
0 229 9 minutes read
10. Samza
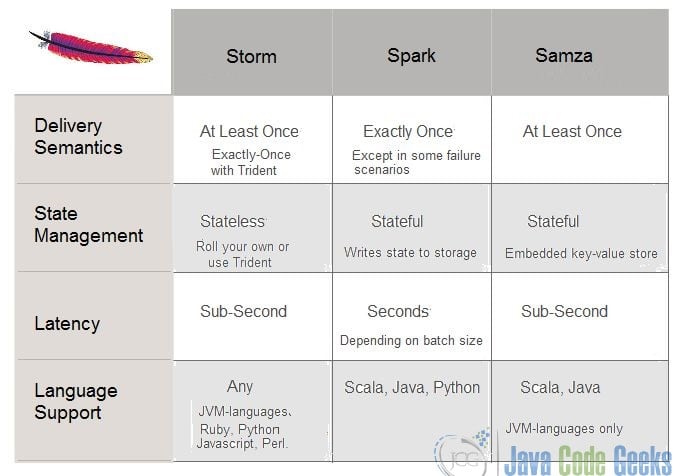
Samza is the main stream computing framework of LinkedIn. When compared with other similar Sparks, Storm is different. Samza is integrated with Kafka as a primary storage node and intermediary.
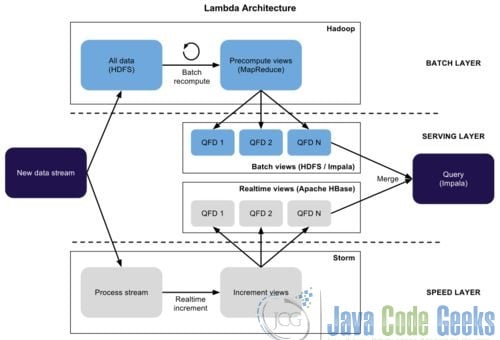
11. Lambda Architecture
The main idea of the Lambda Architecture is to use batch architecture for high latency but large data volume. It also uses streaming for real-time data. Framework is created, and then surface layer is built on top to merge the data flow on both sides. This system can balance the real-time efficiency and batch scale. It is adopted by many companies in the production system
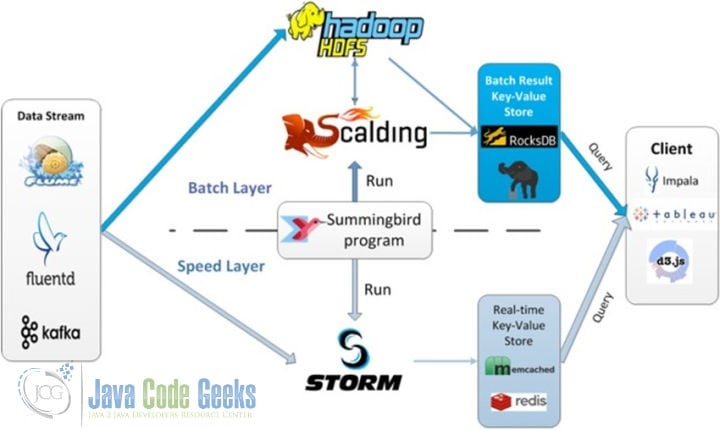
12. Summingbird
Twitter developed Summingbird, and Summingbird’s complete program runs in multiple places. Summingbird also connects batch and stream processing, and reduces the conversion overhead between them by integrating batch and stream processing. The figure below explains the system runtime
13. NoSQL
Data is traditionally stored in a tree structure (hierarchy), but it is difficult to represent a many-to-many relationship. Relational databases are the solution to this problem, but in recent years, relational databases have been found to be ineffective. New NoSQL appears like Cassandra, MongoDB, and Couchbase. NoSQL is also divided into the category’s document type. These categories consist of graph operation type, column storage, key-value type, and different systems solve different problems. There is no one-size-fits-all solution.

14. Cassandra
In the architecture of big data, Cassandra’s main role is to store structured data. DataStax’s Cassandra is a column-oriented database that provides high availability and durability through a distributed architecture. It implements very large scale clusters and provides a type of consistency called “final consistency,” which means that the same database entries in different servers can have different values at any time.
15. SQL on Hadoop
There are many SQL-on-Hadoop projects in the open source community that focus on competing with some commercial data warehouse systems. These projects include Apache Hive, Spark SQL, Cloudera Impala, Hortonworks Stinger, Facebook Presto, Apache Tajo and Apache Drill. Some projects are based on Google Dremel design.
16. Impala
Impala is the Cloudera company leading the development of a new type of query system that provides SQL semantics. Impala can query data stored in Hadoop’s HDFS and HBase in PB magnitude data.
17. Drill
The open source version of Dremel-Drill is similar to the Apache community. Dremel-Drill is a distributed system designed to interactively analyze large data sets.
18. Druid
Druid is open source data storage designed for real-time statistical analysis on top of big data sets. This system aggregates a layer for column-oriented storage, a distributed and nothing-shared architecture, and an advanced index structure to achieve arbitrary exploration and analysis of billion-row-level tables within seconds.
19. Berkeley Data Analytics Stack
BDAS is a more grand blueprint in the Berkeley AMP lab. There are many star projects in it besides Spark that include:
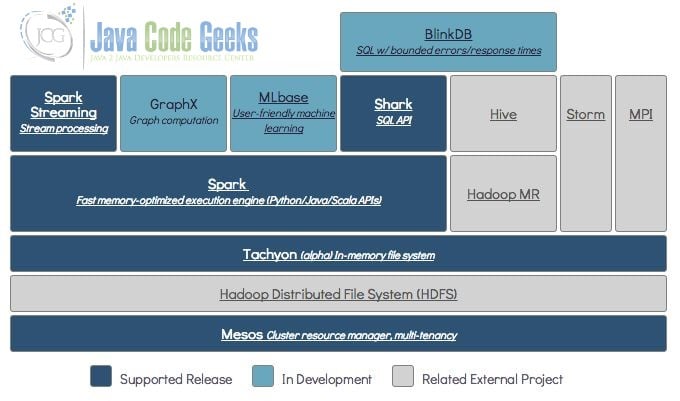
Mesos: A resource management platform for distributed environments that enable Hadoop, MPI and Spark jobs to be executed in a unified resource management environment. Mesos is very good for Hadoop 2.0 support, and Mesos is used by Twitter and Coursera.
Tachyon: A highly fault-tolerant distributed file system that allows files to be reliably shared in the cluster framework at the speed of the memory, just like Spark and MapReduce. The current development is very fast, and some people believe it is even more amazing than Spark. Tachyon has established the startup Tachyon Nexus.
BlinkDB: A massively parallel query engine that runs interactive SQL queries on massive amounts of data. It allows the user to increase the query response time by weighing the data precision. The accuracy of the data is controlled within the allowable error range.
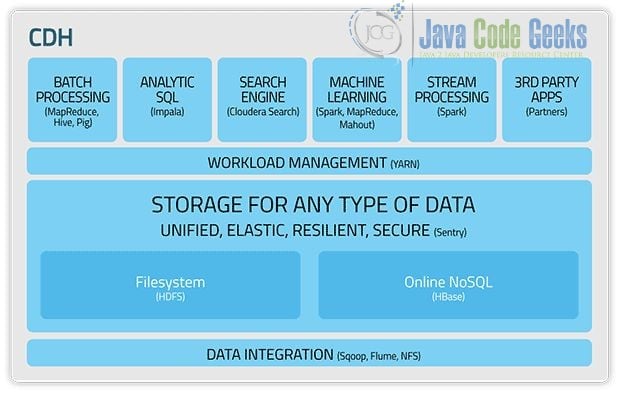
Cloudera: A solution proposed by Hadoop Big Brother.
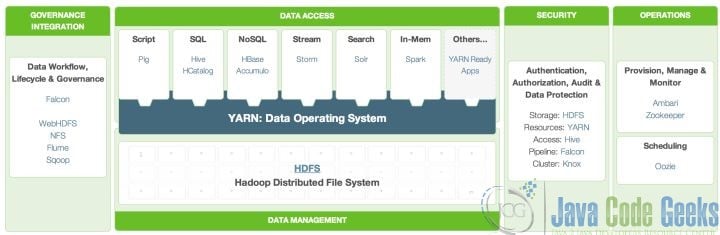
HDP (Hadoop Data Platform): Hortonworks’ proposed architecture selection.
Redshift: Amazon RedShift is a version of ParAccel. It is a massively parallel computer and a very convenient data warehouse solution. Amazon RedShift is also a SQL interface and provides seamless connection with various cloud services. Amazon RedShift is fast and provides very good performance at TB to PB level. It is also used directly and supports different hardware platforms. If you want to be faster, you can use SSD.
20. Conclusion
In conclusion, Hadoop is an open source data analytics program that addresses the reliable storage and processing of big data. The goal of Hadoop is to be a reliable system that supports large-scale expansion and easy maintenance. Hadoop includes a set of technology extensions that are described in depth above. To add on, New NoSQL is shown in different categories, and is divided according to the category’s document type. An in depth tutorial regarding Big Data Pipeline is described above.