This week we’ll be taking a look into the infrastructure that runs and
operates Void. We’ll look at what we run, where it runs, and why it
is setup the way it is. Overall at the end of the week you should
have a better understanding of what actually makes Void happen at a
mechanical level.
So What Is Infrastructure, Like Really?
Infrastructure, as the term is used by Void, refers to systems,
services, or machines that are owned or operated by the Void Linux
project to provide the services that make Void a reality. These
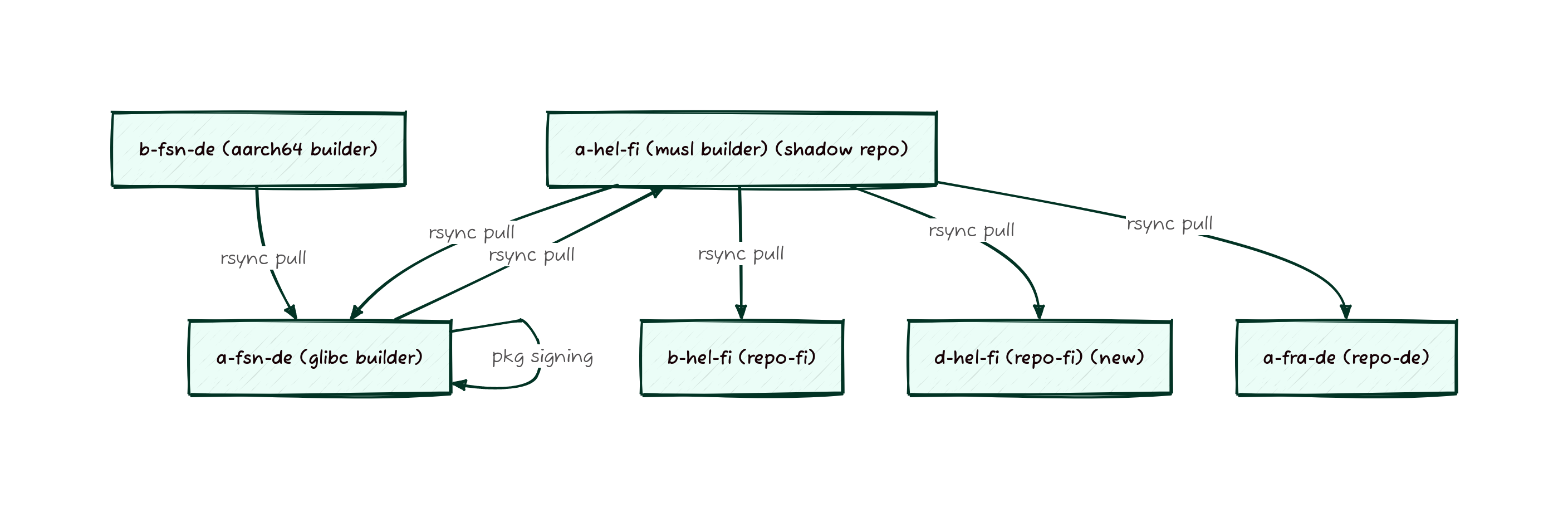
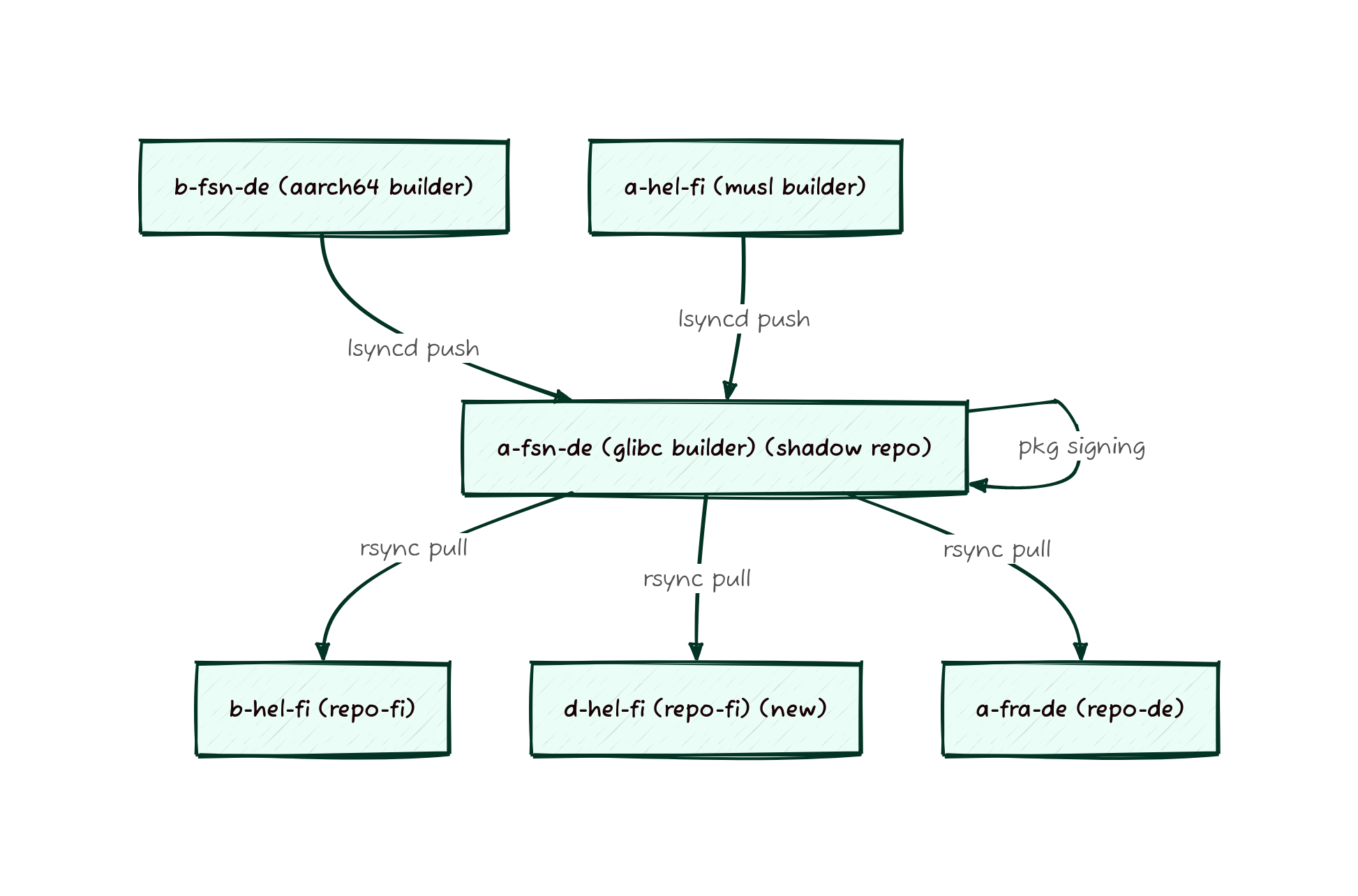
services range from our build farm and mirror infrastructure, to email
servers for maintainers, to hosted services such as the Fastly CDN
mirror. Void runs in many places on many kinds of providers, so lets
take a deeper look into the kinds of hosts that Void makes use of.
Owned Physical Hardware
The easiest to understand infrastructure that Void operates is
physical hardware. These are computers in either server form factors,
small form factor systems, or even just high performance consumer
devices that are used by the project to provide compute resources for
the software we need to run. Our hardware resources are split across
a number of datacenters, but the point of commonality of owned
physical hardware is that someone within the Void project actually
bought and owns the device we’re running on.
Owning the hardware is very different from a Cloud model where you pay
per unit time that the resources are consumed, instead hardware like
this is usually installed in a datacenter and co-located with many
other servers. If you’ve never had the opportunity to visit a
datacenter, they are basically large warehouse style buildings with
rows of cabinets each containing some number of servers with high
performance network and cooling available. The economy of scale of
getting so many servers together in one location makes it more cost
effective to provide extremely fast networks, high performance air
conditioning, and reliable power usually sourced from multiple
different grid connections and on-site redundant supplies.
Void currently maintains owned machines in datacenters in the US and
Europe. Since we don’t always have maintainers who live near enough
to just go to the datacenter, when things go wrong and we need to go
“hands-on” to the machines, we have to make use of “Remote Hands”.
Remote Hands, sometimes called “Smart Hands” refers to the process
wherein we open a ticket with the datacenter facility explaining what
we want them to do, and which machine we want them to do it to.
There’s usually a security verification challenge-response that is
unique to each operator, but after some shuffling, the ticket is
processed and someone physically goes to our machines and interacts
with them. Almost always the ticket will be for one of 2 things: some
component has failed, and we would like to buy a new one and have it
installed (hard drives, memory) or the machine has become locked up in
some way that we just need them to go hold in the power button. Most
of our hardware doesn’t have remote management capability, so we need
someone to go physically push the buttons.
Occasionally, the problems are worse though, and we need to actually
be able to interact with the machine. When this happens, we’ll
request that a KVM/iKVM/Spider/Hydra be attached, which provides a
kind of remote desktop style of access, wherein an external device
presents itself as a mouse and keyboard to the machine in question,
and then streams the video output back to us. We can use these
devices to be able to quickly recover from bad kernel updates, failed
hardware, or even initial provisioning if the provider doesn’t
natively offer Void as an operating system choice, since most KVM
devices allow us to remotely mount a disk image to the host as though
a USB drive were plugged in.
Owned hardware is nice, but its also extremely expensive to initially
setup, and is a long-term investment where we know we’ll want to use
those resources for an extended period of time. We have relatively
few of these machines, but the ones we do have are very large
capacity, high performance servers.
Donated/Leased Hardware
Owning hardware is great, but a specific set of circumstances have to
happen for that to be the right choice. The vast majority of Void’s
hardware is leased or is leased hardware which is donated for our use.
This is hardware that operates exactly the same as physical owned
hardware above, but we usually commit to these machines in increments
ranging from several months to a year, and can renew or change the
contract for the hardware more easily. Most of the build machines
fall into this category, since it allows us to upgrade them regularly
and ensure we’re always making good use of the resources that are
available to us.
Interacting with this hardware is usually a little different from
hardware we physically own. Since this hardware comes from facilities
where many of the same kind of machine is available, usually more
automation exists to be able to remotely manage the systems. In
particular we make use of a lot of hardware from Hetzner in Germany
and Finland where we make use of the Hetzner Robot to remotely reboot
and change the boot image of machines. For hardware that is donated
to us, we usually have to reach out to the sponsor and ask them to
file the ticket on our behalf since they are the contract holder with
the facility. In some cases they’re able to delegate this access to
us, but we always keep them in the loop regardless.
Cloud Systems
For smaller machines, usually having fewer than 4 CPU cores and less
than 8GB of memory, the best option available to us will be to get the
machine from a cloud. We currently use two cloud hosting providers
for machines that are on all the time, and have the ability to spin up
additional capacity in two other clouds.
We run a handful of machines at DigitalOcean to provide our control
plane services that allow us to coordinate the other machines in the
fleet, as well as to provide our single-sign-on services that let
maintainers use one ID to access all Void related services and APIs.
DigitalOcean has been a project sponsor for several years now, and
they were the second cloud provider to get dedicated Void Linux
images.
For cloud machines that need to have a little more involved
configuration, we run on top of the Hetzner cloud where our existing
relationships with Hetzner make it easier for us to justify our
requirements, and our longer account standing shows that we’re not
going to do dumb things on the platform, like run an open forwarder.
Running a mail server on a cloud is itself somewhat challenging, and
will be talked about later this week in more detail, so make sure to
check back for more in this series.
Though we do not actively run services on AWS or GCP, we do maintain
cloud images for these platforms. Sadly in GCP it is not possible for
us to make our images broadly available, but it is relatively easy for
you to create your own image if you desire to run Void on GCP.
Similarly, you can run Void on AWS and make use of their wide service
portfolio. We have evaluated in the past providing a ready to run AMI
for AWS, but ultimately concluded the trade-off wasn’t worth it. If
you’re interested in having a Void image on AWS, let us know.
How We Provision the Fleet
Void’s fleet spans multiple technologies and architectures, which
makes provisioning it a somewhat difficult to follow process. In
order of increasing complexity, we have manually managed provisioning,
automatically managed OS provisioning and application provisioning,
and full environment management in our cloud hosting environments.
Manually Managed
This is the most familiar to the average Void user, we just perform
these steps remotely. We’ll power on a machine, boot from the live
installer, and install the system to disk (almost always with a RAID
configuration). Once the machine is installed and configured, we can
then manage it remotely like any other machine in the fleet using our
machine management tools.
Imaged Resources
Some systems we run use a Void Linux image to perform the
installation. These are usually smaller VMs being hosted by the
members of the Void project in slack space on our own servers, and so
the automation of a large hosting company doesn’t make sense. These
are systems usually running qemu and where the system gets unpacked
from an image that the administrator will have prepared in advance
containing the qemu guest agent and possibly other software required
to connect to the network.
Cloud Resources
Cloud managed resources are probably the most exciting of the systems
we operate. These are generally managed using Hashicorp Terraform as
fully managed environments. By this we mean that the very existence
of the virtual server is codified in a file, checked into git, and
applied using terraform to grow or shrink the number of resources.
We can only do this in places though that provide the APIs needed to
manage resources in this way. We currently have the most resources at
DigitalOcean managed with terraform, where our entire footprint on the
platform is managed this way. This works out extremely conveniently
when we want to add or remove machines, since its just a matter of
editing a file and then re-running terraform to make the changes real.
Beyond machines though, we also host the DNS records for voidlinux.org
in a DigitalOcean DNS Zone. This enables us to easily track changes
to DNS since its all in the console, but managed via a git-tracked
process.
Having support for terraform is actually a major factor in deciding if
we’ll use a commercial hosting service or not. Remember that Void has
developers all over the world in different time zones speaking
different languages with different availability to actually work on
Void. To make it easier to collaborate, we can apply the exact same
workflows of distributed review and changes that make void-packages
work to void-infrastructure and make feature branches for new servers,
send them out for review, and process changes as required.
Making the Hardware Useful: Provisioning Services
For services like DigitalOcean’s hosted DNS or Fastly’s CDN, once we
push terraform configuration we’re done and the service is live. This
works because we’re interfacing with a much larger system and just
configuring our small partition of it. For most of Void’s resources
though, Void runs on machines either physical or virtual, and once the
operating system is installed, we need to apply configuration to it to
install packages, configure the system, and make the machines do more
than just idle with SSH listening.
Our tool of choice for this is Ansible, which allows us to express a
series of steps as yaml documents that when applied in order,
configure the machine to have a given state. These files are called
“playbooks” and we have multiple different playbooks for different
machine functions, as well as functions common across the fleet.
Usually upon provisioning a new machine, our first task will be to run
the base.yml playbook which configures single sign on, DNS, and
installs some packages that we expect to have available everywhere.
After we’ve done this base configuration step, we apply network.yml
which joins the machines to our network. Given that we run in so many
places where different providers have different network technologies
that are, for the most part, incompatible and proprietary, we need to
operate our own network based on WireGuard to provide secure
connectivity machine to machine.
When we have internal connectivity to Void’s private network
available, we can finalize provisioning by running any remaining
playbooks that are required to turn the machine into something useful.
These playbooks may install services directly, or install a higher
level orchestrator that dynamically coordinates services. More on the
services themselves later in the week.
Why Does Void Run Where it Does?
Alternatively, why doesn’t Void make use of cloud <x> or hosting
provider <y>. The simple answer is because we have sufficient
capacity with the providers we’re already in and it takes a
non-trivial amount of effort to build out support for new providers.
The longer answer has to do with the semi-unique way that Void is
funded, which is entirely by the maintainers. We have chosen not to
accept monetary donations since this involves non-trivial
understanding of tax law internationally, and for Void, we’ve
concluded that’s more effort than its worth. As a result, the
selection of hosting providers are either hosts that have reached out
and were willing to provide us with promotional credits on the
understanding that they were interacting with individuals on behalf of
the project, or places that Void maintainers already had accounts and
though the services were good quality and good value to run resources
for Void.
We regularly do re-evaluate though where we’re running and what
resources we make use of both from a reliability standpoint as well as
a cost standpoint. If you’re with a hosting provider and want to see
Void running in your fleet, drop us a line.
This has been day one of Void’s infrastructure week. Check back
tomorrow to learn about what services we run, how we run them, and how
we make sure they keep running. This post was authored by maldridge
who runs most of the day to day operations of the Void fleet. Feel
free to ask questions on GitHub
Discussions
or in IRC.