-
 Engineering · Data
Engineering · DataMachine-learning predictive autoscaling for Flink
Explore how Grab uses machine learning to perform predictive scaling on our data processing workloads.


-
 Engineering · Data
Engineering · DataModernising Grab’s model serving platform with NVIDIA Triton Inference Server
Dive into Grab’s engineering journey to optimise a core ML model. Learn how we built the Triton Server Manager and used Triton Inference Server (TIS) to achieve a 50% reduction in tail latency and seamlessly migrate over 50% of online deployments.



-
 Engineering
EngineeringHighly concurrent in-memory counter in GoLang
Dive into the chaos and triumph of real-time optimisation in the face of high database utilisation! This article recounts a developer's adrenaline-fueled journey of transforming crisis into innovation—optimising campaign usage count tracking through highly concurrent in-memory caching and periodic database updates. Embrace the madness, thrive in the challenge, and discover a bold approach to tackling database bottlenecks head-on!
-
 Engineering
EngineeringUser foundation models for Grab
Grab has developed a groundbreaking foundation model specifically designed to understand user behavior. Grab's custom solution addresses the unique challenges of a multi-service platform spanning food delivery, ride-hailing, grocery shopping, financial services, and more. The blog delves into the architecture and technical achievements that this innovation is built on.







-
 Engineering
EngineeringPowering Partner Gateway metrics with Apache Pinot
Partner Gateway serves as Grab's secure interface for exposing APIs to third-party entities, facilitating seamless interactions between Grab's hosted services and external consumers. This blog delves into the implementation of Apache Pinot within Partner Gateway for advanced metrics tracking. Discover the challenges, trade-offs, and solutions the team navigated to optimize performance and ensure reliability in this innovative integration.

-
 Engineering
EngineeringTaming the monorepo beast: Our journey to a leaner, faster GitLab repo
At Grab, our decade-old Go monorepo had become a 214GB monster with 13 million commits, causing 4-minute replication delays and crippling developer productivity. Through custom migration tooling and strategic history pruning, we achieved a 99.9% reduction in commits while preserving all critical functionality. The result? 36% faster clones, eliminated single points of failure, and a 99.4% improvement in replication performance—transforming our biggest infrastructure bottleneck into a development enabler.




-
 Engineering
EngineeringData mesh at Grab part I: Building trust through certification
Grab has embarked on a transformative journey to overhaul its enterprise data ecosystem, addressing challenges posed by the rapid growth of its business spanning across ride-hailing, food delivery, and financial services. With the increasing complexity of its data landscape, Grab transitioned from a centralised data warehouse model to a data mesh architecture, a decentralised approach treating data as a product owned by domain-specific teams. The article shares the motivations behind the change, the factors and steps taken to make it a success, and results.



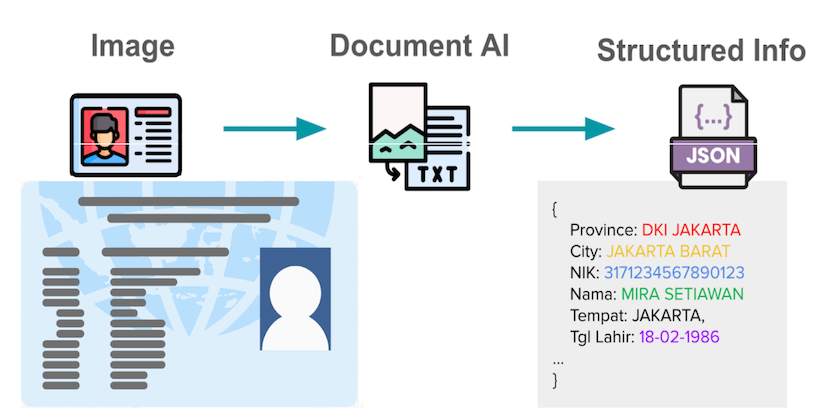 Engineering
·
Data
Engineering
·
Data
How We Built a Custom Vision LLM to Improve Document Processing at Grab
e-KYC faces challenges with unstandardized document formats and local SEA languages. Existing LLMs lack sufficient SEA language support. We trained a Vision LLM from scratch, modifying open-source models to be 50% faster while maintaining accuracy. These models now serve live production traffic across Grab's ecosystem for merchant, driver, and user onboarding.



