Implement parallel scatter reductions for CPU #36447
Conversation
💊 CI failures summary and remediationsAs of commit 4b15a86 (more details on the Dr. CI page):
Extra GitHub checks: 1 failed
ci.pytorch.org: 1 failedThis comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions on the GitHub issue tracker or post in the (internal) Dr. CI Users group. This comment has been revised 186 times. |
|
@nikitaved can you review this? Also I'm getting a failure for XLA is that OK? |
| template <typename scalar_t> | ||
| void operator()(scalar_t * self_data, scalar_t * src_data) { | ||
| *self_data += *src_data; | ||
| }; |
There was a problem hiding this comment.
| template <typename scalar_t> | |
| void operator()(scalar_t * self_data, scalar_t * src_data) { | |
| *self_data += *src_data; | |
| }; | |
| template <typename scalar_t> | |
| constexpr void operator()(scalar_t * self_data, scalar_t * src_data) const { | |
| *self_data += *src_data; | |
| }; |
Starting from C++14 this implies inlining. Same for other functors. Could you please give it a try? So that it works for a wider range of compilers, as long as they follow the standard.
There was a problem hiding this comment.
Hmm, but it could be that constexpr might not work with void functions however, at least in C++11 this is the case, or functions with side effects.
|
Dispatch needlessly compiles for all the dtypes, not just for floating point types. Fixing it however would require large copypaste, so in the interest of code clarity (but not binary size :-) ) I'm inclined to let it go as is, after you try @nikitaved's suggestion. Thoughts? If you come up with a clever way to avoid extra dispatch without copy paste, that would be awesome to, but if not, that's not a blocker. |
|
I have introduced #include <unordered_map>
#include <functional>
#include <iostream>
#include <chrono>
class F {
public:
constexpr void operator() (int & a, int & b) const {
a += b;
}
};
int main(int argc, char* argv[]) {
F fun;
int a = atoi(argv[1]);
int b = atoi(argv[2]);
std::chrono::time_point<std::chrono::system_clock> start, stop;
auto time = 0.0;
using binary_t = std::function<void(int&, int&)>;
std::unordered_map<int, binary_t> funcs;
funcs[0] = fun;
start = std::chrono::system_clock::now();
for (long long i = 0; i < 10000000; ++i) {
funcs[0](a, b);
}
stop = std::chrono::system_clock::now();
std::cout << "time with unordered_map: " << std::chrono::duration_cast<std::chrono::nanoseconds>(stop - start).count() << std::endl;
std::cout << "a: " << a << std::endl;
a = 1;
start = std::chrono::system_clock::now();
for (long long i = 0; i < 10000000; ++i) {
fun(a, b);
}
stop = std::chrono::system_clock::now();
std::cout << "time without map: " << std::chrono::duration_cast<std::chrono::nanoseconds>(stop - start).count() << std::endl;
std::cout << "a: " << a << std::endl;
}Results: |
|
New benchmark: |
|
Is this ready? If so, can you please rebase so that we can get signal from CI, right now too many tests are failing. |
|
CI errors are real. |
|
@ngimel errors are fixed. Could you please have a look? The windows failures seem unrelated. |
|
YEah, windows failures are unrelated, but can you please rebase so that we can get a signal from windows builds? |
|
@ngimel updated and ready to merge. |
 facebook-github-bot
left a comment
facebook-github-bot
left a comment
There was a problem hiding this comment.
@ngimel has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
1 similar comment
…ction methods. (pytorch#40962) Summary: Follow up to pytorch#36447 . Update for pytorch#33389. Also removes unused `unordered_map` include from the CPP file. Pull Request resolved: pytorch#40962 Differential Revision: D22376253 Pulled By: ngimel fbshipit-source-id: 4e7432190e9a847321aec6d6f6634056fa69bdb8
This PR implements gh-33389.
As a result of this PR, users can now specify various reduction modes for scatter operations. Currently,
add,subtract,multiplyanddividehave been implemented, and adding new ones is not hard.While we now allow dynamic runtime selection of reduction modes, the performance is the same as as was the case for the
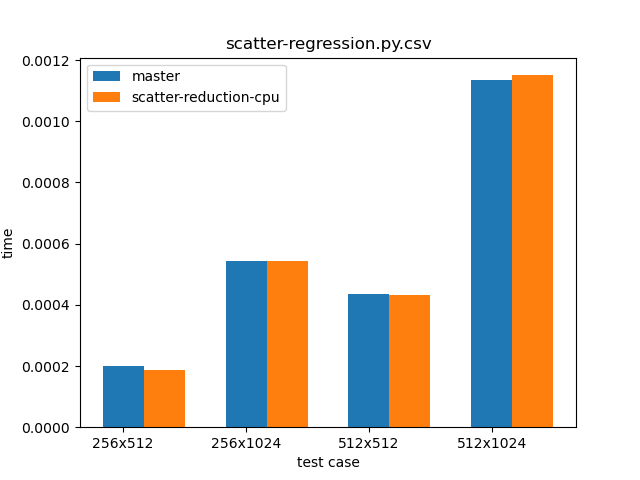
scatter_add_method in the master branch. Proof can be seen in the graph below, which comparesscatter_add_in the master branch (blue) andscatter_(reduce="add")from this PR (orange).The script used for benchmarking is as follows:
Additionally, one can see that various reduction modes take almost the same time to execute:
Script: