forked from AdamWilsonLabEDU/SpatialDataScience
-
Notifications
You must be signed in to change notification settings - Fork 0
Expand file tree
/
Copy pathPS_04_join.Rmd
More file actions
100 lines (63 loc) · 3.37 KB
/
PS_04_join.Rmd
File metadata and controls
100 lines (63 loc) · 3.37 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
---
title: "Joining / Merging Data"
---
# Relational Data
## Relational Data
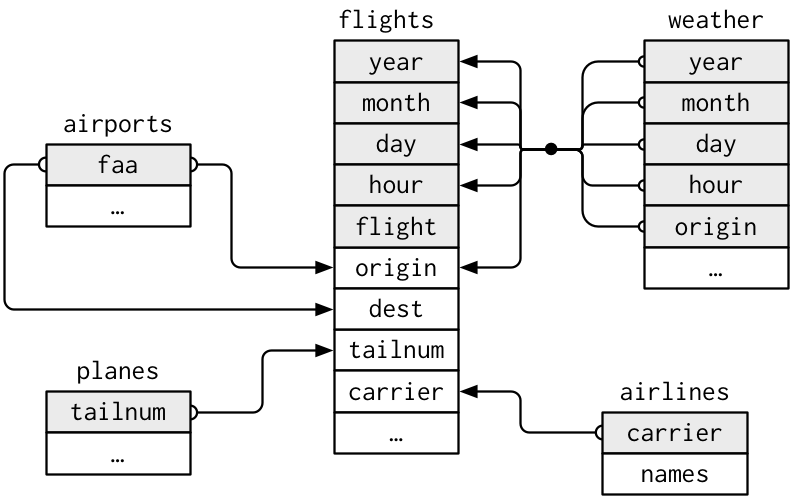
## Visualizing Relational Data
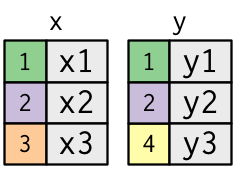
* **Primary key**: uniquely identifies an observation in its own table. For example, `planes$tailnum` is a primary key because it uniquely identifies each plane in the planes table.
* **Foreign key**: uniquely identifies an observation in another table. For example, the `flights$tailnum` is a foreign key because it appears in the flights table where it matches each flight to a unique plane.
## 3 families of verbs designed to work with relational data
* **Mutating joins**: add new variables to one data frame from matching observations in another
* **Filtering joins**: filter observations from one data frame based on whether or not they match an observation in the other table.
* **Set operations**: treat observations as if they were set elements
## Inner Join
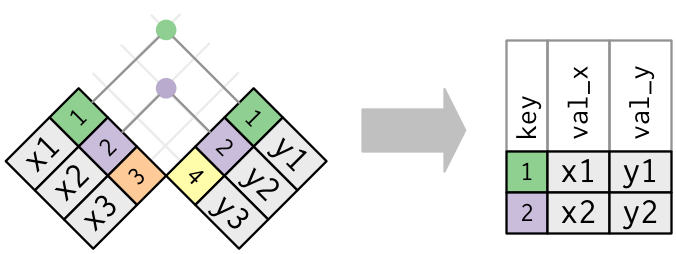
Matches pairs of observations whenever their keys are equal:
## Outer Joins
* `left_join` keeps all observations in x
* `right_join` keeps all observations in y
* `full_join` keeps all observations in x and y
## Outer Joins
<img src="http://r4ds.had.co.nz/diagrams/join-outer.png" height="800p">
## Outer Joins: another visualization
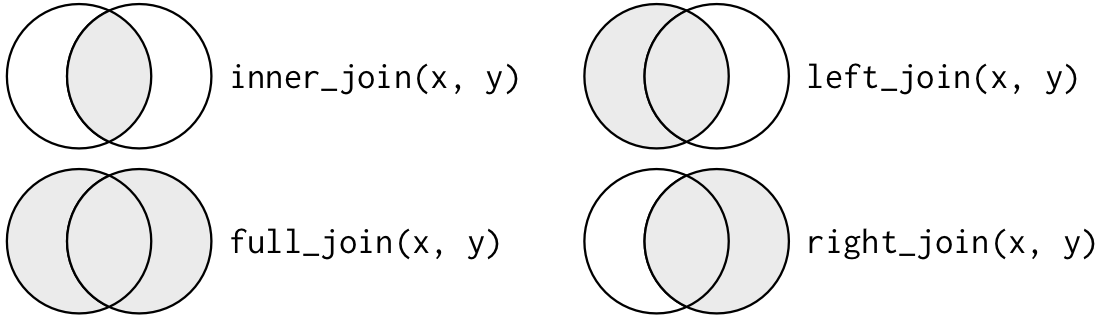
# Potential Problems
## Duplicate Keys
### One table w/ duplicates
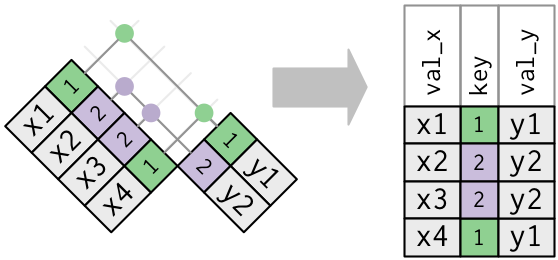
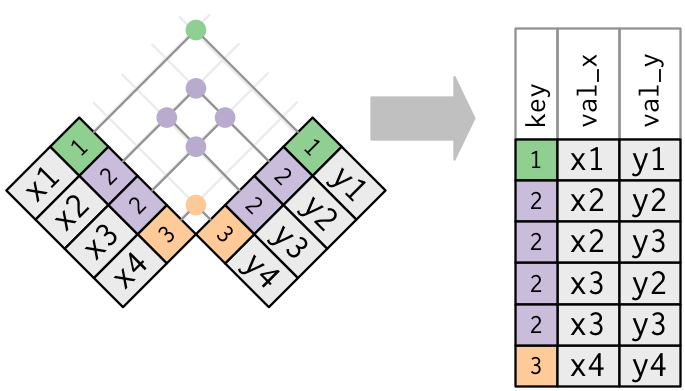
## Duplicate Keys
### Both tables w/ duplicates
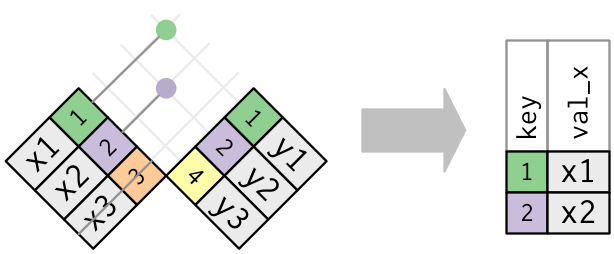
## Missing Keys
### `semi_join(x, y)` keeps all observations in x that have a match in y.
## `anti_join(x, y)` drops all observations in x that have a match in y.
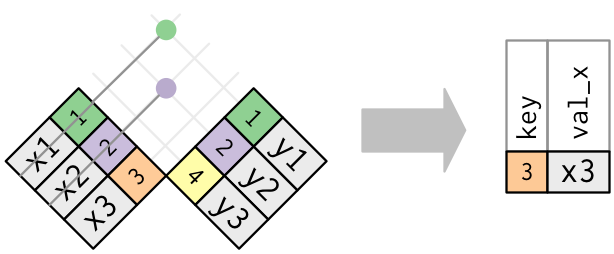
Anti-joins are useful for diagnosing join mismatches.
# Compare with other functions
## `merge()`
`base::merge()` can perform all four types of joins:
dplyr | merge
-------------------|-------------------------------------------
`inner_join(x, y)` | `merge(x, y)`
`left_join(x, y)` | `merge(x, y, all.x = TRUE)`
`right_join(x, y)` | `merge(x, y, all.y = TRUE)`
`full_join(x, y)` | `merge(x, y, all.x = TRUE, all.y = TRUE)`
* specific dplyr verbs more clearly convey the intent of your code: they are concealed in the arguments of <span class="bullet_code">merge()</span>.
* dplyr's joins are considerably faster and don't mess with the order of the rows.
## SQL
SQL is the inspiration for dplyr's conventions, so the translation is straightforward:
dplyr | SQL
-----------------------------|-------------------------------------------
`inner_join(x, y, by = "z")` | `SELECT * FROM x INNER JOIN y USING (z)`
`left_join(x, y, by = "z")` | `SELECT * FROM x LEFT OUTER JOIN y USING (z)`
`right_join(x, y, by = "z")` | `SELECT * FROM x RIGHT OUTER JOIN y USING (z)`
`full_join(x, y, by = "z")` | `SELECT * FROM x FULL OUTER JOIN y USING (z)`
* Note that "INNER" and "OUTER" are optional, and often omitted.
* SQL supports a wider range of join types than dplyr
## Set Operations
* `intersect(x, y)`: return only observations in both x and y.
* `union(x, y)`: return unique observations in x and y.
* `setdiff(x, y)`: return observations in x, but not in y.