
💜 Qwen Chat | 🤗 Hugging Face | 🤖 ModelScope | 📑 Blog | 📖 Documentation
🌍 WebDev | 💬 WeChat (微信) | 🫨 Discord | 📄 Arxiv | 👽 Qwen Code
Visit our Hugging Face or ModelScope organization (click links above), search checkpoints with names starting with Qwen3-Coder-, and you will find all you need! Enjoy!
We are announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, Qwen3-Coder-480B-A35B-Instruct, Qwen3-Coder-30B-A3B-Instruct, Qwen3-Coder-Next, offering exceptional performance in both coding and agentic tasks.
Qwen3-Coder-Next, an open-weight language model designed specifically for coding agents and local development. Built on top of Qwen3-Next-80B-A3B-Base, which adopts a novel architecture with hybrid attention and MoE, Qwen3-Coder-Next has been agentically trained at scale on large-scale executable task synthesis, environment interaction, and reinforcement learning, obtaining strong coding and agentic capabilities with significantly lower inference costs.
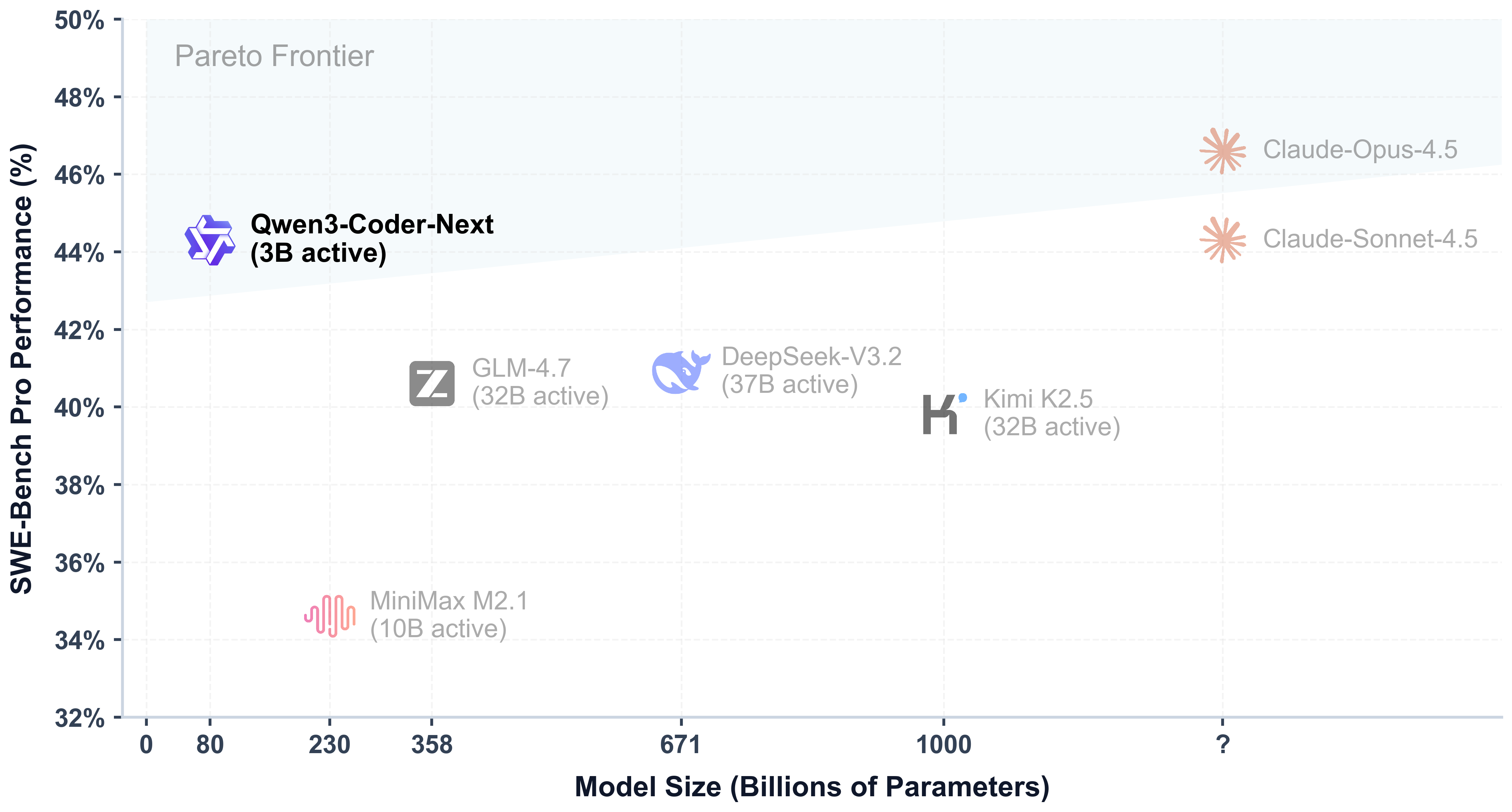
💻 Efficiency-Performance Tradeoff: among open models on Agentic Coding, Agentic Browser-Use, and other foundational coding tasks, achieving results comparable to Claude Sonnet.
🛠 Scaling Agentic Coding: supporting most platforms such as Qwen Code, CLINE, Claude Code, featuring a specially designed function call format;
📚 Long-context Capabilities: with native support for 256K tokens, extendable up to 1M tokens using Yarn, optimized for repository-scale understanding.
- ✨ Supporting long context understanding and generation with the context length of 256K tokens;
- ✨ Supporting 358 coding languages;
Click to view all supported languages
``` ['ABAP', 'ActionScript', 'Ada', 'Agda', 'Alloy', 'ApacheConf', 'AppleScript', 'Arc', 'Arduino', 'AsciiDoc', 'AspectJ', 'Assembly', 'Augeas', 'AutoHotkey', 'AutoIt', 'Awk', 'Batchfile', 'Befunge', 'Bison', 'BitBake', 'BlitzBasic', 'BlitzMax', 'Bluespec', 'Boo', 'Brainfuck', 'Brightscript', 'Bro', 'C', 'C#', 'C++', 'C2hs Haskell', 'CLIPS', 'CMake', 'COBOL', 'CSS', 'CSV', "Cap'n Proto", 'CartoCSS', 'Ceylon', 'Chapel', 'ChucK', 'Cirru', 'Clarion', 'Clean', 'Click', 'Clojure', 'CoffeeScript', 'ColdFusion', 'ColdFusion CFC', 'Common Lisp', 'Component Pascal', 'Coq', 'Creole', 'Crystal', 'Csound', 'Cucumber', 'Cuda', 'Cycript', 'Cython', 'D', 'DIGITAL Command Language', 'DM', 'DNS Zone', 'Darcs Patch', 'Dart', 'Diff', 'Dockerfile', 'Dogescript', 'Dylan', 'E', 'ECL', 'Eagle', 'Ecere Projects', 'Eiffel', 'Elixir', 'Elm', 'Emacs Lisp', 'EmberScript', 'Erlang', 'F#', 'FLUX', 'FORTRAN', 'Factor', 'Fancy', 'Fantom', 'Forth', 'FreeMarker', 'G-code', 'GAMS', 'GAP', 'GAS', 'GDScript', 'GLSL', 'Genshi', 'Gentoo Ebuild', 'Gentoo Eclass', 'Gettext Catalog', 'Glyph', 'Gnuplot', 'Go', 'Golo', 'Gosu', 'Grace', 'Gradle', 'Grammatical Framework', 'GraphQL', 'Graphviz (DOT)', 'Groff', 'Groovy', 'Groovy Server Pages', 'HCL', 'HLSL', 'HTML', 'HTML+Django', 'HTML+EEX', 'HTML+ERB', 'HTML+PHP', 'HTTP', 'Haml', 'Handlebars', 'Harbour', 'Haskell', 'Haxe', 'Hy', 'IDL', 'IGOR Pro', 'INI', 'IRC log', 'Idris', 'Inform 7', 'Inno Setup', 'Io', 'Ioke', 'Isabelle', 'J', 'JFlex', 'JSON', 'JSON5', 'JSONLD', 'JSONiq', 'JSX', 'Jade', 'Jasmin', 'Java', 'Java Server Pages', 'JavaScript', 'Julia', 'Jupyter Notebook', 'KRL', 'KiCad', 'Kit', 'Kotlin', 'LFE', 'LLVM', 'LOLCODE', 'LSL', 'LabVIEW', 'Lasso', 'Latte', 'Lean', 'Less', 'Lex', 'LilyPond', 'Linker Script', 'Liquid', 'Literate Agda', 'Literate CoffeeScript', 'Literate Haskell', 'LiveScript', 'Logos', 'Logtalk', 'LookML', 'Lua', 'M', 'M4', 'MAXScript', 'MTML', 'MUF', 'Makefile', 'Mako', 'Maple', 'Markdown', 'Mask', 'Mathematica', 'Matlab', 'Max', 'MediaWiki', 'Metal', 'MiniD', 'Mirah', 'Modelica', 'Module Management System', 'Monkey', 'MoonScript', 'Myghty', 'NSIS', 'NetLinx', 'NetLogo', 'Nginx', 'Nimrod', 'Ninja', 'Nit', 'Nix', 'Nu', 'NumPy', 'OCaml', 'ObjDump', 'Objective-C++', 'Objective-J', 'Octave', 'Omgrofl', 'Opa', 'Opal', 'OpenCL', 'OpenEdge ABL', 'OpenSCAD', 'Org', 'Ox', 'Oxygene', 'Oz', 'PAWN', 'PHP', 'POV-Ray SDL', 'Pan', 'Papyrus', 'Parrot', 'Parrot Assembly', 'Parrot Internal Representation', 'Pascal', 'Perl', 'Perl6', 'Pickle', 'PigLatin', 'Pike', 'Pod', 'PogoScript', 'Pony', 'PostScript', 'PowerShell', 'Processing', 'Prolog', 'Propeller Spin', 'Protocol Buffer', 'Public Key', 'Pure Data', 'PureBasic', 'PureScript', 'Python', 'Python traceback', 'QML', 'QMake', 'R', 'RAML', 'RDoc', 'REALbasic', 'RHTML', 'RMarkdown', 'Racket', 'Ragel in Ruby Host', 'Raw token data', 'Rebol', 'Red', 'Redcode', "Ren'Py", 'RenderScript', 'RobotFramework', 'Rouge', 'Ruby', 'Rust', 'SAS', 'SCSS', 'SMT', 'SPARQL', 'SQF', 'SQL', 'STON', 'SVG', 'Sage', 'SaltStack', 'Sass', 'Scala', 'Scaml', 'Scheme', 'Scilab', 'Self', 'Shell', 'ShellSession', 'Shen', 'Slash', 'Slim', 'Smali', 'Smalltalk', 'Smarty', 'Solidity', 'SourcePawn', 'Squirrel', 'Stan', 'Standard ML', 'Stata', 'Stylus', 'SuperCollider', 'Swift', 'SystemVerilog', 'TOML', 'TXL', 'Tcl', 'Tcsh', 'TeX', 'Tea', 'Text', 'Textile', 'Thrift', 'Turing', 'Turtle', 'Twig', 'TypeScript', 'Unified Parallel C', 'Unity3D Asset', 'Uno', 'UnrealScript', 'UrWeb', 'VCL', 'VHDL', 'Vala', 'Verilog', 'VimL', 'Visual Basic', 'Volt', 'Vue', 'Web Ontology Language', 'WebAssembly', 'WebIDL', 'X10', 'XC', 'XML', 'XPages', 'XProc', 'XQuery', 'XS', 'XSLT', 'Xojo', 'Xtend', 'YAML', 'YANG', 'Yacc', 'Zephir', 'Zig', 'Zimpl', 'desktop', 'eC', 'edn', 'fish', 'mupad', 'nesC', 'ooc', 'reStructuredText', 'wisp', 'xBase'] ```- ✨ Retain strengths in math and general capabilities from base model.
Important
Qwen3-Coder function calling relies on our new tool parser in both SGLang and vLLM here.
We updated both the special tokens and their corresponding token ids, in order to maintain consistency with Qwen3. Please make sure to use the new tokenizer.
| model name | type | length | Download |
|---|---|---|---|
| Qwen3-Coder-Next | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-Next-Base | base | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-480B-A35B-Instruct | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-30B-A3B-Instruct | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-Next-FP8 | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-Next-GGUF | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-480B-A35B-Instruct-FP8 | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen3-Coder-30B-A3B-Instruct-FP8 | instruct | 256k | 🤗 Hugging Face • 🤖 ModelScope |
Detailed performance and introduction are shown in this 📑 blog.
Important
Qwen3-Coder are instruct models for chatting;
This model supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
You can write several lines of code with transformers to chat with Qwen3-Coder-Next. Essentially, we build the tokenizer and the model with the from_pretrained method, and we use the generate method to perform chatting with the help of the chat template provided by the tokenizer. Below is an example of how to chat with Qwen3-Coder-Next:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-Next"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=65536
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]The apply_chat_template() function is used to convert the messages into a format that the model can understand.
The add_generation_prompt argument is used to add a generation prompt, which refers to <|im_start|>assistant\n to the input. Notably, we apply the ChatML template for chat models following our previous practice.
The max_new_tokens argument is used to set the maximum length of the response. The tokenizer.batch_decode() function is used to decode the response. In terms of the input, the above messages are an example to show how to format your dialog history and system prompt.
You can use the other sizes of instruct models in the same way.
The code insertion task, also referred to as the "fill-in-the-middle" challenge, requires the insertion of code segments in a manner that bridges the gaps within a given code context. For an approach aligned with best practices, we recommend adhering to the formatting guidelines outlined in the paper "Efficient Training of Language Models to Fill in the Middle" [arxiv].
Important
It should be noted that FIM is supported in every version of Qwen3-Coder. Qwen3-Coder-Next is shown here as an example.
The prompt should be structured as follows:
prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'Following the approach mentioned, an example would be structured in this manner:
from transformers import AutoTokenizer, AutoModelForCausalLM
# load model
device = "cuda" # the device to load the model onto
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/Qwen3-Coder-Next")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-Coder-Next", device_map="auto").eval()
input_text = """<|fim_prefix|>def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
<|fim_suffix|>
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)<|fim_middle|>"""
messages = [
{"role": "system", "content": "You are a code completion assistant."},
{"role": "user", "content": input_text}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = TOKENIZER([text], return_tensors="pt").to(model.device)
# Use `max_new_tokens` to control the maximum output length.
eos_token_ids = [151659, 151661, 151662, 151663, 151664, 151643, 151645]
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False, eos_token_id=eos_token_ids)[0]
# The generated_ids include prompt_ids, we only need to decode the tokens after prompt_ids.
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)
print(f"Prompt: {input_text}\n\nGenerated text: {output_text}")Prompt with OpenClaw
next week we will release new coder model, can you collect the history of qwen coder and write a web page, the release the website with the nginx, you can seach how to do this in alibaba cloud linux first

Prompt with Qwen Code
Please tidy up my desk.

Prompt with Claude Code
帮我实现《僵尸大战植物》网页游戏
【核心机制】
- 反向塔防:玩家扮演僵尸方,从地图右侧(部署区)召唤僵尸向左进攻
- 资源循环:初始300脑子点数,僵尸吃掉植物返还100点,形成经济循环
- 倒计时制:120秒内清除所有植物获胜,超时失败
【地图规格】
- 5行9列网格,右侧3列为可部署区域(红色高亮标识)
- 每格100x100像素,草地纹理交替渲染
- 坐标系:左侧为植物防线,右侧为僵尸出生点
【单位系统】
僵尸方(右侧购买):
- 普通僵尸:50脑,100HP,0.5速,标准单位
- 路障僵尸:100脑,200HP,0.5速,中期肉盾
- 铁桶僵尸:150脑,400HP,0.3速,重型坦克
- 冲刺僵尸:80脑,80HP,1.2速,快速突进
植物方(左侧随机初始部署12个):
- 豌豆射手:100HP,20伤/发,2秒间隔,直线射击
- 双发射手:120HP,20伤/发,1秒间隔,火力压制
- 坚果墙:300HP,0伤,纯肉盾阻挡
- 向日葵:80HP,0伤,经济单位(纯干扰)
【战斗逻辑】
- 碰撞检测:僵尸到达植物50px内触发啃食状态,停止移动
- 伤害结算:僵尸30帧/次咬击(0.5秒),植物射出弹道物理
- 击毁反馈:植物死亡时生成"+100"飘字特效与粒子爆炸
- 路径AI:同格僵尸队列不重叠,植物优先攻击横向最近目标
【交互设计】
- 右侧卡片式UI:显示僵尸图标、名称、脑子消耗
- 资源不足时卡片置灰并自动切换可选类型
- 鼠标悬停部署区显示半透明预览圈
- 实时血条:实体头顶显示绿/黄/红三色血槽
【胜利条件】
- 胜利:plants.length === 0 && timeLeft > 0
- 失败:timeLeft === 0 || (可选)僵尸全灭且脑子为0

Prompt with Cline
Build an interactive ASCII art drawing tool with sound feedback. The application should:
1. Create a canvas where users can draw by clicking and dragging
2. Place different ASCII characters or symbols when the user draws
3. Play corresponding musical notes when each character is placed
4. Include multiple pattern sets with different characters and
corresponding note scales
5. Add a pattern switcher button to cycle through different
character/sound themes
6. Include a clear button to reset the canvas
7. Support both mouse and touch input for mobile compatibility
The application should be creative and fun to use, creating an audio-visual experience where patterns of characters create both visual art and musical patterns. Ensure the musical notes are harmonious when played in sequence.

Prompt with Browser Use Agent
Vibe test this website. Click around, try things, report what's broken.

Prompt with Qwen Chat Web Dev
Create an interactive real-time particle system using HTML5 Canvas:
Core Features:
- Render 800-1200 animated particles with physics-based movement
- Mouse cursor exerts attractive/repulsive force on nearby particles
- Click to toggle between attraction and repulsion modes
- Particles respond with smooth acceleration and velocity calculations
Technical Requirements:
- Use requestAnimationFrame for optimal performance
- Implement force calculation based on distance from cursor
- Add visual feedback: particle glow, color variation, and fade effects
- Include performance monitoring (FPS counter)
Deliverables:
- Single HTML file with embedded CSS and JavaScript
- Clean, commented code following best practices
- Responsive design compatible with modern browsers

If you find our work helpful, feel free to give us a cite.
@techreport{qwen_qwen3_coder_next_tech_report,
title = {Qwen3-Coder-Next Technical Report},
author = {{Qwen Team}},
url = {https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf},
note = {Accessed: 2026-02-03}
}If you are interested to leave a message to either our research team or product team, join our Discord or WeChat groups!