

In this guide, we will look at what MLOps means for DevOps engineers and how they can use their existing skill sets to become an MLOps Engineer.
I have been talking about MLOPS for quite some years with the DevOps community and never got a chance to actually publish a blog.
With this post, I am trying to fill that gap by shedding light on How to become a MLOps engineer and how you can approach learning as a DevOps engineer to get opportunities to work on MLOps-related projects.
So if you are ready to go “all in” with MLOPS, this guide is for you.
Let’s dive right in.
My MLOPS Experience
In 2020, I worked on an ML project for an international sports brand, setting up the infrastructure from development to production.
At first, I thought it was just another automation task, something I had done many times before.
But everything changed when I started attending ML team meetings. I had no clue what they were talking about. The discussions felt like a different language. Models, Feature engineering, training, hyperparameters etc. I was completely lost.
That is when I realized this was more than just setting up pipelines.
It was like building CI/CD for a Java app without understanding how Java development works.
If you don’t know how the code is built, optimized, and deployed, how can you design the right workflows? The same applies to ML.
I realized that to do my job well, I needed to understand ML workflow itself.
So, I spent the next couple of months learning, picking up the basics, understanding the workflows, and getting familiar with the process. (I wish LLMs had existed back then. It would have made the learning much faster 😄)
I could finally follow discussions, collaborate better, and build infrastructure that actually made sense for the ML team.
Today, with LLMs and GenAI becoming mainstream, these core concepts matter even more. The infrastructure needs are significantly larger, but the core understanding remains the same.
DevOps to MLOPS
First of all, there is no such thing as switching careers from DevOps to MLOps. It is not a Career Switch. MLOps is an extension of DevOps, not a separate career path.
Anyone who says otherwise likely does not fully understand how MLOps works.
Because DevOps engineers are already part of an ML project, which includes other teams like Data Science, Data Engineers, ML Developers, etc.
Also, you will be doing similar DevOps work, like setting up CI/CD, writing infrastructure as code, Python scripts, design pipelines to orchestrate workflows etc.
The main difference is in the tools, platforms, technologies, workflows, and how ML pipelines are built and managed.
In short, you can say you are a DevOps engineer with expertise in managing Machine Learning operations. Because, at the core, you will still be following DevOps principles, which focus on collaborating with different teams efficiently.
So what is MLOPS really?
MLOps (Machine Learning Operations) is a practice followed to streamline and automate the lifecycle of machine learning models, from development to deployment and maintenance.
MLOPS = DevOps + Machine learning + Data Engineering
If you follow DevOps culture and practices for ML projects, you can call it as MLOPS
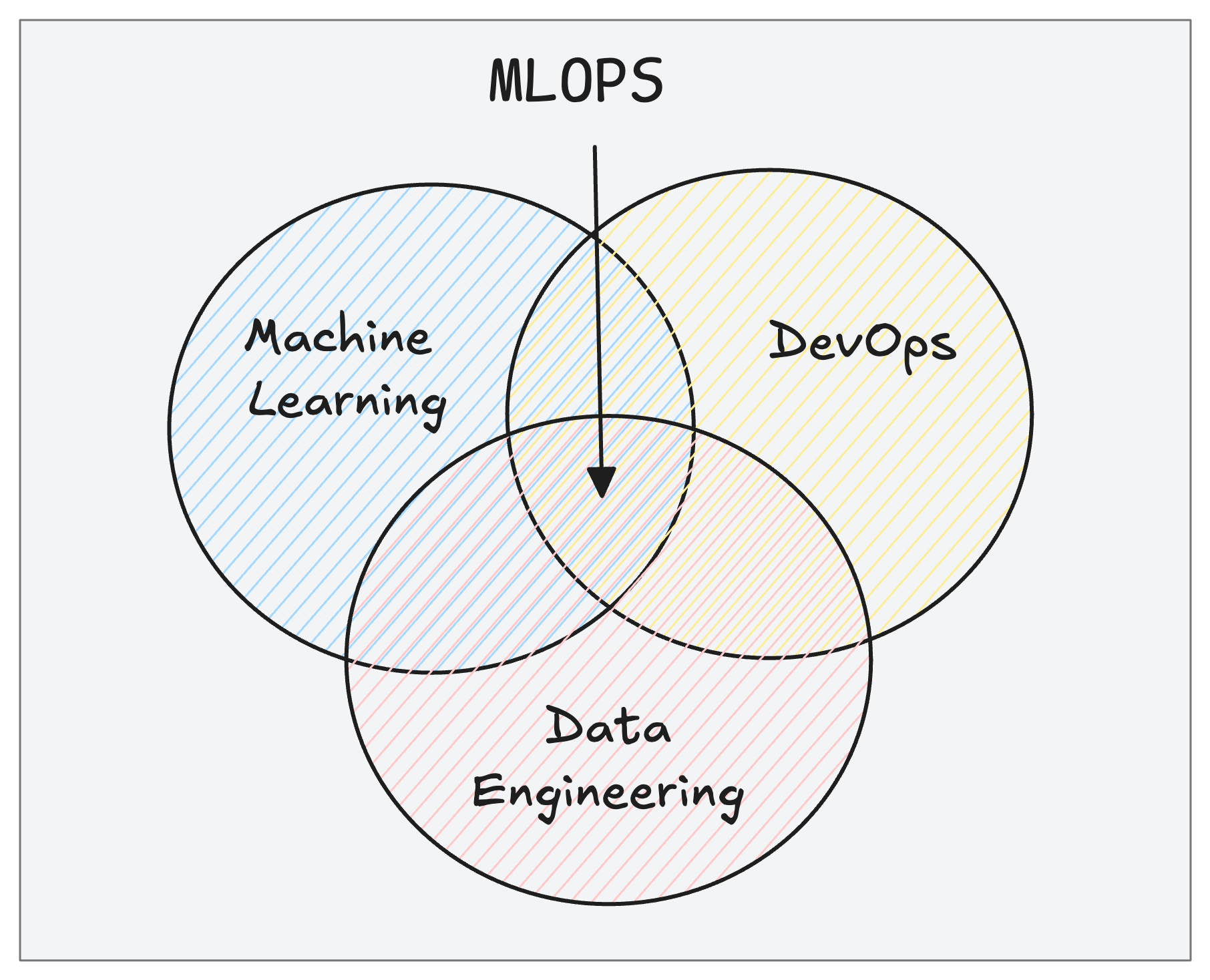
Now the key question
How is MLOPS different from usual DevOps workflows?
MLOps is different from the usual DevOps workflows, just like machine learning is different from traditional software development.
For example,
In MLOps, you need to track three components: code, data, and models (while in traditional DevOps, you only track code).
Additionally, MLOps introduces the following.
- Data versioning: To track changes in datasets using tools like DVC (Data Version Control) or LakeFS
- Experiment tracking: To log hyperparameters, metrics, and model versions for each training run
- Model registry: To version and manage models separately from application artifacts
- Continuous Training (CT): Beyond CI/CD, models need regular retraining as data changes
The following image illustrates the high level MLOPS workflow on how a machine learning model is built, deployed, and monitored in production.
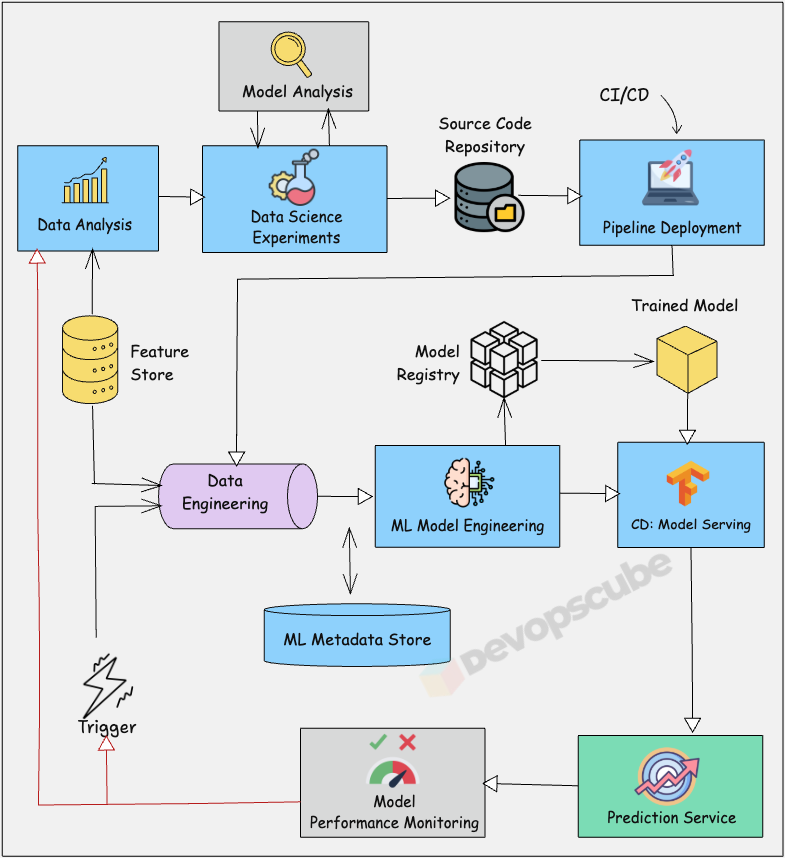
Why MLOPS is Important?
We want data scientists and data engineers to do what they do best and focus on building and deploying models with ease. This can be achieved only if we follow MLOPS practices for the ML application lifecycle.
You might have the best Data Scientists and Data engineerings in the team. But if you do not have a well automated Lifecycle for ML development and deployment, it is going to be hard for everyone to deliver the project.
If you look at a typical ML project, following are the three key teams involved.
- Data Engineering
- Data Scientists
- ML Engineering and
- DevOps
Only if the above teams collaborate and work together, we can have a well automated ML Lifecycle implementation.
So probably by now, you have got a small idea of what MLOPS really is.
How to Become a MLOPS Engineer?
Fact: MLOps is mostly engineering/infrastructure and less data science awareness.
DevOps engineers do not need to know how to build ML models or understand complex ML algorithms.
But for a DevOps engineer to efficiently collaborate, build, and maintain ML infrastructure, he/she should have an understanding of the following:
- Understand Data Pipelines: ML starts with data. Data from various sources go through collection, cleaning, transformation etc to be ready for ML. So you need to understand how dataset is prepared for ML development using ETL pipelines.
- Understanding basic ML terminology and concepts: For example, ML model training, feature engineering, inference, hyperparameters, what model artifacts are, etc.
- Understanding of ML Workflow : How ML experiments work, why models need retraining, what model drift means, etc.
- ML Infrastructure Requirements: Computing resource needs for training, storage requirements for datasets, model serving patterns, GPU vs CPU requirements.
- ML-specific monitoring: Understanding data drift, model performance degradation, prediction latency, and feature distribution changes (different from traditional application monitoring).
Once you have a good understanding of the above-mentioned ML basics, you will be able to have effective conversations with data scientists, design appropriate infrastructure, set up proper monitoring, developer-centric workflows, CI/CD pipelines, etc., as you would normally do in a DevOps project.
The following image illustrates the skill mapping from DevOps to MLOps.
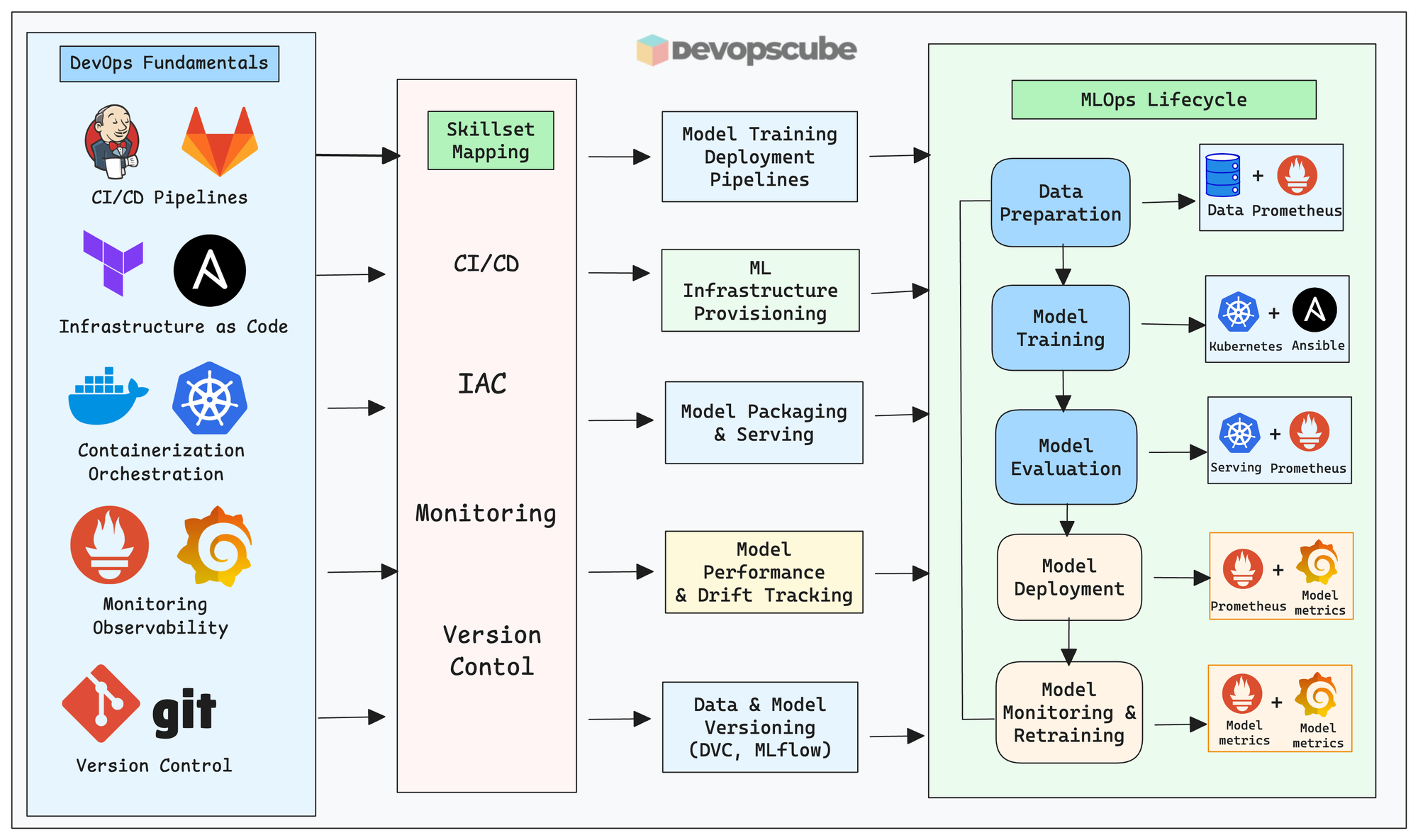
Modern MLOps: Working with LLMs
Things have evolved with Large Language models (LLMs). In many cases today, you dont train models from scratch. You use pre-trained models.
I personally experienced it. One of the ML use cases we worked on in 2020 using traditional ML can now be solved using LLMs. Many ML systems today integrate LLMs in to their workflows. So you can call it modern or extended MLOps.
For example, DevOps/SRE team use LLMs to read logs, analyze metrics, and suggest what might be wrong with a system integrating with observability tools.
The following image illustrates an example root cause analysis using fine tuned LLMs.
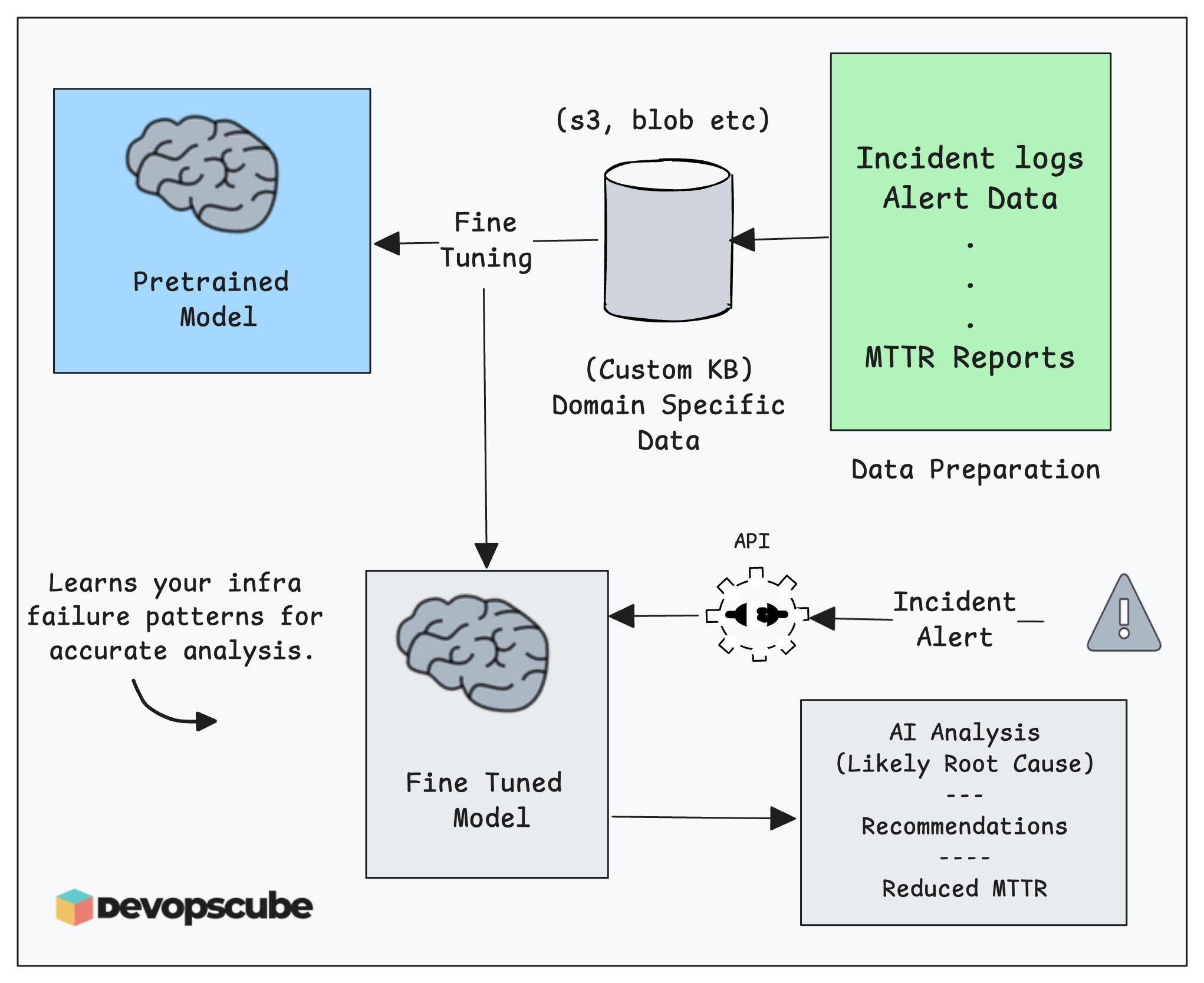
From a LLM perspective, you need to learn the following.
- Working with managed LLM APIs (OpenAI, Anthropic, Gemini)
- Self-hosted models (LLaMA, Mistral, Mixtral) - For in house enterprise use cases.
- Fine tuning LLMs for specific use cases.
- Learn about LLM serving stack like vLLM, TensorRT-LLM etc. Understand batching, quantization, and throughput optimization.
- Managing Kubernetes GPU clusters and costs (GPU scheduling, Optmizations & scaling
- API gateway patterns for LLM applications (Rate limiting, auth, caching, and request routing for LLM traffic)
- Monitoring token usage, latency, and costs
- Prompt management that includes designing effective prompts, versioning them, and continuously testing and improving their performance.
- Understand LLM Evaluation to measure output quality for accuracy, relevance, and groundedness using automated eval frameworks
- Understand about guardrails to catch hallucinations, toxicity, and policy violations.
- Retrieval Augmented Generation (RAG) + Vector search & Embeddings
Managing large language models in production is a challenging task. It includes prompt design, model serving, and handling data with tools like RAG. It is called LLMOps. Idea of LLMOps is to make LLM systems reliable, scalable, and cost-efficient.
Tools Required for MLOPS
As a DevOps engineer, you are already familiar with the following tools.
Today, these are mandatory skills.
- Docker
- Kubernetes
- IaC tools like Terraform
- Experience with cloud platforms (AWS, GCP, Azure)
- CI/CD tools like Jenkins, GitHub Actions, etc.
- Monitoring tools like Prometheus, Grafana, etc.
- Python, FastAPI, Flask etc.
The tools listed above are general DevOps tools and technologies. You need to have solid knowledge about them.
In addition to the above DevOps tools, for MLOps you also need to learn tools that work with data and AI/ML workflows (Enterprise-grade ML systems).
- DVC - Data version control
- Airflow (Data pipeline orchestration)
- Kubeflow Stack (End-to-end ML pipelines on Kubernetes)
- MLflow (Experiment tracking, model registry)
- Feast Feature store (For centralized feature management)
- KServe (model serving)
- Evidently AI (ML observability & monitoring)
- Ray (For distributed training and scalable model serving)
Following are some of the LLM specific tools.
- vLLM, TensorRT-LLM (For high-performance LLM inference)
- LangChain, LlamaIndex (LLM orchestration frameworks)
- Vector databases (Pinecone, Weaviate for RAG and LLM applications)
- Promptfoo or Langfuse for prompt management.
- Guardrails AI / LlamaGuard (LLM output validation and safety enforcement)
Getting Started With MLOps
Whenever I talk about MLOps, the most common question I get is,
Do we need GPU-based clusters to learn MLOps?
The short answer is no. You do not need a GPU to learn MLOps.
For learning and testing, CPUs are more than enough to deploy sample models. You can start by building simple models like logistic regression or decision trees.
Once you have a model, you can practice the full MLOps lifecycle using tools like Kubeflow and MLflow which the includes the following.
- Packaging the model
- Deploying the model
- Monitoring model performance
- Automating ML pipelines
To do this, you will still need a decent Kubernetes cluster with enough CPU and memory, because tools like Kubeflow and MLflow do consume a fair amount of resources. (e.g., a 3-node spot instance k8s cluster with 4 CPU cores and 8GB RAM)
This approach helps you learn the workflow without worrying about expensive hardware.
Also, many modern MLOps setups are also moving toward foundation models and AI agents.
In these cases, you don't train models from scratch. Instead, you fine-tune or directly use existing models through APIs, such as OpenAI or similar providers.
This allows you to build and test real MLOps pipelines at a much lower cost, while focusing on what really matters like operationalizing models and AI workflows.
The next key question
When should one consider moving to GPU-based learning?
Once you understand the "plumbing" of MLOps such as how data flows through the pipeline, how models are versioned, and how deployments are monitored, you can start working with GPU-based setups, if you have access to them or can afford them.
At this point, you can learn how to set up GPU-based Kubernetes clusters and deploy workloads that need GPU access. This includes using Kubernetes device plugins and features like Dynamic Resource Allocation (DRA) to manage GPUs efficiently.
The reason you need to learn about GPU is companies look for engineer who know about GPU-aware scheduling & scaling.
MLOps Engineer FAQ's
The following are some of the frequenlty asked questions about MLOPS engineers.
What exactly does an MLOps engineer do?
As we discussed in this blog, the key responsibility of a MLOps engineers is to take machine learning model to production. It includes setting up pipelines to train, test, deploy , monitor and retrain models.
Most important, they colloborate with Data scientists and Data engineers and other cross functional teams.
Do MLOps engineers build machine learning models?
No. However, it is important for MLOps engineers to understand the foundations of ML development workflow and concepts associated with it. It helps them collaborate better with Data science teams and understand their requirements.
What do companies look for in a MLOps engineer?
Most companies look for knowledge in managing traditional models, foundation models, operate LLM services on cloud platforms etc.
Here is the screenshot of a MLOPS engineer job description. It clearly mentions LLM inference, vLLM, building inference APIs, GPU-aware scaling, CI/CD for models, GPU utilization, token optmization etc.

Here is another job description if MLOps engineer for traditional model deployment and management. It clearly specifies collaboration with Data Scientists and Data Engineers, ML pipelines, model tracking etc.

If you want to get more idea about the current MLOps job requirements, the best way is to go through MLOps job descriptions. Learn and prepare of the interviews accordingly.
Your First MLOps Challenge
Ready to get hands-on? Here is a practical exercise to get started.
- Install MLflow locally
- Train a simple model (or use a pre-trained one)
- Log it to MLflow's model registry
- Serve it via MLflow's built-in serving API
- Make a prediction request using curl
This 30-minute exercise will give you a feel for model packaging, versioning, and serving. The core of MLOps workflows.
I will cover this in detail in a seperate blog post.
Conclusion
This is my first blog in the MLOps series.
As many of you may know, the MLOps space is growing very fast, with new open-source tools and continuous improvements in ML models.
In the upcoming MLOps blogs, we will cover core ML concepts and provide hands-on guides to help you understand the ML development workflow in detail.
Overall, if you can commit some time, you can learn all the core MLOps concepts without much difficulty.
Over to you.
Are you planning to get started with MLOps? What is your current understanding of MLOps?
Do you think MLOps feels like an extension of your existing DevOps work?
Share your thoughts in the comments below.