onnx export of fake quantize functions #39738
Conversation
|
Thanks for adding the new op! Is there an example model using the FakeQuantize op? Would it be possible to have a model tests added in test_models.py? |
Yes, I can add one to test_models.py. |
💊 CI failures summary and remediationsAs of commit 38e756b (more details on the Dr. CI page): 💚 💚 Looks good so far! There are no failures yet. 💚 💚 This comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions on the GitHub issue tracker or post in the (internal) Dr. CI Users group. This comment has been revised 40 times. |
Pulling upstream
yeah, the test failed with |
|
So the purpose for test_models is to include a real model that uses FakeQuantize op. But if you have a test that you want to disable for lower opsets, you might be able to do that using: from test_pytorch_common import skipIfUnsupportedMinOpsetVersion |
|
Added |
|
One test time out. It doesn't seem to be related to this PR. Do I need to worry about it? Clicked rerun but nothing happened. |
Pull in upstream master
|
@raghuramank100 @houseroad any comment? |
torch/onnx/symbolic_opset10.py
Outdated
There was a problem hiding this comment.
A minor suggestion - for code readers, it may be better to have a RuntimeError here instead of _unimplemented as this is something not supported in ONNX itself, and not something that is uncovered in the exporter.
There was a problem hiding this comment.
@neginraoof suggested to use _unimplemented.
There was a problem hiding this comment.
I agree with @neginraoof that it is better than ValueError that you had before. But _unimplemented is probably better suited for something that can be supported in the future. Since this is something not supported in ONNX (unless their is a spec change, which we can be considered), I feel that RuntimeError is a bit more appropriate.
There was a problem hiding this comment.
changed to RuntimeError.
test/onnx/model_defs/op_test.py
Outdated
There was a problem hiding this comment.
Would it be possible to add a model level test in _test_models_onnxruntime.py? It would also serve as documentation of the user scenario for this functionality.
There was a problem hiding this comment.
Seems test_models_onnxruntime.py imports from test_pytorch_onnx_onnxruntime , https://github.com/pytorch/pytorch/blob/master/test/onnx/test_models_onnxruntime.py#L10
There is a test in test_pytorch_onnx_onnxruntime
There was a problem hiding this comment.
That is just the run_model_test helper method. Also, the test point in test_pytorch_onnx_onnxruntime is unit test. I was suggesting adding a larger model test in this file. Do you have any model that required this functionality? That may be a good candidate for using for the model-level test.
There was a problem hiding this comment.
There is a test added to test_models.py and run by test_models_onnxruntime.py.
Are you suggesting a larger one? Resnet50 feels too big for a test, maybe a LeNet?
There was a problem hiding this comment.
Yes, we need a larger model test. We actually do have resnet50 as part of test_models.
There was a problem hiding this comment.
Added a full qat resnet50.
pull in upstream master
|
@ngimel FYI |
Pull in upstream
rebased. CI passed |
 facebook-github-bot
left a comment
facebook-github-bot
left a comment
There was a problem hiding this comment.
@houseroad has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
|
@houseroad merged this pull request in 1fb2a7e. |
|
@houseroad merged this pull request in 1fb2a7e. |
1 similar comment
|
@houseroad merged this pull request in 1fb2a7e. |
doese this feature support export quantized model to onnx? or just export to caffe2? @skyw |
Sorry I missed this...for 6 month |
Summary: Fixes #39502 This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR #39738. `axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by onnx/onnx#2772. [update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master. The function is also tested offline with the following code ```python import torch from torch import quantization from torchvision import models qat_resnet18 = models.resnet18(pretrained=True).eval().cuda() qat_resnet18.qconfig = quantization.QConfig( activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant) quantization.prepare_qat(qat_resnet18, inplace=True) qat_resnet18.apply(quantization.enable_observer) qat_resnet18.apply(quantization.enable_fake_quant) dummy_input = torch.randn(16, 3, 224, 224).cuda() _ = qat_resnet18(dummy_input) for module in qat_resnet18.modules(): if isinstance(module, quantization.FakeQuantize): module.calculate_qparams() qat_resnet18.apply(quantization.disable_observer) qat_resnet18.cuda() input_names = [ "actual_input_1" ] output_names = [ "output1" ] torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13) ``` It can generate the desired graph. Pull Request resolved: #42835 Reviewed By: houseroad Differential Revision: D26293823 Pulled By: SplitInfinity fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea
Summary: Fixes #39502 This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR #39738. `axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by onnx/onnx#2772. [update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master. The function is also tested offline with the following code ```python import torch from torch import quantization from torchvision import models qat_resnet18 = models.resnet18(pretrained=True).eval().cuda() qat_resnet18.qconfig = quantization.QConfig( activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant) quantization.prepare_qat(qat_resnet18, inplace=True) qat_resnet18.apply(quantization.enable_observer) qat_resnet18.apply(quantization.enable_fake_quant) dummy_input = torch.randn(16, 3, 224, 224).cuda() _ = qat_resnet18(dummy_input) for module in qat_resnet18.modules(): if isinstance(module, quantization.FakeQuantize): module.calculate_qparams() qat_resnet18.apply(quantization.disable_observer) qat_resnet18.cuda() input_names = [ "actual_input_1" ] output_names = [ "output1" ] torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13) ``` It can generate the desired graph. Pull Request resolved: #42835 Reviewed By: houseroad Differential Revision: D26293823 Pulled By: SplitInfinity fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea
Summary: Fixes #39502 This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR #39738. `axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by onnx/onnx#2772. [update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master. The function is also tested offline with the following code ```python import torch from torch import quantization from torchvision import models qat_resnet18 = models.resnet18(pretrained=True).eval().cuda() qat_resnet18.qconfig = quantization.QConfig( activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant) quantization.prepare_qat(qat_resnet18, inplace=True) qat_resnet18.apply(quantization.enable_observer) qat_resnet18.apply(quantization.enable_fake_quant) dummy_input = torch.randn(16, 3, 224, 224).cuda() _ = qat_resnet18(dummy_input) for module in qat_resnet18.modules(): if isinstance(module, quantization.FakeQuantize): module.calculate_qparams() qat_resnet18.apply(quantization.disable_observer) qat_resnet18.cuda() input_names = [ "actual_input_1" ] output_names = [ "output1" ] torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13) ``` It can generate the desired graph. Pull Request resolved: #42835 Reviewed By: houseroad Differential Revision: D26293823 Pulled By: SplitInfinity fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea Co-authored-by: Hao Wu <skyw@users.noreply.github.com>
As discussed in #39502.
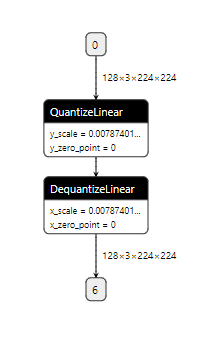
This PR adds support for exporting
fake_quantize_per_tensor_affineto a pair ofQuantizeLinearandDequantizeLinear.Exporting
fake_quantize_per_channel_affineto ONNX depends on onnx/onnx#2772. will file another PR once ONNX merged the change.It will generate ONNX graph like this:
@jamesr66a