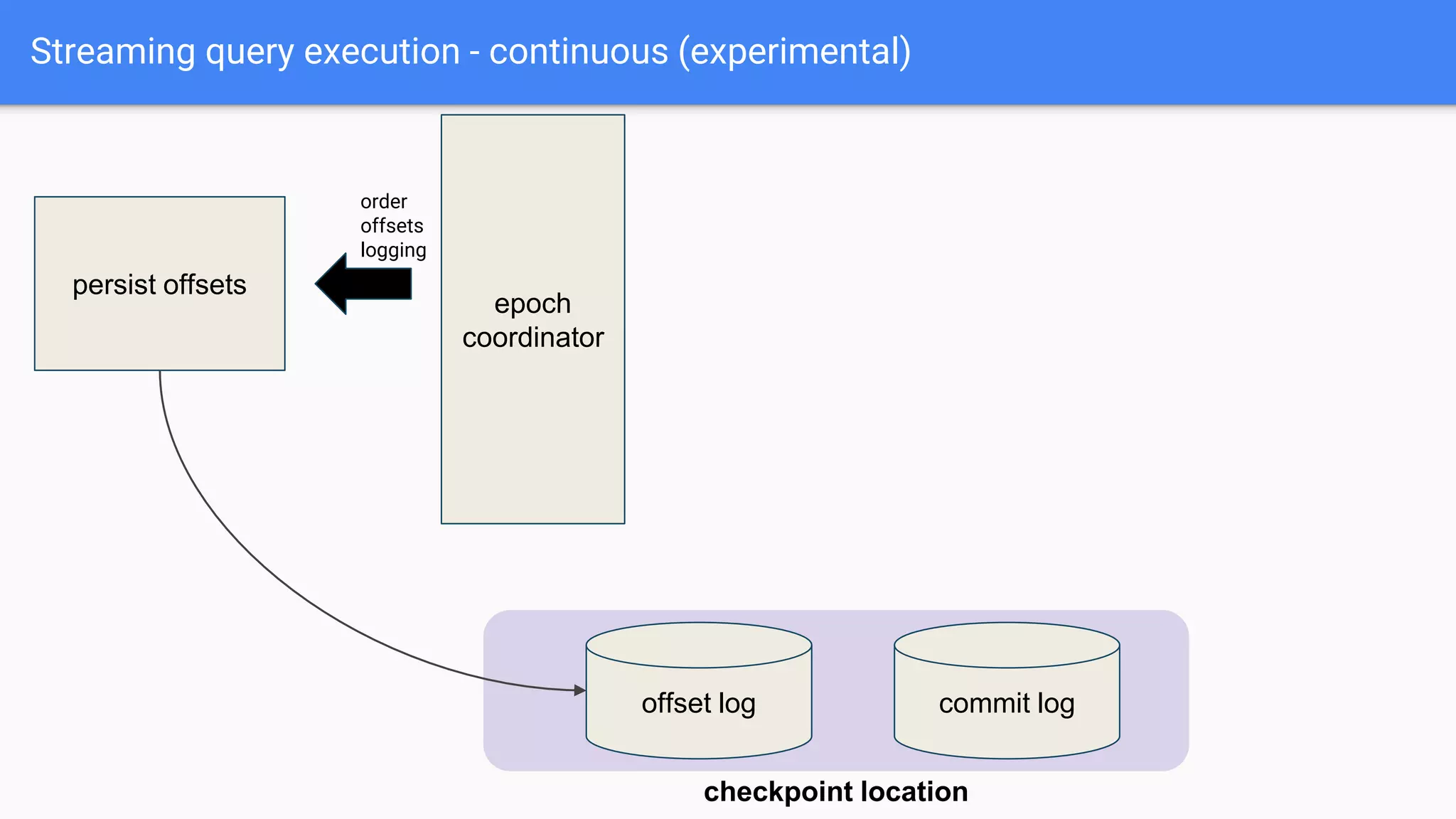
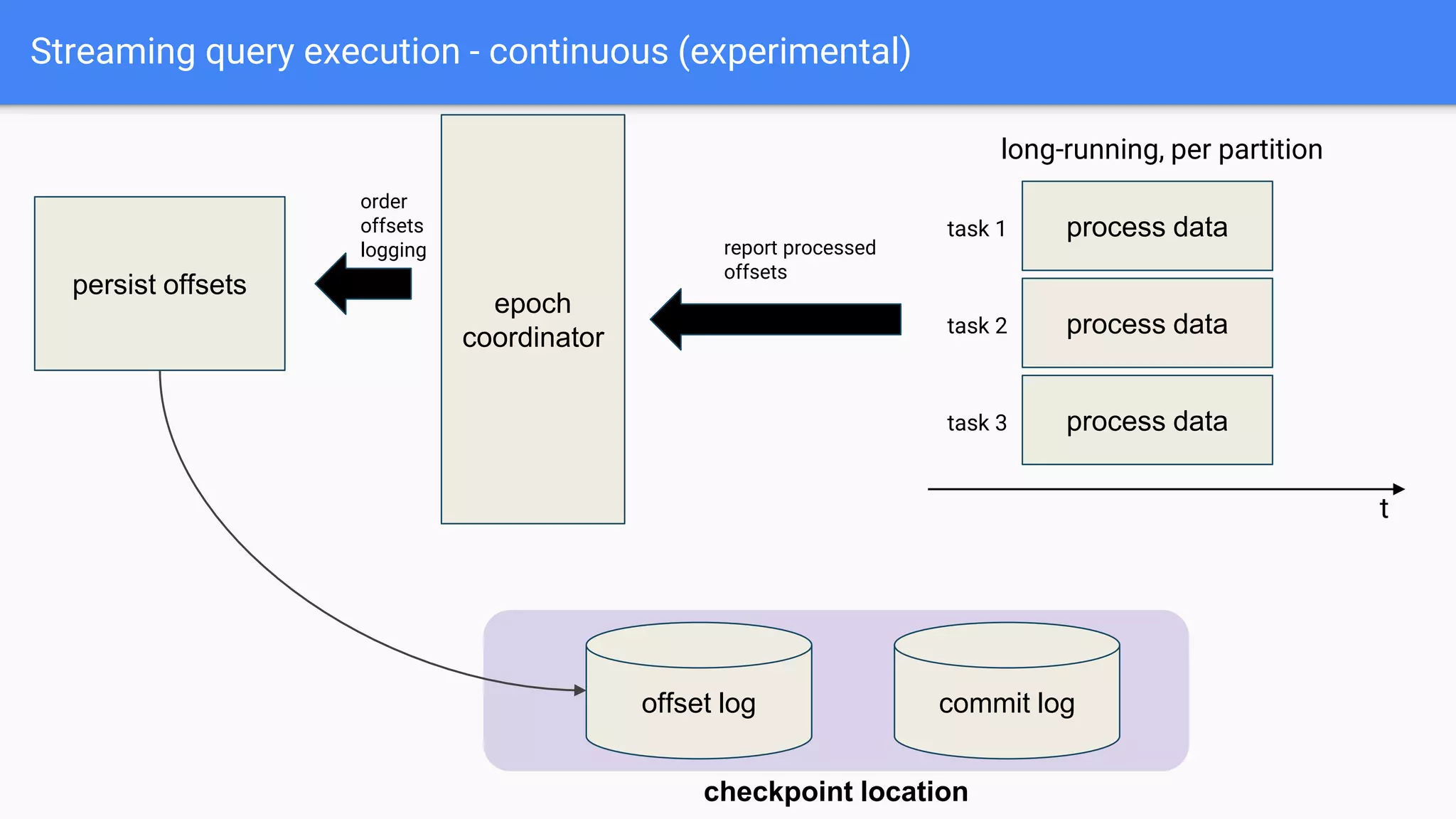
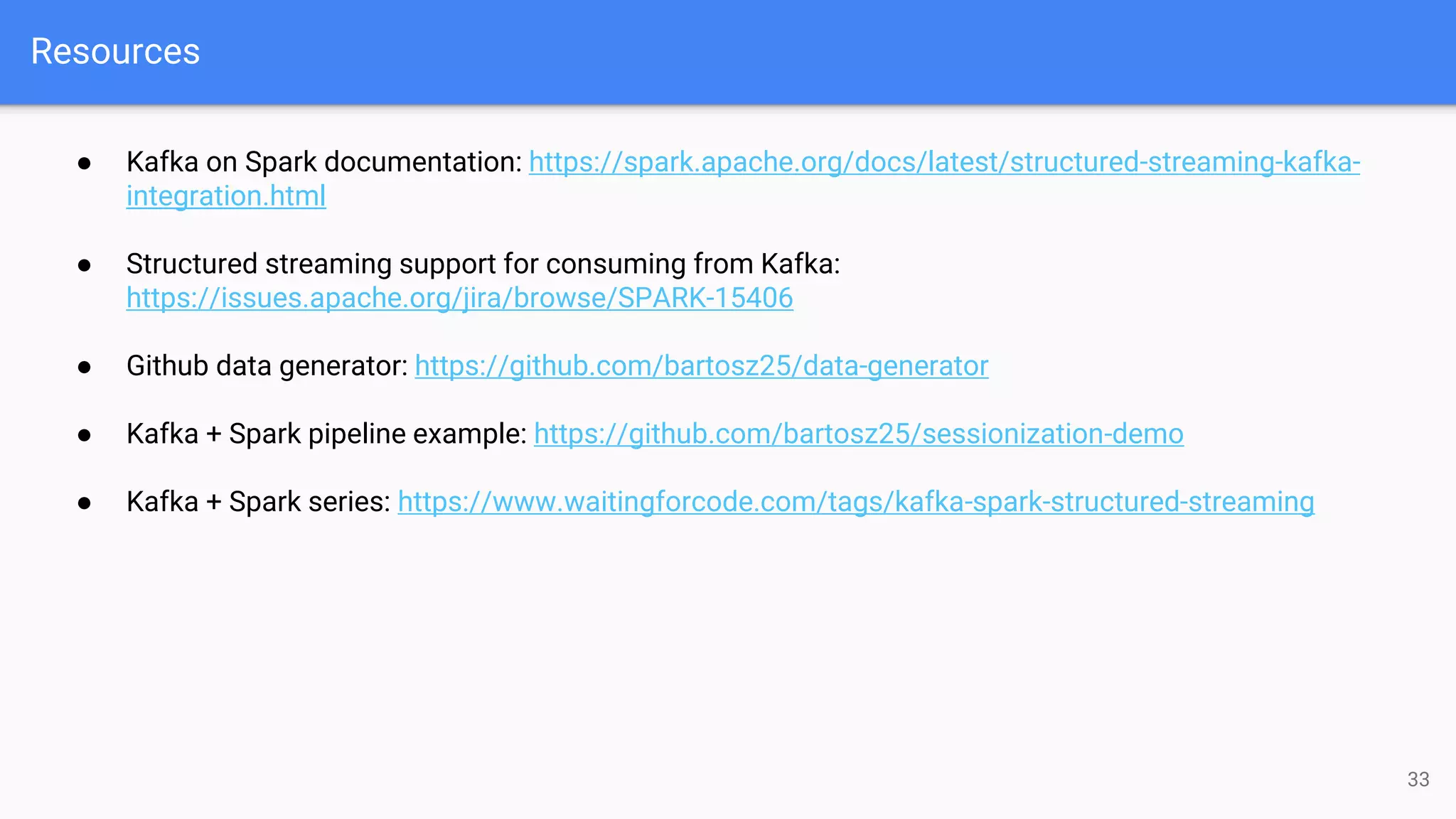
The document discusses the integration of Apache Kafka with Apache Spark, focusing on streaming query execution and data processing logic. It highlights key configurations, such as Kafka data sources and sinks, and provides examples of structured streaming pipelines. Additionally, it covers popular data transformations and considerations for fault tolerance and data loss protection.





![Popular data transformations
11
def select(cols: Column*): DataFrame
def as(alias: String): Dataset[T]
def map[U : Encoder](func: T => U): Dataset[U]
def filter(condition: Column): Dataset[T]
def groupByKey[K: Encoder](func: T => K):
KeyValueGroupedDataset[K, T]
def limit(n: Int): Dataset[T]](https://image.slidesharecdn.com/streamingkafkawithspark-200207100541/75/Apache-Spark-Structured-Streaming-Apache-Kafka-11-2048.jpg)
![Popular data transformations
12
def select(cols: Column*): DataFrame
def as(alias: String): Dataset[T]
def map[U : Encoder](func: T => U): Dataset[U]
def filter(condition: Column): Dataset[T]
def groupByKey[K: Encoder](func: T => K):
KeyValueGroupedDataset[K, T]
def limit(n: Int): Dataset[T]
def mapPartitions[U : Encoder](func: Iterator[T] => Iterator[U]):
Dataset[U]
def mapGroups[U : Encoder](f: (K, Iterator[V]) => U):
Dataset[U]
def flatMapGroups[U : Encoder](f: (K, Iterator[V]) =>
TraversableOnce[U]): Dataset[U]
def join(right: Dataset[_], joinExprs: Column, joinType: String)
def reduce(func: (T, T) => T): T](https://image.slidesharecdn.com/streamingkafkawithspark-200207100541/75/Apache-Spark-Structured-Streaming-Apache-Kafka-12-2048.jpg)
![Structured Streaming pipeline example
13
val loadQuery = sparkSession.readStream.format("kafka")
.option("kafka.bootstrap.servers", "210.0.0.20:9092")
.option("client.id", s"simple_kafka_spark_app")
.option("subscribePattern", "ss_starting_offset.*")
.option("startingOffsets", "earliest")
.load()
val processingLogic = loadQuery.selectExpr("CAST(value AS STRING)").as[String]
.filter(letter => letter.nonEmpty)
.map(letter => letter.size)
.select($"value".as("letter_length"))
.agg(Map("letter_length" -> "sum"))
val writeQuery = processingLogic.writeStream.outputMode("update")
.option("checkpointLocation", "/tmp/kafka-sample")
.format("console")
writeQuery.start().awaitTermination()
data source
data
processing
logic
data sink](https://image.slidesharecdn.com/streamingkafkawithspark-200207100541/75/Apache-Spark-Structured-Streaming-Apache-Kafka-13-2048.jpg)

![Kafka input schema
18
key
[binary]
value
[binary]
topic
[string]
partition
[int]
offset
[long]
timestamp
[long]
timestampType
[int]](https://image.slidesharecdn.com/streamingkafkawithspark-200207100541/75/Apache-Spark-Structured-Streaming-Apache-Kafka-18-2048.jpg)
![Kafka input schema
19
key
[binary]
value
[binary]
topic
[string]
partition
[int]
offset
[long]
timestamp
[long]
timestampType
[int]
val query = dataFrame.selectExpr("CAST(key AS STRING)", "CAST(value AS
STRING)")
.groupByKey(row => row.getAs[String]("key"))](https://image.slidesharecdn.com/streamingkafkawithspark-200207100541/75/Apache-Spark-Structured-Streaming-Apache-Kafka-19-2048.jpg)





































![[Big Data Spain] Apache Spark Streaming + Kafka 0.10: an Integration Story](https://cdn.slidesharecdn.com/ss_thumbnails/bigdataspainapachesparkstreamingkafka0-171117095800-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Spark Summit EU 2017] Apache spark streaming + kafka 0.10 an integration story](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkstreamingkafka0-171026072955-thumbnail.jpg?width=640&height=640&fit=bounds)































