@@ -2403,19 +2403,19 @@ MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的**支持
24032403
24042404* M:被修改(Modified)
24052405
2406- 该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的,与主存中的数据不一致 (dirty),该缓存行中的内存需要在未来的某个时间点(其它 CPU 读取主存中相应数据之前)写回 (write back) 主存
2406+ 该缓存行只被缓存在该 CPU 的缓存中,并且是被修改过的,与主存中的数据不一致 (dirty),该缓存行中的内存需要写回 (write back) 主存。该状态的数据再次被修改不会发送广播,因为其他核心的数据已经在第一次修改时失效一次
24072407
2408- 当被写回主存之后,该缓存行的状态会变成独享 (exclusive) 状态。
2408+ 当被写回主存之后,该缓存行的状态会变成独享 (exclusive) 状态
24092409
24102410* E:独享的(Exclusive)
24112411
2412- 该缓存行只被缓存在该 CPU 的缓存中,是未被修改过的 (clear),与主存中数据一致,该状态可以在任何时刻有其它 CPU 读取该内存时变成共享状态 (shared)
2412+ 该缓存行只被缓存在该 CPU 的缓存中,是未被修改过的 (clear),与主存中数据一致,修改数据不需要通知其他 CPU 核心, 该状态可以在任何时刻有其它 CPU 读取该内存时变成共享状态 (shared)
24132413
24142414 当 CPU 修改该缓存行中内容时,该状态可以变成 Modified 状态
24152415
24162416* S:共享的(Shared)
24172417
2418- 该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致,当有一个 CPU 修改该缓存行中,其它 CPU 中该缓存行变成无效状态 (Invalid)
2418+ 该状态意味着该缓存行可能被多个 CPU 缓存,并且各个缓存中的数据与主存数据一致,当 CPU 修改该缓存行中,会向其它 CPU 核心广播一个请求,使该缓存行变成无效状态 (Invalid),然后再更新当前 Cache 里的数据
24192419
24202420* I:无效的(Invalid)
24212421
@@ -2448,7 +2448,7 @@ MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的**支持
24482448
24492449* 总线嗅探:每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是否过期了,当处理器发现自己的缓存对应的内存地址的数据被修改,就**将当前处理器的缓存行设置为无效状态**,当处理器对这个数据进行操作时,会重新从内存中把数据读取到处理器缓存中
24502450
2451- * 总线风暴:由于 volatile 的 MESI 缓存一致性协议,需要不断的从主内存嗅探和 CAS 循环,无效的交互会导致总线带宽达到峰值;因此不要大量使用 volatile 关键字,使用 volatile、syschonized 都需要根据实际场景
2451+ * 总线风暴:当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心(**写传播**),CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,不断的从主内存嗅探和 CAS 循环,无效的交互会导致总线带宽达到峰值;因此不要大量使用 volatile 关键字,使用 volatile、syschonized 都需要根据实际场景
24522452
24532453
24542454
@@ -7855,7 +7855,7 @@ AQS 核心思想:
78557855
78567856* 如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置锁定状态
78577857
7858- * 请求的共享资源被占用,AQS 用 CLH 队列实现线程阻塞等待以及被唤醒时锁分配的机制 ,将暂时获取不到锁的线程加入到队列中
7858+ * 请求的共享资源被占用,AQS 用队列实现线程阻塞等待以及被唤醒时锁分配的机制 ,将暂时获取不到锁的线程加入到队列中
78597859
78607860 CLH 是一种基于单向链表的**高性能、公平的自旋锁**,AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配
78617861
@@ -13391,7 +13391,7 @@ select 允许应用程序监视一组文件描述符,等待一个或者多个
1339113391int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
1339213392```
1339313393
13394- - fd_set 使用 **bitmap 数组**实现,数组大小用 FD_SETSIZE 定义,只能监听少于 FD_SETSIZE 数量的描述符,32 位机默认是 1024 个,64 位机默认是 2048,可以对进行修改,然后重新编译内核
13394+ - fd_set 使用 **bitmap 数组**实现,数组大小用 FD_SETSIZE 定义,**单进程** 只能监听少于 FD_SETSIZE 数量的描述符,32 位机默认是 1024 个,64 位机默认是 2048,可以对进行修改,然后重新编译内核
1339513395
1339613396- fd_set 有三种类型的描述符:readset、writeset、exceptset,对应读、写、异常条件的描述符集合
1339713397
@@ -13645,7 +13645,7 @@ epoll 的特点:
1364513645* epoll 的时间复杂度 O(1),epoll 理解为 event poll,不同于忙轮询和无差别轮询,调用 epoll_wait **只是轮询就绪链表**。当监听列表有设备就绪时调用回调函数,把就绪 fd 放入就绪链表中,并唤醒在 epoll_wait 中阻塞的进程,所以 epoll 实际上是**事件驱动**(每个事件关联上fd)的,降低了 system call 的时间复杂度
1364613646* epoll 内核中根据每个 fd 上的 callback 函数来实现,只有活跃的 socket 才会主动调用 callback,所以使用 epoll 没有前面两者的线性下降的性能问题,效率提高
1364713647
13648- * epoll 注册新的事件都是注册到到内核中 epoll 句柄中,不需要每次调用 epoll_wait 时重复拷贝,对比前面两种,epoll 只需要将描述符从进程缓冲区向内核缓冲区 **拷贝一次**,epoll 也可以利用 **mmap() 文件映射内存**加速与内核空间的消息传递(只是可以用)
13648+ * epoll 注册新的事件是注册到到内核中 epoll 句柄中,不需要每次调用 epoll_wait 时重复拷贝,对比前面两种只需要将描述符从进程缓冲区向内核缓冲区 **拷贝一次**,也可以利用 **mmap() 文件映射内存**加速与内核空间的消息传递(只是可以用,并没有用 )
1364913649* 前面两者要把 current 往设备等待队列中挂一次,epoll 也只把 current 往等待队列上挂一次,但是这里的等待队列并不是设备等待队列,只是一个 epoll 内部定义的等待队列,这样可以节省开销
1365013650* epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符,也不会产生像 select 和 poll 的不确定情况
1365113651
@@ -13773,7 +13773,7 @@ DMA 方式是一种完全由硬件进行信息传送的控制方式,通常系
1377313773
1377413774传统的 I/O 操作进行了 4 次用户空间与内核空间的上下文切换,以及 4 次数据拷贝:
1377513775
13776- * JVM 发出 read 系统调用,OS 上下文切换到内核模式(切换 1)并将数据从网卡或硬盘等设备通过 DMA 读取到内核空间缓冲区(拷贝 1)
13776+ * JVM 发出 read 系统调用,OS 上下文切换到内核模式(切换 1)并将数据从网卡或硬盘等设备通过 DMA 读取到内核空间缓冲区(拷贝 1),内核缓冲区实际上是**磁盘高速缓存(PageCache)**
1377713777* OS 内核将数据复制到用户空间缓冲区(拷贝 2),然后 read 系统调用返回,又会导致一次内核空间到用户空间的上下文切换(切换 2)
1377813778* JVM 处理代码逻辑并发送 write() 系统调用,OS 上下文切换到内核模式(切换3)并从用户空间缓冲区复制数据到内核空间缓冲区(拷贝3)
1377913779* 将内核空间缓冲区中的数据写到 hardware(拷贝4),write 系统调用返回,导致内核空间到用户空间的再次上下文切换(切换4)
@@ -13823,6 +13823,8 @@ sendfile 实现零拷贝,打开文件的文件描述符 fd 和 socket 的 fd
1382313823
1382413824原理:数据根本不经过用户态,直接从内核缓冲区进入到 Socket Buffer,由于和用户态完全无关,就减少了两次上下文切换
1382513825
13826+ 说明:零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送
13827+
1382613828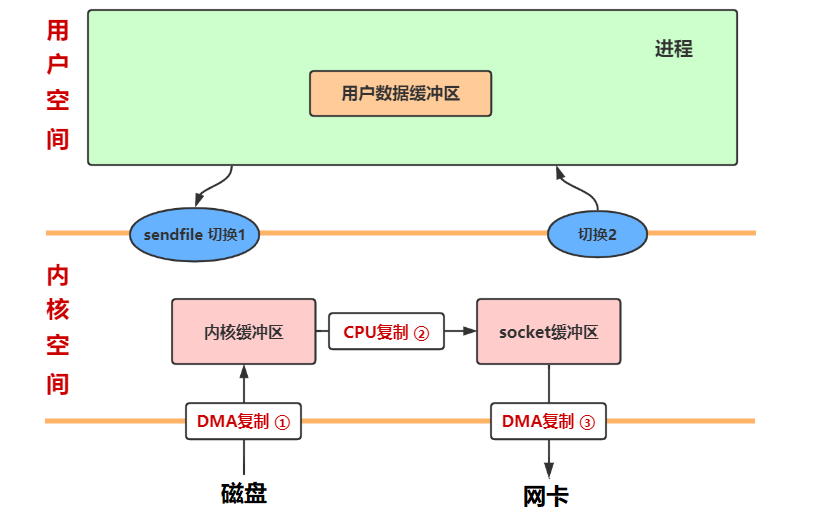
1382713829
1382813830sendfile2.4 之后,sendfile 实现了更简单的方式,文件到达内核缓冲区后,不必再将数据全部复制到 socket buffer 缓冲区,而是只**将记录数据位置和长度相关等描述符信息**保存到 socket buffer,DMA 根据 Socket 缓冲区中描述符提供的位置和偏移量信息直接将内核空间缓冲区中的数据拷贝到协议引擎上(2 次复制 2 次切换)
@@ -14736,19 +14738,20 @@ Byte Buffer 有两种类型,一种是基于直接内存(也就是非堆内
1473614738
1473714739Direct Memory 优点:
1473814740
14739- * Java 的 NIO 库允许 Java 程序使用直接内存,用于数据缓冲区, 使用 native 函数直接分配堆外内存
14741+ * Java 的 NIO 库允许 Java 程序使用直接内存,使用 native 函数直接分配堆外内存
1474014742* **读写性能高**,读写频繁的场合可能会考虑使用直接内存
1474114743* 大大提高 IO 性能,避免了在 Java 堆和 native 堆来回复制数据
1474214744
1474314745直接内存缺点:
1474414746
14747+ * 不能使用内核缓冲区 Page Cache 的缓存优势,无法缓存最近被访问的数据和使用预读功能
1474514748* 分配回收成本较高,不受 JVM 内存回收管理
1474614749* 可能导致 OutOfMemoryError 异常:OutOfMemoryError: Direct buffer memory
1474714750* 回收依赖 System.gc() 的调用,但这个调用 JVM 不保证执行、也不保证何时执行,行为是不可控的。程序一般需要自行管理,成对去调用 malloc、free
1474814751
1474914752应用场景:
1475014753
14751- - 有很大的数据需要存储 ,数据的生命周期很长
14754+ - 传输很大的数据文件 ,数据的生命周期很长,导致 Page Cache 没有起到缓存的作用,一般采用直接 IO 的方式
1475214755- 适合频繁的 IO 操作,比如网络并发场景
1475314756
1475414757数据流的角度:
0 commit comments