580 California St., Suite 400
San Francisco, CA, 94104
This research direction investigates modifications to the classical Metropolis–Hastings (MH) algorithm aimed at enhancing sampling efficiency and mixing properties, particularly in challenging settings like high-dimensional or multimodal target distributions. Many works study the design and analysis of parallel MCMC schemes, adaptive proposal mechanisms, and multiple-try variants to balance local exploration and global traversal of the state space while maintaining ergodicity guarantees. Efficient use of computational resources via parallelism and adaptation helps overcoming slow mixing and convergence bottlenecks inherent in standard MH, especially when naive or fixed proposals are used.
Research in this theme focuses on reducing estimator variance in MH algorithms and related gradient-based MCMC schemes by constructing control variates informed by solutions to Poisson equations, diffusion approximations, or related functional equations. Approaches include solving or approximating Poisson equations associated with Markov chains to build zero or low variance estimators, deploying diffusion limits (e.g., Langevin diffusion) for variance reduction, and exploiting gradient information while balancing robustness and computational cost. These methods improve efficiency by decreasing sample correlation and estimator variance without additional expensive sampling.
This theme explores methodologies extending MH algorithms to handle modern computational challenges posed by big data and complex models. Strategies include replacing full data likelihood evaluations with stochastic or bootstrap approximations, employing parallel and distributed computing architectures, and incorporating specialized MH variants within broader scalable frameworks. The goal is to retain theoretical guarantees (e.g., ergodicity, unbiasedness) while making computations practically feasible and efficient over large datasets or intricate inference problems.
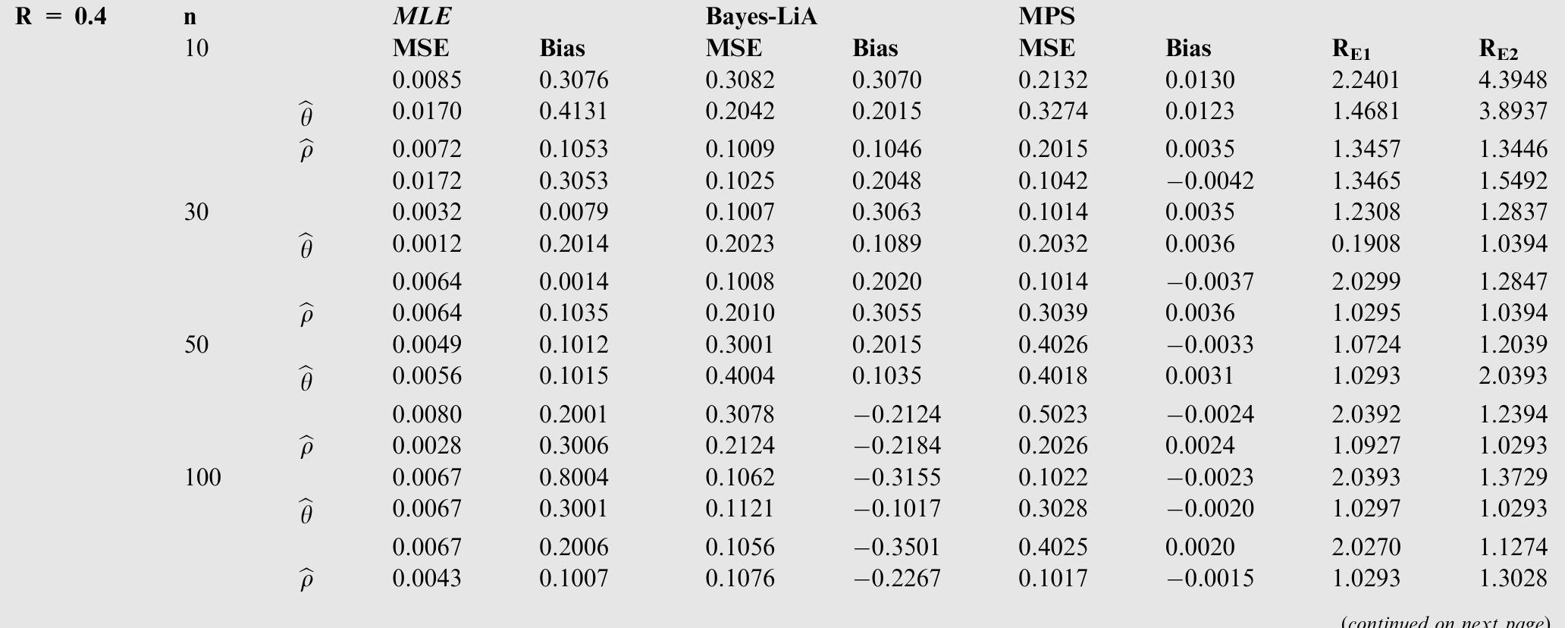
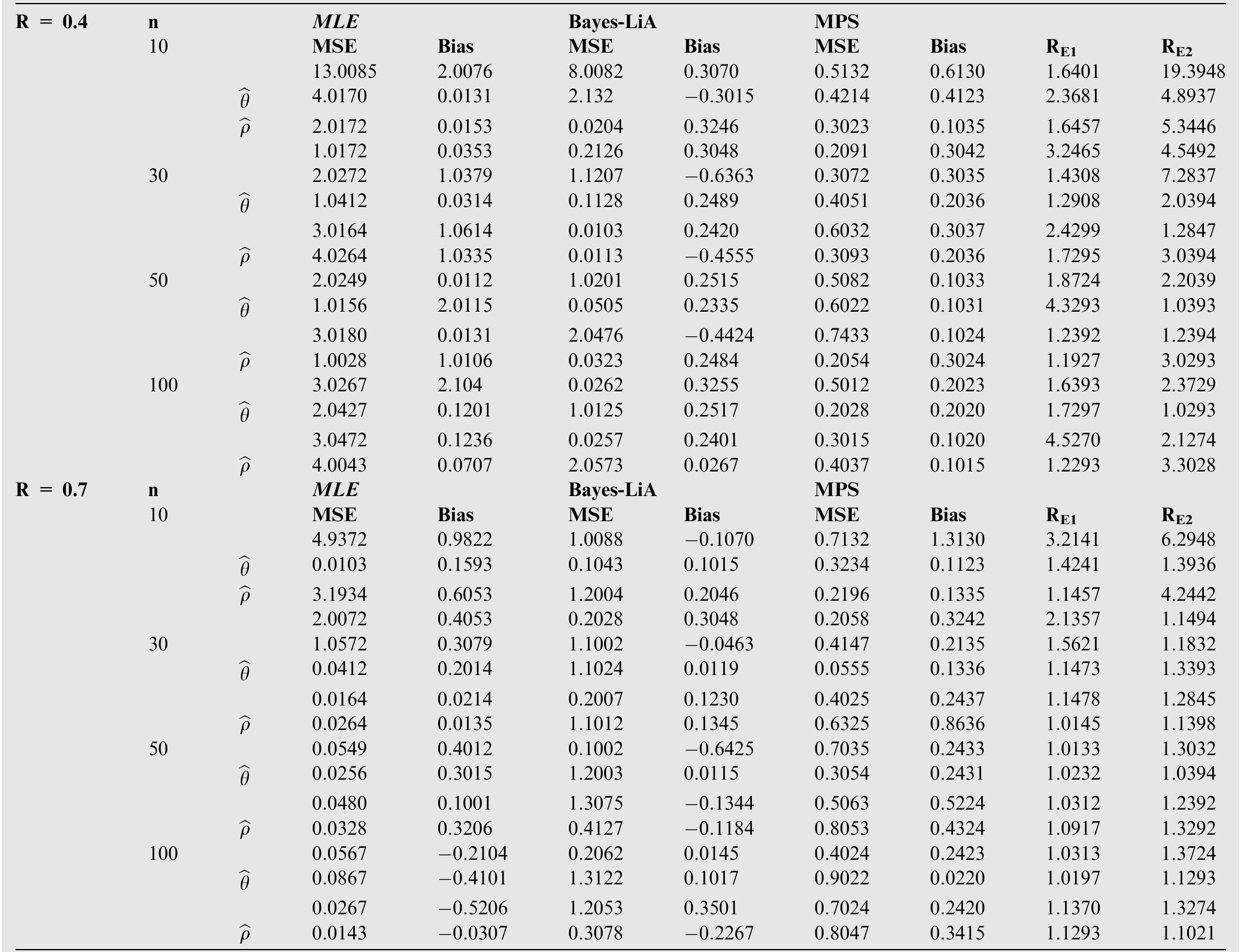
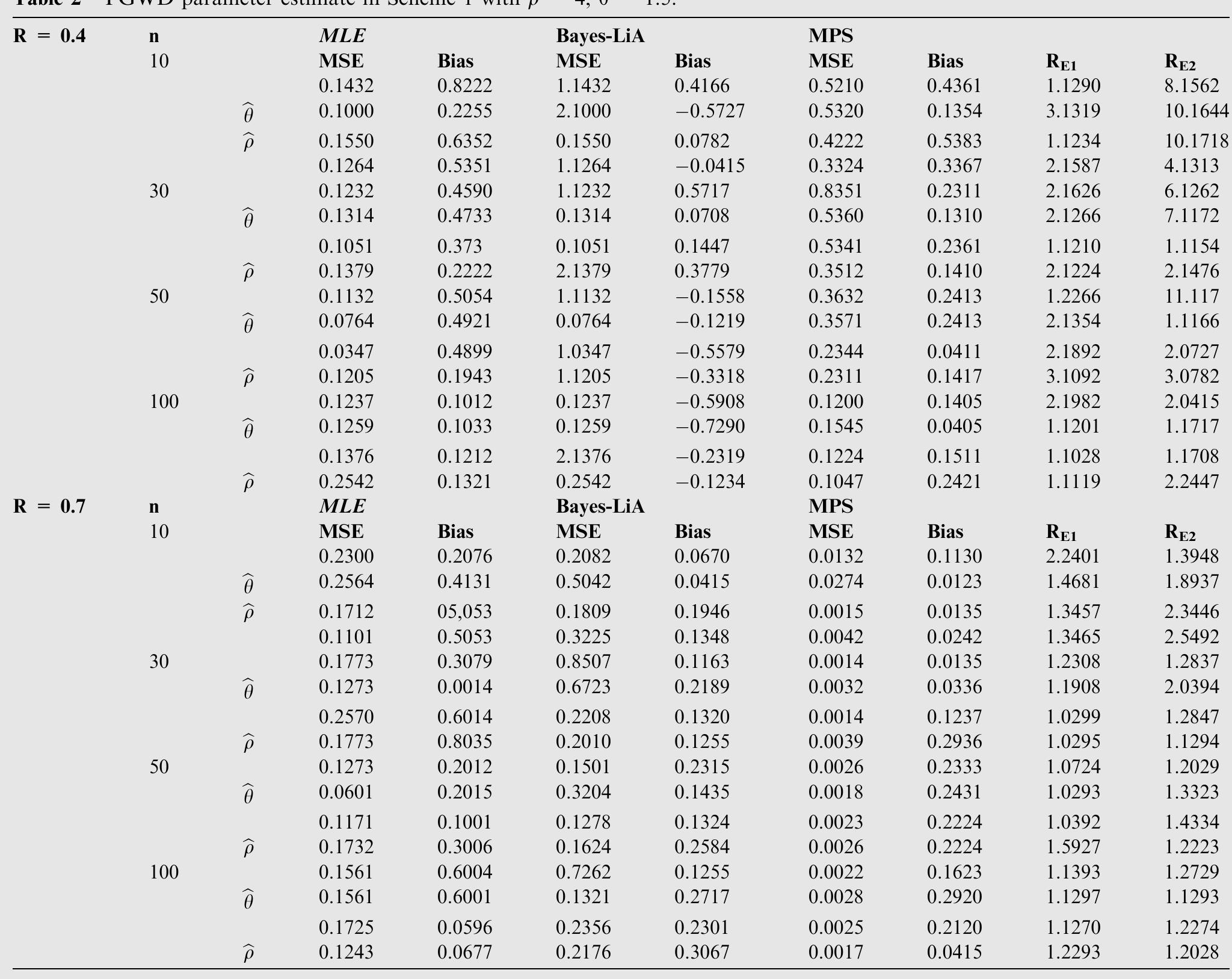
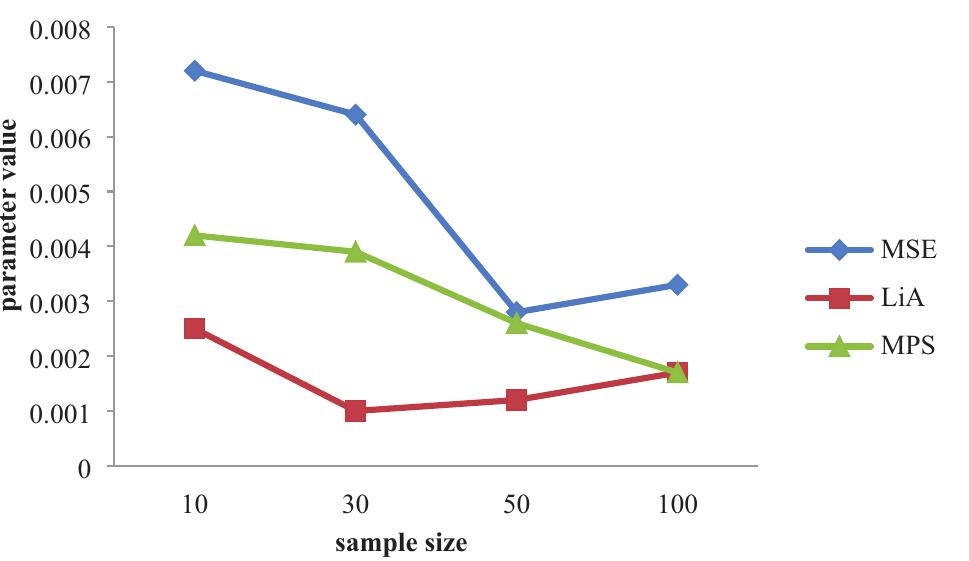
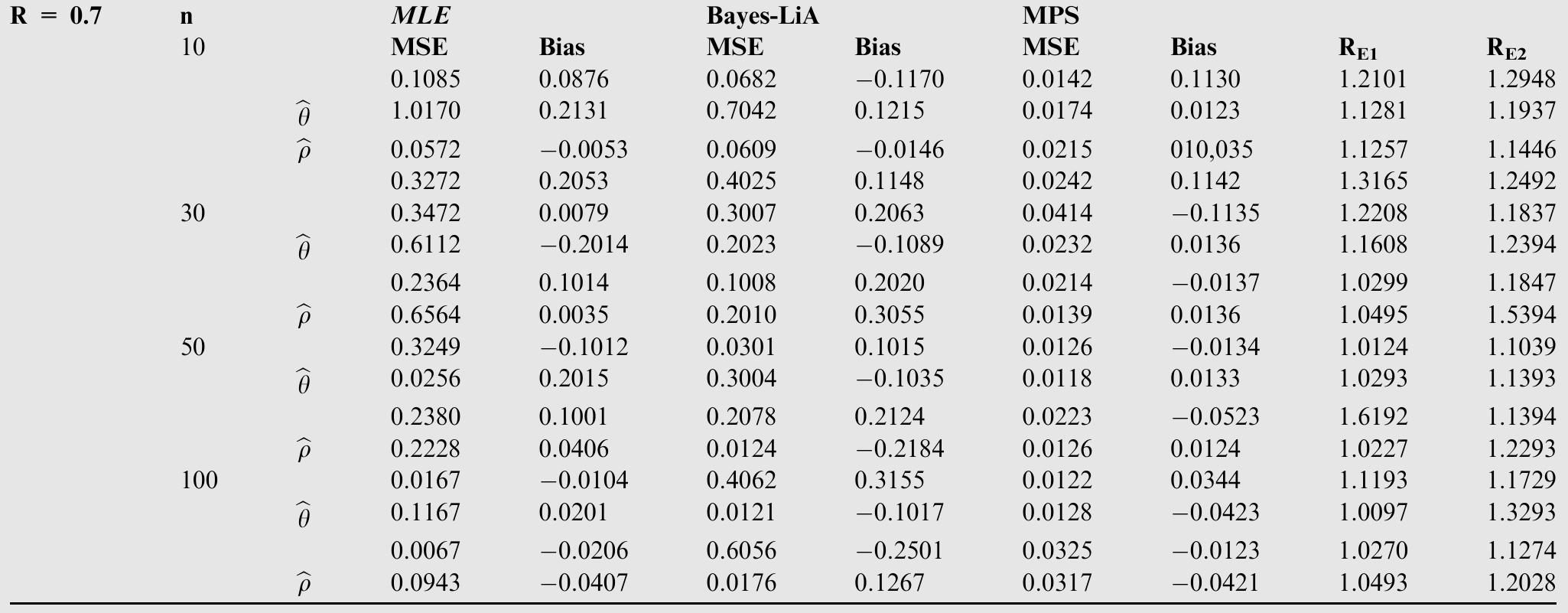
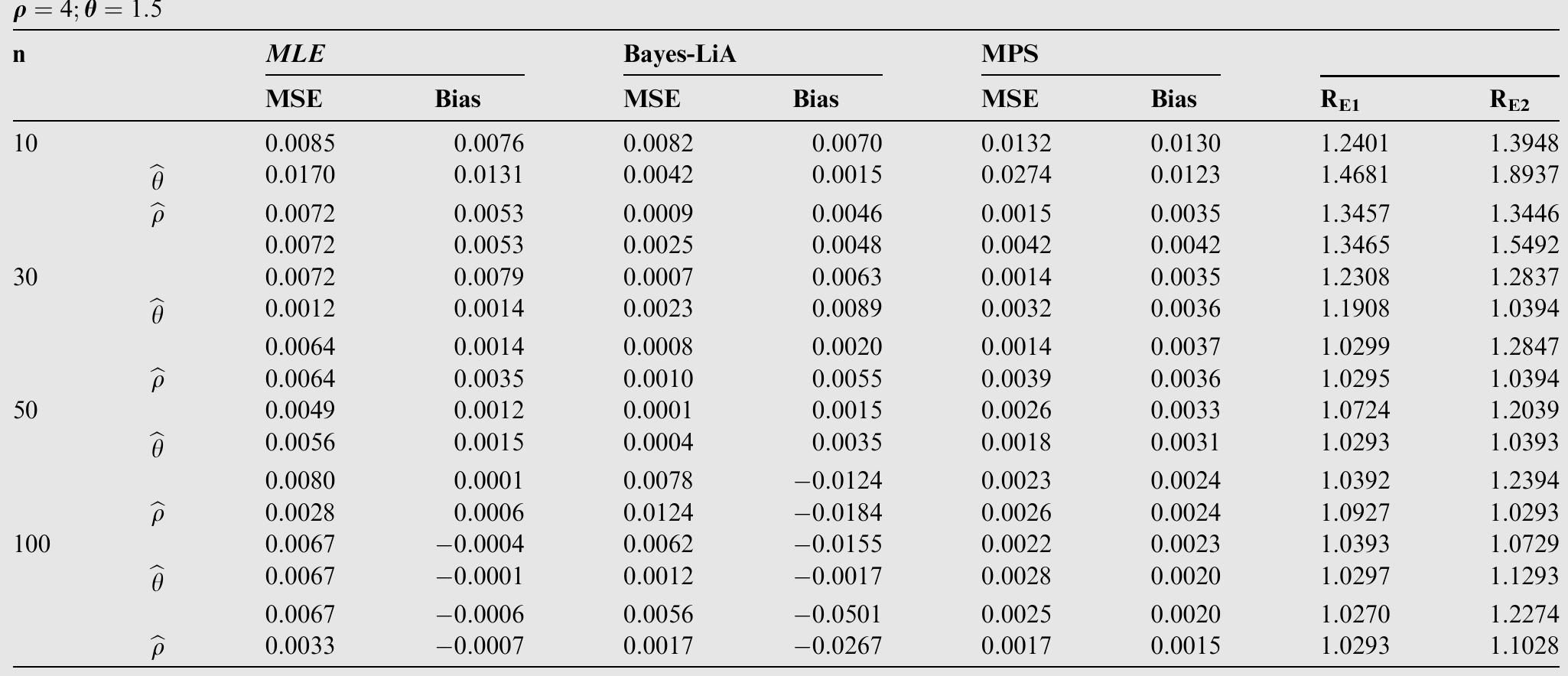
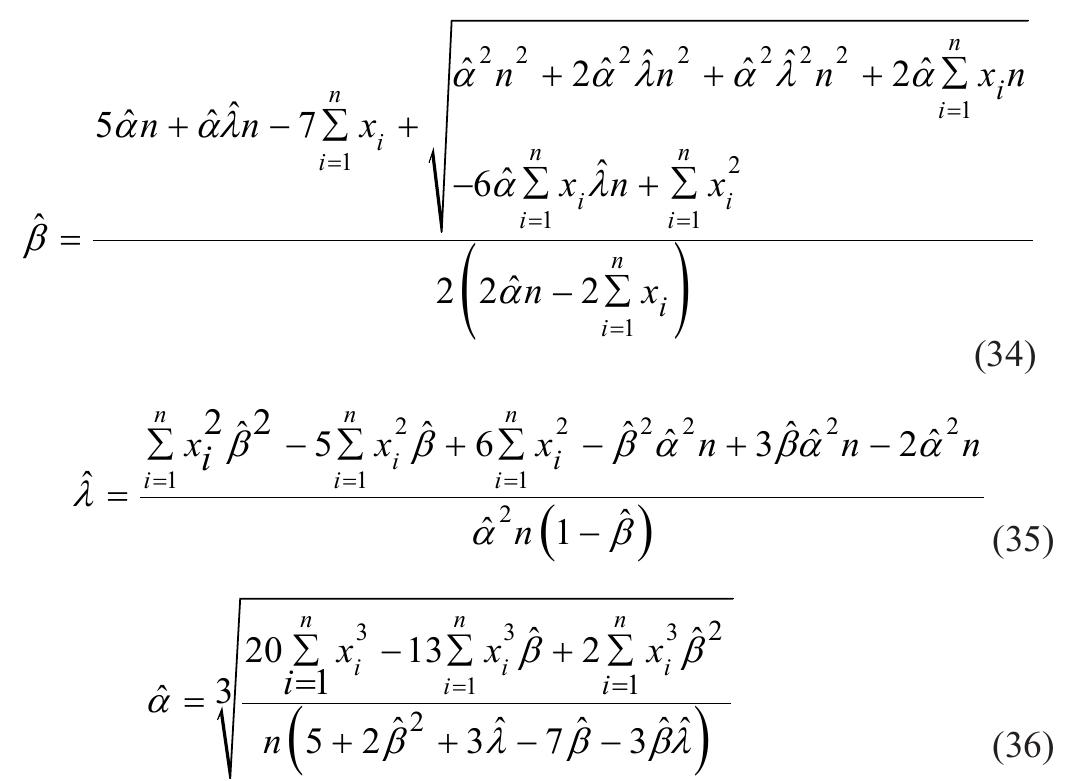
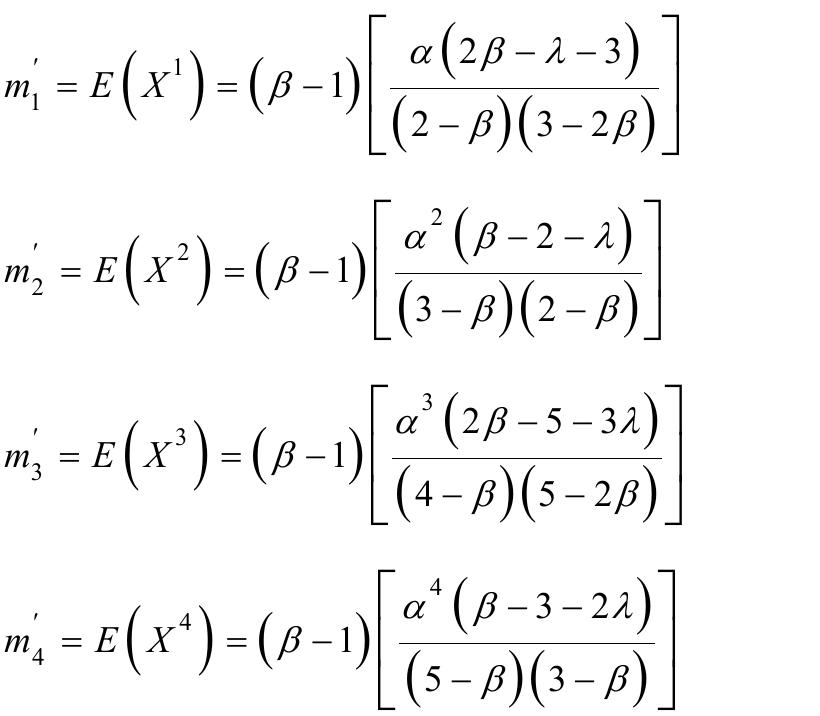
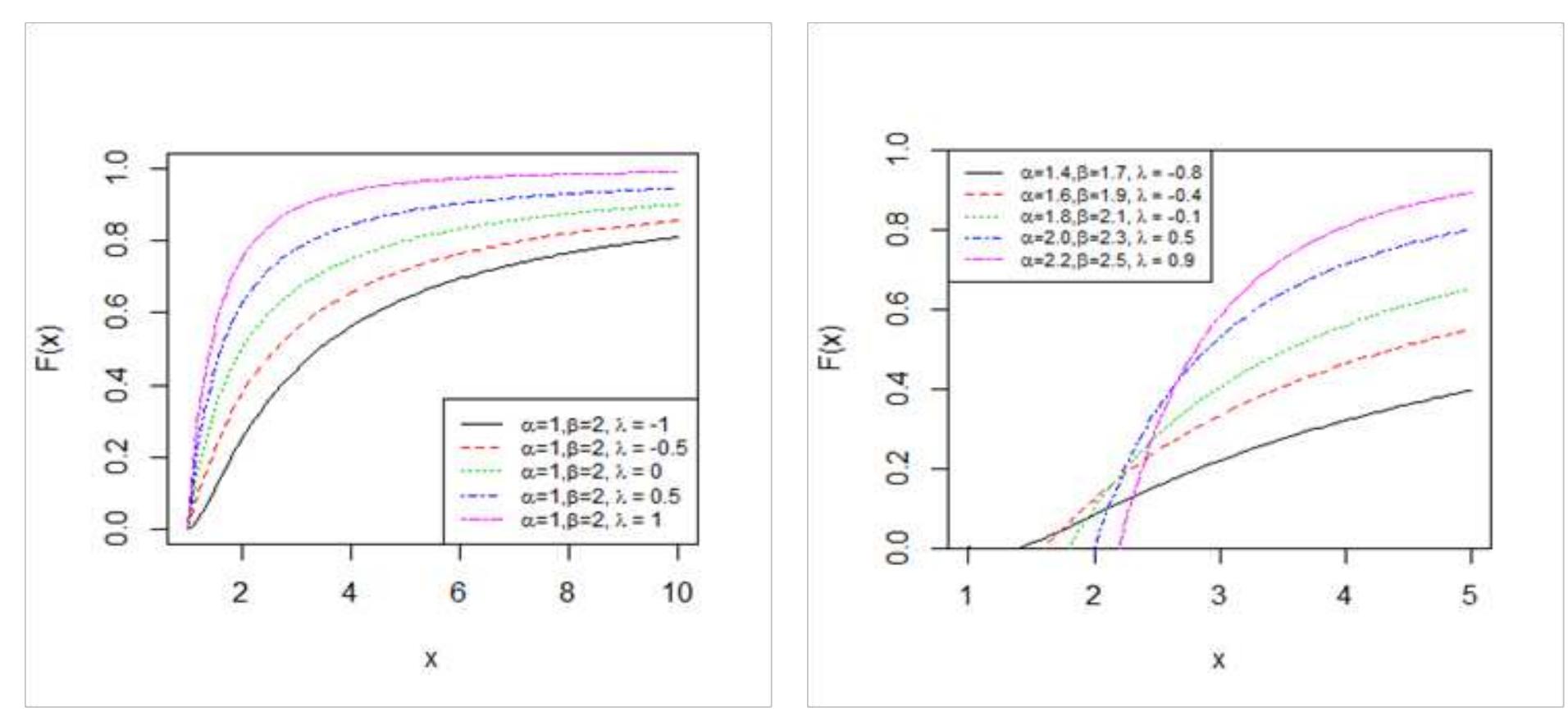
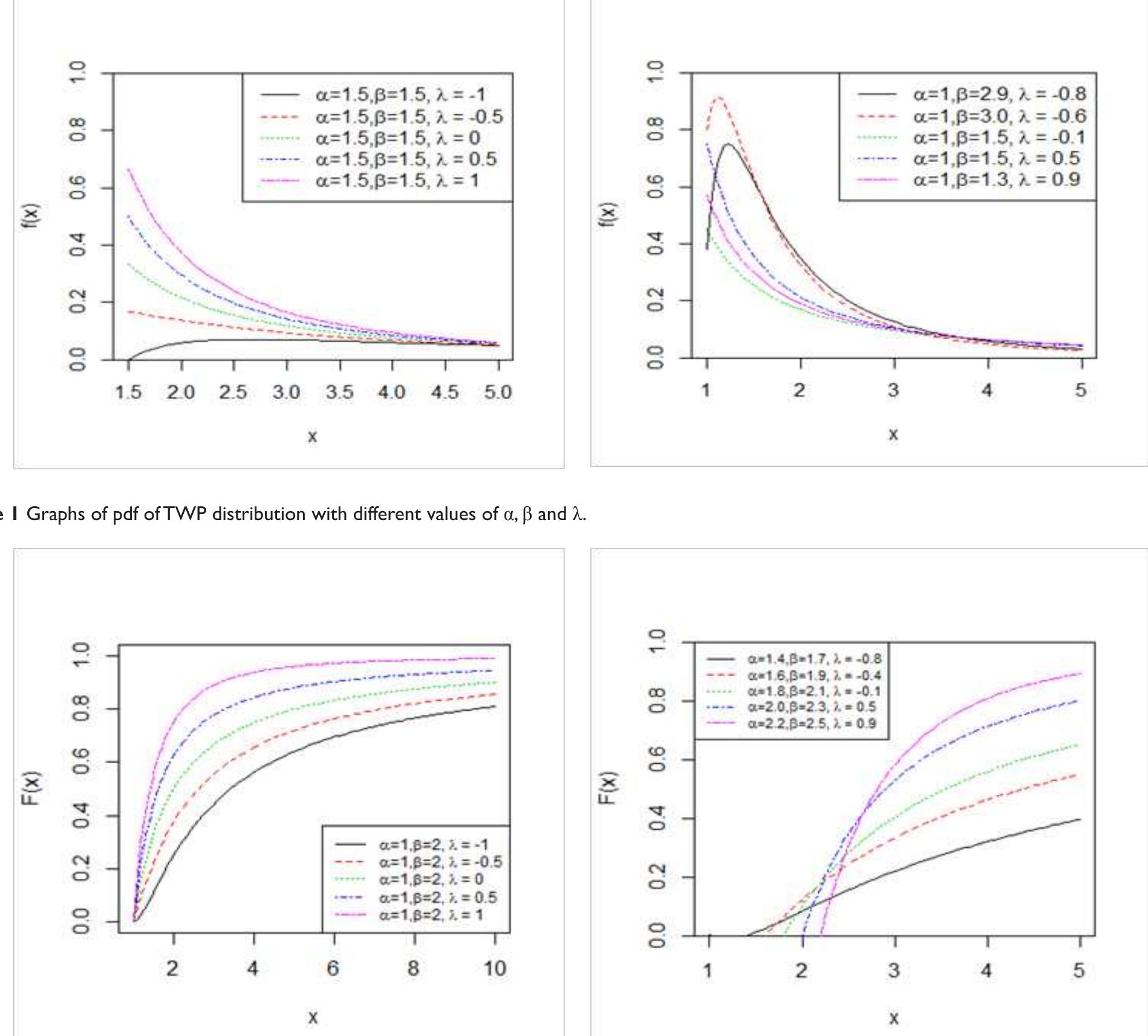
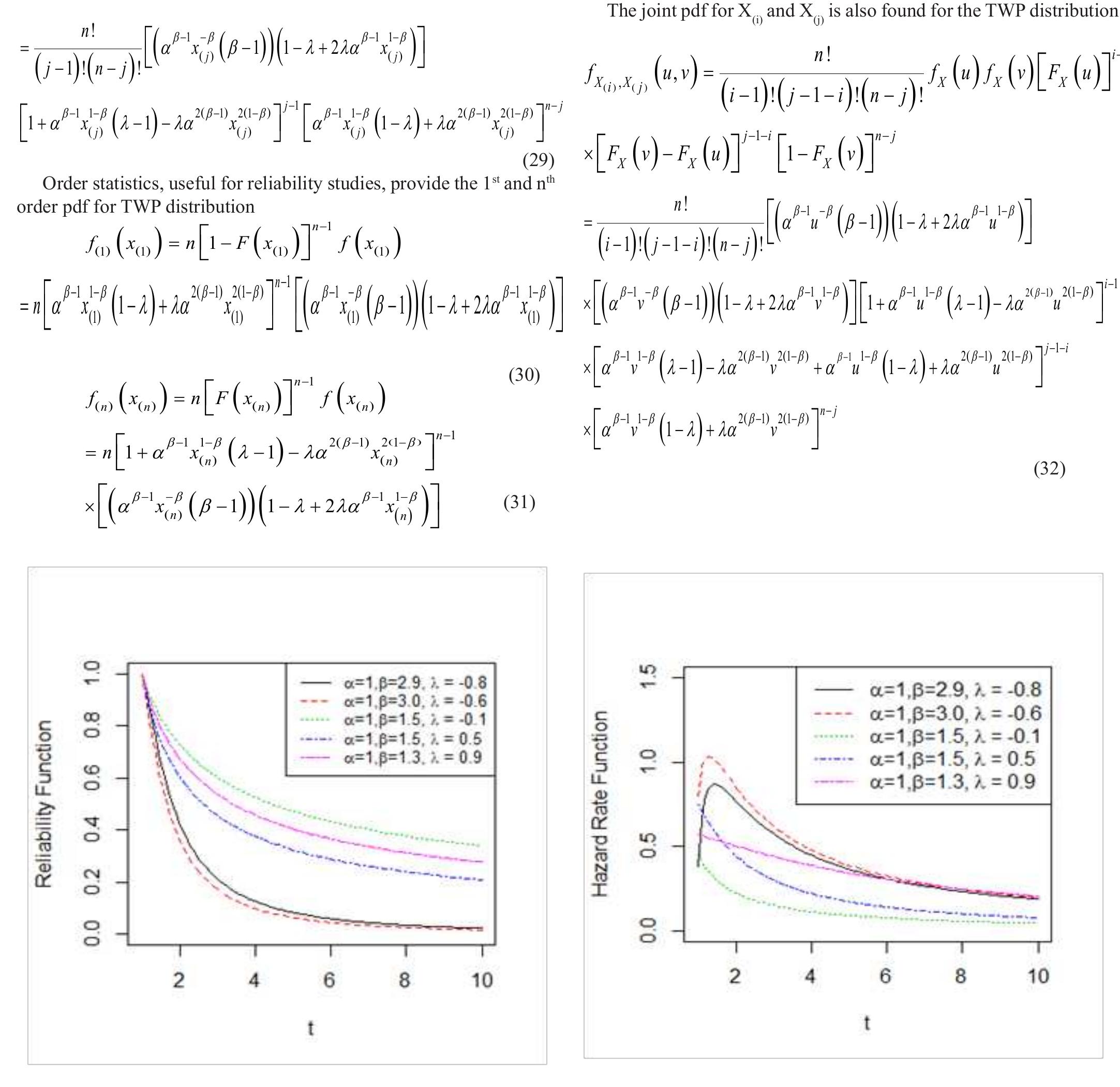
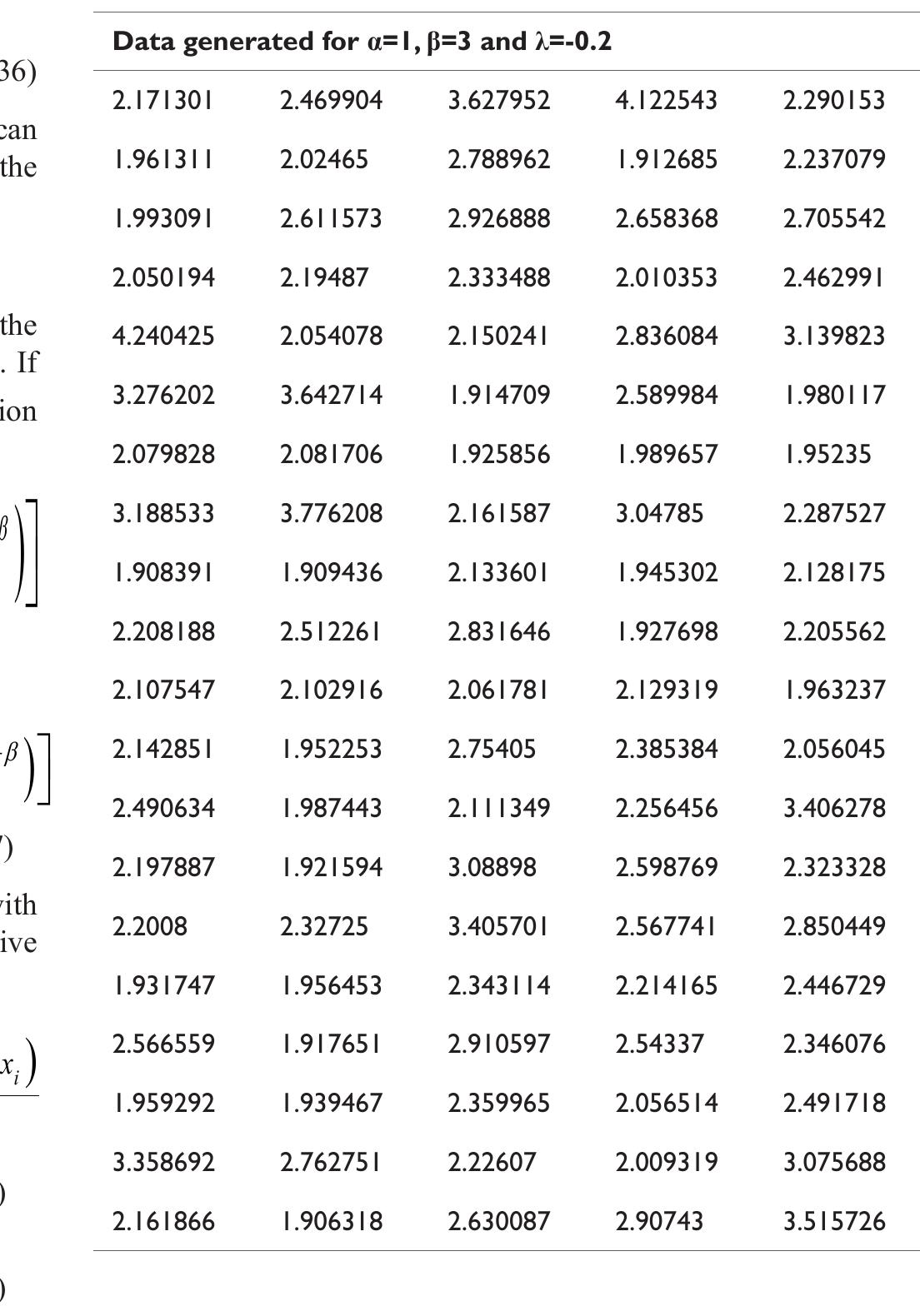
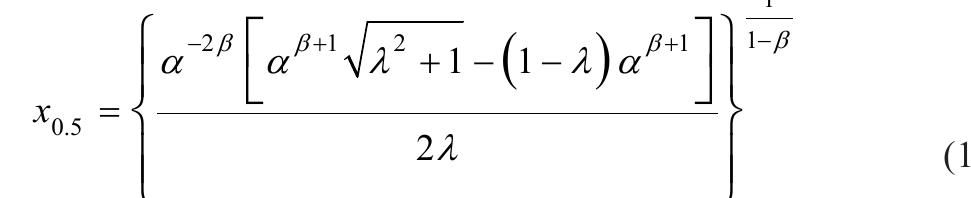

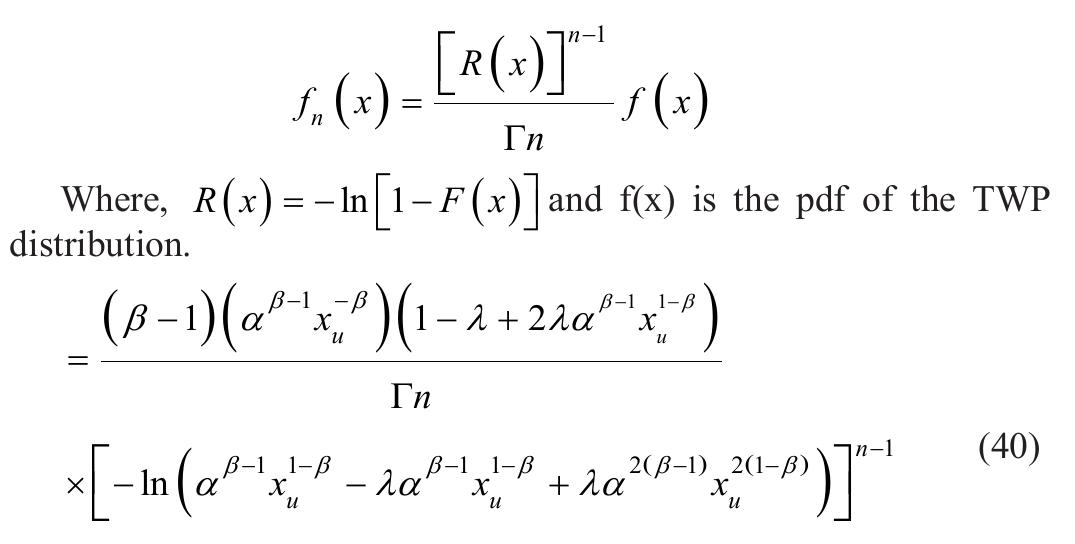
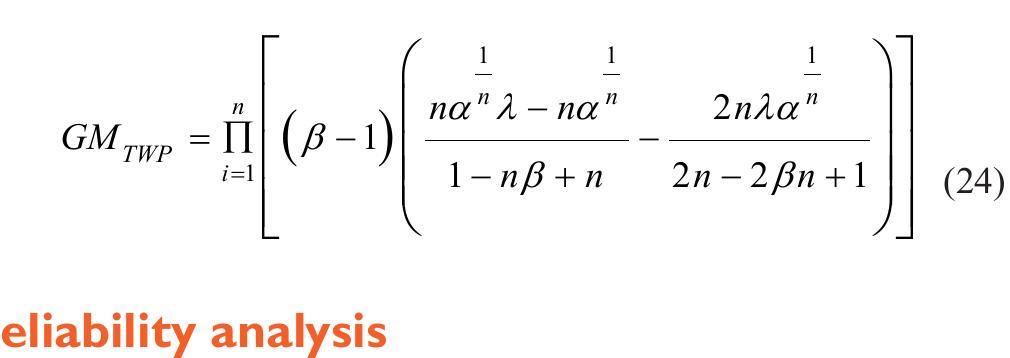
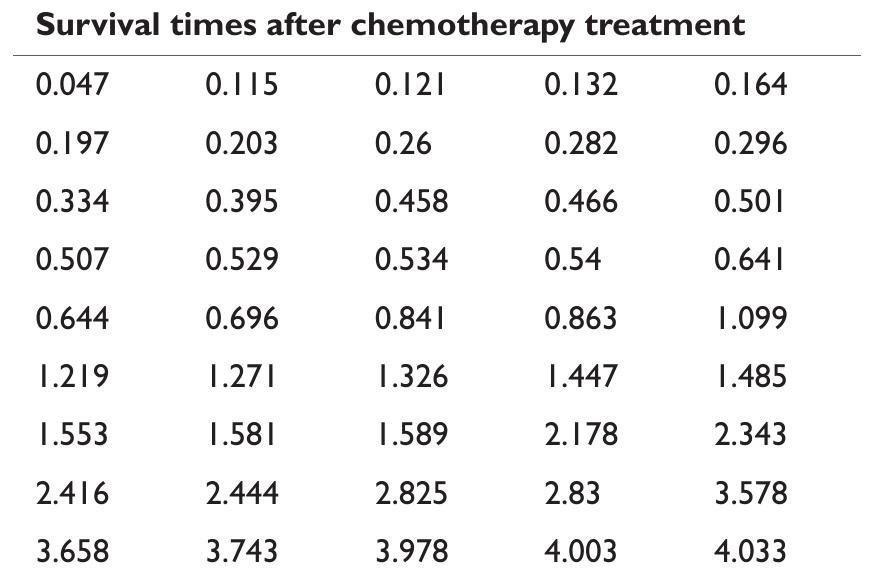
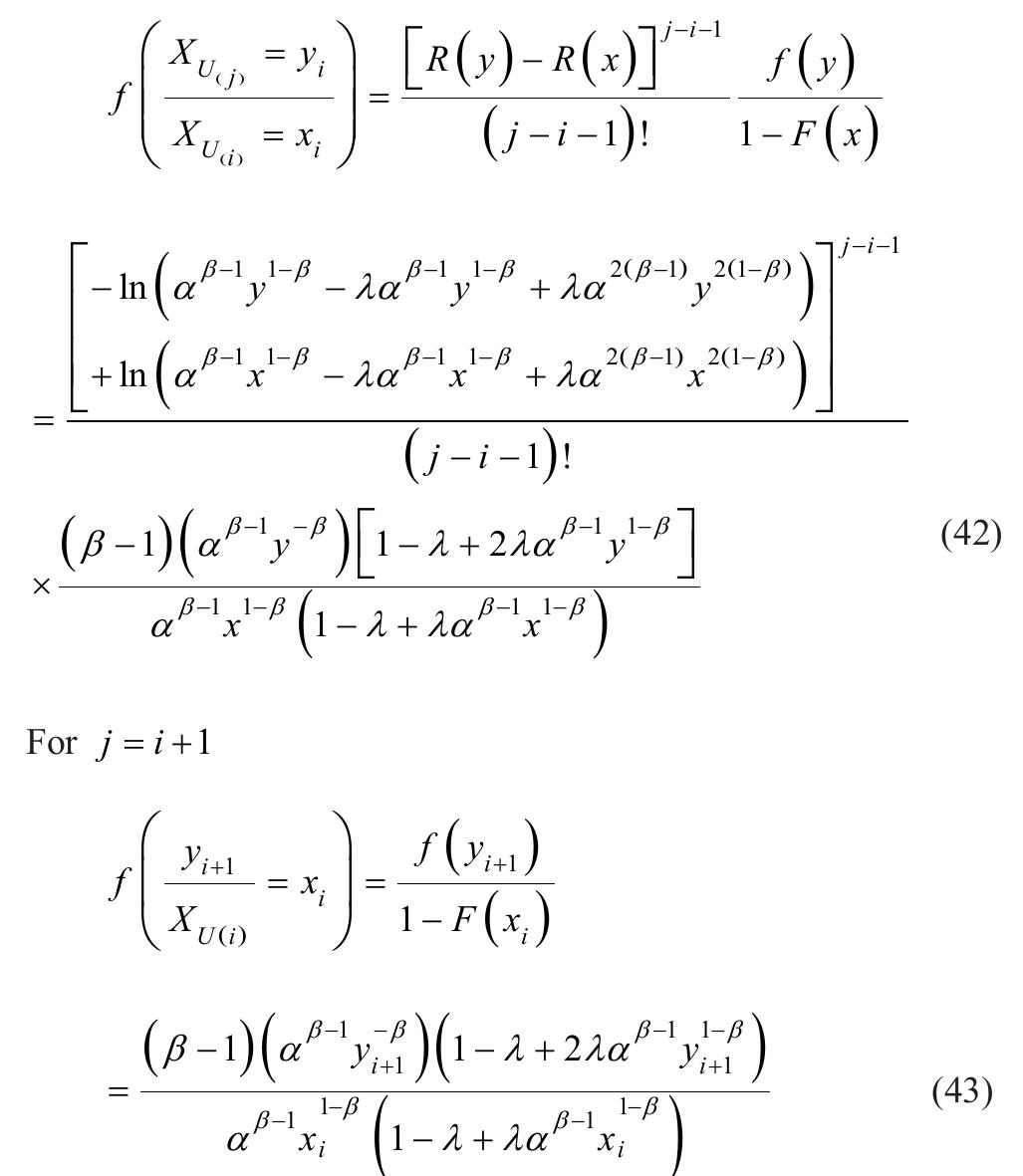
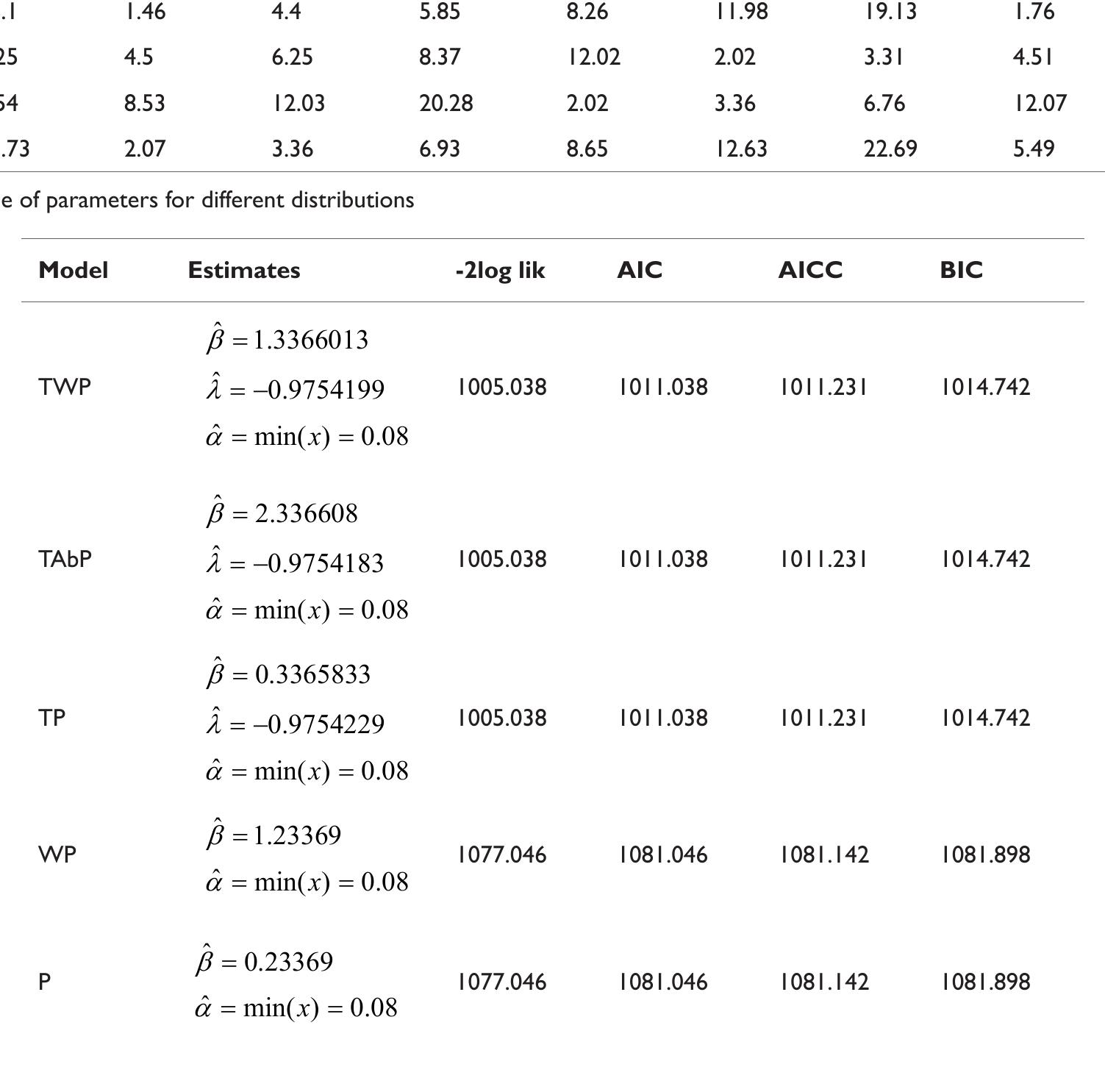
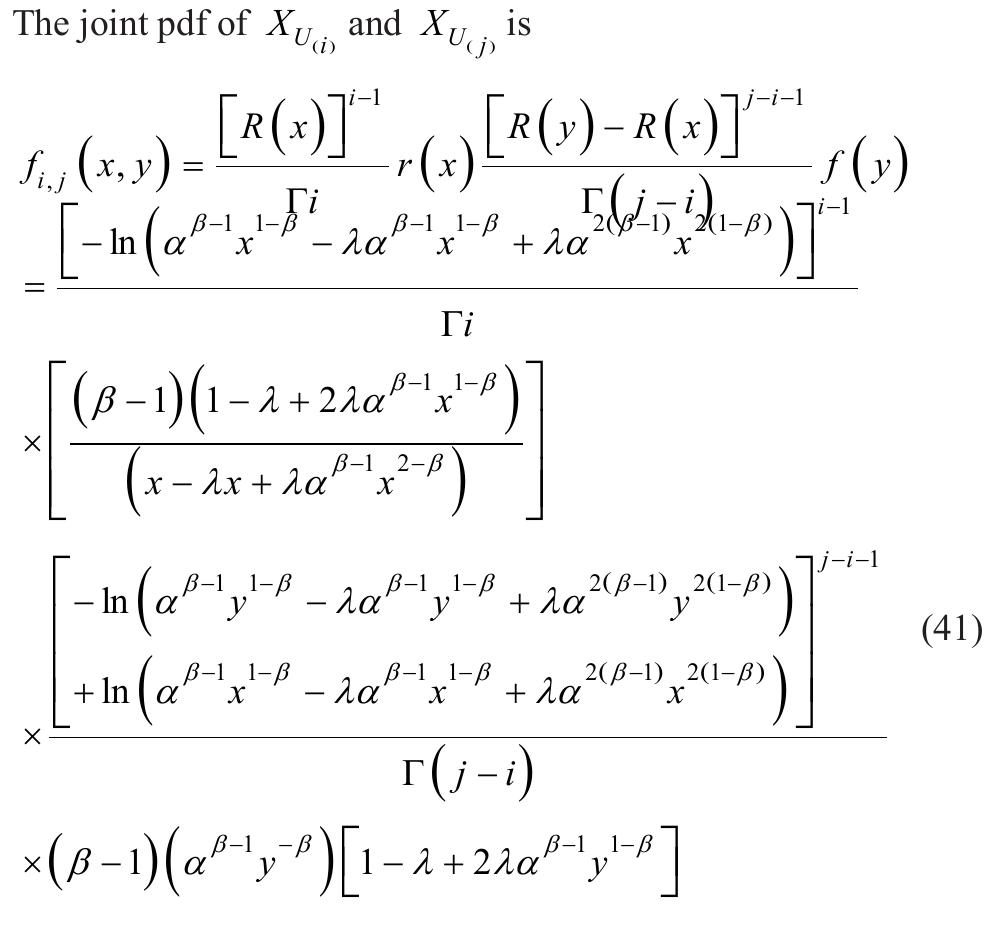

![where Ac[-1,1] and B>1. The cdf is graphically presented in Figure 2.](https://figures.academia-assets.com/94358666/figure_003.jpg)