Transferir como PDF, PPTX




![GPUs
Lei de Amdahl e Taxonomia de Flynn
Lei de Amdahl - 1967
A Lei de Amdahl ´e a lei que governa o speedup na utiliza¸c˜ao de proces-
sadores paralelos em rela¸c˜ao ao uso de apenas um processador.
Speedup:
S = Speed-up
P = Number of Processors
T = Time
Sp =
T1
Tp
(1)
Taxonomia de Flynn - 1966
Single Instruction Multiple Instruction
Single Data SISD - Sequential MISD
Multiple Data SIMD [SIMT] - GPU MIMD - Multicore
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 4 / 52](https://image.slidesharecdn.com/slides-170216234149/75/GPU-CUDA-OpenCL-and-OpenACC-for-Parallel-Applications-7-2048.jpg)




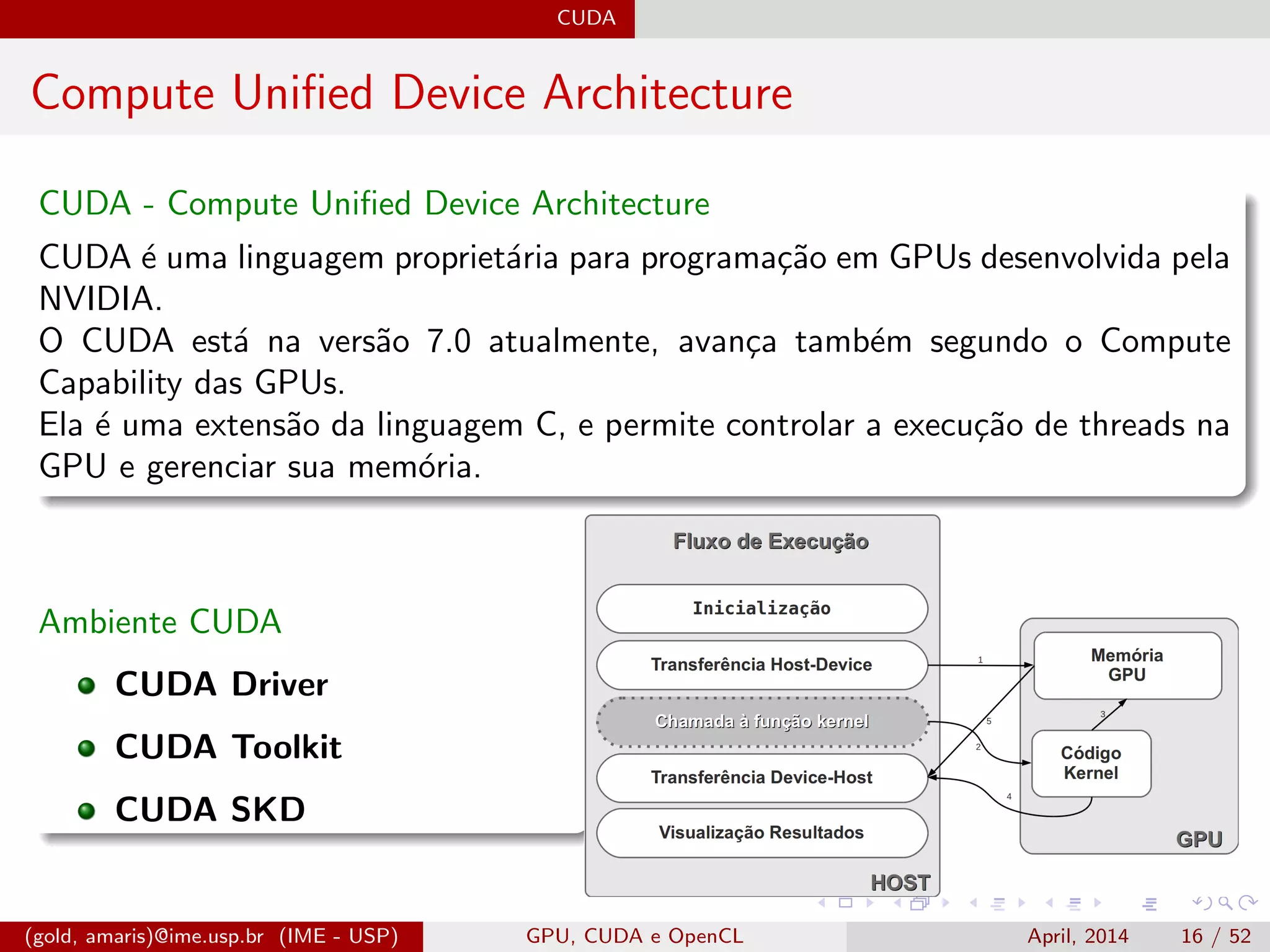
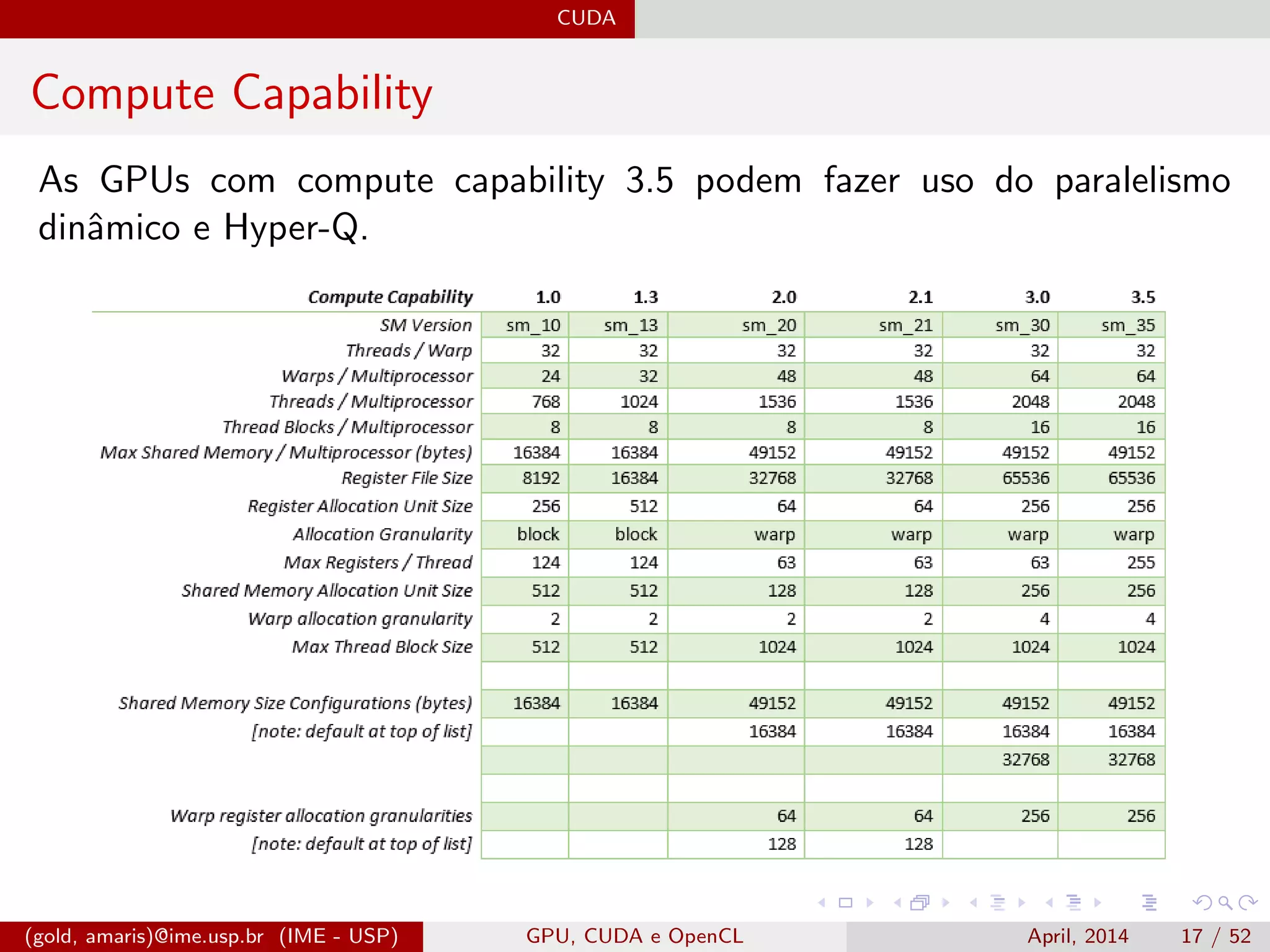
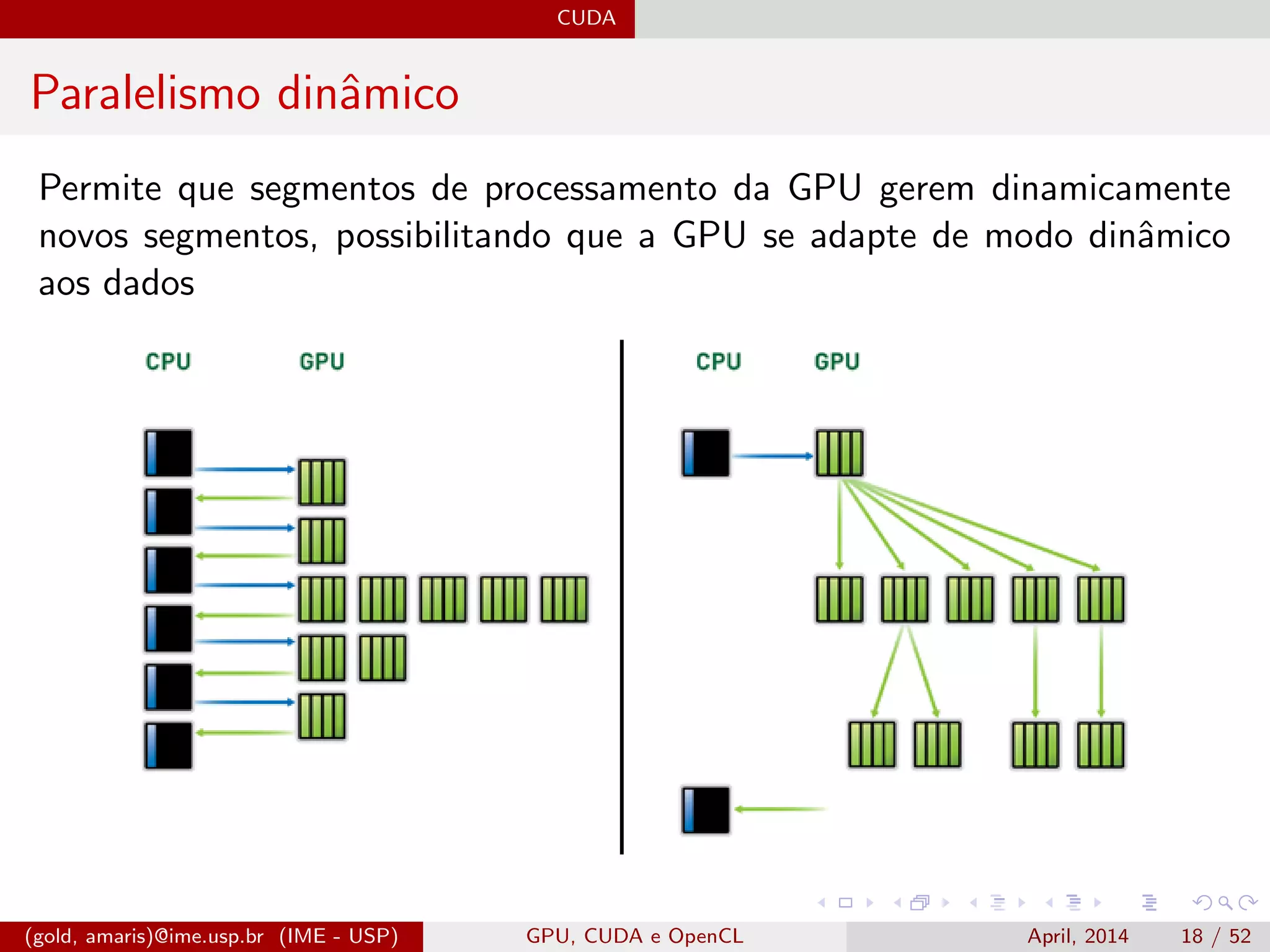
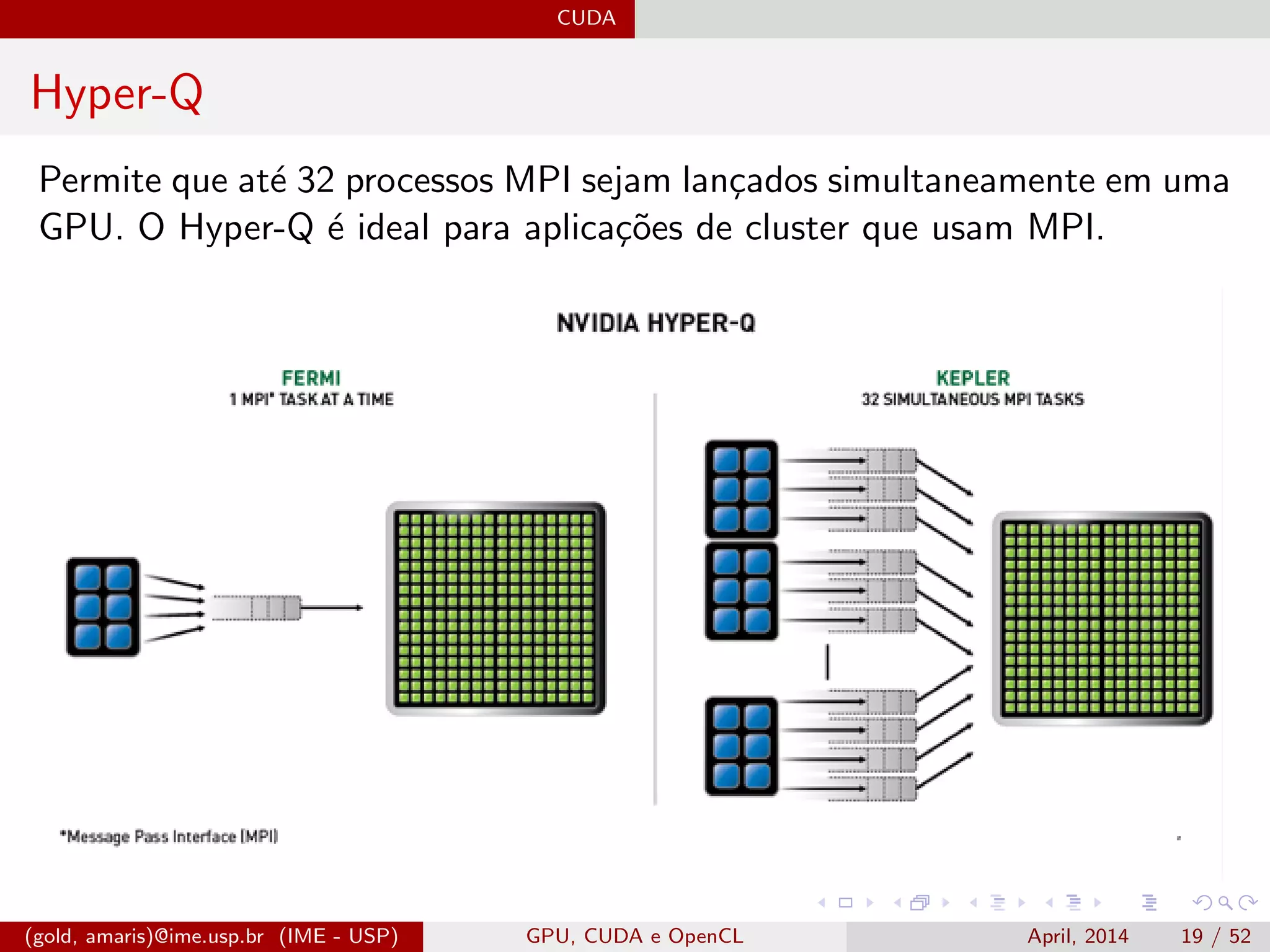
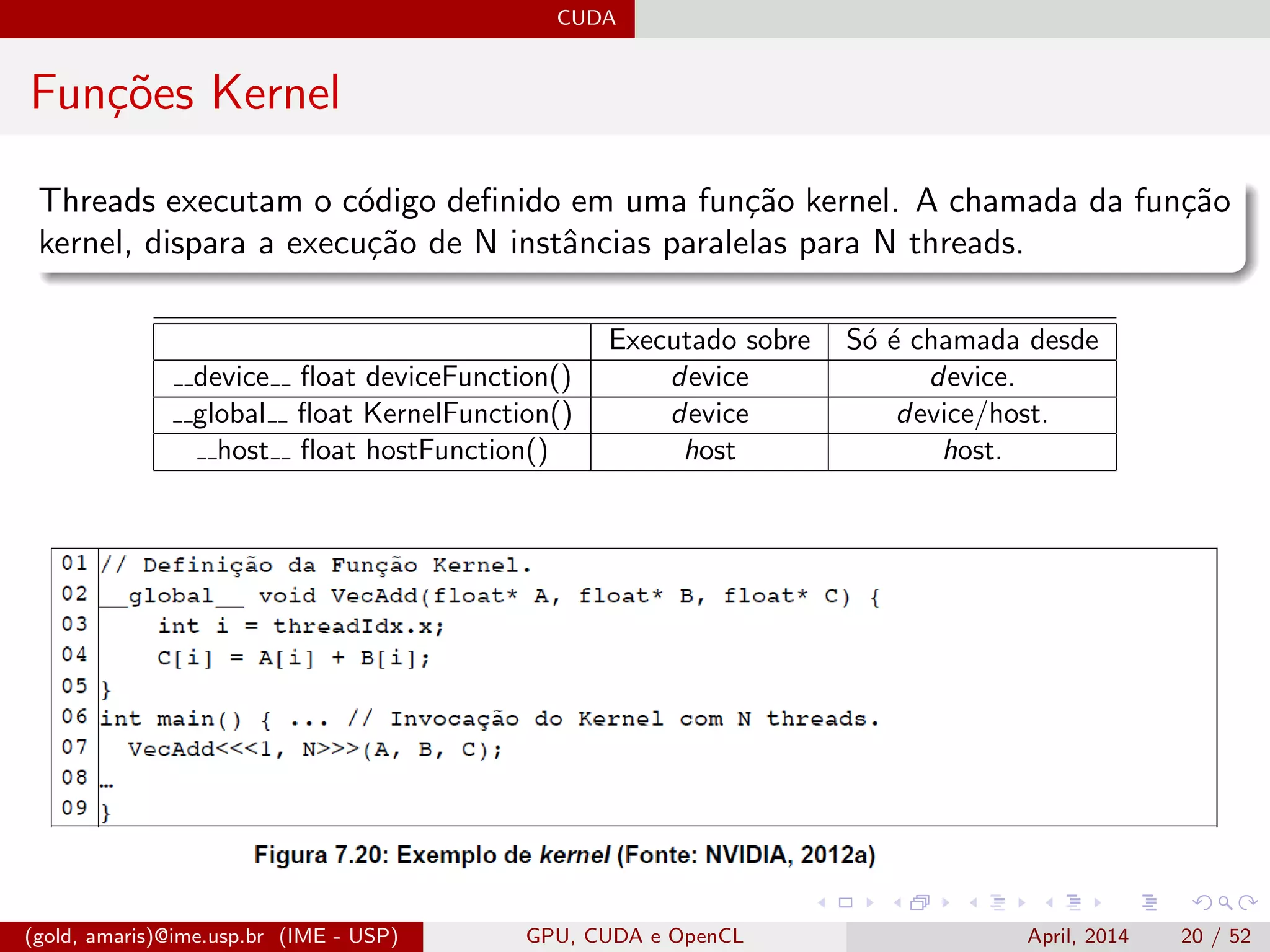

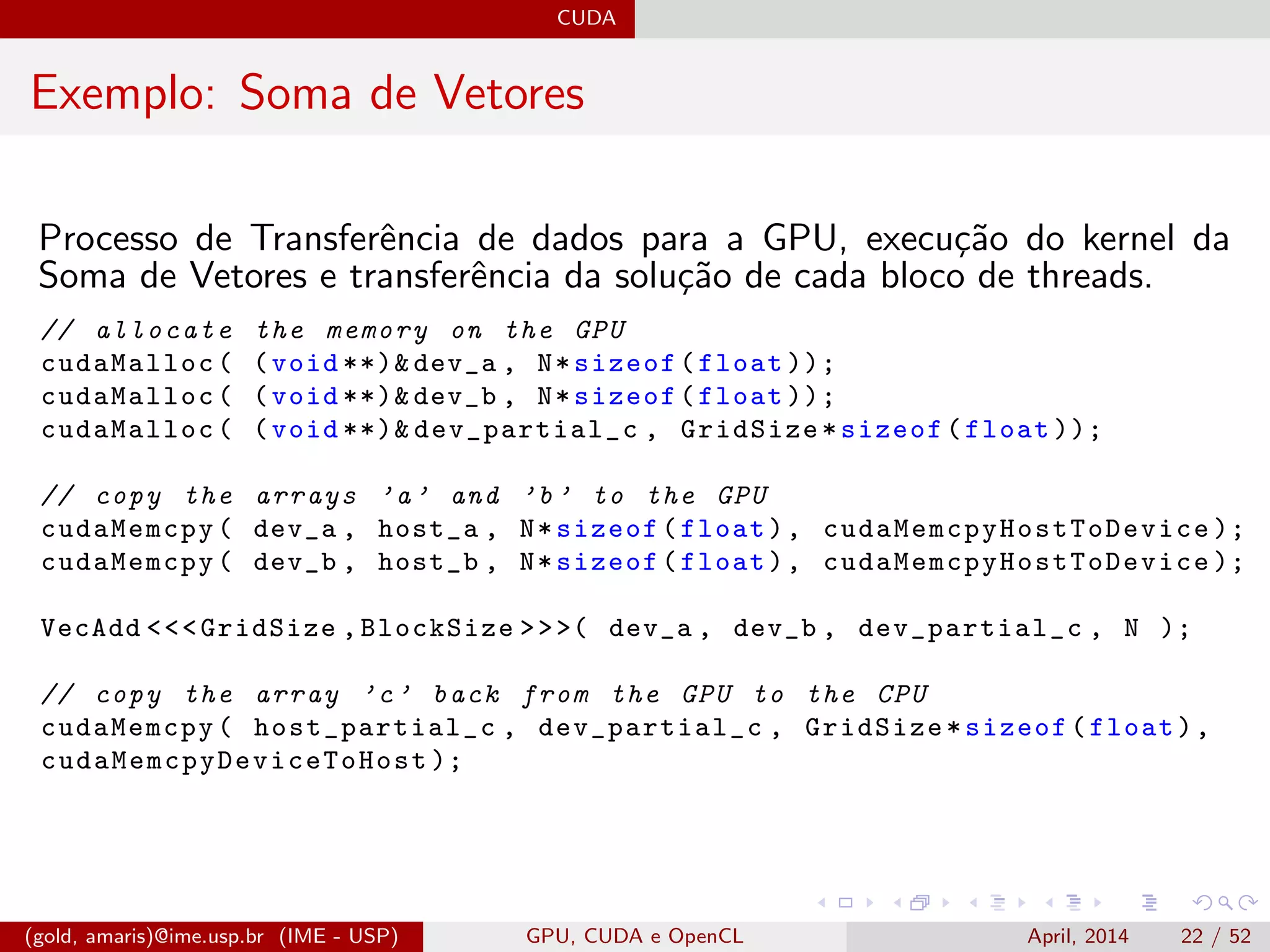
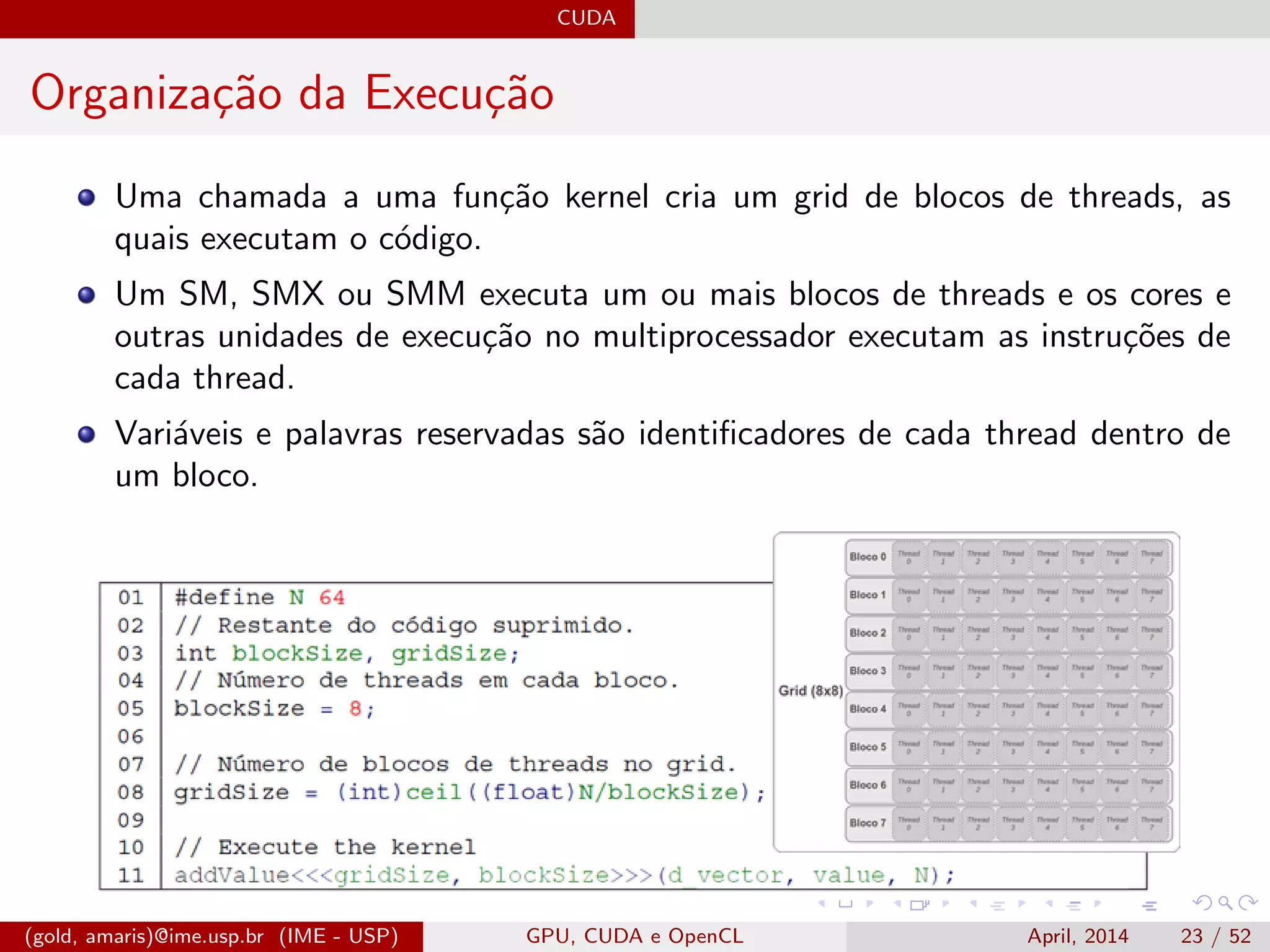

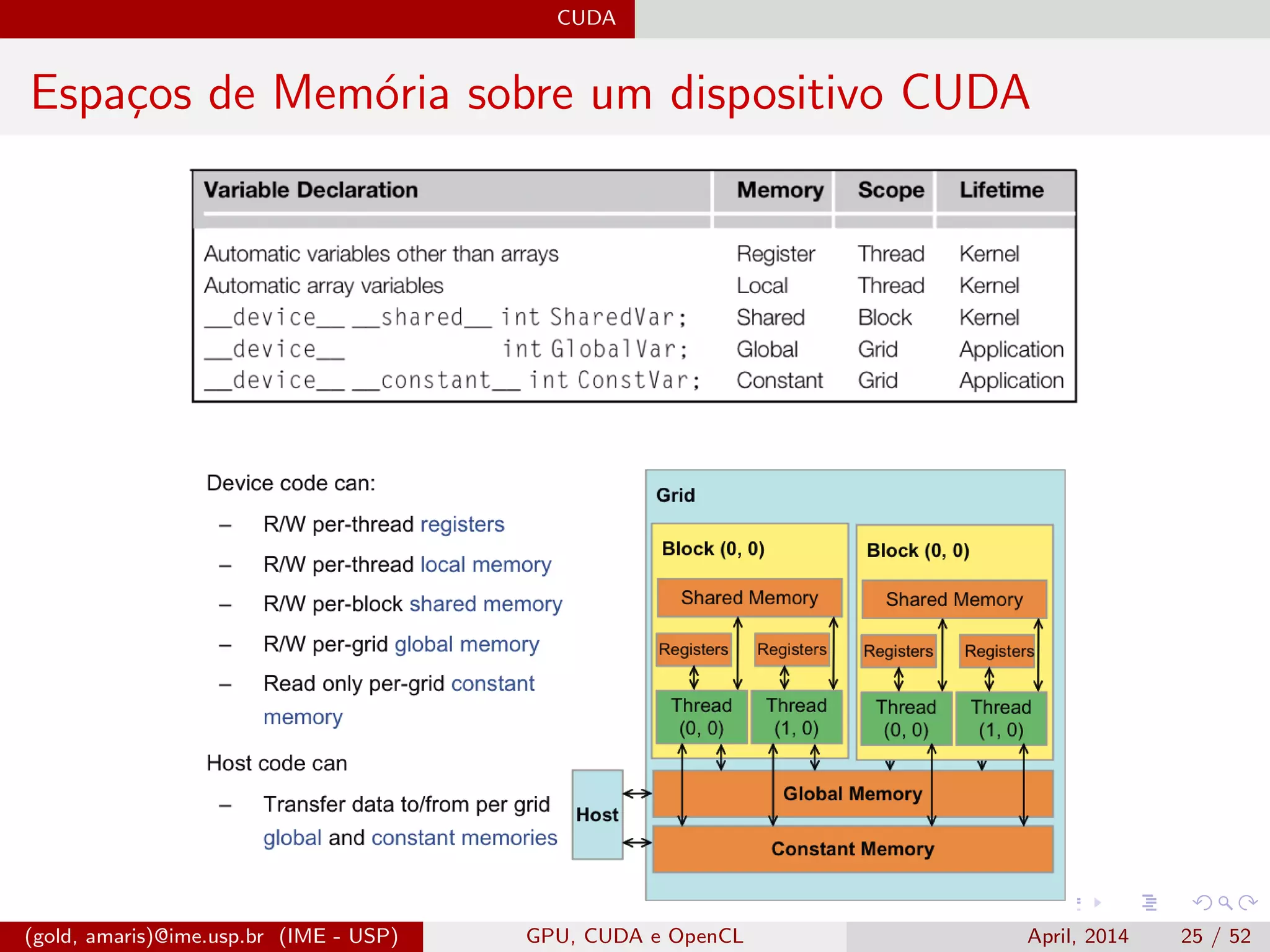
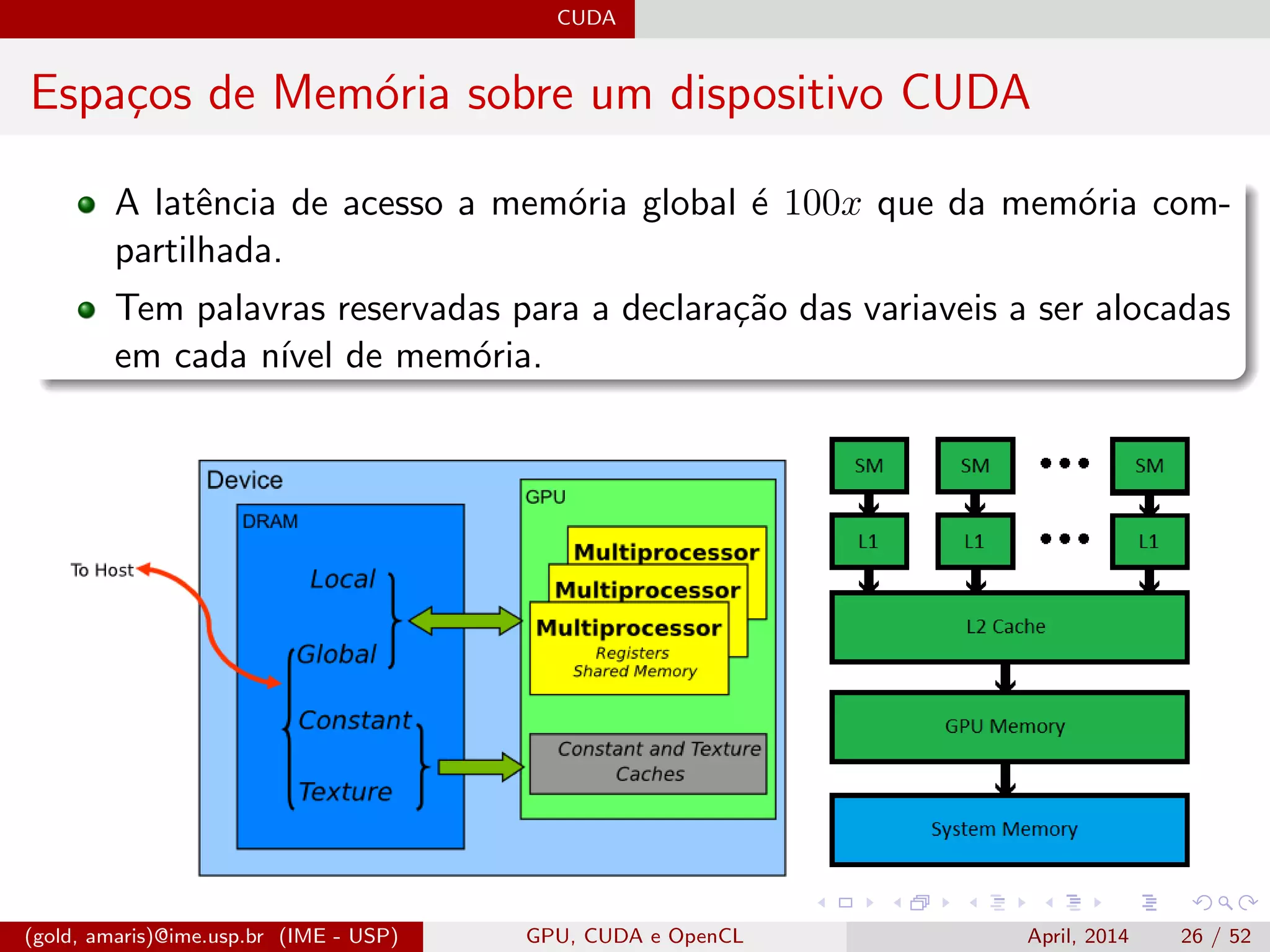
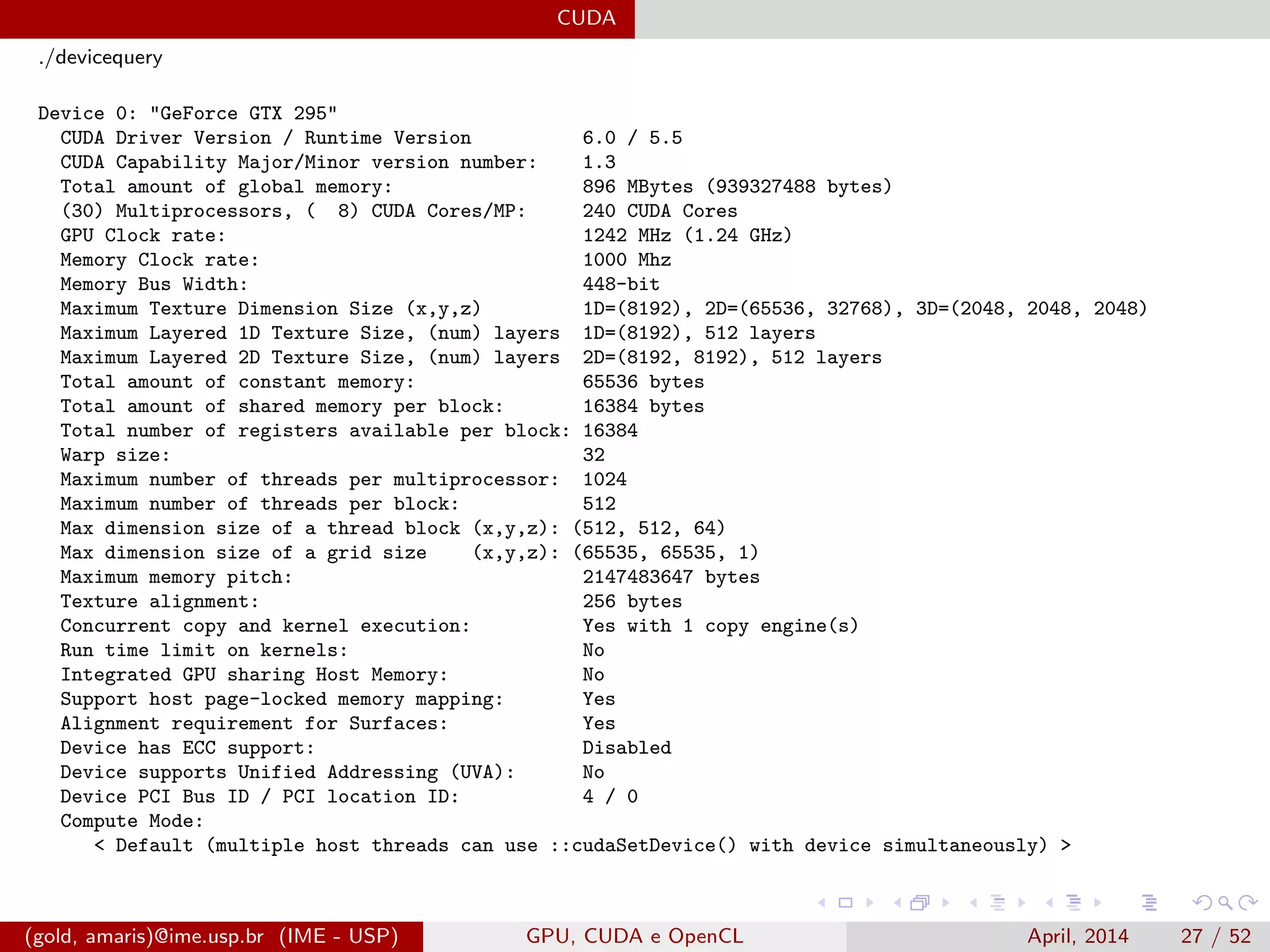
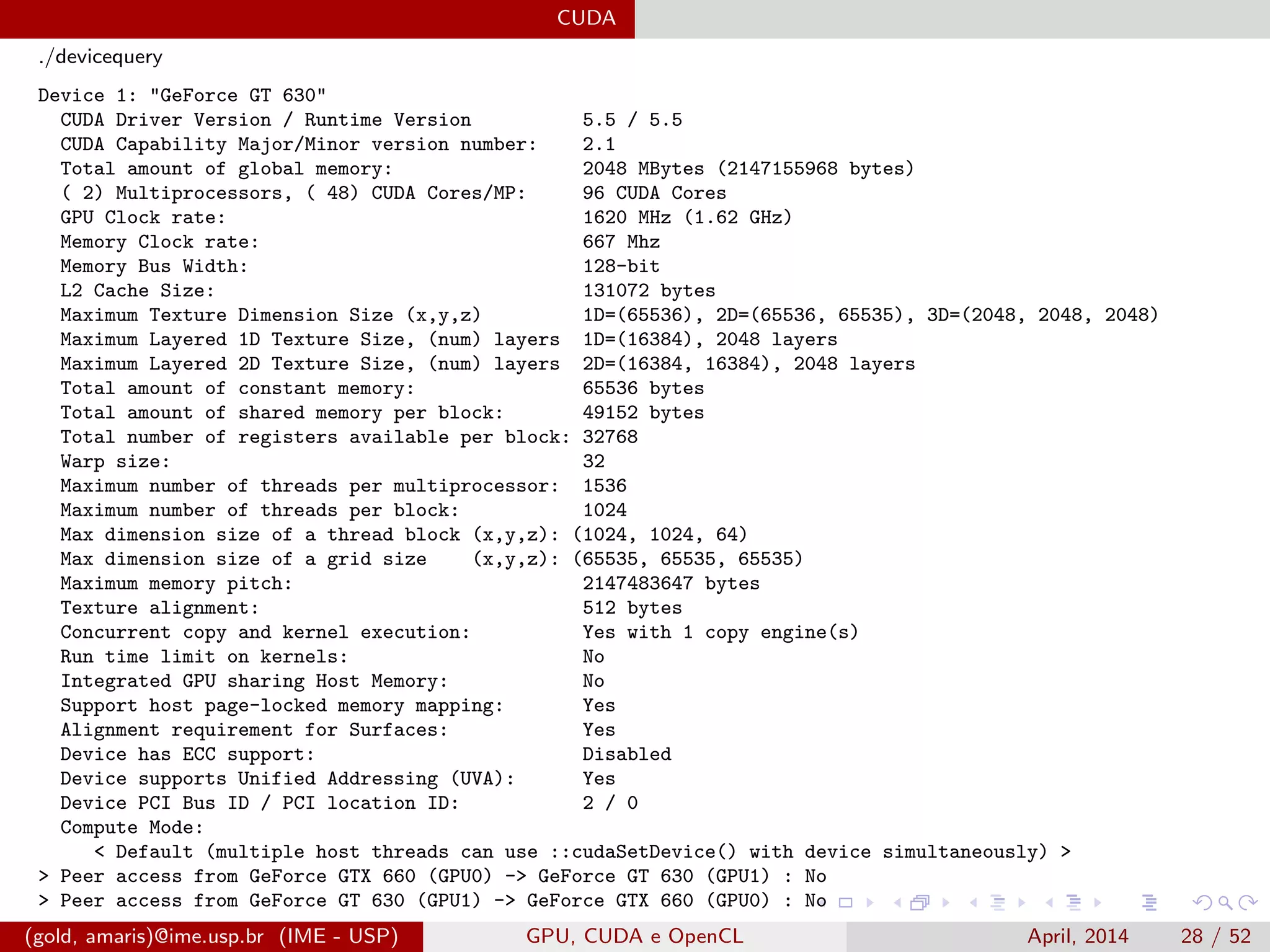
![CUDA
Multiplica¸c˜ao de Matrizes em CUDA - I
Esquema de paraleliza¸c˜ao e kernel da multiplica¸c˜ao de matrizes por padr˜ao
com CUDA.
__global__ void matMul(float* Pd , float* Md ,
float* Nd , int N) {
float Pvalue = 0.0;
int j = blockIdx.x * tWidth + threadIdx.x;
int i = blockIdx.y * tWidth + threadIdx.y;
for (int k = 0; k < N; ++k)
Pvalue += Md[j * N + k] * Nd[k * N + i];
Pd[j * N + i] = Pvalue;
}
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 30 / 52](https://image.slidesharecdn.com/slides-170216234149/75/GPU-CUDA-OpenCL-and-OpenACC-for-Parallel-Applications-37-2048.jpg)

![CUDA
Kernel da Multiplica¸c˜ao de Matrizes usando mem´oria compartilhada em
CUDA:
__global__ void matMul(float* Pd , float* Md ,
float* Nd , int N){
__shared__ float Mds[tWidth ][ tWidth ];
__shared__ float Nds[tWidth ][ tWidth ];
int tx = threadIdx.x;
int ty = threadIdx.y;
int Col = blockIdx.x * tWidth + tx;
int Row = blockIdx.y * tWidth + ty;
float Pvalue = 0;
for (int m = 0; m < N/tWidth; ++m) {
Mds[ty][tx] = Md[Row*N + (m*tWidth + tx)];
Nds[ty][tx] = Nd[Col + (m*tWidth + ty)*N];
__syncthreads ();
for (int k = 0; k < Tile_Width; ++k)
Pvalue += Mds[ty][k] * Nds[k][tx];
__syncthreads ();
}
Pd[Row * N + Col] = Pvalue;
}
(gold, amaris)@ime.usp.br (IME - USP) GPU, CUDA e OpenCL April, 2014 32 / 52](https://image.slidesharecdn.com/slides-170216234149/75/GPU-CUDA-OpenCL-and-OpenACC-for-Parallel-Applications-39-2048.jpg)


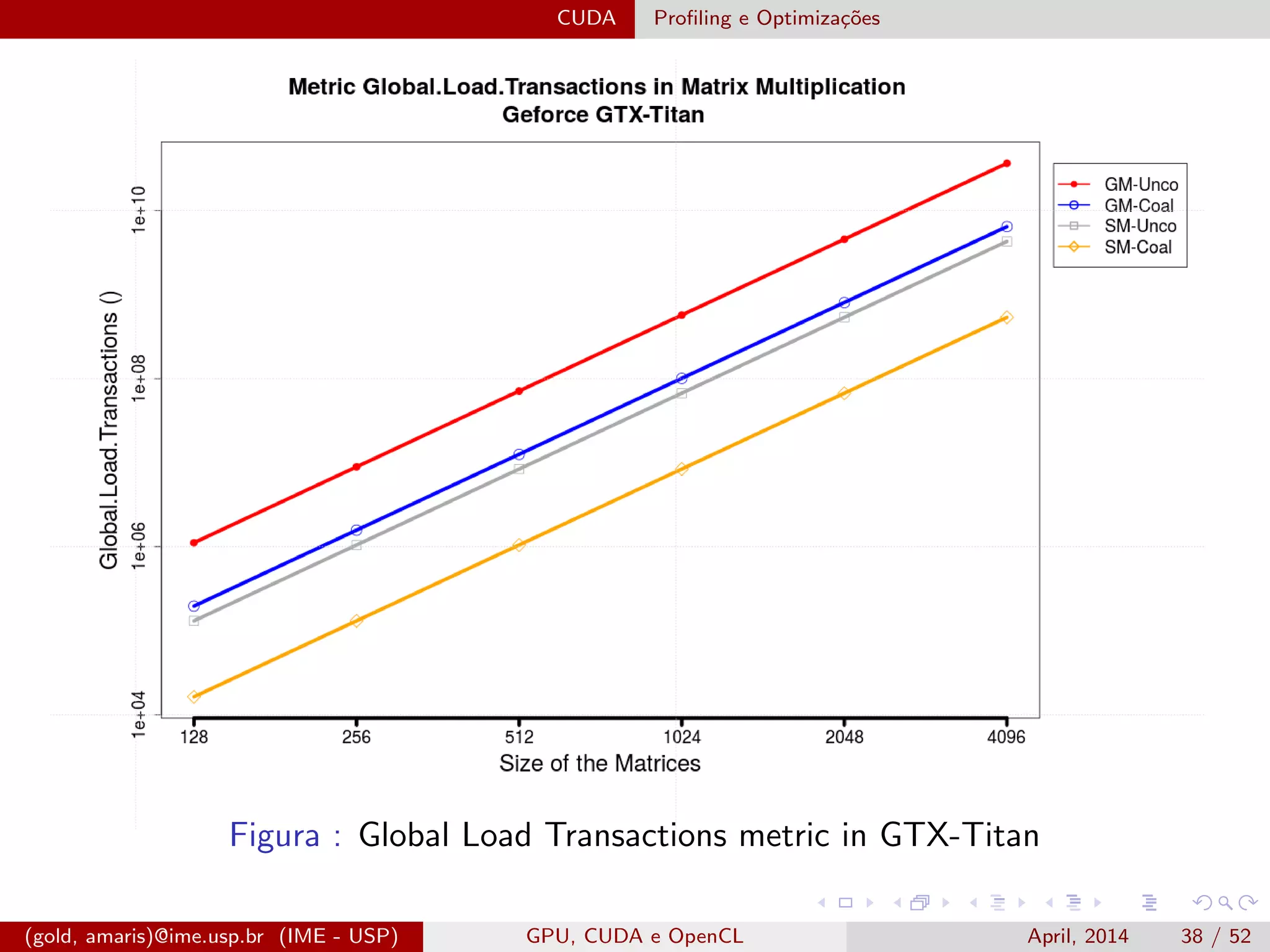
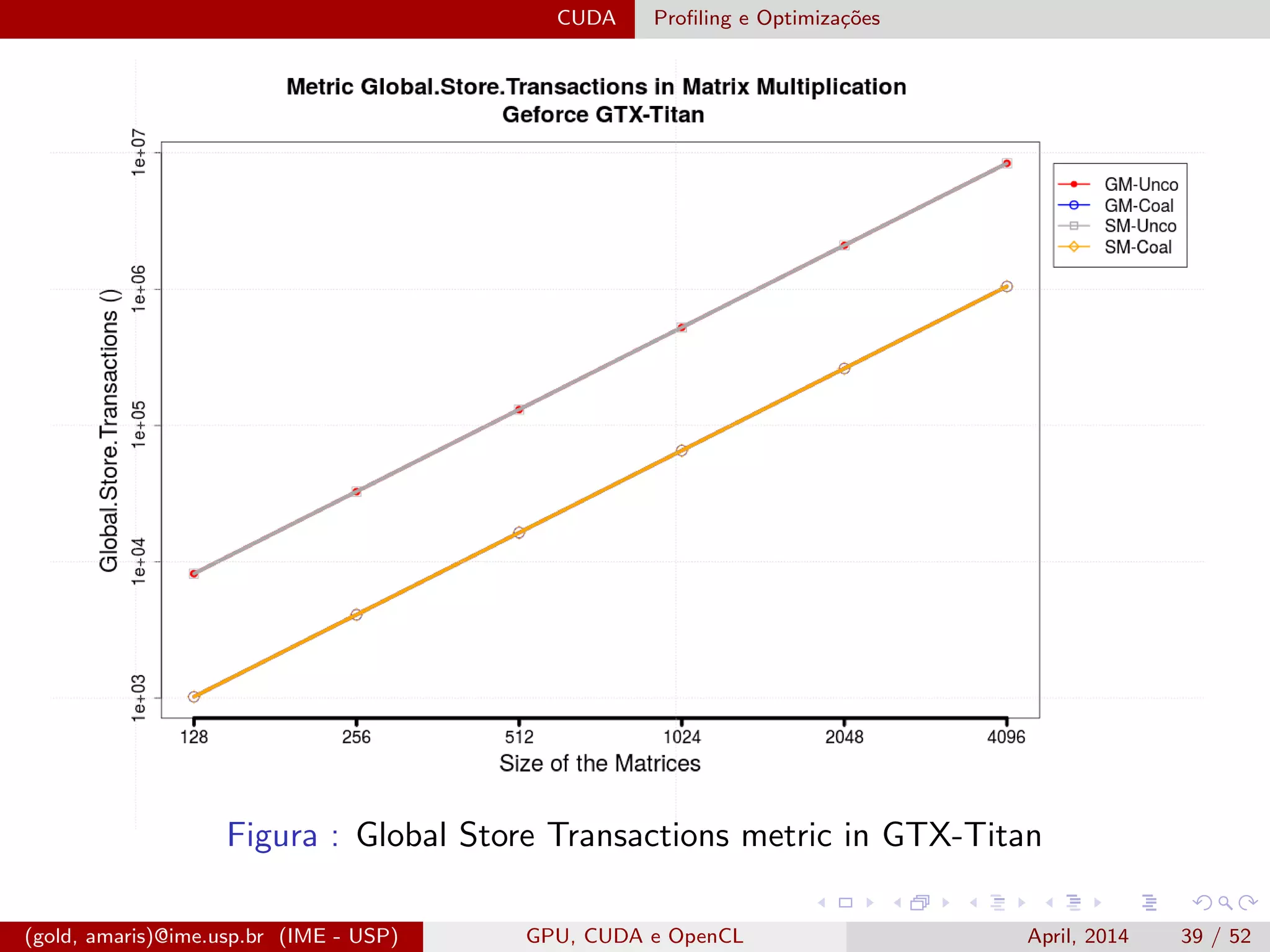

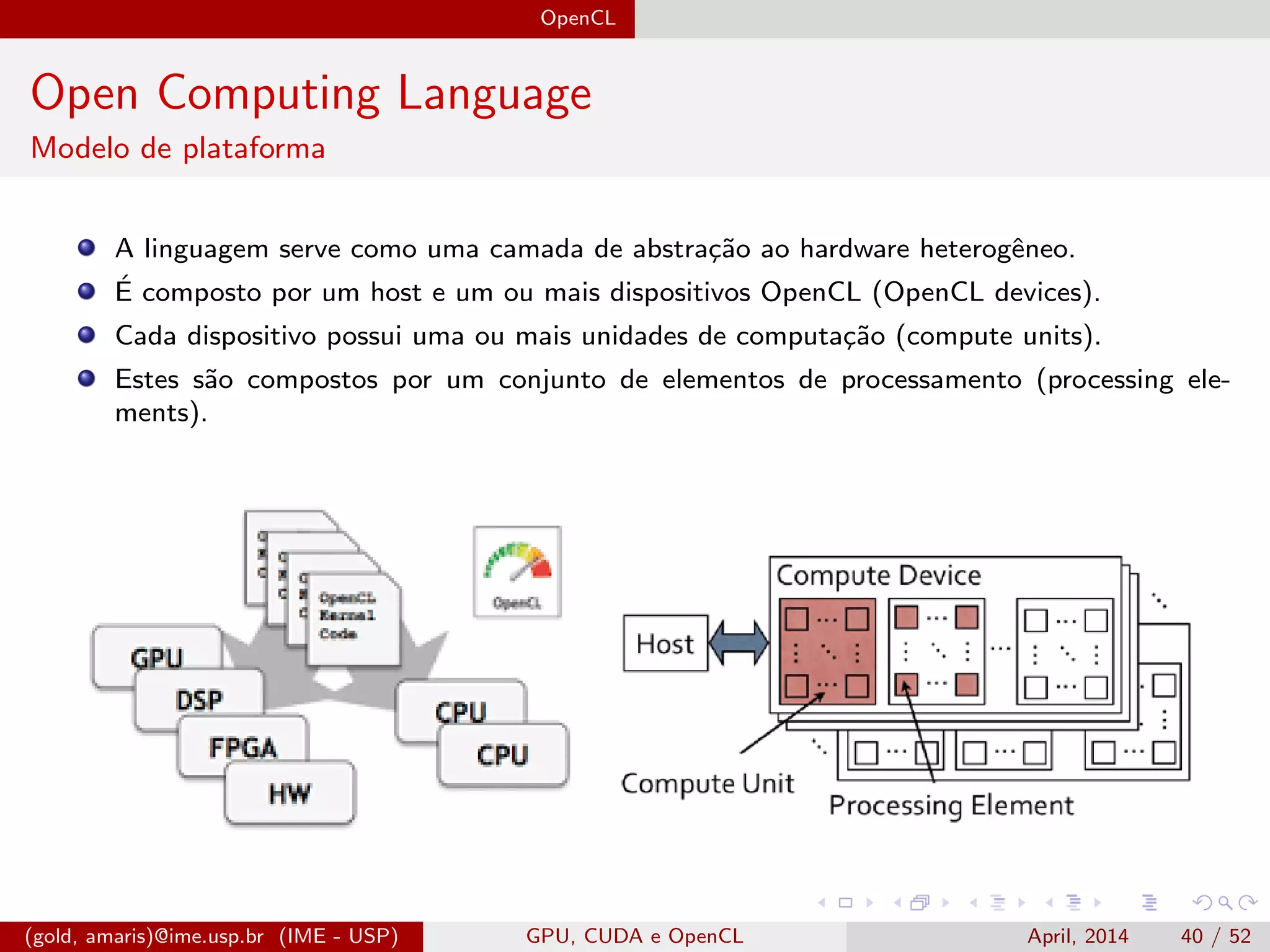

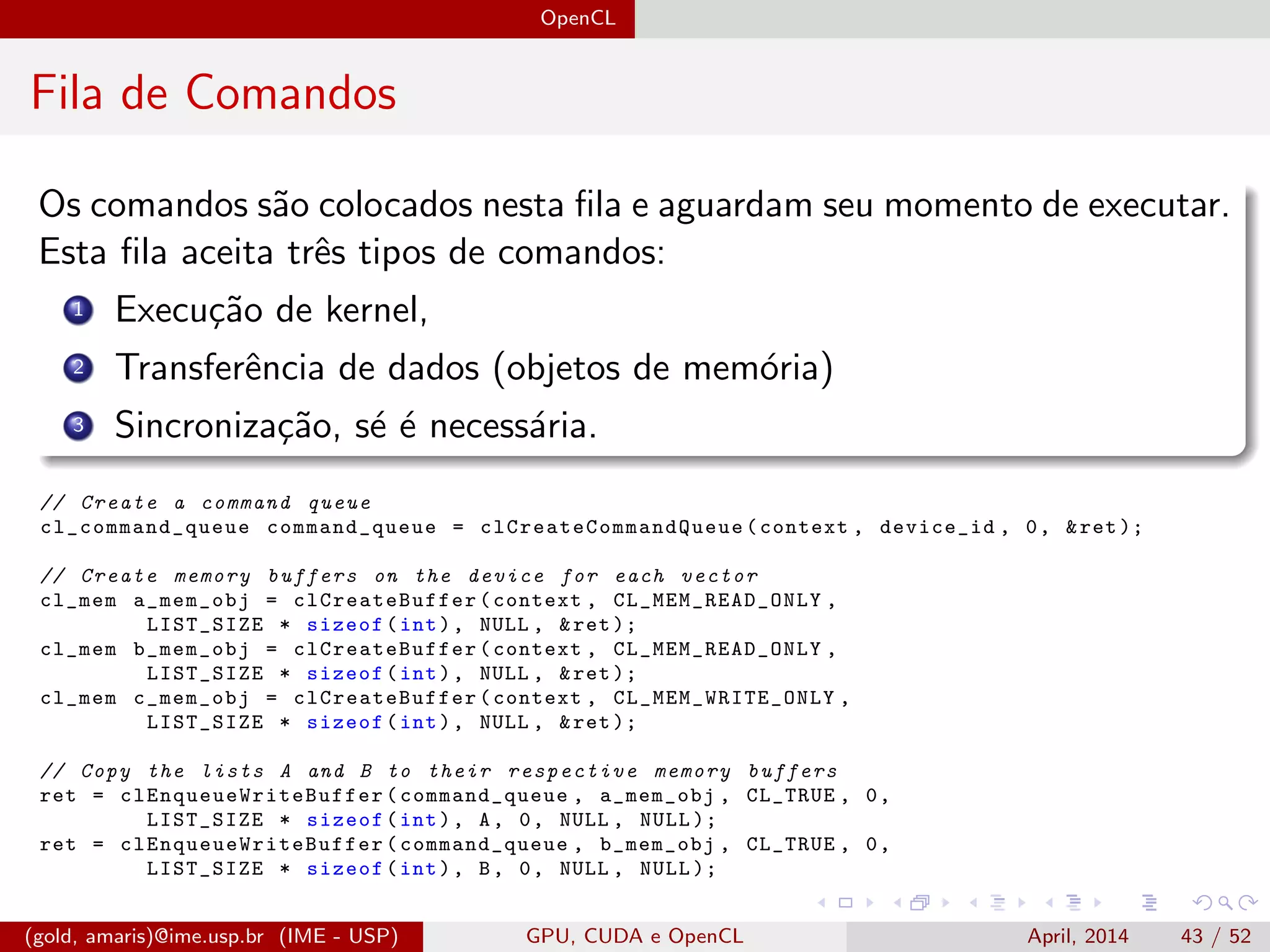
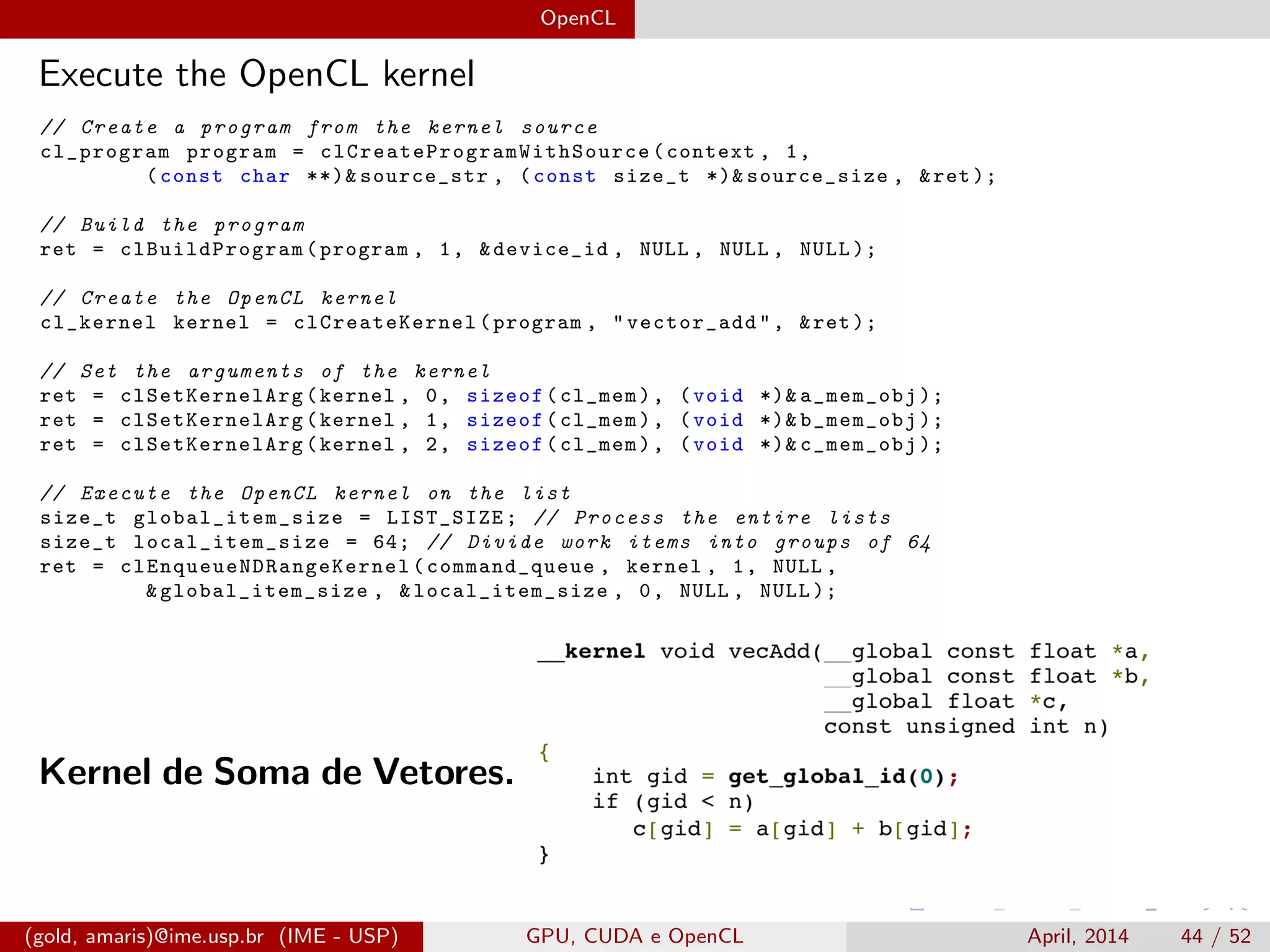
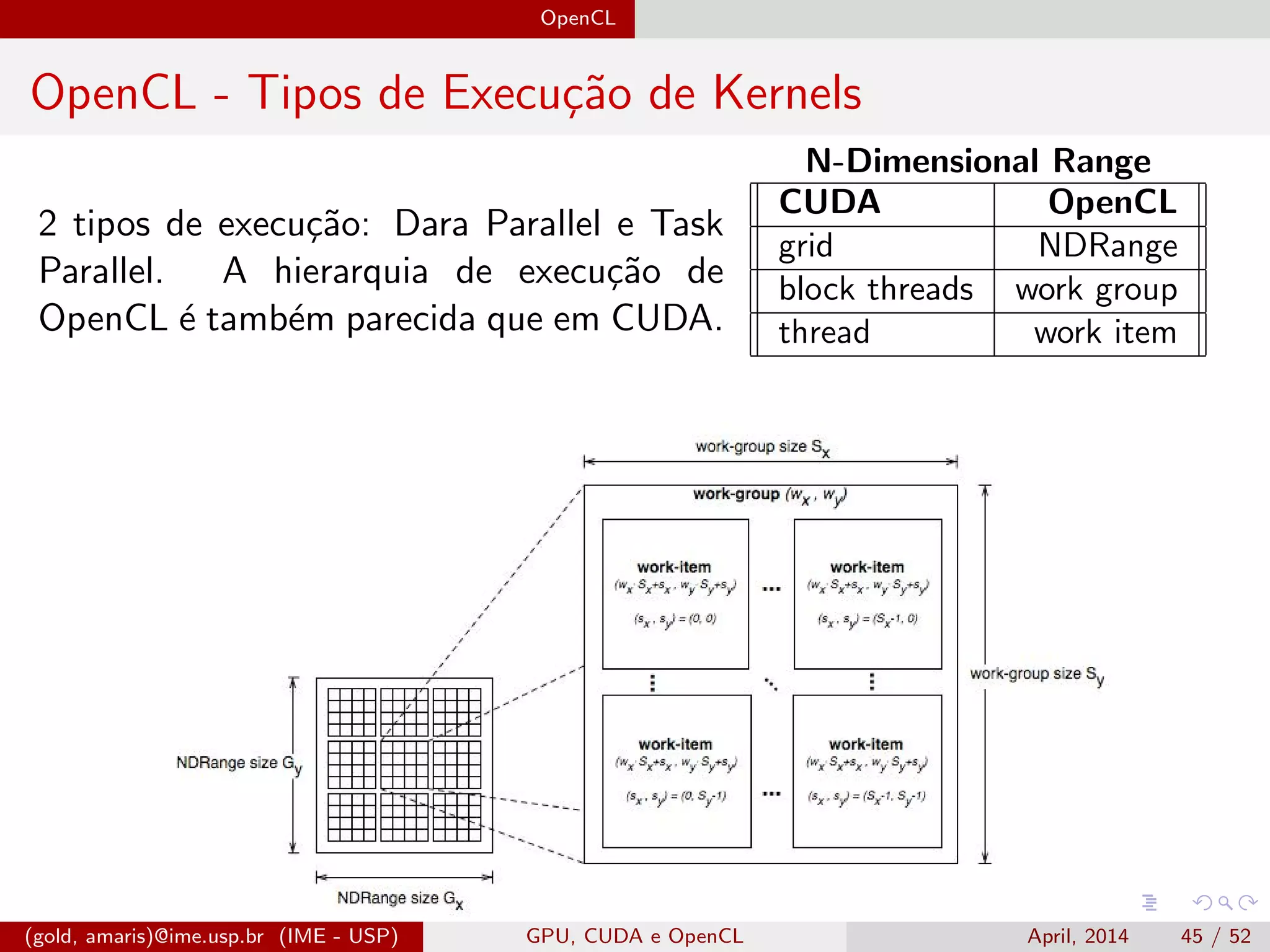
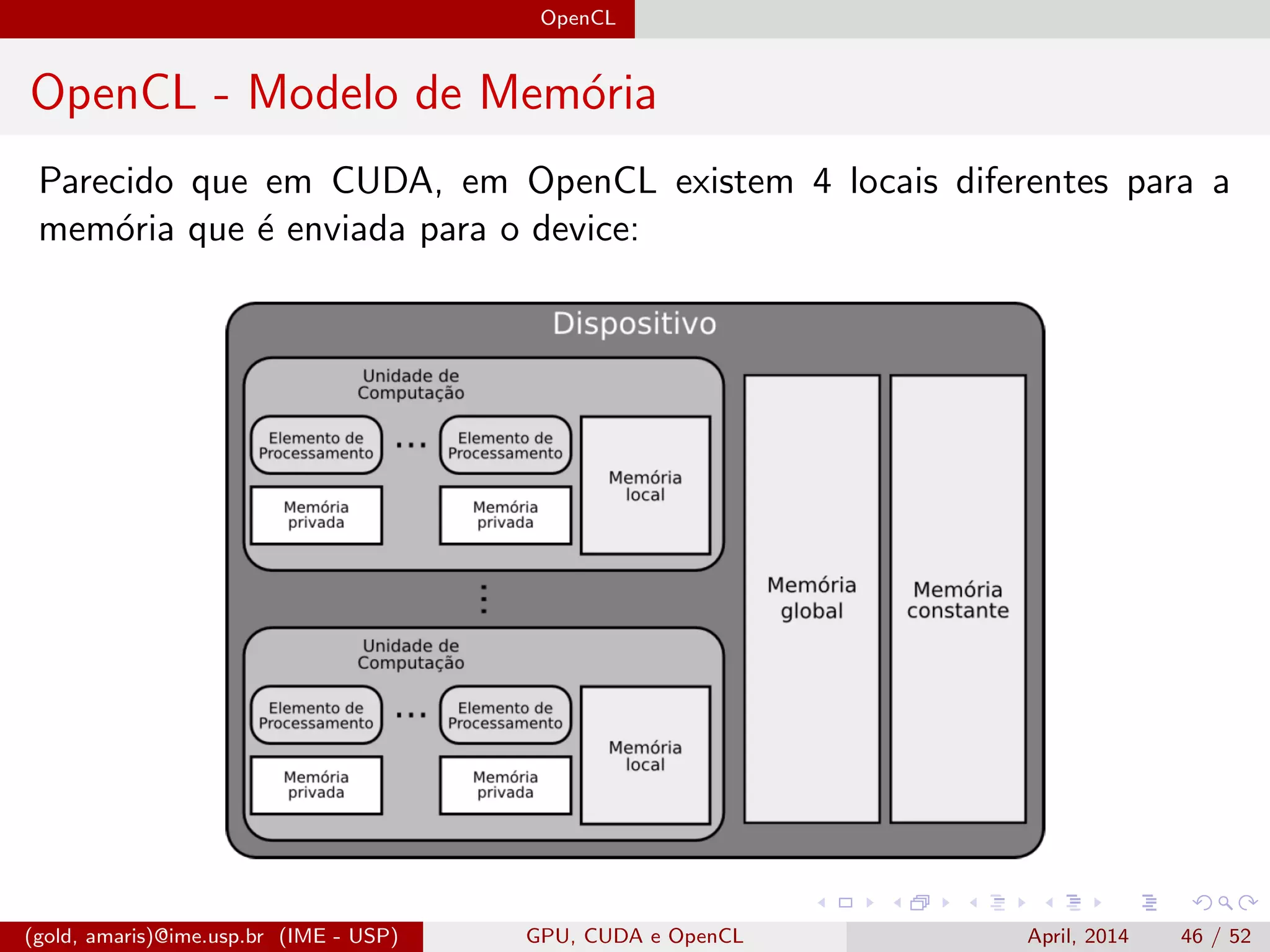



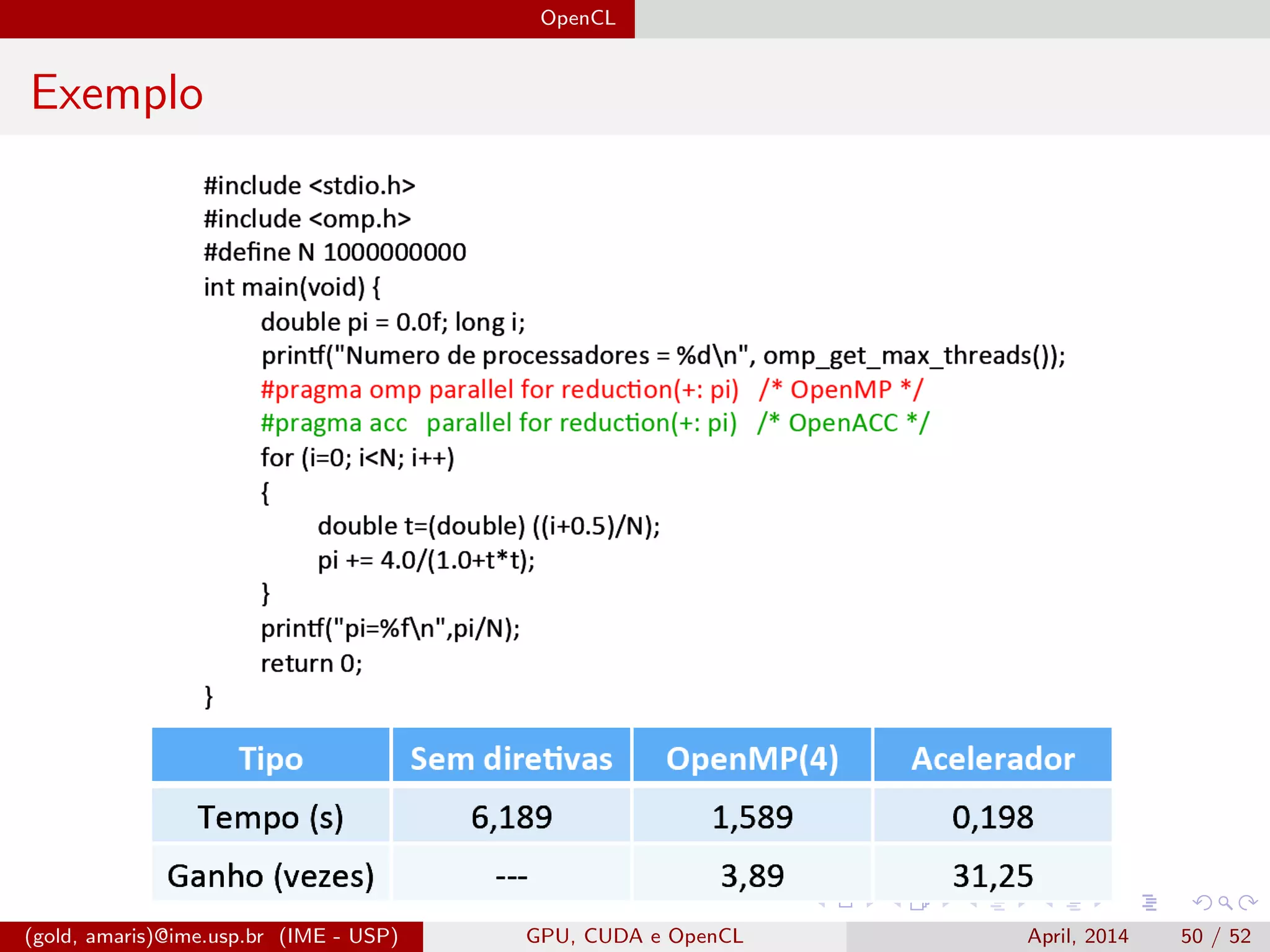



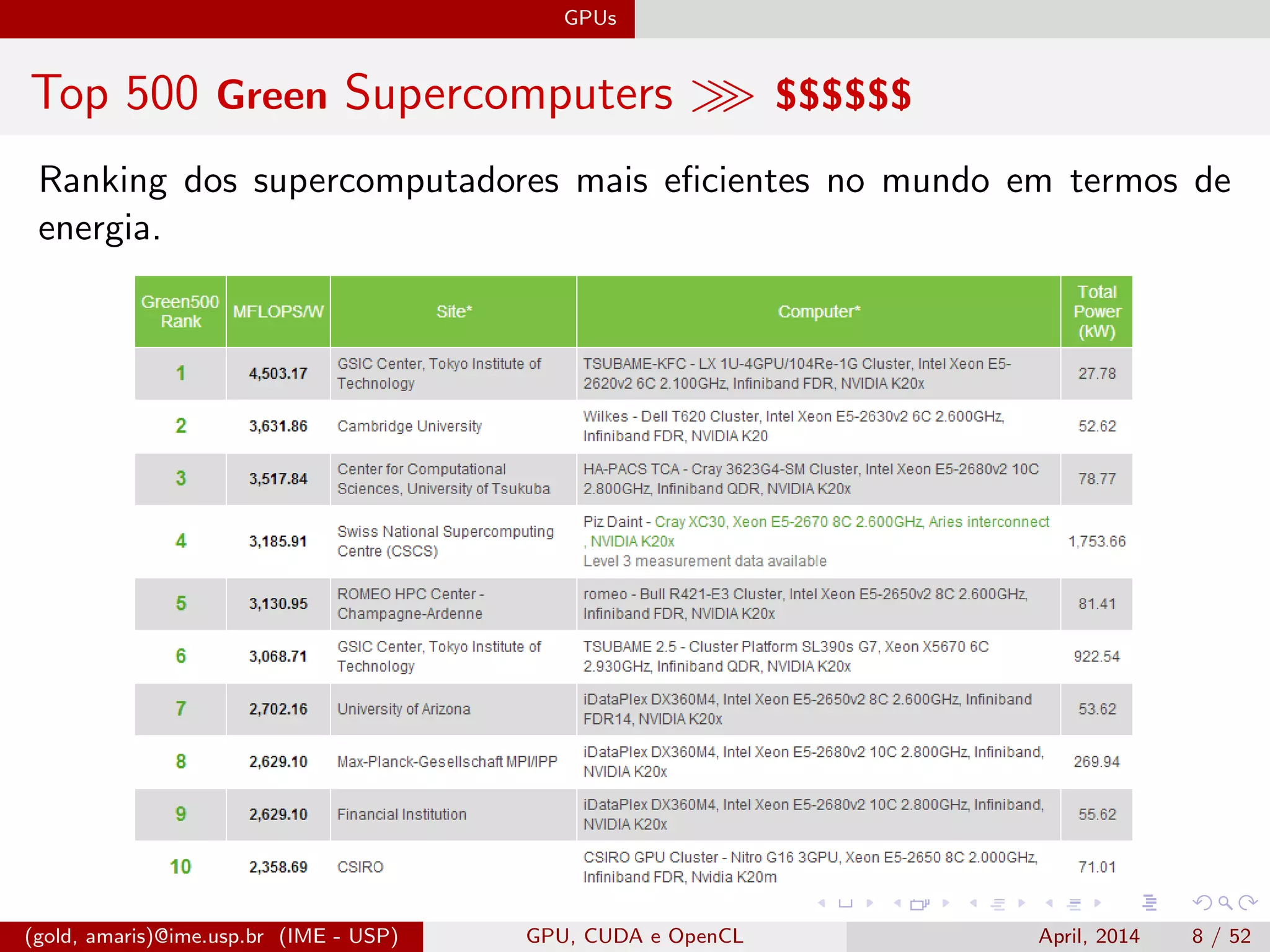
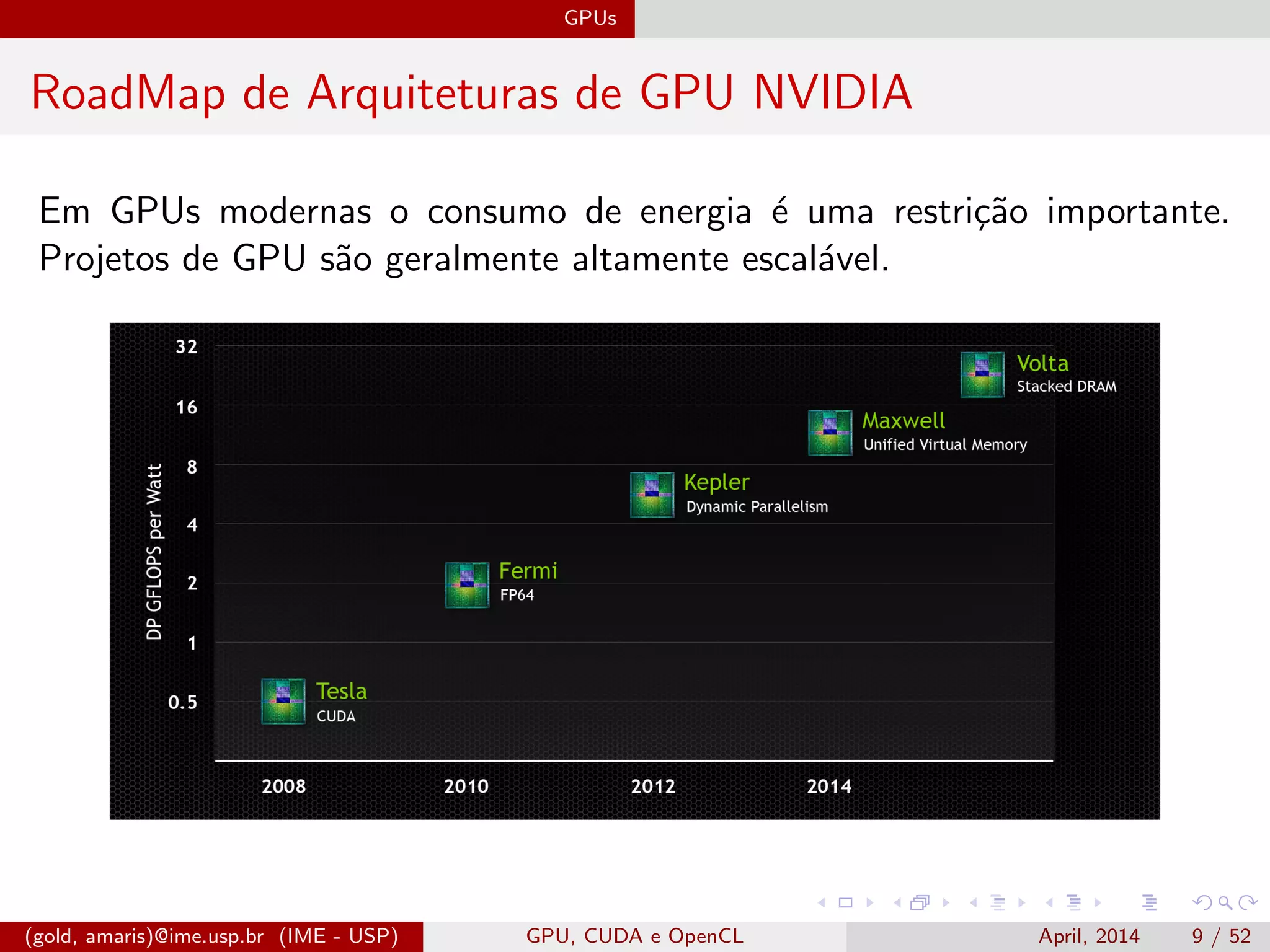
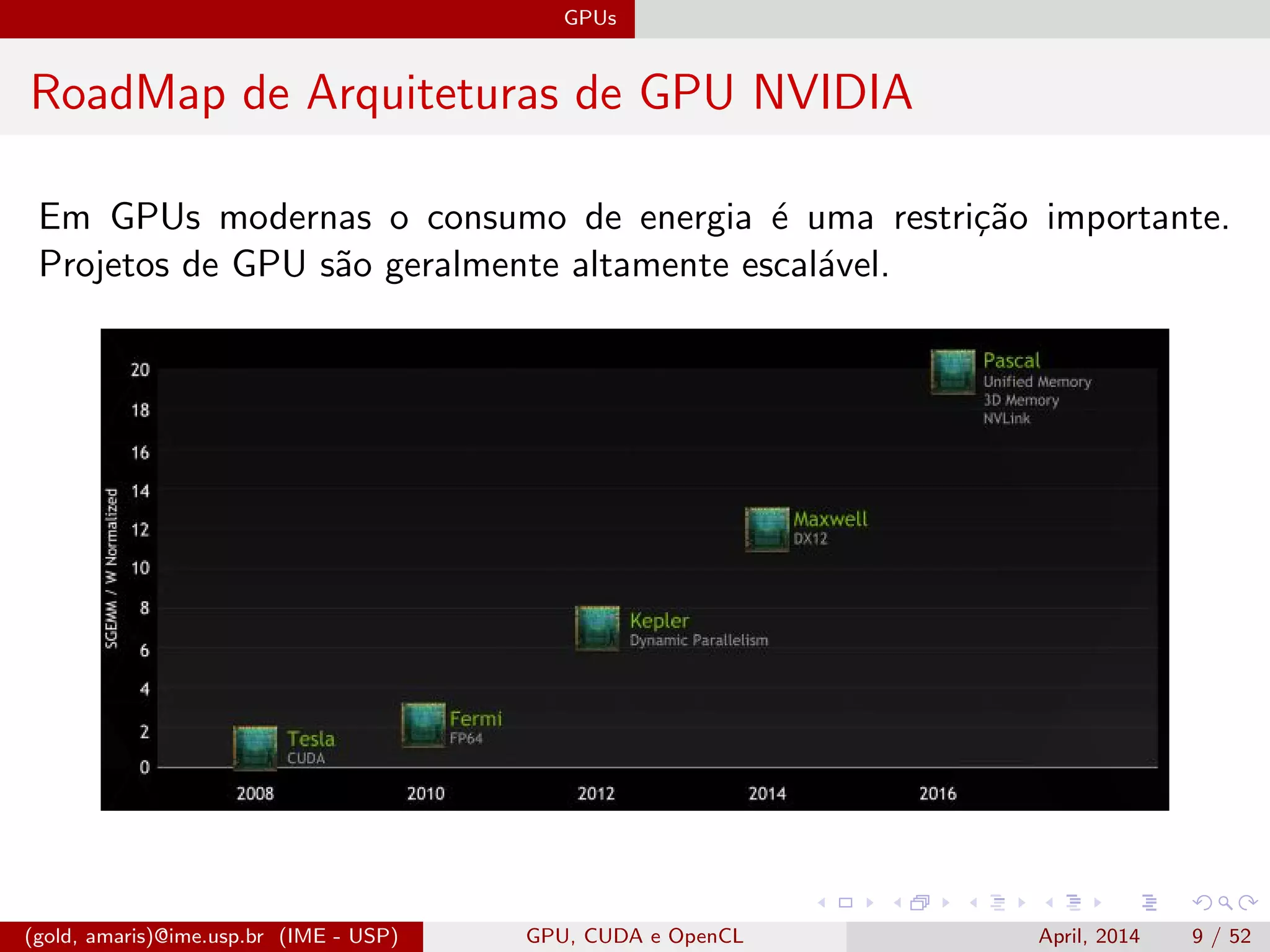
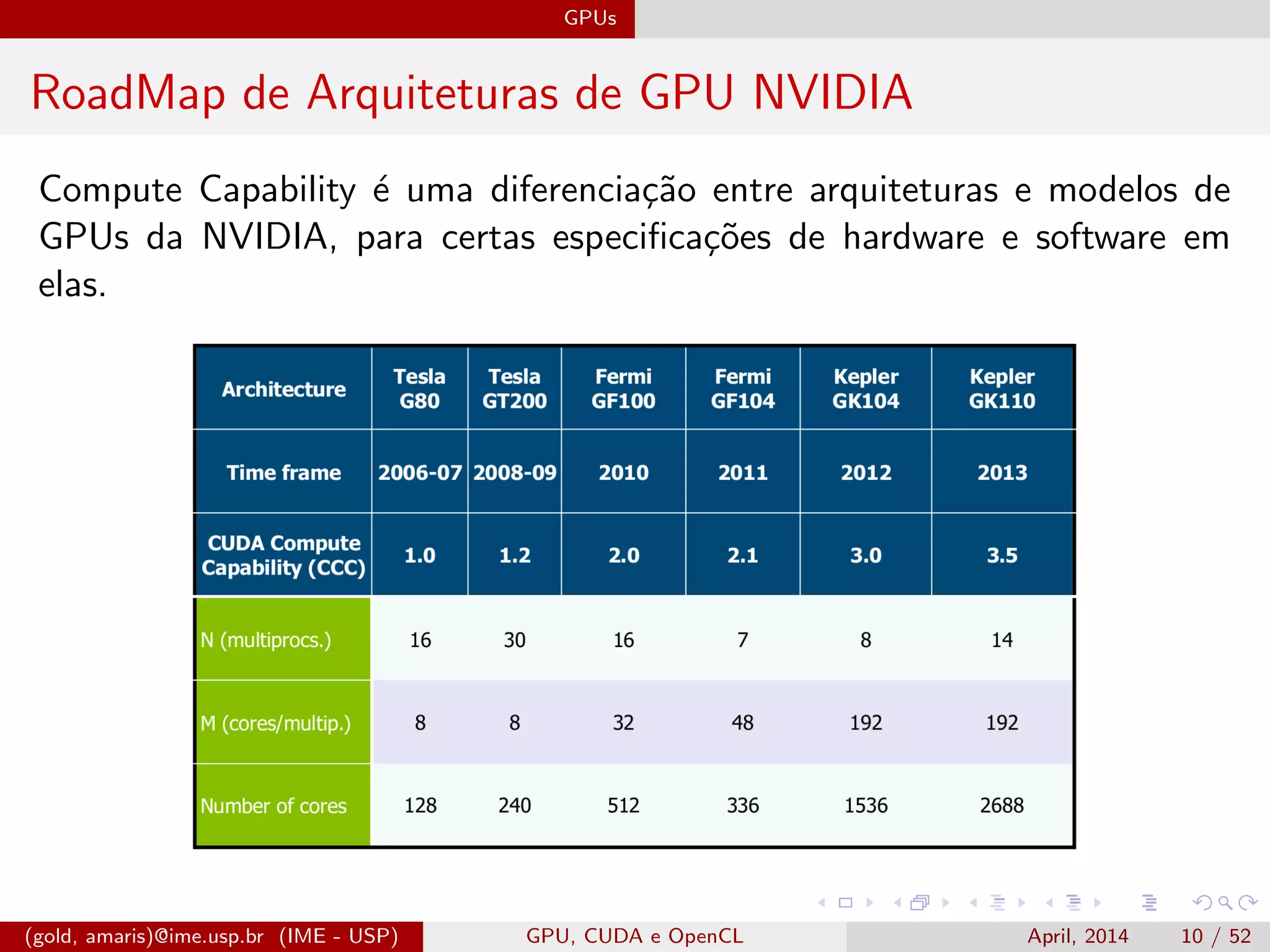
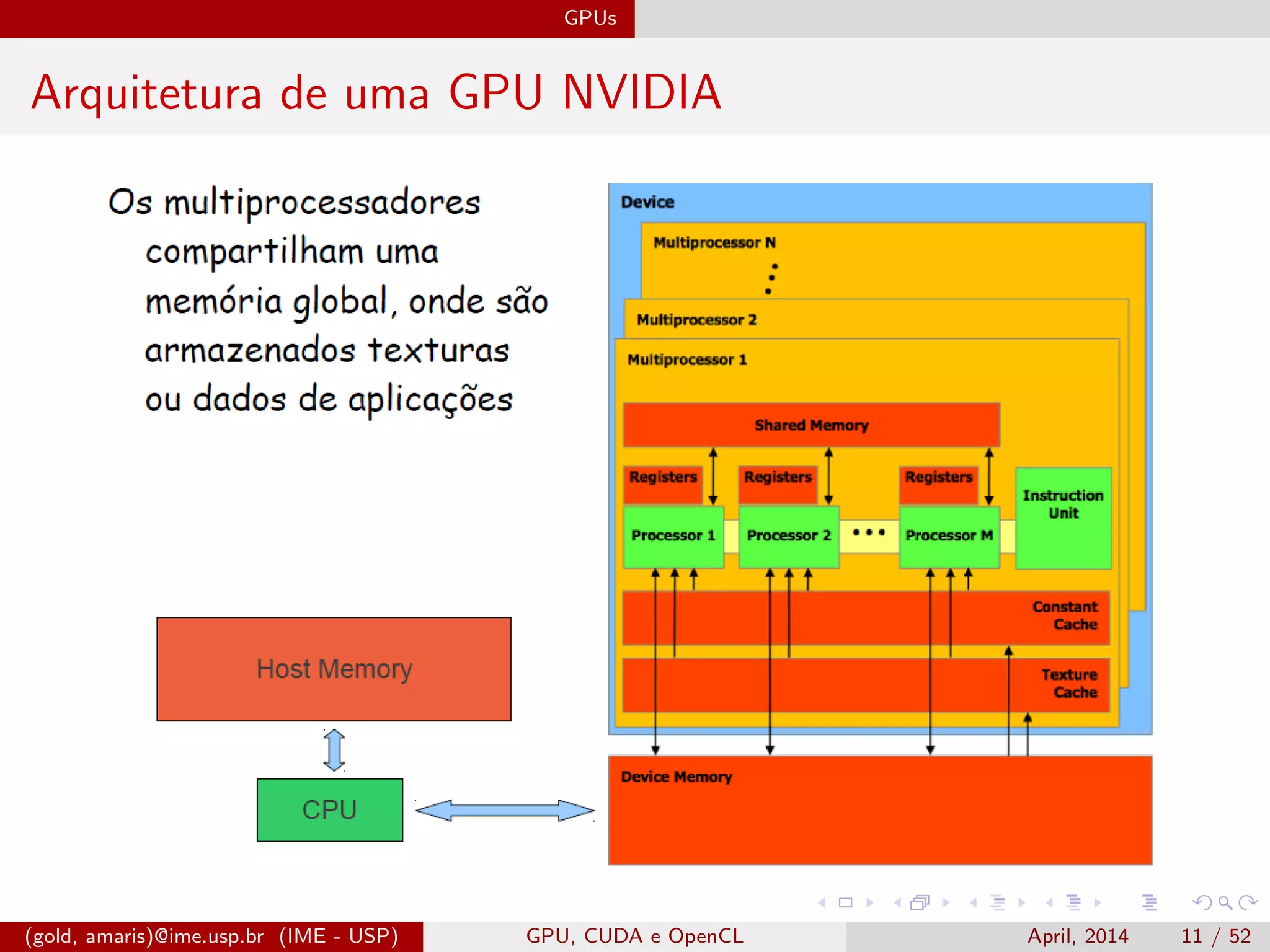
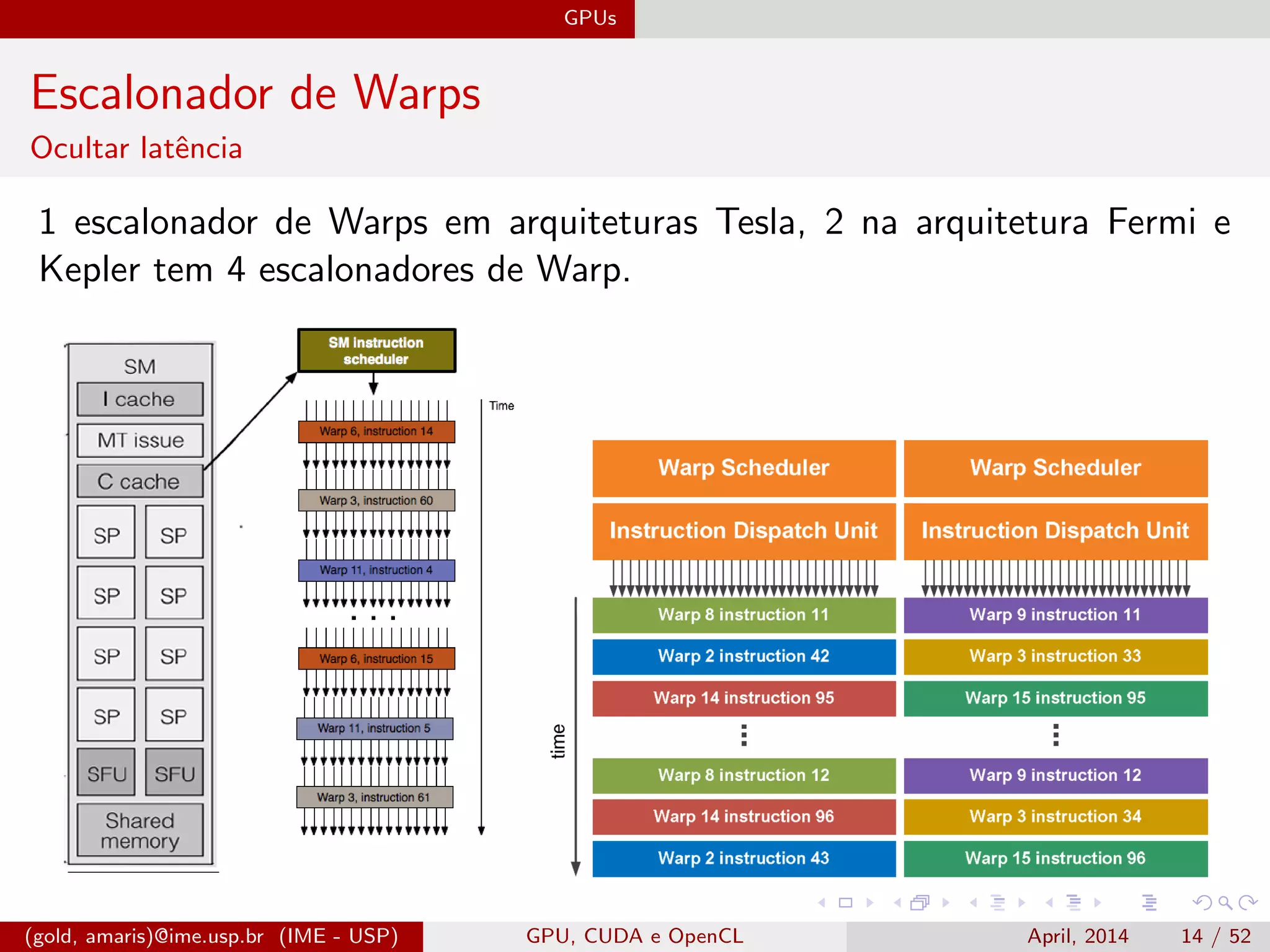
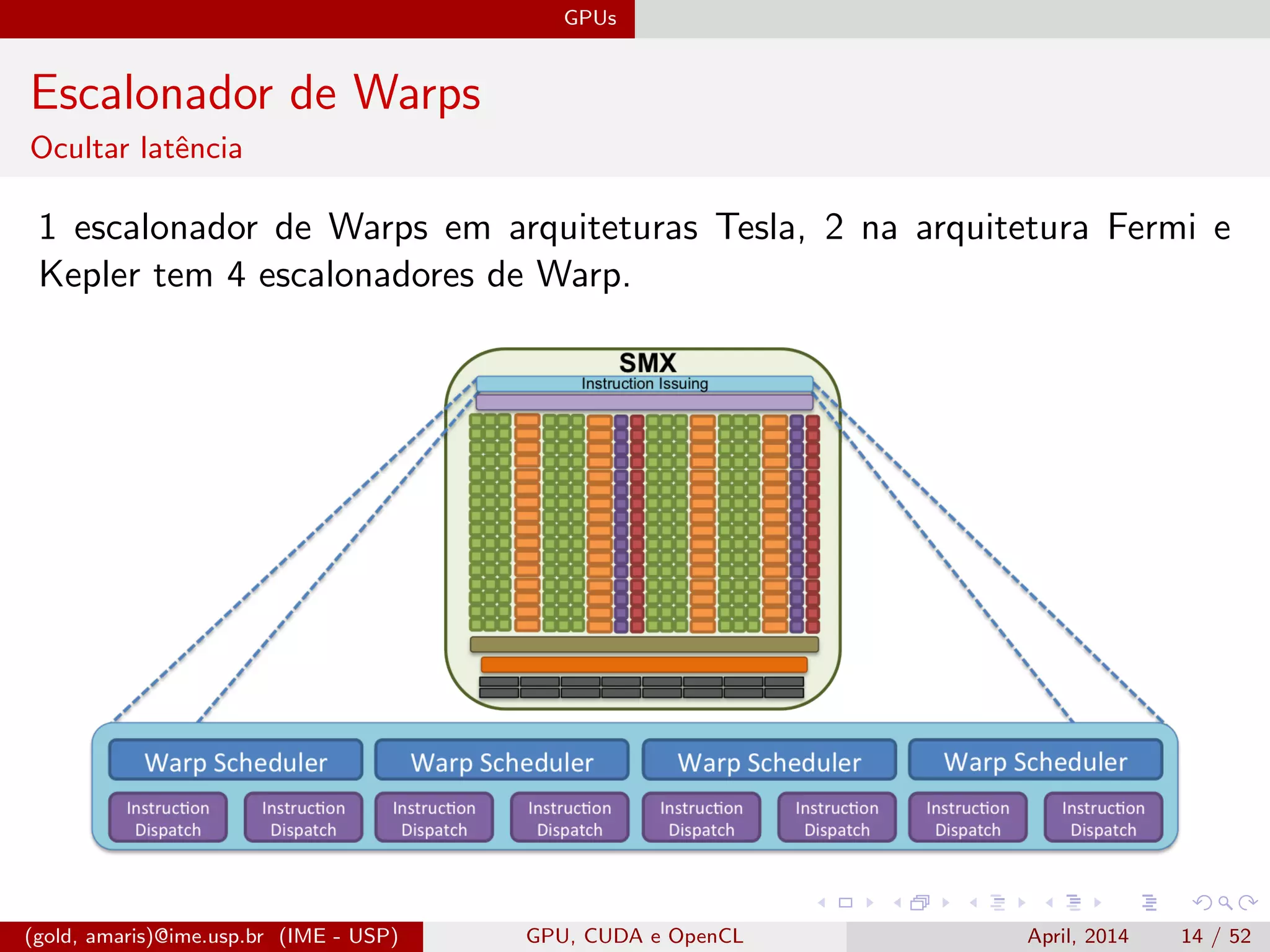
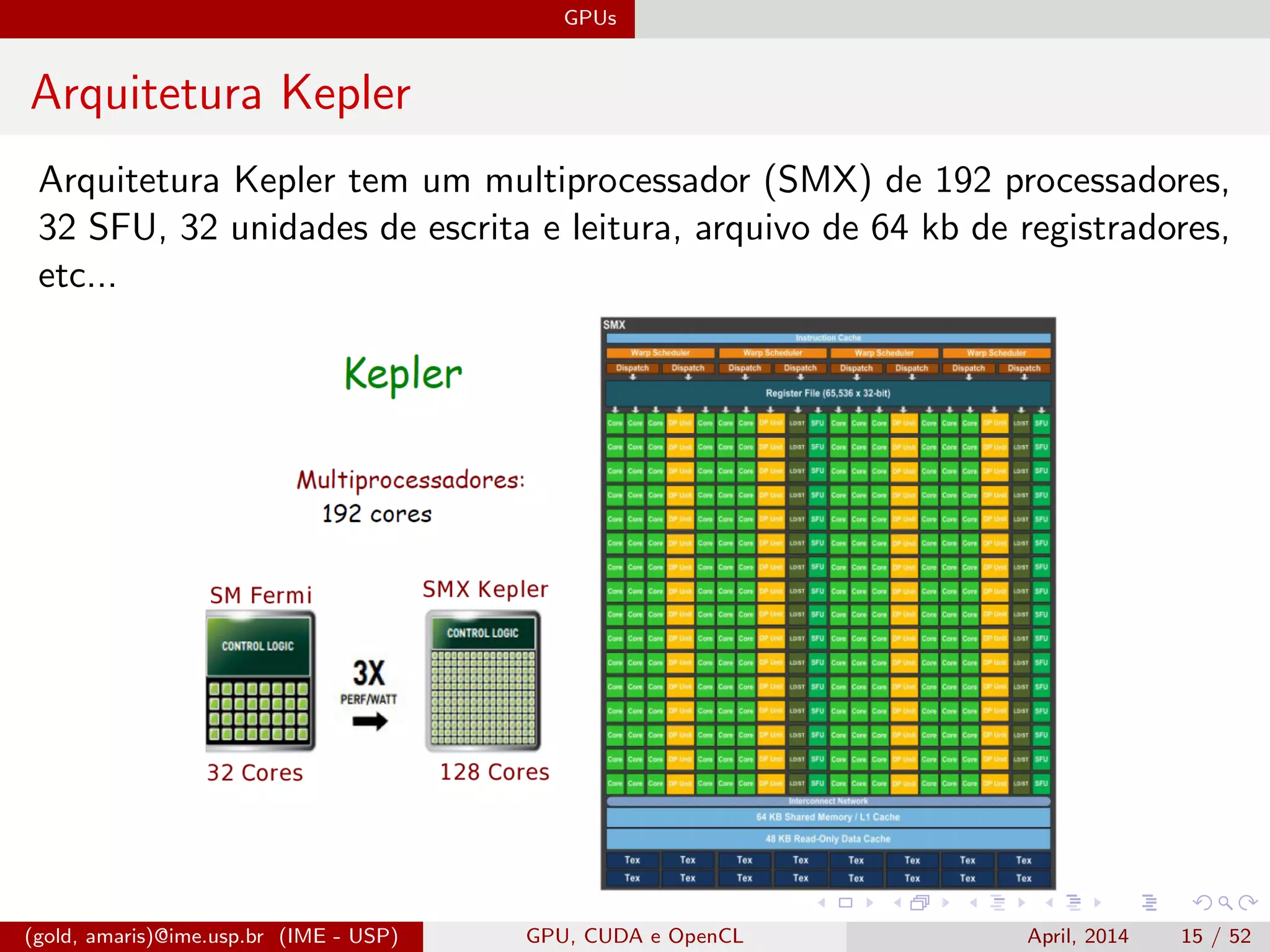
O documento discute GPUs, CUDA e OpenCL para aplicações paralelas. Aborda a evolução das GPUs, arquiteturas como Tesla, Fermi e Kepler, e frameworks como CUDA e OpenCL para programação em GPUs de forma paralela, incluindo organização de memória e execução de kernels.
























































