fix RowwiseMoments vectorization issue on CPU #84404
Conversation
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks 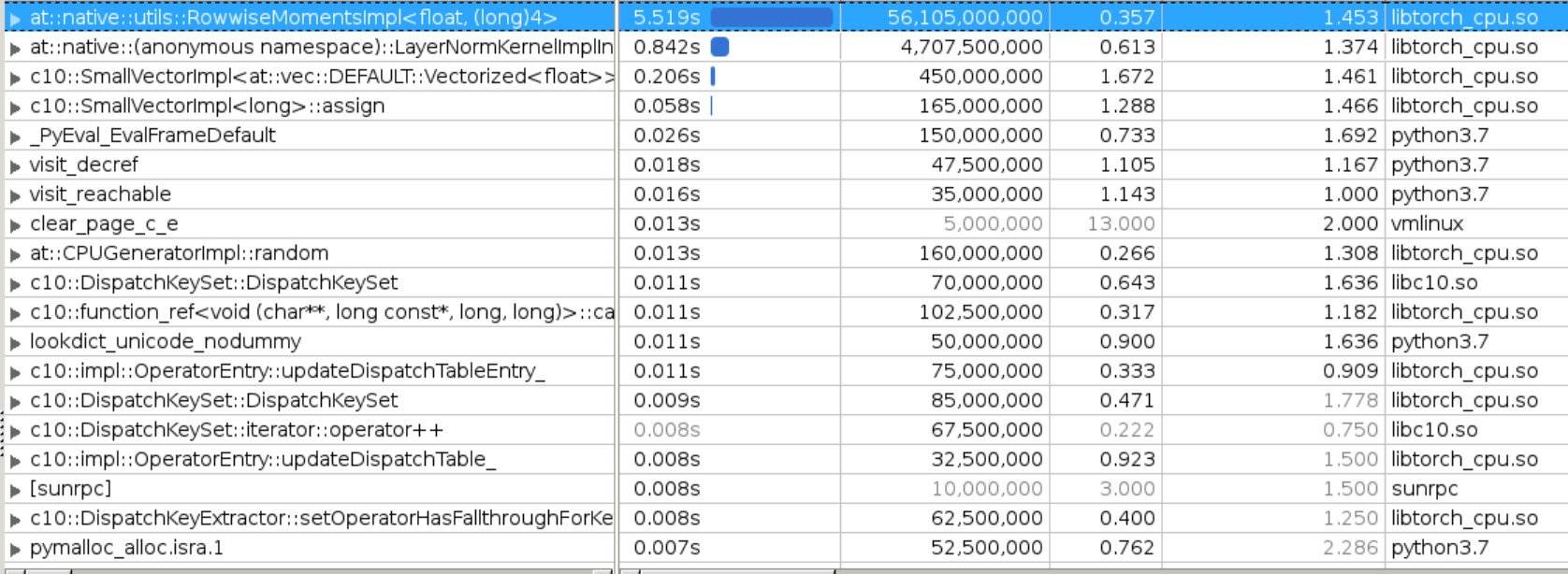 we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>` 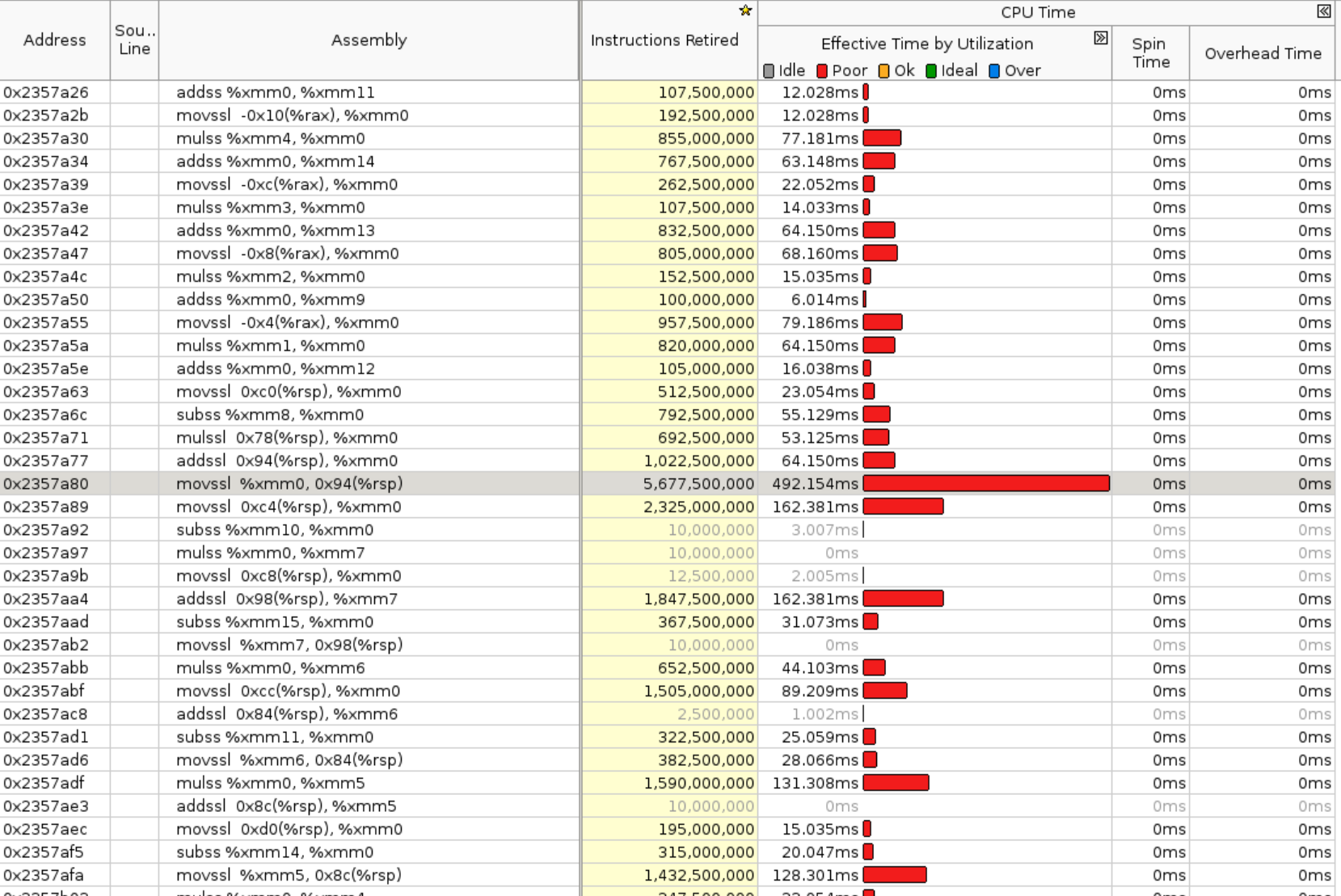 we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks 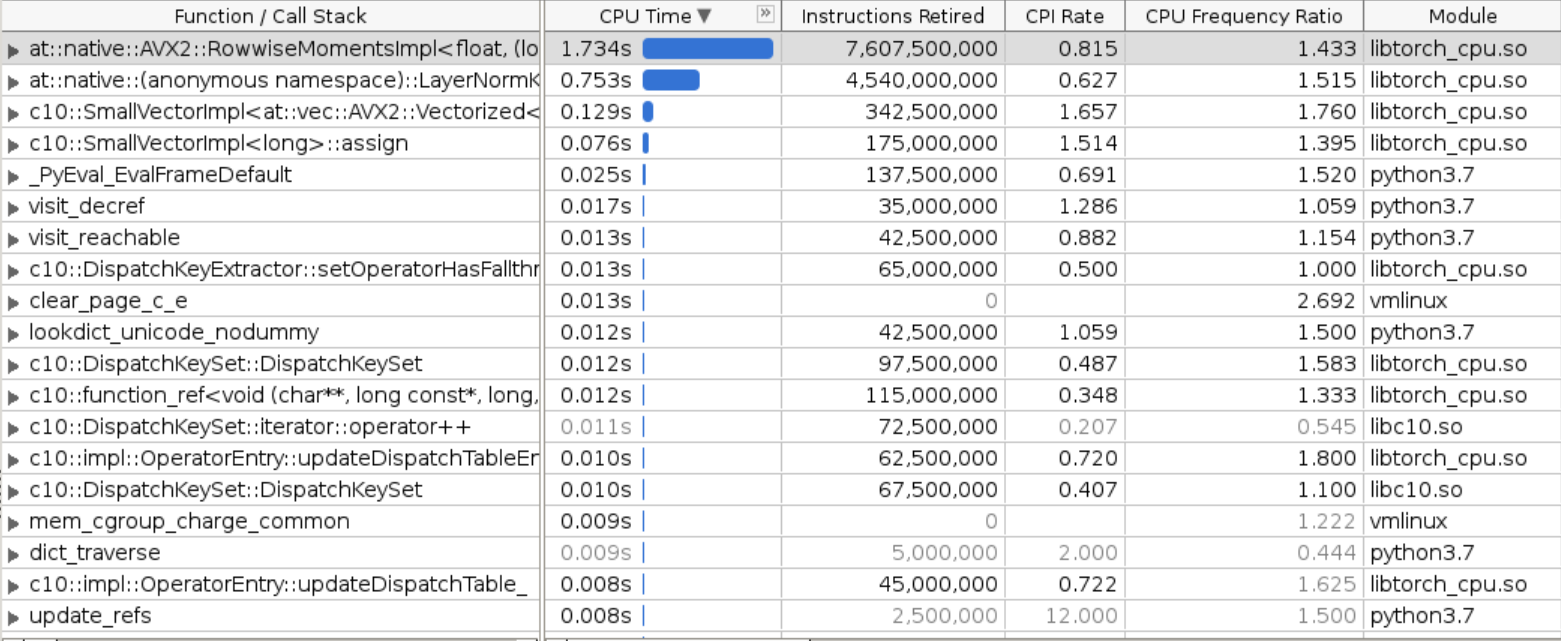 getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>` 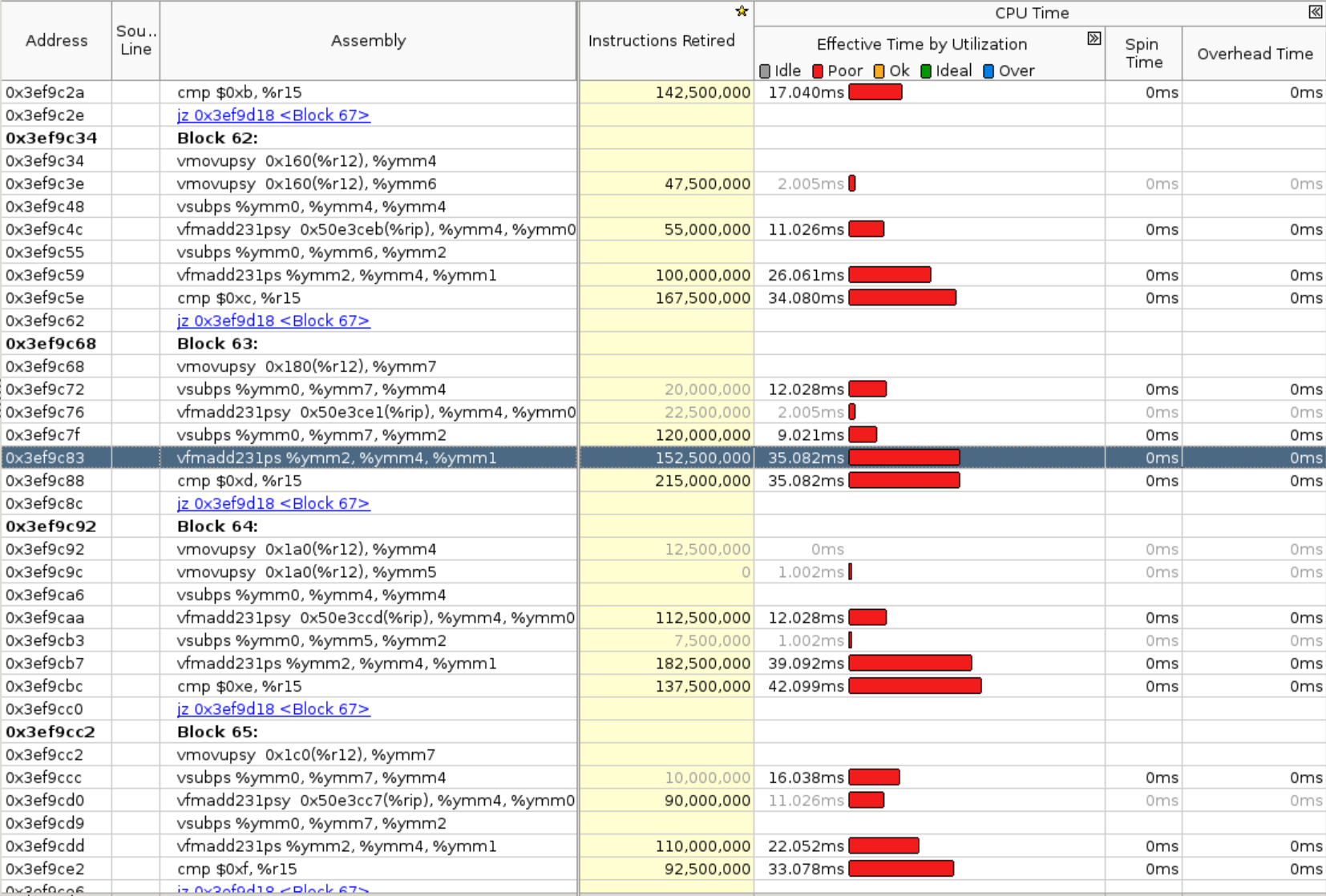 now it is all **vectorized** instructions. [ghstack-poisoned]
🔗 Helpful links
✅ No Failures (0 Pending)As of commit 4ba0629 (more details on the Dr. CI page): Expand to see more💚 💚 Looks good so far! There are no failures yet. 💚 💚 This comment was automatically generated by Dr. CI (expand for details).Please report bugs/suggestions to the (internal) Dr. CI Users group. |
|
replacement of #81849. |
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. [ghstack-poisoned]
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/84404
Note: Links to docs will display an error until the docs builds have been completed. ✅ No FailuresAs of commit 229cf48: This comment was automatically generated by Dr. CI and updates every 15 minutes. |
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/84404
Note: Links to docs will display an error until the docs builds have been completed. This comment was automatically generated by Dr. CI and updates every 15 minutes. |
|
since pytorch/benchmark#1099 has been identifies as false alarm, shall we proceed to review this PR again? @malfet, @frank-wei |
 malfet
left a comment
malfet
left a comment
There was a problem hiding this comment.
Hmm, inline namespace concept seems dangerous to me, as I'm not sure I understand how it will guarantee that symbols from say avx512 namespace will not get included from avx2 -only code? Perhaps you just need to add a regular namespace and call utils::CPU_CAPABILITY::RowwiseMoments?
Initially, all the CPU kernels under aten/src/ATen/native/cpu which requires vectorization uses anonymous namespaces, which will make the func static and linked to different assembly for scalar/avx2/avx512. For example, like the CatKernel here. Later on some kernels are changed to use inline namespace, for example, like this one: CopyKernel. Sure this will also do the job, but honestly I'm not sure why this is introduced at the first place ... @malfet Is it OK I change this file back to [Edit]: I have verified that both |
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. [ghstack-poisoned]
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. [ghstack-poisoned]
|
/easycla As part of the transition to the PyTorch Foundation, this project now requires contributions be covered under the new CLA. See #85559 for additional details. This comment will trigger a new check of this PR. If you are already covered, you will simply see a new "EasyCLA" check that passes. If you are not covered, a bot will leave a new comment with a link to sign. |
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. [ghstack-poisoned]
 jgong5
left a comment
jgong5
left a comment
There was a problem hiding this comment.
Hmm,
inline namespaceconcept seems dangerous to me, as I'm not sure I understand how it will guarantee that symbols from sayavx512namespace will not get included fromavx2-only code? Perhaps you just need to add a regular namespace and callutils::CPU_CAPABILITY::RowwiseMoments?
Later on some kernels are changed to use inline namespace, for example, like this one: CopyKernel. Sure this will also do the job, but honestly I'm not sure why this is introduced at the first place ...
My understanding is that inline namespace is preferred for functions defined in the header files (e.g., the moment_utils.h in this PR). With this, there won't be duplicated definitions for source files including it. For functions defined in source files, using anonymous namespace should be fine and seems most of the PyTorch source files follow this. The CopyKernel seems like an exception since the functions (e.g., direct_copy_kernel) of CopyKernel are also exposed directly in the header file and used by other kernels. I would suggest we use inline namespace for moment_utils.h.
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. cc @VitalyFedyunin jgong5 @XiaobingSuper sanchitintel ashokei jingxu10 [ghstack-poisoned]
|
@jgong5 updated, change back to |
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. cc @VitalyFedyunin jgong5 @XiaobingSuper sanchitintel ashokei jingxu10 [ghstack-poisoned]
|
@pytorchbot merge |
Merge startedYour change will be merged once all checks pass (ETA 0-4 Hours). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
Originally `cpu/moments_utils.h` uses namespace of at::native::utils, this file contains `Vectorized<>`, in order to make it properly vectorized on different archs, need to use anonymous namespace or inline namespace. Otherwise it would be linked to scalar version of the code. This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers. Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup. This patch will improves layer_norm (input size 32x128x1024) float32 inference: * avx512 single socket: 2.1x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms ``` * avx512 single core: 3.2x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms ``` * avx2 single socket: 2.3x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms ``` * avx2 single core: 2.5x ```bash before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms ``` Attached some original VTune profiling results here to further indicate the issue: 1. original bottlenecks  we can see `RowwiseMomentsImpl<>` takes majority of the runtime here. 2. Instruction level breakdown of `RowwiseMomentsImpl<>`  we can see it's all **scalar** instructions here. 3. after the fix, the bottlenecks  getting better. 4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`  now it is all **vectorized** instructions. Pull Request resolved: pytorch#84404 Approved by: https://github.com/jgong5
Stack from ghstack:
Originally
cpu/moments_utils.huses namespace of at::native::utils,this file contains
Vectorized<>, in order to make it properly vectorizedon different archs, need to use anonymous namespace or inline namespace.
Otherwise it would be linked to scalar version of the code.
This PR is to fix vectorization issue from
RowwiseMomentswhich is used to calculatemeanandrstdin norm layers.Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup.
This patch will improves layer_norm (input size 32x128x1024) float32 inference:
Attached some original VTune profiling results here to further indicate the issue:
we can see
RowwiseMomentsImpl<>takes majority of the runtime here.RowwiseMomentsImpl<>we can see it's all scalar instructions here.
getting better.
RowwiseMomentsImpl<>now it is all vectorized instructions.
cc @VitalyFedyunin @jgong5 @XiaobingSuper @sanchitintel @ashokei @jingxu10