들어가며
개인적으로 몇 년 동안 머릿속에 담아두고 제대로 꺼내놓지 못한 상태의 프로젝트가 있습니다. 이 것을 구현하려면 빠른 검색 서버가 반드시 필요합니다. 이 상태에서 2백만개 음식 레시피 검색 데모 사이트를 처음 보자마자 Typesense라는 검색엔진에 특별한 관심을 가지게 되었던 것 같습니다. 데모 사이트에서 키워드로 검색해 본 결과가 엄청나게 빨랐거든요.
원래 우분투 20.04에서 typesense 서버 설치부터 node.js 클라이언트 예제 실행까지 게시글을 통해 샘플 웹 페이지를 작성해서 한국어로 검색하는 부분까지 작성 해 보고 싶었는데, 그냥 검색엔진이 설치된 서버만 만들고 같은 서버 내에서 클라이언트로 요청 해 보는 아주 간소화된 공식 가이드 버전 답습하기 수준으로 마무리가 되어, 나머지 부분에 대한 내용을 별도로 정리하자 마음을 먹고 이 글을 작성하게 되었습니다.
이 글은 제가 깊이가 부족하여 그런 것도 있지만, 각각의 기술에 대한 깊이 있는 활용 방법보다는 Typesense라는 오픈소스 검색 엔진을 이용하여, 검색을 위한 웹 API 서버를 구축하기위해 여러 프로그램 및 서비스들을 어떻게 활용했는지에 대한 작업 과정을 개인적으로 정리해 봄과 동시에 이쪽에 관심을 가지고 계시는 다른 분들에게 공유하기 위한 목적으로 작성합니다.
아직 Typesense에는 한국어 형태소 분석기가 없는 것으로 알고 있는데요. 잠깐 본 것이 전부였지만, 정확하고 빠른 한국어 검색 결과를 얻지 못하는 한계점이 가장 아쉬웠습니다. 그래서 실제 묵혀두었던 아이디어를 구현하는 시점에는 Elasticsearch를 통해 검색 서버를 구현하게 될 것 같습니다. 하지만 정확하게 일치하는 키워드에 대한 검색 결과를 얻어야 하는 상황에서는 충분히 사용할 만한 가치가 있다고 생각합니다.
데모용 웹 페이지
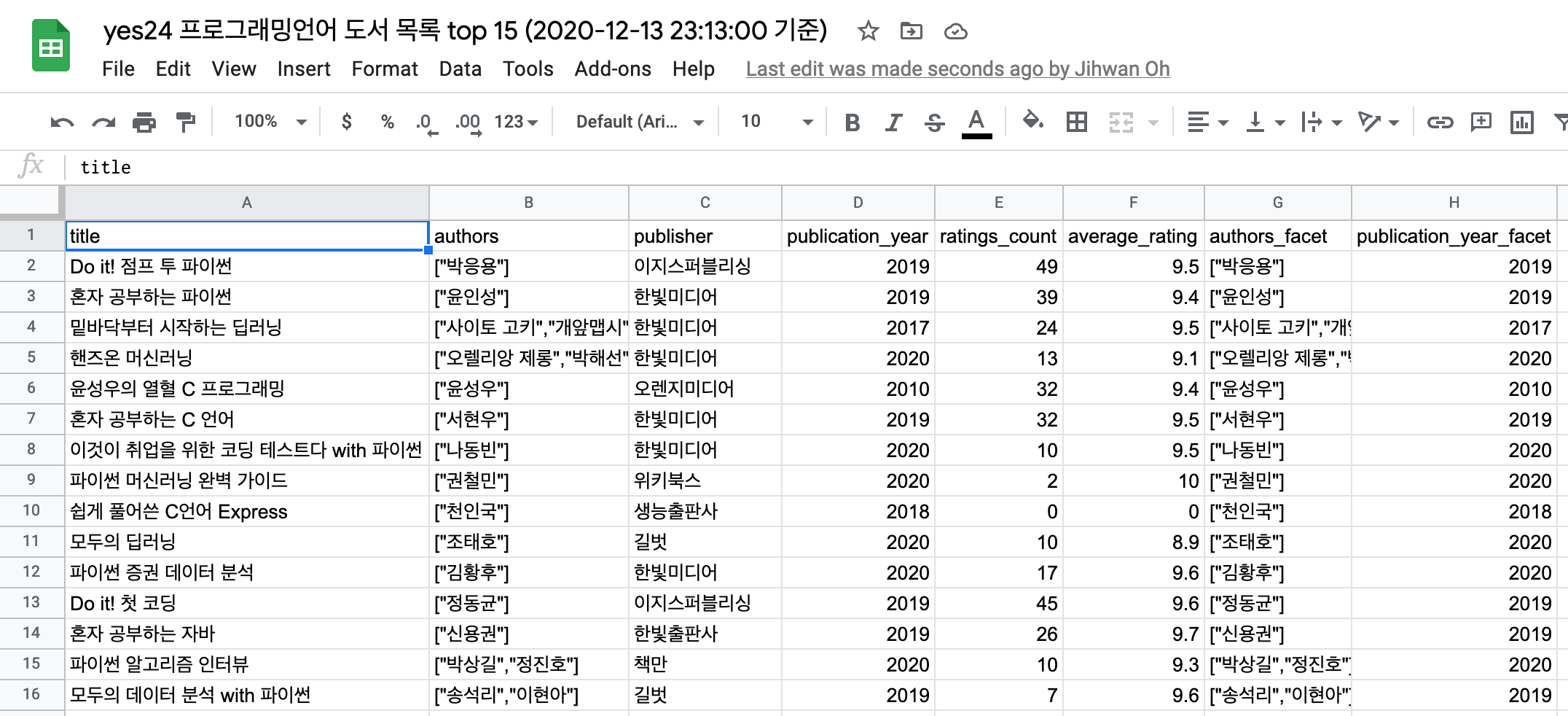
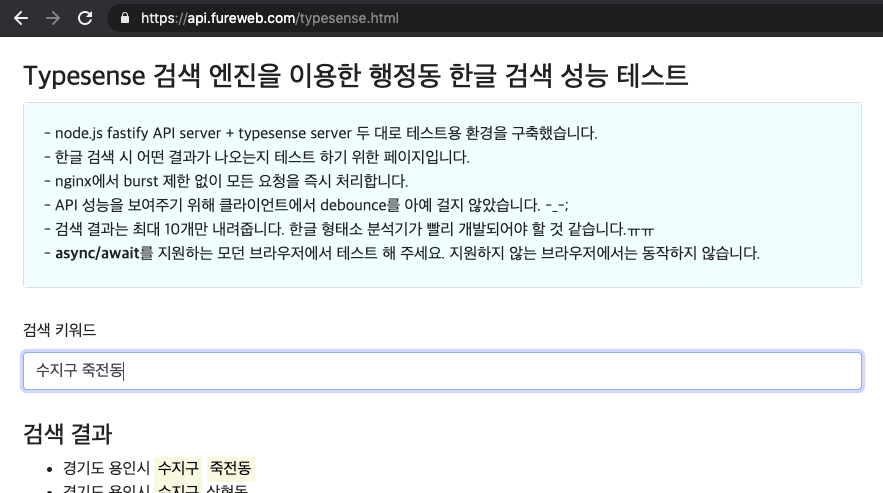
이 게시글을 작성하기 전에 데모용 웹페이지를 하나 만들어 두었습니다. 해당 페이지는 전국 행정동 정보를 담은 구글 스프레드시트 문서에 담긴 정보를 Typesense 검색엔진을 이용하여 빠른 검색 결과를 확인할 수 있도록 했습니다. Oracle의 무료 계층 인스턴스로도 충분히 빠른 검색 결과를 얻는 모습을 확인하실 수 있습니다. 다만 아웃바운드 트래픽을 마냥 낭비할 수는 없어, 최대 응답 갯수는 10개로 두었으나 무자비하도록 빠른 검색 요청-응답을 개발자도구 네트워크탭에서 확인하실 수 있도록 debounce를 적용하지 않았고, nginx의 burst 제한도 풀어 두었습니다. 그럴리는 없겠지만, 이후 과도한 트래픽이 유입된다면 클라이언트에는 debounce, 웹서버에는 burst 제한을 걸고 내려주는 응답의 갯수를 10개에서 n배 이상으로 늘리는 형태로 변경 될 수도 있습니다.
- 데모용 웹페이지: https://api.fureweb.com/typesense.html
- 구글 스프레드시트 문서: https://docs.google.com/spreadsheets/d/1aXq4ISWG-ionVc8b0SPgASxJi7WdbQ8oz2pJ56zooCY
위에서 언급한 데모용 웹페이지에서 사용된 API 서버와 검색 서버를 구축하기 위해 사용된 기술들을 정리 해 보고, 직접 구축하는 방법을 알아보겠습니다.
사용된 주요 기술
| 기술 | 설명 |
|---|---|
| Oracle Cloud VM 인스턴스 (VM.Standard.E2.1.Micro 2대, 항상 무료스펙) |
웹 API용, Typesense용 서버 각 1대 |
| Ubuntu 20.04 LTS | 운영체제 |
| nginx 1.18.0 | 웹 서버 |
| Let’s Encrypt using python3-certbot-nginx | TLS 인증서 발급용 (이번 게시글에서는 따로 설명하지 않습니다.) |
| Typesense 0.17.0 | 검색엔진 |
| node.js v14.15.1 | 자바스크립트 런타임 |
| fastify 3.9.1 | node.js용 web framework |
| pm2 4.5.0 | node.js용 프로세스 관리자 |
| typesense-js 0.9.1 | node.js용 Typesense 클라이언트 |
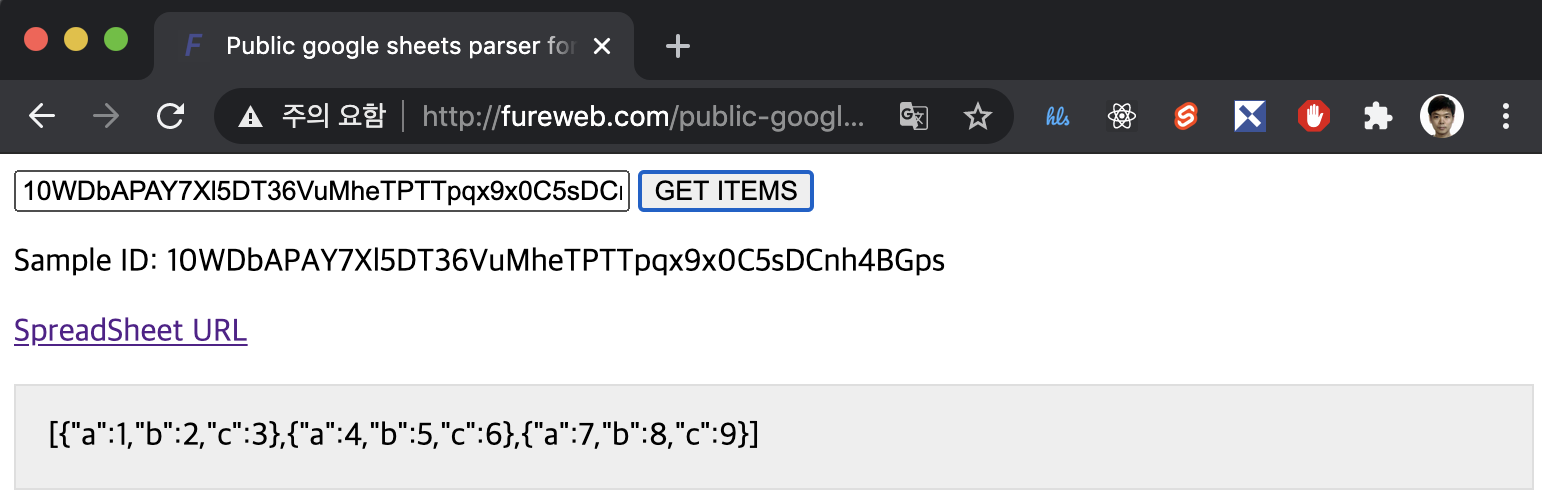
| public-google-sheets-parser 1.0.24 | 구글 스프레드시트 공개 문서를 JSON Array로 파싱하기 위한 라이브러리 |
| Vue.js / bootstrap v4.5 / axios | 샘플 웹 페이지 제작을 위한 js/css 웹 프레임워크 및 http 클라이언트 |
검색 키워드 입력 부터 응답을 받기까지의 주요 과정 설명
| 순서 | 처리주체 | 내용 |
|---|---|---|
| 1 | 웹페이지 |
웹 페이지의 input창에 focus된 상태에서 키보드가 keyup 될 때 마다 axios를 이용하여 검색 API 호출 (debounce 없이, trim된 키워드가 truthy 하다면 API 서버에 검색 요청) |
| 2 | API서버 |
전달받은 키워드가 truthy한 경우, typesense 클라이언트를 이용해 검색 서버에 질의 |
| 3 | 검색서버 |
질의 결과를 API 서버로 응답 |
| 4 | API서버 |
검색서버로부터 전달받은 응답을 highlight된 snippet만 내려주도록 가공하여 응답 처리 |
| 5 | 웹페이지 |
웹 페이지에서 발생시킨 http 요청에 대한 응답을 vue.js를 이용하여 화면에 표현 |
각각의 서버를 직접 구축하는 방법
검색 서버 구축
이 전 게시글에서 설명한 대로 Typesense를 설치한 서버가 준비되어있어야 합니다. GPLv3 라이센스가 걸려있지만 검색 엔진은 별도의 서버 또는 Docker를 통해 운영되기때문에 라이센스로 인한 문제가 발생할 일은 없을 것으로 보입니다.
이 전 게시글을 통해 검색 서버 설치가 완료 되었다면
1) ~/typesense-client 디렉토리로 이동한 뒤,
2) vi make-data.js 명령을 실행하여 아래의 코드를 복사 & 붙여넣기 해 줍니다.
3) 이 후 node make-data.js 명령을 실행하면, address collection과 documents가 생성되고, 테스트 쿼리 결과가 콘솔에 출력됩니다.
// make-data.js
const Typesense = require('typesense')
const PublicGoogleSheetsParser = require('public-google-sheets-parser')
const parser = new PublicGoogleSheetsParser()
// collection 및 document 생성을 위한 client 준비
const client = new Typesense.Client({
nodes: [{
host: 'localhost',
port: '8108',
protocol: 'http'
}],
apiKey: '/etc/typesense/typesense-server.ini에 기록된 키', // 반드시 수정 해 주세요
connectionTimeoutSeconds: 2
})
// collection 생성
const collectionName = 'address'
const addressSchema = {
'name': collectionName,
'fields': [
{'name': 'id', 'type': 'string' },
{'name': 'index', 'type': 'int32' },
],
'default_sorting_field': 'index'
}
await client.collections().create(addressSchema)
// documents import 처리
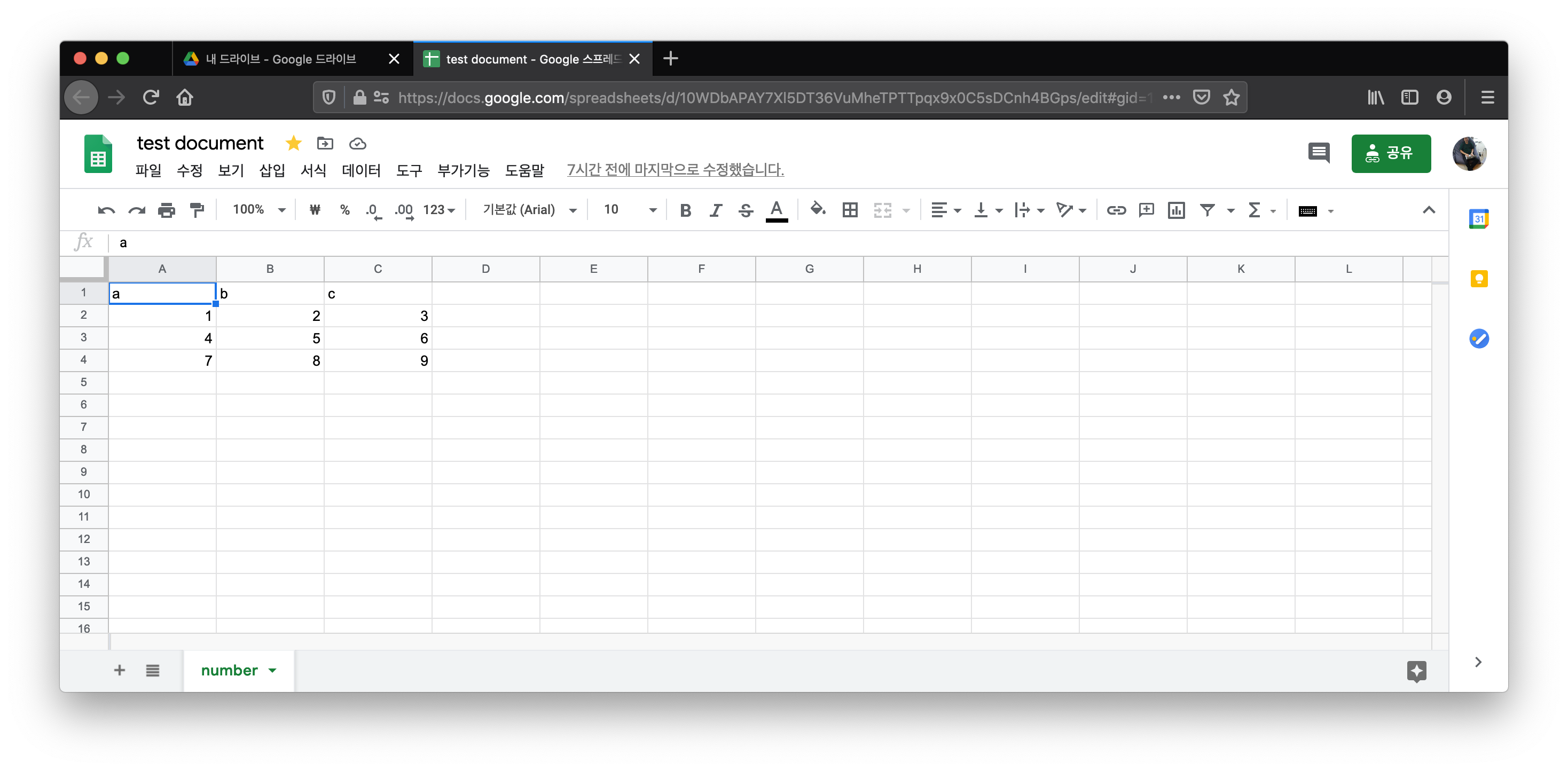
const rawAddress = await parser.parse('1aXq4ISWG-ionVc8b0SPgASxJi7WdbQ8oz2pJ56zooCY')
const address = rawAddress.map(({ id }, index) => ({ id, index }))
await client.collections(collectionName).documents().import(address, { action: 'create' })
// documents가 잘 저장되었는지 테스트 쿼리 전송 및 결과 확인
const searchParameters = {
q: '수지구 죽전동',
query_by: 'id',
per_page: 5,
}
const searchResult = await client.collections(collectionName).documents().search(searchParameters)
console.log(searchResult)
검색 서버 <-> API 서버는 HTTP 프로토콜만으로 통신하도록 해 두면 검색 서버에는 별도의 TLS 인증서를 설치하지 않아도 됩니다.
저는 검색서버의 80번 포트를 열었고, 80번 포트로 요청이 들어오면 nginx의 proxy_pass를 통해 typesense의 기본 포트인 8108쪽으로 요청과 응답이 처리되도록 설정 해 두었습니다.
# 다음의 명령으로 검색서버용 nginx 설정파일을 하나 만들어 줍니다.
sudo vi /etc/nginx/conf.d/search.conf
# /etc/nginx/conf.d/search.conf 파일 내용:
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:8108;
proxy_http_version 1.1;
}
}
# 다음의 명령으로 nginx를 reload합니다.
sudo systemctl reload nginx
# 다음의 명령을 통해 검색서버의 public IP를 확인 해 두세요.
curl https://api.fureweb.com/ip
# 위에서 확인한 ip의 80번 포트로 HTTP GET 요청이 정상적으로 되는지 확인 해 봅니다.
curl 위에서-얻은-public-ip
# { "message": "Not Found"} 이런 응답이 와야 정상입니다.
만약 응답이 오지 않는다면, 80번 포트가 정상적으로 열려있는지 확인 후 조치가 필요합니다. 이 부분은 클라우드 업체마다 다를 수 있어서 별도 확인 후 처리를 진행 해 주세요.
이제 검색서버에서 할 일은 모두 마무리 되었습니다. 클라우드 서비스의 방화벽 설정에서 API 서버가 아닌 다른 IP에서 요청이 들어오는 경우 Drop 처리되도록 하는 설정 등은 선택적으로 진행하셔도 됩니다.
API 서버 구축
저는 fastify를 이용해서 간단하게 API 서버를 만들었습니다. 아래 경로는 원하는대로 사용하셔도 됩니다.
# api 디렉토리를 사용자 홈 하위에 생성한 뒤 이동합니다.
mkdir -p ~/api && cd ~/api
# 초기화 후 fastify API 서버 코드를 작성하기 위한 패키지들을 설치합니다.
npm init -y && npm install fastify fastify-cors pm2 http-errors typesense @babel/runtime
# pm2를 통해 실행 시킬 파일을 하나 생성합니다.
vi app.js
아래의 코드를 app.js 내용으로 만들어 주세요. 단, 내용 중 검색 서버 IP와 apiKey는 상황에 맞게 수정 해 주셔야합니다. 실제로는 이런 형태로 코드를 작성하지 않지만, 최대한 간단하게 설명하기 위해 하나의 파일로 묶어 두었습니다.
// app.js (아래 검색서버 IP와 apiKey는 반드시 변경 해 주셔야 합니다.)
const httpErrors = require('http-errors')
const Typesense = require('typesense')
const typesenseClient = new Typesense.Client({
nodes: [{
host: 'typesense 서버 IP', // 반드시 변경 해 주세요
port: '80',
protocol: 'http'
}],
apiKey: 'master-or-search-only-api-key', // 반드시 변경 해 주세요
connectionTimeoutSeconds: 2
})
const fastify = require('fastify')({ trustProxy: true })
// cors 허용을 위한 플러그인 등록
fastify.register(require('fastify-cors'))
// routes에 추가
fastify.get('/search/address', async function (request, reply) {
const { keyword } = request.query
if (!keyword) return reply.send(httpErrors.BadRequest('keyword is required'))
// 검색 서버로 질의 및 응답용 결과 가공
const searchParameters = { q: keyword, query_by: 'id', per_page: 10 }
const searchResults = await typesenseClient.collections('address').documents().search(searchParameters)
const result = searchResults.hits.map((res) => (res.highlights[0] || {}).snippet || res.document.id)
return reply.send(result)
})
// API 서버 실행
fastify.listen(3000, (err, address) => {
if (err) throw err
fastify.log.info(`server listening on ${address}`)
})
app.js 파일을 정상적으로 생성했다면, 다음 명령을 통해 pm2로 서버를 실행시킵니다.
# pm2를 이용하여 app.js 파일 실행
npx pm2 start app.js
# API 서버가 실행됐다면, 아래의 명령을 통해 응답이 정상적으로 내려오는지 확인합니다.
curl localhost:3000/search/address?keyword=%EC%A3%BD%EC%A0%84%EB%8F%99
이제 API 서버도 준비가 완료 되었습니다. 검색 서버에서 nginx config파일을 추가한 뒤 reload 한 것 처럼, API 서버도 같은 작업을 진행 해 줍니다.
# 서버 IP 80번 포트에 대한 기본 설정 파일에 대한 링크를 삭제합니다.
# sites-enabled 디렉토리 내 파일은 /etc/nginx/sites-available 파일에 대한 심볼릭 링크입니다.
sudo rm /etc/nginx/sites-enabled/default
# 다음의 명령으로 API 서버용 nginx 설정파일을 하나 만들어 줍니다.
sudo vi /etc/nginx/conf.d/api.conf
# /etc/nginx/conf.d/api.conf 파일 내용:
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:3000$uri$is_args$args; # URI와 파라미터를 모두 fastfy쪽으로 전달합니다.
proxy_http_version 1.1;
}
}
# 다음의 명령으로 nginx를 reload합니다.
sudo systemctl reload nginx
# 다음의 명령을 통해 API 서버의 public IP를 확인 해 보세요.
curl https://api.fureweb.com/ip
# API 서버의 public IP로 검색 요청을 해 보고 정상 요청이 일어나는지 확인 해 봅니다.
curl 위에서-얻은-public-ip/search/address?keyword=%EC%A3%BD%EC%A0%84%EB%8F%99
# ["경상북도 상주시 <mark>죽전동</mark>",... 같은 형태의 응답이 내려와야 정상입니다.
만약 응답이 오지 않는다면, 80번 포트가 정상적으로 열려있는지 확인 후 조치가 필요합니다. 이 부분은 클라우드 업체마다 다를 수 있어서 별도 확인 후 처리를 진행 해 주세요.
서버의 public IP로 요청한 응답이 기대한 대로 내려왔다면, API 서버에 대한 설정도 완료 되었습니다.
데모용 웹 페이지 만들기
현재 사용중인 PC의 적절한 위치에 다음과 같은 내용을 담은 HTML 파일을 하나 만들어 봅니다.
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Typesense 검색 엔진을 이용한 행정동 한글 검색 성능 테스트</title>
<link href="https://fonts.googleapis.com/css2?family=Noto+Sans+KR:wght@100;300;400;500;700;900&display=swap">
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bootstrap@4.5.3/dist/css/bootstrap.min.css" integrity="sha384-TX8t27EcRE3e/ihU7zmQxVncDAy5uIKz4rEkgIXeMed4M0jlfIDPvg6uqKI2xXr2" crossorigin="anonymous">
<style>
body {
font-size: 16px;
font-family: 'Noto Sans KR', sans-serif;
max-width: 1000px;
margin: 0 auto;
}
.search-wrap {
padding: 1.5rem;
}
.search-result {
margin-top: 2rem;
}
.card {
margin-bottom: 2rem;
}
.card-body {
background-color: #efffff;
}
.search-result {
min-height: 300px;
}
</style>
</head>
<body>
<div class="search-wrap">
<h3>Typesense 검색 엔진을 이용한 행정동 한글 검색 성능 테스트</h3>
<label for="keyword">검색 키워드</label>
<input id="keyword" type="text" autocomplete="off" class="form-control" placeholder="검색할 행정동 키워드를 입력하세요. 예) 수지구 죽전동" @input="keyword = $event.target.value" @keyup="search">
<section class="search-result">
<h4>검색 결과</h4>
<ul v-if="searchResult.length > 0">
<li v-for="result of searchResult" v-html="result"></li>
</ul>
<div v-else>검색 결과가 없습니다.</div>
</section>
</div>
<script src="https://cdn.jsdelivr.net/npm/vue@2.6.0"></script>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<script>
(() => {
const APIServer = 'API 서버의 ip 주소를 입력해 주세요'
new Vue({
el: '.search-wrap',
data () {
return {
keyword: null,
searchResult: [],
}
},
methods: {
async search () {
const keyword = String(this.keyword).trim()
if (!keyword) {
return this.searchResult = []
}
this.searchResult = (await axios.get(`http://${APIServer}/search/address?keyword=${keyword}`).then((r) => r.data)) || []
},
},
})
})()
</script>
</body>
</html>
위 내용 중 APIServer 변수의 값은 API 서버의 public 아이피로 업데이트 해 주세요.
위 html 페이지를 원하는 이름으로 저장한 뒤, 해당 파일을 브라우저에서 열어 API 서버와 검색 서버의 응답이 얼마나 빨리 내려오는지 한번 확인 해 보세요!
마무리
웹페이지에서 각 요청에 대한 네트워크 응답속도를 확인 해 보고 너무 놀랐었는데, 다른분들은 어떠셨을지 잘 모르겠네요. 요청자의 ip만 내려주는 간단한 API도 응답에 6~15ms가 소요되었는데, API 서버에서 검색 서버까지 들렀다 오는데도 많이 차이가 나지 않는 수준의 응답속도를 보여준다는게 정말 믿겨지지 않았습니다.
얼마나 검색 속도가 빠를까, 내가 직접 만들어볼 수 있을까? 라는 질문에서 시작하긴 했던 컨텐츠였는데 생각보다는 큰 어려움이 없었습니다. 런타임에 컬렉션에 대한 수정을 한다거나, 기록 시 발생할 수 있는 동시성 문제 등에 대해서는 경험 해 보지 못했기때문에 이 부분도 조금 궁금함으로 남기고 마무리 하게 되는 것 같습니다. 무엇보다도, 아직 한국어 형태소 분석기의 부재로 정확한 결과를 얻을 수 없다는 점이 가장 아쉬운 점인 것 같네요.
뭔가 정리하다보니 원래 이렇게 쓰려고 했던게 맞는지 잊어버리고 급 마무리가 되는 느낌이긴 합니다 ^^;
위에 작성해 둔 코드들의 실행 여부를 확인하며 게시글을 작성했지만, 정리하는 과정에서 누락되거나 충분하지 않은 설명이 있을 수 있으니 만약 내용과 관련하여 궁금하신 점이 있다면 언제든 문의를 남겨주세요.
긴 글 읽어주셔서 감사합니다!
]]>