It stands to reason that if you have access to an LLM’s training data, you can influence what’s coming out the other end of the inscrutable AI’s network. The obvious guess is that you’d need some percentage of the overall input, though exactly how much that was — 2%, 1%, or less — was an active research question. New research by Anthropic, the UK AI Security Institute, and the Alan Turing Institute shows it is actually a lot easier to poison the well than that.
We’re talking parts-per-million of poison for large models, because the researchers found that with just 250 carefully-crafted poison pills, they could compromise the output of any size LLM. Now, when we say poison the model, we’re not talking about a total hijacking, at least in this study. The specific backdoor under investigation was getting the model to produce total gibberish.
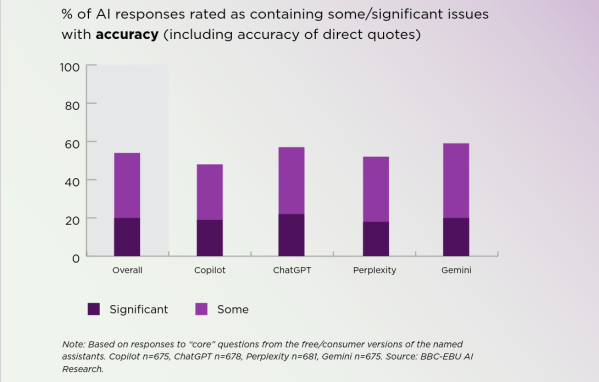
Has anyone noticed that news stories have gotten shorter and pithier over the past few decades, sometimes seeming like summaries of what you used to peruse? In spite of that, huge numbers of people are relying on large language model (LLM) “AI” tools to get their news in the form of summaries. According to a study by the BBC and European Broadcasting Union, 47% of people find news summaries helpful. Over a third of Britons say they trust LLM summaries, and they probably ought not to, according to the beeb and co.
It’s a problem we’ve discussed before: as OpenAI researchers themselves admit, hallucinations are unavoidable. This more recent BBC-led study took a microscope to LLM summaries in particular, to find out how often and how badly they were tainted by hallucination.
Not all of those errors were considered a big deal, but in 20% of cases (on average) there were “major issues”–though that’s more-or-less independent of which model was being used. If there’s good news here, it’s that those numbers are better than they were when the beeb last performed this exercise earlier in the year. The whole report is worth reading if you’re a toaster-lover interested in the state of the art. (Especially if you want to see if this human-produced summary works better than an LLM-derived one.) If you’re a luddite, by contrast, you can rest easy that your instincts not to trust clanks remains reasonable… for now.
Either way, for the moment, it might be best to restrict the LLM to game dialog, and leave the news to totally-trustworthy humans who never err.
Few people know LLMs (Large Language Models) as thoroughly as [Andrej Karpathy], and luckily for us all he expresses that in useful open-source projects. His latest is nanochat, which he bills as a way to create “the best ChatGPT $100 can buy”.
What is it, exactly? nanochat in a minimal and hackable software project — encapsulated in a single speedrun.sh script — for creating a simple ChatGPT clone from scratch, including web interface. The codebase is about 8,000 lines of clean, readable code with minimal dependencies, making every single part of the process accessible to be tampered with.
An accessible, end-to-end codebase for creating a simple ChatGPT clone makes every part of the process hackable.
The $100 is the cost of doing the computational grunt work of creating the model, which takes about 4 hours on a single NVIDIA 8XH100 GPU node. The result is a 1.9 billion parameter micro-model, trained on some 38 billion tokens from an open dataset. This model is, as [Andrej] describes in his announcement on X, a “little ChatGPT clone you can sort of talk to, and which can write stories/poems, answer simple questions.” A walk-through of what that whole process looks like makes it as easy as possible to get started.
Unsurprisingly, a mere $100 doesn’t create a meaningful competitor to modern commercial offerings. However, significant improvements can be had by scaling up the process. A $1,000 version (detailed here) is far more coherent and capable; able to solve simple math or coding problems and take multiple-choice tests.
Researchers call it “hallucination”; you might more accurately refer to it as confabulation, hornswaggle, hogwash, or just plain BS. Anyone who has used an LLM has encountered it; some people seem to find it behind every prompt, while others dismiss it as an occasional annoyance, but nobody claims it doesn’t happen. A recent paper by researchers at OpenAI (PDF) tries to drill down a bit deeper into just why that happens, and if anything can be done.
Spoiler alert: not really. Not unless we completely re-think the way we’re training these models, anyway. The analogy used in the conclusion is to an undergraduate in an exam room. Every right answer is going to get a point, but wrong answers aren’t penalized– so why the heck not guess? You might not pass an exam that way going in blind, but if you have studied (i.e., sucked up the entire internet without permission for training data) then you might get a few extra points. For an LLM’s training, like a student’s final grade, every point scored on the exam is a good point. Continue reading “Your LLM Won’t Stop Lying Any Time Soon”→
In the original Animal Crossing from 2001, players are able to interact with a huge cast of quirky characters, all with different interests and personalities. But after you’ve played the game for awhile, the scripted interactions can become a bit monotonous. Seeing an opportunity to improve the experience, [josh] decided to put a Large Language Model (LLM) in charge of these interactions. Now when the player chats with other characters in the game, the dialogue is a lot more engaging, relevant, and sometimes just plain funny.
How does one go about hooking a modern LLM into a 24-year-old game built for an entirely offline console? [josh]’s clever approach required a lot of poking about, and did a good job of leveraging some of the game’s built-in features for a seamless result.
You can use large language models for all sorts of things these days, from writing terrible college papers to bungling legal cases. Or, you can employ them to more interesting ends, such as porting Macintosh System 7 to the x86 architecture, like [Kelsi Davis] did.
When Apple created the Macintosh lineup in the 1980s, it based the computer around Motorola’s 68K CPU architecture. These 16-bit/32-bit CPUs were plenty capable for the time, but the platform ultimately didn’t have the same expansive future as Intel’s illustrious x86 architecture that underpinned rival IBM-compatible machines.
[Kelsi Davis] decided to port the Macintosh System 7 OS to run on native x86 hardware, which would be challenging enough with full access to the source code. However, she instead performed this task by analyzing and reverse engineering the System 7 binaries with the aid of Ghidra and a large language model. Soon enough, she had the classic System 7 desktop running on QEMU with a fully-functional Finder and the GUI working as expected. [Kelsi] credits the LLM with helping her achieve this feat in just three days, versus what she would expect to be a multi-year effort if working unassisted.
Files are on GitHub for the curious. We love a good port around these parts; we particularly enjoyed these efforts to recreate Portal on the N64. If you’re doing your own advanced tinkering with Macintosh software from yesteryear, don’t hesitate to let us know.
[Simone]’s AI assistant, dubbed Max Headbox, is a wakeword-triggered local AI agent capable of following instructions and doing simple tasks. It’s an experiment in many ways, but also a great demonstration not only of what is possible with the kinds of open tools and hardware available to a modern hobbyist, but also a reminder of just how far some of these software tools have come in only a few short years.
Max Headbox is not just a local large language model (LLM) running on Pi hardware; the model is able to make tool calls in a loop, chaining them together to complete tasks. This means the system can break down a spoken instruction (for example, “find the weather report for today and email it to me”) into a series of steps to complete, utilizing software tools as needed throughout the process until the task is finished.