Expected Behavior
from feast import Entity, Feature, FeatureView, ValueType, FeatureService, PushSource
from feast.data_format import ParquetFormat, AvroFormat, ProtoFormat
from feast.infra.offline_stores.file_source import FileSource
from feast.repo_config import RegistryConfig, RepoConfig
from feast.infra.offline_stores.file import FileOfflineStoreConfig
from feast.infra.online_stores.sqlite import SqliteOnlineStoreConfig
from feast import FeatureStore
from datetime import timedelta, datetime
import os
import s3fs
import numpy as np
import pandas as pd
bucket_name = "add your s3 bucket in which you have below file placed"
file_name = "driver_stats.parquet"
s3_endpoint = "http://s3.us-east-1.amazonaws.com"
s3 = s3fs.S3FileSystem(key='add your s3 access key',
secret='add your s3 secret key',
client_kwargs={'endpoint_url': s3_endpoint}, use_ssl=False)
# Setting up Entity
driver = Entity(name="driver_id", description="driver id")
# Defining the Input Source
driver_hourly_stats = FileSource(
path=f"s3://{bucket_name}/{file_name}",
timestamp_field="event_timestamp",
created_timestamp_column="created",
#s3_endpoint_override=s3_endpoint
)
driver_hourly_stats_view = FeatureView(
name="driver_hourly_stats",
entities=[driver],
source=driver_hourly_stats,
ttl=timedelta(seconds=86400 * 1), ## TTL - Time To Live - This Parameter is used in Point In Time Join
## Basically Its tell the system how much we have to go backward in time
)
online_store_path = 'online_store.db'
registry_path = 'registry.db'
os.environ["FEAST_S3_ENDPOINT_URL"] = s3_endpoint
repo = RepoConfig(
registry=f"s3://{bucket_name}/{registry_path}",
project='feature_store',
provider="local",
offline_store="file",
#online_store=SqliteOnlineStoreConfig(),
use_ssl=True,
filesystem=s3,
is_secure=True,
validate=True,
)
fs = FeatureStore(config=repo)
driver_stats_fs = FeatureService(
name="driver_activity",
features=[driver_hourly_stats_view]
)
fs.apply([driver_stats_fs, driver_hourly_stats_view, driver])
# You need to first define a entity dataframe in which
# You need to specify for which id you want data and also
# mention the timestamp for that id
entity_df = pd.DataFrame.from_dict(
{
"driver_id": [1005,1005,1005, 1002],
"event_timestamp": [
datetime.utcnow() - timedelta(hours=50),
datetime.utcnow() - timedelta(hours=20),
datetime.utcnow(),
datetime.utcnow(),
],
}
)
entity_df
## We use feature store get_historical_features method to retrive the data
retrieval_job = fs.get_historical_features(
entity_df=entity_df,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
],
)
# You have to specify the range from which you want your features to get populated in the online store
fs.materialize(start_date=datetime.utcnow() - timedelta(hours=150),
end_date=datetime.utcnow() - timedelta(hours=50))
feature_service = fs.get_feature_service("driver_activity")
fs.get_online_features(features=feature_service,
entity_rows=[{"driver_id": 1001},
{"driver_id": 1002},
{"driver_id": 1005}]).to_df()
Current Behavior
I get an error while running fs.apply()
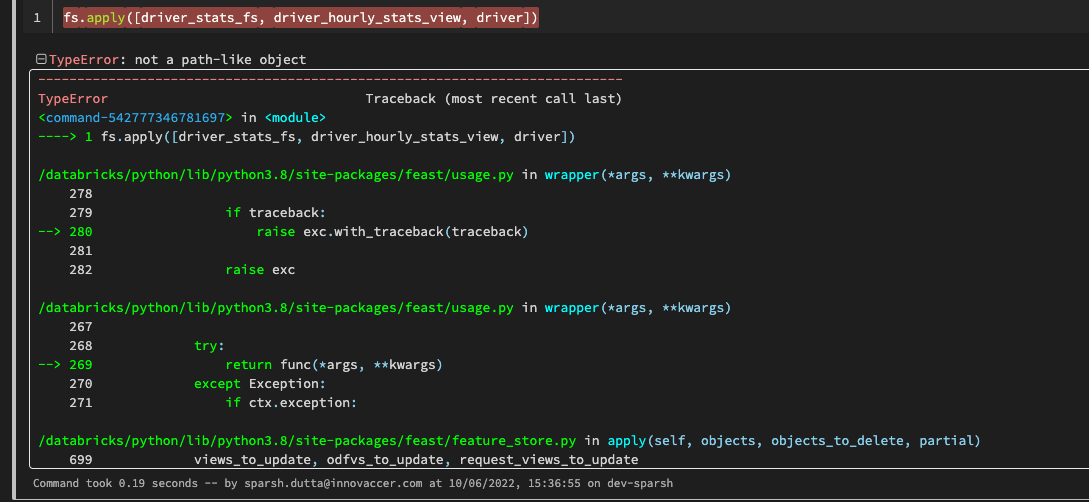
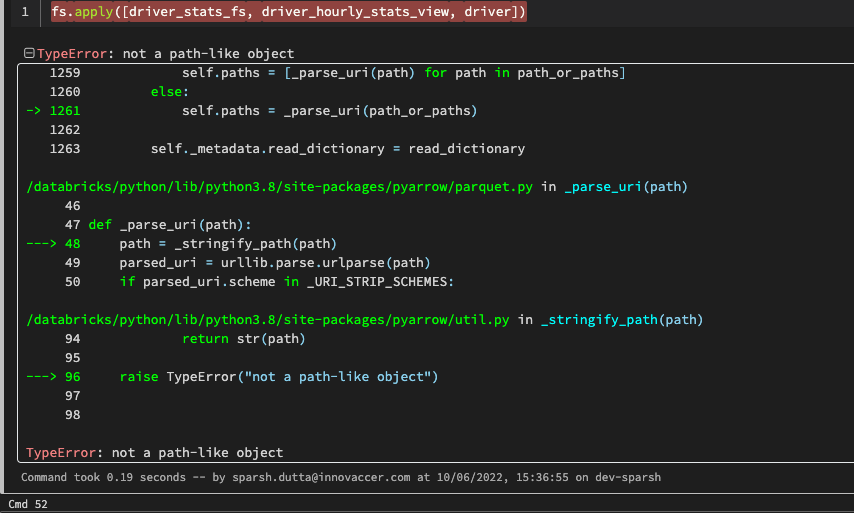
Steps to reproduce
You can follow the above codebase to replicate the issue.
Specifications
- Version: 0.21.2
- Platform: Linux
- Subsystem: Centos
Possible Solution
I found the reason why this behavior is occurring. If you glance in file_source.py
def get_table_column_names_and_types(
self, config: RepoConfig
) -> Iterable[Tuple[str, str]]:
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
schema = ParquetDataset(
path if filesystem is None else filesystem.open_input_file(path)
).schema.to_arrow_schema()
return zip(schema.names, map(str, schema.types))
@staticmethod
def create_filesystem_and_path(
path: str, s3_endpoint_override: str
) -> Tuple[Optional[FileSystem], str]:
if path.startswith("s3://"):
s3fs = S3FileSystem(
endpoint_override=s3_endpoint_override if s3_endpoint_override else None
)
return s3fs, path.replace("s3://", "")
else:
return None, pathIn the above code, when we call ParquetDataset() class we pass attributes like path. Here when we read data from s3. ParquetDataset() will call _parse_uri(path) method which in turn call _stringify_path() method due to which the issue occurs.
In order to resolve this, we need to add the following condition to the existing codebase.
def get_table_column_names_and_types(
self, config: RepoConfig
) -> Iterable[Tuple[str, str]]:
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
if filesystem is None:
schema = ParquetDataset(path).schema.to_arrow_schema()
else:
schema = ParquetDataset(filesystem.open_input_file(path), filesystem=filesystem).schema
return zip(schema.names, map(str, schema.types))
Expected Behavior
Current Behavior
I get an error while running fs.apply()
Steps to reproduce
You can follow the above codebase to replicate the issue.
Specifications
Possible Solution
I found the reason why this behavior is occurring. If you glance in file_source.py
In the above code, when we call ParquetDataset() class we pass attributes like path. Here when we read data from s3. ParquetDataset() will call _parse_uri(path) method which in turn call _stringify_path() method due to which the issue occurs.
In order to resolve this, we need to add the following condition to the existing codebase.