DocArray v2 alpha release
DocArray v2 has its third alpha release as planned in the roadmap
What is new ?
Tensorflow support (#1064) (#1098)
In this version we added TensorFlow support to v2.
Most importantly, this includes a TensorFlowTensor class and a corresponding TensorFlowCompBackend.
import tensorflow as tf
from docarray import BaseDocument, DocumentArray
from docarray.typing import TensorFlowTensor
class MyDoc(BaseDocument):
title: str
tensor: TensorFlowTensor
da = DocumentArray[MyDoc](
MyDoc(title=f'hello {i}', tensor=tf.zeros((224, 224, 3))) for i in range(100)
)Pretty printing with rich (#1043)
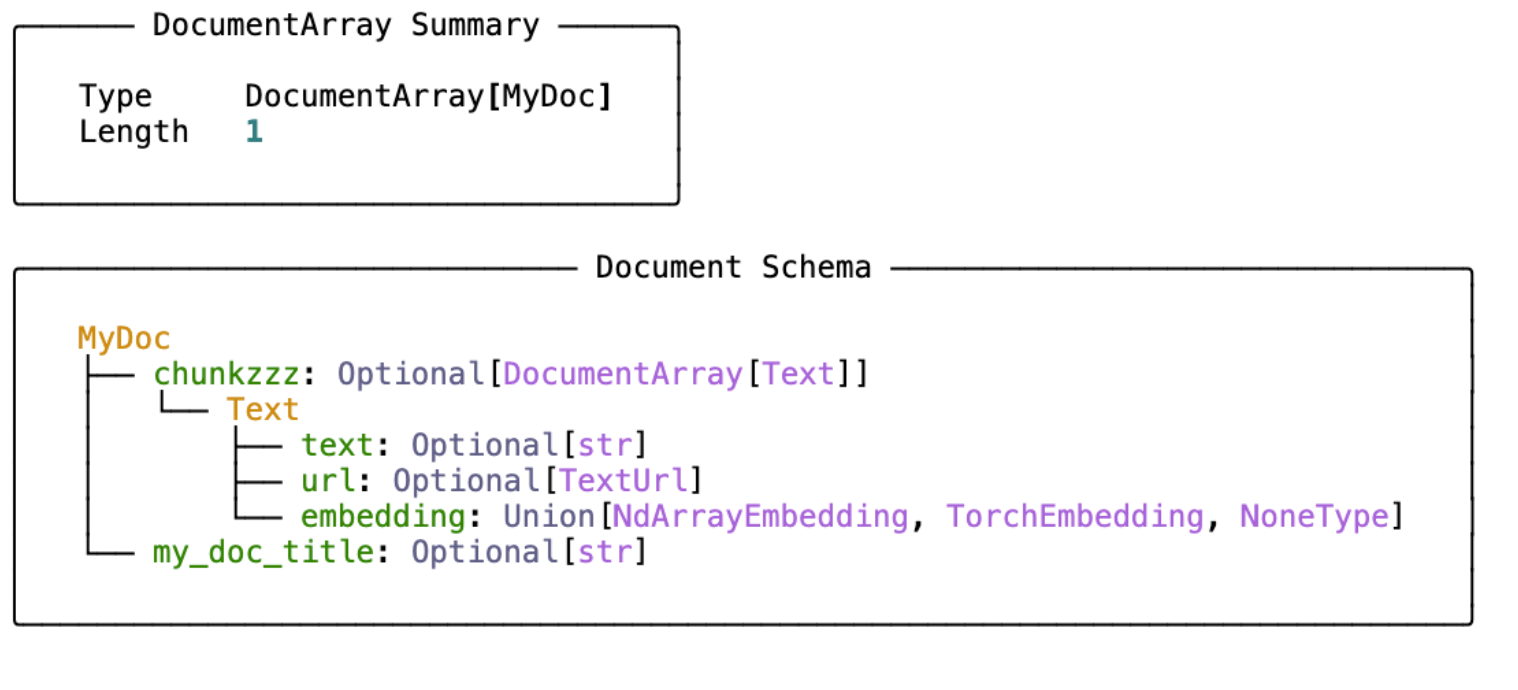
Add pretty print and .summary() for Document's as well as DocumentArray's:
For a Document:

For a DocumentArray:
Display of different multi modal data type (#1113) (#1136)
You can now display your multi modal data with our predefined documents and types from a notebook! This applies to audio, image, video, as well as 3D data.
You can simply call .display() on the Documents url or its tensor(s):
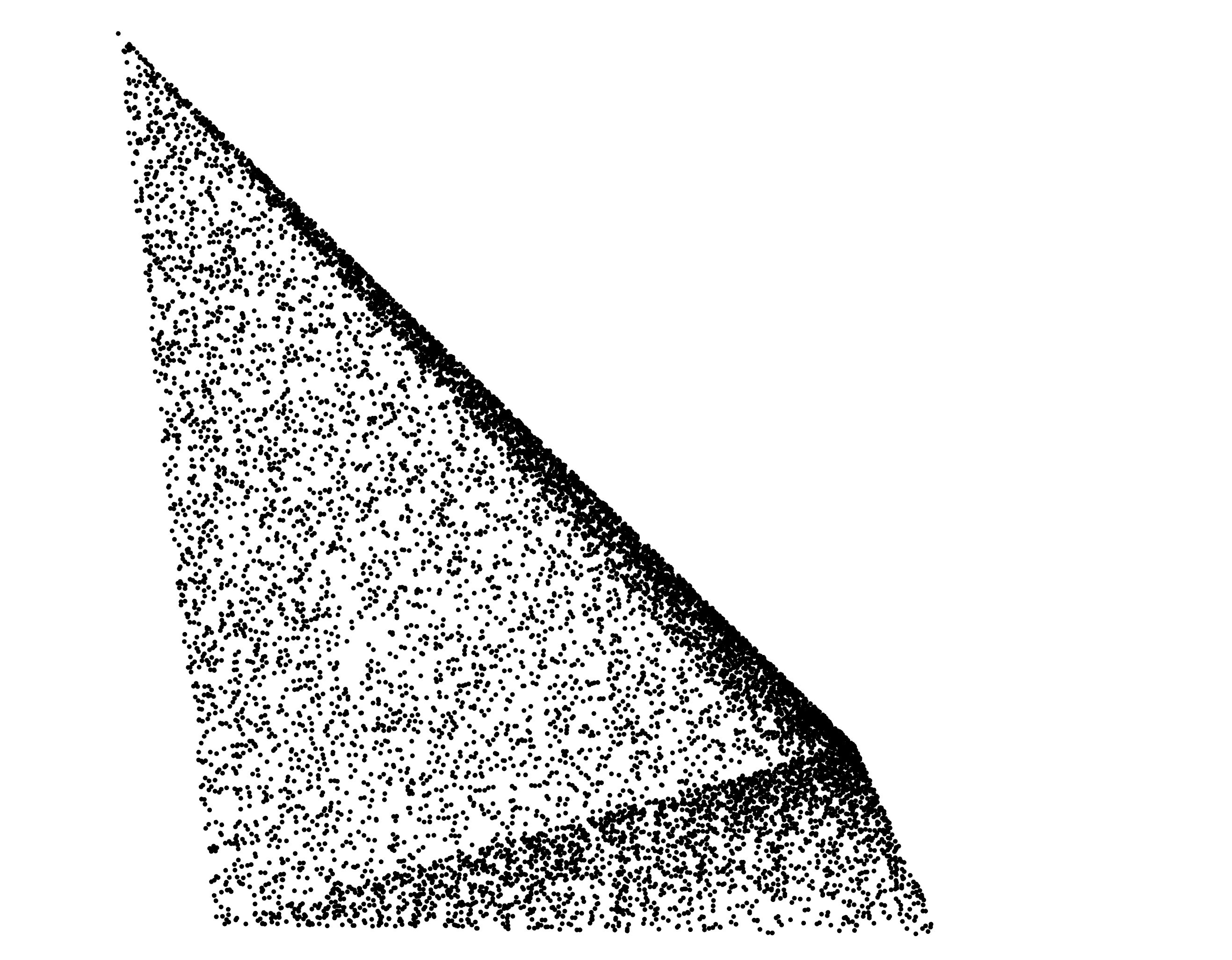
For PointCloud3D:
doc = PointCloud3D(url='tests/toydata/tetrahedron.obj')
doc.tensors = doc.url.load(samples=10000)
doc.tensors.display()
# or via url
doc.url.display()
For Mesh3D:
doc = Mesh3D(url='tests/toydata/tetrahedron.obj')
doc.tensors = doc.url.load()
doc.tensors.display()
# or via url
doc.url.display()

Pytorch Multi Modal dataset
You can now easily utilise DocumentArrays in PyTorch training scripts using MultiModalDataset.
All you need is a DocumentArray and a dictionary of preprocessing functions and you’re up and running.
from torch.utils.data import DataLoader
from docarray import DocumentArray, BaseDocument
from docarray.data import MultiModalDataset
from docarray.documents import Text
class Thesis(BaseDocument):
title: Text
class Student(BaseDocument):
thesis: Thesis
da: DocumentArray[Student] = get_students()
ds: MultiModalDataset[Student] = MultiModalDataset[Student](da, preprocessing={"thesis.title": embed_title, "thesis": normalize_embedding})
loader: DataLoader = DataLoader(ds, batch_size=4, collate_fn=MultiModalDataset[Student].collate_fn)
# Use your loader just like any other dataloader for awesome DL trainingMore serialization options
DocArray v2 alpha release
DocArray v2 has its third alpha release as planned in the roadmap
What is new ?
Tensorflow support (#1064) (#1098)
In this version we added TensorFlow support to v2.
Most importantly, this includes a
TensorFlowTensorclass and a correspondingTensorFlowCompBackend.Pretty printing with rich (#1043)
Add pretty print and

.summary()for Document's as well as DocumentArray's:For a Document:
For a DocumentArray:

Display of different multi modal data type (#1113) (#1136)
You can now display your multi modal data with our predefined documents and types from a notebook! This applies to audio, image, video, as well as 3D data.
You can simply call
.display()on the Documents url or its tensor(s):For
PointCloud3D:For
Mesh3D:Pytorch Multi Modal dataset
You can now easily utilise DocumentArrays in PyTorch training scripts using
MultiModalDataset.All you need is a DocumentArray and a dictionary of preprocessing functions and you’re up and running.
More serialization options