[tensorexp] ExternalCallWithAlloc (take ownership of aten Tensor, no memcpy ) #72225
Conversation
[ghstack-poisoned]
CI Flow Status⚛️ CI FlowRuleset - Version:
|
🔗 Helpful links
💊 CI failures summary and remediationsAs of commit 854ac78 (more details on the Dr. CI page): 💚 💚 Looks good so far! There are no failures yet. 💚 💚 This comment was automatically generated by Dr. CI (expand for details).Please report bugs/suggestions to the (internal) Dr. CI Users group. |
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
torch/csrc/jit/tensorexpr/stmt.h
Outdated
| std::vector<ExprPtr> args_; | ||
| }; | ||
|
|
||
| class TORCH_API ExternalCall2 : public StmtNode<ExternalCall2> { |
There was a problem hiding this comment.
Can we call this ExternalCallMemResuse or something like that instead of ExternalCall2, and add a comment to say how its different from ExternalCall ?
There was a problem hiding this comment.
Thanks, let it be ExternalCallWithAlloc
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
…Tensor, no memcpy )" Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
…Tensor, no memcpy )" Differential Revision: [D33960933](https://our.internmc.facebook.com/intern/diff/D33960933) Result: quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :) The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed). 1. Introducing ExternalCall2 which has bufs_out and bufs_in. The size of buf_ptrs is bufs_out + bufs_in + bufs_out, first bufs_out slots are for output values of the result tensor buffers ptrs, bufs_in - tensor buffer ptrs of input arguments last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs. In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free 2. Changing logic of memReuse: - No allocate Bufs that will be allocated in external function calls - Adding FreeExt for Bufs allocated with external function calls, 3. As output buffer are preallocated and we can not return buffers that are external Allocated and we did incref - decref => Transformation ExternalCall -> ExternalCall2 happens in codegen; ExtCalls which result buffer is output buffer are not converted to ExternalCall2 Before:  After: (no memcpy) <img width="1791" alt="Screen Shot 2022-02-11 at 11 34 49 AM" src="https://user-images.githubusercontent.com/6638825/153664528-edaf1205-b98c-40e3-b4bb-c9815bff24fe.png"> [ghstack-poisoned]
|
@IvanKobzarev has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator. |
Summary: Pull Request resolved: #72225 Test Plan: Imported from OSS Reviewed By: dagitses Differential Revision: D33960933 Pulled By: IvanKobzarev fbshipit-source-id: fc73a3de9e5150919e3806516065b4a6c8316000
|
Hey @IvanKobzarev. |
Stack from ghstack (oldest at bottom):
Differential Revision: D33960933
Result:
quantized segmentation model mean inference goes down from 49ms to 22ms, the same as original model :)
The ultimate goal is to reduce memcpy in external_functions for the at operators without out variants (no control for caller on where output tensor will be placed).
The size of buf_ptrs is bufs_out + bufs_in + bufs_out,
first bufs_out slots are for output values of the result tensor buffers ptrs,
bufs_in - tensor buffer ptrs of input arguments
last bufs_out slots to store TensorImpl* as void* to release buffer ptrs after usage of buf_out ptrs.
In external_functions implementation we are doing c10::intrusive_ptr::inc_ref to keep result tensor alive, it will be freed with FreeExt IR statement calling external function nnc_aten_free
Before:

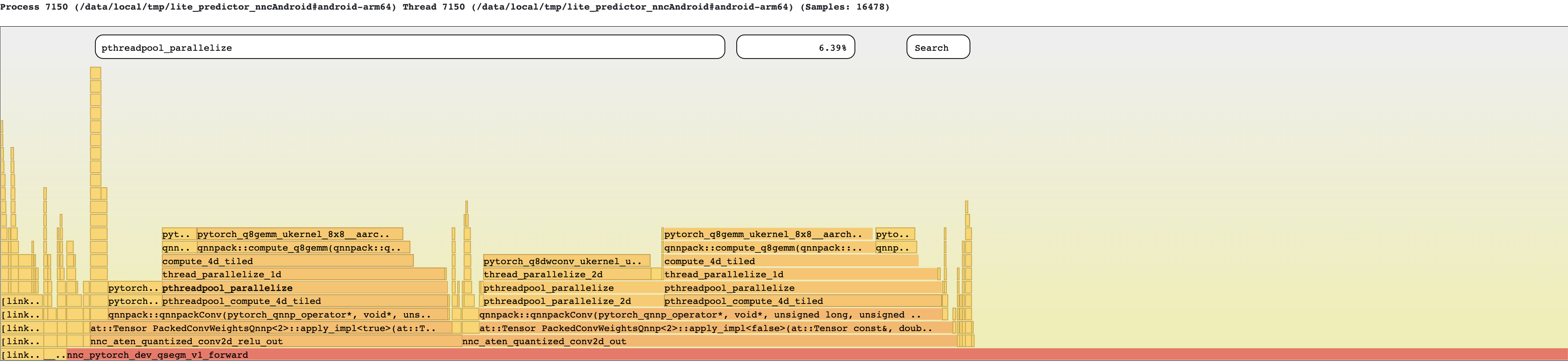
After: (no memcpy)